27.1.5. 内挿
27.1.5.1. ヒートマップ(カーネル密度推定)
カーネル密度推定を使用して、入力ポイントベクタレイヤの密度(ヒートマップ)ラスタを生成します。
密度はその場所にあるポイントの数に基づいて計算され、集まっているポイントの数が多ければ多いほど、値は大きくなります。ヒートマップを用いれば、 ホットスポット や点のクラスター化を簡単に確認できます。
パラメータ
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
入力レイヤ(点) |
|
[ベクタ:ポイント] |
ヒートマップに使用するポイントベクタレイヤ |
半径 |
|
[数値] デフォルト: 100.0 |
地図単位のヒートマップの検索半径(またはカーネルのバンド幅)。この半径は、ある点の周りで影響を受ける点の距離を指定します。大きな値を指定するほどヒートマップは滑らかになり、小さな値を指定すると、細部や点の密度のばらつきが表されます。 |
出力ラスタサイズ |
|
[数値] デフォルト: 0.1 |
レイヤの単位で表した、出力ラスタレイヤのピクセルサイズ GUIでは、出力ラスタサイズは行数( |
半径を示す属性(フィールド) オプション |
|
[テーブルのフィールド:数値] |
入力レイヤの属性フィールドから、各地物の検索半径を設定します。 |
重みに使う属性 オプション |
|
[テーブルのフィールド:数値] |
入力地物を属性フィールドの値で重みづけします。結果のヒートマップにおいて、特定の地物の影響を増加させるために使用します。 |
カーネル関数 |
|
[列挙型] デフォルト: 0 |
ポイントからの距離が長くなるにつれてポイントの影響力が減少する割合を制御します。カーネルによって減衰の速度は異なり、TriweightカーネルはEpanechnikovカーネルよりもポイントに近い距離の地物に大きな重みを与えます。このため、Triweightカーネルは「よりシャープな」、Epanechnikovカーネルは「よりスムーズな」ホットスポットになります。 さまざまなカーネル関数が利用可能です(詳細については Wikipedia を参照してください):
|
減衰比(Triangularのみ) オプション |
|
[数値] デフォルト: 0.0 |
Triangularカーネルで使用します。 ある地物からの熱が距離に従ってどのように減少するかをさらに制御できます。
|
スケーリングするか |
|
[列挙型] デフォルト: そのまま |
出力ヒートマップラスタの値を変更できます。次のいずれかです:
|
ヒートマップ |
|
[ラスタ] デフォルト: |
カーネル密度値の出力ラスタレイヤを指定します。次のいずれかです:
|
出力
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
ヒートマップ |
|
[ラスタ] |
カーネル密度値のラスタレイヤ |
例:ヒートマップの作成
以下の例では、QGISサンプルデータセット( サンプルデータのダウンロード 参照)の airports ベクタポイントレイヤを使用します。ヒートマップ作成に関する素晴らしいQGISチュートリアルは、 http://qgistutorials.com にもあります。
図 27.2 では、アラスカの空港が表示されています。
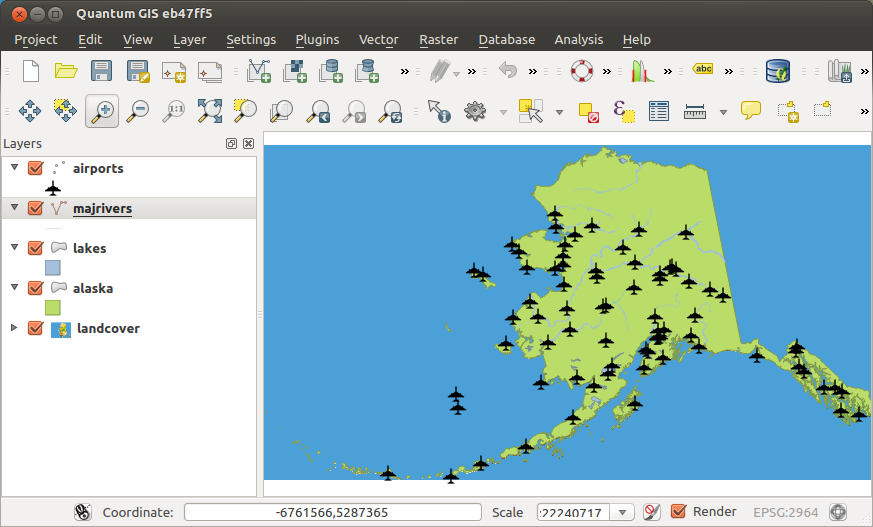
図 27.2 アラスカの空港
QGISアルゴリズムの 内挿 グループから ヒートマップ(カーネル密度推定) アルゴリズム開きます
入力レイヤ(点)
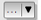 フィールドで、現在のプロジェクトにロードされたポイントレイヤのリストの中から
フィールドで、現在のプロジェクトにロードされたポイントレイヤのリストの中から airportsレイヤを選択します。半径 を
1000000メートルに変更します。ピクセルサイズX を
1000に変更します。 ピクセルサイズY 、 行 、 カラム は自動的に更新されます。実行 をクリックして、airportsのヒートマップを作成し読み込みます( 図 27.4 参照)。
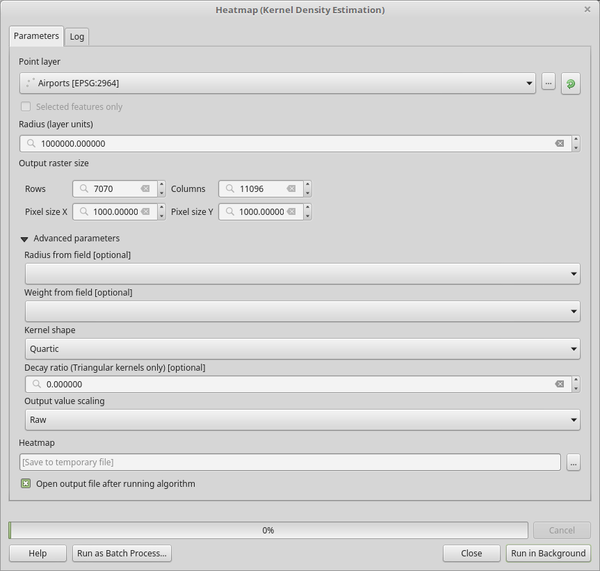
図 27.3 ヒートマップダイアログ
QGISはヒートマップを生成し、マップウィンドウに追加します。デフォルトでは、ヒートマップはグレースケールで表示され、色が明るい領域は空港が集中していることを示しています。QGISでこのヒートマップのスタイルを設定し、見た目を改善しましょう。
図 27.4 グレーの面に見える読み込み直後のヒートマップ
heatmap_airportsレイヤのプロパティダイアログを開きます(heatmap_airportsレイヤを選択し、マウス右ボタンでコンテキストメニューを開いて、 プロパティ を選択します)。シンボロジ タブを選択します。
レンダリングタイプ
を「単バンド疑似カラー」に変更します。適切な カラーランプ
、例えば YlOrRdを選択します。分類 ボタンをクリックします。
OK ボタンを押して、レイヤを更新します。
最終的な結果を 図 27.5 に示します。
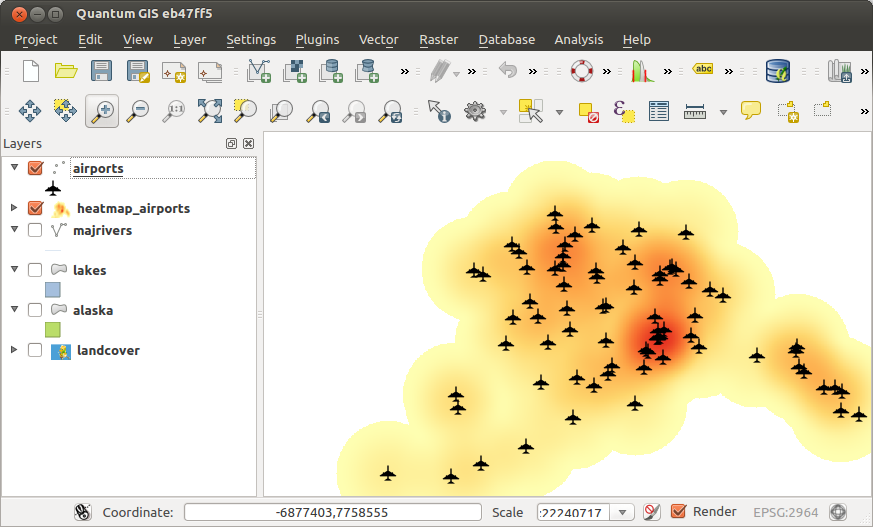
図 27.5 スタイルが設定されたアラスカの空港のヒートマップ
Python コード
Algorithm ID: qgis:heatmapkerneldensityestimation
import processing
processing.run("algorithm_id", {parameter_dictionary})
algorithm id は、プロセシングツールボックス内でアルゴリズムにマウスカーソルを乗せた際に表示されるIDです。 parameter dictionary は、パラメータの「名前」とその値を指定するマッピング型です。Python コンソールからプロセシングアルゴリズムを実行する方法の詳細については、 プロセシングアルゴリズムをコンソールから使う を参照してください。
27.1.5.2. IDW内挿(逆距離加重法)
ポイントベクタレイヤの逆距離加重法(IDW)内挿ラスタを生成します。
作成したい未知の点からの距離に応じてサンプル点からの影響が減少するように、サンプル点は内挿時に重み付けされます。
IDW内挿法には、サンプルデータ点の分布が不均一な場合、内挿結果の質が低下するといった、いくつかの欠点もあります。
その上、内挿面の最大値と最小値はサンプルデータ点上でしか起こりえません。
パラメータ
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
入力レイヤ |
|
[文字列] |
内挿に使用するベクタレイヤとフィールド。コードでは文字列で指定します(詳細については InterpolationWidgets の 内挿データの文字列を構成するために、以下のGUI要素が用意されています:
追加されたレイヤとフィールドの組み合わせごとに、タイプを選択します:
文字列では、複数のレイヤ・フィールド要素は |
距離係数(P) |
|
[数値] デフォルト: 2.0 |
内挿の距離係数を設定します。最小値は 0.0、最大値は 100.0 です。 |
領域 (xmin, xmax, ymin, ymax) |
|
[範囲] |
出力ラスタレイヤの範囲。 利用できる方法:
|
出力ラスタサイズ |
|
[数値] デフォルト: 0.1 |
レイヤの単位で表した、出力ラスタレイヤのピクセルサイズ GUIでは、出力ラスタサイズは行数( |
出力レイヤ |
|
[ラスタ] デフォルト: |
内挿された値のラスタレイヤ。次のいずれかです:
|
出力
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
出力レイヤ |
|
[ラスタ] |
内挿された値のラスタレイヤ |
Python コード
Algorithm ID: qgis:idwinterpolation
import processing
processing.run("algorithm_id", {parameter_dictionary})
algorithm id は、プロセシングツールボックス内でアルゴリズムにマウスカーソルを乗せた際に表示されるIDです。 parameter dictionary は、パラメータの「名前」とその値を指定するマッピング型です。Python コンソールからプロセシングアルゴリズムを実行する方法の詳細については、 プロセシングアルゴリズムをコンソールから使う を参照してください。
27.1.5.3. 線の密度
ラスタの各セルについて、円形状の近傍領域内の線の密度を計算します。この指標は、円形の近傍領域と交差する線分の数をすべて足し合わせ、この合計値をその近傍領域の面積で割ることで得られます。ラインセグメントには、重みづけの係数を適用することができます。
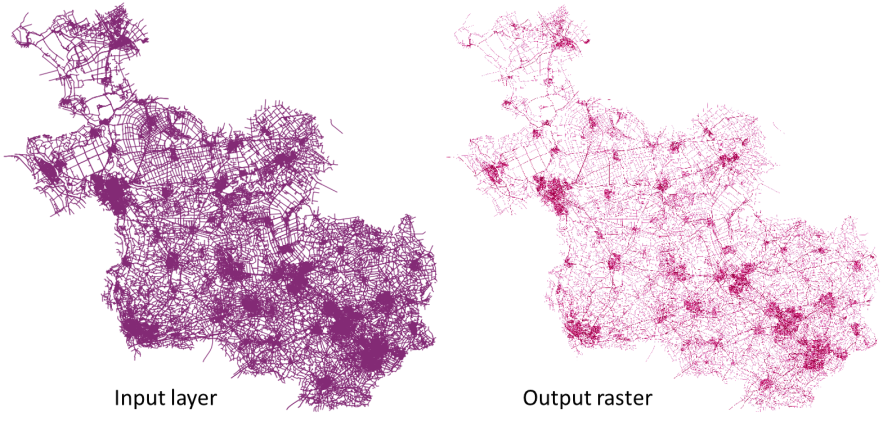
図 27.6 線の密度の例。ソース入力レイヤ:Roads Overijssel - The Netherlands (OSM)
パラメータ
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
入力線レイヤ |
|
[ベクタ:任意] |
ライン地物を含んでいる入力ベクタレイヤ |
重み属性(フィールド) |
|
[数値] |
線の密度の計算の際に使用する重み係数が含まれるレイヤのフィールド |
検索半径 |
|
[数値] デフォルト: 10 |
円形近傍の検索半径。単位を指定できます。 |
ピクセルサイズ |
|
[数値] デフォルト: 10 |
レイヤの単位で表した、出力ラスタレイヤのピクセルサイズ。ラスタのピクセルは正方形です。 |
線密度ラスタ |
|
[ラスタ] デフォルト: |
出力結果のラスタレイヤ。次のいずれかです:
|
出力
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
線密度ラスタ |
|
[ラスタ] |
線密度の計算結果のラスタレイヤ |
Python コード
Algorithm ID: native:linedensity
import processing
processing.run("algorithm_id", {parameter_dictionary})
algorithm id は、プロセシングツールボックス内でアルゴリズムにマウスカーソルを乗せた際に表示されるIDです。 parameter dictionary は、パラメータの「名前」とその値を指定するマッピング型です。Python コンソールからプロセシングアルゴリズムを実行する方法の詳細については、 プロセシングアルゴリズムをコンソールから使う を参照してください。
27.1.5.4. TIN内挿(不規則三角網)
ポイントベクタレイヤの不規則三角網(TIN)内挿ラスタを生成します。
TIN内挿法を使用して、最近傍点の三角形で形成されるサーフェスを作成できます。このサーフェスを作成するために、選択されたサンプル点の周りの外接円を作成し、その交点を、重ならない、できるだけコンパクトな三角形のネットワークに連結します。結果として得られるサーフェスは滑らかではありません。
このアルゴリズムは、内挿値のラスタレイヤと三角網のベクタラインレイヤの両方を作成します。
パラメータ
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
入力レイヤ |
|
[文字列] |
内挿に使用するベクタレイヤとフィールド。コードでは文字列で指定します(詳細については InterpolationWidgets の 内挿データの文字列を構成するために、以下のGUI要素が用意されています:
追加されたレイヤとフィールドの組み合わせごとに、タイプを選択します:
文字列では、複数のレイヤ・フィールド要素は |
内挿方法 |
|
[列挙型] デフォルト: 0 |
使用する内挿方法を設定します。以下のいずれかです:
|
領域 (xmin, xmax, ymin, ymax) |
|
[範囲] |
出力ラスタレイヤの範囲。 利用できる方法:
|
出力ラスタサイズ |
|
[数値] デフォルト: 0.1 |
レイヤの単位で表した、出力ラスタレイヤのピクセルサイズ GUIでは、出力ラスタサイズは行数( |
出力レイヤ |
|
[ラスタ] デフォルト: |
TIN内挿結果のラスタレイヤ。次のいずれかです:
|
TIN内挿出力 |
|
[ベクタ:ライン] デフォルト: |
TIN生成結果のベクタレイヤ。次のいずれかです:
ここでファイルの文字コードを変更することもできます。 |
出力
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
出力レイヤ |
|
[ラスタ] |
TIN内挿結果のラスタレイヤ |
TIN内挿出力 |
|
[ベクタ:ライン] |
TIN生成結果のベクタレイヤ |
Python コード
Algorithm ID: qgis:tininterpolation
import processing
processing.run("algorithm_id", {parameter_dictionary})
algorithm id は、プロセシングツールボックス内でアルゴリズムにマウスカーソルを乗せた際に表示されるIDです。 parameter dictionary は、パラメータの「名前」とその値を指定するマッピング型です。Python コンソールからプロセシングアルゴリズムを実行する方法の詳細については、 プロセシングアルゴリズムをコンソールから使う を参照してください。