15.1. Lesson: Introduction to Databases
Before using PostgreSQL, let’s make sure of our ground by covering general database theory. You will not need to enter any of the example code; it’s only there for illustration purposes.
The goal for this lesson: To understand fundamental database concepts.
15.1.1. What is a Database?
A database consists of an organized collection of data for one or more uses, typically in digital form. - Wikipedia
A database management system (DBMS) consists of software that operates databases, providing storage, access, security, backup and other facilities. - Wikipedia
15.1.2. Tables
In relational databases and flat file databases, a table is a set of data elements (values) that is organized using a model of vertical columns (which are identified by their name) and horizontal rows. A table has a specified number of columns, but can have any number of rows. Each row is identified by the values appearing in a particular column subset which has been identified as a candidate key. - Wikipedia
id | name | age
----+-------+-----
1 | Tim | 20
2 | Horst | 88
(2 rows)
In SQL databases a table is also known as a relation.
15.1.3. Columns / Fields
A column is a set of data values of a particular simple type, one for each row of the table. The columns provide the structure according to which the rows are composed. The term field is often used interchangeably with column, although many consider it more correct to use field (or field value) to refer specifically to the single item that exists at the intersection between one row and one column. - Wikipedia
A column:
| name |
+-------+
| Tim |
| Horst |
A field:
| Horst |
15.1.4. Records
A record is the information stored in a table row. Each record will have a field for each of the columns in the table.
2 | Horst | 88 <-- one record
15.1.5. Datatypes
Datatypes restrict the kind of information that can be stored in a column. - Tim and Horst
There are many kinds of datatypes. Let’s focus on the most common:
String- to store free-form text dataInteger- to store whole numbersReal- to store decimal numbersDate- to store Horst’s birthday so no one forgetsBoolean- to store simple true/false values
You can tell the database to allow you to also store nothing in a field. If there is nothing in a field, then the field content is referred to as a ‘null’ value:
insert into person (age) values (40);
select * from person;
Result:
id | name | age
---+-------+-----
1 | Tim | 20
2 | Horst | 88
4 | | 40 <-- null for name
(3 rows)
There are many more datatypes you can use - check the PostgreSQL manual!
15.1.6. Modelling an Address Database
Let’s use a simple case study to see how a database is constructed. We want to create an address database.
★☆☆ Try Yourself:
Write down the properties which make up a simple address and which we would want to store in our database.
Answer
For our theoretical address table, we might want to store the following properties:
House Number
Street Name
Suburb Name
City Name
Postcode
Country
When creating the table to represent an address object, we would create columns to represent each of these properties and we would name them with SQL-compliant and possibly shortened names:
house_number
street_name
suburb
city
postcode
country
Address Structure
The properties that describe an address are the columns. The type of information stored in each column is its datatype. In the next section we will analyse our conceptual address table to see how we can make it better!
15.1.7. Database Theory
The process of creating a database involves creating a model of the real world; taking real world concepts and representing them in the database as entities.
15.1.8. Normalisation
One of the main ideas in a database is to avoid data duplication / redundancy. The process of removing redundancy from a database is called Normalisation.
Normalization is a systematic way of ensuring that a database structure is suitable for general-purpose querying and free of certain undesirable characteristics - insertion, update, and deletion anomalies - that could lead to a loss of data integrity. - Wikipedia
There are different kinds of normalisation ‘forms’.
Let’s take a look at a simple example:
Table "public.people"
Column | Type | Modifiers
----------+------------------------+------------------------------------
id | integer | not null default
| | nextval('people_id_seq'::regclass)
| |
name | character varying(50) |
address | character varying(200) | not null
phone_no | character varying |
Indexes:
"people_pkey" PRIMARY KEY, btree (id)
select * from people;
id | name | address | phone_no
---+---------------+-----------------------------+-------------
1 | Tim Sutton | 3 Buirski Plein, Swellendam | 071 123 123
2 | Horst Duester | 4 Avenue du Roix, Geneva | 072 121 122
(2 rows)
Imagine you have many friends with the same street name or city. Every time this data is duplicated, it consumes space. Worse still, if a city name changes, you have to do a lot of work to update your database.
15.1.9. ★☆☆ Try Yourself:
Redesign the theoretical people table above to reduce duplication and to
normalise the data structure.
You can read more about database normalisation here
Answer
The major problem with the people table is that there is a single address
field which contains a person’s entire address. Thinking about our theoretical
address table earlier in this lesson, we know that an address is made up of
many different properties. By storing all these properties in one field, we make
it much harder to update and query our data. We therefore need to split the
address field into the various properties. This would give us a table which has
the following structure:
id | name | house_no | street_name | city | phone_no
--+---------------+----------+----------------+------------+-----------------
1 | Tim Sutton | 3 | Buirski Plein | Swellendam | 071 123 123
2 | Horst Duester | 4 | Avenue du Roix | Geneva | 072 121 122
In the next section, you will learn about Foreign Key relationships which could be used in this example to further improve our database’s structure.
15.1.10. Indexes
A database index is a data structure that improves the speed of data retrieval operations on a database table. - Wikipedia
Imagine you are reading a textbook and looking for the explanation of a concept - and the textbook has no index! You will have to start reading at one cover and work your way through the entire book until you find the information you need. The index at the back of a book helps you to jump quickly to the page with the relevant information:
create index person_name_idx on people (name);
Now searches on name will be faster:
Table "public.people"
Column | Type | Modifiers
----------+------------------------+-------------------------------------
id | integer | not null default
| | nextval('people_id_seq'::regclass)
| |
name | character varying(50) |
address | character varying(200) | not null
phone_no | character varying |
Indexes:
"people_pkey" PRIMARY KEY, btree (id)
"person_name_idx" btree (name)
15.1.11. Sequences
A sequence is a unique number generator. It is normally used to create a unique identifier for a column in a table.
In this example, id is a sequence - the number is incremented each time a record is added to the table:
id | name | address | phone_no
---+--------------+-----------------------------+-------------
1 | Tim Sutton | 3 Buirski Plein, Swellendam | 071 123 123
2 | Horst Duster | 4 Avenue du Roix, Geneva | 072 121 122
15.1.12. Entity Relationship Diagramming
In a normalised database, you typically have many relations (tables). The
entity-relationship diagram (ER Diagram) is used to design the logical
dependencies between the relations. Consider our non-normalised people table
from earlier in the lesson:
select * from people;
id | name | address | phone_no
----+--------------+-----------------------------+-------------
1 | Tim Sutton | 3 Buirski Plein, Swellendam | 071 123 123
2 | Horst Duster | 4 Avenue du Roix, Geneva | 072 121 122
(2 rows)
With a little work we can split it into two tables, removing the need to repeat the street name for individuals who live in the same street:
select * from streets;
id | name
----+--------------
1 | Plein Street
(1 row)
and:
select * from people;
id | name | house_no | street_id | phone_no
----+--------------+----------+-----------+-------------
1 | Horst Duster | 4 | 1 | 072 121 122
(1 row)
We can then link the two tables using the ‘keys’ streets.id and
people.streets_id.
If we draw an ER Diagram for these two tables it would look something like this:

The ER Diagram helps us to express ‘one to many’ relationships. In this case the arrow symbol show that one street can have many people living on it.
★★☆ Try Yourself:
Our people model still has some normalisation issues - try to see if you can normalise it further and show your thoughts by means of an ER Diagram.
Answer
Our people table currently looks like this:
id | name | house_no | street_id | phone_no
---+--------------+----------+-----------+-------------
1 | Horst Duster | 4 | 1 | 072 121 122
The street_id column represents a ‘one to many’ relationship between the
people object and the related street object, which is in the streets table.
One way to further normalise the table is to split the name field into first_name and last_name:
id | first_name | last_name | house_no | street_id | phone_no
---+------------+------------+----------+-----------+------------
1 | Horst | Duster | 4 | 1 | 072 121 122
We can also create separate tables for the town or city name and country,
linking them to our people table via ‘one to many’ relationships:
id | first_name | last_name | house_no | street_id | town_id | country_id
---+------------+-----------+----------+-----------+---------+------------
1 | Horst | Duster | 4 | 1 | 2 | 1
An ER Diagram to represent this would look like this:
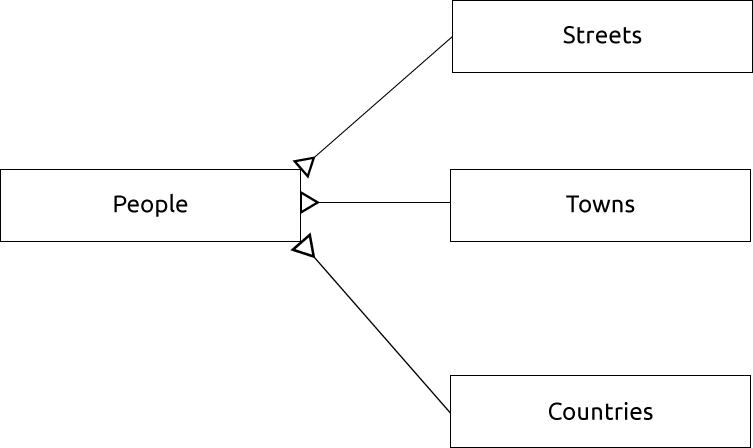
15.1.13. Constraints, Primary Keys and Foreign Keys
A database constraint is used to ensure that data in a relation matches the
modeller’s view of how that data should be stored. For example a constraint on
your postal code could ensure that the number falls between 1000 and
9999.
A Primary key is one or more field values that make a record unique. Usually the primary key is called id and is a sequence.
A Foreign key is used to refer to a unique record on another table (using that other table’s primary key).
In ER Diagramming, the linkage between tables is normally based on Foreign keys linking to Primary keys.
If we look at our people example, the table definition shows that the street column is a foreign key that references the primary key on the streets table:
Table "public.people"
Column | Type | Modifiers
-----------+-----------------------+--------------------------------------
id | integer | not null default
| | nextval('people_id_seq'::regclass)
name | character varying(50) |
house_no | integer | not null
street_id | integer | not null
phone_no | character varying |
Indexes:
"people_pkey" PRIMARY KEY, btree (id)
Foreign-key constraints:
"people_street_id_fkey" FOREIGN KEY (street_id) REFERENCES streets(id)
15.1.14. Transactions
When adding, changing, or deleting data in a database, it is always important that the database is left in a good state if something goes wrong. Most databases provide a feature called transaction support. Transactions allow you to create a rollback position that you can return to if your modifications to the database did not run as planned.
Take a scenario where you have an accounting system. You need to transfer funds from one account and add them to another. The sequence of steps would go like this:
remove R20 from Joe
add R20 to Anne
If something goes wrong during the process (e.g. power failure), the transaction will be rolled back.
15.1.15. In Conclusion
Databases allow you to manage data in a structured way using simple code structures.
15.1.16. What’s Next?
Now that we’ve looked at how databases work in theory, let’s create a new database to implement the theory we’ve covered.