27.1.15. ベクタ解析
27.1.15.1. 属性の基本統計量
ベクタレイヤの属性テーブルのフィールドについて、基本統計量を計算します。
数値型、日付型、時間型、文字列型のフィールドを対象とします。
フィールドの型によって、計算される統計量は異なります。
統計量の結果はHTMLファイルとして作成され、 からアクセスできます。
デフォルトメニュー:
パラメータ
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
入力レイヤ |
|
[ベクタ:任意] |
統計量を計算するベクタレイヤ |
統計量を計算する属性(フィールド) |
|
[テーブルのフィールド:任意] |
統計量の計算に対応した任意のテーブルのフィールド |
統計量の出力 オプション |
|
[html] デフォルト: |
計算した統計を出力するファイルの指定。次のいずれかです:
|
出力
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
統計量の出力 |
|
[html] |
統計量の計算結果のHTMLファイル |
カウント(Count) |
|
[数値] |
|
ユニークな値の種類 |
|
[数値] |
|
空白値(null)の数 |
|
[数値] |
|
非空白値の数 |
|
[数値] |
|
最小値(Minimum) |
|
[入力レイヤと同じ] |
|
最大値(Maximum) |
|
[入力レイヤと同じ] |
|
最短長(Min Length) |
|
[数値] |
|
最大長(Max Length) |
|
[数値] |
|
平均長(Mean Length) |
|
[数値] |
|
分散係数(Coef of Variance) |
|
[数値] |
|
合計(Sum) |
|
[数値] |
|
平均値(Mean) |
|
[数値] |
|
標準偏差(Standard deviation) |
|
[数値] |
|
範囲(Range) |
|
[数値] |
|
中央値(Median) |
|
[数値] |
|
最稀値(rarest occurring value) |
|
[入力レイヤと同じ] |
|
最頻値(most frequently occurring value) |
|
[入力レイヤと同じ] |
|
第1四分位(Q1) |
|
[数値] |
|
第3四分位(Q3) |
|
[数値] |
|
四分位範囲(IQR) |
|
[数値] |
Python コード
Algorithm ID: qgis:basicstatisticsforfields
import processing
processing.run("algorithm_id", {parameter_dictionary})
algorithm id は、プロセシングツールボックス内でアルゴリズムにマウスカーソルを乗せた際に表示されるIDです。 parameter dictionary は、パラメータの「名前」とその値を指定するマッピング型です。Python コンソールからプロセシングアルゴリズムを実行する方法の詳細については、 プロセシングアルゴリズムをコンソールから使う を参照してください。
27.1.15.2. 線に沿った上昇下降量
ラインジオメトリに沿った総上昇量と総下降量を計算します。入力レイヤはZ値を持っていなければなりません。レイヤがZ値を持っていない場合には、 ドレープ(ラスタ値をZ値に代入) アルゴリズムを使用してDEMレイヤからZ値を付加できます。
出力レイヤは入力レイヤのコピーですが、各ラインジオメトリについて総上昇量 (climb) 、総下降量 (descent) 、最低標高 (minelev) 、最高標高 (maxelev) のフィールドが追加されたものです。もし入力レイヤがこれらの追加フィールドと同名のフィールドを持つ場合には、追加されるフィールドは(重複したものについて順に、 "name_2"、 "name_3" 等に)変更されます。
パラメータ
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
線レイヤ |
|
[ベクタ:ライン] |
上昇下降量を計算するラインレイヤ。Z値を持っている必要があります |
上昇下降量の出力レイヤ |
|
[ベクタ:ライン] デフォルト: |
出力(ライン)レイヤの指定。次のいずれかです:
ここでファイルの文字コードを変更することもできます。 |
出力
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
上昇下降量の出力レイヤ |
|
[ベクタ:ライン] |
上昇下降量計算の結果の新しい属性を持ったラインレイヤ |
総上昇量 |
|
[数値] |
入力レイヤの全てのラインジオメトリの上昇量の合計 |
総下降量 |
|
[数値] |
入力レイヤの全てのラインジオメトリの下降量の合計 |
最低標高 |
|
[数値] |
レイヤ内のジオメトリの最小標高値 |
最高標高 |
|
[数値] |
レイヤ内のジオメトリの最高標高値 |
Python コード
Algorithm ID: qgis:climbalongline
import processing
processing.run("algorithm_id", {parameter_dictionary})
algorithm id は、プロセシングツールボックス内でアルゴリズムにマウスカーソルを乗せた際に表示されるIDです。 parameter dictionary は、パラメータの「名前」とその値を指定するマッピング型です。Python コンソールからプロセシングアルゴリズムを実行する方法の詳細については、 プロセシングアルゴリズムをコンソールから使う を参照してください。
27.1.15.3. ポリゴン内の点の数
ポイントレイヤとポリゴンレイヤを引数にとり、ポリゴンレイヤの各ポリゴン内にあるポイントレイヤのポイントの数を数えます。
入力ポリゴンレイヤと同じ内容の新しいポリゴンレイヤが作成されますが、これに加えて、各ポリゴンに対応したポイントの個数のフィールドが追加されています。
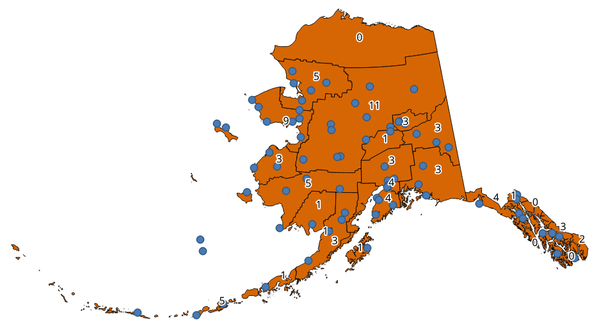
図 27.31 ポイントの数を表示したポリゴンのラベル
オプションの重み属性を使用すると、各ポイントに重みを割り当てることができます。また、ユニークな分類属性を指定することもできます。両方のオプションが使用された場合、重み属性が優先され、ユニークな分類属性は無視されます。
 ポリゴン地物の 地物のIn-place編集 が可能です
ポリゴン地物の 地物のIn-place編集 が可能です
デフォルトメニュー:
パラメータ
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
ポリゴン(Polygons) |
|
[ベクタ:ポリゴン] |
地物内のポイントを数えるポリゴンレイヤ |
ポイント(Points) |
|
[ベクタ:ポイント] |
地物数を数えたいポイントレイヤ |
重み属性(フィールド) オプション |
|
[テーブルのフィールド:任意] |
ポイントレイヤのフィールド。生成されるカウントは、そのポリゴンに含まれるポイントの重み属性の合計になります。重み属性が数値でない場合、カウントは |
分類属性 オプション |
|
[テーブルのフィールド:任意] |
ポイントは選択された分類属性に基づいて分類され、同じ分類属性値を持つ複数のポイントがポリゴン内に存在する場合は、そのうちの1つだけをカウントします。従って、最終的なポリゴン内の点の個数は、ポリゴン内にある相異なるクラスの個数となります。 |
カウント属性名 |
|
[文字列] デフォルト: 'NUMPOINTS' |
ポイントの個数を格納するフィールドの名前 |
カウント(Count) |
|
[ベクタ:ポリゴン] デフォルト: |
出力レイヤの指定。次のいずれかです:
ここでファイルの文字コードを変更することもできます。 |
出力
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
カウント(Count) |
|
[ベクタ:ポリゴン] |
ポイントの個数の新しい列を含む属性テーブルを持つ結果レイヤ |
Python コード
Algorithm ID: native:countpointsinpolygon
import processing
processing.run("algorithm_id", {parameter_dictionary})
algorithm id は、プロセシングツールボックス内でアルゴリズムにマウスカーソルを乗せた際に表示されるIDです。 parameter dictionary は、パラメータの「名前」とその値を指定するマッピング型です。Python コンソールからプロセシングアルゴリズムを実行する方法の詳細については、 プロセシングアルゴリズムをコンソールから使う を参照してください。
27.1.15.4. DBSCANクラスタリング
DBSCAN(Density-based spatial clustering of applications with noise)アルゴリズムの2次元版実装に基づいて、ポイント地物をクラスタリングします。
このアルゴリズムには、最小クラスタサイズと、クラスタ化されたポイント間で許容される最大距離の2つのパラメータが必要です。
パラメータ
基本パラメータ
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
入力レイヤ |
|
[ベクタ:ポイント] |
解析したいレイヤ |
最小クラスタサイズ(minPts) |
|
[数値] デフォルト: 5 |
クラスタを構成する最小の地物数 |
クラスタ化された点の最大距離(eps) |
|
[数値] デフォルト: 1.0 |
2つの地物が同一クラスタとなることのない距離(eps) |
クラスタ(Clusters) |
|
[ベクタ:ポイント] デフォルト: |
クラスタ化の結果を出力するベクタレイヤを指定します。次のいずれかです:
ここでファイルの文字コードを変更することもできます。 |
詳細パラメータ
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
境界点をノイズとして扱う(DBSCAN*) オプション |
|
[ブール値] デフォルト: False |
チェックした場合、クラスタの境界上のポイント自体はクラスタ化されていないポイントとして扱われ、クラスタの内側のポイントのみがクラスタ化されるものとしてタグ付けされます。 |
クラスタを示す属性名 |
|
[文字列] デフォルト: 'CLUSTER_ID' |
クラスタ番号を保存するフィールドの名前 |
クラスタサイズを示す属性名 |
|
[文字列] デフォルト: 'CLUSTER_SIZE' |
同じクラスタにある地物の数のフィールドの名前 |
出力
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
クラスタ(Clusters) |
|
[ベクタ:ポイント] |
そのポイントが属するクラスタを設定するフィールドを持つ、オリジナルの地物を含むベクタレイヤ |
クラスタ数 |
|
[数値] |
検出されたクラスタ数 |
Python コード
Algorithm ID: native:dbscanclustering
import processing
processing.run("algorithm_id", {parameter_dictionary})
algorithm id は、プロセシングツールボックス内でアルゴリズムにマウスカーソルを乗せた際に表示されるIDです。 parameter dictionary は、パラメータの「名前」とその値を指定するマッピング型です。Python コンソールからプロセシングアルゴリズムを実行する方法の詳細については、 プロセシングアルゴリズムをコンソールから使う を参照してください。
27.1.15.5. 距離行列(distance matrix)
ポイント地物について、同じレイヤ内または別のレイヤ内の最も近い地物までの距離を計算します。
デフォルトメニュー:
参考
パラメータ
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
入力点のレイヤ |
|
[ベクタ:ポイント] |
(ポイント からの )距離行列を計算するポイントレイヤ |
入力点のIDを示す属性(フィールド) |
|
[テーブルのフィールド:任意] |
入力レイヤの地物を一意に識別するために使用するフィールド。出力属性テーブルで使用します。 |
ターゲット点のレイヤ |
|
[ベクタ:ポイント] |
(ポイント への )最近傍点を検索するポイントレイヤ |
ターゲット点のIDを示す属性(フィールド) |
|
[テーブルのフィールド:任意] |
ターゲットレイヤの地物を一意に識別するために使用するフィールド。出力属性テーブルで使用します。 |
出力形式 |
|
[列挙型] デフォルト: 0 |
さまざまな計算タイプが利用できます:
|
計算する近傍点の個数(0ならすべての点を計算) |
|
[数値] デフォルト: 0 |
距離を計算するポイントをターゲットレイヤ内のすべてのポイント( 0 )とするか、最近傍の一定数( k )に制限するかを選択できます。 |
距離行列(distance matrix) |
|
[ベクタ:ポイント] デフォルト: |
出力するベクタレイヤの指定。次のいずれかです:
ここでファイルの文字コードを変更することもできます。 |
出力
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
距離行列(distance matrix) |
|
[ベクタ:ポイント] |
各入力地物の距離計算を含むポイント(または 「線形(N * k x 3)」の場合はマルチポイント)ベクタレイヤ。その地物と属性テーブルは、選択した出力行列の種類によって異なります。 |
Python コード
Algorithm ID: qgis:distancematrix
import processing
processing.run("algorithm_id", {parameter_dictionary})
algorithm id は、プロセシングツールボックス内でアルゴリズムにマウスカーソルを乗せた際に表示されるIDです。 parameter dictionary は、パラメータの「名前」とその値を指定するマッピング型です。Python コンソールからプロセシングアルゴリズムを実行する方法の詳細については、 プロセシングアルゴリズムをコンソールから使う を参照してください。
27.1.15.6. 最寄りのハブの距離(ハブへの線)
入力ベクタの各地物をハブレイヤの最も近い地物に結合する線を作成します。距離は各地物の 中心 に基づいて計算されます。
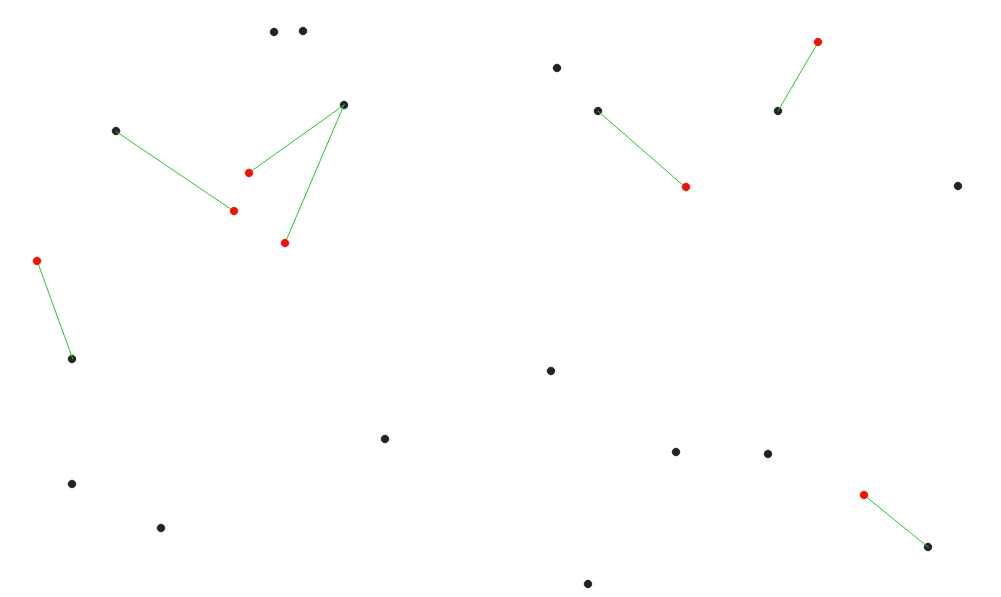
図 27.32 赤色の入力地物に対する最近傍ハブの表示
パラメータ
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
入力レイヤ |
|
[ベクタ:任意] |
最近傍の地物を探すベクタレイヤ |
ハブレイヤ |
|
[ベクタ:任意] |
検索対象の地物を含むベクタレイヤ |
ハブレイヤからコピーされる属性(ハブのIDを想定) |
|
[テーブルのフィールド:任意] |
ハブレイヤの地物を一意に識別するために使用するフィールド。出力属性テーブルで使用します。 |
計測単位 |
|
[列挙型] デフォルト: 0 |
最近傍の地物への距離の単位
|
出力レイヤ |
|
[ベクタ:ライン] デフォルト: |
合致した点を結んだ出力ラインベクタレイヤを指定します。次のいずれかです:
ここでファイルの文字コードを変更することもできます。 |
出力
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
出力レイヤ |
|
[ベクタ:ライン] |
入力地物の属性、最近傍の地物のID、計算された距離の属性を持つラインベクタレイヤ |
Python コード
Algorithm ID: qgis:distancetonearesthublinetohub
import processing
processing.run("algorithm_id", {parameter_dictionary})
algorithm id は、プロセシングツールボックス内でアルゴリズムにマウスカーソルを乗せた際に表示されるIDです。 parameter dictionary は、パラメータの「名前」とその値を指定するマッピング型です。Python コンソールからプロセシングアルゴリズムを実行する方法の詳細については、 プロセシングアルゴリズムをコンソールから使う を参照してください。
27.1.15.7. 最寄りのハブの距離
入力地物の 中心 を表すポイントレイヤを作成します。これには、(中心点に基づく)最も近い地物のIDと、ポイント間の距離の2つのフィールドが追加されています。
参考
パラメータ
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
入力レイヤ |
|
[ベクタ:任意] |
最近傍の地物を探すベクタレイヤ |
ハブレイヤ |
|
[ベクタ:任意] |
検索対象の地物を含むベクタレイヤ |
ハブレイヤからコピーされる属性(ハブのIDを想定) |
|
[テーブルのフィールド:任意] |
ハブレイヤの地物を一意に識別するために使用するフィールド。出力属性テーブルで使用します。 |
計測単位 |
|
[列挙型] デフォルト: 0 |
最近傍の地物への距離の単位
|
出力レイヤ |
|
[ベクタ:ポイント] デフォルト: |
最寄りのハブを持った出力ポイントベクタレイヤを指定します。次のいずれかです:
ここでファイルの文字コードを変更することもできます。 |
出力
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
出力レイヤ |
|
[ベクタ:ポイント] |
ソース地物の属性、最近傍の地物のID、計算された距離を持った、ソース地物の中心を表すポイントベクタレイヤ |
Python コード
Algorithm ID: qgis:distancetonearesthubpoints
import processing
processing.run("algorithm_id", {parameter_dictionary})
algorithm id は、プロセシングツールボックス内でアルゴリズムにマウスカーソルを乗せた際に表示されるIDです。 parameter dictionary は、パラメータの「名前」とその値を指定するマッピング型です。Python コンソールからプロセシングアルゴリズムを実行する方法の詳細については、 プロセシングアルゴリズムをコンソールから使う を参照してください。
27.1.15.8. ハブ&スポーク図
スポークレイヤのポイントから対応するハブレイヤのポイントへ線をつなぐことで、ハブ&スポーク図を作成します。
どのハブが各ポイントに対応するかは、ハブポイント上のハブIDフィールドとスポークポイント上のスポークIDフィールドの一致に基づいて決定されます。
入力レイヤがポイントレイヤでない場合には、ジオメトリの内部保証点(point on surface)を接続する地点として使用します。
オプションとして、測地線(回転楕円体上の最短経路)を作成することもできます。測地線モードを使用する場合、作成する線分を日付変更線(経度±180度)で分割することもできます。これにより、線分のレンダリングが向上します。また、頂点間の距離も指定できます。距離が短いほど線分は密になり、正確な線になります。
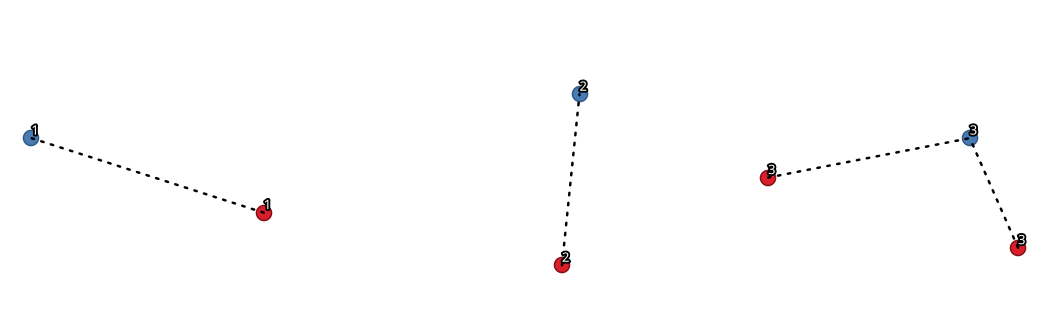
図 27.33 共通のフィールド / 属性に基づくポイントの連結
パラメータ
基本パラメータ
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
ハブレイヤ |
|
[ベクタ:任意] |
入力レイヤ |
ハブID属性 |
|
[テーブルのフィールド:任意] |
連結に使用するハブレイヤのIDフィールド |
コピーするハブレイヤの属性(すべての属性をコピーする場合は空のまま) オプション |
|
[テーブルのフィールド:任意] [リスト] |
コピーするハブレイヤのフィールド(複数可)。フィールドが何も選択されない場合は、すべてのフィールドをコピーします。 |
スポークレイヤ |
|
[ベクタ:任意] |
スポーク点のレイヤ |
スポークID属性 |
|
[テーブルのフィールド:任意] |
連結に使用するスポークレイヤのIDフィールド |
コピーするスポークレイヤの属性(すべての属性をコピーする場合は空のまま) オプション |
|
[テーブルのフィールド:任意] [リスト] |
コピーするスポークレイヤのフィールド(複数可)。フィールドが何も選択されない場合は、すべてのフィールドをコピーします。 |
測地線を作成 |
|
[ブール値] デフォルト: False |
測地線(回転楕円体上の最短経路)を作成します |
出力レイヤ |
|
[ベクタ:ライン] デフォルト: |
出力ハブラインベクタレイヤを指定します。次のいずれかです:
ここでファイルの文字コードを変更することもできます。 |
詳細パラメータ
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
頂点間の距離(測地線のみ) |
|
[数値] デフォルト: 1000.0 (キロメートル) |
連続する頂点間の距離(キロメートル単位)。距離が小さいほど線分は密になり、正確な線となる |
日付変更線(経度180度線)で線を切断 |
|
[ブール値] デフォルト: False |
経度 ±180度で線を切断する(ラインのレンダリングが崩れないようにするため) |
出力
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
出力レイヤ |
|
[ベクタ:ライン] |
入力レイヤの適合した点を接続した、結果ラインレイヤ |
Python コード
Algorithm ID: native:hublines
import processing
processing.run("algorithm_id", {parameter_dictionary})
algorithm id は、プロセシングツールボックス内でアルゴリズムにマウスカーソルを乗せた際に表示されるIDです。 parameter dictionary は、パラメータの「名前」とその値を指定するマッピング型です。Python コンソールからプロセシングアルゴリズムを実行する方法の詳細については、 プロセシングアルゴリズムをコンソールから使う を参照してください。
27.1.15.9. K平均クラスタリング
各入力地物について、2次元的な距離に基づくK平均法によるクラスタ番号を計算します。
K平均クラスタリングは、地物をk個のクラスタに分割し、各地物が最も近い平均を持つクラスタに属するようにすることを目的とします。平均点は、クラスタ化された地物の重心によって表されます。
入力ジオメトリがラインやポリゴンの場合には、クラスタリングは地物の重心に基づいて行われます。
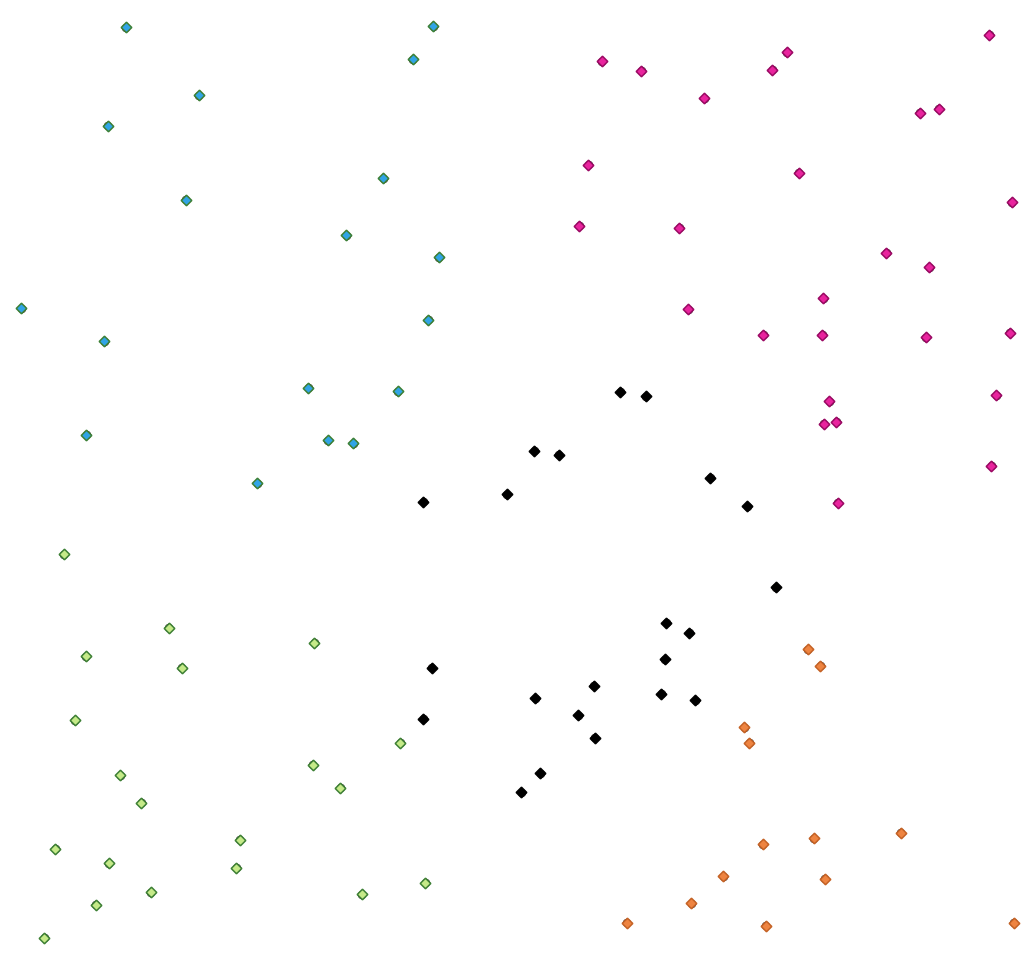
図 27.34 5クラスのポイントクラスタ
パラメータ
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
入力レイヤ |
|
[ベクタ:任意] |
解析したいレイヤ |
クラスタ数 |
|
[数値] デフォルト: 5 |
作成したい地物クラスタ数 |
クラスタ(Clusters) |
|
[ベクタ:任意] デフォルト: |
生成されたクラスタの出力ベクタレイヤを指定します。次のいずれかです:
ここでファイルの文字コードを変更することもできます。 |
詳細パラメータ
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
クラスタを示す属性名 |
|
[文字列] デフォルト: 'CLUSTER_ID' |
クラスタ番号を保存するフィールドの名前 |
クラスタサイズを示す属性名 |
|
[文字列] デフォルト: 'CLUSTER_SIZE' |
同じクラスタにある地物の数のフィールドの名前 |
出力
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
クラスタ(Clusters) |
|
[ベクタ:任意] |
地物が属するクラスタとその番号を指定するフィールドを持つ、オリジナルの地物を格納しているベクタレイヤ |
Python コード
Algorithm ID: native:kmeansclustering
import processing
processing.run("algorithm_id", {parameter_dictionary})
algorithm id は、プロセシングツールボックス内でアルゴリズムにマウスカーソルを乗せた際に表示されるIDです。 parameter dictionary は、パラメータの「名前」とその値を指定するマッピング型です。Python コンソールからプロセシングアルゴリズムを実行する方法の詳細については、 プロセシングアルゴリズムをコンソールから使う を参照してください。
27.1.15.10. ユニーク値のリスト
属性テーブルフィールドのユニーク値をリストし、その数を数えます。
デフォルトメニュー:
パラメータ
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
入力レイヤ |
|
[ベクタ:任意] |
解析したいレイヤ |
対象属性(フィールド) |
|
[テーブルのフィールド:任意] |
分析したいフィールド |
出力レイヤ オプション |
|
[テーブル] デフォルト: |
ユニーク値のサマリテーブルレイヤを指定します。次のいずれかです:
ここでファイルの文字コードを変更することもできます。 |
HTMLレポートの出力 オプション |
|
[html] デフォルト: |
のユニーク値のHTMLレポート。次のいずれかです:
|
出力
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
出力レイヤ |
|
[テーブル] |
ユニーク値の集計テーブルレイヤ |
HTMLレポートの出力 |
|
[html] |
ユニーク値のHTMLレポート。 からアクセスできます。 |
ユニークな値の総数 |
|
[数値] |
入力フィールドにあるユニーク値の数 |
連結したユニーク値 |
|
[文字列] |
入力フィールドで見つかったユニーク値のリストをコンマ区切りで繋げた文字列 |
Python コード
Algorithm ID: qgis:listuniquevalues
import processing
processing.run("algorithm_id", {parameter_dictionary})
algorithm id は、プロセシングツールボックス内でアルゴリズムにマウスカーソルを乗せた際に表示されるIDです。 parameter dictionary は、パラメータの「名前」とその値を指定するマッピング型です。Python コンソールからプロセシングアルゴリズムを実行する方法の詳細については、 プロセシングアルゴリズムをコンソールから使う を参照してください。
27.1.15.11. 加重平均座標(重心の平均)
入力レイヤのジオメトリの重心を計算したポイントレイヤを作成します。
重心を計算する際に、各地物に適用される重み付けの属性を指定できます。
パラメータで属性を選択すると、地物はこのフィールドの値でグループ化されます。出力レイヤには、レイヤ全体の重心を示す単一の点ではなく、各カテゴリの地物の重心が含まれるようになります。
デフォルトメニュー:
パラメータ
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
入力レイヤ |
|
[ベクタ:任意] |
入力ベクタレイヤ |
重み属性(フィールド) オプション |
|
[テーブルのフィールド:数値] |
重み付き平均を計算したい場合に使用するフィールド |
ユニークID属性 |
|
[テーブルのフィールド:数値] |
グループ化した平均の計算を行う上でのユニークフィールド |
出力レイヤ |
|
[ベクタ:ポイント] デフォルト: |
結果の(ポイントベクタ)レイヤを指定します。次のいずれかです:
ここでファイルの文字コードを変更することもできます。 |
出力
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
出力レイヤ |
|
[ベクタ:ポイント] |
結果のポイントレイヤ |
Python コード
Algorithm ID: native:meancoordinates
import processing
processing.run("algorithm_id", {parameter_dictionary})
algorithm id は、プロセシングツールボックス内でアルゴリズムにマウスカーソルを乗せた際に表示されるIDです。 parameter dictionary は、パラメータの「名前」とその値を指定するマッピング型です。Python コンソールからプロセシングアルゴリズムを実行する方法の詳細については、 プロセシングアルゴリズムをコンソールから使う を参照してください。
27.1.15.12. 最近傍解析
ポイントレイヤの最近傍解析を実行します。出力結果は、データがどのように分布しているか(クラスター化しているか、ランダムに分布しているか等)を表します。
出力結果は、計算された以下の統計値を含むHTMLファイルとして生成されます:
観測平均距離
推定平均距離
最近傍インデックス
頂点数
Z-スコア:Z-スコアを正規分布と比較すると、データがどのように分布しているかがわかります。Z-スコアが低いと、データは空間的にランダムなプロセスの結果である可能性が低いことを意味し、反対にZ-スコアが高いと、データは空間的にランダムなプロセスの結果である可能性が高いことを意味します。
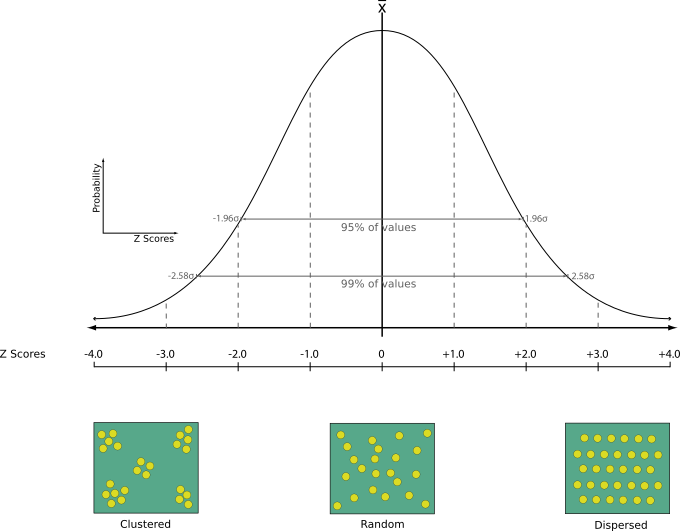
デフォルトメニュー:
参考
パラメータ
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
入力レイヤ |
|
[ベクタ:ポイント] |
統計値を計算したいポイントベクタレイヤ |
最近傍(Nearest neighbor) オプション |
|
[html] デフォルト: |
計算した統計を出力するHTMLファイルの指定。次のいずれかです:
|
出力
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
最近傍(Nearest neighbor) |
|
[html] |
統計量の計算結果のHTMLファイル |
観測平均距離 |
|
[数値] |
観測平均距離 |
推定平均距離 |
|
[数値] |
推定平均距離 |
最近傍インデックス |
|
[数値] |
最近傍インデックス |
点の数 |
|
[数値] |
頂点数 |
Z-スコア |
|
[数値] |
Z-スコア |
Python コード
Algorithm ID: native:nearestneighbouranalysis
import processing
processing.run("algorithm_id", {parameter_dictionary})
algorithm id は、プロセシングツールボックス内でアルゴリズムにマウスカーソルを乗せた際に表示されるIDです。 parameter dictionary は、パラメータの「名前」とその値を指定するマッピング型です。Python コンソールからプロセシングアルゴリズムを実行する方法の詳細については、 プロセシングアルゴリズムをコンソールから使う を参照してください。
27.1.15.13. 重なり分析
入力レイヤの地物が選択したオーバーレイレイヤの地物に対して重なる面積と割合を計算します。
入力地物が選択された各オーバーレイレイヤと重なる部分の面積と割合が、新しい属性として出力レイヤに追加されます。
パラメータ
基本パラメータ
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
入力レイヤ |
|
[ベクタ:任意] |
入力レイヤ |
オーバーレイレイヤ |
|
[ベクタ:任意] [リスト] |
オーバーレイレイヤ |
重なり |
|
[入力レイヤと同じ] デフォルト: |
出力ベクタレイヤを指定します。次のいずれかです:
ここでファイルの文字コードを変更することもできます。 |
詳細パラメータ
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
グリッドサイズ
オプション |
|
[数値] デフォルト:未設定 |
指定された場合、入力ジオメトリは指定されたサイズのグリッドにスナップされ、結果の頂点は同じグリッド上で計算されます。GEOS 3.9.0以上が必要です。 |
出力
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
重なり |
|
[入力レイヤと同じ] |
入力地物と選択された各オーバーレイレイヤとの重なり(地図単位の面積およびパーセンテージ)のフィールドが追加された出力レイヤ |
Python コード
Algorithm ID: native:calculatevectoroverlaps
import processing
processing.run("algorithm_id", {parameter_dictionary})
algorithm id は、プロセシングツールボックス内でアルゴリズムにマウスカーソルを乗せた際に表示されるIDです。 parameter dictionary は、パラメータの「名前」とその値を指定するマッピング型です。Python コンソールからプロセシングアルゴリズムを実行する方法の詳細については、 プロセシングアルゴリズムをコンソールから使う を参照してください。
27.1.15.14. 地物間の最短線
NEW in 3.24
起点レイヤと出力レイヤ間の最短線としてラインレイヤを作成します。デフォルトでは、出力レイヤの最初の最近傍地物のみが考慮されます。n番目に近い地物の数を指定できます。最大距離を指定すると、その距離より近い地物のみが考慮されます。
出力地物は、起点レイヤの全ての属性、n最近傍地物の全ての属性、及び距離の追加フィールドを格納します。
重要
このアルゴリズムでは、距離については純粋にデカルト計算を使用し、地物の近接度を決定する際に測地線や楕円体の特性は考慮しません。測定及び出力の座標系は、 起点レイヤの座標系に基づいてい ます。
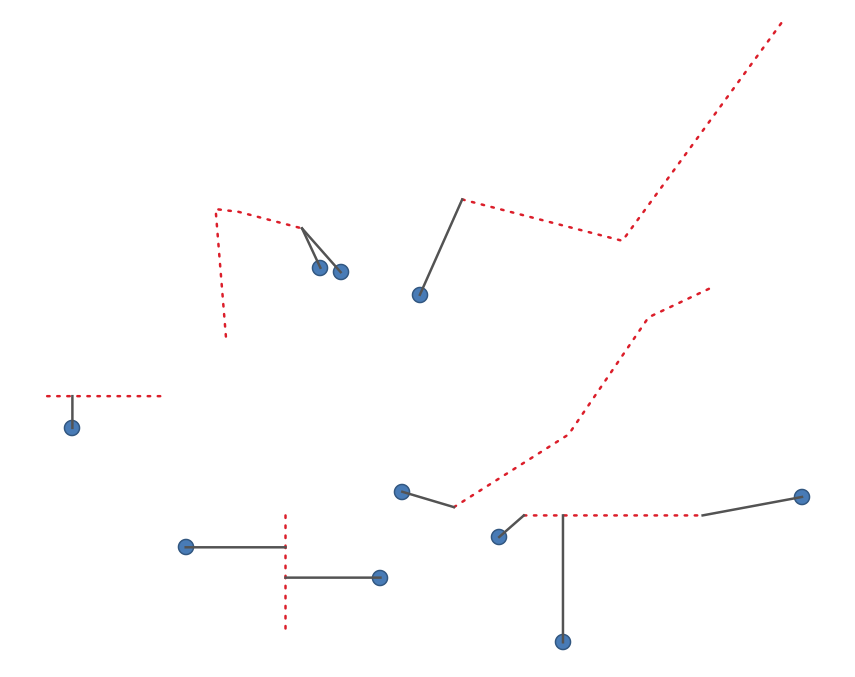
図 27.35 ポイント地物からラインへの最短線
パラメータ
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
起点レイヤ |
|
[ベクタ:任意] |
その最近傍を検索する起点レイヤ |
出力レイヤ |
|
[ベクタ:任意] |
その中にある最近傍を検索する対象レイヤ |
方法 |
|
[列挙型] デフォルト: 0 |
最短距離の計算法。可能な値は次のとおりです:
|
考慮する隣接地物の数 |
|
[数値] デフォルト: 1 |
探索する近隣地物の最大数 |
最大距離 オプション |
|
[数値] |
この距離より近い地物だけが考慮されます。 |
最短線 |
|
[ベクタ:ライン] デフォルト: |
出力ベクタレイヤを指定します。次のいずれかです:
ここでファイルの文字コードを変更することもできます。 |
出力
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
出力レイヤ |
|
[ベクタ:ライン] |
起点地物と出力レイヤの最近傍地物を結ぶラインベクタレイヤ。起点地物と目標地物の全ての属性と、計算された距離が含まれます。 |
Python コード
Algorithm ID: native:shortestline
import processing
processing.run("algorithm_id", {parameter_dictionary})
algorithm id は、プロセシングツールボックス内でアルゴリズムにマウスカーソルを乗せた際に表示されるIDです。 parameter dictionary は、パラメータの「名前」とその値を指定するマッピング型です。Python コンソールからプロセシングアルゴリズムを実行する方法の詳細については、 プロセシングアルゴリズムをコンソールから使う を参照してください。
27.1.15.15. ST-DBSCANクラスタリング
Density-based clustering of applications with noise (ST-DBSCAN)アルゴリズムの2次元実装に基づくポイント地物のクラスタリング。
パラメータ
基本パラメータ
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
入力レイヤ |
|
[ベクタ:ポイント] |
解析したいレイヤ |
日付・時間フィールド |
|
[tablefield: 日付] |
時間情報を格納しているフィールド |
最小クラスタサイズ(minPts) |
|
[数値] デフォルト: 5 |
クラスタを構成する最小の地物数 |
クラスタ化された点の最大距離(eps) |
|
[数値] デフォルト: 1.0 |
2つの地物が同一クラスタとなることのない距離(eps) |
クラスタ化された点の最大継続時間 |
|
[数値] デフォルト: 0.0(日) |
2つの地物が同じクラスターに属することができない時間(eps2)。利用可能な時間単位はミリ秒、秒、分、時、日、週です。 |
クラスタ(Clusters) |
|
[ベクタ:ポイント] デフォルト: |
クラスタ化の結果を出力するベクタレイヤを指定します。次のいずれかです:
ここでファイルの文字コードを変更することもできます。 |
詳細パラメータ
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
境界点をノイズとして扱う(DBSCAN*) オプション |
|
[ブール値] デフォルト: False |
チェックした場合、クラスタの境界上のポイント自体はクラスタ化されていないポイントとして扱われ、クラスタの内側のポイントのみがクラスタ化されるものとしてタグ付けされます。 |
クラスタを示す属性名 |
|
[文字列] デフォルト: 'CLUSTER_ID' |
クラスタ番号を保存するフィールドの名前 |
クラスタサイズを示す属性名 |
|
[文字列] デフォルト: 'CLUSTER_SIZE' |
同じクラスタにある地物の数のフィールドの名前 |
出力
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
クラスタ(Clusters) |
|
[ベクタ:ポイント] |
そのポイントが属するクラスタを設定するフィールドを持つ、オリジナルの地物を含むベクタレイヤ |
クラスタ数 |
|
[数値] |
検出されたクラスタ数 |
Python コード
Algorithm ID: native:stdbscanclustering
import processing
processing.run("algorithm_id", {parameter_dictionary})
algorithm id は、プロセシングツールボックス内でアルゴリズムにマウスカーソルを乗せた際に表示されるIDです。 parameter dictionary は、パラメータの「名前」とその値を指定するマッピング型です。Python コンソールからプロセシングアルゴリズムを実行する方法の詳細については、 プロセシングアルゴリズムをコンソールから使う を参照してください。
27.1.15.16. 出力レイヤ
親クラスに応じたフィールドの統計量を計算します。親クラスは、他のフィールドの値の組み合わせです。
パラメータ
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
入力ベクタレイヤ |
|
[ベクタ:任意] |
ユニークなカテゴリと値を持つ入力ベクタレイヤ |
集計する属性(空の場合はカウントのみ) オプション |
|
[テーブルのフィールド:任意] |
空の場合はカウントのみ計算します |
カテゴリ分けする属性 |
|
[ベクタ:任意] [リスト] |
カテゴリを定義するフィールド(組み合わせ可) |
カテゴリ別の統計量 |
|
[テーブル] デフォルト: |
生成した統計量の出力テーブルを指定します。次のいずれかです:
ここでファイルの文字コードを変更することもできます。 |
出力
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
カテゴリ別の統計量 |
|
[テーブル] |
統計量のテーブル |
集計する属性の型に応じて、各カテゴリについて以下の統計量が返されます:
統計 |
文字列 |
数値 |
日付 |
|---|---|---|---|
個数( |
|
|
|
ユニーク値( |
|
|
|
空値(null)( |
|
|
|
非null値( |
|
|
|
最小値( |
|
|
|
最大値( |
|
|
|
範囲( |
|
||
合計( |
|
||
平均( |
|
||
中央値( |
|
||
標準偏差( |
|
||
分散係数( |
|
||
最稀値(最も頻度の少ない値 - |
|
||
最頻値(最も頻度の多い値 - |
|
||
第1四分位( |
|
||
第3四分位( |
|
||
四分位範囲( |
|
||
最小長さ( |
|
||
平均の長さ( |
|
||
最大長さ( |
|
Python コード
Algorithm ID: qgis:statisticsbycategories
import processing
processing.run("algorithm_id", {parameter_dictionary})
algorithm id は、プロセシングツールボックス内でアルゴリズムにマウスカーソルを乗せた際に表示されるIDです。 parameter dictionary は、パラメータの「名前」とその値を指定するマッピング型です。Python コンソールからプロセシングアルゴリズムを実行する方法の詳細については、 プロセシングアルゴリズムをコンソールから使う を参照してください。
27.1.15.17. 線長の合計
ポリゴンレイヤとラインレイヤを使用して、各ポリゴンを横切るラインの合計長と合計数を計測します。
結果として得られるレイヤは、入力ポリゴンレイヤと同じ地物ですが、各ポリゴンを横切るラインの長さと本数の2つ属性が追加されています。
ポリゴン地物の 地物のIn-place編集 が可能です
デフォルトメニュー:
パラメータ
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
線レイヤ |
|
[ベクタ:ライン] |
入力ベクタラインレイヤ |
ポリゴン(Polygons) |
|
[ベクタ:ポリゴン] |
ポリゴンベクタレイヤ |
交差する線の総延長を格納するフィールドの名前 |
|
[文字列] デフォルト: 'LENGTH' |
線の長さのフィールド名 |
交差する線の数を格納するフィールドの名前 |
|
[文字列] デフォルト: 'COUNT' |
線の数のフィールド名 |
ポリゴンと交差する線の総延長 |
|
[ベクタ:ポリゴン] デフォルト: |
生成した統計量を持った出力ポリゴンレイヤを指定します。次のいずれかです:
ここでファイルの文字コードを変更することもできます。 |
出力
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
ポリゴンと交差する線の総延長 |
|
[ベクタ:ポリゴン] |
ライン長とライン数のフィールドを持つ出力ポリゴンレイヤ |
Python コード
Algorithm ID: native:sumlinelengths
import processing
processing.run("algorithm_id", {parameter_dictionary})
algorithm id は、プロセシングツールボックス内でアルゴリズムにマウスカーソルを乗せた際に表示されるIDです。 parameter dictionary は、パラメータの「名前」とその値を指定するマッピング型です。Python コンソールからプロセシングアルゴリズムを実行する方法の詳細については、 プロセシングアルゴリズムをコンソールから使う を参照してください。