25.1.15. Analisi vettoriale
25.1.15.1. Statistiche elementari per campi
Genera statistiche di base per un campo della tabella degli attributi di un layer vettoriale.
Sono supportati i campi numerici, data, ora e stringa.
Le statistiche che vengono restituite dipendono dal tipo di campo.
Le statistiche sono generate come file HTML e sono disponibili in .
Menu predefinito:
Parametri
Etichetta |
Nome |
Tipo |
Descrizione |
|---|---|---|---|
Vettore in ingresso |
|
[vector: any] |
Layer vettoriale su cui calcolare le statistiche |
Campo su cui calcolare le statistiche |
|
[tablefield: any] |
Qualsiasi campo della tabella compatibile per poter calcolare le statistiche |
Statistiche Opzionale |
|
[html] Predefinito: |
Indicazione del file per le statistiche calcolate. Uno di:
|
In uscita:
Etichetta |
Nome |
Tipo |
Descrizione |
|---|---|---|---|
Statistiche |
|
[html] |
file HTML con le statistiche ottenute |
Conteggio |
|
[number] |
|
Numero di valori univoci |
|
[number] |
|
Numero di valori mancanti (nulli) |
|
[number] |
|
Numero di valori non vuoti |
|
[number] |
|
Valore minimo |
|
[same as input] |
|
Valore massino |
|
[same as input] |
|
Lunghezza minima |
|
[number] |
|
Lunghezza massima |
|
[number] |
|
Lunghezza Media |
|
[number] |
|
Coefficiente di Variazione |
|
[number] |
|
Somma |
|
[number] |
|
Valore medio |
|
[number] |
|
Deviazione Standard |
|
[number] |
|
Intervallo |
|
[number] |
|
Mediana |
|
[number] |
|
Minoritario (valore meno frequente) |
|
[same as input] |
|
maggioranza (valore più frequente) |
|
[same as input] |
|
Primo quartile |
|
[number] |
|
Terzo quartile |
|
[number] |
|
Intervallo Interquartile Range (IQR) |
|
[number] |
Codice Python
ID Algoritmo: qgis:basicstatisticsforfields
import processing
processing.run("algorithm_id", {parameter_dictionary})
L” id algoritmo viene visualizzato quando si passa il mouse sull’algoritmo nella finestra degli strumenti di Processing. Il dizionario dei parametri fornisce i Nomi e i valori dei parametri. Vedi Usare gli algoritmi di Processing dalla console dei comandi per dettagli su come eseguire algoritmi di Processing dalla console Python.
25.1.15.2. Dislivello lungo linea
Calcola la salita e la discesa totale lungo le geometrie lineari. Il layer in ingresso deve avere valori Z presenti. Se i valori Z non sono disponibili, l’algoritmo Drappeggia (imposta il valore Z da raster) può essere usato per aggiungere valori Z da un layer DEM.
Il layer in uscita è una copia del layer in ingresso con campi aggiuntivi che contengono la salita totale (climb), la discesa totale (descent), la quota minima (minelev) e la quota massima (maxelev) per ogni geometria lineare. Se il layer in ingresso contiene campi con gli stessi nomi di questi campi aggiunti, essi saranno rinominati (i nomi dei campi saranno alterati in «name_2», «name_3», ecc, trovando il primo nome non duplicato).
Parametri
Etichetta |
Nome |
Tipo |
Descrizione |
|---|---|---|---|
Vettore lineare |
|
[vector: line] |
Vettore lineare su cui calcolare la salita. Deve avere valori Z |
Dislivello Layer |
|
[vector: line] Predefinito: |
Indicazione del layer in uscita (lineare). Uno di:
La codifica del file può anche essere cambiata qui. |
In uscita:
Etichetta |
Nome |
Tipo |
Descrizione |
|---|---|---|---|
Dislivello Layer |
|
[vector: line] |
Vettore lineare contenente nuovi attributi con i risultati dei conteggi delle salite. |
Totale dislivello |
|
[number] |
La somma dei dislivelli di tutte le geometrie linea nel layer in ingresso |
Totale discesa |
|
[number] |
La somma dei tratti in discesa per tutte le geometrie linea nel layer in ingresso |
Elevazione minima |
|
[number] |
L’elevazione minima delle geometrie nel layer |
Elevazione massima |
|
[number] |
L’elevazione massima delle geometrie nel layer |
Codice Python
ID Algoritmo: qgis:climbalongline
import processing
processing.run("algorithm_id", {parameter_dictionary})
L” id algoritmo viene visualizzato quando si passa il mouse sull’algoritmo nella finestra degli strumenti di Processing. Il dizionario dei parametri fornisce i Nomi e i valori dei parametri. Vedi Usare gli algoritmi di Processing dalla console dei comandi per dettagli su come eseguire algoritmi di Processing dalla console Python.
25.1.15.3. Conta i punti nel poligono
Utilizza un layer di punti e un vettore poligonale e conta il numero di punti del layer di punti in ciascuno dei poligoni del vettore poligonale.
Viene generato un nuovo vettore poligonale, con lo stesso identico contenuto del vettore poligonale in ingresso, ma contenente un campo addizionale con il conteggio dei punti corrispondenti ad ogni poligono.
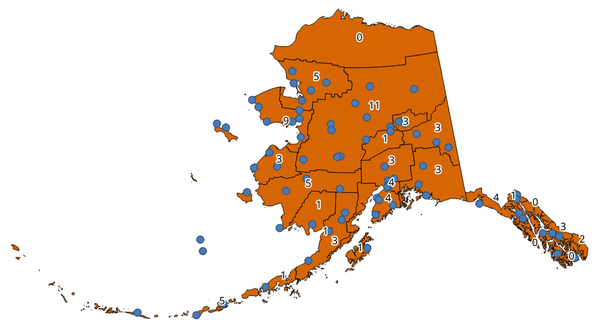
Fig. 25.31 Le etichette nei poligoni mostrano il conteggio dei punti
Un campo peso opzionale può essere usato per assegnare dei pesi ad ogni punto. In alternativa, può essere specificato un campo classe univoca. Se entrambe le opzioni sono usate, il campo peso avrà la precedenza e il campo classe univoca sarà ignorato.
Menu predefinito:
Parametri
Etichetta |
Nome |
Tipo |
Descrizione |
|---|---|---|---|
Poligoni |
|
[vector: polygon] |
Vettore poligonale i cui elementi sono associati al numero di punti che contengono |
Punti |
|
[vector: point] |
Layer punto con elementi da contare |
Campo Sommatoria Opzionale |
|
[tablefield: any] |
Un campo del layer puntuale. Il conteggio generato sarà la somma del campo peso dei punti contenuti nel poligono. Se il campo peso non è numerico, il conteggio sarà |
Campo Classe Opzionale |
|
[tablefield: any] |
I punti sono classificati in base all’attributo selezionato e se più punti con lo stesso valore di attributo sono all’interno del poligono, solo uno di loro viene contato. Il conteggio finale dei punti in un poligono è, quindi, il conteggio delle diverse classi che si trovano in esso. |
Nome campo per il conteggio |
|
[stringa] Predefinito: “NUMPOINTS” |
Il nome del campo per memorizzare il conteggio dei punti |
Conteggio |
|
[vector: polygon] Predefinito: |
Indicazione del layer in uscita. Uno di:
La codifica del file può anche essere cambiata qui. |
In uscita:
Etichetta |
Nome |
Tipo |
Descrizione |
|---|---|---|---|
Conteggio |
|
[vector: polygon] |
Layer risultante con la tabella degli attributi contenente la nuova colonna con il conteggio dei punti |
Codice Python
ID Algoritmo: native:countpointsinpolygon
import processing
processing.run("algorithm_id", {parameter_dictionary})
L” id algoritmo viene visualizzato quando si passa il mouse sull’algoritmo nella finestra degli strumenti di Processing. Il dizionario dei parametri fornisce i Nomi e i valori dei parametri. Vedi Usare gli algoritmi di Processing dalla console dei comandi per dettagli su come eseguire algoritmi di Processing dalla console Python.
25.1.15.4. DBSCAN clustering
Raggruppa gli elementi puntuali basati su un’implementazione 2D dell’algoritmo Density-based spatial clustering of applications with noise (DBSCAN).
L’algoritmo richiede due parametri, una dimensione minima dei cluster e la distanza massima consentita tra i punti raggruppati.
Vedi anche
Parametri
Parametri di base
Etichetta |
Nome |
Tipo |
Descrizione |
|---|---|---|---|
Layer di input |
|
[vector: point] |
Layer da analizzare |
Dimensione minima del cluster |
|
[number] Predefinito: 5 |
Numero minimo di elementi per formare un cluster |
Distanza massima tra i punti raggruppati |
|
[number] Predefinito: 1.0 |
Distanza oltre la quale due elementi non possono appartenere allo stesso cluster (eps) |
Cluster |
|
[vector: point] Predefinito: |
Indicare il layer vettoriale per il risultato del clustering. Uno di:
La codifica del file può anche essere cambiata qui. |
Parametri avanzati
Etichetta |
Nome |
Tipo |
Descrizione |
|---|---|---|---|
Tratta i punti di confine come rumore (DBSCAN*) Opzionale |
|
[boolean] Predefinito: False |
Se spuntato, i punti sul confine di un cluster sono trattati come punti non raggruppati, e solo i punti all’interno di un cluster sono etichettati come raggruppati. |
Nome campo per il cluster |
|
[stringa] Predefinito: “CLUSTER_ID” |
Nome del campo in cui deve essere memorizzato il numero di cluster associato |
Nome campo dimensione cluster |
|
[stringa] Predefinito: “CLUSTER_SIZE” |
Nome del campo con il conteggio degli elementi dello stesso cluster |
In uscita:
Etichetta |
Nome |
Tipo |
Descrizione |
|---|---|---|---|
Cluster |
|
[vector: point] |
Layer vettoriale contenente gli elementi originali con un campo che imposta il cluster a cui appartengono |
Numero di cluster |
|
[number] |
Il numero di cluster trovati |
Codice Python
ID Algoritmo: native:dbscanclustering
import processing
processing.run("algorithm_id", {parameter_dictionary})
L” id algoritmo viene visualizzato quando si passa il mouse sull’algoritmo nella finestra degli strumenti di Processing. Il dizionario dei parametri fornisce i Nomi e i valori dei parametri. Vedi Usare gli algoritmi di Processing dalla console dei comandi per dettagli su come eseguire algoritmi di Processing dalla console Python.
25.1.15.5. Matrice di distanza
Calcola per gli elementi punto le distanze dai loro elementi più vicini nello stesso layer o in un altro layer.
Menu predefinito:
Vedi anche
Parametri
Etichetta |
Nome |
Tipo |
Descrizione |
|---|---|---|---|
Layer punto in ingresso |
|
[vector: point] |
Layer punto per cui viene calcolata la matrice di distanze (dai punti) |
Campo ID univoco in ingresso |
|
[tablefield: any] |
Campo da usare per identificare univocamente gli elementi del layer in ingresso. Usato nella tabella degli attributi del risultato. |
Layer punto obiettivo |
|
[vector: point] |
Layer punto contenente il punto(i) più vicino da cercare (ai punti) |
Campo ID univoco dell’obiettivo |
|
[tablefield: any] |
Campo da usare per identificare univocamente gli elementi del layer obiettivo. Usato nella tabella degli attributi in uscita. |
Tipo di matrice in uscita |
|
[enumeration] Predefinito: 0 |
Sono disponibili diversi tipi di calcolo:
|
Usa solo i punti di destinazione più vicini (k) |
|
[number] Predefinito: 0 |
Puoi scegliere di calcolare la distanza di tutti i punti nel layer di destinazione (0) o limitarti a un numero (k) di elementi più vicini. |
Matrice di distanze |
|
[vector: point] Predefinito: |
Indicazione del layer vettoriale in uscita. Uno di:
La codifica del file può anche essere cambiata qui. |
In uscita:
Etichetta |
Nome |
Tipo |
Descrizione |
|---|---|---|---|
Matrice di distanze |
|
[vector: point] |
Layer vettoriale punto (o multipunto per il caso «Linear (N * k x 3)») contenente il calcolo della distanza per ogni elemento in ingresso. I suoi elementi e la tabella degli attributi dipendono dal tipo di matrice di uscita selezionata. |
Codice Python
ID Algoritmo: qgis:distancematrix
import processing
processing.run("algorithm_id", {parameter_dictionary})
L” id algoritmo viene visualizzato quando si passa il mouse sull’algoritmo nella finestra degli strumenti di Processing. Il dizionario dei parametri fornisce i Nomi e i valori dei parametri. Vedi Usare gli algoritmi di Processing dalla console dei comandi per dettagli su come eseguire algoritmi di Processing dalla console Python.
25.1.15.6. Distanza dal nodo più vicino (genera linee)
Crea linee che uniscono ogni elemento di un vettore in ingresso all’elemento più vicino in un layer di destinazione. Le distanze sono calcolate in base al center di ogni elemento.
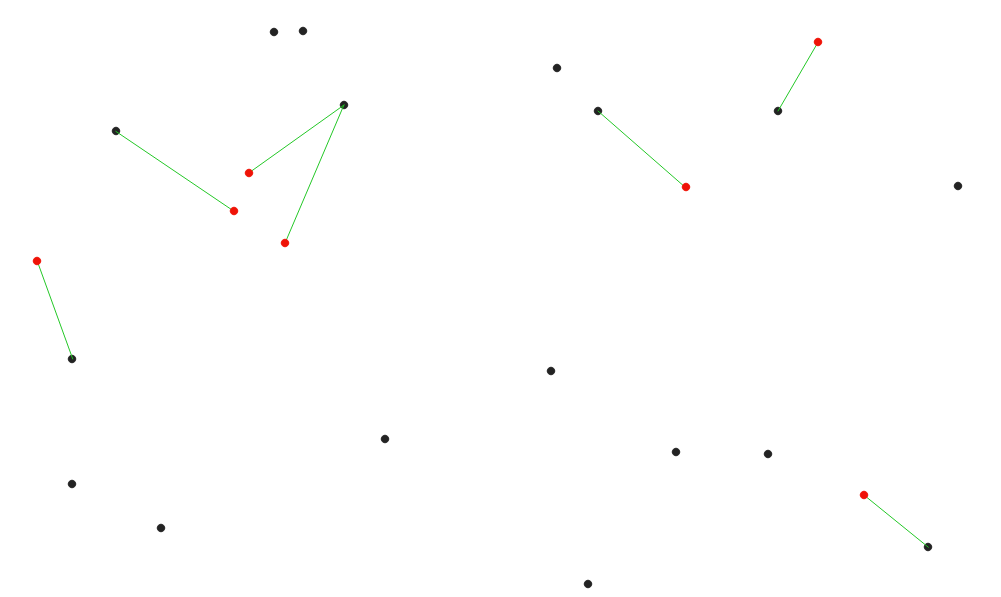
Fig. 25.32 Visualizza l’hub più vicino per gli elementi in ingresso di colore rosso
Parametri
Etichetta |
Nome |
Tipo |
Descrizione |
|---|---|---|---|
Layer punto di origine |
|
[vector: any] |
Layer vettoriale per il quale si cerca l’elemento più vicino |
Layer degli snodi di destinazione |
|
[vector: any] |
Vettore che contiene gli elementi da cercare |
Nome dell’attributo del layer dell’hub |
|
[tablefield: any] |
Campo da usare per identificare univocamente gli elementi del layer di destinazione. Usato nella tabella degli attributi in uscita |
Unità di misura |
|
[enumeration] Predefinito: 0 |
Unità in cui riportare la distanza dall’elemento più vicino:
|
Distanza dall’Hub |
|
[vector: line] Predefinito: |
Indicazione del layer vettoriale linea in uscita che collega i punti in accoppiamento. Uno di:
La codifica del file può anche essere cambiata qui. |
In uscita:
Etichetta |
Nome |
Tipo |
Descrizione |
|---|---|---|---|
Distanza dall’Hub |
|
[vector: line] |
Layer vettoriale linea con gli attributi degli elementi in ingresso, l’identificatore dell’elemento più vicino e la distanza calcolata. |
Codice Python
ID Algoritmo: qgis:distancetonearesthublinetohub
import processing
processing.run("algorithm_id", {parameter_dictionary})
L” id algoritmo viene visualizzato quando si passa il mouse sull’algoritmo nella finestra degli strumenti di Processing. Il dizionario dei parametri fornisce i Nomi e i valori dei parametri. Vedi Usare gli algoritmi di Processing dalla console dei comandi per dettagli su come eseguire algoritmi di Processing dalla console Python.
25.1.15.7. Distanza dal nodo più vicino (genera punti)
Crea un layer punto che rappresenta il center degli elementi in ingresso con l’aggiunta di due campi contenenti l’identificatore dell’elemento più vicino (basato sul suo punto centrale) e la distanza tra i punti.
Parametri
Etichetta |
Nome |
Tipo |
Descrizione |
|---|---|---|---|
Layer punto di origine |
|
[vector: any] |
Layer vettoriale per il quale si cerca l’elemento più vicino |
Layer degli snodi di destinazione |
|
[vector: any] |
Vettore che contiene gli elementi da cercare |
Nome dell’attributo del layer dell’hub |
|
[tablefield: any] |
Campo da usare per identificare univocamente gli elementi del layer di destinazione. Usato nella tabella degli attributi in uscita |
Unità di misura |
|
[enumeration] Predefinito: 0 |
Unità in cui riportare la distanza dall’elemento più vicino:
|
Distanza dall’Hub |
|
[vector: point] Predefinito: |
Indicazione del layer vettoriale punto in uscita con l’hub più vicino. Uno di:
La codifica del file può anche essere cambiata qui. |
In uscita:
Etichetta |
Nome |
Tipo |
Descrizione |
|---|---|---|---|
Distanza dall’Hub |
|
[vector: point] |
Layer vettoriale punto che rappresenta il centro degli elementi di origine con i loro attributi, l’identificatore dell’elemento più vicino e la distanza calcolata. |
Codice Python
ID Algoritmo: qgis:distancetonearesthubpoints
import processing
processing.run("algorithm_id", {parameter_dictionary})
L” id algoritmo viene visualizzato quando si passa il mouse sull’algoritmo nella finestra degli strumenti di Processing. Il dizionario dei parametri fornisce i Nomi e i valori dei parametri. Vedi Usare gli algoritmi di Processing dalla console dei comandi per dettagli su come eseguire algoritmi di Processing dalla console Python.
25.1.15.8. Unisci con linee (hub)
Crea diagrammi punti centrali e punti remoti collegando linee da punti sul layer remoto a punti che si trovano nel layer centrale.
La scelta di quale punto centrale sia associato a ciascun punto si basa su una corrispondenza tra il campo ID Hub dei punti centrali e il campo ID Spoke ID dei punti remoti.
Se i layer in ingresso non sono layer puntuali, un punto sulla superficie delle geometrie sarà preso come posizione di connessione.
Opzionalmente, possono essere create linee geodetiche, che rappresentano il percorso più breve sulla superficie di un ellissoide. Quando si usa la modalità geodetica, è possibile dividere le linee create all’antimeridiano (±180 gradi di longitudine), il che può migliorare la visualizzazione delle linee. Inoltre, la distanza tra i vertici può essere specificata. Una distanza minore risulta in una linea più densa e accurata.
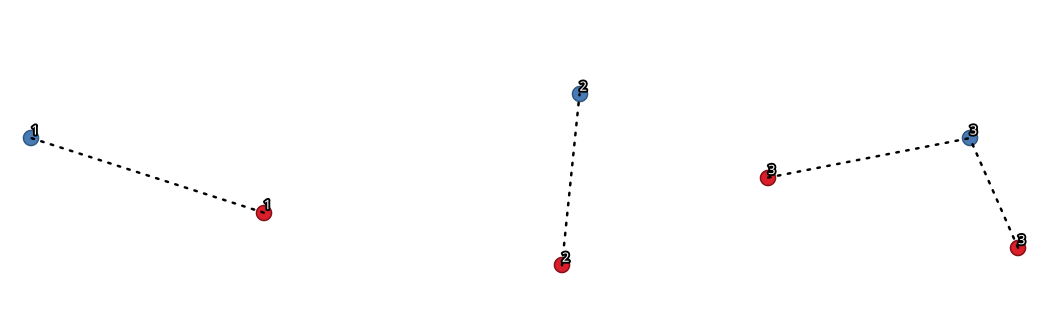
Fig. 25.33 Unire punti sulla base di un campo/attributo comune
Parametri
Parametri di base
Etichetta |
Nome |
Tipo |
Descrizione |
|---|---|---|---|
Hub layer |
|
[vector: any] |
Layer in ingresso |
ID campo Hub |
|
[tablefield: any] |
Campo del layer hub con ID da unire |
Campi del layer Hub da copiare (lasciare vuoto per copiare tutti i campi) Opzionale |
|
[tablefield: any] [list] |
Il campo(i) del layer hub da copiare. Se non viene scelto alcun campo(i), vengono presi tutti i campi. |
Spoke layer |
|
[vector: any] |
Layer aggiuntivo punto spoke |
ID campo spoke |
|
[tablefield: any] |
Campo del layer spoke con ID da unire |
Campi del layer spoke da copiare (lasciare vuoto per copiare tutti i campi) Opzionale |
|
[tablefield: any] [list] |
Campo(i) del layer spoke da copiare. Se non viene scelto nessun campo, vengono presi tutti i campi. |
Creare linee geodetiche |
|
[boolean] Predefinito: False |
Creare linee geodetiche (il percorso più breve sulla superficie di un ellissoide) |
Hub linee |
|
[vector: line] Predefinito: |
Indicazione del layer vettoriale linea del hub in uscita. Uno di:
La codifica del file può anche essere cambiata qui. |
Parametri avanzati
Etichetta |
Nome |
Tipo |
Descrizione |
|---|---|---|---|
Distanza tra i vertici (solo linee geodetiche) |
|
[number] Predefinito: 1000.0 (chilometri) |
Distanza tra vertici consecutivi (in chilometri). Una distanza minore ha come risultato una linea più densa e accurata |
Linee suddivise all’antimeridiano (±180 gradi di longitudine) |
|
[boolean] Predefinito: False |
Linee suddivise a ±180 gradi di longitudine (per migliorare la visualizzazione delle linee) |
In uscita:
Etichetta |
Nome |
Tipo |
Descrizione |
|---|---|---|---|
Hub linee |
|
[vector: line] |
Il vettore lineare risultante che collega i punti corrispondenti nei layer in ingresso |
Codice Python
ID Algoritmo: native:hublines
import processing
processing.run("algorithm_id", {parameter_dictionary})
L” id algoritmo viene visualizzato quando si passa il mouse sull’algoritmo nella finestra degli strumenti di Processing. Il dizionario dei parametri fornisce i Nomi e i valori dei parametri. Vedi Usare gli algoritmi di Processing dalla console dei comandi per dettagli su come eseguire algoritmi di Processing dalla console Python.
25.1.15.9. K-means clustering
Calcola il numero di cluster k-means basato sulla distanza 2D per ogni elemento in ingresso.
Il clustering K-means mira a partizionare gli elementi in k cluster in cui ogni elemento appartiene al cluster con la media più vicina. Il punto medio è rappresentato dal baricentro degli elementi raggruppati.
Se le geometrie in ingresso sono linee o poligoni, il clustering è basato sul centroide dell” elemento.
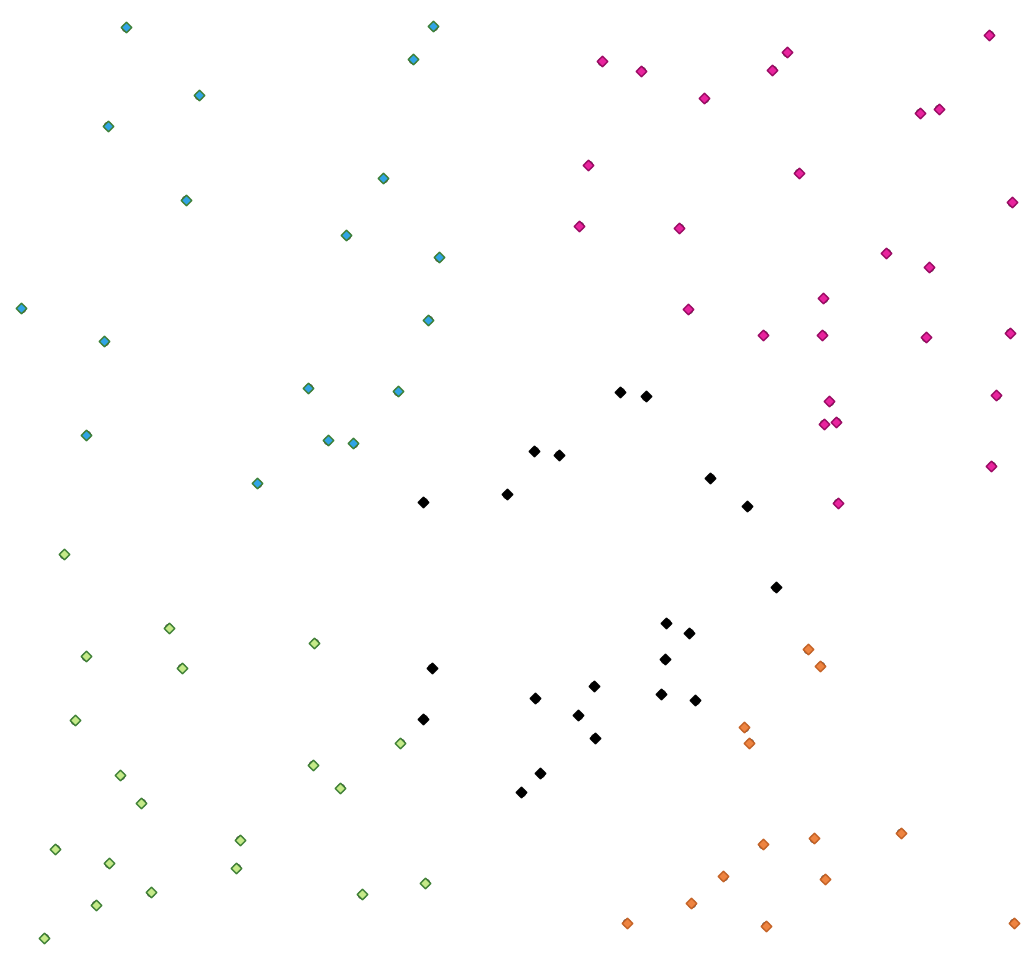
Fig. 25.34 Un gruppo di cinque classi punto
Vedi anche
Parametri
Etichetta |
Nome |
Tipo |
Descrizione |
|---|---|---|---|
Layer di input |
|
[vector: any] |
Layer da analizzare |
Numero di cluster |
|
[number] Predefinito: 5 |
Numero di cluster da creare con gli elementi |
Cluster |
|
[vector: any] Predefinito: |
Indicazione del layer vettoriale in uscita per i cluster generati. Uno di:
La codifica del file può anche essere cambiata qui. |
Parametri avanzati
Etichetta |
Nome |
Tipo |
Descrizione |
|---|---|---|---|
Nome campo per il cluster |
|
[stringa] Predefinito: “CLUSTER_ID” |
Nome del campo in cui deve essere memorizzato il numero di cluster associato |
Nome campo dimensione cluster |
|
[stringa] Predefinito: “CLUSTER_SIZE” |
Nome del campo con il conteggio degli elementi dello stesso cluster |
In uscita:
Etichetta |
Nome |
Tipo |
Descrizione |
|---|---|---|---|
Cluster |
|
[vector: any] |
Layer vettoriale contenente gli elementi originari con campi che specificano il cluster di appartenenza e il loro numero all’interno del cluster. |
Codice Python
ID Algoritmo: native:kmeansclustering
import processing
processing.run("algorithm_id", {parameter_dictionary})
L” id algoritmo viene visualizzato quando si passa il mouse sull’algoritmo nella finestra degli strumenti di Processing. Il dizionario dei parametri fornisce i Nomi e i valori dei parametri. Vedi Usare gli algoritmi di Processing dalla console dei comandi per dettagli su come eseguire algoritmi di Processing dalla console Python.
25.1.15.10. Lista valori univoci
Elenca i valori univoci di un campo della tabella degli attributi e conta il loro numero.
Menu predefinito:
Parametri
Etichetta |
Nome |
Tipo |
Descrizione |
|---|---|---|---|
Layer di input |
|
[vector: any] |
Layer da analizzare |
Campo(i) di destinazione |
|
[tablefield: any] |
Campo da analizzare |
Valori univoci Opzionale |
|
[table] Predefinito: |
Indicazione del layer tabella di riepilogo con valori univoci. Uno di:
La codifica del file può anche essere cambiata qui. |
Report HTML Opzionale |
|
[html] Predefinito: |
Report HTML dei valori univoci in . Uno di:
|
In uscita:
Etichetta |
Nome |
Tipo |
Descrizione |
|---|---|---|---|
Valori univoci |
|
[table] |
Layer tabella riassuntiva con valori univoci |
Report HTML |
|
[html] |
Report HTML dei valori univoci. Può essere aperto da . |
Totale valori univoci |
|
[number] |
Il numero di valori univoci nel campo di input |
UNIQUE_VALUES |
``Valori univoci””. |
[stringa] |
Una stringa con la lista separata da virgole dei valori univoci trovati nel campo in ingresso. |
Codice Python
ID Algoritmo: qgis:listuniquevalues
import processing
processing.run("algorithm_id", {parameter_dictionary})
L” id algoritmo viene visualizzato quando si passa il mouse sull’algoritmo nella finestra degli strumenti di Processing. Il dizionario dei parametri fornisce i Nomi e i valori dei parametri. Vedi Usare gli algoritmi di Processing dalla console dei comandi per dettagli su come eseguire algoritmi di Processing dalla console Python.
25.1.15.11. Media coordinate
Calcolare un layer di punti con il centro di massa delle geometrie in un layer in ingresso.
Un attributo può essere specificato come contenente i pesi da applicare ad ogni elemento quando si calcola il centro di massa.
Se un attributo è selezionato nel parametro, gli elementi saranno raggruppati secondo i valori in questo campo. Invece di un singolo punto con il centro di massa dell’intero layer, il layer in uscita conterrà un centro di massa per gli elementi di ogni categoria.
Menu predefinito:
Parametri
Etichetta |
Nome |
Tipo |
Descrizione |
|---|---|---|---|
Layer di input |
|
[vector: any] |
Layer vettoriale in input |
Campo Sommatoria Opzionale |
|
[tablefield: numeric] |
Campo univoco su cui verrà effettuato il calcolo della media pesata |
Campo ID univoco |
|
[tablefield: numeric] |
Campo univoco su cui verrà effettuato il calcolo della media |
Coordinate medie |
|
[vector: point] Predefinito: |
Indicazione del layer (vettore punto) per il risultato. Uno di:
La codifica del file può anche essere cambiata qui. |
In uscita:
Etichetta |
Nome |
Tipo |
Descrizione |
|---|---|---|---|
Coordinate medie |
|
[vector: point] |
Layer punto(i) risultante |
Codice Python
ID Algoritmo: native:meancoordinates
import processing
processing.run("algorithm_id", {parameter_dictionary})
L” id algoritmo viene visualizzato quando si passa il mouse sull’algoritmo nella finestra degli strumenti di Processing. Il dizionario dei parametri fornisce i Nomi e i valori dei parametri. Vedi Usare gli algoritmi di Processing dalla console dei comandi per dettagli su come eseguire algoritmi di Processing dalla console Python.
25.1.15.12. Analisi vicino più prossimo
Esegue l’analisi del vicino più prossimo per un layer punto. Il risultato ti dice come sono distribuiti i tuoi dati (raggruppati, casuali o distribuiti).
Il risultato viene generato come un file HTML con i valori statistici calcolati:
Distanza media osservata
Distanza media prevista
Indice del vicino più prossimo
Numero di punti
Z-Score: Confrontando lo Z-Score con la distribuzione normale si capisce come sono distribuiti i dati. Un basso Z-Score significa che è improbabile che i dati siano il risultato di un processo spazialmente casuale, mentre un alto Z-Score significa che i tuoi dati sono probabilmente il risultato di un processo spazialmente casuale.
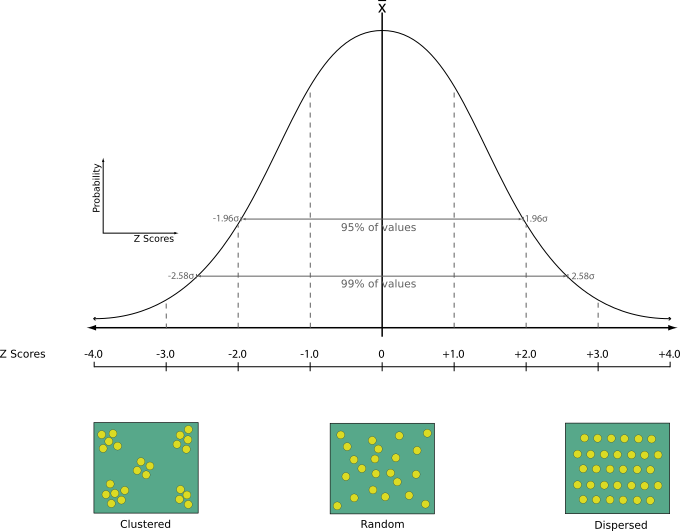
Menu predefinito:
Vedi anche
Parametri
Etichetta |
Nome |
Tipo |
Descrizione |
|---|---|---|---|
Layer di input |
|
[vector: point] |
Layer vettoriale puntuale su cui calcolare le statistiche |
Vicino più prossimo Opzionale |
|
[html] Predefinito: |
Indicazione del file HTML per le statistiche calcolate. Uno di:
|
In uscita:
Etichetta |
Nome |
Tipo |
Descrizione |
|---|---|---|---|
Vicino più prossimo |
|
[html] |
file HTML con le statistiche calcolate |
Distanza media osservata |
|
[number] |
Distanza media osservata |
Distanza media prevista |
|
[number] |
Distanza media prevista |
Indice del vicino più prossimo |
|
[number] |
Indice del vicino più prossimo |
Numero di punti |
|
[number] |
Numero di punti |
Z-Score |
|
[number] |
Z-Score |
Codice Python
ID Algoritmo: native:nearestneighbouranalysis
import processing
processing.run("algorithm_id", {parameter_dictionary})
L” id algoritmo viene visualizzato quando si passa il mouse sull’algoritmo nella finestra degli strumenti di Processing. Il dizionario dei parametri fornisce i Nomi e i valori dei parametri. Vedi Usare gli algoritmi di Processing dalla console dei comandi per dettagli su come eseguire algoritmi di Processing dalla console Python.
25.1.15.13. Analisi di sovrapposizione
Calcola l’area e la percentuale di copertura con cui gli elementi di un layer in ingresso sono sovrapposti agli elementi di una selezione di layer sovrapposti.
Vengono aggiunti nuovi attributi al layer in uscita che riportano l’area totale di sovrapposizione e la percentuale dell” elemento in ingresso sovrapposto a ciascuno dei layer di sovrapposizione selezionati.
Parametri
Etichetta |
Nome |
Tipo |
Descrizione |
|---|---|---|---|
Layer di input |
|
[vector: any] |
Il layer di input. |
Layer sovrapposti |
|
[vector: any] [list] |
Layer in sovrapposizione |
Layer in uscita |
|
[same as input] Predefinito: |
Indicare il layer vettoriale in uscita. Uno di:
La codifica del file può anche essere cambiata qui. |
In uscita:
Etichetta |
Nome |
Tipo |
Descrizione |
|---|---|---|---|
Layer in uscita |
|
[same as input] |
Il layer in uscita con campi aggiuntivi che riportano la sovrapposizione (in unità di mappa e percentuale) dell’elemento in ingresso sovrapposto a ciascuno dei layer selezionati. |
Codice Python
ID Algoritmo: native:calculatevectoroverlaps
import processing
processing.run("algorithm_id", {parameter_dictionary})
L” id algoritmo viene visualizzato quando si passa il mouse sull’algoritmo nella finestra degli strumenti di Processing. Il dizionario dei parametri fornisce i Nomi e i valori dei parametri. Vedi Usare gli algoritmi di Processing dalla console dei comandi per dettagli su come eseguire algoritmi di Processing dalla console Python.
25.1.15.14. ST-DBSCAN clustering
NEW in 3.22
Raggruppa elementi puntuali basati su un’implementazione 2D dell’algoritmo ST-DBSCAN (Density-based clustering spazio temporale di applicazioni con rumore).
Vedi anche
Parametri
Parametri di base
Etichetta |
Nome |
Tipo |
Descrizione |
|---|---|---|---|
Layer di input |
|
[vector: point] |
Layer da analizzare |
Campo Date/time |
|
[tablefield: date] |
Campo contenente le informazioni temporali |
Dimensione minima del cluster |
|
[number] Predefinito: 5 |
Numero minimo di elementi per formare un cluster |
Distanza massima tra i punti raggruppati |
|
[number] Predefinito: 1.0 |
Distanza oltre la quale due elementi non possono appartenere allo stesso cluster (eps) |
Durata massima tra i punti del cluster |
|
[number] Predefinito: 0.0 (giorni) |
Durata del tempo oltre la quale due elementi non possono appartenere allo stesso cluster (eps2). Le unità di tempo disponibili sono millisecondi, secondi, minuti, ore, giorni e settimane. |
Cluster |
|
[vector: point] Predefinito: |
Indicare il layer vettoriale per il risultato del clustering. Uno di:
La codifica del file può anche essere cambiata qui. |
Parametri avanzati
Etichetta |
Nome |
Tipo |
Descrizione |
|---|---|---|---|
Tratta i punti di confine come rumore (DBSCAN*) Opzionale |
|
[boolean] Predefinito: False |
Se spuntato, i punti sul confine di un cluster sono trattati come punti non raggruppati, e solo i punti all’interno di un cluster sono etichettati come raggruppati. |
Nome campo per il cluster |
|
[stringa] Predefinito: “CLUSTER_ID” |
Nome del campo in cui deve essere memorizzato il numero di cluster associato |
Nome campo dimensione cluster |
|
[stringa] Predefinito: “CLUSTER_SIZE” |
Nome del campo con il conteggio degli elementi dello stesso cluster |
In uscita:
Etichetta |
Nome |
Tipo |
Descrizione |
|---|---|---|---|
Cluster |
|
[vector: point] |
Layer vettoriale contenente gli elementi originali con un campo che imposta il cluster a cui appartengono |
Numero di cluster |
|
[number] |
Il numero di cluster trovati |
Codice Python
ID Algoritmo: native:stdbscanclustering
import processing
processing.run("algorithm_id", {parameter_dictionary})
L” id algoritmo viene visualizzato quando si passa il mouse sull’algoritmo nella finestra degli strumenti di Processing. Il dizionario dei parametri fornisce i Nomi e i valori dei parametri. Vedi Usare gli algoritmi di Processing dalla console dei comandi per dettagli su come eseguire algoritmi di Processing dalla console Python.
25.1.15.15. Statistiche per categorie
Calcola le statistiche di un campo in funzione di una classe padre. La classe padre è una combinazione di valori di altri campi.
Parametri
Etichetta |
Nome |
Tipo |
Descrizione |
|---|---|---|---|
Layer vettoriale in ingresso |
|
[vector: any] |
Layer vettoriale in ingresso con classi e valori univoci |
**Campo su cui calcolare le statistiche (se vuoto, viene considerato solo il conteggio) ** Opzionale |
|
[tablefield: any] |
Se vuoto, sarà calcolato solo il conteggio |
Campo(i) con le categorie |
|
[vector: any] [list] |
I campi che (combinati) definiscono le categorie |
Statistiche per categoria |
|
[table] Predefinito: |
Indicazione della tabella in uscita per le statistiche generate. Una delle seguenti opzioni:
La codifica del file può anche essere cambiata qui. |
In uscita:
Etichetta |
Nome |
Tipo |
Descrizione |
|---|---|---|---|
Statistiche per categoria |
|
[table] |
Tabella contenente le statistiche |
A seconda del tipo di campo analizzato, vengono restituite le seguenti statistiche per ogni valore aggregato:
Statistiche |
Stringa |
Numerico |
Data |
|---|---|---|---|
Conteggio ( |
|
|
|
Valori univoci ( |
|
|
|
Valori vuoti (nulli) ( |
|
|
|
Valori non vuoti ( |
|
|
|
Valore minimo ( |
|
|
|
Valore massimo ( |
|
|
|
Intervallo ( |
|
||
Somma ( |
|
||
Valore medio ( |
|
||
Valore mediano ( |
|
||
Deviazione Standard ( |
|
||
Coefficiente di variazione ( |
|
||
Minoranza (valore più raro - |
|
||
Maggioranza (valore più frequente - |
|
||
Primo Quartile ( |
|
||
Terzo Quartile ( |
|
||
Intervallo inter-quartile ( |
|
||
Lunghezza Minima ( |
|
||
Lunghezza medie ( |
|
||
Lunghezza massima ( |
|

Codice Python
ID Algoritmo: qgis:statisticsbycategories
import processing
processing.run("algorithm_id", {parameter_dictionary})
L” id algoritmo viene visualizzato quando si passa il mouse sull’algoritmo nella finestra degli strumenti di Processing. Il dizionario dei parametri fornisce i Nomi e i valori dei parametri. Vedi Usare gli algoritmi di Processing dalla console dei comandi per dettagli su come eseguire algoritmi di Processing dalla console Python.
25.1.15.16. Somma lunghezze linea
Utilizza un vettore poligonale e un vettore lineare e misura la lunghezza totale delle linee e il numero totale di esse che attraversano ogni poligono.
Il layer risultante ha gli stessi elementi del vettore poligonale in ingresso, ma con due attributi aggiuntivi che contengono la lunghezza e il conteggio delle linee che attraversano ogni poligono.
Menu predefinito:
Parametri
Etichetta |
Nome |
Tipo |
Descrizione |
|---|---|---|---|
Linee |
|
[vector: line] |
Vettore lineare in ingresso |
Poligoni |
|
[vector: polygon] |
Layer vettoriale poligonale |
Nome campo lunghezza delle linee |
|
[stringa] Predefinito: “LENGTH” |
Nome del campo per la lunghezza delle linee |
Nome del campo per il conteggio delle linee |
|
[stringa] Predefinito: “COUNT” |
Nome del campo per il conteggio delle linee |
Lunghezza linea |
|
[vector: polygon] Predefinito: |
Indicazione del vettore poligonale in uscita con le statistiche generate. Uno di:
La codifica del file può anche essere cambiata qui. |
In uscita:
Etichetta |
Nome |
Tipo |
Descrizione |
|---|---|---|---|
Lunghezza linea |
|
[vector: polygon] |
Layer poligonale in uscita con i campi della lunghezza delle linee e del numero di linee |
Codice Python
ID Algoritmo: native:sumlinelengths
import processing
processing.run("algorithm_id", {parameter_dictionary})
L” id algoritmo viene visualizzato quando si passa il mouse sull’algoritmo nella finestra degli strumenti di Processing. Il dizionario dei parametri fornisce i Nomi e i valori dei parametri. Vedi Usare gli algoritmi di Processing dalla console dei comandi per dettagli su come eseguire algoritmi di Processing dalla console Python.