27.1.21. ベクタテーブル
27.1.21.1. 自動インクリメント属性を追加
各地物に連続した値を持たせる新しい整数フィールドをベクタレイヤに追加します。
このフィールドは、レイヤ内の地物の一意のIDとして使用できます。新しい属性は入力レイヤに追加されませんが、代わりに新しいレイヤが生成されます。
増加数列の初期開始値を指定できます。必要に応じて、増加数列はグループ化フィールドに基づくことができ、地物のソート順も指定できます。
パラメーター
ラベル |
名前 |
タイプ |
説明 |
|---|---|---|---|
入力レイヤ |
|
[ベクタ:任意] |
入力ベクタレイヤ |
属性名 |
|
[文字列] デフォルト:'AUTO' |
自動増加値を格納するフィールド名 |
開始値 オプション |
|
[数値] デフォルト: 0 |
増加するカウントの最初の数を指定します |
絶対値(modulus) オプション |
|
[数値] デフォルト: 0 |
オプションで絶対値を指定すると、フィールドの値が絶対値に達するたびにカウントをSTARTに戻します。 |
グループ化のための属性 オプション |
|
[テーブルのフィールド:任意] [リスト] |
グループ化フィールドを選択:レイヤー全体に対して1つのカウントを走らせる代わりに、これらのフィールドの組み合わせによって返される各値に対して別々のカウントを処理します。 |
ソート式 オプション |
|
[式] |
式を使い、レイヤの地物をグローバルに、または設定したグループフィールドに基づいて、ソートします。 |
昇順 |
|
[ブール値] デフォルト: True |
|
NULLは最初にソートされる |
|
[ブール値] デフォルト: False |
|
昇順 |
|
[入力レイヤと同じ] デフォルト: |
自動的に増加する属性を持った出力ベクタレイヤを指定します。次のいずれかです:
ここでファイルの文字コードを変更することもできます。 |
出力
ラベル |
名前 |
タイプ |
説明 |
|---|---|---|---|
昇順 |
|
[入力レイヤと同じ] |
自動的に増加する属性を持ったベクタレイヤ |
Python コード
Algorithm ID: native:addautoincrementalfield
import processing
processing.run("algorithm_id", {parameter_dictionary})
algorithm id は、プロセシングツールボックス内でアルゴリズムにマウスカーソルを乗せた際に表示されるIDです。 parameter dictionary は、パラメータの「名前」とその値を指定するマッピング型です。Python コンソールからプロセシングアルゴリズムを実行する方法の詳細については、 プロセシングアルゴリズムをコンソールから使う を参照してください。
27.1.21.2. 属性テーブルに属性を追加
新しいフィールドをベクタレイヤに追加します。
属性の名前と性質はパラメータで定義します。
新しい属性は入力レイヤに追加されず、代わりに新しいレイヤが生成されます。
パラメーター
ラベル |
名前 |
タイプ |
説明 |
|---|---|---|---|
入力レイヤ |
|
[ベクタ:任意] |
入力レイヤ |
属性名 |
|
[文字列] |
新しいフィールドの名前 |
フィールド型 |
|
[列挙型] デフォルト: 0 |
新しいフィールドの型。次から選びます:
|
フィールド精度 |
|
[数値] デフォルト: 10 |
フィールド長さ |
フィールド精度 |
|
[数値] デフォルト: 0 |
フィールドの精度。フィールド型がFloatのときに有用です。 |
出力レイヤ |
|
[入力レイヤと同じ] デフォルト: |
出力ベクタレイヤを指定します。次のいずれかです:
ここでファイルの文字コードを変更することもできます。 |
出力
ラベル |
名前 |
タイプ |
説明 |
|---|---|---|---|
出力レイヤ |
|
[入力レイヤと同じ] |
新しいフィールドが追加されたベクタレイヤ |
Python コード
Algorithm ID: native:addfieldtoattributestable
import processing
processing.run("algorithm_id", {parameter_dictionary})
algorithm id は、プロセシングツールボックス内でアルゴリズムにマウスカーソルを乗せた際に表示されるIDです。 parameter dictionary は、パラメータの「名前」とその値を指定するマッピング型です。Python コンソールからプロセシングアルゴリズムを実行する方法の詳細については、 プロセシングアルゴリズムをコンソールから使う を参照してください。
27.1.21.3. 分類用ユニーク属性を追加
ベクタレイヤとひとつの属性から新しい数値フィールドを追加します。
このフィールドの値は指定された属性の値に対応しているため、その属性に対して同じ値を持つ地物は新しい数値フィールドでも同じ値になります。
これは指定した属性に対して数値的に等価なものを生成し、分類を定義します。
新しい属性は入力レイヤに追加されず、代わりに新しいレイヤが生成されます。
パラメーター
ラベル |
名前 |
タイプ |
説明 |
|---|---|---|---|
入力レイヤ |
|
[ベクタ:任意] |
入力レイヤ |
分類属性 |
|
[テーブルのフィールド:任意] |
このフィールドに同じ値を持つ地物は同じインデックスを得ます。 |
出力する属性(フィールド)の名前 |
|
[文字列] デフォルト: 'NUM_FIELD' |
インデックスを格納する新しいフィールドの名前。 |
出力レイヤ |
|
[ベクタ:任意] デフォルト: |
インデックスを格納する数値フィールドを持つベクタレイヤ。次のいずれかです:
ここでファイルの文字コードを変更することもできます。 |
クラスの要約 |
|
[テーブル] デフォルト: |
対応する一意な値にマップされた分類フィールドの要約を格納するテーブルを指定します。以下のいずれかです:
ここでファイルの文字コードを変更することもできます。 |
出力
ラベル |
名前 |
タイプ |
説明 |
|---|---|---|---|
出力レイヤ |
|
[入力レイヤと同じ] |
インデックスを格納した数値フィールドを持つベクタレイヤ。 |
クラスの要約 |
|
[テーブル] |
対応する一意な値にマップされた分類フィールドの要約を持つテーブル。 |
Python コード
Algorithm ID: native:adduniquevalueindexfield
import processing
processing.run("algorithm_id", {parameter_dictionary})
algorithm id は、プロセシングツールボックス内でアルゴリズムにマウスカーソルを乗せた際に表示されるIDです。 parameter dictionary は、パラメータの「名前」とその値を指定するマッピング型です。Python コンソールからプロセシングアルゴリズムを実行する方法の詳細については、 プロセシングアルゴリズムをコンソールから使う を参照してください。
27.1.21.4. X/Yフィールドを追加
ポイントレイヤに X と Y(または緯度/経度)フィールドを追加します。X/Y フィールドは、レイヤと異なる CRS で計算することができます(例えば、投影CRSのレイヤで緯度/経度フィールドを作成します)。
 ライン地物の 地物のIn-place編集 が可能です
ライン地物の 地物のIn-place編集 が可能です
パラメーター
ラベル |
名前 |
タイプ |
説明 |
|---|---|---|---|
入力レイヤ |
|
[ベクタ:ポイント] |
入力レイヤ |
座標系 |
|
[crs] デフォルト: |
生成するxとyフィールドに使用する座標参照系 |
属性名の接頭辞 オプション |
|
[文字列] |
入力レイヤのフィールドとの名前の衝突を避けるために、新しいフィールド名に加える接頭辞。 |
出力レイヤ |
|
[ベクタ:ポイント] デフォルト: |
出力レイヤを指定します。次のいずれかです:
ここでファイルの文字コードを変更することもできます。 |
出力
ラベル |
名前 |
タイプ |
説明 |
|---|---|---|---|
出力レイヤ |
|
[ベクタ:ポイント] |
出力レイヤ - 2つの新しいdoubleのフィールド、 |
Python コード
Algorithm ID: native:addxyfieldstolayer
import processing
processing.run("algorithm_id", {parameter_dictionary})
algorithm id は、プロセシングツールボックス内でアルゴリズムにマウスカーソルを乗せた際に表示されるIDです。 parameter dictionary は、パラメータの「名前」とその値を指定するマッピング型です。Python コンソールからプロセシングアルゴリズムを実行する方法の詳細については、 プロセシングアルゴリズムをコンソールから使う を参照してください。
27.1.21.5. Pythonフィールド計算機
各地物に式を適用して得られる値を持った、新しい属性をベクタレイヤに加えます。
式はPython関数として定義されます。
パラメーター
ラベル |
名前 |
タイプ |
説明 |
|---|---|---|---|
入力レイヤ |
|
[ベクタ:任意] |
入力ベクタレイヤ |
追加するフィールドの名前 |
|
[文字列] デフォルト: 'NewField' |
新しいフィールドの名前 |
フィールド型 |
|
[列挙型] デフォルト: 0 |
新しいフィールドの型。次のいずれかです:
|
フィールド精度 |
|
[数値] デフォルト: 10 |
フィールド長さ |
フィールド精度 |
|
[数値] デフォルト: 3 |
フィールドの精度。フィールド型がFloatのときに有用です。 |
グローバル式 オプション |
|
[文字列] |
グローバル式セクションのコードは、計算機が入力レイヤのすべての地物を繰り返し処理する前に1回だけ実行されます。 したがって、これは、必要なモジュールをインポートしたり、以降の計算で使用される変数を計算したりするための正しい場所です。 |
計算式 |
|
[文字列] |
評価するPython計算式。例: 入力ポリゴンレイヤの面積を計算するには、次を追加します: value = $geom.area()
|
出力レイヤ |
|
[入力レイヤと同じ] デフォルト: |
新しい計算したフィールドを持ったベクタレイヤを指定します。次のいずれかです:
ここでファイルの文字コードを変更することもできます。 |
出力
ラベル |
名前 |
タイプ |
説明 |
|---|---|---|---|
出力レイヤ |
|
[入力レイヤと同じ] |
新しい計算したフィールドを持ったベクタレイヤ |
Python コード
Algorithm ID: qgis:advancedpythonfieldcalculator
import processing
processing.run("algorithm_id", {parameter_dictionary})
algorithm id は、プロセシングツールボックス内でアルゴリズムにマウスカーソルを乗せた際に表示されるIDです。 parameter dictionary は、パラメータの「名前」とその値を指定するマッピング型です。Python コンソールからプロセシングアルゴリズムを実行する方法の詳細については、 プロセシングアルゴリズムをコンソールから使う を参照してください。
27.1.21.6. 属性を削除
ベクタレイヤを取り、同じ地物を持ちますが、選択した列は持たない、新しいレイヤを生成します。
参考
パラメーター
ラベル |
名前 |
タイプ |
説明 |
|---|---|---|---|
入力レイヤ |
|
[ベクタ:任意] |
フィールドを削除する入力ベクタレイヤ |
削除する属性(フィールド) |
|
[テーブルのフィールド:任意] [リスト] |
削除するフィールド |
出力レイヤ |
|
[入力レイヤと同じ] デフォルト: |
残りのフィールドを持った出力ベクタレイヤを指定します。次のいずれかです:
ここでファイルの文字コードを変更することもできます。 |
出力
ラベル |
名前 |
タイプ |
説明 |
|---|---|---|---|
出力レイヤ |
|
[入力レイヤと同じ] |
残りのフィールドを持ったベクタレイヤ |
Python コード
Algorithm ID: native:deletecolumn
import processing
processing.run("algorithm_id", {parameter_dictionary})
algorithm id は、プロセシングツールボックス内でアルゴリズムにマウスカーソルを乗せた際に表示されるIDです。 parameter dictionary は、パラメータの「名前」とその値を指定するマッピング型です。Python コンソールからプロセシングアルゴリズムを実行する方法の詳細については、 プロセシングアルゴリズムをコンソールから使う を参照してください。
27.1.21.7. HStoreフィールドを展開
入力レイヤのコピーを作成し、HStore フィールドの一意キーごとに新しいフィールドを追加します。
期待されるフィールドリストは、オプションのカンマ区切りリストです。このリストを指定すると、これらのフィールドのみが追加され、HStoreフィールドが更新されます。デフォルトでは、すべての一意キーが追加されます。
PostgreSQL の HStore は、PostgreSQL と GDAL (other_tags フィールドを持つ OSM ファイル を読み込むとき) で使用される、単純なキーと値のストアです。
パラメーター
ラベル |
名前 |
タイプ |
説明 |
|---|---|---|---|
入力レイヤ |
|
[ベクタ:任意] |
入力ベクタレイヤ |
HStoreフィールド |
|
[テーブルのフィールド:任意] |
削除するフィールド |
選択するフィールド(カンマ区切り) オプション |
|
[文字列] デフォルト: '' |
展開するフィールドのコンマ区切りのリスト。HStoreフィールドはそれらのキーを削除することで更新されます。 |
出力レイヤ |
|
[入力レイヤと同じ] デフォルト: |
出力ベクタレイヤを指定します。次のいずれかです:
ここでファイルの文字コードを変更することもできます。 |
出力
ラベル |
名前 |
タイプ |
説明 |
|---|---|---|---|
出力レイヤ |
|
[入力レイヤと同じ] |
出力ベクタレイヤ |
Python コード
Algorithm ID: native:explodehstorefield
import processing
processing.run("algorithm_id", {parameter_dictionary})
algorithm id は、プロセシングツールボックス内でアルゴリズムにマウスカーソルを乗せた際に表示されるIDです。 parameter dictionary は、パラメータの「名前」とその値を指定するマッピング型です。Python コンソールからプロセシングアルゴリズムを実行する方法の詳細については、 プロセシングアルゴリズムをコンソールから使う を参照してください。
27.1.21.8. バイナリ属性を解凍
バイナリ・フィールドからコンテンツを抽出し、個々のファイルに保存します。ファイル名は、ソース・テーブルの属性から取得した値を使用して生成することも、より複雑な式に基づいて生成することもできます。
パラメーター
ラベル |
名前 |
タイプ |
説明 |
|---|---|---|---|
入力レイヤ |
|
[ベクタ:任意] |
バイナリデータを含んでいる入力ベクタレイヤ |
バイナリ属性 |
|
[テーブルのフィールド:任意] |
バイナリデータのフィールド |
ファイル名 |
|
[式] |
各出力ファイルに名前を付けるフィールド又は式のテキスト |
宛先フォルダ |
|
[フォルダ] デフォルト: |
出力ファイルを保存するフォルダ。次のいずれかです:
|
出力
ラベル |
名前 |
タイプ |
説明 |
|---|---|---|---|
フォルダ |
|
[フォルダ] |
出力ファイルを保存するフォルダ。 |
Python コード
Algorithm ID: native:extractbinary
import processing
processing.run("algorithm_id", {parameter_dictionary})
algorithm id は、プロセシングツールボックス内でアルゴリズムにマウスカーソルを乗せた際に表示されるIDです。 parameter dictionary は、パラメータの「名前」とその値を指定するマッピング型です。Python コンソールからプロセシングアルゴリズムを実行する方法の詳細については、 プロセシングアルゴリズムをコンソールから使う を参照してください。
27.1.21.9. フィールド計算機
フィールド計算機(:ref:`vector_expressions`を参照)を開きます。サポートされているすべての式と関数を使うことができます。
式の結果で新しいレイヤが作成されます。
フィールド計算機は モデルデザイナー で使用すると非常に便利です。
パラメーター
ラベル |
名前 |
タイプ |
説明 |
|---|---|---|---|
入力レイヤ |
|
[ベクタ:任意] |
計算するレイヤ |
出力する属性(フィールド)の名前 |
|
[文字列] |
結果のフィールド名 |
フィールド型 |
|
[列挙型] デフォルト: 0 |
フィールドの型。次のいずれかです:
|
フィールド長 |
|
[数値] デフォルト: 10 |
結果フィールドの長さ(最小0) |
フィールド精度 |
|
[数値] デフォルト: 3 |
結果フィールドの精度(最小0、最大15) |
新しいフィールドを作る |
|
[ブール値] デフォルト: True |
結果フィールドを新しいフィールドにする |
計算式 |
|
[式] |
結果を計算するために使う計算式 |
出力ファイル |
|
[ベクタ:任意] デフォルト: |
出力レイヤの指定。
ここでファイルの文字コードを変更することもできます。 |
出力
ラベル |
名前 |
タイプ |
説明 |
|---|---|---|---|
出力レイヤ |
|
[ベクタ:任意] |
計算したフィールド値の出力レイヤ |
Python コード
Algorithm ID: native:fieldcalculator
import processing
processing.run("algorithm_id", {parameter_dictionary})
algorithm id は、プロセシングツールボックス内でアルゴリズムにマウスカーソルを乗せた際に表示されるIDです。 parameter dictionary は、パラメータの「名前」とその値を指定するマッピング型です。Python コンソールからプロセシングアルゴリズムを実行する方法の詳細については、 プロセシングアルゴリズムをコンソールから使う を参照してください。
27.1.21.10. 属性をリファクタリング
ベクタレイヤの属性テーブルの構造を編集できます。
フィールドは、フィールドマッピングを使って、その型と名前を変更することができます。
元のレイヤは変更されません。提供されたフィールドマッピングに従って、変更された属性テーブルを含む新しいレイヤが生成されます。
注釈
フィールドに constraints を持つテンプレートレイヤーを使用する場合、その情報はウィジェットに色付きの背景とツールチップで表示されます。この情報は設定時のヒントとして扱われます。制約が出力レイヤに追加されたり、アルゴリズムによってチェックされたり、強制されたりすることはありません。
リファクタ・フィールド・アルゴリズムは次が可能です:
フィールド名と型を変更する
フィールドを追加または削除する
フィールドを並び替える
式を基づいて新しいフィールドを計算する
他のレイヤからフィールドリストを読み込む
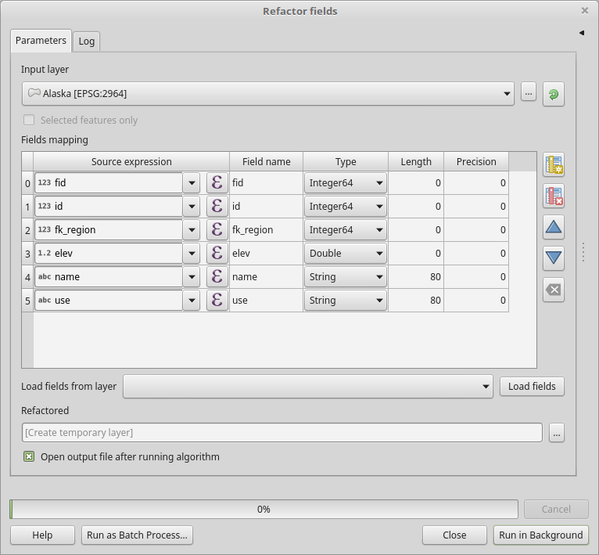
図 27.125 属性をリファクタリングのダイアログ
パラメーター
ラベル |
名前 |
タイプ |
説明 |
|---|---|---|---|
入力レイヤ |
|
[ベクタ:任意] |
変更するレイヤ |
属性の対応関係 |
|
[リスト] |
出力フィールドとその定義の一覧表。埋め込みテーブルは、ソースレイヤーのすべてのフィールドを一覧表にし、それらを編集することができます:
再利用したいフィールドごとに、以下のオプションを入力する必要があります:
|
再構成レイヤ |
|
[ベクタ:任意] デフォルト: |
出力レイヤの指定。次のいずれかです:
ここでファイルの文字コードを変更することもできます。 |




出力
ラベル |
名前 |
タイプ |
説明 |
|---|---|---|---|
再構成レイヤ |
|
[ベクタ:任意] |
リファクタリングされた属性を持つ出力レイヤ |
Python コード
Algorithm ID: native:refactorfields
import processing
processing.run("algorithm_id", {parameter_dictionary})
algorithm id は、プロセシングツールボックス内でアルゴリズムにマウスカーソルを乗せた際に表示されるIDです。 parameter dictionary は、パラメータの「名前」とその値を指定するマッピング型です。Python コンソールからプロセシングアルゴリズムを実行する方法の詳細については、 プロセシングアルゴリズムをコンソールから使う を参照してください。
27.1.21.11. 属性名を変更
ベクタレイヤの既存のフィールドの名前を変更します。
元のレイヤは変更されません。属性テーブルが名前を変更されたフィールドを含んでいる新しいレイヤが生成されます。
参考
パラメーター
ラベル |
名前 |
タイプ |
説明 |
|---|---|---|---|
入力レイヤ |
|
[ベクタ:任意] |
入力ベクタレイヤ |
変更する属性名 |
|
[テーブルのフィールド:任意] |
変更されるフィールド |
新規属性名 |
|
[文字列] |
新しいフィールド名 |
属性名変更済み出力 |
|
[ベクタ: 入力と同じ] デフォルト: |
出力レイヤの指定。次のいずれかです:
ここでファイルの文字コードを変更することもできます。 |
出力
ラベル |
名前 |
タイプ |
説明 |
|---|---|---|---|
属性名変更済み出力 |
|
[ベクタ: 入力と同じ] |
名前を変更されたフィールドを持った出力レイヤ |
Python コード
Algorithm ID: qgis:renametablefield
import processing
processing.run("algorithm_id", {parameter_dictionary})
algorithm id は、プロセシングツールボックス内でアルゴリズムにマウスカーソルを乗せた際に表示されるIDです。 parameter dictionary は、パラメータの「名前」とその値を指定するマッピング型です。Python コンソールからプロセシングアルゴリズムを実行する方法の詳細については、 プロセシングアルゴリズムをコンソールから使う を参照してください。
27.1.21.12. 属性を選択保持
ベクタレイヤをとり、選択されたフィールドのみを保持する新しいレイヤを生成します。他のフィールドはすべて削除されます。
参考
パラメーター
ラベル |
名前 |
タイプ |
説明 |
|---|---|---|---|
入力レイヤ |
|
[ベクタ:任意] |
入力ベクタレイヤ |
保持するフィールド |
|
[テーブルのフィールド:任意] [リスト] |
レイヤの残しておくフィールドのリスト |
保持されたフィールド |
|
[ベクタ: 入力と同じ] デフォルト: |
出力レイヤの指定。次のいずれかです:
ここでファイルの文字コードを変更することもできます。 |
出力
ラベル |
名前 |
タイプ |
説明 |
|---|---|---|---|
保持されたフィールド |
|
[ベクタ: 入力と同じ] |
保持されたフィールドを持った出力レイヤ |
Python コード
Algorithm ID: native:retainfields
import processing
processing.run("algorithm_id", {parameter_dictionary})
algorithm id は、プロセシングツールボックス内でアルゴリズムにマウスカーソルを乗せた際に表示されるIDです。 parameter dictionary は、パラメータの「名前」とその値を指定するマッピング型です。Python コンソールからプロセシングアルゴリズムを実行する方法の詳細については、 プロセシングアルゴリズムをコンソールから使う を参照してください。
27.1.21.13. 文字列を浮動小数点に変換
ベクタレイヤの指定された属性の型を変更し、数値文字列を含むテキスト属性を数値属性に変換します(例えば '1' を 1.0 に)。
アルゴリズムは新しいベクタレイヤを生成するので元のベクタレイヤは変更されません。
変換できない場合、選択した列は NULL 値を持つことになります。
パラメーター
ラベル |
名前 |
タイプ |
説明 |
|---|---|---|---|
入力レイヤ |
|
[ベクタ:任意] |
入力ベクタレイヤ |
浮動小数点に変換する属性 |
|
[テーブルのフィールド:文字列] |
浮動小数点数フィールドに変換される入力レイヤの文字列フィールド。 |
出力レイヤ |
|
[入力レイヤと同じ] デフォルト: |
出力レイヤを指定します。次のいずれかです:
ここでファイルの文字コードを変更することもできます。 |
出力
ラベル |
名前 |
タイプ |
説明 |
|---|---|---|---|
出力レイヤ |
|
[入力レイヤと同じ] |
文字列フィールドを浮動小数点フィールドに変換した出力ベクタレイヤ |
Python コード
Algorithm ID: qgis:texttofloat
import processing
processing.run("algorithm_id", {parameter_dictionary})
algorithm id は、プロセシングツールボックス内でアルゴリズムにマウスカーソルを乗せた際に表示されるIDです。 parameter dictionary は、パラメータの「名前」とその値を指定するマッピング型です。Python コンソールからプロセシングアルゴリズムを実行する方法の詳細については、 プロセシングアルゴリズムをコンソールから使う を参照してください。