11.4. Exploring Data Formats and Fields
11.4.1. Raster data
GIS raster data are matrices of discrete cells that represent features / phenomena on, above or below the earth’s surface. Each cell in the raster grid has the same size, and cells are usually rectangular (in QGIS they will always be rectangular). Typical raster datasets include remote sensing data, such as aerial photography, or satellite imagery and modelled data, such as elevation or temperature.
Unlike vector data, raster data typically do not have an associated database record for each cell. They are geocoded by pixel resolution and the X/Y coordinate of a corner pixel of the raster layer. This allows QGIS to position the data correctly on the map canvas.
The GeoPackage format is convenient for storing raster data when working with QGIS. The popular and powerful GeoTiff format is a good alternative.
QGIS makes use of georeference information inside the raster layer (e.g., GeoTiff) or an associated world file to properly display the data.
11.4.2. Vector Data
Many of the features and tools available in QGIS work the same, regardless of the vector data source. However, because of the differences in format specifications (GeoPackage, ESRI Shapefile, MapInfo and MicroStation file formats, AutoCAD DXF, PostgreSQL, SpatiaLite, Oracle Spatial, MS SQL Server, SAP HANA Spatial databases and many more), QGIS may handle some of their properties differently. Support is provided by the GDAL vector drivers. This section describes how to work with some of these specifics.
Note
QGIS supports (multi)point, (multi)line, (multi)polygon, CircularString, CompoundCurve, CurvePolygon, MultiCurve, MultiSurface feature types, all optionally with Z and/or M values.
You should also note that some drivers don’t support some of these feature types, like CircularString, CompoundCurve, CurvePolygon, MultiCurve, MultiSurface feature type. QGIS will convert them.
11.4.2.1. GeoPackage
The GeoPackage (GPKG) format is platform-independent, and is implemented as a SQLite database container, and can be used to store both vector and raster data. The format was defined by the Open Geospatial Consortium (OGC), and was published in 2014.
GeoPackage can be used to store the following in a SQLite database:
vector features
tile matrix sets of imagery and raster maps
attributes (non-spatial data)
extensions
Since QGIS version 3.8, GeoPackage can also store QGIS projects. GeoPackage layers can have JSON fields.
GeoPackage is the default format for vector data in QGIS.
11.4.2.2. ESRI Shapefile format
The ESRI Shapefile format is still one of the most used vector file formats, even if it has some limitations compared to for instance GeoPackage and SpatiaLite.
An ESRI Shapefile format dataset consists of several files. The following three are required:
.shpfile containing the feature geometries.dbffile containing the attributes in dBase format.shxindex file
An ESRI Shapefile format dataset can also include a file with a
.prj suffix, which contains projection information.
While it is very useful to have a projection file, it is not
mandatory.
A Shapefile format dataset can contain additional files.
For further details, see the the ESRI technical specification.
GDAL has read-write support for compressed ESRI Shapefile
format (shz and shp.zip).
Improving Performance for ESRI Shapefile format datasets
To improve the drawing performance for an ESRI Shapefile format
dataset, you can create a spatial index.
A spatial index will improve the speed of both zooming and panning.
Spatial indexes used by QGIS have a .qix extension.
Use these steps to create the index:
Load an ESRI Shapefile format dataset (see The Browser Panel)
Open the Layer Properties dialog by double-clicking on the layer name in the legend or by right-clicking and choosing from the context menu
In the Source tab, click the Create Spatial Index button
Problem loading a .prj file
If you load an ESRI Shapefile format dataset with a .prj file
and QGIS is not able to read the coordinate reference system from
that file, you will need to define the proper projection manually in
the tab of the layer by
clicking the  Select CRS button.
This is due to the fact that
Select CRS button.
This is due to the fact that .prj files often do not provide
the complete projection parameters as used in QGIS and listed in the
CRS dialog.
For the same reason, if you create a new ESRI Shapefile format dataset
with QGIS, two different projection files are created: a .prj
file with limited projection parameters, compatible with ESRI
software, and a .qpj file, providing all the parameters of the
CRS.
Whenever QGIS finds a .qpj file, it will be used instead of
the .prj.
11.4.2.3. Delimited Text Files
Delimited text files are very common and widely used because of their simplicity and readability – data can be viewed and edited in a plain text editor. A delimited text file is tabular data with columns separated by a defined character and rows separated by line breaks. The first row usually contains the column names. A common type of delimited text file is a CSV (Comma Separated Values), with columns separated by commas. Delimited text files can also contain positional information (see Storing geometry information in delimited text files).
QGIS allows you to load a delimited text file as a layer or an ordinary table (see The Browser Panel or Importing a delimited text file). First check that the file meets the following requirements:
The file must have a delimited header row of field names. This must be the first line of the data (ideally the first row in the text file).
If geometry should be enabled, the file must contain field(s) that define the geometry. These field(s) can have any name.
The X and Y coordinates fields (if geometry is defined by coordinates) must be specified as numbers. The coordinate system is not important.
If you have a CSV file with non-string columns, you can have an accompanying CSVT file (see section Using CSVT file to control field formatting).
The elevation point data file elevp.csv in the QGIS sample
dataset (see section Downloading sample data) is an example of a
valid text file:
X;Y;ELEV
-300120;7689960;13
-654360;7562040;52
1640;7512840;3
[...]
Some things to note about the text file:
The example text file uses
;(semicolon) as delimiter (any character can be used to delimit the fields).The first row is the header row. It contains the fields
X,YandELEV.No quotes (
") are used to delimit text fieldsThe X coordinates are contained in the
XfieldThe Y coordinates are contained in the
Yfield
Storing geometry information in delimited text files
Delimited text files can contain geometry information in two main forms:
As coordinates in separate columns (eg.
Xcol,Ycol… ), for point geometry data;As well-known text (WKT) representation of geometry in a single column, for any geometry type.
Features with curved geometries (CircularString, CurvePolygon and CompoundCurve) are supported. Here are some examples of geometry types in a delimited text file with geometries coded as WKT:
Label;WKT_geom
LineString;LINESTRING(10.0 20.0, 11.0 21.0, 13.0 25.5)
CircularString;CIRCULARSTRING(268 415,227 505,227 406)
CurvePolygon;CURVEPOLYGON(CIRCULARSTRING(1 3, 3 5, 4 7, 7 3, 1 3))
CompoundCurve;COMPOUNDCURVE((5 3, 5 13), CIRCULARSTRING(5 13, 7 15,
9 13), (9 13, 9 3), CIRCULARSTRING(9 3, 7 1, 5 3))
Delimited text files also support Z and M coordinates in geometries:
LINESTRINGZ(10.0 20.0 30.0, 11.0 21.0 31.0, 11.0 22.0 30.0)
Using CSVT file to control field formatting
When loading CSV files, the GDAL driver assumes all fields are strings (i.e. text) unless it is told otherwise. You can create a CSVT file to tell GDAL (and QGIS) the data type of the different columns:
Type |
Name |
Example |
|---|---|---|
Whole number |
Integer |
4 |
Boolean |
Integer(Boolean) |
true |
Decimal number |
Real |
3.456 |
Date |
Date (YYYY-MM-DD) |
2016-07-28 |
Time |
Time (HH:MM:SS+nn) |
18:33:12+00 |
Date & Time |
DateTime (YYYY-MM-DD HH:MM:SS+nn) |
2016-07-28 18:33:12+00 |
CoordX |
CoordX |
8.8249 |
CoordY |
CoordY |
47.2274 |
Point(X) |
Point(X) |
8.8249 |
Point(Y) |
Point(Y) |
47.2274 |
WKT |
WKT |
POINT(15 20) |
The CSVT file is a ONE line plain text file with the data types in quotes and separated by commas, e.g.:
"Integer","Real","String"
You can even specify width and precision of each column, e.g.:
"Integer(6)","Real(5.5)","String(22)"
This file is saved in the same folder as the .csv file, with
the same name, but .csvt as the extension.
You can find more information at GDAL CSV Driver.
Tip
Detect Field Types
Instead of using a CSVT file to tell the data types, QGIS provides the possibility to automatically detect the field types and to change the assumed field types.
11.4.2.4. PostgreSQL Database
In order to process geographical information in a PostgreSQL database, the PostGIS extension must first be installed. PostGIS extends the capabilities of the PostgreSQL relational database by adding support for storing, indexing, and querying geospatial data.
To enable PostGIS in your database you have to activate the extension
in your database (open database and run CREATE EXTENSION postgis;).
PostGIS enabled databases are also often named “PostGIS layer”.
Using PostGIS, vector functions such as select and identify work more
accurately than they do with GDAL layers in QGIS.
Tip
PostGIS Layers
Normally, a PostGIS layer is identified by an entry in the geometry_columns table. QGIS can load layers that do not have an entry in the geometry_columns table. This includes both tables and views. Refer to your PostgreSQL manual for information on creating views.
This section contains some details on how QGIS accesses PostgreSQL layers. Most of the time, QGIS should simply provide you with a list of database tables that can be loaded, and it will load them on request. However, if you have trouble loading a PostgreSQL table into QGIS, the information below may help you understand QGIS messages and give you directions for modifying the PostgreSQL table or view definition to allow QGIS to load it.
Note
A PostgreSQL database can also store QGIS projects.
Primary key
QGIS requires that PostgreSQL layers contain a column that can be used as a unique key for the layer. For tables, this usually means that the table needs a primary key, or a column with a unique constraint on it. In QGIS, this column needs to be of type int4 (an integer of size 4 bytes). Alternatively, the ctid column can be used as primary key. If a table lacks these items, the oid column will be used instead. Performance will be improved if the column is indexed (note that primary keys are automatically indexed in PostgreSQL).
QGIS offers a checkbox Select at id that is activated by default. This option gets the ids without the attributes, which is faster in most cases.
View
If the PostgreSQL layer is a view, the same requirement exists, but views do not always have primary keys or columns with unique constraints on them. You have to define a primary key field (has to be integer) in the QGIS dialog before you can load the view. If a suitable column does not exist in the view, QGIS will not load the layer. If this occurs, the solution is to alter the view so that it does include a suitable column (a type of integer and either a primary key or with a unique constraint, preferably indexed).
As for table, a checkbox Select at id is activated by default (see above for the meaning of the checkbox). It can make sense to disable this option when you use expensive views.
Note
PostgreSQL foreign table
PostgreSQL foreign tables are not explicitly supported by the PostgreSQL provider and will be handled like a view.
QGIS layer_style table and database backup
If you want to make a backup of your PostgreSQL database using the
pg_dump and pg_restore commands, and the default layer
styles as saved by QGIS fail to restore afterwards, you need to set
the XML option to DOCUMENT before the restore command:
Make a PLAIN backup of the
layer_styletableOpen the file within a text editor
Change the line
SET xmloption = content;intoSET XML OPTION DOCUMENT;Save the file
Use psql to restore the table in the new database
Filter database side
QGIS allows to filter features already on server side. Check
 to do so.
Only supported expressions will be sent to the database.
Expressions using unsupported operators or functions will gracefully
fallback to local evaluation.
to do so.
Only supported expressions will be sent to the database.
Expressions using unsupported operators or functions will gracefully
fallback to local evaluation.
Support of PostgreSQL data types
Data types supported by the PostgreSQL provider include: integer, float, boolean, binary object, varchar, geometry, timestamp, array, hstore and json.
Importing Data into PostgreSQL
Data can be imported into PostgreSQL using several tools, including the Browser, DB Manager plugin and the command line tools shp2pgsql and ogr2ogr.
DB Manager
QGIS comes with a core plugin named  DB Manager.
It can be used to load data, and it includes support for schemas.
See section DB Manager Plugin for more information.
DB Manager.
It can be used to load data, and it includes support for schemas.
See section DB Manager Plugin for more information.
shp2pgsql
PostGIS includes a utility called shp2pgsql, that can be used to import
Shapefile format datasets into a PostGIS-enabled database.
For example, to import a Shapefile format dataset named
lakes.shp into a PostgreSQL database named gis_data, use
the following command:
shp2pgsql -s 2964 lakes.shp lakes_new | psql gis_data
This creates a new layer named lakes_new in the gis_data database.
The new layer will have a spatial reference identifier (SRID) of 2964.
See section Working with Projections for more information about spatial
reference systems and projections.
Tip
Exporting datasets from PostgreSQL
There is also a tool for exporting PostgreSQL datasets with geographic data to Shapefile format: pgsql2shp. It is shipped within your PostGIS distribution.
ogr2ogr
In addition to shp2pgsql and DB Manager, there is another tool for feeding geographical data in PostgreSQL: ogr2ogr. It is part of your GDAL installation.
To import a Shapefile format dataset into PostgreSQL, do the following:
ogr2ogr -f "PostgreSQL" PG:"dbname=postgis host=myhost.de user=postgres
password=topsecret" alaska.shp
This will import the Shapefile format dataset alaska.shp into the
database postgis using the user postgres with the password topsecret
on the host server myhost.de.
Note that GDAL must be built with PostgreSQL.
You can verify this by typing (in  ):
):
ogrinfo --formats | grep -i post
If you prefer to use the PostgreSQL’s COPY command instead of the default
INSERT INTO method, you can export the following environment variable
(at least available on and  ):
):
export PG_USE_COPY=YES
ogr2ogr does not create spatial indexes like shp2pgsl does. You need to create them manually, using the normal SQL command CREATE INDEX afterwards, as an extra step (as described in the next section Improving Performance).
Improving Performance
Retrieving features from a PostgreSQL database can be time-consuming, especially over a network. You can improve the drawing performance of PostgreSQL layers by ensuring that a spatial index exists on each layer in the database. PostGIS supports creation of a GiST (Generalized Search Tree) index to speed up spatial searching (GiST index information is taken from the PostGIS documentation available at https://postgis.net).
Tip
You can use the DBManager to create an index for your layer. You should first select the layer and click on , go to tab and click on Add Spatial Index.
The syntax for creating a GiST index is:
CREATE INDEX [indexname] ON [tablename]
USING GIST ( [geometryfield] GIST_GEOMETRY_OPS );
Note that for large tables, creating the index can take a long time.
Once the index is created, you should perform a VACUUM ANALYZE.
See the PostGIS documentation (POSTGIS-PROJECT in
Literature and Web References) for more information.
The following example creates a GiST index:
gsherman@madison:~/current$ psql gis_data
Welcome to psql 8.3.0, the PostgreSQL interactive terminal.
Type: \copyright for distribution terms
\h for help with SQL commands
\? for help with psql commands
\g or terminate with semicolon to execute query
\q to quit
gis_data=# CREATE INDEX sidx_alaska_lakes ON alaska_lakes
gis_data-# USING GIST (geom GIST_GEOMETRY_OPS);
CREATE INDEX
gis_data=# VACUUM ANALYZE alaska_lakes;
VACUUM
gis_data=# \q
gsherman@madison:~/current$
11.4.2.5. SpatiaLite Layers
If you want to save a vector layer using the SpatiaLite format, you
can do this by following instructions at Creating new layers from an existing layer.
You select SpatiaLite as Format and
enter both File name and Layer name.
Also, you can select SQLite as format and then add
SPATIALITE=YES in the
field.
This tells GDAL to create a SpatiaLite database.
See also https://gdal.org/en/latest/drivers/vector/sqlite.html.
QGIS also supports editable views in SpatiaLite. For SpatiaLite data management, you can also use the core plugin DB Manager.
If you want to create a new SpatiaLite layer, please refer to section Creating a new SpatiaLite layer.
11.4.2.6. GeoJSON specific parameters
When exporting layers to GeoJSON, there are some specific Layer Options available. These options come from GDAL which is responsible for the writing of the file:
COORDINATE_PRECISION the maximum number of digits after the decimal separator to write in coordinates. Defaults to 15 (note: for Lat Lon coordinates 6 is considered enough). Truncation will occur to remove trailing zeros.
RFC7946 by default GeoJSON 2008 will be used. If set to YES, the updated RFC 7946 standard will be used. Default is NO (thus GeoJSON 2008). See https://gdal.org/en/latest/drivers/vector/geojson.html#rfc-7946-write-support for the main differences, in short: only EPSG:4326 is allowed, other crs’s will be transformed, polygons will be written such as to follow the right-hand rule for orientation, values of a “bbox” array are [west, south, east, north], not [minx, miny, maxx, maxy]. Some extension member names are forbidden in FeatureCollection, Feature and Geometry objects, the default coordinate precision is 7 decimal digits
WRITE_BBOX set to YES to include the bounding box of the geometries at the feature and feature collection level
Besides GeoJSON there is also an option to export to “GeoJSON - Newline Delimited” (see https://gdal.org/en/latest/drivers/vector/geojsonseq.html). Instead of a FeatureCollection with Features, you can stream one type (probably only Features) sequentially separated with newlines.
GeoJSON - Newline Delimited has some specific Layer options available too:
COORDINATE_PRECISION see above (same as for GeoJSON)
RS whether to start records with the RS=0x1E character. The difference is how the features are separated: only by a newline (LF) character (Newline Delimited JSON, geojsonl) or by also prepending a record-separator (RS) character (giving GeoJSON Text Sequences, geojsons). Default to NO. Files are given the
.jsonextension if extension is not provided.
11.4.2.7. SAP HANA Spatial Layers
This section contains some details on how QGIS accesses SAP HANA layers. Most of the time, QGIS should simply provide you with a list of database tables and views that can be loaded, and it will load them on request. However, if you have trouble loading an SAP HANA table or view into QGIS, the information below may help you understand the root cause and assist in resolving the issue.
Feature Identification
If you’d like to use all of QGIS’ feature editing capabilities, QGIS must be able to unambiguously identify each feature in a layer. Internally, QGIS uses a 64-bit signed integer to identify features, whereas the negative range is reserved for special purposes.
Therefore, the SAP HANA provider requires a unique key that can be mapped to a positive 64-bit integer to fully support QGIS’ feature editing capabilities. If it is not possible to create such a mapping, you might still view the features, but editing might not work.
Adding tables
When adding a table as a layer, the SAP HANA provider uses the table’s primary key to map it to a unique feature id. Therefore, to have full feature editing support, you need to have a primary key to your table definition.
The SAP HANA provider supports multi-column primary keys, but if you’d like to
get the best performance, your primary key should be a single column of type
INTEGER.
Adding views
When adding a view as a layer, the SAP HANA provider cannot automatically identify columns that unambiguously identify a feature. Furthermore, some views are read-only and cannot be edited.
To have full feature editing support, the view must be updatable (check column
IS_READ_ONLY in system view SYS.VIEWS for the view in question) and you
must manually provide QGIS with one or more columns that identify a feature. The
columns can be given by using
and then
selecting the columns in the Feature id column. For best
performance, the Feature id value should be a single INTEGER
column.
11.4.2.8. Field domain
Field domains are rules that define acceptable values for a field in a database table. This is applicable when working with data sources that support field domains, such as GeoPackage and ESRI File Geodatabase. Field domains can be managed from the contextual menu of a field in the Browser panel. The following types are available:
New Range Domain…: creates a new domain to restrict field values to a specified numeric range.
New Coded Values Domain…: creates a new domain to restrict field values to a predefined list of acceptable values.
New Glob Domain…: creates a new domain to restrict field values to matching a regular expression pattern.
When creating a field domain, following options are provided in the dialog:
Name: set the name of the new field domain.
Description: provide a description for the new field domain.
Field type: select the data type of the field domain (e.g., Boolean, Text, Integer, Decimal).
Additional Policies, only available for ESRI File Geodatabase format:
Split policy
Merge policy
Under Range, you can set the following options:
Minimum: set the minimum acceptable value for the field.
Maximum: set the maximum acceptable value for the field.
Check the
Inclusive if you want to include the boundary values in the acceptable range.
Values: click the
 Add row or
Add row or  Remove row to manage
the list of acceptable values for the field.
Remove row to manage
the list of acceptable values for the field.Pattern: define the Glob pattern using wildcard characters.
Update and delete field domains by selecting the desired domain from the list and right-clicking to access the context menu options. You can also view the details of the domain assigned to a field.
Note
When loading vector layers into QGIS, fields with  Field Domains
(such as those defined in a GeoPackage or ESRI File Geodatabase) are automatically
detected. These domains are database-level constraints, meaning they are enforced
by the database itself and apply across different applications, not just QGIS.
Field Domains
(such as those defined in a GeoPackage or ESRI File Geodatabase) are automatically
detected. These domains are database-level constraints, meaning they are enforced
by the database itself and apply across different applications, not just QGIS.
11.4.3. Layers crossing 180° longitude
Many GIS packages don’t wrap layers with a geographic reference system (lat/lon) crossing the 180 degrees longitude line. As result, if we open such a layer in QGIS, we could see two widely separated locations, that should appear near each other. In Fig. 11.42, the tiny point on the far left of the map canvas (Chatham Islands) should be within the grid, to the right of the New Zealand main islands.

Fig. 11.42 Map in lat/lon crossing the 180° longitude line
11.4.3.1. Solving in PostgreSQL
A work-around is to transform the longitude values using PostgreSQL and the ST_ShiftLongitude function. This function reads every point/vertex in every component of every feature in a geometry, and shifts its longitude coordinate from -180..0° to 180..360° and vice versa if between these ranges. This function is symmetrical so the result is a 0..360° representation of a -180..180° data and a -180..180° representation of a 0..360° data.
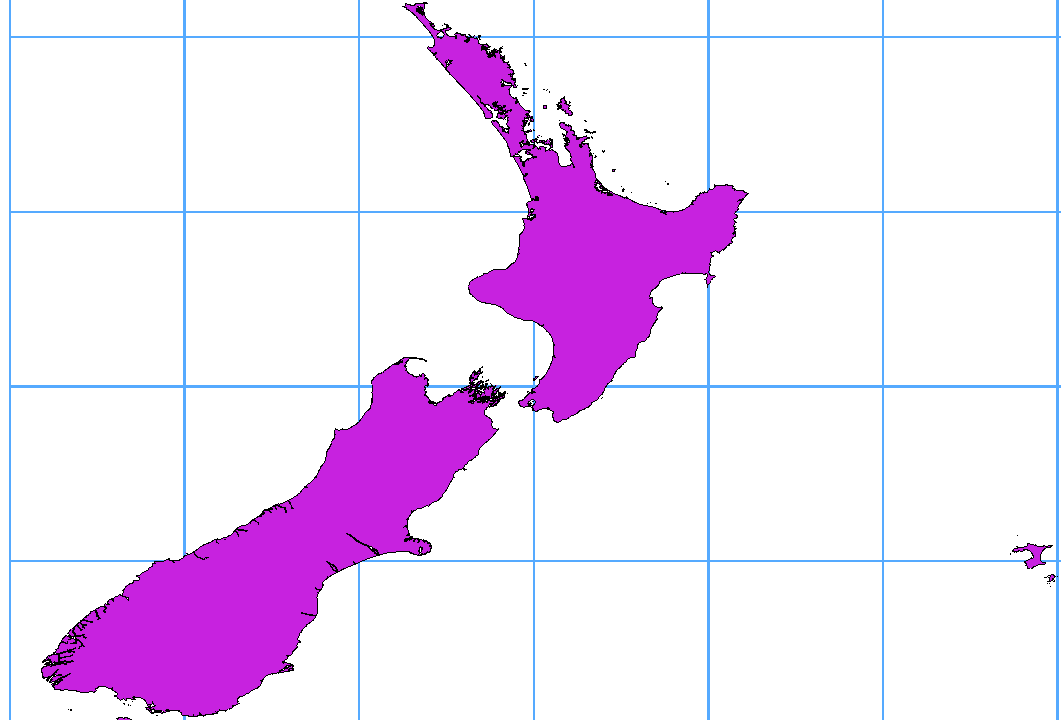
Fig. 11.43 Crossing 180° longitude applying the ST_ShiftLongitude function
Import data into PostgreSQL (Importing Data into PostgreSQL) using, for example, the DB Manager plugin.
Use the PostgreSQL command line interface to issue the following command:
-- In this example, "TABLE" is the actual name of your PostgreSQL table update TABLE set geom=ST_ShiftLongitude(geom);
If everything went well, you should receive a confirmation about the number of features that were updated. Then you’ll be able to load the map and see the difference (Figure_vector_crossing_map).