25.1.15. Vector-analyse
25.1.15.1. Basisstatistieken voor velden
Maakt basisstatistieken voor een veld van de attributentabel van een vectorlaag.
Velden numeriek, date, time en string worden ondersteund.
De teruggegeven statistieken zijn afhankelijk van het type veld.
Statistieken worden als een HTML-bestand gemaakt en zijn beschikbaar in .
Standaard menu:
Parameters
Label |
Naam |
Type |
Beschrijving |
|---|---|---|---|
Invoer vector |
|
[vector: elke] |
Vectorlaag waarvoor de statistieken moeten worden berekend |
Veld waarop statistieken moeten worden berekend |
|
[tabelveld: elk] |
Elk ondersteund tabelveld om de statistieken voor te berekenen |
Statistieken Optioneel |
|
[html] Standaard: |
Specificatie van het bestand voor de berekende statistieken. Één van:
|
Uitvoer
Label |
Naam |
Type |
Beschrijving |
|---|---|---|---|
Statistieken |
|
[html] |
HTML-bestand met de berekende statistieken |
Aantal |
|
[getal] |
|
Aantal unieke waarden |
|
[getal] |
|
Aantal lege (null) waarden |
|
[getal] |
|
Aantal niet-lege waarden |
|
[getal] |
|
Minimum waarde |
|
[hetzelfde als invoer] |
|
Maximum waarde |
|
[hetzelfde als invoer] |
|
Minimum lengte |
|
[getal] |
|
Maximum lengte |
|
[getal] |
|
Gemiddelde lengte |
|
[getal] |
|
Coëfficiënt van variatie |
|
[getal] |
|
Som |
|
[getal] |
|
Gemiddelde waarde |
|
[getal] |
|
Standaard afwijking |
|
[getal] |
|
Bereik |
|
[getal] |
|
Mediaan |
|
[getal] |
|
Minderheid (minst voorkomende waarde) |
|
[hetzelfde als invoer] |
|
Meerderheid (meest frequent voorkomende waarde) |
|
[hetzelfde als invoer] |
|
Eerste kwartiel |
|
[getal] |
|
Derde kwartiel |
|
[getal] |
|
Interkwartiel bereik (IQR) |
|
[getal] |
Pythoncode
ID algoritme: qgis:basicstatisticsforfields
import processing
processing.run("algorithm_id", {parameter_dictionary})
Het ID voor het algoritme wordt weergegeven als u over het algoritme gaat met de muisaanwijzer in de Toolbox van Processing. Het woordenboek voor de parameters verschaft de NAME’s en waarden van de parameters. Bekijk Processing algoritmes gebruiken vanaf de console voor details over hoe algoritmes van Processing uit te voeren vanuit de console voor Python.
25.1.15.2. Klimmen langs lijn
Berekent de totale klim en afdaling langs geometrieën lijn. De invoerlaag moet waarden Z hebben. Als er geen waarden Z beschikbaar zijn, kan het algoritme Drape (Z-waarde instellen vanuit raster) worden gebruikt om waarden Z toe te voegen vanuit een DEM-laag.
De uitvoerlaag is een kopie van de invoerlaag met aanvullende velden die de totale klim (climb), totale afdaling (descent), de minimum hoogte (minelev) en de maximum hoogte (maxelev) bevatten voor elke geometrie lijn. Als de invoerlaag velden bevat met dezelfde namen als deze toegevoegde velden, zullen zij worden hernoemd (veldnamen zullen worden gewijzigd naar “name_2”, “name_3”, etc, totdat de eerste niet-duplicaat naam wordt gevonden).
Parameters
Label |
Naam |
Type |
Beschrijving |
|---|---|---|---|
Lijnlaag |
|
[vector: lijn] |
Lijnlaag waaruit de kim moet worden berekend. Moet waarden Z hebben |
Klimlaag |
|
[vector: lijn] Standaard: |
Specificatie van de uitvoer (lijn)laag. Één van:
De bestandscodering kan hier ook gewijzigd worden. |
Uitvoer
Label |
Naam |
Type |
Beschrijving |
|---|---|---|---|
Klimlaag |
|
[vector: lijn] |
Lijnlaag die de nieuwe attributen bevat met de resultaten uit de berekeningen voor het klimmen. |
Totale klim |
|
[getal] |
De som van het klimmen voor alle geometrieën lijn in de invoerlaag |
Totale afdaling |
|
[getal] |
De som van het afdalen voor alle geometrieën lijn in de invoerlaag |
Minimum hoogte |
|
[getal] |
De minimum hoogte voor de geometrieën in de laag |
Maximum hoogte |
|
[getal] |
De maximum hoogte voor de geometrieën in de laag |
Pythoncode
ID algoritme: qgis:climbalongline
import processing
processing.run("algorithm_id", {parameter_dictionary})
Het ID voor het algoritme wordt weergegeven als u over het algoritme gaat met de muisaanwijzer in de Toolbox van Processing. Het woordenboek voor de parameters verschaft de NAME’s en waarden van de parameters. Bekijk Processing algoritmes gebruiken vanaf de console voor details over hoe algoritmes van Processing uit te voeren vanuit de console voor Python.
25.1.15.3. Punten in polygonen tellen
Neemt een punt- en een polygoonlaag en telt het aantal punten van de puntlaag in elk van de polygonen van de polygoonlaag.
Een nieuwe polygoonlaag wordt gemaakt, met exact dezelfde inhoud als de invoer polygoonlaag, maar met een extra aanvullend veld met het aantal punten dat correspondeert met elke polygoon.
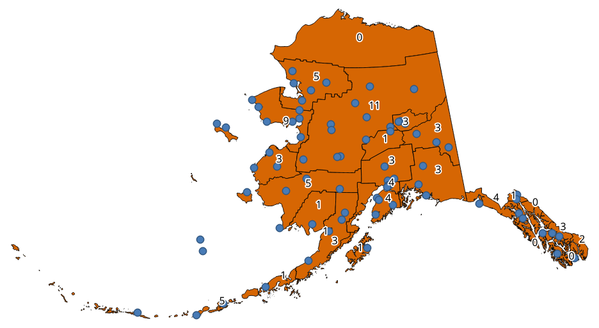
Fig. 25.31 De labels in de polygonen geven de telling van de punten weer
Een optioneel veld voor weging kan worden gebruikt om gewicht toe te kennen aan elk punt. Als alternatief kan een uniek klasseveld gespecificeerd worden. Als beide opties worden gebruikt zal het veld voor weging voorrang hebben en zal het unieke klasseveld worden genegeerd.
Standaard menu:
Parameters
Label |
Naam |
Type |
Beschrijving |
|---|---|---|---|
Polygonen |
|
[vector: polygoon] |
Polygoonlaag waarvan de objecten zijn geassocieerd met de telling van de punten die zij bevatten |
Punten |
|
[vector: punt] |
Puntlaag waarvan de objecten moeten worden geteld |
Veld Gewicht Optioneel |
|
[tabelveld: elk] |
Een veld uit de puntenlaag. De verrichte telling zal de som zijn van het veld Gewicht van de punten die zijn opgenomen in de polygoon. Als het veld Gewicht niet numeriek is, zal de telling |
Veld Klasse Optioneel |
|
[tabelveld: elk] |
Punten worden geclassificeerd gebaseerd op het geselecteerde attribuut en indien er verscheidene punten met dezelfde waarde voor het attribuut binnen de polygoon liggen, wordt er slechts één geteld. De uiteindelijke telling van de punten in een polygoon is daarom het aantal verschillende klassen dat daarin wordt aangetroffen. |
Naam veld voor telling |
|
[tekenreeks] Standaard: ‘NUMPOINTS’ |
De naam van het veld om de telling van de punten in op te slaan |
Aantal |
|
[vector: polygoon] Standaard: |
Specificatie van de uitvoerlaag. Één van:
De bestandscodering kan hier ook gewijzigd worden. |
Uitvoer
Label |
Naam |
Type |
Beschrijving |
|---|---|---|---|
Aantal |
|
[vector: polygoon] |
Resulterende laag met de attributentabel die de nieuwe kolom voor het tellen van de punten bevat |
Pythoncode
ID algoritme: native:countpointsinpolygon
import processing
processing.run("algorithm_id", {parameter_dictionary})
Het ID voor het algoritme wordt weergegeven als u over het algoritme gaat met de muisaanwijzer in de Toolbox van Processing. Het woordenboek voor de parameters verschaft de NAME’s en waarden van de parameters. Bekijk Processing algoritmes gebruiken vanaf de console voor details over hoe algoritmes van Processing uit te voeren vanuit de console voor Python.
25.1.15.4. DBSCAN clusteren
Clustert puntobjecten, gebaseerd op een 2D-implementatie van het algoritme Density-based spatial clustering of applications with noise (DBSCAN).
Het algoritme vereist twee parameters, een minimum grootte voor de cluster, en de maximale toegestane afstand tussen de geclusterde punten.
Parameters
Basis parameters
Label |
Naam |
Type |
Beschrijving |
|---|---|---|---|
Invoerlaag |
|
[vector: punt] |
Laag om te analyseren |
Minimale grootte clusters |
|
[getal] Standaard: 5 |
Minimale aantal objecten om een cluster te maken |
Maximale afstand tussen punten van de cluster |
|
[getal] Standaard: 1.0 |
Afstand waarboven twee objecten niet kunnen behoren tot dezelfde cluster (eps) |
Clusters |
|
[vector: punt] Standaard: |
Specificeer de vectorlaag voor het resultaat van het clusteren. Één van:
De bestandscodering kan hier ook gewijzigd worden. |
Gevorderde parameters
Label |
Naam |
Type |
Beschrijving |
|---|---|---|---|
Randpunten als vervuiling beschouwen (DBSCAN*) Optioneel |
|
[Booleaanse waarde] Standaard: False |
Indien geselecteerd worden punten op de rand van een cluster op zichzelf beschouwd als niet geclusterde punten, en alleen punten binnen een cluster worden getagd als geclusterd. |
Naam veld voor cluster |
|
[tekenreeks] Standaard: ‘CLUSTER_ID’ |
Naam van het veld waar het geassocieerde nummer van de cluster moet worden opgeslagen |
Naam veld voor grootte cluster |
|
[tekenreeks] Standaard: ‘CLUSTER_SIZE’ |
Naam van het veld met het aantal objecten in dezelfde cluster |
Uitvoer
Label |
Naam |
Type |
Beschrijving |
|---|---|---|---|
Clusters |
|
[vector: punt] |
Vectorlaag die de originele objecten bevat met een veld die de cluster instelt waartoe zij behoren |
Aantal clusters |
|
[getal] |
Aantal ontdekte clusters |
Pythoncode
ID algoritme: native:dbscanclustering
import processing
processing.run("algorithm_id", {parameter_dictionary})
Het ID voor het algoritme wordt weergegeven als u over het algoritme gaat met de muisaanwijzer in de Toolbox van Processing. Het woordenboek voor de parameters verschaft de NAME’s en waarden van de parameters. Bekijk Processing algoritmes gebruiken vanaf de console voor details over hoe algoritmes van Processing uit te voeren vanuit de console voor Python.
25.1.15.5. Afstandsmatrix
Berekent voor puntobjecten afstanden tot hun dichtstbijzijnde objecten op dezelfde laag of op een andere laag.
Standaard menu:
Parameters
Label |
Naam |
Type |
Beschrijving |
|---|---|---|---|
Invoer puntenlaag |
|
[vector: punt] |
Puntlaag waarvoor de afstandsmatrix wordt berekend (punten vanaf) |
Invoer unieke ID-veld |
|
[tabelveld: elk] |
Te gebruiken veld om objecten van de invoerlaag uniek te kunnen identificeren. Gebruikt in de attributentabel voor de uitvoer. |
Doel-puntenlaag |
|
[vector: punt] |
Puntenlaag die de gezochte dichtstbijzijnde punt(en) bevat (punten tot) |
Doel unieke ID-veld |
|
[tabelveld: elk] |
Te gebruiken veld om objecten van de doellaag uniek te kunnen identificeren. Gebruikt in de attributentabel voor de uitvoer. |
Uitvoer matrixtype |
|
[enumeratie] Standaard: 0 |
Verschillende typen berekening zijn beschikbaar:
|
Alleen dichtstbijzijnde (k) doelpunten gebruiken |
|
[getal] Standaard: 0 |
U kunt er voor kiezen om de afstanden tot alle punten in de doellaag te berekenen (0) of te beperken tot een aantal (k) dichtstbijzijnde objecten. |
Afstandsmatrix |
|
[vector: punt] Standaard: |
Specificatie van de uitvoer vectorlaag. Één van:
De bestandscodering kan hier ook gewijzigd worden. |
Uitvoer
Label |
Naam |
Type |
Beschrijving |
|---|---|---|---|
Afstandsmatrix |
|
[vector: punt] |
Punt (of MultiPunt in het geval van de “Lineaire (N * k x 3)”) vectorlaag die de berekening van de afstand bevat voor elk object van de invoer. De objecten en attributentabel ervan zijn afhankelijk van het geselecteerde matrixtype voor de uitvoer. |
Pythoncode
ID algoritme: qgis:distancematrix
import processing
processing.run("algorithm_id", {parameter_dictionary})
Het ID voor het algoritme wordt weergegeven als u over het algoritme gaat met de muisaanwijzer in de Toolbox van Processing. Het woordenboek voor de parameters verschaft de NAME’s en waarden van de parameters. Bekijk Processing algoritmes gebruiken vanaf de console voor details over hoe algoritmes van Processing uit te voeren vanuit de console voor Python.
25.1.15.6. Afstand tot dichtstbijzijnde naaf (lijn naar naaf)
Maakt lijnen die elk object van een invoer vector verbinden met het dichtstbijzijnde object in een doellaag. Afstanden worden berekend op basis van het midden van elk object.
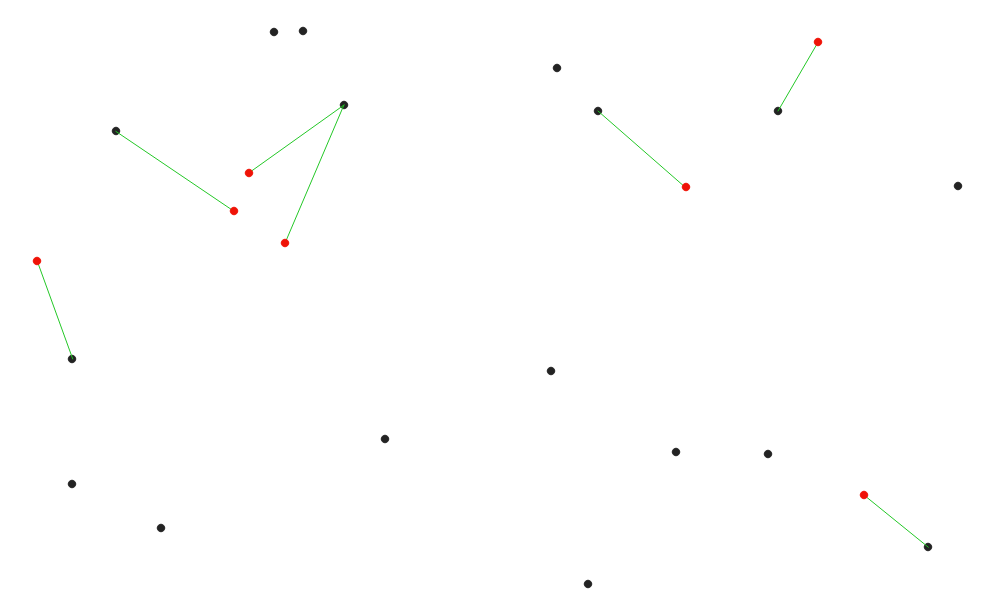
Fig. 25.32 Geef de dichtstbijzijnde naaf weer voor de rode objecten voor invoer
Parameters
Label |
Naam |
Type |
Beschrijving |
|---|---|---|---|
Bron puntenlaag |
|
[vector: elke] |
Vectorlaag waarvoor het dichtstbijzijnde object wordt gezocht |
Doel navenlaag |
|
[vector: elke] |
Vectorlaag die de objecten bevat waarnaar gezocht moet worden |
Naaflaag naam attribuut |
|
[tabelveld: elk] |
Te gebruiken veld om objecten van de doellaag uniek te kunnen identificeren. Gebruikt in de attributentabel voor de uitvoer |
Maateenheid |
|
[enumeratie] Standaard: 0 |
Eenheden waarin de afstand tot het dichtstbijzijnde object moet worden gerapporteerd:
|
Afstand tot hub |
|
[vector: lijn] Standaard: |
Specificeer de uitvoer lijnlaag die de overeenkomende punten verbindt. Één van:
De bestandscodering kan hier ook gewijzigd worden. |
Uitvoer
Label |
Naam |
Type |
Beschrijving |
|---|---|---|---|
Afstand tot hub |
|
[vector: lijn] |
Lijn vectorlaag met de attributen van de objecten voor de invoer, de identificatie voor hun dichtstbijzijnde object en de berekende afstand. |
Pythoncode
ID algoritme: qgis:distancetonearesthublinetohub
import processing
processing.run("algorithm_id", {parameter_dictionary})
Het ID voor het algoritme wordt weergegeven als u over het algoritme gaat met de muisaanwijzer in de Toolbox van Processing. Het woordenboek voor de parameters verschaft de NAME’s en waarden van de parameters. Bekijk Processing algoritmes gebruiken vanaf de console voor details over hoe algoritmes van Processing uit te voeren vanuit de console voor Python.
25.1.15.7. Afstand tot dichtstbijzijnde naaf (punten)
Maakt een puntlaag die het midden van de invoerobjecten weergeeft, met als aanvulling twee velden die de identificatie bevatten van het dichtstbijzijnde object (gebaseerd op zijn middelpunt) en de afstand tussen de punten.
Parameters
Label |
Naam |
Type |
Beschrijving |
|---|---|---|---|
Bron puntenlaag |
|
[vector: elke] |
Vectorlaag waarvoor het dichtstbijzijnde object wordt gezocht |
Doel navenlaag |
|
[vector: elke] |
Vectorlaag die de objecten bevat waarnaar gezocht moet worden |
Naaflaag naam attribuut |
|
[tabelveld: elk] |
Te gebruiken veld om objecten van de doellaag uniek te kunnen identificeren. Gebruikt in de attributentabel voor de uitvoer |
Maateenheid |
|
[enumeratie] Standaard: 0 |
Eenheden waarin de afstand tot het dichtstbijzijnde object moet worden gerapporteerd:
|
Afstand tot hub |
|
[vector: punt] Standaard: |
Specificeer de uitvoer punt vectorlaag met de dichtstbijzijnde hub. Één van:
De bestandscodering kan hier ook gewijzigd worden. |
Uitvoer
Label |
Naam |
Type |
Beschrijving |
|---|---|---|---|
Afstand tot hub |
|
[vector: punt] |
Punt vectorlaag die het midden van de bronobjecten met hun attributen, de identificatie van het dichtstbijzijnde object en hun berekende afstand weergeeft. |
Pythoncode
ID algoritme: qgis:distancetonearesthubpoints
import processing
processing.run("algorithm_id", {parameter_dictionary})
Het ID voor het algoritme wordt weergegeven als u over het algoritme gaat met de muisaanwijzer in de Toolbox van Processing. Het woordenboek voor de parameters verschaft de NAME’s en waarden van de parameters. Bekijk Processing algoritmes gebruiken vanaf de console voor details over hoe algoritmes van Processing uit te voeren vanuit de console voor Python.
25.1.15.8. Samenvoegen op lijnen (naaflijnen)
Maakt naaf- en spaakdiagrammen door lijnen uit punten op de spaaklaag te verbinden met overeenkomende punten op de naaflaag.
Het bepalen van welke naaf naar elk punt gaat is gebaseerd op een overeenkomst in het Naaf ID-veld van de naafpunten en het Spaak ID-veld van de spaakpunten.
Als invoerlagen geen puntlagen zijn wordt een punt op de oppervlakte van de geometrieën genomen als de locatie om te verbinden.
Optioneel kunnen geodetische lijnen worden gemaakt, die het kortste pad weergeven op het oppervlak van een ellipsoïde. Wanneer Geodetische lijnen maken wordt gebruikt, is het mogelijk de gemaakte lijnen te splitsen op de antimeridiaan (±180 graden longitude), wat het renderen van de lijnen kan verbeteren. Aanvullend kan de afstand tussen punten worden gespecificeerd. Een kleinere afstand resulteert in een dichter, meer nauwkeuriger lijn.
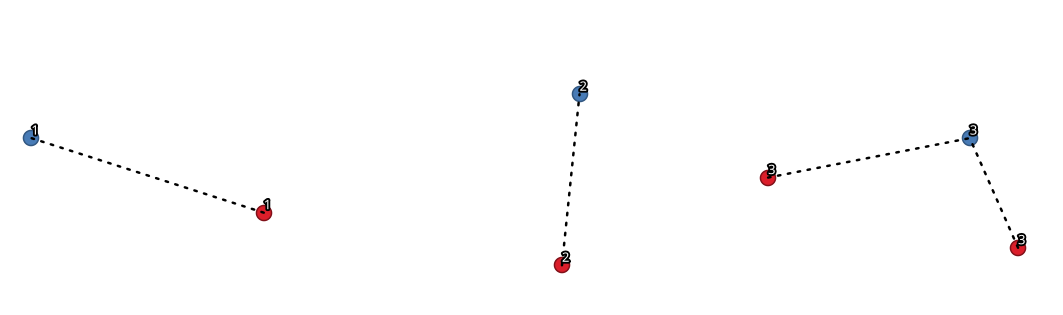
Fig. 25.33 Punten koppelen, gebaseerd op een gedeeld veld / attribuut
Parameters
Basis parameters
Label |
Naam |
Type |
Beschrijving |
|---|---|---|---|
Naaf puntlaag |
|
[vector: elke] |
Invoerlaag |
Naaf ID-veld |
|
[tabelveld: elk] |
Veld van de naaflaag met samen te voegen ID |
Velden van naaflaag om te kopiëren (laat leeg om alle velden te kopiëren) Optioneel |
|
[tabelveld: elk] [lijst] |
De veld(en) van de spaaklaag om te kopiëren. Indien geen veld(en) wordt/worden gekozen worden alle velden genomen. |
Spaak puntlaag |
|
[vector: elke] |
Aanvullende spaak puntlaag |
Spaak ID-veld |
|
[tabelveld: elk] |
Veld van de spaaklaag met samen te voegen ID |
Velden van spaaklaag om te kopiëren (laat leeg om alle velden te kopiëren) Optioneel |
|
[tabelveld: elk] [lijst] |
Veld(en) van de spaaklaag om te kopiëren. Indien geen velden worden gekozen worden alle velden behouden. |
Geodetische lijnen maken |
|
[Booleaanse waarde] Standaard: False |
Maak geodetische lijnen (het kortste pad op het oppervlak van een ellipsoïde) |
Naaflijnen |
|
[vector: lijn] Standaard: |
Specificeer de uitvoer hub lijn vectorlaag. Één van:
De bestandscodering kan hier ook gewijzigd worden. |
Gevorderde parameters
Label |
Naam |
Type |
Beschrijving |
|---|---|---|---|
Afstand tussen punten (alleen geodetische lijnen) |
|
[getal] Standaard: 1000.0 (kilometers) |
Afstand tussen opeenvolgende punten (in kilometers). Een kleinere afstand resulteert in een dichtere, meer nauwkeuriger lijn |
Splitst lijnen op de antimeridiaan (±180 graden longitude) |
|
[Booleaanse waarde] Standaard: False |
Splitst lijnen op ±180 graden longitude (om renderen van de lijnen te verbeteren) |
Uitvoer
Label |
Naam |
Type |
Beschrijving |
|---|---|---|---|
Naaflijnen |
|
[vector: lijn] |
De resulterende lijnlaag die overeenkomende punten in invoerlagen verbindt |
Pythoncode
ID algoritme: native:hublines
import processing
processing.run("algorithm_id", {parameter_dictionary})
Het ID voor het algoritme wordt weergegeven als u over het algoritme gaat met de muisaanwijzer in de Toolbox van Processing. Het woordenboek voor de parameters verschaft de NAME’s en waarden van de parameters. Bekijk Processing algoritmes gebruiken vanaf de console voor details over hoe algoritmes van Processing uit te voeren vanuit de console voor Python.
25.1.15.9. Clusteren K-gemiddelde
Berekent het op 2D-afstand gebaseerde K-gemiddelde nummer voor de cluster voor elk invoerobject.
Clusteren op K-gemiddelde heeft tot doel de objecten op te delen in K clusters, waarin elk object behoort tot de cluster met het dichtstbij gelegen gemiddelde. Het gemiddelde punt wordt weergegeven door het massamiddelpunt van de geclusterde objecten.
Als invoergeometrieën lijnen of polygonen zijn, wordt het clusteren gebaseerd op het zwaartepunt van het object.
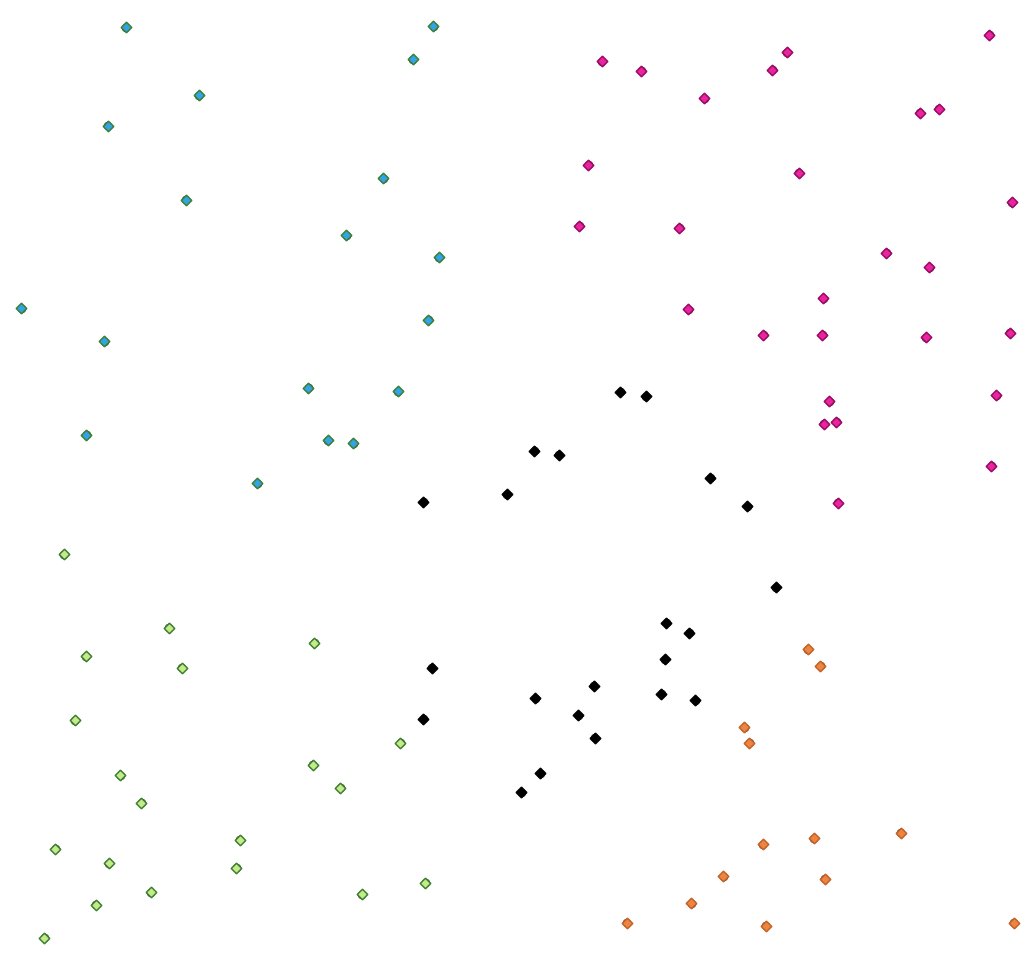
Fig. 25.34 Een vijf klassen punt clusters
Zie ook
Parameters
Label |
Naam |
Type |
Beschrijving |
|---|---|---|---|
Invoerlaag |
|
[vector: elke] |
Laag om te analyseren |
Aantal clusters |
|
[getal] Standaard: 5 |
Aantal te maken clusters met de objecten |
Clusters |
|
[vector: elke] Standaard: [Tijdelijke laag maken] |
Specificeer de uitvoer vectorlaag voor de gemaakte clusters. Één van:
De bestandscodering kan hier ook gewijzigd worden. |
Gevorderde parameters
Label |
Naam |
Type |
Beschrijving |
|---|---|---|---|
Naam veld voor cluster |
|
[tekenreeks] Standaard: ‘CLUSTER_ID’ |
Naam van het veld waar het geassocieerde nummer van de cluster moet worden opgeslagen |
Naam veld voor grootte cluster |
|
[tekenreeks] Standaard: ‘CLUSTER_SIZE’ |
Naam van het veld met het aantal objecten in dezelfde cluster |
Uitvoer
Label |
Naam |
Type |
Beschrijving |
|---|---|---|---|
Clusters |
|
[vector: elke] |
Vectorlaag die de originele objecten bevat met velden die de cluster specificeert waartoe zij behoren en hun nummer erin |
Pythoncode
ID algoritme: native:kmeansclustering
import processing
processing.run("algorithm_id", {parameter_dictionary})
Het ID voor het algoritme wordt weergegeven als u over het algoritme gaat met de muisaanwijzer in de Toolbox van Processing. Het woordenboek voor de parameters verschaft de NAME’s en waarden van de parameters. Bekijk Processing algoritmes gebruiken vanaf de console voor details over hoe algoritmes van Processing uit te voeren vanuit de console voor Python.
25.1.15.10. Lijst unieke waarden
Vermeldt unieke waarden van een veld in een attributentabel en telt hun aantal.
Standaard menu:
Parameters
Label |
Naam |
Type |
Beschrijving |
|---|---|---|---|
Invoerlaag |
|
[vector: elke] |
Laag om te analyseren |
Doelveld(en) |
|
[tabelveld: elk] |
Veld om te analyseren |
Unieke waarden Optioneel |
|
[tabel] Standaard: [Tijdelijke laag maken] |
Specificeer de samenvattende tabellaag met unieke waarden. Één van:
De bestandscodering kan hier ook gewijzigd worden. |
HTMLrapport Optioneel |
|
[html] Standaard: |
HTML-rapport van unieke waarden in de . Één van:
|
Uitvoer
Label |
Naam |
Type |
Beschrijving |
|---|---|---|---|
Unieke waarden |
|
[tabel] |
Overzicht tabellaag met unieke waarden |
HTMLrapport |
|
[html] |
HTML-rapport van unieke waarden. Kan worden geopend in . |
Totaal unieke waarden |
|
[getal] |
Het aantal unieke waarden in het invoerveld |
UNIQUE_VALUES |
|
[tekenreeks] |
Een tekenreeks met de kommagescheiden lijst van unieke waarden, gevonden in het invoerveld |
Pythoncode
ID algoritme: qgis:listuniquevalues
import processing
processing.run("algorithm_id", {parameter_dictionary})
Het ID voor het algoritme wordt weergegeven als u over het algoritme gaat met de muisaanwijzer in de Toolbox van Processing. Het woordenboek voor de parameters verschaft de NAME’s en waarden van de parameters. Bekijk Processing algoritmes gebruiken vanaf de console voor details over hoe algoritmes van Processing uit te voeren vanuit de console voor Python.
25.1.15.11. Gemiddelde coördina(a)t(en)
Berekent een puntlaag met het massamiddelpunt van de geometrieën op de invoerlaag.
Een attribuut kan worden gespecificeerd om het gewicht te bevatten dat aan elk object moet worden toegekend bij het berekenen van het massacentrum.
Als een attribuut is geselecteerd in de parameter, zullen objecten worden gegroepeerd overeenkomstig de waarden in dit veld. In plaats van één enkel punt met het massacentrum van de gehele laag, zal de uitvoerlaag een massacentrum bevatten van de objecten voor elke categorie.
Standaard menu:
Parameters
Label |
Naam |
Type |
Beschrijving |
|---|---|---|---|
Invoerlaag |
|
[vector: elke] |
Invoer vectorlaag |
Veld Gewicht Optioneel |
|
[tabelveld: numeriek] |
Te gebruiken veld als u een gewogen gemiddelde wilt uitvoeren |
Uniek ID-veld |
|
[tabelveld: numeriek] |
Uniek veld waarop het berekenen van het gemiddelde zal worden uitgevoerd |
Gemiddelde coördinaten |
|
[vector: punt] Standaard: [Tijdelijke laag maken] |
Specificeer de (punt vector)laag voor het resultaat. Één van:
De bestandscodering kan hier ook gewijzigd worden. |
Uitvoer
Label |
Naam |
Type |
Beschrijving |
|---|---|---|---|
Gemiddelde coördinaten |
|
[vector: punt] |
Resulterende punt(en)laag |
Pythoncode
ID algoritme: native:meancoordinates
import processing
processing.run("algorithm_id", {parameter_dictionary})
Het ID voor het algoritme wordt weergegeven als u over het algoritme gaat met de muisaanwijzer in de Toolbox van Processing. Het woordenboek voor de parameters verschaft de NAME’s en waarden van de parameters. Bekijk Processing algoritmes gebruiken vanaf de console voor details over hoe algoritmes van Processing uit te voeren vanuit de console voor Python.
25.1.15.12. ‘Dichtstbijzijnde buur’-analyse
Voert een analyse Nearest neighbor uit op een puntenlaag. De uitvoer vertelt u hou uw gegevens zijn verdeeld (geclusterd, willekeurig of verdeeld).
Uitvoer wordt gemaakt als een HTML-bestand met de berekende statistische waarden:
Aangetroffen gemiddelde afstand
Verwachtte gemiddelde afstand
‘Nearest neighbour’-index
Aantal punten
Z-score: Vergelijken van de Z-score met de normale verdeling vertelt u hoe uw gegevens zijn verdeeld. Een lage Z-score betekent dat de gegevens waarschijnlijk niet het resultaat zijn van een ruimtelijk willekeurig proces, terwijl een hoge Z-score betekent dat uw gegevens waarschijnlijk het resultaat zijn van een ruimtelijk willekeurig proces.
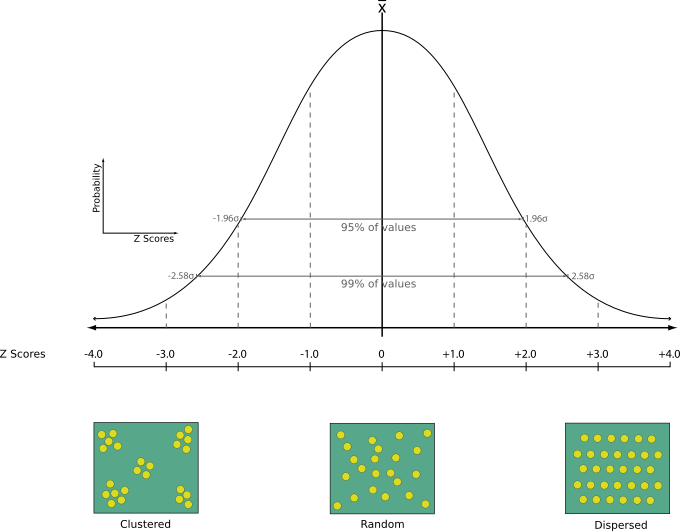
Standaard menu:
Parameters
Label |
Naam |
Type |
Beschrijving |
|---|---|---|---|
Invoerlaag |
|
[vector: punt] |
Punt vectorlaag waarvoor de statistieken moeten worden berekend |
Dichtstbijzijnde buur Optioneel |
|
[html] Standaard: |
Specificatie van het HTML-bestand voor de berekende statistieken. Één van:
|
Uitvoer
Label |
Naam |
Type |
Beschrijving |
|---|---|---|---|
Dichtstbijzijnde buur |
|
[html] |
HTML-bestand met de berekende statistieken |
Aangetroffen gemiddelde afstand |
|
[getal] |
Aangetroffen gemiddelde afstand |
Verwachtte gemiddelde afstand |
|
[getal] |
Verwachtte gemiddelde afstand |
‘Nearest neighbour’-index |
|
[getal] |
‘Nearest neighbour’-index |
Aantal punten |
|
[getal] |
Aantal punten |
Z-score |
|
[getal] |
Z-score |
Pythoncode
ID algoritme: native:nearestneighbouranalysis
import processing
processing.run("algorithm_id", {parameter_dictionary})
Het ID voor het algoritme wordt weergegeven als u over het algoritme gaat met de muisaanwijzer in de Toolbox van Processing. Het woordenboek voor de parameters verschaft de NAME’s en waarden van de parameters. Bekijk Processing algoritmes gebruiken vanaf de console voor details over hoe algoritmes van Processing uit te voeren vanuit de console voor Python.
25.1.15.13. Analyse Overlappen
Berekent het gebied en het bedekkingspercentage waarmee objecten op een invoerlaag worden overlapt door objecten uit een selectie van overleglagen.
Nieuwe attributen worden toegevoegd aan de uitvoerlaag die het totale overlappende gebied aangeven en het percentage van de invoerobjecten die worden overlapt door elk van de geselecteerde overleglagen.
Parameters
Label |
Naam |
Type |
Beschrijving |
|---|---|---|---|
Invoerlaag |
|
[vector: elke] |
De invoerlaag. |
Overleglagen |
|
[vector: elke] [lijst] |
De over te leggen lagen. |
Uitvoerlaag |
|
[hetzelfde als invoer] Standaard: |
Specificeer de uitvoer vectorlaag. Één van:
De bestandscodering kan hier ook gewijzigd worden. |
Uitvoer
Label |
Naam |
Type |
Beschrijving |
|---|---|---|---|
Uitvoerlaag |
|
[hetzelfde als invoer] |
De uitvoerlaag met aanvullende velden die de overlapping rapporteren (in kaarteenheden en percentage) van het invoerobject, overlapt door elk van de geselecteerde lagen. |
Pythoncode
ID algoritme: native:calculatevectoroverlaps
import processing
processing.run("algorithm_id", {parameter_dictionary})
Het ID voor het algoritme wordt weergegeven als u over het algoritme gaat met de muisaanwijzer in de Toolbox van Processing. Het woordenboek voor de parameters verschaft de NAME’s en waarden van de parameters. Bekijk Processing algoritmes gebruiken vanaf de console voor details over hoe algoritmes van Processing uit te voeren vanuit de console voor Python.
25.1.15.14. ST-DBSCAN clusteren
NEW in 3.22
Clustert puntobjecten, gebaseerd op een 2D-implementatie van het tijdruimte algoritme Density-based clustering of applications with noise (ST-DBSCAN).
Zie ook
Parameters
Basis parameters
Label |
Naam |
Type |
Beschrijving |
|---|---|---|---|
Invoerlaag |
|
[vector: punt] |
Laag om te analyseren |
Datum/tijd veld |
|
[tabelveld: datum] |
Veld dat de informatie over tijd bevat |
Minimale grootte clusters |
|
[getal] Standaard: 5 |
Minimale aantal objecten om een cluster te maken |
Maximale afstand tussen punten van de cluster |
|
[getal] Standaard: 1.0 |
Afstand waarboven twee objecten niet kunnen behoren tot dezelfde cluster (eps) |
Maximale tijdsduur tussen geclusterde punten |
|
[getal] Standaard: 0.0 (dagen) |
Tijdsduur waarbuiten twee objecten niet kunnen behoren tot dezelfde cluster (eps2). Beschikbare eenheden voor tijd zijn milliseconden, seconden, minuten, uren, dagen en weken. |
Clusters |
|
[vector: punt] Standaard: |
Specificeer de vectorlaag voor het resultaat van het clusteren. Één van:
De bestandscodering kan hier ook gewijzigd worden. |
Gevorderde parameters
Label |
Naam |
Type |
Beschrijving |
|---|---|---|---|
Randpunten als vervuiling beschouwen (DBSCAN*) Optioneel |
|
[Booleaanse waarde] Standaard: False |
Indien geselecteerd worden punten op de rand van een cluster op zichzelf beschouwd als niet geclusterde punten, en alleen punten binnen een cluster worden getagd als geclusterd. |
Naam veld voor cluster |
|
[tekenreeks] Standaard: ‘CLUSTER_ID’ |
Naam van het veld waar het geassocieerde nummer van de cluster moet worden opgeslagen |
Naam veld voor grootte cluster |
|
[tekenreeks] Standaard: ‘CLUSTER_SIZE’ |
Naam van het veld met het aantal objecten in dezelfde cluster |
Uitvoer
Label |
Naam |
Type |
Beschrijving |
|---|---|---|---|
Clusters |
|
[vector: punt] |
Vectorlaag die de originele objecten bevat met een veld die de cluster instelt waartoe zij behoren |
Aantal clusters |
|
[getal] |
Aantal ontdekte clusters |
Pythoncode
ID algoritme: native:stdbscanclustering
import processing
processing.run("algorithm_id", {parameter_dictionary})
Het ID voor het algoritme wordt weergegeven als u over het algoritme gaat met de muisaanwijzer in de Toolbox van Processing. Het woordenboek voor de parameters verschaft de NAME’s en waarden van de parameters. Bekijk Processing algoritmes gebruiken vanaf de console voor details over hoe algoritmes van Processing uit te voeren vanuit de console voor Python.
25.1.15.15. Statistieken op categorieën
Berekent statistieken van velden, afhankelijk van een ouderklasse. De ouderklasse is een combinatie van waarden uit andere velden.
Parameters
Label |
Naam |
Type |
Beschrijving |
|---|---|---|---|
Invoer vectorlaag |
|
[vector: elke] |
Invoer vectorlaag met unieke klassen en waarden |
Veld waarop statistieken moeten worden berekend (indien leeg wordt alleen aantal berekend) Optioneel |
|
[tabelveld: elk] |
Indien leeg zal alleen het aantal worden berekend |
Veld(en) met categorieën |
|
[vector: elke] [lijst] |
De velden die (gecombineerd) de categorieën definiëren |
Statistieken op categorie |
|
[tabel] Standaard: |
Specificatie van de uitvoertabel voor de berekende statistieken. Één van:
De bestandscodering kan hier ook gewijzigd worden. |
Uitvoer
Label |
Naam |
Type |
Beschrijving |
|---|---|---|---|
Statistieken op categorie |
|
[tabel] |
Tabel die de statistieken bevat |
Afhankelijk van het veld dat wordt geanalyseerd, worden de volgende statistieken teruggegeven voor elke gegroepeerde waarde:
Statistieken |
Tekenreeks |
Numeriek |
Datum |
|---|---|---|---|
Aantal ( |
|
|
|
Unieke waarden ( |
|
|
|
Lege (Null) waarden ( |
|
|
|
Niet-lege waarden ( |
|
|
|
Minimale waarde ( |
|
|
|
Maximale waarde ( |
|
|
|
Bereik ( |
|
||
Som ( |
|
||
Gemiddelde waarde ( |
|
||
Waarde mediaan ( |
|
||
Standaardafwijking ( |
|
||
Coëfficiënt van variatie ( |
|
||
Minderheid (minst voorkomende waarde - |
|
||
Meerderheid (meest voorkomende waarde - |
|
||
Eerste kwartiel ( |
|
||
Derde kwartiel ( |
|
||
Interkwartiel bereik ( |
|
||
Minimum lengte ( |
|
||
Gemiddelde lengte ( |
|
||
Maximum lengte ( |
|

Pythoncode
ID algoritme: qgis:statisticsbycategories
import processing
processing.run("algorithm_id", {parameter_dictionary})
Het ID voor het algoritme wordt weergegeven als u over het algoritme gaat met de muisaanwijzer in de Toolbox van Processing. Het woordenboek voor de parameters verschaft de NAME’s en waarden van de parameters. Bekijk Processing algoritmes gebruiken vanaf de console voor details over hoe algoritmes van Processing uit te voeren vanuit de console voor Python.
25.1.15.16. Lijnlengtes sommeren
Neemt een polygoonlaag en een lijnlaag en meet de totale lengte van de lijnen en het totale aantal daarvan dat elke polygoon kruist.
De resulterende laag heeft dezelfde objecten als de invoer polygoonlaag, maar met twee aanvullende attributen die de lengte van en het aantal lijnen bevatten voor elke polygoon.
Standaard menu:
Parameters
Label |
Naam |
Type |
Beschrijving |
|---|---|---|---|
Lijnen |
|
[vector: lijn] |
Invoer lijn vectorlaag |
Polygonen |
|
[vector: polygoon] |
Polygoon vectorlaag |
Veldnaam voor lengte lijnen |
|
[tekenreeks] Standaard: ‘LENGTH’ |
Naam van het veld voor de lengten van de lijnen |
Veldnaam voor aantal lijnen |
|
[tekenreeks] Standaard: ‘COUNT’ |
Naam van het veld voor de telling van de lijnen |
Lijn lengte |
|
[vector: polygoon] Standaard: |
Specificeer de uitvoer polygoonlaag met de gemaakte statistieken. Één van:
De bestandscodering kan hier ook gewijzigd worden. |
Uitvoer
Label |
Naam |
Type |
Beschrijving |
|---|---|---|---|
Lijn lengte |
|
[vector: polygoon] |
Polygoon uitvoerlaag met velden voor lengten van lijnen en aantal lijnen |
Pythoncode
ID algoritme: native:sumlinelengths
import processing
processing.run("algorithm_id", {parameter_dictionary})
Het ID voor het algoritme wordt weergegeven als u over het algoritme gaat met de muisaanwijzer in de Toolbox van Processing. Het woordenboek voor de parameters verschaft de NAME’s en waarden van de parameters. Bekijk Processing algoritmes gebruiken vanaf de console voor details over hoe algoritmes van Processing uit te voeren vanuit de console voor Python.