重要
翻訳は あなたが参加できる コミュニティの取り組みです。このページは現在 100.00% 翻訳されています。
17.16. 水文解析
注釈
このレッスンでは、ちょっとした水文解析を実行します。この分析は解析ワークフローの非常に良い例を構成しているので、後のいくつかのレッスンの一部に使用されます。そして、いくつかの高度な機能を実行して見せるために使います。
目的:DEMから始めて、水路網を抽出し、流域を描写し、いくつかの統計を計算します。
最初にDEM だけが含まれているレッスンデータを持つプロジェクトを読み込みます。
最初に実行するモジュールは 集水域 です(一部のSAGAバージョンでは、 累積流量(トップダウン) と呼ばれます)。 集水域 という名前の他の任意のものを使用できます。それらは下に異なるアルゴリズムを持っていますが、結果は基本的に同じです。
標高 フィールドでDEMを選択し、残りのパラメータはデフォルト値のままにしておきます。
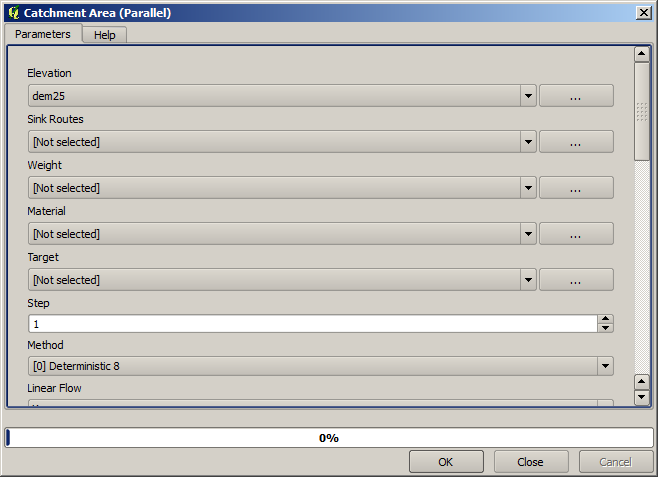
一部のアルゴリズムは多くのレイヤを計算しますが、ここで使用するのは 集水域 レイヤだけです。必要に応じて、他のものを取り除くことができます。
レイヤのこのレンダリングはあまり有益ではありません。
理由を知るために、ヒストグラムを見ると、値が均等に分散されていないことがわかります(非常に高い値のセルがいくつかあります。水路ネットワークに対応するものです)。 ラスター計算機 アルゴリズムを使用して、集水域の値の領域の対数を計算すると、より多くの情報を含むレイヤーが得られます。

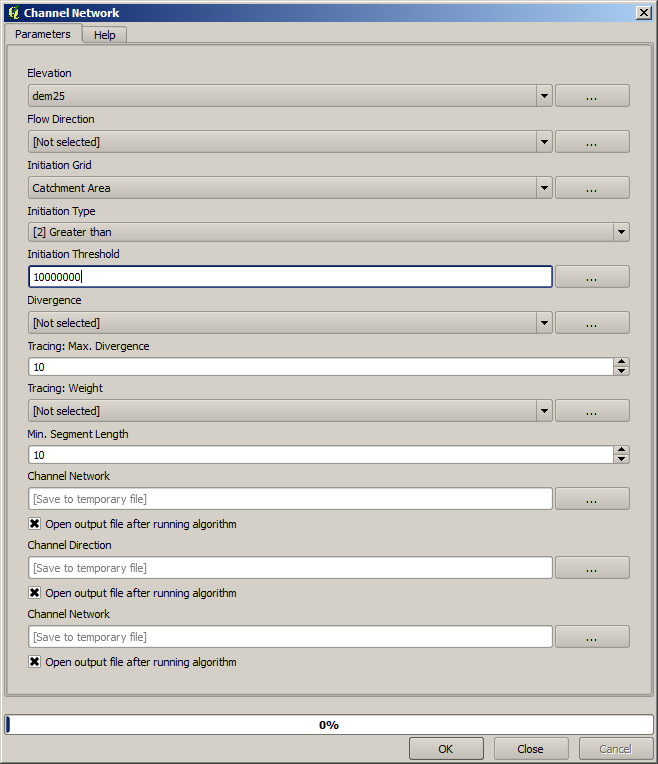
集水域(累積流量としても知られます)は、水路の開始の閾値を設定するために使用することができます。これは 水路網 アルゴリズムを使用して行うことができます。
Initiation grid: 対数ではなく、集水域のレイヤを使用します。
Initiation threshold:
10.000.000Initiation type: Greater than
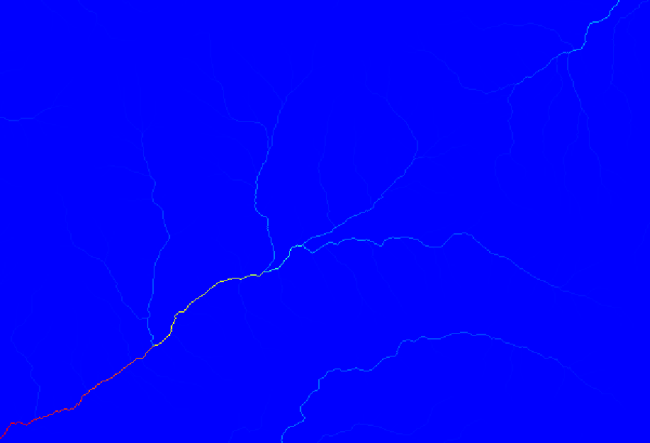
Initiation threshold の値を大きくすると、より疎な水路網が得られます。値を小さくすると、より密な網になります。提案された値では、このような結果になります。
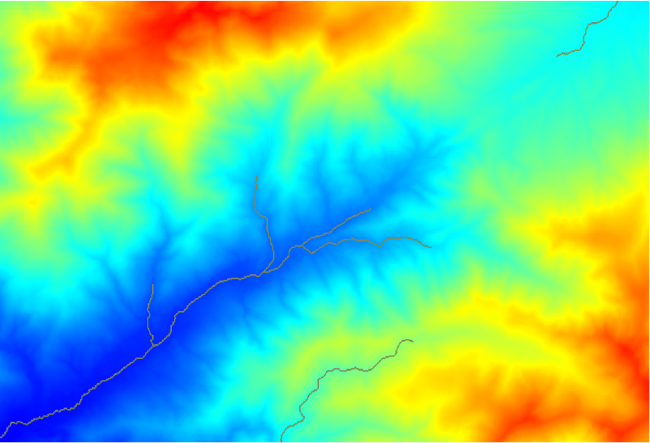
上の画像は、出来上がったベクタレイヤとDEMだけですが、同じ水路網を持つラスタレイヤも存在するはずです。このラスタレイヤが、これから使用するレイヤとなります。
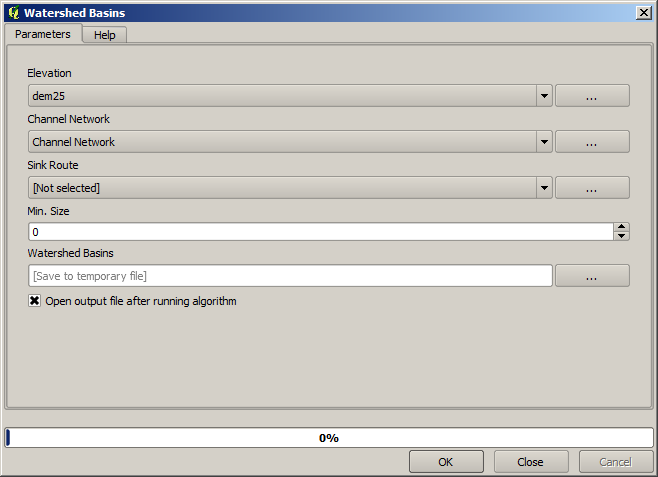
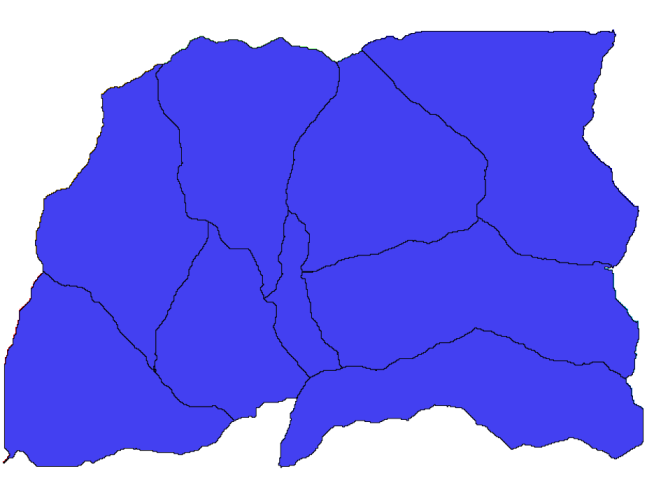
次に、Watersheds basins アルゴリズムを使って、水路網に対応する第二次流域を、その中のすべてのジャンクションを出口点として定義します。ここでは、対応するパラメータをダイアログで設定する必要があります。
そして、得られるものはこれです。
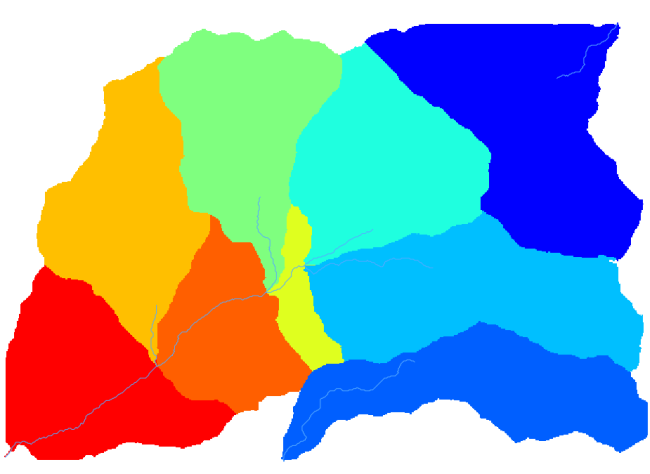
これはラスタの結果です。Vectorising grid classes アルゴリズムを使ってベクタ化できます。
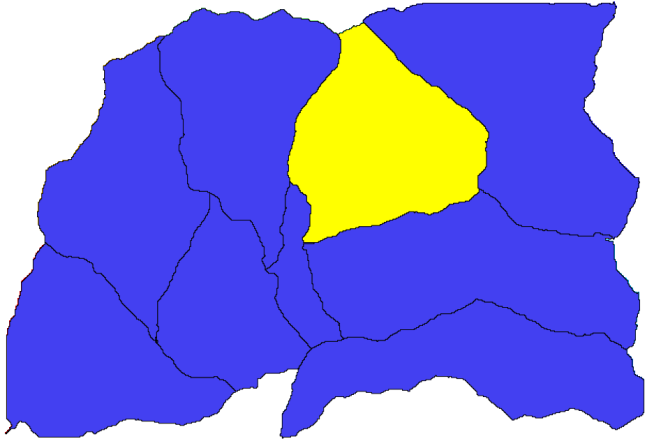
さて、第二次流域の一つで標高値についての統計を計算してみましょう。考え方は、ちょうどその第二次流域内だけの標高を表しているレイヤを得て、それをそれらの統計を計算するモジュールに渡すことです。
まず、第二次流域を表すポリゴンを使用して元のDEMをクリップします。 ポリゴンでラスタをクリップ アルゴリズムを使用します。単一の第二次流域ポリゴンを選択してからクリッピングアルゴリズムを呼び出すと、アルゴリズムが選択を認識しているため、DEMをそのポリゴンでカバーされる領域にクリップできます。
ポリゴンを選びます
次のパラメータでクリッピングアルゴリズムを呼び出します:
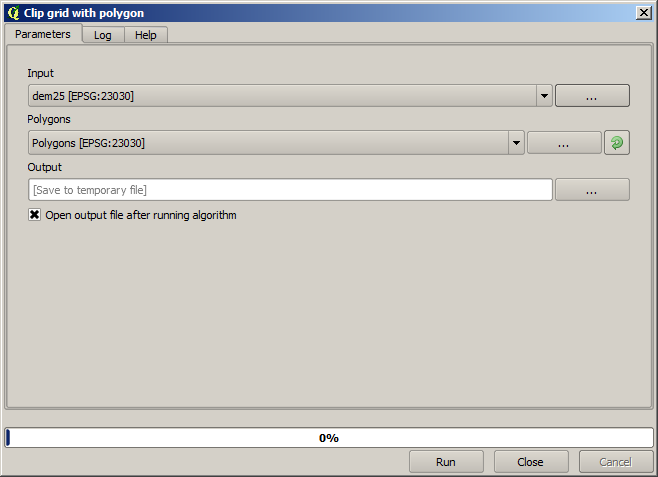
入力フィールドで選択された要素は、もちろん、クリップしたいDEMです。
このようなものが得られます。
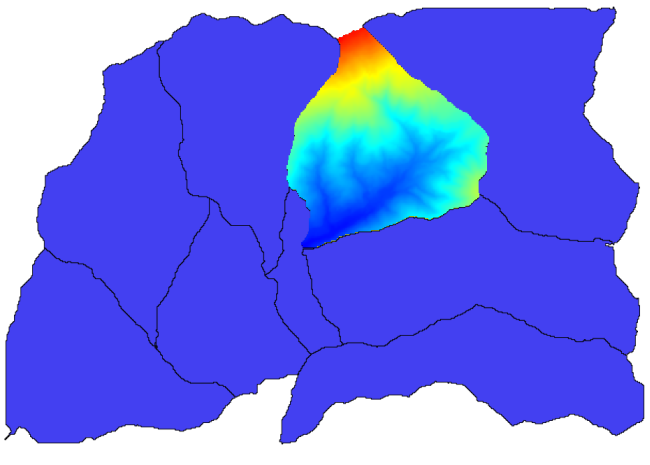
このレイヤは ラスタレイヤの統計量 アルゴリズムで使う準備ができています。
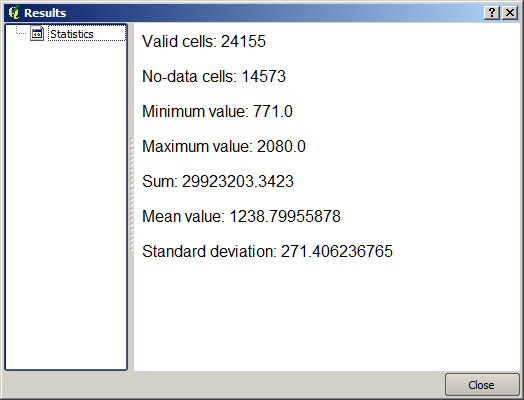
結果の統計は以下のものです。
他のレッスンでは流域の計算手順および統計計算の両方を使用するでしょう。そして他の要素がそれらの両方を自動化しより効率的に作業するのにどのように役立ちうるかを見ます。