Viktigt
Översättning är en gemenskapsinsats du kan gå med i. Den här sidan är för närvarande översatt till 100.00%.
17.23. Mer interpolering
Observera
Detta kapitel visar ett annat praktiskt fall där interpolationsalgoritmer används.
Interpolering är en vanlig teknik och kan användas för att demonstrera flera tekniker som kan tillämpas med hjälp av QGIS bearbetningsramverk. I den här lektionen används några interpolationsalgoritmer som redan har introducerats, men med ett annat tillvägagångssätt.
Data för den här lektionen innehåller också ett punktlager, i det här fallet med höjddata. Vi ska interpolera det på ungefär samma sätt som vi gjorde i den föregående lektionen, men den här gången sparar vi en del av originaldata för att använda dem för att bedöma kvaliteten på interpoleringsprocessen.
Först måste vi rasterisera punktlagret och fylla de resulterande cellerna utan data, men bara använda en bråkdel av punkterna i lagret. Vi kommer att spara 10% of punkter för en senare kontroll, så vi måste ha 90% of punkter redo för interpoleringen. För att göra det kan vi använda algoritmen Split shapes layer randomly, som vi redan har använt i en tidigare lektion, men det finns ett bättre sätt att göra det, utan att behöva skapa något nytt mellanlager. Istället kan vi bara välja de punkter som vi vill använda för interpoleringen (90% f-raktionen) och sedan köra algoritmen. Som vi redan har sett kommer rastreringsalgoritmen bara att använda de valda punkterna och ignorera resten. Urvalet kan göras med hjälp av algoritmen Random selection. Kör den med följande parametrar.
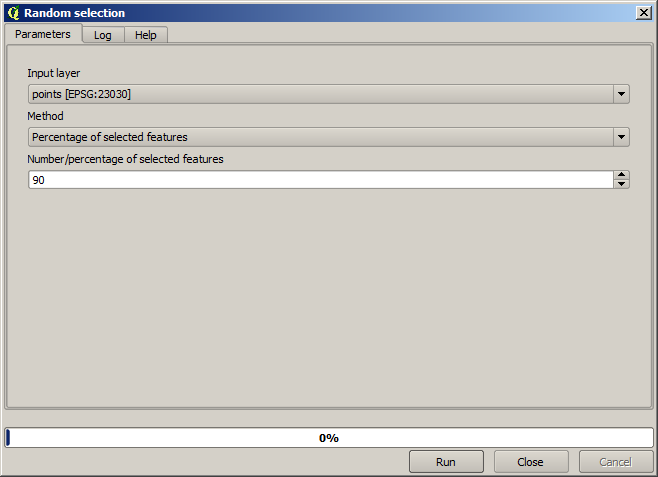
Det kommer att välja 90% of punkterna i lagret för att rasterisera

Urvalet är slumpmässigt, så ditt urval kan skilja sig från det urval som visas i bilden ovan.
Kör nu algoritmen Rasterize för att få det första rasterlagret och kör sedan algoritmen Close gaps för att fylla cellerna utan data [Cellupplösning: 100 m].

För att kontrollera kvaliteten på interpoleringen kan vi nu använda de punkter som inte är valda. Nu känner vi till den verkliga höjden (värdet i punktlagret) och den interpolerade höjden (värdet i det interpolerade rasterlagret). Vi kan jämföra de två genom att beräkna skillnaderna mellan dessa värden.
Eftersom vi ska använda de punkter som inte är markerade, ska vi först invertera markeringen.

Punkterna innehåller de ursprungliga värdena, men inte de interpolerade. För att lägga till dem i ett nytt fält kan vi använda algoritmen Add raster values to points (Lägg till rastervärden till punkter)
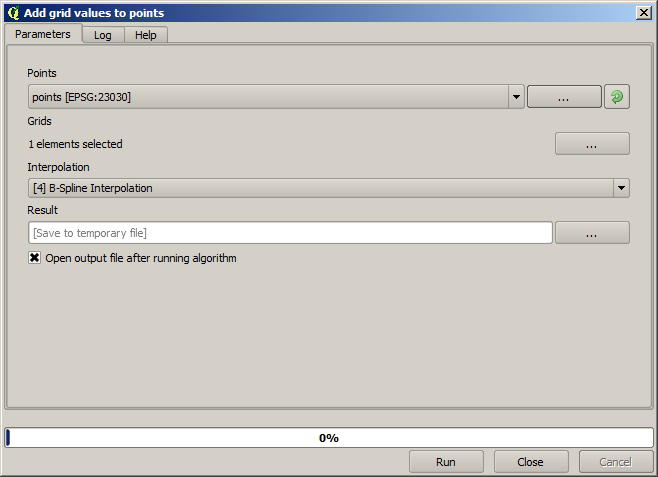
Det rasterlager som ska väljas (algoritmen stöder flera raster, men vi behöver bara ett) är det som blir resultatet av interpoleringen. Vi har döpt om det till interpolera och det lagernamnet är det som kommer att användas för namnet på det fält som ska läggas till.
Nu har vi ett vektorlager som innehåller båda värdena, med punkter som inte användes för interpoleringen.
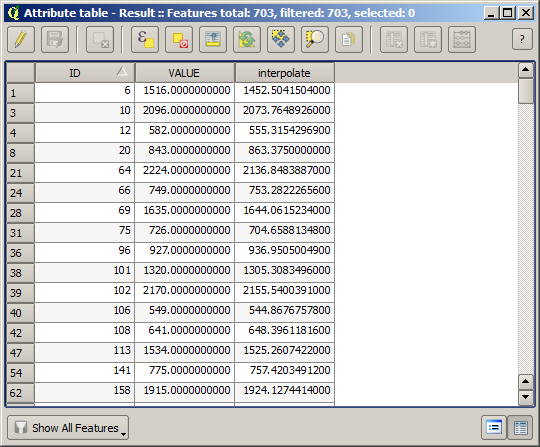
Nu ska vi använda fältkalkylatorn för denna uppgift. Öppna algoritmen Field calculator och kör den med följande parametrar.
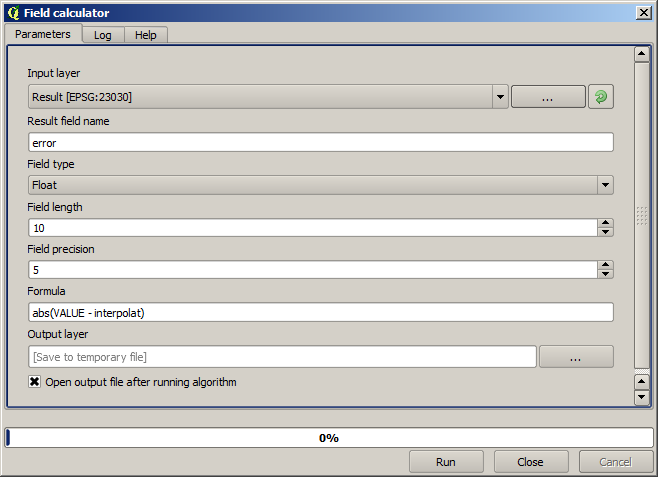
Om ditt fält med värdena från rasterlagret har ett annat namn, bör du ändra ovanstående formel i enlighet med detta. Om du kör den här algoritmen får du ett nytt lager med bara de punkter som vi inte har använt för interpoleringen, var och en av dem innehåller skillnaden mellan de två höjdvärdena.
Genom att representera lagret enligt detta värde får vi en första uppfattning om var de största avvikelserna finns.
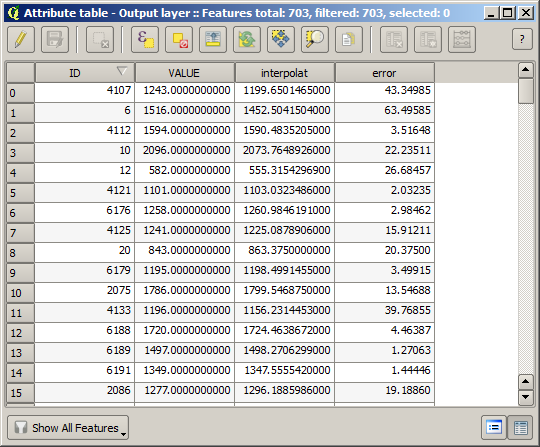
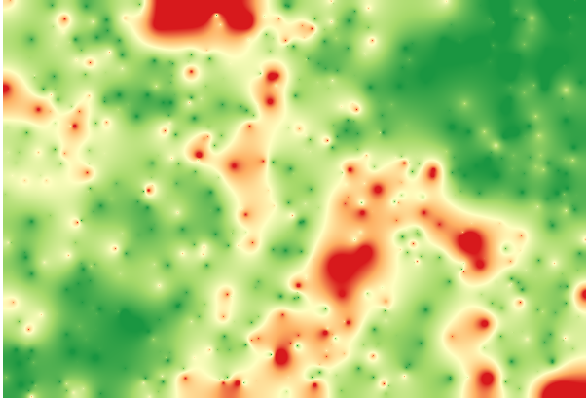
Om du interpolerar det lagret får du ett rasterlager med det beräknade felet i alla punkter i det interpolerade området.
Du kan också få samma information (skillnaden mellan ursprungliga punktvärden och interpolerade värden) direkt med .
Dina resultat kan skilja sig från dessa, eftersom det finns en slumpmässig komponent som infördes när du körde det slumpmässiga urvalet i början av den här lektionen.