27.1.17. Vector algemeen
27.1.17.1. Projectie toekennen
Wijst een nieuwe projectie toe aan een vectorlaag.
Het maakt een nieuwe laag met exact dezelfde objecten en geometrieën als die van de invoer, maar toegewezen aan een ander CRS. De geometrieën worden niet opnieuw geprojecteerd, maar aan hen wordt slechts een ander CRS toegewezen.
Dit algoritme kan worden gebruikt om lagen te repareren die een onjuiste projectie hebben toegewezen gekregen.
Attributen worden niet aangepast door dit algoritme.
Parameters
Label |
Naam |
Type |
Omschrijving |
|---|---|---|---|
Invoerlaag |
|
[vector: elke] |
Vectorlaag met verkeerd of ontbrekend CRS |
Toegewezen CRS |
|
[crs] Standaard: |
Selecteer het nieuwe toe te wijzen CRS voor de vectorlaag |
Toegewezen CRS Optioneel |
|
[hetzelfde als invoer] Standaard: |
Specificeer de uitvoer vectorlaag. Één van:
De bestandscodering kan hier ook gewijzigd worden. |
Uitvoer
Label |
Naam |
Type |
Omschrijving |
|---|---|---|---|
Toegewezen CRS |
|
[hetzelfde als invoer] |
Vectorlaag met toegewezen projectie |
Pythoncode
ID algoritme: native:assignprojection
import processing
processing.run("algorithm_id", {parameter_dictionary})
Het ID voor het algoritme wordt weergegeven als u over het algoritme gaat met de muisaanwijzer in de Toolbox van Processing. Het woordenboek voor de parameters verschaft de NAME’s en waarden van de parameters. Bekijk Processing algoritmes gebruiken vanaf de console voor details over hoe algoritmes van Processing uit te voeren vanuit de console voor Python.
27.1.17.2. Bulk geocodering Nominatim
Voert geocoderen in bulk uit met behulp van de service Nominatim tegen een veld tekenreeks van een invoerlaag. De uitvoerlaag zal een geometrie punt hebben die de geogecodeerde locatie weergeeft, als ook een aantal attributen die zijn geassocieerd aan de geogecodeerde locatie.
 Maakt objecten op hun plaats aanpassen mogelijk voor objecten punt
Maakt objecten op hun plaats aanpassen mogelijk voor objecten punt
Notitie
Dit algoritme voldoet aan het gebruiksbeleid van de service voor geocodering Nominatim die wordt verschaft door de OpenStreetMap Foundation.
Parameters
Label |
Naam |
Type |
Omschrijving |
|---|---|---|---|
Invoerlaag |
|
[vector: elke] |
Vectorlaag waaruit de objecten moeten worden voorzien van geocodering |
Adresveld |
|
[tabelveld: string] |
Veld dat de adressen bevat voor geocodering |
Voorzien van geocode |
|
[vector: punt] Standaard: |
Specificeer de uitvoerlaag die alleen de adressen met geocode bevat. Één van:
De bestandscodering kan hier ook gewijzigd worden. |
Uitvoer
Label |
Naam |
Type |
Omschrijving |
|---|---|---|---|
Voorzien van geocode |
|
[vector: punt] |
Vectorlaag met objecten punt die corresponderen met de adressen met geocode |
Pythoncode
ID algoritme: native:batchnominatimgeocoder
import processing
processing.run("algorithm_id", {parameter_dictionary})
Het ID voor het algoritme wordt weergegeven als u over het algoritme gaat met de muisaanwijzer in de Toolbox van Processing. Het woordenboek voor de parameters verschaft de NAME’s en waarden van de parameters. Bekijk Processing algoritmes gebruiken vanaf de console voor details over hoe algoritmes van Processing uit te voeren vanuit de console voor Python.
27.1.17.3. Laag converteren naar Favoriete plaatsen
Maakt Favoriete plaatsen, corresponderend met het bereik van objecten die zijn opgenomen in een laag.
Parameters
Label |
Naam |
Type |
Omschrijving |
|---|---|---|---|
Invoerlaag |
|
[vector: lijn, polygoon] |
De invoer vectorlaag |
Doel Favoriete plaats |
|
[enumeratie] Standaard: 0 |
Selecteer het doel voor de Favoriete plaatsen. Één van:
|
Veld Naam |
|
[expressie] |
Veld of expressie dat namen zal geven aan de gemaakte Favoriete plaatsen |
Groeperingsveld |
|
[expressie] |
Veld of expressie dat groepen zal maken voor de gemaakte Favoriete plaatsen |
Uitvoer
Label |
Naam |
Type |
Omschrijving |
|---|---|---|---|
Aantal toegevoegde Favoriete plaatsen |
|
[getal] |
Pythoncode
ID algoritme: native:layertobookmarks
import processing
processing.run("algorithm_id", {parameter_dictionary})
Het ID voor het algoritme wordt weergegeven als u over het algoritme gaat met de muisaanwijzer in de Toolbox van Processing. Het woordenboek voor de parameters verschaft de NAME’s en waarden van de parameters. Bekijk Processing algoritmes gebruiken vanaf de console voor details over hoe algoritmes van Processing uit te voeren vanuit de console voor Python.
27.1.17.4. Favoriete plaatsen converteren naar laag
Maakt een nieuwe laag die objecten polygoon bevat voor opgeslagen Favoriete plaatsen. Het exporteren kan worden gefilterd op alleen Favoriete plaatsen die tot het huidige project behoren, op alle Favoriete plaatsen van de gebruiker, of een combinatie van beide.
Parameters
Label |
Naam |
Type |
Omschrijving |
|---|---|---|---|
Bron Favoriete plaats |
|
[enumeratie] [lijst] Standaard: [0,1] |
Selecteer de bron(nen) voor de Favoriete plaatsen. Één of meer van:
|
Uitvoer CRS |
|
[crs] Standaard: |
Het CRS van de uitvoerlaag |
Uitvoer |
|
[vector: polygoon] Standaard: |
Specificeer de uitvoerlaag. Één van:
De bestandscodering kan hier ook gewijzigd worden. |
Uitvoer
Label |
Naam |
Type |
Omschrijving |
|---|---|---|---|
Uitvoer |
|
[vector: polygoon] |
De uitvoer (Favoriete plaatsen) vectorlaag |
Pythoncode
ID algoritme: native:bookmarkstolayer
import processing
processing.run("algorithm_id", {parameter_dictionary})
Het ID voor het algoritme wordt weergegeven als u over het algoritme gaat met de muisaanwijzer in de Toolbox van Processing. Het woordenboek voor de parameters verschaft de NAME’s en waarden van de parameters. Bekijk Processing algoritmes gebruiken vanaf de console voor details over hoe algoritmes van Processing uit te voeren vanuit de console voor Python.
27.1.17.5. Index voor attributen aanmaken
Maakt een index van een veld in de attributentabel om bevragingen sneller te maken. De ondersteuning voor het maken van indexen is afhankelijk van de provider van de gegevenslaag en het type veld.
Er wordt geen uitvoer gemaakt: de index wordt opgeslagen op de laag zelf.
Parameters
Label |
Naam |
Type |
Omschrijving |
|---|---|---|---|
Invoerlaag |
|
[vector: elke] |
Selecteer de vectorlaag die u wilt gebruiken om een index voor attributen te maken |
Attribuut voor de index |
|
[tabelveld: elk] |
Veld van de vectorlaag |
Uitvoer
Label |
Naam |
Type |
Omschrijving |
|---|---|---|---|
Geïndexeerde laag |
|
[hetzelfde als invoer] |
Een kopie van de invoer vectorlaag met een index voor het gespecificeerde veld |
Pythoncode
ID algoritme: native:createattributeindex
import processing
processing.run("algorithm_id", {parameter_dictionary})
Het ID voor het algoritme wordt weergegeven als u over het algoritme gaat met de muisaanwijzer in de Toolbox van Processing. Het woordenboek voor de parameters verschaft de NAME’s en waarden van de parameters. Bekijk Processing algoritmes gebruiken vanaf de console voor details over hoe algoritmes van Processing uit te voeren vanuit de console voor Python.
27.1.17.6. Ruimtelijke index maken
Maakt een index om toegang tot de objecten in een laag sneller te maken, gebaseerd op hun ruimtelijke locatie. Ondersteuning voor het maken van ruimtelijke indexen is afhankelijk van de provider van de gegevenslaag.
Er worden geen nieuwe lagen voor uitvoer gemaakt.
Standaard menu:
Parameters
Label |
Naam |
Type |
Omschrijving |
|---|---|---|---|
Invoerlaag |
|
[vector: elke] |
Invoer vectorlaag |
Uitvoer
Label |
Naam |
Type |
Omschrijving |
|---|---|---|---|
Geïndexeerde laag |
|
[hetzelfde als invoer] |
Een kopie van de invoer vectorlaag met een ruimtelijke index |
Pythoncode
ID algoritme: native:createspatialindex
import processing
processing.run("algorithm_id", {parameter_dictionary})
Het ID voor het algoritme wordt weergegeven als u over het algoritme gaat met de muisaanwijzer in de Toolbox van Processing. Het woordenboek voor de parameters verschaft de NAME’s en waarden van de parameters. Bekijk Processing algoritmes gebruiken vanaf de console voor details over hoe algoritmes van Processing uit te voeren vanuit de console voor Python.
27.1.17.7. Projectie voor Shapefile definiëren
Stelt het CRS (projectie) van een bestaande gegevensset in de indeling Shapefile in op het opgegeven CRS. Dit is bijzonder nuttig als een gegevensset in de indeling Shapefile het bestand prj mist en u de juiste projectie weet.
In tegenstelling tot het algoritme Projectie toekennen, past het de huidige laag aan en zal het geen nieuwe laag uitvoeren.
Notitie
Voor gegevenssets van Shapefile zullen de bestanden .prj en .qpj worden overschreven - of gemaakt indien ze ontbreken - om overeen te komen met het opgegeven CRS.
Standaard menu:
Parameters
Label |
Naam |
Type |
Omschrijving |
|---|---|---|---|
Invoerlaag |
|
[vector: elke] |
Vectorlaag met ontbrekende informatie voor projectie |
CRS |
|
[crs] |
Selecteer het toe te wijzen CRS voor de vectorlaag |
Uitvoer
Label |
Naam |
Type |
Omschrijving |
|---|---|---|---|
|
[hetzelfde als invoer] |
De invoer vectorlaag met de gedefinieerde projectie |
Pythoncode
ID algoritme: qgis:definecurrentprojection
import processing
processing.run("algorithm_id", {parameter_dictionary})
Het ID voor het algoritme wordt weergegeven als u over het algoritme gaat met de muisaanwijzer in de Toolbox van Processing. Het woordenboek voor de parameters verschaft de NAME’s en waarden van de parameters. Bekijk Processing algoritmes gebruiken vanaf de console voor details over hoe algoritmes van Processing uit te voeren vanuit de console voor Python.
27.1.17.8. Duplicaten van geometrieën verwijderen
Zoekt en verwijdert duplicaten van geometrieën.
Attributen worden niet gecontroleerd, dus in het geval dat twee objecten identieke geometrieën hebben, maar verschillende attributen, zal slechts één ervan worden toegevoegd aan de laag met resultaten.
Parameters
Label |
Naam |
Type |
Omschrijving |
|---|---|---|---|
Invoerlaag |
|
[vector: elke] |
De laag met duplicaat-geometrieën die u wilt opruimen |
Schoongemaakt |
|
[hetzelfde als invoer] Standaard: |
Specificeer de uitvoerlaag. Één van:
De bestandscodering kan hier ook gewijzigd worden. |
Uitvoer
Label |
Naam |
Type |
Omschrijving |
|---|---|---|---|
Aantal verwijderde duplicaatrecords |
|
[getal] |
Aantal verwijderde duplicaatrecords |
Schoongemaakt |
|
[hetzelfde als invoer] |
De uitvoer vectorlaag zonder duplicaat-geometrieën |
Aantal behouden records |
|
[getal] |
Aantal unieke records |
Pythoncode
ID algoritme: native:deleteduplicategeometries
import processing
processing.run("algorithm_id", {parameter_dictionary})
Het ID voor het algoritme wordt weergegeven als u over het algoritme gaat met de muisaanwijzer in de Toolbox van Processing. Het woordenboek voor de parameters verschaft de NAME’s en waarden van de parameters. Bekijk Processing algoritmes gebruiken vanaf de console voor details over hoe algoritmes van Processing uit te voeren vanuit de console voor Python.
27.1.17.9. Duplicaten verwijderen op attribuut
Verwijdert duplicaatrijen door alleen rekening te houden met het/de gespecificeerde veld / velden. De eerste overeenkomende rij zal worden behouden, en duplicaten zullen worden verwijderd.
Optioneel kunnen deze duplicaatrecords worden opgeslagen naar een afzonderlijke uitvoer, voor analyse.
Parameters
Label |
Naam |
Type |
Omschrijving |
|---|---|---|---|
Invoerlaag |
|
[vector: elke] |
De invoerlaag |
Veld waarvoor duplicaten moet overeenkomen |
|
[tabelveld: elk] [lijst] |
Velden die duplicaten definiëren. Objecten met identieke waarden voor al deze velden worden geacht duplicaten te zijn. |
Gefilterd (geen duplicaten) |
|
[hetzelfde als invoer] Standaard: |
Specificeer de uitvoerlaag die de unieke objecten bevat. Één van:
De bestandscodering kan hier ook gewijzigd worden. |
Gefilterd (duplicaten) Optioneel |
|
[hetzelfde als invoer] Standaard: |
Specificeer de uitvoerlaag die alleen de duplicaten bevat. Één van:
De bestandscodering kan hier ook gewijzigd worden. |
Uitvoer
Label |
Naam |
Type |
Omschrijving |
|---|---|---|---|
Gefilterd (duplicaten) Optioneel |
|
[hetzelfde als invoer] Standaard: |
Vectorlaag die de verwijderde objecten bevat. Zal niet worden gemaakt indien niet gespecificeerd (gelaten als |
Aantal verwijderde duplicaatrecords |
|
[getal] |
Aantal verwijderde duplicaatrecords |
Gefilterd (geen duplicaten) |
|
[hetzelfde als invoer] |
Vectorlaag die de unieke objecten bevat. |
Aantal behouden records |
|
[getal] |
Aantal unieke records |
Pythoncode
ID algoritme: native:removeduplicatesbyattribute
import processing
processing.run("algorithm_id", {parameter_dictionary})
Het ID voor het algoritme wordt weergegeven als u over het algoritme gaat met de muisaanwijzer in de Toolbox van Processing. Het woordenboek voor de parameters verschaft de NAME’s en waarden van de parameters. Bekijk Processing algoritmes gebruiken vanaf de console voor details over hoe algoritmes van Processing uit te voeren vanuit de console voor Python.
27.1.17.10. Wijzigingen in gegevensset detecteren
Vergelijkt twee vectorlagen en bepaalt welk objecten niet gewijzigd, toegevoegd of verwijderd zijn tussen die twee. Het is ontworpen voor het vergelijken van twee verschillende versies van dezelfde gegevensset.
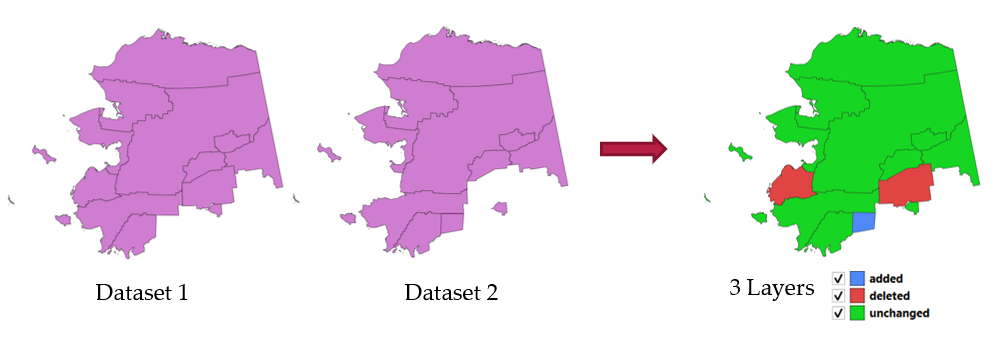
Fig. 27.46 Voorbeeld Wijzigingen in gegevensset detecteren
Parameters
Label |
Naam |
Type |
Omschrijving |
|---|---|---|---|
Originele laag |
|
[vector: elke] |
De vectorlaag die wordt beschouwd als de originele versie |
Gereviseerde laag |
|
[vector: elke] |
De gereviseerde of aangepaste vectorlaag |
Attributen waarmee rekening moet worden gehouden voor een overeenkomst Optioneel |
|
[tabelveld: elk] [lijst] |
Attributen waarmee rekening moet worden gehouden voor een overeenkomst. Standaard worden alle attributen vergeleken. |
Gedrag voor vergelijken van geometrie Optioneel |
|
[enumeratie] Standaard: 1 |
Definieert de criteria voor vergelijken. Opties:
|
Ongewijzigde objecten Optioneel |
|
[vector: hetzelfde als de Originele laag] |
Specificeer de uitvoerlaag die de ongewijzigde objecten bevat. Één van:
De bestandscodering kan hier ook gewijzigd worden. |
Toegevoegde objecten Optioneel |
|
[vector: hetzelfde als de Originele laag] |
Specificeer de uitvoerlaag die de toegevoegde objecten bevat. Één van:
De bestandscodering kan hier ook gewijzigd worden. |
Verwijderde objecten Optioneel |
|
[vector: hetzelfde als de Originele laag] |
Specificeer de uitvoerlaag die de verwijderde objecten bevat. Één van:
De bestandscodering kan hier ook gewijzigd worden. |
Uitvoer
Label |
Naam |
Type |
Omschrijving |
|---|---|---|---|
Ongewijzigde objecten |
|
[vector: hetzelfde als de Originele laag] |
Vectorlaag die de ongewijzigde objecten bevat. |
Toegevoegde objecten |
|
[vector: hetzelfde als de Originele laag] |
Vectorlaag die de toegevoegde objecten bevat. |
Verwijderde objecten |
|
[vector: hetzelfde als de Originele laag] |
Vectorlaag die de verwijderde objecten bevat. |
Aantal ongewijzigde objecten |
|
[getal] |
Aantal ongewijzigde objecten. |
Aantal toegevoegde objecten in gereviseerde laag |
|
[getal] |
Aantal toegevoegde objecten in gereviseerde laag. |
Aantal verwijderde objecten uit originele laag |
|
[getal] |
Aantal verwijderde objecten uit originele laag. |
Pythoncode
ID algoritme: native:detectvectorchanges
import processing
processing.run("algorithm_id", {parameter_dictionary})
Het ID voor het algoritme wordt weergegeven als u over het algoritme gaat met de muisaanwijzer in de Toolbox van Processing. Het woordenboek voor de parameters verschaft de NAME’s en waarden van de parameters. Bekijk Processing algoritmes gebruiken vanaf de console voor details over hoe algoritmes van Processing uit te voeren vanuit de console voor Python.
27.1.17.11. Geometrieën verwijderen
Maakt een eenvoudige kopie zonder geometrie van de attributentabel van de invoerlaag van de bronlaag.
Als het bestand wordt opgeslagen in een lokale map kunt u kiezen uit veel verschillende bestandsindelingen.
Maakt objecten op hun plaats aanpassen mogelijk voor objecten punt, lijn en polygoon
Parameters
Label |
Naam |
Type |
Omschrijving |
|---|---|---|---|
Invoerlaag |
|
[vector: elke] |
De invoer vectorlaag |
Verwijderde geometrieën |
|
[tabel] |
Specificeer de uitvoerlaag zonder geometrieën. Één van:
De bestandscodering kan hier ook gewijzigd worden. |
Uitvoer
Label |
Naam |
Type |
Omschrijving |
|---|---|---|---|
Verwijderde geometrieën |
|
[tabel] |
De uitvoerlaag zonder geometrieën. Een kopie van de originele attributentabel. |
Pythoncode
ID algoritme: native:dropgeometries
import processing
processing.run("algorithm_id", {parameter_dictionary})
Het ID voor het algoritme wordt weergegeven als u over het algoritme gaat met de muisaanwijzer in de Toolbox van Processing. Het woordenboek voor de parameters verschaft de NAME’s en waarden van de parameters. Bekijk Processing algoritmes gebruiken vanaf de console voor details over hoe algoritmes van Processing uit te voeren vanuit de console voor Python.
27.1.17.12. SQL uitvoeren
Voert een eenvoudige of complexe query met syntaxis van SQL uit op de bronlaag.
Databronnen voor invoer worden geïdentificeerd met input1, input2… inputN en een eenvoudige query zou eruit zien als SELECT * FROM input1.
Naast een eenvoudige query kunt u expressies of variabelen toevoegen binnen de parameter SQL query zelf. Dit is in het bijzonder nuttig als dit algoritme wordt uitgevoerd in een model van Processing en u wilt een model invoer gebruiken als een parameter van de query. Een voorbeeld van een query zou dan zijn SELECT * FROM [% @table %] waar @table de variabele is die de model invoer identificeert.
Het resultaat van de query zal worden toegevoegd als een nieuwe laag.
Parameters
Label |
Naam |
Type |
Omschrijving |
|---|---|---|---|
Aanvullende databronnen voor invoer (input1, …, inputN genoemd in de query) |
|
[vector: elke] [lijst] |
Lijst van te bevragen lagen. In de bewerker voor SQL kunt u naar deze lagen verwijzen met hun echte naam, maar ook als invoer1, invoer2, invoerN, afhankelijk van hoeveel lagen zijn gekozen. |
SQL-query |
|
[tekenreeks] |
Typ de tekenreeks van uw query voor SQL, bijv. |
Uniek veld voor identificatie Optioneel |
|
[tekenreeks] |
Specificeer de kolom met de unieke ID |
Geometrie-veld Optioneel |
|
[tekenreeks] |
Specificeer het geometrie-veld |
Type geometrie Optioneel |
|
[enumeratie] Standaard: 0 |
Kies de geometrie voor het resultaat. Standaard zal het algoritme het automatisch detecteren. Één van:
|
CRS Optioneel |
|
[crs] |
Het CRS dat aan de uitvoerlaag moet worden toegewezen |
SQL uitvoer |
|
[vector: elke] Standaard: |
Specificeer de uitvoerlaag die wordt gemaakt door de query. Één van:
De bestandscodering kan hier ook gewijzigd worden. |
Uitvoer
Label |
Naam |
Type |
Omschrijving |
|---|---|---|---|
SQL uitvoer |
|
[vector: elke] |
Vectorlaag gemaakt door de query |
Pythoncode
ID algoritme: qgis:executesql
import processing
processing.run("algorithm_id", {parameter_dictionary})
Het ID voor het algoritme wordt weergegeven als u over het algoritme gaat met de muisaanwijzer in de Toolbox van Processing. Het woordenboek voor de parameters verschaft de NAME’s en waarden van de parameters. Bekijk Processing algoritmes gebruiken vanaf de console voor details over hoe algoritmes van Processing uit te voeren vanuit de console voor Python.
27.1.17.13. Lagen naar DXF exporteren
Exporteert lagen naar een bestand DXF. Voor elke laag kunt u een veld kiezen waarvan de waarden worden gebruikt om objecten te splitsen in de gemaakte doellagen in de uitvoer voor DXF.
Zie ook
Parameters
Label |
Naam |
Type |
Omschrijving |
|---|---|---|---|
Invoerlagen |
|
[vector: elke] [lijst] |
Te exporteren invoer vectorlagen |
Symbologie modus |
|
[enumeratie] Standaard: 0 |
Type symbologie die moet worden toegepast op de uitvoerlagen. U kunt kiezen uit:
|
Symbologie schaal |
|
[schaal] Standaard: 1:1 000 000 |
Standaard schaal voor de gegevensexport. |
Codering |
|
[enumeratie] |
Codering die moet worden toegepast op de lagen. |
CRS |
|
[crs] |
Het CRS van de uitvoerlaag kiezen |
Titel van laag als naam gebruiken |
|
[Booleaanse waarde] Standaard: False |
Benoem de uitvoerlaag met de titel van de laag (zoals ingesteld in QGIS) in plaats van de naam van de laag. |
2D uitvoer forceren |
|
[Booleaanse waarde] Standaard: False |
|
Labels als elementen MTEXT exporteren |
|
[Booleaanse waarde] Standaard: False |
Labels als elementen MTEXT of TEXT exporteren |
DXF |
|
[bestand] Standaard: |
Specificatie van het uitvoer DXF-bestand. Één van:
|
Uitvoer
Label |
Naam |
Type |
Omschrijving |
|---|---|---|---|
DXF |
|
[bestand] |
|
Pythoncode
ID algoritme: native:dxfexport
import processing
processing.run("algorithm_id", {parameter_dictionary})
Het ID voor het algoritme wordt weergegeven als u over het algoritme gaat met de muisaanwijzer in de Toolbox van Processing. Het woordenboek voor de parameters verschaft de NAME’s en waarden van de parameters. Bekijk Processing algoritmes gebruiken vanaf de console voor details over hoe algoritmes van Processing uit te voeren vanuit de console voor Python.
27.1.17.14. Geselecteerde objecten uitnemen
Slaat de geselecteerde objecten als een nieuwe laag op.
Notitie
Als de geselecteerde laag geen geselecteerde objecten heeft, zal de nieuw gemaakte laag leeg zijn.
Parameters
Label |
Naam |
Type |
Omschrijving |
|---|---|---|---|
Invoerlaag |
|
[vector: elke] |
Laag waaruit de selectie moet worden geselecteerd |
Geselecteerde objecten |
|
[hetzelfde als invoer] Standaard: |
Specificeer de vectorlaag voor de geselecteerde objecten. Één van:
De bestandscodering kan hier ook gewijzigd worden. |
Uitvoer
Label |
Naam |
Type |
Omschrijving |
|---|---|---|---|
Geselecteerde objecten |
|
[hetzelfde als invoer] |
Vectorlaag met alleen de geselecteerde objecten, of zonder objecten als niets werd geselecteerd. |
Pythoncode
ID algoritme: native:saveselectedfeatures
import processing
processing.run("algorithm_id", {parameter_dictionary})
Het ID voor het algoritme wordt weergegeven als u over het algoritme gaat met de muisaanwijzer in de Toolbox van Processing. Het woordenboek voor de parameters verschaft de NAME’s en waarden van de parameters. Bekijk Processing algoritmes gebruiken vanaf de console voor details over hoe algoritmes van Processing uit te voeren vanuit de console voor Python.
27.1.17.15. Codering Shapefile uitnemen
Neemt de informatie uit voor de codering van attributen, die is ingebed in een Shapefile. Zowel de codering die is gespecificeerd in een optioneel bestand .:file:.cpg als details voor de codering die aanwezig zijn in het .dbf LDID kopblok worden uitgenomen.
Parameters
Label |
Naam |
Type |
Omschrijving |
|---|---|---|---|
Invoerlaag |
|
[vector: elke] |
Laag van ESRI Shapefile ( |
Uitvoer
Label |
Naam |
Type |
Omschrijving |
|---|---|---|---|
Shapefile codering |
|
[tekenreeks] |
Informatie voor de codering gespecificeerd in het invoerbestand |
CPG-codering |
|
[tekenreeks] |
Informatie voor de codering gespecificeerd in een optioneel bestand |
LDID-codering |
|
[tekenreeks] |
Informatie voor de codering gespecificeerd in het |
Pythoncode
ID algoritme: native:shpencodinginfo
import processing
processing.run("algorithm_id", {parameter_dictionary})
Het ID voor het algoritme wordt weergegeven als u over het algoritme gaat met de muisaanwijzer in de Toolbox van Processing. Het woordenboek voor de parameters verschaft de NAME’s en waarden van de parameters. Bekijk Processing algoritmes gebruiken vanaf de console voor details over hoe algoritmes van Processing uit te voeren vanuit de console voor Python.
27.1.17.16. Projectie zoeken
Maakt een verkorte lijst van kandidaat coördinaten referentiesystemen, bijvoorbeeld voor een laag met een onbekende projectie.
Het gebied, dat de laag verwacht wordt te bedekken, moet zijn gespecificeerd via de parameter Doelgebied. Het coördinaten referentiesysteem voor dit doelgebied moet bekend zijn bij QGIS.
Het algoritme werkt door het bereik van de laag te testen in elk bekend referentiesysteem en dan die te vermelden waarvan de grenzen nabij het doelgebied liggen, als de laag in deze projectie zou zijn.
Parameters
Label |
Naam |
Type |
Omschrijving |
|---|---|---|---|
Invoerlaag |
|
[vector: elke] |
Laag met onbekende projectie |
Doelgebied voor laag (xmin, xmax, ymin, ymax) |
|
[bereik] |
Het gebied dat de laag bedekt. Beschikbare methoden zijn:
|
CRS-kandidaten |
|
[tabel] Standaard: |
Specificeer de tabel (laag zonder geometrie) voor de suggesties voor het CRS (EPSG-codes). Één van:
De bestandscodering kan hier ook gewijzigd worden. |
Uitvoer
Label |
Naam |
Type |
Omschrijving |
|---|---|---|---|
CRS-kandidaten |
|
[tabel] |
Een tabel met alle CRSen (EPSG-codes) van de overeenkomende criteria. |
Pythoncode
ID algoritme: qgis:findprojection
import processing
processing.run("algorithm_id", {parameter_dictionary})
Het ID voor het algoritme wordt weergegeven als u over het algoritme gaat met de muisaanwijzer in de Toolbox van Processing. Het woordenboek voor de parameters verschaft de NAME’s en waarden van de parameters. Bekijk Processing algoritmes gebruiken vanaf de console voor details over hoe algoritmes van Processing uit te voeren vanuit de console voor Python.
27.1.17.17. Relatie afvlakken
Vlakt een relatie af voor een vectorlaag, exporteert een enkele laag die één ouderobject per gerelateerd object bevat. Dit ouderobject bevat alle attributen voor de gerelateerde objecten. Dit maakt het mogelijk de relatie te verkrijgen als een gewone tabel die bijv. kan worden geëxporteerd naar CSV.
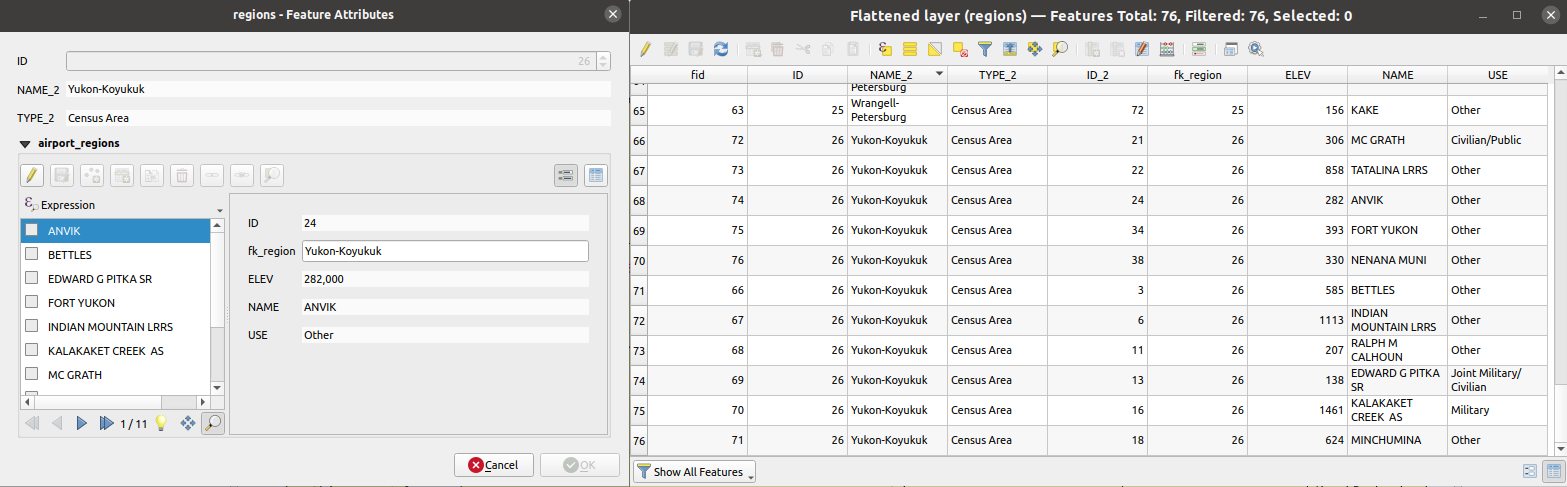
Fig. 27.47 Formulier van een region met gerelateerde kinderen (links) - Een duplicaat region-object voor elk gerelateerd kind, met samengevoegde attributen (rechts)
Parameters
Label |
Naam |
Type |
Omschrijving |
|---|---|---|---|
Invoerlaag |
|
[vector: elke] |
Laag met de relatie die gede-normaliseerd zou moeten worden |
Afgevlakte laag Optioneel |
|
[hetzelfde als invoer] Standaard: |
Specificeer de uitvoer (afgevlakte) laag. Één van:
De bestandscodering kan hier ook gewijzigd worden. |
Uitvoer
Label |
Naam |
Type |
Omschrijving |
|---|---|---|---|
Afgevlakte laag |
|
[hetzelfde als invoer] |
Een laag die hoofdobjecten bevat met alle attributen voor de gerelateerde objecten |
Pythoncode
ID algoritme: native:flattenrelationships
import processing
processing.run("algorithm_id", {parameter_dictionary})
Het ID voor het algoritme wordt weergegeven als u over het algoritme gaat met de muisaanwijzer in de Toolbox van Processing. Het woordenboek voor de parameters verschaft de NAME’s en waarden van de parameters. Bekijk Processing algoritmes gebruiken vanaf de console voor details over hoe algoritmes van Processing uit te voeren vanuit de console voor Python.
27.1.17.18. Attributen koppelen op veldwaarde
Neemt een invoer vectorlaag en maakt een nieuwe vectorlaag die een uitgebreide versie is van die van de invoer, met aanvullende attributen in zijn attributentabel.
De aanvullende attributen en hun waarden worden uit een tweede vectorlaag genomen. Een attribuut is geselecteerd in elk van hen om de criteria voor het samenvoegen te definiëren.
Parameters
Label |
Naam |
Type |
Omschrijving |
|---|---|---|---|
Invoerlaag |
|
[vector: elke] |
Invoer vectorlaag. De uitvoerlaag zal bestaan uit de objecten van deze laag met attributen van overeenkomende objecten in de tweede laag. |
Tabelveld |
|
[tabelveld: elk] |
Veld van de bronlaag te gebruiken voor het samenvoegen |
Invoerlaag 2 |
|
[vector: elke] |
Laag met de te koppelen attributentabel |
Tabelveld 2 |
|
[tabelveld: elk] |
Veld van de tweede (koppel-) laag om te gebruiken om samen te voegen. Het type veld moet gelijk zijn aan (of compatibel met) het type tabelveld voor de invoer. |
Velden van laag 2 om te kopiëren Optioneel |
|
[tabelveld: elk] [lijst] |
Selecteer de specifieke velden die u wilt toevoegen. Standaard worden alle velden toegevoegd. |
Verbindingsstijl |
|
[enumeratie] Standaard: 1 |
Het type van de uiteindelijke gekoppelde laag. Één van:
|
Records verwijderen die niet konden worden gekoppeld |
|
[Booleaanse waarde] Standaard: True |
Selecteren als u de objecten, die niet konden worden gekoppeld, niet wilt behouden |
Voorvoegsel samengevoegde velden Optioneel |
|
[tekenreeks] |
Voeg een voorvoegsel toe aan gekoppelde velden om ze gemakkelijk te kunnen identificeren en botsingen tussen namen van velden te vermijden |
Samengevoegde laag Optioneel |
|
[hetzelfde als invoer] Standaard: |
Specificeer de uitvoer vectorlaag voor de koppeling. Één van:
De bestandscodering kan hier ook gewijzigd worden. |
Niet samen te voegen objecten uit eerste laag Optioneel |
|
[hetzelfde als invoer] Standaard: |
Specificeer de uitvoer vectorlaag voor niet samen te voegen objecten uit de eerste laag. Één van:
De bestandscodering kan hier ook gewijzigd worden. |
Uitvoer
Label |
Naam |
Type |
Omschrijving |
|---|---|---|---|
Aantal niet samen te voegen objecten uit invoertabel |
|
[getal] |
|
Niet samen te voegen objecten uit eerste laag Optioneel |
|
[hetzelfde als invoer] |
Vectorlaag met de niet-overeenkomende objecten |
Samengevoegde laag Optioneel |
|
[hetzelfde als invoer] |
Uitvoer vectorlaag met toegevoegde attributen van de koppeling |
Aantal samengevoegde objecten uit invoertabel Optioneel |
|
[getal] |
Pythoncode
ID algoritme: native:joinattributestable
import processing
processing.run("algorithm_id", {parameter_dictionary})
Het ID voor het algoritme wordt weergegeven als u over het algoritme gaat met de muisaanwijzer in de Toolbox van Processing. Het woordenboek voor de parameters verschaft de NAME’s en waarden van de parameters. Bekijk Processing algoritmes gebruiken vanaf de console voor details over hoe algoritmes van Processing uit te voeren vanuit de console voor Python.
27.1.17.19. Koppel attributen op basis van plaats
Neemt een invoer vectorlaag en maakt een nieuwe vectorlaag die een uitgebreide versie is van die van de invoer, met aanvullende attributen in zijn attributentabel.
De aanvullende attributen en hun waarden worden uit een tweede vectorlaag genomen. Een ruimtelijk criterium wordt toegepast om de waarden uit de tweede vectorlaag te selecteren die worden toegevoegd aan elk object uit de eerste laag.
Standaard menu:
Zie ook
Koppel attributen op dichtstbijzijnde, Attributen koppelen op veldwaarde, Koppel attributen op basis van plaats (samenvatting)
Ruimtelijke relaties verkennen
Geometrische gezegdes zijn functies met Booleaanse waarden die worden gebruikt om de ruimtelijke relatie te bepalen die een object heeft met een ander door te vergelijken of en hoe hun geometrieën een portie van hun ruimte delen.
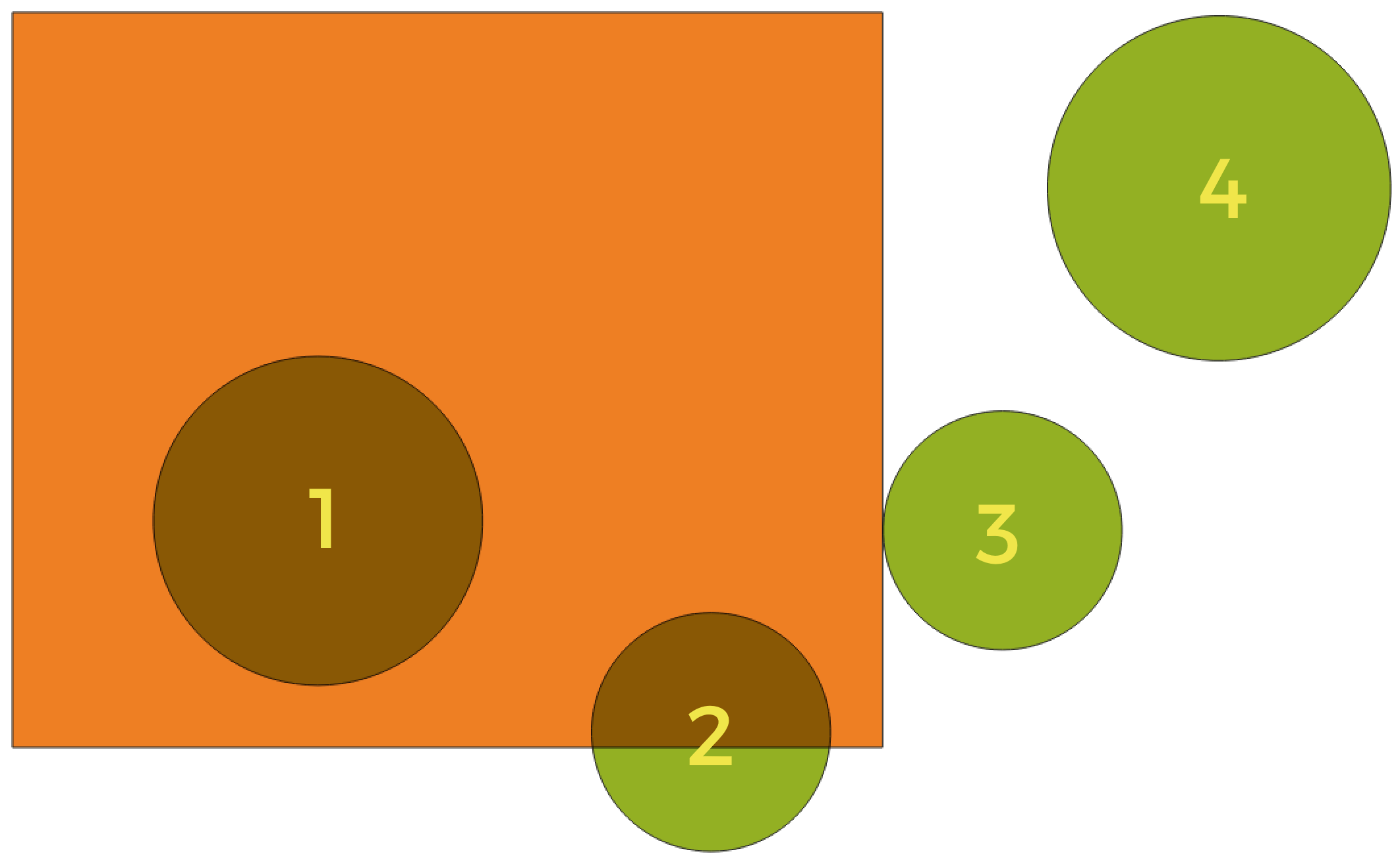
Fig. 27.48 Zoeken naar ruimtelijke relaties tussen lagen
Gebruik makend van de afbeelding hierboven zoeken we naar de groene cirkels door ze ruimtelijk te vergelijken met het rechthoekige oranje object. Beschikbare geometrische gezegdes zijn:
- Kruisen
Test of een geometrie een andere kruist. Geeft 1 ( true) terug als de geometrieën elkaar ruimtelijk kruisen (een stukje ruimte met elkaar delen - overlappen of raken) en 0 als zij dat niet doen. In de afbeelding hierboven zou dit de cirkels 1, 2 en 3 teruggeven.
- Bevat
Geeft 1 (true) terug als en alleen als er geen punten van b in het buitenste van a liggen, en ten minste één punt van het interieur van b ligt in het interieur van a. In de afbeelding zou geen cirkel worden teruggegeven, maar de rechthoek zou dat wel worden als u er op de omgekeerde wijze naar zou zoeken, omdat het cirkel 1 volledig bevat. Dit is het tegengestelde van zijn binnen.
- Raakt niet
Geeft 1 (true) terug als de geometrieën geen deel van de ruimte met elkaar delen (niet overlappen, elkaar niet raken). Alleen cirkel 4 wordt teruggegeven.
- Gelijk
Geeft 1 (true) terug als en alleen als geometrieën exact hetzelfde zijn. Geen cirkels zullen worden teruggegeven.
- Raakt
Test of een geometrie een andere raakt. Geeft 1 (true) terug als de geometrieën tenminste één gemeenschappelijk punt hebben, maar hun interieurs niet kruisen. Alleen cirkel 3 wordt teruggegeven.
- Overlapt
Test of een geometrie een andere overlapt. Geeft 1 (true) terug als de geometrieën ruimte delen, van dezelfde dimensie zijn, maar niet volledig door elkaar worden omvat. Alleen cirkel 2 wordt teruggegeven.
- Zijn binnen
Test of een geometrie in een andere ligt. Geeft 1 (true) terug als geometrie a volledig binnen geometrie b ligt. Alleen cirkel 1 wordt teruggegeven.
- Kruisen
Geeft 1 (true) terug als de opgegeven geometrieën enkele, maar niet alle, punten in het interieur gemeenschappelijk hebben en de feitelijke kruising van een lagere dimensie is dan de hoogste opgegeven geometrie. Bijvoorbeeld een lijn die een polygoon kruist zal een lijn kruisen (true). Twee lijnen die elkaar kruisen zal als een punt kruisen (true). Twee polygonen kruisen als een polygoon (false). In de afbeelding zullen geen cirkels worden teruggegeven.
Parameters
Label |
Naam |
Type |
Omschrijving |
|---|---|---|---|
Samenvoegen met objecten in |
|
[vector: elke] |
Invoer vectorlaag. De uitvoerlaag zal bestaan uit de objecten van deze laag met attributen van overeenkomende objecten in de tweede laag. |
Waar de objecten |
|
[enumeratie] [lijst] Standaard: [0] |
Type ruimtelijke relatie dat het bronobject zou moeten hebben met een doelobject, zodat zij zouden kunnen worden samengevoegd. Één of meer van:
Als meer dan één voorwaarde wordt gekozen, moet aan tenminste één worden voldaan (bewerking OR) om een object uit te kunnen nemen. |
In vergelijking met |
|
[vector: elke] |
De samen te voegen laag. Objecten van deze vectorlaag zullen hun attributen toevoegen aan de attributentabel van de bronlaag, als zij voldoen aan de ruimtelijke relatie. |
Velden die moeten worden toegevoegd (laat leeg om alle velden te gebruiken) Optioneel |
|
[tabelveld: elk] [lijst] |
Selecteer de specifieke velden die u wilt toevoegen vanuit de samen te voegen laag. Standaard worden alle velden toegevoegd. |
Verbindingsstijl |
|
[enumeratie] |
Het type van de uiteindelijke gekoppelde laag. Één van:
|
Records verwijderen die niet konden worden gekoppeld |
|
[Booleaanse waarde] Standaard: False |
Verwijder objecten van de invoerlaag, die niet konden worden gekoppeld, uit de uitvoer |
Voorvoegsel samengevoegde velden Optioneel |
|
[tekenreeks] |
Voeg een voorvoegsel toe aan gekoppelde velden om ze gemakkelijk te kunnen identificeren en botsingen tussen namen van velden te vermijden |
Samengevoegde laag Optioneel |
|
[hetzelfde als invoer] Standaard: |
Specificeer de uitvoer vectorlaag voor de koppeling. Één van:
De bestandscodering kan hier ook gewijzigd worden. |
Niet samen te voegen objecten uit eerste laag Optioneel |
|
[hetzelfde als invoer] Standaard: |
Specificeer de uitvoer vectorlaag voor niet samen te voegen objecten uit de eerste laag. Één van:
De bestandscodering kan hier ook gewijzigd worden. |
Uitvoer
Label |
Naam |
Type |
Omschrijving |
|---|---|---|---|
Aantal niet samen te voegen objecten uit invoertabel |
|
[getal] |
|
Niet samen te voegen objecten uit eerste laag Optioneel |
|
[hetzelfde als invoer] |
Vectorlaag met de niet overeenkomende objecten |
Samengevoegde laag |
|
[hetzelfde als invoer] |
Uitvoer vectorlaag met toegevoegde attributen van de koppeling |
Pythoncode
ID algoritme: native:joinattributesbylocation
import processing
processing.run("algorithm_id", {parameter_dictionary})
Het ID voor het algoritme wordt weergegeven als u over het algoritme gaat met de muisaanwijzer in de Toolbox van Processing. Het woordenboek voor de parameters verschaft de NAME’s en waarden van de parameters. Bekijk Processing algoritmes gebruiken vanaf de console voor details over hoe algoritmes van Processing uit te voeren vanuit de console voor Python.
27.1.17.20. Koppel attributen op basis van plaats (samenvatting)
Neemt een invoer vectorlaag en maakt een nieuwe vectorlaag die een uitgebreide versie is van die van de invoer, met aanvullende attributen in zijn attributentabel.
De aanvullende attributen en hun waarden worden uit een tweede vectorlaag genomen. Een ruimtelijk criterium wordt toegepast om de waarden uit de tweede vectorlaag te selecteren die worden toegevoegd aan elk object uit de eerste laag.
Het algoritme berekent een statistische samenvatting voor de waarden uit overeenkomende objecten op de tweede laag (bijv. maximum waarde, gemiddelde waarde, etc).
Ruimtelijke relaties verkennen
Geometrische gezegdes zijn functies met Booleaanse waarden die worden gebruikt om de ruimtelijke relatie te bepalen die een object heeft met een ander door te vergelijken of en hoe hun geometrieën een portie van hun ruimte delen.
Fig. 27.49 Zoeken naar ruimtelijke relaties tussen lagen
Gebruik makend van de afbeelding hierboven zoeken we naar de groene cirkels door ze ruimtelijk te vergelijken met het rechthoekige oranje object. Beschikbare geometrische gezegdes zijn:
- Kruisen
Test of een geometrie een andere kruist. Geeft 1 ( true) terug als de geometrieën elkaar ruimtelijk kruisen (een stukje ruimte met elkaar delen - overlappen of raken) en 0 als zij dat niet doen. In de afbeelding hierboven zou dit de cirkels 1, 2 en 3 teruggeven.
- Bevat
Geeft 1 (true) terug als en alleen als er geen punten van b in het buitenste van a liggen, en ten minste één punt van het interieur van b ligt in het interieur van a. In de afbeelding zou geen cirkel worden teruggegeven, maar de rechthoek zou dat wel worden als u er op de omgekeerde wijze naar zou zoeken, omdat het cirkel 1 volledig bevat. Dit is het tegengestelde van zijn binnen.
- Raakt niet
Geeft 1 (true) terug als de geometrieën geen deel van de ruimte met elkaar delen (niet overlappen, elkaar niet raken). Alleen cirkel 4 wordt teruggegeven.
- Gelijk
Geeft 1 (true) terug als en alleen als geometrieën exact hetzelfde zijn. Geen cirkels zullen worden teruggegeven.
- Raakt
Test of een geometrie een andere raakt. Geeft 1 (true) terug als de geometrieën tenminste één gemeenschappelijk punt hebben, maar hun interieurs niet kruisen. Alleen cirkel 3 wordt teruggegeven.
- Overlapt
Test of een geometrie een andere overlapt. Geeft 1 (true) terug als de geometrieën ruimte delen, van dezelfde dimensie zijn, maar niet volledig door elkaar worden omvat. Alleen cirkel 2 wordt teruggegeven.
- Zijn binnen
Test of een geometrie in een andere ligt. Geeft 1 (true) terug als geometrie a volledig binnen geometrie b ligt. Alleen cirkel 1 wordt teruggegeven.
- Kruisen
Geeft 1 (true) terug als de opgegeven geometrieën enkele, maar niet alle, punten in het interieur gemeenschappelijk hebben en de feitelijke kruising van een lagere dimensie is dan de hoogste opgegeven geometrie. Bijvoorbeeld een lijn die een polygoon kruist zal een lijn kruisen (true). Twee lijnen die elkaar kruisen zal als een punt kruisen (true). Twee polygonen kruisen als een polygoon (false). In de afbeelding zullen geen cirkels worden teruggegeven.
Parameters
Label |
Naam |
Type |
Omschrijving |
|---|---|---|---|
Samenvoegen met objecten in |
|
[vector: elke] |
Invoer vectorlaag. De uitvoerlaag zal bestaan uit de objecten van deze laag met attributen van overeenkomende objecten in de tweede laag. |
Waar de objecten |
|
[enumeratie] [lijst] Standaard: [0] |
Type ruimtelijke relatie dat het bronobject zou moeten hebben met een doelobject, zodat zij zouden kunnen worden samengevoegd. Één of meer van:
Als meer dan één voorwaarde wordt gekozen, moet aan tenminste één worden voldaan (bewerking OR) om een object uit te kunnen nemen. |
In vergelijking met |
|
[vector: elke] |
De samen te voegen laag. Objecten van deze vectorlaag zullen hun samenvattingen van hun attributen toevoegen aan de attributentabel van de bronlaag, als zij voldoen aan de ruimtelijke relatie. |
Velden die moeten worden samengevat (laat leeg om alle velden te gebruiken) Optioneel |
|
[tabelveld: elk] [lijst] |
Selecteer de specifieke velden die u wilt toevoegen vanuit de samen te voegen laag. Standaard worden alle velden toegevoegd. |
Overzichten die moeten worden berekend (laat leeg om alle velden te gebruiken) Optioneel |
|
[enumeratie] [lijst] Standaard: [] |
Voor elk invoerobject worden statistieken berekend voor samengevoegde velden of hun overeenkomende objecten. Één of meer van:
|
Records verwijderen die niet konden worden gekoppeld |
|
[Booleaanse waarde] Standaard: False |
Verwijder objecten van de invoerlaag, die niet konden worden gekoppeld, uit de uitvoer |
Samengevoegde laag |
|
[hetzelfde als invoer] Standaard: |
Specificeer de uitvoer vectorlaag voor de koppeling. Één van:
De bestandscodering kan hier ook gewijzigd worden. |
Uitvoer
Label |
Naam |
Type |
Omschrijving |
|---|---|---|---|
Samengevoegde laag |
|
[hetzelfde als invoer] |
Uitvoer vectorlaag met samengevatte attributen van de koppeling |
Pythoncode
ID algoritme: qgis:joinbylocationsummary
import processing
processing.run("algorithm_id", {parameter_dictionary})
Het ID voor het algoritme wordt weergegeven als u over het algoritme gaat met de muisaanwijzer in de Toolbox van Processing. Het woordenboek voor de parameters verschaft de NAME’s en waarden van de parameters. Bekijk Processing algoritmes gebruiken vanaf de console voor details over hoe algoritmes van Processing uit te voeren vanuit de console voor Python.
27.1.17.21. Koppel attributen op dichtstbijzijnde
Neemt een invoer vectorlaag en maakt een nieuwe vectorlaag met aanvullende velden in zijn attributentabel. De aanvullende attributen en hun waarden worden genomen uit een tweede vectorlaag. Objecten worden gekoppeld door de dichtstbijzijnde objecten uit elke laag te zoeken.
Standaard wordt alleen het dichtstbijzijnde object gekoppeld, maar de koppeling kan ook de k-dichtstbijzijnde naburige objecten koppelen.
Als een maximum afstand is gespecificeerd, zullen alleen objecten die dichterbij liggen dan deze afstand overeenkomen.
Zie ook
‘Dichtstbijzijnde buur’-analyse, Attributen koppelen op veldwaarde, Koppel attributen op basis van plaats, Afstandsmatrix
Parameters
Label |
Naam |
Type |
Omschrijving |
|---|---|---|---|
Invoerlaag |
|
[vector: elke] |
De invoerlaag. |
Invoerlaag 2 |
|
[vector: elke] |
De koppellaag. |
Velden van laag 2 om te kopiëren (laat leeg om alle velden te kopiëren) |
|
[velden] |
Velden van koppellaag om te kopiëren (indien leeg, worden alle velden gekopieerd). |
Records verwijderen die niet konden worden gekoppeld |
|
[Booleaanse waarde] Standaard: False |
Verwijder records van de invoerlaag, die niet konden worden gekoppeld, uit de uitvoer |
Voorvoegsel samengevoegde velden |
|
[tekenreeks] |
Voorvoegsel samengevoegde velden |
Maximum dichtstbijzijnde buren |
|
[getal] Standaard: 1 |
Maximum aantal dichtstbijzijnde buren |
Maximum afstand |
|
[getal] |
Maximum zoekafstand |
Samengevoegde laag Optioneel |
|
[hetzelfde als invoer] Standaard: |
Specificeer de uitvoerlaag die de samengevoegde objecten bevat. Één van:
De bestandscodering kan hier ook gewijzigd worden. |
Niet samen te voegen objecten uit eerste laag |
|
[hetzelfde als invoer] Standaard: |
Specificeer de vectorlaag die de objecten bevat die niet samengevoegd konden worden. Één van:
De bestandscodering kan hier ook gewijzigd worden. |
Uitvoer
Label |
Naam |
Type |
Omschrijving |
|---|---|---|---|
Samengevoegde laag |
|
[hetzelfde als invoer] |
De uitvoer samengevoegde laag |
Niet samen te voegen objecten uit eerste laag |
|
[hetzelfde als invoer] |
Laag die de objecten bevat uit de eerste laag, die niet konden worden samengevoegd met objecten in de koppellaag. |
Aantal niet samen te voegen objecten uit invoertabel |
|
[getal] |
Aantal objecten uit de invoertabel die zijn samengevoegd. |
Aantal samengevoegde objecten uit invoertabel |
|
[getal] |
Aantal objecten uit de invoertabel die niet konden worden samengevoegd. |
Pythoncode
ID algoritme: native:joinbynearest
import processing
processing.run("algorithm_id", {parameter_dictionary})
Het ID voor het algoritme wordt weergegeven als u over het algoritme gaat met de muisaanwijzer in de Toolbox van Processing. Het woordenboek voor de parameters verschaft de NAME’s en waarden van de parameters. Bekijk Processing algoritmes gebruiken vanaf de console voor details over hoe algoritmes van Processing uit te voeren vanuit de console voor Python.
27.1.17.22. Vectorlagen samenvoegen
Combineert meerdere vectorlagen met hetzelfde type geometrie naar één enkele.
De attributentabel van de resulterende laag zal de velden bevatten uit alle invoerlagen. Als er velden worden gevonden met dezelfde naam, maar van een ander type, dan zal het geëxporteerde veld automatisch worden geconverteerd naar een veldtype tekenreeks. Nieuwe velden die de originele naam van de laag en de bron opslaan worden ook toegevoegd.
Als een van de invoerlagen waarden Z of M bevat, dan zal de uitvoerlaag die waarden ook bevatten. Soortgelijk geldt ook dat als een van de invoerlagen meerdelig is, dan zal de uitvoerlaag ook een meerdelige laag zijn.
Optioneel kan het doel coördinaten referentiesysteem (CRS) voor de samengevoegde laag worden ingesteld. Als dat niet is ingesteld zal het CRS uit de eerste invoerlaag worden genomen. Alle lagen zullen opnieuw worden geprojecteerd om overeen te komen met dit CRS.
Standaard menu:
Zie ook
Parameters
Label |
Naam |
Type |
Omschrijving |
|---|---|---|---|
Invoerlagen |
|
[vector: elke] [lijst] |
De lagen die moeten worden samengevoegd naar één enkele laag. Lagen zouden van hetzelfde type geometrie moeten zijn. |
Doel-CRS Optioneel |
|
[crs] |
Kies het CRS voor de uitvoerlaag. Indien niet gespecificeerd, zal het CRS van de eerste invoerlaag worden gebruikt. |
Samengevoegd |
|
[hetzelfde als invoer] Standaard: |
Specificeer de uitvoer vectorlaag. Één van:
De bestandscodering kan hier ook gewijzigd worden. |
Uitvoer
Label |
Naam |
Type |
Omschrijving |
|---|---|---|---|
Samengevoegd |
|
[hetzelfde als invoer] |
Uitvoer vectorlaag die alle objecten en attributen uit de invoerlagen bevat. |
Pythoncode
ID algoritme: native:mergevectorlayers
import processing
processing.run("algorithm_id", {parameter_dictionary})
Het ID voor het algoritme wordt weergegeven als u over het algoritme gaat met de muisaanwijzer in de Toolbox van Processing. Het woordenboek voor de parameters verschaft de NAME’s en waarden van de parameters. Bekijk Processing algoritmes gebruiken vanaf de console voor details over hoe algoritmes van Processing uit te voeren vanuit de console voor Python.
27.1.17.23. Sorteren op expressie
Sorteert een vectorlaag overeenkomstig een expressie: wijzigt de index van objecten overeenkomstig een expressie.
Wees voorzichtig, het zou misschien niet werken zoals verwacht met enkele providers, de volgorde zou niet elke keer behouden kunnen worden.
Parameters
Label |
Naam |
Type |
Omschrijving |
|---|---|---|---|
Invoerlaag |
|
[vector: elke] |
Te sorteren invoer vectorlaag |
Expressie |
|
[expressie] |
Expressie om mee te sorteren |
Oplopend sorteren |
|
[Booleaanse waarde] Standaard: True |
Indien geselecteerd zal de vectorlaag worden gesorteerd van lage naar hoge waarden. |
Eerst null sorteren |
|
[Booleaanse waarde] Standaard: False |
Indien geselecteerd worden waarden Null als eerste geplaatst |
Gesorteerd |
|
[hetzelfde als invoer] Standaard: |
Specificeer de uitvoer vectorlaag. Één van:
De bestandscodering kan hier ook gewijzigd worden. |
Uitvoer
Label |
Naam |
Type |
Omschrijving |
|---|---|---|---|
Gesorteerd |
|
[hetzelfde als invoer] |
Uitvoer (gesorteerde) vectorlaag |
Pythoncode
ID algoritme: native:orderbyexpression
import processing
processing.run("algorithm_id", {parameter_dictionary})
Het ID voor het algoritme wordt weergegeven als u over het algoritme gaat met de muisaanwijzer in de Toolbox van Processing. Het woordenboek voor de parameters verschaft de NAME’s en waarden van de parameters. Bekijk Processing algoritmes gebruiken vanaf de console voor details over hoe algoritmes van Processing uit te voeren vanuit de console voor Python.
27.1.17.24. Shapefile repareren
Repareert een defecte gegevensset ESRI Shapefile door het SHX-bestand (opnieuw) te maken.
Parameters
Label |
Naam |
Type |
Omschrijving |
|---|---|---|---|
Invoer shapefile |
|
[bestand] |
Volledige pad naar de gegevensset ESRI Shapefile met een ontbrekend of defect SHX-bestand |
Uitvoer
Label |
Naam |
Type |
Omschrijving |
|---|---|---|---|
Gerepareerde laag |
|
[vector: elke] |
De invoer vectorlaag met het gerepareerde SHX-bestand |
Pythoncode
ID algoritme: native:repairshapefile
import processing
processing.run("algorithm_id", {parameter_dictionary})
Het ID voor het algoritme wordt weergegeven als u over het algoritme gaat met de muisaanwijzer in de Toolbox van Processing. Het woordenboek voor de parameters verschaft de NAME’s en waarden van de parameters. Bekijk Processing algoritmes gebruiken vanaf de console voor details over hoe algoritmes van Processing uit te voeren vanuit de console voor Python.
27.1.17.25. Laag opnieuw projecteren
Projecteert een vectorlaag opnieuw naar een ander CRS. De opnieuw geprojecteerde laag zal dezelfde objecten en attributen als de invoerlaag hebben.
Maakt objecten op hun plaats aanpassen mogelijk voor objecten punt, lijn en polygoon
Parameters
Basis parameters
Label |
Naam |
Type |
Omschrijving |
|---|---|---|---|
Invoerlaag |
|
[vector: elke] |
Invoer vectorlaag om opnieuw te projecteren |
Doel-CRS |
|
[crs] Standaard: |
Doel coördinaten referentie systeem |
Opnieuw geprojecteerd |
|
[hetzelfde als invoer] Standaard: |
Specificeer de uitvoer vectorlaag. Één van:
De bestandscodering kan hier ook gewijzigd worden. |
Gevorderde parameters
Label |
Naam |
Type |
Omschrijving |
|---|---|---|---|
Coördinaten bewerken Optioneel |
|
[tekenreeks] |
Specifieke te gebruiken bewerking voor een bepaalde taak voor opnieuw projecteren, in plaats van het altijd gebruiken van het forceren van de transformatie-instellingen van het huidige project. Nuttig bij het opnieuw projecteren van een bepaalde laag en beheer over de exacte transformatie-pijplijn is vereist. Vereist proj versie >= 6. Lees meer op Datumtransformaties. |
Uitvoer
Label |
Naam |
Type |
Omschrijving |
|---|---|---|---|
Opnieuw geprojecteerd |
|
[hetzelfde als invoer] |
Uitvoer (opnieuw geprojecteerde) vectorlaag |
Pythoncode
ID algoritme: native:reprojectlayer
import processing
processing.run("algorithm_id", {parameter_dictionary})
Het ID voor het algoritme wordt weergegeven als u over het algoritme gaat met de muisaanwijzer in de Toolbox van Processing. Het woordenboek voor de parameters verschaft de NAME’s en waarden van de parameters. Bekijk Processing algoritmes gebruiken vanaf de console voor details over hoe algoritmes van Processing uit te voeren vanuit de console voor Python.
27.1.17.26. Vectorobjecten opslaan naar bestand
Slaat vectorobjecten op naar een gespecificeerd bestand voor de gegevensset.
Voor indelingen van gegevenssets ondersteunde lagen mag een optionele parameter voor de laagnaam worden gebruikt om een aangepaste tekenreeks te specificeren. Optionele opties voor GDAL-gedefinieerde gegevensset en laag kunnen worden gespecificeerd. Voor meer informatie hierover, lees de online documentatie van GDAL over de indeling.
Parameters
Basis parameters
Label |
Naam |
Type |
Omschrijving |
|---|---|---|---|
Vectorobjecten |
|
[vector: elke] |
Invoer vectorlaag. |
Opgeslagen objecten |
|
[hetzelfde als invoer] Standaard: |
Specificeer het bestand waarin de objecten moeten worden opgeslagen. Één van:
|
Gevorderde parameters
Label |
Naam |
Type |
Omschrijving |
|---|---|---|---|
Laagnaam Optioneel |
|
[tekenreeks] |
Te gebruiken naam voor de uitvoerlaag |
Opties voor GDAL-gegevensset Optioneel |
|
[tekenreeks] |
Opties voor het maken van GDAL-gegevensset voor de indeling van de uitvoer. Afzonderlijke individuele opties met puntkomma’s. |
Opties voor laag van GDAL Optioneel |
|
[tekenreeks] |
Opties voor het maken van laag van GDAL voor de indeling van de uitvoer. Afzonderlijke individuele opties met puntkomma’s. |
Uitvoer
Label |
Naam |
Type |
Omschrijving |
|---|---|---|---|
Opgeslagen objecten |
|
[hetzelfde als invoer] |
Vectorlaag met de opgeslagen objecten. |
Bestandsnaam en pad |
|
[tekenreeks] |
Naam voor uitvoerbestand en pad. |
Laagnaam |
|
[tekenreeks] |
Naam van de laag, indien aanwezig. |
Pythoncode
ID algoritme: native:savefeatures
import processing
processing.run("algorithm_id", {parameter_dictionary})
Het ID voor het algoritme wordt weergegeven als u over het algoritme gaat met de muisaanwijzer in de Toolbox van Processing. Het woordenboek voor de parameters verschaft de NAME’s en waarden van de parameters. Bekijk Processing algoritmes gebruiken vanaf de console voor details over hoe algoritmes van Processing uit te voeren vanuit de console voor Python.
27.1.17.27. Codering van laag instellen
Stelt de gebruikte codering in voor het lezen van de attributen van de laag. Er worden geen permanente wijzigingen aan de laag gemaakt, anders dan hoe het lezen van de laag wordt beïnvloed gedurende de huidige sessie.
Notitie
Wijzigen van de codering wordt alleen ondersteund voor sommige gegevensbronnen voor de vectorlaag.
Parameters
Label |
Naam |
Type |
Omschrijving |
|---|---|---|---|
Opgeslagen objecten |
|
[vector: elke] |
Vectorlaag waarvoor de codering moet worden ingesteld. |
Codering |
|
[tekenreeks] |
Codering van tekst om de laag toe te wijzen aan de huidige sessie van QGIS. |
Uitvoer
Label |
Naam |
Type |
Omschrijving |
|---|---|---|---|
Uitvoerlaag |
|
[hetzelfde als invoer] |
Invoer vectorlaag met de ingestelde codering. |
Pythoncode
ID algoritme: native:setlayerencoding
import processing
processing.run("algorithm_id", {parameter_dictionary})
Het ID voor het algoritme wordt weergegeven als u over het algoritme gaat met de muisaanwijzer in de Toolbox van Processing. Het woordenboek voor de parameters verschaft de NAME’s en waarden van de parameters. Bekijk Processing algoritmes gebruiken vanaf de console voor details over hoe algoritmes van Processing uit te voeren vanuit de console voor Python.
27.1.17.28. Objecten splitsen op teken
Objecten worden gesplitst in meerdere uitvoerobjecten, door de waarde van een veld te splitsen op een gespecificeerd teken. Als bijvoorbeeld een laag objecten bevat met meerdere kommagescheiden waarden opgenomen in één veld, kan dit algoritme worden gebruikt om deze waarden te splitsen naar meerdere uitvoerobjecten. Geometrieën en andere attributen blijven in de uitvoer ongewijzigd. Optioneel mag de tekenreeks voor de scheiding een reguliere expressie zijn, voor toegevoegde flexibiliteit.
Maakt objecten op hun plaats aanpassen mogelijk voor objecten punt, lijn en polygoon
Parameters
Label |
Naam |
Type |
Omschrijving |
|---|---|---|---|
Invoerlaag |
|
[vector: elke] |
Invoer vectorlaag |
Splitsen op waarden in veld |
|
[tabelveld: elk] |
Te gebruiken veld voor splitsen |
Waarden splitsen op teken |
|
[tekenreeks] |
Te gebruiken teken voor splitsen |
Reguliere expressie als scheiding gebruiken |
|
[Booleaanse waarde] Standaard: False |
|
Splitsen |
|
[hetzelfde als invoer] Standaard: |
Specificeer de uitvoer vectorlaag. Één van:
De bestandscodering kan hier ook gewijzigd worden. |
Uitvoer
Label |
Naam |
Type |
Omschrijving |
|---|---|---|---|
Splitsen |
|
[hetzelfde als invoer] |
De uitvoer vectorlaag. |
Pythoncode
ID algoritme: native:splitfeaturesbycharacter
import processing
processing.run("algorithm_id", {parameter_dictionary})
Het ID voor het algoritme wordt weergegeven als u over het algoritme gaat met de muisaanwijzer in de Toolbox van Processing. Het woordenboek voor de parameters verschaft de NAME’s en waarden van de parameters. Bekijk Processing algoritmes gebruiken vanaf de console voor details over hoe algoritmes van Processing uit te voeren vanuit de console voor Python.
27.1.17.29. Vectorlaag splitsen
Maakt een set van vectors in een map voor uitvoer, gebaseerd op een invoerlaag en een attribuut. De map voor de uitvoer zal net zoveel lagen bevatten als de gevonden unieke waarden in het gewenste veld.
Het aantal gemaakte bestanden is gelijk aan het aantal verschillende gevonden waarden voor het gespecificeerde attribuut.
Dit is de tegengestelde bewerking van samenvoegen.
Standaard menu:
Zie ook
Parameters
Basis parameters
Label |
Naam |
Type |
Omschrijving |
|---|---|---|---|
Invoerlaag |
|
[vector: elke] |
Invoer vectorlaag |
Uniek ID-veld |
|
[tabelveld: elk] |
Te gebruiken veld voor splitsen |
Map voor uitvoer |
|
[map] Standaard: |
Specificeer de map voor de uitvoerlagen. Één van:
|
Gevorderde parameters
Label |
Naam |
Type |
Omschrijving |
|---|---|---|---|
Type uitvoerbestand Optioneel |
|
[enumeratie] Standaard: |
Selecteer de extensie voor de uitvoerbestanden. Indien niet gespecificeerd of ongeldig, zal de indeling voor de uitvoerbestanden die zijn welke is ingesteld voor de instelling van Processing “Standaard uitvoer vectorlaagextensie”. |
Uitvoer
Label |
Naam |
Type |
Omschrijving |
|---|---|---|---|
Map voor uitvoer |
|
[map] |
De map voor de uitvoerlagen |
Uitvoerlagen |
|
[hetzelfde als invoer] [lijst] |
De uitvoer vectorlagen die het resultaat van het splitsen zijn. |
Pythoncode
ID algoritme: native:splitvectorlayer
import processing
processing.run("algorithm_id", {parameter_dictionary})
Het ID voor het algoritme wordt weergegeven als u over het algoritme gaat met de muisaanwijzer in de Toolbox van Processing. Het woordenboek voor de parameters verschaft de NAME’s en waarden van de parameters. Bekijk Processing algoritmes gebruiken vanaf de console voor details over hoe algoritmes van Processing uit te voeren vanuit de console voor Python.
27.1.17.30. Tabel afbreken
Verkleint een laag door alle objecten van die laag te verwijderen.
Waarschuwing
Dit algoritme past de laag ter plekke aan en verwijderde objecten kunnen niet worden teruggeplaatst!
Parameters
Label |
Naam |
Type |
Omschrijving |
|---|---|---|---|
Invoerlaag |
|
[vector: elke] |
Invoer vectorlaag |
Uitvoer
Label |
Naam |
Type |
Omschrijving |
|---|---|---|---|
Afgebroken laag |
|
[map] |
De afgebroken (lege) laag |
Pythoncode
ID algoritme: native:truncatetable
import processing
processing.run("algorithm_id", {parameter_dictionary})
Het ID voor het algoritme wordt weergegeven als u over het algoritme gaat met de muisaanwijzer in de Toolbox van Processing. Het woordenboek voor de parameters verschaft de NAME’s en waarden van de parameters. Bekijk Processing algoritmes gebruiken vanaf de console voor details over hoe algoritmes van Processing uit te voeren vanuit de console voor Python.