24.1.9. Analyse raster
24.1.9.1. Statistiques des cellules
Calcule les statistiques par cellule sur la base des couches raster d’entrée et, pour chaque cellule, écrit les statistiques résultantes sur un raster de sortie. À chaque emplacement de cellule, la valeur de sortie est définie en fonction de toutes les valeurs de cellules superposées des raster d’entrée.
Par défaut, une cellule NoData dans n’importe laquelle des couches d’entrée se traduira par une cellule NoData dans le raster de sortie. Si l’option Ignorer les valeurs NoData est cochée, alors les entrées NoData seront ignorées dans le calcul des statistiques. Cela peut entraîner la sortie de NoData pour les endroits où toutes les cellules sont NoData.
Le paramètre Couche référence spécifie une couche raster existante à utiliser comme référence lors de la création du raster de sortie. Le raster de sortie aura la même étendue, le même CRS et les mêmes dimensions en pixels que cette couche.
**Détails du calcul : Les couches raster d’entrée qui ne correspondent pas à la taille de cellule de la couche raster de référence seront rééchantillonnées en utilisant le rééchantillonnage du plus proche voisin. Le type de données raster de sortie sera réglé sur le type de données le plus complexe présent dans les ensembles de données d’entrée, sauf si l’on utilise les fonctions Moyenne, Écart-type et Variance (le type de données est toujours Float32 ou `Float64` selon le type de flottant d'entrée) ou ``Count et Variety (le type de données est toujours Int32).
Count: La statistique de comptage donnera toujours le nombre de cellules sans valeur NoData à l’emplacement actuel de la cellule.Médiane: Si le nombre de couches d’entrée est pair, la médiane sera calculée comme la moyenne arithmétique des deux valeurs moyennes des valeurs d’entrée des cellules ordonnées.Minorité/Majorité: Si aucune minorité ou majorité unique n’a pu être trouvée, le résultat est NoData, sauf que toutes les valeurs des cellules d’entrée sont égales.
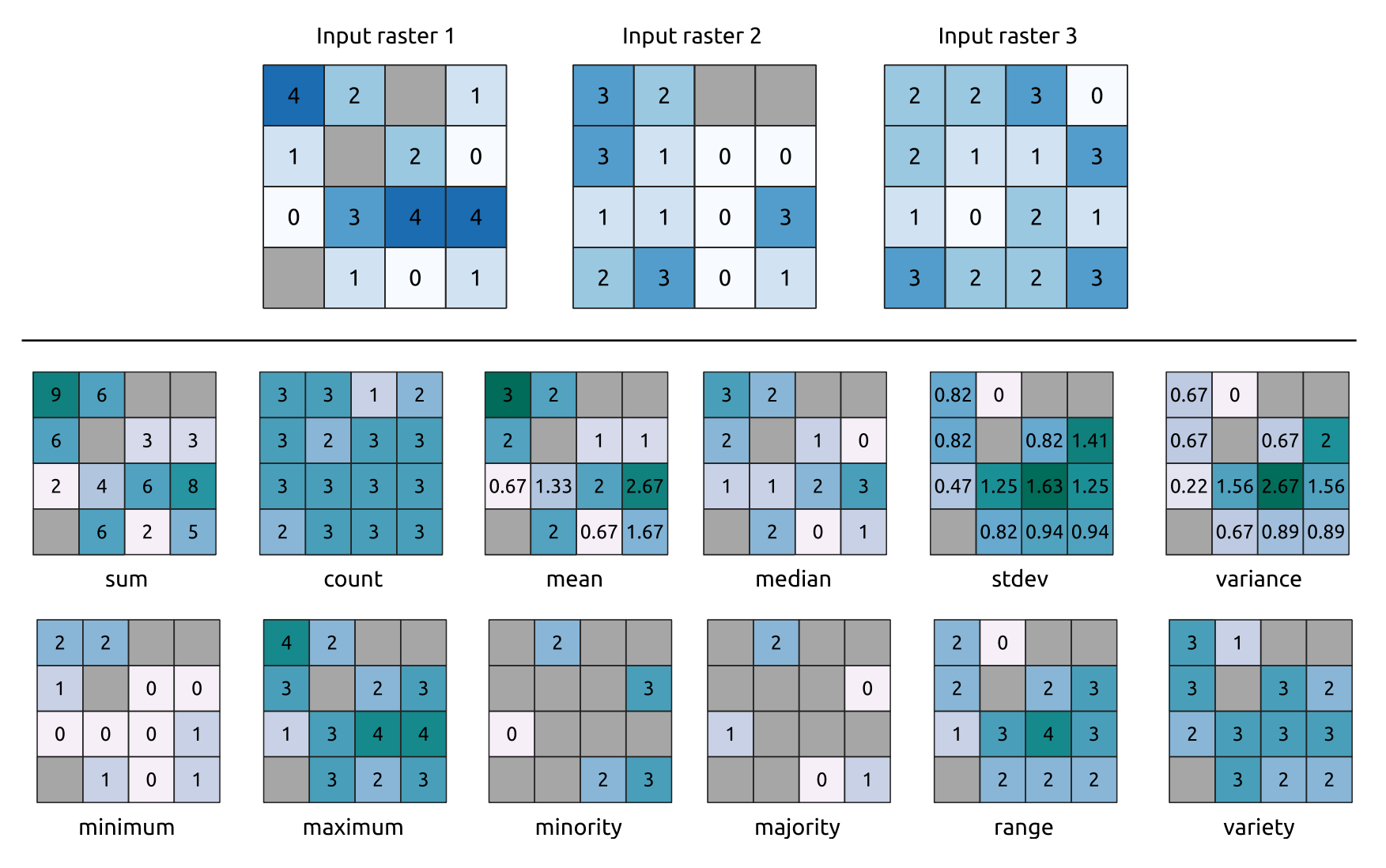
Fig. 24.8 Exemple avec toutes les fonctions statistiques. Les cellules NoData (en gris) sont prises en compte.
Paramètres
Étiquette |
Nom |
Type |
Description |
|---|---|---|---|
Couches d’entrée |
|
[raster] [list] |
Couches raster d’entrée |
Statistique |
|
[enumeration] Par défaut : 0 |
Statistiques disponibles. Options :
|
Ignorer les valeurs NoData |
|
[boolean] Default: True |
Calculer également les statistiques pour toutes les piles de cellules, en ignorant l’occurrence des NoData. |
Couche de référence |
|
[raster] |
La couche de référence à partir de laquelle créer la couche de sortie (étendue, SCR, dimensions en pixels) |
Sortie no data Optionnel |
|
[number] Default: -9999.0 |
Valeur à utiliser pour les nodata dans la couche de sortie |
Couche en sortie |
|
[identique à l’entrée] |
Spécification pour le raster en sortie. Au choix :
L’encodage du fichier peut également être modifié ici. |
Sorties
Étiquette |
Nom |
Type |
Description |
|---|---|---|---|
Identifiant d’autorité CRS |
|
[crs] |
Le système de référence de coordonnées de la couche raster en sortie |
Extent |
|
[emprise] |
L’étendue spatiale de la couche raster de sortie |
Hauteur en pixels |
|
[integer] |
La hauteur en pixels de la couche raster en sortie |
Sortie raster |
|
[raster] |
Couche raster en sortie contenant le résultat |
Nombre total de pixels |
|
[integer] |
Nombre de pixels dans la couche raster en sortie |
Largeur en pixels |
|
[integer] |
La largeur en pixels de la couche raster en sortie |
Code Python
ID de l’algorithme : qgis:cellstatistics
import processing
processing.run("algorithm_id", {parameter_dictionary})
L”id de l’algorithme est affiché lors du survol du nom de l’algorithme dans la boîte à outils Traitements. Les nom et valeur de chaque paramètre sont fournis via un dictionnaire de paramètres. Voir Utiliser les algorithmes du module de traitements depuis la console Python pour plus de détails sur l’exécution d’algorithmes via la console Python.
24.1.9.2. Equal to frequency
Evaluates on a cell-by-cell basis the frequency (number of times) the values
of an input stack of rasters are equal to the value of a value layer.
The output raster extent and resolution are defined by the input raster layer
and is always of Int32 type.
If multiband rasters are used in the data raster stack, the algorithm will always perform the analysis on the first band of the rasters - use GDAL to use other bands in the analysis. The output NoData value can be set manually.
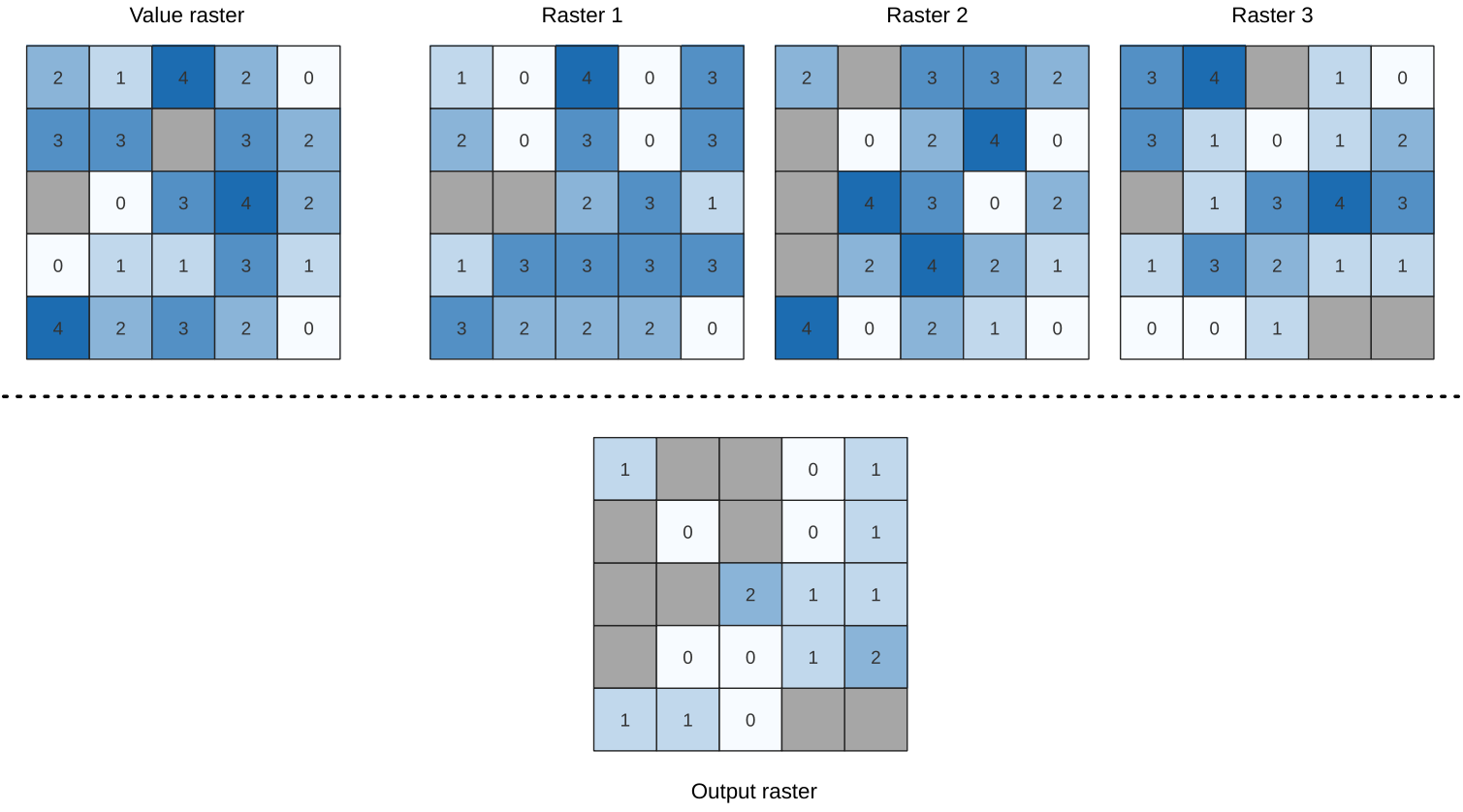
Fig. 24.9 For each cell in the output raster, the value represents the number of times
that the corresponding cells in the list of rasters are the same as the value raster.
NoData cells (grey) are taken into account.
Voir aussi
Paramètres
Basic parameters
Étiquette |
Nom |
Type |
Description |
|---|---|---|---|
Input value raster |
|
[raster] |
The input value layer serves as reference layer for the sample layers |
Value raster band |
|
[raster band] Par défaut: la première bande de la couche raster |
Select the band you want to use as sample |
Input raster layers |
|
[raster] [list] |
Raster layers to evaluate. If multiband rasters are used in the data raster stack, the algorithm will always perform the analysis on the first band of the rasters |
Ignorer les valeurs NoData |
|
[boolean] Par défaut : Faux |
If unchecked, any NoData cells in the value raster or the data layer stack will result in a NoData cell in the output raster |
Couche en sortie |
|
[identique à l’entrée] Default: |
Spécification pour le raster en sortie. Au choix :
|
Advanced parameters
Étiquette |
Nom |
Type |
Description |
|---|---|---|---|
Sortie no data Optionnel |
|
[number] Default: -9999.0 |
Valeur à utiliser pour les nodata dans la couche de sortie |
Sorties
Étiquette |
Nom |
Type |
Description |
|---|---|---|---|
Couche en sortie |
|
[raster] |
Couche raster en sortie contenant le résultat |
Identifiant d’autorité CRS |
|
[string] |
Le système de référence de coordonnées de la couche raster en sortie |
Extent |
|
[string] |
L’étendue spatiale de la couche raster de sortie |
Count of cells with equal value occurrences |
|
[number] |
|
Hauteur en pixels |
|
[number] |
Le nombre de lignes dans la couche raster de sortie |
Nombre total de pixels |
|
[integer] |
Nombre de pixels dans la couche raster en sortie |
Mean frequency at valid cell locations |
|
[number] |
|
Count of value occurrences |
|
[number] |
|
Largeur en pixels |
|
[integer] |
Le nombre de colonnes dans la couche raster de sortie |
Code Python
Algorithm ID: native:equaltofrequency
import processing
processing.run("algorithm_id", {parameter_dictionary})
L”id de l’algorithme est affiché lors du survol du nom de l’algorithme dans la boîte à outils Traitements. Les nom et valeur de chaque paramètre sont fournis via un dictionnaire de paramètres. Voir Utiliser les algorithmes du module de traitements depuis la console Python pour plus de détails sur l’exécution d’algorithmes via la console Python.
24.1.9.3. Raster Flouté (adhésion gaussienne)
Transforme un raster d’entrée en un raster flou en attribuant une valeur d’appartenance à chaque pixel, en utilisant une fonction d’appartenance gaussienne. Les valeurs d’appartenance varient de 0 à 1. Dans le raster flou, une valeur de 0 implique aucune appartenance à l’ensemble flou défini, alors qu’une valeur de 1 signifie une appartenance complète. La fonction d’appartenance gaussienne est définie comme 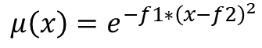 , où f1 est l’écart et f2 le point médian.
, où f1 est l’écart et f2 le point médian.
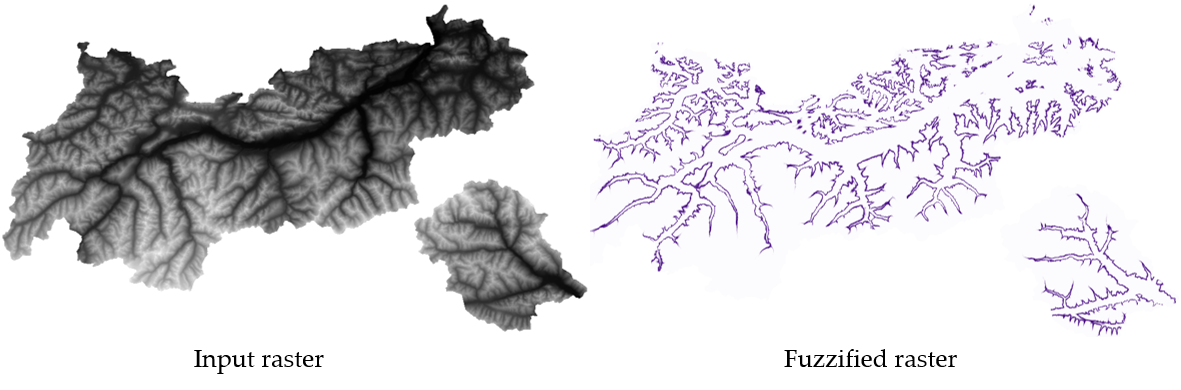
Fig. 24.10 Exemple raster flouté. Saisir la source du raster : Land Tirol - data.tirol.gv.at.
Voir aussi
Raster flouté (grand nombre de membres) Raster flouté (adhésion linéaire), Raster flouté (proche appartenance), Raster flouté (appartenance à la puissance), Raster flouté (appartenance du petit nombre)
Paramètres
Étiquette |
Nom |
Type |
Description |
|---|---|---|---|
Source raster |
|
[raster] |
Couche raster source |
Numéro de la bande |
|
[raster band] Par défaut: la première bande de la couche raster |
Si le raster est multibande, choisissez la bande que vous voulez flouté. |
Fonction à mi-parcours |
|
[number] Default: 10 |
Point médian de la fonction gaussienne |
Répartition des fonctions |
|
[number] Default: 0.01 |
Diffusion de la fonction gaussienne |
Raster flouté |
|
[identique à l’entrée] |
Spécification pour le raster en sortie. Au choix :
L’encodage du fichier peut également être modifié ici. |
Sorties
Étiquette |
Nom |
Type |
Description |
|---|---|---|---|
Raster flouté |
|
[identique à l’entrée] |
Couche raster en sortie contenant le résultat |
Identifiant d’autorité CRS |
|
[crs] |
Le système de référence de coordonnées de la couche raster en sortie |
Extent |
|
[emprise] |
L’étendue spatiale de la couche raster de sortie |
Largeur en pixels |
|
[integer] |
La largeur en pixels de la couche raster en sortie |
Hauteur en pixels |
|
[integer] |
La hauteur en pixels de la couche raster en sortie |
Nombre total de pixels |
|
[integer] |
Nombre de pixels dans la couche raster en sortie |
Code Python
ID de l’algorithme : qgis:fuzzifyrastergaussianmembership
import processing
processing.run("algorithm_id", {parameter_dictionary})
L”id de l’algorithme est affiché lors du survol du nom de l’algorithme dans la boîte à outils Traitements. Les nom et valeur de chaque paramètre sont fournis via un dictionnaire de paramètres. Voir Utiliser les algorithmes du module de traitements depuis la console Python pour plus de détails sur l’exécution d’algorithmes via la console Python.
24.1.9.4. Raster flouté (grand nombre de membres)
Transforme un raster d’entrée en un raster flou en attribuant une valeur d’appartenance à chaque pixel, à l’aide d’une fonction d’appartenance large. Les valeurs d’appartenance varient de 0 à 1. Dans le raster flou, une valeur de 0 implique aucune appartenance à l’ensemble flou défini, alors qu’une valeur de 1 signifie une appartenance complète. La fonction d’appartenance large est définie comme 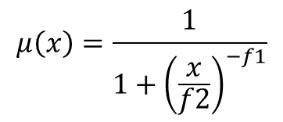 , où f1 est l’écart et f2 le point médian.
, où f1 est l’écart et f2 le point médian.
Voir aussi
Raster Flouté (adhésion gaussienne), Raster flouté (adhésion linéaire), Raster flouté (proche appartenance), Raster flouté (appartenance à la puissance), Raster flouté (appartenance du petit nombre)
Paramètres
Étiquette |
Nom |
Type |
Description |
|---|---|---|---|
Source raster |
|
[raster] |
Couche raster source |
Numéro de la bande |
|
[raster band] Par défaut: la première bande de la couche raster |
Si le raster est multibande, choisissez la bande que vous voulez flouté. |
Fonction à mi-parcours |
|
[number] Default: 50 |
Point médian de la grande fonction |
Répartition des fonctions |
|
[number] Par défaut: 5 |
Diffusion de la grande fonction |
Raster flouté |
|
[identique à l’entrée] |
Spécification pour le raster en sortie. Au choix :
L’encodage du fichier peut également être modifié ici. |
Sorties
Étiquette |
Nom |
Type |
Description |
|---|---|---|---|
Raster flouté |
|
[identique à l’entrée] |
Couche raster en sortie contenant le résultat |
Identifiant d’autorité CRS |
|
[crs] |
Le système de référence de coordonnées de la couche raster en sortie |
Extent |
|
[emprise] |
L’étendue spatiale de la couche raster de sortie |
Largeur en pixels |
|
[integer] |
La largeur en pixels de la couche raster en sortie |
Hauteur en pixels |
|
[integer] |
La hauteur en pixels de la couche raster en sortie |
Nombre total de pixels |
|
[integer] |
Nombre de pixels dans la couche raster en sortie |
Code Python
ID de l’algorithme : qgis:fuzzifyrasterlargemembership
import processing
processing.run("algorithm_id", {parameter_dictionary})
L”id de l’algorithme est affiché lors du survol du nom de l’algorithme dans la boîte à outils Traitements. Les nom et valeur de chaque paramètre sont fournis via un dictionnaire de paramètres. Voir Utiliser les algorithmes du module de traitements depuis la console Python pour plus de détails sur l’exécution d’algorithmes via la console Python.
24.1.9.5. Raster flouté (adhésion linéaire)
Transforme un raster d’entrée en un raster flou en attribuant une valeur d’appartenance à chaque pixel, à l’aide d’une fonction d’appartenance linéaire. Les valeurs d’appartenance varient de 0 à 1. Dans le raster flou, une valeur de 0 implique aucune appartenance à l’ensemble flou défini, alors qu’une valeur de 1 signifie une appartenance complète. La fonction linéaire est définie comme 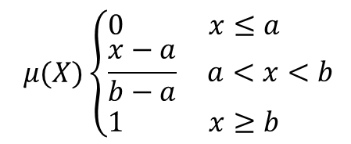 , où a est la limite inférieure et b la limite supérieure. Cette équation attribue des valeurs d’appartenance en utilisant une transformation linéaire pour les valeurs de pixels entre les limites inférieure et supérieure. Les valeurs de pixels inférieures à la limite inférieure se voient attribuer 0 appartenance, tandis que les valeurs de pixels supérieures à la limite supérieure se voient attribuer 1 appartenance.
, où a est la limite inférieure et b la limite supérieure. Cette équation attribue des valeurs d’appartenance en utilisant une transformation linéaire pour les valeurs de pixels entre les limites inférieure et supérieure. Les valeurs de pixels inférieures à la limite inférieure se voient attribuer 0 appartenance, tandis que les valeurs de pixels supérieures à la limite supérieure se voient attribuer 1 appartenance.
Voir aussi
Raster Flouté (adhésion gaussienne), Raster flouté (grand nombre de membres), Raster flouté (proche appartenance), Raster flouté (appartenance à la puissance), Raster flouté (appartenance du petit nombre)
Paramètres
Étiquette |
Nom |
Type |
Description |
|---|---|---|---|
Source raster |
|
[raster] |
Couche raster source |
Numéro de la bande |
|
[raster band] Par défaut: la première bande de la couche raster |
Si le raster est multibande, choisissez la bande que vous voulez flouté. |
Faiblement lié à appartenance floue |
|
[number] Par défaut : 0 |
Limite inférieure de la fonction linéaire |
Limite fortement flou |
|
[number] Par défaut : 1 |
Limite supérieure de la fonction linéaire |
Raster flouté |
|
[identique à l’entrée] |
Spécification pour le raster en sortie. Au choix :
L’encodage du fichier peut également être modifié ici. |
Sorties
Étiquette |
Nom |
Type |
Description |
|---|---|---|---|
Raster flouté |
|
[identique à l’entrée] |
Couche raster en sortie contenant le résultat |
Identifiant d’autorité CRS |
|
[crs] |
Le système de référence de coordonnées de la couche raster en sortie |
Extent |
|
[emprise] |
L’étendue spatiale de la couche raster de sortie |
Largeur en pixels |
|
[integer] |
La largeur en pixels de la couche raster en sortie |
Hauteur en pixels |
|
[integer] |
La hauteur en pixels de la couche raster en sortie |
Nombre total de pixels |
|
[integer] |
Nombre de pixels dans la couche raster en sortie |
Code Python
ID de l’algorithme : qgisfuzzifyrasterlinearmembership
import processing
processing.run("algorithm_id", {parameter_dictionary})
L”id de l’algorithme est affiché lors du survol du nom de l’algorithme dans la boîte à outils Traitements. Les nom et valeur de chaque paramètre sont fournis via un dictionnaire de paramètres. Voir Utiliser les algorithmes du module de traitements depuis la console Python pour plus de détails sur l’exécution d’algorithmes via la console Python.
24.1.9.6. Raster flouté (proche appartenance)
Transforme un raster d’entrée en un raster floue en attribuant une valeur d’appartenance à chaque pixel, à l’aide d’une fonction d’appartenance proche. Les valeurs d’appartenance varient de 0 à 1. Dans la trame floue, une valeur de 0 implique aucune appartenance à l’ensemble flou défini, alors qu’une valeur de 1 signifie une appartenance complète. La fonction d’appartenance proche est définie comme |proche_formule|, où f1 est l’écart et f2 le point médian.
Voir aussi
Raster Flouté (adhésion gaussienne), Raster flouté (grand nombre de membres), Raster flouté (adhésion linéaire), Raster flouté (appartenance à la puissance), Raster flouté (appartenance du petit nombre)
Paramètres
Étiquette |
Nom |
Type |
Description |
|---|---|---|---|
Source raster |
|
[raster] |
Couche raster source |
Numéro de la bande |
|
[raster band] Par défaut: la première bande de la couche raster |
Si le raster est multibande, choisissez la bande que vous voulez flouté. |
Fonction à mi-parcours |
|
[number] Default: 50 |
Point médian de la fonction de proximité |
Répartition des fonctions |
|
[number] Default: 0.01 |
Propagation de la fonction de proximité |
Raster flouté |
|
[identique à l’entrée] |
Spécification pour le raster en sortie. Au choix :
L’encodage du fichier peut également être modifié ici. |
Sorties
Étiquette |
Nom |
Type |
Description |
|---|---|---|---|
Raster flouté |
|
[identique à l’entrée] |
Couche raster en sortie contenant le résultat |
Identifiant d’autorité CRS |
|
[crs] |
Le système de référence de coordonnées de la couche raster en sortie |
Extent |
|
[emprise] |
L’étendue spatiale de la couche raster de sortie |
Largeur en pixels |
|
[integer] |
La largeur en pixels de la couche raster en sortie |
Hauteur en pixels |
|
[integer] |
La hauteur en pixels de la couche raster en sortie |
Nombre total de pixels |
|
[integer] |
Nombre de pixels dans la couche raster en sortie |
Code Python
ID de l’algorithme : qgis:fuzzifyrasternearmembership
import processing
processing.run("algorithm_id", {parameter_dictionary})
L”id de l’algorithme est affiché lors du survol du nom de l’algorithme dans la boîte à outils Traitements. Les nom et valeur de chaque paramètre sont fournis via un dictionnaire de paramètres. Voir Utiliser les algorithmes du module de traitements depuis la console Python pour plus de détails sur l’exécution d’algorithmes via la console Python.
24.1.9.7. Raster flouté (appartenance à la puissance)
Transforme un raster d’entrée en un raster flou en attribuant une valeur d’appartenance à chaque pixel, à l’aide d’une fonction d’appartenance à la puissance. Les valeurs d’appartenance varient de 0 à 1. Dans le raster flou, une valeur de 0 implique aucune appartenance à l’ensemble flou défini, alors qu’une valeur de 1 signifie une appartenance complète. La fonction de puissance est définie comme 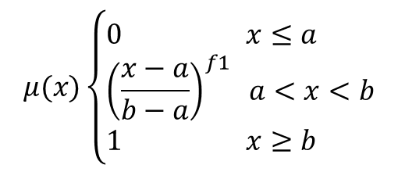 , où a est la limite inférieure, b est la limite supérieure et f1 l’exposant. Cette équation attribue des valeurs d’appartenance en utilisant la transformation de puissance pour les valeurs de pixel entre les limites inférieure et supérieure. Les valeurs de pixels inférieures à la limite inférieure se voient attribuer 0 appartenance, tandis que les valeurs de pixels supérieures à la limite supérieure se voient attribuer 1 appartenance.
, où a est la limite inférieure, b est la limite supérieure et f1 l’exposant. Cette équation attribue des valeurs d’appartenance en utilisant la transformation de puissance pour les valeurs de pixel entre les limites inférieure et supérieure. Les valeurs de pixels inférieures à la limite inférieure se voient attribuer 0 appartenance, tandis que les valeurs de pixels supérieures à la limite supérieure se voient attribuer 1 appartenance.
Voir aussi
Raster Flouté (adhésion gaussienne), Raster flouté (grand nombre de membres), Raster flouté (adhésion linéaire), Raster flouté (proche appartenance), Raster flouté (appartenance du petit nombre)
Paramètres
Étiquette |
Nom |
Type |
Description |
|---|---|---|---|
Source raster |
|
[raster] |
Couche raster source |
Numéro de la bande |
|
[raster band] Par défaut: la première bande de la couche raster |
Si le raster est multibande, choisissez la bande que vous voulez flouté. |
Faiblement lié à appartenance floue |
|
[number] Par défaut : 0 |
Limite inférieure de la fonction de puissance |
Limite fortement flou |
|
[number] Par défaut : 1 |
Limite supérieure de la fonction puissance |
Limite fortement flou |
|
[number] Default: 2 |
Exposant de la fonction puissance |
Raster flouté |
|
[identique à l’entrée] |
Spécification pour le raster en sortie. Au choix :
L’encodage du fichier peut également être modifié ici. |
Sorties
Étiquette |
Nom |
Type |
Description |
|---|---|---|---|
Raster flouté |
|
[identique à l’entrée] |
Couche raster en sortie contenant le résultat |
Identifiant d’autorité CRS |
|
[crs] |
Le système de référence de coordonnées de la couche raster en sortie |
Extent |
|
[emprise] |
L’étendue spatiale de la couche raster de sortie |
Largeur en pixels |
|
[integer] |
La largeur en pixels de la couche raster en sortie |
Hauteur en pixels |
|
[integer] |
La hauteur en pixels de la couche raster en sortie |
Nombre total de pixels |
|
[integer] |
Nombre de pixels dans la couche raster en sortie |
Code Python
ID de l’algorithme : qgisfuzzifyrasterpowermembership
import processing
processing.run("algorithm_id", {parameter_dictionary})
L”id de l’algorithme est affiché lors du survol du nom de l’algorithme dans la boîte à outils Traitements. Les nom et valeur de chaque paramètre sont fournis via un dictionnaire de paramètres. Voir Utiliser les algorithmes du module de traitements depuis la console Python pour plus de détails sur l’exécution d’algorithmes via la console Python.
24.1.9.8. Raster flouté (appartenance du petit nombre)
Transforme un raster d’entrée en un raster flou en attribuant une valeur d’appartenance à chaque pixel, à l’aide d’une fonction d’appartenance petite. Les valeurs d’appartenance varient de 0 à 1. Dans , le raster une valeur de 0 implique aucune appartenance à l’ensemble flou défini, alors qu’une valeur de 1 signifie une appartenance complète. La petite fonction d’appartenance est définie comme 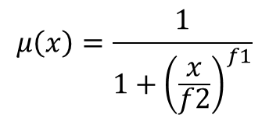 , où f1 est la dispersion et f2 le point médian.
, où f1 est la dispersion et f2 le point médian.
Voir aussi
Raster Flouté (adhésion gaussienne), Raster flouté (grand nombre de membres) Raster flouté (adhésion linéaire), Raster flouté (proche appartenance), Raster flouté (appartenance à la puissance)
Paramètres
Étiquette |
Nom |
Type |
Description |
|---|---|---|---|
Source raster |
|
[raster] |
Couche raster source |
Numéro de la bande |
|
[raster band] Par défaut: la première bande de la couche raster |
Si le raster est multibande, choisissez la bande que vous voulez flouté. |
Fonction à mi-parcours |
|
[number] Default: 50 |
Point médian de la petite fonction |
Répartition des fonctions |
|
[number] Par défaut: 5 |
Diffusion de la petite fonction |
Raster flouté |
|
[identique à l’entrée] |
Spécification pour le raster en sortie. Au choix :
L’encodage du fichier peut également être modifié ici. |
Sorties
Étiquette |
Nom |
Type |
Description |
|---|---|---|---|
Raster flouté |
|
[identique à l’entrée] |
Couche raster en sortie contenant le résultat |
Identifiant d’autorité CRS |
|
[crs] |
Le système de référence de coordonnées de la couche raster en sortie |
Extent |
|
[emprise] |
L’étendue spatiale de la couche raster de sortie |
Largeur en pixels |
|
[integer] |
La largeur en pixels de la couche raster en sortie |
Hauteur en pixels |
|
[integer] |
La hauteur en pixels de la couche raster en sortie |
Nombre total de pixels |
|
[integer] |
Nombre de pixels dans la couche raster en sortie |
Code Python
ID de l’algorithme : qgisfuzzifyrastersmallmembership
import processing
processing.run("algorithm_id", {parameter_dictionary})
L”id de l’algorithme est affiché lors du survol du nom de l’algorithme dans la boîte à outils Traitements. Les nom et valeur de chaque paramètre sont fournis via un dictionnaire de paramètres. Voir Utiliser les algorithmes du module de traitements depuis la console Python pour plus de détails sur l’exécution d’algorithmes via la console Python.
24.1.9.9. Greater than frequency
Evaluates on a cell-by-cell basis the frequency (number of times) the values
of an input stack of rasters are equal to the value of a value raster.
The output raster extent and resolution is defined by the input raster layer
and is always of Int32 type.
If multiband rasters are used in the data raster stack, the algorithm will always perform the analysis on the first band of the rasters - use GDAL to use other bands in the analysis. The output NoData value can be set manually.
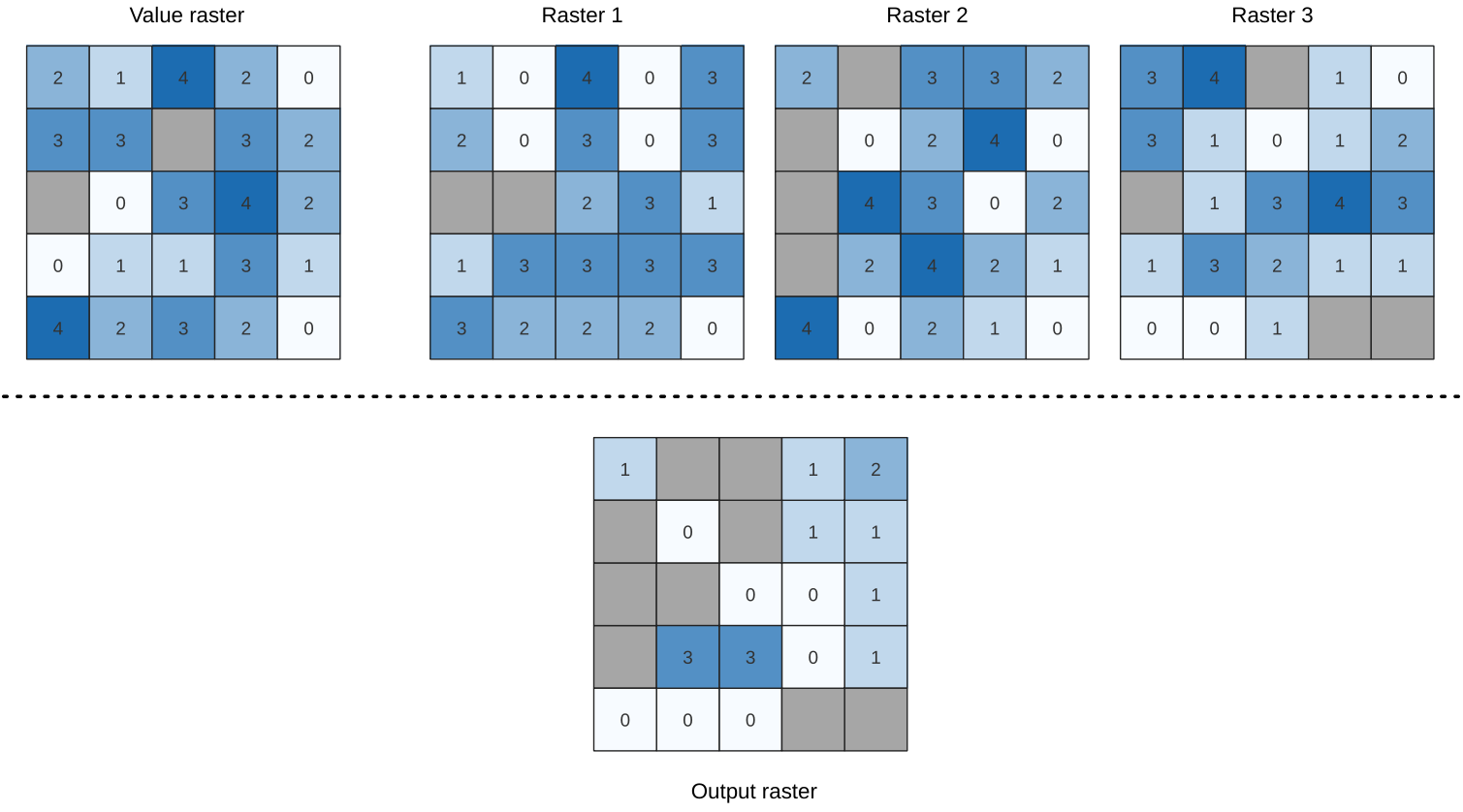
Fig. 24.11 For each cell in the output raster, the value represents the number of times
that the corresponding cells in the list of rasters are greater than the value raster.
NoData cells (grey) are taken into account.
Voir aussi
Paramètres
Basic parameters
Étiquette |
Nom |
Type |
Description |
|---|---|---|---|
Input value raster |
|
[raster] |
The input value layer serves as reference layer for the sample layers |
Value raster band |
|
[raster band] Par défaut: la première bande de la couche raster |
Select the band you want to use as sample |
Input raster layers |
|
[raster] [list] |
Raster layers to evaluate. If multiband rasters are used in the data raster stack, the algorithm will always perform the analysis on the first band of the rasters |
Ignorer les valeurs NoData |
|
[boolean] Par défaut : Faux |
If unchecked, any NoData cells in the value raster or the data layer stack will result in a NoData cell in the output raster |
Couche en sortie |
|
[identique à l’entrée] Default: |
Spécification pour le raster en sortie. Au choix :
|
Advanced parameters
Étiquette |
Nom |
Type |
Description |
|---|---|---|---|
Sortie no data Optionnel |
|
[number] Default: -9999.0 |
Valeur à utiliser pour les nodata dans la couche de sortie |
Sorties
Étiquette |
Nom |
Type |
Description |
|---|---|---|---|
Couche en sortie |
|
[raster] |
Couche raster en sortie contenant le résultat |
Identifiant d’autorité CRS |
|
[string] |
Le système de référence de coordonnées de la couche raster en sortie |
Extent |
|
[string] |
L’étendue spatiale de la couche raster de sortie |
Count of cells with equal value occurrences |
|
[number] |
|
Hauteur en pixels |
|
[number] |
Le nombre de lignes dans la couche raster de sortie |
Nombre total de pixels |
|
[integer] |
Nombre de pixels dans la couche raster en sortie |
Mean frequency at valid cell locations |
|
[number] |
|
Count of value occurrences |
|
[number] |
|
Largeur en pixels |
|
[integer] |
Le nombre de colonnes dans la couche raster de sortie |
Code Python
Algorithm ID: native:greaterthanfrequency
import processing
processing.run("algorithm_id", {parameter_dictionary})
L”id de l’algorithme est affiché lors du survol du nom de l’algorithme dans la boîte à outils Traitements. Les nom et valeur de chaque paramètre sont fournis via un dictionnaire de paramètres. Voir Utiliser les algorithmes du module de traitements depuis la console Python pour plus de détails sur l’exécution d’algorithmes via la console Python.
24.1.9.10. Highest position in raster stack
Evaluates on a cell-by-cell basis the position of the raster with the highest value in a stack of rasters. Position counts start with 1 and range to the total number of input rasters. The order of the input rasters is relevant for the algorithm. If multiple rasters feature the highest value, the first raster will be used for the position value.
If multiband rasters are used in the data raster stack, the algorithm will
always perform the analysis on the first band of the rasters - use GDAL to use
other bands in the analysis.
Any NoData cells in the raster layer stack will result in a NoData cell
in the output raster unless the « ignore NoData » parameter is checked.
The output NoData value can be set manually. The output rasters extent and
resolution is defined by a reference raster layer and is always of Int32 type.
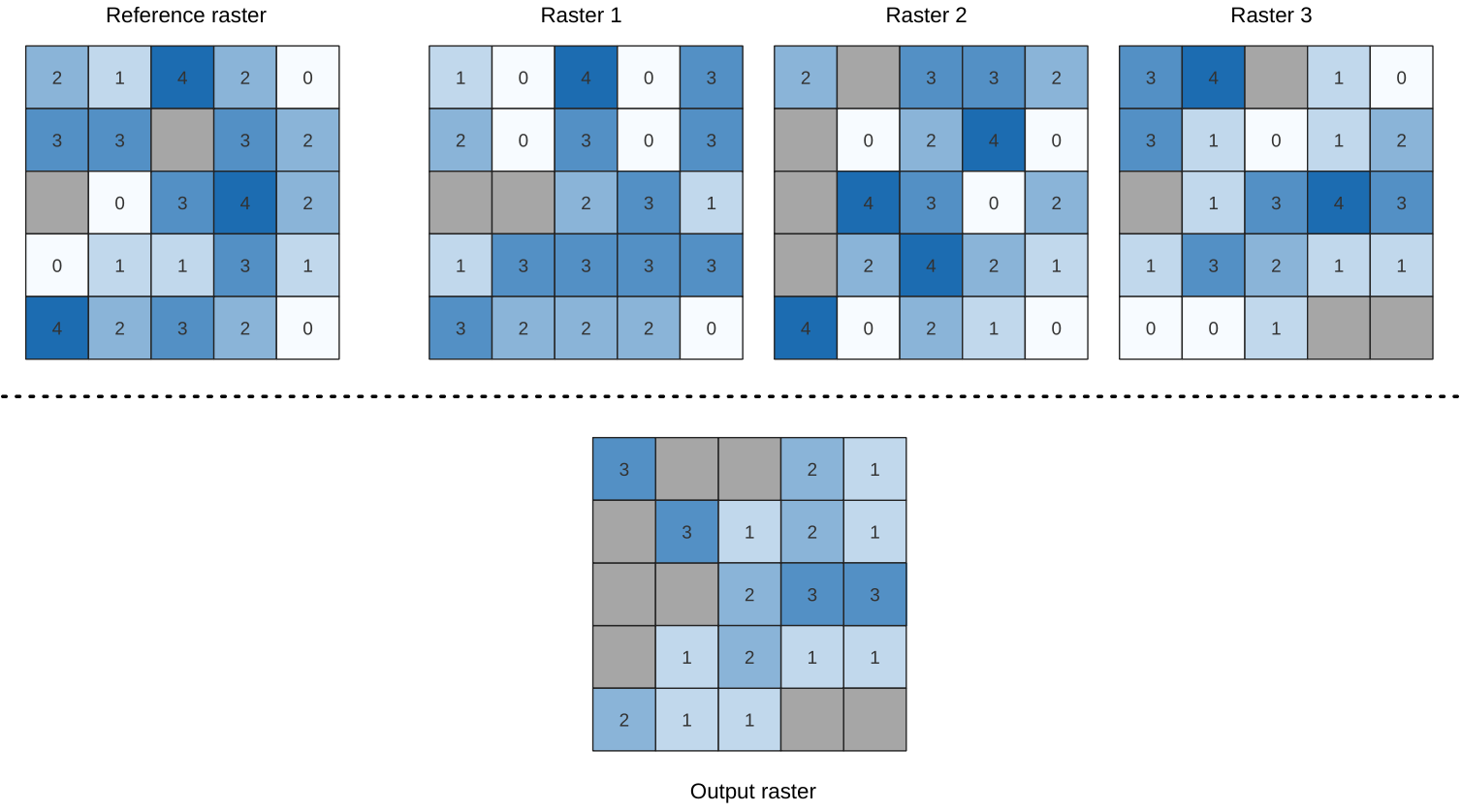
Voir aussi
Paramètres
Basic parameters
Étiquette |
Nom |
Type |
Description |
|---|---|---|---|
Input raster layers |
|
[raster] [list] |
List of raster layers to compare with |
Couche de référence |
|
[raster] |
The reference layer for the output layer creation (extent, CRS, pixel dimensions) |
Ignorer les valeurs NoData |
|
[boolean] Par défaut : Faux |
If unchecked, any NoData cells in the data layer stack will result in a NoData cell in the output raster |
Couche en sortie |
|
[raster] Default: |
Specification of the output raster containing the result. One of:
|
Advanced parameters
Étiquette |
Nom |
Type |
Description |
|---|---|---|---|
Sortie no data |
|
[number] Default: -9999.0 |
Valeur à utiliser pour les nodata dans la couche de sortie |
Sorties
Étiquette |
Nom |
Type |
Description |
|---|---|---|---|
Couche en sortie |
|
[raster] |
Couche raster en sortie contenant le résultat |
Identifiant d’autorité CRS |
|
[string] |
Le système de référence de coordonnées de la couche raster en sortie |
Extent |
|
[string] |
L’étendue spatiale de la couche raster de sortie |
Largeur en pixels |
|
[integer] |
Le nombre de colonnes dans la couche raster de sortie |
Hauteur en pixels |
|
[integer] |
Le nombre de lignes dans la couche raster de sortie |
Nombre total de pixels |
|
[integer] |
Nombre de pixels dans la couche raster en sortie |
Code Python
Algorithm ID: native:highestpositioninrasterstack
import processing
processing.run("algorithm_id", {parameter_dictionary})
L”id de l’algorithme est affiché lors du survol du nom de l’algorithme dans la boîte à outils Traitements. Les nom et valeur de chaque paramètre sont fournis via un dictionnaire de paramètres. Voir Utiliser les algorithmes du module de traitements depuis la console Python pour plus de détails sur l’exécution d’algorithmes via la console Python.
24.1.9.11. Less than frequency
Evaluates on a cell-by-cell basis the frequency (number of times) the values
of an input stack of rasters are less than the value of a value raster.
The output raster extent and resolution is defined by the input raster layer
and is always of Int32 type.
If multiband rasters are used in the data raster stack, the algorithm will always perform the analysis on the first band of the rasters - use GDAL to use other bands in the analysis. The output NoData value can be set manually.
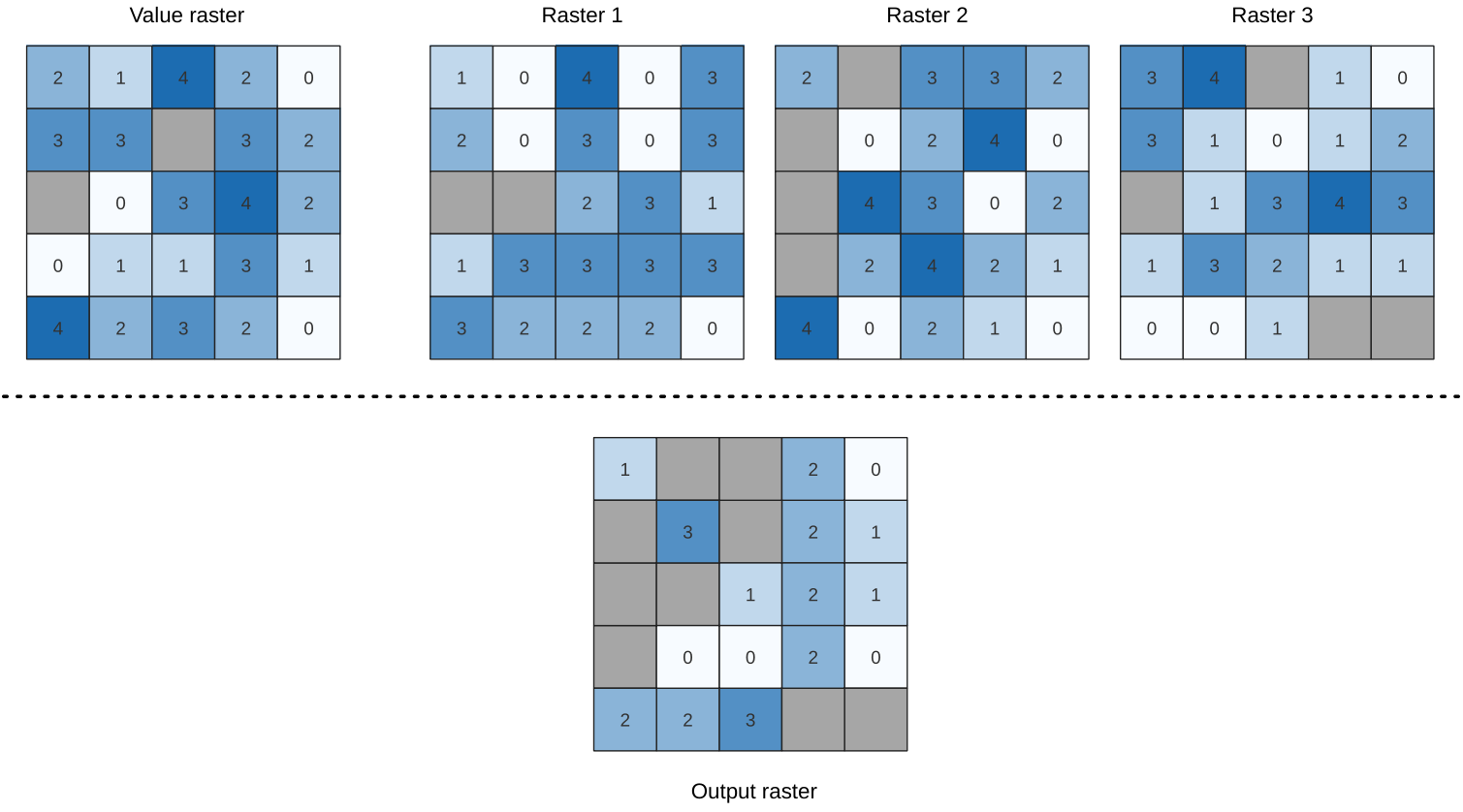
Fig. 24.12 For each cell in the output raster, the value represents the number of times
that the corresponding cells in the list of rasters are less than the value raster.
NoData cells (grey) are taken into account.
Voir aussi
Paramètres
Basic parameters
Étiquette |
Nom |
Type |
Description |
|---|---|---|---|
Input value raster |
|
[raster] |
The input value layer serves as reference layer for the sample layers |
Value raster band |
|
[raster band] Par défaut: la première bande de la couche raster |
Select the band you want to use as sample |
Input raster layers |
|
[raster] [list] |
Raster layers to evaluate. If multiband rasters are used in the data raster stack, the algorithm will always perform the analysis on the first band of the rasters |
Ignorer les valeurs NoData |
|
[boolean] Par défaut : Faux |
If unchecked, any NoData cells in the value raster or the data layer stack will result in a NoData cell in the output raster |
Couche en sortie |
|
[identique à l’entrée] Default: |
Spécification pour le raster en sortie. Au choix :
|
Advanced parameters
Étiquette |
Nom |
Type |
Description |
|---|---|---|---|
Sortie no data Optionnel |
|
[number] Default: -9999.0 |
Valeur à utiliser pour les nodata dans la couche de sortie |
Sorties
Étiquette |
Nom |
Type |
Description |
|---|---|---|---|
Couche en sortie |
|
[raster] |
Couche raster en sortie contenant le résultat |
Identifiant d’autorité CRS |
|
[string] |
Le système de référence de coordonnées de la couche raster en sortie |
Extent |
|
[string] |
L’étendue spatiale de la couche raster de sortie |
Count of cells with equal value occurrences |
|
[number] |
|
Hauteur en pixels |
|
[number] |
Le nombre de lignes dans la couche raster de sortie |
Nombre total de pixels |
|
[integer] |
Nombre de pixels dans la couche raster en sortie |
Mean frequency at valid cell locations |
|
[number] |
|
Count of value occurrences |
|
[number] |
|
Largeur en pixels |
|
[integer] |
Le nombre de colonnes dans la couche raster de sortie |
Code Python
Algorithm ID: native:lessthanfrequency
import processing
processing.run("algorithm_id", {parameter_dictionary})
L”id de l’algorithme est affiché lors du survol du nom de l’algorithme dans la boîte à outils Traitements. Les nom et valeur de chaque paramètre sont fournis via un dictionnaire de paramètres. Voir Utiliser les algorithmes du module de traitements depuis la console Python pour plus de détails sur l’exécution d’algorithmes via la console Python.
24.1.9.12. Lowest position in raster stack
Evaluates on a cell-by-cell basis the position of the raster with the lowest value in a stack of rasters. Position counts start with 1 and range to the total number of input rasters. The order of the input rasters is relevant for the algorithm. If multiple rasters feature the lowest value, the first raster will be used for the position value.
If multiband rasters are used in the data raster stack, the algorithm will
always perform the analysis on the first band of the rasters - use GDAL to use
other bands in the analysis.
Any NoData cells in the raster layer stack will result in a NoData cell
in the output raster unless the « ignore NoData » parameter is checked.
The output NoData value can be set manually. The output rasters extent and
resolution is defined by a reference raster layer and is always of Int32 type.
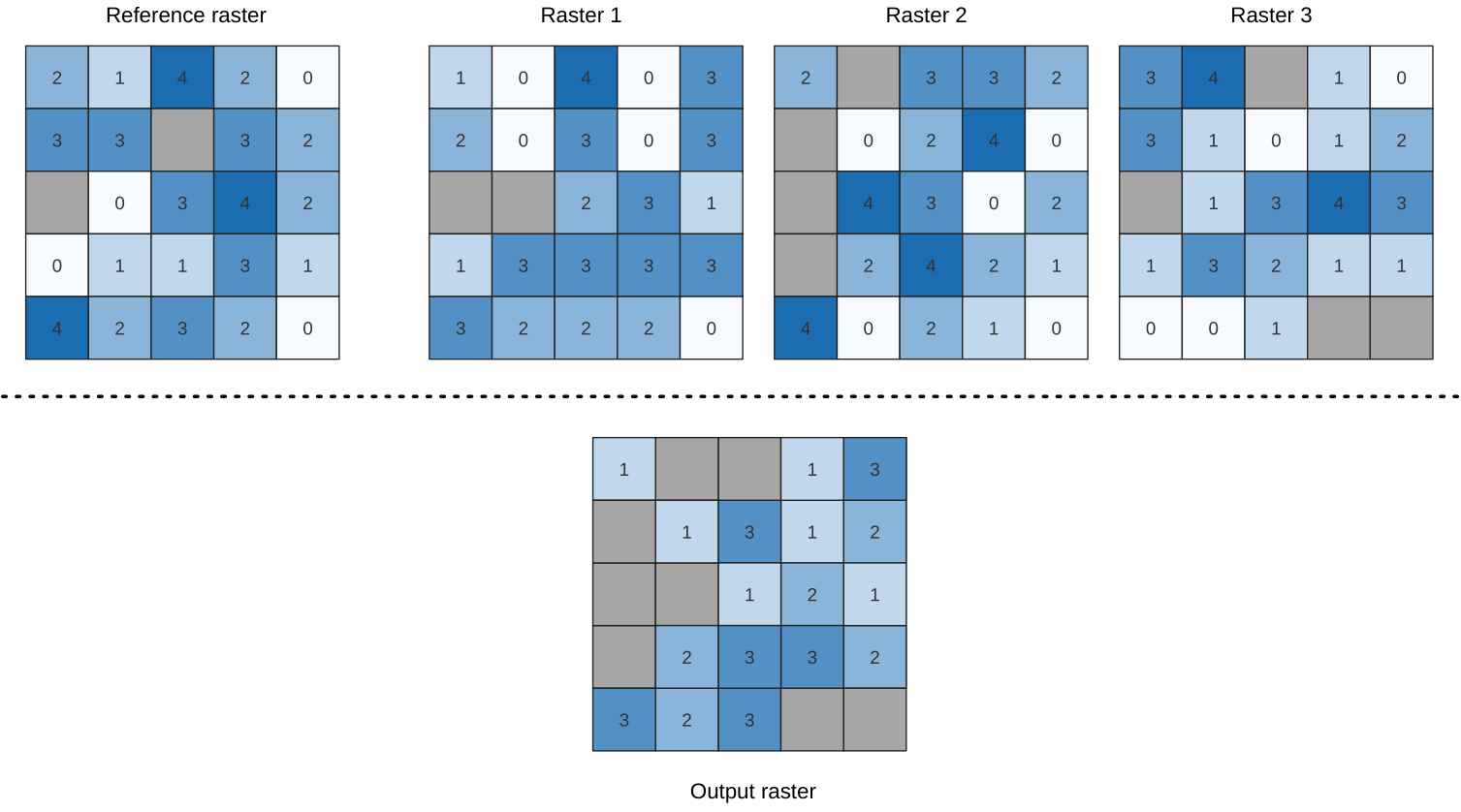
Voir aussi
Paramètres
Basic parameters
Étiquette |
Nom |
Type |
Description |
|---|---|---|---|
Input raster layers |
|
[raster] [list] |
List of raster layers to compare with |
Couche de référence |
|
[raster] |
The reference layer for the output layer creation (extent, CRS, pixel dimensions) |
Ignorer les valeurs NoData |
|
[boolean] Par défaut : Faux |
If unchecked, any NoData cells in the data layer stack will result in a NoData cell in the output raster |
Couche en sortie |
|
[raster] Default: |
Specification of the output raster containing the result. One of:
|
Advanced parameters
Étiquette |
Nom |
Type |
Description |
|---|---|---|---|
Sortie no data |
|
[number] Default: -9999.0 |
Valeur à utiliser pour les nodata dans la couche de sortie |
Sorties
Étiquette |
Nom |
Type |
Description |
|---|---|---|---|
Couche en sortie |
|
[raster] |
Couche raster en sortie contenant le résultat |
Identifiant d’autorité CRS |
|
[string] |
Le système de référence de coordonnées de la couche raster en sortie |
Extent |
|
[string] |
L’étendue spatiale de la couche raster de sortie |
Largeur en pixels |
|
[integer] |
Le nombre de colonnes dans la couche raster de sortie |
Hauteur en pixels |
|
[integer] |
Le nombre de lignes dans la couche raster de sortie |
Nombre total de pixels |
|
[integer] |
Nombre de pixels dans la couche raster en sortie |
Code Python
Algorithm ID: native:lowestpositioninrasterstack
import processing
processing.run("algorithm_id", {parameter_dictionary})
L”id de l’algorithme est affiché lors du survol du nom de l’algorithme dans la boîte à outils Traitements. Les nom et valeur de chaque paramètre sont fournis via un dictionnaire de paramètres. Voir Utiliser les algorithmes du module de traitements depuis la console Python pour plus de détails sur l’exécution d’algorithmes via la console Python.
24.1.9.13. Raster booléen ET
Calcule le booléen AND pour un ensemble de rasters en entrée. Si tous les rasters en entrée ont une valeur non nulle pour un pixel, ce pixel sera défini sur 1 dans le raster en sortie. Si l’un des rasters en entrée a des valeurs 0 pour le pixel, il sera défini sur 0 dans le raster en sortie.
Le paramètre de couche de référence spécifie une couche raster existante à utiliser comme référence lors de la création du raster en sortie. Le raster en sortie aura la même étendue, SCR et dimensions en pixels que cette couche.
Par défaut, un pixel nodata dans N’IMPORTE QUELLE couche en entrée se traduira par un pixel nodata dans le raster en sortie. Si l’option Traiter les valeurs nodata comme fausses est cochée, les entrées nodata seront traitées de la même manière qu’une valeur d’entrée 0.
Voir aussi
Paramètres
Étiquette |
Nom |
Type |
Description |
|---|---|---|---|
Couches d’entrée |
|
[raster] [list] |
Liste des couches raster en entrée |
Couche de référence |
|
[raster] |
La couche de référence à partir de laquelle créer la couche de sortie (étendue, SCR, dimensions en pixels) |
Traitez les valeurs de nodata comme fausses |
|
[boolean] Par défaut : Faux |
Traitez les valeurs de nodata dans les fichiers d’entrée comme 0 lors de l’exécution de l’opération |
Sortie no data |
|
[number] Default: -9999.0 |
Valeur à utiliser pour les nodata dans la couche de sortie |
Type de données de sortie |
|
[enumeration] Par défaut: 5 |
Type de données raster en sortie. Options:
|
Couche en sortie |
|
[raster] |
Couche raster en sortie |
Sorties
Étiquette |
Nom |
Type |
Description |
|---|---|---|---|
Extent |
|
[emprise] |
L’étendue de la couche raster en sortie |
Identifiant d’autorité CRS |
|
[crs] |
Le système de référence de coordonnées de la couche raster en sortie |
Largeur en pixels |
|
[integer] |
La largeur en pixels de la couche raster en sortie |
Hauteur en pixels |
|
[integer] |
La hauteur en pixels de la couche raster en sortie |
Nombre total de pixels |
|
[integer] |
Nombre de pixels dans la couche raster en sortie |
Nombre de pixels NODATA |
|
[integer] |
Le nombre de pixels nodata dans la couche raster en sortie |
Nombre de pixels vrai |
|
[integer] |
Le nombre de vrais pixels (valeur = 1) dans la couche raster en sortie |
Nombre de faux pixels |
|
[integer] |
Nombre de faux pixels (valeur = 0) dans la couche raster en sortie |
Couche en sortie |
|
[raster] |
Couche raster en sortie contenant le résultat |
Code Python
ID de l’algorithme : qgis:rasterbooleanand
import processing
processing.run("algorithm_id", {parameter_dictionary})
L”id de l’algorithme est affiché lors du survol du nom de l’algorithme dans la boîte à outils Traitements. Les nom et valeur de chaque paramètre sont fournis via un dictionnaire de paramètres. Voir Utiliser les algorithmes du module de traitements depuis la console Python pour plus de détails sur l’exécution d’algorithmes via la console Python.
24.1.9.14. Raster booléen OR
Calcule le booléen OR pour un ensemble de rasters en entrée. Si tous les rasters en entrée ont une valeur nulle pour un pixel, ce pixel sera défini sur 0 dans le raster en sortie. Si l’un des rasters en entrée a des valeurs 1 pour le pixel, il sera défini sur 1 dans le raster en sortie.
Le paramètre de couche de référence spécifie une couche raster existante à utiliser comme référence lors de la création du raster en sortie. Le raster en sortie aura la même étendue, SCR et dimensions en pixels que cette couche.
Par défaut, un pixel nodata dans N’IMPORTE QUELLE couche en entrée se traduira par un pixel nodata dans le raster en sortie. Si l’option Traiter les valeurs nodata comme fausses est cochée, les entrées nodata seront traitées de la même manière qu’une valeur d’entrée 0.
Voir aussi
Paramètres
Étiquette |
Nom |
Type |
Description |
|---|---|---|---|
Couches d’entrée |
|
[raster] [list] |
Liste des couches raster en entrée |
Couche de référence |
|
[raster] |
La couche de référence à partir de laquelle créer la couche de sortie (étendue, SCR, dimensions en pixels) |
Traitez les valeurs de nodata comme fausses |
|
[boolean] Par défaut : Faux |
Traitez les valeurs de nodata dans les fichiers d’entrée comme 0 lors de l’exécution de l’opération |
Sortie no data |
|
[number] Default: -9999.0 |
Valeur à utiliser pour les nodata dans la couche de sortie |
Type de données de sortie |
|
[enumeration] Par défaut: 5 |
Type de données raster en sortie. Options:
|
Couche en sortie |
|
[raster] |
Couche raster en sortie |
Sorties
Étiquette |
Nom |
Type |
Description |
|---|---|---|---|
Extent |
|
[emprise] |
L’étendue de la couche raster en sortie |
Identifiant d’autorité CRS |
|
[crs] |
Le système de référence de coordonnées de la couche raster en sortie |
Largeur en pixels |
|
[integer] |
La largeur en pixels de la couche raster en sortie |
Hauteur en pixels |
|
[integer] |
La hauteur en pixels de la couche raster en sortie |
Nombre total de pixels |
|
[integer] |
Nombre de pixels dans la couche raster en sortie |
Nombre de pixels NODATA |
|
[integer] |
Le nombre de pixels nodata dans la couche raster en sortie |
Nombre de pixels vrai |
|
[integer] |
Le nombre de vrais pixels (valeur = 1) dans la couche raster en sortie |
Nombre de faux pixels |
|
[integer] |
Nombre de faux pixels (valeur = 0) dans la couche raster en sortie |
Couche en sortie |
|
[raster] |
Couche raster en sortie contenant le résultat |
Code Python
ID de l’algorithme : qgis:rasterbooleanor
import processing
processing.run("algorithm_id", {parameter_dictionary})
L”id de l’algorithme est affiché lors du survol du nom de l’algorithme dans la boîte à outils Traitements. Les nom et valeur de chaque paramètre sont fournis via un dictionnaire de paramètres. Voir Utiliser les algorithmes du module de traitements depuis la console Python pour plus de détails sur l’exécution d’algorithmes via la console Python.
24.1.9.15. Calculatrice raster
Effectue des opérations algébriques à l’aide de couches raster.
La couche résultante verra ses valeurs calculées en fonction d’une expression. L’expression peut contenir des valeurs numériques, des opérateurs et des références à n’importe quelle couche du projet en cours.
Note
Lorsque vous utilisez la calculatrice dans L’interface de traitement par lot ou depuis la La console Python de QGIS, les fichiers à utiliser doivent être spécifiés. Les couches correspondantes sont référencées en utilisant le nom de base du fichier (sans le chemin complet). Par exemple, si vous utilisez une couche dans path/to/my/rasterfile.tif, la première bande de cette couche sera appelée rasterfile.tif@1.
Voir aussi
Paramètres
Étiquette |
Nom |
Type |
Description |
|---|---|---|---|
Couches |
GUI only |
Affiche la liste de toutes les couches raster chargées dans la légende. Ceux-ci peuvent être utilisés pour remplir la zone d’expression (double-cliquez pour ajouter). Les couches raster sont référencées par leur nom et le numéro de la bande: |
|
Les opérateurs |
GUI only |
Contient des boutons de type calculatrice qui peuvent être utilisés pour remplir la zone d’expression. |
|
Expression |
|
[string] |
Expression qui sera utilisée pour calculer la couche raster en sortie. Vous pouvez utiliser les boutons d’opérateur fournis pour saisir directement l’expression dans cette zone. |
Expressions prédéfinies |
GUI only |
Vous pouvez utiliser l’expression |
|
Couche (s) de référence (utilisée pour l’étendue automatisée, la taille de cellule et le SCR) Optionnel |
|
[raster] [list] |
Couche (s) qui seront utilisées pour extraire l’étendue, la taille des cellules et le SCR. En choisissant la couche dans cette case, vous évitez de remplir tous les autres paramètres à la main. Les couches raster sont référencées par leur nom et le numéro de la bande: |
Taille de la cellule (utilisez 0 ou vide pour la définir automatiquement) Optionnel |
|
[number] |
Taille de cellule de la couche raster en sortie. Si la taille de cellule n’est pas spécifiée, la taille de cellule minimale des couches de référence sélectionnées sera utilisée. La taille des cellules sera la même pour les axes X et Y. |
Étendue de sortie (xmin, xmax, ymin, ymax) Optionnel |
|
[emprise] |
Étendue de la couche raster en sortie. Si l’étendue n’est pas spécifiée, l’étendue minimale qui couvre toutes les couches de référence sélectionnées sera utilisée. |
SCR en sortie Optionnel |
|
[crs] |
SCR de la couche raster en sortie. Si le SCR de sortie n’est pas spécifié, le SCR de la première couche de référence sera utilisé. |
Rendu |
|
[raster] Default: |
Spécification pour le raster en sortie. Au choix :
L’encodage du fichier peut également être modifié ici. |
Sorties
Étiquette |
Nom |
Type |
Description |
|---|---|---|---|
Rendu |
|
[raster] |
Fichier raster en sortie avec les valeurs calculées. |
Code Python
ID de l’algorithme : qgis:rastercalculator
import processing
processing.run("algorithm_id", {parameter_dictionary})
L”id de l’algorithme est affiché lors du survol du nom de l’algorithme dans la boîte à outils Traitements. Les nom et valeur de chaque paramètre sont fournis via un dictionnaire de paramètres. Voir Utiliser les algorithmes du module de traitements depuis la console Python pour plus de détails sur l’exécution d’algorithmes via la console Python.
24.1.9.16. Statistiques de couche raster
Calcule les statistiques de base à partir des valeurs dans une bande donnée de la couche raster. La sortie est chargée dans le menu .
Paramètres
Étiquette |
Nom |
Type |
Description |
|---|---|---|---|
Couche en entrée |
|
[raster] |
Couche raster source |
Numéro de bande |
|
[raster band] Par défaut: la première bande de la couche d’entrée |
Si le raster est multibande, choisissez la bande pour laquelle vous souhaitez obtenir des statistiques. |
Rendu |
|
[html] Default: |
Spécification du fichier de sortie:
L’encodage du fichier peut également être modifié ici. |
Sorties
Étiquette |
Nom |
Type |
Description |
|---|---|---|---|
Valeur maximale |
|
[number] |
|
Valeur moyenne |
|
[number] |
|
Valeur minimum |
|
[number] |
|
Rendu |
|
[html] |
Le fichier de sortie contient les informations suivantes:
|
Gamme |
|
[number] |
|
Écart-type |
|
[number] |
|
Somme |
|
[number] |
|
Somme des carrés |
|
[number] |
Code Python
ID de l’algorithme : qgis:rasterlayerstatistics
import processing
processing.run("algorithm_id", {parameter_dictionary})
L”id de l’algorithme est affiché lors du survol du nom de l’algorithme dans la boîte à outils Traitements. Les nom et valeur de chaque paramètre sont fournis via un dictionnaire de paramètres. Voir Utiliser les algorithmes du module de traitements depuis la console Python pour plus de détails sur l’exécution d’algorithmes via la console Python.
24.1.9.17. Rapport sur les valeurs uniques de la couche raster
Renvoie le nombre et la surface de chaque valeur unique dans une couche raster donnée.
Paramètres
Étiquette |
Nom |
Type |
Description |
|---|---|---|---|
Couche en entrée |
|
[raster] |
Couche raster source |
Numéro de bande |
|
[raster band] Par défaut: la première bande de la couche d’entrée |
Si le raster est multibande, choisissez la bande pour laquelle vous souhaitez obtenir des statistiques. |
Rapport sur les valeurs uniques |
|
[file] Default: |
Spécification du fichier de sortie:
L’encodage du fichier peut également être modifié ici. |
Table des valeurs uniques |
|
[table] Par défaut: |
Spécification de la table pour les valeurs uniques:
L’encodage du fichier peut également être modifié ici. |
Sorties
Étiquette |
Nom |
Type |
Description |
|---|---|---|---|
Identifiant d’autorité CRS |
|
[crs] |
|
Extent |
|
[emprise] |
|
Hauteur en pixels |
|
[number] |
|
Nombre de pixels NODATA |
|
[number] |
|
Nombre total de pixels |
|
[number] |
|
Rapport sur les valeurs uniques |
|
[html] |
Le fichier HTML de sortie contient les informations suivantes:
|
Table des valeurs uniques |
|
[table] |
Une table à trois colonnes:
|
Largeur en pixels |
|
[number] |
Code Python
ID de l’algorithme : qgis:rasterlayeruniquevaluesreport
import processing
processing.run("algorithm_id", {parameter_dictionary})
L”id de l’algorithme est affiché lors du survol du nom de l’algorithme dans la boîte à outils Traitements. Les nom et valeur de chaque paramètre sont fournis via un dictionnaire de paramètres. Voir Utiliser les algorithmes du module de traitements depuis la console Python pour plus de détails sur l’exécution d’algorithmes via la console Python.
24.1.9.18. Statistiques zonales de la couche raster
Calcule les statistiques des valeurs d’une couche raster, classées par zones définies dans une autre couche raster.
Voir aussi
Paramètres
Étiquette |
Nom |
Type |
Description |
|---|---|---|---|
Couche d’entrée |
|
[raster] |
Couche raster source |
Numéro de bande |
|
[raster band] Par défaut: la première bande de la couche raster |
Si le raster est multibande, choisissez la bande pour laquelle vous souhaitez calculer les statistiques. |
Couche Zones |
|
[raster] |
Zones de définition de couche raster. Les zones sont données par des pixels contigus ayant la même valeur de pixel. |
Numéro de bande des zones |
|
[raster band] Par défaut: la première bande de la couche raster |
Si le raster est multibande, choisissez la bande qui définit les zones |
Couche de référence Optionnel |
|
[enumeration] Par défaut : 0 |
Couche raster utilisée pour calculer les centroïdes qui seront utilisés comme référence lors de la détermination des zones dans la couche en sortie. Un des:
|
Statistiques |
|
[table] |
Tableau avec les statistiques calculées |
Sorties
Étiquette |
Nom |
Type |
Description |
|---|---|---|---|
Identifiant d’autorité CRS |
|
[crs] |
|
Extent |
|
[emprise] |
|
Hauteur en pixels |
|
[number] |
|
Nombre de pixels NODATA |
|
[number] |
|
Statistiques |
|
[table] |
La couche de sortie contient les informations suivantes pour chaque zone:
|
Nombre total de pixels |
|
[number] |
|
Largeur en pixels |
|
[number] |
Code Python
ID de l’algorithme : qgis:rasterlayerzonalstats
import processing
processing.run("algorithm_id", {parameter_dictionary})
L”id de l’algorithme est affiché lors du survol du nom de l’algorithme dans la boîte à outils Traitements. Les nom et valeur de chaque paramètre sont fournis via un dictionnaire de paramètres. Voir Utiliser les algorithmes du module de traitements depuis la console Python pour plus de détails sur l’exécution d’algorithmes via la console Python.
24.1.9.19. Volume de surface raster
Calcule le volume sous une surface raster par rapport à un niveau de base donné. Ceci est principalement utile pour les modèles numériques d’élévation (DEM).
Paramètres
Étiquette |
Nom |
Type |
Description |
|---|---|---|---|
Couche INPUT |
|
[raster] |
Raster en entrée, représentant une surface |
Numéro de bande |
|
[raster band] Par défaut: la première bande de la couche raster |
Si le raster est multibande, choisissez la bande qui définira la surface. |
Niveau de base |
|
[number] Par défaut : 0.0 |
Définissez une valeur de base ou de référence. Cette base est utilisée dans le calcul du volume selon le paramètre |
Méthode |
|
[enumeration] Par défaut : 0 |
Définir la méthode de calcul du volume donné par la différence entre la valeur du pixel du raster et le « niveau de base ». Options :
|
Rapport de volume de surface |
|
[html] Default: |
Spécification du rapport HTML de sortie. Un des:
L’encodage du fichier peut également être modifié ici. |
Table des volumes de surface |
|
[table] Par défaut: |
Spécification de la table de sortie. Un des:
L’encodage du fichier peut également être modifié ici. |
Sorties
Étiquette |
Nom |
Type |
Description |
|---|---|---|---|
Volume |
|
[number] |
Le volume calculé |
Surface |
|
[number] |
La surface en unités de carte carrée |
Pixel_count |
|
[number] |
Le nombre total de pixels qui ont été analysés |
Rapport de volume de surface |
|
[html] |
Le rapport de sortie (contenant le volume, la surface et le nombre de pixels) au format HTML |
Table des volumes de surface |
|
[table] |
La table de sortie (contenant le volume, la surface et le nombre de pixels) |
Code Python
ID de l’algorithme : qgis:rastersurfacevolume
import processing
processing.run("algorithm_id", {parameter_dictionary})
L”id de l’algorithme est affiché lors du survol du nom de l’algorithme dans la boîte à outils Traitements. Les nom et valeur de chaque paramètre sont fournis via un dictionnaire de paramètres. Voir Utiliser les algorithmes du module de traitements depuis la console Python pour plus de détails sur l’exécution d’algorithmes via la console Python.
24.1.9.20. Reclassifier par couche
Reclassifie une bande raster en attribuant de nouvelles valeurs de classe en fonction des plages spécifiées dans une table vectorielle.
Paramètres
Étiquette |
Nom |
Type |
Description |
|---|---|---|---|
Couche raster |
|
[raster] |
Couche raster à reclasser |
Numéro de bande |
|
[raster band] Par défaut: la première bande de la couche raster |
Si le raster est multibande, choisissez la bande que vous souhaitez reclasser. |
Couche contenant des sauts de classe |
|
[vector: any] |
Couche vectorielle contenant les valeurs à utiliser pour la classification. |
Champ de valeur de classe minimum |
|
[tablefield: numeric] |
Champ avec la valeur minimale de la plage pour la classe. |
Champ de valeur de classe maximum |
|
[tablefield: numeric] |
Champ avec la valeur maximale de la plage pour la classe. |
Champ de valeur de sortie |
|
[tablefield: numeric] |
Champ avec la valeur qui sera affectée aux pixels qui entrent dans la classe (entre les valeurs min et max correspondantes). |
Sortie no data |
|
[number] Default: -9999.0 |
Valeur à appliquer aux valeurs no data. |
Limites de plage |
|
[enumeration] Par défaut : 0 |
Définit des règles de comparaison pour la classification. Options:
|
N’utilisez no data lorsqu’aucune plage ne correspond à la valeur |
|
[boolean] Par défaut : Faux |
Les valeurs qui n’appartiennent pas à une classe entraîneront la valeur no data. Si False, la valeur d’origine est conservée. |
Type de données de sortie |
|
[enumeration] Par défaut: 5 |
Définit le type de données du fichier raster en sortie. Options:
|
Raster reclassifié |
|
[raster] |
Spécification pour le raster en sortie. Au choix :
L’encodage du fichier peut également être modifié ici. |
Sorties
Étiquette |
Nom |
Type |
Description |
|---|---|---|---|
Raster reclassifié |
|
[raster] |
Couche raster en sortie avec des valeurs de bande reclassées |
Code Python
ID de l’algorithme : qgis:reclassifybylayer
import processing
processing.run("algorithm_id", {parameter_dictionary})
L”id de l’algorithme est affiché lors du survol du nom de l’algorithme dans la boîte à outils Traitements. Les nom et valeur de chaque paramètre sont fournis via un dictionnaire de paramètres. Voir Utiliser les algorithmes du module de traitements depuis la console Python pour plus de détails sur l’exécution d’algorithmes via la console Python.
24.1.9.21. Reclassifier par table
Reclassifie une bande raster en attribuant de nouvelles valeurs de classe en fonction des plages spécifiées dans une table fixe.
Paramètres
Étiquette |
Nom |
Type |
Description |
|---|---|---|---|
Couche raster |
|
[raster] |
Couche raster à reclasser |
Numéro de bande |
|
[raster band] Par défaut : 1 |
Bande raster pour laquelle vous souhaitez recalculer les valeurs. |
Reclassement la table |
|
[table] |
Un tableau à 3 colonnes à remplir avec les valeurs pour définir les limites de chaque classe ( |
Sortie no data |
|
[number] Default: -9999.0 |
Valeur à appliquer aux valeurs no data. |
Limites de plage |
|
[enumeration] Par défaut : 0 |
Définit des règles de comparaison pour la classification. Options:
|
N’utilisez no data lorsqu’aucune plage ne correspond à la valeur |
|
[boolean] Par défaut : Faux |
Applique la valeur no data aux valeurs de bande qui n’appartiennent à aucune classe. Si False, la valeur d’origine est conservée. |
Type de données de sortie |
|
[enumeration] Par défaut: 5 |
Définit le format du fichier raster en sortie. Options :
|
Raster reclassifié |
|
[raster] Default: “[Save to temporary file]” |
Spécification de la couche raster en sortie. Un des:
L’encodage du fichier peut également être modifié ici |
Sorties
Étiquette |
Nom |
Type |
Description |
|---|---|---|---|
Raster reclassifié |
|
[raster] Default: “[Save to temporary file]” |
Couche raster en sortie. |
Code Python
ID de l’algorithme : qgis:reclassifybytable
import processing
processing.run("algorithm_id", {parameter_dictionary})
L”id de l’algorithme est affiché lors du survol du nom de l’algorithme dans la boîte à outils Traitements. Les nom et valeur de chaque paramètre sont fournis via un dictionnaire de paramètres. Voir Utiliser les algorithmes du module de traitements depuis la console Python pour plus de détails sur l’exécution d’algorithmes via la console Python.
24.1.9.22. Rescale raster
Rescales raster layer to a new value range, while preserving the shape (distribution) of the raster’s histogram (pixel values). Input values are mapped using a linear interpolation from the source raster’s minimum and maximum pixel values to the destination minimum and miximum pixel range.
By default the algorithm preserves the original NODATA value, but there is an option to override it.
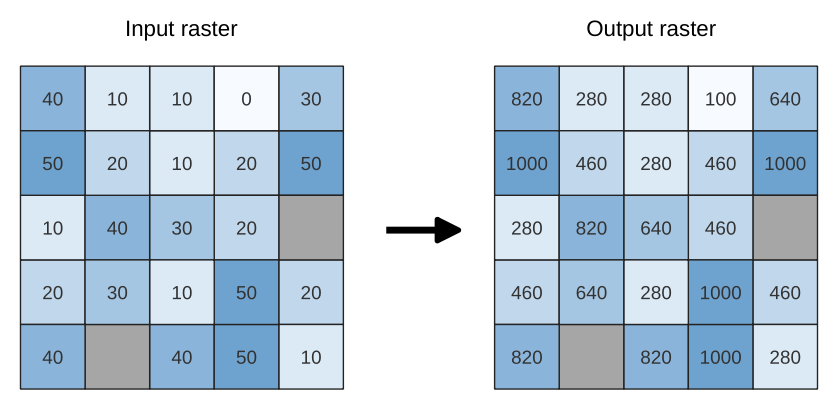
Fig. 24.13 Rescaling values of a raster layer from [0 - 50] to [100 - 1000]
Paramètres
Étiquette |
Nom |
Type |
Description |
|---|---|---|---|
Source raster |
|
[raster] |
Raster layer to use for rescaling |
Numéro de bande |
|
[raster band] Par défaut: la première bande de la couche d’entrée |
Si le raster est multibande, choisissez une bande. |
New minimum value |
|
[number] Default value: 0.0 |
Minimum pixel value to use in the rescaled layer |
New maximum value |
|
[number] Default value: 255.0 |
Maximum pixel value to use in the rescaled layer |
New NODATA value Optionnel |
|
[number] Default value: Not set |
Value to assign to the NODATA pixels. If unset, original NODATA values are preserved. |
Rescaled |
|
[raster] Default: |
Spécification de la couche raster en sortie. Un des:
|
Sorties
Étiquette |
Nom |
Type |
Description |
|---|---|---|---|
Rescaled |
|
[raster] |
Output raster layer with rescaled band values |
Code Python
Algorithm ID: native:rescaleraster
import processing
processing.run("algorithm_id", {parameter_dictionary})
L”id de l’algorithme est affiché lors du survol du nom de l’algorithme dans la boîte à outils Traitements. Les nom et valeur de chaque paramètre sont fournis via un dictionnaire de paramètres. Voir Utiliser les algorithmes du module de traitements depuis la console Python pour plus de détails sur l’exécution d’algorithmes via la console Python.
24.1.9.23. Round raster
Rounds the cell values of a raster dataset according to the specified number of decimals.
Alternatively, a negative number of decimal places may be used to round values to powers of a base n. For example, with a Base value n of 10 and Decimal places of -1, the algorithm rounds cell values to multiples of 10, -2 rounds to multiples of 100, and so on. Arbitrary base values may be chosen, the algorithm applies the same multiplicative principle. Rounding cell values to multiples of a base n may be used to generalize raster layers.
The algorithm preserves the data type of the input raster. Therefore byte/integer rasters can only be rounded to multiples of a base n, otherwise a warning is raised and the raster gets copied as byte/integer raster.
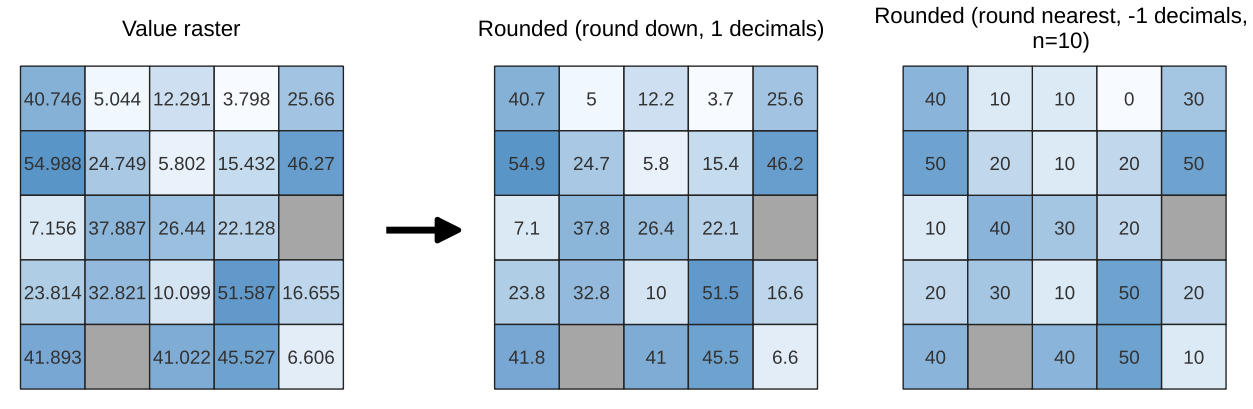
Fig. 24.14 Rounding values of a raster
Paramètres
Basic parameters
Étiquette |
Nom |
Type |
Description |
|---|---|---|---|
Input raster |
|
[raster] |
The raster to process. |
Numéro de bande |
|
[number] Par défaut : 1 |
La bande du raster |
Rounding direction |
|
[list] Par défaut : 1 |
How to choose the target rounded value. Options are: 0 - Round up 1 - Round to nearest 2 - Round down |
Number of decimals places |
|
[number] Default: 2 |
Number of decimals places to round to. Use negative values to round cell values to a multiple of a base n |
Sortie raster |
|
[raster] Default: |
Specification of the output file. One of:
|
Advanced parameters
Étiquette |
Nom |
Type |
Description |
|---|---|---|---|
Base n for rounding to multiples of n |
|
[number] Default: 10 |
When the |
Sorties
Étiquette |
Nom |
Type |
Description |
|---|---|---|---|
Sortie raster |
|
[raster] |
The output raster layer with values rounded for the selected band. |
Code Python
Algorithm ID: native:roundrastervalues
import processing
processing.run("algorithm_id", {parameter_dictionary})
L”id de l’algorithme est affiché lors du survol du nom de l’algorithme dans la boîte à outils Traitements. Les nom et valeur de chaque paramètre sont fournis via un dictionnaire de paramètres. Voir Utiliser les algorithmes du module de traitements depuis la console Python pour plus de détails sur l’exécution d’algorithmes via la console Python.
24.1.9.24. Exemples de valeurs raster
Extrait des valeurs raster aux emplacements des points. Si la couche raster est multibande, chaque bande est échantillonnée.
La table attributaire de la couche résultante aura autant de nouvelles colonnes que le nombre de bandes de couche raster.
Paramètres
Étiquette |
Nom |
Type |
Description |
|---|---|---|---|
Couche de points d’entrée |
|
[vector: point] |
Couche vectorielle ponctuelle à utiliser pour l’échantillonnage |
Couche raster à échantillonner |
|
[raster] |
Couche raster à échantillonner aux emplacements de points donnés. |
Préfixe de la colonne de sortie |
|
[string] Default: “rvalue” |
Préfixe pour les noms des colonnes ajoutées. |
Points échantillonnés Optionnel |
|
[vector: point] Par défaut: |
Spécifiez la couche de sortie contenant les valeurs échantillonnées. Un des:
L’encodage du fichier peut également être modifié ici. |
Sorties
Étiquette |
Nom |
Type |
Description |
|---|---|---|---|
Points échantillonnés Optionnel |
|
[vector: point] |
Couche de sortie contenant les valeurs échantillonnées. |
Code Python
ID de l’algorithme : qgis:rastersampling
import processing
processing.run("algorithm_id", {parameter_dictionary})
L”id de l’algorithme est affiché lors du survol du nom de l’algorithme dans la boîte à outils Traitements. Les nom et valeur de chaque paramètre sont fournis via un dictionnaire de paramètres. Voir Utiliser les algorithmes du module de traitements depuis la console Python pour plus de détails sur l’exécution d’algorithmes via la console Python.
24.1.9.25. Histogramme zonal
Ajoute des champs représentant le nombre de chaque valeur unique d’une couche raster contenue dans les entités surfaciques.
La table d’attributs de la couche de sortie aura autant de champs que les valeurs uniques de la couche raster qui intersecte le ou les polygones.
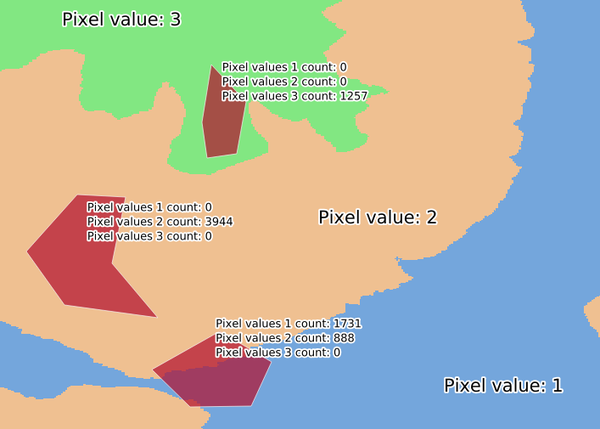
Fig. 24.15 Exemple d’histogramme de couche raster
Paramètres
Étiquette |
Nom |
Type |
Description |
|---|---|---|---|
Couche raster |
|
[raster] |
Couche raster en entrée. |
Numéro de bande |
|
[raster band] Par défaut: la première bande de la couche d’entrée |
Si le raster est multibande, choisissez une bande. |
Couche vectorielle contenant des zones |
|
[vector: polygon] |
Couche de polygones vectoriels qui définit les zones. |
Préfixe de la colonne de sortie |
Optionnel |
[string] Default: “HISTO_” |
Préfixe pour les noms des colonnes de sortie. |
Zones de sortie |
|
[vector: polygon] Par défaut: |
Spécifiez la couche de polygones de vecteur de sortie. Un des:
L’encodage du fichier peut également être modifié ici. |
Sorties
Étiquette |
Nom |
Type |
Description |
|---|---|---|---|
Zones de sortie Optionnel |
|
[vector: polygon] Par défaut: |
Couche de polygones de vecteur de sortie. |
Code Python
ID de l’algorithme : qgis:zonalhistogram
import processing
processing.run("algorithm_id", {parameter_dictionary})
L”id de l’algorithme est affiché lors du survol du nom de l’algorithme dans la boîte à outils Traitements. Les nom et valeur de chaque paramètre sont fournis via un dictionnaire de paramètres. Voir Utiliser les algorithmes du module de traitements depuis la console Python pour plus de détails sur l’exécution d’algorithmes via la console Python.
24.1.9.26. Statistiques zonales
Calcule les statistiques d’une couche raster pour chaque entité d’une couche vectorielle polygone qui se chevauchent.
Avant QGIS 3.16, l’algorithme éditait la couche en place, en y ajoutant les nouveaux champs statistiques. Maintenant, il produit une nouvelle couche avec ces statistiques.
Paramètres
Étiquette |
Nom |
Type |
Description |
|---|---|---|---|
Couche en entrée |
|
[vector: polygon] |
Couche de polygones vecteur qui contient les zones. |
Couche raster |
|
[raster] |
Couche raster en entrée. |
Bande raster |
|
[raster band] Par défaut: la première bande de la couche d’entrée |
Si le raster est multibande, choisissez une bande pour les statistiques. |
Préfixe de la colonne de sortie |
|
[string] Default: “_” |
Préfixe pour les noms des colonnes de sortie. |
Statistiques à calculer |
|
[enumeration] [list] Default: [0,1,2] |
Liste des opérateurs statistiques pour la sortie. Options:
|
Zonal Statistics |
|
[vector: polygon] Par défaut: |
Spécifiez la couche de polygones de vecteur de sortie. Un des:
L’encodage du fichier peut également être modifié ici. |
Sorties
Étiquette |
Nom |
Type |
Description |
|---|---|---|---|
Zonal Statistics |
|
[vector: polygon] |
La couche vecteurs de zone avec des statistiques ajoutées. |
Code Python
ID de l’algorithme : qgis:zonalstatisticsfb
import processing
processing.run("algorithm_id", {parameter_dictionary})
L”id de l’algorithme est affiché lors du survol du nom de l’algorithme dans la boîte à outils Traitements. Les nom et valeur de chaque paramètre sont fournis via un dictionnaire de paramètres. Voir Utiliser les algorithmes du module de traitements depuis la console Python pour plus de détails sur l’exécution d’algorithmes via la console Python.