25.1.11. Análise Raster
25.1.11.1. Porcentagem da pilha de células em relação ao valor
Calculates the cell-wise percentrank value of a stack of rasters based on a single input value and writes them to an output raster.
At each cell location, the specified value is ranked among the respective values in the stack of all overlaid and sorted cell values from the input rasters. For values outside of the stack value distribution, the algorithm returns NoData because the value cannot be ranked among the cell values.
Há dois métodos para o cálculo do percentil:
Interpolação linear inclusiva (PERCENTRANK.INC)
Interpolação linear exclusiva (PERCENTRANK.EXC)
O método de interpolação linear retorna a porcentagem única para valores diferentes. Ambos os métodos de interpolação seguem seus métodos equivalentes implementados pelo LibreOffice ou pelo Microsoft Excel.
The output raster’s extent and resolution is defined by a reference raster.
Input raster layers that do not match the cell size of the reference
raster layer will be resampled using nearest neighbor resampling.
NoData values in any of the input layers will result in a NoData cell output
if the “Ignore NoData values” parameter is not set.
The output raster data type will always be Float32.
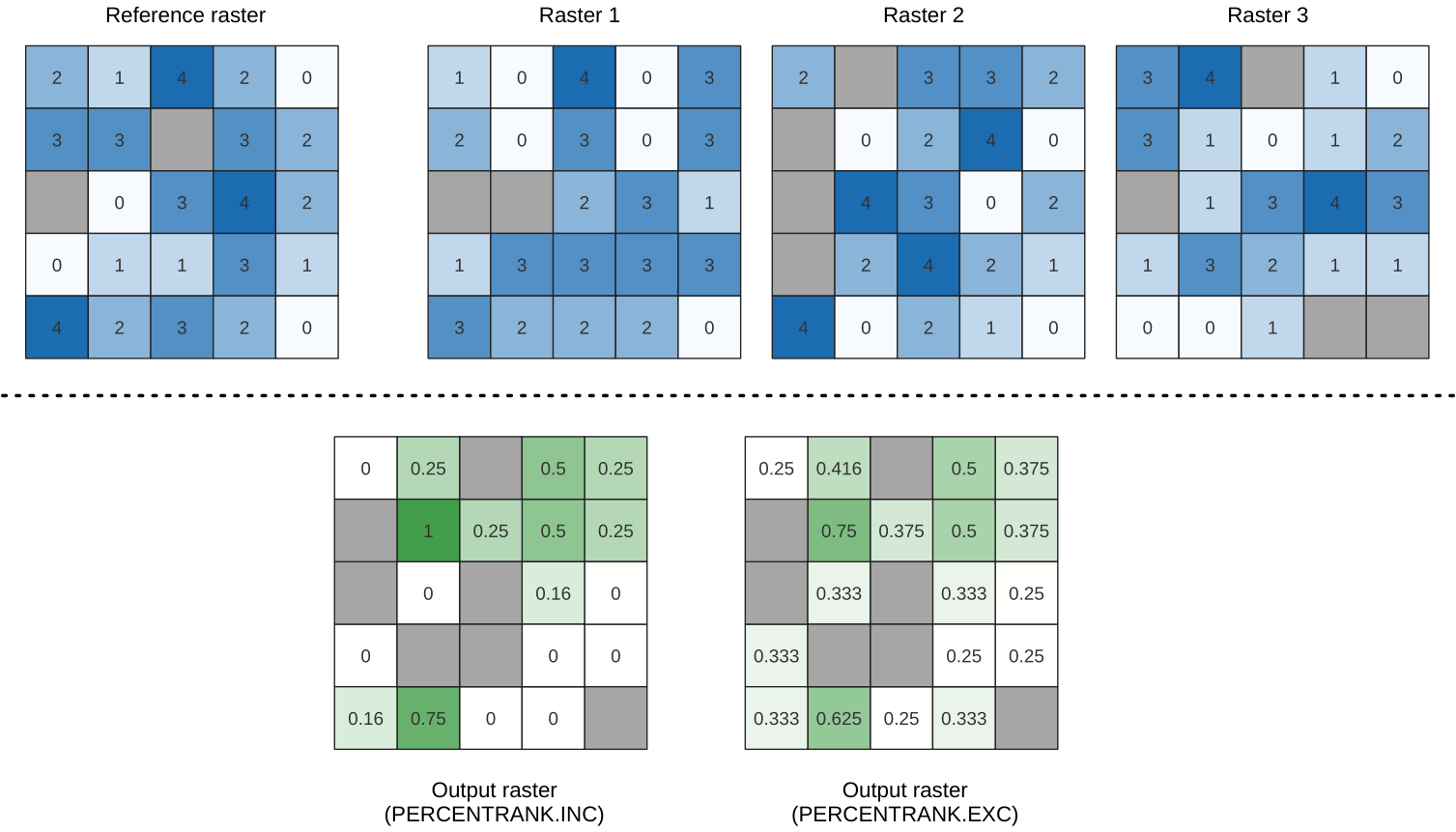
Fig. 25.10 Percent ranking Value = 1. NoData cells (grey) are ignored.
Parâmetros
Parâmetros básicos
Etiqueta |
Nome |
Tipo |
Descrição |
|---|---|---|---|
Camadas de entrada |
|
[raster] [lista] |
Raster layers to evaluate. If multiband rasters are used in the data raster stack, the algorithm will always perform the analysis on the first band of the rasters |
Método |
|
[enumeração] Padrão: 0 |
Método para cálculo de percentil:
|
Valor |
|
[número] Padrão: 10.0 |
Value to rank among the respective values in the stack of all overlaid and sorted cell values from the input rasters |
Ignorar valores sem dados |
|
[boleano] Padrão: Verdadeiro |
If unchecked, any NoData cells in the input layers will result in a NoData cell in the output raster |
Camada de referência |
“CAMADA_REFERÊNCIA” |
[raster] |
A camada de referência para a criação da camada de saída (extensão, SRC, dimensões dos pixels) |
Camada de saída |
|
[o mesmo que entrada] Padrão: |
Especificação do raster de saída. Um de:
|
Parâmetros avançados
Etiqueta |
Nome |
Tipo |
Descrição |
|---|---|---|---|
Saída de valores ‘sem dados’ |
|
[número] Padrão: -9999.0 |
Valor a ser usado para ‘sem dados’ na camada de saída |
Saídas
Etiqueta |
Nome |
Tipo |
Descrição |
|---|---|---|---|
Camada de saída |
|
[raster] |
Camada raster de saída contendo o resultado |
Identificador da autoridade SRC |
|
[string] |
O sistema de referência de coordenadas da camada raster de saída |
Extensão |
`` EXTENSÃO`` |
[string] |
A extensão espacial da camada raster de saída |
Largura em pixels |
|
[inteiro] |
O número de colunas na camada de saída raster |
Altura em pixels |
|
[inteiro] |
O número de linhas na camada de saída raster |
Contagem total de pixels |
|
[inteiro] |
A contagem de pixels na camada de saída raster |
Código Python
Algorithm ID: native:cellstackpercentrankfromvalue
import processing
processing.run("algorithm_id", {parameter_dictionary})
The algorithm id is displayed when you hover over the algorithm in the Processing Toolbox. The parameter dictionary provides the parameter NAMEs and values. See Usando os algoritmos do processamento a partir do Terminal Python. for details on how to run processing algorithms from the Python console.
25.1.11.2. Percentil de pilha celular
Calculates the cell-wise percentile value of a stack of rasters and writes the results to an output raster. The percentile to return is determined by the percentile input value (ranges between 0 and 1). At each cell location, the specified percentile is obtained using the respective value from the stack of all overlaid and sorted cell values of the input rasters.
Há três métodos para o cálculo do percentil:
Classificação mais próxima: retorna o valor mais próximo do percentil especificado
Interpolação linear inclusiva (PERCENTRANK.INC)
Interpolação linear exclusiva (PERCENTRANK.EXC)
Os métodos de interpolação linear retornam os valores únicos para diferentes percentis. Ambos os métodos de interpolação seguem seus métodos de contrapartida implementados pelo LibreOffice ou pelo Microsoft Excel.
The output raster’s extent and resolution is defined by a reference raster.
Input raster layers that do not match the cell size of the reference
raster layer will be resampled using nearest neighbor resampling.
NoData values in any of the input layers will result in a NoData cell output
if the “Ignore NoData values” parameter is not set.
The output raster data type will always be Float32.
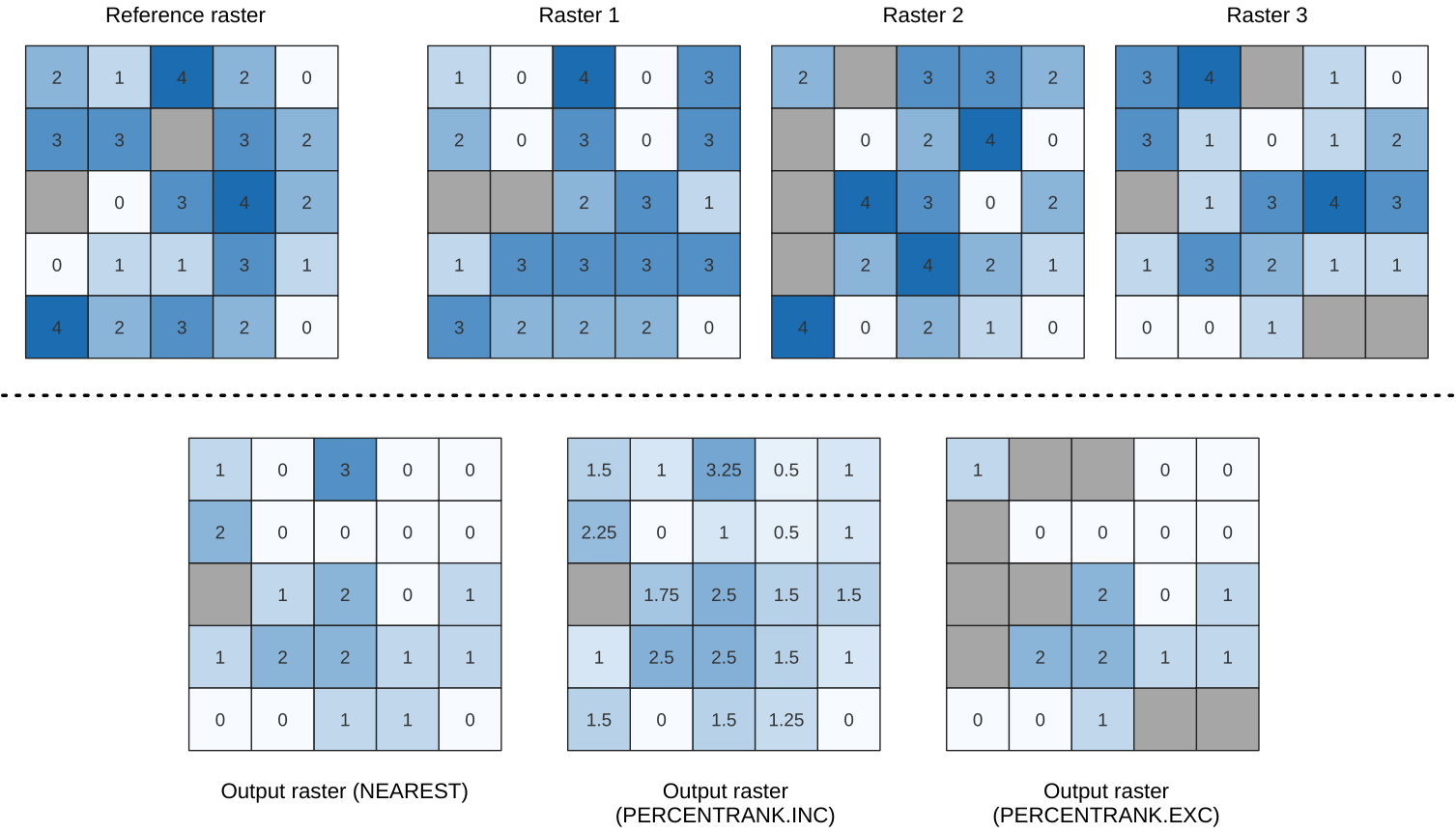
Fig. 25.11 Percentil = 0,25. As células “SemDado” (cinza) são ignoradas.
Parâmetros
Parâmetros básicos
Etiqueta |
Nome |
Tipo |
Descrição |
|---|---|---|---|
Camadas de entrada |
|
[raster] [lista] |
Raster layers to evaluate. If multiband rasters are used in the data raster stack, the algorithm will always perform the analysis on the first band of the rasters |
Método |
|
[enumeração] Padrão: 0 |
Método para cálculo de percentil:
|
Percentil |
|
[número] Padrão: 0,25 |
Value to rank among the respective values in the stack of all overlaid and sorted cell values from the input rasters. Between 0 and 1. |
Ignorar valores sem dados |
|
[boleano] Padrão: Verdadeiro |
If unchecked, any NoData cells in the input layers will result in a NoData cell in the output raster |
Camada de referência |
“CAMADA_REFERÊNCIA” |
[raster] |
A camada de referência para a criação da camada de saída (extensão, SRC, dimensões dos pixels) |
Camada de saída |
|
[o mesmo que entrada] Padrão: |
Especificação do raster de saída. Um de:
|
Parâmetros avançados
Etiqueta |
Nome |
Tipo |
Descrição |
|---|---|---|---|
Saída de valores ‘sem dados’ |
|
[número] Padrão: -9999.0 |
Valor a ser usado para ‘sem dados’ na camada de saída |
Saídas
Etiqueta |
Nome |
Tipo |
Descrição |
|---|---|---|---|
Camada de saída |
|
[raster] |
Camada raster de saída contendo o resultado |
Identificador da autoridade SRC |
|
[string] |
O sistema de referência de coordenadas da camada raster de saída |
Extensão |
`` EXTENSÃO`` |
[string] |
A extensão espacial da camada raster de saída |
Largura em pixels |
|
[inteiro] |
O número de colunas na camada de saída raster |
Altura em pixels |
|
[inteiro] |
O número de linhas na camada de saída raster |
Contagem total de pixels |
|
[inteiro] |
A contagem de pixels na camada de saída raster |
Código Python
Algorithm ID: native:cellstackpercentile
import processing
processing.run("algorithm_id", {parameter_dictionary})
The algorithm id is displayed when you hover over the algorithm in the Processing Toolbox. The parameter dictionary provides the parameter NAMEs and values. See Usando os algoritmos do processamento a partir do Terminal Python. for details on how to run processing algorithms from the Python console.
25.1.11.3. Cell stack percentrank from raster layer
Calculates the cell-wise percentrank value of a stack of rasters based on an input value raster and writes them to an output raster.
At each cell location, the current value of the value raster is ranked among the respective values in the stack of all overlaid and sorted cell values of the input rasters. For values outside of the the stack value distribution, the algorithm returns NoData because the value cannot be ranked among the cell values.
Há dois métodos para o cálculo do percentil:
Interpolação linear inclusiva (PERCENTRANK.INC)
Interpolação linear exclusiva (PERCENTRANK.EXC)
Os métodos de interpolação linear retornam os valores únicos para diferentes percentis. Ambos os métodos de interpolação seguem seus métodos de contrapartida implementados pelo LibreOffice ou pelo Microsoft Excel.
The output raster’s extent and resolution is defined by a reference raster.
Input raster layers that do not match the cell size of the reference
raster layer will be resampled using nearest neighbor resampling.
NoData values in any of the input layers will result in a NoData cell output
if the “Ignore NoData values” parameter is not set.
The output raster data type will always be Float32.
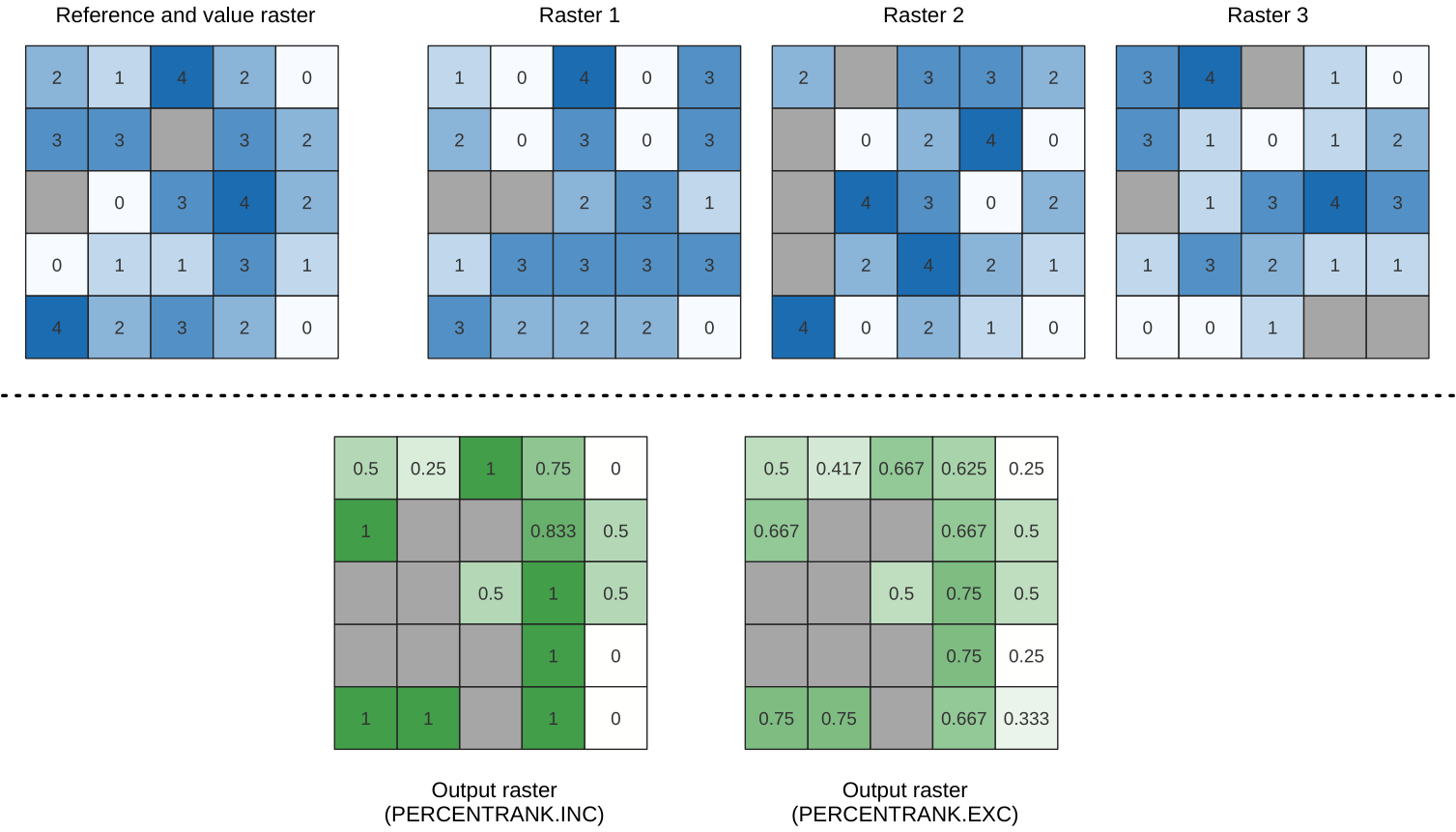
Fig. 25.12 Ranking the value raster layer cells. NoData cells (grey) are ignored.
Parâmetros
Parâmetros básicos
Etiqueta |
Nome |
Tipo |
Descrição |
|---|---|---|---|
Camadas de entrada |
|
[raster] [lista] |
Raster layers to evaluate. If multiband rasters are used in the data raster stack, the algorithm will always perform the analysis on the first band of the rasters |
Valor da camada raster |
“VALOR DE ENTRADA RASTER” |
[raster] |
The layer to rank the values among the stack of all overlaid layers |
Faixa de valor raster |
‘’FAIXA DE VALOR RASTER’’ |
[inteiro] Padrão: 1 |
Banda da “camada de valor raster” para comparar com |
Método |
|
[enumeração] Padrão: 0 |
Método para cálculo de percentil:
|
Ignorar valores sem dados |
|
[boleano] Padrão: Verdadeiro |
If unchecked, any NoData cells in the input layers will result in a NoData cell in the output raster |
Camada de referência |
“CAMADA_REFERÊNCIA” |
[raster] |
A camada de referência para a criação da camada de saída (extensão, SRC, dimensões dos pixels) |
Camada de saída |
|
[o mesmo que entrada] Padrão: |
Especificação do raster de saída. Um de:
|
Parâmetros avançados
Etiqueta |
Nome |
Tipo |
Descrição |
|---|---|---|---|
Saída de valores ‘sem dados’ |
|
[número] Padrão: -9999.0 |
Valor a ser usado para ‘sem dados’ na camada de saída |
Saídas
Etiqueta |
Nome |
Tipo |
Descrição |
|---|---|---|---|
Camada de saída |
|
[raster] |
Camada raster de saída contendo o resultado |
Identificador da autoridade SRC |
|
[string] |
O sistema de referência de coordenadas da camada raster de saída |
Extensão |
`` EXTENSÃO`` |
[string] |
A extensão espacial da camada raster de saída |
Largura em pixels |
|
[inteiro] |
O número de colunas na camada de saída raster |
Altura em pixels |
|
[inteiro] |
O número de linhas na camada de saída raster |
Contagem total de pixels |
|
[inteiro] |
A contagem de pixels na camada de saída raster |
Código Python
Algorithm ID: native:cellstackpercentrankfromrasterlayer
import processing
processing.run("algorithm_id", {parameter_dictionary})
The algorithm id is displayed when you hover over the algorithm in the Processing Toolbox. The parameter dictionary provides the parameter NAMEs and values. See Usando os algoritmos do processamento a partir do Terminal Python. for details on how to run processing algorithms from the Python console.
25.1.11.4. Estatísticas de células
Computes per-cell statistics based on input raster layers and for each cell writes the resulting statistics to an output raster. At each cell location, the output value is defined as a function of all overlaid cell values of the input rasters.
By default, a NoData cell in ANY of the input layers will result in a NoData cell in the output raster. If the Ignore NoData values option is checked, then NoData inputs will be ignored in the statistic calculation. This may result in NoData output for locations where all cells are NoData.
O parâmetro Camada de referência especifica uma camada raster existente a ser utilizada como referência ao criar o raster de saída. O raster de saída terá a mesma extensão, SRC, e dimensões de pixel que esta camada.
Calculation details:
Input raster layers that do not match the cell size of the reference
raster layer will be resampled using nearest neighbor resampling.
The output raster data type will be set to the most complex
data type present in the input datasets except when using the
functions Mean, Standard deviation and Variance (data type is always
Float32 or Float64 depending on input float type) or Count
and Variety (data type is always Int32).
Count: The count statistic will always result in the number of cells without NoData values at the current cell location.Mediana: Se o número de camadas de entrada for par, a mediana será calculada como a média aritmética dos dois valores centrais dos valores de entrada da célula ordenada.Minority/Majority: If no unique minority or majority could be found, the result is NoData, except all input cell values are equal.
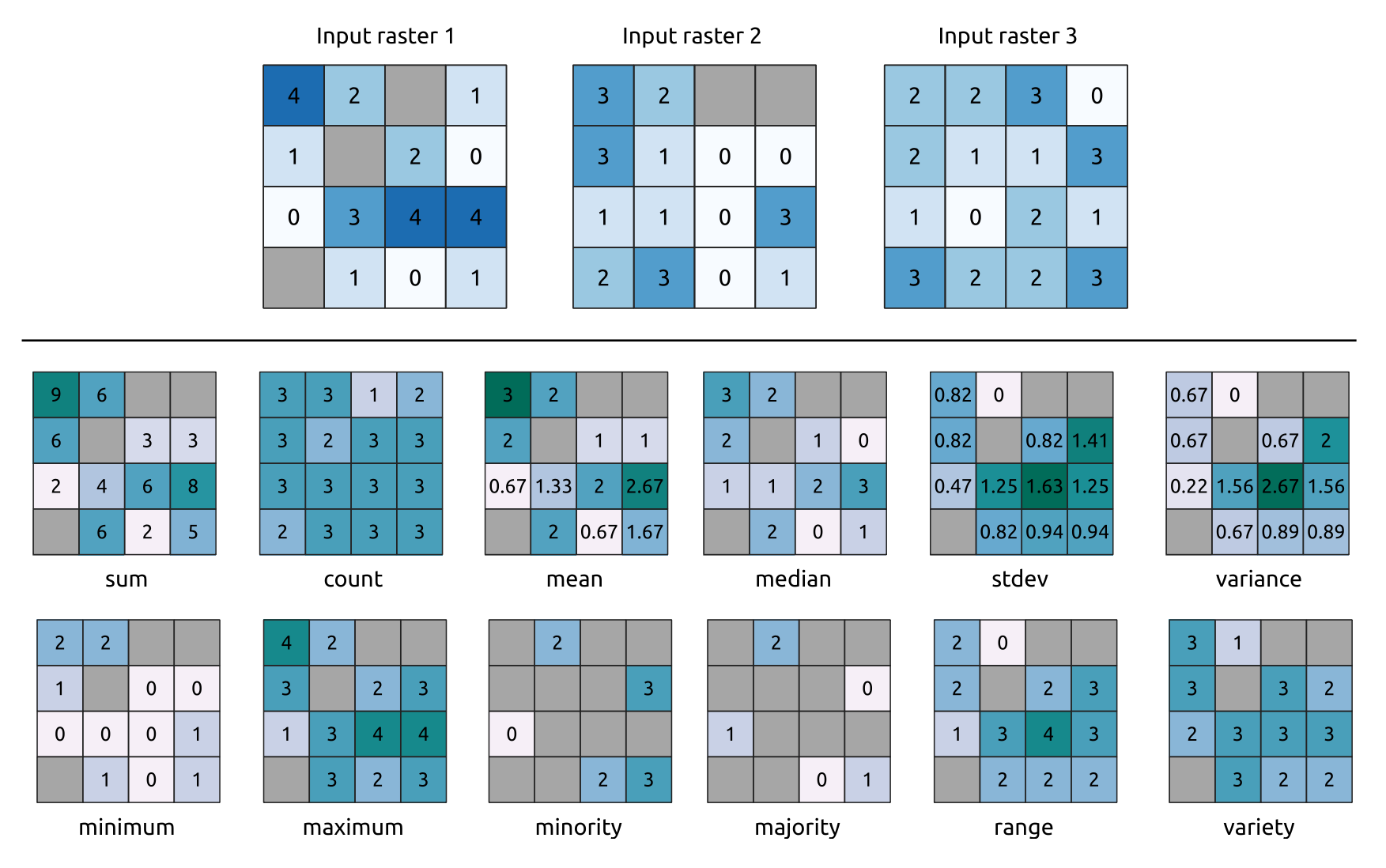
Fig. 25.13 Example with all the statistic functions. NoData cells (grey) are taken into account.
Parâmetros
Parâmetros básicos
Etiqueta |
Nome |
Tipo |
Descrição |
|---|---|---|---|
Camadas de entrada |
|
[raster] [lista] |
Camada raster de entrada |
Statistica |
|
[enumeração] Padrão: 0 |
Estatísticas disponíveis. Opções:
|
Ignorar valores sem dados |
|
[boleano] Padrão: Verdadeiro |
Calculate statistics also for all cells stacks, ignoring NoData occurrence. |
Camada de referência |
‘’Referecia da camada” |
[raster] |
A camada de referência para criar a camada de saída (extensão, SRC, dimensões de pixel) |
Camada de saída |
|
[o mesmo que entrada] Padrão: |
Especificação do raster de saída. Um de:
|
Parâmetros avançados
Etiqueta |
Nome |
Tipo |
Descrição |
|---|---|---|---|
Saída de valores ‘sem dados’ Opcional |
“SEM VALOR DE DADOS” |
[número] Padrão: -9999.0 |
Valor a ser usado para ‘sem dados’ na camada de saída |
Saídas
Etiqueta |
Nome |
Tipo |
Descrição |
|---|---|---|---|
Identificador da autoridade SRC |
|
[src] |
O sistema de referência de coordenadas da camada raster de saída |
Extensão |
`` EXTENSÃO`` |
[string] |
A extensão espacial da camada raster de saída |
Altura em pixels |
|
[inteiro] |
O número de linhas na camada de saída raster |
Matriz de saída |
|
[raster] |
Camada raster de saída contendo o resultado |
Contagem total de pixels |
|
[inteiro] |
A contagem de pixels na camada de saída raster |
Largura em pixels |
|
[inteiro] |
O número de colunas na camada de saída raster |
Código Python
Algorithm ID: native:cellstatistics
import processing
processing.run("algorithm_id", {parameter_dictionary})
The algorithm id is displayed when you hover over the algorithm in the Processing Toolbox. The parameter dictionary provides the parameter NAMEs and values. See Usando os algoritmos do processamento a partir do Terminal Python. for details on how to run processing algorithms from the Python console.
25.1.11.5. Igual a frequência
Evaluates on a cell-by-cell basis the frequency (number of times) the values
of an input stack of rasters are equal to the value of a value layer.
The output raster extent and resolution are defined by the input raster layer
and is always of Int32 type.
If multiband rasters are used in the data raster stack, the algorithm will always perform the analysis on the first band of the rasters - use GDAL to use other bands in the analysis. The output NoData value can be set manually.
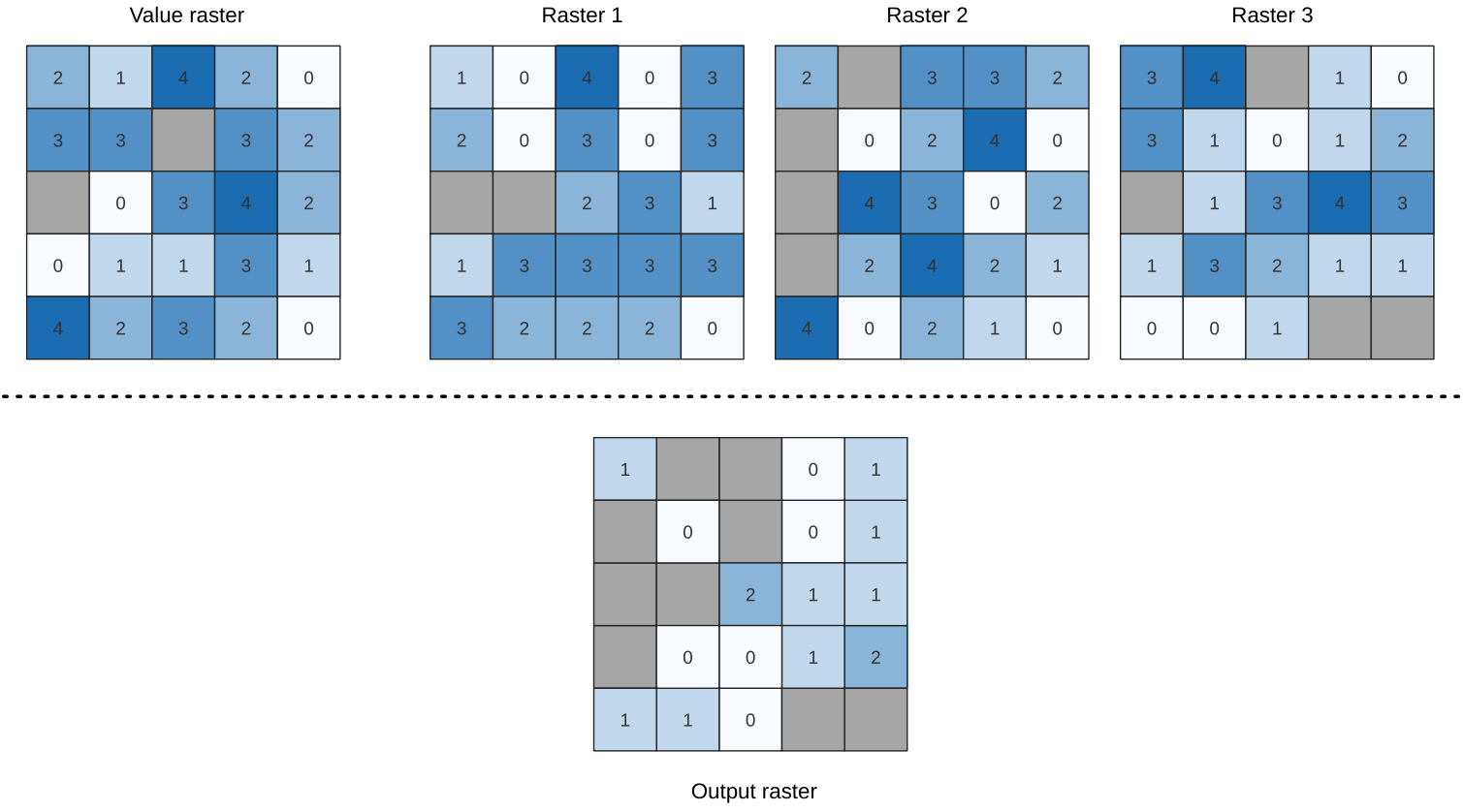
Fig. 25.14 Para cada célula na matriz de saída, o valor representa o número de vezes que as células correspondentes na lista de matrizes são iguais à matriz de valor. As células SemDados (cinza) são levadas em consideração.
Ver também
Parâmetros
Parâmetros básicos
Etiqueta |
Nome |
Tipo |
Descrição |
|---|---|---|---|
Valor de entrada raster |
“VALOR DE ENTRADA RASTER” |
[raster] |
A camada de valor de entrada serve como camada de referência para as camadas de amostra |
Faixa de valor raster |
|
[banda raster] Padrão: A primeira faixa da camada raster |
Selecione a faixa que você deseja usar como amostra |
Camadas de entrada raster |
‘’INSERIR RASTERS’’ |
[raster] [lista] |
Raster layers to evaluate. If multiband rasters are used in the data raster stack, the algorithm will always perform the analysis on the first band of the rasters |
Ignorar valores sem dados |
|
[boleano] Padrão: Falso |
If unchecked, any NoData cells in the value raster or the data layer stack will result in a NoData cell in the output raster |
Camada de saída |
|
[o mesmo que entrada] Padrão: |
Especificação do raster de saída. Um de:
|
Parâmetros avançados
Etiqueta |
Nome |
Tipo |
Descrição |
|---|---|---|---|
Saída de valores ‘sem dados’ Opcional |
“SEM VALOR DE DADOS” |
[número] Padrão: -9999.0 |
Valor a ser usado para ‘sem dados’ na camada de saída |
Saídas
Etiqueta |
Nome |
Tipo |
Descrição |
|---|---|---|---|
Camada de saída |
|
[raster] |
Camada raster de saída contendo o resultado |
Identificador da autoridade SRC |
|
[string] |
O sistema de referência de coordenadas da camada raster de saída |
Extensão |
`` EXTENSÃO`` |
[string] |
A extensão espacial da camada raster de saída |
Contagem de células com ocorrências de valor igual |
“CONTAGEM DE LOCALIZAÇÕES ENCONTRADAS’’ |
[número] |
|
Altura em pixels |
|
[número] |
O número de linhas na camada de saída raster |
Contagem total de pixels |
|
[inteiro] |
A contagem de pixels na camada de saída raster |
Mean frequency at valid cell locations |
|
[número] |
|
Contagem de ocorrências de valor |
‘’CONTAGEM DE OCORRÊNCIAS’’ |
[número] |
|
Largura em pixels |
|
[inteiro] |
O número de colunas na camada de saída raster |
Código Python
ID do algoritmo: native:equaltofrequency
import processing
processing.run("algorithm_id", {parameter_dictionary})
The algorithm id is displayed when you hover over the algorithm in the Processing Toolbox. The parameter dictionary provides the parameter NAMEs and values. See Usando os algoritmos do processamento a partir do Terminal Python. for details on how to run processing algorithms from the Python console.
25.1.11.6. Fuzzify raster (gaussian membership)
Transforms an input raster to a fuzzified raster by assigning a
membership value to each pixel, using a Gaussian membership function.
Membership values range from 0 to 1.
In the fuzzified raster, a value of 0 implies no membership of the
defined fuzzy set, whereas a value of 1 means full membership.
The gaussian membership function is defined as 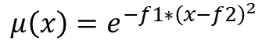 ,
where f1 is the spread and f2 the midpoint.
,
where f1 is the spread and f2 the midpoint.
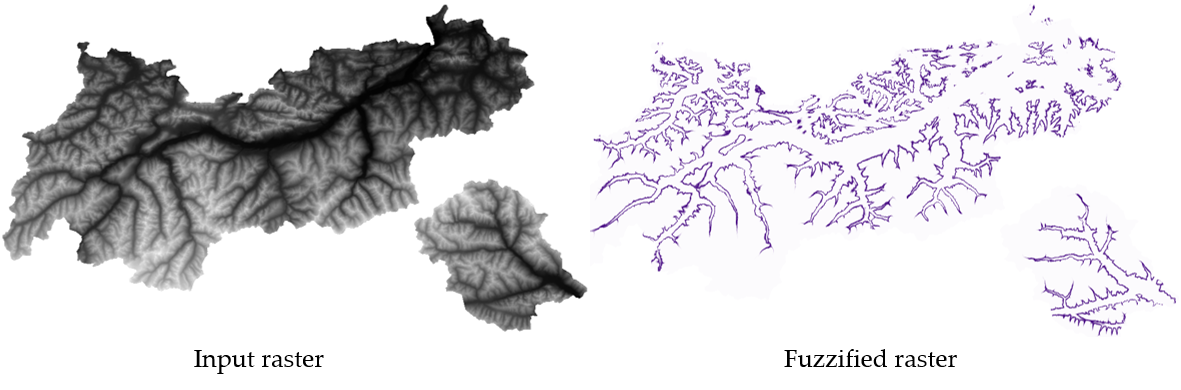
Fig. 25.15 Fuzzify raster example. Input raster source: Land Tirol - data.tirol.gv.at.
Ver também
Fuzzify raster (large membership) Fuzzify raster (linear membership), Fuzzify raster (near membership), Fuzzify raster (power membership), Fuzzify raster (small membership)
Parâmetros
Etiqueta |
Nome |
Tipo |
Descrição |
|---|---|---|---|
Entrada raster |
|
[raster] |
Camada raster de entrada |
Número da banda |
|
[banda raster] Padrão: A primeira faixa da camada raster |
If the raster is multiband, choose the band that you want to fuzzify. |
Função ponto médio |
|
[número] Padrão: 10 |
Ponto médio da função gaussiana |
Função de espalhamento |
|
[número] Padrão: 0,01 |
Difusão da função gaussiana |
Fuzzified raster |
|
[o mesmo que entrada] Padrão: |
Especificação do raster de saída. Um de:
|
Saídas
Etiqueta |
Nome |
Tipo |
Descrição |
|---|---|---|---|
Fuzzified raster |
|
[o mesmo que entrada] |
Camada raster de saída contendo o resultado |
Identificador da autoridade SRC |
|
[src] |
O sistema de referência de coordenadas da camada raster de saída |
Extensão |
`` EXTENSÃO`` |
[string] |
A extensão espacial da camada raster de saída |
Largura em pixels |
|
[inteiro] |
O número de colunas na camada de saída raster |
Altura em pixels |
|
[inteiro] |
O número de linhas na camada de saída raster |
Contagem total de pixels |
|
[inteiro] |
A contagem de pixels na camada de saída raster |
Código Python
Algorithm ID: native:fuzzifyrastergaussianmembership
import processing
processing.run("algorithm_id", {parameter_dictionary})
The algorithm id is displayed when you hover over the algorithm in the Processing Toolbox. The parameter dictionary provides the parameter NAMEs and values. See Usando os algoritmos do processamento a partir do Terminal Python. for details on how to run processing algorithms from the Python console.
25.1.11.7. Fuzzify raster (large membership)
Transforms an input raster to a fuzzified raster by assigning a
membership value to each pixel, using a Large membership function.
Membership values range from 0 to 1.
In the fuzzified raster, a value of 0 implies no membership of the
defined fuzzy set, whereas a value of 1 means full membership.
The large membership function is defined as 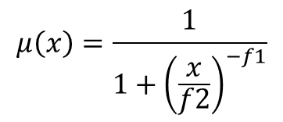 ,
where f1 is the spread and f2 the midpoint.
,
where f1 is the spread and f2 the midpoint.
Ver também
Fuzzify raster (gaussian membership), Fuzzify raster (linear membership), Fuzzify raster (near membership), Fuzzify raster (power membership), Fuzzify raster (small membership)
Parâmetros
Etiqueta |
Nome |
Tipo |
Descrição |
|---|---|---|---|
Entrada raster |
|
[raster] |
Camada raster de entrada |
Número da banda |
|
[banda raster] Padrão: A primeira faixa da camada raster |
If the raster is multiband, choose the band that you want to fuzzify. |
Função ponto médio |
|
[número] Padrão: 50 |
Midpoint of the large function |
Função de espalhamento |
|
[número] Padrão: 5 |
Espalhamento da grande função |
Fuzzified raster |
|
[o mesmo que entrada] Padrão: |
Especificação do raster de saída. Um de:
|
Saídas
Etiqueta |
Nome |
Tipo |
Descrição |
|---|---|---|---|
Fuzzified raster |
|
[o mesmo que entrada] |
Camada raster de saída contendo o resultado |
Identificador da autoridade SRC |
|
[src] |
O sistema de referência de coordenadas da camada raster de saída |
Extensão |
`` EXTENSÃO`` |
[string] |
A extensão espacial da camada raster de saída |
Largura em pixels |
|
[inteiro] |
O número de colunas na camada de saída raster |
Altura em pixels |
|
[inteiro] |
O número de linhas na camada de saída raster |
Contagem total de pixels |
|
[inteiro] |
A contagem de pixels na camada de saída raster |
Código Python
Algorithm ID: native:fuzzifyrasterlargemembership
import processing
processing.run("algorithm_id", {parameter_dictionary})
The algorithm id is displayed when you hover over the algorithm in the Processing Toolbox. The parameter dictionary provides the parameter NAMEs and values. See Usando os algoritmos do processamento a partir do Terminal Python. for details on how to run processing algorithms from the Python console.
25.1.11.8. Fuzzify raster (linear membership)
Transforms an input raster to a fuzzified raster by assigning a
membership value to each pixel, using a Linear membership function.
Membership values range from 0 to 1. In the fuzzified raster, a value
of 0 implies no membership of the defined fuzzy set, whereas a value
of 1 means full membership.
The linear function is defined as 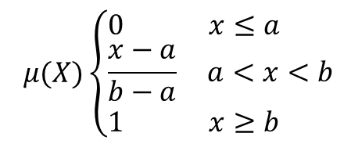 , where a
is the low bound and b the high bound. This equation assigns
membership values using a linear transformation for pixel values
between the low and high bounds.
Pixels values smaller than the low bound are given 0 membership
whereas pixel values greater than the high bound are given 1
membership.
, where a
is the low bound and b the high bound. This equation assigns
membership values using a linear transformation for pixel values
between the low and high bounds.
Pixels values smaller than the low bound are given 0 membership
whereas pixel values greater than the high bound are given 1
membership.
Ver também
Fuzzify raster (gaussian membership), Fuzzify raster (large membership), Fuzzify raster (near membership), Fuzzify raster (power membership), Fuzzify raster (small membership)
Parâmetros
Etiqueta |
Nome |
Tipo |
Descrição |
|---|---|---|---|
Entrada raster |
|
[raster] |
Camada raster de entrada |
Número da banda |
|
[banda raster] Padrão: A primeira faixa da camada raster |
If the raster is multiband, choose the band that you want to fuzzify. |
Baixo nível de adesão |
|
[número] Padrão: 0 |
Baixo limite da função linear |
High fuzzy membership bound |
|
[número] Padrão: 1 |
Alto limite da função linear |
Fuzzified raster |
|
[o mesmo que entrada] Padrão: |
Especificação do raster de saída. Um de:
|
Saídas
Etiqueta |
Nome |
Tipo |
Descrição |
|---|---|---|---|
Fuzzified raster |
|
[o mesmo que entrada] |
Camada raster de saída contendo o resultado |
Identificador da autoridade SRC |
|
[src] |
O sistema de referência de coordenadas da camada raster de saída |
Extensão |
`` EXTENSÃO`` |
[string] |
A extensão espacial da camada raster de saída |
Largura em pixels |
|
[inteiro] |
O número de colunas na camada de saída raster |
Altura em pixels |
|
[inteiro] |
O número de linhas na camada de saída raster |
Contagem total de pixels |
|
[inteiro] |
A contagem de pixels na camada de saída raster |
Código Python
Algorithm ID: native:fuzzifyrasterlinearmembership
import processing
processing.run("algorithm_id", {parameter_dictionary})
The algorithm id is displayed when you hover over the algorithm in the Processing Toolbox. The parameter dictionary provides the parameter NAMEs and values. See Usando os algoritmos do processamento a partir do Terminal Python. for details on how to run processing algorithms from the Python console.
25.1.11.9. Fuzzify raster (near membership)
Transforms an input raster to a fuzzified raster by assigning a
membership value to each pixel, using a Near membership function.
Membership values range from 0 to 1.
In the fuzzified raster, a value of 0 implies no membership of the
defined fuzzy set, whereas a value of 1 means full membership.
The near membership function is defined as 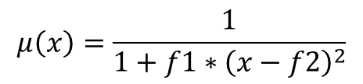 , where
f1 is the spread and f2 the midpoint.
, where
f1 is the spread and f2 the midpoint.
Ver também
Fuzzify raster (gaussian membership), Fuzzify raster (large membership), Fuzzify raster (linear membership), Fuzzify raster (power membership), Fuzzify raster (small membership)
Parâmetros
Etiqueta |
Nome |
Tipo |
Descrição |
|---|---|---|---|
Entrada raster |
|
[raster] |
Camada raster de entrada |
Número da banda |
|
[banda raster] Padrão: A primeira faixa da camada raster |
If the raster is multiband, choose the band that you want to fuzzify. |
Função ponto médio |
|
[número] Padrão: 50 |
Ponto médio da função próxima |
Função de espalhamento |
|
[número] Padrão: 0,01 |
Espalhamento da função próxima |
Fuzzified raster |
|
[o mesmo que entrada] Padrão: |
Especificação do raster de saída. Um de:
|
Saídas
Etiqueta |
Nome |
Tipo |
Descrição |
|---|---|---|---|
Fuzzified raster |
|
[o mesmo que entrada] |
Camada raster de saída contendo o resultado |
Identificador da autoridade SRC |
|
[src] |
O sistema de referência de coordenadas da camada raster de saída |
Extensão |
`` EXTENSÃO`` |
[string] |
A extensão espacial da camada raster de saída |
Largura em pixels |
|
[inteiro] |
O número de colunas na camada de saída raster |
Altura em pixels |
|
[inteiro] |
O número de linhas na camada de saída raster |
Contagem total de pixels |
|
[inteiro] |
A contagem de pixels na camada de saída raster |
Código Python
Algorithm ID: native:fuzzifyrasternearmembership
import processing
processing.run("algorithm_id", {parameter_dictionary})
The algorithm id is displayed when you hover over the algorithm in the Processing Toolbox. The parameter dictionary provides the parameter NAMEs and values. See Usando os algoritmos do processamento a partir do Terminal Python. for details on how to run processing algorithms from the Python console.
25.1.11.10. Fuzzify raster (power membership)
Transforms an input raster to a fuzzified raster by assigning a
membership value to each pixel, using a Power membership function.
Membership values range from 0 to 1.
In the fuzzified raster, a value of 0 implies no membership of the
defined fuzzy set, whereas a value of 1 means full membership.
The power function is defined as 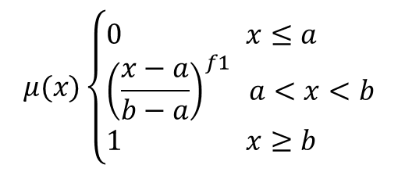 , where a is the
low bound, b is the high bound, and f1 the exponent.
This equation assigns membership values using the power transformation
for pixel values between the low and high bounds.
Pixels values smaller than the low bound are given 0 membership
whereas pixel values greater than the high bound are given 1
membership.
, where a is the
low bound, b is the high bound, and f1 the exponent.
This equation assigns membership values using the power transformation
for pixel values between the low and high bounds.
Pixels values smaller than the low bound are given 0 membership
whereas pixel values greater than the high bound are given 1
membership.
Ver também
Fuzzify raster (gaussian membership), Fuzzify raster (large membership), Fuzzify raster (linear membership), Fuzzify raster (near membership), Fuzzify raster (small membership)
Parâmetros
Etiqueta |
Nome |
Tipo |
Descrição |
|---|---|---|---|
Entrada raster |
|
[raster] |
Camada raster de entrada |
Número da banda |
|
[banda raster] Padrão: A primeira faixa da camada raster |
If the raster is multiband, choose the band that you want to fuzzify. |
Baixo nível de adesão |
|
[número] Padrão: 0 |
Low bound of the power function |
High fuzzy membership bound |
|
[número] Padrão: 1 |
High bound of the power function |
High fuzzy membership bound |
|
[número] Padrão: 2 |
Expoente da função de potência |
Fuzzified raster |
|
[o mesmo que entrada] Padrão: |
Especificação do raster de saída. Um de:
|
Saídas
Etiqueta |
Nome |
Tipo |
Descrição |
|---|---|---|---|
Fuzzified raster |
|
[o mesmo que entrada] |
Camada raster de saída contendo o resultado |
Identificador da autoridade SRC |
|
[src] |
O sistema de referência de coordenadas da camada raster de saída |
Extensão |
`` EXTENSÃO`` |
[string] |
A extensão espacial da camada raster de saída |
Largura em pixels |
|
[inteiro] |
O número de colunas na camada de saída raster |
Altura em pixels |
|
[inteiro] |
O número de linhas na camada de saída raster |
Contagem total de pixels |
|
[inteiro] |
A contagem de pixels na camada de saída raster |
Código Python
Algorithm ID: native:fuzzifyrasterpowermembership
import processing
processing.run("algorithm_id", {parameter_dictionary})
The algorithm id is displayed when you hover over the algorithm in the Processing Toolbox. The parameter dictionary provides the parameter NAMEs and values. See Usando os algoritmos do processamento a partir do Terminal Python. for details on how to run processing algorithms from the Python console.
25.1.11.11. Fuzzify raster (small membership)
Transforms an input raster to a fuzzified raster by assigning a
membership value to each pixel, using a Small membership function.
Membership values range from 0 to 1.
In the fuzzified raster, a value of 0 implies no membership of the
defined fuzzy set, whereas a value of 1 means full membership.
The small membership function is defined as 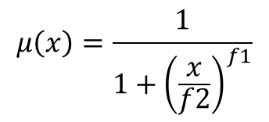 , where
f1 is the spread and f2 the midpoint.
, where
f1 is the spread and f2 the midpoint.
Ver também
Fuzzify raster (gaussian membership), Fuzzify raster (large membership) Fuzzify raster (linear membership), Fuzzify raster (near membership), Fuzzify raster (power membership)
Parâmetros
Etiqueta |
Nome |
Tipo |
Descrição |
|---|---|---|---|
Entrada raster |
|
[raster] |
Camada raster de entrada |
Número da banda |
|
[banda raster] Padrão: A primeira faixa da camada raster |
If the raster is multiband, choose the band that you want to fuzzify. |
Função ponto médio |
|
[número] Padrão: 50 |
Ponto médio da função pequena |
Função de espalhamento |
|
[número] Padrão: 5 |
Espalhamento da pequena função |
Fuzzified raster |
|
[o mesmo que entrada] Padrão: |
Especificação do raster de saída. Um de:
|
Saídas
Etiqueta |
Nome |
Tipo |
Descrição |
|---|---|---|---|
Fuzzified raster |
|
[o mesmo que entrada] |
Camada raster de saída contendo o resultado |
Identificador da autoridade SRC |
|
[src] |
O sistema de referência de coordenadas da camada raster de saída |
Extensão |
`` EXTENSÃO`` |
[string] |
A extensão espacial da camada raster de saída |
Largura em pixels |
|
[inteiro] |
O número de colunas na camada de saída raster |
Altura em pixels |
|
[inteiro] |
O número de linhas na camada de saída raster |
Contagem total de pixels |
|
[inteiro] |
A contagem de pixels na camada de saída raster |
Código Python
Algorithm ID: native:fuzzifyrastersmallmembership
import processing
processing.run("algorithm_id", {parameter_dictionary})
The algorithm id is displayed when you hover over the algorithm in the Processing Toolbox. The parameter dictionary provides the parameter NAMEs and values. See Usando os algoritmos do processamento a partir do Terminal Python. for details on how to run processing algorithms from the Python console.
25.1.11.12. Maior do que a freqüência
Evaluates on a cell-by-cell basis the frequency (number of times) the values
of an input stack of rasters are equal to the value of a value raster.
The output raster extent and resolution is defined by the input raster layer
and is always of Int32 type.
If multiband rasters are used in the data raster stack, the algorithm will always perform the analysis on the first band of the rasters - use GDAL to use other bands in the analysis. The output NoData value can be set manually.
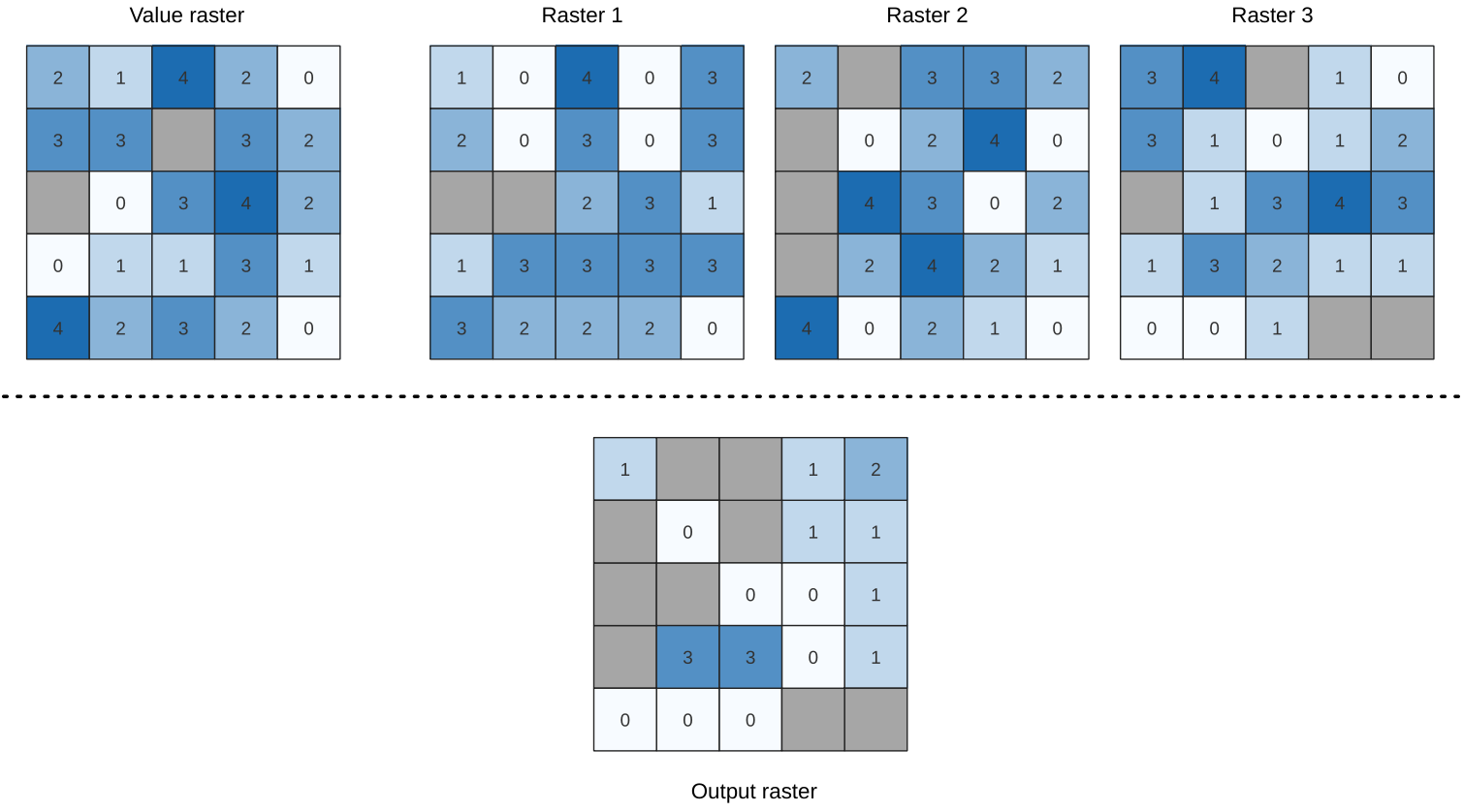
Fig. 25.16 For each cell in the output raster, the value represents the number of times
that the corresponding cells in the list of rasters are greater than the value raster.
NoData cells (grey) are taken into account.
Parâmetros
Parâmetros básicos
Etiqueta |
Nome |
Tipo |
Descrição |
|---|---|---|---|
Valor de entrada raster |
“VALOR DE ENTRADA RASTER” |
[raster] |
A camada de valor de entrada serve como camada de referência para as camadas de amostra |
Faixa de valor raster |
|
[banda raster] Padrão: A primeira faixa da camada raster |
Selecione a faixa que você deseja usar como amostra |
Camadas de entrada raster |
‘’INSERIR RASTERS’’ |
[raster] [lista] |
Raster layers to evaluate. If multiband rasters are used in the data raster stack, the algorithm will always perform the analysis on the first band of the rasters |
Ignorar valores sem dados |
|
[boleano] Padrão: Falso |
If unchecked, any NoData cells in the value raster or the data layer stack will result in a NoData cell in the output raster |
Camada de saída |
|
[o mesmo que entrada] Padrão: |
Especificação do raster de saída. Um de:
|
Parâmetros avançados
Etiqueta |
Nome |
Tipo |
Descrição |
|---|---|---|---|
Saída de valores ‘sem dados’ Opcional |
“SEM VALOR DE DADOS” |
[número] Padrão: -9999.0 |
Valor a ser usado para ‘sem dados’ na camada de saída |
Saídas
Etiqueta |
Nome |
Tipo |
Descrição |
|---|---|---|---|
Camada de saída |
|
[raster] |
Camada raster de saída contendo o resultado |
Identificador da autoridade SRC |
|
[string] |
O sistema de referência de coordenadas da camada raster de saída |
Extensão |
`` EXTENSÃO`` |
[string] |
A extensão espacial da camada raster de saída |
Contagem de células com ocorrências de valor igual |
“CONTAGEM DE LOCALIZAÇÕES ENCONTRADAS’’ |
[número] |
|
Altura em pixels |
|
[número] |
O número de linhas na camada de saída raster |
Contagem total de pixels |
|
[inteiro] |
A contagem de pixels na camada de saída raster |
Mean frequency at valid cell locations |
|
[número] |
|
Contagem de ocorrências de valor |
‘’CONTAGEM DE OCORRÊNCIAS’’ |
[número] |
|
Largura em pixels |
|
[inteiro] |
O número de colunas na camada de saída raster |
Código Python
Algorithm ID: native:greaterthanfrequency
import processing
processing.run("algorithm_id", {parameter_dictionary})
The algorithm id is displayed when you hover over the algorithm in the Processing Toolbox. The parameter dictionary provides the parameter NAMEs and values. See Usando os algoritmos do processamento a partir do Terminal Python. for details on how to run processing algorithms from the Python console.
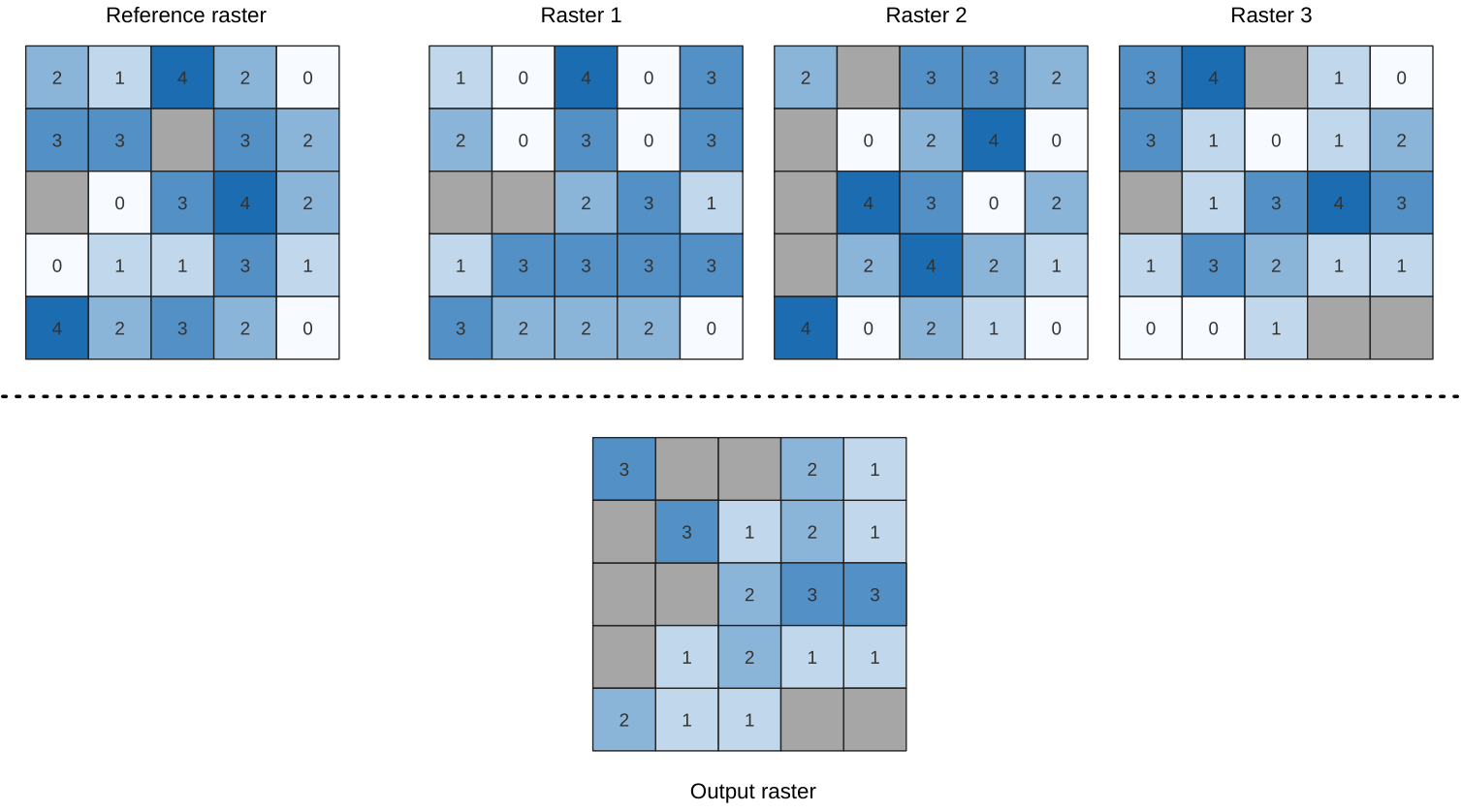
25.1.11.13. Posição mais alta na pilha raster
Evaluates on a cell-by-cell basis the position of the raster with the highest value in a stack of rasters. Position counts start with 1 and range to the total number of input rasters. The order of the input rasters is relevant for the algorithm. If multiple rasters feature the highest value, the first raster will be used for the position value.
If multiband rasters are used in the data raster stack, the algorithm will
always perform the analysis on the first band of the rasters - use GDAL to use
other bands in the analysis.
Any NoData cells in the raster layer stack will result in a NoData cell
in the output raster unless the “ignore NoData” parameter is checked.
The output NoData value can be set manually. The output rasters extent and
resolution is defined by a reference raster layer and is always of Int32 type.
Ver também
Parâmetros
Parâmetros básicos
Etiqueta |
Nome |
Tipo |
Descrição |
|---|---|---|---|
Camadas de entrada raster |
‘’INSERIR RASTERS’’ |
[raster] [lista] |
Lista de camadas rasterizadas para comparar com |
Camada de referência |
“CAMADA_REFERÊNCIA” |
[raster] |
A camada de referência para a criação da camada de saída (extensão, SRC, dimensões dos pixels) |
Ignorar valores sem dados |
|
[boleano] Padrão: Falso |
If unchecked, any NoData cells in the data layer stack will result in a NoData cell in the output raster |
Camada de saída |
|
[raster] Padrão: |
Especificação do raster de saída contendo o resultado. Um de:
|
Parâmetros avançados
Etiqueta |
Nome |
Tipo |
Descrição |
|---|---|---|---|
Saída de valores ‘sem dados’ |
|
[número] Padrão: -9999.0 |
Valor a ser usado para ‘sem dados’ na camada de saída |
Saídas
Etiqueta |
Nome |
Tipo |
Descrição |
|---|---|---|---|
Camada de saída |
|
[raster] |
Camada raster de saída contendo o resultado |
Identificador da autoridade SRC |
|
[string] |
O sistema de referência de coordenadas da camada raster de saída |
Extensão |
`` EXTENSÃO`` |
[string] |
A extensão espacial da camada raster de saída |
Largura em pixels |
|
[inteiro] |
O número de colunas na camada de saída raster |
Altura em pixels |
|
[inteiro] |
O número de linhas na camada de saída raster |
Contagem total de pixels |
|
[inteiro] |
A contagem de pixels na camada de saída raster |
Código Python
Algorithm ID: native:highestpositioninrasterstack
import processing
processing.run("algorithm_id", {parameter_dictionary})
The algorithm id is displayed when you hover over the algorithm in the Processing Toolbox. The parameter dictionary provides the parameter NAMEs and values. See Usando os algoritmos do processamento a partir do Terminal Python. for details on how to run processing algorithms from the Python console.
25.1.11.14. Menor do que a freqüência
Evaluates on a cell-by-cell basis the frequency (number of times) the values
of an input stack of rasters are less than the value of a value raster.
The output raster extent and resolution is defined by the input raster layer
and is always of Int32 type.
If multiband rasters are used in the data raster stack, the algorithm will always perform the analysis on the first band of the rasters - use GDAL to use other bands in the analysis. The output NoData value can be set manually.
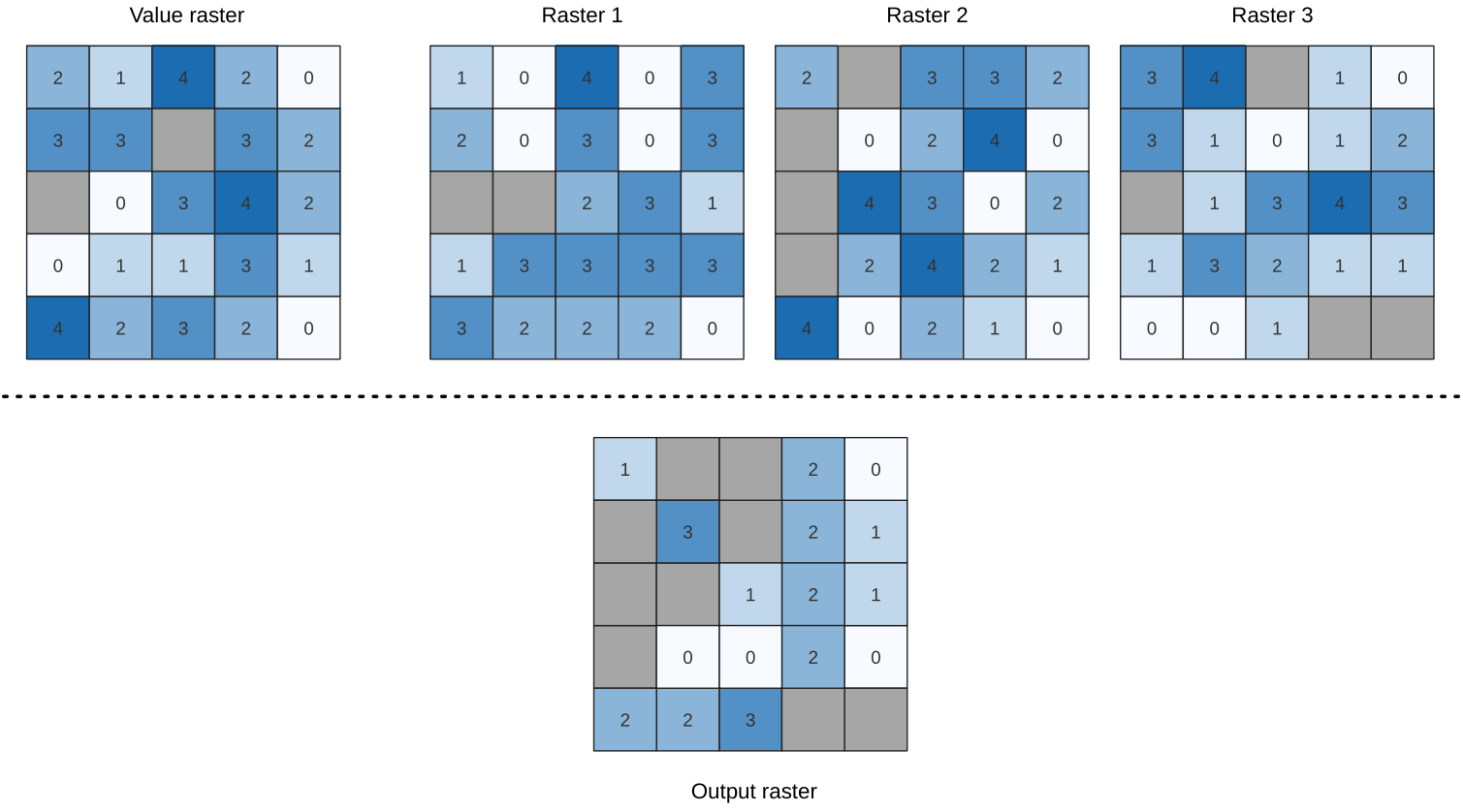
Fig. 25.17 For each cell in the output raster, the value represents the number of times
that the corresponding cells in the list of rasters are less than the value raster.
NoData cells (grey) are taken into account.
Ver também
Parâmetros
Parâmetros básicos
Etiqueta |
Nome |
Tipo |
Descrição |
|---|---|---|---|
Valor de entrada raster |
“VALOR DE ENTRADA RASTER” |
[raster] |
A camada de valor de entrada serve como camada de referência para as camadas de amostra |
Faixa de valor raster |
|
[banda raster] Padrão: A primeira faixa da camada raster |
Selecione a faixa que você deseja usar como amostra |
Camadas de entrada raster |
‘’INSERIR RASTERS’’ |
[raster] [lista] |
Raster layers to evaluate. If multiband rasters are used in the data raster stack, the algorithm will always perform the analysis on the first band of the rasters |
Ignorar valores sem dados |
|
[boleano] Padrão: Falso |
If unchecked, any NoData cells in the value raster or the data layer stack will result in a NoData cell in the output raster |
Camada de saída |
|
[o mesmo que entrada] Padrão: |
Especificação do raster de saída. Um de:
|
Parâmetros avançados
Etiqueta |
Nome |
Tipo |
Descrição |
|---|---|---|---|
Saída de valores ‘sem dados’ Opcional |
“SEM VALOR DE DADOS” |
[número] Padrão: -9999.0 |
Valor a ser usado para ‘sem dados’ na camada de saída |
Saídas
Etiqueta |
Nome |
Tipo |
Descrição |
|---|---|---|---|
Camada de saída |
|
[raster] |
Camada raster de saída contendo o resultado |
Identificador da autoridade SRC |
|
[string] |
O sistema de referência de coordenadas da camada raster de saída |
Extensão |
`` EXTENSÃO`` |
[string] |
A extensão espacial da camada raster de saída |
Contagem de células com ocorrências de valor igual |
“CONTAGEM DE LOCALIZAÇÕES ENCONTRADAS’’ |
[número] |
|
Altura em pixels |
|
[número] |
O número de linhas na camada de saída raster |
Contagem total de pixels |
|
[inteiro] |
A contagem de pixels na camada de saída raster |
Mean frequency at valid cell locations |
|
[número] |
|
Contagem de ocorrências de valor |
‘’CONTAGEM DE OCORRÊNCIAS’’ |
[número] |
|
Largura em pixels |
|
[inteiro] |
O número de colunas na camada de saída raster |
Código Python
Algorithm ID: native:lessthanfrequency
import processing
processing.run("algorithm_id", {parameter_dictionary})
The algorithm id is displayed when you hover over the algorithm in the Processing Toolbox. The parameter dictionary provides the parameter NAMEs and values. See Usando os algoritmos do processamento a partir do Terminal Python. for details on how to run processing algorithms from the Python console.
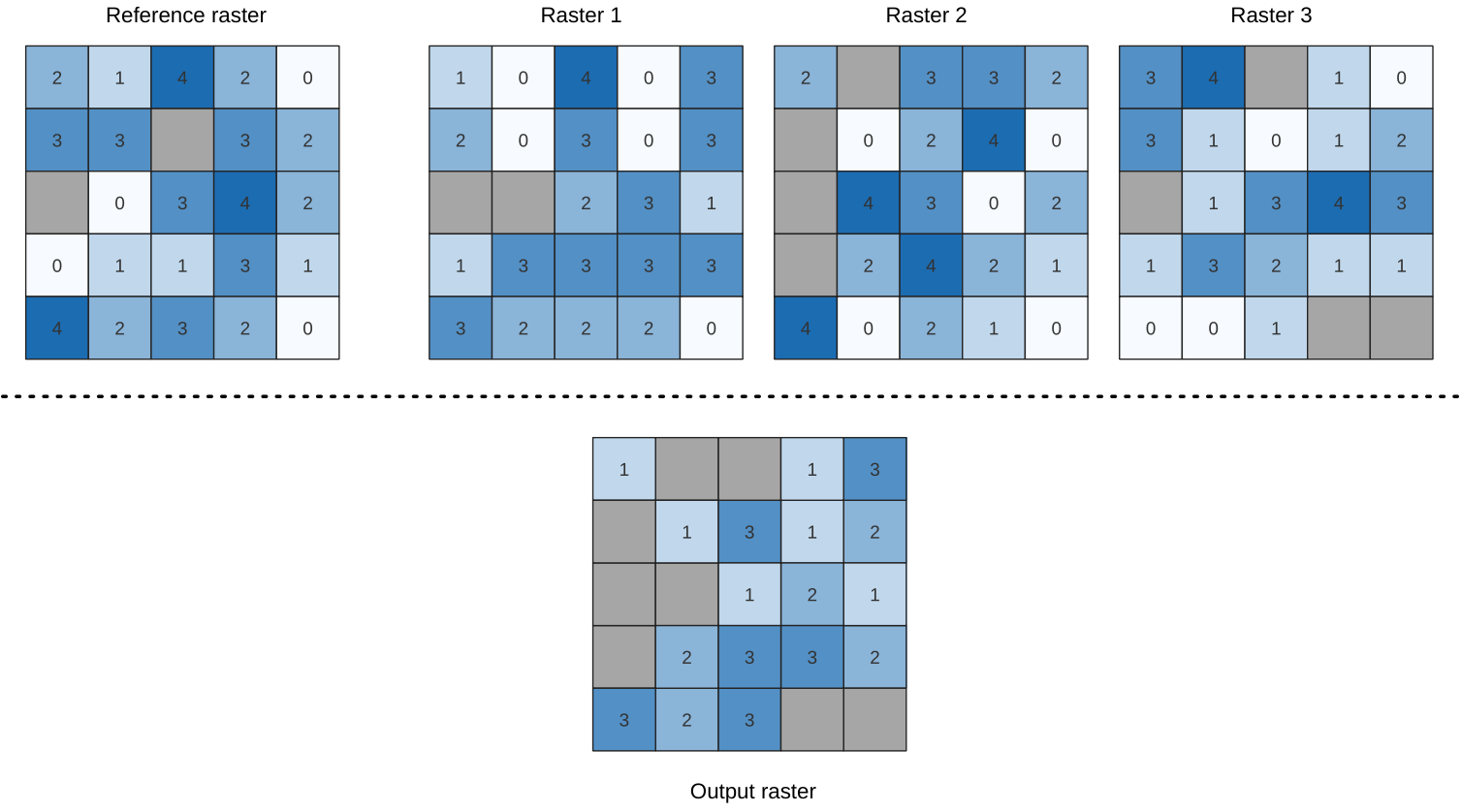
25.1.11.15. Posição mais baixa na pilha rasterizada
Evaluates on a cell-by-cell basis the position of the raster with the lowest value in a stack of rasters. Position counts start with 1 and range to the total number of input rasters. The order of the input rasters is relevant for the algorithm. If multiple rasters feature the lowest value, the first raster will be used for the position value.
If multiband rasters are used in the data raster stack, the algorithm will
always perform the analysis on the first band of the rasters - use GDAL to use
other bands in the analysis.
Any NoData cells in the raster layer stack will result in a NoData cell
in the output raster unless the “ignore NoData” parameter is checked.
The output NoData value can be set manually. The output rasters extent and
resolution is defined by a reference raster layer and is always of Int32 type.
Ver também
Parâmetros
Parâmetros básicos
Etiqueta |
Nome |
Tipo |
Descrição |
|---|---|---|---|
Camadas de entrada raster |
‘’INSERIR RASTERS’’ |
[raster] [lista] |
Lista de camadas rasterizadas para comparar com |
Camada de referência |
“CAMADA_REFERÊNCIA” |
[raster] |
A camada de referência para a criação da camada de saída (extensão, SRC, dimensões dos pixels) |
Ignorar valores sem dados |
|
[boleano] Padrão: Falso |
If unchecked, any NoData cells in the data layer stack will result in a NoData cell in the output raster |
Camada de saída |
|
[raster] Padrão: |
Especificação do raster de saída contendo o resultado. Um de:
|
Parâmetros avançados
Etiqueta |
Nome |
Tipo |
Descrição |
|---|---|---|---|
Saída de valores ‘sem dados’ |
|
[número] Padrão: -9999.0 |
Valor a ser usado para ‘sem dados’ na camada de saída |
Saídas
Etiqueta |
Nome |
Tipo |
Descrição |
|---|---|---|---|
Camada de saída |
|
[raster] |
Camada raster de saída contendo o resultado |
Identificador da autoridade SRC |
|
[string] |
O sistema de referência de coordenadas da camada raster de saída |
Extensão |
`` EXTENSÃO`` |
[string] |
A extensão espacial da camada raster de saída |
Largura em pixels |
|
[inteiro] |
O número de colunas na camada de saída raster |
Altura em pixels |
|
[inteiro] |
O número de linhas na camada de saída raster |
Contagem total de pixels |
|
[inteiro] |
A contagem de pixels na camada de saída raster |
Código Python
Algorithm ID: native:lowestpositioninrasterstack
import processing
processing.run("algorithm_id", {parameter_dictionary})
The algorithm id is displayed when you hover over the algorithm in the Processing Toolbox. The parameter dictionary provides the parameter NAMEs and values. See Usando os algoritmos do processamento a partir do Terminal Python. for details on how to run processing algorithms from the Python console.
25.1.11.16. Raster Booleano E
Calculates the boolean AND for a set of input rasters.
If all of the input rasters have a non-zero value for a pixel, that
pixel will be set to 1 in the output raster.
If any of the input rasters have 0 values for the pixel it will
be set to 0 in the output raster.
The reference layer parameter specifies an existing raster layer to use as a reference when creating the output raster. The output raster will have the same extent, CRS, and pixel dimensions as this layer.
By default, a nodata pixel in ANY of the input layers will result in a
nodata pixel in the output raster.
If the Treat nodata values as false option is checked,
then nodata inputs will be treated the same as a 0 input value.
Ver também
Parâmetros
Parâmetros básicos
Etiqueta |
Nome |
Tipo |
Descrição |
|---|---|---|---|
Camadas de entrada |
|
[raster] [lista] |
Lista de camadas rasterizadas de entrada |
Camada de referência |
‘’Referecia da camada” |
[raster] |
A camada de referência para criar a camada de saída (extensão, SRC, dimensões de pixel) |
Trate os valores ‘sem dados’ como falsos |
‘’SEM DADOS COMO FALSOS’’ |
[boleano] Padrão: Falso |
Trate os valores sem dados nos arquivos de entrada como 0 ao realizar a operação |
Camada de saída |
|
[raster] Padrão: |
Especificação do raster de saída contendo o resultado. Um de:
|
Parâmetros avançados
Etiqueta |
Nome |
Tipo |
Descrição |
|---|---|---|---|
Saída de valores ‘sem dados’ |
|
[número] Padrão: -9999.0 |
Valor a ser usado para ‘sem dados’ na camada de saída |
Tipo de dados de saída |
‘’TIPO DE DADO’’ |
[enumeração] Padrão: 5 |
Tipo de dados raster de saída. Opções:
|
Saídas
Etiqueta |
Nome |
Tipo |
Descrição |
|---|---|---|---|
Extensão |
`` EXTENSÃO`` |
[string] |
A extensão espacial da camada raster de saída |
Identificador da autoridade SRC |
|
[src] |
O sistema de referência de coordenadas da camada raster de saída |
Largura em pixels |
|
[inteiro] |
O número de colunas na camada de saída raster |
Altura em pixels |
|
[inteiro] |
O número de linhas na camada de saída raster |
Contagem total de pixels |
|
[inteiro] |
A contagem de pixels na camada de saída raster |
Contagem de pixels SEMDADOS |
|
[inteiro] |
A contagem de pixels sem dados na camada raster de saída |
Contagem de pixels verdadeiros |
‘’CONTAGEM DE PIXELS VERDADEIROS’’ |
[inteiro] |
A contagem de pixels verdadeiros (valor = 1) na camada raster de saída |
‘’Contagem de pixels falsos’’ |
‘’CONTAGEM DE PIXELS FALSOS’’ |
[inteiro] |
A contagem de pixels falsos (valor = 0) na camada raster de saída |
Camada de saída |
|
[raster] |
Camada raster de saída contendo o resultado |
Código Python
Algorithm ID: native:rasterbooleanand
import processing
processing.run("algorithm_id", {parameter_dictionary})
The algorithm id is displayed when you hover over the algorithm in the Processing Toolbox. The parameter dictionary provides the parameter NAMEs and values. See Usando os algoritmos do processamento a partir do Terminal Python. for details on how to run processing algorithms from the Python console.
25.1.11.17. Raster Booleano OU
Calculates the boolean OR for a set of input rasters.
If all of the input rasters have a zero value for a pixel, that
pixel will be set to 0 in the output raster.
If any of the input rasters have 1 values for the pixel it will
be set to 1 in the output raster.
The reference layer parameter specifies an existing raster layer to use as a reference when creating the output raster. The output raster will have the same extent, CRS, and pixel dimensions as this layer.
By default, a nodata pixel in ANY of the input layers will result in a
nodata pixel in the output raster.
If the Treat nodata values as false option is checked,
then nodata inputs will be treated the same as a 0 input value.
Ver também
Parâmetros
Parâmetros básicos
Etiqueta |
Nome |
Tipo |
Descrição |
|---|---|---|---|
Camadas de entrada |
|
[raster] [lista] |
Lista de camadas rasterizadas de entrada |
Camada de referência |
‘’Referecia da camada” |
[raster] |
A camada de referência para criar a camada de saída (extensão, SRC, dimensões de pixel) |
Trate os valores ‘sem dados’ como falsos |
‘’SEM DADOS COMO FALSOS’’ |
[boleano] Padrão: Falso |
Trate os valores sem dados nos arquivos de entrada como 0 ao realizar a operação |
Camada de saída |
|
[raster] Padrão: |
Especificação do raster de saída contendo o resultado. Um de:
|
Parâmetros avançados
Etiqueta |
Nome |
Tipo |
Descrição |
|---|---|---|---|
Saída de valores ‘sem dados’ |
|
[número] Padrão: -9999.0 |
Valor a ser usado para ‘sem dados’ na camada de saída |
Tipo de dados de saída |
‘’TIPO DE DADO’’ |
[enumeração] Padrão: 5 |
Tipo de dados raster de saída. Opções:
|
Saídas
Etiqueta |
Nome |
Tipo |
Descrição |
|---|---|---|---|
Extensão |
`` EXTENSÃO`` |
[string] |
A extensão espacial da camada raster de saída |
Identificador da autoridade SRC |
|
[src] |
O sistema de referência de coordenadas da camada raster de saída |
Largura em pixels |
|
[inteiro] |
O número de colunas na camada de saída raster |
Altura em pixels |
|
[inteiro] |
O número de linhas na camada de saída raster |
Contagem total de pixels |
|
[inteiro] |
A contagem de pixels na camada de saída raster |
Contagem de pixels SEMDADOS |
|
[inteiro] |
A contagem de pixels sem dados na camada raster de saída |
Contagem de pixels verdadeiros |
‘’CONTAGEM DE PIXELS VERDADEIROS’’ |
[inteiro] |
A contagem de pixels verdadeiros (valor = 1) na camada raster de saída |
‘’Contagem de pixels falsos’’ |
‘’CONTAGEM DE PIXELS FALSOS’’ |
[inteiro] |
A contagem de pixels falsos (valor = 0) na camada raster de saída |
Camada de saída |
|
[raster] |
Camada raster de saída contendo o resultado |
Código Python
Algorithm ID: native:rasterbooleanor
import processing
processing.run("algorithm_id", {parameter_dictionary})
The algorithm id is displayed when you hover over the algorithm in the Processing Toolbox. The parameter dictionary provides the parameter NAMEs and values. See Usando os algoritmos do processamento a partir do Terminal Python. for details on how to run processing algorithms from the Python console.
25.1.11.18. Calculadora Raster
Executa operações algébricas usando camadas matriciais.
The resulting layer will have its values computed according to an expression. The expression can contain numerical values, operators and references to any of the layers in the current project.
Nota
When using the calculator in A interface de processamento em lote or from
the Terminal Python QGIS the files to use have to be specified.
The corresponding layers are referred using the base name of the
file (without the full path).
For instance, if using a layer at path/to/my/rasterfile.tif,
the first band of that layer will be referred as
rasterfile.tif@1.
Ver também
Parâmetros
Etiqueta |
Nome |
Tipo |
Descrição |
|---|---|---|---|
Camadas |
Apenas GUI |
Shows the list of all raster layers loaded in the legend.
These can be used to fill the expression box (double click to
add).
Raster layers are referred by their name and the number of the
band: |
|
Operadores |
Apenas GUI |
Contains some calculator like buttons that can be used to fill the expression box. |
|
Expressão |
|
[string] |
Expression that will be used to calculate the output raster layer. You can use the operator buttons provided to type directly the expression in this box. |
Expressões pré-definidas |
Apenas GUI |
You can use the predefined |
|
Camada(s) de referência (usada(s) para extensão automatizada, tamanho de célula e SRC) Opcional |
|
[raster] [lista] |
Layer(s) that will be used to fetch extent, cell size and CRS.
By choosing the layer in this box you avoid filling in all the
other parameters by hand.
Raster layers are referred by their name and the number of
the band: |
Tamanho da célula (use 0 ou vazia para defini-la automaticamente) Opcional |
|
[número] |
Cell size of the output raster layer. If the cell size is not specified, the minimum cell size of the selected reference layer(s) will be used. The cell size will be the same for the X and Y axes. |
Extensão da produção Opcional |
`` EXTENSÃO`` |
[extensão] |
Especifique a extensão espacial da camada rasterizada de saída. Se a extensão não for especificada, será utilizada a extensão mínima que cobre todas as camadas de referência selecionadas. Os métodos disponíveis são:
|
SRC de Saída Opcional |
|
[src] |
SRC da camada raster da saída. Se o SRC de saída não for especificado, será usado o SRC da primeira camada de referência. |
Saída |
|
[raster] Padrão: |
Especificação do raster de saída. Um de:
|
Saídas
Etiqueta |
Nome |
Tipo |
Descrição |
|---|---|---|---|
Saída |
|
[raster] |
Arquivo raster de saída com os valores calculados. |
Código Python
ID do algoritmo: qgis:calculadoraRaster
import processing
processing.run("algorithm_id", {parameter_dictionary})
The algorithm id is displayed when you hover over the algorithm in the Processing Toolbox. The parameter dictionary provides the parameter NAMEs and values. See Usando os algoritmos do processamento a partir do Terminal Python. for details on how to run processing algorithms from the Python console.
25.1.11.19. Propriedades da camada rasterizada
NEW in 3.20
Retorna propriedades básicas da camada matricial fornecida, incluindo extensão, tamanho em pixels e dimensões de pixels (em unidades de mapa), número de bandas e nenhum valor de dados.
Este algoritmo destina-se a ser usado como um meio de extrair estas propriedades úteis para usar como valores de entrada para outros algoritmos em um modelo - por exemplo, para permitir a passagem dos tamanhos de pixel de um raster existente para um algoritmo raster GDAL.
Parâmetros
Etiqueta |
Nome |
Tipo |
Descrição |
|---|---|---|---|
Camada de entrada |
|
[raster] |
Camada raster de entrada |
Número da banda Opcional |
|
[banda raster] Padrão: Não definido |
Whether to also return properties of a specific band. If a band is specified, the noData value for the selected band is also returned. |
Saídas
Etiqueta |
Nome |
Tipo |
Descrição |
|---|---|---|---|
Número de bandas no raster |
‘’CONTAGEM DE BANDAS’’ |
[número] |
O número de bandas na matriz |
Identificador da autoridade SRC |
|
[string] |
O sistema de referência de coordenadas da camada raster de saída |
Extensão |
`` EXTENSÃO`` |
[string] |
A extensão da camada raster no SRC |
Band has a NoData value set |
‘’SEM VOLUME DE DADOS’’ |
[Boleano] |
Indicates whether the raster layer has a value set for NODATA pixels in the selected band |
Altura em pixels |
|
[inteiro] |
O número de colunas na camada matriz |
‘’Banda sem dados de valores’’ |
|
[número] |
The value (if set) of the NoData pixels in the selected band |
Tamanho Pixel (altura) em unidades do mapa |
``PIXEL_ALTURA` |
[inteiro] |
Tamanho vertical em unidades do mapa do pixel |
Tamanho Pixel (largura) em unidades do mapa |
|
[inteiro] |
Tamanho horizontal em unidades de mapa do pixel |
Largura em pixels |
|
[inteiro] |
O número de linhas na camada raster |
Coordenada x máxima |
|
[número] |
|
Coordenada x mínima |
|
[número] |
|
Coordenada y máxima |
|
[número] |
|
Coordenada y-mínima |
|
[número] |
Código Python
Algorithm ID: native:rasterlayerproperties
import processing
processing.run("algorithm_id", {parameter_dictionary})
The algorithm id is displayed when you hover over the algorithm in the Processing Toolbox. The parameter dictionary provides the parameter NAMEs and values. See Usando os algoritmos do processamento a partir do Terminal Python. for details on how to run processing algorithms from the Python console.
25.1.11.20. Estatísticas da camada rasterizada
Calculates basic statistics from the values in a given band of the raster layer. The output is loaded in the menu.
Parâmetros
Etiqueta |
Nome |
Tipo |
Descrição |
|---|---|---|---|
Camada de entrada |
|
[raster] |
Camada raster de entrada |
Número da banda |
|
[banda raster] Padrão: A primeira banda da camada de entrada |
Se o raster for multibanda, escolha a banda para a qual deseja obter estatísticas. |
Estatísticas |
|
[html] Padrão: |
Especificação do arquivo de saída:
|
Saídas
Etiqueta |
Nome |
Tipo |
Descrição |
|---|---|---|---|
Valor máximo |
|
[número] |
|
Valor médio |
|
[número] |
|
Valor mínimo |
|
[número] |
|
Estatísticas |
|
[html] |
O arquivo de saída contém as seguintes informações:
|
Faixa |
|
[número] |
|
Desvio padrão |
|
[número] |
|
Soma |
|
[número] |
|
Soma dos quadrados |
|
[número] |
Código Python
Algorithm ID: native:rasterlayerstatistics
import processing
processing.run("algorithm_id", {parameter_dictionary})
The algorithm id is displayed when you hover over the algorithm in the Processing Toolbox. The parameter dictionary provides the parameter NAMEs and values. See Usando os algoritmos do processamento a partir do Terminal Python. for details on how to run processing algorithms from the Python console.
25.1.11.21. Relatório de valores únicos da camada raster
Retorna a contagem e a área de cada valor exclusivo em uma determinada camada raster.
Parâmetros
Etiqueta |
Nome |
Tipo |
Descrição |
|---|---|---|---|
Camada de entrada |
|
[raster] |
Camada raster de entrada |
Número da banda |
|
[banda raster] Padrão: A primeira banda da camada de entrada |
Se o raster for multibanda, escolha a banda para a qual deseja obter estatísticas. |
Relatório de valores únicos |
|
[arquivo] Padrão: |
Especificação do arquivo de saída:
|
Tabela de valores únicos |
‘’TABELA DE SAÍDA’’ |
[tabela] Default: |
Especificação da tabela para valores únicos:
A codificação do arquivo também pode ser alterada aqui. |
Saídas
Etiqueta |
Nome |
Tipo |
Descrição |
|---|---|---|---|
Identificador da autoridade SRC |
|
[string] |
O sistema de referência de coordenadas da camada raster de saída |
Extensão |
`` EXTENSÃO`` |
[string] |
A extensão espacial da camada raster de saída |
Altura em pixels |
|
[inteiro] |
O número de linhas na camada de saída raster |
Contagem de pixels SEMDADOS |
|
[número] |
O número de pixels SEMDADO na camada raster de saída |
Contagem total de pixels |
|
[inteiro] |
A contagem de pixels na camada de saída raster |
Relatório de valores únicos |
|
[html] |
O arquivo HTML de saída contém as seguintes informações:
|
Tabela de valores únicos |
‘’TABELA DE SAÍDA’’ |
[tabela] |
Uma tabela com três colunas:
|
Largura em pixels |
|
[inteiro] |
O número de colunas na camada de saída raster |
Código Python
Algorithm ID: native:rasterlayeruniquevaluesreport
import processing
processing.run("algorithm_id", {parameter_dictionary})
The algorithm id is displayed when you hover over the algorithm in the Processing Toolbox. The parameter dictionary provides the parameter NAMEs and values. See Usando os algoritmos do processamento a partir do Terminal Python. for details on how to run processing algorithms from the Python console.
25.1.11.22. Estatísticas zonais da camada rasterizada
Calcula estatísticas para os valores de uma camada raster, categorizados por zonas definidas em outra camada raster.
Ver também
Parâmetros
Parâmetros básicos
Etiqueta |
Nome |
Tipo |
Descrição |
|---|---|---|---|
Camada de entrada |
|
[raster] |
Camada raster de entrada |
Número da banda |
|
[banda raster] Padrão: A primeira faixa da camada raster |
Se o raster for multibanda, escolha a banda para a qual deseja calcular as estatísticas. |
** Camada de zonas** |
|
[raster] |
Camada raster definindo zonas. As zonas são dadas por pixels contíguos com o mesmo valor de pixel. |
Número da bandas de zonas |
|
[banda raster] Padrão: A primeira faixa da camada raster |
Se o raster for multibandas, escolha a banda que define as zonas |
Estatísticas |
‘’TABELA DE SAÍDA’’ |
[tabela] Padrão: |
Especificação do relatório de saída. Uma de:
A codificação do arquivo também pode ser alterada aqui. |
Parâmetros avançados
Etiqueta |
Nome |
Tipo |
Descrição |
|---|---|---|---|
Camada de referência Opcional |
‘’Referecia da camada” |
[enumeração] Padrão: 0 |
Camada raster usada para calcular os centróides que serão usados como referência ao determinar as zonas na camada de saída. Um de:
|
Saídas
Etiqueta |
Nome |
Tipo |
Descrição |
|---|---|---|---|
Identificador da autoridade SRC |
|
[string] |
O sistema de referência de coordenadas da camada raster de saída |
Extensão |
`` EXTENSÃO`` |
[string] |
A extensão espacial da camada raster de saída |
Altura em pixels |
|
[inteiro] |
O número de linhas na camada de saída raster |
Contagem de pixels SEMDADOS |
|
[número] |
O número de pixels SEMDADO na camada raster de saída |
Estatísticas |
‘’TABELA DE SAÍDA’’ |
[tabela] |
A camada de saída contém as seguintes informações para cada zona:
|
Contagem total de pixels |
|
[número] |
A contagem de pixels na camada de saída raster |
Largura em pixels |
|
[número] |
O número de colunas na camada de saída raster |
Código Python
Algorithm ID: native:rasterlayerzonalstats
import processing
processing.run("algorithm_id", {parameter_dictionary})
The algorithm id is displayed when you hover over the algorithm in the Processing Toolbox. The parameter dictionary provides the parameter NAMEs and values. See Usando os algoritmos do processamento a partir do Terminal Python. for details on how to run processing algorithms from the Python console.
25.1.11.23. Volume de superfície rasterizada
Calcula o volume sob uma superfície rasterizada em relação a um determinado nível de base. Isto é útil principalmente para os Modelos Digitais de Elevação (MDE).
Parâmetros
Etiqueta |
Nome |
Tipo |
Descrição |
|---|---|---|---|
**CAMADA de entrada”” |
|
[raster] |
Raster de entrada, representando uma superfície |
Número da banda |
|
[banda raster] Padrão: A primeira faixa da camada raster |
Se o raster for multibandas, escolha a banda que define a superfície |
Nível base |
`` NÍVEL`` |
[número] Padrão: 0.0 |
Definir um valor base ou de referência. Esta base é utilizada no cálculo do volume de acordo com o parâmetro |
Método |
|
[enumeração] Padrão: 0 |
Define the method for the volume calculation given by the
difference between the raster pixel value and the
|
Relatório de volume de superfície |
|
[html] Padrão: |
Especificação do relatório HTML de saída. Um de:
A codificação do arquivo também pode ser alterada aqui. |
Tabela de volume de superfície |
‘’TABELA DE SAÍDA’’ |
[tabela] Default: |
Especificação da tabela de saída. Um de:
A codificação do arquivo também pode ser alterada aqui. |
Saídas
Etiqueta |
Nome |
Tipo |
Descrição |
|---|---|---|---|
Volume |
|
[número] |
O volume calculado |
Área |
|
[número] |
A área em unidades de mapa quadrado |
Contagem_pixel |
‘’CONTAGEM DE PIXELS’’ |
[número] |
O número total de pixels que foram analisados |
Relatório de volume de superfície |
|
[html] |
O relatório de saída (contendo volume, área e contagem de pixels) em formato HTML |
Tabela de volume de superfície |
‘’TABELA DE SAÍDA’’ |
[tabela] |
A tabela de saída (contendo volume, área e contagem de pixels) |
Código Python
Algorithm ID: native:rastersurfacevolume
import processing
processing.run("algorithm_id", {parameter_dictionary})
The algorithm id is displayed when you hover over the algorithm in the Processing Toolbox. The parameter dictionary provides the parameter NAMEs and values. See Usando os algoritmos do processamento a partir do Terminal Python. for details on how to run processing algorithms from the Python console.
25.1.11.24. Reclassificar por camada
Reclassificar uma banda matricial atribuindo novos valores de classe com base nos intervalos especificados em uma tabela de vetores.
Parâmetros
Parâmetros básicos
Etiqueta |
Nome |
Tipo |
Descrição |
|---|---|---|---|
Camada raster |
‘’RASTER DE ENTRADA’’ |
[raster] |
Camada raster para reclassificar |
Número da banda |
|
[banda raster] Padrão: A primeira faixa da camada raster |
Se o raster for multibandas, escolha a banda que você deseja reclassificar. |
Camada que contém quebras de classe |
‘’TABELA DE ENTRADA’’ |
[vetor: qualquer] |
Camada vetorial contendo os valores a serem usados para classificação. |
Campo de valor mínimo da classe |
|
[campo de tabela: numérico] |
Campo com o valor mínimo do intervalo para a classe. |
Campo de valor máximo da classe |
``MAX_CAMPO` |
[campo de tabela: numérico] |
Campo com o valor máximo do intervalo para a classe. |
Campo de valor de saída |
|
[campo de tabela: numérico] |
Campo com o valor que será atribuído aos pixels que se enquadram na classe (entre os valores mínimo e máximo correspondentes). |
Raster reclassificado |
|
[raster] Padrão: |
Especificação do raster de saída. Um de:
|
Parâmetros avançados
Etiqueta |
Nome |
Tipo |
Descrição |
|---|---|---|---|
Saída de valores ‘sem dados’ |
|
[número] Padrão: -9999.0 |
Valor a ser aplicado a nenhum valor de dados. |
Limites de alcance |
‘’LIMITES DE ALCANCE’’ |
[enumeração] Padrão: 0 |
Define regras de comparação para a classificação. Opções:
|
Não use dados quando nenhum intervalo corresponder ao valor |
‘’SEM DADOS PARA PERDIDO’’ |
[boleano] Padrão: Falso |
Aplica o valor sem dados a valores de banda que não se enquadram em nenhuma classe. Se Falso, o valor original é mantido. |
Tipo de dados de saída |
‘’TIPO DE DADO’’ |
[enumeração] Padrão: 5 |
Define o formato do arquivo raster de saída. Opções:
|
Saídas
Etiqueta |
Nome |
Tipo |
Descrição |
|---|---|---|---|
Raster reclassificado |
|
[raster] |
Camada raster de saída com valores de faixa reclassificados |
Código Python
Algorithm ID: native:reclassifybylayer
import processing
processing.run("algorithm_id", {parameter_dictionary})
The algorithm id is displayed when you hover over the algorithm in the Processing Toolbox. The parameter dictionary provides the parameter NAMEs and values. See Usando os algoritmos do processamento a partir do Terminal Python. for details on how to run processing algorithms from the Python console.
25.1.11.25. Reclassificar por tabela
Reclassifies a raster band by assigning new class values based on the ranges specified in a fixed table.
Parâmetros
Parâmetros básicos
Etiqueta |
Nome |
Tipo |
Descrição |
|---|---|---|---|
Camada raster |
‘’RASTER DE ENTRADA’’ |
[raster] |
Camada raster para reclassificar |
Número da banda |
|
[banda raster] Padrão: 1 |
Banda raster para a qual você deseja recalcular valores. |
Tabela de reclassificação |
|
[tabela] |
A 3-columns table to fill with the values to set the boundaries
of each class ( |
Raster reclassificado |
|
[raster] Padrão: |
Especificação da camada raster de saída. Um de:
|
Parâmetros avançados
Etiqueta |
Nome |
Tipo |
Descrição |
|---|---|---|---|
Saída de valores ‘sem dados’ |
|
[número] Padrão: -9999.0 |
Valor a ser aplicado a nenhum valor de dados. |
Limites de alcance |
‘’LIMITES DE ALCANCE’’ |
[enumeração] Padrão: 0 |
Define regras de comparação para a classificação. Opções:
|
Não use dados quando nenhum intervalo corresponder ao valor |
‘’SEM DADOS PARA PERDIDO’’ |
[boleano] Padrão: Falso |
Aplica o valor sem dados a valores de banda que não se enquadram em nenhuma classe. Se Falso, o valor original é mantido. |
Tipo de dados de saída |
‘’TIPO DE DADO’’ |
[enumeração] Padrão: 5 |
Define o formato do arquivo raster de saída. Opções:
|
Saídas
Etiqueta |
Nome |
Tipo |
Descrição |
|---|---|---|---|
Raster reclassificado |
|
[raster] |
Camada raster de saída com valores de faixa reclassificados |
Código Python
Algorithm ID: native:reclassifybytable
import processing
processing.run("algorithm_id", {parameter_dictionary})
The algorithm id is displayed when you hover over the algorithm in the Processing Toolbox. The parameter dictionary provides the parameter NAMEs and values. See Usando os algoritmos do processamento a partir do Terminal Python. for details on how to run processing algorithms from the Python console.
25.1.11.26. Redimensionar matriz
Redimensiona a camada matricial para um novo intervalo de valores, preservando a forma (distribuição) do histograma da matriz (valores de pixel). Os valores de entrada são mapeados usando uma interpolação linear dos valores de pixel mínimo e máximo da matricial de origem para o intervalo de pixels mínimo e mínimo de destino.
By default the algorithm preserves the original NODATA value, but there is an option to override it.
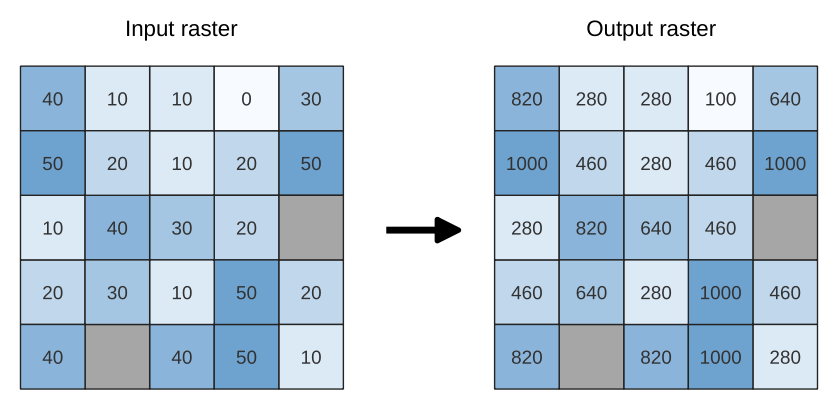
Fig. 25.18 Redimensionando valores de uma camada matricial de [0 - 50] para [100 - 1000]
Parâmetros
Etiqueta |
Nome |
Tipo |
Descrição |
|---|---|---|---|
Entrada raster |
|
[raster] |
Camada raster a ser utilizada para redimensionamento |
Número da banda |
|
[banda raster] Padrão: A primeira banda da camada de entrada |
Se a matriz for multibanda, escolha uma banda. |
Novo valor mínimo |
|
[número] Valor padrão: 0,0 |
Valor mínimo de pixel a ser usado na camada redimensionada |
Novo valor máximo |
|
[número] Valor padrão: 255,0 |
Valor máximo de pixel a ser usado na camada redimensionada |
Novo valor sem dados Opcional |
|
[número] Valor padrão: Não definido |
Value to assign to the NODATA pixels. If unset, original NODATA values are preserved. |
Escalonado |
|
[raster] Padrão: |
Especificação da camada raster de saída. Um de:
|
Saídas
Etiqueta |
Nome |
Tipo |
Descrição |
|---|---|---|---|
Escalonado |
|
[raster] |
Camada raster de saída com valores de banda redimensionados |
Código Python
Algorithm ID: native:rescaleraster
import processing
processing.run("algorithm_id", {parameter_dictionary})
The algorithm id is displayed when you hover over the algorithm in the Processing Toolbox. The parameter dictionary provides the parameter NAMEs and values. See Usando os algoritmos do processamento a partir do Terminal Python. for details on how to run processing algorithms from the Python console.
25.1.11.27. Rodada de raster
Rounds the cell values of a raster dataset according to the specified number of decimals.
Alternatively, a negative number of decimal places may be used to round values to powers of a base n. For example, with a Base value n of 10 and Decimal places of -1, the algorithm rounds cell values to multiples of 10, -2 rounds to multiples of 100, and so on. Arbitrary base values may be chosen, the algorithm applies the same multiplicative principle. Rounding cell values to multiples of a base n may be used to generalize raster layers.
O algoritmo preserva o tipo de dados da matriz de entrada. Portanto, matrizes de byte/inteiro só podem ser arredondadas para múltiplos de uma base n, caso contrário, um aviso é gerado e a matriz é copiada como matriz de byte/inteiro.
Fig. 25.19 Arredondamento de valores de um raster
Parâmetros
Parâmetros básicos
Etiqueta |
Nome |
Tipo |
Descrição |
|---|---|---|---|
Entrada raster |
|
[raster] |
O raster a ser processado. |
Número da banda |
|
[número] Padrão: 1 |
A banda da matriz |
Direção de rotação |
|
[lista] Padrão: 1 |
Como escolher o valor alvo arredondado. As opções são:
|
Número de casas decimais |
|
[número] Padrão: 2 |
Número de casas decimais para arredondar. Usar valores negativos para arredondar os valores das células para um múltiplo de uma base n |
Matriz de saída |
|
[raster] Padrão: |
Especificação do arquivo de saída. Um de:
|
Parâmetros avançados
Etiqueta |
Nome |
Tipo |
Descrição |
|---|---|---|---|
Base n para arredondamento para múltiplos de n |
|
[número] Padrão: 10 |
Quando o parâmetro |
Saídas
Etiqueta |
Nome |
Tipo |
Descrição |
|---|---|---|---|
Matriz de saída |
|
[raster] |
A camada matricial de saída com valores arredondados para a banda selecionada. |
Código Python
Algorithm ID: native:roundrastervalues
import processing
processing.run("algorithm_id", {parameter_dictionary})
The algorithm id is displayed when you hover over the algorithm in the Processing Toolbox. The parameter dictionary provides the parameter NAMEs and values. See Usando os algoritmos do processamento a partir do Terminal Python. for details on how to run processing algorithms from the Python console.
25.1.11.28. Amostra de valores raster
Extrai valores matriciais nas localizações dos pontos. Se a camada matricial for multibanda, cada banda é amostrada.
A tabela de atributos da camada resultante terá tantas colunas novas quanto a contagem de bandas da camada raster.
Parâmetros
Etiqueta |
Nome |
Tipo |
Descrição |
|---|---|---|---|
Camada de entrada |
|
[vetor: ponto] |
Camada vetorial de ponto a ser usada para amostragem |
Camada Raster |
‘’CÓPIA DO RASTER’’ |
[raster] |
Camada raster para amostragem nos locais determinados. |
Prefixo da coluna de saída |
|
[string] Padrão: ‘AMOSTRA_’ |
Prefixo para os nomes das colunas adicionadas. |
Amostrado Opcional |
|
[vetor: ponto] Padrão: |
Especificar a camada de saída contendo os valores amostrados. Um de:
A codificação do arquivo também pode ser alterada aqui. |
Saídas
Etiqueta |
Nome |
Tipo |
Descrição |
|---|---|---|---|
Amostrado |
|
[vetor: ponto] |
A camada de saída que contém os valores amostrados. |
Código Python
Algorithm ID: native:rastersampling
import processing
processing.run("algorithm_id", {parameter_dictionary})
The algorithm id is displayed when you hover over the algorithm in the Processing Toolbox. The parameter dictionary provides the parameter NAMEs and values. See Usando os algoritmos do processamento a partir do Terminal Python. for details on how to run processing algorithms from the Python console.
25.1.11.29. Histograma zonal
Appends fields representing counts of each unique value from a raster layer contained within polygon features.
The output layer attribute table will have as many fields as the unique values of the raster layer that intersects the polygon(s).
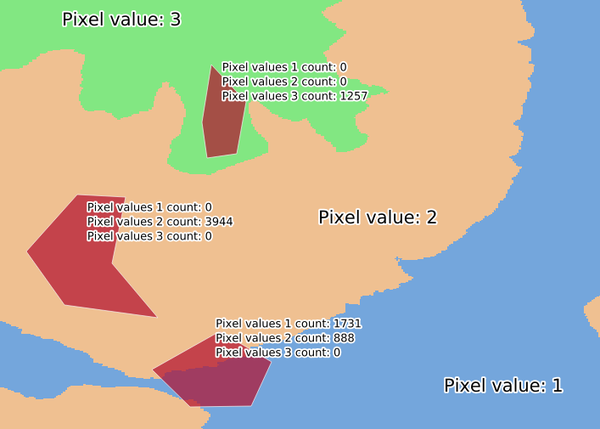
Fig. 25.20 Exemplo de histograma da camada raster
Parâmetros
Etiqueta |
Nome |
Tipo |
Descrição |
|---|---|---|---|
Camada raster |
‘’RASTER DE ENTRADA’’ |
[raster] |
Camada raster de entrada |
Número da banda |
|
[banda raster] Padrão: A primeira banda da camada de entrada |
Se a matriz for multibanda, escolha uma banda. |
Camada vetorial contendo zonas |
‘’VETOR DE ENTRADA’’ |
[vetor: polígono] |
Camada de polígono vetorial que define as zonas. |
Prefixo da coluna de saída |
Opcional |
[string] Default: ‘HISTO_’ |
Prefixo para os nomes das colunas de saída. |
‘’Áreas de saída’’ |
|
[vetor: polígono] Padrão: |
Especifique a camada de polígono vetorial de saída. Um de:
A codificação do arquivo também pode ser alterada aqui. |
Saídas
Etiqueta |
Nome |
Tipo |
Descrição |
|---|---|---|---|
‘’Áreas de saída’’ |
|
[vetor: polígono] |
A camada de polígono vetorial de saída. |
Código Python
Algorithm ID: native:zonalhistogram
import processing
processing.run("algorithm_id", {parameter_dictionary})
The algorithm id is displayed when you hover over the algorithm in the Processing Toolbox. The parameter dictionary provides the parameter NAMEs and values. See Usando os algoritmos do processamento a partir do Terminal Python. for details on how to run processing algorithms from the Python console.
25.1.11.30. Estatísticas zonais
Calcula estatísticas de uma camada matricial para cada feição de uma camada vetorial de polígono sobreposta.
Parâmetros
Etiqueta |
Nome |
Tipo |
Descrição |
|---|---|---|---|
Camada de entrada |
|
[vetor: polígono] |
Camada de polígono vetorial que contém as zonas. |
Camada raster |
‘’RASTER DE ENTRADA’’ |
[raster] |
Camada raster de entrada |
Banda Raster |
|
[banda raster] Padrão: A primeira banda da camada de entrada |
Se o raster for multibanda, escolha uma banda para as estatísticas. |
Prefixo da coluna de saída |
|
[string] Default: ‘_’ |
Prefixo para os nomes das colunas de saída. |
Estatísticas para calcular |
ESTATÍSTICAS` |
[enumeração] [lista] Padrão: [0,1,2] |
Lista de operadores estatísticos para a saída. Opções:
|
Estatísticas zonal |
|
[vetor: polígono] Padrão: |
Especifique a camada de polígono vetorial de saída. Um de:
A codificação do arquivo também pode ser alterada aqui. |
Saídas
Etiqueta |
Nome |
Tipo |
Descrição |
|---|---|---|---|
Estatísticas zonal |
|
[vetor: polígono] |
A camada vetorial da zona com estatísticas adicionais. |
Código Python
Algorithm ID: native:zonalstatisticsfb
import processing
processing.run("algorithm_id", {parameter_dictionary})
The algorithm id is displayed when you hover over the algorithm in the Processing Toolbox. The parameter dictionary provides the parameter NAMEs and values. See Usando os algoritmos do processamento a partir do Terminal Python. for details on how to run processing algorithms from the Python console.