25.1.11. ラスタ分析
25.1.11.1. Cell stack percent rank from value
Calculates the cell-wise percentrank value of a stack of rasters based on a single input value and writes them to an output raster.
At each cell location, the specified value is ranked among the respective values in the stack of all overlaid and sorted cell values from the input rasters. For values outside of the stack value distribution, the algorithm returns NoData because the value cannot be ranked among the cell values.
There are two methods for percentile calculation:
Inclusive linear interpolation (PERCENTRANK.INC)
Exclusive linear interpolation (PERCENTRANK.EXC)
The linear interpolation method return the unique percent rank for different values. Both interpolation methods follow their counterpart methods implemented by LibreOffice or Microsoft Excel.
The output raster's extent and resolution is defined by a reference raster.
Input raster layers that do not match the cell size of the reference
raster layer will be resampled using nearest neighbor resampling.
NoData values in any of the input layers will result in a NoData cell output
if the "Ignore NoData values" parameter is not set.
The output raster data type will always be Float32.
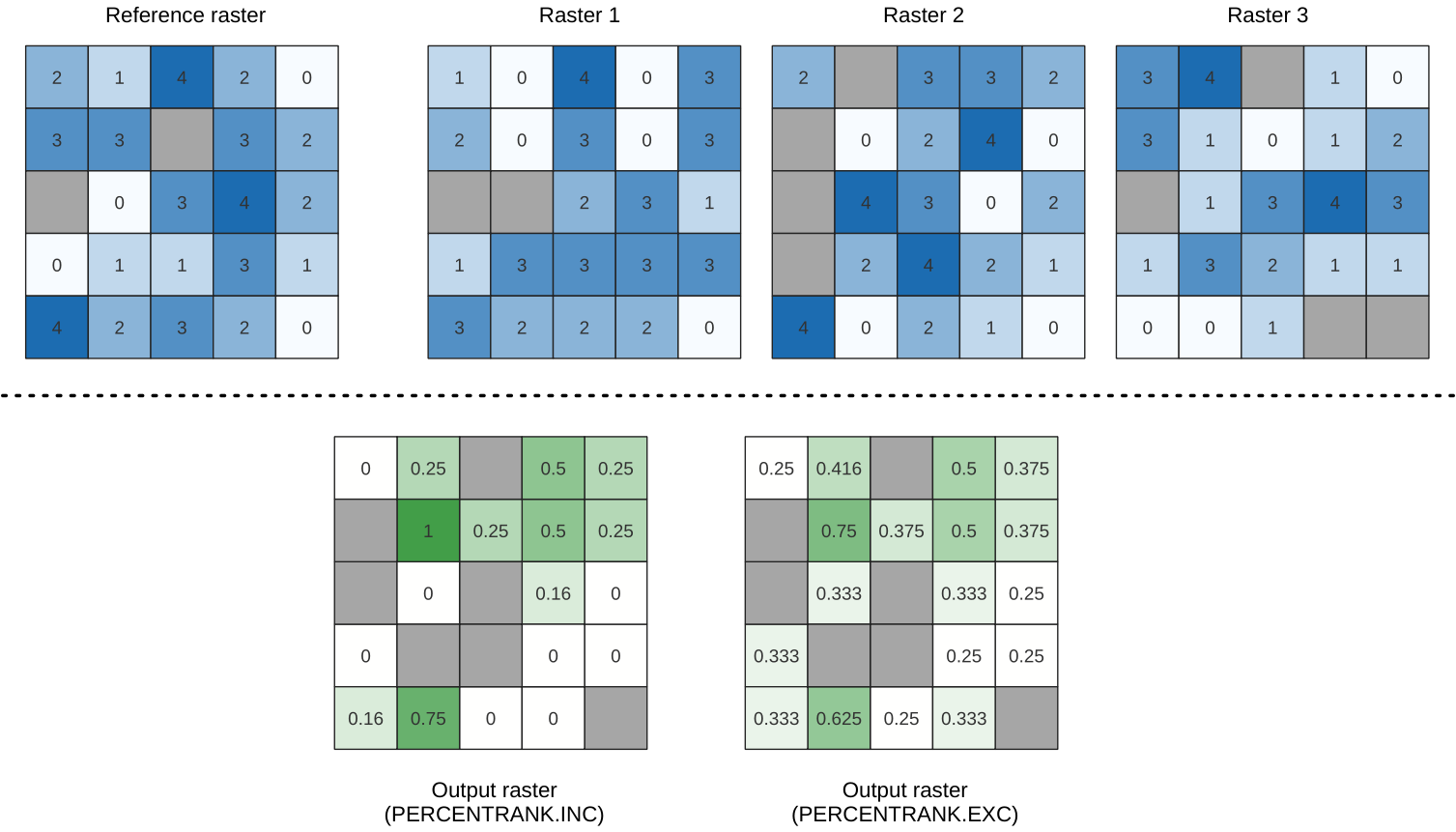
図 25.10 Percent ranking Value = 1. NoData cells (grey) are ignored.
パラメータ
基本パラメータ
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
入力レイヤ |
|
[ラスタ] [リスト] |
評価したいラスタレイヤ群。データラスタスタックにマルチバンドラスタを使用する場合には、このアルゴリズムは常にラスタの最初のバンドに対して解析を行う |
方法 |
|
[列挙型] デフォルト: 0 |
Method for percentile calculation:
|
Value |
|
[数値] Default: 10.0 |
Value to rank among the respective values in the stack of all overlaid and sorted cell values from the input rasters |
nodataを無視する |
|
[ブール値] デフォルト: True |
If unchecked, any NoData cells in the input layers will result in a NoData cell in the output raster |
スナップで参照するレイヤ |
|
[ラスタ] |
出力レイヤの作成に使用する参照レイヤ(範囲、CRS、ピクセルの大きさ) |
出力レイヤ |
|
[入力レイヤと同じ] デフォルト: |
出力ラスタレイヤを指定します。次のいずれかです:
|
詳細パラメータ
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
nodataを出力する |
|
[数値] デフォルト: -9999.0 |
出力レイヤのnodataに使用する値 |
出力
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
出力レイヤ |
|
[ラスタ] |
結果が含まれる出力ラスタレイヤ |
CRS権限識別子 |
|
[文字列] |
出力ラスタレイヤの座標参照系 |
領域 |
|
[文字列] |
出力ラスタレイヤの空間範囲 |
幅(ピクセル単位) |
|
[整数] |
出力ラスタレイヤの列数 |
高さ(ピクセル単位) |
|
[整数] |
出力ラスタレイヤの行数 |
総ピクセル数 |
|
[整数] |
出力ラスタレイヤのピクセル数 |
Python コード
Algorithm ID: native:cellstackpercentrankfromvalue
import processing
processing.run("algorithm_id", {parameter_dictionary})
algorithm id は、プロセシングツールボックス内でアルゴリズムにマウスカーソルを乗せた際に表示されるIDです。 parameter dictionary は、パラメータの「名前」とその値を指定するマッピング型です。Python コンソールからプロセシングアルゴリズムを実行する方法の詳細については、 プロセシングアルゴリズムをコンソールから使う を参照してください。
25.1.11.2. Cell stack percentile
Calculates the cell-wise percentile value of a stack of rasters and writes the results to an output raster. The percentile to return is determined by the percentile input value (ranges between 0 and 1). At each cell location, the specified percentile is obtained using the respective value from the stack of all overlaid and sorted cell values of the input rasters.
There are three methods for percentile calculation:
Nearest rank: returns the value that is nearest to the specified percentile
Inclusive linear interpolation (PERCENTRANK.INC)
Exclusive linear interpolation (PERCENTRANK.EXC)
The linear interpolation methods return the unique values for different percentiles. Both interpolation methods follow their counterpart methods implemented by LibreOffice or Microsoft Excel.
The output raster's extent and resolution is defined by a reference raster.
Input raster layers that do not match the cell size of the reference
raster layer will be resampled using nearest neighbor resampling.
NoData values in any of the input layers will result in a NoData cell output
if the "Ignore NoData values" parameter is not set.
The output raster data type will always be Float32.
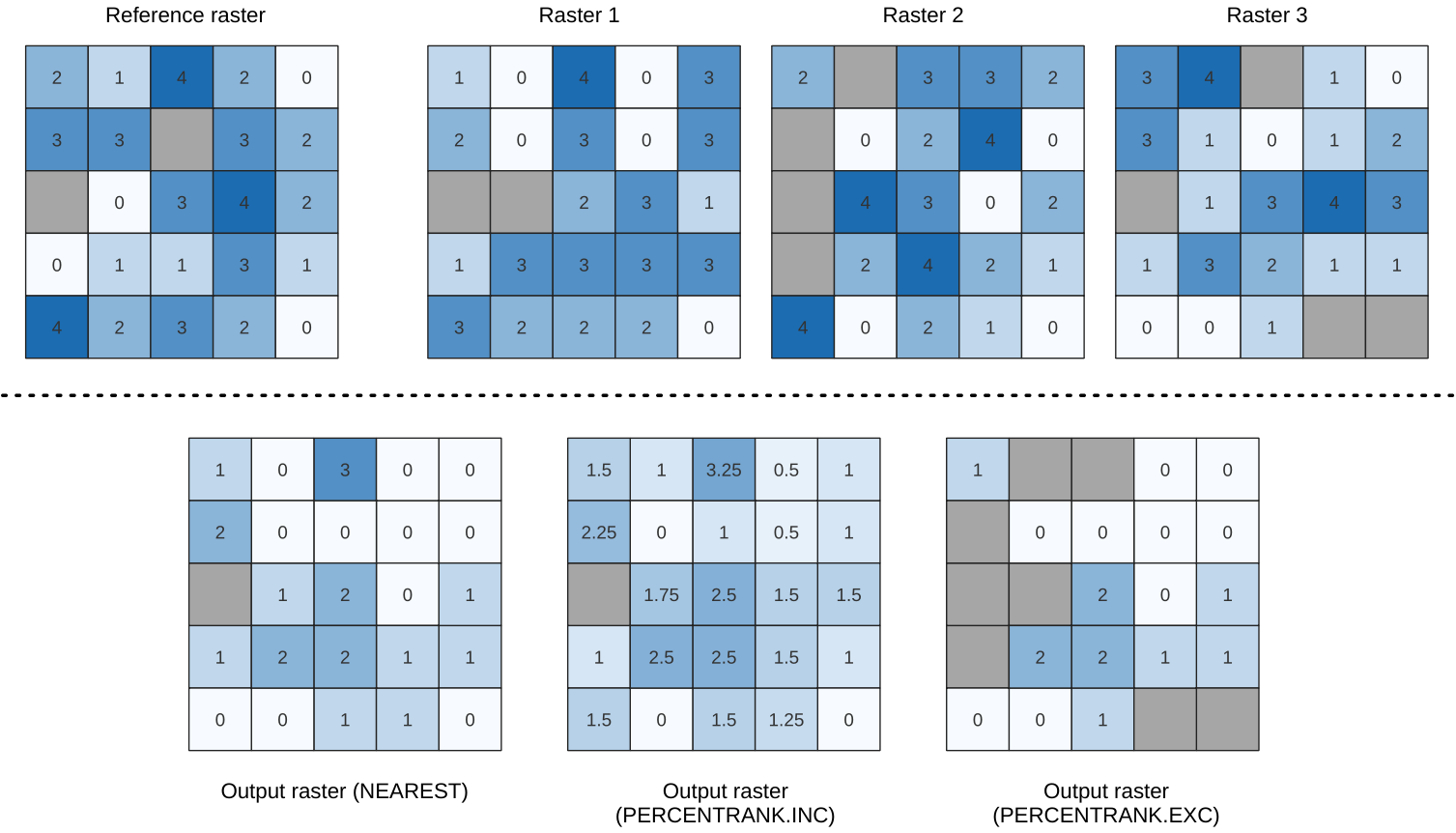
図 25.11 Percentile = 0.25. NoData cells (grey) are ignored.
パラメータ
基本パラメータ
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
入力レイヤ |
|
[ラスタ] [リスト] |
評価したいラスタレイヤ群。データラスタスタックにマルチバンドラスタを使用する場合には、このアルゴリズムは常にラスタの最初のバンドに対して解析を行う |
方法 |
|
[列挙型] デフォルト: 0 |
Method for percentile calculation:
|
Percentile |
|
[数値] Default: 0.25 |
Value to rank among the respective values in the stack of all overlaid and sorted cell values from the input rasters. Between 0 and 1. |
nodataを無視する |
|
[ブール値] デフォルト: True |
If unchecked, any NoData cells in the input layers will result in a NoData cell in the output raster |
スナップで参照するレイヤ |
|
[ラスタ] |
出力レイヤの作成に使用する参照レイヤ(範囲、CRS、ピクセルの大きさ) |
出力レイヤ |
|
[入力レイヤと同じ] デフォルト: |
出力ラスタレイヤを指定します。次のいずれかです:
|
詳細パラメータ
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
nodataを出力する |
|
[数値] デフォルト: -9999.0 |
出力レイヤのnodataに使用する値 |
出力
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
出力レイヤ |
|
[ラスタ] |
結果が含まれる出力ラスタレイヤ |
CRS権限識別子 |
|
[文字列] |
出力ラスタレイヤの座標参照系 |
領域 |
|
[文字列] |
出力ラスタレイヤの空間範囲 |
幅(ピクセル単位) |
|
[整数] |
出力ラスタレイヤの列数 |
高さ(ピクセル単位) |
|
[整数] |
出力ラスタレイヤの行数 |
総ピクセル数 |
|
[整数] |
出力ラスタレイヤのピクセル数 |
Python コード
Algorithm ID: native:cellstackpercentile
import processing
processing.run("algorithm_id", {parameter_dictionary})
algorithm id は、プロセシングツールボックス内でアルゴリズムにマウスカーソルを乗せた際に表示されるIDです。 parameter dictionary は、パラメータの「名前」とその値を指定するマッピング型です。Python コンソールからプロセシングアルゴリズムを実行する方法の詳細については、 プロセシングアルゴリズムをコンソールから使う を参照してください。
25.1.11.3. Cell stack percentrank from raster layer
Calculates the cell-wise percentrank value of a stack of rasters based on an input value raster and writes them to an output raster.
At each cell location, the current value of the value raster is ranked among the respective values in the stack of all overlaid and sorted cell values of the input rasters. For values outside of the the stack value distribution, the algorithm returns NoData because the value cannot be ranked among the cell values.
There are two methods for percentile calculation:
Inclusive linear interpolation (PERCENTRANK.INC)
Exclusive linear interpolation (PERCENTRANK.EXC)
The linear interpolation methods return the unique values for different percentiles. Both interpolation methods follow their counterpart methods implemented by LibreOffice or Microsoft Excel.
The output raster's extent and resolution is defined by a reference raster.
Input raster layers that do not match the cell size of the reference
raster layer will be resampled using nearest neighbor resampling.
NoData values in any of the input layers will result in a NoData cell output
if the "Ignore NoData values" parameter is not set.
The output raster data type will always be Float32.
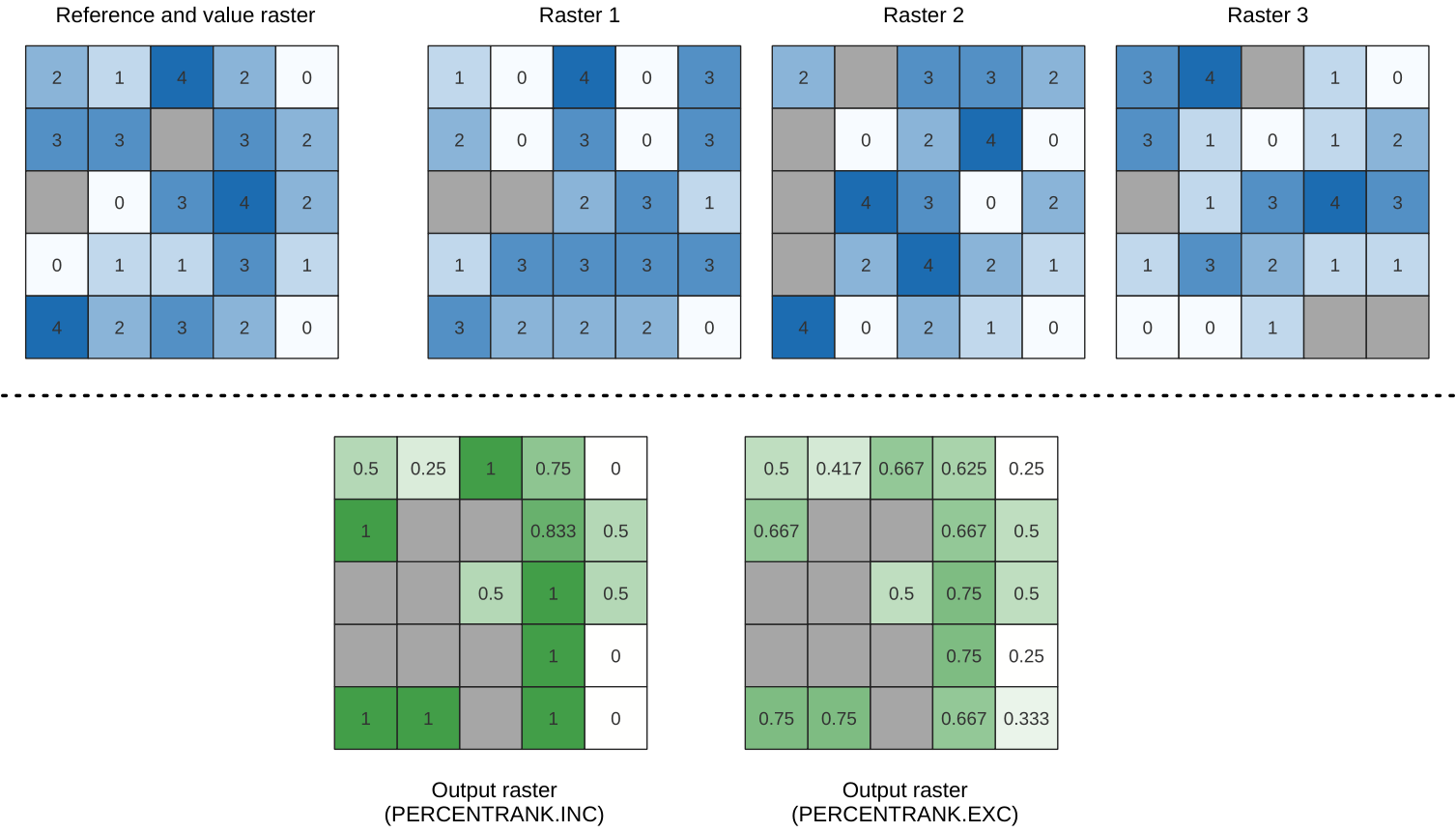
図 25.12 Ranking the value raster layer cells. NoData cells (grey) are ignored.
パラメータ
基本パラメータ
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
入力レイヤ |
|
[ラスタ] [リスト] |
評価したいラスタレイヤ群。データラスタスタックにマルチバンドラスタを使用する場合には、このアルゴリズムは常にラスタの最初のバンドに対して解析を行う |
Value raster layer |
|
[ラスタ] |
The layer to rank the values among the stack of all overlaid layers |
対象バンド |
|
[整数] デフォルト: 1 |
Band of the "value raster layer" to compare to |
方法 |
|
[列挙型] デフォルト: 0 |
Method for percentile calculation:
|
nodataを無視する |
|
[ブール値] デフォルト: True |
If unchecked, any NoData cells in the input layers will result in a NoData cell in the output raster |
スナップで参照するレイヤ |
|
[ラスタ] |
出力レイヤの作成に使用する参照レイヤ(範囲、CRS、ピクセルの大きさ) |
出力レイヤ |
|
[入力レイヤと同じ] デフォルト: |
出力ラスタレイヤを指定します。次のいずれかです:
|
詳細パラメータ
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
nodataを出力する |
|
[数値] デフォルト: -9999.0 |
出力レイヤのnodataに使用する値 |
出力
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
出力レイヤ |
|
[ラスタ] |
結果が含まれる出力ラスタレイヤ |
CRS権限識別子 |
|
[文字列] |
出力ラスタレイヤの座標参照系 |
領域 |
|
[文字列] |
出力ラスタレイヤの空間範囲 |
幅(ピクセル単位) |
|
[整数] |
出力ラスタレイヤの列数 |
高さ(ピクセル単位) |
|
[整数] |
出力ラスタレイヤの行数 |
総ピクセル数 |
|
[整数] |
出力ラスタレイヤのピクセル数 |
Python コード
Algorithm ID: native:cellstackpercentrankfromrasterlayer
import processing
processing.run("algorithm_id", {parameter_dictionary})
algorithm id は、プロセシングツールボックス内でアルゴリズムにマウスカーソルを乗せた際に表示されるIDです。 parameter dictionary は、パラメータの「名前」とその値を指定するマッピング型です。Python コンソールからプロセシングアルゴリズムを実行する方法の詳細については、 プロセシングアルゴリズムをコンソールから使う を参照してください。
25.1.11.4. セル統計量
入力ラスタレイヤに基づいてセル毎の統計量を計算し、出力ラスタの各セルに結果の統計量を書き込みます。各セル位置において、入力ラスタのセルの値の全ての重ね合わせに対する関数値で出力値が定義されます。
デフォルトでは、任意の入力レイヤにnodataセルがあると、出力ラスタはnodataセルとなります。 nodataを無視する オプションにチェックが入っている場合は、nodataの入力値は統計量の計算において無視されます。これにより、ある位置ですべての入力レイヤがnodataのセルである場合に、結果がnodataのセルとなります。
スナップで参照するレイヤ パラメータは、出力ラスタの作成時に参照として使用する既存のラスタレイヤを指定します。出力ラスタは、このレイヤと同じ範囲、CRS、およびピクセル寸法を持ちます。
統計量計算の詳細: 参照ラスタレイヤのセルサイズと一致しない入力ラスタレイヤについては、 最近傍リサンプリング を使用して値がリサンプリングされます。出力ラスタのデータ型は、入力ラスタデータセットのうち最も複雑なデータ型になります。ただし、 平均 と 標準偏差 、 分散(Variance) は入力の浮動小数点型に応じて常に Float32 または Float64 となり、 カウント(Count) と 種類(Variety) は常に Int32 となります。
カウント(Count):カウント統計は、現在のセル位置で nodata 値以外のセルの数になります。中央値:入力レイヤのセルが偶数個の場合には、中央値はセル入力値を並べた中央の2つの値の算術平均で計算されます。最稀値(Minority)/最頻値(Majority):最稀値や最頻値が一つに決まらない場合には、入力セルの値がすべて等しいのでない限り、結果は nodata となります。
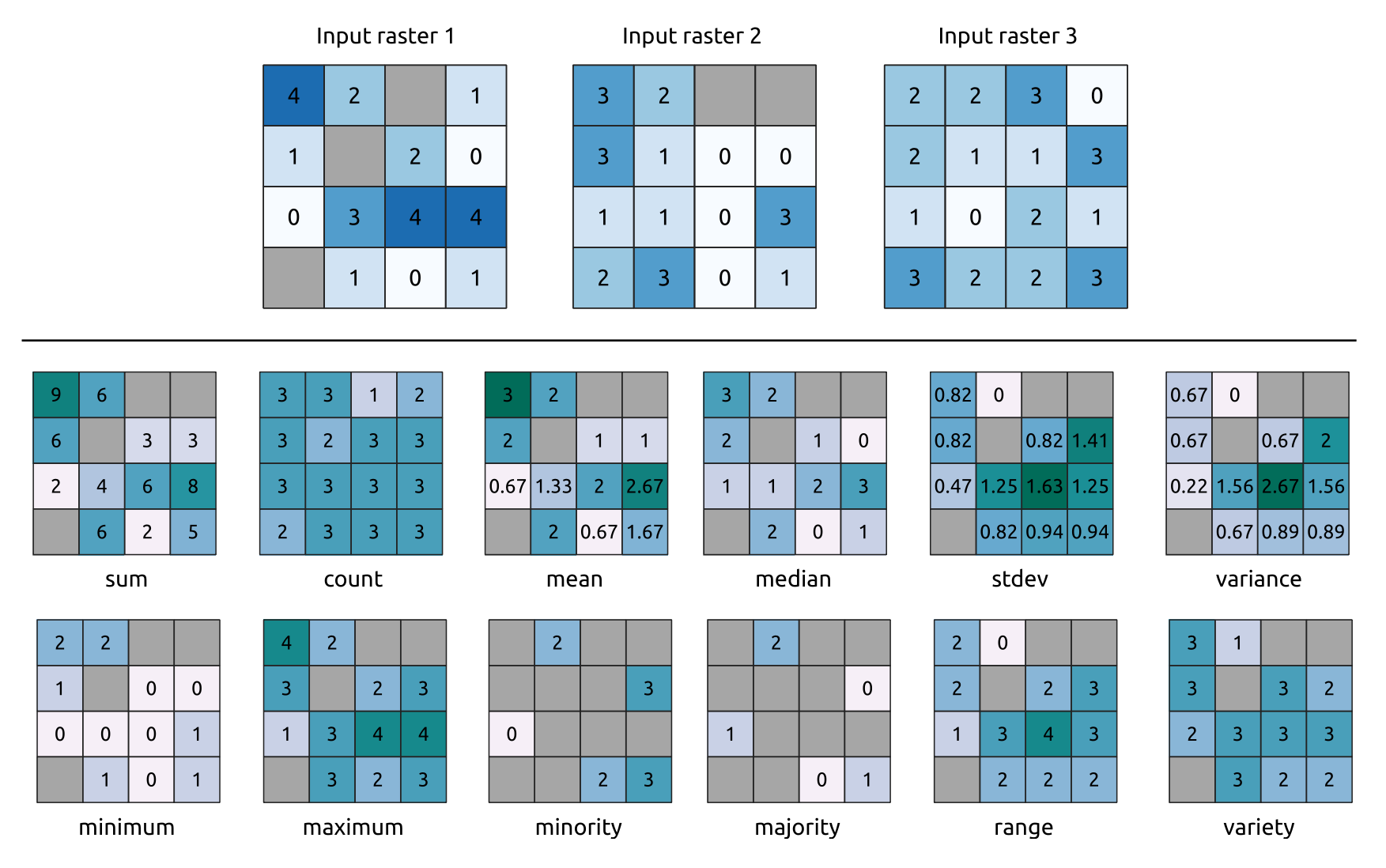
図 25.13 全ての統計関数の例。 nodata (灰色)セルが考慮される
パラメータ
基本パラメータ
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
入力レイヤ |
|
[ラスタ] [リスト] |
入力ラスタレイヤ |
統計量 |
|
[列挙型] デフォルト: 0 |
利用可能な統計量。オプションは次のとおり:
|
nodataを無視する |
|
[ブール値] デフォルト: True |
nodataの存在を無視してすべてのセルの統計量を計算します。 |
スナップで参照するレイヤ |
|
[ラスタ] |
出力レイヤの作成に参照するレイヤ(範囲、CRS、ピクセルの大きさ等) |
出力レイヤ |
|
[入力レイヤと同じ] デフォルト: |
出力ラスタレイヤを指定します。次のいずれかです:
|
詳細パラメータ
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
nodataを出力する オプション |
|
[数値] デフォルト: -9999.0 |
出力レイヤのnodataに使用する値 |
出力
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
CRS権限識別子 |
|
[crs] |
出力ラスタレイヤの座標参照系 |
領域 |
|
[文字列] |
出力ラスタレイヤの空間範囲 |
高さ(ピクセル単位) |
|
[整数] |
出力ラスタレイヤの行数 |
出力レイヤ |
|
[ラスタ] |
結果が含まれる出力ラスタレイヤ |
総ピクセル数 |
|
[整数] |
出力ラスタレイヤのピクセル数 |
幅(ピクセル単位) |
|
[整数] |
出力ラスタレイヤの列数 |
Python コード
Algorithm ID: native:cellstatistics
import processing
processing.run("algorithm_id", {parameter_dictionary})
algorithm id は、プロセシングツールボックス内でアルゴリズムにマウスカーソルを乗せた際に表示されるIDです。 parameter dictionary は、パラメータの「名前」とその値を指定するマッピング型です。Python コンソールからプロセシングアルゴリズムを実行する方法の詳細については、 プロセシングアルゴリズムをコンソールから使う を参照してください。
25.1.11.5. ラスタスタックの値の一致頻度
入力ラスタスタックの値が値ラスタレイヤの値と一致する頻度(回数)をセル単位で評価します。出力ラスタの範囲と解像度は入力ラスタと同じで、データ型は常に Int32 です。
データラスタスタックにマルチバンドラスタを使用する場合、このアルゴリズムは常にラスタの最初のバンドに対して解析を行います。解析に他のバンドを使用したい場合には、GDALを使用してください。出力のnodata値は手入力で設定できます。
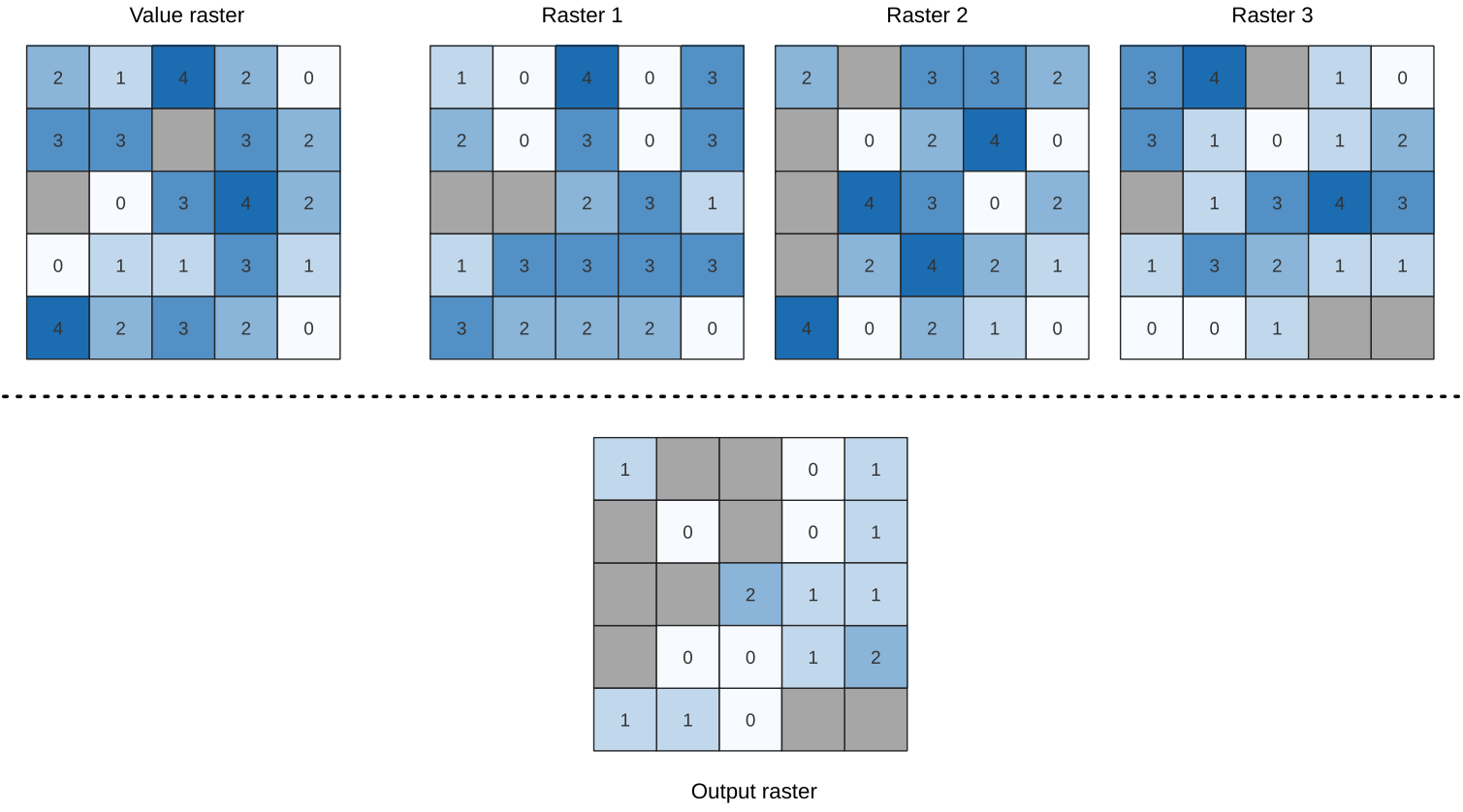
図 25.14 出力ラスタの各セルについて、セルの値はラスタスタックのラスタの値が対応する値ラスタと同じである回数を表す。 nodata セル(灰色)が考慮される
パラメータ
基本パラメータ
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
入力ラスタ |
|
[ラスタ] |
サンプリングするレイヤ群に対する参照レイヤとなる、入力値レイヤ |
対象バンド |
|
[ラスタのバンド] デフォルト:ラスタレイヤの1番目のバンド |
値を取得したいバンドを選択します |
入力ラスタ(複数) |
|
[ラスタ] [リスト] |
評価したいラスタレイヤ群。データラスタスタックにマルチバンドラスタを使用する場合には、このアルゴリズムは常にラスタの最初のバンドに対して解析を行う |
nodataを無視する |
|
[ブール値] デフォルト: False |
チェックを入れない場合、値ラスタやデータレイヤスタックにnodataセルが一つでもあれば、出力ラスタはnodataセルとなります。 |
出力レイヤ |
|
[入力レイヤと同じ] デフォルト: |
出力ラスタレイヤを指定します。次のいずれかです:
|
詳細パラメータ
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
nodataを出力する オプション |
|
[数値] デフォルト: -9999.0 |
出力レイヤのnodataに使用する値 |
出力
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
出力レイヤ |
|
[ラスタ] |
結果が含まれる出力ラスタレイヤ |
CRS権限識別子 |
|
[文字列] |
出力ラスタレイヤの座標参照系 |
領域 |
|
[文字列] |
出力ラスタレイヤの空間範囲 |
同じ出現頻度のセル数 |
|
[数値] |
|
高さ(ピクセル単位) |
|
[数値] |
出力ラスタレイヤの行数 |
総ピクセル数 |
|
[整数] |
出力ラスタレイヤのピクセル数 |
有効セルの場所の平均頻度 |
|
[数値] |
|
値の頻度 |
|
[数値] |
|
幅(ピクセル単位) |
|
[整数] |
出力ラスタレイヤの列数 |
Python コード
アルゴリズムID: native:equaltofrequency
import processing
processing.run("algorithm_id", {parameter_dictionary})
algorithm id は、プロセシングツールボックス内でアルゴリズムにマウスカーソルを乗せた際に表示されるIDです。 parameter dictionary は、パラメータの「名前」とその値を指定するマッピング型です。Python コンソールからプロセシングアルゴリズムを実行する方法の詳細については、 プロセシングアルゴリズムをコンソールから使う を参照してください。
25.1.11.6. ラスタのファジー化(gaussian membership)
ガウシアンメンバーシップ関数を使用して入力ラスタの各ピクセルにメンバーシップ値を割り当てることにより、入力ラスタをファジー化されたラスタに変換します。メンバーシップ値は0から1の範囲の値です。ファジー化されたラスタにおいて、値0はメンバーではないこと、値1は完全にメンバーであることを意味しています。ガウシアンメンバーシップ関数は、 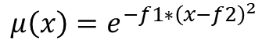 で定義されます。ここで、 f1 は拡がり、 f2 は中点を表します。
で定義されます。ここで、 f1 は拡がり、 f2 は中点を表します。
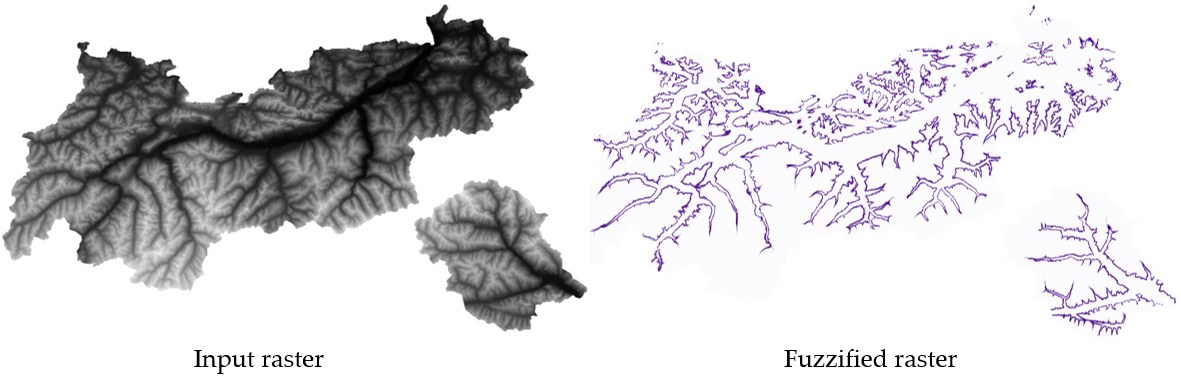
図 25.15 ラスタのファジー化の例。入力ラスタソース:Land Tirol - data.tirol.gv.at
参考
ラスタのファジー化(large membership) 、 ラスタのファジー化(linear membership) 、 ラスタのファジー化(near membership) 、 ラスタのファジー化(power membership) 、 ラスタのファジー化(small membership)
パラメータ
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
入力ラスタ |
|
[ラスタ] |
入力ラスタレイヤ |
バンド番号 |
|
[ラスタのバンド] デフォルト:ラスタレイヤの1番目のバンド |
ラスタがマルチバンドの場合には、ファジー化したいバンドを選択してください。 |
Function midpoint |
|
[数値] デフォルト: 10 |
ガウス関数の中点 |
Function spread |
|
[数値] デフォルト: 0.01 |
ガウス関数の拡がり |
出力ラスタ |
|
[入力レイヤと同じ] デフォルト: |
出力ラスタレイヤを指定します。次のいずれかです:
|
出力
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
出力ラスタ |
|
[入力レイヤと同じ] |
結果が含まれる出力ラスタレイヤ |
CRS権限識別子 |
|
[crs] |
出力ラスタレイヤの座標参照系 |
領域 |
|
[文字列] |
出力ラスタレイヤの空間範囲 |
幅(ピクセル単位) |
|
[整数] |
出力ラスタレイヤの列数 |
高さ(ピクセル単位) |
|
[整数] |
出力ラスタレイヤの行数 |
総ピクセル数 |
|
[整数] |
出力ラスタレイヤのピクセル数 |
Python コード
Algorithm ID: native:fuzzifyrastergaussianmembership
import processing
processing.run("algorithm_id", {parameter_dictionary})
algorithm id は、プロセシングツールボックス内でアルゴリズムにマウスカーソルを乗せた際に表示されるIDです。 parameter dictionary は、パラメータの「名前」とその値を指定するマッピング型です。Python コンソールからプロセシングアルゴリズムを実行する方法の詳細については、 プロセシングアルゴリズムをコンソールから使う を参照してください。
25.1.11.7. ラスタのファジー化(large membership)
largeメンバーシップ関数を使用して入力ラスタの各ピクセルにメンバーシップ値を割り当てることにより、入力ラスタをファジー化されたラスタに変換します。メンバーシップ値は0から1の範囲の値です。ファジー化されたラスタにおいて、値0はメンバーではないこと、値1は完全にメンバーであることを意味しています。largeメンバーシップ関数は、 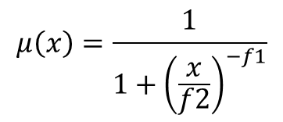 で定義されます。ここで、 f1 は拡がり、 f2 は中点を表します。
で定義されます。ここで、 f1 は拡がり、 f2 は中点を表します。
参考
ラスタのファジー化(gaussian membership) 、 ラスタのファジー化(linear membership) 、 ラスタのファジー化(near membership) 、 ラスタのファジー化(power membership) 、 ラスタのファジー化(small membership)
パラメータ
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
入力ラスタ |
|
[ラスタ] |
入力ラスタレイヤ |
バンド番号 |
|
[ラスタのバンド] デフォルト:ラスタレイヤの1番目のバンド |
ラスタがマルチバンドの場合には、ファジー化したいバンドを選択してください。 |
Function midpoint |
|
[数値] デフォルト: 50 |
large関数の中点 |
Function spread |
|
[数値] デフォルト: 5 |
large関数の拡がり |
出力ラスタ |
|
[入力レイヤと同じ] デフォルト: |
出力ラスタレイヤを指定します。次のいずれかです:
|
出力
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
出力ラスタ |
|
[入力レイヤと同じ] |
結果が含まれる出力ラスタレイヤ |
CRS権限識別子 |
|
[crs] |
出力ラスタレイヤの座標参照系 |
領域 |
|
[文字列] |
出力ラスタレイヤの空間範囲 |
幅(ピクセル単位) |
|
[整数] |
出力ラスタレイヤの列数 |
高さ(ピクセル単位) |
|
[整数] |
出力ラスタレイヤの行数 |
総ピクセル数 |
|
[整数] |
出力ラスタレイヤのピクセル数 |
Python コード
Algorithm ID: native:fuzzifyrasterlargemembership
import processing
processing.run("algorithm_id", {parameter_dictionary})
algorithm id は、プロセシングツールボックス内でアルゴリズムにマウスカーソルを乗せた際に表示されるIDです。 parameter dictionary は、パラメータの「名前」とその値を指定するマッピング型です。Python コンソールからプロセシングアルゴリズムを実行する方法の詳細については、 プロセシングアルゴリズムをコンソールから使う を参照してください。
25.1.11.8. ラスタのファジー化(linear membership)
線形メンバーシップ関数を使用して入力ラスタの各ピクセルにメンバーシップ値を割り当てることにより、入力ラスタをファジー化されたラスタに変換します。メンバーシップ値は0から1の範囲の値です。ファジー化されたラスタにおいて、値0はメンバーではないこと、値1は完全にメンバーであることを意味しています。線形メンバーシップ関数は、 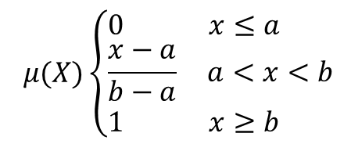 で定義されます。ここで、 a は下限、 b は上限を表します。この式は、上下限の間でピクセル値を線形変換してメンバーシップ値を割り当てます。下限よりも小さなピクセル値はメンバーシップ値0、上限よりも大きなピクセル値はメンバーシップ値1となります。
で定義されます。ここで、 a は下限、 b は上限を表します。この式は、上下限の間でピクセル値を線形変換してメンバーシップ値を割り当てます。下限よりも小さなピクセル値はメンバーシップ値0、上限よりも大きなピクセル値はメンバーシップ値1となります。
参考
ラスタのファジー化(gaussian membership) 、 ラスタのファジー化(large membership) 、 ラスタのファジー化(near membership) 、 ラスタのファジー化(power membership) 、 ラスタのファジー化(small membership)
パラメータ
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
入力ラスタ |
|
[ラスタ] |
入力ラスタレイヤ |
バンド番号 |
|
[ラスタのバンド] デフォルト:ラスタレイヤの1番目のバンド |
ラスタがマルチバンドの場合には、ファジー化したいバンドを選択してください。 |
Low fuzzy membership bound |
|
[数値] デフォルト: 0 |
線形関数の下限 |
High fuzzy membership bound |
|
[数値] デフォルト: 1 |
線形関数の上限 |
出力ラスタ |
|
[入力レイヤと同じ] デフォルト: |
出力ラスタレイヤを指定します。次のいずれかです:
|
出力
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
出力ラスタ |
|
[入力レイヤと同じ] |
結果が含まれる出力ラスタレイヤ |
CRS権限識別子 |
|
[crs] |
出力ラスタレイヤの座標参照系 |
領域 |
|
[文字列] |
出力ラスタレイヤの空間範囲 |
幅(ピクセル単位) |
|
[整数] |
出力ラスタレイヤの列数 |
高さ(ピクセル単位) |
|
[整数] |
出力ラスタレイヤの行数 |
総ピクセル数 |
|
[整数] |
出力ラスタレイヤのピクセル数 |
Python コード
Algorithm ID: native:fuzzifyrasterlinearmembership
import processing
processing.run("algorithm_id", {parameter_dictionary})
algorithm id は、プロセシングツールボックス内でアルゴリズムにマウスカーソルを乗せた際に表示されるIDです。 parameter dictionary は、パラメータの「名前」とその値を指定するマッピング型です。Python コンソールからプロセシングアルゴリズムを実行する方法の詳細については、 プロセシングアルゴリズムをコンソールから使う を参照してください。
25.1.11.9. ラスタのファジー化(near membership)
nearメンバーシップ関数を使用して入力ラスタの各ピクセルにメンバーシップ値を割り当てることにより、入力ラスタをファジー化されたラスタに変換します。メンバーシップ値は0から1の範囲の値です。ファジー化されたラスタにおいて、値0はメンバーではないこと、値1は完全にメンバーであることを意味しています。nearメンバーシップ関数は、 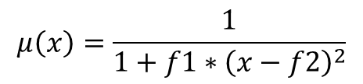 で定義されます。ここで、 f1 は拡がり、 f2 は中点を表します。
で定義されます。ここで、 f1 は拡がり、 f2 は中点を表します。
参考
ラスタのファジー化(gaussian membership) 、 ラスタのファジー化(large membership) 、 ラスタのファジー化(linear membership) 、 ラスタのファジー化(power membership) 、 ラスタのファジー化(small membership)
パラメータ
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
入力ラスタ |
|
[ラスタ] |
入力ラスタレイヤ |
バンド番号 |
|
[ラスタのバンド] デフォルト:ラスタレイヤの1番目のバンド |
ラスタがマルチバンドの場合には、ファジー化したいバンドを選択してください。 |
Function midpoint |
|
[数値] デフォルト: 50 |
near関数の中点 |
Function spread |
|
[数値] デフォルト: 0.01 |
near関数の拡がり |
出力ラスタ |
|
[入力レイヤと同じ] デフォルト: |
出力ラスタレイヤを指定します。次のいずれかです:
|
出力
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
出力ラスタ |
|
[入力レイヤと同じ] |
結果が含まれる出力ラスタレイヤ |
CRS権限識別子 |
|
[crs] |
出力ラスタレイヤの座標参照系 |
領域 |
|
[文字列] |
出力ラスタレイヤの空間範囲 |
幅(ピクセル単位) |
|
[整数] |
出力ラスタレイヤの列数 |
高さ(ピクセル単位) |
|
[整数] |
出力ラスタレイヤの行数 |
総ピクセル数 |
|
[整数] |
出力ラスタレイヤのピクセル数 |
Python コード
Algorithm ID: native:fuzzifyrasternearmembership
import processing
processing.run("algorithm_id", {parameter_dictionary})
algorithm id は、プロセシングツールボックス内でアルゴリズムにマウスカーソルを乗せた際に表示されるIDです。 parameter dictionary は、パラメータの「名前」とその値を指定するマッピング型です。Python コンソールからプロセシングアルゴリズムを実行する方法の詳細については、 プロセシングアルゴリズムをコンソールから使う を参照してください。
25.1.11.10. ラスタのファジー化(power membership)
べき乗メンバーシップ関数を使用して入力ラスタの各ピクセルにメンバーシップ値を割り当てることにより、入力ラスタをファジー化されたラスタに変換します。メンバーシップ値は0から1の範囲の値です。ファジー化されたラスタにおいて、値0はメンバーではないこと、値1は完全にメンバーであることを意味しています。べき乗メンバーシップ関数は、 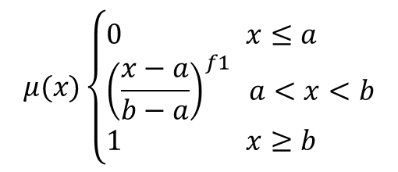 で定義されます。ここで、 a は下限、 b は上限、 f1 は指数を表します。この式は、上下限の間でピクセル値をべき乗変換してメンバーシップ値を割り当てます。下限よりも小さなピクセル値はメンバーシップ値0、上限よりも大きなピクセル値はメンバーシップ値1となります。
で定義されます。ここで、 a は下限、 b は上限、 f1 は指数を表します。この式は、上下限の間でピクセル値をべき乗変換してメンバーシップ値を割り当てます。下限よりも小さなピクセル値はメンバーシップ値0、上限よりも大きなピクセル値はメンバーシップ値1となります。
参考
ラスタのファジー化(gaussian membership) 、 ラスタのファジー化(large membership) 、 ラスタのファジー化(linear membership) 、 ラスタのファジー化(near membership) 、 ラスタのファジー化(small membership)
パラメータ
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
入力ラスタ |
|
[ラスタ] |
入力ラスタレイヤ |
バンド番号 |
|
[ラスタのバンド] デフォルト:ラスタレイヤの1番目のバンド |
ラスタがマルチバンドの場合には、ファジー化したいバンドを選択してください。 |
Low fuzzy membership bound |
|
[数値] デフォルト: 0 |
べき乗関数の下限 |
High fuzzy membership bound |
|
[数値] デフォルト: 1 |
べき乗関数の上限 |
High fuzzy membership bound |
|
[数値] デフォルト: 2 |
べき乗関数の指数 |
出力ラスタ |
|
[入力レイヤと同じ] デフォルト: |
出力ラスタレイヤを指定します。次のいずれかです:
|
出力
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
出力ラスタ |
|
[入力レイヤと同じ] |
結果が含まれる出力ラスタレイヤ |
CRS権限識別子 |
|
[crs] |
出力ラスタレイヤの座標参照系 |
領域 |
|
[文字列] |
出力ラスタレイヤの空間範囲 |
幅(ピクセル単位) |
|
[整数] |
出力ラスタレイヤの列数 |
高さ(ピクセル単位) |
|
[整数] |
出力ラスタレイヤの行数 |
総ピクセル数 |
|
[整数] |
出力ラスタレイヤのピクセル数 |
Python コード
Algorithm ID: native:fuzzifyrasterpowermembership
import processing
processing.run("algorithm_id", {parameter_dictionary})
algorithm id は、プロセシングツールボックス内でアルゴリズムにマウスカーソルを乗せた際に表示されるIDです。 parameter dictionary は、パラメータの「名前」とその値を指定するマッピング型です。Python コンソールからプロセシングアルゴリズムを実行する方法の詳細については、 プロセシングアルゴリズムをコンソールから使う を参照してください。
25.1.11.11. ラスタのファジー化(small membership)
smallメンバーシップ関数を使用して入力ラスタの各ピクセルにメンバーシップ値を割り当てることにより、入力ラスタをファジー化されたラスタに変換します。メンバーシップ値は0から1の範囲の値です。ファジー化されたラスタにおいて、値0はメンバーではないこと、値1は完全にメンバーであることを意味しています。smallメンバーシップ関数は、 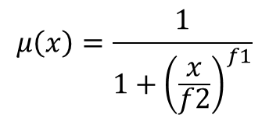 で定義されます。ここで、 f1 は拡がり、 f2 は中点を表します。
で定義されます。ここで、 f1 は拡がり、 f2 は中点を表します。
参考
ラスタのファジー化(gaussian membership) 、 ラスタのファジー化(large membership) 、 ラスタのファジー化(linear membership) 、 ラスタのファジー化(near membership) 、 ラスタのファジー化(power membership)
パラメータ
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
入力ラスタ |
|
[ラスタ] |
入力ラスタレイヤ |
バンド番号 |
|
[ラスタのバンド] デフォルト:ラスタレイヤの1番目のバンド |
ラスタがマルチバンドの場合には、ファジー化したいバンドを選択してください。 |
Function midpoint |
|
[数値] デフォルト: 50 |
small関数の中点 |
Function spread |
|
[数値] デフォルト: 5 |
small関数の拡がり |
出力ラスタ |
|
[入力レイヤと同じ] デフォルト: |
出力ラスタレイヤを指定します。次のいずれかです:
|
出力
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
出力ラスタ |
|
[入力レイヤと同じ] |
結果が含まれる出力ラスタレイヤ |
CRS権限識別子 |
|
[crs] |
出力ラスタレイヤの座標参照系 |
領域 |
|
[文字列] |
出力ラスタレイヤの空間範囲 |
幅(ピクセル単位) |
|
[整数] |
出力ラスタレイヤの列数 |
高さ(ピクセル単位) |
|
[整数] |
出力ラスタレイヤの行数 |
総ピクセル数 |
|
[整数] |
出力ラスタレイヤのピクセル数 |
Python コード
Algorithm ID: native:fuzzifyrastersmallmembership
import processing
processing.run("algorithm_id", {parameter_dictionary})
algorithm id は、プロセシングツールボックス内でアルゴリズムにマウスカーソルを乗せた際に表示されるIDです。 parameter dictionary は、パラメータの「名前」とその値を指定するマッピング型です。Python コンソールからプロセシングアルゴリズムを実行する方法の詳細については、 プロセシングアルゴリズムをコンソールから使う を参照してください。
25.1.11.12. ラスタスタックの値の超過頻度
入力ラスタスタックの値が値ラスタレイヤの値よりも大きい頻度(回数)をセル単位で評価します。出力ラスタの範囲と解像度は入力ラスタと同じで、データ型は常に Int32 です。
データラスタスタックにマルチバンドラスタを使用する場合、このアルゴリズムは常にラスタの最初のバンドに対して解析を行います。解析に他のバンドを使用したい場合には、GDALを使用してください。出力のnodata値は手入力で設定できます。
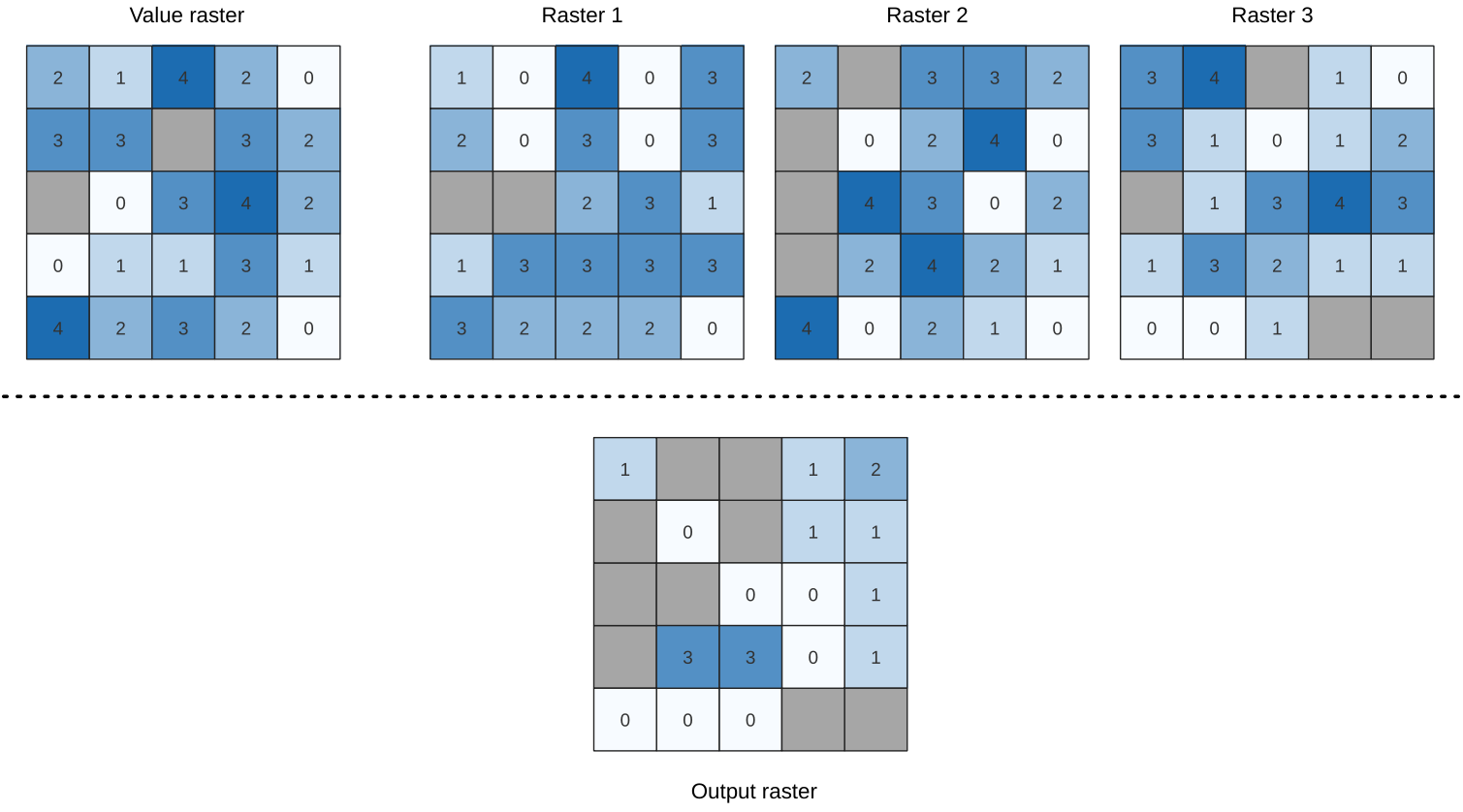
図 25.16 出力ラスタの各セルについて、セルの値はラスタスタックのラスタの値が対応する値ラスタよりも大きい回数を表す。 nodata セル(灰色)が考慮される
パラメータ
基本パラメータ
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
入力ラスタ |
|
[ラスタ] |
サンプリングするレイヤ群に対する参照レイヤとなる、入力値レイヤ |
対象バンド |
|
[ラスタのバンド] デフォルト:ラスタレイヤの1番目のバンド |
値を取得したいバンドを選択します |
入力ラスタ(複数) |
|
[ラスタ] [リスト] |
評価したいラスタレイヤ群。データラスタスタックにマルチバンドラスタを使用する場合には、このアルゴリズムは常にラスタの最初のバンドに対して解析を行う |
nodataを無視する |
|
[ブール値] デフォルト: False |
チェックを入れない場合、値ラスタやデータレイヤスタックにnodataセルが一つでもあれば、出力ラスタはnodataセルとなります。 |
出力レイヤ |
|
[入力レイヤと同じ] デフォルト: |
出力ラスタレイヤを指定します。次のいずれかです:
|
詳細パラメータ
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
nodataを出力する オプション |
|
[数値] デフォルト: -9999.0 |
出力レイヤのnodataに使用する値 |
出力
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
出力レイヤ |
|
[ラスタ] |
結果が含まれる出力ラスタレイヤ |
CRS権限識別子 |
|
[文字列] |
出力ラスタレイヤの座標参照系 |
領域 |
|
[文字列] |
出力ラスタレイヤの空間範囲 |
同じ出現頻度のセル数 |
|
[数値] |
|
高さ(ピクセル単位) |
|
[数値] |
出力ラスタレイヤの行数 |
総ピクセル数 |
|
[整数] |
出力ラスタレイヤのピクセル数 |
有効セルの場所の平均頻度 |
|
[数値] |
|
値の頻度 |
|
[数値] |
|
幅(ピクセル単位) |
|
[整数] |
出力ラスタレイヤの列数 |
Python コード
アルゴリズムID: native:greaterthanfrequency
import processing
processing.run("algorithm_id", {parameter_dictionary})
algorithm id は、プロセシングツールボックス内でアルゴリズムにマウスカーソルを乗せた際に表示されるIDです。 parameter dictionary は、パラメータの「名前」とその値を指定するマッピング型です。Python コンソールからプロセシングアルゴリズムを実行する方法の詳細については、 プロセシングアルゴリズムをコンソールから使う を参照してください。
25.1.11.13. ラスタスタックの最大値の位置
入力ラスタスタック内で最大値をとるラスタの位置をセル単位で評価します。位置のカウントは1から始まり、入力ラスタの総数までの値をとります。このアルゴリズムでは、入力ラスタの順序が関係します。複数のラスタが最大値となる場合、最初のラスタが位置の値として使用されます。
データラスタスタックにマルチバンドラスタを使用する場合、このアルゴリズムは常にラスタの最初のバンドに対して解析を行います。解析に他のバンドを使用したい場合には、GDALを使用してください。ラスタレイヤスタックのセルにnodataが一つでもあれば、 "nodataを無視する" パラメータにチェックを入れていない限りは、出力ラスタはnodataセルとなります。出力のnodata値は手入力で設定できます。出力ラスタの範囲と解像度は参照ラスタレイヤで定義され、データ型は常に Int32 です。
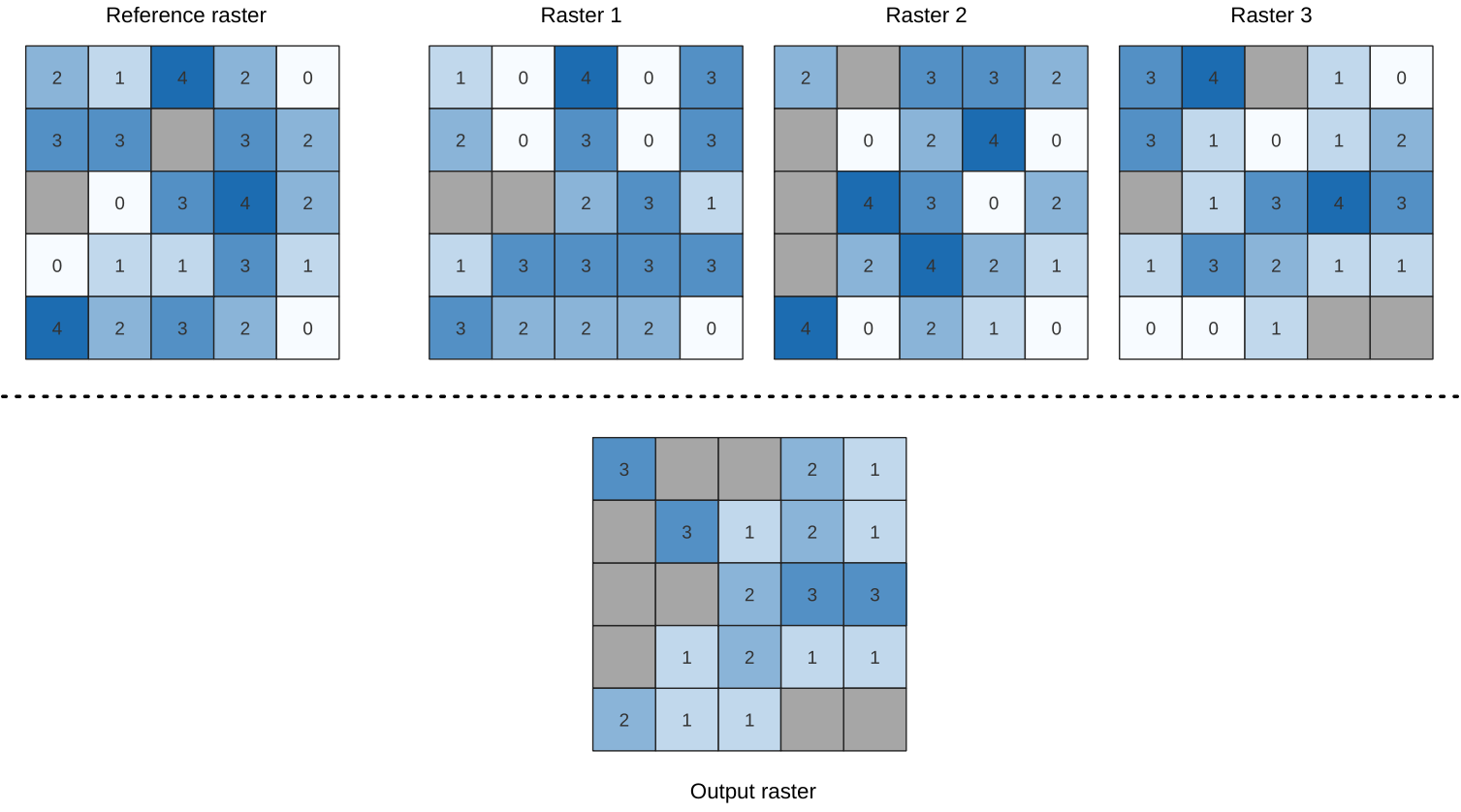
パラメータ
基本パラメータ
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
入力ラスタ(複数) |
|
[ラスタ] [リスト] |
比較を行うラスタレイヤのリスト |
スナップで参照するレイヤ |
|
[ラスタ] |
出力レイヤの作成に使用する参照レイヤ(範囲、CRS、ピクセルの大きさ) |
nodataを無視する |
|
[ブール値] デフォルト: False |
チェックを入れない場合、データレイヤスタックにnodataセルが一つでもあれば、出力ラスタはnodataセルとなります。 |
出力レイヤ |
|
[ラスタ] デフォルト: |
結果の出力レイヤを指定します。つぎのいずれかです:
|
詳細パラメータ
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
nodataを出力する |
|
[数値] デフォルト: -9999.0 |
出力レイヤのnodataに使用する値 |
出力
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
出力レイヤ |
|
[ラスタ] |
結果が含まれる出力ラスタレイヤ |
CRS権限識別子 |
|
[文字列] |
出力ラスタレイヤの座標参照系 |
領域 |
|
[文字列] |
出力ラスタレイヤの空間範囲 |
幅(ピクセル単位) |
|
[整数] |
出力ラスタレイヤの列数 |
高さ(ピクセル単位) |
|
[整数] |
出力ラスタレイヤの行数 |
総ピクセル数 |
|
[整数] |
出力ラスタレイヤのピクセル数 |
Python コード
アルゴリズムID: native:highestpositioninrasterstack
import processing
processing.run("algorithm_id", {parameter_dictionary})
algorithm id は、プロセシングツールボックス内でアルゴリズムにマウスカーソルを乗せた際に表示されるIDです。 parameter dictionary は、パラメータの「名前」とその値を指定するマッピング型です。Python コンソールからプロセシングアルゴリズムを実行する方法の詳細については、 プロセシングアルゴリズムをコンソールから使う を参照してください。
25.1.11.14. ラスタスタックの値の未満頻度
入力ラスタスタックの値が値ラスタレイヤの値よりも小さい頻度(回数)をセル単位で評価します。出力ラスタの範囲と解像度は入力ラスタと同じで、データ型は常に Int32 です。
データラスタスタックにマルチバンドラスタを使用する場合、このアルゴリズムは常にラスタの最初のバンドに対して解析を行います。解析に他のバンドを使用したい場合には、GDALを使用してください。出力のnodata値は手入力で設定できます。
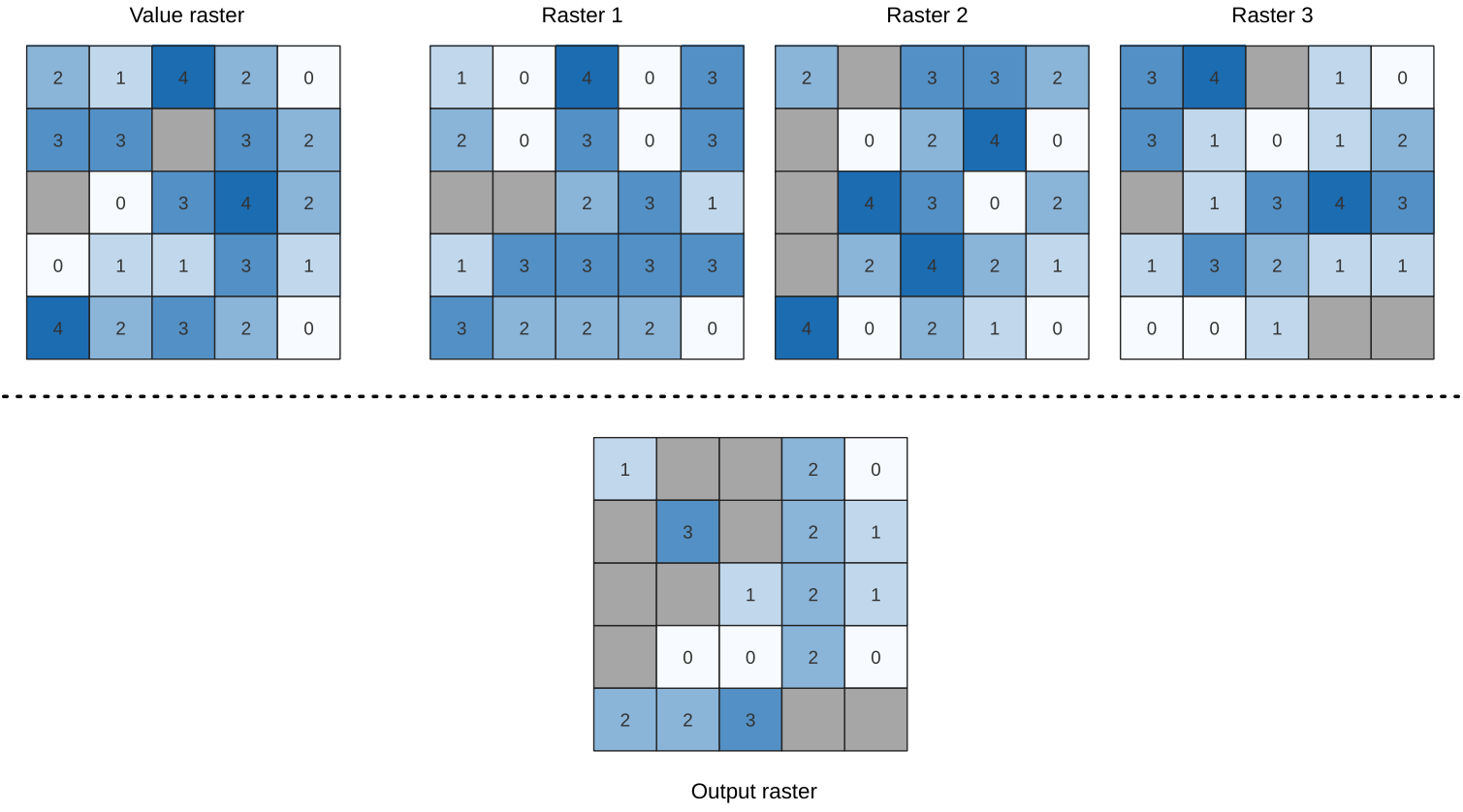
図 25.17 出力ラスタの各セルについて、セルの値はラスタスタックのラスタの値が対応する値ラスタよりも小さい回数を表す。 nodata セル(灰色)が考慮される
パラメータ
基本パラメータ
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
入力ラスタ |
|
[ラスタ] |
サンプリングするレイヤ群に対する参照レイヤとなる、入力値レイヤ |
対象バンド |
|
[ラスタのバンド] デフォルト:ラスタレイヤの1番目のバンド |
値を取得したいバンドを選択します |
入力ラスタ(複数) |
|
[ラスタ] [リスト] |
評価したいラスタレイヤ群。データラスタスタックにマルチバンドラスタを使用する場合には、このアルゴリズムは常にラスタの最初のバンドに対して解析を行う |
nodataを無視する |
|
[ブール値] デフォルト: False |
チェックを入れない場合、値ラスタやデータレイヤスタックにnodataセルが一つでもあれば、出力ラスタはnodataセルとなります。 |
出力レイヤ |
|
[入力レイヤと同じ] デフォルト: |
出力ラスタレイヤを指定します。次のいずれかです:
|
詳細パラメータ
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
nodataを出力する オプション |
|
[数値] デフォルト: -9999.0 |
出力レイヤのnodataに使用する値 |
出力
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
出力レイヤ |
|
[ラスタ] |
結果が含まれる出力ラスタレイヤ |
CRS権限識別子 |
|
[文字列] |
出力ラスタレイヤの座標参照系 |
領域 |
|
[文字列] |
出力ラスタレイヤの空間範囲 |
同じ出現頻度のセル数 |
|
[数値] |
|
高さ(ピクセル単位) |
|
[数値] |
出力ラスタレイヤの行数 |
総ピクセル数 |
|
[整数] |
出力ラスタレイヤのピクセル数 |
有効セルの場所の平均頻度 |
|
[数値] |
|
値の頻度 |
|
[数値] |
|
幅(ピクセル単位) |
|
[整数] |
出力ラスタレイヤの列数 |
Python コード
アルゴリズムID: native:lessthanfrequency
import processing
processing.run("algorithm_id", {parameter_dictionary})
algorithm id は、プロセシングツールボックス内でアルゴリズムにマウスカーソルを乗せた際に表示されるIDです。 parameter dictionary は、パラメータの「名前」とその値を指定するマッピング型です。Python コンソールからプロセシングアルゴリズムを実行する方法の詳細については、 プロセシングアルゴリズムをコンソールから使う を参照してください。
25.1.11.15. ラスタスタックの最小値の位置
入力ラスタスタック内で最小値をとるラスタの位置をセル単位で評価します。位置のカウントは1から始まり、入力ラスタの総数までの値をとります。このアルゴリズムでは、入力ラスタの順序が関係します。複数のラスタが最小値となる場合、最初のラスタが位置の値として使用されます。
データラスタスタックにマルチバンドラスタを使用する場合、このアルゴリズムは常にラスタの最初のバンドに対して解析を行います。解析に他のバンドを使用したい場合には、GDALを使用してください。ラスタレイヤスタックのセルにnodataが一つでもあれば、 "nodataを無視する" パラメータにチェックを入れていない限りは、出力ラスタはnodataセルとなります。出力のnodata値は手入力で設定できます。出力ラスタの範囲と解像度は参照ラスタレイヤで定義され、データ型は常に Int32 です。
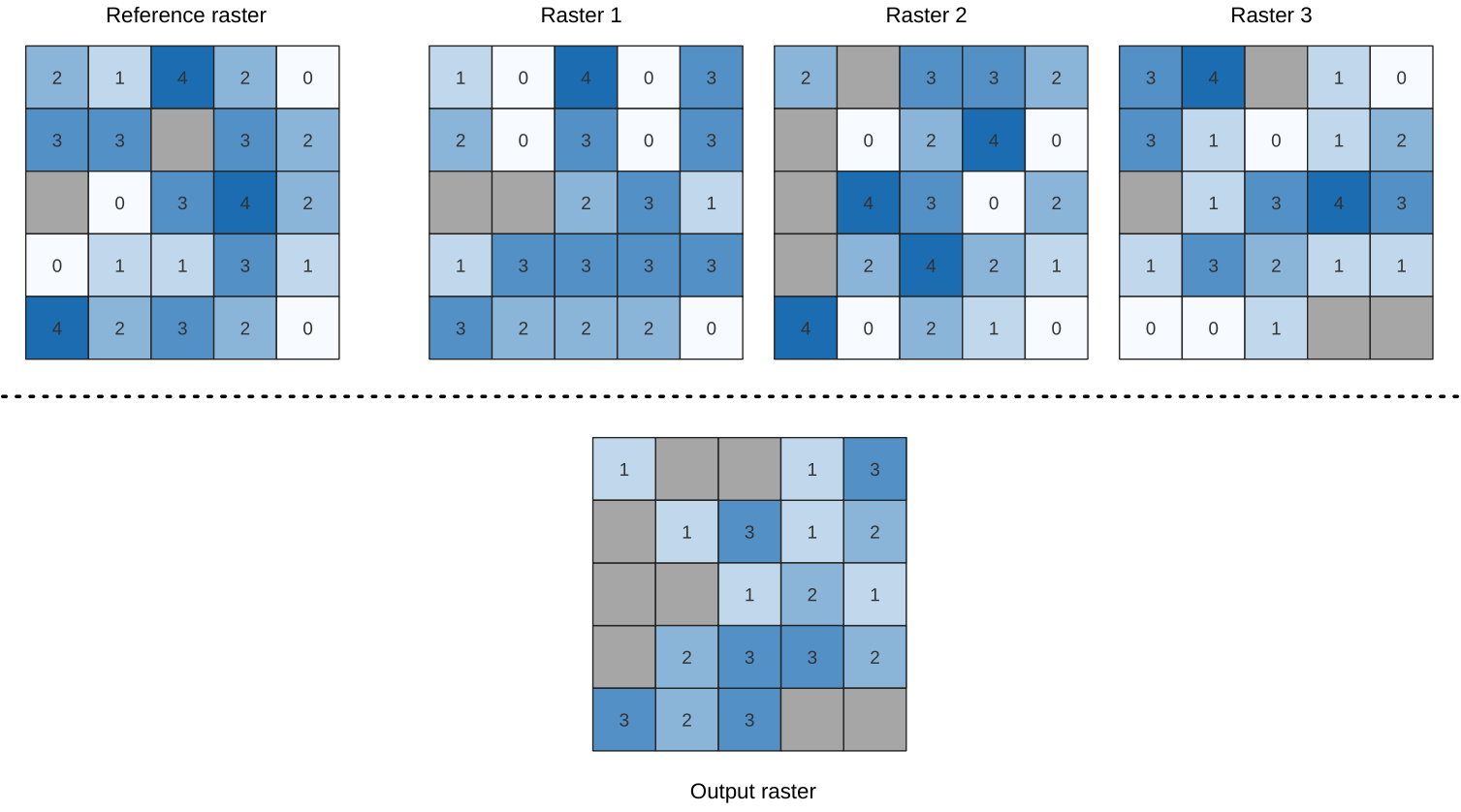
パラメータ
基本パラメータ
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
入力ラスタ(複数) |
|
[ラスタ] [リスト] |
比較を行うラスタレイヤのリスト |
スナップで参照するレイヤ |
|
[ラスタ] |
出力レイヤの作成に使用する参照レイヤ(範囲、CRS、ピクセルの大きさ) |
nodataを無視する |
|
[ブール値] デフォルト: False |
チェックを入れない場合、データレイヤスタックにnodataセルが一つでもあれば、出力ラスタはnodataセルとなります。 |
出力レイヤ |
|
[ラスタ] デフォルト: |
結果の出力レイヤを指定します。つぎのいずれかです:
|
詳細パラメータ
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
nodataを出力する |
|
[数値] デフォルト: -9999.0 |
出力レイヤのnodataに使用する値 |
出力
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
出力レイヤ |
|
[ラスタ] |
結果が含まれる出力ラスタレイヤ |
CRS権限識別子 |
|
[文字列] |
出力ラスタレイヤの座標参照系 |
領域 |
|
[文字列] |
出力ラスタレイヤの空間範囲 |
幅(ピクセル単位) |
|
[整数] |
出力ラスタレイヤの列数 |
高さ(ピクセル単位) |
|
[整数] |
出力ラスタレイヤの行数 |
総ピクセル数 |
|
[整数] |
出力ラスタレイヤのピクセル数 |
Python コード
アルゴリズムID: native:lowestpositioninrasterstack
import processing
processing.run("algorithm_id", {parameter_dictionary})
algorithm id は、プロセシングツールボックス内でアルゴリズムにマウスカーソルを乗せた際に表示されるIDです。 parameter dictionary は、パラメータの「名前」とその値を指定するマッピング型です。Python コンソールからプロセシングアルゴリズムを実行する方法の詳細については、 プロセシングアルゴリズムをコンソールから使う を参照してください。
25.1.11.16. 複数ラスタのAND論理値
一連の入力ラスタの論理 AND を計算します。あるピクセルについて、すべての入力ラスタが非ゼロ値をもつ場合、そのピクセルは出力ラスタで 1 になります。入力ラスタのいずれかに 0 値がある場合、そのピクセルは出力ラスタで 0 になります。
参照レイヤパラメータには、出力ラスタの作成時に参照として使用する既存のラスタレイヤを指定します。出力ラスタは、このレイヤと同じ範囲、CRS、およびピクセル寸法を持ちます。
デフォルトでは、任意の入力レイヤにnodataピクセルがあると、出力ラスタはnodataピクセルとなります。 nodataをfalseとみなす オプションにチェックが入っている場合には、nodataの入力値は入力値 0 と同じものとして扱われます。
参考
パラメータ
基本パラメータ
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
入力レイヤ |
|
[ラスタ] [リスト] |
入力ラスタレイヤのリスト |
スナップで参照するレイヤ |
|
[ラスタ] |
出力レイヤの作成に参照するレイヤ(範囲、CRS、ピクセルの大きさ等) |
nodataをfalseとみなす |
|
[ブール値] デフォルト: False |
演算を実行する際に、入力ファイルのnodata値を0として扱います |
出力レイヤ |
|
[ラスタ] デフォルト: |
結果の出力レイヤを指定します。つぎのいずれかです:
|
詳細パラメータ
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
nodataを出力する |
|
[数値] デフォルト: -9999.0 |
出力レイヤのnodataに使用する値 |
出力のデータ型 |
|
[列挙型] デフォルト: 5 |
出力ラスタのデータ型。オプションは以下のとおり:
|
出力
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
領域 |
|
[文字列] |
出力ラスタレイヤの空間範囲 |
CRS権限識別子 |
|
[crs] |
出力ラスタレイヤの座標参照系 |
幅(ピクセル単位) |
|
[整数] |
出力ラスタレイヤの列数 |
高さ(ピクセル単位) |
|
[整数] |
出力ラスタレイヤの行数 |
総ピクセル数 |
|
[整数] |
出力ラスタレイヤのピクセル数 |
nodataピクセルの数 |
|
[整数] |
出力ラスタレイヤのnodataピクセルの数 |
Trueのピクセル数 |
|
[整数] |
出力ラスタレイヤのTrueピクセル(value=1)の数 |
Falseのピクセル数 |
|
[整数] |
出力ラスタレイヤのFalseピクセル(value=0)の数 |
出力レイヤ |
|
[ラスタ] |
結果が含まれる出力ラスタレイヤ |
Python コード
Algorithm ID: native:rasterbooleanand
import processing
processing.run("algorithm_id", {parameter_dictionary})
algorithm id は、プロセシングツールボックス内でアルゴリズムにマウスカーソルを乗せた際に表示されるIDです。 parameter dictionary は、パラメータの「名前」とその値を指定するマッピング型です。Python コンソールからプロセシングアルゴリズムを実行する方法の詳細については、 プロセシングアルゴリズムをコンソールから使う を参照してください。
25.1.11.17. 複数ラスタのOR論理値
一連の入力ラスタの論理 OR を計算します。あるピクセルについて、すべての入力ラスタがゼロ値をもつ場合、そのピクセルは出力ラスタで 0 になります。入力ラスタのいずれかに 1 値がある場合、そのピクセルは出力ラスタで 1 になります。
参照レイヤパラメータには、出力ラスタの作成時に参照として使用する既存のラスタレイヤを指定します。出力ラスタは、このレイヤと同じ範囲、CRS、およびピクセル寸法を持ちます。
デフォルトでは、任意の入力レイヤにnodataピクセルがあると、出力ラスタはnodataピクセルとなります。 nodataをfalseとみなす オプションにチェックが入っている場合には、nodataの入力値は入力値 0 と同じものとして扱われます。
参考
パラメータ
基本パラメータ
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
入力レイヤ |
|
[ラスタ] [リスト] |
入力ラスタレイヤのリスト |
スナップで参照するレイヤ |
|
[ラスタ] |
出力レイヤの作成に参照するレイヤ(範囲、CRS、ピクセルの大きさ等) |
nodataをfalseとみなす |
|
[ブール値] デフォルト: False |
演算を実行する際に、入力ファイルのnodata値を0として扱います |
出力レイヤ |
|
[ラスタ] デフォルト: |
結果の出力レイヤを指定します。つぎのいずれかです:
|
詳細パラメータ
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
nodataを出力する |
|
[数値] デフォルト: -9999.0 |
出力レイヤのnodataに使用する値 |
出力のデータ型 |
|
[列挙型] デフォルト: 5 |
出力ラスタのデータ型。オプションは以下のとおり:
|
出力
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
領域 |
|
[文字列] |
出力ラスタレイヤの空間範囲 |
CRS権限識別子 |
|
[crs] |
出力ラスタレイヤの座標参照系 |
幅(ピクセル単位) |
|
[整数] |
出力ラスタレイヤの列数 |
高さ(ピクセル単位) |
|
[整数] |
出力ラスタレイヤの行数 |
総ピクセル数 |
|
[整数] |
出力ラスタレイヤのピクセル数 |
nodataピクセルの数 |
|
[整数] |
出力ラスタレイヤのnodataピクセルの数 |
Trueのピクセル数 |
|
[整数] |
出力ラスタレイヤのTrueピクセル(value=1)の数 |
Falseのピクセル数 |
|
[整数] |
出力ラスタレイヤのFalseピクセル(value=0)の数 |
出力レイヤ |
|
[ラスタ] |
結果が含まれる出力ラスタレイヤ |
Python コード
Algorithm ID: native:rasterbooleanor
import processing
processing.run("algorithm_id", {parameter_dictionary})
algorithm id は、プロセシングツールボックス内でアルゴリズムにマウスカーソルを乗せた際に表示されるIDです。 parameter dictionary は、パラメータの「名前」とその値を指定するマッピング型です。Python コンソールからプロセシングアルゴリズムを実行する方法の詳細については、 プロセシングアルゴリズムをコンソールから使う を参照してください。
25.1.11.18. ラスタ計算機
ラスタレイヤを使用して代数演算を実行します。
結果のレイヤは、式に従って計算された値になります。式には、数値、演算子、現在のプロジェクト内の任意のレイヤへの参照を含めることができます。
注釈
バッチ処理インターフェイス または QGIS Python コンソール から計算機を使用するときは、使用するファイルを指定する必要があります。対応するレイヤは、ファイルのベース名を使用して参照されます(フルパスなし)。例えば、 path/to/my/rasterfile.tif にあるレイヤーを使用している場合、そのレイヤーの最初のバンドは rasterfile.tif@1 として参照されます。
参考
パラメータ
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
レイヤ |
GUI版のみ |
凡例に読み込まれているすべてのラスタレイヤのリストが表示されます。これを使って式ボックスに入力できます(ダブルクリックで追加)。ラスタレイヤは、 |
|
演算子 |
GUI版のみ |
電卓のようなボタンがあり、これを使って式ボックスに入力できます。 |
|
式 |
|
[文字列] |
出力ラスタレイヤの計算に使用する式。用意されている演算子ボタンを使用して、このボックスに式を直接入力できます。 |
定義済みの式 |
GUI版のみ |
定義済みの |
|
Reference layer(s) (used for automated extent, cellsize, and CRS) オプション |
|
[ラスタ] [リスト] |
範囲やセルサイズ、CRSを取得するために使用するレイヤ。このボックスでレイヤを選択すると、その他全てのパラメータを手入力せずに済みます。ラスタレイヤは、 |
Cell size (use 0 or empty to set it automatically) オプション |
|
[数値] |
出力ラスタレイヤのセルサイズ。セルサイズが指定されていない場合は、選択した参照レイヤの最小セルサイズが使用されます。セルサイズは、X軸とY軸の両方で同じ長さです。 |
Output extent オプション |
|
[範囲] |
Specify the spatial extent of the output raster layer. If the extent is not specified, the minimum extent that covers all the selected reference layers will be used. Available methods are:
|
Output CRS オプション |
|
[crs] |
出力ラスタレイヤのCRS。出力CRSが指定されていない場合は、最初の参照レイヤのCRSが使用されます。 |
出力 |
|
[ラスタ] デフォルト: |
出力ラスタレイヤを指定します。次のいずれかです:
|
出力
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
出力 |
|
[ラスタ] |
計算した値の出力ラスタファイル。 |
Python コード
アルゴリズムID: qgis:rastercalculator
import processing
processing.run("algorithm_id", {parameter_dictionary})
algorithm id は、プロセシングツールボックス内でアルゴリズムにマウスカーソルを乗せた際に表示されるIDです。 parameter dictionary は、パラメータの「名前」とその値を指定するマッピング型です。Python コンソールからプロセシングアルゴリズムを実行する方法の詳細については、 プロセシングアルゴリズムをコンソールから使う を参照してください。
25.1.11.19. Raster layer properties
NEW in 3.20
Returns basic properties of the given raster layer, including the extent, size in pixels and dimensions of pixels (in map units), number of bands, and no data value.
This algorithm is intended for use as a means of extracting these useful properties to use as the input values to other algorithms in a model - e.g. to allow to pass an existing raster's pixel sizes over to a GDAL raster algorithm.
パラメータ
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
入力レイヤ |
|
[ラスタ] |
入力ラスタレイヤ |
バンド番号 オプション |
|
[ラスタのバンド] Default: Not set |
Whether to also return properties of a specific band. If a band is specified, the noData value for the selected band is also returned. |
出力
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
Number of bands in raster |
|
[数値] |
The number of bands in the raster |
CRS権限識別子 |
|
[文字列] |
出力ラスタレイヤの座標参照系 |
領域 |
|
[文字列] |
The raster layer extent in the CRS |
Band has a NoData value set |
|
[Boolean] |
Indicates whether the raster layer has a value set for NODATA pixels in the selected band |
高さ(ピクセル単位) |
|
[整数] |
The number of columns in the raster layer |
Band NoData value |
|
[数値] |
The value (if set) of the NoData pixels in the selected band |
Pixel size (height) in map units |
|
[整数] |
Vertical size in map units of the pixel |
Pixel size (width) in map units |
|
[整数] |
Horizontal size in map units of the pixel |
幅(ピクセル単位) |
|
[整数] |
The number of rows in the raster layer |
Maximum x-coordinate |
|
[数値] |
|
Minimum x-coordinate |
|
[数値] |
|
Maximum y-coordinate |
|
[数値] |
|
Minimum y-coordinate |
|
[数値] |
Python コード
Algorithm ID: native:rasterlayerproperties
import processing
processing.run("algorithm_id", {parameter_dictionary})
algorithm id は、プロセシングツールボックス内でアルゴリズムにマウスカーソルを乗せた際に表示されるIDです。 parameter dictionary は、パラメータの「名前」とその値を指定するマッピング型です。Python コンソールからプロセシングアルゴリズムを実行する方法の詳細については、 プロセシングアルゴリズムをコンソールから使う を参照してください。
25.1.11.20. ラスタレイヤの統計量
ラスタレイヤの指定したバンドの値に関する基本統計量を計算します。結果は メニューに読み込まれます。
パラメータ
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
入力レイヤ |
|
[ラスタ] |
入力ラスタレイヤ |
バンド番号 |
|
[ラスタのバンド] デフォルト:入力レイヤの1番目のバンド |
ラスタがマルチバンドの場合には、統計量を計算したいバンドを選択してください。 |
統計量の出力 |
|
[html] デフォルト: |
出力ファイルの指定:
|
出力
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
最大値 |
|
[数値] |
|
平均値 |
|
[数値] |
|
最小値 |
|
[数値] |
|
統計量の出力 |
|
[html] |
出力ファイルには以下の情報が含まれます:
|
範囲 |
|
[数値] |
|
標準偏差 |
|
[数値] |
|
合計 |
|
[数値] |
|
平方和 |
|
[数値] |
Python コード
Algorithm ID: native:rasterlayerstatistics
import processing
processing.run("algorithm_id", {parameter_dictionary})
algorithm id は、プロセシングツールボックス内でアルゴリズムにマウスカーソルを乗せた際に表示されるIDです。 parameter dictionary は、パラメータの「名前」とその値を指定するマッピング型です。Python コンソールからプロセシングアルゴリズムを実行する方法の詳細については、 プロセシングアルゴリズムをコンソールから使う を参照してください。
25.1.11.21. ラスタレイヤのユニーク値
指定したラスタレイヤの値ごとの個数と面積を返します。
パラメータ
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
入力レイヤ |
|
[ラスタ] |
入力ラスタレイヤ |
バンド番号 |
|
[ラスタのバンド] デフォルト:入力レイヤの1番目のバンド |
ラスタがマルチバンドの場合には、統計量を計算したいバンドを選択してください。 |
ユニーク値の集計出力 |
|
[ファイル] デフォルト: |
出力ファイルの指定:
|
ユニーク値の表 |
|
[テーブル] デフォルト: |
ユニーク値のテーブルの指定:
ここでファイルの文字コードを変更することもできます。 |
出力
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
CRS権限識別子 |
|
[文字列] |
出力ラスタレイヤの座標参照系 |
領域 |
|
[文字列] |
出力ラスタレイヤの空間範囲 |
高さ(ピクセル単位) |
|
[整数] |
出力ラスタレイヤの行数 |
nodataピクセルの数 |
|
[数値] |
The number of NODATA pixels in the output raster layer |
総ピクセル数 |
|
[整数] |
出力ラスタレイヤのピクセル数 |
ユニーク値の集計出力 |
|
[html] |
出力HTMLファイルには以下の情報が含まれます:
|
ユニーク値の表 |
|
[テーブル] |
テーブルには3つのカラムがあります:
|
幅(ピクセル単位) |
|
[整数] |
出力ラスタレイヤの列数 |
Python コード
Algorithm ID: native:rasterlayeruniquevaluesreport
import processing
processing.run("algorithm_id", {parameter_dictionary})
algorithm id は、プロセシングツールボックス内でアルゴリズムにマウスカーソルを乗せた際に表示されるIDです。 parameter dictionary は、パラメータの「名前」とその値を指定するマッピング型です。Python コンソールからプロセシングアルゴリズムを実行する方法の詳細については、 プロセシングアルゴリズムをコンソールから使う を参照してください。
25.1.11.22. ゾーン統計量(ラスタ)
別のラスタレイヤで定義されたゾーンで分類して、ラスタレイヤの値の統計量を計算します。
参考
パラメータ
基本パラメータ
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
入力レイヤ |
|
[ラスタ] |
入力ラスタレイヤ |
バンド番号 |
|
[ラスタのバンド] デフォルト:ラスタレイヤの1番目のバンド |
ラスタがマルチバンドの場合には、統計量を計算したいバンドを選択してください。 |
ゾーン統計の対象レイヤ |
|
[ラスタ] |
ゾーンを定義するラスタレイヤ。ゾーンとは、同じピクセル値を持つ連続したピクセルです。 |
対象バンド |
|
[ラスタのバンド] デフォルト:ラスタレイヤの1番目のバンド |
ラスタがマルチバンドの場合には、ゾーンを定義するバンドを選択してください。 |
統計量の出力 |
|
[テーブル] デフォルト: |
Specification of the output report. One of:
ここでファイルの文字コードを変更することもできます。 |
詳細パラメータ
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
スナップで参照するレイヤ オプション |
|
[列挙型] デフォルト: 0 |
出力レイヤのゾーンの判定時に参照点として用いる重心の計算に使用するラスタレイヤ。次のいずれかです:
|
出力
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
CRS権限識別子 |
|
[文字列] |
出力ラスタレイヤの座標参照系 |
領域 |
|
[文字列] |
出力ラスタレイヤの空間範囲 |
高さ(ピクセル単位) |
|
[整数] |
出力ラスタレイヤの行数 |
nodataピクセルの数 |
|
[数値] |
The number of NODATA pixels in the output raster layer |
統計量の出力 |
|
[テーブル] |
出力レイヤには 各ゾーンについての 以下の情報が含まれます:
|
総ピクセル数 |
|
[数値] |
出力ラスタレイヤのピクセル数 |
幅(ピクセル単位) |
|
[数値] |
出力ラスタレイヤの列数 |
Python コード
Algorithm ID: native:rasterlayerzonalstats
import processing
processing.run("algorithm_id", {parameter_dictionary})
algorithm id は、プロセシングツールボックス内でアルゴリズムにマウスカーソルを乗せた際に表示されるIDです。 parameter dictionary は、パラメータの「名前」とその値を指定するマッピング型です。Python コンソールからプロセシングアルゴリズムを実行する方法の詳細については、 プロセシングアルゴリズムをコンソールから使う を参照してください。
25.1.11.23. ラスタのサーフェス体積
指定したベースレベルを基準とした、ラスタサーフェスの下の体積を計算します。主に数値標高モデル(DEM)で便利なアルゴリズムです。
パラメータ
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
入力レイヤ |
|
[ラスタ] |
サーフェスを表す入力ラスタ |
バンド番号 |
|
[ラスタのバンド] デフォルト:ラスタレイヤの1番目のバンド |
ラスタがマルチバンドの場合には、サーフェスを定義するバンドを選択してください。 |
基準値(ベースレベル) |
|
[数値] デフォルト: 0.0 |
ベース、あるいは基準値を定義します。この基準値は、 |
方法 |
|
[列挙型] デフォルト: 0 |
ラスタピクセル値と
|
体積計算のレポート |
|
[html] デフォルト: |
出力HTMLレポートを指定します。次のいずれかです:
ここでファイルの文字コードを変更することもできます。 |
体積計算の表 |
|
[テーブル] デフォルト: |
出力テーブルを指定します。次のいずれかです:
ここでファイルの文字コードを変更することもできます。 |
出力
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
体積 |
|
[数値] |
計算された体積 |
領域(Area) |
|
[数値] |
面積をマップ単位の2乗で表した値 |
ピクセル数 |
|
[数値] |
解析したピクセルの合計数 |
体積計算のレポート |
|
[html] |
HTML形式の出力レポート(体積、面積、ピクセル数を含む) |
体積計算の表 |
|
[テーブル] |
出力テーブル(体積、面積、ピクセル数を含む) |
Python コード
Algorithm ID: native:rastersurfacevolume
import processing
processing.run("algorithm_id", {parameter_dictionary})
algorithm id は、プロセシングツールボックス内でアルゴリズムにマウスカーソルを乗せた際に表示されるIDです。 parameter dictionary は、パラメータの「名前」とその値を指定するマッピング型です。Python コンソールからプロセシングアルゴリズムを実行する方法の詳細については、 プロセシングアルゴリズムをコンソールから使う を参照してください。
25.1.11.24. 属性テーブルによる再分類
ベクタテーブルで指定された値の範囲に基づいて新しいクラス値を割り当てて、ラスタバンドを再分類します。
パラメータ
基本パラメータ
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
ラスタレイヤ |
|
[ラスタ] |
再分類するラスタレイヤ |
バンド番号 |
|
[ラスタのバンド] デフォルト:ラスタレイヤの1番目のバンド |
ラスタがマルチバンドの場合には、再分類したいバンドを選択してください。 |
クラス区分のテーブルを含むレイヤ |
|
[ベクタ:任意] |
分類に使用する値を含むベクタレイヤ |
区分の下限を示す属性(フィールド) |
|
[テーブルのフィールド:数値] |
クラス範囲の最小値のフィールド |
区分の上限を示す属性(フィールド) |
|
[テーブルのフィールド:数値] |
クラス範囲の最大値のフィールド |
クラスを示す属性(フィールド) |
|
[テーブルのフィールド:数値] |
そのクラスに該当するピクセルに割り当てられる値のフィールド(対応する最小値と最大値の間) |
出力ラスタ |
|
[ラスタ] デフォルト: |
出力ラスタレイヤを指定します。次のいずれかです:
|
詳細パラメータ
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
nodataを出力する |
|
[数値] デフォルト: -9999.0 |
nodata値に適用する値 |
分類区分の境界上の扱い |
|
[列挙型] デフォルト: 0 |
クラス分類の比較ルールを定義します。オプションは次のとおり:
|
値と一致する区分がない場合はnodata |
|
[ブール値] デフォルト: False |
どのクラスにも該当しないバンド値をnodata値とします。Falseの場合には、元の値を保持します。 |
出力のデータ型 |
|
[列挙型] デフォルト: 5 |
Defines the format of the output raster file. Options:
|
出力
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
出力ラスタ |
|
[ラスタ] |
再分類されたバンド値を持つ出力ラスタレイヤ |
Python コード
Algorithm ID: native:reclassifybylayer
import processing
processing.run("algorithm_id", {parameter_dictionary})
algorithm id は、プロセシングツールボックス内でアルゴリズムにマウスカーソルを乗せた際に表示されるIDです。 parameter dictionary は、パラメータの「名前」とその値を指定するマッピング型です。Python コンソールからプロセシングアルゴリズムを実行する方法の詳細については、 プロセシングアルゴリズムをコンソールから使う を参照してください。
25.1.11.25. 区分表(テーブル)で再分類
固定テーブルで指定された値の範囲に基づいて新しいクラス値を割り当てて、ラスタバンドを再分類します。
パラメータ
基本パラメータ
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
ラスタレイヤ |
|
[ラスタ] |
再分類するラスタレイヤ |
バンド番号 |
|
[ラスタのバンド] デフォルト: 1 |
値を再計算したいラスタのバンド |
再分類の区分表(テーブル) |
|
[テーブル] |
値を入力する3カラムのテーブル。各クラスの境界( |
出力ラスタ |
|
[ラスタ] デフォルト: |
出力ラスタレイヤを指定します。次のいずれかです:
|
詳細パラメータ
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
nodataを出力する |
|
[数値] デフォルト: -9999.0 |
nodata値に適用する値 |
分類区分の境界上の扱い |
|
[列挙型] デフォルト: 0 |
クラス分類の比較ルールを定義します。オプションは次のとおり:
|
値と一致する区分がない場合はnodata |
|
[ブール値] デフォルト: False |
どのクラスにも該当しないバンド値をnodata値とします。Falseの場合には、元の値を保持します。 |
出力のデータ型 |
|
[列挙型] デフォルト: 5 |
Defines the format of the output raster file. Options:
|
出力
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
出力ラスタ |
|
[ラスタ] |
再分類されたバンド値を持つ出力ラスタレイヤ |
Python コード
Algorithm ID: native:reclassifybytable
import processing
processing.run("algorithm_id", {parameter_dictionary})
algorithm id は、プロセシングツールボックス内でアルゴリズムにマウスカーソルを乗せた際に表示されるIDです。 parameter dictionary は、パラメータの「名前」とその値を指定するマッピング型です。Python コンソールからプロセシングアルゴリズムを実行する方法の詳細については、 プロセシングアルゴリズムをコンソールから使う を参照してください。
25.1.11.26. ラスタの範囲変更
ラスタのヒストグラム(ピクセル値)の形状(分布)は保ったまま、ラスタレイヤを再スケーリングして新しい値の範囲に変更します。入力値は、ソースラスタのピクセル最小値・最大値から出力結果のピクセル最小・最大範囲へと線形補間でマッピングされます。
デフォルトでは、このアルゴリズムは元のnodata値をそのまま維持しますが、この動作を上書きするオプションがあります。
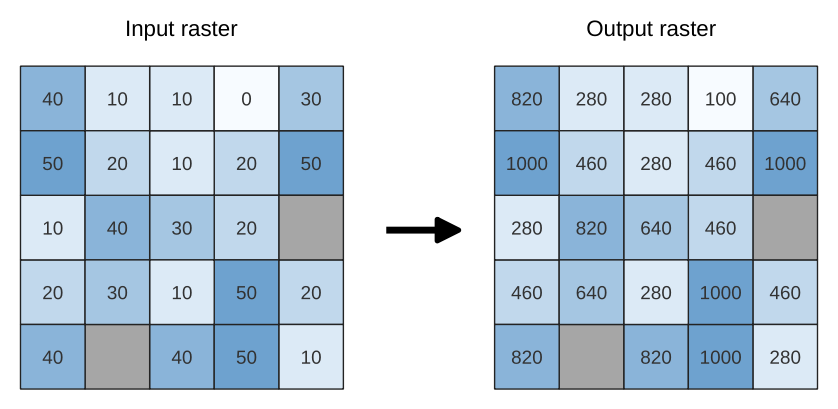
図 25.18 ラスタレイヤの値の範囲を [0 - 50] から [100 - 1000] へと再スケーリング
パラメータ
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
入力ラスタ |
|
[ラスタ] |
値の範囲を変更するラスタレイヤ |
バンド番号 |
|
[ラスタのバンド] デフォルト:入力レイヤの1番目のバンド |
ラスタがマルチバンドの場合には、バンドを選択してください。 |
最小値 |
|
[数値] デフォルト値: 0.0 |
範囲変更後のレイヤのピクセル最小値 |
最大値 |
|
[数値] デフォルト値: 255.0 |
範囲変更後のレイヤのピクセル最大値 |
nodata値 オプション |
|
[数値] デフォルト値:未設定 |
NODATAのピクセルに割り当てる値。未設定の場合には、元のNODATA値が保持されます。 |
リスケール出力 |
|
[ラスタ] デフォルト: |
出力ラスタレイヤを指定します。次のいずれかです:
|
出力
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
リスケール出力 |
|
[ラスタ] |
範囲変更後のバンド値を持つ出力ラスタレイヤ |
Python コード
アルゴリズムID: native:rescaleraster
import processing
processing.run("algorithm_id", {parameter_dictionary})
algorithm id は、プロセシングツールボックス内でアルゴリズムにマウスカーソルを乗せた際に表示されるIDです。 parameter dictionary は、パラメータの「名前」とその値を指定するマッピング型です。Python コンソールからプロセシングアルゴリズムを実行する方法の詳細については、 プロセシングアルゴリズムをコンソールから使う を参照してください。
25.1.11.27. ラスタを丸める
ラスタデータセットのセル値を指定した小数点桁数で丸めます。
小数点以下とする代わりに、負の小数点以下桁数を使用して、値を基数n の累乗に丸めることもできます。例えば、基数n が10 で小数点以下の桁数が-1 の場合、このアルゴリズムはセルの値を10 の倍数に丸め、-2 の場合は100 の倍数に丸めるといった具合です。任意の基数を選択しても、このアルゴリズムは同じ乗法の原理を適用します。セル値を基数n の倍数に丸めることで、ラスタレイヤの値を簡略化することができます。
このアルゴリズムは、入力ラスタのデータ型を維持します。このため、byte型や整数型のラスタは基数nの倍数に丸めることしかできません。基数nの倍数に丸められない場合には警告が発生し、byte型や整数型のラスタとして、入力ラスタのコピーが返ります。
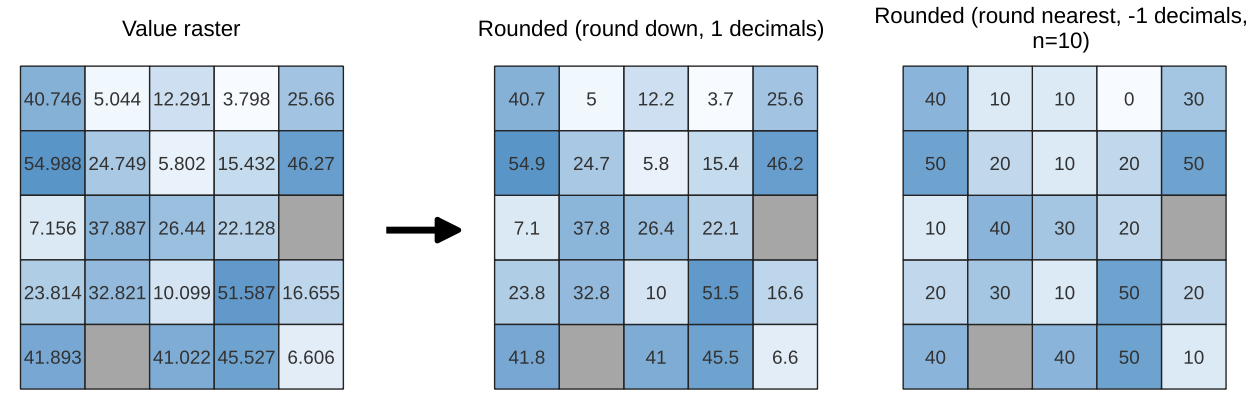
図 25.19 ラスタの値の丸め
パラメータ
基本パラメータ
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
入力ラスタ |
|
[ラスタ] |
処理するラスタ |
バンド番号 |
|
[数値] デフォルト: 1 |
ラスタのバンド番号 |
丸める方向 |
|
[リスト] デフォルト: 1 |
値を丸める方法。オプションは次のとおり:
|
小数点以下の桁数 |
|
[数値] デフォルト: 2 |
丸める小数点以下の桁数。負の値を使用すると、セルの値を基数nの桁数で丸める |
出力レイヤ |
|
[ラスタ] デフォルト: |
出力ファイルを指定します。次のいずれかです:
|
詳細パラメータ
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
基数 |
|
[数値] デフォルト: 10 |
|
出力
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
出力レイヤ |
|
[ラスタ] |
選択したバンドの値が丸められた出力ラスタレイヤ |
Python コード
アルゴリズムID: native:roundrastervalues
import processing
processing.run("algorithm_id", {parameter_dictionary})
algorithm id は、プロセシングツールボックス内でアルゴリズムにマウスカーソルを乗せた際に表示されるIDです。 parameter dictionary は、パラメータの「名前」とその値を指定するマッピング型です。Python コンソールからプロセシングアルゴリズムを実行する方法の詳細については、 プロセシングアルゴリズムをコンソールから使う を参照してください。
25.1.11.28. ベクタレイヤにラスタ値を付加
ポイントの位置におけるラスタ値を抽出します。ラスタレイヤがマルチバンドの場合には、各バンドの値がサンプリングされます。
結果レイヤの属性テーブルには、ラスタレイヤのバンド数分の新しい列が追加されます。
パラメータ
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
入力レイヤ |
|
[ベクタ:ポイント] |
サンプリングに使用するポイントベクタレイヤ |
Raster Layer |
|
[ラスタ] |
与えられたポイント位置でサンプリングされるラスタレイヤ |
ラスタ値を収納するカラム名の接頭辞 |
|
[文字列] Default: 'SAMPLE_' |
追加されるカラム名の接頭辞 |
Sampled オプション |
|
[ベクタ:ポイント] デフォルト: |
サンプリングされた値の出力レイヤを指定します。次のいずれかです:
ここでファイルの文字コードを変更することもできます。 |
出力
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
Sampled |
|
[ベクタ:ポイント] |
サンプリングされた値の出力レイヤ |
Python コード
Algorithm ID: native:rastersampling
import processing
processing.run("algorithm_id", {parameter_dictionary})
algorithm id は、プロセシングツールボックス内でアルゴリズムにマウスカーソルを乗せた際に表示されるIDです。 parameter dictionary は、パラメータの「名前」とその値を指定するマッピング型です。Python コンソールからプロセシングアルゴリズムを実行する方法の詳細については、 プロセシングアルゴリズムをコンソールから使う を参照してください。
25.1.11.29. ゾーンヒストグラム
ポリゴン地物内に含まれるラスタレイヤの各ユニーク値の個数を表すフィールドを追加します。
出力レイヤの属性テーブルには、ポリゴンと交差するラスタレイヤのユニーク値の種類数分のフィールドが追加されます。
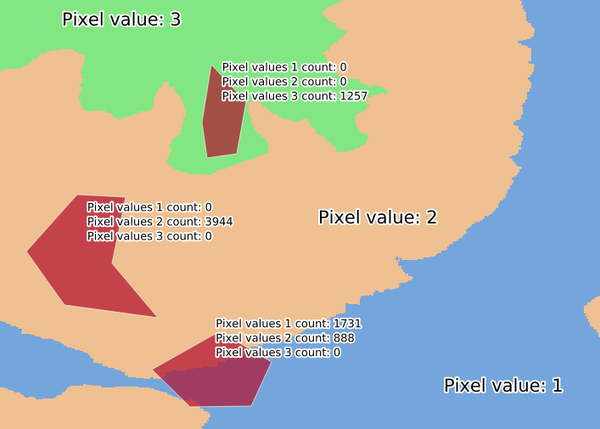
図 25.20 ラスタレイヤのヒストグラムの例
パラメータ
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
ラスタレイヤ |
|
[ラスタ] |
入力ラスタレイヤ |
バンド番号 |
|
[ラスタのバンド] デフォルト:入力レイヤの1番目のバンド |
ラスタがマルチバンドの場合には、バンドを選択してください。 |
ゾーンのベクタレイヤ |
|
[ベクタ:ポリゴン] |
ゾーンを定義するベクタポリゴンレイヤ |
ラスタ値を収納するカラム名の接頭辞 |
オプション |
[文字列] デフォルト: 'HISTO_' |
出力カラム名の接頭辞 |
出力レイヤ |
|
[ベクタ:ポリゴン] デフォルト: |
出力ベクタポリゴンレイヤを指定します。次のいずれかです:
ここでファイルの文字コードを変更することもできます。 |
出力
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
出力レイヤ |
|
[ベクタ:ポリゴン] |
出力ベクタポリゴンレイヤ |
Python コード
Algorithm ID: native:zonalhistogram
import processing
processing.run("algorithm_id", {parameter_dictionary})
algorithm id は、プロセシングツールボックス内でアルゴリズムにマウスカーソルを乗せた際に表示されるIDです。 parameter dictionary は、パラメータの「名前」とその値を指定するマッピング型です。Python コンソールからプロセシングアルゴリズムを実行する方法の詳細については、 プロセシングアルゴリズムをコンソールから使う を参照してください。
25.1.11.30. ゾーン統計量(ベクタ)
ラスタレイヤの統計量を、重なっているポリゴンベクタレイヤの地物ごとに計算します。
パラメータ
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
入力レイヤ |
|
[ベクタ:ポリゴン] |
ゾーンを含むベクタポリゴンレイヤ |
ラスタレイヤ |
|
[ラスタ] |
入力ラスタレイヤ |
対象バンド |
|
[ラスタのバンド] デフォルト:入力レイヤの1番目のバンド |
ラスタがマルチバンドの場合には、統計量を計算したいバンドを選択してください。 |
ラスタ値を収納するカラム名の接頭辞 |
|
[文字列] デフォルト: '_' |
出力カラム名の接頭辞 |
計算する統計量 |
|
[列挙型] [リスト] デフォルト: [0,1,2] |
出力する統計演算のリスト。オプションは以下のとおり:
|
Zonal Statistics |
|
[ベクタ:ポリゴン] デフォルト: |
出力ベクタポリゴンレイヤを指定します。次のいずれかです:
ここでファイルの文字コードを変更することもできます。 |
出力
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
Zonal Statistics |
|
[ベクタ:ポリゴン] |
統計量が追加されたゾーンのベクタレイヤ |
Python コード
Algorithm ID: native:zonalstatisticsfb
import processing
processing.run("algorithm_id", {parameter_dictionary})
algorithm id は、プロセシングツールボックス内でアルゴリズムにマウスカーソルを乗せた際に表示されるIDです。 parameter dictionary は、パラメータの「名前」とその値を指定するマッピング型です。Python コンソールからプロセシングアルゴリズムを実行する方法の詳細については、 プロセシングアルゴリズムをコンソールから使う を参照してください。