Viktigt
Översättning är en gemenskapsinsats du kan gå med i. Den här sidan är för närvarande översatt till 73.68%.
17.22. Interpolation
Observera
I det här kapitlet visas hur du interpolerar punktdata och ett annat verkligt exempel på hur du utför en spatial analys
I den här lektionen ska vi interpolera punktdata för att få fram ett rasterlager. Innan vi gör det måste vi göra en del dataförberedelser, och efter interpoleringen lägger vi till lite extra bearbetning för att modifiera det resulterande lagret, så att vi får en komplett analysrutin.
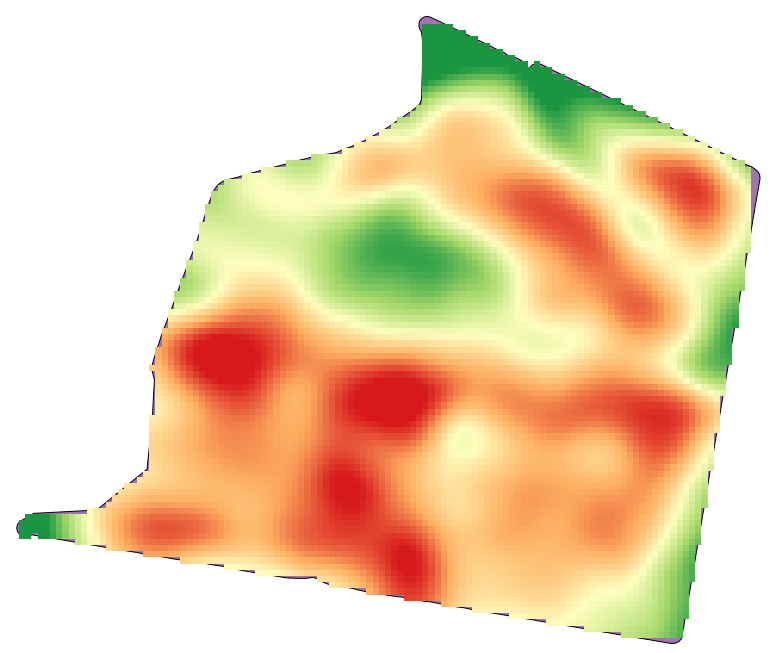
Öppna exempeldata för den här lektionen, som ska se ut så här.

Uppgifterna motsvarar skördeavkastningsdata, som produceras av en modern skördetröska, och vi kommer att använda dem för att få ett rasterlager över skördeavkastningen. Vi planerar inte att göra någon ytterligare analys med det lagret, utan bara att använda det som ett bakgrundslager för att enkelt identifiera de mest produktiva områdena och även de områden där produktiviteten kan förbättras.
The first thing to do is to clean–up the layer, since it contains redundant points. These are caused by the movement of the harvester, in places where it has to do a turn or it changes its speed for some reason. The Points filter algorithm will be useful for this. We will use it twice, to remove points that can be considered outliers both in the upper and lower part of the distribution.
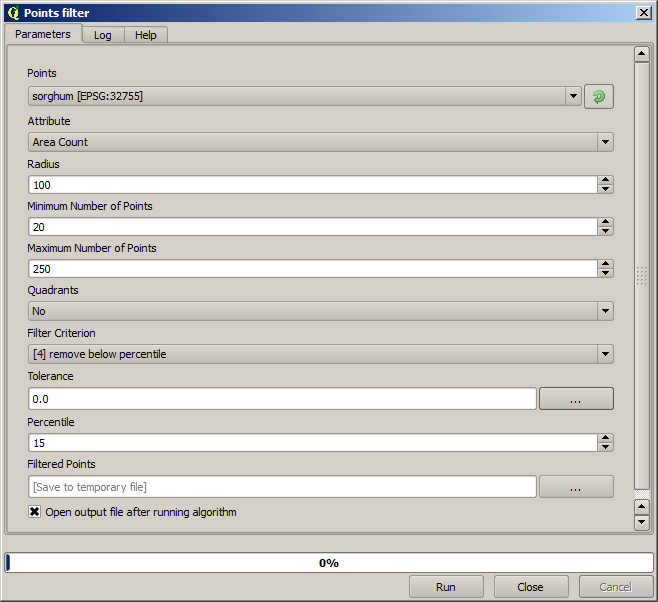
Använd följande parametervärden för den första körningen.
För nästa använder du den konfiguration som visas nedan.
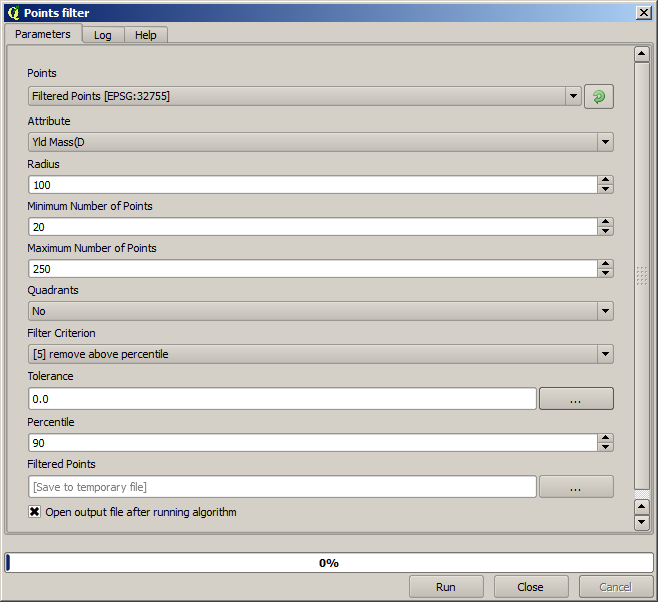
Observera att vi inte använder det ursprungliga lagret som indata, utan utdata från den föregående körningen istället.
Det slutliga filterlagret, med en reducerad uppsättning punkter, ska se ut som det ursprungliga, men det innehåller ett mindre antal punkter. Du kan kontrollera det genom att jämföra deras attributtabeller.
Now let’s rasterize the layer using the Rasterize algorithm.
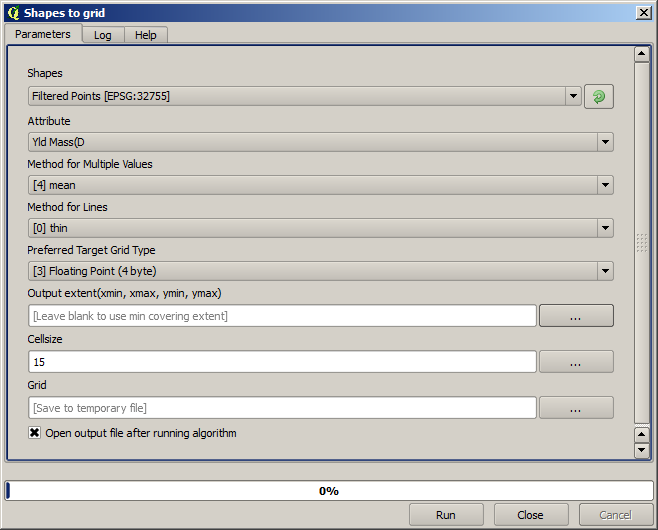
The Filtered points layer refers to the resulting one of the second filter.
It has the same name as the one produced by the first filter, since the name
is assigned by the algorithm, but you should not use the first one. Since we
will not be using it for anything else, you can safely remove it from your
project to avoid confusion, and leave just the last filtered layer.
Det resulterande rasterlagret ser ut så här.

It is already a raster layer, but it is missing data in some of its cells. It only contain valid values in those cells that contained a point from the vector layer that we have just rasterized, and a no–data value in all the other ones. To fill the missing values, we can use the Close gaps algorithm.
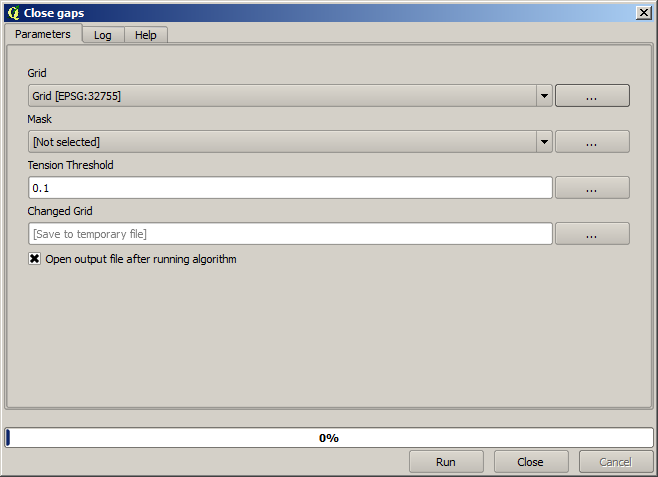
Lagret utan no-data-värden ser ut så här.

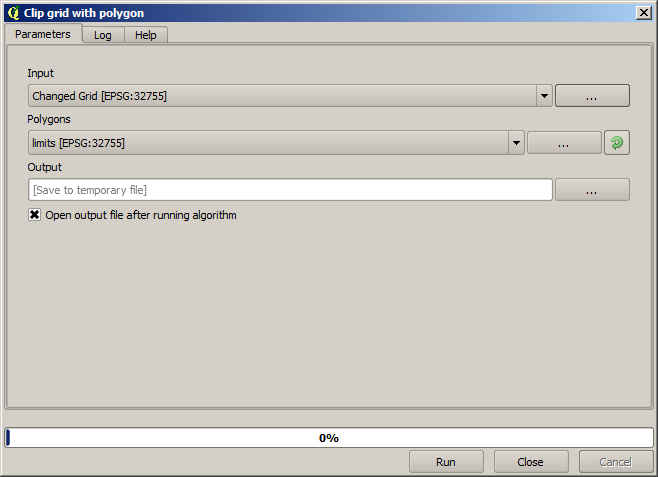
För att begränsa det område som omfattas av data till endast den region där skördeavkastningen mättes kan vi klippa ihop rasterlagret med det tillhandahållna gränsskiktet.
And for a smoother result (less accurate but better for rendering in the background as a support layer), we can apply a Gaussian filter to the layer.
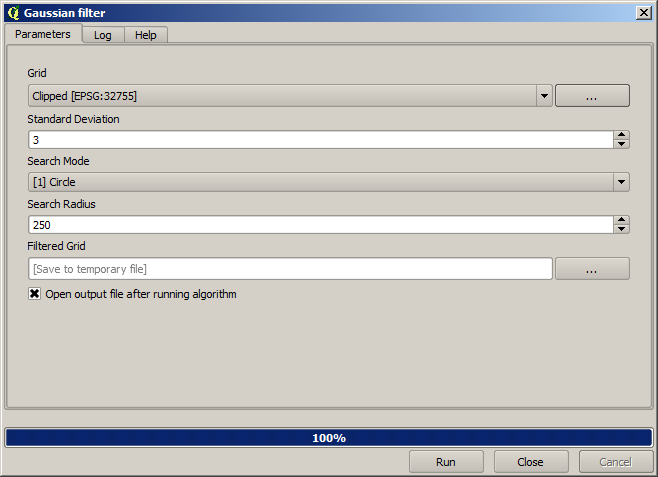
Med ovanstående parametrar får du följande resultat