Viktigt
Översättning är en gemenskapsinsats du kan gå med i. Den här sidan är för närvarande översatt till 100.00%.
17.10. Rasterkalkylatorn. Värden utan data
Observera
I den här lektionen ska vi se hur man använder rasterkalkylatorn för att utföra vissa operationer på rasterlager. Vi kommer också att förklara vad som är no–data-värden och hur kalkylatorn och andra algoritmer hanterar dem
Rasterkalkylatorn är en av de mest kraftfulla algoritmerna som du kan hitta. Det är en mycket flexibel och mångsidig algoritm som kan användas för många olika beräkningar och som snart kommer att bli en viktig del av din verktygslåda.
I den här lektionen kommer vi att utföra några beräkningar med rasterkalkylatorn, de flesta av dem ganska enkla. På så sätt får vi se hur den används och hur den hanterar vissa speciella situationer som den kan stöta på. Att förstå detta är viktigt för att senare få de förväntade resultaten när man använder räknaren, och även för att förstå vissa tekniker som vanligtvis tillämpas med den.
Öppna QGIS-projektet som motsvarar den här lektionen och du kommer att se att det innehåller flera rasterlager.
Öppna nu verktygslådan och öppna den dialogruta som motsvarar rasterkalkylatorn.
Observera
Gränssnittet är annorlunda i de senaste versionerna.
Dialogrutan innehåller 2 parametrar.
De lager som ska användas för analysen. Detta är en multiple input, vilket innebär att du kan välja så många lager som du vill. Klicka på knappen till höger och välj sedan de lager som du vill använda i den dialogruta som visas.
Formeln som ska tillämpas. Formeln använder de lager som valts i parametern ovan och som namnges med bokstäver i alfabetet (
a, b, c...) ellerg1, g2, g3...som variabelnamn. Det innebär att formelna + 2 * bär densamma somg1 + 2 * g2och beräknar summan av värdet i det första lagret plus två gånger värdet i det andra lagret. Ordningen på lagren är densamma som du ser i urvalsdialogen.
Varning
Kalkylatorn är skiftlägeskänslig.
Till att börja med ändrar vi enheterna för DEM från meter till fot. Formeln vi behöver är följande:
h' = h * 3.28084
Välj DEM i fältet Lager och skriv a * 3.28084 i formelfältet.
Varning
För personer som inte använder engelska: använd alltid ”.”, inte ”,”.
Klicka på Run för att köra algoritmen. Du kommer att få ett lager som har samma utseende som inputlagret, men med olika värden. Ingångslageret som vi använde har giltiga värden i alla sina celler, så den sista parametern har ingen effekt alls.
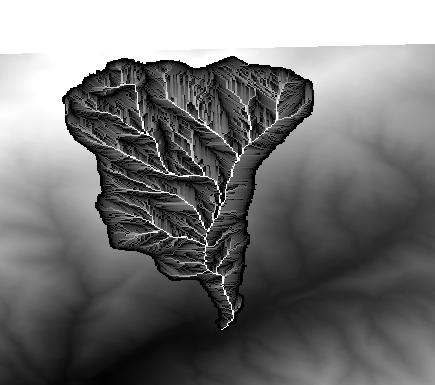
Låt oss nu utföra en ny beräkning, den här gången på lageret accflow. Detta lager innehåller värden för ackumulerat flöde, en hydrologisk parameter. Det innehåller dessa värden endast inom området för en viss vattendelare, utan några datavärden utanför det. Som du kan se är renderingen inte särskilt informativ på grund av hur värdena är fördelade. Om man använder logaritmen för flödesackumuleringen får man en mycket mer informativ representation. Vi kan beräkna det med hjälp av rasterkalkylatorn.
Öppna algoritmdialogen igen, välj accflow-lagret som det enda inmatningslagret och ange följande formel: log(a).
Här är lagret som du kommer att få.
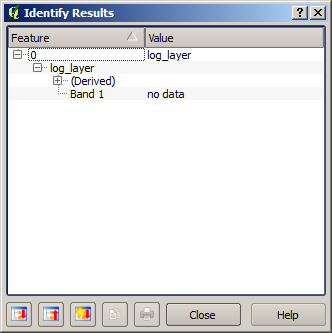
Om du väljer verktyget Identify för att få veta värdet på ett lager vid en viss punkt, väljer det lager som vi just har skapat och klickar på en punkt utanför bassängen, ser du att det innehåller ett no-data-värde.
I nästa övning ska vi använda två lager i stället för ett, och vi ska få en DEM med giltiga höjdvärden endast inom den bassäng som definieras i det andra lageret. Öppna kalkylatorns dialogruta och välj projektets båda lager i fältet Input layers. Ange följande formel i motsvarande fält:
a/a * b
”a” avser det ackumulerade flödeslageret (eftersom det är det första som visas i listan) och ”b” avser DEM. Vad vi gör i den första delen av formeln här är att dividera det ackumulerade flödeslageret med sig självt, vilket resulterar i ett värde på 1 inuti bassängen och ett värde utan data utanför. Sedan multiplicerar vi med DEM för att få höjdvärdet i dessa celler inne i bassängen (DEM * 1 = DEM) och värdet utan data utanför (DEM * no_data = no_data)
Här är det resulterande lagret.

Denna teknik används ofta för att mask värden i ett rasterlager och är användbar när du vill utföra beräkningar för en annan region än den godtyckliga rektangulära region som används av rasterlagret. Till exempel har ett höjdhistogram för ett rasterlager inte så stor betydelse. Om det istället beräknas med hjälp av endast värden som motsvarar en bassäng (som i fallet ovan), får vi ett meningsfullt resultat som faktiskt ger information om bassängens konfiguration.
Det finns andra intressanta saker med den här algoritmen som vi just har kört, bortsett från no–data-värdena och hur de hanteras. Om du tittar på omfattningen av de lager som vi har multiplicerat (du kan göra det genom att dubbelklicka på lagernamnen i innehållsförteckningen och titta på deras egenskaper), kommer du att se att de inte är desamma, eftersom omfattningen som täcks av flödesackumuleringslagret är mindre än omfattningen av hela DEM.
Det innebär att dessa lager inte matchar varandra och att de inte kan multipliceras direkt utan att homogenisera dessa storlekar och utbredning genom att omsampla ett eller båda lagren. Vi har dock inte gjort någonting. QGIS tar hand om den här situationen och omsamplar automatiskt indatalageren när det behövs. Den utgående utbredningen är den minsta täckande utbredningen som beräknas från de ingående lageren och den minsta cellstorleken för deras cellstorlekar.
I det här fallet (och i de flesta fall) ger detta önskat resultat, men du bör alltid vara medveten om de ytterligare operationer som äger rum, eftersom de kan påverka resultatet. I de fall då detta beteende kanske inte är det önskade bör manuell omsampling göras i förväg. I senare kapitel kommer vi att se mer om hur algoritmerna beter sig när man använder flera rasterlager.
Låt oss avsluta den här lektionen med en annan maskeringsövning. Vi ska beräkna lutningen i alla områden med en höjd mellan 1000 och 1500 meter.
I det här fallet har vi inte något lager att använda som mask, men vi kan skapa en sådan med hjälp av kalkylatorn.
Kör kalkylatorn med DEM som enda inmatningslager och följande formel
ifelse(abs(a-1250) < 250, 1, 0/0)
Som du ser kan vi använda miniräknaren inte bara för att göra enkla algebraiska operationer, utan också för att göra mer komplexa beräkningar med villkorliga meningar, som den ovan.
Resultatet har värdet 1 inom det intervall vi vill arbeta med, och ingen data i celler utanför det.

Värdet utan data kommer från 0/0-uttrycket. Eftersom det är ett obestämt värde kommer SAGA att lägga till ett NaN-värde (Not a Number), som faktiskt hanteras som ett no-data-värde. Med det här lilla tricket kan du ställa in ett no-data-värde utan att behöva veta vad cellens no-data-värde är.
Nu behöver du bara multiplicera det med det sluttningslager som ingår i projektet, så får du önskat resultat.
Allt detta kan göras i en enda operation med miniräknaren. Vi lämnar det som en övning för läsaren.