Importante
La traduzione è uno sforzo comunitario you can join. Questa pagina è attualmente tradotta al 100.00%.
24.1.22. Vettore generalità
24.1.22.1. Assegnare proiezione
Assegna una nuova proiezione ad un layer vettoriale.
Crea un nuovo layer con le stesse identiche caratteristiche e geometrie di quello in ingresso, ma assegnato a un nuovo SR. Le geometrie non sono riproiettate, sono solo assegnate a un diverso SR.
Questo algoritmo può essere usato per aggiustare i layer ai quali è stata assegnata una proiezione errata.
Gli attributi non vengono modificati da questo algoritmo.
Parametri
Etichetta |
Nome |
Tipo |
Descrizione |
|---|---|---|---|
Layer in ingresso |
|
[vector: geometry] |
Layer vettoriale con SR errato o mancante |
SR assegnato |
|
[crs] Predefinito: |
Seleziona il nuovo SR da assegnare al layer vettoriale |
SR assegnato Opzionale |
|
[same as input] Predefinito: |
Specifica il layer vettoriale in uscita. One of:
La codifica del file può anche essere cambiata qui. |
In uscita:
Etichetta |
Nome |
Tipo |
Descrizione |
|---|---|---|---|
SR assegnato |
|
[same as input] |
Layer vettoriale con proiezione assegnata |
Codice Python
ID Algoritmo: native:assignprojection
import processing
processing.run("algorithm_id", {parameter_dictionary})
L”id algoritmo viene visualizzato quando passi il mouse sull’algoritmo nella finestra degli strumenti di Processing. Il dizionario dei parametri fornisce i nomi e i valori dei parametri. Vedi Usare gli algoritmi di Processing dalla console dei comandi per i dettagli su come eseguire gli algoritmi di processing dalla console Python.
24.1.22.2. Geocodificatore batch Nominatim
Esegue la geocodifica in batch utilizzando il servizio Nominatim rispetto a un campo stringa del layer in ingresso. Il layer in uscita avrà una geometria punto che rappresenta la posizione geocodificata e una serie di attributi associati alla posizione geocodificata.
 Permette features in-place modification degli elementi punto
Permette features in-place modification degli elementi punto
Nota
Questo algoritmo è conforme alla usage policy del servizio di geocodifica Nominatim fornito dalla OpenStreetMap Foundation.
Parametri
Etichetta |
Nome |
Tipo |
Descrizione |
|---|---|---|---|
Layer in ingresso |
|
[vector: any] |
Layer vettoriale di geocodifica degli elementi |
Campo indirizzo |
|
[tablefield: string] |
Campo contenente gli indirizzi da geocodificare |
Geocodificati |
|
[vector: point] Predefinito: |
Specifica il layer in uscita contenente solo gli indirizzi geocodificati. One of 1:
La codifica del file può anche essere cambiata qui. |
In uscita:
Etichetta |
Nome |
Tipo |
Descrizione |
|---|---|---|---|
Geocodificati |
|
[vector: point] |
Layer vettoriale con elementi punto corrispondenti agli indirizzi geocodificati |
Codice Python
ID Algoritmo: native:batchnominatimgeocoder
import processing
processing.run("algorithm_id", {parameter_dictionary})
L”id algoritmo viene visualizzato quando passi il mouse sull’algoritmo nella finestra degli strumenti di Processing. Il dizionario dei parametri fornisce i nomi e i valori dei parametri. Vedi Usare gli algoritmi di Processing dalla console dei comandi per i dettagli su come eseguire gli algoritmi di processing dalla console Python.
24.1.22.3. Converti vettore in segnalibri spaziali
Crea segnalibri spaziali corrispondenti all’estensione degli elementi contenuti in un layer.
Parametri
Etichetta |
Nome |
Tipo |
Descrizione |
|---|---|---|---|
Layer in ingresso |
|
[vector: line, polygon] |
Il layer vettoriale in ingresso |
Destinazione segnalibro |
|
[enumeration] Valore predefinito: 0 |
Seleziona la destinazione per i segnalibri. Una delle seguenti:
|
Nome campo |
|
[expression] |
Campo o espressione che darà i nomi ai segnalibri generati |
Campo del gruppo |
|
[expression] |
Campo o espressione che fornirà i gruppi per i segnalibri generati |
In uscita:
Etichetta |
Nome |
Tipo |
Descrizione |
|---|---|---|---|
Conteggio dei segnalibri aggiunti |
|
[numeric: integer] |
Codice Python
ID Algoritmo: native:layertobookmarks
import processing
processing.run("algorithm_id", {parameter_dictionary})
L”id algoritmo viene visualizzato quando passi il mouse sull’algoritmo nella finestra degli strumenti di Processing. Il dizionario dei parametri fornisce i nomi e i valori dei parametri. Vedi Usare gli algoritmi di Processing dalla console dei comandi per i dettagli su come eseguire gli algoritmi di processing dalla console Python.
24.1.22.4. Converti segnalibri spaziali in vettore
Crea un nuovo layer contenente elementi poligonali per i segnalibri spaziali memorizzati. L’esportazione può essere filtrata solo per i segnalibri appartenenti al progetto corrente, per tutti i segnalibri dell’utente, o una combinazione di entrambi.
Parametri
Etichetta |
Nome |
Tipo |
Descrizione |
|---|---|---|---|
Fonte segnalibro |
|
[enumeration] [list] Predefinito: [0,1] |
Seleziona la fonte(i) dei segnalibri. Una o diverse tra:
|
SR in uscita |
|
[crs] Predefinito: |
Il SR del layer in uscita |
In Uscita |
|
[vector: polygon] Predefinito: |
Specificare il layer in uscita. One of 1:
La codifica del file può anche essere cambiata qui. |
In uscita:
Etichetta |
Nome |
Tipo |
Descrizione |
|---|---|---|---|
In Uscita |
|
[vector: polygon] |
Il layer vettoriale in uscita (segnalibri) |
Codice Python
ID Algoritmo: native:bookmarkstolayer
import processing
processing.run("algorithm_id", {parameter_dictionary})
L”id algoritmo viene visualizzato quando passi il mouse sull’algoritmo nella finestra degli strumenti di Processing. Il dizionario dei parametri fornisce i nomi e i valori dei parametri. Vedi Usare gli algoritmi di Processing dalla console dei comandi per i dettagli su come eseguire gli algoritmi di processing dalla console Python.
24.1.22.5. Crea indice attributo
Crea un indice su un campo della tabella degli attributi per velocizzare le query. Il supporto per la creazione di un indice dipende sia dal fornitore di dati del layer che dal tipo di campo.
Nessun risultato viene creato: l’indice viene memorizzato sul layer stesso.
Parametri
Etichetta |
Nome |
Tipo |
Descrizione |
|---|---|---|---|
Layer in ingresso |
|
[vector: any] |
Seleziona il layer vettoriale per il quale vuoi creare un attributo indice |
Attributo per l’indice |
|
[tablefield: any] |
Campo del layer vettoriale |
In uscita:
Etichetta |
Nome |
Tipo |
Descrizione |
|---|---|---|---|
Layer indicizzato |
|
[same as input] |
Una copia del layer vettoriale in ingresso con un indice per il campo specificato |
Codice Python
ID Algoritmo: native:createattributeindex
import processing
processing.run("algorithm_id", {parameter_dictionary})
L”id algoritmo viene visualizzato quando passi il mouse sull’algoritmo nella finestra degli strumenti di Processing. Il dizionario dei parametri fornisce i nomi e i valori dei parametri. Vedi Usare gli algoritmi di Processing dalla console dei comandi per i dettagli su come eseguire gli algoritmi di processing dalla console Python.
24.1.22.6. Crea indice spaziale
Crea un indice per accelerare l’accesso agli elementi di un layer in base alla loro posizione spaziale. Il supporto per la creazione di un indice spaziale dipende dal fornitore di dati del layer.
Nessun nuovo layer in uscita viene generato
Menu predefinito:
Parametri
Etichetta |
Nome |
Tipo |
Descrizione |
|---|---|---|---|
Layer in ingresso |
|
[vector: geometry] |
Layer vettoriale in input |
In uscita:
Etichetta |
Nome |
Tipo |
Descrizione |
|---|---|---|---|
Layer indicizzato |
|
[same as input] |
Una copia del layer vettoriale in ingresso con un indice spaziale |
Codice Python
ID Algoritmo:native:createspatialindex
import processing
processing.run("algorithm_id", {parameter_dictionary})
L”id algoritmo viene visualizzato quando passi il mouse sull’algoritmo nella finestra degli strumenti di Processing. Il dizionario dei parametri fornisce i nomi e i valori dei parametri. Vedi Usare gli algoritmi di Processing dalla console dei comandi per i dettagli su come eseguire gli algoritmi di processing dalla console Python.
24.1.22.7. Definisci la proiezione dello Shapefile
Imposta il SR (proiezione) di un insieme di dati in formato Shapefile esistente al SR fornito. È molto utile quando un dataset in formato Shapefile manca del file prj e si conosce la proiezione corretta.
Contrariamente all’algoritmo Assegnare proiezione, modifica il layer corrente e non produce un nuovo layer.
Nota
Per gli insiemi di dati Shapefile, i file .prj e .qpj saranno sovrascritti - o creati se mancanti - per corrispondere al SR fornito.
Menu predefinito:
Vedi anche
Parametri
Etichetta |
Nome |
Tipo |
Descrizione |
|---|---|---|---|
Layer in ingresso |
|
[vector: geometry] |
Layer vettoriale con informazioni di proiezione mancanti |
SR |
|
[crs] |
Selezionare il SR da assegnare al layer vettoriale |
In uscita:
Etichetta |
Nome |
Tipo |
Descrizione |
|---|---|---|---|
|
[same as input] |
Il layer in ingresso con la proiezione definita |
Codice Python
ID Algoritmo: qgis:definecurrentprojection
import processing
processing.run("algorithm_id", {parameter_dictionary})
L”id algoritmo viene visualizzato quando passi il mouse sull’algoritmo nella finestra degli strumenti di Processing. Il dizionario dei parametri fornisce i nomi e i valori dei parametri. Vedi Usare gli algoritmi di Processing dalla console dei comandi per i dettagli su come eseguire gli algoritmi di processing dalla console Python.
24.1.22.8. Elimina geometrie duplicate
Trova e rimuove le geometrie duplicate.
Gli attributi non sono verificati, quindi nel caso in cui due elementi abbiano geometrie identiche ma attributi diversi, solo una di esse sarà aggiunta al layer risultante.
Nota
Questo algoritmo non richiede geometrie valide in ingresso.
Parametri
Etichetta |
Nome |
Tipo |
Descrizione |
|---|---|---|---|
Layer in ingresso |
|
[vector: geometry] |
Il layer con geometrie duplicate che vuoi pulire |
Pulito |
|
[same as input] Predefinito: |
Specificare il layer in uscita. One of 1:
La codifica del file può anche essere cambiata qui. |
In uscita:
Etichetta |
Nome |
Tipo |
Descrizione |
|---|---|---|---|
Conteggio dei record duplicati scartati |
|
[numeric: integer] |
Conteggio dei record duplicati scartati |
Pulito |
|
[same as input] |
Il layer in uscita senza geometrie duplicate |
Conteggio dei record mantenuti |
|
[numeric: integer] |
Conteggio dei record univoci |
Codice Python
ID Algoritmo: native:deleteduplicategeometries
import processing
processing.run("algorithm_id", {parameter_dictionary})
L”id algoritmo viene visualizzato quando passi il mouse sull’algoritmo nella finestra degli strumenti di Processing. Il dizionario dei parametri fornisce i nomi e i valori dei parametri. Vedi Usare gli algoritmi di Processing dalla console dei comandi per i dettagli su come eseguire gli algoritmi di processing dalla console Python.
24.1.22.9. Eliminare i duplicati in base all’attributo
Elimina le righe duplicate considerando solo il campo o i campi specificati. La prima riga corrispondente sarà mantenuta, e i duplicati saranno scartati.
Opzionalmente, questi record duplicati possono essere salvati in un risultato separato per l’analisi.
Vedi anche
Parametri
Etichetta |
Nome |
Tipo |
Descrizione |
|---|---|---|---|
Layer in ingresso |
|
[vector: any] |
Il layer in ingresso |
Campi su cui trovare i duplicati |
|
[tablefield: any] [list] |
Campi che contengono duplicati. Gli elementi con valori identici per tutti questi campi sono considerati duplicati. |
Filrati (nessun duplicato) |
|
[same as input] Predefinito: |
Specifica il layer in uscita contenente gli elementi univoci. One of:
La codifica del file può anche essere cambiata qui. |
Filtrati (duplicati) Opzionale |
|
[same as input] Predefinito: |
Specifica il layer in uscita contenente solo i duplicati. One of:
La codifica del file può anche essere cambiata qui. |
In uscita:
Etichetta |
Nome |
Tipo |
Descrizione |
|---|---|---|---|
Filtrati (duplicati) Opzionale |
|
[same as input] Predefinito: |
Layer vettoriale contenente gli elementi rimossi. Non verrà generato se non specificato (lasciato come |
Conteggio dei record duplicati scartati |
|
[numeric: integer] |
Conteggio dei record duplicati scartati |
Filrati (nessun duplicato) |
|
[same as input] |
Layer vettoriale contenente gli elementi univoci. |
Conteggio dei record mantenuti |
|
[numeric: integer] |
Conteggio dei record univoci |
Codice Python
ID Algoritmo: native:removeduplicatesbyattribute
import processing
processing.run("algorithm_id", {parameter_dictionary})
L”id algoritmo viene visualizzato quando passi il mouse sull’algoritmo nella finestra degli strumenti di Processing. Il dizionario dei parametri fornisce i nomi e i valori dei parametri. Vedi Usare gli algoritmi di Processing dalla console dei comandi per i dettagli su come eseguire gli algoritmi di processing dalla console Python.
24.1.22.10. Rileva modifiche nel dataset
Confronta due layer vettoriali e determina quali elementi sono invariati, aggiunti o cancellati tra i due. È progettato per confrontare due diverse versioni dello stesso insieme di dati.
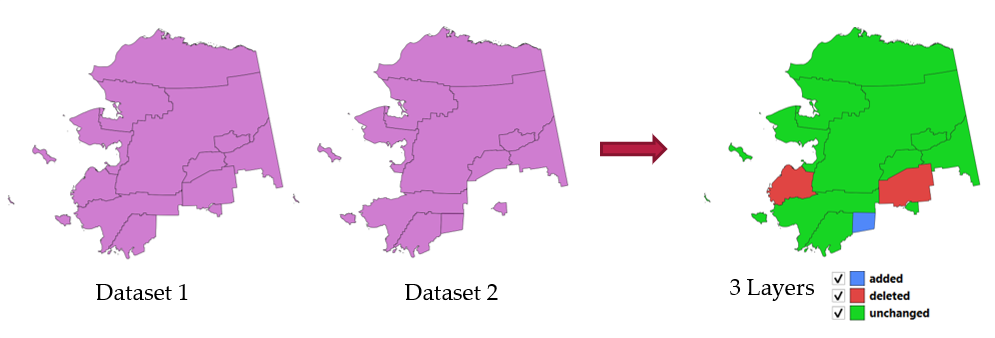
Fig. 24.55 Rilevare il cambiamento dell’insieme dei dati di esempio
Parametri
Etichetta |
Nome |
Tipo |
Descrizione |
|---|---|---|---|
Layer originale |
|
[vector: geometry] |
Il layer vettoriale considerato come versione originale |
Layer revisionato |
|
[vector: geometry] |
Il layer vettoriale revisionato o modificato |
Attributi da considerare per il confronto Opzionale |
|
[tablefield: any] [list] |
Attributi da considerare per il confronto. Per impostazione predefinita, vengono confrontati tutti gli attributi. |
Composizione confronto geometrie Opzionale |
|
[enumeration] Predefinito: 1 |
Definisce i criteri di confronto. Opzioni:
|
Elementi immutati Opzionale |
|
[vector: same as Original layer] |
Specifica il layer vettoriale in uscita contenente gli elementi invariati. One of 1:
La codifica del file può anche essere cambiata qui. |
Elementi aggiunti Opzionale |
|
[vector: same as Original layer] |
Specifica il layer vettoriale in uscita contenente gli elementi aggiunti. One of:
La codifica del file può anche essere cambiata qui. |
Elementi eliminati Opzionale |
|
[vector: same as Original layer] |
Specifica il layer vettoriale in uscita contenente gli elementi eliminati. One of 1:
La codifica del file può anche essere cambiata qui. |
In uscita:
Etichetta |
Nome |
Tipo |
Descrizione |
|---|---|---|---|
Elementi immutati |
|
[vector: same as Original layer] |
Layer vettoriale contenente gli elementi immutati. |
Elementi aggiunti |
|
[vector: same as Original layer] |
Layer vettoriale contenente gli elementi aggiunti. |
Elementi eliminati |
|
[vector: same as Original layer] |
Layer vettoriale contenente gli elementi eliminati. |
Conteggio degli elementi immutati |
|
[numeric: integer] |
Conteggio degli elementi immutati |
Conteggio degli elementi aggiunti nel layer revisionato |
|
[numeric: integer] |
Conteggio degli elementi aggiunti nel layer revisionato |
Conteggio degli elementi eliminati dal layer originale |
|
[numeric: integer] |
Conteggio degli elementi eliminati dal layer originale |
Codice Python
ID Algoritmo: native:detectvectorchanges
import processing
processing.run("algorithm_id", {parameter_dictionary})
L”id algoritmo viene visualizzato quando passi il mouse sull’algoritmo nella finestra degli strumenti di Processing. Il dizionario dei parametri fornisce i nomi e i valori dei parametri. Vedi Usare gli algoritmi di Processing dalla console dei comandi per i dettagli su come eseguire gli algoritmi di processing dalla console Python.
24.1.22.11. Elimina geometrie
Crea una semplice copia senza geometria della tabella degli attributi del layer in ingresso. Mantiene la tabella degli attributi del layer di origine.
Se il file viene salvato in una cartella locale, puoi scegliere tra molti formati di file.
Permette features in-place modification di punti, linee e poligoni
Vedi anche
Parametri
Etichetta |
Nome |
Tipo |
Descrizione |
|---|---|---|---|
Layer in ingresso |
|
[vector: geometry] |
Il layer vettoriale in ingresso |
Geometrie Eliminate |
|
[vector: table] |
Specifica il layer in uscita privo di geometria. One of:
La codifica del file può anche essere cambiata qui. |
In uscita:
Etichetta |
Nome |
Tipo |
Descrizione |
|---|---|---|---|
Geometrie Eliminate |
|
[vector: table] |
Il layer senza geometria in uscita. Una copia della tabella degli attributi originale. |
Codice Python
ID Algoritmo: native:dropgeometries
import processing
processing.run("algorithm_id", {parameter_dictionary})
L”id algoritmo viene visualizzato quando passi il mouse sull’algoritmo nella finestra degli strumenti di Processing. Il dizionario dei parametri fornisce i nomi e i valori dei parametri. Vedi Usare gli algoritmi di Processing dalla console dei comandi per i dettagli su come eseguire gli algoritmi di processing dalla console Python.
24.1.22.12. Esegui SQL
Esegue una query semplice o complessa basata solo su SELECT con sintassi SQL sul layer di origine.
Le fonti di dati di input sono identificate con input1, input2… inputN e una semplice query sarà del tipo SELECT * FROM input1.
Oltre a una semplice query, è possibile aggiungere espressioni o variabili all’interno del parametro SQL query stesso. Questo è particolarmente utile se questo algoritmo viene eseguito all’interno di un modello di elaborazione e si desidera utilizzare un input del modello come parametro della query. Un esempio di query sarà quindi SELECT * FROM [% @table %] dove @table è la variabile che identifica l’input del modello.
Il risultato della query sarà aggiunto come un nuovo layer.
Vedi anche
Parametri
Etichetta |
Nome |
Tipo |
Descrizione |
|---|---|---|---|
Fonti di dati in entrata aggiuntive (chiamate input1, .., inputN nella query). |
|
[vector: any] [list] |
Elenco dei layer da interrogare. Nell’editor SQL si può fare riferimento a questi layer con il loro nome reale o anche con input1, input2, inputN a seconda di quanti layer sono stati scelti. |
Interrogazione SQL |
|
[string] |
Scrivi la stringa della tua query SQL, ad esempio |
Campo di identificazione univoco Opzionale |
|
[string] |
Specificare la colonna con ID univoco |
Campo geometria Opzionale |
|
[string] |
Specificare il campo geometria |
Tipo di geometria Opzionale |
|
[enumeration] Valore predefinito: 0 |
Scegli la geometria per il risultato. Per default l’algoritmo la rileverà automaticamente. Uno di:
|
SR Opzionale |
|
[crs] |
Il SR da assegnare al layer in uscita |
Risultato SQL |
|
[vector: geometry] Predefinito: |
Specificare il layer in uscita creato dalla query. One of:
La codifica del file può anche essere cambiata qui. |
In uscita:
Etichetta |
Nome |
Tipo |
Descrizione |
|---|---|---|---|
Risultato SQL |
|
[vector: geometry] |
Layer vettoriale creato dalla query |
Codice Python
ID Algoritmo: qgis:executesql
import processing
processing.run("algorithm_id", {parameter_dictionary})
L”id algoritmo viene visualizzato quando passi il mouse sull’algoritmo nella finestra degli strumenti di Processing. Il dizionario dei parametri fornisce i nomi e i valori dei parametri. Vedi Usare gli algoritmi di Processing dalla console dei comandi per i dettagli su come eseguire gli algoritmi di processing dalla console Python.
24.1.22.13. Esportazione dei layer in DXF
Esporta i layer in un file DXF. Per ogni layer, puoi scegliere un campo i cui valori sono usati per suddividere gli elementi nei layer di destinazione generati nel DXF in uscita.
Vedi anche
Parametri
Etichetta |
Nome |
Tipo |
Descrizione |
|---|---|---|---|
Layer in ingresso |
|
[vector: geometry] [list] |
Elenco dei layer vettoriali in ingresso con opzioni associate (riempito come elemento
Consenti blocchi di simboli definiti dai dati [booleano] (
|
Modalità simbologia |
|
[enumeration] Valore predefinito: 0 |
Tipo di simbologia da applicare ai layer in uscita. Puoi scegliere tra:
|
Simbologia scala |
|
[scale] Predefinito: 1:1 000 000 |
Scala predefinita dell’esportazione dati. |
Tema Mappa Opzionale |
|
[map theme] |
Abbina lo stile del layer al tema della mappa fornito. |
Codifica |
|
[enumeration] |
Codifica da applicare ai layer. |
SR |
|
[crs] |
Scegliere il SR per il layer in uscita. |
Estensione Opzionale |
|
[extent] |
Limita gli elementi esportati a quelli con geometrie che intersecano l’estensione fornita. |
Usa il titolo del layer come nome |
|
[boolean] Predefinito: False |
Assegna al layer in uscita il nome del titolo del layer (come impostato nei metadati del layer o nelle proprietà del server QGIS) anziché il nome del layer. |
Forza 2D |
|
[boolean] Predefinito: False |
|
Esportazione di etichette come elementi MTEXT |
|
[boolean] Predefinito: True |
Esporta le etichette come elementi MTEXT o TEXT |
Usa solo elementi selezionati |
|
[boolean] Predefinito: False |
Esporta solo elementi selezionati |
DXF |
|
[file] Predefinito: |
Specifica del file DXF in uscita. One of:
|
In uscita:
Etichetta |
Nome |
Tipo |
Descrizione |
|---|---|---|---|
DXF |
|
[file] |
|
Codice Python
ID Algoritmo: native:dxfexport
import processing
processing.run("algorithm_id", {parameter_dictionary})
L”id algoritmo viene visualizzato quando passi il mouse sull’algoritmo nella finestra degli strumenti di Processing. Il dizionario dei parametri fornisce i nomi e i valori dei parametri. Vedi Usare gli algoritmi di Processing dalla console dei comandi per i dettagli su come eseguire gli algoritmi di processing dalla console Python.
24.1.22.14. Estrai elementi selezionati
Salva gli elementi selezionati come un nuovo layer.
Nota
Se il layer selezionato non ha elementi selezionati, il nuovo layer creato sarà vuoto.
Parametri
Etichetta |
Nome |
Tipo |
Descrizione |
|---|---|---|---|
Layer in ingresso |
|
[vector: any] |
Layer da cui salvare la selezione |
Elementi selezionati |
|
[same as input] Predefinito: |
Specifica il layer vettoriale per gli elementi selezionati. One of:
La codifica del file può anche essere cambiata qui. |
In uscita:
Etichetta |
Nome |
Tipo |
Descrizione |
|---|---|---|---|
Elementi selezionati |
|
[same as input] |
Layer vettoriale con solo gli elementi selezionati, o nessun elemento se nessuno è stato selezionato. |
Codice Python
ID Algoritmo: native:saveselectedfeatures
import processing
processing.run("algorithm_id", {parameter_dictionary})
L”id algoritmo viene visualizzato quando passi il mouse sull’algoritmo nella finestra degli strumenti di Processing. Il dizionario dei parametri fornisce i nomi e i valori dei parametri. Vedi Usare gli algoritmi di Processing dalla console dei comandi per i dettagli su come eseguire gli algoritmi di processing dalla console Python.
24.1.22.15. Estrarre codifica Shapefile
Estrae le informazioni sulla codifica degli attributi incorporati in uno Shapefile. Vengono prese in considerazione sia la codifica specificata da un file opzionale .cpg che qualsiasi dettaglio di codifica presente nel blocco di intestazione .dbf LDID.
Parametri
Etichetta |
Nome |
Tipo |
Descrizione |
|---|---|---|---|
Layer in ingresso |
|
[vector: geometry] |
ESRI Shapefile ( |
In uscita:
Etichetta |
Nome |
Tipo |
Descrizione |
|---|---|---|---|
Codifica Shapefile |
|
[string] |
Informazioni di codifica specificate nel file in ingresso |
Codifica CPG |
|
[string] |
Informazioni sulla codifica specificate in un eventuale file opzionale |
Codifica LDID |
|
[string] |
Informazioni sulla codifica specificate nel blocco di intestazione |
Codice Python
ID Algoritmo: native:shpencodinginfo
import processing
processing.run("algorithm_id", {parameter_dictionary})
L”id algoritmo viene visualizzato quando passi il mouse sull’algoritmo nella finestra degli strumenti di Processing. Il dizionario dei parametri fornisce i nomi e i valori dei parametri. Vedi Usare gli algoritmi di Processing dalla console dei comandi per i dettagli su come eseguire gli algoritmi di processing dalla console Python.
24.1.22.16. Cerca la proiezione
Crea un elenco di sistemi di riferimento delle coordinate possibili, per esempio per un layer con una proiezione sconosciuta.
L’area che il layer dovrebbe coprire deve essere specificata tramite il parametro dell’area di destinazione. Il sistema di riferimento delle coordinate per questa area di destinazione deve essere noto a QGIS.
L’algoritmo opera testando l’estensione del layer in ogni sistema di riferimento conosciuto e poi elencando tutti quelli per i quali i confini sarebbero vicini all’area di destinazione se il layer fosse in tale proiezione.
Parametri
Etichetta |
Nome |
Tipo |
Descrizione |
|---|---|---|---|
Layer in ingresso |
|
[vector: geometry] |
Layer con proiezione sconosciuta |
Area di destinazione per il layer (xmin, xmax, ymin, ymax) |
|
[extent] |
L’area coperta dal layer. I metodi disponibili sono:
|
SR possibili |
|
[vector: table] Predefinito: |
Specifica la tabella (layer senza geometria) per i SR suggeriti (codici EPSG). One of:
La codifica del file può anche essere cambiata qui. |
In uscita:
Etichetta |
Nome |
Tipo |
Descrizione |
|---|---|---|---|
SR possibili |
|
[vector: table] |
Una tabella con tutti i SR (codici EPSG) che corrispondono ai criteri. |
Codice Python
ID Algoritmo: qgis:findprojection
import processing
processing.run("algorithm_id", {parameter_dictionary})
L”id algoritmo viene visualizzato quando passi il mouse sull’algoritmo nella finestra degli strumenti di Processing. Il dizionario dei parametri fornisce i nomi e i valori dei parametri. Vedi Usare gli algoritmi di Processing dalla console dei comandi per i dettagli su come eseguire gli algoritmi di processing dalla console Python.
24.1.22.17. Appiattisci relazione
Appiattisce una relazione per un layer vettoriale, esportando un singolo layer contenente un elemento padre per ogni elemento figlio correlato. Questo elemento principale contiene tutti gli attributi per gli elementi correlati. Questo permette di avere la relazione come una semplice tabella che può essere per esempio esportata in CSV.
Avvertimento
Questo algoritmo elimina le chiavi primarie o i valori FID esistenti e li rigenera nei layer di output.
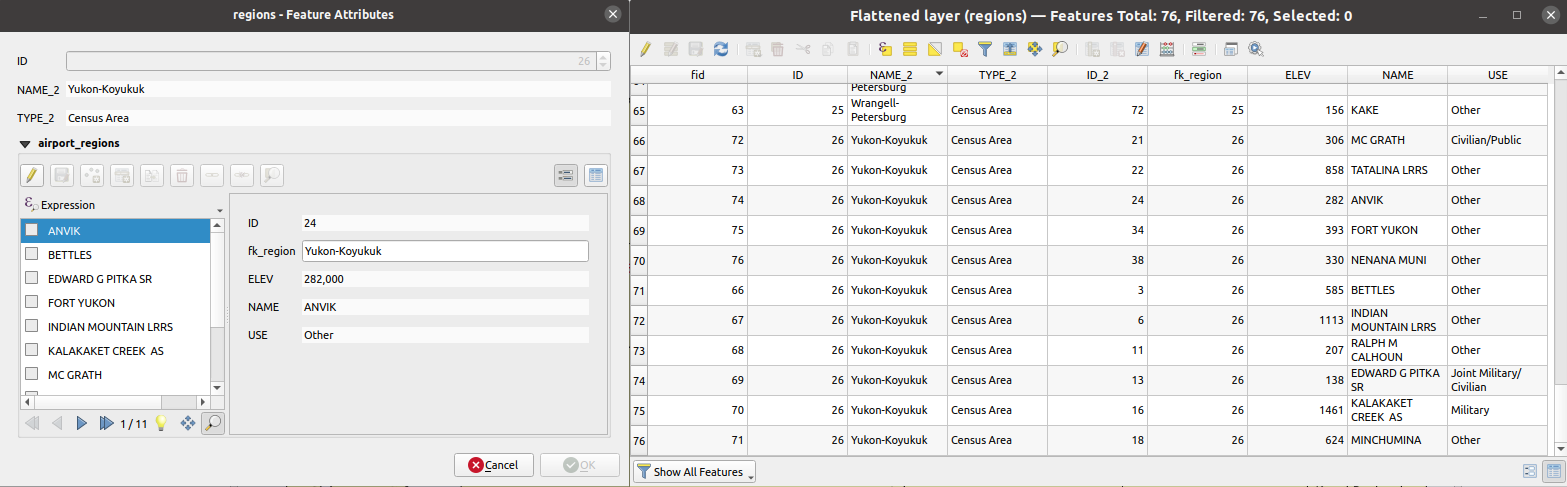
Fig. 24.56 Scheda di una regione con figli correlati (sinistra) - Un elemento regione duplicato per ogni figlio correlato, con attributi uniti (destra)
Parametri
Etichetta |
Nome |
Tipo |
Descrizione |
|---|---|---|---|
Layer in ingresso |
|
[vector: any] |
Layer con la relazione che dovrebbe essere rinormalizzata |
Layer appiattito Opzionale |
|
[same as input] Predefinito: |
Specificare il layer in uscita (piano). One of:
La codifica del file può anche essere cambiata qui. |
In uscita:
Etichetta |
Nome |
Tipo |
Descrizione |
|---|---|---|---|
Layer appiattito |
|
[same as input] |
Un layer contenente gli elementi principali con tutti gli attributi per gli elementi correlati |
Codice Python
ID Algoritmo: native:flattenrelationships
import processing
processing.run("algorithm_id", {parameter_dictionary})
L”id algoritmo viene visualizzato quando passi il mouse sull’algoritmo nella finestra degli strumenti di Processing. Il dizionario dei parametri fornisce i nomi e i valori dei parametri. Vedi Usare gli algoritmi di Processing dalla console dei comandi per i dettagli su come eseguire gli algoritmi di processing dalla console Python.
24.1.22.18. Unisci attributi secondo il valore del campo
Prende un layer vettoriale in ingresso e crea un nuovo layer vettoriale che è una versione estesa di quello in ingresso, con attributi aggiuntivi nella sua tabella degli attributi.
Gli attributi aggiuntivi e i loro valori sono presi da un secondo layer vettoriale. Un attributo è selezionato in ciascuno di essi per definire i criteri di unione.
Avvertimento
Questo algoritmo elimina le chiavi primarie o i valori FID esistenti e li rigenera nei layer di output.
Parametri
Etichetta |
Nome |
Tipo |
Descrizione |
|---|---|---|---|
Layer in ingresso |
|
[vector: any] |
Layer vettoriale in ingresso. Il layer in uscita consisterà di elementi di questo layer con gli attributi degli elementi corrispondenti nel secondo layer. |
Campo tabella |
|
[tablefield: any] |
Campo del layer di origine da usare per l’unione |
Layer in ingresso 2 |
|
[vector: any] |
Layer con la tabella degli attributi da unire |
Campo tabella 2 |
|
[tablefield: any] |
Campo del secondo layer (join) da usare per l’unione. La tipologia del campo deve essere uguale a (o compatibile con) la tipologia del campo della tabella in ingresso. |
Campi del layer 2 da copiare Opzionale |
|
[tablefield: any] [list] |
Seleziona i campi specifici che vuoi aggiungere. Per impostazione predefinita vengono aggiunti tutti i campi. |
Tipologie di unione |
|
[enumeration] Predefinito: 1 |
Il tipo del layer finale unito. Uno di:
|
Scartare i record che non possono essere uniti |
|
[boolean] Predefinito: True |
Verifica se non vuoi conservare gli elementi che non possono essere uniti |
Prefisso per il campo unito Opzionale |
|
[string] |
Aggiungi un prefisso ai campi uniti per identificarli facilmente ed evitare la collisione dei nomi dei campi |
Layer unito Opzionale |
|
[same as input] Predefinito: |
Specificare il layer vettoriale in uscita per il join. One of:
La codifica del file può anche essere cambiata qui. |
Elementi non collegabili del primo layer Opzionale |
|
[same as input] Predefinito: |
Specificare il layer vettoriale in uscita per gli elementi non collegabili dal primo layer. One of:
La codifica del file può anche essere cambiata qui. |
In uscita:
Etichetta |
Nome |
Tipo |
Descrizione |
|---|---|---|---|
Numero di elementi uniti dalla tabella di ingresso |
|
[numeric: integer] |
|
Elementi non collegabili del primo layer Opzionale |
|
[same as input] |
Layer vettoriale con gli elementi non accoppiati |
Layer unito Opzionale |
|
[same as input] |
Layer vettoriale in uscita con gli attributi aggiunti in seguito all’unione |
Numero di elementi non accoppiabili provenienti dalla tabella in ingresso Opzionale |
|
[numeric: integer] |
Codice Python
ID Algoritmo: native:joinattributestable
import processing
processing.run("algorithm_id", {parameter_dictionary})
L”id algoritmo viene visualizzato quando passi il mouse sull’algoritmo nella finestra degli strumenti di Processing. Il dizionario dei parametri fornisce i nomi e i valori dei parametri. Vedi Usare gli algoritmi di Processing dalla console dei comandi per i dettagli su come eseguire gli algoritmi di processing dalla console Python.
24.1.22.19. Unisci attributi per posizione
Prende un layer vettoriale in ingresso e crea un nuovo layer vettoriale che è una versione estesa di quello in ingresso, con attributi aggiuntivi nella sua tabella degli attributi.
Gli attributi addizionali e i loro valori sono presi da un secondo layer vettoriale. Un criterio spaziale è applicato per selezionare i valori del secondo layer che sono aggiunti ad ogni elemento del primo layer.
Menu predefinito:
Avvertimento
Questo algoritmo elimina le chiavi primarie o i valori FID esistenti e li rigenera nei layer di output.
Vedi anche
Unisci attributi dal vettore più vicino, Unisci attributi secondo il valore del campo, Unisci attributi per posizione (statistiche di sintesi)
Esplorare le relazioni spaziali
I predicati geometrici sono funzioni booleane utilizzate per determinare la relazione spaziale di un elemento con un altro, confrontando se e come le loro geometrie condividono una porzione di spazio.
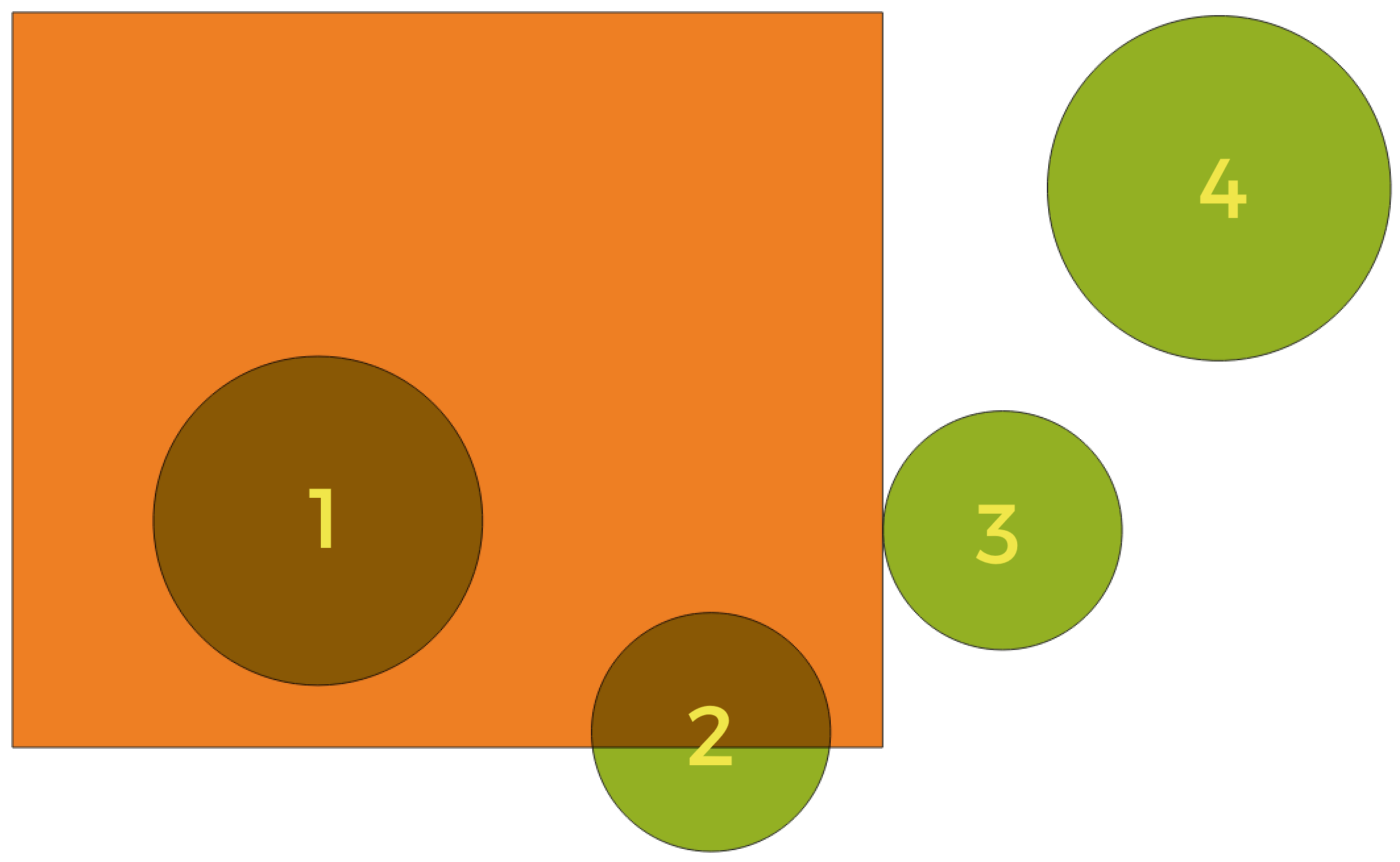
Fig. 24.57 Ricerca di relazioni spaziali tra i layer
Utilizzando la figura precedente, cerchiamo i cerchi verdi confrontandoli spazialmente con il rettangolo arancione. I predicati geometrici disponibili sono:
- Interseca
Verifica se una geometria ne interseca un’altra. Restituisce 1 (vero) se le geometrie si intersecano spazialmente (condividono una qualsiasi porzione di spazio - si sovrappongono o si toccano) e 0 se non si intersecano. Nell’immagine qui sopra, questo restituisce i cerchi 1, 2 e 3.
- Contiene
Restituisce 1 (vero) se e solo se nessun punto di b si trova nell’esterno di a e almeno un punto dell’interno di b si trova nell’interno di a. Nell’immagine, non viene restituito alcun cerchio, ma il rettangolo lo sarebbe se lo si cercasse al contrario, poiché contiene completamente il cerchio 1. Questo è l’opposto di sono dentro.
- Disgiunto
Restituisce 1 (vero) se le geometrie non condividono alcuna porzione di spazio (nessuna sovrapposizione, non si toccano). Viene restituito solo il cerchio 4.
- Uguale
Restituisce 1 (vero) se e solo se le geometrie sono esattamente uguali. Non viene restituito alcun cerchio.
- Tocca
Verifica se una geometria ne tocca un’altra. Restituisce 1 (vero) se le geometrie hanno almeno un punto in comune, ma i loro interni non si intersecano. Viene restituito solo il cerchio 3.
- Sovrapposizione
Verifica se una geometria si sovrappone a un’altra. Restituisce 1 (vero) se le geometrie condividono lo spazio, hanno la stessa dimensione, ma non sono completamente contenute l’una dall’altra. Viene restituito solo il cerchio 2.
- Sono all’interno
Verifica se una geometria è all’interno di un’altra. Restituisce 1 (vero) se la geometria a si trova completamente all’interno della geometria b. Viene restituito solo il cerchio 1.
- Attraversa
Restituisce 1 (vero) se le geometrie fornite hanno alcuni, ma non tutti, i punti interni in comune e l’incrocio è di una dimensione inferiore rispetto alla geometria più alta fornita. Ad esempio, una linea che attraversa un poligono si incrocia come una linea (true). Due linee che si incrociano si incrociano come un punto (vero). Due poligoni si incrociano come poligoni (falso). Nell’immagine, non verrà restituito alcun cerchio.
Parametri
Etichetta |
Nome |
Tipo |
Descrizione |
|---|---|---|---|
Unire elementi |
|
[vector: geometry] |
Layer vettoriale in ingresso. Il layer in uscita consisterà di elementi di questo layer con gli attributi degli elementi corrispondenti nel secondo layer. |
Quando gli elementi |
|
[enumeration] [list] Predefinito: [0] |
Tipo di relazione spaziale che l’elemento di origine deve avere con l’elemento di destinazione per poterli unire. Una o più di:
Se viene scelta più di una condizione, almeno una di esse (operazione OR) deve essere soddisfatta perché un elemento sia estratto. |
Con riferimento a |
|
[vector: geometry] |
Il layer unione. Gli elementi di questo layer vettoriale aggiungeranno i loro attributi alla tabella degli attributi del layer di origine se soddisfano la relazione spaziale. |
Campi da aggiungere (lasciare vuoto per usare tutti i campi) Opzionale |
|
[tablefield: any] [list] |
Seleziona i campi specifici che vuoi aggiungere dal layer di unione. Per impostazione predefinita, vengono aggiunti tutti i campi. |
Tipologie di unione |
|
[enumeration] |
Il tipo del layer finale unito. Uno di:
|
Scartare i record che non possono essere uniti |
|
[boolean] Predefinito: False |
Rimuovere dal risultato gli elementi del layer in ingresso che non è stato possibile unire. |
Prefisso per il campo unito Opzionale |
|
[string] |
Aggiungi un prefisso ai campi uniti per identificarli facilmente ed evitare la collisione dei nomi dei campi |
Layer unito Opzionale |
|
[same as input] Predefinito: |
Specificare il layer vettoriale in uscita per il join. One of:
La codifica del file può anche essere cambiata qui. |
Elementi non collegabili del primo layer Opzionale |
|
[same as input] Predefinito: |
Specificare il layer vettoriale in uscita per gli elementi non collegabili dal primo layer. One of:
La codifica del file può anche essere cambiata qui. |
In uscita:
Etichetta |
Nome |
Tipo |
Descrizione |
|---|---|---|---|
Numero di elementi uniti dalla tabella di ingresso |
|
[numeric: integer] |
|
Elementi non collegabili del primo layer Opzionale |
|
[same as input] |
Layer vettoriale degli elementi non accoppiati |
Layer unito |
|
[same as input] |
Layer vettoriale in uscita con gli attributi aggiunti in seguito all’unione |
Codice Python
ID Algoritmo: native:joinattributesbylocation
import processing
processing.run("algorithm_id", {parameter_dictionary})
L”id algoritmo viene visualizzato quando passi il mouse sull’algoritmo nella finestra degli strumenti di Processing. Il dizionario dei parametri fornisce i nomi e i valori dei parametri. Vedi Usare gli algoritmi di Processing dalla console dei comandi per i dettagli su come eseguire gli algoritmi di processing dalla console Python.
24.1.22.20. Unisci attributi per posizione (statistiche di sintesi)
Prende un layer vettoriale in ingresso e crea un nuovo layer vettoriale che è una versione estesa di quello in ingresso, con attributi aggiuntivi nella sua tabella degli attributi.
Gli attributi addizionali e i loro valori sono presi da un secondo layer vettoriale. Un criterio spaziale è applicato per selezionare i valori del secondo layer che sono aggiunti ad ogni elemento del primo layer.
L’algoritmo calcola una sintesi statistica per i valori degli elementi corrispondenti nel secondo layer (ad es. valore massimo, valore medio, ecc.).
Vedi anche
Esplorare le relazioni spaziali
I predicati geometrici sono funzioni booleane utilizzate per determinare la relazione spaziale di un elemento con un altro, confrontando se e come le loro geometrie condividono una porzione di spazio.
Fig. 24.58 Ricerca di relazioni spaziali tra i layer
Utilizzando la figura precedente, cerchiamo i cerchi verdi confrontandoli spazialmente con il rettangolo arancione. I predicati geometrici disponibili sono:
- Interseca
Verifica se una geometria ne interseca un’altra. Restituisce 1 (vero) se le geometrie si intersecano spazialmente (condividono una qualsiasi porzione di spazio - si sovrappongono o si toccano) e 0 se non si intersecano. Nell’immagine qui sopra, questo restituisce i cerchi 1, 2 e 3.
- Contiene
Restituisce 1 (vero) se e solo se nessun punto di b si trova nell’esterno di a e almeno un punto dell’interno di b si trova nell’interno di a. Nell’immagine, non viene restituito alcun cerchio, ma il rettangolo lo sarebbe se lo si cercasse al contrario, poiché contiene completamente il cerchio 1. Questo è l’opposto di sono dentro.
- Disgiunto
Restituisce 1 (vero) se le geometrie non condividono alcuna porzione di spazio (nessuna sovrapposizione, non si toccano). Viene restituito solo il cerchio 4.
- Uguale
Restituisce 1 (vero) se e solo se le geometrie sono esattamente uguali. Non viene restituito alcun cerchio.
- Tocca
Verifica se una geometria ne tocca un’altra. Restituisce 1 (vero) se le geometrie hanno almeno un punto in comune, ma i loro interni non si intersecano. Viene restituito solo il cerchio 3.
- Sovrapposizione
Verifica se una geometria si sovrappone a un’altra. Restituisce 1 (vero) se le geometrie condividono lo spazio, hanno la stessa dimensione, ma non sono completamente contenute l’una dall’altra. Viene restituito solo il cerchio 2.
- Sono all’interno
Verifica se una geometria è all’interno di un’altra. Restituisce 1 (vero) se la geometria a si trova completamente all’interno della geometria b. Viene restituito solo il cerchio 1.
- Attraversa
Restituisce 1 (vero) se le geometrie fornite hanno alcuni, ma non tutti, i punti interni in comune e l’incrocio è di una dimensione inferiore rispetto alla geometria più alta fornita. Ad esempio, una linea che attraversa un poligono si incrocia come una linea (true). Due linee che si incrociano si incrociano come un punto (vero). Due poligoni si incrociano come poligoni (falso). Nell’immagine, non verrà restituito alcun cerchio.
Parametri
Etichetta |
Nome |
Tipo |
Descrizione |
|---|---|---|---|
Unire elementi |
|
[vector: geometry] |
Layer vettoriale in ingresso. Il layer in uscita consisterà di elementi di questo layer con gli attributi degli elementi corrispondenti nel secondo layer. |
Quando gli elementi |
|
[enumeration] [list] Predefinito: [0] |
Tipo di relazione spaziale che l’elemento di origine deve avere con l’elemento di destinazione per poterli unire. Una o più di:
Se viene scelta più di una condizione, almeno una di esse (operazione OR) deve essere soddisfatta perché un elemento sia estratto. |
Con riferimento a |
|
[vector: geometry] |
Il layer unione. Gli elementi di questo livello vettoriale aggiungeranno i totali dei loro attributi alla tabella degli attributi del layer di origine, se soddisfano la relazione spaziale. |
Campi da sintetizzare (lasciare vuoto per usare tutti i campi) Opzionale |
|
[tablefield: any] [list] |
Seleziona i campi specifici che vuoi aggiungere dal layer di unione. Per impostazione predefinita, vengono aggiunti tutti i campi. |
Sintesi da elaborare (lasciare vuoto per utilizzare tutti i campi) Opzionale |
|
[enumeration] [list] Predefinito: [] |
Per ogni elemento in ingresso, vengono calcolate le statistiche sui campi uniti degli elementi corrispondenti. Uno o più di:
|
Scartare i record che non possono essere uniti |
|
[boolean] Predefinito: False |
Rimuovere dal risultato gli elementi del layer in ingresso che non è stato possibile unire. |
Layer unito |
|
[same as input] Predefinito: |
Specificare il layer vettoriale in uscita per il join. One of:
La codifica del file può anche essere cambiata qui. |
In uscita:
Etichetta |
Nome |
Tipo |
Descrizione |
|---|---|---|---|
Layer unito |
|
[same as input] |
Layer vettoriale in uscita con gli attributi sintetizzati dall” unione |
Codice Python
ID Algoritmo: qgis:joinbylocationsummary
import processing
processing.run("algorithm_id", {parameter_dictionary})
L”id algoritmo viene visualizzato quando passi il mouse sull’algoritmo nella finestra degli strumenti di Processing. Il dizionario dei parametri fornisce i nomi e i valori dei parametri. Vedi Usare gli algoritmi di Processing dalla console dei comandi per i dettagli su come eseguire gli algoritmi di processing dalla console Python.
24.1.22.21. Unisci attributi dal vettore più vicino
Prende un layer vettoriale in ingresso e crea un nuovo layer vettoriale con campi aggiuntivi nella sua tabella degli attributi. Gli attributi aggiuntivi e i loro valori sono presi da un secondo layer vettoriale. Gli elementi sono uniti trovando gli elementi più vicini da ciascun layer.
Per impostazione predefinita viene unito solo l’elemento più vicino, ma l’unione può anche essere fatta con gli elementi k più vicini.
Se viene specificata una distanza massima, solo gli elementi che sono più vicini di questa distanza saranno accoppiati.
Avvertimento
Questo algoritmo elimina le chiavi primarie o i valori FID esistenti e li rigenera nei layer di output.
Vedi anche
Analisi vicino più prossimo, Unisci attributi secondo il valore del campo, Unisci attributi per posizione, Matrice di distanza
Parametri
Etichetta |
Nome |
Tipo |
Descrizione |
|---|---|---|---|
Layer in ingresso |
|
[vector: geometry] |
Il layer di input. |
Layer in ingresso 2 |
|
[vector: geometry] |
Il layer per l’unione. |
Campi del layer 2 da copiare (lasciare vuoto per copiare tutti i campi) |
|
[fields] |
Unire i campi del layer da copiare (se vuoto, tutti i campi saranno copiati). |
Scartare i record che non possono essere uniti |
|
[boolean] Predefinito: False |
Rimuovere dal risultato i record del layer in ingresso che non è stato possibile unire |
Prefisso per il campo unito |
|
[string] |
Prefisso del campo unito |
Massimo più vicino |
|
[numeric: integer] Predefinito: 1 |
Numero massimo di vicini più vicini |
Massima distanza |
|
[numeric: double] |
Distanza di ricerca massima |
Layer unito Opzionale |
|
[same as input] Predefinito: |
Specifica il layer vettoriale contenente gli elementi uniti. One of:
La codifica del file può anche essere cambiata qui. |
Elementi non collegabili del primo layer |
|
[same as input] Predefinito: |
Specifica il layer vettoriale contenente gli elementi che non è stato possibile unire. One of:
La codifica del file può anche essere cambiata qui. |
In uscita:
Etichetta |
Nome |
Tipo |
Descrizione |
|---|---|---|---|
Layer unito |
|
[same as input] |
Il layer unito in uscita. |
Elementi non collegabili del primo layer |
|
[same as input] |
Layer contenente gli elementi del primo layer che non possono essere uniti a nessun elemento nel layer unito. |
Numero di elementi uniti dalla tabella di ingresso |
|
[numeric: integer] |
Numero di elementi della tabella in ingresso che sono stati uniti. |
Numero di elementi non accoppiabili provenienti dalla tabella in ingresso |
|
[numeric: integer] |
Numero di elementi della tabella in ingresso che non è stato possibile unire. |
Codice Python
ID Algoritmo: native:joinbynearest
import processing
processing.run("algorithm_id", {parameter_dictionary})
L”id algoritmo viene visualizzato quando passi il mouse sull’algoritmo nella finestra degli strumenti di Processing. Il dizionario dei parametri fornisce i nomi e i valori dei parametri. Vedi Usare gli algoritmi di Processing dalla console dei comandi per i dettagli su come eseguire gli algoritmi di processing dalla console Python.
24.1.22.22. Fondi vettori (merge)
Accorpa più layer vettoriali dello stesso tipo di geometria in uno solo.
La tabella degli attributi del layer risultante conterrà i campi di tutti i layer in ingresso. Se si trovano campi con lo stesso nome ma di tipo diverso, allora il campo esportato sarà automaticamente convertito in un campo di tipo stringa. Vengono anche aggiunti nuovi campi che memorizzano il nome del layer originale e la fonte.
Se uno qualsiasi dei layer in ingresso contiene valori Z o M, allora anche il layer in uscita conterrà questi valori. Allo stesso modo, se uno qualsiasi dei layer in ingresso è composto da più parti, anche il layer di uscita sarà un layer composto da più parti.
Opzionalmente, il sistema di riferimento delle coordinate di destinazione (SR) per il layer fuso può essere impostato. Se non è impostato, il SR sarà preso dal primo layer in ingresso. Tutti i layer saranno riproiettati per corrispondere a questo SR.
Menu predefinito:
Avvertimento
Questo algoritmo elimina le chiavi primarie o i valori FID esistenti e li rigenera nei layer di output.
Vedi anche
Parametri
Etichetta |
Nome |
Tipo |
Descrizione |
|---|---|---|---|
Layer in ingresso |
|
[vector: any] [list] |
I layer che devono essere uniti in un unico layer. I layer dovrebbero essere dello stesso tipo di geometria. |
SR di destinazione Opzionale |
|
[crs] |
Scegliere il SR per il layer in uscita. Se non viene specificato, viene usato il SR del primo layer in ingresso. |
Fuso |
|
[same as input] Predefinito: |
Specifica il layer vettoriale in uscita. One of:
La codifica del file può anche essere cambiata qui. |
In uscita:
Etichetta |
Nome |
Tipo |
Descrizione |
|---|---|---|---|
Fuso |
|
[same as input] |
Layer vettoriale in uscita che contiene tutti gli elementi e gli attributi dei layer in ingresso. |
Codice Python
ID Algoritmo: native:mergevectorlayers
import processing
processing.run("algorithm_id", {parameter_dictionary})
L”id algoritmo viene visualizzato quando passi il mouse sull’algoritmo nella finestra degli strumenti di Processing. Il dizionario dei parametri fornisce i nomi e i valori dei parametri. Vedi Usare gli algoritmi di Processing dalla console dei comandi per i dettagli su come eseguire gli algoritmi di processing dalla console Python.
24.1.22.23. Ordina tramite espressione
Ordina un layer vettoriale secondo un’espressione: cambia l’indice dell’elemento in base a un’espressione.
Fai attenzione, potrebbe non funzionare come previsto con alcuni provider, l’ordine potrebbe non essere rispettato ogni volta.
Avvertimento
Questo algoritmo elimina le chiavi primarie o i valori FID esistenti e li rigenera nei layer di output.
Parametri
Etichetta |
Nome |
Tipo |
Descrizione |
|---|---|---|---|
Layer in ingresso |
|
[vector: any] |
Layer vettoriale in ingresso da ordinare |
Espressione |
|
[expression] |
Espressione da usare per l’ordinamento |
Ordinamento ascendente |
|
[boolean] Predefinito: True |
Se spuntato, il layer vettoriale sarà ordinato da valori piccoli a valori grandi. |
Ordina i nulli come primi |
|
[boolean] Predefinito: False |
Se spuntato, i valori Null sono messi per primi |
Ordinato |
|
[same as input] Predefinito: |
Specifica il layer vettoriale in uscita. One of:
La codifica del file può anche essere cambiata qui. |
In uscita:
Etichetta |
Nome |
Tipo |
Descrizione |
|---|---|---|---|
Ordinato |
|
[same as input] |
Layer vettoriale in uscita (ordinato) |
Codice Python
ID Algoritmo: native:orderbyexpression
import processing
processing.run("algorithm_id", {parameter_dictionary})
L”id algoritmo viene visualizzato quando passi il mouse sull’algoritmo nella finestra degli strumenti di Processing. Il dizionario dei parametri fornisce i nomi e i valori dei parametri. Vedi Usare gli algoritmi di Processing dalla console dei comandi per i dettagli su come eseguire gli algoritmi di processing dalla console Python.
24.1.22.24. Ripara Shapefile
Ripara un insieme dei dati ESRI Shapefile corrotto (ri)creando il file SHX.
Parametri
Etichetta |
Nome |
Tipo |
Descrizione |
|---|---|---|---|
Shapefile in ingresso |
|
[file] |
Percorso completo all’insieme dei dati ESRI Shapefile con un file SHX mancante o corrotto. |
In uscita:
Etichetta |
Nome |
Tipo |
Descrizione |
|---|---|---|---|
Layer riparato |
|
[vector: geometry] |
Il layer vettoriale in ingresso con il file SHX riparato |
Codice Python
ID Algoritmo: native:repairshapefile
import processing
processing.run("algorithm_id", {parameter_dictionary})
L”id algoritmo viene visualizzato quando passi il mouse sull’algoritmo nella finestra degli strumenti di Processing. Il dizionario dei parametri fornisce i nomi e i valori dei parametri. Vedi Usare gli algoritmi di Processing dalla console dei comandi per i dettagli su come eseguire gli algoritmi di processing dalla console Python.
24.1.22.25. Riproietta layer
Riproietta un layer vettoriale in un diverso SR. Il layer riproiettato avrà gli stessi elementi e attributi del layer in ingresso.
Permette features in-place modification di punti, linee e poligoni
Parametri
Parametri di Base
Etichetta |
Nome |
Tipo |
Descrizione |
|---|---|---|---|
Layer in ingresso |
|
[vector: geometry] |
Layer vettoriale in ingresso da riproiettare |
SR di destinazione |
|
[crs] Predefinito: |
Sistema di riferimento delle coordinate di destinazione |
Convertire geometrie curve in segmenti rettilinei |
|
[boolean] Predefinito: False |
Se l’opzione è selezionata, le geometrie curve saranno convertite in segmenti rettilinei durante il processo, evitando potenziali problemi di distorsione. |
Riproiettato |
|
[same as input] Predefinito: |
Specifica il layer vettoriale in uscita. One of:
La codifica del file può anche essere cambiata qui. |
Parametri Avanzati
Etichetta |
Nome |
Tipo |
Descrizione |
|---|---|---|---|
Operazione sulle coordinate Opzionale |
|
[string] |
Operazione specifica da usare per un particolare task di riproiezione, invece di forzare sempre l’uso delle impostazioni di trasformazione del progetto corrente. Utile quando si riproietta un particolare layer ed è richiesto il controllo sull’esatta procedura di trasformazione. Richiede la versione di proj >= 6. Leggi di più su Trasformazioni Datum. |
In uscita:
Etichetta |
Nome |
Tipo |
Descrizione |
|---|---|---|---|
Riproiettato |
|
[same as input] |
Layer vettoriale in uscita (riproiettato) |
Codice Python
ID Algoritmo: native:reprojectlayer
import processing
processing.run("algorithm_id", {parameter_dictionary})
L”id algoritmo viene visualizzato quando passi il mouse sull’algoritmo nella finestra degli strumenti di Processing. Il dizionario dei parametri fornisce i nomi e i valori dei parametri. Vedi Usare gli algoritmi di Processing dalla console dei comandi per i dettagli su come eseguire gli algoritmi di processing dalla console Python.
24.1.22.26. Salva gli elementi vettoriali in un file
Salva gli elementi vettoriali in un file di dati specifico.
Per i formati di set di dati che supportano i layeri, è possibile utilizzare un parametro facoltativo del nome del layer per specificare una stringa personalizzata. È possibile specificare opzioni opzionali per set di dati e layer definiti da GDAL. Per maggiori informazioni a riguardo, leggere la documentazione online sul formato GDAL documentation .
Parametri
Parametri di Base
Etichetta |
Nome |
Tipo |
Descrizione |
|---|---|---|---|
Elementi vettoriali |
|
[vector: any] |
Layer vettoriale in ingresso. |
Elementi salvati |
|
[same as input] Predefinito: |
Specifica il file in cui salvare gli elementi. One of:
|
Parametri Avanzati
Etichetta |
Nome |
Tipo |
Descrizione |
|---|---|---|---|
Nome layer Opzionale |
|
[string] |
Nome da usare per il layer in uscita |
GDAL opzioni dataset Opzionale |
|
[string] |
Opzioni di creazione del dataset GDAL del formato in uscita. Separare le singole opzioni con il punto e virgola. |
GDAL opzioni layer Opzionale |
|
[string] |
Opzioni di creazione del layer GDAL del formato in uscita. Separare le singole opzioni con il punto e virgola. |
Azione da effettuare su un file preesistente |
|
[enumeration] Valore predefinito: 0 |
Come gestire gli elementi esistenti. I metodi validi sono:
|
In uscita:
Etichetta |
Nome |
Tipo |
Descrizione |
|---|---|---|---|
Elementi salvati |
|
[same as input] |
Layer vettoriale con gli elementi salvati. |
Nome file e percorso |
|
[string] |
Nome file in uscita e percorso. |
Nome layer |
|
[string] |
Nome del layer, se esiste. |
Codice Python
ID Algoritmo: native:savefeatures
import processing
processing.run("algorithm_id", {parameter_dictionary})
L”id algoritmo viene visualizzato quando passi il mouse sull’algoritmo nella finestra degli strumenti di Processing. Il dizionario dei parametri fornisce i nomi e i valori dei parametri. Vedi Usare gli algoritmi di Processing dalla console dei comandi per i dettagli su come eseguire gli algoritmi di processing dalla console Python.
24.1.22.27. Impostare la codifica dei layer
Imposta la codifica utilizzata per leggere gli attributi di un layer. Non vengono apportate modifiche permanenti al layer, ma influisce solo sul modo in cui il layer viene letto durante la sessione corrente.
Nota
La modifica della codifica è supportata solo per alcune fonti di dati del layer vettoriale.
Parametri
Etichetta |
Nome |
Tipo |
Descrizione |
|---|---|---|---|
Elementi salvati |
|
[vector: geometry] |
Layer vettoriale in cui impostare la codifica. |
Codifica |
|
[string] |
Codifica testo da assegnare al layer nella sessione QGIS corrente. |
In uscita:
Etichetta |
Nome |
Tipo |
Descrizione |
|---|---|---|---|
Layer in uscita |
|
[same as input] |
Layer vettoriale in ingresso con l’impostazione della codifica. |
Codice Python
ID Algoritmo: native:setlayerencoding
import processing
processing.run("algorithm_id", {parameter_dictionary})
L”id algoritmo viene visualizzato quando passi il mouse sull’algoritmo nella finestra degli strumenti di Processing. Il dizionario dei parametri fornisce i nomi e i valori dei parametri. Vedi Usare gli algoritmi di Processing dalla console dei comandi per i dettagli su come eseguire gli algoritmi di processing dalla console Python.
24.1.22.28. Dividi elementi per carattere
Gli elementi sono suddivisi in più elementi in uscita dividendo il valore di un campo in corrispondenza di un carattere specificato. Per esempio, se un layer contiene elementi con più valori separati da virgola contenuti in un singolo campo, questo algoritmo può essere usato per dividere questi valori in più elementi in uscita. Le geometrie e gli altri attributi rimangono invariati in uscita. Opzionalmente, la stringa separatrice può essere un’espressione regolare per una maggiore flessibilità.
Permette features in-place modification di punti, linee e poligoni
Avvertimento
Questo algoritmo elimina le chiavi primarie o i valori FID esistenti e li rigenera nei layer di output.
Parametri
Etichetta |
Nome |
Tipo |
Descrizione |
|---|---|---|---|
Layer in ingresso |
|
[vector: any] |
Layer vettoriale in input |
Dividere usando valori nel campo |
|
[tablefield: any] |
Campo da usare per la divisione |
Valore di divisione tramite carattere |
|
[string] |
Carattere da usare per la divisione |
Usa il separatore di espressione regolare. |
|
[boolean] Predefinito: False |
|
Suddiviso |
|
[same as input] Predefinito: |
Specifica il layer vettoriale in uscita. One of:
La codifica del file può anche essere cambiata qui. |
In uscita:
Etichetta |
Nome |
Tipo |
Descrizione |
|---|---|---|---|
Suddiviso |
|
[same as input] |
Il layer vettoriale in uscita. |
Codice Python
ID Algoritmo: native:splitfeaturesbycharacter
import processing
processing.run("algorithm_id", {parameter_dictionary})
L”id algoritmo viene visualizzato quando passi il mouse sull’algoritmo nella finestra degli strumenti di Processing. Il dizionario dei parametri fornisce i nomi e i valori dei parametri. Vedi Usare gli algoritmi di Processing dalla console dei comandi per i dettagli su come eseguire gli algoritmi di processing dalla console Python.
24.1.22.29. Dividi vettore
Crea un insieme di vettori in una cartella in uscita sulla base di un layer in ingresso e di un attributo. La cartella di output conterrà tanti layer quanti sono i valori univoci trovati nel campo scelto.
Il numero di file generati è uguale al numero di valori diversi trovati per l’attributo specificato.
È l’operazione opposta a quella di fusione.
Menu predefinito:
Vedi anche
Parametri
Parametri di Base
Etichetta |
Nome |
Tipo |
Descrizione |
|---|---|---|---|
Layer in ingresso |
|
[vector: any] |
Layer vettoriale in input |
Campo ID univoco |
|
[tablefield: any] |
Campo da usare per la divisione |
Cartella in uscita |
|
[folder] Predefinito: |
Specifica la cartella per i layer in uscita. One of 1:
|
Parametri Avanzati
Etichetta |
Nome |
Tipo |
Descrizione |
|---|---|---|---|
Tipo file in uscita Opzionale |
|
[enumeration] Predefinito: |
Seleziona l’estensione dei file in uscita. Se non viene specificata o non è valida, il formato dei file in uscita sarà quello impostato nell’impostazione di elaborazione «Estensione predefinita del layer vettoriale in uscita». |
In uscita:
Etichetta |
Nome |
Tipo |
Descrizione |
|---|---|---|---|
Cartella in uscita |
|
[folder] |
La cartella per i layer in uscita |
Layer in uscita |
|
[same as input] [list] |
I layer vettoriali in uscita risultanti dalla divisione. |
Codice Python
ID Algoritmo: native:splitvectorlayer
import processing
processing.run("algorithm_id", {parameter_dictionary})
L”id algoritmo viene visualizzato quando passi il mouse sull’algoritmo nella finestra degli strumenti di Processing. Il dizionario dei parametri fornisce i nomi e i valori dei parametri. Vedi Usare gli algoritmi di Processing dalla console dei comandi per i dettagli su come eseguire gli algoritmi di processing dalla console Python.
24.1.22.30. Tronca tabella
Ridurre un layer, cancellando tutti gli elementi dall’interno del layer.
Avvertimento
Questo algoritmo modifica il layer sul posto, e gli elementi cancellati non possono essere ripristinati!
Parametri
Etichetta |
Nome |
Tipo |
Descrizione |
|---|---|---|---|
Layer in ingresso |
|
[vector: any] |
Layer vettoriale in input |
In uscita:
Etichetta |
Nome |
Tipo |
Descrizione |
|---|---|---|---|
Layer ridotto |
|
[folder] |
Il layer in ingresso, tutte gli elementi eliminati |
Codice Python
ID Algoritmo: native:truncatetable
import processing
processing.run("algorithm_id", {parameter_dictionary})
L”id algoritmo viene visualizzato quando passi il mouse sull’algoritmo nella finestra degli strumenti di Processing. Il dizionario dei parametri fornisce i nomi e i valori dei parametri. Vedi Usare gli algoritmi di Processing dalla console dei comandi per i dettagli su come eseguire gli algoritmi di processing dalla console Python.