Viktigt
Översättning är en gemenskapsinsats du kan gå med i. Den här sidan är för närvarande översatt till 100.00%.
17.14. Exempel på första analys
Observera
I den här lektionen kommer vi att utföra några riktiga analyser med hjälp av bara verktygslådan, så att du kan bli mer bekant med ramverkselementen för bearbetning.
Nu när allt är konfigurerat och vi kan använda externa algoritmer har vi ett mycket kraftfullt verktyg för att utföra spatial analys. Det är dags att göra en större övning med lite verkliga data.
Vi kommer att använda det välkända dataset som John Snow använde 1854 i sitt banbrytande arbete (https://en.wikipedia.org/wiki/John_Snow_%28physician%29), och vi kommer att få några intressanta resultat. Analysen av det här datasetet är ganska uppenbar och det behövs inga sofistikerade GIS-tekniker för att få bra resultat och slutsatser, men det är ett bra sätt att visa hur dessa spatiala problem kan analyseras och lösas med hjälp av olika bearbetningsverktyg.
Datasetet innehåller shapefiler med koleradödsfall och pumplägen, och en OSM-renderad karta i TIFF-format. Öppna motsvarande QGIS-projekt för den här lektionen.
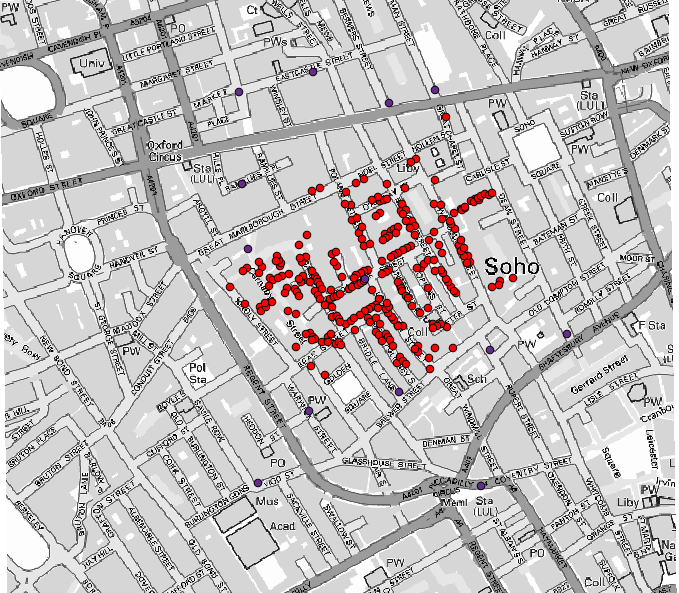
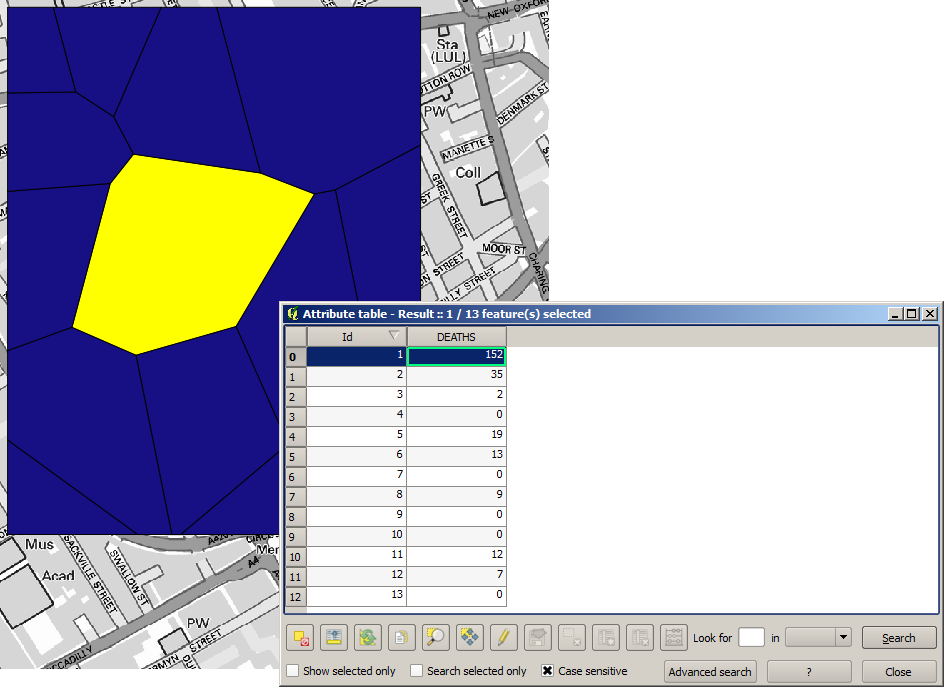
Det första du måste göra är att beräkna Voronoi-diagrammet (även kallat Thiessen-polygoner) för pumplagret för att få fram varje pumps influenszon. Algoritmen Voronoi-diagram kan användas för detta.
Ganska enkelt, men det kommer redan att ge oss intressant information.
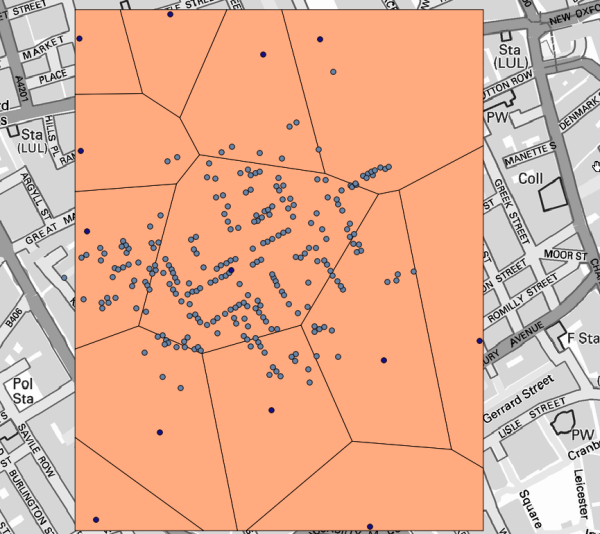
Det är uppenbart att de flesta fall ligger inom någon av polygonerna
För att få ett mer kvantitativt resultat kan vi räkna antalet dödsfall i varje polygon. Eftersom varje punkt representerar en byggnad där dödsfall inträffade, och antalet dödsfall lagras i ett attribut, kan vi inte bara räkna punkterna. Vi behöver en viktad räkning, så vi använder verktyget Count points in polygon (weighted).
Det nya fältet kommer att kallas DEATHS, och vi använder fältet COUNT som viktningsfält. Den resulterande tabellen visar tydligt att antalet dödsfall i den polygon som motsvarar den första pumpen är mycket större än de andra.
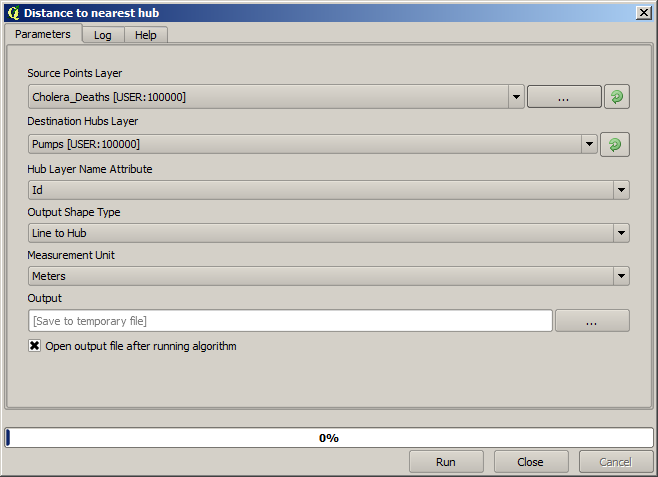
Ett annat bra sätt att visualisera beroendet mellan varje punkt i lagret Cholera_deaths och en punkt i lagret Pumps är att dra en linje till den närmaste. Detta kan göras med verktyget Distance to nearest hub och med hjälp av den konfiguration som visas härnäst.
Resultatet ser ut så här:
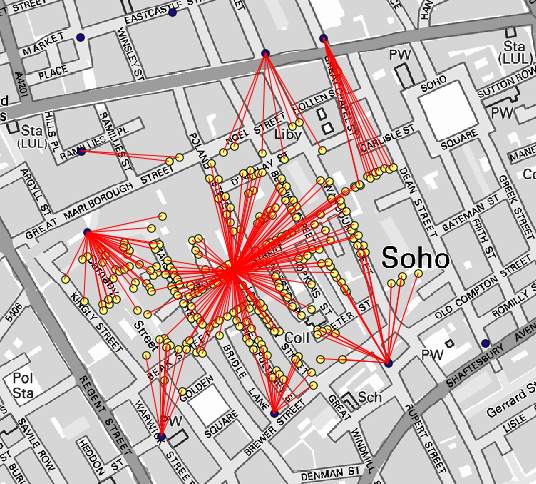
Även om antalet rader är större när det gäller den centrala pumpen, får man inte glömma att detta inte representerar antalet dödsfall, utan antalet platser där kolerafall påträffades. Det är en representativ parameter, men den tar inte hänsyn till att vissa platser kan ha fler fall än andra.
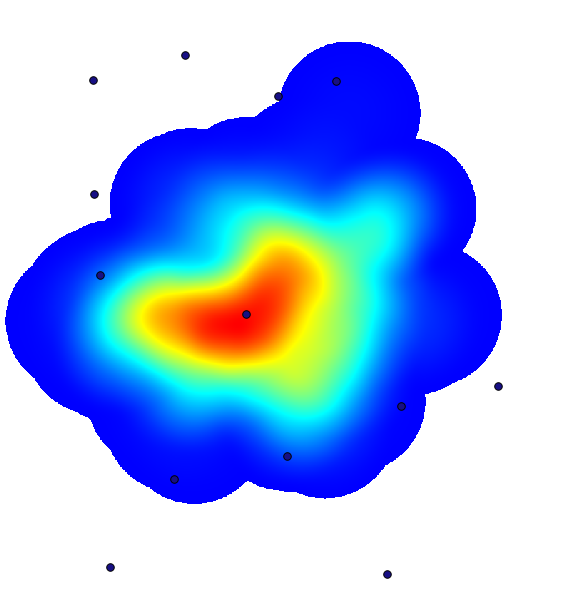
Ett densitetsskikt ger oss också en mycket tydlig bild av vad som händer. Vi kan skapa det med algoritmen Kernel density. Med hjälp av lagret Cholera_deaths, dess fält COUNT som viktfält, med en radie på 100, omfattningen och cellstorleken för rasterlagret streets, får vi något liknande detta.
Kom ihåg att du inte behöver skriva in utdataomfånget för att få det. Klicka på knappen på höger sida och välj Use layer/canvas extent.
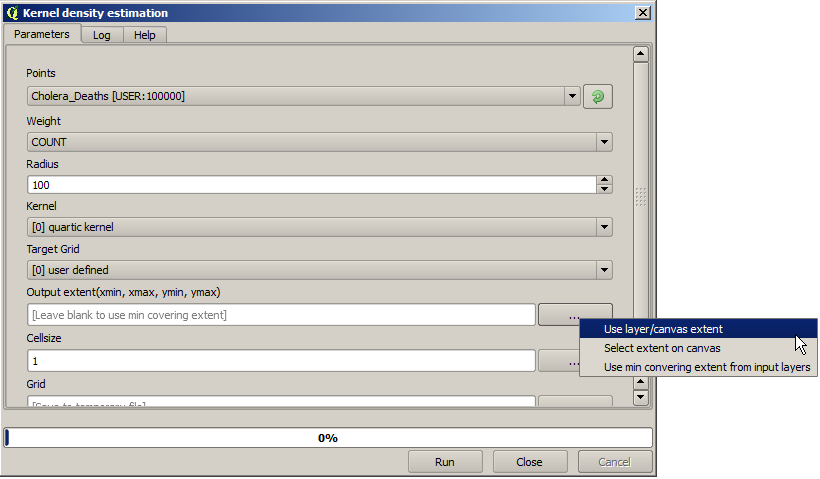
Välj rasterlagret för gatorna så läggs dess utsträckning automatiskt till i textfältet. Du måste göra samma sak med cellstorleken genom att välja cellstorleken för det lagret också.
I kombination med pumplagret ser vi att det finns en pump tydligt i den hotspot där den maximala tätheten av dödsfall finns.