27.1.17. ベクタ一般
27.1.17.1. 投影法の割り当て
ベクタレイヤに新しい投影法を割り当てます。
これが作成するのは、入力されたものとまったく同じ地物とジオメトリを持つ新しいレイヤですが、新しいCRSに割り当てられています。ジオメトリは再投影 されません 。異なるCRSに割り当てられるだけです。
このアルゴリズムは、誤った投影法が割り当てられたレイヤを修復するために使用します。
属性値は、このアルゴリズムでは変更されません。
参考
パラメータ
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
入力レイヤ |
|
[ベクタ:任意] |
間違ったCRS、またはCRSの無いベクタレイヤ |
割り当てられたCRS |
|
[crs] デフォルト: |
ベクタレイヤに割り当てたい新しいCRSを選択します |
割り当てられたCRS オプション |
|
[入力レイヤと同じ] デフォルト: |
出力ベクタレイヤを指定します。次のいずれかです:
ここでファイルの文字コードを変更することもできます。 |
出力
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
割り当てられたCRS |
|
[入力レイヤと同じ] |
指定した投影法のベクタレイヤ |
Python コード
Algorithm ID: native:assignprojection
import processing
processing.run("algorithm_id", {parameter_dictionary})
algorithm id は、プロセシングツールボックス内でアルゴリズムにマウスカーソルを乗せた際に表示されるIDです。 parameter dictionary は、パラメータの「名前」とその値を指定するマッピング型です。Python コンソールからプロセシングアルゴリズムを実行する方法の詳細については、 プロセシングアルゴリズムをコンソールから使う を参照してください。
27.1.17.2. Nominatimジオコーディング
入力レイヤの文字列フィールドに対して、Nominatimサービスを使ったバッチジオコーディングを実行します。出力レイヤは、ジオコーディングされた場所を反映したポイントジオメトリと、ジオコーディングされた場所に関連するいくつかの属性を持ちます。
 ライン地物の 地物のIn-place編集 が可能です
ライン地物の 地物のIn-place編集 が可能です
注釈
このアルゴリズムは、OpenStreetMap財団が提供するNominatimジオコーディングサービスの 使用ポリシー に準拠しています。
パラメータ
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
入力レイヤ |
|
[ベクタ:任意] |
地物をジオコーディングするベクタレイヤ |
住所フィールド |
|
[テーブルのフィールド:文字列] |
ジオコーディングする住所を格納しているフィールド |
出力 |
|
[ベクタ:ポイント] デフォルト: |
ジオコーディングされた住所のみを含む出力レイヤを指定します。以下のいずれかです:
ここでファイルの文字コードを変更することもできます。 |
出力
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
出力 |
|
[ベクタ:ポイント] |
ジオコーディングされた住所に対応する点地物を持つベクタレイヤ |
Python コード
Algorithm ID: native:batchnominatimgeocoder
import processing
processing.run("algorithm_id", {parameter_dictionary})
algorithm id は、プロセシングツールボックス内でアルゴリズムにマウスカーソルを乗せた際に表示されるIDです。 parameter dictionary は、パラメータの「名前」とその値を指定するマッピング型です。Python コンソールからプロセシングアルゴリズムを実行する方法の詳細については、 プロセシングアルゴリズムをコンソールから使う を参照してください。
27.1.17.3. レイヤをブックマークに変換
レイヤ内の地物の範囲に対応する空間ブックマークを作成します。
パラメータ
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
入力レイヤ |
|
[ベクタ:ライン、ポリゴン] |
入力ベクタレイヤ |
ブックマーク先 |
|
[列挙型] デフォルト: 0 |
ブックマークの保存先を選択します。次のいずれかです:
|
ブックマーク名になる属性 |
|
[式] |
作成されるブックマークの名前を表すフィールドまたは式 |
グループを示すフィールド |
|
[式] |
作成されるブックマークのグループを示すフィールドまたは式 |
出力
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
追加したブックマークの数 |
|
[数値] |
Python コード
Algorithm ID: native:layertobookmarks
import processing
processing.run("algorithm_id", {parameter_dictionary})
algorithm id は、プロセシングツールボックス内でアルゴリズムにマウスカーソルを乗せた際に表示されるIDです。 parameter dictionary は、パラメータの「名前」とその値を指定するマッピング型です。Python コンソールからプロセシングアルゴリズムを実行する方法の詳細については、 プロセシングアルゴリズムをコンソールから使う を参照してください。
27.1.17.4. ブックマークをレイヤに変換
保存済みの空間ブックマークのポリゴンを含む新しいレイヤを作成します。現在のプロジェクトに保存されたブックマーク(プロジェクト・ブックマーク)、あるいは全ユーザー用の保存されたブックマーク(ユーザー・ブックマーク)、またはその両方を出力するように選択できます。
パラメータ
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
出力する対象 |
|
[列挙型] [リスト] デフォルト: [0,1] |
ブックマークのソース(複数可)を選択します。次のうちの1つ以上を選択します:
|
出力CRS |
|
[crs] デフォルト: |
出力レイヤのCRS |
出力 |
|
[ベクタ:ポリゴン] デフォルト: |
出力レイヤを指定します。次のいずれかです:
ここでファイルの文字コードを変更することもできます。 |
出力
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
出力 |
|
[ベクタ:ポリゴン] |
(ブックマークの)出力ベクタレイヤ |
Python コード
Algorithm ID: native:bookmarkstolayer
import processing
processing.run("algorithm_id", {parameter_dictionary})
algorithm id は、プロセシングツールボックス内でアルゴリズムにマウスカーソルを乗せた際に表示されるIDです。 parameter dictionary は、パラメータの「名前」とその値を指定するマッピング型です。Python コンソールからプロセシングアルゴリズムを実行する方法の詳細については、 プロセシングアルゴリズムをコンソールから使う を参照してください。
27.1.17.5. 属性インデックスを作成
属性テーブルのフィールドに対して、クエリを高速化するための属性インデックスを作成します。属性インデックスの作成をサポートしているかは、レイヤのデータプロバイダとフィールドの型の両方によります。
出力はありません。インデックスはレイヤ自体に保存されます。
パラメータ
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
入力レイヤ |
|
[ベクタ:任意] |
属性インデックスを作成したいベクタレイヤを選択します |
対象属性(フィールド) |
|
[テーブルのフィールド:任意] |
ベクタレイヤのフィールド |
出力
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
インデックス作成済み |
|
[入力レイヤと同じ] |
指定したフィールドにインデックスが作成された入力ベクタレイヤ |
Python コード
Algorithm ID: native:createattributeindex
import processing
processing.run("algorithm_id", {parameter_dictionary})
algorithm id は、プロセシングツールボックス内でアルゴリズムにマウスカーソルを乗せた際に表示されるIDです。 parameter dictionary は、パラメータの「名前」とその値を指定するマッピング型です。Python コンソールからプロセシングアルゴリズムを実行する方法の詳細については、 プロセシングアルゴリズムをコンソールから使う を参照してください。
27.1.17.6. 空間インデックスを作成
レイヤ内の地物へのアクセスを高速化するための、地物の空間的な位置に基づく空間インデックスを作成します。空間インデックスの作成をサポートしているかは、レイヤのデータプロバイダによります。
出力レイヤは何も作成されません。
デフォルトメニュー:
パラメータ
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
入力レイヤ |
|
[ベクタ:任意] |
入力ベクタレイヤ |
出力
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
インデックス作成済み |
|
[入力レイヤと同じ] |
空間インデックスが作成された入力ベクタレイヤ |
Python コード
Algorithm ID: native:createspatialindex
import processing
processing.run("algorithm_id", {parameter_dictionary})
algorithm id は、プロセシングツールボックス内でアルゴリズムにマウスカーソルを乗せた際に表示されるIDです。 parameter dictionary は、パラメータの「名前」とその値を指定するマッピング型です。Python コンソールからプロセシングアルゴリズムを実行する方法の詳細については、 プロセシングアルゴリズムをコンソールから使う を参照してください。
27.1.17.7. シェープファイルの投影法の定義
既存のシェープファイル形式のデータセットに指定したCRS(投影法)を設定します。シェープファイル形式のデータセットに prj ファイルが無いが、正しい投影法は分かっている場合に便利です。
投影法の割り当て アルゴリズムとは異なり、このアルゴリズムは入力レイヤを変更するため、新しいレイヤの出力はありません。
注釈
シェープファイルのデータセットは、指定したCRSとなるよう .prj ファイルと .qpj ファイルが上書きされます。ファイルが無い場合には新たに作成されます。
デフォルトメニュー:
パラメータ
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
入力レイヤ |
|
[ベクタ:任意] |
投影法の情報が欠落したベクタレイヤ |
CRS |
|
[crs] |
ベクタレイヤに割り当てたいCRSを選択します |
出力
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
|
[入力レイヤと同じ] |
指定した投影法の入力ベクタレイヤ |
Python コード
Algorithm ID: qgis:definecurrentprojection
import processing
processing.run("algorithm_id", {parameter_dictionary})
algorithm id は、プロセシングツールボックス内でアルゴリズムにマウスカーソルを乗せた際に表示されるIDです。 parameter dictionary は、パラメータの「名前」とその値を指定するマッピング型です。Python コンソールからプロセシングアルゴリズムを実行する方法の詳細については、 プロセシングアルゴリズムをコンソールから使う を参照してください。
27.1.17.8. 重複ジオメトリの削除
重複したジオメトリを見つけて削除します。
属性はチェックされないため、2つの地物のジオメトリが同一で属性値が異なる場合、どちらか一つのみしか結果レイヤに出力されません。
参考
パラメータ
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
入力レイヤ |
|
[ベクタ:任意] |
重複するジオメトリを削除したいレイヤ |
クリーニング済み出力 |
|
[入力レイヤと同じ] デフォルト: |
出力レイヤを指定します。次のいずれかです:
ここでファイルの文字コードを変更することもできます。 |
出力
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
破棄された重複レコードの数 |
|
[数値] |
破棄された重複レコードの数 |
クリーニング済み出力 |
|
[入力レイヤと同じ] |
重複するジオメトリのない出力レイヤ |
保持されているレコード数 |
|
[数値] |
ジオメトリの重複のないレコードの数 |
Python コード
Algorithm ID: native:deleteduplicategeometries
import processing
processing.run("algorithm_id", {parameter_dictionary})
algorithm id は、プロセシングツールボックス内でアルゴリズムにマウスカーソルを乗せた際に表示されるIDです。 parameter dictionary は、パラメータの「名前」とその値を指定するマッピング型です。Python コンソールからプロセシングアルゴリズムを実行する方法の詳細については、 プロセシングアルゴリズムをコンソールから使う を参照してください。
27.1.17.9. 属性値重複を削除
指定されたフィールド(複数可)を考慮して、重複する行を削除します。最初にマッチした行は残され、その後にマッチした重複行は破棄されます。
オプションとして、重複し破棄されたレコードは分析用として別の出力に保存することができます。
参考
パラメータ
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
入力レイヤ |
|
[ベクタ:任意] |
入力レイヤ |
次の項目で重複するフィールド |
|
[テーブルのフィールド:任意] [リスト] |
重複を定義するフィールド。これらのフィールドの値がすべて同じである地物は、重複しているものとみなされます。 |
フィルタリング済み(重複なし) |
|
[入力レイヤと同じ] デフォルト: |
属性値に重複のない地物の出力レイヤを指定します。次のいずれかです:
ここでファイルの文字コードを変更することもできます。 |
フィルタリング済み(重複含む) オプション |
|
[入力レイヤと同じ] デフォルト: |
出力レイヤを指定します。次のいずれかです:
ここでファイルの文字コードを変更することもできます。 |
出力
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
フィルタリング済み(重複含む) オプション |
|
[入力レイヤと同じ] デフォルト: |
削除された地物が含まれるベクタレイヤ。指定しない( |
破棄された重複レコードの数 |
|
[数値] |
破棄された重複レコードの数 |
フィルタリング済み(重複なし) |
|
[入力レイヤと同じ] |
属性値に重複のない地物のベクタレイヤ |
保持されているレコード数 |
|
[数値] |
ジオメトリの重複のないレコードの数 |
Python コード
Algorithm ID: native:removeduplicatesbyattribute
import processing
processing.run("algorithm_id", {parameter_dictionary})
algorithm id は、プロセシングツールボックス内でアルゴリズムにマウスカーソルを乗せた際に表示されるIDです。 parameter dictionary は、パラメータの「名前」とその値を指定するマッピング型です。Python コンソールからプロセシングアルゴリズムを実行する方法の詳細については、 プロセシングアルゴリズムをコンソールから使う を参照してください。
27.1.17.10. ベクタレイヤを比較
2つのベクタレイヤを比較し、両者の間で変更がない地物、追加された地物、削除された地物を判別します。同じデータセットの異なる2つのバージョンを比較するためのアルゴリズムです。
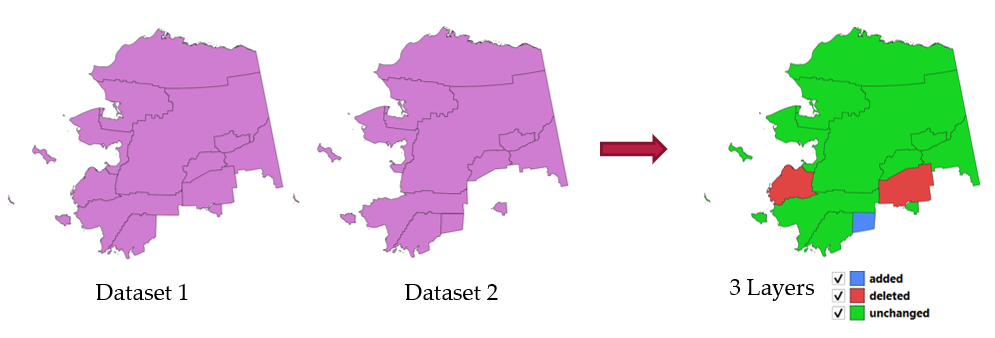
図 27.46 データセット変更の検出の例
パラメータ
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
オリジナルレイヤ |
|
[ベクタ:任意] |
オリジナルバージョンとするベクタレイヤ |
比較レイヤ |
|
[ベクタ:任意] |
修正または変更されたベクタレイヤ |
考慮する属性(ない場合はジオメトリのみ比較) オプション |
|
[テーブルのフィールド:任意] [リスト] |
マッチングに考慮する属性。デフォルトでは、すべての属性値が比較されます。 |
ジオメトリ比較法 オプション |
|
[列挙型] デフォルト: 1 |
比較の基準を指定します。選択肢は次のとおりです:
|
変更がない地物 オプション |
|
[ベクタ:元のレイヤと同じ] |
変更がない地物を含む出力ベクタレイヤを指定します。次のいずれかです:
ここでファイルの文字コードを変更することもできます。 |
追加された地物 オプション |
|
[ベクタ:元のレイヤと同じ] |
追加された地物を含む出力ベクタレイヤを指定します。次のいずれかです:
ここでファイルの文字コードを変更することもできます。 |
削除された地物 オプション |
|
[ベクタ:元のレイヤと同じ] |
削除された地物を含む出力ベクタレイヤを指定します。次のいずれかです:
ここでファイルの文字コードを変更することもできます。 |
出力
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
変更がない地物 |
|
[ベクタ:元のレイヤと同じ] |
変更がない地物のベクタレイヤ |
追加された地物 |
|
[ベクタ:元のレイヤと同じ] |
追加された地物のベクタレイヤ |
削除された地物 |
|
[ベクタ:元のレイヤと同じ] |
削除された地物のベクタレイヤ |
変更がない地物の数 |
|
[数値] |
変更がない地物の数 |
追加された地物の数 |
|
[数値] |
比較レイヤに追加された地物の数 |
削除された地物の数 |
|
[数値] |
オリジナルレイヤから削除された地物の数 |
Python コード
Algorithm ID: native:detectvectorchanges
import processing
processing.run("algorithm_id", {parameter_dictionary})
algorithm id は、プロセシングツールボックス内でアルゴリズムにマウスカーソルを乗せた際に表示されるIDです。 parameter dictionary は、パラメータの「名前」とその値を指定するマッピング型です。Python コンソールからプロセシングアルゴリズムを実行する方法の詳細については、 プロセシングアルゴリズムをコンソールから使う を参照してください。
27.1.17.11. ジオメトリの削除
入力レイヤの属性テーブルの ジオメトリのない 単なるコピーを作成します。入力レイヤの属性テーブルはそのままです。
出力ファイルをローカルフォルダに保存する場合には、さまざまなファイルフォーマットの中から選択できます。
ポイント、ライン、ポリゴン地物の 地物のIn-place編集 が可能です
参考
パラメータ
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
入力レイヤ |
|
[ベクタ:任意] |
入力ベクタレイヤ |
出力レイヤ |
|
[テーブル] |
ジオメトリなしの出力レイヤを指定します。次のいずれかです:
ここでファイルの文字コードを変更することもできます。 |
出力
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
出力レイヤ |
|
[テーブル] |
ジオメトリなしの出力レイヤ。つまり入力レイヤの属性テーブルのコピー |
Python コード
Algorithm ID: native:dropgeometries
import processing
processing.run("algorithm_id", {parameter_dictionary})
algorithm id は、プロセシングツールボックス内でアルゴリズムにマウスカーソルを乗せた際に表示されるIDです。 parameter dictionary は、パラメータの「名前」とその値を指定するマッピング型です。Python コンソールからプロセシングアルゴリズムを実行する方法の詳細については、 プロセシングアルゴリズムをコンソールから使う を参照してください。
27.1.17.12. SQLの実行
ソースレイヤに対して、 SQL 構文の単純な、あるいは複雑なクエリを実行します。
入力データソースは input1, input2... inputN として識別されます。単純なクエリは、 SELECT * FROM input1 のような形式です。
単純なクエリの他に、式や変数を SQLクエリ パラメータ自体の中に追加できます。これは、このアルゴリズムがプロセシングモデル内で実行される場合に、モデルの入力をクエリのパラメータとして使用したいときに特に便利です。クエリの例は、 SELECT * FROM [% @table %] のような形になり、この @table がモデル入力を識別する変数です。
クエリによる結果は、新しいレイヤとして追加されます。
パラメータ
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
追加のデータソース(クエリ内ではinput1, .., inputNになる) |
|
[ベクタ:任意] [リスト] |
クエリのレイヤのリスト。SQLエディタでは、これらのレイヤを 実際の レイヤ名でも参照できますが、選択したレイヤ数に応じて input1 、 input2 、 inputN という名前でも参照できます。 |
SQLクエリ |
|
[文字列] |
|
ユニークIDフィールド オプション |
|
[文字列] |
ユニークなIDを持ったカラムを指定します |
ジオメトリフィールド オプション |
|
[文字列] |
ジオメトリフィールドを指定します |
ジオメトリタイプ オプション |
|
[列挙型] デフォルト: 0 |
結果のジオメトリを選択します。デフォルトでは、アルゴリズムがジオメトリを自動検出します。次のいずれかです:
|
CRS オプション |
|
[crs] |
出力レイヤに割り当てるCRS |
出力レイヤ |
|
[ベクタ:任意] デフォルト: |
クエリによって作成される出力レイヤを指定します。次のいずれかです:
ここでファイルの文字コードを変更することもできます。 |
出力
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
出力レイヤ |
|
[ベクタ:任意] |
クエリによって作成されるベクタレイヤ |
Python コード
Algorithm ID: qgis:executesql
import processing
processing.run("algorithm_id", {parameter_dictionary})
algorithm id は、プロセシングツールボックス内でアルゴリズムにマウスカーソルを乗せた際に表示されるIDです。 parameter dictionary は、パラメータの「名前」とその値を指定するマッピング型です。Python コンソールからプロセシングアルゴリズムを実行する方法の詳細については、 プロセシングアルゴリズムをコンソールから使う を参照してください。
27.1.17.13. レイヤをDXFにエクスポート
レイヤを DXF ファイルにエクスポートします。各レイヤについてフィールドを選択し、その値によってDXF 出力の生成された出力先レイヤに地物を分けることができます。
パラメータ
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
入力レイヤ |
|
[ベクタ:任意] [リスト] |
エクスポートしたい入力ベクタレイヤ |
シンボロジーモード |
|
[列挙型] デフォルト: 0 |
出力レイヤに適用するシンボロジの種類。次から選ぶことができます:
|
シンボルのスケール |
|
[縮尺] デフォルト: 1:1 000 000 |
デフォルトのエクスポートするデータの縮尺 |
文字コード |
|
[列挙型] |
レイヤに適用する文字コード |
CRS |
|
[crs] |
出力レイヤのCRSを選びます |
レイヤ名を名前に使用 |
|
[ブール値] デフォルト: False |
レイヤ名の代わりに(QGISで付けられた)レイヤタイトルを使って出力レイヤに名前を付けます。 |
二次元出力を強制 |
|
[ブール値] デフォルト: False |
|
ラベルをMTEXT要素としてエクスポートする |
|
[ブール値] デフォルト: False |
ラベルをMTEXTまたはTEXT要素としてエクスポートします |
DXF |
|
[ファイル] デフォルト: |
DXF出力ファイルを指定します。次のいずれかです:
|
出力
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
DXF |
|
[ファイル] |
|
Python コード
Algorithm ID: native:dxfexport
import processing
processing.run("algorithm_id", {parameter_dictionary})
algorithm id は、プロセシングツールボックス内でアルゴリズムにマウスカーソルを乗せた際に表示されるIDです。 parameter dictionary は、パラメータの「名前」とその値を指定するマッピング型です。Python コンソールからプロセシングアルゴリズムを実行する方法の詳細については、 プロセシングアルゴリズムをコンソールから使う を参照してください。
27.1.17.14. 選択した地物で別レイヤ
選択された地物を新しいレイヤとして保存します。
注釈
選択されたレイヤに選択された地物がない場合には、新しく作成されるレイヤは空のレイヤです。
パラメータ
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
入力レイヤ |
|
[ベクタ:任意] |
選択地物を保存したいレイヤ |
選択されている地物 |
|
[入力レイヤと同じ] デフォルト: |
選択地物によるベクタレイヤを指定します。次のいずれかです:
ここでファイルの文字コードを変更することもできます。 |
出力
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
選択されている地物 |
|
[入力レイヤと同じ] |
選択地物のみのベクタレイヤ。地物選択がない場合には地物のないレイヤ。 |
Python コード
Algorithm ID: native:saveselectedfeatures
import processing
processing.run("algorithm_id", {parameter_dictionary})
algorithm id は、プロセシングツールボックス内でアルゴリズムにマウスカーソルを乗せた際に表示されるIDです。 parameter dictionary は、パラメータの「名前」とその値を指定するマッピング型です。Python コンソールからプロセシングアルゴリズムを実行する方法の詳細については、 プロセシングアルゴリズムをコンソールから使う を参照してください。
27.1.17.15. シェープファイルの文字コードを抽出
シェープファイルに埋め込まれた属性値の文字コード情報を抽出します。オプションファイルの .cpg ファイルで指定される文字コードと、 .dbf ファイルのLDIDヘッダブロックにある文字コード詳細の両方がチェックされます。
パラメータ
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
入力レイヤ |
|
[ベクタ:任意] |
文字コード情報を抽出したいESRIシェープファイル( |
出力
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
文字コード |
|
[文字列] |
入力ファイル内で指定されている文字コードの情報 |
CPGファイルの文字コード |
|
[文字列] |
オプションファイルの |
LDID部分の文字コード |
|
[文字列] |
|
Python コード
Algorithm ID: native:shpencodinginfo
import processing
processing.run("algorithm_id", {parameter_dictionary})
algorithm id は、プロセシングツールボックス内でアルゴリズムにマウスカーソルを乗せた際に表示されるIDです。 parameter dictionary は、パラメータの「名前」とその値を指定するマッピング型です。Python コンソールからプロセシングアルゴリズムを実行する方法の詳細については、 プロセシングアルゴリズムをコンソールから使う を参照してください。
27.1.17.16. 投影法を調べる
例えば投影法が不明なレイヤのために、座標参照系の候補のリストを作成します。
レイヤがカバーする領域は「レイヤのターゲット領域」パラメータで指定する必要があります。このターゲット領域の座標参照系はQGISに渡す必要があります。
このアルゴリズムは、レイヤの範囲を既知のすべての座標参照系でテストし、レイヤがこの投影法であると仮定するとその境界がターゲット領域の近くになる可能性があるものをすべてリスト化します。
参考
パラメータ
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
入力レイヤ |
|
[ベクタ:任意] |
投影法が不明なレイヤ |
レイヤのターゲット領域 (xmin, xmax, ymin, ymax) |
|
[範囲] |
レイヤがカバーする領域 利用できる方法:
|
出力レイヤ |
|
[テーブル] デフォルト: |
CRSの提案(EPSGコード)をリストしたテーブル(ジオメトリなしのレイヤ)の出力を指定します。次のいずれかです:
ここでファイルの文字コードを変更することもできます。 |
出力
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
出力レイヤ |
|
[テーブル] |
基準にマッチするすべてのCRS(EPSG コード)をリストしたテーブル |
Python コード
Algorithm ID: qgis:findprojection
import processing
processing.run("algorithm_id", {parameter_dictionary})
algorithm id は、プロセシングツールボックス内でアルゴリズムにマウスカーソルを乗せた際に表示されるIDです。 parameter dictionary は、パラメータの「名前」とその値を指定するマッピング型です。Python コンソールからプロセシングアルゴリズムを実行する方法の詳細については、 プロセシングアルゴリズムをコンソールから使う を参照してください。
27.1.17.17. リレーションのフラット化
ベクタレイヤの リレーション のフラット化、すなわち、関連する子地物ごとに1つの親地物を含んだ単一のレイヤを作成します。このマスタ地物には、関連する地物のすべての属性が含まれます。これにより、リレーションを単純なテーブルとして持たせられ、例えばCSVにエクスポートすることができます。
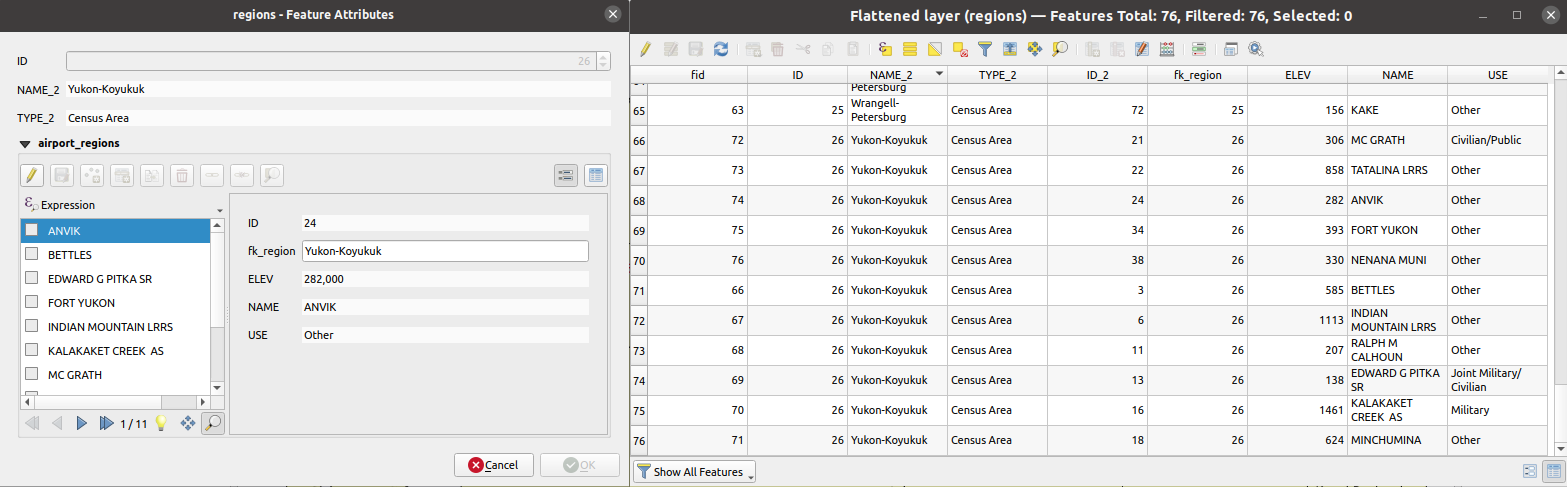
図 27.47 region のフォームと、リレーションのある子地物(左)― リレーションのある子地物ごとに複製されたregion の地物と、結合された属性(右)
パラメータ
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
入力レイヤ |
|
[ベクタ:任意] |
リレーションの非正規化を行いたいレイヤ |
フラット化出力 オプション |
|
[入力レイヤと同じ] デフォルト: |
出力レイヤ(フラット化されたレイヤ)を指定します。次のいずれかです:
ここでファイルの文字コードを変更することもできます。 |
出力
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
フラット化出力 |
|
[入力レイヤと同じ] |
マスタ地物と、リレーションのある地物の全ての属性を含むレイヤ |
Python コード
Algorithm ID: native:flattenrelationships
import processing
processing.run("algorithm_id", {parameter_dictionary})
algorithm id は、プロセシングツールボックス内でアルゴリズムにマウスカーソルを乗せた際に表示されるIDです。 parameter dictionary は、パラメータの「名前」とその値を指定するマッピング型です。Python コンソールからプロセシングアルゴリズムを実行する方法の詳細については、 プロセシングアルゴリズムをコンソールから使う を参照してください。
27.1.17.18. 属性テーブルで結合(table join)
入力ベクタレイヤを受け取り、その属性テーブルに別の属性を追加して、入力レイヤの拡張版となる新しいベクタレイヤを作成します。
追加の属性とその値は、第2のベクタレイヤから取得されます。それぞれのレイヤで属性を選択し、結合の条件が定義されます。
パラメータ
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
入力レイヤ |
|
[ベクタ:任意] |
入力ベクタレイヤ。出力レイヤはこのレイヤの地物と、第2のレイヤでマッチする地物の属性からなります。 |
入力レイヤの結合対象フィールド |
|
[テーブルのフィールド:任意] |
ソースレイヤで結合に使用するフィールド |
第2の入力レイヤ |
|
[ベクタ:任意] |
属性テーブルを結合させたいレイヤ |
第2の入力レイヤの結合対象フィールド |
|
[テーブルのフィールド:任意] |
結合に使用する第2のレイヤ(結合レイヤ)のフィールド。このフィールドの型は、入力テーブルのフィールド型と等しい(または互換性がある)ものでなければなりません。 |
第2の入力レイヤからコピーする属性(全属性をコピーする場合は空のまま) オプション |
|
[テーブルのフィールド:任意] [リスト] |
追加したいフィールドを指定して選択します。デフォルトでは、すべてのフィールドが追加されます。 |
結合のタイプ |
|
[列挙型] デフォルト: 1 |
レイヤの結合のタイプ。次のいずれかです:
|
結合対象がなかった地物を破棄 |
|
[ブール値] デフォルト: True |
結合できなかった地物を残したくない場合には、チェックを入れてください |
コピーしたフィールドの接頭辞 オプション |
|
[文字列] |
結合したフィールドを区別しやすくし、フィールド名の衝突を避けるため、結合フィールドに接頭辞を追加します |
出力レイヤ オプション |
|
[入力レイヤと同じ] デフォルト: |
結合したベクタレイヤの出力を指定します。次のいずれかです:
ここでファイルの文字コードを変更することもできます。 |
入力レイヤのうち、結合対象がなかった地物 オプション |
|
[入力レイヤと同じ] デフォルト: |
最初のレイヤの地物のうち、結合できなかった地物のベクタレイヤの出力を指定します。次のいずれかです:
ここでファイルの文字コードを変更することもできます。 |
出力
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
入力テーブルから結合された地物の数 |
|
[数値] |
|
入力レイヤのうち、結合対象がなかった地物 オプション |
|
[入力レイヤと同じ] |
結合できなかった地物のベクタレイヤ |
出力レイヤ オプション |
|
[入力レイヤと同じ] |
結合レイヤの属性が追加された出力ベクタレイヤ |
入力テーブルから結合できなかった地物の数 オプション |
|
[数値] |
Python コード
Algorithm ID: native:joinattributestable
import processing
processing.run("algorithm_id", {parameter_dictionary})
algorithm id は、プロセシングツールボックス内でアルゴリズムにマウスカーソルを乗せた際に表示されるIDです。 parameter dictionary は、パラメータの「名前」とその値を指定するマッピング型です。Python コンソールからプロセシングアルゴリズムを実行する方法の詳細については、 プロセシングアルゴリズムをコンソールから使う を参照してください。
27.1.17.19. 属性の空間結合
入力ベクタレイヤを受け取り、その属性テーブルに別の属性を追加して、入力レイヤの拡張版となる新しいベクタレイヤを作成します。
追加される属性とその値は、第2のベクタレイヤから取得されます。空間的な基準を適用して選択された第2のレイヤの値が、第1のレイヤの各地物に追加されます。
デフォルトメニュー:
空間的関係を調べる
幾何学的述語は、ある地物が他の地物と空間の一部を共有しているかどうか、またどのように共有しているかを比較することによって、空間的関係を持つかどうかを決定するために使用されるブール関数です。
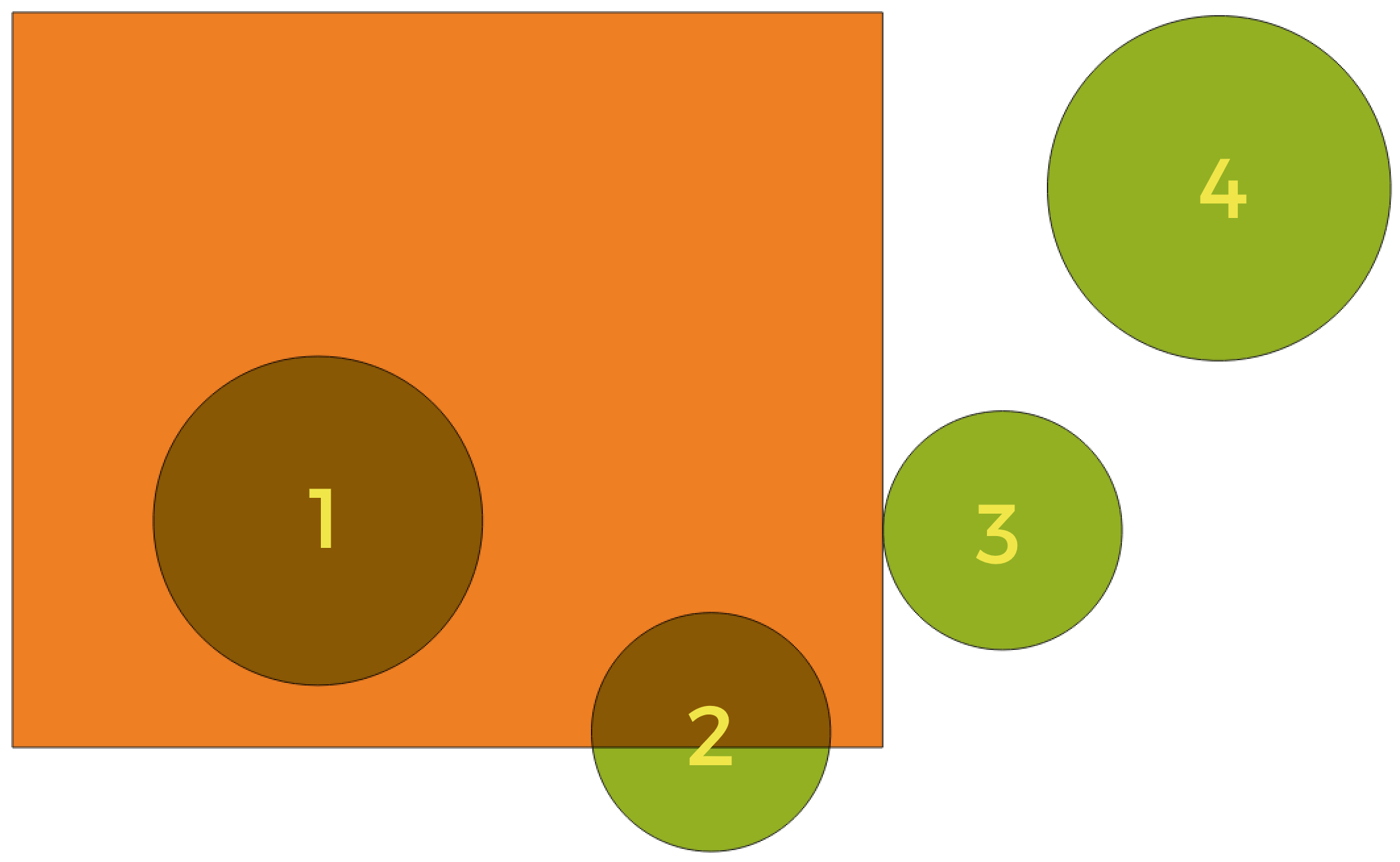
図 27.48 レイヤ間の空間的関係を求める
上の図を使って、オレンジ色の長方形の地物と空間的に比較することで、緑色の円を求めます。利用可能な幾何学的述語は以下の通りです:
- 交差する(intersect)
あるジオメトリが他のジオメトリと交差しているかどうかをテストします。ジオメトリが空間的に交差している(空間の一部を共有している - 重なり合うか接触している)場合は1(true)を返し、交差していない場合は0を返す。上の図では、円 1、2、3 を返す。
- 含む(contain)
b の点が a の外側になく、かつ b の内側の少なくとも1点が a の内側にある場合にのみ、1 (true)を返す。この図では、どの円も返さないが、逆を探せば、長方形は円 1 を完全に含むので、返す。これは 含まれる(within) の逆である。
- 離れている(disjoint)
ジオメトリが空間のどの部分も共有していない(重なっていない、接触していない)場合、1 (true)を返す。円4のみが返される。
- 等しい(equal)
ジオメトリが完全に同じ場合のみ、1 (true)を返す。どの円も返されない。
- 接触する(touch)
あるジオメトリが別のジオメトリに接しているかどうかを調べます。ジオメトリに少なくとも1つの共通点があるが、内部が交差していない場合は1 (true)を返します。円3のみが返されます。
- 重なる(overtap)
あるジオメトリが別のジオメトリに重なっているかどうかを調べます。ジオメトリが空間を共有し、同じ大きさであるが、互いに完全に含まれない場合は1 (true)を返します。円2のみが返されます。
- 含まれる(within)
あるジオメトリが他のジオメトリの中にあるかどうかを調べます。ジオメトリ a が完全にジオメトリ b の内側にある場合は 1 (true)を返します。
- 交差する(cross)
与えられたジオメトリが、すべてではなく、いくつかの内部点を共通に持ち、交差部が与えられたジオメトリの最大よりも小さい次元の場合、1 (true)を返します。例えば、ポリゴンを横切るラインは、ラインとして交差します (true)。交差する2本のラインは、ポイントとして交差します (true)。2つのポリゴンはポリゴンとして交差します (false)。図では、どの円は返されません。
パラメータ
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
地物を結合するレイヤ |
|
[ベクタ:任意] |
入力ベクタレイヤ。出力レイヤはこのレイヤの地物と、第2のレイヤでマッチする地物の属性からなります。 |
空間的関係 |
|
[列挙型] [リスト] デフォルト: [0] |
ソース地物がターゲット地物との間に持っている場合に結合される、空間関係の種類。次の1つ以上:
複数の条件が選択された場合、そのうちの少なくとも1つ(OR演算)を満たさなければ地物は抽出されません。 |
比較対象 |
|
[ベクタ:任意] |
結合レイヤ。このベクタレイヤの地物の空間的関係が満たされるとき、その属性がソースレイヤの属性テーブルに 追加 されます。 |
結合するフィールド(すべてのフィールドを結合する場合は空のまま) オプション |
|
[テーブルのフィールド:任意] [リスト] |
結合レイヤから追加したい特定のフィールドを選択します。デフォルトでは、すべてのフィールドが追加されます。 |
結合のタイプ |
|
[列挙型] |
レイヤの結合のタイプ。次のいずれかです:
|
結合対象がなかった地物を破棄 |
|
[ブール値] デフォルト: False |
結合できなかった入力レイヤの地物を出力結果では削除します |
コピーしたフィールドの接頭辞 オプション |
|
[文字列] |
結合したフィールドを区別しやすくし、フィールド名の衝突を避けるため、結合フィールドに接頭辞を追加します |
出力レイヤ オプション |
|
[入力レイヤと同じ] デフォルト: |
結合したベクタレイヤの出力を指定します。次のいずれかです:
ここでファイルの文字コードを変更することもできます。 |
入力レイヤのうち、結合対象がなかった地物 オプション |
|
[入力レイヤと同じ] デフォルト: |
最初のレイヤの地物のうち、結合できなかった地物のベクタレイヤの出力を指定します。次のいずれかです:
ここでファイルの文字コードを変更することもできます。 |
出力
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
入力テーブルから結合された地物の数 |
|
[数値] |
|
入力レイヤのうち、結合対象がなかった地物 オプション |
|
[入力レイヤと同じ] |
結合できなかった地物のベクタレイヤ |
出力レイヤ |
|
[入力レイヤと同じ] |
結合レイヤの属性が追加された出力ベクタレイヤ |
Python コード
Algorithm ID: native:joinattributesbylocation
import processing
processing.run("algorithm_id", {parameter_dictionary})
algorithm id は、プロセシングツールボックス内でアルゴリズムにマウスカーソルを乗せた際に表示されるIDです。 parameter dictionary は、パラメータの「名前」とその値を指定するマッピング型です。Python コンソールからプロセシングアルゴリズムを実行する方法の詳細については、 プロセシングアルゴリズムをコンソールから使う を参照してください。
27.1.17.20. 空間結合(集計つき)
入力ベクタレイヤを受け取り、その属性テーブルに別の属性を追加して、入力レイヤの拡張版となる新しいベクタレイヤを作成します。
追加される属性とその値は、第2のベクタレイヤから取得されます。空間的な基準を適用して選択された第2のレイヤの値が、第1のレイヤの各地物に追加されます。
このアルゴリズムは、マッチングする第2のレイヤの地物の値について、要約統計量(最大値、平均値など)を計算します。
参考
空間的関係を調べる
幾何学的述語は、ある地物が他の地物と空間の一部を共有しているかどうか、またどのように共有しているかを比較することによって、空間的関係を持つかどうかを決定するために使用されるブール関数です。
図 27.49 レイヤ間の空間的関係を求める
上の図を使って、オレンジ色の長方形の地物と空間的に比較することで、緑色の円を求めます。利用可能な幾何学的述語は以下の通りです:
- 交差する(intersect)
あるジオメトリが他のジオメトリと交差しているかどうかをテストします。ジオメトリが空間的に交差している(空間の一部を共有している - 重なり合うか接触している)場合は1(true)を返し、交差していない場合は0を返す。上の図では、円 1、2、3 を返す。
- 含む(contain)
b の点が a の外側になく、かつ b の内側の少なくとも1点が a の内側にある場合にのみ、1 (true)を返す。この図では、どの円も返さないが、逆を探せば、長方形は円 1 を完全に含むので、返す。これは 含まれる(within) の逆である。
- 離れている(disjoint)
ジオメトリが空間のどの部分も共有していない(重なっていない、接触していない)場合、1 (true)を返す。円4のみが返される。
- 等しい(equal)
ジオメトリが完全に同じ場合のみ、1 (true)を返す。どの円も返されない。
- 接触する(touch)
あるジオメトリが別のジオメトリに接しているかどうかを調べます。ジオメトリに少なくとも1つの共通点があるが、内部が交差していない場合は1 (true)を返します。円3のみが返されます。
- 重なる(overtap)
あるジオメトリが別のジオメトリに重なっているかどうかを調べます。ジオメトリが空間を共有し、同じ大きさであるが、互いに完全に含まれない場合は1 (true)を返します。円2のみが返されます。
- 含まれる(within)
あるジオメトリが他のジオメトリの中にあるかどうかを調べます。ジオメトリ a が完全にジオメトリ b の内側にある場合は 1 (true)を返します。
- 交差する(cross)
与えられたジオメトリが、すべてではなく、いくつかの内部点を共通に持ち、交差部が与えられたジオメトリの最大よりも小さい次元の場合、1 (true)を返します。例えば、ポリゴンを横切るラインは、ラインとして交差します (true)。交差する2本のラインは、ポイントとして交差します (true)。2つのポリゴンはポリゴンとして交差します (false)。図では、どの円は返されません。
パラメータ
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
地物を結合するレイヤ |
|
[ベクタ:任意] |
入力ベクタレイヤ。出力レイヤはこのレイヤの地物と、第2のレイヤでマッチする地物の属性からなります。 |
空間的関係 |
|
[列挙型] [リスト] デフォルト: [0] |
ソース地物がターゲット地物との間に持っている場合に結合される、空間関係の種類。次の1つ以上:
複数の条件が選択された場合、そのうちの少なくとも1つ(OR演算)を満たさなければ地物は抽出されません。 |
比較対象 |
|
[ベクタ:任意] |
結合レイヤ。このベクタレイヤの地物の空間的関係が満たされるとき、その属性の集計がソースレイヤの属性テーブルに 追加 されます。 |
集計する属性(全属性の場合は空のまま) オプション |
|
[テーブルのフィールド:任意] [リスト] |
結合レイヤから追加したい特定のフィールドを選択します。デフォルトでは、すべてのフィールドが追加されます。 |
計算する集計関数(すべて計算する場合は空のまま) オプション |
|
[列挙型] [リスト] デフォルト: [] |
各入力地物について、マッチする地物の結合フィールドの統計が計算されます。次のひとつ以上です:
|
結合対象がなかった地物を破棄 |
|
[ブール値] デフォルト: False |
結合できなかった入力レイヤの地物を出力結果では削除します |
出力レイヤ |
|
[入力レイヤと同じ] デフォルト: |
結合したベクタレイヤの出力を指定します。次のいずれかです:
ここでファイルの文字コードを変更することもできます。 |
出力
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
出力レイヤ |
|
[入力レイヤと同じ] |
結合レイヤの属性の統計量を持つ出力レイヤ |
Python コード
Algorithm ID: qgis:joinbylocationsummary
import processing
processing.run("algorithm_id", {parameter_dictionary})
algorithm id は、プロセシングツールボックス内でアルゴリズムにマウスカーソルを乗せた際に表示されるIDです。 parameter dictionary は、パラメータの「名前」とその値を指定するマッピング型です。Python コンソールからプロセシングアルゴリズムを実行する方法の詳細については、 プロセシングアルゴリズムをコンソールから使う を参照してください。
27.1.17.21. 属性の最近傍結合
入力ベクタレイヤを受け取り、その属性テーブルにフィールドを追加した新しいベクタレイヤを作成します。追加される属性と値は2つ目のベクタレイヤから取得されます。地物は、お互いのレイヤで最も近い地物を見つけて結合します。
デフォルトでは最も近い地物のみが結合しますが、結合は近くのk個の地物と行うこともできます。
最大距離を指定した場合には、この距離よりも近い地物のみがマッチします。
パラメータ
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
入力レイヤ |
|
[ベクタ:任意] |
入力レイヤ |
第2の入力レイヤ |
|
[ベクタ:任意] |
結合レイヤ |
第2の入力レイヤからコピーする属性(全属性をコピーする場合は空のまま) |
|
[フィールド] |
コピーしたい結合レイヤのフィールド(空の場合には、すべてのフィールドがコピーされます) |
結合対象がなかった地物を破棄 |
|
[ブール値] デフォルト: False |
結合できなかった入力レイヤのレコードを出力結果では削除します |
コピーしたフィールドの接頭辞 |
|
[文字列] |
コピーしたフィールドの接頭辞 |
近接地物の個数(n) |
|
[数値] デフォルト: 1 |
最近傍の個数の最大値 |
最大距離 |
|
[数値] |
検索距離の最大値 |
出力レイヤ オプション |
|
[入力レイヤと同じ] デフォルト: |
結合した地物を含むベクタレイヤを指定します。次のいずれかです:
ここでファイルの文字コードを変更することもできます。 |
入力レイヤのうち、結合対象がなかった地物 |
|
[入力レイヤと同じ] デフォルト: |
結合できなかった地物を含むベクタレイヤを指定します。次のいずれかです:
ここでファイルの文字コードを変更することもできます。 |
出力
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
出力レイヤ |
|
[入力レイヤと同じ] |
結合した出力レイヤ |
入力レイヤのうち、結合対象がなかった地物 |
|
[入力レイヤと同じ] |
結合レイヤのどの地物とも結合できなかった最初のレイヤの地物を含むレイヤ |
入力テーブルから結合された地物の数 |
|
[数値] |
入力テーブルから結合された地物の数 |
入力テーブルから結合できなかった地物の数 |
|
[数値] |
入力テーブルから結合できなかった地物の数 |
Python コード
Algorithm ID: native:joinbynearest
import processing
processing.run("algorithm_id", {parameter_dictionary})
algorithm id は、プロセシングツールボックス内でアルゴリズムにマウスカーソルを乗せた際に表示されるIDです。 parameter dictionary は、パラメータの「名前」とその値を指定するマッピング型です。Python コンソールからプロセシングアルゴリズムを実行する方法の詳細については、 プロセシングアルゴリズムをコンソールから使う を参照してください。
27.1.17.22. ベクタレイヤのマージ
同じジオメトリタイプ の複数のベクタレイヤを単一のベクタレイヤに統合します。
結果レイヤの属性テーブルには、すべての入力レイヤからのフィールドが含まれます。同じ名前であるが異なる型のフィールドがある場合には、出力されるフィールドは自動的に文字列型のフィールドに変換されます。元のレイヤ名とソースを保存する新しいフィールドも追加されます。
入力レイヤにZ座標やM値がある場合には、出力レイヤにもZ座標やM値が含まれます。同様に、任意の入力レイヤがマルチパートの場合には、出力レイヤもマルチパートレイヤとなります。
オプションとして、マージしたレイヤの変換先座標参照系(CRS)を設定することができます。これを設定しない場合には、CRSは最初の入力レイヤから取得されます。すべての入力レイヤはこのCRSに一致するように再投影されます。
デフォルトメニュー:
参考
パラメータ
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
入力レイヤ |
|
[ベクタ:任意] [リスト] |
単一のレイヤにマージしたいレイヤ群。レイヤは同じジオメトリタイプである必要があります。 |
変換先の座標参照系(CRS) オプション |
|
[crs] |
出力レイヤのCRSを選択します。指定しない場合には、最初の入力レイヤのCRSが使用されます。 |
出力レイヤ |
|
[入力レイヤと同じ] デフォルト: |
出力ベクタレイヤを指定します。次のいずれかです:
ここでファイルの文字コードを変更することもできます。 |
出力
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
出力レイヤ |
|
[入力レイヤと同じ] |
入力レイヤのすべての地物と属性を持つ出力ベクタレイヤ |
Python コード
Algorithm ID: native:mergevectorlayers
import processing
processing.run("algorithm_id", {parameter_dictionary})
algorithm id は、プロセシングツールボックス内でアルゴリズムにマウスカーソルを乗せた際に表示されるIDです。 parameter dictionary は、パラメータの「名前」とその値を指定するマッピング型です。Python コンソールからプロセシングアルゴリズムを実行する方法の詳細については、 プロセシングアルゴリズムをコンソールから使う を参照してください。
27.1.17.23. 式による並べ替え
式に従ってベクタレイヤをソートします。つまり、式に従って地物のインデックスを変更します。
データプロバイダによっては順序が毎回維持されない場合があり、期待通りに機能しない可能性があるため注意して下さい。
パラメータ
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
入力レイヤ |
|
[ベクタ:任意] |
ソートしたい入力ベクタレイヤ |
式 |
|
[式] |
ソートに使用する式 |
昇順 |
|
[ブール値] デフォルト: True |
チェックを入れた場合には、ベクタレイヤは小さい値から大きい値となるように並べられます。 |
NULLは最初にソートされる |
|
[ブール値] デフォルト: False |
チェックを入れた場合には、NULL値が最初に並びます。 |
出力レイヤ |
|
[入力レイヤと同じ] デフォルト: |
出力ベクタレイヤを指定します。次のいずれかです:
ここでファイルの文字コードを変更することもできます。 |
出力
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
出力レイヤ |
|
[入力レイヤと同じ] |
(ソートされた)出力ベクタレイヤ |
Python コード
Algorithm ID: native:orderbyexpression
import processing
processing.run("algorithm_id", {parameter_dictionary})
algorithm id は、プロセシングツールボックス内でアルゴリズムにマウスカーソルを乗せた際に表示されるIDです。 parameter dictionary は、パラメータの「名前」とその値を指定するマッピング型です。Python コンソールからプロセシングアルゴリズムを実行する方法の詳細については、 プロセシングアルゴリズムをコンソールから使う を参照してください。
27.1.17.24. シェープファイルを修復
SHXファイルを(再度)作成することによって、壊れたESRIシェープファイルデータセットを修復します。
パラメータ
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
シェープファイル |
|
[ファイル] |
SHXファイルが無い、あるいはSHXファイルが壊れたESRIシェープファイルデータセットのフルパス |
出力
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
修復済みファイル |
|
[ベクタ:任意] |
入力ベクタレイヤのSHXファイルが修復されたレイヤ |
Python コード
Algorithm ID: native:repairshapefile
import processing
processing.run("algorithm_id", {parameter_dictionary})
algorithm id は、プロセシングツールボックス内でアルゴリズムにマウスカーソルを乗せた際に表示されるIDです。 parameter dictionary は、パラメータの「名前」とその値を指定するマッピング型です。Python コンソールからプロセシングアルゴリズムを実行する方法の詳細については、 プロセシングアルゴリズムをコンソールから使う を参照してください。
27.1.17.25. レイヤの再投影
ベクタレイヤを別のCRSに再投影します。再投影されたレイヤは、入力レイヤと同じ地物と同じ属性を持ちます。
ポイント、ライン、ポリゴン地物の 地物のIn-place編集 が可能です
参考
パラメータ
基本パラメータ
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
入力レイヤ |
|
[ベクタ:任意] |
再投影したい入力ベクタレイヤ |
ラスタのCRS |
|
[crs] デフォルト: |
変換先の座標参照系 |
再投影したラスタファイル |
|
[入力レイヤと同じ] デフォルト: |
出力ベクタレイヤを指定します。次のいずれかです:
ここでファイルの文字コードを変更することもできます。 |
詳細パラメータ
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
座標演算 オプション |
|
[文字列] |
現在のプロジェクトの変換設定を常に強制的に使用する代わりの、特定の再投影タスクに使用するための特定の操作です。特定のレイヤを再投影する際に、正確な変換パイプラインによる再投影が必要な場合に便利です。proj のバージョン6 以上が必要です。 詳細は 測地系変換 を参照してください。 |
出力
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
再投影したラスタファイル |
|
[入力レイヤと同じ] |
(再投影された)出力ベクタレイヤ |
Python コード
Algorithm ID: native:reprojectlayer
import processing
processing.run("algorithm_id", {parameter_dictionary})
algorithm id は、プロセシングツールボックス内でアルゴリズムにマウスカーソルを乗せた際に表示されるIDです。 parameter dictionary は、パラメータの「名前」とその値を指定するマッピング型です。Python コンソールからプロセシングアルゴリズムを実行する方法の詳細については、 プロセシングアルゴリズムをコンソールから使う を参照してください。
27.1.17.26. ベクタ地物をファイルに保存
ベクタ地物を指定したファイルデータセットに保存します。
レイヤをサポートするデータセット形式では、オプションとしてレイヤ名パラメータにカスタム文字列を指定することができます。また、オプションとして、GDALで定義されているデータセット作成オプションやレイヤ作成オプションを指定することもできます。これに関する詳細については、その形式に関するオンラインの GDAL documentation を参照してください。
パラメータ
基本パラメータ
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
ベクタ地物 |
|
[ベクタ:任意] |
入力ベクタレイヤ |
保存先出力 |
|
[入力レイヤと同じ] デフォルト: |
地物を保存するファイルを指定します。次のいずれかです:
|
詳細パラメータ
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
レイヤ名 オプション |
|
[文字列] |
出力レイヤに使用するレイヤ名 |
GDALデータセットオプション オプション |
|
[文字列] |
出力ファイル形式に関するGDALデータセット作成オプション。複数ある場合は各オプションをセミコロンで区切ります。 |
GDALレイヤオプション オプション |
|
[文字列] |
出力ファイル形式に関するGDALレイヤ作成オプション。複数ある場合は各オプションをセミコロンで区切ります。 |
出力
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
保存先出力 |
|
[入力レイヤと同じ] |
地物が保存されたベクタレイヤ |
ファイルとパス |
|
[文字列] |
出力ファイルのファイル名とパス |
レイヤ名 |
|
[文字列] |
レイヤ名(あれば) |
Python コード
Algorithm ID: native:savefeatures
import processing
processing.run("algorithm_id", {parameter_dictionary})
algorithm id は、プロセシングツールボックス内でアルゴリズムにマウスカーソルを乗せた際に表示されるIDです。 parameter dictionary は、パラメータの「名前」とその値を指定するマッピング型です。Python コンソールからプロセシングアルゴリズムを実行する方法の詳細については、 プロセシングアルゴリズムをコンソールから使う を参照してください。
27.1.17.27. レイヤの文字コードを設定
レイヤの属性値の読み込みに使用する文字コードを設定します。レイヤに変更を行うのではなく、現在のセッションにおけるレイヤの読み込みのみが影響します。
注釈
文字コードの変更をサポートするのは、一部のベクタレイヤデータソースのみです。
パラメータ
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
保存先出力 |
|
[ベクタ:任意] |
文字コードを設定したいベクタレイヤ |
文字コード |
|
[文字列] |
現在のQGISセッションにおいてレイヤに適用されるテキストエンコーディング |
出力
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
出力レイヤ |
|
[入力レイヤと同じ] |
設定された文字コードの入力ベクタレイヤ |
Python コード
Algorithm ID: native:setlayerencoding
import processing
processing.run("algorithm_id", {parameter_dictionary})
algorithm id は、プロセシングツールボックス内でアルゴリズムにマウスカーソルを乗せた際に表示されるIDです。 parameter dictionary は、パラメータの「名前」とその値を指定するマッピング型です。Python コンソールからプロセシングアルゴリズムを実行する方法の詳細については、 プロセシングアルゴリズムをコンソールから使う を参照してください。
27.1.17.28. 文字で地物を分割
フィールドの値を指定した区切り文字で分割することで、地物を複数に分割します。例えば、あるレイヤの単一のフィールドに複数のカンマ区切りの値を含む地物がある場合に、このアルゴリズムを使用してそれらの値を分割し、複数の出力地物に分割することができます。ジオメトリやその他の属性値はそのままです。オプションとして、区切り文字に正規表現を使うことができ、区切り文字を柔軟に指定できます。
ポイント、ライン、ポリゴン地物の 地物のIn-place編集 が可能です
パラメータ
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
入力レイヤ |
|
[ベクタ:任意] |
入力ベクタレイヤ |
分割するフィールド |
|
[テーブルのフィールド:任意] |
分割に使用するフィールド |
区切り文字 |
|
[文字列] |
分割に使用する区切り文字 |
区切り文字に正規表現を使う |
|
[ブール値] デフォルト: False |
|
出力レイヤ |
|
[入力レイヤと同じ] デフォルト: |
出力ベクタレイヤを指定します。次のいずれかです:
ここでファイルの文字コードを変更することもできます。 |
出力
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
出力レイヤ |
|
[入力レイヤと同じ] |
入力ベクタレイヤ |
Python コード
Algorithm ID: native:splitfeaturesbycharacter
import processing
processing.run("algorithm_id", {parameter_dictionary})
algorithm id は、プロセシングツールボックス内でアルゴリズムにマウスカーソルを乗せた際に表示されるIDです。 parameter dictionary は、パラメータの「名前」とその値を指定するマッピング型です。Python コンソールからプロセシングアルゴリズムを実行する方法の詳細については、 プロセシングアルゴリズムをコンソールから使う を参照してください。
27.1.17.29. 属性でレイヤを分割
入力レイヤと属性に基づいて、出力フォルダにベクタレイヤの組を作成します。出力フォルダには、指定したフィールドで見つかったユニーク値の個数分のレイヤが作成されます。
生成されるファイルの数は、指定した属性に見つかった相異なる値の数と同じです。
これは、 ベクタレイヤのマージ とは反対の操作です。
デフォルトメニュー:
参考
パラメータ
基本パラメータ
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
入力レイヤ |
|
[ベクタ:任意] |
入力ベクタレイヤ |
ユニークID属性 |
|
[テーブルのフィールド:任意] |
分割に使用するフィールド |
出力フォルダ |
|
[フォルダ] デフォルト: |
出力レイヤの保存ディレクトリを指定します。次のいずれかです:
|
詳細パラメータ
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
出力ファイル型 オプション |
|
[列挙型] デフォルト:ダイアログウィンドウで |
出力ファイルの拡張子を選択します。未指定または無効の場合、出力ファイル形式はプロセシング設定の「デフォルトのベクタレイヤ拡張子」で設定されたものになります。 |
出力
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
出力フォルダ |
|
[フォルダ] |
出力レイヤの保存ディレクトリ |
出力レイヤ |
|
[入力レイヤと同じ] [リスト] |
分割による結果の出力ベクタレイヤ |
Python コード
Algorithm ID: native:splitvectorlayer
import processing
processing.run("algorithm_id", {parameter_dictionary})
algorithm id は、プロセシングツールボックス内でアルゴリズムにマウスカーソルを乗せた際に表示されるIDです。 parameter dictionary は、パラメータの「名前」とその値を指定するマッピング型です。Python コンソールからプロセシングアルゴリズムを実行する方法の詳細については、 プロセシングアルゴリズムをコンソールから使う を参照してください。
27.1.17.30. テーブルを空にする
レイヤ内のすべての地物を削除することで、レイヤのテーブルを空にします。
警告
このアルゴリズムはレイヤを直接編集し、削除された地物は元に戻すことはできません。
パラメータ
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
入力レイヤ |
|
[ベクタ:任意] |
入力ベクタレイヤ |
出力
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
空のレイヤ |
|
[フォルダ] |
削除された(空の)レイヤ |
Python コード
Algorithm ID: native:truncatetable
import processing
processing.run("algorithm_id", {parameter_dictionary})
algorithm id は、プロセシングツールボックス内でアルゴリズムにマウスカーソルを乗せた際に表示されるIDです。 parameter dictionary は、パラメータの「名前」とその値を指定するマッピング型です。Python コンソールからプロセシングアルゴリズムを実行する方法の詳細については、 プロセシングアルゴリズムをコンソールから使う を参照してください。