Viktigt
Översättning är en gemenskapsinsats du kan gå med i. Den här sidan är för närvarande översatt till 100.00%.
24.1.15. Rasteranalys
24.1.15.1. Cellstapel procent rang från värde
Beräknar det cellvisa procentrankvärdet för en stapel raster baserat på ett enda indatavärde och skriver dem till ett utdataraster.
Vid varje cellplats rangordnas det angivna värdet bland respektive värden i stapeln med alla överlagrade och sorterade cellvärden från indatagrastren. För värden som ligger utanför stapelns värdefördelning returnerar algoritmen NoData eftersom värdet inte kan rangordnas bland cellvärdena.
Det finns två metoder för percentilberäkning:
Inkluderande linjär interpolation (PERCENTRANK.INC)
Exklusiv linjär interpolation (PERCENTRANK.EXC)
De linjära interpoleringsmetoderna returnerar den unika procentuella rangordningen för olika värden. Båda interpoleringsmetoderna följer sina motsvarigheter som implementeras av LibreOffice eller Microsoft Excel.
Utdatarasterns utsträckning och upplösning definieras av en referensraster. Rasterlager i indata som inte matchar cellstorleken i referensrasterlagret kommer att omsamplas med hjälp av omsampling med närmaste granne. NoData-värden i något av inmatningslagren kommer att resultera i en NoData-cellutmatning om parametern ”Ignore NoData values” inte är inställd. Rasterdatatypen för utdata kommer alltid att vara Float32.
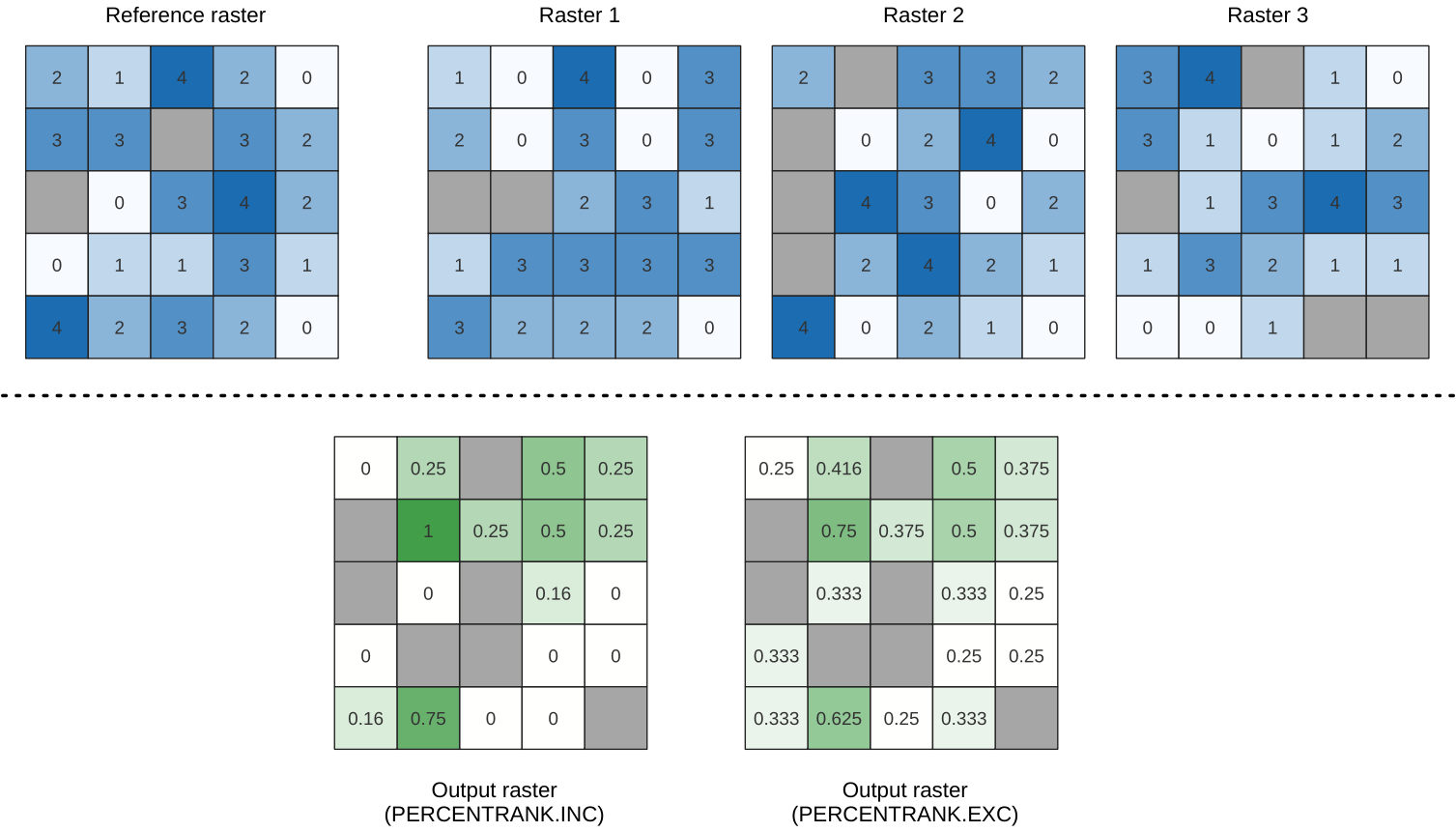
Fig. 24.19 Procentuell ranking Värde = 1. NoData celler (grå) ignoreras.
Parametrar
Grundläggande parametrar
Etikett |
Namn |
Typ |
Beskrivning |
|---|---|---|---|
Inmatningslager |
|
[raster] [lista] |
Rasterlager som ska utvärderas. Om flerbandsraster används i datarasterstacken kommer algoritmen alltid att utföra analysen på det första bandet i rastren |
Metod |
|
[uppräkning] Standard: 0 |
Metod för percentilberäkning:
|
Värde |
|
[numerisk: dubbel] Standard: 10.0 |
Värde att rangordna bland de respektive värdena i stapeln av alla överlagrade och sorterade cellvärden från inmatningsrastrarna |
Ignorera NoData-värden |
|
[boolean] Standard: Sann |
Om det inte är markerat kommer alla NoData-celler i inmatningslagren att resultera i en NoData-cell i utmatningsrastret |
Reference layer |
|
[raster] |
Referenslagret för skapandet av utdatalagret (utsträckning, CRS, pixeldimensioner) |
Utdatalager |
|
[samma som inmatning] Standard: |
Specifikation av utmatningsrastret. En av:
|
Avancerade parametrar
Etikett |
Namn |
Typ |
Beskrivning |
|---|---|---|---|
Utmatning av NoData-värde |
|
[numerisk: dubbel] Standard: -9999.0 |
Värde som ska användas för NoData i utdatalagret |
Alternativ för skapande Valfritt |
|
[sträng] Standard: ’’ |
För att lägga till ett eller flera skapandealternativ som styr det raster som ska skapas (färger, blockstorlek, filkomprimering …). För enkelhetens skull kan du förlita dig på fördefinierade profiler (se GDAL driver options section). Batch Process and Model Designer: separera flera alternativ med ett pipe-tecken ( |
Utgångar
Etikett |
Namn |
Typ |
Beskrivning |
|---|---|---|---|
Utdatalager |
|
[raster] |
Utgående rasterlager som innehåller resultatet |
CRS auktoritetsidentifierare |
|
[sträng] |
Koordinatreferenssystemet för det utgående rasterlagret |
Extent |
|
[sträng] |
Den spatiala omfattningen av det utgående rasterlagret |
Bredd i pixlar |
|
[numerisk: heltal] |
Antalet kolumner i det utgående rasterlagret |
Höjd i pixlar |
|
[numerisk: heltal] |
Antalet rader i det utgående rasterlagret |
Totalt antal pixlar |
|
[numerisk: heltal] |
Antalet pixlar i det utgående rasterlagret |
Python-kod
Algoritm-id: native:cellstackpercentrankfromvalue
import processing
processing.run("algorithm_id", {parameter_dictionary})
algoritm id visas när du håller muspekaren över algoritmen i verktygslådan Processing Toolbox. I parameter dictionary finns parameternamn och värden. Se Använda bearbetningsalgoritmer från konsolen för information om hur du kör bearbetningsalgoritmer från Python-konsolen.
24.1.15.2. Percentil för cellstapel
Beräknar det cellvisa percentilvärdet för en stack med raster och skriver resultatet till ett utdataraster. Percentilen som ska returneras bestäms av percentilinmatningsvärdet (varierar mellan 0 och 1). På varje cellplats erhålls den angivna percentilen med hjälp av respektive värde från stapeln med alla överlagrade och sorterade cellvärden i indatarastren.
Det finns tre metoder för percentilberäkning:
Närmaste rang: returnerar det värde som ligger närmast den angivna percentilen
Inkluderande linjär interpolation (PERCENTRANK.INC)
Exklusiv linjär interpolation (PERCENTRANK.EXC)
De linjära interpoleringsmetoderna returnerar de unika värdena för olika percentiler. Båda interpoleringsmetoderna följer sina motsvarigheter som implementeras av LibreOffice eller Microsoft Excel.
Utdatarasterns utsträckning och upplösning definieras av en referensraster. Rasterlager i indata som inte matchar cellstorleken i referensrasterlagret kommer att omsamplas med hjälp av omsampling med närmaste granne. NoData-värden i något av inmatningslagren kommer att resultera i en NoData-cellutmatning om parametern ”Ignore NoData values” inte är inställd. Rasterdatatypen för utdata kommer alltid att vara Float32.
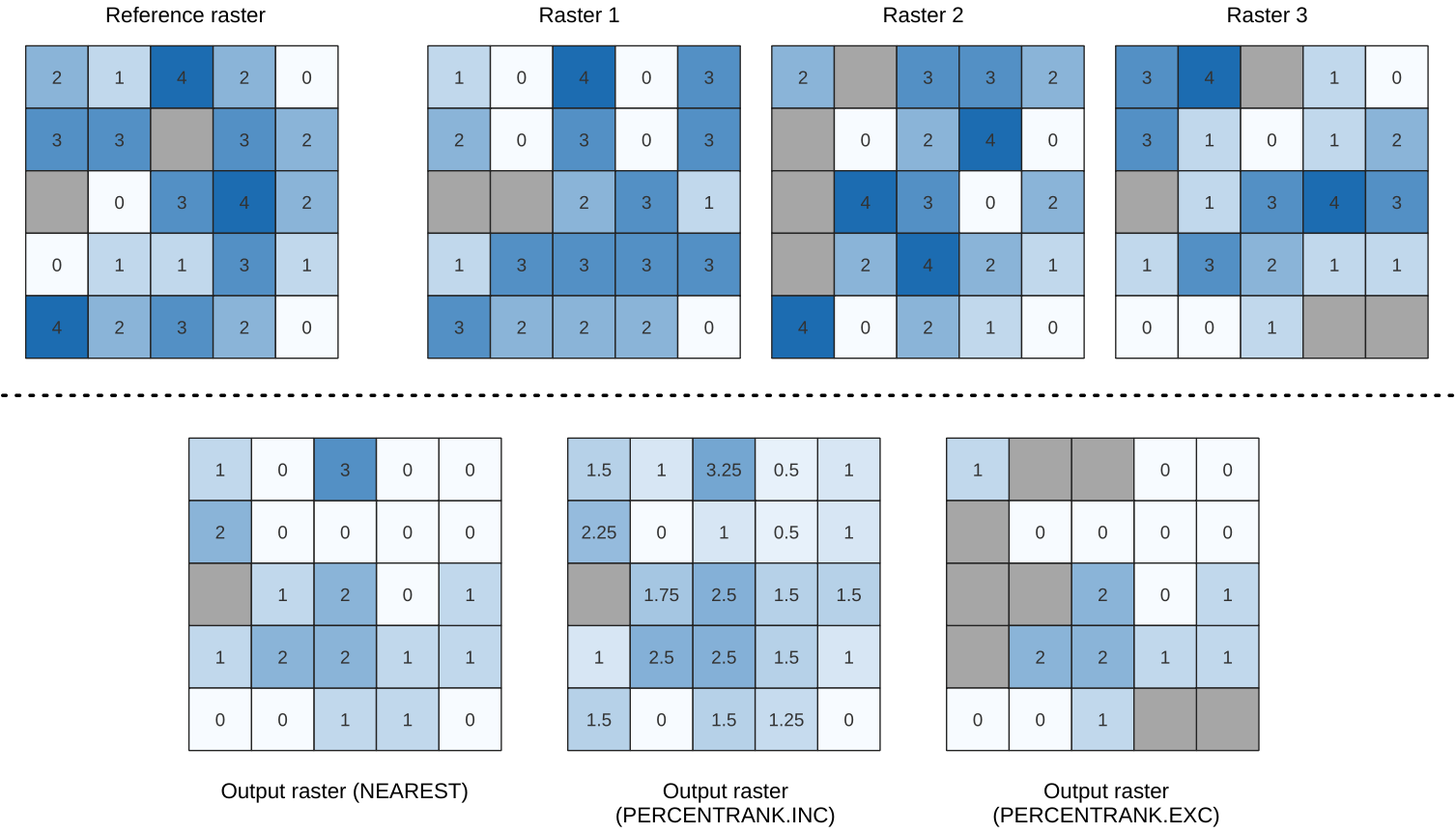
Fig. 24.20 Percentil = 0,25. NoData-celler (grå) ignoreras.
Parametrar
Grundläggande parametrar
Etikett |
Namn |
Typ |
Beskrivning |
|---|---|---|---|
Inmatningslager |
|
[raster] [lista] |
Rasterlager som ska utvärderas. Om flerbandsraster används i datarasterstacken kommer algoritmen alltid att utföra analysen på det första bandet i rastren |
Metod |
|
[uppräkning] Standard: 0 |
Metod för percentilberäkning:
|
Percentil |
|
[numerisk: dubbel] Standard: 0,25 |
Värde som ska rangordnas bland respektive värden i stapeln med alla överlagrade och sorterade cellvärden från indatarastren. Mellan 0 och 1. |
Ignorera NoData-värden |
|
[boolean] Standard: Sann |
Om det inte är markerat kommer alla NoData-celler i inmatningslagren att resultera i en NoData-cell i utmatningsrastret |
Reference layer |
|
[raster] |
Referenslagret för skapandet av utdatalagret (utsträckning, CRS, pixeldimensioner) |
Utdatalager |
|
[samma som inmatning] Standard: |
Specifikation av utmatningsrastret. En av:
|
Avancerade parametrar
Etikett |
Namn |
Typ |
Beskrivning |
|---|---|---|---|
Utmatning av NoData-värde |
|
[numerisk: dubbel] Standard: -9999.0 |
Värde som ska användas för NoData i utdatalagret |
Alternativ för skapande Valfritt |
|
[sträng] Standard: ’’ |
För att lägga till ett eller flera skapandealternativ som styr det raster som ska skapas (färger, blockstorlek, filkomprimering …). För enkelhetens skull kan du förlita dig på fördefinierade profiler (se GDAL driver options section). Batch Process and Model Designer: separera flera alternativ med ett pipe-tecken ( |
Utgångar
Etikett |
Namn |
Typ |
Beskrivning |
|---|---|---|---|
Utdatalager |
|
[raster] |
Utgående rasterlager som innehåller resultatet |
CRS auktoritetsidentifierare |
|
[sträng] |
Koordinatreferenssystemet för det utgående rasterlagret |
Extent |
|
[sträng] |
Den spatiala omfattningen av det utgående rasterlagret |
Bredd i pixlar |
|
[numerisk: heltal] |
Antalet kolumner i det utgående rasterlagret |
Höjd i pixlar |
|
[numerisk: heltal] |
Antalet rader i det utgående rasterlagret |
Totalt antal pixlar |
|
[numerisk: heltal] |
Antalet pixlar i det utgående rasterlagret |
Python-kod
Algoritm-id: native:cellstackpercentile
import processing
processing.run("algorithm_id", {parameter_dictionary})
algoritm id visas när du håller muspekaren över algoritmen i verktygslådan Processing Toolbox. I parameter dictionary finns parameternamn och värden. Se Använda bearbetningsalgoritmer från konsolen för information om hur du kör bearbetningsalgoritmer från Python-konsolen.
24.1.15.3. Cellstapel procentrank från rasterlager
Beräknar det cellvisa procentrankvärdet för en stack med raster baserat på ett indatavärdesraster och skriver dem till ett utdataraster.
Vid varje cellplats rangordnas det aktuella värdet i värderastret bland respektive värden i stapeln av alla överlagrade och sorterade cellvärden i indatarastren. För värden som ligger utanför stapelns värdefördelning returnerar algoritmen NoData eftersom värdet inte kan rangordnas bland cellvärdena.
Det finns två metoder för percentilberäkning:
Inkluderande linjär interpolation (PERCENTRANK.INC)
Exklusiv linjär interpolation (PERCENTRANK.EXC)
De linjära interpoleringsmetoderna returnerar de unika värdena för olika percentiler. Båda interpoleringsmetoderna följer sina motsvarigheter som implementeras av LibreOffice eller Microsoft Excel.
Utdatarasterns utsträckning och upplösning definieras av en referensraster. Rasterlager i indata som inte matchar cellstorleken i referensrasterlagret kommer att omsamplas med hjälp av omsampling med närmaste granne. NoData-värden i något av inmatningslagren kommer att resultera i en NoData-cellutmatning om parametern ”Ignore NoData values” inte är inställd. Rasterdatatypen för utdata kommer alltid att vara Float32.
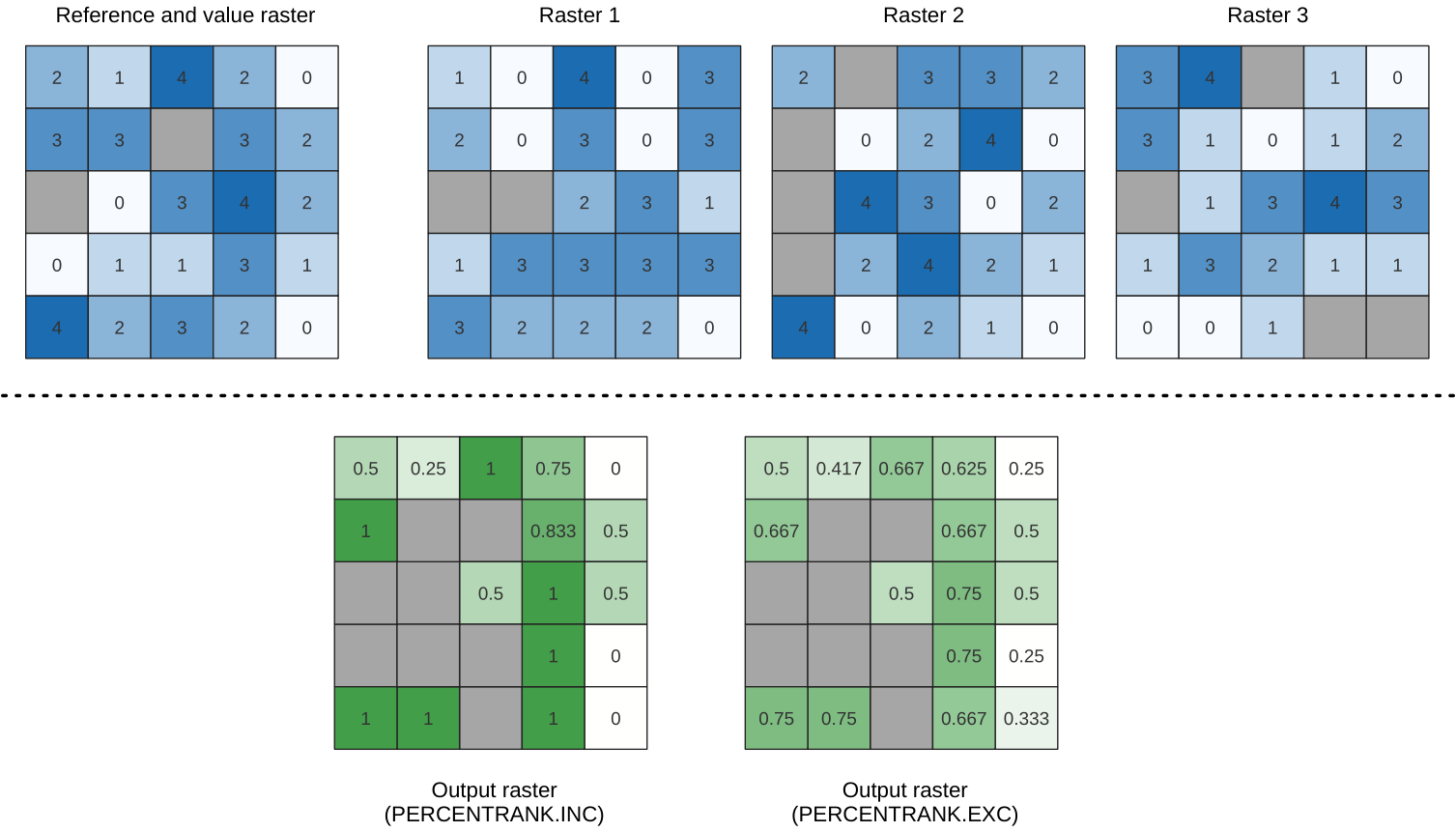
Fig. 24.21 Rangordnar rasterlagrets värdeceller. celler med NoData (grå) ignoreras.
Parametrar
Grundläggande parametrar
Etikett |
Namn |
Typ |
Beskrivning |
|---|---|---|---|
Inmatningslager |
|
[raster] [lista] |
Rasterlager som ska utvärderas. Om flerbandsraster används i datarasterstacken kommer algoritmen alltid att utföra analysen på det första bandet i rastren |
Värde rasterlager |
|
[raster] |
Det lager som ska rangordna värdena bland stapeln av alla överlagrade lager |
Värde rasterband |
|
[numerisk: heltal] Standard: 1 |
Band av ”value raster layer” att jämföra med |
Metod |
|
[uppräkning] Standard: 0 |
Metod för percentilberäkning:
|
Ignorera NoData-värden |
|
[boolean] Standard: Sann |
Om det inte är markerat kommer alla NoData-celler i inmatningslagren att resultera i en NoData-cell i utmatningsrastret |
Reference layer |
|
[raster] |
Referenslagret för skapandet av utdatalagret (utsträckning, CRS, pixeldimensioner) |
Utdatalager |
|
[samma som inmatning] Standard: |
Specifikation av utmatningsrastret. En av:
|
Avancerade parametrar
Etikett |
Namn |
Typ |
Beskrivning |
|---|---|---|---|
Utmatning av NoData-värde |
|
[numerisk: dubbel] Standard: -9999.0 |
Värde som ska användas för NoData i utdatalagret |
Alternativ för skapande Valfritt |
|
[sträng] Standard: ’’ |
För att lägga till ett eller flera skapandealternativ som styr det raster som ska skapas (färger, blockstorlek, filkomprimering …). För enkelhetens skull kan du förlita dig på fördefinierade profiler (se GDAL driver options section). Batch Process and Model Designer: separera flera alternativ med ett pipe-tecken ( |
Utgångar
Etikett |
Namn |
Typ |
Beskrivning |
|---|---|---|---|
Utdatalager |
|
[raster] |
Utgående rasterlager som innehåller resultatet |
CRS auktoritetsidentifierare |
|
[sträng] |
Koordinatreferenssystemet för det utgående rasterlagret |
Extent |
|
[sträng] |
Den spatiala omfattningen av det utgående rasterlagret |
Bredd i pixlar |
|
[numerisk: heltal] |
Antalet kolumner i det utgående rasterlagret |
Höjd i pixlar |
|
[numerisk: heltal] |
Antalet rader i det utgående rasterlagret |
Totalt antal pixlar |
|
[numerisk: heltal] |
Antalet pixlar i det utgående rasterlagret |
Python-kod
Algoritm-id: native:cellstackpercentrankfromrasterlayer
import processing
processing.run("algorithm_id", {parameter_dictionary})
algoritm id visas när du håller muspekaren över algoritmen i verktygslådan Processing Toolbox. I parameter dictionary finns parameternamn och värden. Se Använda bearbetningsalgoritmer från konsolen för information om hur du kör bearbetningsalgoritmer från Python-konsolen.
24.1.15.4. Cellstatistik
Beräknar statistik per cell baserat på ingående rasterlager och för varje cell skrivs den resulterande statistiken till ett utdataraster. På varje cellplats definieras utdatavärdet som en funktion av alla överlagrade cellvärden i indatarastren.
Som standard kommer en NoData-cell i NÅGOT av inmatningslagren att resultera i en NoData-cell i utdatarastret. Om alternativet Ignore NoData values är markerat ignoreras NoData-ingångar i den statistiska beräkningen. Detta kan resultera i NoData-utdata för platser där alla celler är NoData.
Parametern Reference layer anger ett befintligt rasterlager som ska användas som referens när utdatarastern skapas. Utdatarastret kommer att ha samma utsträckning, CRS och pixeldimensioner som detta lager.
Beräkningsdetaljer: Rasterlager i indata som inte matchar cellstorleken i referensrasterlagret kommer att omsamplas med hjälp av närmaste granne omsampling. Rasterdatatypen för utdata sätts till den mest komplexa datatypen i indatasetet, utom när funktionerna Mean, Standardavvikelse och Varians används (datatypen är alltid Float32 eller Float64 beroende på indatatyp) eller Count och Variety (datatypen är alltid Int32).
Count: Count-statistiken resulterar alltid i antalet celler utan NoData-värden på den aktuella cellpositionen.Median: Om antalet inmatningslager är jämnt beräknas medianen som det aritmetiska medelvärdet av de två mellersta värdena i de ordnade cellinmatningsvärdena.Minoritet/Majoritet: Om ingen unik minoritet eller majoritet kunde hittas, blir resultatet NoData, förutom att alla indatacellvärden är lika.
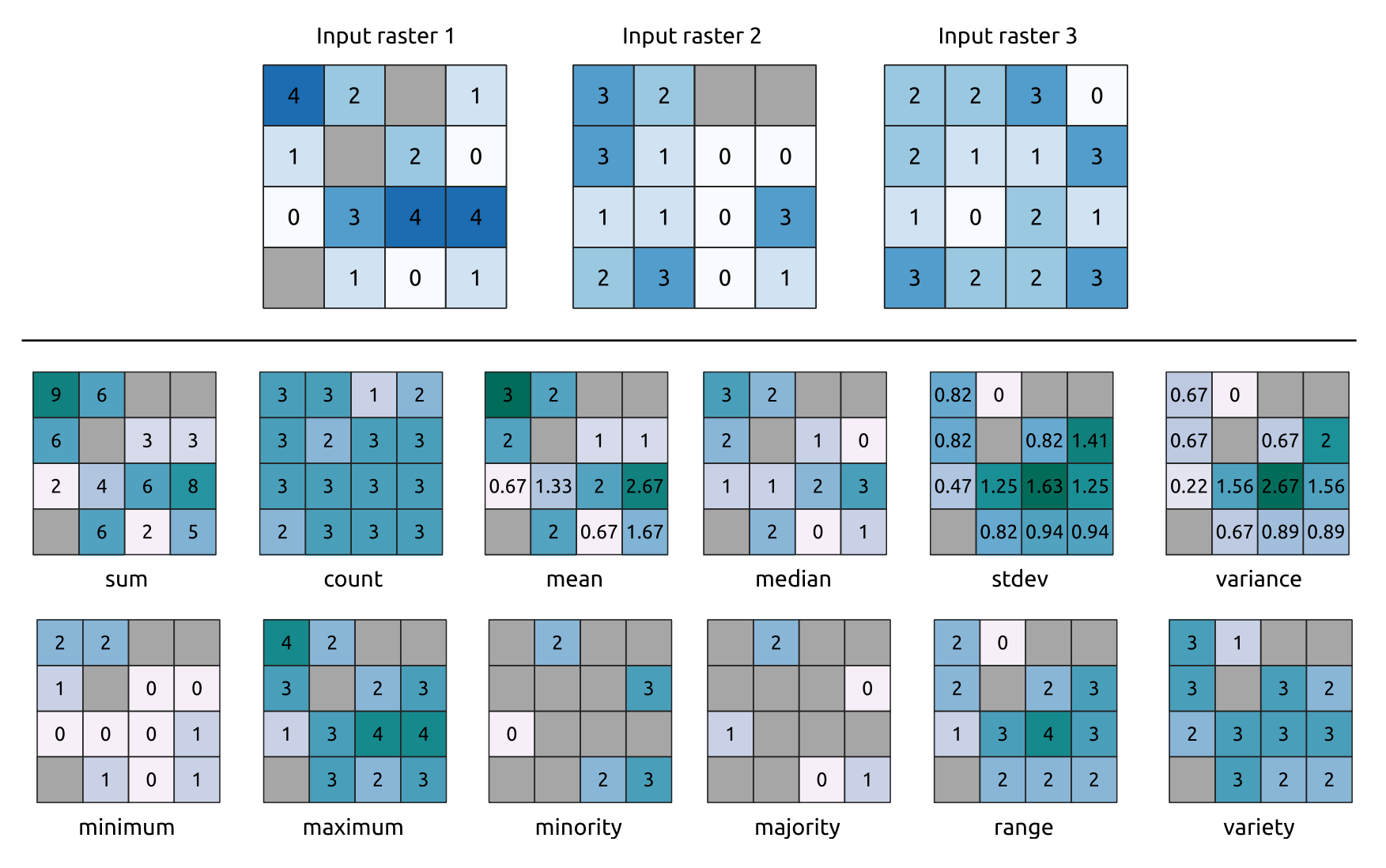
Fig. 24.22 Exempel med alla statistiska funktioner. NoData-celler (grå) tas med i beräkningen.
Parametrar
Grundläggande parametrar
Etikett |
Namn |
Typ |
Beskrivning |
|---|---|---|---|
Inmatningslager |
|
[raster] [lista] |
Inmatade rasterlager |
Statistik |
|
[uppräkning] Standard: 0 |
Tillgänglig statistik. Alternativ:
|
Ignorera NoData-värden |
|
[boolean] Standard: Sann |
Beräkna statistik även för alla cellstaplar, utan hänsyn till NoData-frekvensen. |
Reference layer |
|
[raster] |
Referenslagret att skapa utdatalagret från (utsträckning, CRS, pixeldimensioner) |
Utdatalager |
|
[samma som inmatning] Standard: |
Specifikation av utmatningsrastret. En av:
|
Avancerade parametrar
Etikett |
Namn |
Typ |
Beskrivning |
|---|---|---|---|
Utmatning av NoData-värde Valfritt |
|
[numerisk: dubbel] Standard: -9999.0 |
Värde som ska användas för NoData i utdatalagret |
Alternativ för skapande Valfritt |
|
[sträng] Standard: ’’ |
För att lägga till ett eller flera skapandealternativ som styr det raster som ska skapas (färger, blockstorlek, filkomprimering …). För enkelhetens skull kan du förlita dig på fördefinierade profiler (se GDAL driver options section). Batch Process and Model Designer: separera flera alternativ med ett pipe-tecken ( |
Utgångar
Etikett |
Namn |
Typ |
Beskrivning |
|---|---|---|---|
CRS auktoritetsidentifierare |
|
[crs] |
Koordinatreferenssystemet för det utgående rasterlagret |
Extent |
|
[sträng] |
Den spatiala omfattningen av det utgående rasterlagret |
Höjd i pixlar |
|
[numerisk: heltal] |
Antalet rader i det utgående rasterlagret |
Utgångsraster |
|
[raster] |
Utgående rasterlager som innehåller resultatet |
Totalt antal pixlar |
|
[numerisk: heltal] |
Antalet pixlar i det utgående rasterlagret |
Bredd i pixlar |
|
[numerisk: heltal] |
Antalet kolumner i det utgående rasterlagret |
Python-kod
Algoritm-ID: native:cellstatistik
import processing
processing.run("algorithm_id", {parameter_dictionary})
algoritm id visas när du håller muspekaren över algoritmen i verktygslådan Processing Toolbox. I parameter dictionary finns parameternamn och värden. Se Använda bearbetningsalgoritmer från konsolen för information om hur du kör bearbetningsalgoritmer från Python-konsolen.
24.1.15.5. Lika med frekvens
Utvärderar cell för cell frekvensen (antalet gånger) som värdena i en inmatningsstapel med raster är lika med värdet i ett värdelager. Utgångsrastrets utsträckning och upplösning definieras av ingångsrasterlagret och är alltid av typen Int32.
Om flerbandsraster används i datarasterstacken kommer algoritmen alltid att utföra analysen på det första bandet i rastren - använd GDAL för att använda andra band i analysen. NoData-värdet för utdata kan ställas in manuellt.
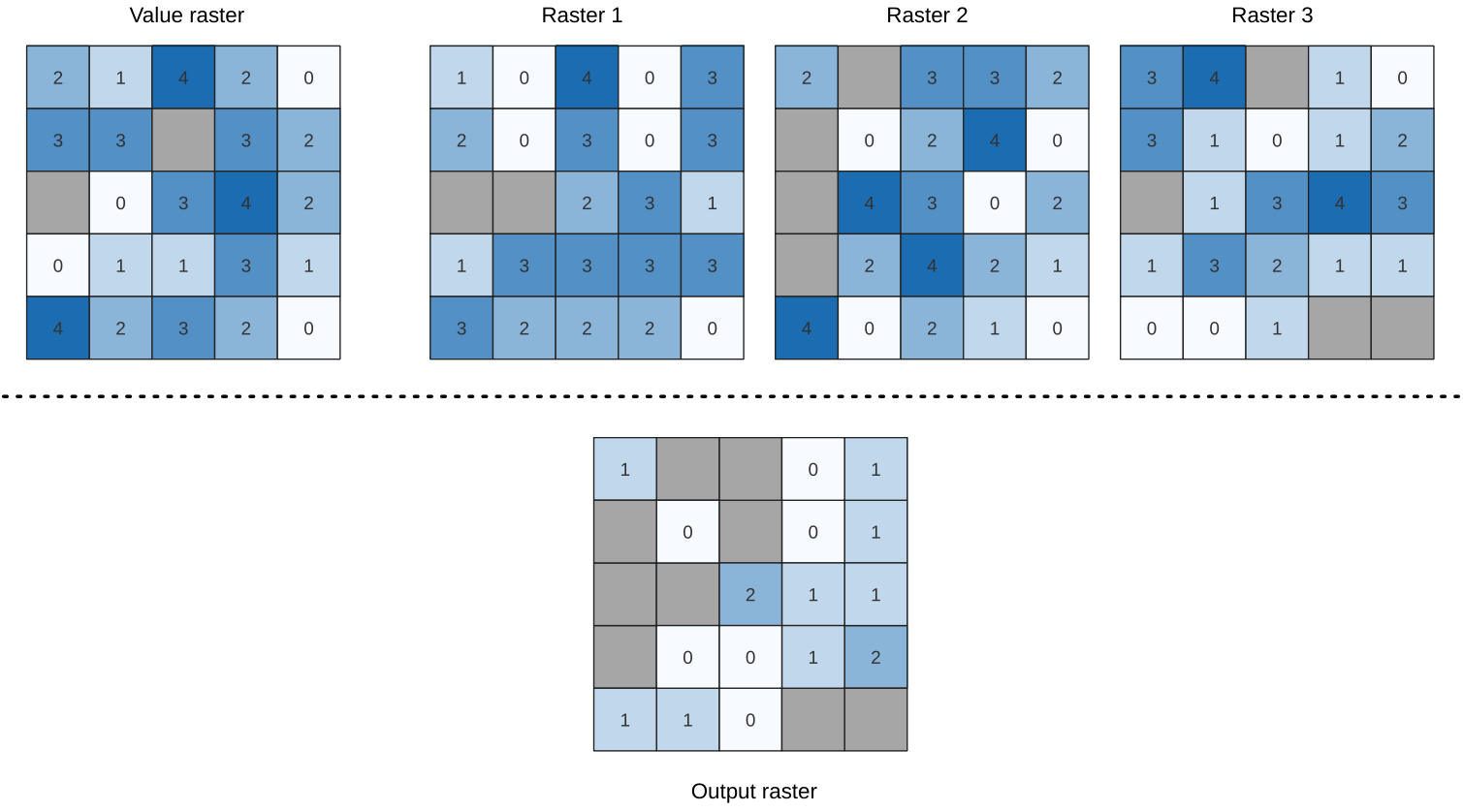
Fig. 24.23 För varje cell i utdatarastret representerar värdet det antal gånger som motsvarande celler i listan med raster är desamma som värderastret. NoData-celler (grå) tas med i beräkningen.
Se även
Parametrar
Grundläggande parametrar
Etikett |
Namn |
Typ |
Beskrivning |
|---|---|---|---|
Inmatningsvärde raster |
|
[raster] |
Ingångsvärdeslagret fungerar som referenslager för provlagren |
Värde rasterband |
|
[rasterband] Standard: Det första bandet i rasterlagret |
Välj det band du vill använda som prov |
Rasterlager för inmatning |
|
[raster] [lista] |
Rasterlager som ska utvärderas. Om flerbandsraster används i datarasterstacken kommer algoritmen alltid att utföra analysen på det första bandet i rastren |
Ignorera NoData-värden |
|
[boolean] Standard: Falsk |
Om det inte är markerat kommer alla NoData-celler i värderastret eller datalagerstapeln att resultera i en NoData-cell i utdatarastret |
Utdatalager |
|
[samma som inmatning] Standard: |
Specifikation av utmatningsrastret. En av:
|
Avancerade parametrar
Etikett |
Namn |
Typ |
Beskrivning |
|---|---|---|---|
Utmatning av NoData-värde Valfritt |
|
[numerisk: dubbel] Standard: -9999.0 |
Värde som ska användas för NoData i utdatalagret |
Alternativ för skapande Valfritt |
|
[sträng] Standard: ’’ |
För att lägga till ett eller flera skapandealternativ som styr det raster som ska skapas (färger, blockstorlek, filkomprimering …). För enkelhetens skull kan du förlita dig på fördefinierade profiler (se GDAL driver options section). Batch Process and Model Designer: separera flera alternativ med ett pipe-tecken ( |
Utgångar
Etikett |
Namn |
Typ |
Beskrivning |
|---|---|---|---|
Utdatalager |
|
[raster] |
Utgående rasterlager som innehåller resultatet |
CRS auktoritetsidentifierare |
|
[sträng] |
Koordinatreferenssystemet för det utgående rasterlagret |
Extent |
|
[sträng] |
Den spatiala omfattningen av det utgående rasterlagret |
Antal celler med förekomster av lika värde |
|
[numerisk: heltal] |
|
Höjd i pixlar |
|
[numerisk: heltal] |
Antalet rader i det utgående rasterlagret |
Totalt antal pixlar |
|
[numerisk: heltal] |
Antalet pixlar i det utgående rasterlagret |
Medelfrekvens vid giltiga cellpositioner |
|
[numerisk: dubbel] |
|
Antal värdeförekomster |
|
[numerisk: heltal] |
|
Bredd i pixlar |
|
[numerisk: heltal] |
Antalet kolumner i det utgående rasterlagret |
Python-kod
Algoritm-id: native:equaltofrequency
import processing
processing.run("algorithm_id", {parameter_dictionary})
algoritm id visas när du håller muspekaren över algoritmen i verktygslådan Processing Toolbox. I parameter dictionary finns parameternamn och värden. Se Använda bearbetningsalgoritmer från konsolen för information om hur du kör bearbetningsalgoritmer från Python-konsolen.
24.1.15.6. Fuzzifiera raster (gaussiskt medlemskap)
Omvandlar ett inmatningsraster till ett fuzzifierat raster genom att tilldela ett medlemsvärde till varje pixel med hjälp av en gaussisk medlemsfunktion. Medlemskapsvärdena sträcker sig från 0 till 1. I det fuzzifierade rastret innebär ett värde på 0 inget medlemskap i den definierade fuzzy-uppsättningen, medan ett värde på 1 innebär fullt medlemskap. Den gaussiska medlemskapsfunktionen definieras som 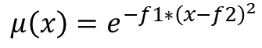 , där f1 är spridningen och f2 mittpunkten.
, där f1 är spridningen och f2 mittpunkten.
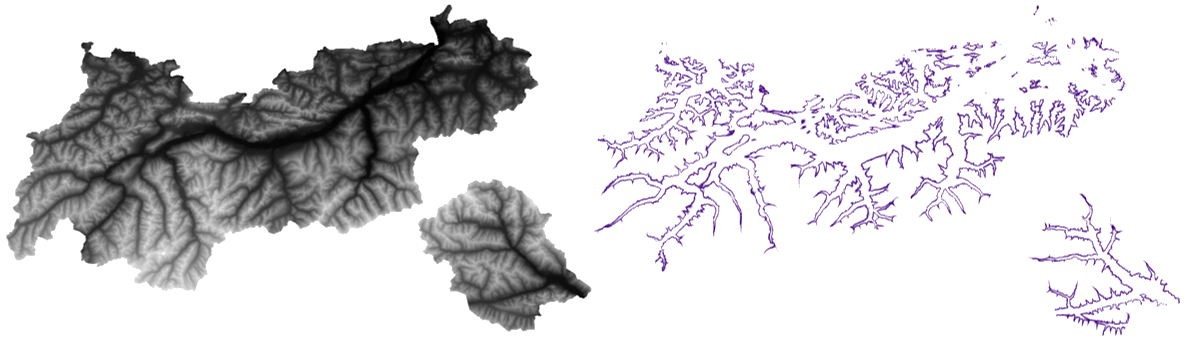
Fig. 24.24 Exempel på Fuzzify-raster. Ingångsrasterkälla: Land Tirol - data.tirol.gv.at.
Se även
Fuzzifiera raster (stort medlemskap), Fuzzifiera raster (linjärt medlemskap), Fuzzifiera raster (nära medlemskap), Fuzzifiera raster (kraftmedlemskap), Fuzzifiera raster (litet antal medlemmar)
Parametrar
Grundläggande parametrar
Etikett |
Namn |
Typ |
Beskrivning |
|---|---|---|---|
Input Raster |
|
[raster] |
Inmatat rasterlager |
Bandnummer |
|
[rasterband] Standard: Det första bandet i rasterlagret |
Om rastret är multibandigt väljer du det band som du vill fuzzifiera. |
Funktionens mittpunkt |
|
[numerisk: dubbel] Standard: 10.0 |
Mittpunkt för den gaussiska funktionen |
Funktionsfördelning |
|
[numerisk: dubbel] Standard: 0,01 |
Spridning av den gaussiska funktionen |
Fuzzifierat raster |
|
[samma som inmatning] Standard: |
Specifikation av utmatningsrastret. En av:
|
Avancerade parametrar
Etikett |
Namn |
Typ |
Beskrivning |
|---|---|---|---|
Alternativ för skapande Valfritt |
|
[sträng] Standard: ’’ |
För att lägga till ett eller flera skapandealternativ som styr det raster som ska skapas (färger, blockstorlek, filkomprimering …). För enkelhetens skull kan du förlita dig på fördefinierade profiler (se GDAL driver options section). Batch Process and Model Designer: separera flera alternativ med ett pipe-tecken ( |
Utgångar
Etikett |
Namn |
Typ |
Beskrivning |
|---|---|---|---|
Fuzzifierat raster |
|
[samma som inmatning] |
Utgående rasterlager som innehåller resultatet |
CRS auktoritetsidentifierare |
|
[crs] |
Koordinatreferenssystemet för det utgående rasterlagret |
Extent |
|
[sträng] |
Den spatiala omfattningen av det utgående rasterlagret |
Bredd i pixlar |
|
[numerisk: heltal] |
Antalet kolumner i det utgående rasterlagret |
Höjd i pixlar |
|
[numerisk: heltal] |
Antalet rader i det utgående rasterlagret |
Totalt antal pixlar |
|
[numerisk: heltal] |
Antalet pixlar i det utgående rasterlagret |
Python-kod
Algoritm-ID: native:fuzzifyrastergaussianmembership
import processing
processing.run("algorithm_id", {parameter_dictionary})
algoritm id visas när du håller muspekaren över algoritmen i verktygslådan Processing Toolbox. I parameter dictionary finns parameternamn och värden. Se Använda bearbetningsalgoritmer från konsolen för information om hur du kör bearbetningsalgoritmer från Python-konsolen.
24.1.15.7. Fuzzifiera raster (stort medlemskap)
Omvandlar ett inmatningsraster till ett fuzzifierat raster genom att tilldela ett medlemsvärde till varje pixel med hjälp av en stor medlemsfunktion. Medlemskapsvärdena sträcker sig från 0 till 1. I det fuzzifierade rastret innebär ett värde på 0 inget medlemskap i den definierade fuzzy-uppsättningen, medan ett värde på 1 innebär fullt medlemskap. Den stora medlemsfunktionen definieras som 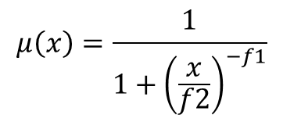 , där f1 är spridningen och f2 mittpunkten.
, där f1 är spridningen och f2 mittpunkten.
Se även
Fuzzifiera raster (gaussiskt medlemskap), Fuzzifiera raster (linjärt medlemskap), Fuzzifiera raster (nära medlemskap), Fuzzifiera raster (kraftmedlemskap), Fuzzifiera raster (litet antal medlemmar)
Parametrar
Grundläggande parametrar
Etikett |
Namn |
Typ |
Beskrivning |
|---|---|---|---|
Input Raster |
|
[raster] |
Inmatat rasterlager |
Bandnummer |
|
[rasterband] Standard: Det första bandet i rasterlagret |
Om rastret är multibandigt väljer du det band som du vill fuzzifiera. |
Funktionens mittpunkt |
|
[numerisk: dubbel] Standard: 50,0 |
Mittpunkt för den stora funktionen |
Funktionsfördelning |
|
[numerisk: dubbel] Standard: 5,0 |
Utbredning av den stora funktionen |
Fuzzifierat raster |
|
[samma som inmatning] Standard: |
Specifikation av utmatningsrastret. En av:
|
Avancerade parametrar
Etikett |
Namn |
Typ |
Beskrivning |
|---|---|---|---|
Alternativ för skapande Valfritt |
|
[sträng] Standard: ’’ |
För att lägga till ett eller flera skapandealternativ som styr det raster som ska skapas (färger, blockstorlek, filkomprimering …). För enkelhetens skull kan du förlita dig på fördefinierade profiler (se GDAL driver options section). Batch Process and Model Designer: separera flera alternativ med ett pipe-tecken ( |
Utgångar
Etikett |
Namn |
Typ |
Beskrivning |
|---|---|---|---|
Fuzzifierat raster |
|
[samma som inmatning] |
Utgående rasterlager som innehåller resultatet |
CRS auktoritetsidentifierare |
|
[crs] |
Koordinatreferenssystemet för det utgående rasterlagret |
Extent |
|
[sträng] |
Den spatiala omfattningen av det utgående rasterlagret |
Bredd i pixlar |
|
[numerisk: heltal] |
Antalet kolumner i det utgående rasterlagret |
Höjd i pixlar |
|
[numerisk: heltal] |
Antalet rader i det utgående rasterlagret |
Totalt antal pixlar |
|
[numerisk: heltal] |
Antalet pixlar i det utgående rasterlagret |
Python-kod
Algoritm-ID: `native:fuzzifyrasterlargemembership
import processing
processing.run("algorithm_id", {parameter_dictionary})
algoritm id visas när du håller muspekaren över algoritmen i verktygslådan Processing Toolbox. I parameter dictionary finns parameternamn och värden. Se Använda bearbetningsalgoritmer från konsolen för information om hur du kör bearbetningsalgoritmer från Python-konsolen.
24.1.15.8. Fuzzifiera raster (linjärt medlemskap)
Omvandlar ett inmatningsraster till ett fuzzifierat raster genom att tilldela ett medlemsvärde till varje pixel med hjälp av en linjär medlemsfunktion. Medlemskapsvärdena sträcker sig från 0 till 1. I det fuzzifierade rastret innebär ett värde på 0 inget medlemskap i den definierade fuzzy-uppsättningen, medan ett värde på 1 innebär fullt medlemskap. Den linjära funktionen definieras som 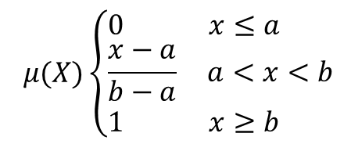 , där a är den låga gränsen och b den höga gränsen. Den här ekvationen tilldelar medlemsvärden med hjälp av en linjär transformation för pixelvärden mellan de låga och höga gränserna. Pixelvärden som är mindre än den låga gränsen får 0 medlemskap medan pixelvärden som är större än den höga gränsen får 1 medlemskap.
, där a är den låga gränsen och b den höga gränsen. Den här ekvationen tilldelar medlemsvärden med hjälp av en linjär transformation för pixelvärden mellan de låga och höga gränserna. Pixelvärden som är mindre än den låga gränsen får 0 medlemskap medan pixelvärden som är större än den höga gränsen får 1 medlemskap.
Se även
Fuzzifiera raster (gaussiskt medlemskap), Fuzzifiera raster (stort medlemskap), Fuzzifiera raster (nära medlemskap), Fuzzifiera raster (kraftmedlemskap), Fuzzifiera raster (litet antal medlemmar)
Parametrar
Grundläggande parametrar
Etikett |
Namn |
Typ |
Beskrivning |
|---|---|---|---|
Input Raster |
|
[raster] |
Inmatat rasterlager |
Bandnummer |
|
[rasterband] Standard: Det första bandet i rasterlagret |
Om rastret är multibandigt väljer du det band som du vill fuzzifiera. |
Låg gräns för fuzzy-medlemskap |
|
[numerisk: dubbel] Standard: 0,0 |
Låg gräns för den linjära funktionen |
Hög gräns för fuzzy-medlemskap |
|
[numerisk: dubbel] Standard: 1,0 |
Hög gräns för den linjära funktionen |
Fuzzifierat raster |
|
[samma som inmatning] Standard: |
Specifikation av utmatningsrastret. En av:
|
Avancerade parametrar
Etikett |
Namn |
Typ |
Beskrivning |
|---|---|---|---|
Alternativ för skapande Valfritt |
|
[sträng] Standard: ’’ |
För att lägga till ett eller flera skapandealternativ som styr det raster som ska skapas (färger, blockstorlek, filkomprimering …). För enkelhetens skull kan du förlita dig på fördefinierade profiler (se GDAL driver options section). Batch Process and Model Designer: separera flera alternativ med ett pipe-tecken ( |
Utgångar
Etikett |
Namn |
Typ |
Beskrivning |
|---|---|---|---|
Fuzzifierat raster |
|
[samma som inmatning] |
Utgående rasterlager som innehåller resultatet |
CRS auktoritetsidentifierare |
|
[crs] |
Koordinatreferenssystemet för det utgående rasterlagret |
Extent |
|
[sträng] |
Den spatiala omfattningen av det utgående rasterlagret |
Bredd i pixlar |
|
[numerisk: heltal] |
Antalet kolumner i det utgående rasterlagret |
Höjd i pixlar |
|
[numerisk: heltal] |
Antalet rader i det utgående rasterlagret |
Totalt antal pixlar |
|
[numerisk: heltal] |
Antalet pixlar i det utgående rasterlagret |
Python-kod
Algoritm-ID: `native:fuzzifyrasterlinearmembership
import processing
processing.run("algorithm_id", {parameter_dictionary})
algoritm id visas när du håller muspekaren över algoritmen i verktygslådan Processing Toolbox. I parameter dictionary finns parameternamn och värden. Se Använda bearbetningsalgoritmer från konsolen för information om hur du kör bearbetningsalgoritmer från Python-konsolen.
24.1.15.9. Fuzzifiera raster (nära medlemskap)
Omvandlar ett inmatningsraster till ett fuzzifierat raster genom att tilldela ett medlemsvärde till varje pixel med hjälp av en Near-medlemsfunktion. Medlemskapsvärdena sträcker sig från 0 till 1. I det fuzzifierade rastret innebär ett värde på 0 inget medlemskap i den definierade fuzzy-uppsättningen, medan ett värde på 1 innebär fullt medlemskap. Near-medlemsfunktionen definieras som 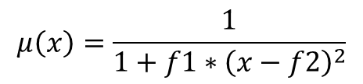 , där f1 är spridningen och f2 mittpunkten.
, där f1 är spridningen och f2 mittpunkten.
Se även
Fuzzifiera raster (gaussiskt medlemskap), Fuzzifiera raster (stort medlemskap), Fuzzifiera raster (linjärt medlemskap), Fuzzifiera raster (kraftmedlemskap), Fuzzifiera raster (litet antal medlemmar)
Parametrar
Grundläggande parametrar
Etikett |
Namn |
Typ |
Beskrivning |
|---|---|---|---|
Input Raster |
|
[raster] |
Inmatat rasterlager |
Bandnummer |
|
[rasterband] Standard: Det första bandet i rasterlagret |
Om rastret är multibandigt väljer du det band som du vill fuzzifiera. |
Funktionens mittpunkt |
|
[numerisk: dubbel] Standard: 50,0 |
Mittpunkt för den nära funktionen |
Funktionsfördelning |
|
[numerisk: dubbel] Standard: 0,01 |
Spridning av den närmaste funktionen |
Fuzzifierat raster |
|
[samma som inmatning] Standard: |
Specifikation av utmatningsrastret. En av:
|
Avancerade parametrar
Etikett |
Namn |
Typ |
Beskrivning |
|---|---|---|---|
Alternativ för skapande Valfritt |
|
[sträng] Standard: ’’ |
För att lägga till ett eller flera skapandealternativ som styr det raster som ska skapas (färger, blockstorlek, filkomprimering …). För enkelhetens skull kan du förlita dig på fördefinierade profiler (se GDAL driver options section). Batch Process and Model Designer: separera flera alternativ med ett pipe-tecken ( |
Utgångar
Etikett |
Namn |
Typ |
Beskrivning |
|---|---|---|---|
Fuzzifierat raster |
|
[samma som inmatning] |
Utgående rasterlager som innehåller resultatet |
CRS auktoritetsidentifierare |
|
[crs] |
Koordinatreferenssystemet för det utgående rasterlagret |
Extent |
|
[sträng] |
Den spatiala omfattningen av det utgående rasterlagret |
Bredd i pixlar |
|
[numerisk: heltal] |
Antalet kolumner i det utgående rasterlagret |
Höjd i pixlar |
|
[numerisk: heltal] |
Antalet rader i det utgående rasterlagret |
Totalt antal pixlar |
|
[numerisk: heltal] |
Antalet pixlar i det utgående rasterlagret |
Python-kod
Algoritm-ID: `native:fuzzifyrasternearmembership
import processing
processing.run("algorithm_id", {parameter_dictionary})
algoritm id visas när du håller muspekaren över algoritmen i verktygslådan Processing Toolbox. I parameter dictionary finns parameternamn och värden. Se Använda bearbetningsalgoritmer från konsolen för information om hur du kör bearbetningsalgoritmer från Python-konsolen.
24.1.15.10. Fuzzifiera raster (kraftmedlemskap)
Omvandlar ett inmatningsraster till ett fuzzifierat raster genom att tilldela ett medlemsvärde till varje pixel med hjälp av en Power-medlemsfunktion. Medlemskapsvärdena sträcker sig från 0 till 1. I det fuzzifierade rastret innebär ett värde på 0 inget medlemskap i den definierade fuzzy-uppsättningen, medan ett värde på 1 innebär fullt medlemskap. Power-funktionen definieras som 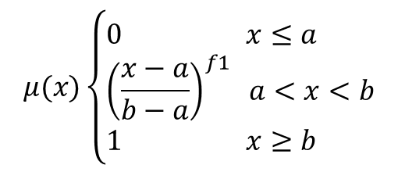 , där a är den låga gränsen, b är den höga gränsen och f1 är exponenten. Den här ekvationen tilldelar medlemsvärden med hjälp av power-transformationen för pixelvärden mellan den låga och den höga gränsen. Pixelvärden som är mindre än den låga gränsen får 0 medlemskap medan pixelvärden som är större än den höga gränsen får 1 medlemskap.
, där a är den låga gränsen, b är den höga gränsen och f1 är exponenten. Den här ekvationen tilldelar medlemsvärden med hjälp av power-transformationen för pixelvärden mellan den låga och den höga gränsen. Pixelvärden som är mindre än den låga gränsen får 0 medlemskap medan pixelvärden som är större än den höga gränsen får 1 medlemskap.
Se även
Fuzzifiera raster (gaussiskt medlemskap), Fuzzifiera raster (stort medlemskap), Fuzzifiera raster (linjärt medlemskap), Fuzzifiera raster (nära medlemskap), Fuzzifiera raster (litet antal medlemmar)
Parametrar
Grundläggande parametrar
Etikett |
Namn |
Typ |
Beskrivning |
|---|---|---|---|
Input Raster |
|
[raster] |
Inmatat rasterlager |
Bandnummer |
|
[rasterband] Standard: Det första bandet i rasterlagret |
Om rastret är multibandigt väljer du det band som du vill fuzzifiera. |
Låg gräns för fuzzy-medlemskap |
|
[numerisk: dubbel] Standard: 0,0 |
Låg gräns för effektfunktionen |
Hög gräns för fuzzy-medlemskap |
|
[numerisk: dubbel] Standard: 1,0 |
Hög gräns för effektfunktionen |
Hög gräns för fuzzy-medlemskap |
|
[numerisk: dubbel] Standard: 2,0 |
Exponent för potensfunktionen |
Fuzzifierat raster |
|
[samma som inmatning] Standard: |
Specifikation av utmatningsrastret. En av:
|
Avancerade parametrar
Etikett |
Namn |
Typ |
Beskrivning |
|---|---|---|---|
Alternativ för skapande Valfritt |
|
[sträng] Standard: ’’ |
För att lägga till ett eller flera skapandealternativ som styr det raster som ska skapas (färger, blockstorlek, filkomprimering …). För enkelhetens skull kan du förlita dig på fördefinierade profiler (se GDAL driver options section). Batch Process and Model Designer: separera flera alternativ med ett pipe-tecken ( |
Utgångar
Etikett |
Namn |
Typ |
Beskrivning |
|---|---|---|---|
Fuzzifierat raster |
|
[samma som inmatning] |
Utgående rasterlager som innehåller resultatet |
CRS auktoritetsidentifierare |
|
[crs] |
Koordinatreferenssystemet för det utgående rasterlagret |
Extent |
|
[sträng] |
Den spatiala omfattningen av det utgående rasterlagret |
Bredd i pixlar |
|
[numerisk: heltal] |
Antalet kolumner i det utgående rasterlagret |
Höjd i pixlar |
|
[numerisk: heltal] |
Antalet rader i det utgående rasterlagret |
Totalt antal pixlar |
|
[numerisk: heltal] |
Antalet pixlar i det utgående rasterlagret |
Python-kod
Algoritm-ID: `native:fuzzifyrasterpowermembership
import processing
processing.run("algorithm_id", {parameter_dictionary})
algoritm id visas när du håller muspekaren över algoritmen i verktygslådan Processing Toolbox. I parameter dictionary finns parameternamn och värden. Se Använda bearbetningsalgoritmer från konsolen för information om hur du kör bearbetningsalgoritmer från Python-konsolen.
24.1.15.11. Fuzzifiera raster (litet antal medlemmar)
Omvandlar ett inmatningsraster till ett fuzzifierat raster genom att tilldela ett medlemsvärde till varje pixel med hjälp av en Small-medlemsfunktion. Medlemskapsvärdena sträcker sig från 0 till 1. I det fuzzifierade rastret innebär ett värde på 0 inget medlemskap i den definierade fuzzy-uppsättningen, medan ett värde på 1 innebär fullt medlemskap. Den lilla medlemskapsfunktionen definieras som 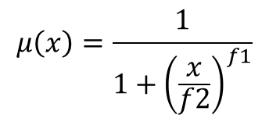 , där f1 är spridningen och f2 mittpunkten.
, där f1 är spridningen och f2 mittpunkten.
Se även
Fuzzifiera raster (gaussiskt medlemskap), Fuzzifiera raster (stort medlemskap) Fuzzifiera raster (linjärt medlemskap), Fuzzifiera raster (nära medlemskap), Fuzzifiera raster (kraftmedlemskap)
Parametrar
Grundläggande parametrar
Etikett |
Namn |
Typ |
Beskrivning |
|---|---|---|---|
Input Raster |
|
[raster] |
Inmatat rasterlager |
Bandnummer |
|
[rasterband] Standard: Det första bandet i rasterlagret |
Om rastret är multibandigt väljer du det band som du vill fuzzifiera. |
Funktionens mittpunkt |
|
[numerisk: dubbel] Standard: 50,0 |
Mittpunkt för den lilla funktionen |
Funktionsfördelning |
|
[numerisk: dubbel] Standard: 5,0 |
Utbredning av den lilla funktionen |
Fuzzifierat raster |
|
[samma som inmatning] Standard: |
Specifikation av utmatningsrastret. En av:
|
Avancerade parametrar
Etikett |
Namn |
Typ |
Beskrivning |
|---|---|---|---|
Alternativ för skapande Valfritt |
|
[sträng] Standard: ’’ |
För att lägga till ett eller flera skapandealternativ som styr det raster som ska skapas (färger, blockstorlek, filkomprimering …). För enkelhetens skull kan du förlita dig på fördefinierade profiler (se GDAL driver options section). Batch Process and Model Designer: separera flera alternativ med ett pipe-tecken ( |
Utgångar
Etikett |
Namn |
Typ |
Beskrivning |
|---|---|---|---|
Fuzzifierat raster |
|
[samma som inmatning] |
Utgående rasterlager som innehåller resultatet |
CRS auktoritetsidentifierare |
|
[crs] |
Koordinatreferenssystemet för det utgående rasterlagret |
Extent |
|
[sträng] |
Den spatiala omfattningen av det utgående rasterlagret |
Bredd i pixlar |
|
[numerisk: heltal] |
Antalet kolumner i det utgående rasterlagret |
Höjd i pixlar |
|
[numerisk: heltal] |
Antalet rader i det utgående rasterlagret |
Totalt antal pixlar |
|
[numerisk: heltal] |
Antalet pixlar i det utgående rasterlagret |
Python-kod
Algoritm-ID: `native:fuzzifyrastersmallmembership
import processing
processing.run("algorithm_id", {parameter_dictionary})
algoritm id visas när du håller muspekaren över algoritmen i verktygslådan Processing Toolbox. I parameter dictionary finns parameternamn och värden. Se Använda bearbetningsalgoritmer från konsolen för information om hur du kör bearbetningsalgoritmer från Python-konsolen.
24.1.15.12. Större än frekvensen
Utvärderar cell för cell frekvensen (antalet gånger) som värdena i en inmatningsstapel av raster är lika med värdet i ett värderaster. Utgångsrastrets utsträckning och upplösning definieras av ingångsrasterlagret och är alltid av typen Int32.
Om flerbandsraster används i datarasterstacken kommer algoritmen alltid att utföra analysen på det första bandet i rastren - använd GDAL för att använda andra band i analysen. NoData-värdet för utdata kan ställas in manuellt.
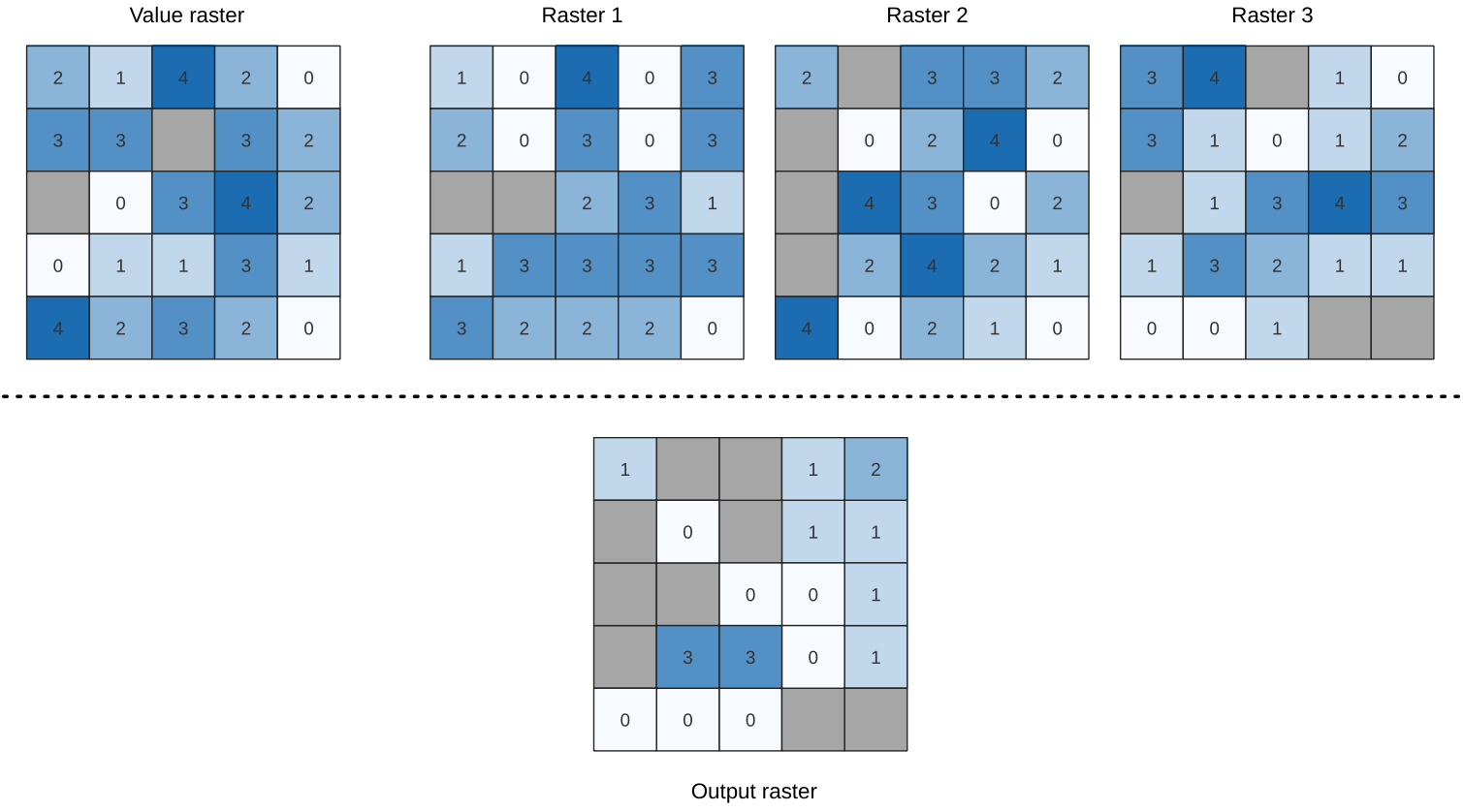
Fig. 24.25 För varje cell i utdatarastret representerar värdet det antal gånger som motsvarande celler i listan över raster är större än värdet raster. NoData-celler (grå) tas med i beräkningen.
Se även
Parametrar
Grundläggande parametrar
Etikett |
Namn |
Typ |
Beskrivning |
|---|---|---|---|
Inmatningsvärde raster |
|
[raster] |
Ingångsvärdeslagret fungerar som referenslager för provlagren |
Värde rasterband |
|
[rasterband] Standard: Det första bandet i rasterlagret |
Välj det band du vill använda som prov |
Rasterlager för inmatning |
|
[raster] [lista] |
Rasterlager som ska utvärderas. Om flerbandsraster används i datarasterstacken kommer algoritmen alltid att utföra analysen på det första bandet i rastren |
Ignorera NoData-värden |
|
[boolean] Standard: Falsk |
Om det inte är markerat kommer alla NoData-celler i värderastret eller datalagerstapeln att resultera i en NoData-cell i utdatarastret |
Utdatalager |
|
[samma som inmatning] Standard: |
Specifikation av utmatningsrastret. En av:
|
Avancerade parametrar
Etikett |
Namn |
Typ |
Beskrivning |
|---|---|---|---|
Utmatning av NoData-värde Valfritt |
|
[numerisk: dubbel] Standard: -9999.0 |
Värde som ska användas för NoData i utdatalagret |
Alternativ för skapande Valfritt |
|
[sträng] Standard: ’’ |
För att lägga till ett eller flera skapandealternativ som styr det raster som ska skapas (färger, blockstorlek, filkomprimering …). För enkelhetens skull kan du förlita dig på fördefinierade profiler (se GDAL driver options section). Batch Process and Model Designer: separera flera alternativ med ett pipe-tecken ( |
Utgångar
Etikett |
Namn |
Typ |
Beskrivning |
|---|---|---|---|
Utdatalager |
|
[raster] |
Utgående rasterlager som innehåller resultatet |
CRS auktoritetsidentifierare |
|
[sträng] |
Koordinatreferenssystemet för det utgående rasterlagret |
Extent |
|
[sträng] |
Den spatiala omfattningen av det utgående rasterlagret |
Antal celler med förekomster av lika värde |
|
[numerisk: heltal] |
|
Höjd i pixlar |
|
[numerisk: heltal] |
Antalet rader i det utgående rasterlagret |
Totalt antal pixlar |
|
[numerisk: heltal] |
Antalet pixlar i det utgående rasterlagret |
Medelfrekvens vid giltiga cellpositioner |
|
[numerisk: dubbel] |
|
Antal värdeförekomster |
|
[numerisk: heltal] |
|
Bredd i pixlar |
|
[numerisk: heltal] |
Antalet kolumner i det utgående rasterlagret |
Python-kod
Algoritm-id: native:greaterthanfrequency
import processing
processing.run("algorithm_id", {parameter_dictionary})
algoritm id visas när du håller muspekaren över algoritmen i verktygslådan Processing Toolbox. I parameter dictionary finns parameternamn och värden. Se Använda bearbetningsalgoritmer från konsolen för information om hur du kör bearbetningsalgoritmer från Python-konsolen.
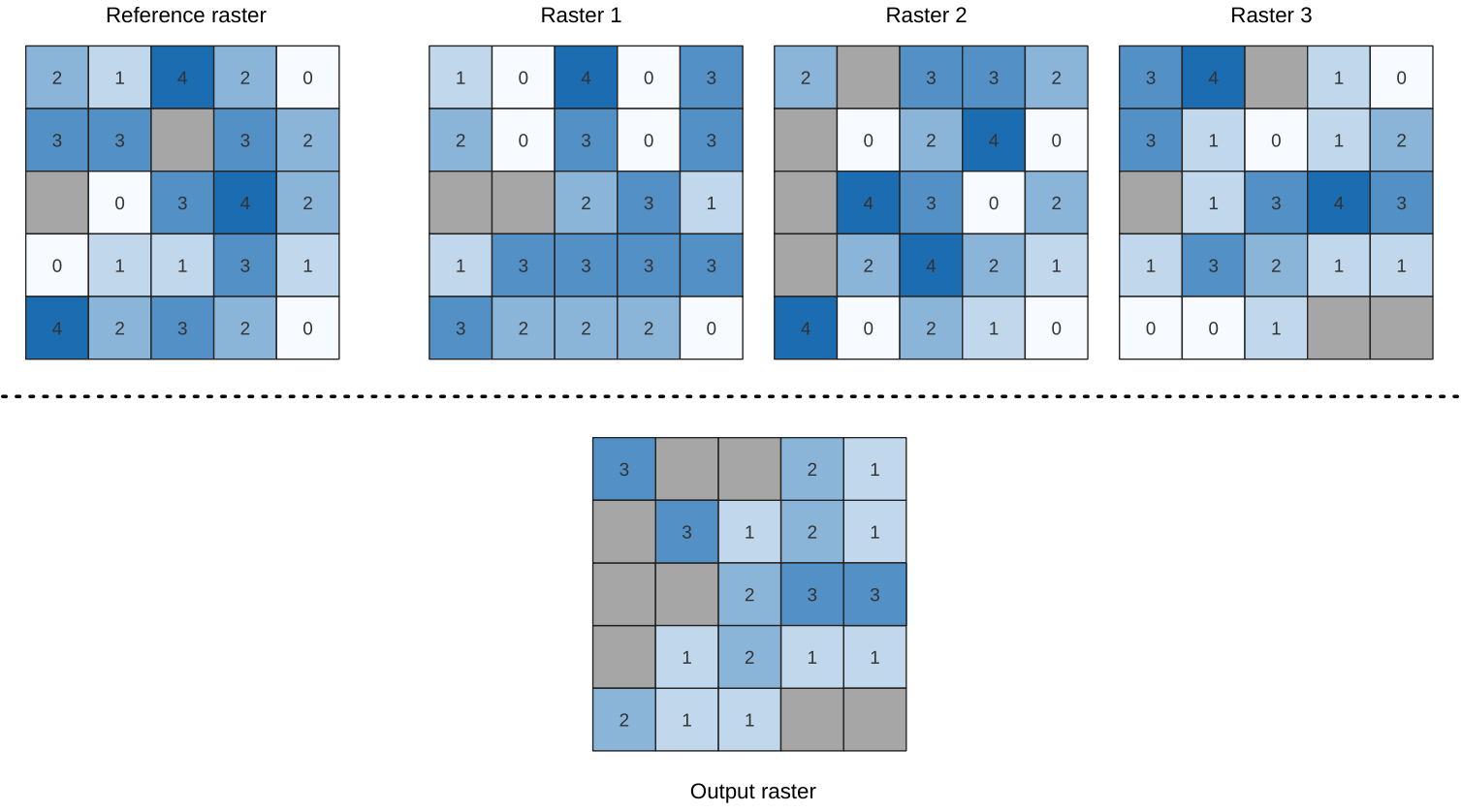
24.1.15.13. Högsta positionen i rasterstacken
Utvärderar cell för cell positionen för det raster som har det högsta värdet i en stapel med raster. Positionsräkningarna börjar med 1 och sträcker sig till det totala antalet inmatningsraster. Ordningen på de ingående rastrerna är relevant för algoritmen. Om flera raster har det högsta värdet kommer det första rastret att användas för positionsvärdet.
Om flerbandsraster används i datarasterstacken kommer algoritmen alltid att utföra analysen på det första bandet i rastren - använd GDAL för att använda andra band i analysen. Alla NoData-celler i rasterlagerstacken kommer att resultera i en NoData-cell i utdatarastret om inte parametern ”ignore NoData” är markerad. NoData-värdet för utdata kan ställas in manuellt. Utdatarasterns utsträckning och upplösning definieras av ett referensrasterlager och är alltid av typen Int32.
Parametrar
Grundläggande parametrar
Etikett |
Namn |
Typ |
Beskrivning |
|---|---|---|---|
Rasterlager för inmatning |
|
[raster] [lista] |
Lista över rasterlager att jämföra med |
Reference layer |
|
[raster] |
Referenslagret för skapandet av utdatalagret (utsträckning, CRS, pixeldimensioner) |
Ignorera NoData-värden |
|
[boolean] Standard: Falsk |
Om det inte är markerat kommer alla NoData-celler i datalagerstapeln att resultera i en NoData-cell i utdatarastern |
Utdatalager |
|
[raster] Standard: |
Specifikation av utdatarastret som innehåller resultatet. En av:
|
Avancerade parametrar
Etikett |
Namn |
Typ |
Beskrivning |
|---|---|---|---|
Utmatning av NoData-värde |
|
[numerisk: dubbel] Standard: -9999.0 |
Värde som ska användas för NoData i utdatalagret |
Alternativ för skapande Valfritt |
|
[sträng] Standard: ’’ |
För att lägga till ett eller flera skapandealternativ som styr det raster som ska skapas (färger, blockstorlek, filkomprimering …). För enkelhetens skull kan du förlita dig på fördefinierade profiler (se GDAL driver options section). Batch Process and Model Designer: separera flera alternativ med ett pipe-tecken ( |
Utgångar
Etikett |
Namn |
Typ |
Beskrivning |
|---|---|---|---|
Utdatalager |
|
[raster] |
Utgående rasterlager som innehåller resultatet |
CRS auktoritetsidentifierare |
|
[sträng] |
Koordinatreferenssystemet för det utgående rasterlagret |
Extent |
|
[sträng] |
Den spatiala omfattningen av det utgående rasterlagret |
Bredd i pixlar |
|
[numerisk: heltal] |
Antalet kolumner i det utgående rasterlagret |
Höjd i pixlar |
|
[numerisk: heltal] |
Antalet rader i det utgående rasterlagret |
Totalt antal pixlar |
|
[numerisk: heltal] |
Antalet pixlar i det utgående rasterlagret |
Python-kod
Algoritm-id: native:highestpositioninrasterstack
import processing
processing.run("algorithm_id", {parameter_dictionary})
algoritm id visas när du håller muspekaren över algoritmen i verktygslådan Processing Toolbox. I parameter dictionary finns parameternamn och värden. Se Använda bearbetningsalgoritmer från konsolen för information om hur du kör bearbetningsalgoritmer från Python-konsolen.
24.1.15.14. Mindre än frekvensen
Utvärderar cell för cell frekvensen (antalet gånger) som värdena i en inmatningsstapel av raster är mindre än värdet i ett värderaster. Utgångsrastrets utsträckning och upplösning definieras av ingångsrasterlagret och är alltid av typen Int32.
Om flerbandsraster används i datarasterstacken kommer algoritmen alltid att utföra analysen på det första bandet i rastren - använd GDAL för att använda andra band i analysen. NoData-värdet för utdata kan ställas in manuellt.
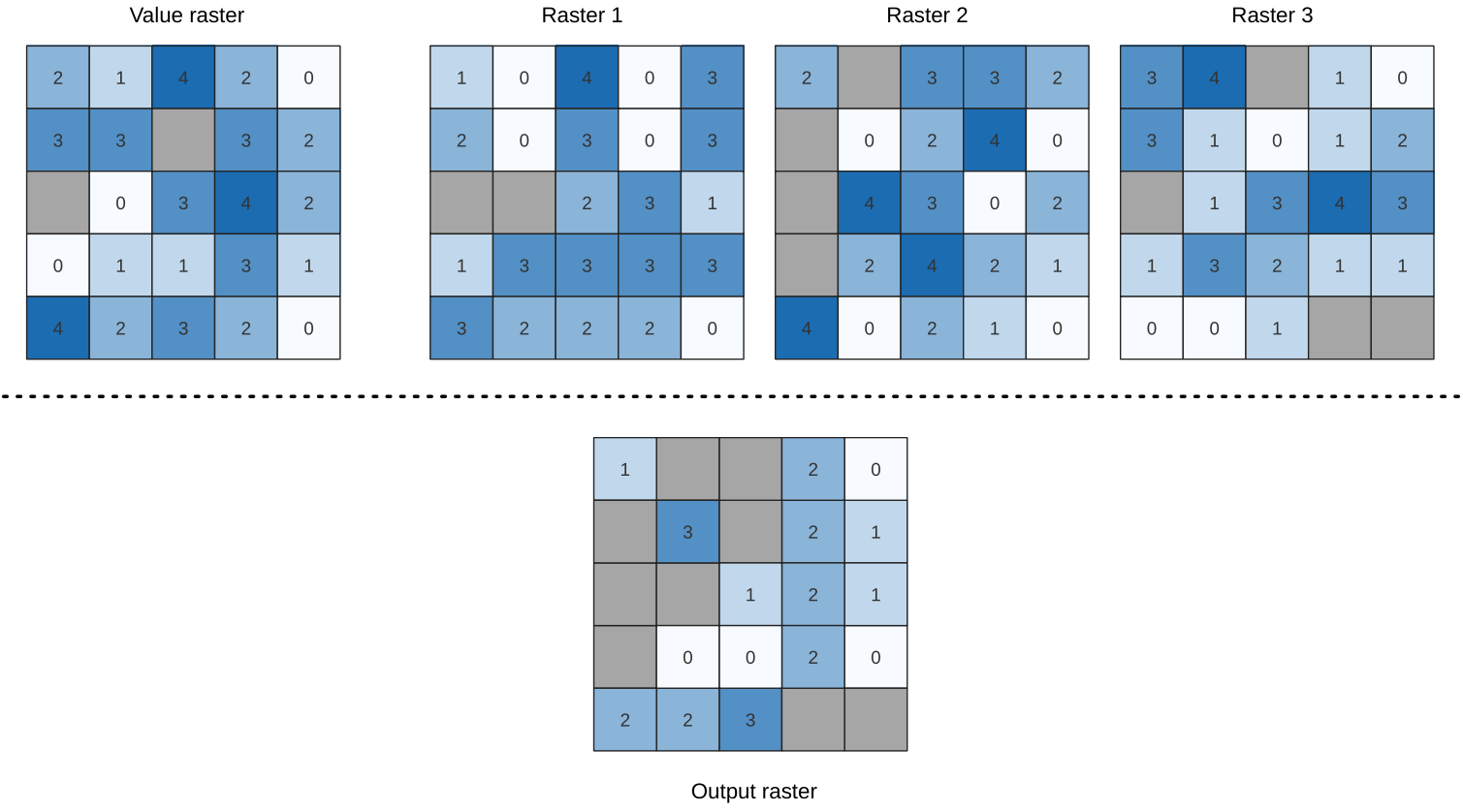
Fig. 24.26 För varje cell i utdatarastret representerar värdet det antal gånger som motsvarande celler i listan med raster är mindre än värdet raster. NoData-celler (grå) tas med i beräkningen.
Se även
Parametrar
Grundläggande parametrar
Etikett |
Namn |
Typ |
Beskrivning |
|---|---|---|---|
Inmatningsvärde raster |
|
[raster] |
Ingångsvärdeslagret fungerar som referenslager för provlagren |
Värde rasterband |
|
[rasterband] Standard: Det första bandet i rasterlagret |
Välj det band du vill använda som prov |
Rasterlager för inmatning |
|
[raster] [lista] |
Rasterlager som ska utvärderas. Om flerbandsraster används i datarasterstacken kommer algoritmen alltid att utföra analysen på det första bandet i rastren |
Ignorera NoData-värden |
|
[boolean] Standard: Falsk |
Om det inte är markerat kommer alla NoData-celler i värderastret eller datalagerstapeln att resultera i en NoData-cell i utdatarastret |
Utdatalager |
|
[samma som inmatning] Standard: |
Specifikation av utmatningsrastret. En av:
|
Avancerade parametrar
Etikett |
Namn |
Typ |
Beskrivning |
|---|---|---|---|
Utmatning av NoData-värde Valfritt |
|
[numerisk: dubbel] Standard: -9999.0 |
Värde som ska användas för NoData i utdatalagret |
Alternativ för skapande Valfritt |
|
[sträng] Standard: ’’ |
För att lägga till ett eller flera skapandealternativ som styr det raster som ska skapas (färger, blockstorlek, filkomprimering …). För enkelhetens skull kan du förlita dig på fördefinierade profiler (se GDAL driver options section). Batch Process and Model Designer: separera flera alternativ med ett pipe-tecken ( |
Utgångar
Etikett |
Namn |
Typ |
Beskrivning |
|---|---|---|---|
Utdatalager |
|
[raster] |
Utgående rasterlager som innehåller resultatet |
CRS auktoritetsidentifierare |
|
[sträng] |
Koordinatreferenssystemet för det utgående rasterlagret |
Extent |
|
[sträng] |
Den spatiala omfattningen av det utgående rasterlagret |
Antal celler med förekomster av lika värde |
|
[numerisk: heltal] |
|
Höjd i pixlar |
|
[numerisk: heltal] |
Antalet rader i det utgående rasterlagret |
Totalt antal pixlar |
|
[numerisk: heltal] |
Antalet pixlar i det utgående rasterlagret |
Medelfrekvens vid giltiga cellpositioner |
|
[numerisk: dubbel] |
|
Antal värdeförekomster |
|
[numerisk: heltal] |
|
Bredd i pixlar |
|
[numerisk: heltal] |
Antalet kolumner i det utgående rasterlagret |
Python-kod
Algoritm-id: native:lessthanfrequency
import processing
processing.run("algorithm_id", {parameter_dictionary})
algoritm id visas när du håller muspekaren över algoritmen i verktygslådan Processing Toolbox. I parameter dictionary finns parameternamn och värden. Se Använda bearbetningsalgoritmer från konsolen för information om hur du kör bearbetningsalgoritmer från Python-konsolen.
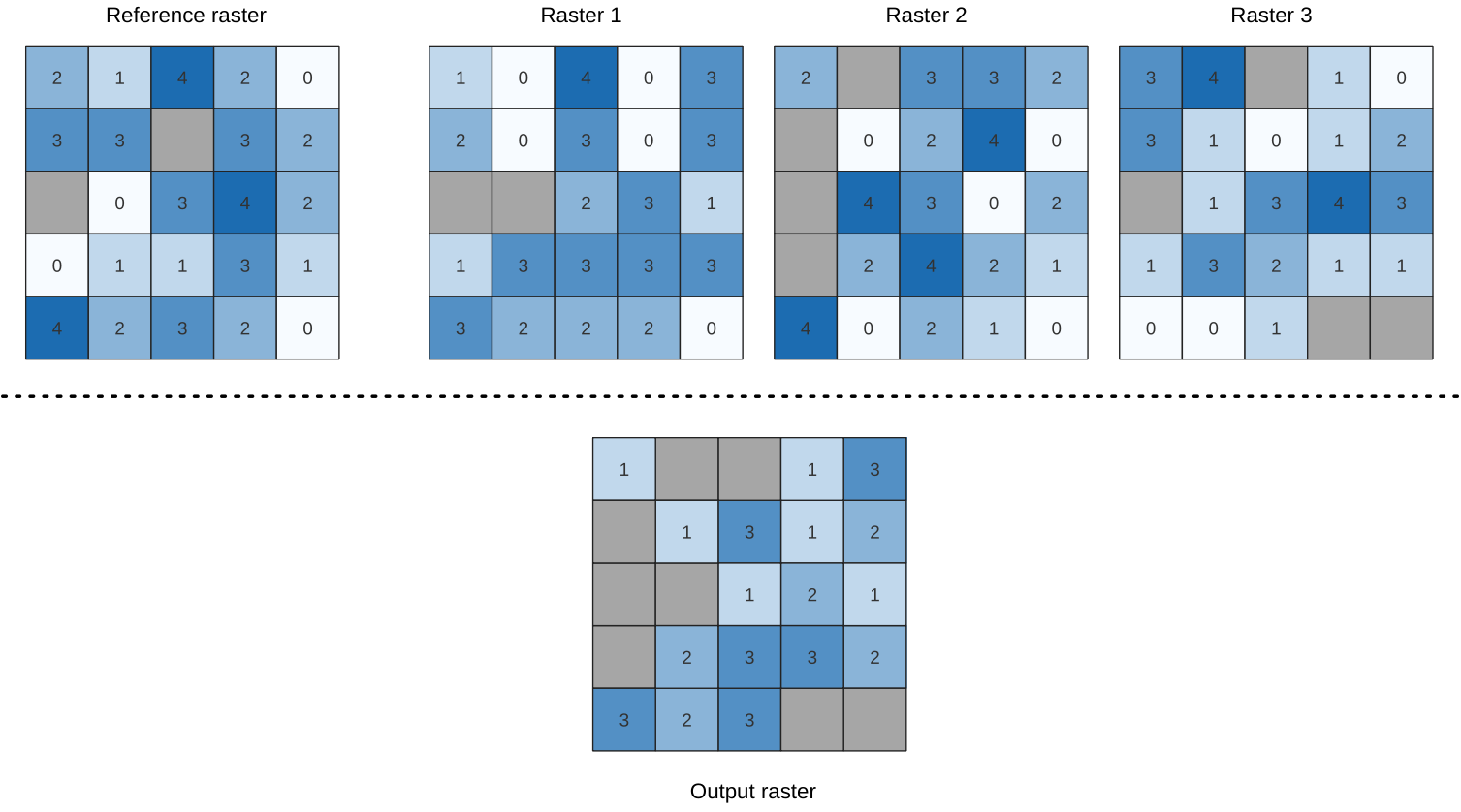
24.1.15.15. Lägsta positionen i rasterstapeln
Utvärderar cell för cell positionen för det raster som har det lägsta värdet i en stapel med raster. Positionsräkningarna börjar med 1 och sträcker sig till det totala antalet inmatningsraster. Ordningen på de ingående rastrerna är relevant för algoritmen. Om flera raster har det lägsta värdet kommer det första rastret att användas för positionsvärdet.
Om flerbandsraster används i datarasterstacken kommer algoritmen alltid att utföra analysen på det första bandet i rastren - använd GDAL för att använda andra band i analysen. Alla NoData-celler i rasterlagerstacken kommer att resultera i en NoData-cell i utdatarastret om inte parametern ”ignore NoData” är markerad. NoData-värdet för utdata kan ställas in manuellt. Utdatarasterns utsträckning och upplösning definieras av ett referensrasterlager och är alltid av typen Int32.
Parametrar
Grundläggande parametrar
Etikett |
Namn |
Typ |
Beskrivning |
|---|---|---|---|
Rasterlager för inmatning |
|
[raster] [lista] |
Lista över rasterlager att jämföra med |
Reference layer |
|
[raster] |
Referenslagret för skapandet av utdatalagret (utsträckning, CRS, pixeldimensioner) |
Ignorera NoData-värden |
|
[boolean] Standard: Falsk |
Om det inte är markerat kommer alla NoData-celler i datalagerstapeln att resultera i en NoData-cell i utdatarastern |
Utdatalager |
|
[raster] Standard: |
Specifikation av utdatarastret som innehåller resultatet. En av:
|
Avancerade parametrar
Etikett |
Namn |
Typ |
Beskrivning |
|---|---|---|---|
Utmatning av NoData-värde |
|
[numerisk: dubbel] Standard: -9999.0 |
Värde som ska användas för NoData i utdatalagret |
Alternativ för skapande Valfritt |
|
[sträng] Standard: ’’ |
För att lägga till ett eller flera skapandealternativ som styr det raster som ska skapas (färger, blockstorlek, filkomprimering …). För enkelhetens skull kan du förlita dig på fördefinierade profiler (se GDAL driver options section). Batch Process and Model Designer: separera flera alternativ med ett pipe-tecken ( |
Utgångar
Etikett |
Namn |
Typ |
Beskrivning |
|---|---|---|---|
Utdatalager |
|
[raster] |
Utgående rasterlager som innehåller resultatet |
CRS auktoritetsidentifierare |
|
[sträng] |
Koordinatreferenssystemet för det utgående rasterlagret |
Extent |
|
[sträng] |
Den spatiala omfattningen av det utgående rasterlagret |
Bredd i pixlar |
|
[numerisk: heltal] |
Antalet kolumner i det utgående rasterlagret |
Höjd i pixlar |
|
[numerisk: heltal] |
Antalet rader i det utgående rasterlagret |
Totalt antal pixlar |
|
[numerisk: heltal] |
Antalet pixlar i det utgående rasterlagret |
Python-kod
Algoritm-id: native:lowestpositioninrasterstack
import processing
processing.run("algorithm_id", {parameter_dictionary})
algoritm id visas när du håller muspekaren över algoritmen i verktygslådan Processing Toolbox. I parameter dictionary finns parameternamn och värden. Se Använda bearbetningsalgoritmer från konsolen för information om hur du kör bearbetningsalgoritmer från Python-konsolen.
24.1.15.16. Raster boolean AND
Beräknar det booleska AND för en uppsättning inmatningsraster. Om alla indataraster har ett värde som inte är noll för en pixel, kommer den pixeln att sättas till 1 i utdatarastret. Om något av indatarastren har värden på 0 för pixeln kommer den att sättas till 0 i utdatarastret.
Parametern referenslager anger ett befintligt rasterlager som ska användas som referens när utdatarastern skapas. Utdatarastern kommer att ha samma utsträckning, CRS och pixeldimensioner som detta lager.
Som standard kommer en NoData-pixel i NÅGOT av inmatningslagren att resultera i en NoData-pixel i utdatarastret. Om alternativet Behandla NoData-värden som falska är markerat, behandlas NoData-ingångar på samma sätt som ett ingångsvärde på 0.
Se även
Parametrar
Grundläggande parametrar
Etikett |
Namn |
Typ |
Beskrivning |
|---|---|---|---|
Inmatningslager |
|
[raster] [lista] |
Lista över ingående rasterlager |
Reference layer |
|
[raster] |
Referenslagret att skapa utdatalagret från (utsträckning, CRS, pixeldimensioner) |
Behandla NoData-värden som falska |
|
[boolean] Standard: Falsk |
Behandla NoData-värden i indatafilerna som 0 när du utför operationen |
Utdatalager |
|
[raster] Standard: |
Specifikation av utdatarastret som innehåller resultatet. En av:
|
Avancerade parametrar
Etikett |
Namn |
Typ |
Beskrivning |
|---|---|---|---|
Utmatning av NoData-värde |
|
[numerisk: dubbel] Standard: -9999.0 |
Värde som ska användas för NoData i utdatalagret |
Typ av utdata |
|
[uppräkning] Standard: 5 |
Typ av rasterdata som matas ut. Alternativ:
Tillgängliga alternativ beror på vilken GDAL-version som byggts med QGIS (se -menyn) |
Alternativ för skapande Valfritt |
|
[sträng] Standard: ’’ |
För att lägga till ett eller flera skapandealternativ som styr det raster som ska skapas (färger, blockstorlek, filkomprimering …). För enkelhetens skull kan du förlita dig på fördefinierade profiler (se GDAL driver options section). Batch Process and Model Designer: separera flera alternativ med ett pipe-tecken ( |
Utgångar
Etikett |
Namn |
Typ |
Beskrivning |
|---|---|---|---|
Extent |
|
[sträng] |
Den spatiala omfattningen av det utgående rasterlagret |
CRS auktoritetsidentifierare |
|
[crs] |
Koordinatreferenssystemet för det utgående rasterlagret |
Bredd i pixlar |
|
[numerisk: heltal] |
Antalet kolumner i det utgående rasterlagret |
Höjd i pixlar |
|
[numerisk: heltal] |
Antalet rader i det utgående rasterlagret |
Totalt antal pixlar |
|
[numerisk: heltal] |
Antalet pixlar i det utgående rasterlagret |
NoData pixelantal |
|
[numerisk: heltal] |
Antalet NoData-pixlar i det utgående rasterlagret |
Antal verkliga pixlar |
|
[numerisk: heltal] |
Antalet True-pixlar (värde = 1) i det utgående rasterlagret |
Felaktigt pixelantal |
|
[numerisk: heltal] |
Antalet falska pixlar (värde = 0) i det utgående rasterlagret |
Utdatalager |
|
[raster] |
Utgående rasterlager som innehåller resultatet |
Python-kod
Algoritm-ID: native:rasterbooleanand
import processing
processing.run("algorithm_id", {parameter_dictionary})
algoritm id visas när du håller muspekaren över algoritmen i verktygslådan Processing Toolbox. I parameter dictionary finns parameternamn och värden. Se Använda bearbetningsalgoritmer från konsolen för information om hur du kör bearbetningsalgoritmer från Python-konsolen.
24.1.15.17. Raster boolean OR
Beräknar det booleska OR för en uppsättning inmatningsraster. Om alla indataraster har ett nollvärde för en pixel, kommer den pixeln att sättas till 0 i utdatarastret. Om något av indatarastren har värden på 1 för pixeln kommer den att sättas till 1 i utdatarastret.
Parametern referenslager anger ett befintligt rasterlager som ska användas som referens när utdatarastern skapas. Utdatarastern kommer att ha samma utsträckning, CRS och pixeldimensioner som detta lager.
Som standard kommer en NoData-pixel i NÅGOT av inmatningslagren att resultera i en NoData-pixel i utdatarastret. Om alternativet Behandla NoData-värden som falska är markerat, behandlas NoData-ingångar på samma sätt som ett ingångsvärde på 0.
Se även
Parametrar
Grundläggande parametrar
Etikett |
Namn |
Typ |
Beskrivning |
|---|---|---|---|
Inmatningslager |
|
[raster] [lista] |
Lista över ingående rasterlager |
Reference layer |
|
[raster] |
Referenslagret att skapa utdatalagret från (utsträckning, CRS, pixeldimensioner) |
Behandla NoData-värden som falska |
|
[boolean] Standard: Falsk |
Behandla NoData-värden i indatafilerna som 0 när du utför operationen |
Utdatalager |
|
[raster] Standard: |
Specifikation av utdatarastret som innehåller resultatet. En av:
|
Avancerade parametrar
Etikett |
Namn |
Typ |
Beskrivning |
|---|---|---|---|
Utmatning av NoData-värde |
|
[numerisk: dubbel] Standard: -9999.0 |
Värde som ska användas för NoData i utdatalagret |
Typ av utdata |
|
[uppräkning] Standard: 5 |
Typ av rasterdata som matas ut. Alternativ:
Tillgängliga alternativ beror på vilken GDAL-version som byggts med QGIS (se -menyn) |
Alternativ för skapande Valfritt |
|
[sträng] Standard: ’’ |
För att lägga till ett eller flera skapandealternativ som styr det raster som ska skapas (färger, blockstorlek, filkomprimering …). För enkelhetens skull kan du förlita dig på fördefinierade profiler (se GDAL driver options section). Batch Process and Model Designer: separera flera alternativ med ett pipe-tecken ( |
Utgångar
Etikett |
Namn |
Typ |
Beskrivning |
|---|---|---|---|
Extent |
|
[sträng] |
Den spatiala omfattningen av det utgående rasterlagret |
CRS auktoritetsidentifierare |
|
[crs] |
Koordinatreferenssystemet för det utgående rasterlagret |
Bredd i pixlar |
|
[numerisk: heltal] |
Antalet kolumner i det utgående rasterlagret |
Höjd i pixlar |
|
[numerisk: heltal] |
Antalet rader i det utgående rasterlagret |
Totalt antal pixlar |
|
[numerisk: heltal] |
Antalet pixlar i det utgående rasterlagret |
NoData pixelantal |
|
[numerisk: heltal] |
Antalet NoData-pixlar i det utgående rasterlagret |
Antal verkliga pixlar |
|
[numerisk: heltal] |
Antalet True-pixlar (värde = 1) i det utgående rasterlagret |
Felaktigt pixelantal |
|
[numerisk: heltal] |
Antalet falska pixlar (värde = 0) i det utgående rasterlagret |
Utdatalager |
|
[raster] |
Utgående rasterlager som innehåller resultatet |
Python-kod
Algoritm-id: native:rasterbooleanor
import processing
processing.run("algorithm_id", {parameter_dictionary})
algoritm id visas när du håller muspekaren över algoritmen i verktygslådan Processing Toolbox. I parameter dictionary finns parameternamn och värden. Se Använda bearbetningsalgoritmer från konsolen för information om hur du kör bearbetningsalgoritmer från Python-konsolen.
24.1.15.18. Rasterkalkylator
Utför algebraiska operationer med hjälp av rasterlager.
Det resulterande lagret får sina värden beräknade enligt ett uttryck. Uttrycket kan innehålla numeriska värden, operatorer och referenser till något av lagren i det aktuella projektet.
Parametrar
Etikett |
Namn |
Typ |
Beskrivning |
|---|---|---|---|
Inmatningslager |
|
[raster] [lista] |
Lista över ingående rasterlager |
Uttryck |
|
[uttryck] |
Rasterbaserat uttryck som kommer att användas för att beräkna det utgående rasterlagret. |
Utmatning omfattning Valfritt |
|
[omfattning] |
Ange den spatiala omfattningen för det utgående rasterlagret. Om omfattningen inte anges kommer den minsta omfattning som täcker alla valda referenslager att användas. Tillgängliga metoder är:
|
Cellstorlek för utmatning (lämna tomt för automatisk inställning) Valfritt |
|
[numerisk: dubbel] |
Cellstorlek för det utgående rasterlagret. Om cellstorleken inte anges kommer den minsta cellstorleken för det/de valda referenslagren att användas. Cellstorleken kommer att vara densamma för X- och Y-axlarna. |
Utgång CRS Valfritt |
|
[crs] |
CRS för det utgående rasterlagret. Om CRS för utdata inte anges kommer CRS för det första referenslagret att användas. |
Beräknad |
|
[raster] Standard: |
Specifikation av utmatningsrastret. En av:
|
Utgångar
Etikett |
Namn |
Typ |
Beskrivning |
|---|---|---|---|
Beräknad |
|
[raster] |
Utmatning av rasterfil med de beräknade värdena. |
Python-kod
Algoritm-id: native:rastercalc
import processing
processing.run("algorithm_id", {parameter_dictionary})
algoritm id visas när du håller muspekaren över algoritmen i verktygslådan Processing Toolbox. I parameter dictionary finns parameternamn och värden. Se Använda bearbetningsalgoritmer från konsolen för information om hur du kör bearbetningsalgoritmer från Python-konsolen.
24.1.15.19. Rasterkalkylator (virtuell)
Utför algebraiska operationer med hjälp av rasterlager och genererar resultat i minnet.
Det resulterande lagret får sina värden beräknade enligt ett uttryck. Uttrycket kan innehålla numeriska värden, operatorer och referenser till något av lagren i det aktuella projektet.
Ett virtuellt rasterlager är ett rasterlager som definieras av dess URI och vars pixlar beräknas i realtid. Det är inte en ny fil på disken; det virtuella lagret är fortfarande kopplat till de raster som används i beräkningen, vilket innebär att radering eller flyttning av dessa raster skulle förstöra det. Ett Layernamn kan anges, annars används beräkningsuttrycket som sådant. Om det virtuella lagret tas bort från projektet raderas det, och det kan göras beständigt i filen med hjälp av lagrets kontextuella meny.
Se även
Parametrar
Etikett |
Namn |
Typ |
Beskrivning |
|---|---|---|---|
Inmatningslager |
|
[raster] [lista] |
Lista över ingående rasterlager |
Uttryck |
|
[uttryck] |
Rasterbaserat uttryck som kommer att användas för att beräkna det utgående rasterlagret. |
Utmatning omfattning Valfritt |
|
[omfattning] |
Ange den spatiala omfattningen för det utgående rasterlagret. Om omfattningen inte anges kommer den minsta omfattning som täcker alla valda referenslager att användas. Tillgängliga metoder är:
|
Cellstorlek för utmatning (lämna tomt för automatisk inställning) Valfritt |
|
[numerisk: dubbel] |
Cellstorlek för det utgående rasterlagret. Om cellstorleken inte anges kommer den minsta cellstorleken för det/de valda referenslagren att användas. Cellstorleken kommer att vara densamma för X- och Y-axlarna. |
Utgång CRS Valfritt |
|
[crs] |
CRS för det utgående rasterlagret. Om CRS för utdata inte anges kommer CRS för det första referenslagret att användas. |
Namn på utmatningslager Valfritt |
|
[sträng] |
Det namn som ska tilldelas det genererade lagret. Om det inte anges används texten i beräkningsuttrycket. |
Utgångar
Etikett |
Namn |
Typ |
Beskrivning |
|---|---|---|---|
Beräknad |
|
[raster] |
Utmatning av virtuellt rasterlager med de beräknade värdena. |
Python-kod
Algoritm-id: native:virtualrastercalc
import processing
processing.run("algorithm_id", {parameter_dictionary})
algoritm id visas när du håller muspekaren över algoritmen i verktygslådan Processing Toolbox. I parameter dictionary finns parameternamn och värden. Se Använda bearbetningsalgoritmer från konsolen för information om hur du kör bearbetningsalgoritmer från Python-konsolen.
24.1.15.20. Egenskaper för rasterlager
Returnerar grundläggande egenskaper för det angivna rasterlagret, inklusive utsträckning, storlek i pixlar och pixeldimensioner (i kartenheter), antal band och NoData-värde.
Denna algoritm är avsedd att användas som ett sätt att extrahera dessa användbara egenskaper för att använda som ingångsvärden till andra algoritmer i en modell - t.ex. för att göra det möjligt att överföra ett befintligt rasters pixelstorlekar till en GDAL-rasteralgoritm.
Parametrar
Etikett |
Namn |
Typ |
Beskrivning |
|---|---|---|---|
Inmatningslager |
|
[raster] |
Inmatat rasterlager |
Bandnummer Valfritt |
|
[rasterband] Standard: Ej inställd |
Om egenskaper för ett specifikt band också ska returneras. Om ett band anges returneras även noData-värdet för det valda bandet. |
Utgångar
Etikett |
Namn |
Typ |
Beskrivning |
|---|---|---|---|
Antal band i rastret |
|
[numerisk: heltal] |
Antalet band i rastret |
CRS auktoritetsidentifierare |
|
[sträng] |
Koordinatreferenssystemet för det utgående rasterlagret |
Extent |
|
[sträng] |
Rasterlagrets utsträckning i CRS |
Bandet har en NoData-värdeuppsättning |
|
[Boolean] |
Anger om rasterlagret har ett värde inställt för NoData-pixlar i det valda bandet |
Höjd i pixlar |
|
[numerisk: heltal] |
Antalet kolumner i rasterlagret |
Band NoData-värde |
|
[numerisk: dubbel] |
Värdet (om det är inställt) för NoData-pixlarna i det valda bandet |
Pixelstorlek (höjd) i kartenheter |
|
[numerisk: heltal] |
Vertikal storlek i kartenheter för pixeln |
Pixelstorlek (bredd) i kartenheter |
|
[numerisk: heltal] |
Pixelns horisontella storlek i kartenheter |
Bredd i pixlar |
|
[numerisk: heltal] |
Antalet rader i rasterlagret |
Maximal x-koordinat |
|
[numerisk: dubbel] |
|
Minsta x-koordinat |
|
[numerisk: dubbel] |
|
Maximal y-koordinat |
|
[numerisk: dubbel] |
|
Minsta y-koordinat |
|
[numerisk: dubbel] |
Python-kod
Algoritm-ID: native:rasterlayerproperties
import processing
processing.run("algorithm_id", {parameter_dictionary})
algoritm id visas när du håller muspekaren över algoritmen i verktygslådan Processing Toolbox. I parameter dictionary finns parameternamn och värden. Se Använda bearbetningsalgoritmer från konsolen för information om hur du kör bearbetningsalgoritmer från Python-konsolen.
24.1.15.21. Statistik för rasterlager
Beräknar grundläggande statistik från värdena i ett givet band i rasterlagret. Utdata laddas i menyn .
Parametrar
Etikett |
Namn |
Typ |
Beskrivning |
|---|---|---|---|
Inmatningslager |
|
[raster] |
Inmatat rasterlager |
Bandnummer |
|
[rasterband] Standard: Det första bandet i inmatningslagret |
Om rastret är flerbandigt väljer du det band som du vill få statistik för. |
Statistik |
|
[html] Standard: |
Specifikation av utdatafilen:
|
Utgångar
Etikett |
Namn |
Typ |
Beskrivning |
|---|---|---|---|
Maximalt värde |
|
[numerisk: dubbel] |
|
Medelvärde |
|
[numerisk: dubbel] |
|
Minsta värde |
|
[numerisk: dubbel] |
|
Statistik |
|
[html] |
Utdatafilen innehåller följande information:
|
Omfång |
|
[numerisk: dubbel] |
|
Standardavvikelse |
|
[numerisk: dubbel] |
|
Summa |
|
[numerisk: dubbel] |
|
Summan av kvadraterna |
|
[numerisk: dubbel] |
Python-kod
Algoritm-ID: native:rasterlayerstatistics
import processing
processing.run("algorithm_id", {parameter_dictionary})
algoritm id visas när du håller muspekaren över algoritmen i verktygslådan Processing Toolbox. I parameter dictionary finns parameternamn och värden. Se Använda bearbetningsalgoritmer från konsolen för information om hur du kör bearbetningsalgoritmer från Python-konsolen.
24.1.15.22. Rapport om unika värden för rasterlager
Returnerar antal och area för varje unikt värde i ett givet rasterlager. Beräkningen av arean görs i areaenheten för lagrets CRS.
Parametrar
Etikett |
Namn |
Typ |
Beskrivning |
|---|---|---|---|
Inmatningslager |
|
[raster] |
Inmatat rasterlager |
Bandnummer |
|
[rasterband] Standard: Det första bandet i inmatningslagret |
Om rastret är flerbandigt väljer du det band som du vill få statistik för. |
Rapport om unika värden |
|
&Arkiv Standard: |
Specifikation av utdatafilen:
|
Tabell över unika värden |
|
[vektor: tabell] Standard: |
Specifikation av tabellen för unika värden:
Här kan du också ändra filkodningen. |
Utgångar
Etikett |
Namn |
Typ |
Beskrivning |
|---|---|---|---|
CRS auktoritetsidentifierare |
|
[sträng] |
Koordinatreferenssystemet för det utgående rasterlagret |
Extent |
|
[sträng] |
Den spatiala omfattningen av det utgående rasterlagret |
Höjd i pixlar |
|
[numerisk: heltal] |
Antalet rader i det utgående rasterlagret |
NoData pixelantal |
|
[numerisk: heltal] |
Antalet NoData-pixlar i det utgående rasterlagret |
Totalt antal pixlar |
|
[numerisk: heltal] |
Antalet pixlar i det utgående rasterlagret |
Rapport om unika värden |
|
[html] |
HTML-filen som skickas ut innehåller följande information:
|
Tabell över unika värden |
|
[vektor: tabell] |
En tabell med tre kolumner:
|
Bredd i pixlar |
|
[numerisk: heltal] |
Antalet kolumner i det utgående rasterlagret |
Python-kod
Algoritm-ID: `native:rasterlayeruniquevaluesreport
import processing
processing.run("algorithm_id", {parameter_dictionary})
algoritm id visas när du håller muspekaren över algoritmen i verktygslådan Processing Toolbox. I parameter dictionary finns parameternamn och värden. Se Använda bearbetningsalgoritmer från konsolen för information om hur du kör bearbetningsalgoritmer från Python-konsolen.
24.1.15.23. Zonal statistik för rasterlager
Beräknar statistik för ett rasterlagers värden, kategoriserade efter zoner som definierats i ett annat rasterlager.
Se även
Parametrar
Grundläggande parametrar
Etikett |
Namn |
Typ |
Beskrivning |
|---|---|---|---|
Inmatningslager |
|
[raster] |
Inmatat rasterlager |
Bandnummer |
|
[rasterband] Standard: Det första bandet i rasterlagret |
Om rastret är flerbandigt väljer du det band som du vill beräkna statistiken för. |
Zoner lager |
|
[raster] |
Rasterlager som definierar zoner. Zonerna består av sammanhängande pixlar som har samma pixelvärde. |
Zoner bandnummer |
|
[rasterband] Standard: Det första bandet i rasterlagret |
Om rastret är flerbandigt väljer du det band som definierar zonerna |
Statistik |
|
[vektor: tabell] Standard: |
Specifikation av utdatarapporten. En av:
Här kan du också ändra filkodningen. |
Avancerade parametrar
Etikett |
Namn |
Typ |
Beskrivning |
|---|---|---|---|
Reference layer Valfritt |
|
[uppräkning] Standard: 0 |
Rasterlager som används för att beräkna de centroider som kommer att användas som referens när zonerna i utdatalagret bestäms. Ett av följande:
|
Utgångar
Etikett |
Namn |
Typ |
Beskrivning |
|---|---|---|---|
CRS auktoritetsidentifierare |
|
[sträng] |
Koordinatreferenssystemet för det utgående rasterlagret |
Extent |
|
[sträng] |
Den spatiala omfattningen av det utgående rasterlagret |
Höjd i pixlar |
|
[numerisk: heltal] |
Antalet rader i det utgående rasterlagret |
NoData pixelantal |
|
[numerisk: heltal] |
Antalet NoData-pixlar i det utgående rasterlagret |
Statistik |
|
[vektor: tabell] |
Utmatningslagret innehåller följande information för varje zon:
|
Totalt antal pixlar |
|
[numerisk: heltal] |
Antalet pixlar i det utgående rasterlagret |
Bredd i pixlar |
|
[numerisk: heltal] |
Antalet kolumner i det utgående rasterlagret |
Python-kod
Algoritm-ID: native:rasterlayerzonalstats
import processing
processing.run("algorithm_id", {parameter_dictionary})
algoritm id visas när du håller muspekaren över algoritmen i verktygslådan Processing Toolbox. I parameter dictionary finns parameternamn och värden. Se Använda bearbetningsalgoritmer från konsolen för information om hur du kör bearbetningsalgoritmer från Python-konsolen.
24.1.15.24. Rasterytans volym
Beräknar volymen under en rasteryta i förhållande till en given basnivå. Detta är främst användbart för digitala höjdmodeller (DEM).
Parametrar
Etikett |
Namn |
Typ |
Beskrivning |
|---|---|---|---|
INPUT-lager |
|
[raster] |
Ingångsraster som representerar en yta |
Bandnummer |
|
[rasterband] Standard: Det första bandet i rasterlagret |
Om rastret är flerbandigt väljer du det band som ska definiera ytan. |
Basisnivå |
|
[numerisk: dubbel] Standard: 0,0 |
Definiera en bas eller ett referensvärde. Denna bas används vid volymberäkningen enligt parametern |
Metod |
|
[uppräkning] Standard: 0 |
Definiera metoden för volymberäkningen som ges av skillnaden mellan rasterpixelvärdet och
|
Rapport om ytvolym |
|
[html] Standard: |
Specifikation av HTML-utdatarapporten. En av:
Här kan du också ändra filkodningen. |
Tabell över ytvolym |
|
[vektor: tabell] Standard: |
Specifikation av utmatningstabellen. En av:
Här kan du också ändra filkodningen. |
Utgångar
Etikett |
Namn |
Typ |
Beskrivning |
|---|---|---|---|
Volym |
|
[numerisk: dubbel] |
Den beräknade volymen |
Område |
|
[numerisk: dubbel] |
Området i kvadratiska kartenheter |
Pixel_antal |
|
[numerisk: heltal] |
Det totala antalet pixlar som har analyserats |
Rapport om ytvolym |
|
[html] |
Utdatarapport (med volym, yta och pixelantal) i HTML-format |
Tabell över ytvolym |
|
[vektor: tabell] |
Utmatningstabellen (som innehåller volym, yta och pixelantal) |
Python-kod
Algoritm-ID: native:rastersurfacevolym
import processing
processing.run("algorithm_id", {parameter_dictionary})
algoritm id visas när du håller muspekaren över algoritmen i verktygslådan Processing Toolbox. I parameter dictionary finns parameternamn och värden. Se Använda bearbetningsalgoritmer från konsolen för information om hur du kör bearbetningsalgoritmer från Python-konsolen.
24.1.15.25. Omklassificering per lager
Omklassificerar ett rasterband genom att tilldela nya klassvärden baserat på de intervall som anges i en vektortabell.
Parametrar
Grundläggande parametrar
Etikett |
Namn |
Typ |
Beskrivning |
|---|---|---|---|
Ett rasterlager |
|
[raster] |
Rasterlager att omklassificera |
Bandnummer |
|
[rasterband] Standard: Det första bandet i rasterlagret |
Om rastret är flerbandigt väljer du det band som du vill omklassificera. |
Lager som innehåller klassresor |
|
[vektor: vilken som helst] |
Vektorlager som innehåller de värden som ska användas för klassificering. |
Minsta fält för klassvärde |
|
[tabellfält: numerisk] |
Fält med det lägsta värdet i intervallet för klassen. Använd |
Maximalt klassvärdesfält |
|
[tabellfält: numerisk] |
Fält med det högsta värdet i intervallet för klassen. Använd |
Fält för utdatavärde |
|
[tabellfält: numerisk] |
Fält med det värde som kommer att tilldelas de pixlar som faller inom klassen (mellan motsvarande min- och maxvärden). Använd |
Omklassificerat raster |
|
[raster] Standard: |
Specifikation av utmatningsrastret. En av:
|
Avancerade parametrar
Etikett |
Namn |
Typ |
Beskrivning |
|---|---|---|---|
Utmatning av NoData-värde |
|
[numerisk: dubbel] Standard: -9999.0 |
Värde som ska tillämpas på NoData-värden. |
Range-gränser |
|
[uppräkning] Standard: 0 |
Definierar jämförelseregler för klassificeringen. Alternativ:
|
Använd NoData när inget intervall matchar värdet |
|
[boolean] Standard: Falsk |
Tillämpar NoData-värdet på bandvärden som inte tillhör någon klass. Om False, behålls det ursprungliga värdet. |
Typ av utdata |
|
[uppräkning] Standard: 5 |
Definierar formatet för den utgående rasterfilen. Alternativ för:
Tillgängliga alternativ beror på vilken GDAL-version som byggts med QGIS (se -menyn) |
Alternativ för skapande Valfritt |
|
[sträng] Standard: ’’ |
För att lägga till ett eller flera skapandealternativ som styr det raster som ska skapas (färger, blockstorlek, filkomprimering …). För enkelhetens skull kan du förlita dig på fördefinierade profiler (se GDAL driver options section). Batch Process and Model Designer: separera flera alternativ med ett pipe-tecken ( |
Utgångar
Etikett |
Namn |
Typ |
Beskrivning |
|---|---|---|---|
Omklassificerat raster |
|
[raster] |
Utmatat rasterlager med omklassificerade bandvärden |
Python-kod
Algoritm-ID: native:reclassifybylayer
import processing
processing.run("algorithm_id", {parameter_dictionary})
algoritm id visas när du håller muspekaren över algoritmen i verktygslådan Processing Toolbox. I parameter dictionary finns parameternamn och värden. Se Använda bearbetningsalgoritmer från konsolen för information om hur du kör bearbetningsalgoritmer från Python-konsolen.
24.1.15.26. Omklassificering per tabell
Omklassificerar ett rasterband genom att tilldela nya klassvärden baserat på de intervall som anges i en fast tabell.
Parametrar
Grundläggande parametrar
Etikett |
Namn |
Typ |
Beskrivning |
|---|---|---|---|
Ett rasterlager |
|
[raster] |
Rasterlager att omklassificera |
Bandnummer |
|
[rasterband] Standard: 1 |
Rasterband för vilket du vill räkna om värden. |
Omklassificeringstabell |
|
[vektor: tabell] |
En tabell med 3 kolumner som ska fyllas med de värden som anger gränserna för varje klass ( |
Omklassificerat raster |
|
[raster] Standard: |
Specifikation av rasterlagret för utdata. En av:
|
Avancerade parametrar
Etikett |
Namn |
Typ |
Beskrivning |
|---|---|---|---|
Utmatning av NoData-värde |
|
[numerisk: dubbel] Standard: -9999.0 |
Värde som ska tillämpas på NoData-värden. |
Range-gränser |
|
[uppräkning] Standard: 0 |
Definierar jämförelseregler för klassificeringen. Alternativ:
|
Använd NoData när inget intervall matchar värdet |
|
[boolean] Standard: Falsk |
Tillämpar NoData-värdet på bandvärden som inte tillhör någon klass. Om False, behålls det ursprungliga värdet. |
Typ av utdata |
|
[uppräkning] Standard: 5 |
Definierar formatet för den utgående rasterfilen. Alternativ för:
Tillgängliga alternativ beror på vilken GDAL-version som byggts med QGIS (se -menyn) |
Alternativ för skapande Valfritt |
|
[sträng] Standard: ’’ |
För att lägga till ett eller flera skapandealternativ som styr det raster som ska skapas (färger, blockstorlek, filkomprimering …). För enkelhetens skull kan du förlita dig på fördefinierade profiler (se GDAL driver options section). Batch Process and Model Designer: separera flera alternativ med ett pipe-tecken ( |
Utgångar
Etikett |
Namn |
Typ |
Beskrivning |
|---|---|---|---|
Omklassificerat raster |
|
[raster] |
Utmatat rasterlager med omklassificerade bandvärden |
Python-kod
Algoritm-ID: `native:reclassifybytable
import processing
processing.run("algorithm_id", {parameter_dictionary})
algoritm id visas när du håller muspekaren över algoritmen i verktygslådan Processing Toolbox. I parameter dictionary finns parameternamn och värden. Se Använda bearbetningsalgoritmer från konsolen för information om hur du kör bearbetningsalgoritmer från Python-konsolen.
24.1.15.27. Omskalning av raster
Omskalerar rasterlagret till ett nytt värdeintervall, samtidigt som formen (fördelningen) på rastrets histogram (pixelvärden) bevaras. Ingångsvärden mappas med hjälp av en linjär interpolering från källrastrets lägsta och högsta pixelvärden till målrastrets lägsta och högsta pixelintervall.
Som standard bevarar algoritmen det ursprungliga NoData-värdet, men det finns en möjlighet att åsidosätta det.
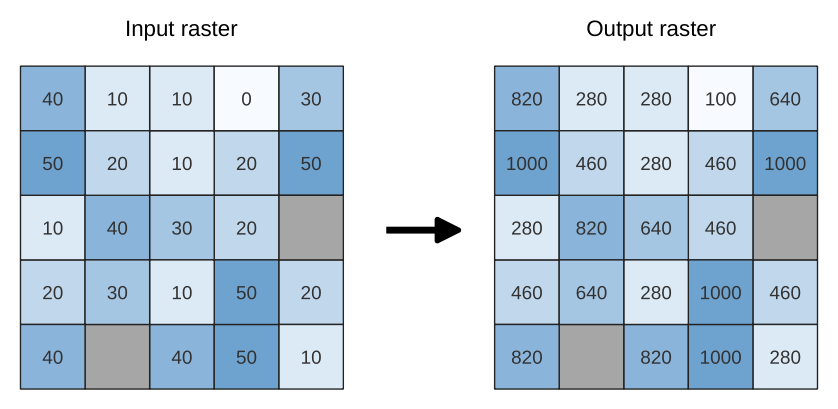
Fig. 24.27 Omskalning av värden för ett rasterlager från [0 - 50] till [100 - 1000]
Parametrar
Grundläggande parametrar
Etikett |
Namn |
Typ |
Beskrivning |
|---|---|---|---|
Input Raster |
|
[raster] |
Rasterlager att använda för omskalning |
Bandnummer |
|
[rasterband] Standard: Det första bandet i inmatningslagret |
Om rastret är multibandigt väljer du ett band. |
Nytt minimivärde |
|
[numerisk: dubbel] Standardvärde: 0,0 |
Lägsta pixelvärde som ska användas i det skalade lagret |
Nytt maximalt värde |
|
[numerisk: dubbel] Standardvärde: 255.0 |
Maximalt pixelvärde att använda i det omskalade lagret |
Nytt NoData-värde Valfritt |
|
[numerisk: dubbel] Standardvärde: Ej inställt |
Värde som ska tilldelas NoData-pixlarna. Om den inte är inställd bevaras de ursprungliga NoData-värdena. |
Rescaled |
|
[raster] Standard: |
Specifikation av rasterlagret för utdata. En av:
|
Avancerade parametrar
Etikett |
Namn |
Typ |
Beskrivning |
|---|---|---|---|
Alternativ för skapande Valfritt |
|
[sträng] Standard: ’’ |
För att lägga till ett eller flera skapandealternativ som styr det raster som ska skapas (färger, blockstorlek, filkomprimering …). För enkelhetens skull kan du förlita dig på fördefinierade profiler (se GDAL driver options section). Batch Process and Model Designer: separera flera alternativ med ett pipe-tecken ( |
Utgångar
Etikett |
Namn |
Typ |
Beskrivning |
|---|---|---|---|
Rescaled |
|
[raster] |
Utmatning av rasterlager med omskalade bandvärden |
Python-kod
Algoritm-ID: native:rescaleraster
import processing
processing.run("algorithm_id", {parameter_dictionary})
algoritm id visas när du håller muspekaren över algoritmen i verktygslådan Processing Toolbox. I parameter dictionary finns parameternamn och värden. Se Använda bearbetningsalgoritmer från konsolen för information om hur du kör bearbetningsalgoritmer från Python-konsolen.
24.1.15.28. Rund raster
Avrundar cellvärdena i en rasterdatauppsättning enligt det angivna antalet decimaler.
Alternativt kan ett negativt antal decimaler användas för att avrunda värden till potenser av basen n. Till exempel, med ett basvärde n på 10 och decimaler på -1, avrundar algoritmen cellvärden till multiplar av 10, -2 avrundar till multiplar av 100, och så vidare. Man kan välja godtyckliga basvärden, men algoritmen tillämpar samma multiplikativa princip. Avrundning av cellvärden till multiplar av en bas n kan användas för att generalisera rasterlager.
Algoritmen bevarar datatypen för inmatningsrastret. Därför kan byte/integer-raster endast avrundas till multiplar av basen n, annars utfärdas en varning och rastret kopieras som byte/integer-raster.
Fig. 24.28 Avrundning av värden i ett raster
Parametrar
Grundläggande parametrar
Etikett |
Namn |
Typ |
Beskrivning |
|---|---|---|---|
Ingångsraster |
|
[raster] |
Rastret till processen. |
Bandnummer |
|
[rasterband] Standard: 1 |
Rasterns band |
Rundgångsriktning |
|
Konfigurationens id %1 finns redan i listan Standard: 1 |
Hur man väljer målet avrundat värde. Alternativen är:
|
Antal decimaler |
|
[numerisk: heltal] Standard: 2 |
Antal decimaler att avrunda till. Använd negativa värden för att avrunda cellvärden till en multipel av en bas n |
Utgångsraster |
|
[raster] Standard: |
Specifikation av utdatafilen. En av:
|
Avancerade parametrar
Etikett |
Namn |
Typ |
Beskrivning |
|---|---|---|---|
Bas n för avrundning till multiplar av n |
|
[numerisk: heltal] Standard: 10 |
När parametern |
Alternativ för skapande Valfritt |
|
[sträng] Standard: ’’ |
För att lägga till ett eller flera skapandealternativ som styr det raster som ska skapas (färger, blockstorlek, filkomprimering …). För enkelhetens skull kan du förlita dig på fördefinierade profiler (se GDAL driver options section). Batch Process and Model Designer: separera flera alternativ med ett pipe-tecken ( |
Utgångar
Etikett |
Namn |
Typ |
Beskrivning |
|---|---|---|---|
Utgångsraster |
|
[raster] |
Det utgående rasterlagret med avrundade värden för det valda bandet. |
Python-kod
Algoritm-ID: native:roundrastervalues
import processing
processing.run("algorithm_id", {parameter_dictionary})
algoritm id visas när du håller muspekaren över algoritmen i verktygslådan Processing Toolbox. I parameter dictionary finns parameternamn och värden. Se Använda bearbetningsalgoritmer från konsolen för information om hur du kör bearbetningsalgoritmer från Python-konsolen.
24.1.15.29. Exempel på rastervärden
Extraherar rastervärden på punktplatserna. Om rasterlagret är flerbandigt samplas varje band.
Attributtabellen för det resulterande lagret kommer att ha lika många nya kolumner som rasterlagrets bandantal.
Parametrar
Etikett |
Namn |
Typ |
Beskrivning |
|---|---|---|---|
Inmatningslager |
|
[vektor: punkt] |
Punktvektorlager att använda för provtagning |
Ett rasterlager |
|
[raster] |
Rasterlager som ska provtas vid de angivna punktlägena. |
Prefix för utdatakolumn |
|
[sträng] Standard: ’SAMPLE_’ |
Prefix för namnen på de kolumner som läggs till. |
Samplad Valfritt |
|
[vektor: punkt] Standard: |
Ange utdatalagret som innehåller de samplade värdena. En av:
Här kan du också ändra filkodningen. |
Utgångar
Etikett |
Namn |
Typ |
Beskrivning |
|---|---|---|---|
Samplad |
|
[vektor: punkt] |
Utmatningslagret som innehåller de samplade värdena. |
Python-kod
Algoritm-id: native:rastersampling
import processing
processing.run("algorithm_id", {parameter_dictionary})
algoritm id visas när du håller muspekaren över algoritmen i verktygslådan Processing Toolbox. I parameter dictionary finns parameternamn och värden. Se Använda bearbetningsalgoritmer från konsolen för information om hur du kör bearbetningsalgoritmer från Python-konsolen.
24.1.15.30. Zonalt histogram
Lägger till fält som representerar räkningar av varje unikt värde från ett rasterlager som ingår i polygonfunktioner.
Attributtabellen för utdatalagret kommer att ha lika många fält som de unika värdena för det rasterlager som skär polygonen/polygonerna.
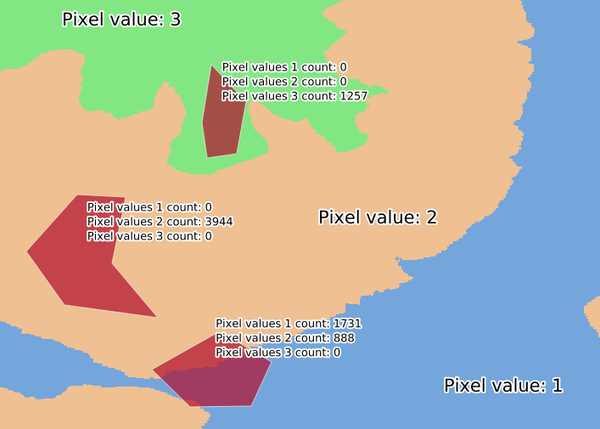
Fig. 24.29 Exempel på histogram för rasterlager
Parametrar
Etikett |
Namn |
Typ |
Beskrivning |
|---|---|---|---|
Ett rasterlager |
|
[raster] |
Inmatat rasterlager. |
Bandnummer |
|
[rasterband] Standard: Det första bandet i inmatningslagret |
Om rastret är multibandigt väljer du ett band. |
Vektorlager som innehåller zoner |
|
[vektor: polygon] |
Vektorpolygonlager som definierar zonerna. |
Prefix för utdatakolumn |
Valfritt |
[sträng] Standard: ”HISTO_ |
Prefix för utdatakolumnernas namn. |
Utgångszoner |
|
[vektor: polygon] Standard: |
Ange polygonlagret för utdatavektorn. En av:
Här kan du också ändra filkodningen. |
Utgångar
Etikett |
Namn |
Typ |
Beskrivning |
|---|---|---|---|
Utgångszoner |
|
[vektor: polygon] |
Polygonlager för utmatningsvektor. |
Python-kod
Algoritm-ID: native:zonalhistogram
import processing
processing.run("algorithm_id", {parameter_dictionary})
algoritm id visas när du håller muspekaren över algoritmen i verktygslådan Processing Toolbox. I parameter dictionary finns parameternamn och värden. Se Använda bearbetningsalgoritmer från konsolen för information om hur du kör bearbetningsalgoritmer från Python-konsolen.
24.1.15.31. Zonvis statistik
Beräknar statistik för ett rasterlager för varje egenskap i ett överlappande polygonvektorlager.
Parametrar
Etikett |
Namn |
Typ |
Beskrivning |
|---|---|---|---|
Inmatningslager |
|
[vektor: polygon] |
Vektorpolygonlager som innehåller zonerna. |
Ett rasterlager |
|
[raster] |
Inmatat rasterlager. |
Rasterband |
|
[rasterband] Standard: Det första bandet i inmatningslagret |
Om rastret är flerbandigt väljer du ett band för statistiken. |
Prefix för utdatakolumn |
|
[sträng] Standard: ’_’ |
Prefix för utdatakolumnernas namn. |
Statistik att beräkna |
|
[uppräkning] [lista] Standard: [0,1,2] |
Lista över statistiska operatorer för utdata. Alternativ:
|
Zonal statistik |
|
[vektor: polygon] Standard: |
Ange polygonlagret för utdatavektorn. En av:
Här kan du också ändra filkodningen. |
Utgångar
Etikett |
Namn |
Typ |
Beskrivning |
|---|---|---|---|
Zonal statistik |
|
[vektor: polygon] |
Zonens vektorlager med extra statistik. |
Python-kod
Algoritm-ID: native:zonalstatisticsfb
import processing
processing.run("algorithm_id", {parameter_dictionary})
algoritm id visas när du håller muspekaren över algoritmen i verktygslådan Processing Toolbox. I parameter dictionary finns parameternamn och värden. Se Använda bearbetningsalgoritmer från konsolen för information om hur du kör bearbetningsalgoritmer från Python-konsolen.