25.1.11. 래스터 분석
25.1.11.1. Cell stack percent rank from value
Calculates the cell-wise percentrank value of a stack of rasters based on a single input value and writes them to an output raster.
At each cell location, the specified value is ranked among the respective values in the stack of all overlaid and sorted cell values from the input rasters. For values outside of the stack value distribution, the algorithm returns NoData because the value cannot be ranked among the cell values.
There are two methods for percentile calculation:
Inclusive linear interpolation (PERCENTRANK.INC)
Exclusive linear interpolation (PERCENTRANK.EXC)
The linear interpolation method return the unique percent rank for different values. Both interpolation methods follow their counterpart methods implemented by LibreOffice or Microsoft Excel.
The output raster’s extent and resolution is defined by a reference raster.
Input raster layers that do not match the cell size of the reference
raster layer will be resampled using nearest neighbor resampling.
NoData values in any of the input layers will result in a NoData cell output
if the “Ignore NoData values” parameter is not set.
The output raster data type will always be Float32.
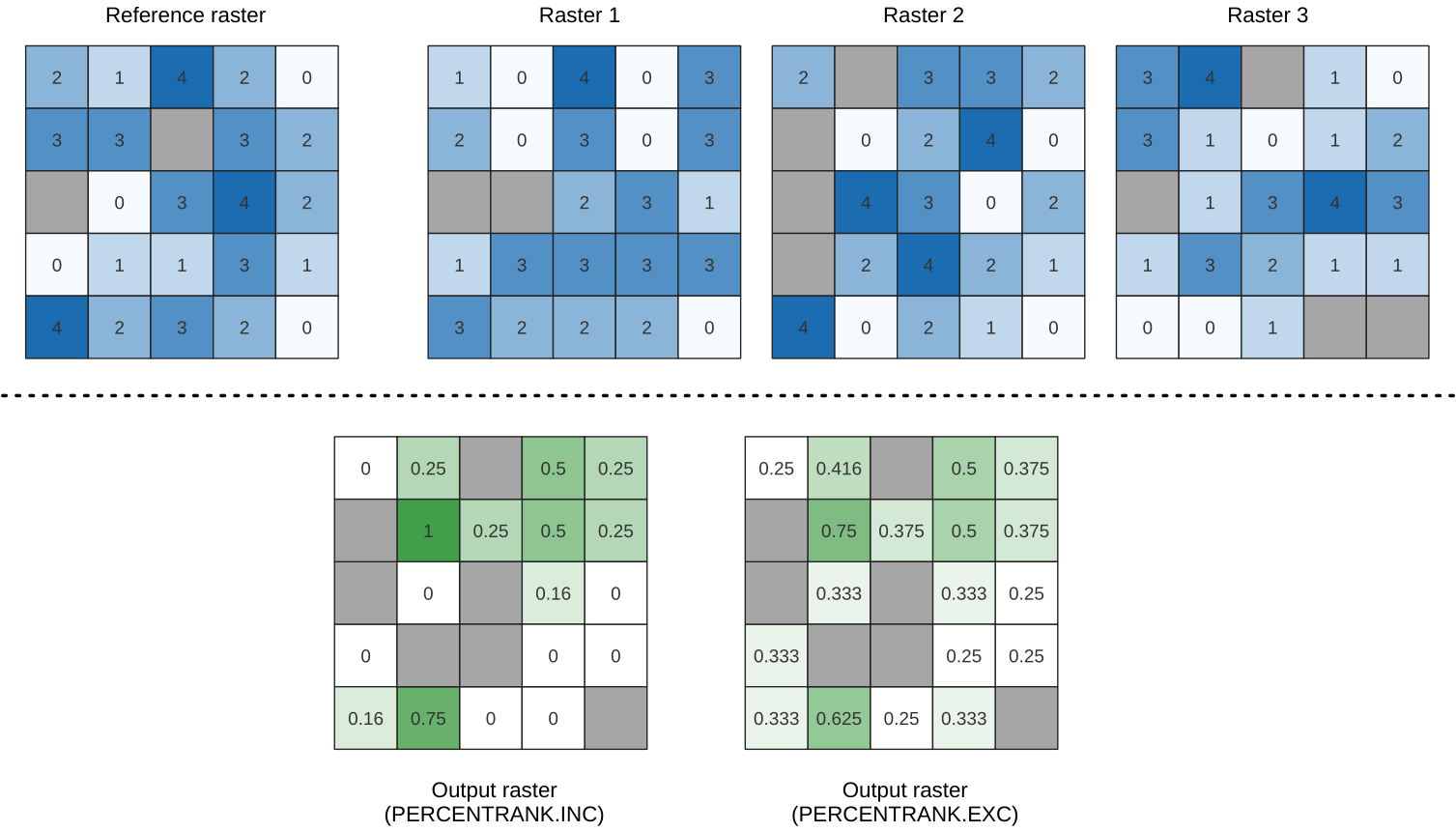
그림 25.10 Percent ranking Value = 1. NoData cells (grey) are ignored.
파라미터
기본 파라미터
라벨 |
명칭 |
유형 |
설명 |
|---|---|---|---|
Input layers |
|
[raster] [list] |
평가할 래스터 레이어들입니다. 데이터 래스터 스택에 다중밴드 래스터가 쓰인 경우, 이 알고리즘은 항상 래스터의 첫 번째 밴드에 분석을 수행할 것입니다. |
Method |
|
[enumeration] 기본값: 0 |
Method for percentile calculation:
|
Value |
|
[number] Default: 10.0 |
Value to rank among the respective values in the stack of all overlaid and sorted cell values from the input rasters |
Ignore NoData values |
|
[boolean] 기본값: True |
If unchecked, any NoData cells in the input layers will result in a NoData cell in the output raster |
Reference layer |
|
[raster] |
산출 래스터를 생성하기 위한 (범위, 좌표계, 픽셀 크기) 기준 레이어 |
Output layer |
|
[same as input] 기본값: |
산출 레이어를 지정합니다. 다음 가운데 하나로 저장할 수 있습니다:
|
고급 파라미터
라벨 |
명칭 |
유형 |
설명 |
|---|---|---|---|
Output no data value |
|
[number] 기본값: -9999.0 |
산출 레이어에서 NODATA용으로 사용할 값 |
산출물
라벨 |
명칭 |
유형 |
설명 |
|---|---|---|---|
Output layer |
|
[raster] |
결과물을 담고 있는 산출 래스터 레이어 |
CRS authority identifier |
|
[string] |
산출 래스터 레이어의 좌표계 |
Extent |
|
[string] |
산출 래스터 레이어의 공간 영역 |
Width in pixels |
|
[integer] |
산출 래스터 레이어의 열 개수 |
Height in pixels |
|
[integer] |
산출 래스터 레이어의 행 개수 |
Total pixel count |
|
[integer] |
산출 래스터 레이어의 픽셀 개수 |
파이썬 코드
Algorithm ID: native:cellstackpercentrankfromvalue
import processing
processing.run("algorithm_id", {parameter_dictionary})
공간 처리 툴박스에 있는 알고리즘 위에 마우스를 가져가면 알고리즘 ID 를 표시합니다. 파라미터 목록(dictionary) 은 파라미터 명칭 및 값을 제공합니다. 파이썬 콘솔에서 공간 처리 알고리즘을 어떻게 실행하는지 자세히 알고 싶다면 콘솔에서 공간 처리 알고리즘 사용 을 참조하세요.
25.1.11.2. Cell stack percentile
Calculates the cell-wise percentile value of a stack of rasters and writes the results to an output raster. The percentile to return is determined by the percentile input value (ranges between 0 and 1). At each cell location, the specified percentile is obtained using the respective value from the stack of all overlaid and sorted cell values of the input rasters.
There are three methods for percentile calculation:
Nearest rank: returns the value that is nearest to the specified percentile
Inclusive linear interpolation (PERCENTRANK.INC)
Exclusive linear interpolation (PERCENTRANK.EXC)
The linear interpolation methods return the unique values for different percentiles. Both interpolation methods follow their counterpart methods implemented by LibreOffice or Microsoft Excel.
The output raster’s extent and resolution is defined by a reference raster.
Input raster layers that do not match the cell size of the reference
raster layer will be resampled using nearest neighbor resampling.
NoData values in any of the input layers will result in a NoData cell output
if the “Ignore NoData values” parameter is not set.
The output raster data type will always be Float32.
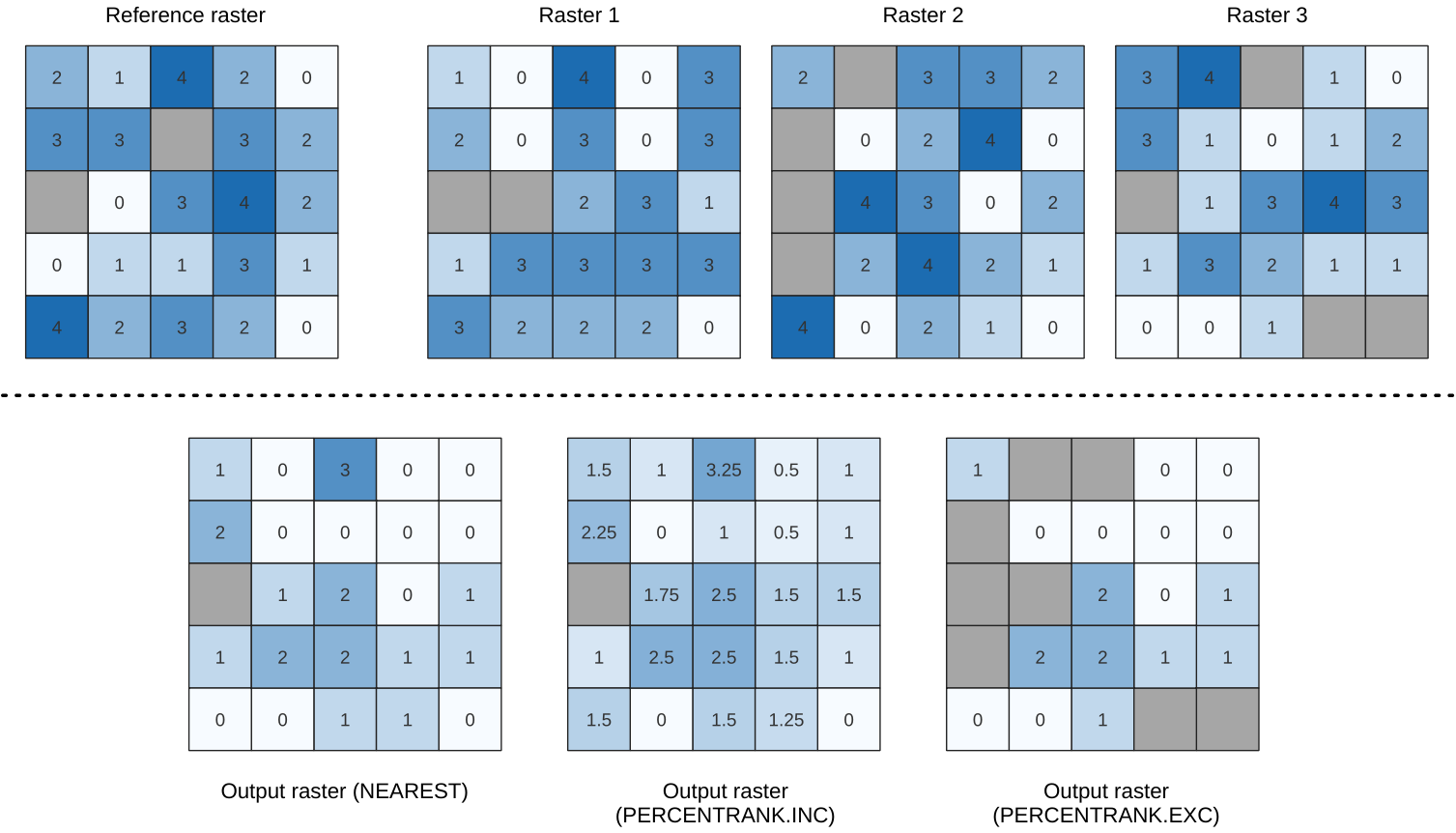
그림 25.11 Percentile = 0.25. NoData cells (grey) are ignored.
파라미터
기본 파라미터
라벨 |
명칭 |
유형 |
설명 |
|---|---|---|---|
Input layers |
|
[raster] [list] |
평가할 래스터 레이어들입니다. 데이터 래스터 스택에 다중밴드 래스터가 쓰인 경우, 이 알고리즘은 항상 래스터의 첫 번째 밴드에 분석을 수행할 것입니다. |
Method |
|
[enumeration] 기본값: 0 |
Method for percentile calculation:
|
Percentile |
|
[number] Default: 0.25 |
Value to rank among the respective values in the stack of all overlaid and sorted cell values from the input rasters. Between 0 and 1. |
Ignore NoData values |
|
[boolean] 기본값: True |
If unchecked, any NoData cells in the input layers will result in a NoData cell in the output raster |
Reference layer |
|
[raster] |
산출 래스터를 생성하기 위한 (범위, 좌표계, 픽셀 크기) 기준 레이어 |
Output layer |
|
[same as input] 기본값: |
산출 레이어를 지정합니다. 다음 가운데 하나로 저장할 수 있습니다:
|
고급 파라미터
라벨 |
명칭 |
유형 |
설명 |
|---|---|---|---|
Output no data value |
|
[number] 기본값: -9999.0 |
산출 레이어에서 NODATA용으로 사용할 값 |
산출물
라벨 |
명칭 |
유형 |
설명 |
|---|---|---|---|
Output layer |
|
[raster] |
결과물을 담고 있는 산출 래스터 레이어 |
CRS authority identifier |
|
[string] |
산출 래스터 레이어의 좌표계 |
Extent |
|
[string] |
산출 래스터 레이어의 공간 영역 |
Width in pixels |
|
[integer] |
산출 래스터 레이어의 열 개수 |
Height in pixels |
|
[integer] |
산출 래스터 레이어의 행 개수 |
Total pixel count |
|
[integer] |
산출 래스터 레이어의 픽셀 개수 |
파이썬 코드
Algorithm ID: native:cellstackpercentile
import processing
processing.run("algorithm_id", {parameter_dictionary})
공간 처리 툴박스에 있는 알고리즘 위에 마우스를 가져가면 알고리즘 ID 를 표시합니다. 파라미터 목록(dictionary) 은 파라미터 명칭 및 값을 제공합니다. 파이썬 콘솔에서 공간 처리 알고리즘을 어떻게 실행하는지 자세히 알고 싶다면 콘솔에서 공간 처리 알고리즘 사용 을 참조하세요.
25.1.11.3. Cell stack percentrank from raster layer
Calculates the cell-wise percentrank value of a stack of rasters based on an input value raster and writes them to an output raster.
At each cell location, the current value of the value raster is ranked among the respective values in the stack of all overlaid and sorted cell values of the input rasters. For values outside of the the stack value distribution, the algorithm returns NoData because the value cannot be ranked among the cell values.
There are two methods for percentile calculation:
Inclusive linear interpolation (PERCENTRANK.INC)
Exclusive linear interpolation (PERCENTRANK.EXC)
The linear interpolation methods return the unique values for different percentiles. Both interpolation methods follow their counterpart methods implemented by LibreOffice or Microsoft Excel.
The output raster’s extent and resolution is defined by a reference raster.
Input raster layers that do not match the cell size of the reference
raster layer will be resampled using nearest neighbor resampling.
NoData values in any of the input layers will result in a NoData cell output
if the “Ignore NoData values” parameter is not set.
The output raster data type will always be Float32.
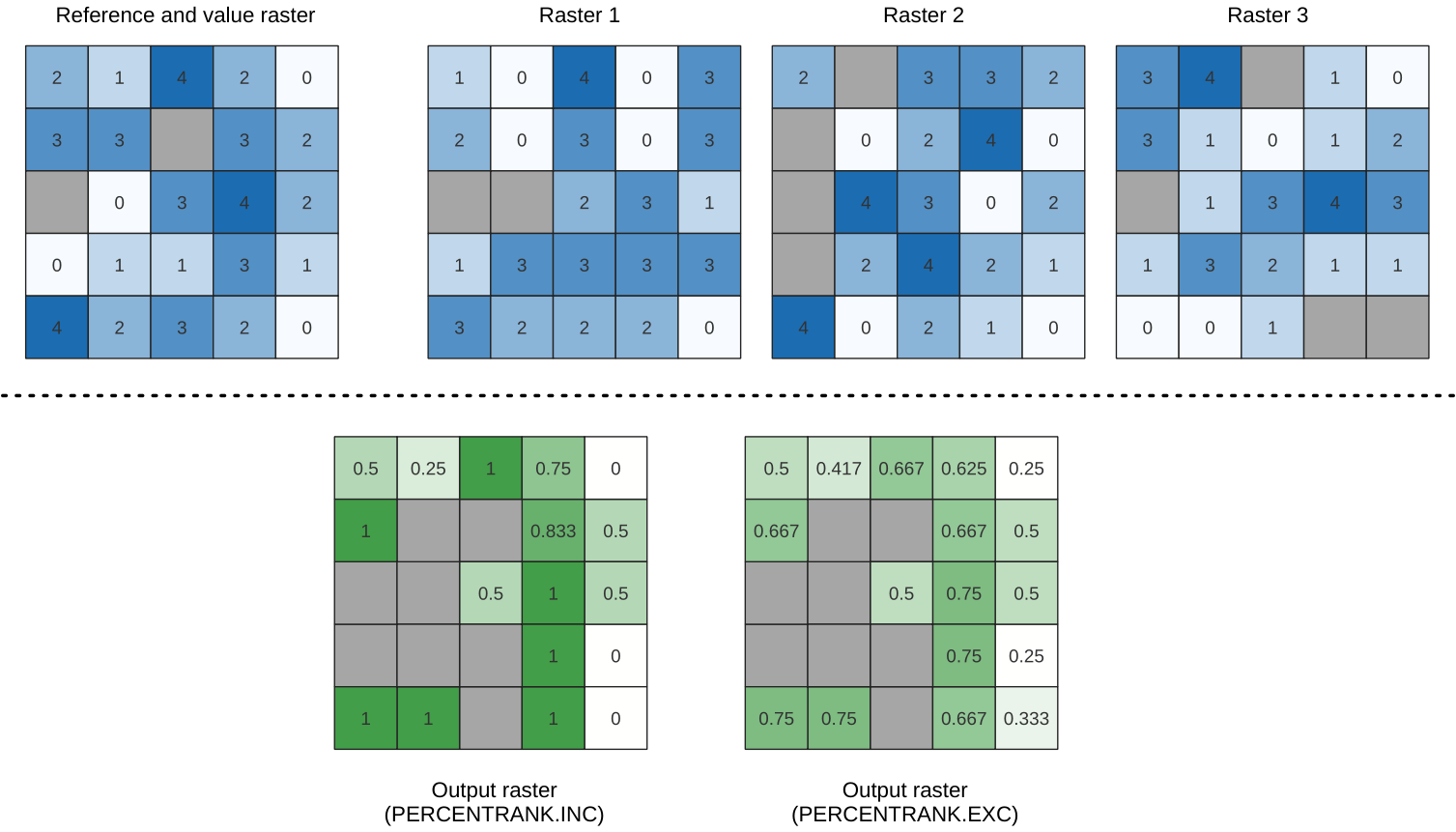
그림 25.12 Ranking the value raster layer cells. NoData cells (grey) are ignored.
파라미터
기본 파라미터
라벨 |
명칭 |
유형 |
설명 |
|---|---|---|---|
Input layers |
|
[raster] [list] |
평가할 래스터 레이어들입니다. 데이터 래스터 스택에 다중밴드 래스터가 쓰인 경우, 이 알고리즘은 항상 래스터의 첫 번째 밴드에 분석을 수행할 것입니다. |
Value raster layer |
|
[raster] |
The layer to rank the values among the stack of all overlaid layers |
Value raster band |
|
[integer] 기본값: 1 |
Band of the “value raster layer” to compare to |
Method |
|
[enumeration] 기본값: 0 |
Method for percentile calculation:
|
Ignore NoData values |
|
[boolean] 기본값: True |
If unchecked, any NoData cells in the input layers will result in a NoData cell in the output raster |
Reference layer |
|
[raster] |
산출 래스터를 생성하기 위한 (범위, 좌표계, 픽셀 크기) 기준 레이어 |
Output layer |
|
[same as input] 기본값: |
산출 레이어를 지정합니다. 다음 가운데 하나로 저장할 수 있습니다:
|
고급 파라미터
라벨 |
명칭 |
유형 |
설명 |
|---|---|---|---|
Output no data value |
|
[number] 기본값: -9999.0 |
산출 레이어에서 NODATA용으로 사용할 값 |
산출물
라벨 |
명칭 |
유형 |
설명 |
|---|---|---|---|
Output layer |
|
[raster] |
결과물을 담고 있는 산출 래스터 레이어 |
CRS authority identifier |
|
[string] |
산출 래스터 레이어의 좌표계 |
Extent |
|
[string] |
산출 래스터 레이어의 공간 영역 |
Width in pixels |
|
[integer] |
산출 래스터 레이어의 열 개수 |
Height in pixels |
|
[integer] |
산출 래스터 레이어의 행 개수 |
Total pixel count |
|
[integer] |
산출 래스터 레이어의 픽셀 개수 |
파이썬 코드
Algorithm ID: native:cellstackpercentrankfromrasterlayer
import processing
processing.run("algorithm_id", {parameter_dictionary})
공간 처리 툴박스에 있는 알고리즘 위에 마우스를 가져가면 알고리즘 ID 를 표시합니다. 파라미터 목록(dictionary) 은 파라미터 명칭 및 값을 제공합니다. 파이썬 콘솔에서 공간 처리 알고리즘을 어떻게 실행하는지 자세히 알고 싶다면 콘솔에서 공간 처리 알고리즘 사용 을 참조하세요.
25.1.11.4. 셀 통계
이 알고리즘은 입력 래스터 레이어를 기반으로 셀 당 통계를 계산한 다음 산출 래스터의 각 셀에 산출된 통계를 씁니다. 각 셀의 위치에서, 산출값은 모든 입력 래스터의 중첩된 셀 값들의 함수로 정의됩니다.
입력 레이어 가운데 하나에만 NODATA 셀이 있어도, 기본적으로 산출 래스터에서도 NODATA 셀로 산출될 것입니다. Ignore NoData values 옵션을 활성화한 경우, 통계 계산에서 NODATA 입력을 무시할 것입니다. 이때 해당 위치의 모든 셀이 NODATA인 경우 NODATA를 산출할 수도 있습니다.
Reference layer 파라미터는 산출 래스터 생성 시 참조물로 사용할 기존 래스터 레이어를 지정합니다. 산출 래스터는 참조 레이어와 동일한 범위, 좌표계, 그리고 픽셀 크기를 가질 것입니다.
계산 방법: 입력 레이어의 셀 크기가 참조 래스터 레이어의 셀 크기와 일치하지 않는 경우 입력 레이어를 nearest neighbor resampling 방법으로 리샘플링할 것입니다. Mean, Standard deviation 및 Variance 함수(입력 부동소수점 유형에 따라 항상 Float32 또는 Float64 유형입니다) 또는 Count 및 Variety 함수(항상 Int32 유형입니다)를 이용하는 경우를 제외하면, 산출 래스터 데이터 유형은 입력 데이터셋 가운데 가장 복잡도가 높은 데이터 유형으로 설정될 것입니다.
Count: 개수 통계는 언제나 현재 셀 위치에서 NODATA 값이 아닌 셀의 개수를 산출할 것입니다.Median: 입력 레이어의 숫자가 짝수일 경우, 정렬된 셀 입력 값의 두 가운데 값의 산술 평균으로 중간값을 계산할 것입니다.Minority/Majority: 유일한 희귀값이나 최빈값을 찾을 수 없는 경우, 모든 입력 셀의 값이 동등할 경우를 제외하고, NODATA를 산출합니다.
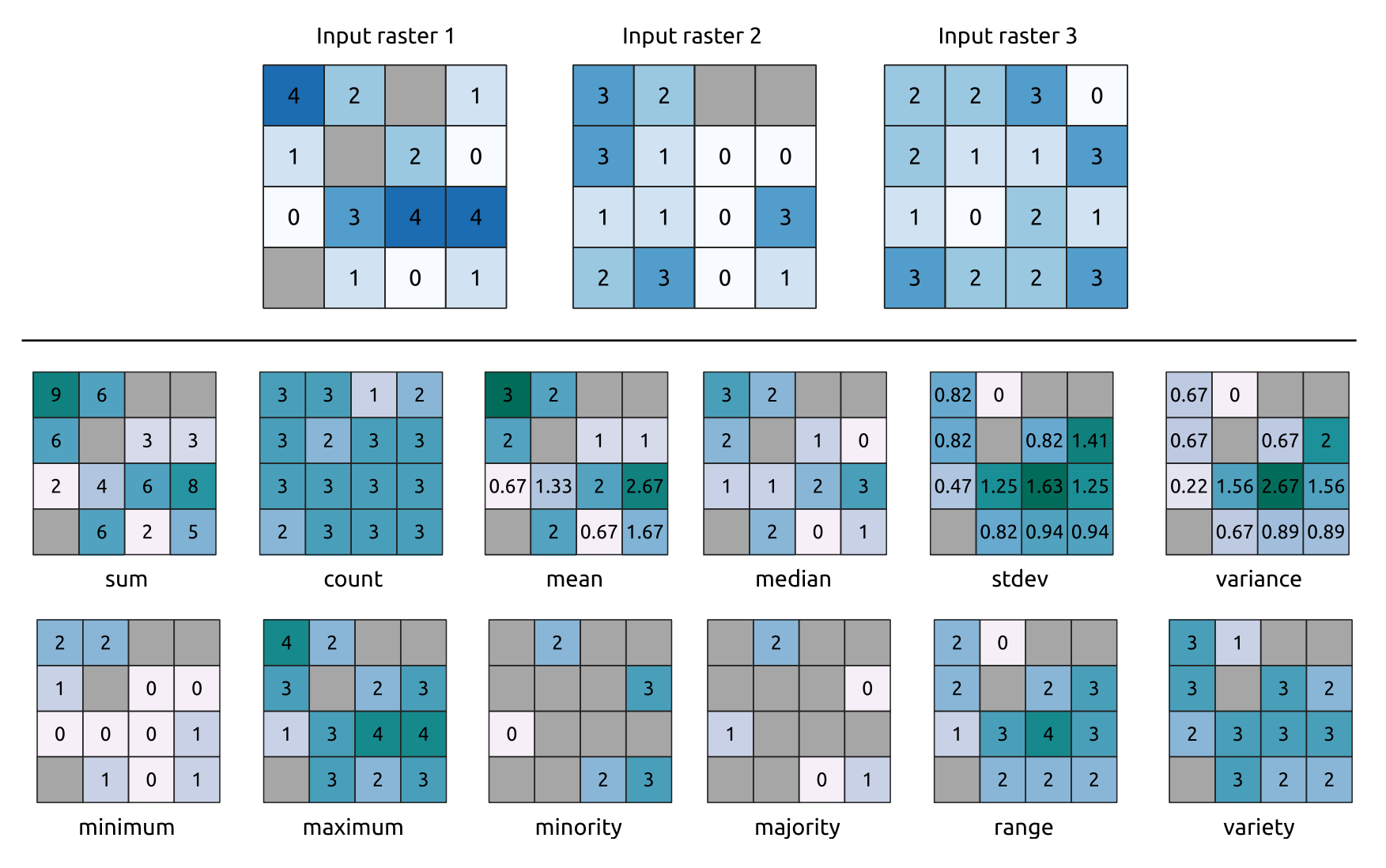
그림 25.13 모든 통계 함수의 예. NoData (회색) 셀도 계산에 넣습니다.
파라미터
기본 파라미터
라벨 |
명칭 |
유형 |
설명 |
|---|---|---|---|
Input layers |
|
[raster] [list] |
입력 래스터 레이어 |
Statistic |
|
[enumeration] 기본값: 0 |
다음과 같은 통계를 낼 수 있습니다:
|
Ignore NoData values |
|
[boolean] 기본값: True |
NODATA 셀을 무시하고 중첩한 모든 셀에 대해 통계를 계산합니다. |
Reference layer |
|
[raster] |
산출 레이어 생성 시 (범위, 좌표계, 픽셀 크기를) 참조할 참조 레이어 |
Output layer |
|
[same as input] 기본값: |
산출 레이어를 지정합니다. 다음 가운데 하나로 저장할 수 있습니다:
|
고급 파라미터
라벨 |
명칭 |
유형 |
설명 |
|---|---|---|---|
Output no data value 부가적 |
|
[number] 기본값: -9999.0 |
산출 레이어에서 NODATA용으로 사용할 값 |
산출물
라벨 |
명칭 |
유형 |
설명 |
|---|---|---|---|
CRS authority identifier |
|
[crs] |
산출 래스터 레이어의 좌표계 |
Extent |
|
[string] |
산출 래스터 레이어의 공간 영역 |
Height in pixels |
|
[integer] |
산출 래스터 레이어의 행 개수 |
Output raster |
|
[raster] |
결과물을 담고 있는 산출 래스터 레이어 |
Total pixel count |
|
[integer] |
산출 래스터 레이어의 픽셀 개수 |
Width in pixels |
|
[integer] |
산출 래스터 레이어의 열 개수 |
파이썬 코드
Algorithm ID: native:cellstatistics
import processing
processing.run("algorithm_id", {parameter_dictionary})
공간 처리 툴박스에 있는 알고리즘 위에 마우스를 가져가면 알고리즘 ID 를 표시합니다. 파라미터 목록(dictionary) 은 파라미터 명칭 및 값을 제공합니다. 파이썬 콘솔에서 공간 처리 알고리즘을 어떻게 실행하는지 자세히 알고 싶다면 콘솔에서 공간 처리 알고리즘 사용 을 참조하세요.
25.1.11.5. 빈도와 동일
이 알고리즘은 셀바이셀(cell-by-cell) 기준으로 입력 래스터 스택의 값들의 빈도(횟수)가 값 레이어의 값과 동일한지 평가합니다. 입력 래스터 레이어가 산출 래스터의 범위 및 해상도를 정의하고, 산출 래스터는 언제나 Int32 유형입니다.
데이터 래스터 스택에 다중밴드 래스터가 쓰인 경우, 이 알고리즘은 항상 래스터의 첫 번째 밴드에 분석을 수행할 것입니다 – 다른 밴드를 분석하려면 GDAL을 이용하십시오. 산출 NODATA 값은 직접 설정할 수 있습니다.
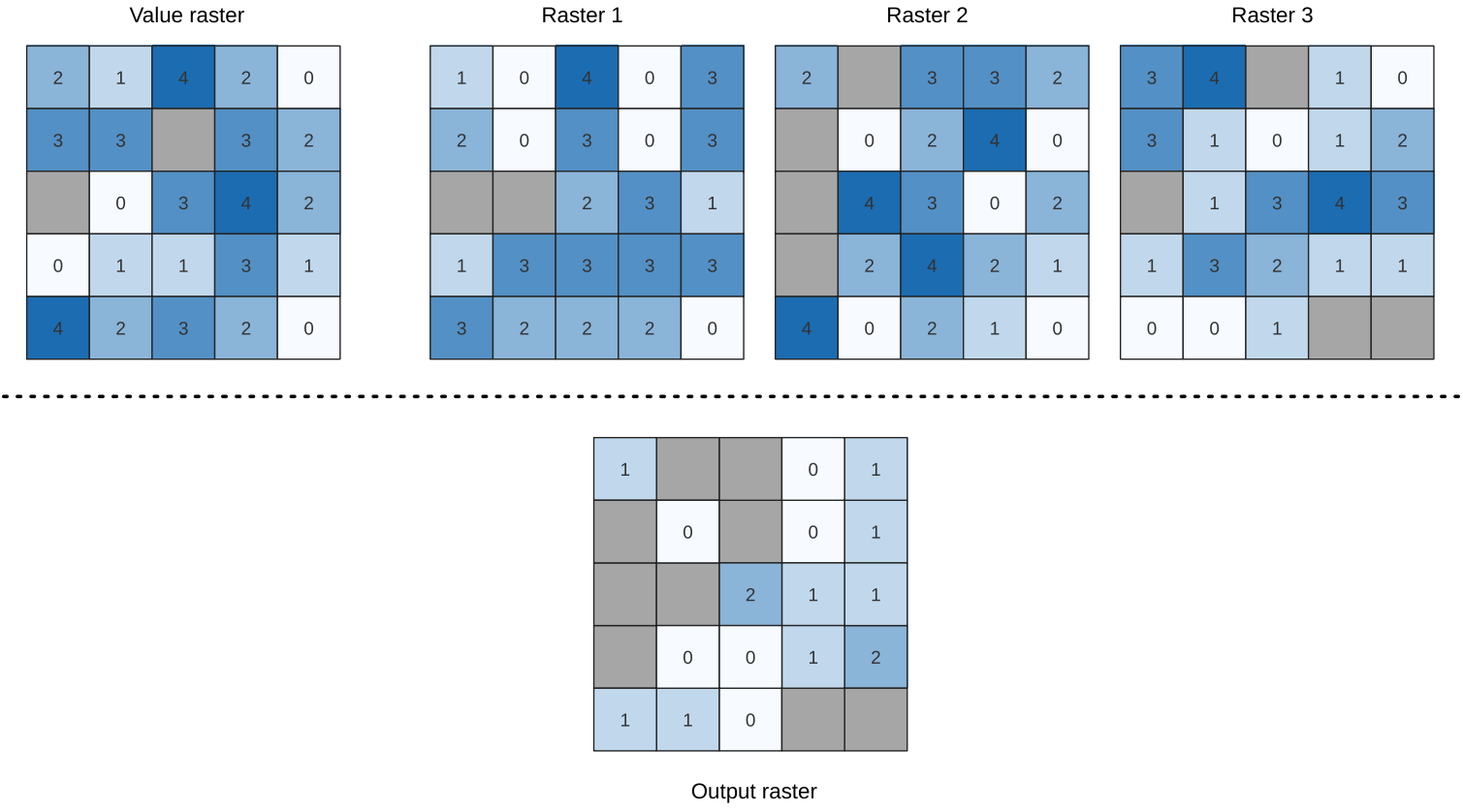
그림 25.14 산출 래스터에 있는 각 셀의 값은 래스터 목록에서 대응하는 셀의 값이 값 래스터의 해당 셀의 값과 동일한 횟수를 나타냅니다. NoData (회색) 셀도 고려합니다.
파라미터
기본 파라미터
라벨 |
명칭 |
유형 |
설명 |
|---|---|---|---|
Input value raster |
|
[raster] |
입력 값 레이어는 샘플 레이어들을 위한 기준 레이어 역할을 합니다. |
Value raster band |
|
[raster band] 기본값: 래스터 레이어의 첫 번째 밴드 |
샘플로 사용하려는 밴드를 선택하십시오. |
Input raster layers |
|
[raster] [list] |
평가할 래스터 레이어들입니다. 데이터 래스터 스택에 다중밴드 래스터가 쓰인 경우, 이 알고리즘은 항상 래스터의 첫 번째 밴드에 분석을 수행할 것입니다. |
Ignore NoData values |
|
[boolean] 기본값: False |
이 옵션을 체크하지 않을 경우, 값 래스터 또는 데이터 레이어 스택에 있는 모든 NODATA 셀이 산출 래스터에서 NODATA 셀로 산출될 것입니다. |
Output layer |
|
[same as input] 기본값: |
산출 레이어를 지정합니다. 다음 가운데 하나로 저장할 수 있습니다:
|
고급 파라미터
라벨 |
명칭 |
유형 |
설명 |
|---|---|---|---|
Output no data value 부가적 |
|
[number] 기본값: -9999.0 |
산출 레이어에서 NODATA용으로 사용할 값 |
산출물
라벨 |
명칭 |
유형 |
설명 |
|---|---|---|---|
Output layer |
|
[raster] |
결과물을 담고 있는 산출 래스터 레이어 |
CRS authority identifier |
|
[string] |
산출 래스터 레이어의 좌표계 |
Extent |
|
[string] |
산출 래스터 레이어의 공간 영역 |
Count of cells with equal value occurrences |
|
[number] |
|
Height in pixels |
|
[number] |
산출 래스터 레이어의 행 개수 |
Total pixel count |
|
[integer] |
산출 래스터 레이어의 픽셀 개수 |
Mean frequency at valid cell locations |
|
[number] |
|
Count of value occurrences |
|
[number] |
|
Width in pixels |
|
[integer] |
산출 래스터 레이어의 열 개수 |
파이썬 코드
알고리즘 ID: native:equaltofrequency
import processing
processing.run("algorithm_id", {parameter_dictionary})
공간 처리 툴박스에 있는 알고리즘 위에 마우스를 가져가면 알고리즘 ID 를 표시합니다. 파라미터 목록(dictionary) 은 파라미터 명칭 및 값을 제공합니다. 파이썬 콘솔에서 공간 처리 알고리즘을 어떻게 실행하는지 자세히 알고 싶다면 콘솔에서 공간 처리 알고리즘 사용 을 참조하세요.
25.1.11.6. 래스터 퍼지화 (가우스 멤버십)
이 알고리즘은 가우스 멤버십(gaussian membership) 함수를 통해 입력 래스터의 각 셀에 멤버십 값을 할당해서 입력 래스터를 퍼지화한 래스터로 변형시킵니다. 멤버십 값의 범위는 0에서 1까지입니다. 퍼지화된 래스터에서 0값은 정의된 퍼지 집합(fuzzy set)에 속하지 않는다는 의미이며, 1은 완전히 속한다는 뜻입니다. 가우스 멤버십 함수는 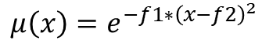 으로 정의되는데, f1 이 확산(spread)이고 f2 는 중점(midpoint)입니다.
으로 정의되는데, f1 이 확산(spread)이고 f2 는 중점(midpoint)입니다.
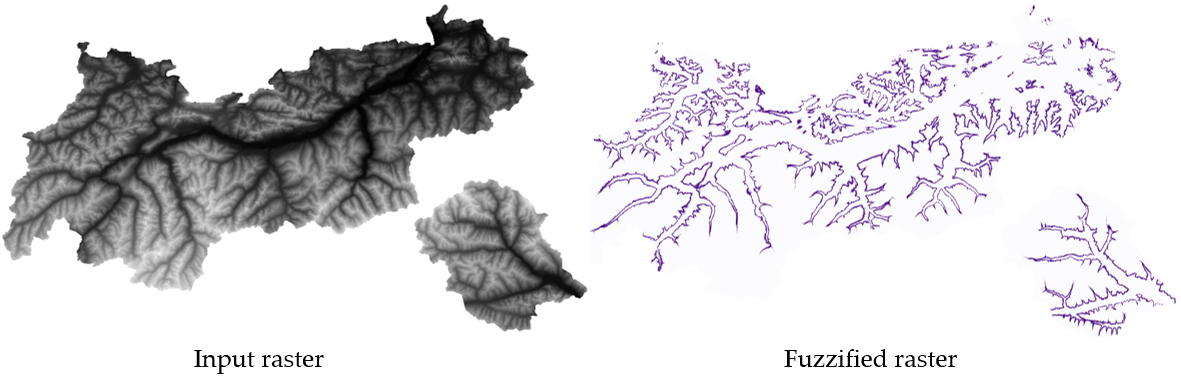
그림 25.15 래스터 퍼지화의 예. 입력 래스터 소스: 오스트리아 티롤 지역 - data.tirol.gv.at
파라미터
라벨 |
명칭 |
유형 |
설명 |
|---|---|---|---|
Input Raster |
|
[raster] |
입력 래스터 레이어 |
Band Number |
|
[raster band] 기본값: 래스터 레이어의 첫 번째 밴드 |
래스터가 다중 밴드인 경우, 퍼지화하려는 밴드를 선택하십시오. |
Function midpoint |
|
[number] 기본값: 10 |
가우스 함수의 중점 |
Function spread |
|
[number] 기본값: 0.01 |
가우스 함수의 확산 |
Fuzzified raster |
|
[same as input] 기본값: |
산출 레이어를 지정합니다. 다음 가운데 하나로 저장할 수 있습니다:
|
산출물
라벨 |
명칭 |
유형 |
설명 |
|---|---|---|---|
Fuzzified raster |
|
[same as input] |
결과물을 담고 있는 산출 래스터 레이어 |
CRS authority identifier |
|
[crs] |
산출 래스터 레이어의 좌표계 |
Extent |
|
[string] |
산출 래스터 레이어의 공간 영역 |
Width in pixels |
|
[integer] |
산출 래스터 레이어의 열 개수 |
Height in pixels |
|
[integer] |
산출 래스터 레이어의 행 개수 |
Total pixel count |
|
[integer] |
산출 래스터 레이어의 픽셀 개수 |
파이썬 코드
Algorithm ID: native:fuzzifyrastergaussianmembership
import processing
processing.run("algorithm_id", {parameter_dictionary})
공간 처리 툴박스에 있는 알고리즘 위에 마우스를 가져가면 알고리즘 ID 를 표시합니다. 파라미터 목록(dictionary) 은 파라미터 명칭 및 값을 제공합니다. 파이썬 콘솔에서 공간 처리 알고리즘을 어떻게 실행하는지 자세히 알고 싶다면 콘솔에서 공간 처리 알고리즘 사용 을 참조하세요.
25.1.11.7. 래스터 퍼지화 (큰 값 멤버십)
이 알고리즘은 큰 값 멤버십(large membership) 함수를 통해 입력 래스터의 각 셀에 멤버십 값을 할당해서 입력 래스터를 퍼지화한 래스터로 변형시킵니다. 멤버십 값의 범위는 0에서 1까지입니다. 퍼지화된 래스터에서 0값은 정의된 퍼지 집합(fuzzy set)에 속하지 않는다는 의미이며, 1은 완전히 속한다는 뜻입니다. 큰 값 멤버십 함수는 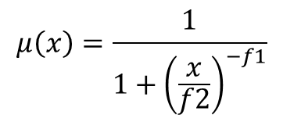 로 정의되는데, f1 이 확산(spread)이고 f2 는 중점(midpoint)입니다.
로 정의되는데, f1 이 확산(spread)이고 f2 는 중점(midpoint)입니다.
파라미터
라벨 |
명칭 |
유형 |
설명 |
|---|---|---|---|
Input Raster |
|
[raster] |
입력 래스터 레이어 |
Band Number |
|
[raster band] 기본값: 래스터 레이어의 첫 번째 밴드 |
래스터가 다중 밴드인 경우, 퍼지화하려는 밴드를 선택하십시오. |
Function midpoint |
|
[number] 기본값: 50 |
큰 값 함수의 중점 |
Function spread |
|
[number] 기본값: 5 |
큰 값 함수의 확산 |
Fuzzified raster |
|
[same as input] 기본값: |
산출 레이어를 지정합니다. 다음 가운데 하나로 저장할 수 있습니다:
|
산출물
라벨 |
명칭 |
유형 |
설명 |
|---|---|---|---|
Fuzzified raster |
|
[same as input] |
결과물을 담고 있는 산출 래스터 레이어 |
CRS authority identifier |
|
[crs] |
산출 래스터 레이어의 좌표계 |
Extent |
|
[string] |
산출 래스터 레이어의 공간 영역 |
Width in pixels |
|
[integer] |
산출 래스터 레이어의 열 개수 |
Height in pixels |
|
[integer] |
산출 래스터 레이어의 행 개수 |
Total pixel count |
|
[integer] |
산출 래스터 레이어의 픽셀 개수 |
파이썬 코드
Algorithm ID: native:fuzzifyrasterlargemembership
import processing
processing.run("algorithm_id", {parameter_dictionary})
공간 처리 툴박스에 있는 알고리즘 위에 마우스를 가져가면 알고리즘 ID 를 표시합니다. 파라미터 목록(dictionary) 은 파라미터 명칭 및 값을 제공합니다. 파이썬 콘솔에서 공간 처리 알고리즘을 어떻게 실행하는지 자세히 알고 싶다면 콘솔에서 공간 처리 알고리즘 사용 을 참조하세요.
25.1.11.8. 래스터 퍼지화 (선형 멤버십)
이 알고리즘은 선형 멤버십(linear membership) 함수를 통해 입력 래스터의 각 셀에 멤버십 값을 할당해서 입력 래스터를 퍼지화한 래스터로 변형시킵니다. 멤버십 값의 범위는 0에서 1까지입니다. 퍼지화된 래스터에서 0값은 정의된 퍼지 집합(fuzzy set)에 속하지 않는다는 의미이며, 1은 완전히 속한다는 뜻입니다. 선형 멤버십 함수는 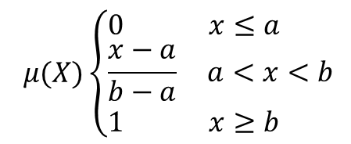 로 정의되는데, a 가 하한(low bound)이고 b 는 상한(high bound)입니다. 이 방정식은 하한과 상한 사이에 있는 픽셀 값에 선형 변형을 통해 멤버십 값을 할당합니다. 하한보다 작은 픽셀 값은 0을 할당받으며, 상한보다 큰 픽셀 값은 1을 할당받습니다.
로 정의되는데, a 가 하한(low bound)이고 b 는 상한(high bound)입니다. 이 방정식은 하한과 상한 사이에 있는 픽셀 값에 선형 변형을 통해 멤버십 값을 할당합니다. 하한보다 작은 픽셀 값은 0을 할당받으며, 상한보다 큰 픽셀 값은 1을 할당받습니다.
파라미터
라벨 |
명칭 |
유형 |
설명 |
|---|---|---|---|
Input Raster |
|
[raster] |
입력 래스터 레이어 |
Band Number |
|
[raster band] 기본값: 래스터 레이어의 첫 번째 밴드 |
래스터가 다중 밴드인 경우, 퍼지화하려는 밴드를 선택하십시오. |
Low fuzzy membership bound |
|
[number] 기본값: 0 |
선형 함수의 하한 |
High fuzzy membership bound |
|
[number] 기본값: 1 |
선형 함수의 상한 |
Fuzzified raster |
|
[same as input] 기본값: |
산출 레이어를 지정합니다. 다음 가운데 하나로 저장할 수 있습니다:
|
산출물
라벨 |
명칭 |
유형 |
설명 |
|---|---|---|---|
Fuzzified raster |
|
[same as input] |
결과물을 담고 있는 산출 래스터 레이어 |
CRS authority identifier |
|
[crs] |
산출 래스터 레이어의 좌표계 |
Extent |
|
[string] |
산출 래스터 레이어의 공간 영역 |
Width in pixels |
|
[integer] |
산출 래스터 레이어의 열 개수 |
Height in pixels |
|
[integer] |
산출 래스터 레이어의 행 개수 |
Total pixel count |
|
[integer] |
산출 래스터 레이어의 픽셀 개수 |
파이썬 코드
Algorithm ID: native:fuzzifyrasterlinearmembership
import processing
processing.run("algorithm_id", {parameter_dictionary})
공간 처리 툴박스에 있는 알고리즘 위에 마우스를 가져가면 알고리즘 ID 를 표시합니다. 파라미터 목록(dictionary) 은 파라미터 명칭 및 값을 제공합니다. 파이썬 콘솔에서 공간 처리 알고리즘을 어떻게 실행하는지 자세히 알고 싶다면 콘솔에서 공간 처리 알고리즘 사용 을 참조하세요.
25.1.11.9. 래스터 퍼지화 (근접 멤버십)
이 알고리즘은 근접 멤버십(near membership) 함수를 통해 입력 래스터의 각 셀에 멤버십 값을 할당해서 입력 래스터를 퍼지화한 래스터로 변형시킵니다. 멤버십 값의 범위는 0에서 1까지입니다. 퍼지화된 래스터에서 0값은 정의된 퍼지 집합(fuzzy set)에 속하지 않는다는 의미이며, 1은 완전히 속한다는 뜻입니다. 근접 멤버십 함수는 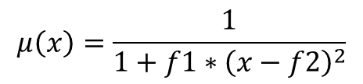 로 정의되는데, f1 이 확산(spread)이고 f2 는 중점(midpoint)입니다.
로 정의되는데, f1 이 확산(spread)이고 f2 는 중점(midpoint)입니다.
파라미터
라벨 |
명칭 |
유형 |
설명 |
|---|---|---|---|
Input Raster |
|
[raster] |
입력 래스터 레이어 |
Band Number |
|
[raster band] 기본값: 래스터 레이어의 첫 번째 밴드 |
래스터가 다중 밴드인 경우, 퍼지화하려는 밴드를 선택하십시오. |
Function midpoint |
|
[number] 기본값: 50 |
근접 함수의 중점 |
Function spread |
|
[number] 기본값: 0.01 |
근접 함수의 확산 |
Fuzzified raster |
|
[same as input] 기본값: |
산출 레이어를 지정합니다. 다음 가운데 하나로 저장할 수 있습니다:
|
산출물
라벨 |
명칭 |
유형 |
설명 |
|---|---|---|---|
Fuzzified raster |
|
[same as input] |
결과물을 담고 있는 산출 래스터 레이어 |
CRS authority identifier |
|
[crs] |
산출 래스터 레이어의 좌표계 |
Extent |
|
[string] |
산출 래스터 레이어의 공간 영역 |
Width in pixels |
|
[integer] |
산출 래스터 레이어의 열 개수 |
Height in pixels |
|
[integer] |
산출 래스터 레이어의 행 개수 |
Total pixel count |
|
[integer] |
산출 래스터 레이어의 픽셀 개수 |
파이썬 코드
Algorithm ID: native:fuzzifyrasternearmembership
import processing
processing.run("algorithm_id", {parameter_dictionary})
공간 처리 툴박스에 있는 알고리즘 위에 마우스를 가져가면 알고리즘 ID 를 표시합니다. 파라미터 목록(dictionary) 은 파라미터 명칭 및 값을 제공합니다. 파이썬 콘솔에서 공간 처리 알고리즘을 어떻게 실행하는지 자세히 알고 싶다면 콘솔에서 공간 처리 알고리즘 사용 을 참조하세요.
25.1.11.10. 래스터 퍼지화 (거듭제곱 멤버십)
이 알고리즘은 거듭제곱 멤버십(power membership) 함수를 통해 입력 래스터의 각 셀에 멤버십 값을 할당해서 입력 래스터를 퍼지화한 래스터로 변형시킵니다. 멤버십 값의 범위는 0에서 1까지입니다. 퍼지화된 래스터에서 0값은 정의된 퍼지 집합(fuzzy set)에 속하지 않는다는 의미이며, 1은 완전히 속한다는 뜻입니다. 거듭제곱 멤버십 함수는 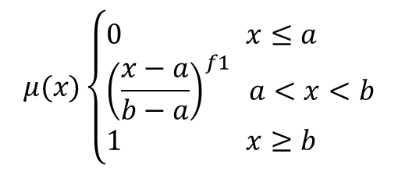 로 정의되는데, a 가 하한(low bound)이고 b 는 상한(high bound)이며, f1 은 지수(exponent)입니다. 이 방정식은 하한과 상한 사이에 있는 픽셀 값에 거듭제곱 변형을 통해 멤버십 값을 할당합니다. 하한보다 작은 픽셀 값은 0을 할당받으며, 상한보다 큰 픽셀 값은 1을 할당받습니다.
로 정의되는데, a 가 하한(low bound)이고 b 는 상한(high bound)이며, f1 은 지수(exponent)입니다. 이 방정식은 하한과 상한 사이에 있는 픽셀 값에 거듭제곱 변형을 통해 멤버십 값을 할당합니다. 하한보다 작은 픽셀 값은 0을 할당받으며, 상한보다 큰 픽셀 값은 1을 할당받습니다.
파라미터
라벨 |
명칭 |
유형 |
설명 |
|---|---|---|---|
Input Raster |
|
[raster] |
입력 래스터 레이어 |
Band Number |
|
[raster band] 기본값: 래스터 레이어의 첫 번째 밴드 |
래스터가 다중 밴드인 경우, 퍼지화하려는 밴드를 선택하십시오. |
Low fuzzy membership bound |
|
[number] 기본값: 0 |
거듭제곱 함수의 하한 |
High fuzzy membership bound |
|
[number] 기본값: 1 |
거듭제곱 함수의 상한 |
High fuzzy membership bound |
|
[number] 기본값: 2 |
거듭제곱 함수의 지수 |
Fuzzified raster |
|
[same as input] 기본값: |
산출 레이어를 지정합니다. 다음 가운데 하나로 저장할 수 있습니다:
|
산출물
라벨 |
명칭 |
유형 |
설명 |
|---|---|---|---|
Fuzzified raster |
|
[same as input] |
결과물을 담고 있는 산출 래스터 레이어 |
CRS authority identifier |
|
[crs] |
산출 래스터 레이어의 좌표계 |
Extent |
|
[string] |
산출 래스터 레이어의 공간 영역 |
Width in pixels |
|
[integer] |
산출 래스터 레이어의 열 개수 |
Height in pixels |
|
[integer] |
산출 래스터 레이어의 행 개수 |
Total pixel count |
|
[integer] |
산출 래스터 레이어의 픽셀 개수 |
파이썬 코드
Algorithm ID: native:fuzzifyrasterpowermembership
import processing
processing.run("algorithm_id", {parameter_dictionary})
공간 처리 툴박스에 있는 알고리즘 위에 마우스를 가져가면 알고리즘 ID 를 표시합니다. 파라미터 목록(dictionary) 은 파라미터 명칭 및 값을 제공합니다. 파이썬 콘솔에서 공간 처리 알고리즘을 어떻게 실행하는지 자세히 알고 싶다면 콘솔에서 공간 처리 알고리즘 사용 을 참조하세요.
25.1.11.11. 래스터 퍼지화 (작은 값 멤버십)
이 알고리즘은 작은 값 멤버십(small membership) 함수를 통해 입력 래스터의 각 셀에 멤버십 값을 할당해서 입력 래스터를 퍼지화한 래스터로 변형시킵니다. 멤버십 값의 범위는 0에서 1까지입니다. 퍼지화된 래스터에서 0값은 정의된 퍼지 집합(fuzzy set)에 속하지 않는다는 의미이며, 1은 완전히 속한다는 뜻입니다. 작은 값 멤버십 함수는 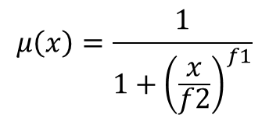 로 정의되는데, f1 이 확산(spread)이고 f2 는 중점(midpoint)입니다.
로 정의되는데, f1 이 확산(spread)이고 f2 는 중점(midpoint)입니다.
파라미터
라벨 |
명칭 |
유형 |
설명 |
|---|---|---|---|
Input Raster |
|
[raster] |
입력 래스터 레이어 |
Band Number |
|
[raster band] 기본값: 래스터 레이어의 첫 번째 밴드 |
래스터가 다중 밴드인 경우, 퍼지화하려는 밴드를 선택하십시오. |
Function midpoint |
|
[number] 기본값: 50 |
작은 값 함수의 중점 |
Function spread |
|
[number] 기본값: 5 |
작은 값 함수의 확산 |
Fuzzified raster |
|
[same as input] 기본값: |
산출 레이어를 지정합니다. 다음 가운데 하나로 저장할 수 있습니다:
|
산출물
라벨 |
명칭 |
유형 |
설명 |
|---|---|---|---|
Fuzzified raster |
|
[same as input] |
결과물을 담고 있는 산출 래스터 레이어 |
CRS authority identifier |
|
[crs] |
산출 래스터 레이어의 좌표계 |
Extent |
|
[string] |
산출 래스터 레이어의 공간 영역 |
Width in pixels |
|
[integer] |
산출 래스터 레이어의 열 개수 |
Height in pixels |
|
[integer] |
산출 래스터 레이어의 행 개수 |
Total pixel count |
|
[integer] |
산출 래스터 레이어의 픽셀 개수 |
파이썬 코드
Algorithm ID: native:fuzzifyrastersmallmembership
import processing
processing.run("algorithm_id", {parameter_dictionary})
공간 처리 툴박스에 있는 알고리즘 위에 마우스를 가져가면 알고리즘 ID 를 표시합니다. 파라미터 목록(dictionary) 은 파라미터 명칭 및 값을 제공합니다. 파이썬 콘솔에서 공간 처리 알고리즘을 어떻게 실행하는지 자세히 알고 싶다면 콘솔에서 공간 처리 알고리즘 사용 을 참조하세요.
25.1.11.12. 빈도 초과
이 알고리즘은 셀바이셀(cell-by-cell) 기준으로 입력 래스터 스택의 값들의 빈도(횟수)가 값 래스터의 값을 초과하는지 평가합니다. 입력 래스터 레이어가 산출 래스터의 범위 및 해상도를 정의하고, 산출 래스터는 언제나 Int32 유형입니다.
데이터 래스터 스택에 다중밴드 래스터가 쓰인 경우, 이 알고리즘은 항상 래스터의 첫 번째 밴드에 분석을 수행할 것입니다 – 다른 밴드를 분석하려면 GDAL을 이용하십시오. 산출 NODATA 값은 직접 설정할 수 있습니다.
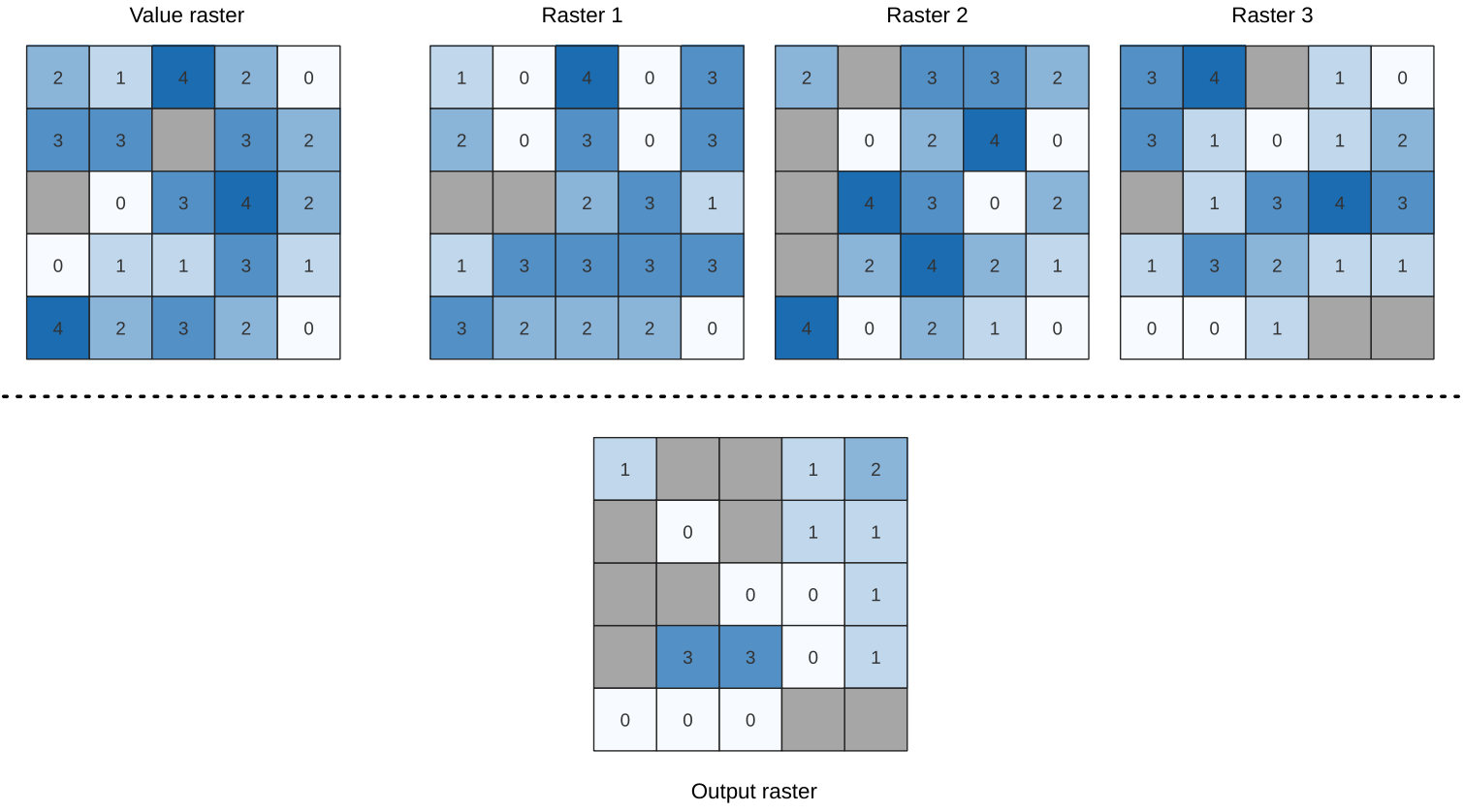
그림 25.16 산출 래스터에 있는 각 셀의 값은 래스터 목록에서 대응하는 셀의 값이 값 래스터의 해당 셀의 값을 초과하는 횟수를 나타냅니다. NoData (회색) 셀도 고려합니다.
파라미터
기본 파라미터
라벨 |
명칭 |
유형 |
설명 |
|---|---|---|---|
Input value raster |
|
[raster] |
입력 값 레이어는 샘플 레이어들을 위한 기준 레이어 역할을 합니다. |
Value raster band |
|
[raster band] 기본값: 래스터 레이어의 첫 번째 밴드 |
샘플로 사용하려는 밴드를 선택하십시오. |
Input raster layers |
|
[raster] [list] |
평가할 래스터 레이어들입니다. 데이터 래스터 스택에 다중밴드 래스터가 쓰인 경우, 이 알고리즘은 항상 래스터의 첫 번째 밴드에 분석을 수행할 것입니다. |
Ignore NoData values |
|
[boolean] 기본값: False |
이 옵션을 체크하지 않을 경우, 값 래스터 또는 데이터 레이어 스택에 있는 모든 NODATA 셀이 산출 래스터에서 NODATA 셀로 산출될 것입니다. |
Output layer |
|
[same as input] 기본값: |
산출 레이어를 지정합니다. 다음 가운데 하나로 저장할 수 있습니다:
|
고급 파라미터
라벨 |
명칭 |
유형 |
설명 |
|---|---|---|---|
Output no data value 부가적 |
|
[number] 기본값: -9999.0 |
산출 레이어에서 NODATA용으로 사용할 값 |
산출물
라벨 |
명칭 |
유형 |
설명 |
|---|---|---|---|
Output layer |
|
[raster] |
결과물을 담고 있는 산출 래스터 레이어 |
CRS authority identifier |
|
[string] |
산출 래스터 레이어의 좌표계 |
Extent |
|
[string] |
산출 래스터 레이어의 공간 영역 |
Count of cells with equal value occurrences |
|
[number] |
|
Height in pixels |
|
[number] |
산출 래스터 레이어의 행 개수 |
Total pixel count |
|
[integer] |
산출 래스터 레이어의 픽셀 개수 |
Mean frequency at valid cell locations |
|
[number] |
|
Count of value occurrences |
|
[number] |
|
Width in pixels |
|
[integer] |
산출 래스터 레이어의 열 개수 |
파이썬 코드
알고리즘 ID: native:greaterthanfrequency
import processing
processing.run("algorithm_id", {parameter_dictionary})
공간 처리 툴박스에 있는 알고리즘 위에 마우스를 가져가면 알고리즘 ID 를 표시합니다. 파라미터 목록(dictionary) 은 파라미터 명칭 및 값을 제공합니다. 파이썬 콘솔에서 공간 처리 알고리즘을 어떻게 실행하는지 자세히 알고 싶다면 콘솔에서 공간 처리 알고리즘 사용 을 참조하세요.
25.1.11.13. 래스터 스택에서 가장 높은 위치
이 알고리즘은 셀바이셀(cell-by-cell) 기준으로 래스터 스택에서 가장 높은 값을 가진 래스터의 위치를 평가합니다. 위치는 1로 시작해서 입력 래스터의 총 개수까지 셉니다. 입력 래스터들의 순서와 알고리즘은 관계가 있습니다. 가장 높은 값을 가진 래스터가 여러 개일 경우, 첫 번째 래스터를 위치 값으로 사용할 것입니다.
데이터 래스터 스택에 다중밴드 래스터가 쓰인 경우, 이 알고리즘은 항상 래스터의 첫 번째 밴드에 분석을 수행할 것입니다 – 다른 밴드를 분석하려면 GDAL을 이용하십시오. “ignore NoData” 파라미터를 체크하지 않을 경우, 래스터 레이어 스택에 있는 모든 NODATA 셀이 산출 래스터에서 NODATA 셀로 산출될 것입니다. 산출 NODATA 값은 직접 설정할 수 있습니다. 기준 래스터 레이어가 산출 래스터의 범위 및 해상도를 정의하고, 산출 래스터는 언제나 Int32 유형입니다.
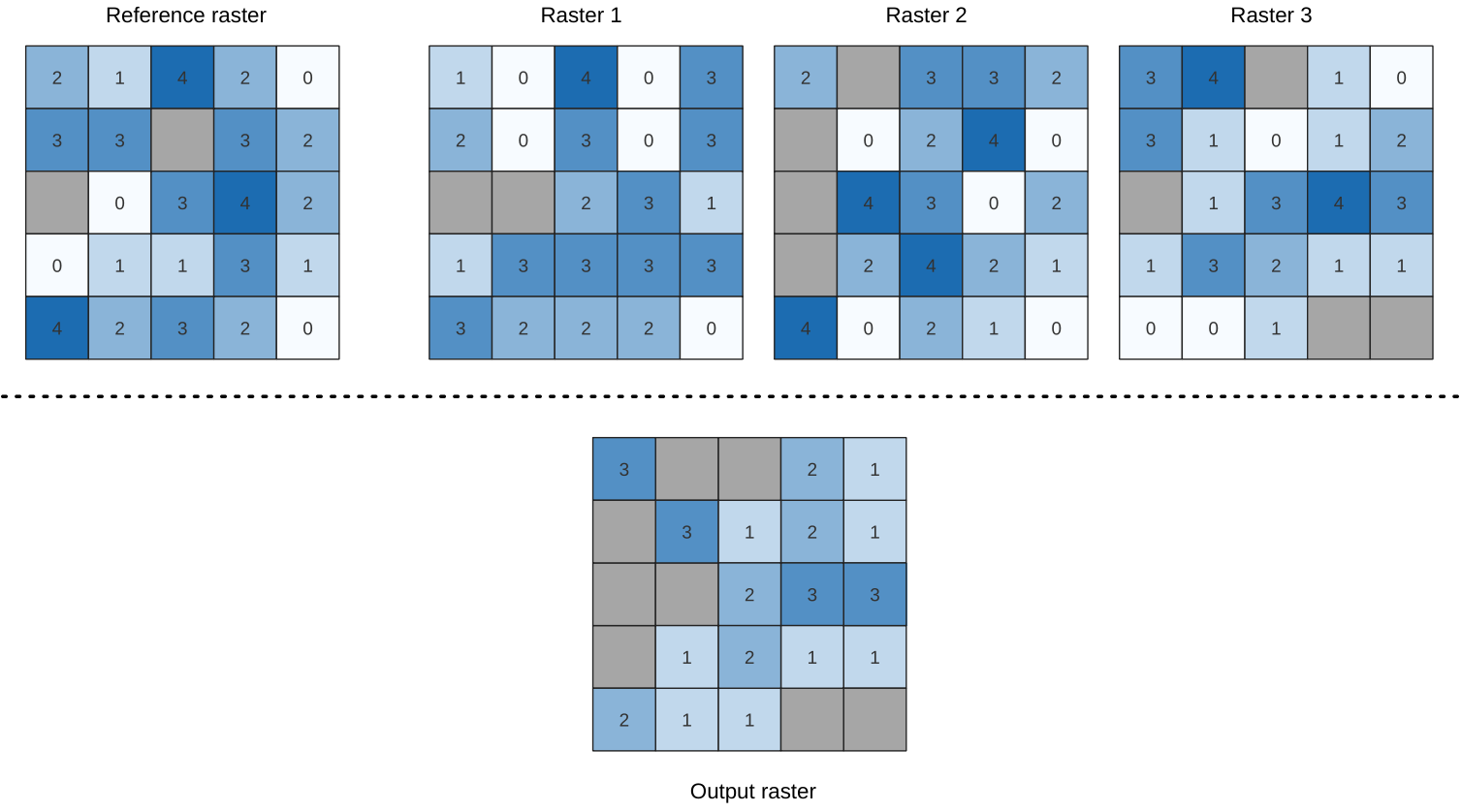
더 보기
파라미터
기본 파라미터
라벨 |
명칭 |
유형 |
설명 |
|---|---|---|---|
Input raster layers |
|
[raster] [list] |
비교할 래스터 레이어들의 목록 |
Reference layer |
|
[raster] |
산출 래스터를 생성하기 위한 (범위, 좌표계, 픽셀 크기) 기준 레이어 |
Ignore NoData values |
|
[boolean] 기본값: False |
이 옵션을 체크하지 않을 경우, 데이터 레이어 스택에 있는 모든 NODATA 셀이 산출 래스터에서 NODATA 셀로 산출될 것입니다. |
Output layer |
|
[raster] 기본값: |
결과를 담을 산출 래스터를 지정합니다. 다음 가운데 하나로 저장할 수 있습니다:
|
고급 파라미터
라벨 |
명칭 |
유형 |
설명 |
|---|---|---|---|
Output no data value |
|
[number] 기본값: -9999.0 |
산출 레이어에서 NODATA용으로 사용할 값 |
산출물
라벨 |
명칭 |
유형 |
설명 |
|---|---|---|---|
Output layer |
|
[raster] |
결과물을 담고 있는 산출 래스터 레이어 |
CRS authority identifier |
|
[string] |
산출 래스터 레이어의 좌표계 |
Extent |
|
[string] |
산출 래스터 레이어의 공간 영역 |
Width in pixels |
|
[integer] |
산출 래스터 레이어의 열 개수 |
Height in pixels |
|
[integer] |
산출 래스터 레이어의 행 개수 |
Total pixel count |
|
[integer] |
산출 래스터 레이어의 픽셀 개수 |
파이썬 코드
알고리즘 ID: native:highestpositioninrasterstack
import processing
processing.run("algorithm_id", {parameter_dictionary})
공간 처리 툴박스에 있는 알고리즘 위에 마우스를 가져가면 알고리즘 ID 를 표시합니다. 파라미터 목록(dictionary) 은 파라미터 명칭 및 값을 제공합니다. 파이썬 콘솔에서 공간 처리 알고리즘을 어떻게 실행하는지 자세히 알고 싶다면 콘솔에서 공간 처리 알고리즘 사용 을 참조하세요.
25.1.11.14. 빈도 미만
이 알고리즘은 셀바이셀(cell-by-cell) 기준으로 입력 래스터 스택의 값들의 빈도(횟수)가 값 래스터의 값 미만인지 평가합니다. 입력 래스터 레이어가 산출 래스터의 범위 및 해상도를 정의하고, 산출 래스터는 언제나 Int32 유형입니다.
데이터 래스터 스택에 다중밴드 래스터가 쓰인 경우, 이 알고리즘은 항상 래스터의 첫 번째 밴드에 분석을 수행할 것입니다 – 다른 밴드를 분석하려면 GDAL을 이용하십시오. 산출 NODATA 값은 직접 설정할 수 있습니다.
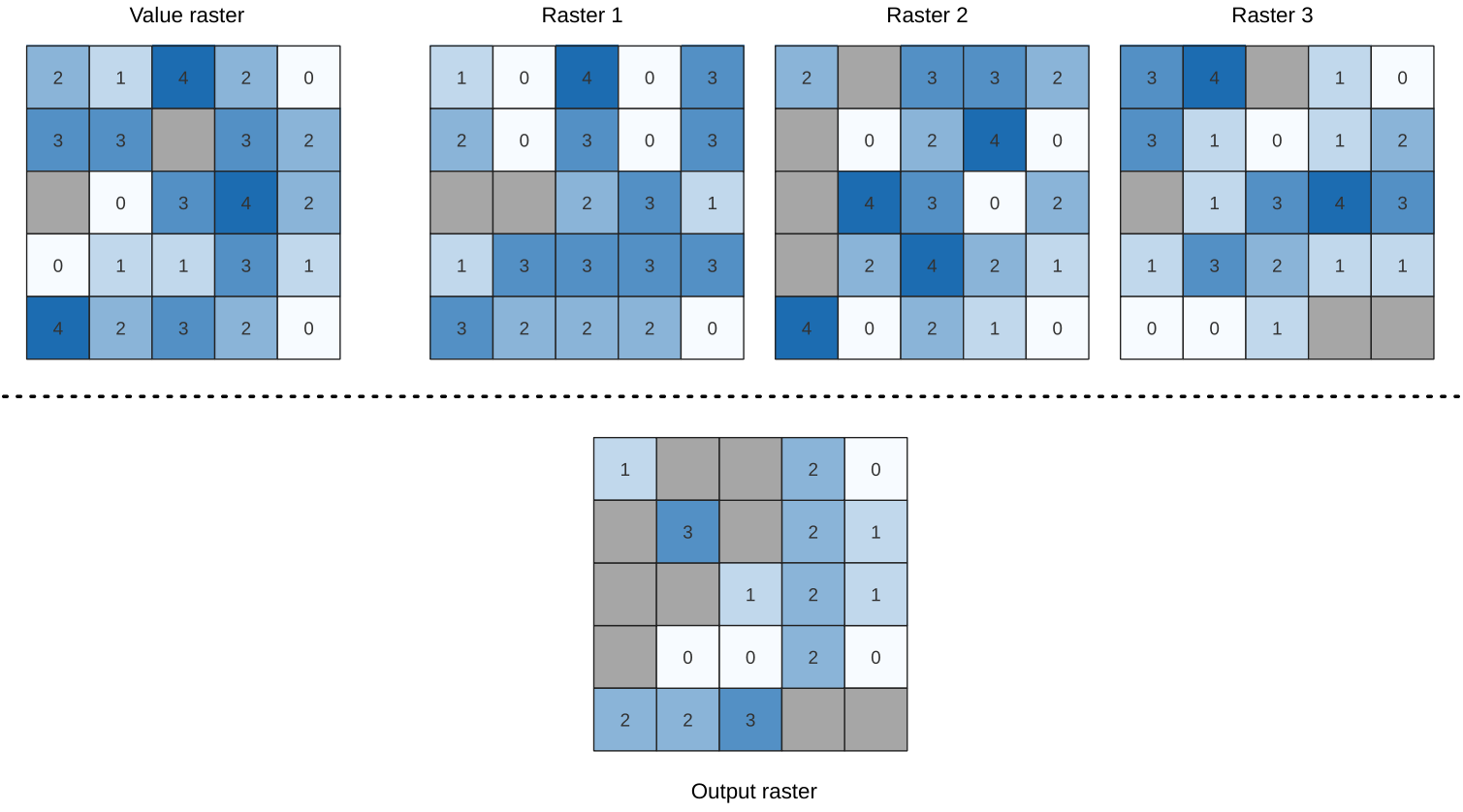
그림 25.17 산출 래스터에 있는 각 셀의 값은 래스터 목록에서 대응하는 셀의 값이 값 래스터의 해당 셀의 값에 미만하는 횟수를 나타냅니다. NoData (회색) 셀도 고려합니다.
파라미터
기본 파라미터
라벨 |
명칭 |
유형 |
설명 |
|---|---|---|---|
Input value raster |
|
[raster] |
입력 값 레이어는 샘플 레이어들을 위한 기준 레이어 역할을 합니다. |
Value raster band |
|
[raster band] 기본값: 래스터 레이어의 첫 번째 밴드 |
샘플로 사용하려는 밴드를 선택하십시오. |
Input raster layers |
|
[raster] [list] |
평가할 래스터 레이어들입니다. 데이터 래스터 스택에 다중밴드 래스터가 쓰인 경우, 이 알고리즘은 항상 래스터의 첫 번째 밴드에 분석을 수행할 것입니다. |
Ignore NoData values |
|
[boolean] 기본값: False |
이 옵션을 체크하지 않을 경우, 값 래스터 또는 데이터 레이어 스택에 있는 모든 NODATA 셀이 산출 래스터에서 NODATA 셀로 산출될 것입니다. |
Output layer |
|
[same as input] 기본값: |
산출 레이어를 지정합니다. 다음 가운데 하나로 저장할 수 있습니다:
|
고급 파라미터
라벨 |
명칭 |
유형 |
설명 |
|---|---|---|---|
Output no data value 부가적 |
|
[number] 기본값: -9999.0 |
산출 레이어에서 NODATA용으로 사용할 값 |
산출물
라벨 |
명칭 |
유형 |
설명 |
|---|---|---|---|
Output layer |
|
[raster] |
결과물을 담고 있는 산출 래스터 레이어 |
CRS authority identifier |
|
[string] |
산출 래스터 레이어의 좌표계 |
Extent |
|
[string] |
산출 래스터 레이어의 공간 영역 |
Count of cells with equal value occurrences |
|
[number] |
|
Height in pixels |
|
[number] |
산출 래스터 레이어의 행 개수 |
Total pixel count |
|
[integer] |
산출 래스터 레이어의 픽셀 개수 |
Mean frequency at valid cell locations |
|
[number] |
|
Count of value occurrences |
|
[number] |
|
Width in pixels |
|
[integer] |
산출 래스터 레이어의 열 개수 |
파이썬 코드
알고리즘 ID: native:lessthanfrequency
import processing
processing.run("algorithm_id", {parameter_dictionary})
공간 처리 툴박스에 있는 알고리즘 위에 마우스를 가져가면 알고리즘 ID 를 표시합니다. 파라미터 목록(dictionary) 은 파라미터 명칭 및 값을 제공합니다. 파이썬 콘솔에서 공간 처리 알고리즘을 어떻게 실행하는지 자세히 알고 싶다면 콘솔에서 공간 처리 알고리즘 사용 을 참조하세요.
25.1.11.15. 래스터 스택에서 가장 낮은 위치
이 알고리즘은 셀바이셀(cell-by-cell) 기준으로 래스터 스택에서 가장 낮은 값을 가진 래스터의 위치를 평가합니다. 위치는 1로 시작해서 입력 래스터의 총 개수까지 셉니다. 입력 래스터들의 순서와 알고리즘은 관계가 있습니다. 가장 낮은 값을 가진 래스터가 여러 개일 경우, 첫 번째 래스터를 위치 값으로 사용할 것입니다.
데이터 래스터 스택에 다중밴드 래스터가 쓰인 경우, 이 알고리즘은 항상 래스터의 첫 번째 밴드에 분석을 수행할 것입니다 – 다른 밴드를 분석하려면 GDAL을 이용하십시오. “ignore NoData” 파라미터를 체크하지 않을 경우, 래스터 레이어 스택에 있는 모든 NODATA 셀이 산출 래스터에서 NODATA 셀로 산출될 것입니다. 산출 NODATA 값은 직접 설정할 수 있습니다. 기준 래스터 레이어가 산출 래스터의 범위 및 해상도를 정의하고, 산출 래스터는 언제나 Int32 유형입니다.
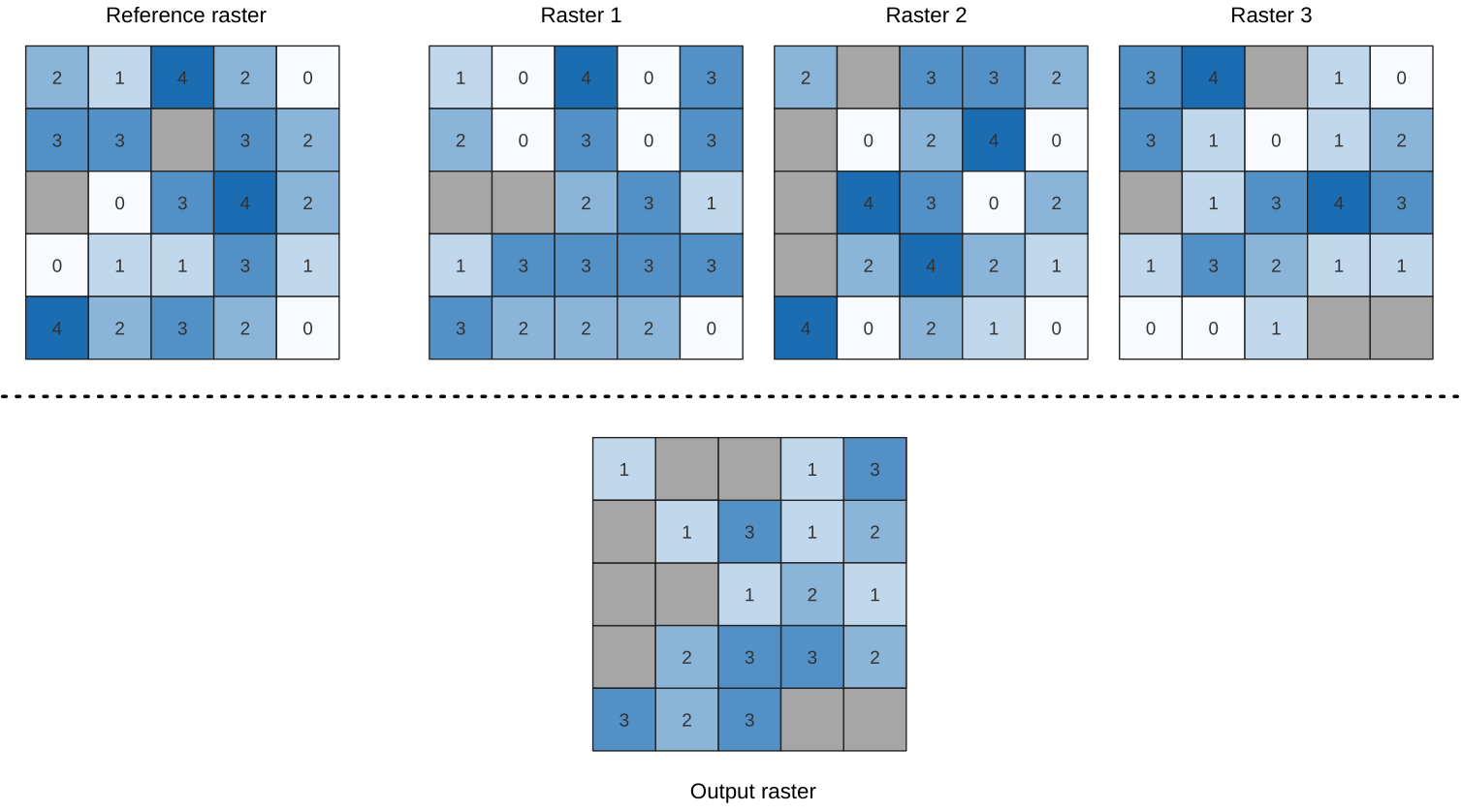
더 보기
파라미터
기본 파라미터
라벨 |
명칭 |
유형 |
설명 |
|---|---|---|---|
Input raster layers |
|
[raster] [list] |
비교할 래스터 레이어들의 목록 |
Reference layer |
|
[raster] |
산출 래스터를 생성하기 위한 (범위, 좌표계, 픽셀 크기) 기준 레이어 |
Ignore NoData values |
|
[boolean] 기본값: False |
이 옵션을 체크하지 않을 경우, 데이터 레이어 스택에 있는 모든 NODATA 셀이 산출 래스터에서 NODATA 셀로 산출될 것입니다. |
Output layer |
|
[raster] 기본값: |
결과를 담을 산출 래스터를 지정합니다. 다음 가운데 하나로 저장할 수 있습니다:
|
고급 파라미터
라벨 |
명칭 |
유형 |
설명 |
|---|---|---|---|
Output no data value |
|
[number] 기본값: -9999.0 |
산출 레이어에서 NODATA용으로 사용할 값 |
산출물
라벨 |
명칭 |
유형 |
설명 |
|---|---|---|---|
Output layer |
|
[raster] |
결과물을 담고 있는 산출 래스터 레이어 |
CRS authority identifier |
|
[string] |
산출 래스터 레이어의 좌표계 |
Extent |
|
[string] |
산출 래스터 레이어의 공간 영역 |
Width in pixels |
|
[integer] |
산출 래스터 레이어의 열 개수 |
Height in pixels |
|
[integer] |
산출 래스터 레이어의 행 개수 |
Total pixel count |
|
[integer] |
산출 래스터 레이어의 픽셀 개수 |
파이썬 코드
알고리즘 ID: native:lowestpositioninrasterstack
import processing
processing.run("algorithm_id", {parameter_dictionary})
공간 처리 툴박스에 있는 알고리즘 위에 마우스를 가져가면 알고리즘 ID 를 표시합니다. 파라미터 목록(dictionary) 은 파라미터 명칭 및 값을 제공합니다. 파이썬 콘솔에서 공간 처리 알고리즘을 어떻게 실행하는지 자세히 알고 싶다면 콘솔에서 공간 처리 알고리즘 사용 을 참조하세요.
25.1.11.16. 래스터 불(boolean) AND
입력 래스터 집합에 대해 불(boolean) AND 를 계산합니다. 모든 입력 래스터들이 어떤 픽셀에 대해 0이 아닌 값을 가지고 있다면, 산출 래스터에서 해당 픽셀의 값을 1 로 설정할 것입니다. 입력 래스터 가운데 하나라도 어떤 픽셀에 대해 0 값을 가지고 있다면, 산출 래스터에서 해당 픽셀의 값을 0 으로 설정할 것입니다.
참조 레이어 파라미터는 산출 래스터 생성 시 참조물로 사용할 기존 래스터 레이어를 지정합니다. 산출 래스터는 참조 레이어와 동일한 범위, 좌표계, 그리고 픽셀 크기를 가질 것입니다.
입력 레이어 가운데 하나에만 NODATA 픽셀이 있어도, 기본적으로 산출 래스터에서도 NODATA 픽셀로 산출될 것입니다. Treat nodata values as false 옵션을 활성화한 경우, NODATA 입력을 0 입력값과 동일하게 취급할 것입니다.
더 보기
파라미터
기본 파라미터
라벨 |
명칭 |
유형 |
설명 |
|---|---|---|---|
Input layers |
|
[raster] [list] |
입력 래스터 레이어의 목록 |
Reference layer |
|
[raster] |
산출 레이어 생성 시 (범위, 좌표계, 픽셀 크기를) 참조할 참조 레이어 |
Treat nodata values as false |
|
[boolean] 기본값: False |
작업 수행 시 입력 파일에 있는 NODATA 값을 0으로 취급 |
Output layer |
|
[raster] 기본값: |
결과를 담을 산출 래스터를 지정합니다. 다음 가운데 하나로 저장할 수 있습니다:
|
고급 파라미터
라벨 |
명칭 |
유형 |
설명 |
|---|---|---|---|
Output no data value |
|
[number] 기본값: -9999.0 |
산출 레이어에서 NODATA용으로 사용할 값 |
Output data type |
|
[enumeration] 기본값: 5 |
산출 래스터 데이터 유형입니다. 다음 가운데 하나를 선택할 수 있습니다:
|
산출물
라벨 |
명칭 |
유형 |
설명 |
|---|---|---|---|
Extent |
|
[string] |
산출 래스터 레이어의 공간 영역 |
CRS authority identifier |
|
[crs] |
산출 래스터 레이어의 좌표계 |
Width in pixels |
|
[integer] |
산출 래스터 레이어의 열 개수 |
Height in pixels |
|
[integer] |
산출 래스터 레이어의 행 개수 |
Total pixel count |
|
[integer] |
산출 래스터 레이어의 픽셀 개수 |
NODATA pixel count |
|
[integer] |
산출 래스터 레이어의 NODATA 픽셀 개수 |
True pixel count |
|
[integer] |
산출 래스터 레이어에 있는 (값이 1인) 참 픽셀의 개수 |
False pixel count |
|
[integer] |
산출 래스터 레이어에 있는 (값이 0인) 거짓 픽셀의 개수 |
Output layer |
|
[raster] |
결과물을 담고 있는 산출 래스터 레이어 |
파이썬 코드
Algorithm ID: native:rasterbooleanand
import processing
processing.run("algorithm_id", {parameter_dictionary})
공간 처리 툴박스에 있는 알고리즘 위에 마우스를 가져가면 알고리즘 ID 를 표시합니다. 파라미터 목록(dictionary) 은 파라미터 명칭 및 값을 제공합니다. 파이썬 콘솔에서 공간 처리 알고리즘을 어떻게 실행하는지 자세히 알고 싶다면 콘솔에서 공간 처리 알고리즘 사용 을 참조하세요.
25.1.11.17. 래스터 불(boolean) OR
입력 래스터 집합에 대해 불(boolean) OR 를 계산합니다. 모든 입력 래스터들이 어떤 픽셀에 대해 0 값을 가지고 있다면, 산출 래스터에서 해당 픽셀의 값을 0 으로 설정할 것입니다. 입력 래스터 가운데 하나라도 어떤 픽셀에 대해 1 값을 가지고 있다면, 산출 래스터에서 해당 픽셀의 값을 1 로 설정할 것입니다.
참조 레이어 파라미터는 산출 래스터 생성 시 참조물로 사용할 기존 래스터 레이어를 지정합니다. 산출 래스터는 참조 레이어와 동일한 범위, 좌표계, 그리고 픽셀 크기를 가질 것입니다.
입력 레이어 가운데 하나에만 NODATA 픽셀이 있어도, 기본적으로 산출 래스터에서도 NODATA 픽셀로 산출될 것입니다. Treat nodata values as false 옵션을 활성화한 경우, NODATA 입력을 0 입력값과 동일하게 취급할 것입니다.
더 보기
파라미터
기본 파라미터
라벨 |
명칭 |
유형 |
설명 |
|---|---|---|---|
Input layers |
|
[raster] [list] |
입력 래스터 레이어의 목록 |
Reference layer |
|
[raster] |
산출 레이어 생성 시 (범위, 좌표계, 픽셀 크기를) 참조할 참조 레이어 |
Treat nodata values as false |
|
[boolean] 기본값: False |
작업 수행 시 입력 파일에 있는 NODATA 값을 0으로 취급 |
Output layer |
|
[raster] 기본값: |
결과를 담을 산출 래스터를 지정합니다. 다음 가운데 하나로 저장할 수 있습니다:
|
고급 파라미터
라벨 |
명칭 |
유형 |
설명 |
|---|---|---|---|
Output no data value |
|
[number] 기본값: -9999.0 |
산출 레이어에서 NODATA용으로 사용할 값 |
Output data type |
|
[enumeration] 기본값: 5 |
산출 래스터 데이터 유형입니다. 다음 가운데 하나를 선택할 수 있습니다:
|
산출물
라벨 |
명칭 |
유형 |
설명 |
|---|---|---|---|
Extent |
|
[string] |
산출 래스터 레이어의 공간 영역 |
CRS authority identifier |
|
[crs] |
산출 래스터 레이어의 좌표계 |
Width in pixels |
|
[integer] |
산출 래스터 레이어의 열 개수 |
Height in pixels |
|
[integer] |
산출 래스터 레이어의 행 개수 |
Total pixel count |
|
[integer] |
산출 래스터 레이어의 픽셀 개수 |
NODATA pixel count |
|
[integer] |
산출 래스터 레이어의 NODATA 픽셀 개수 |
True pixel count |
|
[integer] |
산출 래스터 레이어에 있는 (값이 1인) 참 픽셀의 개수 |
False pixel count |
|
[integer] |
산출 래스터 레이어에 있는 (값이 0인) 거짓 픽셀의 개수 |
Output layer |
|
[raster] |
결과물을 담고 있는 산출 래스터 레이어 |
파이썬 코드
Algorithm ID: native:rasterbooleanor
import processing
processing.run("algorithm_id", {parameter_dictionary})
공간 처리 툴박스에 있는 알고리즘 위에 마우스를 가져가면 알고리즘 ID 를 표시합니다. 파라미터 목록(dictionary) 은 파라미터 명칭 및 값을 제공합니다. 파이썬 콘솔에서 공간 처리 알고리즘을 어떻게 실행하는지 자세히 알고 싶다면 콘솔에서 공간 처리 알고리즘 사용 을 참조하세요.
25.1.11.18. 래스터 계산기
래스터 레이어를 사용해 대수(algebra) 작업을 수행합니다.
산출되는 레이어는 표현식에 따라 계산된 값을 가질 것입니다. 표현식은 숫자값, 연산자를 담을 수 있고, 현재 프로젝트에 있는 모든 레이어를 참조할 수 있습니다.
참고
배치 프로세스 인터페이스 또는 QGIS 파이썬 콘솔 에서 계산기를 사용하는 경우 사용할 파일을 지정해야 합니다. 대응하는 레이어는 (전체 경로가 아닌) 기본명을 사용해서 참조시켜야 합니다. 예를 들어, path/to/my/rasterfile.tif 위치에 있는 레이어를 사용하는 경우 해당 레이어의 첫 번째 밴드는 rasterfile.tif@1 로 참조될 것입니다.
더 보기
파라미터
라벨 |
명칭 |
유형 |
설명 |
|---|---|---|---|
Layers |
GUI 전용 |
범례에 불러온 모든 래스터 레이어의 목록을 표시합니다. 이 목록을 사용해서 (레이어명을 더블 클릭하면) 표현식란에 해당 레이어를 추가할 수 있습니다. 래스터 레이어는 |
|
Operators |
GUI 전용 |
표현식란을 채울 수 있는 몇몇 계산기 버튼을 담고 있습니다. |
|
Expression |
|
[string] |
산출 래스터 레이어를 계산하기 위해 사용할 수 있는 표현식입니다. 제공된 연산자 버튼을 사용해서 표현식란에 표현식을 직접 입력할 수 있습니다. |
Predefined expressions |
GUI 전용 |
사전 정의된 |
|
Reference layer(s) (used for automated extent, cellsize, and CRS) 부가적 |
|
[raster] [list] |
범위, 셀 크기 및 좌표계를 가져올 레이어(들)입니다. 이 상자에서 레이어를 선택하면 사용자가 직접 다른 모든 파라미터를 지정해야 할 필요가 사라집니다. 래스터 레이어는 |
Cell size (use 0 or empty to set it automatically) 부가적 |
|
[number] |
산출 래스터 레이어의 셀 크기입니다. 셀 크기를 지정하지 않은 경우, 선택한 참조 레이어(들)의 최소 셀 크기를 사용할 것입니다. 셀 크기는 X축 및 Y축에 대해 동일할 것입니다. |
Output extent 부가적 |
|
[extent] |
Specify the spatial extent of the output raster layer. If the extent is not specified, the minimum extent that covers all the selected reference layers will be used. Available methods are:
|
Output CRS 부가적 |
|
[crs] |
산출 래스터 레이어의 좌표계입니다. 좌표계를 지정하지 않은 경우, 첫 번째 참조 레이어의 좌표계를 사용할 것입니다. |
Output |
|
[raster] 기본값: |
산출 레이어를 지정합니다. 다음 가운데 하나로 저장할 수 있습니다:
|
산출물
라벨 |
명칭 |
유형 |
설명 |
|---|---|---|---|
Output |
|
[raster] |
계산된 값을 가진 산출 래스터 파일 |
파이썬 코드
알고리즘 ID: qgis:rastercalculator
import processing
processing.run("algorithm_id", {parameter_dictionary})
공간 처리 툴박스에 있는 알고리즘 위에 마우스를 가져가면 알고리즘 ID 를 표시합니다. 파라미터 목록(dictionary) 은 파라미터 명칭 및 값을 제공합니다. 파이썬 콘솔에서 공간 처리 알고리즘을 어떻게 실행하는지 자세히 알고 싶다면 콘솔에서 공간 처리 알고리즘 사용 을 참조하세요.
25.1.11.19. Raster layer properties
NEW in 3.20
Returns basic properties of the given raster layer, including the extent, size in pixels and dimensions of pixels (in map units), number of bands, and no data value.
This algorithm is intended for use as a means of extracting these useful properties to use as the input values to other algorithms in a model - e.g. to allow to pass an existing raster’s pixel sizes over to a GDAL raster algorithm.
파라미터
라벨 |
명칭 |
유형 |
설명 |
|---|---|---|---|
Input layer |
|
[raster] |
입력 래스터 레이어 |
Band number 부가적 |
|
[raster band] Default: Not set |
Whether to also return properties of a specific band. If a band is specified, the noData value for the selected band is also returned. |
산출물
라벨 |
명칭 |
유형 |
설명 |
|---|---|---|---|
Number of bands in raster |
|
[number] |
The number of bands in the raster |
CRS authority identifier |
|
[string] |
산출 래스터 레이어의 좌표계 |
Extent |
|
[string] |
The raster layer extent in the CRS |
Band has a NoData value set |
|
[Boolean] |
Indicates whether the raster layer has a value set for NODATA pixels in the selected band |
Height in pixels |
|
[integer] |
The number of columns in the raster layer |
Band NoData value |
|
[number] |
The value (if set) of the NoData pixels in the selected band |
Pixel size (height) in map units |
|
[integer] |
Vertical size in map units of the pixel |
Pixel size (width) in map units |
|
[integer] |
Horizontal size in map units of the pixel |
Width in pixels |
|
[integer] |
The number of rows in the raster layer |
Maximum x-coordinate |
|
[number] |
|
Minimum x-coordinate |
|
[number] |
|
Maximum y-coordinate |
|
[number] |
|
Minimum y-coordinate |
|
[number] |
파이썬 코드
Algorithm ID: native:rasterlayerproperties
import processing
processing.run("algorithm_id", {parameter_dictionary})
공간 처리 툴박스에 있는 알고리즘 위에 마우스를 가져가면 알고리즘 ID 를 표시합니다. 파라미터 목록(dictionary) 은 파라미터 명칭 및 값을 제공합니다. 파이썬 콘솔에서 공간 처리 알고리즘을 어떻게 실행하는지 자세히 알고 싶다면 콘솔에서 공간 처리 알고리즘 사용 을 참조하세요.
25.1.11.20. 래스터 레이어 통계
래스터 레이어의 지정한 밴드의 값으로부터 기본 통계를 계산합니다. 메뉴로 산출물을 불러옵니다.
파라미터
라벨 |
명칭 |
유형 |
설명 |
|---|---|---|---|
Input layer |
|
[raster] |
입력 래스터 레이어 |
Band number |
|
[raster band] 기본값: 입력 레이어의 첫 번째 밴드 |
래스터가 다중 밴드인 경우, 통계를 얻고자 하는 밴드를 선택하십시오. |
Statistics |
|
[html] 기본값: |
산출 레이어를 지정합니다:
|
산출물
라벨 |
명칭 |
유형 |
설명 |
|---|---|---|---|
Maximum value |
|
[number] |
|
Mean value |
|
[number] |
|
Minimum value |
|
[number] |
|
Statistics |
|
[html] |
산출물 파일은 다음 정보를 담고 있습니다:
|
Range |
|
[number] |
|
Standard deviation |
|
[number] |
|
Sum |
|
[number] |
|
Sum of the squares |
|
[number] |
파이썬 코드
Algorithm ID: native:rasterlayerstatistics
import processing
processing.run("algorithm_id", {parameter_dictionary})
공간 처리 툴박스에 있는 알고리즘 위에 마우스를 가져가면 알고리즘 ID 를 표시합니다. 파라미터 목록(dictionary) 은 파라미터 명칭 및 값을 제공합니다. 파이썬 콘솔에서 공간 처리 알고리즘을 어떻게 실행하는지 자세히 알고 싶다면 콘솔에서 공간 처리 알고리즘 사용 을 참조하세요.
25.1.11.21. 래스터 레이어 유일값 보고
지정한 래스터 레이어에 있는 각 유일값의 개수와 면적을 반환합니다.
파라미터
라벨 |
명칭 |
유형 |
설명 |
|---|---|---|---|
Input layer |
|
[raster] |
입력 래스터 레이어 |
Band number |
|
[raster band] 기본값: 입력 레이어의 첫 번째 밴드 |
래스터가 다중 밴드인 경우, 통계를 얻고자 하는 밴드를 선택하십시오. |
Unique values report |
|
[file] 기본값: |
산출 레이어를 지정합니다:
|
Unique values table |
|
[table] 기본값: |
유일값을 위한 테이블을 지정합니다:
이 파라미터에서 파일 인코딩도 변경할 수 있습니다. |
산출물
라벨 |
명칭 |
유형 |
설명 |
|---|---|---|---|
CRS authority identifier |
|
[string] |
산출 래스터 레이어의 좌표계 |
Extent |
|
[string] |
산출 래스터 레이어의 공간 영역 |
Height in pixels |
|
[integer] |
산출 래스터 레이어의 행 개수 |
NODATA pixel count |
|
[number] |
The number of NODATA pixels in the output raster layer |
Total pixel count |
|
[integer] |
산출 래스터 레이어의 픽셀 개수 |
Unique values report |
|
[html] |
산출 HTML 파일은 다음 정보를 담고 있습니다:
|
Unique values table |
|
[table] |
다음 열 3개를 가진 테이블:
|
Width in pixels |
|
[integer] |
산출 래스터 레이어의 열 개수 |
파이썬 코드
Algorithm ID: native:rasterlayeruniquevaluesreport
import processing
processing.run("algorithm_id", {parameter_dictionary})
공간 처리 툴박스에 있는 알고리즘 위에 마우스를 가져가면 알고리즘 ID 를 표시합니다. 파라미터 목록(dictionary) 은 파라미터 명칭 및 값을 제공합니다. 파이썬 콘솔에서 공간 처리 알고리즘을 어떻게 실행하는지 자세히 알고 싶다면 콘솔에서 공간 처리 알고리즘 사용 을 참조하세요.
25.1.11.22. 래스터 레이어 구역 통계
래스터 레이어의 값을 또다른 레이어에서 정의한 구역(zone)으로 범주화한 통계를 계산합니다.
더 보기
파라미터
기본 파라미터
라벨 |
명칭 |
유형 |
설명 |
|---|---|---|---|
Input Layer |
|
[raster] |
입력 래스터 레이어 |
Band number |
|
[raster band] 기본값: 래스터 레이어의 첫 번째 밴드 |
래스터가 다중 밴드인 경우, 통계를 계산하고자 하는 밴드를 선택하십시오. |
Zones layer |
|
[raster] |
구역을 정의하는 래스터 레이어. 동일한 픽셀 값을 가진 인접한 픽셀들로 구역을 지정합니다. |
Zones band number |
|
[raster band] 기본값: 래스터 레이어의 첫 번째 밴드 |
래스터가 다중 밴드인 경우, 구역을 정의하는 밴드를 선택하십시오. |
Statistics |
|
[table] 기본값: |
Specification of the output report. One of:
이 파라미터에서 파일 인코딩도 변경할 수 있습니다. |
고급 파라미터
라벨 |
명칭 |
유형 |
설명 |
|---|---|---|---|
Reference layer 부가적 |
|
[enumeration] 기본값: 0 |
산출 레이어에 구역을 결정할 때 참조물로 사용될 중심(centroid)을 계산하기 위해 사용되는 래스터 레이어입니다. 다음 가운데 하나를 선택할 수 있습니다:
|
산출물
라벨 |
명칭 |
유형 |
설명 |
|---|---|---|---|
CRS authority identifier |
|
[string] |
산출 래스터 레이어의 좌표계 |
Extent |
|
[string] |
산출 래스터 레이어의 공간 영역 |
Height in pixels |
|
[integer] |
산출 래스터 레이어의 행 개수 |
NODATA pixel count |
|
[number] |
The number of NODATA pixels in the output raster layer |
Statistics |
|
[table] |
산출 레이어는 각 구역별로 다음 정보를 담고 있습니다:
|
Total pixel count |
|
[number] |
산출 래스터 레이어의 픽셀 개수 |
Width in pixels |
|
[number] |
산출 래스터 레이어의 열 개수 |
파이썬 코드
Algorithm ID: native:rasterlayerzonalstats
import processing
processing.run("algorithm_id", {parameter_dictionary})
공간 처리 툴박스에 있는 알고리즘 위에 마우스를 가져가면 알고리즘 ID 를 표시합니다. 파라미터 목록(dictionary) 은 파라미터 명칭 및 값을 제공합니다. 파이썬 콘솔에서 공간 처리 알고리즘을 어떻게 실행하는지 자세히 알고 싶다면 콘솔에서 공간 처리 알고리즘 사용 을 참조하세요.
25.1.11.23. 래스터 표면 부피
지정한 기준면(base level)에 따라 래스터 표면 아래의 부피를 계산합니다. 주로 수치 표고 모델(DEM; Digital Elevation Model)에 유용한 알고리즘입니다.
파라미터
라벨 |
명칭 |
유형 |
설명 |
|---|---|---|---|
INPUT layer |
|
[raster] |
표면을 표현하는 입력 래스터 |
Band number |
|
[raster band] 기본값: 래스터 레이어의 첫 번째 밴드 |
래스터가 다중 밴드인 경우, 표면을 정의할 밴드를 선택하십시오. |
Base level |
|
[number] 기본값: 0.0 |
기준 또는 참조 값을 정의합니다. 부피를 |
Method |
|
[enumeration] 기본값: 0 |
래스터 픽셀 값과
|
Surface volume report |
|
[html] 기본값: |
산출 HTML 파일을 지정합니다. 다음 가운데 하나를 선택할 수 있습니다:
이 파라미터에서 파일 인코딩도 변경할 수 있습니다. |
Surface volume table |
|
[table] 기본값: |
산출 테이블을 지정합니다. 다음 가운데 하나로 저장할 수 있습니다:
이 파라미터에서 파일 인코딩도 변경할 수 있습니다. |
산출물
라벨 |
명칭 |
유형 |
설명 |
|---|---|---|---|
Volume |
|
[number] |
계산된 부피 |
Area |
|
[number] |
제곱 맵 단위의 면적 |
Pixel_count |
|
[number] |
분석된 픽셀의 총 개수 |
Surface volume report |
|
[html] |
HTML 서식으로 된 (부피, 면적 및 픽셀 개수를 담고 있는) 산출 보고서 |
Surface volume table |
|
[table] |
(부피, 면적 및 픽셀 개수를 담고 있는) 산출 테이블 |
파이썬 코드
Algorithm ID: native:rastersurfacevolume
import processing
processing.run("algorithm_id", {parameter_dictionary})
공간 처리 툴박스에 있는 알고리즘 위에 마우스를 가져가면 알고리즘 ID 를 표시합니다. 파라미터 목록(dictionary) 은 파라미터 명칭 및 값을 제공합니다. 파이썬 콘솔에서 공간 처리 알고리즘을 어떻게 실행하는지 자세히 알고 싶다면 콘솔에서 공간 처리 알고리즘 사용 을 참조하세요.
25.1.11.24. 래스터로 재범주화
래스터를 벡터 테이블에서 지정된 범위를 기반으로 하는 새 범주 값을 할당해서 재범주화합니다.
파라미터
기본 파라미터
라벨 |
명칭 |
유형 |
설명 |
|---|---|---|---|
Raster layer |
|
[raster] |
재범주화할 래스터 레이어 |
Band number |
|
[raster band] 기본값: 래스터 레이어의 첫 번째 밴드 |
래스터가 다중 밴드인 경우, 재범주화하려는 밴드를 선택하십시오. |
Layer containing class breaks |
|
[vector: any] |
범주화에 사용할 값을 담고 있는 벡터 레이어 |
Minimum class value field |
|
[tablefield: numeric] |
범주용 범위의 최소값을 가진 필드 |
Maximum class value field |
|
[tablefield: numeric] |
범주용 범위의 최대값을 가진 필드 |
Output value field |
|
[tablefield: numeric] |
(대응하는 최소 및 최대값 사이의) 범주에 들어오는 픽셀에 할당될 값을 가진 필드 |
Reclassified raster |
|
[raster] 기본값: |
산출 레이어를 지정합니다. 다음 가운데 하나로 저장할 수 있습니다:
|
고급 파라미터
라벨 |
명칭 |
유형 |
설명 |
|---|---|---|---|
Output no data value |
|
[number] 기본값: -9999.0 |
NODATA 값에 적용할 값 |
Range boundaries |
|
[enumeration] 기본값: 0 |
범주화를 위한 비교 규칙을 정의합니다. 다음 옵션 가운데 선택할 수 있습니다:
|
Use no data when no range matches value |
|
[boolean] 기본값: False |
어떤 범주에도 들어오지 않는 밴드 값에 NODATA 값을 적용합니다. False로 설정한 경우, 원본 값을 유지합니다. |
Output data type |
|
[enumeration] 기본값: 5 |
Defines the format of the output raster file. Options:
|
산출물
라벨 |
명칭 |
유형 |
설명 |
|---|---|---|---|
Reclassified raster |
|
[raster] |
재범주화된 밴드 값을 가진 산출 래스터 레이어 |
파이썬 코드
Algorithm ID: native:reclassifybylayer
import processing
processing.run("algorithm_id", {parameter_dictionary})
공간 처리 툴박스에 있는 알고리즘 위에 마우스를 가져가면 알고리즘 ID 를 표시합니다. 파라미터 목록(dictionary) 은 파라미터 명칭 및 값을 제공합니다. 파이썬 콘솔에서 공간 처리 알고리즘을 어떻게 실행하는지 자세히 알고 싶다면 콘솔에서 공간 처리 알고리즘 사용 을 참조하세요.
25.1.11.25. 테이블로 재범주화
래스터를 고정 테이블에서 지정된 범위를 기반으로 하는 새 범주 값을 할당해서 재범주화합니다.
파라미터
기본 파라미터
라벨 |
명칭 |
유형 |
설명 |
|---|---|---|---|
Raster layer |
|
[raster] |
재범주화할 래스터 레이어 |
Band number |
|
[raster band] 기본값: 1 |
값을 재계산하고자 하는 래스터 밴드 |
Reclassification table |
|
[table] |
각 범주의 범위( |
Reclassified raster |
|
[raster] 기본값: |
산출 래스터 레이어를 지정합니다. 다음 가운데 하나로 저장할 수 있습니다:
|
고급 파라미터
라벨 |
명칭 |
유형 |
설명 |
|---|---|---|---|
Output no data value |
|
[number] 기본값: -9999.0 |
NODATA 값에 적용할 값 |
Range boundaries |
|
[enumeration] 기본값: 0 |
범주화를 위한 비교 규칙을 정의합니다. 다음 옵션 가운데 선택할 수 있습니다:
|
Use no data when no range matches value |
|
[boolean] 기본값: False |
어떤 범주에도 들어오지 않는 밴드 값에 NODATA 값을 적용합니다. False로 설정한 경우, 원본 값을 유지합니다. |
Output data type |
|
[enumeration] 기본값: 5 |
Defines the format of the output raster file. Options:
|
산출물
라벨 |
명칭 |
유형 |
설명 |
|---|---|---|---|
Reclassified raster |
|
[raster] |
재범주화된 밴드 값을 가진 산출 래스터 레이어 |
파이썬 코드
Algorithm ID: native:reclassifybytable
import processing
processing.run("algorithm_id", {parameter_dictionary})
공간 처리 툴박스에 있는 알고리즘 위에 마우스를 가져가면 알고리즘 ID 를 표시합니다. 파라미터 목록(dictionary) 은 파라미터 명칭 및 값을 제공합니다. 파이썬 콘솔에서 공간 처리 알고리즘을 어떻게 실행하는지 자세히 알고 싶다면 콘솔에서 공간 처리 알고리즘 사용 을 참조하세요.
25.1.11.26. 래스터 크기 조정
래스터 레이어의 히스토그램(픽셀 값)의 형태(분포)를 유지하면서, 래스터 레이어를 새 값의 범위로 크기 조정(rescale)합니다. 소스 래스터의 최소 및 최대 픽셀값에서 대상 최소 및 최대 픽셀 범위로 선형 보간을 사용해서 입력값을 매핑합니다.
이 알고리즘은 기본적으로 원본 NODATA 값을 유지하지만, 이를 무시할 수 있는 옵션이 있습니다.
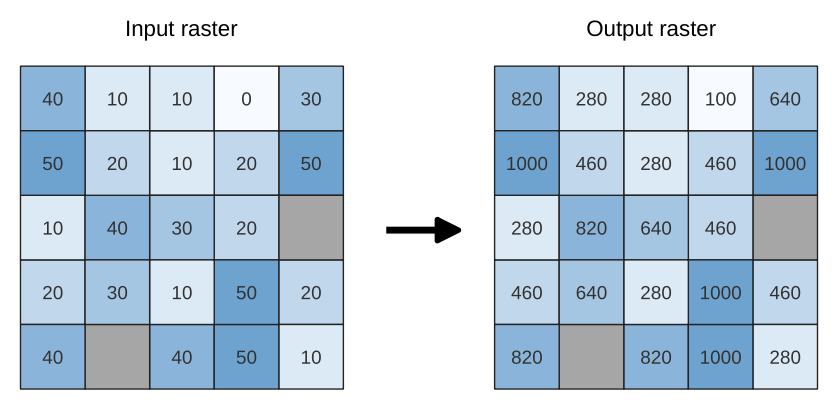
그림 25.18 래스터 레이어의 값을 [0 - 50] 에서 [100 - 1000] 으로 크기 조정하기
파라미터
라벨 |
명칭 |
유형 |
설명 |
|---|---|---|---|
Input Raster |
|
[raster] |
크기 조정에 사용할 래스터 레이어 |
Band number |
|
[raster band] 기본값: 입력 레이어의 첫 번째 밴드 |
래스터가 다중 밴드인 경우, 밴드를 선택하십시오. |
New minimum value |
|
[number] 기본값: 0.0 |
크기 조정된 레이어에 사용할 최소 픽셀값 |
New maximum value |
|
[number] 기본값: 255.0 |
크기 조정된 레이어에 사용할 최대 픽셀값 |
New NODATA value 부가적 |
|
[number] 기본값: 설정하지 않음 |
NODATA 픽셀에 할당할 값. 이 값을 설정하지 않으면, 원본 NODATA 값을 유지합니다. |
Rescaled |
|
[raster] 기본값: |
산출 래스터 레이어를 지정합니다. 다음 가운데 하나로 저장할 수 있습니다:
|
산출물
라벨 |
명칭 |
유형 |
설명 |
|---|---|---|---|
Rescaled |
|
[raster] |
크기 조정된 밴드 값을 가진 산출 래스터 레이어 |
파이썬 코드
알고리즘 ID: native:rescaleraster
import processing
processing.run("algorithm_id", {parameter_dictionary})
공간 처리 툴박스에 있는 알고리즘 위에 마우스를 가져가면 알고리즘 ID 를 표시합니다. 파라미터 목록(dictionary) 은 파라미터 명칭 및 값을 제공합니다. 파이썬 콘솔에서 공간 처리 알고리즘을 어떻게 실행하는지 자세히 알고 싶다면 콘솔에서 공간 처리 알고리즘 사용 을 참조하세요.
25.1.11.27. 래스터 반올림
래스터 데이터셋의 셀 값을 지정한 소수점 이하의 자릿수에 따라 반올림합니다.
그 반대로, 음의 소수점 이하 자릿수를 이용해서 값을 밑 n의 거듭제곱으로 반올림할 수도 있습니다. 예를 들어 밑 n의 값이 10이고 소수점 이하 자릿수가 -1인 경우 이 알고리즘은 셀 값을 10의 배수로, -2인 경우 100의 배수로, …로 반올림합니다. 임의의 밑 값을 선택하더라도, 이 알고리즘은 동일한 곱셈 원칙을 적용합니다. 래스터 레이어를 일반화(generalize)하는 데 셀 값을 밑 n의 배수로 반올림하는 방법을 쓸 수도 있습니다.
이 알고리즘은 입력 래스터의 데이터 유형을 유지합니다. 즉 바이트/정수형 래스터는 밑 n의 배수로만 반올림될 수 있습니다. 그렇지 않을 경우 경고가 뜨면서 해당 래스터를 바이트/정수형 래스터로서 복사할 것입니다.
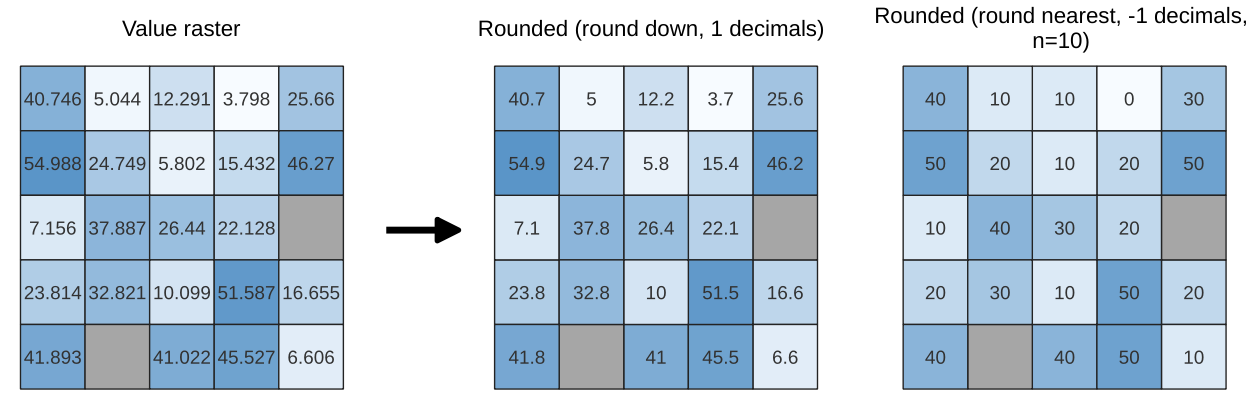
그림 25.19 래스터의 값을 반올림하기
파라미터
기본 파라미터
라벨 |
명칭 |
유형 |
설명 |
|---|---|---|---|
Input raster |
|
[raster] |
공간 처리할 래스터 |
Band number |
|
[number] 기본값: 1 |
래스터의 밴드 |
Rounding direction |
|
[list] 기본값: 1 |
대상의 값을 반올림할 방법을 선택하는 방식입니다. 다음 옵션 가운데 하나를 선택할 수 있습니다:
|
Number of decimals places |
|
[number] 기본값: 2 |
반올림할 소수점 이하 자릿수. 셀 값을 밑 n의 배수로 반올림하려면 음의 값을 사용하십시오. |
Output raster |
|
[raster] 기본값: |
산출 파일을 지정합니다. 다음 가운데 하나로 저장할 수 있습니다:
|
고급 파라미터
라벨 |
명칭 |
유형 |
설명 |
|---|---|---|---|
Base n for rounding to multiples of n |
|
[number] 기본값: 10 |
|
산출물
라벨 |
명칭 |
유형 |
설명 |
|---|---|---|---|
Output raster |
|
[raster] |
선택한 밴드의 값을 반올림한 산출 래스터 레이어 |
파이썬 코드
알고리즘 ID: native:roundrastervalues
import processing
processing.run("algorithm_id", {parameter_dictionary})
공간 처리 툴박스에 있는 알고리즘 위에 마우스를 가져가면 알고리즘 ID 를 표시합니다. 파라미터 목록(dictionary) 은 파라미터 명칭 및 값을 제공합니다. 파이썬 콘솔에서 공간 처리 알고리즘을 어떻게 실행하는지 자세히 알고 싶다면 콘솔에서 공간 처리 알고리즘 사용 을 참조하세요.
25.1.11.28. 래스터 값 샘플링
포인트 위치에 있는 래스터 값을 추출합니다. 래스터 레이어가 다중 밴드인 경우, 각 밴드를 샘플링합니다.
산출 레이어의 속성 테이블은 래스터 레이어의 밴드 개수만큼의 새 열을 가질 것입니다.
파라미터
라벨 |
명칭 |
유형 |
설명 |
|---|---|---|---|
Input Layer |
|
[vector: point] |
샘플링에 사용할 포인트 벡터 레이어 |
Raster Layer |
|
[raster] |
지정한 포인트 위치에서 샘플링할 래스터 레이어 |
Output column prefix |
|
[string] Default: ‘SAMPLE_’ |
추가될 열의 명칭 앞에 붙일 접두어 |
Sampled 부가적 |
|
[vector: point] 기본값: |
샘플링된 값을 담고 있는 산출 레이어를 지정합니다. 다음 가운데 하나로 저장할 수 있습니다:
이 파라미터에서 파일 인코딩도 변경할 수 있습니다. |
산출물
라벨 |
명칭 |
유형 |
설명 |
|---|---|---|---|
Sampled |
|
[vector: point] |
샘플링된 값을 담고 있는 산출 레이어 |
파이썬 코드
Algorithm ID: native:rastersampling
import processing
processing.run("algorithm_id", {parameter_dictionary})
공간 처리 툴박스에 있는 알고리즘 위에 마우스를 가져가면 알고리즘 ID 를 표시합니다. 파라미터 목록(dictionary) 은 파라미터 명칭 및 값을 제공합니다. 파이썬 콘솔에서 공간 처리 알고리즘을 어떻게 실행하는지 자세히 알고 싶다면 콘솔에서 공간 처리 알고리즘 사용 을 참조하세요.
25.1.11.29. 구역 히스토그램
폴리곤 피처 내부에 담겨진 래스터 레이어에서 나온 각 유일값의 개수를 표현하는 필드를 추가합니다.
산출 레이어의 속성 테이블은 폴리곤(들)과 교차하는 래스터 레이어의 유일값 개수만큼의 필드를 가질 것입니다.
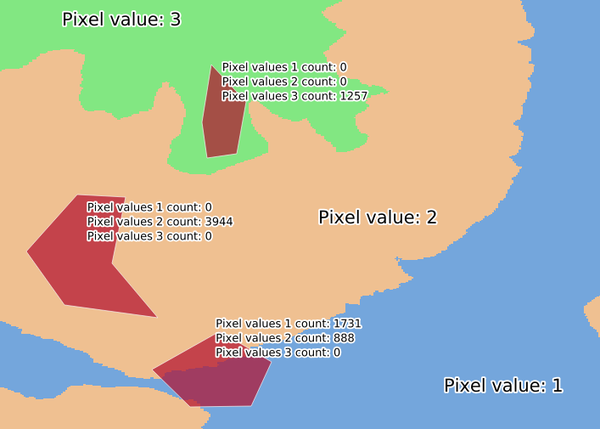
그림 25.20 래스터 레이어 히스토그램 예시
파라미터
라벨 |
명칭 |
유형 |
설명 |
|---|---|---|---|
Raster layer |
|
[raster] |
입력 래스터 레이어 |
Band number |
|
[raster band] 기본값: 입력 레이어의 첫 번째 밴드 |
래스터가 다중 밴드인 경우, 밴드를 선택하십시오. |
Vector layer containing zones |
|
[vector: polygon] |
구역을 정의하는 벡터 폴리곤 레이어 |
Output column prefix |
부가적 |
[string] 기본값: ‘HISTO_’ |
산출 열의 명칭 앞에 붙일 접두어 |
Output zones |
|
[vector: polygon] 기본값: |
산출 벡터 폴리곤 레이어를 지정합니다. 다음 가운데 하나로 저장할 수 있습니다:
이 파라미터에서 파일 인코딩도 변경할 수 있습니다. |
산출물
라벨 |
명칭 |
유형 |
설명 |
|---|---|---|---|
Output zones |
|
[vector: polygon] |
산출 벡터 폴리곤 레이어 |
파이썬 코드
Algorithm ID: native:zonalhistogram
import processing
processing.run("algorithm_id", {parameter_dictionary})
공간 처리 툴박스에 있는 알고리즘 위에 마우스를 가져가면 알고리즘 ID 를 표시합니다. 파라미터 목록(dictionary) 은 파라미터 명칭 및 값을 제공합니다. 파이썬 콘솔에서 공간 처리 알고리즘을 어떻게 실행하는지 자세히 알고 싶다면 콘솔에서 공간 처리 알고리즘 사용 을 참조하세요.
25.1.11.30. 구역 통계
중첩하는 폴리곤 벡터 레이어의 각 피처에 해당하는 래스터 레이어 영역의 통계를 계산합니다.
파라미터
라벨 |
명칭 |
유형 |
설명 |
|---|---|---|---|
Input layer |
|
[vector: polygon] |
구역을 담고 있는 벡터 폴리곤 레이어 |
Raster layer |
|
[raster] |
입력 래스터 레이어 |
Raster band |
|
[raster band] 기본값: 입력 레이어의 첫 번째 밴드 |
래스터가 다중 밴드인 경우, 통계를 얻고자 하는 밴드를 선택하십시오. |
Output column prefix |
|
[string] 기본값: ‘_’ |
산출 열의 명칭 앞에 붙일 접두어 |
Statistics to calculate |
|
[enumeration] [list] 기본값: [0,1,2] |
산출물을 위한 통계 연산자의 목록. 다음 옵션 가운데 선택할 수 있습니다:
|
Zonal Statistics |
|
[vector: polygon] 기본값: |
산출 벡터 폴리곤 레이어를 지정합니다. 다음 가운데 하나로 저장할 수 있습니다:
이 파라미터에서 파일 인코딩도 변경할 수 있습니다. |
산출물
라벨 |
명칭 |
유형 |
설명 |
|---|---|---|---|
Zonal Statistics |
|
[vector: polygon] |
통계를 추가한 입력 구역 벡터 레이어 |
파이썬 코드
Algorithm ID: native:zonalstatisticsfb
import processing
processing.run("algorithm_id", {parameter_dictionary})
공간 처리 툴박스에 있는 알고리즘 위에 마우스를 가져가면 알고리즘 ID 를 표시합니다. 파라미터 목록(dictionary) 은 파라미터 명칭 및 값을 제공합니다. 파이썬 콘솔에서 공간 처리 알고리즘을 어떻게 실행하는지 자세히 알고 싶다면 콘솔에서 공간 처리 알고리즘 사용 을 참조하세요.