Viktigt
Översättning är en gemenskapsinsats du kan gå med i. Den här sidan är för närvarande översatt till 60.00%.
17.13. HTML-utdata
Observera
I den här lektionen lär vi oss hur QGIS hanterar utdata i HTML-format, som används för att producera textutdata och grafer.
All the outputs we have produced so far were layers (whether raster or vector). However, some algorithms generate outputs in the form of text and graphics. All this outputs are wrapped in HTML files and displayed in the so–called Results viewer, which is another element of the processing framework.
Låt oss titta på en av dessa algoritmer för att förstå hur de fungerar.
Open the project with the data to be used in this lesson and then open the Basic statistics for fields algorithm.
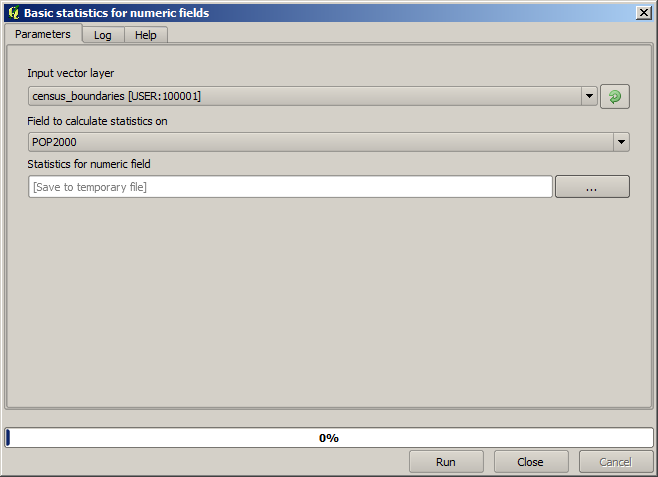
Algoritmen är ganska enkel, och du behöver bara välja det lager som ska användas och ett av dess fält (ett numeriskt). Utdata är av typen HTML, men motsvarande ruta fungerar precis som den som du kan hitta när det gäller en raster- eller vektorutdata. Du kan ange en filväg eller lämna den tom för att spara i en tillfällig fil. I det här fallet är det dock bara filtilläggen html och htm som tillåts, så det går inte att ändra utdataformatet genom att använda ett annat.
Run the algorithm selecting the only layer in the project as input, and
the POP2000 field, and a new dialog like the one shown next will appear
once the algorithm is executed and the parameters dialog is closed.
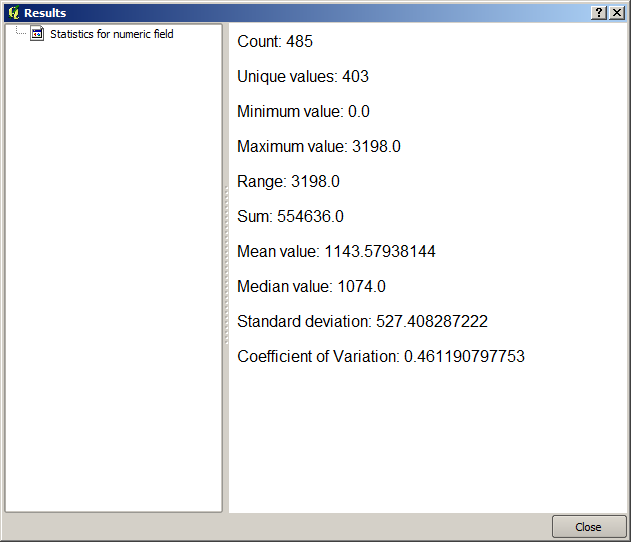
This is the Results viewer. It keeps all the HTML result generated during the current session, easily accessible, so you can check them quickly whenever you need it. As it happens with layers, if you have saved the output to a temporary file, it will be deleted once you close QGIS. If you have saved to a non-temporary path, the file will remain, but it will not appear in the Results viewer the next time you open QGIS.
Vissa algoritmer genererar text som inte kan delas upp i andra mer detaljerade utdata. Så är fallet om algoritmen t.ex. fångar upp textutdata från en extern process. I andra fall presenteras utdata som text, men internt delas utdata upp i flera mindre utdata, vanligtvis i form av numeriska värden. Den algoritm som vi just har kört är en av dem. Vart och ett av dessa värden hanteras som en enda utdata och lagras i en variabel. Detta har ingen betydelse alls nu, men när vi går över till modelldesignern kommer du att se att vi kan använda dessa värden som numeriska indata för andra algoritmer.