15.3. 데이터 포맷 및 필드 탐구
15.3.1. 래스터 데이터
GIS에서 래스터 데이터는 지표면 상, 위 또는 아래에 있는 객체/현상을 표현하는 개별 셀들의 매트릭스를 뜻합니다. 래스터 그리드의 각 셀은 모두 동일한 크기이며 대부분의 경우 직사각형입니다. (QGIS에서는 언제나 직사각형일 겁니다.) 전형적인 래스터 데이터는 항공사진 또는 위성 이미지와, 표고 또는 기온 같은 모델 데이터 등의 원격탐사 데이터를 포함합니다.
벡터 데이터와는 달리, 래스터 데이터는 일반적으로 각 셀에 관련된 데이터베이스 레코드를 보유하지 않습니다. 래스터 데이터는 래스터 레이어의 픽셀 해상도 및 모서리 픽셀의 X/Y 좌표로 지오코딩돼 있습니다. 덕분에 QGIS가 맵 캔버스에 데이터를 정확하게 배치할 수 있습니다.
QGIS 작업 시 래스터 데이터를 저장하는 데에는 GeoPackage 포맷이 편리합니다. 유명하고 강력한 GeoTiff 포맷도 훌륭한 대안이지요.
QGIS는 GeoTiff 같은 래스터 레이어 또는 관련 월드 파일(world file) 내부에 있는 지리참조 정보를 이용해서 데이터를 제대로 표시합니다.
15.3.2. 벡터 데이터
벡터 데이터소스와 상관없이, QGIS에서 사용할 수 있는 많은 기능과 도구들은 동일하게 작동합니다. 하지만 GeoPackage, ESRI Shapefile, MapInfo 및 MicroStation 파일 포맷, AutoCAD DXF, PostGIS, SpatiaLite, Oracle Spatial, MS SQL 서버, SAP HANA 공간 데이터베이스, 그 외에도 수많은 포맷들의 사양 차이 때문에 QGIS가 포맷들의 일부 속성들을 서로 다르게 처리할 수도 있습니다. GDAL 벡터 드라이버 가 지원을 제공합니다. 이 단락에서는 이런 사양들을 어떻게 작업하는지에 대해 설명합니다.
참고
QGIS는 Z 그리고/또는 M 값을 보유할 수도 있는 [멀티]포인트, [멀티]라인, [멀티]폴리곤, CircularString, CompoundCurve, CurvePolygon, MultiCurve, MultiSurface 피처 유형을 지원합니다.
일부 드라이버가 CircularString, CompoundCurve, CurvePolygon, MultiCurve, MultiSurface 같은 일부 피처 유형을 지원하지 않는다는 사실도 알아두어야 합니다. 이 경우 QGIS는 이 유형들을 변환할 것입니다.
15.3.2.1. GeoPackage
GeoPackage (GPKG) 포맷은 플랫폼 독립적이며, SQLite 데이터베이스 컨테이너로 실행되고, 벡터와 래스터 데이터 둘 다 저장할 수 있습니다. OGC(Open Geospatial Consortium)가 정의한 이 포맷은 2014년 공개되었습니다.
SQLite 데이터베이스에 다음을 저장하는 데 GeoPackage를 사용할 수 있습니다:
벡터 피처
이미지의 타일 매트릭스 집합 및 래스터 맵
속성 (비공간 데이터)
확장자
GeoPackage는 QGIS 3.8 버전부터 QGIS 프로젝트도 저장할 수 있습니다. GeoPackage 레이어는 JSON 필드를 보유할 수 있습니다.
GeoPackage는 QGIS의 벡터 데이터용 기본 포맷입니다.
15.3.2.2. ESRI Shapefile 포맷
ESRI Shapefile 포맷은, 예를 들어 GeoPackage 및 SpatiaLite와 비교하면 몇몇 제한이 존재하더라도, 지금도 QGIS에서 가장 자주 이용되는 벡터 파일 포맷 가운데 하나입니다.
ESRI Shapefile 포맷 데이터셋은 파일 몇 개로 이루어져 있습니다. 다음은 필수적인 파일 3개입니다:
.shp: 피처 도형을 담고 있는 파일.dbf: dBase 서식으로 속성을 담고 있는 파일.shx: 인덱스 파일
ESRI Shapefile 포맷 데이터셋은 .prj 확장자를 쓰는 파일도 포함할 수 있는데, 이 파일은 투영체 정보를 담고 있습니다. 투영체 파일이 있다면 매우 유용하지만, 필수적인 파일은 아닙니다. Shapefile 포맷 데이터셋은 추가 파일들을 포함할 수도 있습니다. 더 자세한 내용은 ESRI 기술 사양 문서 를 참조하세요.
GDAL은 압축 ESRI Shapefile 포맷(shz 및 shp.zip) 읽고 쓰기를 지원합니다.
ESRI Shapefile 포맷 데이터셋 성능 향상
ESRI Shapefile 포맷 데이터셋 렌더링 성능을 향상시키려면, 공간 인덱스를 생성하면 됩니다. 공간 인덱스가 있다면 확대/축소 및 이동 속도도 향상됩니다. QGIS가 이용하는 공간 인덱스 파일의 확장자는 .qix 입니다.
다음 단계를 통해 인덱스를 생성하십시오:
ESRI Shapefile 포맷 데이터셋을 불러옵니다. (탐색기 패널 참조)
범례에 있는 레이어명을 더블클릭하거나, 또는 오른쪽 클릭한 다음 컨텍스트 메뉴에서 를 선택해서 Layer Properties 대화창을 엽니다.
Source 탭에서 Create Spatial Index 버튼을 클릭하십시오.
.prj 파일을 불러올 때의 문제
.prj 파일을 보유한 ESRI Shapefile 포맷 데이터셋을 불러올 때 QGIS가 해당 파일에서 좌표계를 읽어들일 수 없는 경우, 해당 레이어의 탭에서  Select CRS 버튼을 클릭한 다음 적절한 투영체를 직접 정의해줘야 합니다.
Select CRS 버튼을 클릭한 다음 적절한 투영체를 직접 정의해줘야 합니다. .prj 파일이 QGIS에서 사용되는, CRS 대화창 목록에 있는 완전한 투영체 파라미터를 제공하지 못 하는 경우가 많기 때문입니다.
같은 이유로, QGIS에서 새 ESRI Shapefile 포맷 데이터셋을 생성할 때, ESRI 소프트웨어와 호환되는 제한적인 투영체 파라미터를 담고 있는 .prj 파일과, 사용 좌표계의 완전한 파라미터를 제공하는 .qpj 파일, 2개의 서로 다른 투영체 파일을 생성합니다. .qpj 파일이 존재하는 경우, QGIS는 .prj 파일 대신 .qpj 파일을 이용할 것입니다.
15.3.2.3. 구분 텍스트 파일
구분(delimited) 텍스트 파일은 그 단순성과 가독성 때문에 ─ 평범한 텍스트 편집기에서도 데이터를 살펴보고 편집할 수 있기 때문에 ─ 매우 흔하고 널리 쓰입니다. 구분 텍스트 파일은 각 열을 지정된 문자로 구분하고 각 행을 줄바꿈으로 구분하는 테이블형 데이터입니다. 첫 행은 보통 열 이름을 담고 있습니다. CSV(Comma Separated Values)는 각 열을 쉼표로 구분하는 흔한 구분 텍스트 파일 유형입니다. 구분 텍스트 파일은 위치 정보를 담을 수도 있습니다. (구분 텍스트 파일에 지리 정보 저장하기 참조)
QGIS는 구분 텍스트 파일을 레이어 또는 일반 테이블로 불러올 수 있습니다. (탐색기 패널 또는 구분 텍스트 파일 가져오기 를 참조하세요.) 먼저 파일이 다음 조건을 만족시키는지 확인하십시오:
파일이 필드명을 담은 구분된 헤더(header) 행을 보유해야만 합니다. 헤더 행은 데이터의 첫 줄(이상적으로는 텍스트 파일의 첫 행)이어야만 합니다.
도형을 활성화해야 하는 경우, 파일이 도형 정의 필드(들)를 포함해야만 합니다. 이 필드(들)의 이름은 어떤 것이라도 가능합니다.
도형이 좌표로 정의된 경우, X와 Y 좌표 필드는 숫자로 지정돼야만 합니다. 어떤 좌표계인지는 중요하지 않습니다.
문자열이 아닌 데이터를 CSV 파일로 저장하는 경우 CSVT 파일을 이용하면 됩니다. (필드 서식 제어에 CSVT 파일 사용하기 를 참조하세요.)
유효한 텍스트 파일의 예로, QGIS 예시 데이터셋(예시 데이터 다운로드 참조)에 들어 있는 다음 elevp.csv 표고 포인트 데이터 파일을 불러들이겠습니다:
X;Y;ELEV
-300120;7689960;13
-654360;7562040;52
1640;7512840;3
[...]
이 텍스트 파일에 대해 알아두어야 할 점은 다음과 같습니다:
이 예시 텍스트 파일은 구분자로
;(쌍반점)을 씁니다. (어떤 문자라도 필드를 구분하는 데 쓸 수 있습니다.)첫 줄이 헤더 행입니다.
X,Y및ELEV필드를 담고 있습니다.텍스트 필드를 구분하는 데 큰따옴표(
")를 쓰지 않습니다.X 좌표는
X필드에 담겨 있습니다.Y 좌표는
Y필드에 담겨 있습니다.
구분 텍스트 파일에 지리 정보 저장하기
구분 텍스트 파일은 다음과 같은 주된 양식 2개로 지리 정보를 담을 수 있습니다:
포인트 도형 데이터의 경우, 분리된 열에 (예:
Xcol,Ycol등등) 좌표로 저장모든 도형 유형의 경우, 단일 열에 도형의 WKT(Well-Known Text) 표현으로 저장
만곡 도형(CircularString, CurvePolygon 및 CompoundCurve) 피처를 지원합니다. 다음은 구분 텍스트 파일에 도형을 WKT로 코딩한 도형 유형의 예시입니다:
Label;WKT_geom
LineString;LINESTRING(10.0 20.0, 11.0 21.0, 13.0 25.5)
CircularString;CIRCULARSTRING(268 415,227 505,227 406)
CurvePolygon;CURVEPOLYGON(CIRCULARSTRING(1 3, 3 5, 4 7, 7 3, 1 3))
CompoundCurve;COMPOUNDCURVE((5 3, 5 13), CIRCULARSTRING(5 13, 7 15,
9 13), (9 13, 9 3), CIRCULARSTRING(9 3, 7 1, 5 3))
구분 텍스트 파일은 도형의 Z 및 M 좌표도 지원합니다:
LINESTRINGZ(10.0 20.0 30.0, 11.0 21.0 31.0, 11.0 22.0 30.0)
필드 서식 제어에 CSVT 파일 사용하기
CSV 파일을 불러올 때, 달리 지정하지 않는 이상 GDAL 드라이버는 모든 필드가 (텍스트 등의) 문자열이라고 가정합니다. GDAL 드라이버에 (그리고 QGIS에) 서로 다른 열들이 어떤 데이터 유형인지 알려준 다음 CSVT 파일을 생성할 수 있습니다:
유형 |
이름 |
예시 |
|---|---|---|
범자연수(Whole number) |
Integer |
4 |
불(Boolean) |
Integer(Boolean) |
true |
십진수(Decimal number) |
Real |
3.456 |
날짜 |
Date (YYYY-MM-DD) |
2016-07-28 |
시간 |
Time (HH:MM:SS+nn) |
18:33:12+00 |
날짜&시간 |
DateTime (YYYY-MM-DD HH:MM:SS+nn) |
2016-07-28 18:33:12+00 |
CoordX |
CoordX |
8.8249 |
CoordY |
CoordY |
47.2274 |
Point(X) |
Point(X) |
8.8249 |
Point(Y) |
Point(Y) |
47.2274 |
WKT |
WKT |
POINT(15 20) |
CSVT 파일은 데이터 유형을 따옴표로 표현하고 쉼표 등으로 구분하는, 다음과 같은 한 줄 짜리 평문 텍스트 파일입니다:
"Integer","Real","String"
각 열의 길이(width)와 정밀도도 다음과 같이 설정할 수 있습니다:
"Integer(6)","Real(5.5)","String(22)"
이 파일은 .csv 파일과 동일한 폴더에 저장됩니다. 파일명은 CSV 파일과 동일해야 하지만, 확장자는 .csvt 를 씁니다.
더 자세한 내용은 GDAL CSV 드라이버 에서 찾아볼 수 있습니다.
팁
필드 유형 탐지
데이터 유형을 말해주는 CSVT 파일을 사용하는 대신, QGIS는 필드 유형을 자동으로 탐지하고 해당 필드 유형으로 변경시킬 수 있는 기능을 제공하고 있습니다.
15.3.2.4. PostGIS 레이어
PostGIS 레이어는 PostgreSQL 데이터베이스에 저장돼 있습니다. PostGIS의 장점은 공간 인덱스, 필터링 및 쿼리 작업 능력입니다. PostGIS를 이용하면, 선택 및 식별 같은 벡터 기능들을 QGIS에서 GDAL 레이어로 작업하는 것보다 더 정확하게 작업할 수 있습니다.
팁
PostGIS 레이어
일반적으로, geometry_columns 테이블의 항목이 PostGIS 레이어를 식별합니다. QGIS는 geometry_columns 테이블에 항목이 없는 레이어를 불러올 수 있습니다. 테이블과 뷰 둘 다 말입니다. 뷰 생성에 대한 정보는 PostgreSQL 사용자 지침서를 참조하십시오.
QGIS가 PostgreSQL 레이어에 접근하는 몇몇 방법에 대해 자세히 설명하겠습니다. 대부분의 경우 QGIS는 불러올 수 있는 데이터베이스 테이블 목록을 제공하고, 사용자 요청에 따라 테이블을 불러올 것입니다. 하지만 QGIS로 PostgreSQL 테이블을 불러오는 데 문제가 있을 경우, 다음 내용을 통해 QGIS 메시지를 이해해서 PostgreSQL 테이블 또는 뷰 정의를 수정하면 QGIS가 테이블 또는 뷰를 불러올 수 있을 것입니다.
참고
PostgreSQL 데이터베이스도 QGIS 프로젝트를 저장할 수 있습니다.
기본 키
QGIS가 PostgreSQL 레이어를 불러오려면, 레이어에 유일(unique) 키로 이용할 수 있는 열이 있어야 합니다. 테이블의 경우, 일반적으로 테이블에 기본 키(primary key) 또는 유일 제약조건 열이 있어야 한다는 뜻입니다. QGIS에서 이 열은 int4(4바이트 정수) 유형이어야 합니다. CTID 열을 기본 키로 대신 쓸 수도 있습니다. 테이블에 이런 항목들이 없는 경우, OID 열을 대신 사용할 것입니다. 열을 인덱스 작업하면 성능이 향상됩니다. (PostgreSQL은 기본 키를 자동적으로 인덱스 작업한다는 사실을 기억하십시오.)
QGIS 의  Select at id 체크박스는 기본적으로 활성화돼 있습니다. 이 옵션을 활성화하면 속성 없이 ID를 가져오는데, 대부분의 경우 훨씬 빠릅니다.
Select at id 체크박스는 기본적으로 활성화돼 있습니다. 이 옵션을 활성화하면 속성 없이 ID를 가져오는데, 대부분의 경우 훨씬 빠릅니다.
뷰
PostgreSQL 레이어가 뷰인 경우 요구 사항은 동일하지만, 뷰가 언제나 기본 키 또는 유일 제약조건 열을 보유하고 있는 것은 아닙니다. QGIS에 뷰를 불러오려면 먼저 대화창에서 기본 키 항목을 (정수 유형으로) 정의해야 합니다. 뷰에 적당한 열이 없는 경우, QGIS는 레이어를 불러오지 못 합니다. 이 경우 적당한 열을 (기본 키 또는 유일 제약조건을 가진 정수 유형, 인덱스 작업 추천) 포함하도록 뷰를 수정해야 합니다.
테이블인 경우, Select at id 체크박스가 기본적으로 활성화돼 있습니다. (이 체크박스의 의미는 바로 앞에서 설명했습니다.) 사용자가 대용량 뷰를 이용하는 경우 이 옵션을 비활성화하는 편이 좋습니다.
참고
PostgreSQL 외래 테이블
PostgreSQL 제공자는 PostgreSQL 외래(foreign) 테이블을 분명하게 지원하지 않으며, 뷰처럼 처리할 것입니다.
QGIS layer_style 테이블 및 데이터베이스 백업
pg_dump 와 pg_restore 명령어를 이용해서 사용자 PostGIS 데이터베이스를 백업하려 하는데 기본 레이어 스타일을 QGIS에서 저장한 대로 복구되지 않는다면, 복구 명령 전에 DOCUMENT 에 XML 옵션을 설정해줘야 합니다.
layer_style테이블을 평문으로 백업하십시오.텍스트 편집기에서 백업 파일을 여십시오.
SET xmloption = content;줄을SET XML OPTION DOCUMENT;로 변경하십시오.파일을 저장하십시오.
PostgreSQL의 psql을 이용해서 새 데이터베이스에 테이블을 복원하십시오.
데이터베이스 쪽에서 필터링
QGIS 는 서버 쪽에 있는 피처를 필터링할 수 있습니다. 체크박스를 활성화하면 됩니다. 이 옵션을 활성화하면 데이터베이스에 지원하는 표현식만 전송할 것입니다. 지원하지 않는 연산자 또는 함수를 이용한 표현식은 자연스럽게 폴백(fallback)되어 로컬에서 평가될 것입니다.
PostgreSQL 데이터 유형의 지원
PostgreSQL 제공자는 정수형, 부동소수점 실수형, 불린(boolean), 2진 객체(binary object), 문자형(varchar), 도형형, 타임스탬프(timestamp), 배열(array), HStore, JSON 등의 데이터 유형을 지원합니다.
15.3.2.5. PostgreSQL로 데이터 가져오기
DB 관리자 플러그인과 shp2pgsql 및 ogr2ogr 명령 줄 도구를 포함하는 도구 몇 가지를 이용해서 PostgreSQL/PostGIS로 데이터를 가져올 수 있습니다.
DB 관리자
QGIS는  DB Manager 라는 핵심 플러그인을 내장하고 있습니다. 이 도구는 데이터를 불러오는 데 쓸 수 있으며, 스키마를 지원하기도 합니다. 더 자세한 내용은 데이터베이스 관리자 플러그인 을 참조하세요.
DB Manager 라는 핵심 플러그인을 내장하고 있습니다. 이 도구는 데이터를 불러오는 데 쓸 수 있으며, 스키마를 지원하기도 합니다. 더 자세한 내용은 데이터베이스 관리자 플러그인 을 참조하세요.
shp2pgsql
PostGIS는 PostGIS 호환 데이터베이스로 Shapefile 포맷 데이터셋을 불러올 수 있는 shp2pgsql 이라는 기능을 포함하고 있습니다. 예를 들어, gis_data 라는 PostgreSQL 데이터베이스로 lakes.shp 이라는 Shapefile 포맷 데이터셋을 가져오려면, 다음 명령어를 사용하십시오:
shp2pgsql -s 2964 lakes.shp lakes_new | psql gis_data
이 명령어는 gis_data 데이터베이스에 lakes_new 라는 새 레이어를 생성합니다. 이 새 레이어는 SRID(Spatial Reference IDentifier) 2964를 적용받게 됩니다. 공간 참조 시스템 및 투영체에 대한 더 자세한 내용은 투영 작업 을 참조하세요.
팁
PostGIS에서 데이터셋 내보내기
PostGIS 데이터베이스를 Shapefile 포맷 데이터셋으로 내보내는 도구인 pgsql2shp 도 있습니다. 이 도구도 PostGIS 배포판에 내장돼 있습니다.
ogr2ogr
shp2pgsql 및 DB 관리자 이외에, PostGIS로 지리 데이터를 불러올 수 있는 또다른 도구인 ogr2ogr 도 있습니다. 이 도구는 사용자가 GDAL 을 설치할 때 함께 설치됩니다.
PostGIS로 Shapefile 포맷 데이터셋을 가져오려면, 다음 명령어를 입력하십시오:
ogr2ogr -f "PostgreSQL" PG:"dbname=postgis host=myhost.de user=postgres
password=topsecret" alaska.shp
이 명령어는 호스트 서버 myhost.de 에 있는 PostGIS 데이터베이스 postgis 로 Shapefile 포맷 데이터셋 alaska.shp 를 사용자 postgre 와 비밀번호 topsecret 을 이용해서 불러올 것입니다.
PostGIS를 지원하려면 GDAL을 PostgreSQL과 함께 빌드해야만 한다는 사실을 기억하십시오. 함께 빌드했는지 확인하려면 ( 에서) 다음과 같이 입력해보세요:
에서) 다음과 같이 입력해보세요:
ogrinfo --formats | grep -i post
PostgreSQL의 기본 메소드인 INSERT INTO 대신 COPY 명령어를 더 선호하는 경우, 다음 명령어로 (적어도 와  에서는) 다음 환경 변수를 내보낼 수 있습니다:
에서는) 다음 환경 변수를 내보낼 수 있습니다:
export PG_USE_COPY=YES
ogr2ogr 도구는 shp2pgsl 처럼 공간 인덱스를 생성하지 않습니다. Shapefile 포맷 데이터셋을 불러온 후에 (다음 성능 향상시키기 에서 설명하는 대로) 추가 단계로 일반적인 SQL 명령어 CREATE INDEX 를 이용해서 직접 생성해야 합니다.
성능 향상시키기
특히 네트워크를 통할 경우, PostgreSQL 데이터베이스에서 피처를 받아오는 작업에 시간이 많이 걸릴 수 있습니다. 데이터베이스에 있는 각 레이어가 PostGIS 공간 인덱스를 보유하도록 보장해서 PostgreSQL 레이어의 렌더링 속도를 향상시킬 수 있습니다. PostGIS는 공간 검색 속도를 높이기 위해 GiST(Generalized Search Tree) 인덱스를 생성할 수 있습니다. (GiST 인덱스에 대한 정보는 PostGIS 문서 를 참조하세요.)
팁
DB 관리자를 이용해서 사용자 레이어에 인덱스를 생성할 수 있습니다. 먼저 레이어를 선택한 다음 메뉴를 클릭하고, 탭에서 Add Spatial Index 를 클릭하십시오.
GiST 인덱스를 생성하기 위한 문법은 다음과 같습니다:
CREATE INDEX [indexname] ON [tablename]
USING GIST ( [geometryfield] GIST_GEOMETRY_OPS );
대용량 테이블의 경우 인덱스 생성 작업이 오래 걸릴 수 있다는 점을 기억하십시오. 인덱스가 생성되고 나면, VACUUM ANALYZE 명령을 실행해야 합니다. 더 자세한 내용은 PostGIS 문서(참고 문헌 및 웹사이트 에 있는 POSTGIS-PROJECT)를 참조하세요.
다음은 GiST 인덱스를 생성하는 예시입니다:
gsherman@madison:~/current$ psql gis_data
Welcome to psql 8.3.0, the PostgreSQL interactive terminal.
Type: \copyright for distribution terms
\h for help with SQL commands
\? for help with psql commands
\g or terminate with semicolon to execute query
\q to quit
gis_data=# CREATE INDEX sidx_alaska_lakes ON alaska_lakes
gis_data-# USING GIST (the_geom GIST_GEOMETRY_OPS);
CREATE INDEX
gis_data=# VACUUM ANALYZE alaska_lakes;
VACUUM
gis_data=# \q
gsherman@madison:~/current$
15.3.2.6. SpatiaLite 레이어
벡터 레이어를 SpatiaLite 포맷으로 저장하고 싶다면, 기존 레이어로부터 레이어 생성 에 있는 지침을 따르면 됩니다. Format 을 SpatiaLite 으로 선택하고 File name 과 Layer name 을 둘 다 입력하십시오.
또는 포맷을 SQLite 으로 선택한 다음 란에 SPATIALITE=YES 를 추가해도 됩니다. 이렇게 하면 GDAL이 SpatiaLite 데이터베이스를 추가할 겁니다. https://gdal.org/drivers/vector/sqlite.html 도 참조하세요.
QGIS는 SpatiaLite에서 편집할 수 있는 뷰도 지원합니다. SpatiaLite 데이터를 관리하고자 한다면, 핵심 플러그인인 DB 관리자 를 이용할 수도 있습니다.
새 SpatiaLite 레이어를 생성하고 싶다면, 새 SpatiaLite 레이어 생성하기 를 참조해주세요.
15.3.2.7. GeoJSON 특화 파라미터
GeoJSON으로 레이어를 내보내는 경우, 특화된 몇몇 Layer Options 를 사용할 수 있습니다. 이 특화 옵션은 해당 파일의 작성을 책임지는 GDAL이 제공합니다.
COORDINATE_PRECISION: 좌표 작성 시 소수점 뒤에 올 최대 자릿수입니다. 기본값은 15입니다. (참고: 위경도 좌표의 경우 6이면 충분하다고 간주합니다.) 잘라내기(truncation) 기능이 이 자릿수 뒤의 0들을 제거할 것입니다.
RFC7946: 기본값(NO)은 GeoJSON 2008입니다. YES로 설정하면 업데이트된 RFC 7946 표준을 사용할 것입니다. 주요 차이점은 https://gdal.org/drivers/vector/geojson.html#rfc-7946-write-support 를 참조하세요. 간단히 요약하면: EPSG:4326만 사용할 수 있고, 다른 좌표계는 변환될 것이며, 방향의 오른손 법칙을 따르도록 폴리곤을 작성할 것이고, “경계 상자(bbox)” 배열의 값은 [minx, miny, maxx, maxy]가 아닌 [west, south, east, north]입니다. 피처 집합(FeatureCollection), 피처 및 도형 객체에서 일부 확장자 이름들을 사용할 수 없으며, 기본 좌표 정밀도는 십진수 7자리입니다.
WRITE_BBOX: YES로 설정하면 피처 및 피처 집합 수준에서 도형의 경계 상자를 포함합니다.
GeoJSON 이외에, “GeoJSON - 새줄 문자 구분(Newline Delimited)” 으로 내보낼 수 있는 옵션도 있습니다. (https://gdal.org/drivers/vector/geojsonseq.html 참조) 피처를 가진 피처 집합(FeatureCollection with Features) 대신 새줄 문자(newline)로 연속적으로 구분된 (아마도 피처만의) 한 유형을 줄줄이 이어지게 할 수 있습니다.
GeoJSON - 새줄 문자 구분도 몇몇 특화된 레이어 옵션을 사용할 수 있습니다:
COORDINATE_PRECISION: 앞의 설명 참조 (GeoJSON과 동일)
RS: 레코드를 RS=0x1E 문자로 시작할지 여부를 결정합니다. 피처를 어떻게 구분하는가의 차이입니다: 새줄(LF) 문자만으로 구분할 수도 있고 (새줄 문자 구분 JSON, geojsonl) 또는 접두어로 레코드 구분자(RS) 문자를 붙일 수도 (GeoJSON 텍스트 시퀀스, geojsons) 있습니다. 기본값은 NO입니다. 확장자를 지정하지 않을 경우 파일에
.json확장자를 붙입니다.
15.3.2.8. SAP HANA 공간 레이어
QGIS가 SAP HANA 레이어에 접근하는 몇몇 방법에 대해 자세히 설명하겠습니다. 대부분의 경우 QGIS는 불러올 수 있는 데이터베이스 테이블 및 뷰 목록을 제공하고, 사용자 요청에 따라 테이블을 불러올 것입니다. 하지만 QGIS로 SAP HANA 테이블 및 뷰를 불러오는 데 문제가 있을 경우, 다음 내용을 통해 기저 원인을 이해하고 문제점을 해결할 수 있을 것입니다.
피처 식별
QGIS의 모든 편집 작업 케이퍼빌리티를 이용하고 싶다면, QGIS가 레이어에 있는 각 피처를 확실하게 식별할 수 있어야만 합니다. QGIS는 내부적으로 64비트 부호 있는 정수형을 사용해서 피처를 식별하는 데, 이때 음수 범위를 특수 목적 용으로 예약해 둡니다.
따라서 SAP HANA 제공자가 QGIS의 피처 편집 작업 케이퍼빌리티를 완전하게 지원하려면 양의 64비트 정수형에 매핑될 수 있는 유일 키가 필요하게 됩니다. 이런 매핑을 할 수 없는 경우, 그래도 피처를 볼 수는 있겠지만 편집 작업은 할 수 없을지도 모릅니다.
테이블 추가하기
테이블을 레이어로 추가하는 경우 SAP HANA 제공자는 테이블의 기본 키를 이용해서 유일 FID(Feature ID)에 매핑시킵니다. 따라서 피처 편집 작업을 완전하게 지원하려면 사용자의 테이블 정의에 기본 키가 있어야 합니다.
SAP HANA 제공자가 다중 열 기본 키를 지원하긴 하지만, 최고의 성능을 보이길 원한다면 사용자의 기본 키가 INTEGER 유형의 단일 열이어야 합니다.
뷰 추가하기
뷰를 레이어로 추가하는 경우 SAP HANA 제공자는 피처를 확실하게 식별하는 열을 자동으로 식별하지 못 합니다. 게다가 몇몇 뷰는 읽기 전용으로 편집할 수 없기도 합니다.
피처 편집 작업을 완전하게 지원하려면, 뷰가 업데이트 가능해야 하며 (해당 뷰에 대한 SYS.VIEWS 시스템 뷰에 있는 IS_READ_ONLY 열을 확인하십시오) 사용자가 QGIS에 피처를 식별하는 하나 이상의 열을 직접 지정해줘야만 합니다. 메뉴에서 Feature id 열에 있는 열을 선택하면 열을 지정할 수 있습니다. 최고의 성능을 바란다면, Feature id 값이 단일 INTEGER 열이어야 합니다.
15.3.3. 경도 180° 선을 가로지르는 레이어
많은 GIS 패키지들이 경도 180˚ 선을 가로지르는 지리 참조 시스템(위도/경도)으로 레이어를 감싸고 있지 않습니다. 그 결과, QGIS에서 이런 레이어를 열었을 때, 서로 가까이 있어야 하지만 멀리 떨어져 있는 두 위치를 보게 됩니다. 그림 15.27 에서, 맵 캔버스 왼쪽 구석에 있는 작은 점들(채텀 제도)은 그리드 내부, 뉴질랜드 본도의 오른쪽에 있어야 합니다.

그림 15.27 경도 180° 선을 가로지르는 위도/경도 맵
15.3.3.1. PostGIS에서 해결하기
PostGIS와 ST_ShiftLongitude 함수를 이용해서 경도값을 변환시키는 것도 해결책이 될 수 있습니다. 이 함수는 도형의 모든 피처에 있는 모든 요소의 모든 포인트/꼭짓점을 읽어들여 그 경도 좌표가 -180~0° 또는 180~360° 범위에 있을 경우 좌표를 각각 180~360° 또는 -180~0° 범위로 변이시킵니다. 이 함수는 대칭적이기 때문에, -180~180° 범위의 데이터를 0~360° 범위로 산출하고 0~360° 범위의 데이터를 -180~180° 범위로 산출합니다.
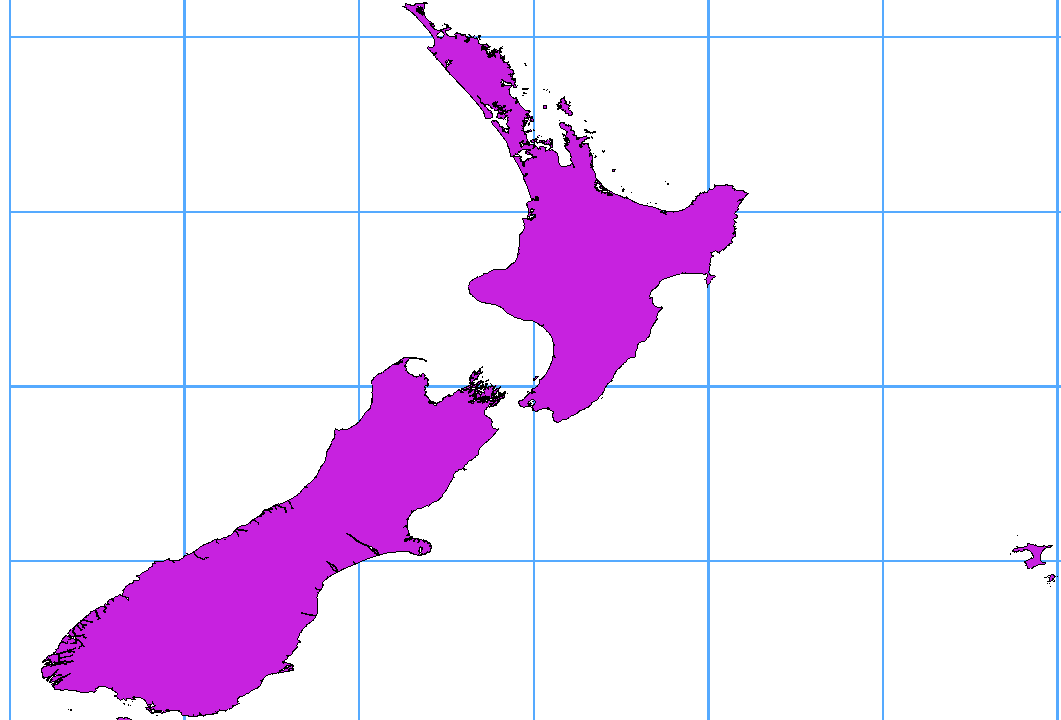
그림 15.28 경도 180° 선을 가로지르는 데이터에 ST_ShiftLongitude 함수를 적용
DB 관리자 플러그인 등을 이용해서 PostGIS로 데이터를 불러옵니다. (PostgreSQL로 데이터 가져오기 참조)
PostGIS 명령 줄 인터페이스를 이용해서 다음 명령어를 실행하십시오:
-- In this example, "TABLE" is the actual name of your PostGIS table update TABLE set geom=ST_ShiftLongitude(geom);
모든 작업이 제대로 됐다면, 업데이트한 피처의 개수를 확인하는 메시지를 볼 수 있을 겁니다. 그리고 나서야 맵을 불러와서 바뀐 모습(그림 15.28)을 볼 수 있습니다.