24.1.13. Analyse vectorielle
24.1.13.1. Statistiques de base pour les champs
Génère des statistiques de base pour un champ de la table attributaire d’une couche vectorielle.
Les champs numériques, date, heure et chaîne sont pris en charge.
Les statistiques renvoyées dépendront du type de champ.
Les statistiques sont générées sous forme de fichier HTML et sont disponibles dans .
Menu par défaut:
Paramètres
Étiquette |
Nom |
Type |
Description |
|---|---|---|---|
Vecteur en entrée |
|
[vector: any] |
Couche vectorielle pour calculer les statistiques |
Champ pour calculer les statistiques sur |
|
[tablefield: any] |
Tout champ de tableau pris en charge pour calculer les statistiques |
Statistiques |
|
[html] |
Fichier HTML pour les statistiques calculées |
Les sorties
Étiquette |
Nom |
Type |
Description |
|---|---|---|---|
Statistiques |
|
[html] |
Fichier HTML avec les statistiques calculées |
Compte |
|
[number] |
|
Nombre de valeurs uniques |
|
[number] |
|
Nombre de valeurs vides (nulles) |
|
[number] |
|
Nombre de valeurs non vides |
|
[number] |
|
Valeur minimum |
|
[identique à l’entrée] |
|
Valeur maximale |
|
[identique à l’entrée] |
|
Longueur minimale |
|
[number] |
|
Longueur maximale |
|
[number] |
|
Longueur moyenne |
|
[number] |
|
Coefficient de variation |
|
[number] |
|
Somme |
|
[number] |
|
Valeur moyenne |
|
[number] |
|
Écart-type |
|
[number] |
|
Gamme |
|
[number] |
|
Médiane |
|
[number] |
|
Minorité (valeur la plus rare) |
|
[identique à l’entrée] |
|
Majorité (valeur la plus fréquente) |
|
[identique à l’entrée] |
|
Premier quartile |
|
[number] |
|
Troisième quartile |
|
[number] |
|
Intervalle interquartile (IQR) |
|
[number] |
Code Python
ID de l’algorithme : qgis:basicstatisticsforfields
import processing
processing.run("algorithm_id", {parameter_dictionary})
L”id de l’algorithme est affiché lors du survol du nom de l’algorithme dans la boîte à outils Traitements. Les nom et valeur de chaque paramètre sont fournis via un dictionnaire de paramètres. Voir Utiliser les algorithmes du module de traitements depuis la console Python pour plus de détails sur l’exécution d’algorithmes via la console Python.
24.1.13.2. Montée le long de la ligne
Calcule la montée et la descente totales le long des géométries de ligne. La couche d’entrée doit avoir des valeurs Z présentes. Si les valeurs Z ne sont pas disponibles, l’algorithme Draper (définir la valeur z du raster) peut être utilisé pour ajouter des valeurs Z à partir d’une couche DEM.
La couche de sortie est une copie de la couche d’entrée avec des champs supplémentaires qui contiennent la montée totale (montée), la descente totale (descente), l’élévation minimale (minelev) et l’élévation maximale (maxelev) pour chaque géométrie de ligne. Si la couche d’entrée contient des champs portant les mêmes noms que ces champs ajoutés, ils seront renommés (les noms de champ seront modifiés en « nom_2 », « nom_3 », etc., en trouvant le premier nom non dupliqué).
Paramètres
Étiquette |
Nom |
Type |
Description |
|---|---|---|---|
Couche de ligne |
|
[vector: line] |
Couche de ligne pour calculer la montée. Doit avoir des valeurs Z |
Couche de montée |
|
[vector: line] |
La couche de sortie (ligne) |
Les sorties
Étiquette |
Nom |
Type |
Description |
|---|---|---|---|
Couche de montée |
|
[vector: line] |
Couche de ligne contenant de nouveaux attributs avec les résultats des calculs de montée. |
Montée totale |
|
[number] |
Somme de la montée pour toutes les géométries de ligne dans la couche d’entrée |
Descente totale |
|
[number] |
La somme de la descente pour toutes les géométries de ligne dans la couche d’entrée |
Élévation minimale |
|
[number] |
L’élévation minimale des géométries dans la couche |
Altitude maximale |
|
[number] |
L’élévation maximale pour les géométries dans la couche |
Code Python
ID de l’algorithme : qgis:climbalongline
import processing
processing.run("algorithm_id", {parameter_dictionary})
L”id de l’algorithme est affiché lors du survol du nom de l’algorithme dans la boîte à outils Traitements. Les nom et valeur de chaque paramètre sont fournis via un dictionnaire de paramètres. Voir Utiliser les algorithmes du module de traitements depuis la console Python pour plus de détails sur l’exécution d’algorithmes via la console Python.
24.1.13.3. Compter les points dans le polygone
Prend un point et une couche de polygones et compte le nombre de points de la couche de points dans chacun des polygones de la couche de polygones.
Une nouvelle couche de polygones est générée, avec exactement le même contenu que la couche de polygones en entrée, mais contenant un champ supplémentaire avec le nombre de points correspondant à chaque polygone.
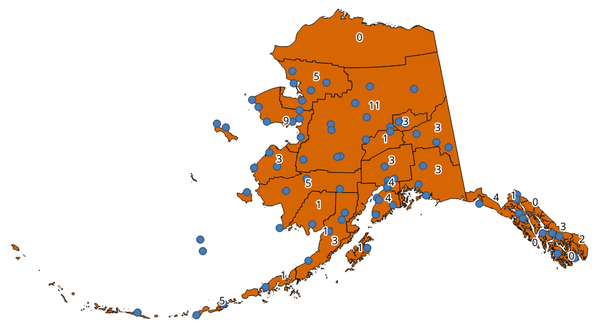
Fig. 24.26 Les étiquettes dans les polygones indiquent le nombre de points
Un champ de coefficient facultatif peut être utilisé pour attribuer des coefficients à chaque point. Alternativement, un champ de classe unique peut être spécifié. Si les deux options sont utilisées, le champ de coefficient aura priorité et le champ de classe unique sera ignoré.
Menu par défaut:
Paramètres
Étiquette |
Nom |
Type |
Description |
|---|---|---|---|
Polygones |
|
[vector: polygon] |
Couche de polygones dont les caractéristiques sont associées au nombre de points qu’elles contiennent |
Points |
|
[vector: point] |
Couche de points avec caractéristiques à compter |
Champ de coefficient Optionnel |
|
[tablefield: any] |
Un champ de la couche de points. Le compte généré sera la somme du champ de coefficient des points contenus par le polygone. Si le champ de coefficient n’est pas numérique, le compte sera |
Champ de classe Optionnel |
|
[tablefield: any] |
Les points sont classés en fonction de l’attribut sélectionné et si plusieurs points avec la même valeur d’attribut se trouvent dans le polygone, un seul d’entre eux est compté. Le décompte final des points d’un polygone est donc le décompte des différentes classes qui s’y trouvent. |
Nom du champ de comptage |
|
[string] Par défaut: “NUMPOINTS” |
Le nom du champ pour stocker le nombre de points |
Compte |
|
[vector: polygon] |
Spécification de la couche de sortie |
Les sorties
Étiquette |
Nom |
Type |
Description |
|---|---|---|---|
Compte |
|
[vector: polygon] |
Couche résultante avec la table attributaire contenant la nouvelle colonne avec le nombre de points |
24.1.13.4. Mise en cluster DBSCAN
Regroupe en clusters des entités ponctuelles selon une implémentation 2D de l’algorithme de clustering spatial basé sur la densité d’applications avec bruit (DBSCAN).
L’algorithme nécessite deux paramètres, une taille minimale de cluster et la distance maximale autorisée entre les points groupés.
Voir aussi
Paramètres
Étiquette |
Nom |
Type |
Description |
|---|---|---|---|
Couche en entrée |
|
[vector: point] |
Couche à analyser |
Taille minimale du cluster |
|
[number] Par défaut: 5 |
Nombre minimum d’entités pour générer un cluster |
Distance maximale entre les points groupés |
|
[number] Par défaut: 1.0 |
Distance au-delà de laquelle deux entités ne peuvent pas appartenir au même cluster (eps) |
Nom du champ du cluster |
|
[string] Par défaut: “CLUSTER_ID” |
Nom du champ où le numéro de cluster associé doit être stocké |
Traitez les points en limite comme du bruit (DBSCAN *) Optionnel |
|
[boolean] Par défaut: False |
Si cette case est cochée, les points situés à la limite d’un cluster sont eux-mêmes traités comme des points non clusterisés, et seuls les points à l’intérieur d’un cluster sont marqués comme cluster. |
Clusters |
|
[vector: point] |
Couche vectorielle pour le résultat du clustering |
Les sorties
Étiquette |
Nom |
Type |
Description |
|---|---|---|---|
Clusters |
|
[vector: point] |
Couche vectorielle contenant les entités originales avec un champ définissant le cluster auquel elles appartiennent |
Nombre de clusters |
|
[number] |
Le nombre de clusters découverts |
Code Python
ID de l’algorithme : qgis:dbscanclustering
import processing
processing.run("algorithm_id", {parameter_dictionary})
L”id de l’algorithme est affiché lors du survol du nom de l’algorithme dans la boîte à outils Traitements. Les nom et valeur de chaque paramètre sont fournis via un dictionnaire de paramètres. Voir Utiliser les algorithmes du module de traitements depuis la console Python pour plus de détails sur l’exécution d’algorithmes via la console Python.
24.1.13.5. Matrice de distance
Calcul des distances des entités ponctuelles aux entités les plus proches dans la même couche ou dans une autre couche.
Menu par défaut:
Voir aussi
Paramètres
Étiquette |
Nom |
Type |
Description |
|---|---|---|---|
Couche de points d’entrée |
|
[vector: point] |
Couche de points pour laquelle la matrice de distance est calculée (à partir de points) |
Entrez le champ ID unique |
|
[tablefield: any] |
Champ à utiliser pour identifier de manière unique les caractéristiques de la couche d’entrée. Utilisé dans la table attributaire de sortie. |
Couche de points sortie |
|
[vector: point] |
Couche de points contenant le ou les points les plus proches à rechercher (to* points) |
Champ d’identification unique sortie |
|
[tablefield: any] |
Champ à utiliser pour identifier de manière unique les caractéristiques de la couche cible. Utilisé dans la table attributaire de sortie. |
Type de matrice de sortie |
|
[enumeration] Par défaut: 0 |
Différents types de calcul sont disponibles:
|
Utilisez uniquement les points cibles les plus proches (k) |
|
[number] Par défaut: 0 |
Vous pouvez choisir de calculer la distance à tous les points de la couche cible (0) ou de limiter à un nombre (k) d’entités les plus proches. |
Matrice de distance |
|
[vector: point] |
Les sorties
Étiquette |
Nom |
Type |
Description |
|---|---|---|---|
Matrice de distance |
|
[vector: point] |
Couche vectorielle Point (ou MultiPoint pour le cas « Linéaire (N * k x 3) ») contenant le calcul de la distance pour chaque entité en entrée. Ses caractéristiques et sa table d’attributs dépendent du type de matrice de sortie sélectionné. |
Code Python
ID de l’algorithme : qgis:distancematrix
import processing
processing.run("algorithm_id", {parameter_dictionary})
L”id de l’algorithme est affiché lors du survol du nom de l’algorithme dans la boîte à outils Traitements. Les nom et valeur de chaque paramètre sont fournis via un dictionnaire de paramètres. Voir Utiliser les algorithmes du module de traitements depuis la console Python pour plus de détails sur l’exécution d’algorithmes via la console Python.
24.1.13.6. Distance au plus proche centre (ligne vers centre)
Crée des lignes qui joignent chaque entité d’un vecteur d’entrée à l’entité la plus proche dans une couche de destination. Les distances sont calculées en fonction du centre de chaque entité.
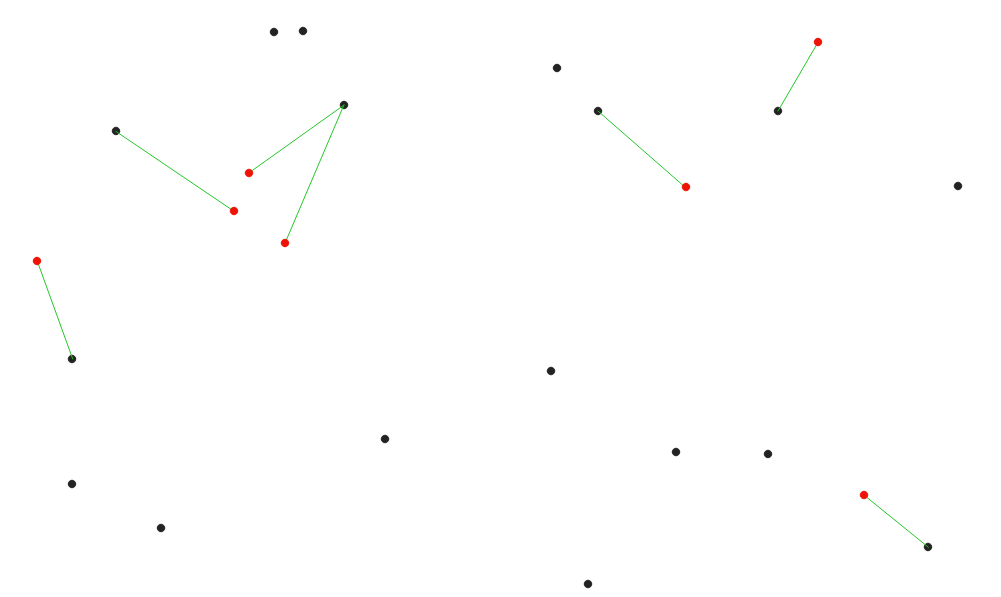
Fig. 24.27 Afficher le centre le plus proche pour les entités en entrée (en rouge)
Paramètres
Étiquette |
Nom |
Type |
Description |
|---|---|---|---|
Couche de points source |
|
[vector: any] |
Couche vectorielle pour laquelle l’entité la plus proche est recherchée |
Couche de concentration de destination |
|
[vector: any] |
Couche vectorielle contenant les entités à rechercher |
Attribut de nom de couche centre |
|
[tablefield: any] |
Champ à utiliser pour identifier de manière unique les entités de la couche de destination. Utilisé dans la table des attributs de sortie |
Unité de mesure |
|
[enumeration] Par défaut: 0 |
Unités pour signaler la distance à l’entité la plus proche:
|
Distance au centre |
|
[vector: line] |
Couche de vecteur de ligne pour la sortie de la matrice de distance |
Les sorties
Étiquette |
Nom |
Type |
Description |
|---|---|---|---|
Distance au centre |
|
[vector: line] |
Couche de vecteur de ligne avec les attributs des entités en entrée, l’identifiant de leur entité la plus proche et la distance calculée. |
Code Python
ID de l’algorithme : qgis:distancetonearesthublinetohub
import processing
processing.run("algorithm_id", {parameter_dictionary})
L”id de l’algorithme est affiché lors du survol du nom de l’algorithme dans la boîte à outils Traitements. Les nom et valeur de chaque paramètre sont fournis via un dictionnaire de paramètres. Voir Utiliser les algorithmes du module de traitements depuis la console Python pour plus de détails sur l’exécution d’algorithmes via la console Python.
24.1.13.7. Distance au plus proche centre (points)
Crée une couche de points représentant le centre des entités en entrée avec l’ajout de deux champs contenant l’identifiant de l’entité la plus proche (en fonction de son point central) et la distance entre les points.
Voir aussi
Distance au plus proche centre (ligne vers centre), Joindre les attributs par le plus proche
Paramètres
Étiquette |
Nom |
Type |
Description |
|---|---|---|---|
Couche de points source |
|
[vector: any] |
Couche vectorielle pour laquelle l’entité la plus proche est recherchée |
Couche de concentration de destination |
|
[vector: any] |
Couche vectorielle contenant les entités à rechercher |
Attribut de nom de couche centre |
|
[tablefield: any] |
Champ à utiliser pour identifier de manière unique les entités de la couche de destination. Utilisé dans la table des attributs de sortie |
Unité de mesure |
|
[enumeration] Par défaut: 0 |
Unités pour signaler la distance à l’entité la plus proche:
|
Distance au centre |
|
[vector: point] |
Couche vectorielle de point pour la sortie de la matrice de distance. |
Les sorties
Étiquette |
Nom |
Type |
Description |
|---|---|---|---|
Distance au centre |
|
[vector: point] |
Couche vectorielle ponctuelle avec les attributs des entités en entrée, l’identifiant de leur entité la plus proche et la distance calculée. |
Code Python
ID de l’algorithme : qgis:distancetonearesthubpoints
import processing
processing.run("algorithm_id", {parameter_dictionary})
L”id de l’algorithme est affiché lors du survol du nom de l’algorithme dans la boîte à outils Traitements. Les nom et valeur de chaque paramètre sont fournis via un dictionnaire de paramètres. Voir Utiliser les algorithmes du module de traitements depuis la console Python pour plus de détails sur l’exécution d’algorithmes via la console Python.
24.1.13.8. Rejoindre par des lignes (ligne de centre)
Crée des diagrammes de concentration et de rayons en connectant les lignes des points de la couche Rayon aux points correspondants de la couche Concentration.
La détermination de la concentration qui va avec chaque point est basée sur une correspondance entre le champ ID de la concentration sur les points du hub et le champ ID du rayon sur les points de rayon.
Si les couches en entrée ne sont pas des couches ponctuelles, un point sur la surface des géométries sera pris comme emplacement de connexion.
Facultativement, des lignes géodésiques peuvent être créées, qui représentent le chemin le plus court sur la surface d’un ellipsoïde. Lorsque le mode géodésique est utilisé, il est possible de diviser les lignes créées à l’antiméridien (± 180 degrés de longitude), ce qui peut améliorer le rendu des lignes. De plus, la distance entre les sommets peut être spécifiée. Une distance plus petite donne une ligne plus dense et plus précise.
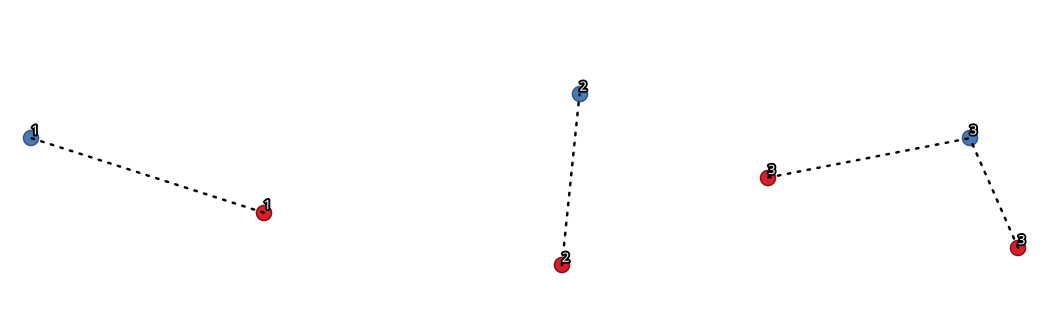
Fig. 24.28 Joindre des points sur la base d’un champ / attribut commun
Paramètres
Étiquette |
Nom |
Type |
Description |
|---|---|---|---|
Couche Hub |
|
[vector: any] |
Couche en entrée |
Champ identifiant du Hub |
|
[tablefield: any] |
Champ de la couche Hub avec ID à joindre |
Champs de la couche Hub à copier (laissez vide pour copier tous les champs) Optionnel |
|
[tablefield: any] [list] |
Le ou les champs de la couche Hub à copier. Si aucun champ n’est choisi, tous les champs sont pris. |
Couche Spoke |
|
[vector: any] |
Couche de point de rayon supplémentaire |
Champ ID spoke |
|
[tablefield: any] |
Champ de la couche de rayons avec ID à joindre |
Champs de la couche spoke à copier (laissez vide pour copier tous les champs) Optionnel |
|
[tablefield: any] [list] |
Champ (s) de la couche spoke à copier. Si aucun champ n’est choisi, tous les champs sont pris. |
Créez des lignes géodésiques |
|
[boolean] Par défaut: False |
Créer des lignes géodésiques (le chemin le plus court à la surface d’un ellipsoïde) |
Distance entre les sommets (lignes géodésiques uniquement) |
|
[number] Default: 1000.0 (kilometers) |
Distance entre sommets consécutifs (en kilomètres). Une distance plus petite donne une ligne plus dense et plus précise |
Lignes découpées à l’antiméridien (± 180 degrés de longitude) |
|
[boolean] Par défaut: False |
Couper les lignes à ± 180 degrés de longitude (pour améliorer le rendu des lignes) |
Lignes centre |
|
[vector: line] |
La couche ligne résultante |
Les sorties
Étiquette |
Nom |
Type |
Description |
|---|---|---|---|
Lignes centre |
|
[vector: line] |
La couche ligne résultante |
Code Python
ID de l’algorithme : qgis:hublines
import processing
processing.run("algorithm_id", {parameter_dictionary})
L”id de l’algorithme est affiché lors du survol du nom de l’algorithme dans la boîte à outils Traitements. Les nom et valeur de chaque paramètre sont fournis via un dictionnaire de paramètres. Voir Utiliser les algorithmes du module de traitements depuis la console Python pour plus de détails sur l’exécution d’algorithmes via la console Python.
24.1.13.9. Partitionnement en K-moyennes
Calcule le nombre de clusters k-moyennes en fonction de la distance 2D pour chaque entité en entrée.
Le clustering K-moyennes vise à partitionner les entités en k clusters dans lesquelles chaque entité appartient au cluster ayant la moyenne la plus proche. Le point moyen est représenté par le barycentre des entités groupées.
Si les géométries en entrée sont des lignes ou des polygones, le regroupement est basé sur le centre de gravité de l’entité.
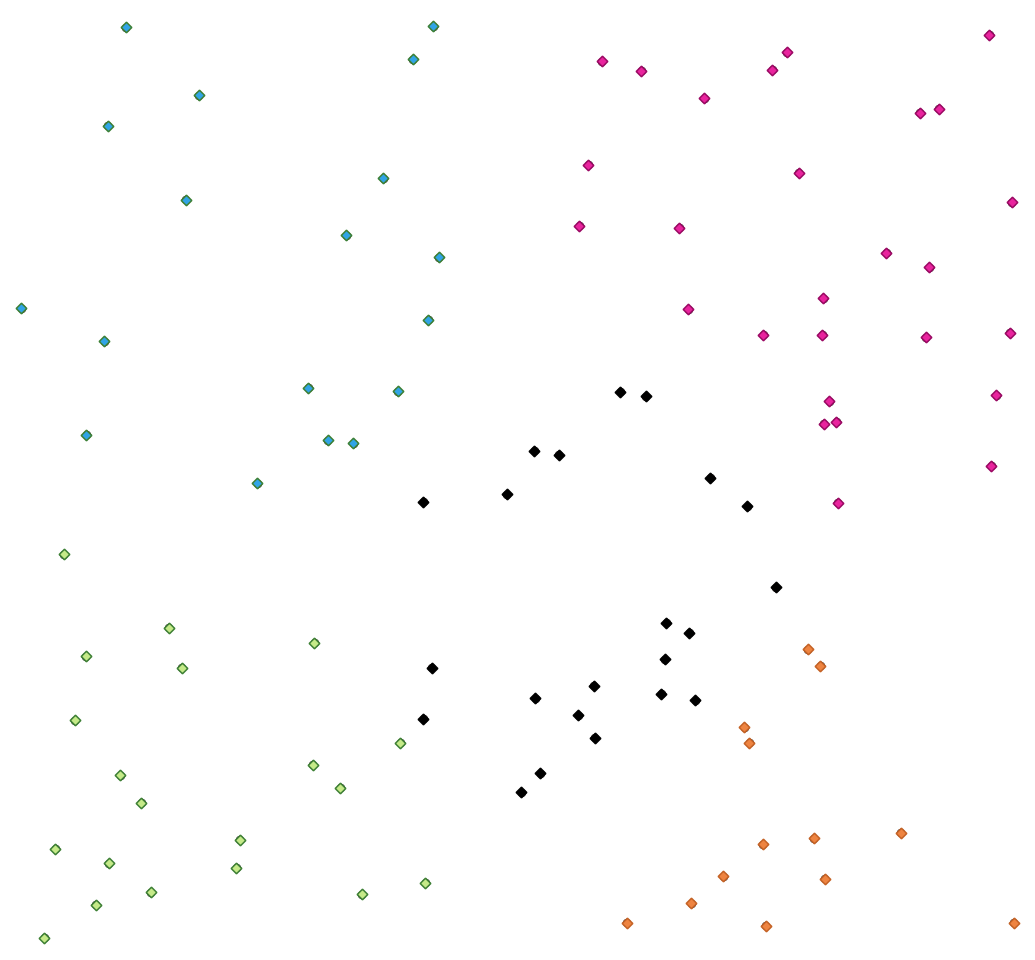
Fig. 24.29 Un groupe de points de cinq classes
Voir aussi
Paramètres
Étiquette |
Nom |
Type |
Description |
|---|---|---|---|
Couche en entrée |
|
[vector: any] |
Couche à analyser |
Nombre de clusters |
|
[number] Par défaut: 5 |
Nombre de clusters à créer avec les entités |
Nom du champ du cluster |
|
[string] Par défaut: “CLUSTER_ID” |
Nom du numéro de champ du cluster |
Clusters |
|
[vector: any] |
Couche vectorielle pour générer les clusters |
Les sorties
Étiquette |
Nom |
Type |
Description |
|---|---|---|---|
Clusters |
|
[vector: any] |
Couche vectorielle contenant les entités originales avec un champ spécifiant le cluster auquel elles appartiennent |
Code Python
ID de l’algorithme : qgis:kmeansclustering
import processing
processing.run("algorithm_id", {parameter_dictionary})
L”id de l’algorithme est affiché lors du survol du nom de l’algorithme dans la boîte à outils Traitements. Les nom et valeur de chaque paramètre sont fournis via un dictionnaire de paramètres. Voir Utiliser les algorithmes du module de traitements depuis la console Python pour plus de détails sur l’exécution d’algorithmes via la console Python.
24.1.13.10. Liste les valeurs uniques
Répertorie les valeurs uniques d’un champ de table d’attributs et compte leur nombre.
Menu par défaut:
Paramètres
Étiquette |
Nom |
Type |
Description |
|---|---|---|---|
Couche en entrée |
|
[vector: any] |
Couche à analyser |
Champ (s) cible (s) |
|
[tablefield: any] |
Champ à analyser |
Valeurs uniques |
|
[table] |
Couche du tableau récapitulatif avec des valeurs uniques |
Rapport HTML |
|
[html] |
Rapport HTML de valeurs uniques dans |
Les sorties
Étiquette |
Nom |
Type |
Description |
|---|---|---|---|
Valeurs uniques |
|
[table] |
Couche du tableau récapitulatif avec des valeurs uniques |
Rapport HTML |
|
[html] |
Rapport HTML de valeurs uniques. Peut être ouvert à partir de |
Total des valeurs uniques |
|
[number] |
Le nombre de valeurs uniques dans le champ de saisie |
UNIQUE_VALUES |
|
[string] |
Une chaîne avec la liste séparée par des virgules de valeurs uniques trouvées dans le champ de saisie |
Code Python
ID de l’algorithme : qgis:listuniquevalues
import processing
processing.run("algorithm_id", {parameter_dictionary})
L”id de l’algorithme est affiché lors du survol du nom de l’algorithme dans la boîte à outils Traitements. Les nom et valeur de chaque paramètre sont fournis via un dictionnaire de paramètres. Voir Utiliser les algorithmes du module de traitements depuis la console Python pour plus de détails sur l’exécution d’algorithmes via la console Python.
24.1.13.11. Coordonnées moyennes
Calcule une couche ponctuelle avec le centre de masse des géométries dans une couche en entrée.
Un attribut peut être spécifié comme contenant des poids à appliquer à chaque entité lors du calcul du centre de masse.
Si un attribut est sélectionné dans le paramètre, les entités seront regroupées selon les valeurs de ce champ. Au lieu d’un seul point avec le centre de masse de l’ensemble de la couche, la couche de sortie contiendra un centre de masse pour les entités de chaque catégorie.
Menu par défaut:
Paramètres
Étiquette |
Nom |
Type |
Description |
|---|---|---|---|
Couche en entrée |
|
[vector: any] |
Couche vectorielle en entrée |
Champ de coefficient Optionnel |
|
[tablefield: numeric] |
Champ à utiliser si vous souhaitez effectuer une moyenne pondérée |
Champ ID unique |
|
[tablefield: numeric] |
Champ unique sur lequel sera effectué le calcul de la moyenne |
Coordonnées moyennes |
|
[vector: point] |
La couche (vecteur de type ponctuel) du résultat |
Les sorties
Étiquette |
Nom |
Type |
Description |
|---|---|---|---|
Coordonnées moyennes |
|
[vector: point] |
Couche de point (s) résultant |
Code Python
ID de l’algorithme : qgis:meancoordinates
import processing
processing.run("algorithm_id", {parameter_dictionary})
L”id de l’algorithme est affiché lors du survol du nom de l’algorithme dans la boîte à outils Traitements. Les nom et valeur de chaque paramètre sont fournis via un dictionnaire de paramètres. Voir Utiliser les algorithmes du module de traitements depuis la console Python pour plus de détails sur l’exécution d’algorithmes via la console Python.
24.1.13.12. Analyse du plus proche voisin
Effectue l’analyse du plus proche voisin pour une couche de points. La sortie vous dit comment vos données sont distribuées (regroupées par cluster, aléatoirement, ou régulièrement).
La sortie est générée sous forme de fichier HTML avec les valeurs statistiques calculées:
Distance moyenne observée
Distance moyenne attendue
Indice de voisin le plus proche
Nombre de points
Score Z : Comparer le Score Z avec la distribution normale vous dit comment vos données sont distribuées. Un Score Z bas signifie qu’il est peu probable que la distribution des données soit le résultat d’un processus aléatoire alors qu’un Score Z élevé signifie qu’il est très probable que la distribution de vos données soit le résultat d’un processus aléatoire.
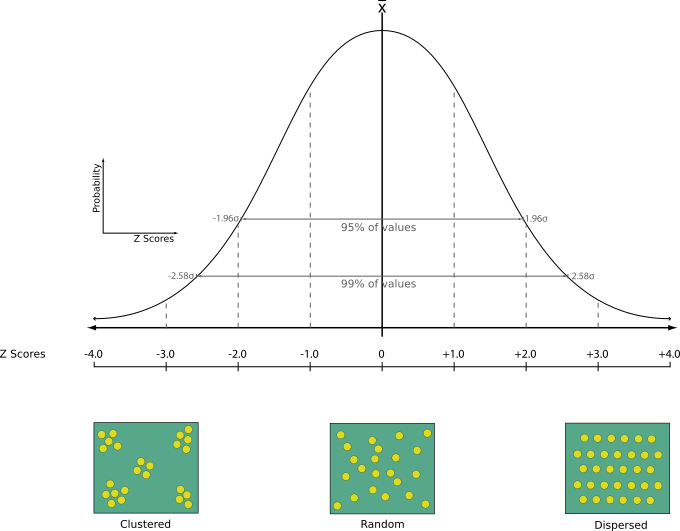
Menu par défaut:
Voir aussi
Paramètres
Étiquette |
Nom |
Type |
Description |
|---|---|---|---|
Couche en entrée |
|
[vector: point] |
Couche vectorielle ponctuelle sur laquelle calculer les statistiques |
Voisin le plus proche |
|
[html] |
Fichier HTML pour les statistiques calculées |
Les sorties
Étiquette |
Nom |
Type |
Description |
|---|---|---|---|
Voisin le plus proche |
|
[html] |
Fichier HTML avec les statistiques calculées |
Distance moyenne observée |
|
[number] |
Distance moyenne observée |
Distance moyenne attendue |
|
[number] |
Distance moyenne attendue |
Indice de voisin le plus proche |
|
[number] |
Indice de voisin le plus proche |
Nombre de points |
|
[number] |
Nombre de points |
Z-Score |
|
[number] |
Z-Score |
Code Python
ID de l’algorithme : qgis:nearestneighbouranalysis
import processing
processing.run("algorithm_id", {parameter_dictionary})
L”id de l’algorithme est affiché lors du survol du nom de l’algorithme dans la boîte à outils Traitements. Les nom et valeur de chaque paramètre sont fournis via un dictionnaire de paramètres. Voir Utiliser les algorithmes du module de traitements depuis la console Python pour plus de détails sur l’exécution d’algorithmes via la console Python.
24.1.13.13. Analyse de superposition
Calcule la surface et le pourcentage de couverture par lesquels les entités d’une couche en entrée sont chevauchées par les entités d’une sélection de couches de superposition.
De nouveaux attributs sont ajoutés à la couche de sortie indiquant la surface totale de chevauchement et le pourcentage de l’entité d’entrée chevauchée par chacune des couches de superposition sélectionnées.
Paramètres
Étiquette |
Nom |
Type |
Description |
|---|---|---|---|
Couche en entrée |
|
[vector: any] |
La couche d’entrée. |
Couches de superposition |
|
[vector: any] [list] |
Les couches de superposition. |
Couche en sortie |
|
[identique à l’entrée] Par défaut: |
Spécifiez la couche vectorielle de sortie. Un des:
L’encodage du fichier peut également être modifié ici. |
Les sorties
Étiquette |
Nom |
Type |
Description |
|---|---|---|---|
Couche en sortie |
|
[identique à l’entrée] |
La couche de sortie avec des champs supplémentaires signalant le chevauchement (en unités de carte et en pourcentage) de l’entité en entrée chevauchée par chacune des couches sélectionnées. |
Code Python
ID de l’algorithme : qgis:calculatevectoroverlaps
import processing
processing.run("algorithm_id", {parameter_dictionary})
L”id de l’algorithme est affiché lors du survol du nom de l’algorithme dans la boîte à outils Traitements. Les nom et valeur de chaque paramètre sont fournis via un dictionnaire de paramètres. Voir Utiliser les algorithmes du module de traitements depuis la console Python pour plus de détails sur l’exécution d’algorithmes via la console Python.
24.1.13.14. Statistiques par catégories
Calcule les statistiques d’un champ en fonction d’une classe parent. La classe parente est une combinaison de valeurs provenant d’autres champs.
Paramètres
Étiquette |
Nom |
Type |
Description |
|---|---|---|---|
Couche vectorielle source |
|
[vector: any] |
Couche vectorielle source avec des classes et des valeurs uniques |
Champ sur lequel calculer les statistiques (s’il est vide, seul le décompte est calculé) Optionnel |
|
[tablefield: any] |
S’il est vide, seul le nombre sera calculé |
Champ (s) avec catégories |
|
[vector: any] [list] |
Les champs qui (combinés) définissent les catégories |
Statistiques par catégorie |
|
[table] |
Tableau des statistiques générées |
Les sorties
Étiquette |
Nom |
Type |
Description |
|---|---|---|---|
Statistiques par catégorie |
|
[table] |
Tableau contenant les statistiques |
Selon le type de champ en cours d’analyse, les statistiques suivantes sont renvoyées pour chaque valeur groupée:
Statistiques |
Caractère |
Numérique |
Date |
|---|---|---|---|
Count ( |
|
|
|
Valeurs uniques ( |
|
|
|
Valeurs vides (nulles) ( |
|
|
|
Valeurs non vides ( |
|
|
|
Valeur minimale ( |
|
|
|
Valeur maximale ( |
|
|
|
Plage ( |
|
||
somme ( |
|
||
Valeur moyenne ( |
|
||
Valeur médiane ( |
|
||
Standard Deviation ( |
|
||
Coefficient of variation ( |
|
||
Minorité (valeur la plus rare survenue - |
|
||
Majorité (valeur la plus fréquente - |
|
||
Premier quartile ( |
|
||
Troisième quartile ( |
|
||
Plage interquartile ( |
|
||
Longueur minimale ( |
|
||
Longueur moyenne ( |
|
||
Longueur maximale ( |
|

Code Python
ID de l’algorithme : qgis:statisticsbycategories
import processing
processing.run("algorithm_id", {parameter_dictionary})
L”id de l’algorithme est affiché lors du survol du nom de l’algorithme dans la boîte à outils Traitements. Les nom et valeur de chaque paramètre sont fournis via un dictionnaire de paramètres. Voir Utiliser les algorithmes du module de traitements depuis la console Python pour plus de détails sur l’exécution d’algorithmes via la console Python.
24.1.13.15. Longueurs de la somme des lignes
Prend une couche de polygones et une couche de lignes et mesure la longueur totale des lignes et le nombre total de celles qui traversent chaque polygone.
La couche résultante a les mêmes caractéristiques que la couche de polygone source, mais avec deux attributs supplémentaires contenant la longueur et le nombre de lignes à travers chaque polygone.
Menu par défaut:
Paramètres
Étiquette |
Nom |
Type |
Description |
|---|---|---|---|
Lignes |
|
[vector: line] |
Couche de ligne source |
Polygones |
|
[vector: polygon] |
Couche vectorielle polygone |
Nom du champ de longueur des lignes |
|
[string] Par défaut: “LENGTH” |
Nom du champ pour la longueur des lignes |
Nom du champ de comptage lignes |
|
[string] Par défaut : “COUNT” |
Nom du champ pour le nombre de lignes |
Longueur de la ligne |
|
[vector: polygon] |
La couche vectorielle de polygone en sortie |
Les sorties
Étiquette |
Nom |
Type |
Description |
|---|---|---|---|
Longueur de la ligne |
|
[vector: polygon] |
Couche de sortie de polygone avec champs de longueur de ligne et le comptage des lignes |
Code Python
ID de l’algorithme : qgis:sumlinelengths
import processing
processing.run("algorithm_id", {parameter_dictionary})
L”id de l’algorithme est affiché lors du survol du nom de l’algorithme dans la boîte à outils Traitements. Les nom et valeur de chaque paramètre sont fournis via un dictionnaire de paramètres. Voir Utiliser les algorithmes du module de traitements depuis la console Python pour plus de détails sur l’exécution d’algorithmes via la console Python.