Viktigt
Översättning är en gemenskapsinsats du kan gå med i. Den här sidan är för närvarande översatt till 100.00%.
17.13. HTML-utdata
Observera
I den här lektionen lär vi oss hur QGIS hanterar utdata i HTML-format, som används för att producera textutdata och grafer.
Alla utdata som vi har producerat hittills var lager (oavsett om det var raster eller vektor). Vissa algoritmer genererar dock utdata i form av text och grafik. Alla dessa utdata paketeras i HTML-filer och visas i den så kallade Results viewer, som är en annan del av bearbetningsramen.
Låt oss titta på en av dessa algoritmer för att förstå hur de fungerar.
Öppna projektet med de data som ska användas i den här lektionen och öppna sedan algoritmen Basic statistics for numeric fields.
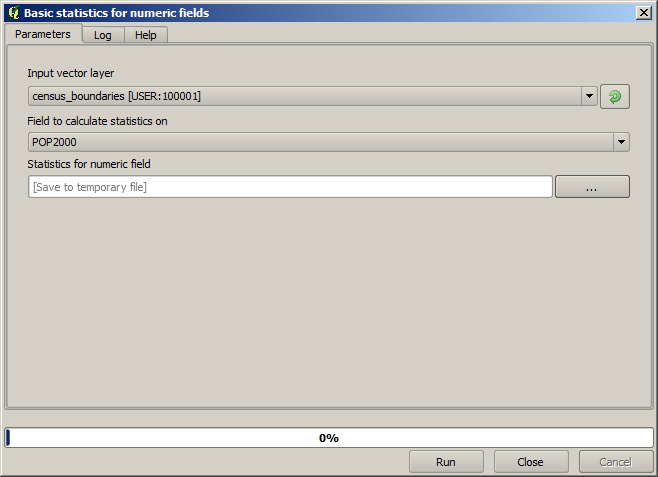
Algoritmen är ganska enkel, och du behöver bara välja det lager som ska användas och ett av dess fält (ett numeriskt). Utdata är av typen HTML, men motsvarande ruta fungerar precis som den som du kan hitta när det gäller en raster- eller vektorutdata. Du kan ange en filväg eller lämna den tom för att spara i en tillfällig fil. I det här fallet är det dock bara filtilläggen html och htm som tillåts, så det går inte att ändra utdataformatet genom att använda ett annat.
Kör algoritmen genom att välja det enda lagret i projektet som indata och fältet POP2000, så visas en ny dialogruta som den som visas här intill när algoritmen har körts och parameterdialogrutan har stängts.
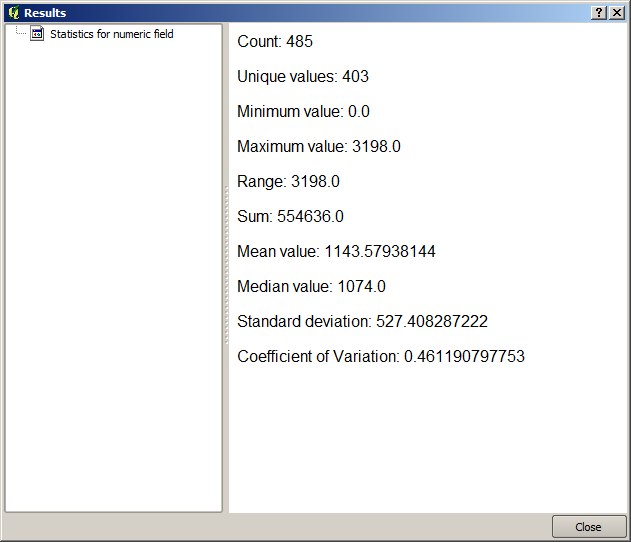
Detta är Resultatvisaren. Den håller alla HTML-resultat som genererats under den aktuella sessionen lättillgängliga, så att du snabbt kan kontrollera dem när du behöver det. Om du har sparat resultatet i en temporär fil kommer den att raderas när du stänger QGIS, precis som med lager. Om du har sparat till en sökväg som inte är temporär kommer filen att finnas kvar, men den kommer inte att visas i Results viewer nästa gång du öppnar QGIS.
Vissa algoritmer genererar text som inte kan delas upp i andra mer detaljerade utdata. Så är fallet om algoritmen t.ex. fångar upp textutdata från en extern process. I andra fall presenteras utdata som text, men internt delas utdata upp i flera mindre utdata, vanligtvis i form av numeriska värden. Den algoritm som vi just har kört är en av dem. Vart och ett av dessa värden hanteras som en enda utdata och lagras i en variabel. Detta har ingen betydelse alls nu, men när vi går över till modelldesignern kommer du att se att vi kan använda dessa värden som numeriska indata för andra algoritmer.