Wichtig
Übersetzen ist eine Gemeinschaftsleistung Sie können mitmachen. Diese Seite ist aktuell zu 56.43% übersetzt.
28.1.21. Vector general
28.1.21.1. Projektion zuweisen
Weist einem Vektorlayer eine neue Projektion zu.
Erzeugt einen neuen Layer mit exakt den gleichen Objekten und Geometrien wie die Eingabe, aber mit einem neu zugewiesenen KBS. Die Geometrien werden nicht umprojiziert, sondern es wird nur ein neues KBS zugewiesen.
Der Algorithmus kann benutzt werden, um Layer zu reparieren, denen eine falsche Projektion zugewiesen wurde.
Attribute werden von diesem Algorithmus nicht verändert.
Siehe auch
Define Shapefile projection, Find projection, Reproject layer
Parameter
Bezeichnung |
Name |
Typ |
Beschreibung |
|---|---|---|---|
Eingabe-Layer |
|
[Vektor: alle] |
Vector layer with wrong or missing CRS |
Assigned CRS |
|
[KBS] Default: |
Select the new CRS to assign to the vector layer |
Assigned CRS Optional |
|
[wie input] Standard: |
Specify the output vector layer. One of:
Auch die Dateikodierung kann hier geändert werden. |
Ausgaben
Bezeichnung |
Name |
Typ |
Beschreibung |
|---|---|---|---|
Assigned CRS |
|
[wie input] |
Vector layer with assigned projection |
Pythoncode
Algorithm ID: native:assignprojection
import processing
processing.run("algorithm_id", {parameter_dictionary})
Die Algorithmus-Kennung wird angezeigt, wenn Sie den Mauszeiger über den Algorithmus in der Verarbeitungs-Werkzeugkiste bewegen. Die Parameter-Liste (parameter_dictionary) enthält die Namen und Werte der Parameter. Siehe Verarbeitungs-Algorithmen von der Konsole aus verwenden für Details zur Ausführung von Verarbeitungsalgorithmen über die Python-Konsole.
28.1.21.2. Batch Nominatim geocoder
Performs batch geocoding using the Nominatim service against an input layer string field. The output layer will have a point geometry reflecting the geocoded location as well as a number of attributes associated to the geocoded location.
 Allows
features in-place modification
of point features
Allows
features in-place modification
of point features
Bemerkung
This algorithm is compliant with the usage policy of the Nominatim geocoding service provided by the OpenStreetMap Foundation.
Parameter
Bezeichnung |
Name |
Typ |
Beschreibung |
|---|---|---|---|
Eingabe-Layer |
|
[Vektor: alle] |
Vector layer to geocode the features |
Address field |
|
[tablefield: string] |
Field containing the addresses to geocode |
Geocoded |
|
[vector: point] Standard: |
Specify the output layer containing only the geocoded addresses. One of:
Auch die Dateikodierung kann hier geändert werden. |
Ausgaben
Bezeichnung |
Name |
Typ |
Beschreibung |
|---|---|---|---|
Geocoded |
|
[vector: point] |
Vector layer with point features corresponding to the geocoded addresses |
Pythoncode
Algorithm ID: native:batchnominatimgeocoder
import processing
processing.run("algorithm_id", {parameter_dictionary})
Die Algorithmus-Kennung wird angezeigt, wenn Sie den Mauszeiger über den Algorithmus in der Verarbeitungs-Werkzeugkiste bewegen. Die Parameter-Liste (parameter_dictionary) enthält die Namen und Werte der Parameter. Siehe Verarbeitungs-Algorithmen von der Konsole aus verwenden für Details zur Ausführung von Verarbeitungsalgorithmen über die Python-Konsole.
28.1.21.3. Convert layer to spatial bookmarks
Creates spatial bookmarks corresponding to the extent of features contained in a layer.
Parameter
Bezeichnung |
Name |
Typ |
Beschreibung |
|---|---|---|---|
Input Layer |
|
[vector: line, polygon] |
The input vector layer |
Bookmark destination |
|
[Aufzählung] Standard: 0 |
Select the destination for the bookmarks. One of:
|
Name field |
|
[Ausdruck] |
Field or expression that will give names to the generated bookmarks |
Group field |
|
[Ausdruck] |
Field or expression that will provide groups for the generated bookmarks |
Ausgaben
Bezeichnung |
Name |
Typ |
Beschreibung |
|---|---|---|---|
Count of bookmarks added |
|
[Zahl] |
Pythoncode
Algorithm ID: native:layertobookmarks
import processing
processing.run("algorithm_id", {parameter_dictionary})
Die Algorithmus-Kennung wird angezeigt, wenn Sie den Mauszeiger über den Algorithmus in der Verarbeitungs-Werkzeugkiste bewegen. Die Parameter-Liste (parameter_dictionary) enthält die Namen und Werte der Parameter. Siehe Verarbeitungs-Algorithmen von der Konsole aus verwenden für Details zur Ausführung von Verarbeitungsalgorithmen über die Python-Konsole.
28.1.21.4. Convert spatial bookmarks to layer
Creates a new layer containing polygon features for stored spatial bookmarks. The export can be filtered to only bookmarks belonging to the current project, to all user bookmarks, or a combination of both.
Parameter
Bezeichnung |
Name |
Typ |
Beschreibung |
|---|---|---|---|
Bookmark source |
|
[enumeration] [list] Default: [0,1] |
Select the source(s) of the bookmarks. One or more of:
|
Output CRS |
|
[KBS] Default: |
The CRS of the output layer |
Ergebnis |
|
[Vektor: Polygon] Standard: |
Specify the output layer. One of:
Auch die Dateikodierung kann hier geändert werden. |
Ausgaben
Bezeichnung |
Name |
Typ |
Beschreibung |
|---|---|---|---|
Ergebnis |
|
[Vektor: Polygon] |
The output (bookmarks) vector layer |
Pythoncode
Algorithm ID: native:bookmarkstolayer
import processing
processing.run("algorithm_id", {parameter_dictionary})
Die Algorithmus-Kennung wird angezeigt, wenn Sie den Mauszeiger über den Algorithmus in der Verarbeitungs-Werkzeugkiste bewegen. Die Parameter-Liste (parameter_dictionary) enthält die Namen und Werte der Parameter. Siehe Verarbeitungs-Algorithmen von der Konsole aus verwenden für Details zur Ausführung von Verarbeitungsalgorithmen über die Python-Konsole.
28.1.21.5. Create attribute index
Creates an index against a field of the attribute table to speed up queries. The support for index creation depends on both the layer’s data provider and the field type.
No outputs are created: the index is stored on the layer itself.
Parameter
Bezeichnung |
Name |
Typ |
Beschreibung |
|---|---|---|---|
Input Layer |
|
[Vektor: alle] |
Select the vector layer you want to create an attribute index for |
Attribute to index |
|
[tablefield: any] |
Field of the vector layer |
Ausgaben
Bezeichnung |
Name |
Typ |
Beschreibung |
|---|---|---|---|
Indexed layer |
|
[wie input] |
A copy of the input vector layer with an index for the specified field |
Pythoncode
Algorithm ID: native:createattributeindex
import processing
processing.run("algorithm_id", {parameter_dictionary})
Die Algorithmus-Kennung wird angezeigt, wenn Sie den Mauszeiger über den Algorithmus in der Verarbeitungs-Werkzeugkiste bewegen. Die Parameter-Liste (parameter_dictionary) enthält die Namen und Werte der Parameter. Siehe Verarbeitungs-Algorithmen von der Konsole aus verwenden für Details zur Ausführung von Verarbeitungsalgorithmen über die Python-Konsole.
28.1.21.6. Create spatial index
Creates an index to speed up access to the features in a layer based on their spatial location. Support for spatial index creation is dependent on the layer’s data provider.
No new output layers are created.
Default menu:
Parameter
Bezeichnung |
Name |
Typ |
Beschreibung |
|---|---|---|---|
Input Layer |
|
[Vektor: alle] |
Eingabe-Vektorlayer |
Ausgaben
Bezeichnung |
Name |
Typ |
Beschreibung |
|---|---|---|---|
Indexed layer |
|
[wie input] |
A copy of the input vector layer with a spatial index |
Pythoncode
Algorithm ID: native:createspatialindex
import processing
processing.run("algorithm_id", {parameter_dictionary})
Die Algorithmus-Kennung wird angezeigt, wenn Sie den Mauszeiger über den Algorithmus in der Verarbeitungs-Werkzeugkiste bewegen. Die Parameter-Liste (parameter_dictionary) enthält die Namen und Werte der Parameter. Siehe Verarbeitungs-Algorithmen von der Konsole aus verwenden für Details zur Ausführung von Verarbeitungsalgorithmen über die Python-Konsole.
28.1.21.7. Define Shapefile projection
Sets the CRS (projection) of an existing Shapefile format dataset to
the provided CRS.
It is very useful when a Shapefile format dataset is missing the
prj file and you know the correct projection.
Contrary to the Projektion zuweisen algorithm, it modifies the current layer and will not output a new layer.
Bemerkung
For Shapefile datasets, the .prj and .qpj files will
be overwritten - or created if missing - to match the provided CRS.
Default menu:
Siehe auch
Parameter
Bezeichnung |
Name |
Typ |
Beschreibung |
|---|---|---|---|
Eingabe-Layer |
|
[Vektor: alle] |
Vector layer with missing projection information |
CRS |
|
[KBS] |
Select the CRS to assign to the vector layer |
Ausgaben
Bezeichnung |
Name |
Typ |
Beschreibung |
|---|---|---|---|
|
[wie input] |
The input vector layer with the defined projection |
Pythoncode
Algorithm ID: qgis:definecurrentprojection
import processing
processing.run("algorithm_id", {parameter_dictionary})
Die Algorithmus-Kennung wird angezeigt, wenn Sie den Mauszeiger über den Algorithmus in der Verarbeitungs-Werkzeugkiste bewegen. Die Parameter-Liste (parameter_dictionary) enthält die Namen und Werte der Parameter. Siehe Verarbeitungs-Algorithmen von der Konsole aus verwenden für Details zur Ausführung von Verarbeitungsalgorithmen über die Python-Konsole.
28.1.21.8. Delete duplicate geometries
Finds and removes duplicated geometries.
Attributes are not checked, so in case two features have identical geometries but different attributes, only one of them will be added to the result layer.
Parameter
Bezeichnung |
Name |
Typ |
Beschreibung |
|---|---|---|---|
Eingabe-Layer |
|
[Vektor: alle] |
The layer with duplicate geometries you want to clean |
Cleaned |
|
[wie input] Standard: |
Specify the output layer. One of:
Auch die Dateikodierung kann hier geändert werden. |
Ausgaben
Bezeichnung |
Name |
Typ |
Beschreibung |
|---|---|---|---|
Count of discarded duplicate records |
|
[Zahl] |
Count of discarded duplicate records |
Cleaned |
|
[wie input] |
The output layer without any duplicated geometries |
Count of retained records |
|
[Zahl] |
Count of unique records |
Pythoncode
Algorithm ID: native:deleteduplicategeometries
import processing
processing.run("algorithm_id", {parameter_dictionary})
Die Algorithmus-Kennung wird angezeigt, wenn Sie den Mauszeiger über den Algorithmus in der Verarbeitungs-Werkzeugkiste bewegen. Die Parameter-Liste (parameter_dictionary) enthält die Namen und Werte der Parameter. Siehe Verarbeitungs-Algorithmen von der Konsole aus verwenden für Details zur Ausführung von Verarbeitungsalgorithmen über die Python-Konsole.
28.1.21.9. Delete duplicates by attribute
Deletes duplicate rows by only considering the specified field / fields. The first matching row will be retained, and duplicates will be discarded.
Optionally, these duplicate records can be saved to a separate output for analysis.
Siehe auch
Parameter
Bezeichnung |
Name |
Typ |
Beschreibung |
|---|---|---|---|
Eingabe-Layer |
|
[Vektor: alle] |
The input layer |
Fields to match duplicates by |
|
[tablefield: any] [list] |
Fields defining duplicates. Features with identical values for all these fields are considered duplicates. |
Filtered (no duplicates) |
|
[wie input] Standard: |
Specify the output layer containing the unique features. One of:
Auch die Dateikodierung kann hier geändert werden. |
Filtered (duplicates) Optional |
|
[wie input] Standard: |
Specify the output layer containing only the duplicates. One of:
Auch die Dateikodierung kann hier geändert werden. |
Ausgaben
Bezeichnung |
Name |
Typ |
Beschreibung |
|---|---|---|---|
Filtered (duplicates) Optional |
|
[wie input] Standard: |
Vector layer containing the removed features.
Will not be produced if not specified (left as
|
Count of discarded duplicate records |
|
[Zahl] |
Count of discarded duplicate records |
Filtered (no duplicates) |
|
[wie input] |
Vector layer containing the unique features. |
Count of retained records |
|
[Zahl] |
Count of unique records |
Pythoncode
Algorithm ID: native:removeduplicatesbyattribute
import processing
processing.run("algorithm_id", {parameter_dictionary})
Die Algorithmus-Kennung wird angezeigt, wenn Sie den Mauszeiger über den Algorithmus in der Verarbeitungs-Werkzeugkiste bewegen. Die Parameter-Liste (parameter_dictionary) enthält die Namen und Werte der Parameter. Siehe Verarbeitungs-Algorithmen von der Konsole aus verwenden für Details zur Ausführung von Verarbeitungsalgorithmen über die Python-Konsole.
28.1.21.10. Detect dataset changes
Compares two vector layers, and determines which features are unchanged, added or deleted between the two. It is designed for comparing two different versions of the same dataset.
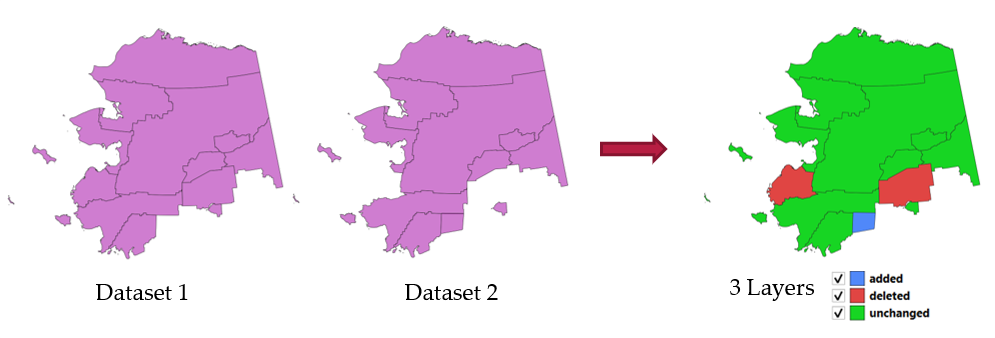
Abb. 28.55 Detect dataset change example
Parameter
Bezeichnung |
Name |
Typ |
Beschreibung |
|---|---|---|---|
Original layer |
|
[Vektor: alle] |
The vector layer considered as the original version |
Revised layer |
|
[Vektor: alle] |
The revised or modified vector layer |
Attributes to consider for match Optional |
|
[tablefield: any] [list] |
Attributes to consider for match. By default, all attributes are compared. |
Geometry comparison behavior Optional |
|
[Aufzählung] Standard: 1 |
Defines the criteria for comparison. Options:
|
Unchanged features Optional |
|
[vector: same as Original layer] |
Specify the output vector layer containing the unchanged features. One of:
Auch die Dateikodierung kann hier geändert werden. |
Added features Optional |
|
[vector: same as Original layer] |
Specify the output vector layer containing the added features. One of:
Auch die Dateikodierung kann hier geändert werden. |
Deleted features Optional |
|
[vector: same as Original layer] |
Specify the output vector layer containing the deleted features. One of:
Auch die Dateikodierung kann hier geändert werden. |
Ausgaben
Bezeichnung |
Name |
Typ |
Beschreibung |
|---|---|---|---|
Unchanged features |
|
[vector: same as Original layer] |
Vector layer containing the unchanged features. |
Added features |
|
[vector: same as Original layer] |
Vector layer containing the added features. |
Deleted features |
|
[vector: same as Original layer] |
Vector layer containing the deleted features. |
Count of unchanged features |
|
[Zahl] |
Count of unchanged features. |
Count of features added in revised layer |
|
[Zahl] |
Count of features added in revised layer. |
Count of features deleted from original layer |
|
[Zahl] |
Count of features deleted from original layer. |
Pythoncode
Algorithm ID: native:detectvectorchanges
import processing
processing.run("algorithm_id", {parameter_dictionary})
Die Algorithmus-Kennung wird angezeigt, wenn Sie den Mauszeiger über den Algorithmus in der Verarbeitungs-Werkzeugkiste bewegen. Die Parameter-Liste (parameter_dictionary) enthält die Namen und Werte der Parameter. Siehe Verarbeitungs-Algorithmen von der Konsole aus verwenden für Details zur Ausführung von Verarbeitungsalgorithmen über die Python-Konsole.
28.1.21.11. Drop geometries
Creates a simple geometryless copy of the input layer attribute table. It keeps the attribute table of the source layer.
If the file is saved in a local folder, you can choose between many file formats.
Allows features in-place modification
of point, line, and polygon features
Siehe auch
Parameter
Bezeichnung |
Name |
Typ |
Beschreibung |
|---|---|---|---|
Eingabe-Layer |
|
[Vektor: alle] |
The input vector layer |
Dropped geometries |
|
[table] |
Specify the output geometryless layer. One of:
Auch die Dateikodierung kann hier geändert werden. |
Ausgaben
Bezeichnung |
Name |
Typ |
Beschreibung |
|---|---|---|---|
Dropped geometries |
|
[table] |
The output geometryless layer. A copy of the original attribute table. |
Pythoncode
Algorithm ID: native:dropgeometries
import processing
processing.run("algorithm_id", {parameter_dictionary})
Die Algorithmus-Kennung wird angezeigt, wenn Sie den Mauszeiger über den Algorithmus in der Verarbeitungs-Werkzeugkiste bewegen. Die Parameter-Liste (parameter_dictionary) enthält die Namen und Werte der Parameter. Siehe Verarbeitungs-Algorithmen von der Konsole aus verwenden für Details zur Ausführung von Verarbeitungsalgorithmen über die Python-Konsole.
28.1.21.12. Execute SQL
Runs a simple or complex query based only on SELECT with SQL syntax
on the source layer.
Input datasources are identified with input1, input2… inputN and
a simple query will look like SELECT * FROM input1.
Beside a simple query, you can add expressions or variables within the
SQL query parameter itself. This is particulary useful if this algorithm is
executed within a Processing model and you want to use a model input as a
parameter of the query. An example of a query will then be SELECT * FROM
[% @table %] where @table is the variable that identifies the model input.
The result of the query will be added as a new layer.
Siehe auch
Parameter
Bezeichnung |
Name |
Typ |
Beschreibung |
|---|---|---|---|
Additional input datasources (called input1, .., inputN in the query) |
|
[vector: any] [list] |
List of layers to query. In the SQL editor you can refer these layers with their real name or also with input1, input2, inputN depending on how many layers have been chosen. |
SQL query |
|
[string] |
Type the string of your SQL query, e.g.
|
Unique identifier field Optional |
|
[string] |
Specify the column with unique ID |
Geometry field Optional |
|
[string] |
Specify the geometry field |
Geometry type Optional |
|
[Aufzählung] Standard: 0 |
Choose the geometry of the result. By default the algorithm will autodetect it. One of:
|
CRS Optional |
|
[KBS] |
The CRS to assign to the output layer |
SQL Output |
|
[Vektor: alle] Standard: |
Specify the output layer created by the query. One of:
Auch die Dateikodierung kann hier geändert werden. |
Ausgaben
Bezeichnung |
Name |
Typ |
Beschreibung |
|---|---|---|---|
SQL Output |
|
[Vektor: alle] |
Vector layer created by the query |
Pythoncode
Algorithm ID: qgis:executesql
import processing
processing.run("algorithm_id", {parameter_dictionary})
Die Algorithmus-Kennung wird angezeigt, wenn Sie den Mauszeiger über den Algorithmus in der Verarbeitungs-Werkzeugkiste bewegen. Die Parameter-Liste (parameter_dictionary) enthält die Namen und Werte der Parameter. Siehe Verarbeitungs-Algorithmen von der Konsole aus verwenden für Details zur Ausführung von Verarbeitungsalgorithmen über die Python-Konsole.
28.1.21.13. Export layers to DXF
Exports layers to DXF file. For each layer, you can choose a field whose values are used to split features in generated destination layers in DXF output.
Siehe auch
Parameter
Bezeichnung |
Name |
Typ |
Beschreibung |
|---|---|---|---|
Eingabelayer |
|
[vector: any] [list] |
Input vector layers to export |
Symbology mode |
|
[Aufzählung] Standard: 0 |
Type of symbology to apply to output layers. You can choose between:
|
Symbology scale |
|
[scale] Default: 1:1 000 000 |
Default scale of data export. |
Encoding |
|
[Aufzählung] |
Encoding to apply to layers. |
CRS |
|
[KBS] |
Choose the CRS for the output layer. |
Use layer title as name |
|
[Boolean] Standard: falsch |
Name the output layer with the layer title (as set in QGIS) instead of the layer name. |
Force 2D |
|
[Boolean] Standard: falsch |
|
Export labels as MTEXT elements |
|
[Boolean] Standard: falsch |
Exports labels as MTEXT or TEXT elements |
DXF |
|
[Datei] Standard: |
Specification of the output DXF file. One of:
|
Ausgaben
Bezeichnung |
Name |
Typ |
Beschreibung |
|---|---|---|---|
DXF |
|
[Datei] |
|
Pythoncode
Algorithm ID: native:dxfexport
import processing
processing.run("algorithm_id", {parameter_dictionary})
Die Algorithmus-Kennung wird angezeigt, wenn Sie den Mauszeiger über den Algorithmus in der Verarbeitungs-Werkzeugkiste bewegen. Die Parameter-Liste (parameter_dictionary) enthält die Namen und Werte der Parameter. Siehe Verarbeitungs-Algorithmen von der Konsole aus verwenden für Details zur Ausführung von Verarbeitungsalgorithmen über die Python-Konsole.
28.1.21.14. Extract selected features
Saves the selected features as a new layer.
Bemerkung
If the selected layer has no selected features, the newly created layer will be empty.
Parameter
Bezeichnung |
Name |
Typ |
Beschreibung |
|---|---|---|---|
Input Layer |
|
[Vektor: alle] |
Layer to save the selection from |
Selected features |
|
[wie input] Standard: |
Specify the vector layer for the selected features. One of:
Auch die Dateikodierung kann hier geändert werden. |
Ausgaben
Bezeichnung |
Name |
Typ |
Beschreibung |
|---|---|---|---|
Selected features |
|
[wie input] |
Vector layer with only the selected features, or no feature if none was selected. |
Pythoncode
Algorithm ID: native:saveselectedfeatures
import processing
processing.run("algorithm_id", {parameter_dictionary})
Die Algorithmus-Kennung wird angezeigt, wenn Sie den Mauszeiger über den Algorithmus in der Verarbeitungs-Werkzeugkiste bewegen. Die Parameter-Liste (parameter_dictionary) enthält die Namen und Werte der Parameter. Siehe Verarbeitungs-Algorithmen von der Konsole aus verwenden für Details zur Ausführung von Verarbeitungsalgorithmen über die Python-Konsole.
28.1.21.15. Extract Shapefile encoding
Extracts the attribute encoding information embedded in a Shapefile.
Both the encoding specified by an optional .cpg file and
any encoding details present in the .dbf LDID header block are considered.
Parameter
Bezeichnung |
Name |
Typ |
Beschreibung |
|---|---|---|---|
Input Layer |
|
[Vektor: alle] |
ESRI Shapefile ( |
Ausgaben
Bezeichnung |
Name |
Typ |
Beschreibung |
|---|---|---|---|
Shapefile encoding |
|
[string] |
Encoding information specified in the input file |
CPG encoding |
|
[string] |
Encoding information specified in any optional |
LDID encoding |
|
[string] |
Encoding information specified in |
Pythoncode
Algorithm ID: native:shpencodinginfo
import processing
processing.run("algorithm_id", {parameter_dictionary})
Die Algorithmus-Kennung wird angezeigt, wenn Sie den Mauszeiger über den Algorithmus in der Verarbeitungs-Werkzeugkiste bewegen. Die Parameter-Liste (parameter_dictionary) enthält die Namen und Werte der Parameter. Siehe Verarbeitungs-Algorithmen von der Konsole aus verwenden für Details zur Ausführung von Verarbeitungsalgorithmen über die Python-Konsole.
28.1.21.16. Find projection
Creates a shortlist of candidate coordinate reference systems, for instance for a layer with an unknown projection.
The area that the layer is expected to cover must be specified via the target area parameter. The coordinate reference system for this target area must be known to QGIS.
The algorithm operates by testing the layer’s extent in every known reference system and then listing any for which the bounds would be near the target area if the layer was in this projection.
Parameter
Bezeichnung |
Name |
Typ |
Beschreibung |
|---|---|---|---|
Input Layer |
|
[Vektor: alle] |
Layer with unknown projection |
Target area for layer (xmin, xmax, ymin, ymax) |
|
[Ausdehnung] |
The area that the layer covers. Verfügbare Methoden sind:
|
CRS candidates |
|
[table] Standard: |
Specify the table (geometryless layer) for the CRS suggestions (EPSG codes). One of:
Auch die Dateikodierung kann hier geändert werden. |
Ausgaben
Bezeichnung |
Name |
Typ |
Beschreibung |
|---|---|---|---|
CRS candidates |
|
[table] |
A table with all the CRS (EPSG codes) of the matching criteria. |
Pythoncode
Algorithm ID: qgis:findprojection
import processing
processing.run("algorithm_id", {parameter_dictionary})
Die Algorithmus-Kennung wird angezeigt, wenn Sie den Mauszeiger über den Algorithmus in der Verarbeitungs-Werkzeugkiste bewegen. Die Parameter-Liste (parameter_dictionary) enthält die Namen und Werte der Parameter. Siehe Verarbeitungs-Algorithmen von der Konsole aus verwenden für Details zur Ausführung von Verarbeitungsalgorithmen über die Python-Konsole.
28.1.21.17. Flatten relationship
Flattens a relationship for a vector layer, exporting a single layer containing one parent feature per related child feature. This master feature contains all the attributes for the related features. This allows to have the relation as a plain table that can be e.g. exported to CSV.
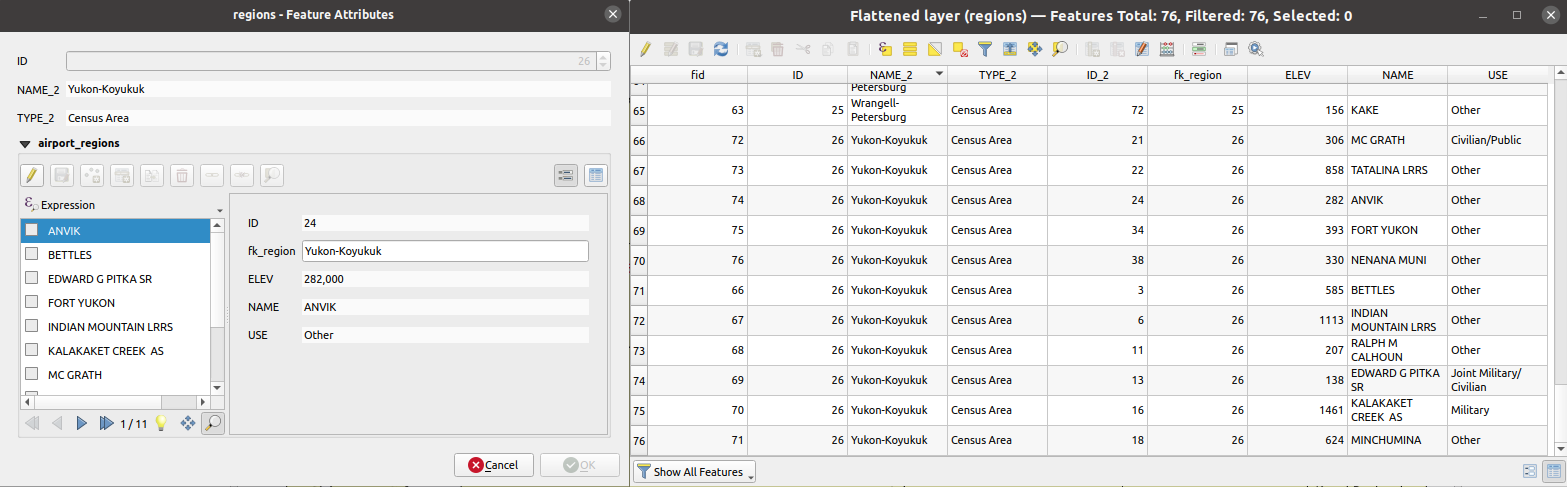
Abb. 28.56 Form of a region with related children (left) - A duplicate region feature for each related child, with joined attributes (right)
Parameter
Bezeichnung |
Name |
Typ |
Beschreibung |
|---|---|---|---|
Input Layer |
|
[Vektor: alle] |
Layer with the relationship that should be de-normalized |
Flattened Layer Optional |
|
[wie input] Standard: |
Specify the output (flattened) layer. One of:
Auch die Dateikodierung kann hier geändert werden. |
Ausgaben
Bezeichnung |
Name |
Typ |
Beschreibung |
|---|---|---|---|
Flattened layer |
|
[wie input] |
A layer containing master features with all the attributes for the related features |
Pythoncode
Algorithm ID: native:flattenrelationships
import processing
processing.run("algorithm_id", {parameter_dictionary})
Die Algorithmus-Kennung wird angezeigt, wenn Sie den Mauszeiger über den Algorithmus in der Verarbeitungs-Werkzeugkiste bewegen. Die Parameter-Liste (parameter_dictionary) enthält die Namen und Werte der Parameter. Siehe Verarbeitungs-Algorithmen von der Konsole aus verwenden für Details zur Ausführung von Verarbeitungsalgorithmen über die Python-Konsole.
28.1.21.18. Join attributes by field value
Takes an input vector layer and creates a new vector layer that is an extended version of the input one, with additional attributes in its attribute table.
The additional attributes and their values are taken from a second vector layer. An attribute is selected in each of them to define the join criteria.
Parameter
Bezeichnung |
Name |
Typ |
Beschreibung |
|---|---|---|---|
Input Layer |
|
[Vektor: alle] |
Input vector layer. The output layer will consist of the features of this layer with attributes from matching features in the second layer. |
Table field |
|
[tablefield: any] |
Field of the source layer to use for the join |
Input layer 2 |
|
[Vektor: alle] |
Layer with the attribute table to join |
Table field 2 |
|
[tablefield: any] |
Field of the second (join) layer to use for the join The type of the field must be equal to (or compatible with) the input table field type. |
Layer 2 fields to copy Optional |
|
[tablefield: any] [list] |
Select the specific fields you want to add. By default all the fields are added. |
Join type |
|
[Aufzählung] Standard: 1 |
The type of the final joined layer. One of:
|
Discard records which could not be joined |
|
[Boolean] Default: True |
Check if you don’t want to keep the features that could not be joined |
Joined field prefix Optional |
|
[string] |
Add a prefix to joined fields in order to easily identify them and avoid field name collision |
Joined layer Optional |
|
[wie input] Standard: |
Specify the output vector layer for the join. One of:
Auch die Dateikodierung kann hier geändert werden. |
Unjoinable features from first layer Optional |
|
[wie input] Standard: |
Specify the output vector layer for unjoinable features from first layer. One of:
Auch die Dateikodierung kann hier geändert werden. |
Ausgaben
Bezeichnung |
Name |
Typ |
Beschreibung |
|---|---|---|---|
Number of joined features from input table |
|
[Zahl] |
|
Unjoinable features from first layer Optional |
|
[wie input] |
Vector layer with the non-matched features |
Joined layer Optional |
|
[wie input] |
Output vector layer with added attributes from the join |
Number of unjoinable features from input table Optional |
|
[Zahl] |
Pythoncode
Algorithm ID: native:joinattributestable
import processing
processing.run("algorithm_id", {parameter_dictionary})
Die Algorithmus-Kennung wird angezeigt, wenn Sie den Mauszeiger über den Algorithmus in der Verarbeitungs-Werkzeugkiste bewegen. Die Parameter-Liste (parameter_dictionary) enthält die Namen und Werte der Parameter. Siehe Verarbeitungs-Algorithmen von der Konsole aus verwenden für Details zur Ausführung von Verarbeitungsalgorithmen über die Python-Konsole.
28.1.21.19. Join attributes by location
Takes an input vector layer and creates a new vector layer that is an extended version of the input one, with additional attributes in its attribute table.
The additional attributes and their values are taken from a second vector layer. A spatial criteria is applied to select the values from the second layer that are added to each feature from the first layer.
Default menu:
Siehe auch
Join attributes by nearest, Join attributes by field value, Join attributes by location (summary)
Exploring spatial relations
Geometrische Prädikate sind boolesche Funktionen, die verwendet werden, um die räumliche Beziehung eines Features zu einem anderen zu bestimmen, indem verglichen wird, ob und wie ihre Geometrien einen Teil des Raums teilen.
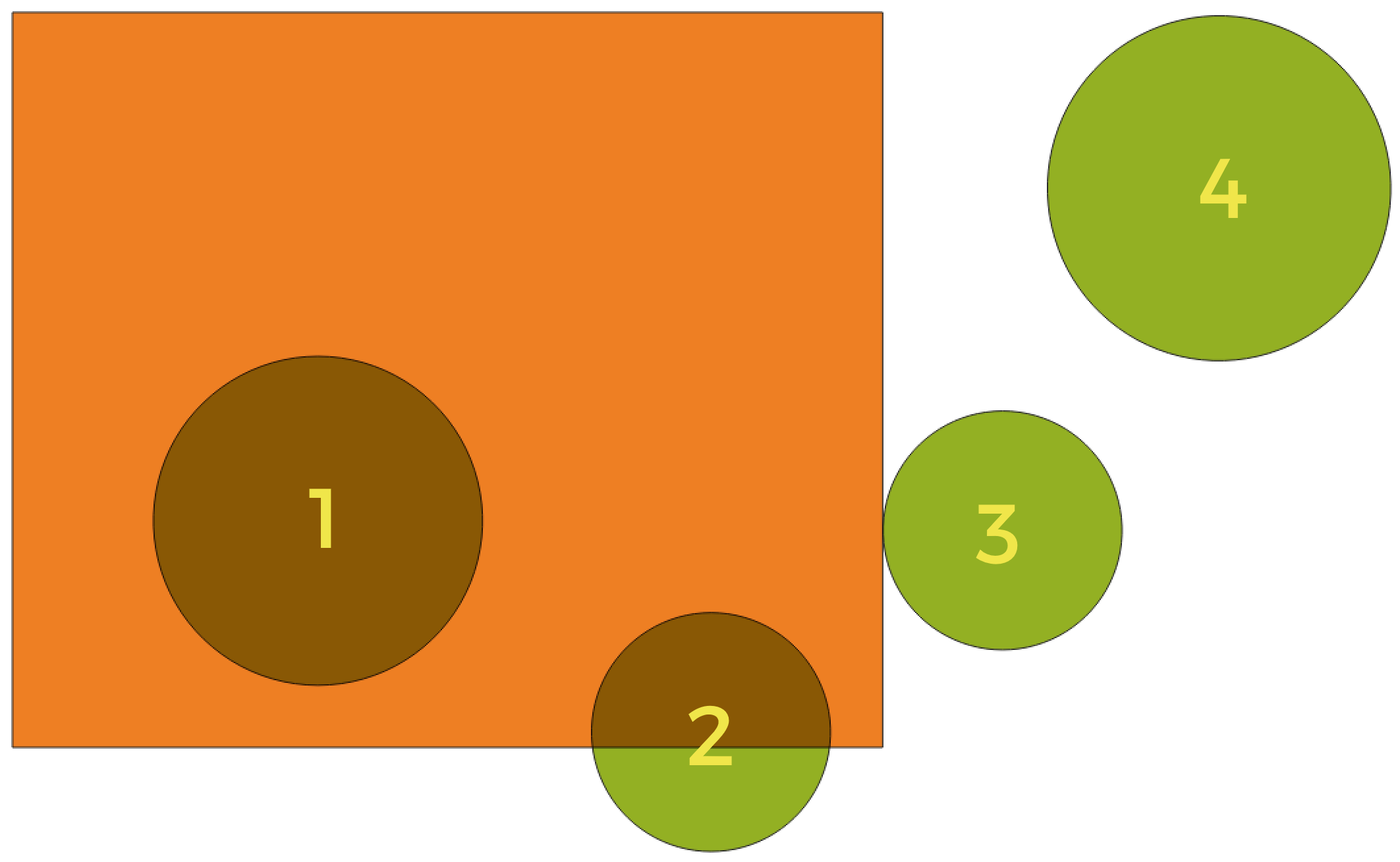
Abb. 28.57 Suche nach räumlichen Beziehungen zwischen Layern
Unter Verwendung der obigen Abbildung suchen wir nach den grünen Kreisen, indem wir sie räumlich mit dem orangefarbenen Rechteck-Feature vergleichen. Verfügbare geometrische Prädikate sind:
- Schneidet
Testet, ob eine Geometrie eine andere schneidet. Gibt 1 (wahr) zurück, wenn sich die Geometrien räumlich überschneiden (einen Teil des Raums teilen – überlappen oder berühren) und 0, wenn dies nicht der Fall ist. Im obigen Bild werden die Kreise 1, 2 und 3 zurückgegeben.
- Enthält
Gibt 1 (wahr) zurück, wenn und nur wenn keine Punkte von b außerhalb von a liegen und mindestens ein Punkt des Inneren von b innerhalb von a liegt. Im Bild wird kein Kreis zurückgegeben, sondern das Rechteck wäre es, wenn man es umgekehrt suchen würde, da es den Kreis 1 komplett enthält. Das ist das Gegenteil von sind innerhalb.
- Getrennt
Gibt 1 (wahr) zurück, wenn die Geometrien keinen Teil des Raums teilen (keine Überlappung, keine Berührung). Nur Kreis 4 wird zurückgegeben.
- Gleich
Gibt 1 (wahr) zurück, wenn und nur wenn die Geometrien genau gleich sind. Es werden keine Kreise zurückgegeben.
- Berührt
Testet, ob eine Geometrie eine andere berührt. Gibt 1 (wahr) zurück, wenn die Geometrien mindestens einen Punkt gemeinsam haben, aber ihre Innenräume sich nicht schneiden. Nur Kreis 3 wird zurückgegeben.
- Überlappt
Testet, ob eine Geometrie eine andere überlappt. Gibt 1 (wahr) zurück, wenn die Geometrien sich den Raum teilen, dieselbe Dimension haben, aber nicht vollständig ineinander liegen. Nur Kreis 2 wird zurückgegeben.
- Sind innerhalb
Testet, ob sich eine Geometrie in einer anderen befindet. Gibt 1 (wahr) zurück, wenn sich Geometrie a vollständig innerhalb von Geometrie b befindet. Nur Kreis 1 wird zurückgegeben.
- Kreuzen
Gibt 1 (wahr) zurück, wenn die bereitgestellten Geometrien einige, aber nicht alle inneren Punkte gemeinsam haben und die tatsächliche Kreuzung eine geringere Dimension als die höchste bereitgestellte Geometrie hat. Beispielsweise wird eine Linie, die ein Polygon kreuzt, als Linie gekreuzt (wahr). Zwei Linien, die sich kreuzen, kreuzen sich als Punkt (wahr). Zwei Polygone kreuzen sich als Polygon (falsch). Im Bild werden keine Kreise zurückgegeben.
Parameter
Bezeichnung |
Name |
Typ |
Beschreibung |
|---|---|---|---|
Join to features in |
|
[Vektor: alle] |
Input vector layer. The output layer will consist of the features of this layer with attributes from matching features in the second layer. |
Where the features |
|
[enumeration] [list] Default: [0] |
Type of spatial relation the source feature should have with the target feature so that they could be joined. One or more of:
If more than one condition is chosen, at least one of them (OR operation) has to be met for a feature to be extracted. |
By comparing to |
|
[Vektor: alle] |
The join layer. Features of this vector layer will add their attributes to the source layer attribute table if they satisfy the spatial relationship. |
Fields to add (leave empty to use all fields) Optional |
|
[tablefield: any] [list] |
Select the specific fields you want to add from the join layer. By default all the fields are added. |
Join type |
|
[Aufzählung] |
The type of the final joined layer. One of:
|
Discard records which could not be joined |
|
[Boolean] Standard: falsch |
Remove from the output the input layer’s features which could not be joined |
Joined field prefix Optional |
|
[string] |
Add a prefix to joined fields in order to easily identify them and avoid field name collision |
Joined layer Optional |
|
[wie input] Standard: |
Specify the output vector layer for the join. One of:
Auch die Dateikodierung kann hier geändert werden. |
Unjoinable features from first layer Optional |
|
[wie input] Standard: |
Specify the output vector layer for unjoinable features from first layer. One of:
Auch die Dateikodierung kann hier geändert werden. |
Ausgaben
Bezeichnung |
Name |
Typ |
Beschreibung |
|---|---|---|---|
Number of joined features from input table |
|
[Zahl] |
|
Unjoinable features from first layer Optional |
|
[wie input] |
Vector layer of the non-matched features |
Joined layer |
|
[wie input] |
Output vector layer with added attributes from the join |
Pythoncode
Algorithm ID: native:joinattributesbylocation
import processing
processing.run("algorithm_id", {parameter_dictionary})
Die Algorithmus-Kennung wird angezeigt, wenn Sie den Mauszeiger über den Algorithmus in der Verarbeitungs-Werkzeugkiste bewegen. Die Parameter-Liste (parameter_dictionary) enthält die Namen und Werte der Parameter. Siehe Verarbeitungs-Algorithmen von der Konsole aus verwenden für Details zur Ausführung von Verarbeitungsalgorithmen über die Python-Konsole.
28.1.21.20. Join attributes by location (summary)
Takes an input vector layer and creates a new vector layer that is an extended version of the input one, with additional attributes in its attribute table.
The additional attributes and their values are taken from a second vector layer. A spatial criteria is applied to select the values from the second layer that are added to each feature from the first layer.
The algorithm calculates a statistical summary for the values from matching features in the second layer (e.g. maximum value, mean value, etc).
Siehe auch
Exploring spatial relations
Geometrische Prädikate sind boolesche Funktionen, die verwendet werden, um die räumliche Beziehung eines Features zu einem anderen zu bestimmen, indem verglichen wird, ob und wie ihre Geometrien einen Teil des Raums teilen.
Abb. 28.58 Suche nach räumlichen Beziehungen zwischen Layern
Unter Verwendung der obigen Abbildung suchen wir nach den grünen Kreisen, indem wir sie räumlich mit dem orangefarbenen Rechteck-Feature vergleichen. Verfügbare geometrische Prädikate sind:
- Schneidet
Testet, ob eine Geometrie eine andere schneidet. Gibt 1 (wahr) zurück, wenn sich die Geometrien räumlich überschneiden (einen Teil des Raums teilen – überlappen oder berühren) und 0, wenn dies nicht der Fall ist. Im obigen Bild werden die Kreise 1, 2 und 3 zurückgegeben.
- Enthält
Gibt 1 (wahr) zurück, wenn und nur wenn keine Punkte von b außerhalb von a liegen und mindestens ein Punkt des Inneren von b innerhalb von a liegt. Im Bild wird kein Kreis zurückgegeben, sondern das Rechteck wäre es, wenn man es umgekehrt suchen würde, da es den Kreis 1 komplett enthält. Das ist das Gegenteil von sind innerhalb.
- Getrennt
Gibt 1 (wahr) zurück, wenn die Geometrien keinen Teil des Raums teilen (keine Überlappung, keine Berührung). Nur Kreis 4 wird zurückgegeben.
- Gleich
Gibt 1 (wahr) zurück, wenn und nur wenn die Geometrien genau gleich sind. Es werden keine Kreise zurückgegeben.
- Berührt
Testet, ob eine Geometrie eine andere berührt. Gibt 1 (wahr) zurück, wenn die Geometrien mindestens einen Punkt gemeinsam haben, aber ihre Innenräume sich nicht schneiden. Nur Kreis 3 wird zurückgegeben.
- Überlappt
Testet, ob eine Geometrie eine andere überlappt. Gibt 1 (wahr) zurück, wenn die Geometrien sich den Raum teilen, dieselbe Dimension haben, aber nicht vollständig ineinander liegen. Nur Kreis 2 wird zurückgegeben.
- Sind innerhalb
Testet, ob sich eine Geometrie in einer anderen befindet. Gibt 1 (wahr) zurück, wenn sich Geometrie a vollständig innerhalb von Geometrie b befindet. Nur Kreis 1 wird zurückgegeben.
- Kreuzen
Gibt 1 (wahr) zurück, wenn die bereitgestellten Geometrien einige, aber nicht alle inneren Punkte gemeinsam haben und die tatsächliche Kreuzung eine geringere Dimension als die höchste bereitgestellte Geometrie hat. Beispielsweise wird eine Linie, die ein Polygon kreuzt, als Linie gekreuzt (wahr). Zwei Linien, die sich kreuzen, kreuzen sich als Punkt (wahr). Zwei Polygone kreuzen sich als Polygon (falsch). Im Bild werden keine Kreise zurückgegeben.
Parameter
Bezeichnung |
Name |
Typ |
Beschreibung |
|---|---|---|---|
Join to features in |
|
[Vektor: alle] |
Input vector layer. The output layer will consist of the features of this layer with attributes from matching features in the second layer. |
Where the features |
|
[enumeration] [list] Default: [0] |
Type of spatial relation the source feature should have with the target feature so that they could be joined. One or more of:
If more than one condition is chosen, at least one of them (OR operation) has to be met for a feature to be extracted. |
By comparing to |
|
[Vektor: alle] |
The join layer. Features of this vector layer will add summaries of their attributes to the source layer attribute table if they satisfy the spatial relationship. |
Fields to summarize (leave empty to use all fields) Optional |
|
[tablefield: any] [list] |
Select the specific fields you want to add from the join layer. By default all the fields are added. |
Summaries to calculate (leave empty to use all fields) Optional |
|
[enumeration] [list] Default: [] |
For each input feature, statistics are calculated on joined fields of their matching features. One or more of:
|
Discard records which could not be joined |
|
[Boolean] Standard: falsch |
Remove from the output the input layer’s features which could not be joined |
Joined layer |
|
[wie input] Standard: |
Specify the output vector layer for the join. One of:
Auch die Dateikodierung kann hier geändert werden. |
Ausgaben
Bezeichnung |
Name |
Typ |
Beschreibung |
|---|---|---|---|
Joined layer |
|
[wie input] |
Output vector layer with summarized attributes from the join |
Pythoncode
Algorithm ID: qgis:joinbylocationsummary
import processing
processing.run("algorithm_id", {parameter_dictionary})
Die Algorithmus-Kennung wird angezeigt, wenn Sie den Mauszeiger über den Algorithmus in der Verarbeitungs-Werkzeugkiste bewegen. Die Parameter-Liste (parameter_dictionary) enthält die Namen und Werte der Parameter. Siehe Verarbeitungs-Algorithmen von der Konsole aus verwenden für Details zur Ausführung von Verarbeitungsalgorithmen über die Python-Konsole.
28.1.21.21. Join attributes by nearest
Takes an input vector layer and creates a new vector layer with additional fields in its attribute table. The additional attributes and their values are taken from a second vector layer. Features are joined by finding the closest features from each layer.
By default only the nearest feature is joined, but the join can also join to the k-nearest neighboring features.
If a maximum distance is specified, only features which are closer than this distance will be matched.
Siehe auch
Nearest neighbour analysis, Join attributes by field value, Join attributes by location, Distance matrix
Parameter
Bezeichnung |
Name |
Typ |
Beschreibung |
|---|---|---|---|
Eingabe-Layer |
|
[Vektor: alle] |
The input layer. |
Input layer 2 |
|
[Vektor: alle] |
The join layer. |
Layer 2 fields to copy (leave empty to copy all fields) |
|
[fields] |
Join layer fields to copy (if empty, all fields will be copied). |
Discard records which could not be joined |
|
[Boolean] Standard: falsch |
Remove from the output the input layer records which could not be joined |
Joined field prefix |
|
[string] |
Joined field prefix |
Maximum nearest neighbors |
|
[Zahl] Standard: 1 |
Maximum number of nearest neighbors |
Maximum distance |
|
[Zahl] |
Maximum search distance |
Joined layer Optional |
|
[wie input] Standard: |
Specify the vector layer containing the joined features. One of:
Auch die Dateikodierung kann hier geändert werden. |
Unjoinable features from first layer |
|
[wie input] Standard: |
Specify the vector layer containing the features that could not be joined. One of:
Auch die Dateikodierung kann hier geändert werden. |
Ausgaben
Bezeichnung |
Name |
Typ |
Beschreibung |
|---|---|---|---|
Joined layer |
|
[wie input] |
The output joined layer. |
Unjoinable features from first layer |
|
[wie input] |
Layer containing the features from first layer that could not be joined to any features in the join layer. |
Number of joined features from input table |
|
[Zahl] |
Number of features from the input table that have been joined. |
Number of unjoinable features from input table |
|
[Zahl] |
Number of features from the input table that could not be joined. |
Pythoncode
Algorithm ID: native:joinbynearest
import processing
processing.run("algorithm_id", {parameter_dictionary})
Die Algorithmus-Kennung wird angezeigt, wenn Sie den Mauszeiger über den Algorithmus in der Verarbeitungs-Werkzeugkiste bewegen. Die Parameter-Liste (parameter_dictionary) enthält die Namen und Werte der Parameter. Siehe Verarbeitungs-Algorithmen von der Konsole aus verwenden für Details zur Ausführung von Verarbeitungsalgorithmen über die Python-Konsole.
28.1.21.22. Merge vector layers
Combines multiple vector layers of the same geometry type into a single one.
The attribute table of the resulting layer will contain the fields from all input layers. If fields with the same name but different types are found then the exported field will be automatically converted into a string type field. New fields storing the original layer name and source are also added.
If any input layers contain Z or M values, then the output layer will also contain these values. Similarly, if any of the input layers are multi-part, the output layer will also be a multi-part layer.
Optionally, the destination coordinate reference system (CRS) for the merged layer can be set. If it is not set, the CRS will be taken from the first input layer. All layers will be reprojected to match this CRS.
Default menu:
Siehe auch
Parameter
Bezeichnung |
Name |
Typ |
Beschreibung |
|---|---|---|---|
Input Layers |
|
[vector: any] [list] |
The layers that are to be merged into a single layer. Layers should be of the same geometry type. |
Destination CRS Optional |
|
[KBS] |
Choose the CRS for the output layer. If not specified, the CRS of the first input layer is used. |
Zusammengeführt |
|
[wie input] Standard: |
Specify the output vector layer. One of:
Auch die Dateikodierung kann hier geändert werden. |
Ausgaben
Bezeichnung |
Name |
Typ |
Beschreibung |
|---|---|---|---|
Zusammengeführt |
|
[wie input] |
Output vector layer containing all the features and attributes from the input layers. |
Pythoncode
Algorithm ID: native:mergevectorlayers
import processing
processing.run("algorithm_id", {parameter_dictionary})
Die Algorithmus-Kennung wird angezeigt, wenn Sie den Mauszeiger über den Algorithmus in der Verarbeitungs-Werkzeugkiste bewegen. Die Parameter-Liste (parameter_dictionary) enthält die Namen und Werte der Parameter. Siehe Verarbeitungs-Algorithmen von der Konsole aus verwenden für Details zur Ausführung von Verarbeitungsalgorithmen über die Python-Konsole.
28.1.21.23. Order by expression
Sorts a vector layer according to an expression: changes the feature index according to an expression.
Be careful, it might not work as expected with some providers, the order might not be kept every time.
Parameter
Bezeichnung |
Name |
Typ |
Beschreibung |
|---|---|---|---|
Input Layer |
|
[Vektor: alle] |
Input vector layer to sort |
Expression |
|
[Ausdruck] |
Expression to use for the sorting |
Sort ascending |
|
[Boolean] Default: True |
If checked the vector layer will be sorted from small to large values. |
Sort nulls first |
|
[Boolean] Standard: falsch |
If checked, Null values are placed first |
Ordered |
|
[wie input] Standard: |
Specify the output vector layer. One of:
Auch die Dateikodierung kann hier geändert werden. |
Ausgaben
Bezeichnung |
Name |
Typ |
Beschreibung |
|---|---|---|---|
Ordered |
|
[wie input] |
Output (sorted) vector layer |
Pythoncode
Algorithm ID: native:orderbyexpression
import processing
processing.run("algorithm_id", {parameter_dictionary})
Die Algorithmus-Kennung wird angezeigt, wenn Sie den Mauszeiger über den Algorithmus in der Verarbeitungs-Werkzeugkiste bewegen. Die Parameter-Liste (parameter_dictionary) enthält die Namen und Werte der Parameter. Siehe Verarbeitungs-Algorithmen von der Konsole aus verwenden für Details zur Ausführung von Verarbeitungsalgorithmen über die Python-Konsole.
28.1.21.24. Repair Shapefile
Repairs a broken ESRI Shapefile dataset by (re)creating the SHX file.
Parameter
Bezeichnung |
Name |
Typ |
Beschreibung |
|---|---|---|---|
Input Shapefile |
|
[Datei] |
Full path to the ESRI Shapefile dataset with a missing or broken SHX file |
Ausgaben
Bezeichnung |
Name |
Typ |
Beschreibung |
|---|---|---|---|
Repaired layer |
|
[Vektor: alle] |
The input vector layer with the SHX file repaired |
Pythoncode
Algorithm ID: native:repairshapefile
import processing
processing.run("algorithm_id", {parameter_dictionary})
Die Algorithmus-Kennung wird angezeigt, wenn Sie den Mauszeiger über den Algorithmus in der Verarbeitungs-Werkzeugkiste bewegen. Die Parameter-Liste (parameter_dictionary) enthält die Namen und Werte der Parameter. Siehe Verarbeitungs-Algorithmen von der Konsole aus verwenden für Details zur Ausführung von Verarbeitungsalgorithmen über die Python-Konsole.
28.1.21.25. Reproject layer
Reprojects a vector layer in a different CRS. The reprojected layer will have the same features and attributes of the input layer.
Allows features in-place modification
of point, line, and polygon features
Parameter
Grundlegende Parameter
Bezeichnung |
Name |
Typ |
Beschreibung |
|---|---|---|---|
Input Layer |
|
[Vektor: alle] |
Input vector layer to reproject |
Ziel KBS |
|
[KBS] Default: |
Destination coordinate reference system |
Convert curved geometries to straight segments
Optional |
|
[Boolean] Standard: falsch |
If checked, curved geometries will be converted to straight segments in the process, avoiding potential distortion issues. |
Reprojiziert |
|
[wie input] Standard: |
Specify the output vector layer. One of:
Auch die Dateikodierung kann hier geändert werden. |
Fortgeschrittene Parameter
Bezeichnung |
Name |
Typ |
Beschreibung |
|---|---|---|---|
Coordinate Operation Optional |
|
[string] |
Specific operation to use for a particular reprojection task, instead of always forcing use of the current project’s transformation settings. Useful when reprojecting a particular layer and control over the exact transformation pipeline is required. Requires proj version >= 6. Read more at Datumstransformationen. |
Ausgaben
Bezeichnung |
Name |
Typ |
Beschreibung |
|---|---|---|---|
Reprojiziert |
|
[wie input] |
Output (reprojected) vector layer |
Pythoncode
Algorithm ID: native:reprojectlayer
import processing
processing.run("algorithm_id", {parameter_dictionary})
Die Algorithmus-Kennung wird angezeigt, wenn Sie den Mauszeiger über den Algorithmus in der Verarbeitungs-Werkzeugkiste bewegen. Die Parameter-Liste (parameter_dictionary) enthält die Namen und Werte der Parameter. Siehe Verarbeitungs-Algorithmen von der Konsole aus verwenden für Details zur Ausführung von Verarbeitungsalgorithmen über die Python-Konsole.
28.1.21.26. Save vector features to file
Saves vector features to a specified file dataset.
For dataset formats supporting layers, an optional layer name parameter can be used to specify a custom string. Optional GDAL-defined dataset and layer options can be specified. For more information on this, read the online GDAL documentation on the format.
Parameter
Grundlegende Parameter
Bezeichnung |
Name |
Typ |
Beschreibung |
|---|---|---|---|
Vector features |
|
[Vektor: alle] |
Input vector layer. |
Saved features |
|
[wie input] Standard: |
Specify the file to save the features to. One of:
|
Fortgeschrittene Parameter
Bezeichnung |
Name |
Typ |
Beschreibung |
|---|---|---|---|
Layer name Optional |
|
[string] |
Name to use for the output layer |
GDAL dataset options Optional |
|
[string] |
GDAL dataset creation options of the output format. Separate individual options with semicolons. |
GDAL layer options Optional |
|
[string] |
GDAL layer creation options of the output format. Separate individual options with semicolons. |
Action to take on pre-existing file |
|
[Aufzählung] Standard: 0 |
How to manage existing features. Valid methods are: 0 — Create or overwrite file 1 — Create or overwrite layer 2 — Append features to existing layer, but do not create new fields 3 — Append features to existing layer, and create new fields if needed |
Ausgaben
Bezeichnung |
Name |
Typ |
Beschreibung |
|---|---|---|---|
Saved features |
|
[wie input] |
Vector layer with the saved features. |
File name and path |
|
[string] |
Output file name and path. |
Layer name |
|
[string] |
Name of the layer, if any. |
Pythoncode
Algorithm ID: native:savefeatures
import processing
processing.run("algorithm_id", {parameter_dictionary})
Die Algorithmus-Kennung wird angezeigt, wenn Sie den Mauszeiger über den Algorithmus in der Verarbeitungs-Werkzeugkiste bewegen. Die Parameter-Liste (parameter_dictionary) enthält die Namen und Werte der Parameter. Siehe Verarbeitungs-Algorithmen von der Konsole aus verwenden für Details zur Ausführung von Verarbeitungsalgorithmen über die Python-Konsole.
28.1.21.27. Set layer encoding
Sets the encoding used for reading a layer’s attributes. No permanent changes are made to the layer, rather it affects only how the layer is read during the current session.
Bemerkung
Changing the encoding is only supported for some vector layer data sources.
Parameter
Bezeichnung |
Name |
Typ |
Beschreibung |
|---|---|---|---|
Saved features |
|
[Vektor: alle] |
Vector layer to set the encoding. |
Encoding |
|
[string] |
Text encoding to assign to the layer in the current QGIS session. |
Ausgaben
Bezeichnung |
Name |
Typ |
Beschreibung |
|---|---|---|---|
Ausgabelayer |
|
[wie input] |
Input vector layer with the set encoding. |
Pythoncode
Algorithm ID: native:setlayerencoding
import processing
processing.run("algorithm_id", {parameter_dictionary})
Die Algorithmus-Kennung wird angezeigt, wenn Sie den Mauszeiger über den Algorithmus in der Verarbeitungs-Werkzeugkiste bewegen. Die Parameter-Liste (parameter_dictionary) enthält die Namen und Werte der Parameter. Siehe Verarbeitungs-Algorithmen von der Konsole aus verwenden für Details zur Ausführung von Verarbeitungsalgorithmen über die Python-Konsole.
28.1.21.28. Split features by character
Features are split into multiple output features by splitting a field’s value at a specified character. For instance, if a layer contains features with multiple comma separated values contained in a single field, this algorithm can be used to split these values up across multiple output features. Geometries and other attributes remain unchanged in the output. Optionally, the separator string can be a regular expression for added flexibility.
Allows
features in-place modification
of point, line, and polygon features
Parameter
Bezeichnung |
Name |
Typ |
Beschreibung |
|---|---|---|---|
Input Layer |
|
[Vektor: alle] |
Eingabe-Vektorlayer |
Split using values in the field |
|
[tablefield: any] |
Field to use for splitting |
Split value using character |
|
[string] |
Character to use for splitting |
Use regular expression separator |
|
[Boolean] Standard: falsch |
|
Split |
|
[wie input] Default: |
Specify output vector layer. One of:
Auch die Dateikodierung kann hier geändert werden. |
Ausgaben
Bezeichnung |
Name |
Typ |
Beschreibung |
|---|---|---|---|
Split |
|
[wie input] |
The output vector layer. |
Pythoncode
Algorithm ID: native:splitfeaturesbycharacter
import processing
processing.run("algorithm_id", {parameter_dictionary})
Die Algorithmus-Kennung wird angezeigt, wenn Sie den Mauszeiger über den Algorithmus in der Verarbeitungs-Werkzeugkiste bewegen. Die Parameter-Liste (parameter_dictionary) enthält die Namen und Werte der Parameter. Siehe Verarbeitungs-Algorithmen von der Konsole aus verwenden für Details zur Ausführung von Verarbeitungsalgorithmen über die Python-Konsole.
28.1.21.29. Split vector layer
Creates a set of vectors in an output folder based on an input layer and an attribute. The output folder will contain as many layers as the unique values found in the desired field.
The number of files generated is equal to the number of different values found for the specified attribute.
It is the opposite operation of merging.
Default menu:
Siehe auch
Parameter
Grundlegende Parameter
Bezeichnung |
Name |
Typ |
Beschreibung |
|---|---|---|---|
Input Layer |
|
[Vektor: alle] |
Eingabe-Vektorlayer |
Unique ID field |
|
[tablefield: any] |
Field to use for splitting |
Ausgabeverzeichnis |
|
[Verzeichnis] Standard: |
Specify the directory for the output layers. One of:
|
Fortgeschrittene Parameter
Bezeichnung |
Name |
Typ |
Beschreibung |
|---|---|---|---|
Output file type Optional |
|
[Aufzählung] Default: |
Select the extension of the output files. If not specified or invalid, the output files format will be the one set in the „Default output vector layer extension“ Processing setting. |
Ausgaben
Bezeichnung |
Name |
Typ |
Beschreibung |
|---|---|---|---|
Ausgabeverzeichnis |
|
[Verzeichnis] |
The directory for the output layers |
Output layers |
|
[same as input] [list] |
The output vector layers resulting from the split. |
Pythoncode
Algorithm ID: native:splitvectorlayer
import processing
processing.run("algorithm_id", {parameter_dictionary})
Die Algorithmus-Kennung wird angezeigt, wenn Sie den Mauszeiger über den Algorithmus in der Verarbeitungs-Werkzeugkiste bewegen. Die Parameter-Liste (parameter_dictionary) enthält die Namen und Werte der Parameter. Siehe Verarbeitungs-Algorithmen von der Konsole aus verwenden für Details zur Ausführung von Verarbeitungsalgorithmen über die Python-Konsole.
28.1.21.30. Truncate table
Truncates a layer, by deleting all features from within the layer.
Warnung
This algorithm modifies the layer in place, and deleted features cannot be restored!
Parameter
Bezeichnung |
Name |
Typ |
Beschreibung |
|---|---|---|---|
Input Layer |
|
[Vektor: alle] |
Eingabe-Vektorlayer |
Ausgaben
Bezeichnung |
Name |
Typ |
Beschreibung |
|---|---|---|---|
Truncated layer |
|
[Verzeichnis] |
The truncated (empty) layer |
Pythoncode
Algorithm ID: native:truncatetable
import processing
processing.run("algorithm_id", {parameter_dictionary})
Die Algorithmus-Kennung wird angezeigt, wenn Sie den Mauszeiger über den Algorithmus in der Verarbeitungs-Werkzeugkiste bewegen. Die Parameter-Liste (parameter_dictionary) enthält die Namen und Werte der Parameter. Siehe Verarbeitungs-Algorithmen von der Konsole aus verwenden für Details zur Ausführung von Verarbeitungsalgorithmen über die Python-Konsole.