重要
翻訳は あなたが参加できる コミュニティの取り組みです。このページは現在 93.57% 翻訳されています。
24.1.16. 点群データ管理
注意
Running these algorithms requires QGIS installed with PDAL >= 2.5.0 (see menu).
24.1.16.1. 投影法を設定
Added in 3.32
点群レイヤの座標参照系が欠落していたり誤っているときに割り当てます。新規レイヤが作られます。
参考
パラメータ
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
入力レイヤ |
|
[point cloud] |
CRSを割り当てる入力点群レイヤ |
設定する座標参照系(CRS) |
|
[crs] |
レイヤに適用するCRS |
出力レイヤ |
|
[point cloud] デフォルト: |
出力として使用する点群ファイルを指定します。次のいずれかです:
|
出力
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
出力レイヤ |
|
[point cloud] |
新しいCRSを持った出力点群レイヤ。現在サポートしている形式は |
Python コード
Algorithm ID: pdal:assignprojection
import processing
processing.run("algorithm_id", {parameter_dictionary})
algorithm id は、プロセシングツールボックス内でアルゴリズムにマウスカーソルを乗せた際に表示されるIDです。 parameter dictionary は、パラメータの「名前」とその値を指定するマッピング型です。Python コンソールからプロセシングアルゴリズムを実行する方法の詳細については、 プロセシングアルゴリズムをコンソールから使う を参照してください。
24.1.16.2. 仮想点群(VPC)を作成
Added in 3.32
入力点群データから 仮想点群 (VPC) を作ります。
オプションのパラメータのチェックを外しておくと、アルゴリズムは入力ファイルのメタデータのみを読み込むため、VPCファイルは非常に短時間で構築されます。オプションのパラメータのどれかを設定すると、アルゴリズムはすべてのポイントを読み込むので、時間がかかることがあります。

図 24.44 点群タイルのセットから全体図を持った仮想点群を生成する
参考
パラメータ
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
入力レイヤ |
|
[point cloud] [list] |
仮想点群レイヤの中に結合する点群レイヤを入力する |
境界ポリゴンを計算 |
|
[ブール値] デフォルト: False |
(単なる矩形の範囲ではなく)データの正確な境界を表示するにはTrueに設定します |
**統計量を計算*: |
|
[ブール値] デフォルト: False |
様々な属性の値の範囲を理解するにはTrueに設定します |
概観点群をビルド |
|
[ブール値] デフォルト: False |
(元のデータから1000点ごとの点のみを使って)全ての入力データから1つの「間引き」点群を生成します。 概観点群はVPCファイルの隣に生成されます - 例えば |
仮想点群 |
|
[point cloud] デフォルト: |
作成したデータを入れる点群ファイルを指定します。次のいずれかです:
|
出力
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
仮想点群 |
|
[ラスタ] |
全ての入力データを結合した点群レイヤを仮想ファイルとして出力します。 |
Python コード
Algorithm ID: pdal:virtualpointcloud
import processing
processing.run("algorithm_id", {parameter_dictionary})
algorithm id は、プロセシングツールボックス内でアルゴリズムにマウスカーソルを乗せた際に表示されるIDです。 parameter dictionary は、パラメータの「名前」とその値を指定するマッピング型です。Python コンソールからプロセシングアルゴリズムを実行する方法の詳細については、 プロセシングアルゴリズムをコンソールから使う を参照してください。
24.1.16.3. 切り抜く
Added in 3.32
ポリゴンレイヤで点群レイヤを切り抜き、ポリゴン内の点のみが結果の点群に含まれるようにします。
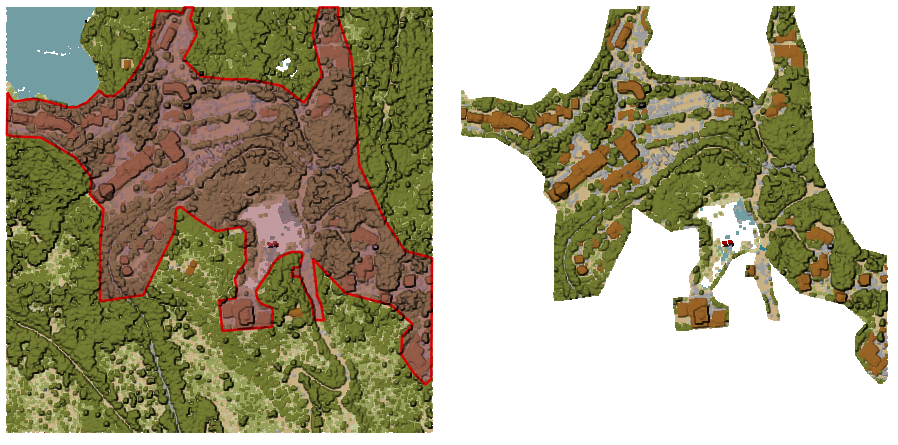
図 24.45 入力点群レイヤをポリゴンの範囲で切り抜く
パラメータ
基本パラメータ
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
入力レイヤ |
|
[point cloud] |
切り抜く入力点群レイヤ |
切り抜き範囲のポリゴン |
|
[ベクタ:ポリゴン] |
点を切り抜く範囲として使うポリゴンベクタレイヤ |
切り抜き結果 |
|
[point cloud] デフォルト: |
切り抜かれた点をエクスポートする点群ファイルを指定します。次のいずれかです:
|
詳細パラメータ
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
フィルタ式 オプション |
|
[式] |
点群データ内の地物のサブセットを選択するための PDAL式 |
切り抜く範囲 オプション |
|
[範囲] |
点群データ内の地物のサブセットを選択するためのマップ範囲 利用可能な方法:
|
出力
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
切り抜き結果 |
|
[point cloud] |
被覆ポリゴンレイヤの内側にあるポイントを地物とする出力点群。 |
Python コード
Algorithm ID: pdal:clip
import processing
processing.run("algorithm_id", {parameter_dictionary})
algorithm id は、プロセシングツールボックス内でアルゴリズムにマウスカーソルを乗せた際に表示されるIDです。 parameter dictionary は、パラメータの「名前」とその値を指定するマッピング型です。Python コンソールからプロセシングアルゴリズムを実行する方法の詳細については、 プロセシングアルゴリズムをコンソールから使う を参照してください。
24.1.16.4. COPCの作成
Added in 3.32
入力点群のインデックスをバッチモードで作成します.
パラメータ
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
入力レイヤ |
|
[point cloud] [list] |
インデックスを作成する点群レイヤを入力して下さい |
出力フォルダ オプション |
|
[フォルダ] デフォルト: |
新しいファイルを入れるフォルダを指定します。次のいずれかです:
|
出力
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
出力フォルダ |
|
[フォルダ] |
点群レイヤと付随するCOPCインデックスファイルを格納する出力フォルダ。 |
Python コード
Algorithm ID: pdal:createcopc
import processing
processing.run("algorithm_id", {parameter_dictionary})
algorithm id は、プロセシングツールボックス内でアルゴリズムにマウスカーソルを乗せた際に表示されるIDです。 parameter dictionary は、パラメータの「名前」とその値を指定するマッピング型です。Python コンソールからプロセシングアルゴリズムを実行する方法の詳細については、 プロセシングアルゴリズムをコンソールから使う を参照してください。
24.1.16.5. 情報
Added in 3.32
入力点群ファイルの基本メタデータを出力します。
出力される情報の例
LAS 1.4
point format 6
count 56736130
scale 0.001 0.001 0.001
offset 431749.999 5440919.999 968.898
extent 431250 5440420 424.266
432249.999 5441419.999 1513.531
crs ETRS89 / UTM zone 34N (N-E) (EPSG:3046) (vertical CRS missing!)
units horizontal=metre vertical=unknown
Attributes:
- X floating 8
- Y floating 8
- Z floating 8
- Intensity unsigned 2
- ReturnNumber unsigned 1
- NumberOfReturns unsigned 1
- ScanDirectionFlag unsigned 1
- EdgeOfFlightLine unsigned 1
- Classification unsigned 1
- ScanAngleRank floating 4
- UserData unsigned 1
- PointSourceId unsigned 2
- GpsTime floating 8
- ScanChannel unsigned 1
- ClassFlags unsigned 1
パラメータ
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
入力レイヤ |
|
[point cloud] |
メタデータ情報を抽出する入力点群レイヤ |
出力ファイル |
|
[ファイル] デフォルト: |
メタデータ情報を保存するファイルを指定します。次のいずれかです:
|
出力
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
出力ファイル |
|
[html] |
メタデータ情報を保存する |
Python コード
Algorithm ID: pdal:info
import processing
processing.run("algorithm_id", {parameter_dictionary})
algorithm id は、プロセシングツールボックス内でアルゴリズムにマウスカーソルを乗せた際に表示されるIDです。 parameter dictionary は、パラメータの「名前」とその値を指定するマッピング型です。Python コンソールからプロセシングアルゴリズムを実行する方法の詳細については、 プロセシングアルゴリズムをコンソールから使う を参照してください。
24.1.16.6. 結合
Added in 3.32
複数の点群ファイルを1つに結合する.
参考
パラメータ
基本パラメータ
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
入力レイヤ |
|
[point cloud] [list] |
ひとつに結合される入力点群レイヤ |
出力レイヤ |
|
[point cloud] デフォルト: |
入力ファイルを結合している出力点群を指定します。次のいずれかです:
|
詳細パラメータ
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
フィルタ式 オプション |
|
[式] |
点群データ内の地物のサブセットを選択するための PDAL式 |
切り抜く範囲 オプション |
|
[範囲] |
点群データ内の地物のサブセットを選択するためのマップ範囲 利用可能な方法:
|
出力
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
出力レイヤ |
|
[point cloud] |
入力ファイル全てを統合した出力点群レイヤ |
Python コード
Algorithm ID: pdal:merge
import processing
processing.run("algorithm_id", {parameter_dictionary})
algorithm id は、プロセシングツールボックス内でアルゴリズムにマウスカーソルを乗せた際に表示されるIDです。 parameter dictionary は、パラメータの「名前」とその値を指定するマッピング型です。Python コンソールからプロセシングアルゴリズムを実行する方法の詳細については、 プロセシングアルゴリズムをコンソールから使う を参照してください。
24.1.16.7. 再投影
Added in 3.32
点群を別の座標参照系 (CRS) に再投影します。
参考
パラメータ
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
入力レイヤ |
|
[point cloud] |
別のCRSに再投影する入力点群レイヤ |
ラスタのCRS |
|
[crs] |
レイヤに適用するCRS |
再投影したラスタファイル |
|
[point cloud] デフォルト: |
再投影された点群ファイルを指定します。次のいずれかです:
|
詳細パラメータ
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
座標演算 オプション |
|
[datum] |
元の系から対象の系へデータを再投影するために使用する 測地系変換。 |
出力
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
REPROJECTED |
|
[point cloud] |
対象CRSになった出力点群レイヤ |
Python コード
Algorithm ID: pdal:reproject
import processing
processing.run("algorithm_id", {parameter_dictionary})
algorithm id は、プロセシングツールボックス内でアルゴリズムにマウスカーソルを乗せた際に表示されるIDです。 parameter dictionary は、パラメータの「名前」とその値を指定するマッピング型です。Python コンソールからプロセシングアルゴリズムを実行する方法の詳細については、 プロセシングアルゴリズムをコンソールから使う を参照してください。
24.1.16.8. 点群を軽量化(距離)
Added in 3.32
距離点によるサンプリングを実行して点群を間引いたバージョンを作成します(特定の半径内の点の数を削減します)。

図 24.46 入力レイヤ
パラメータ
基本パラメータ
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
入力レイヤ |
|
[point cloud] |
間引いたバージョンを作る入力点群レイヤ |
サンプリング半径(地図上の単位) |
|
[数値: double] デフォルト: 1.0 |
点が一意の点にサンプリングされる距離 |
軽量化点群(距離) |
|
[point cloud] デフォルト: |
Specify the output point cloud with reduced points. One of:
|
詳細パラメータ
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
フィルタ式 オプション |
|
[式] |
点群データ内の地物のサブセットを選択するための PDAL式 |
切り抜く範囲 オプション |
|
[範囲] |
点群データ内の地物のサブセットを選択するためのマップ範囲 利用可能な方法:
|
出力
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
軽量化点群(距離) |
|
[point cloud] |
Output point cloud layer with reduced points. |
Python コード
Algorithm ID: pdal:thinbyradius
import processing
processing.run("algorithm_id", {parameter_dictionary})
algorithm id は、プロセシングツールボックス内でアルゴリズムにマウスカーソルを乗せた際に表示されるIDです。 parameter dictionary は、パラメータの「名前」とその値を指定するマッピング型です。Python コンソールからプロセシングアルゴリズムを実行する方法の詳細については、 プロセシングアルゴリズムをコンソールから使う を参照してください。
24.1.16.9. Thin (by skipping points)
Added in 3.32
Creates a thinned version of the point cloud by keeping only every N-th point (reduces the number of points by skipping nearby points).
参考
パラメータ
基本パラメータ
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
入力レイヤ |
|
[point cloud] |
間引いたバージョンを作る入力点群レイヤ |
Number of points to skip |
|
[数値: Integer] デフォルト: 1 |
Keep only every N-th point in the input layer |
Thinned (by decimation) |
|
[point cloud] デフォルト: |
Specify the output point cloud with reduced points. One of:
|
詳細パラメータ
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
フィルタ式 オプション |
|
[式] |
点群データ内の地物のサブセットを選択するための PDAL式 |
切り抜く範囲 オプション |
|
[範囲] |
点群データ内の地物のサブセットを選択するためのマップ範囲 利用可能な方法:
|
出力
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
Thinned (by decimation) |
|
[point cloud] |
Output point cloud layer with reduced points. |
Python コード
Algorithm ID: pdal:thinbydecimate
import processing
processing.run("algorithm_id", {parameter_dictionary})
algorithm id は、プロセシングツールボックス内でアルゴリズムにマウスカーソルを乗せた際に表示されるIDです。 parameter dictionary は、パラメータの「名前」とその値を指定するマッピング型です。Python コンソールからプロセシングアルゴリズムを実行する方法の詳細については、 プロセシングアルゴリズムをコンソールから使う を参照してください。
24.1.16.10. Tile
Creates tiles from input point cloud files, recommended for best performance (in display or analysis) with such datasets in QGIS.
参考
パラメータ
基本パラメータ
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
入力レイヤ |
|
[point cloud] [list] |
Input point cloud layers to create tiles from |
Tile length |
|
[数値: double] Default: 1000.0 |
Size of the edge of each generated tile |
出力フォルダ |
|
[フォルダ] デフォルト: |
Specify the folder to store the generated tiles. One of:
|
詳細パラメータ
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
Assign CRS オプション |
|
[crs] |
レイヤに適用するCRS |
出力
ラベル |
名前 |
データ型 |
説明 |
|---|---|---|---|
出力フォルダ |
|
[フォルダ] |
Output folder containing the tiles generated from input files. |
Python コード
Algorithm ID: pdal:tile
import processing
processing.run("algorithm_id", {parameter_dictionary})
algorithm id は、プロセシングツールボックス内でアルゴリズムにマウスカーソルを乗せた際に表示されるIDです。 parameter dictionary は、パラメータの「名前」とその値を指定するマッピング型です。Python コンソールからプロセシングアルゴリズムを実行する方法の詳細については、 プロセシングアルゴリズムをコンソールから使う を参照してください。