Viktigt
Översättning är en gemenskapsinsats du kan gå med i. Den här sidan är för närvarande översatt till 100.00%.
24.1.19. Vektoranalys
24.1.19.1. Grundläggande statistik för fält
Genererar grundläggande statistik för ett fält i attributtabellen för ett vektorlager. Numeriska fält, datum-, tids- och strängfält stöds. Den statistik som returneras beror på fälttypen.
Statistik kan genereras som en tabell eller en HTML-fil och finns tillgänglig i .
Standardmeny:
Parametrar
Etikett |
Namn |
Typ |
Beskrivning |
|---|---|---|---|
Inmatningsvektor |
|
[vektor: vilken som helst] |
Vektorlager för att beräkna statistiken på |
Fält att beräkna statistik på |
|
[tabellfält: alla] |
Alla tabellfält som stöds för att beräkna statistiken |
Statistik Valfritt |
|
[vektor: tabell] Standard: |
Ange utmatningstabellen för den genererade statistiken. En av:
Här kan du också ändra filkodningen. |
Statistikrapport Valfritt |
|
[html] Standard: |
Specifikation av filen för den beräknade statistiken. En av:
|
Utgångar
Etikett |
Namn |
Typ |
Beskrivning |
|---|---|---|---|
Statistik |
|
[vektor: tabell] |
Tabell som innehåller den beräknade statistiken |
Statistikrapport |
|
[html] |
HTML-fil med den beräknade statistiken |
Räkna |
|
[numerisk: heltal] |
|
Antal unika värden |
|
[numerisk: heltal] |
|
Antal tomma (null) värden |
|
[numerisk: heltal] |
|
Antal icke-tomma värden |
|
[numerisk: heltal] |
|
Minsta värde |
|
[samma som inmatning] |
|
Maximalt värde |
|
[samma som inmatning] |
|
Minsta längd |
|
[numerisk: heltal] |
|
Maximala längden |
|
[numerisk: heltal] |
|
Genomsnittlig längd |
|
[numerisk: dubbel] |
|
Koefficient för variation |
|
[numerisk: dubbel] |
|
Summa |
|
[numerisk: dubbel] |
|
Medelvärde |
|
[numerisk: dubbel] |
|
Standardavvikelse |
|
[numerisk: dubbel] |
|
Omfång |
|
[numerisk: dubbel] |
|
Median |
|
[numerisk: dubbel] |
|
Minority (sällsynt förekommande värde) |
|
[samma som inmatning] |
|
Majoritet (mest frekvent förekommande värde) |
|
[samma som inmatning] |
|
Första kvartilen |
|
[numerisk: dubbel] |
|
Tredje kvartilen |
|
[numerisk: dubbel] |
|
Interkvartilintervall (IQR) |
|
[numerisk: dubbel] |
Python-kod
Algoritm ID: qgis:grundläggande statistik för fält
import processing
processing.run("algorithm_id", {parameter_dictionary})
algoritm id visas när du håller muspekaren över algoritmen i verktygslådan Processing Toolbox. I parameter dictionary finns parameternamn och värden. Se Använda bearbetningsalgoritmer från konsolen för information om hur du kör bearbetningsalgoritmer från Python-konsolen.
24.1.19.2. Klättra längs linjen
Beräknar den totala stigningen och nedstigningen längs linjegeometrier. Inmatningslagret måste ha Z-värden. Om Z-värden inte finns tillgängliga kan algoritmen Drape (ställ in Z-värde från raster) användas för att lägga till Z-värden från ett DEM-lager.
Utmatningslagret är en kopia av inmatningslagret med ytterligare fält som innehåller den totala stigningen (climb), den totala nedstigningen (descent), den lägsta höjden (minelev) och den högsta höjden (maxelev) för varje linjegeometri. Om inmatningslagret innehåller fält med samma namn som de tillagda fälten, byter de namn (fältnamnen ändras till ”name_2”, ”name_3”, etc., varvid det första icke-duplicerade namnet hittas).
Parametrar
Etikett |
Namn |
Typ |
Beskrivning |
|---|---|---|---|
Linjelager |
|
[vektor: linje] |
Linjelager att beräkna stigningen för. Måste ha Z-värden |
Klättringslager |
|
[vektor: linje] Standard: |
Specifikation av utdatalagret (linje). En av:
Här kan du också ändra filkodningen. |
Utgångar
Etikett |
Namn |
Typ |
Beskrivning |
|---|---|---|---|
Klättringslager |
|
[vektor: linje] |
Linjelager som innehåller nya attribut med resultat från klättringsberäkningar. |
Total klättring |
|
[numerisk: dubbel] |
Summan av stigningen för alla linjegeometrier i inmatningslagret |
Total nedstigning |
|
[numerisk: dubbel] |
Summan av nedstigningen för alla linjegeometrier i inmatningslagret |
Minsta höjd |
|
[numerisk: dubbel] |
Den lägsta höjden för geometrierna i lagret |
Maximal höjd över havet |
|
[numerisk: dubbel] |
Den maximala höjden för geometrierna i lagret |
Python-kod
Algoritm-ID: qgis:climbalongline
import processing
processing.run("algorithm_id", {parameter_dictionary})
algoritm id visas när du håller muspekaren över algoritmen i verktygslådan Processing Toolbox. I parameter dictionary finns parameternamn och värden. Se Använda bearbetningsalgoritmer från konsolen för information om hur du kör bearbetningsalgoritmer från Python-konsolen.
24.1.19.3. Räkna punkter i polygonen
Tar ett punkt- och ett polygonlager och räknar antalet punkter från punktlagret i var och en av polygonerna i polygonlagret.
Ett nytt polygonlager genereras, med exakt samma innehåll som det inmatade polygonlagret, men med ett extra fält med poängantalet för varje polygon.
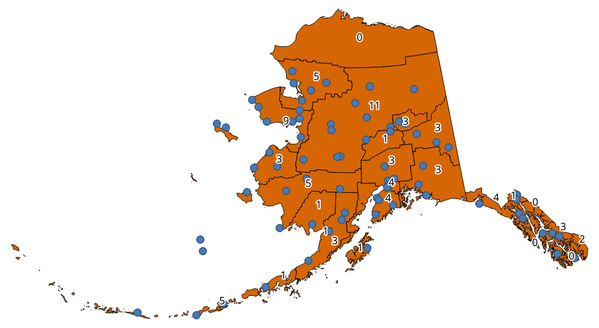
Fig. 24.40 Etiketterna i polygonerna visar antalet punkter
Ett valfritt viktfält kan användas för att tilldela vikter till varje punkt. Alternativt kan ett unikt klassfält anges. Om båda alternativen används kommer viktfältet att ha företräde och det unika klassfältet kommer att ignoreras.
 Tillåter features in-place modification av polygonfeatures
Tillåter features in-place modification av polygonfeatures
Förvalda menyn:
Parametrar
Etikett |
Namn |
Typ |
Beskrivning |
|---|---|---|---|
Polygoner |
|
[vektor: polygon] |
Polygonlager vars egenskaper är associerade med antalet punkter de innehåller |
Punkter |
|
[vektor: punkt] |
Punktlager med funktioner att räkna |
Viktfält Valfritt |
|
[tabellfält: alla] |
Ett fält från punktlagret. Det antal som genereras blir summan av viktfältet för de punkter som ingår i polygonen. Om viktfältet inte är numeriskt kommer antalet att vara |
Klassfält Valfritt |
|
[tabellfält: alla] |
Punkterna klassificeras utifrån det valda attributet och om flera punkter med samma attributvärde finns inom polygonen räknas bara en av dem. Det slutliga antalet punkter i en polygon är därför antalet olika klasser som finns i den. |
namn på fältet *Count* |
|
[sträng] Standard: ”NUMPOINTS |
Namnet på det fält som ska lagra antalet poäng |
Räkna |
|
[vektor: polygon] Standard: |
Specifikation av utdatalagret. En av:
Här kan du också ändra filkodningen. |
Utgångar
Etikett |
Namn |
Typ |
Beskrivning |
|---|---|---|---|
Räkna |
|
[vektor: polygon] |
Resulterande lager med attributtabellen som innehåller den nya kolumnen med poängantalet |
Python-kod
Algoritm-id: native:countpointsinpolygon
import processing
processing.run("algorithm_id", {parameter_dictionary})
algoritm id visas när du håller muspekaren över algoritmen i verktygslådan Processing Toolbox. I parameter dictionary finns parameternamn och värden. Se Använda bearbetningsalgoritmer från konsolen för information om hur du kör bearbetningsalgoritmer från Python-konsolen.
24.1.19.4. DBSCAN-klustring
Klustrar punktfunktioner baserat på en 2D-implementering av DBSCAN-algoritmen (Density-based spatial clustering of applications with noise).
Algoritmen kräver två parametrar, en minsta klusterstorlek och det största tillåtna avståndet mellan klusterpunkterna.
Se även
Parametrar
Grundläggande parametrar
Etikett |
Namn |
Typ |
Beskrivning |
|---|---|---|---|
Inmatningslager |
|
[vektor: punkt] |
Lager att analysera |
Minsta klusterstorlek |
|
[numerisk: heltal] Standard: 5 |
Minsta antal funktioner för att generera ett kluster |
Maximalt avstånd mellan klustrade punkter |
|
[numerisk: dubbel] Standard: 1,0 |
Avstånd bortom vilket två funktioner inte kan tillhöra samma kluster (eps) |
Clusters |
|
[vektor: punkt] Standard: |
Ange vektorlagret för resultatet av klustringen. Ett av:
Här kan du också ändra filkodningen. |
Avancerade parametrar
Etikett |
Namn |
Typ |
Beskrivning |
|---|---|---|---|
Behandla gränspunkter som brus (DBSCAN*) |
|
[boolean] Standard: Falsk |
Om den är markerad behandlas punkter på gränsen till ett kluster som punkter utan kluster, och endast punkter i det inre av ett kluster taggas som klustrade. |
Klustrets fältnamn |
|
[sträng] Standard: ”CLUSTER_ID |
Namn på det fält där det associerade klusternumret ska lagras |
Namn på fält för klusterstorlek |
|
[sträng] Standard: ”CLUSTER_SIZE |
Namnet på fältet med antalet funktioner i samma kluster |
Utgångar
Etikett |
Namn |
Typ |
Beskrivning |
|---|---|---|---|
Clusters |
|
[vektor: punkt] |
Vektorlager som innehåller de ursprungliga objekten med ett fält som anger vilket kluster de tillhör |
Antal kluster |
|
[numerisk: heltal] |
Antalet kluster som upptäckts |
Python-kod
Algoritm-ID: native:dbscanclustering
import processing
processing.run("algorithm_id", {parameter_dictionary})
algoritm id visas när du håller muspekaren över algoritmen i verktygslådan Processing Toolbox. I parameter dictionary finns parameternamn och värden. Se Använda bearbetningsalgoritmer från konsolen för information om hur du kör bearbetningsalgoritmer från Python-konsolen.
24.1.19.5. Avståndsmatris
Beräknar för punktobjekt avstånd till närmaste objekt i samma lager eller i ett annat lager.
Standardmeny:
Parametrar
Etikett |
Namn |
Typ |
Beskrivning |
|---|---|---|---|
Inmatningspunkt lager |
|
[vektor: punkt] |
Punktlager för vilket avståndsmatrisen beräknas (från punkter) |
Ange unikt ID-fält |
|
[tabellfält: alla] |
Fält som ska användas för att unikt identifiera egenskaper i inmatningslagret. Används i tabellen för utdataattribut. |
Målpunkt lager |
|
[vektor: punkt] |
Punktlager som innehåller den eller de punkter som ligger närmast sökningen (till punkter) |
Målets unika ID-fält |
|
[tabellfält: alla] |
Fält som ska användas för att unikt identifiera egenskaper i mållagret. Används i tabellen för utdataattribut. |
Typ av utmatningsmatris |
|
[uppräkning] Standard: 0 |
Olika typer av beräkningar finns tillgängliga:
|
Använd endast de närmaste (k) målpunkterna |
|
[numerisk: heltal] Standard: 0 |
Du kan välja att beräkna avståndet till alla punkter i mållagret (0) eller begränsa till ett antal (k) av de närmaste objekten. |
Avståndsmatris |
|
[vektor: punkt] Standard: |
Specifikation av utmatningsvektorlagret. En av:
Här kan du också ändra filkodningen. |
Utgångar
Etikett |
Namn |
Typ |
Beskrivning |
|---|---|---|---|
Avståndsmatris |
|
[vektor: punkt] |
Punkt (eller MultiPoint för fallet ”Linear (N * k x 3)”) vektorlager som innehåller avståndsberäkningen för varje indatafunktion. Dess funktioner och attributtabell beror på den valda typen av utmatningsmatris. |
Python-kod
Algoritm-ID: qgis:distancematrix
import processing
processing.run("algorithm_id", {parameter_dictionary})
algoritm id visas när du håller muspekaren över algoritmen i verktygslådan Processing Toolbox. I parameter dictionary finns parameternamn och värden. Se Använda bearbetningsalgoritmer från konsolen för information om hur du kör bearbetningsalgoritmer från Python-konsolen.
24.1.19.6. Avstånd till närmaste hubb (linje till hubb)
Skapar linjer som förbinder varje funktion i en inmatningsvektor med den närmaste funktionen i ett destinationslager. Avstånden beräknas baserat på center för varje objekt.
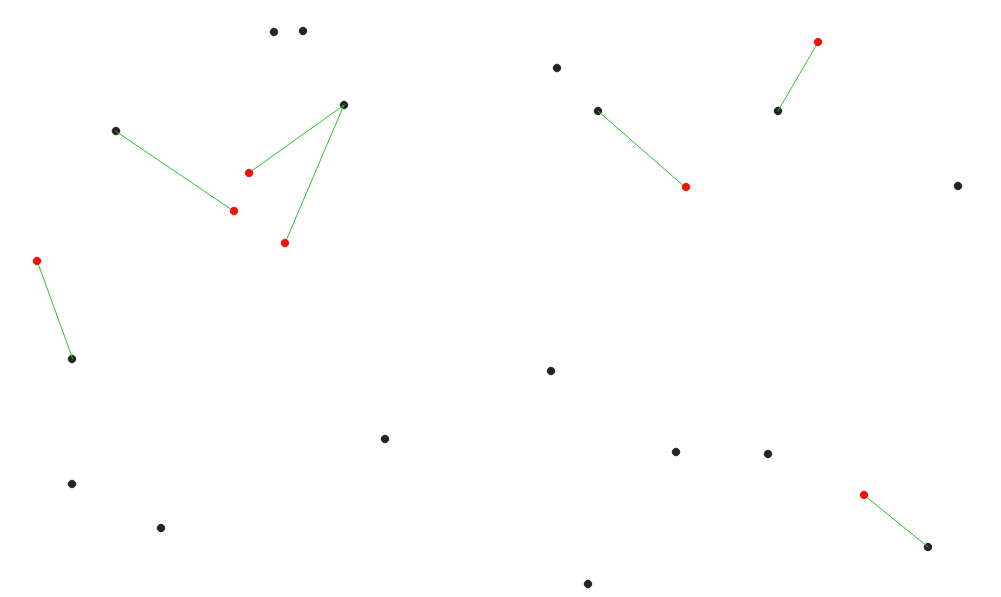
Fig. 24.41 Visa närmaste hubb för de röda inmatningsfunktionerna
Parametrar
Etikett |
Namn |
Typ |
Beskrivning |
|---|---|---|---|
Källpunkter lager |
|
[vektor: geometri] |
Vektorlager för vilket den närmaste funktionen söks |
Destination hubbar lager |
|
[vektor: geometri] |
Vektorlager som innehåller de funktioner som ska sökas efter |
Navlagrets namnattribut |
|
[tabellfält: alla] |
Fält som ska användas för att unikt identifiera egenskaper i destinationsskiktet. Används i tabellen för utdataattribut |
Mätenhet |
|
[uppräkning] Standard: 0 |
Enheter i vilka avståndet till närmaste objekt ska rapporteras:
|
Hubavstånd |
|
[vektor: linje] Standard: |
Ange det utgående linjevektorskiktet som förbinder de matchande punkterna. En av:
Här kan du också ändra filkodningen. |
Utgångar
Etikett |
Namn |
Typ |
Beskrivning |
|---|---|---|---|
Hubavstånd |
|
[vektor: linje] |
Linjevektorlager med attributen för de ingående objekten, identifieraren för deras närmaste objekt och det beräknade avståndet. |
Python-kod
Algoritm-ID: qgis:distancetonearesthublinetohub
import processing
processing.run("algorithm_id", {parameter_dictionary})
algoritm id visas när du håller muspekaren över algoritmen i verktygslådan Processing Toolbox. I parameter dictionary finns parameternamn och värden. Se Använda bearbetningsalgoritmer från konsolen för information om hur du kör bearbetningsalgoritmer från Python-konsolen.
24.1.19.7. Avstånd till närmaste hubb (punkter)
Skapar ett punktlager som representerar center för de ingående funktionerna med tillägg av två fält som innehåller identifieraren för den närmaste funktionen (baserat på dess mittpunkt) och avståndet mellan punkterna.
Parametrar
Etikett |
Namn |
Typ |
Beskrivning |
|---|---|---|---|
Källpunkter lager |
|
[vektor: vilken som helst] |
Vektorlager för vilket den närmaste funktionen söks |
Destination hubbar lager |
|
[vektor: vilken som helst] |
Vektorlager som innehåller de funktioner som ska sökas efter |
Navlagrets namnattribut |
|
[tabellfält: alla] |
Fält som ska användas för att unikt identifiera egenskaper i destinationsskiktet. Används i tabellen för utdataattribut |
Mätenhet |
|
[uppräkning] Standard: 0 |
Enheter i vilka avståndet till närmaste objekt ska rapporteras:
|
Hubavstånd |
|
[vektor: punkt] Standard: |
Ange utmatningspunktens vektorlager med närmaste nav. Ett av:
Här kan du också ändra filkodningen. |
Utgångar
Etikett |
Namn |
Typ |
Beskrivning |
|---|---|---|---|
Hubavstånd |
|
[vektor: punkt] |
Punktvektorlager som representerar mitten av källobjekten med deras attribut, identifieraren för deras närmaste objekt och det beräknade avståndet. |
Python-kod
Algoritm-ID: qgis:avståndtillnärmstahubpunkter
import processing
processing.run("algorithm_id", {parameter_dictionary})
algoritm id visas när du håller muspekaren över algoritmen i verktygslådan Processing Toolbox. I parameter dictionary finns parameternamn och värden. Se Använda bearbetningsalgoritmer från konsolen för information om hur du kör bearbetningsalgoritmer från Python-konsolen.
24.1.19.8. Förbindelse med linjer (navlinjer)
Skapar nav- och ekerdiagram genom att ansluta linjer från punkter i lagret Spoke till matchande punkter i lagret Hub.
Avgörandet av vilken hubb som hör till varje punkt baseras på en matchning mellan Hub ID-fältet på hubbpunkterna och Spoke ID-fältet på ekerpunkterna.
Om inmatningslagren inte är punktlager kommer en punkt på geometriernas yta att användas som anslutningsplats.
Som tillval kan geodetiska linjer skapas, som representerar den kortaste vägen på ytan av en ellipsoid. När geodetiskt läge används är det möjligt att dela de skapade linjerna vid antimeridianen (±180 graders longitud), vilket kan förbättra återgivningen av linjerna. Dessutom kan avståndet mellan hörnen specificeras. Ett mindre avstånd resulterar i en tätare och mer exakt linje.
Varning
Den här algoritmen tar bort befintliga primärnycklar eller FID-värden och återskapar dem i utdatalagren.
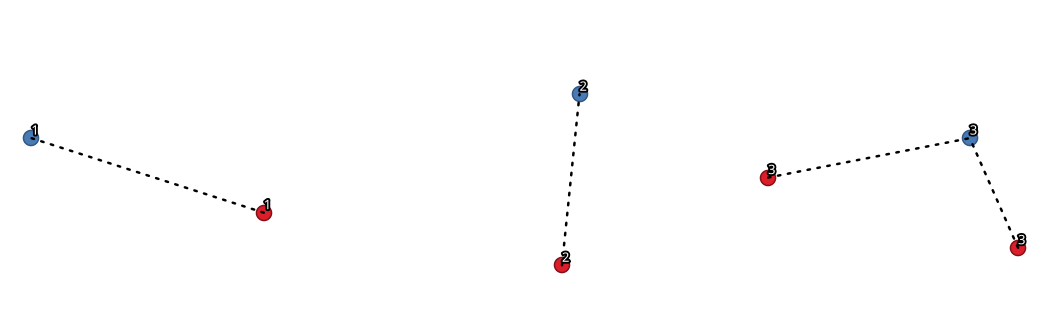
Fig. 24.42 Sammanfoga punkter baserat på ett gemensamt fält/attribut
Parametrar
Grundläggande parametrar
Etikett |
Namn |
Typ |
Beskrivning |
|---|---|---|---|
Hublager |
|
[vektor: geometri] |
Inmatningslager |
Hub ID-fält |
|
[tabellfält: alla] |
Fält för navlagret med ID för att gå med |
Hublagerfält att kopiera (lämna tomt för att kopiera alla fält) Valfritt |
|
[tabellfält: valfritt] [lista] |
Det eller de fält i navlagret som ska kopieras. Om inget eller inga fält väljs tas alla fält med. |
Spoke lager |
|
[vektor: geometri] |
Ytterligare lager av ekerpunkter |
Spoke ID-fält |
|
[tabellfält: alla] |
Fält för det talade lagret med ID för att gå med |
Spoke layer-fält som ska kopieras (lämna tomt för att kopiera alla fält) Valfritt |
|
[tabellfält: valfritt] [lista] |
Fält(en) i det talskikt som ska kopieras. Om inga fält väljs tas alla fält med. |
Skapa geodetiska linjer |
|
[boolean] Standard: Falsk |
Skapa geodetiska linjer (den kortaste vägen på ytan av en ellipsoid) |
Hublinjer |
|
[vektor: linje] Standard: |
Ange utdatahubbens linjevektorlager. En av:
Här kan du också ändra filkodningen. |
Avancerade parametrar
Etikett |
Namn |
Typ |
Beskrivning |
|---|---|---|---|
Avstånd mellan hörnpunkter (endast geodetiska linjer) |
|
[numerisk: dubbel] Standard: 1000,0 (kilometer) |
Avstånd mellan på varandra följande hörn (i kilometer). Ett mindre avstånd resulterar i en tätare och mer exakt linje |
Delade linjer vid antimeridianen (±180 graders longitud) |
|
[boolean] Standard: Falsk |
Delade linjer på ±180 graders longitud (för att förbättra återgivningen av linjerna) |
Utgångar
Etikett |
Namn |
Typ |
Beskrivning |
|---|---|---|---|
Hublinjer |
|
[vektor: linje] |
Det resulterande linjelagret som förbinder matchande punkter i ingående lager |
Python-kod
Algoritm-ID: native:hublines
import processing
processing.run("algorithm_id", {parameter_dictionary})
algoritm id visas när du håller muspekaren över algoritmen i verktygslådan Processing Toolbox. I parameter dictionary finns parameternamn och värden. Se Använda bearbetningsalgoritmer från konsolen för information om hur du kör bearbetningsalgoritmer från Python-konsolen.
24.1.19.9. K-means klustring
Beräknar det 2D-avståndsbaserade k-means-klusternumret för varje inmatad funktion.
K-means-klustring syftar till att dela upp funktionerna i k kluster där varje funktion tillhör det kluster som har det närmaste medelvärdet. Medelpunkten representeras av barycentrum för de klustrade funktionerna.
Om indatageometrierna är linjer eller polygoner baseras klusterbildningen på objektets centroid.
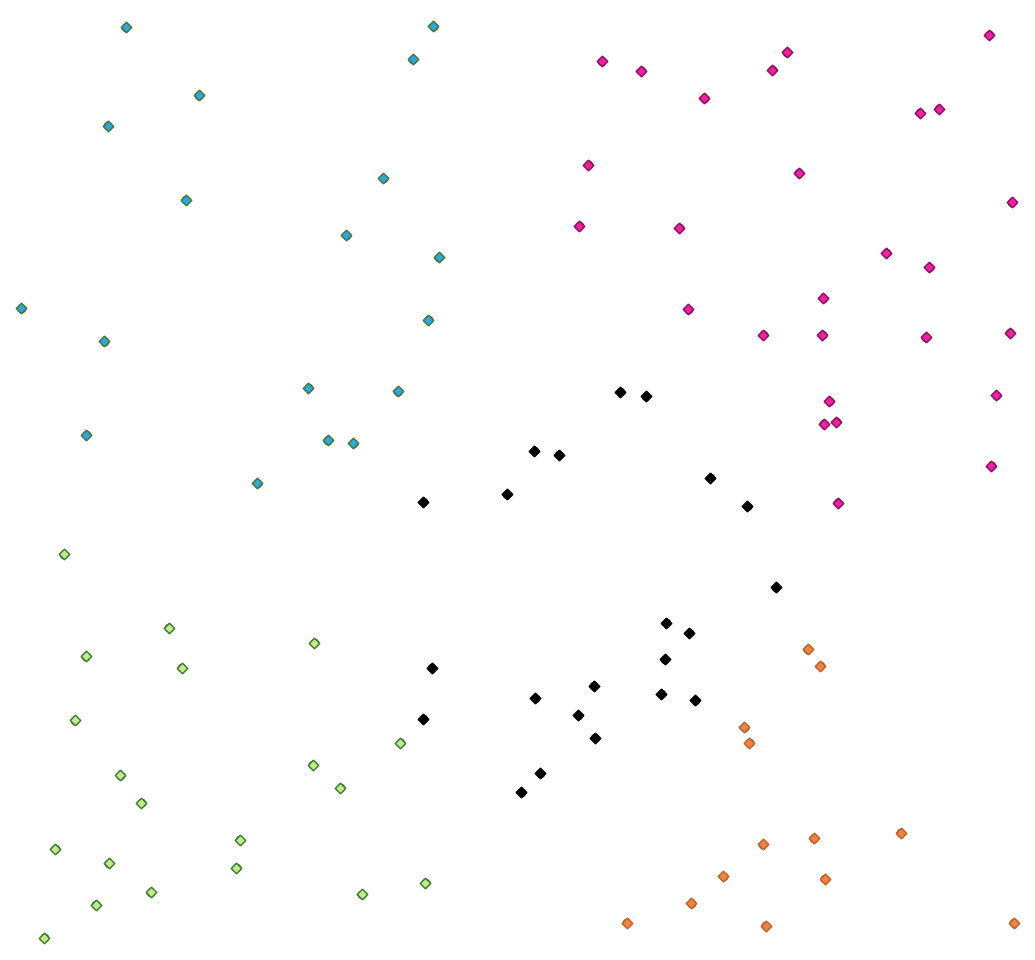
Fig. 24.43 Ett kluster med fem klasspoäng
Se även
Parametrar
Etikett |
Namn |
Typ |
Beskrivning |
|---|---|---|---|
Inmatningslager |
|
[vektor: geometri] |
Lager att analysera |
Antal kluster |
|
[numerisk: heltal] Standard: 5 |
Antal kluster som ska skapas med funktionerna |
Clusters |
|
[vektor: samma som indata] Standard: |
Ange utdatavektorlagret för de genererade klustren. Ett av:
Här kan du också ändra filkodningen. |
Avancerade parametrar
Etikett |
Namn |
Typ |
Beskrivning |
|---|---|---|---|
Klustrets fältnamn |
|
[sträng] Standard: ”CLUSTER_ID |
Namn på det fält där det associerade klusternumret ska lagras |
Namn på fält för klusterstorlek |
|
[sträng] Standard: ”CLUSTER_SIZE |
Namnet på fältet med antalet funktioner i samma kluster |
Utgångar
Etikett |
Namn |
Typ |
Beskrivning |
|---|---|---|---|
Clusters |
|
[vektor: samma som indata] |
Vektorlager som innehåller de ursprungliga egenskaperna med fält som anger vilket kluster de tillhör och deras nummer i det |
Python-kod
Algoritm-ID: native:kmeansclustering
import processing
processing.run("algorithm_id", {parameter_dictionary})
algoritm id visas när du håller muspekaren över algoritmen i verktygslådan Processing Toolbox. I parameter dictionary finns parameternamn och värden. Se Använda bearbetningsalgoritmer från konsolen för information om hur du kör bearbetningsalgoritmer från Python-konsolen.
24.1.19.10. Lista unika värden
Listar unika värden för ett attributtabellfält och räknar deras antal.
Standardmeny:
Parametrar
Etikett |
Namn |
Typ |
Beskrivning |
|---|---|---|---|
Inmatningslager |
|
[vektor: vilken som helst] |
Lager att analysera |
Målområde(n) |
|
[tabellfält: valfritt] [lista] |
Område(n) som ska analyseras |
Unika värden Valfritt |
|
[vektor: tabell] Standard: |
Ange lagret för sammanfattningstabellen med unika värden. En av:
Här kan du också ändra filkodningen. |
HTML-rapport Valfritt |
|
[html] Standard: |
HTML-rapport av unika värden i . En av:
|
Utgångar
Etikett |
Namn |
Typ |
Beskrivning |
|---|---|---|---|
Unika värden |
|
[vektor: tabell] |
Sammanfattande tabellager med unika värden |
HTML-rapport |
|
[html] |
HTML-rapport över unika värden. Kan öppnas från |
Totala unika värden |
|
[numerisk: heltal] |
Antalet unika värden i inmatningsfältet |
Unika värden sammanlänkade |
|
[sträng] |
En sträng med en kommaseparerad lista över unika värden som finns i inmatningsfältet |
Python-kod
Algoritm-ID: qgis:listuniquevalues
import processing
processing.run("algorithm_id", {parameter_dictionary})
algoritm id visas när du håller muspekaren över algoritmen i verktygslådan Processing Toolbox. I parameter dictionary finns parameternamn och värden. Se Använda bearbetningsalgoritmer från konsolen för information om hur du kör bearbetningsalgoritmer från Python-konsolen.
24.1.19.11. Medelkoordinat(er)
Beräknar ett punktlager med masscentrum för geometrierna i ett inmatningslager.
Ett attribut kan specificeras som innehållande vikter som ska tillämpas på varje egenskap vid beräkning av masscentrum.
Om ett attribut har valts i parametern grupperas funktionerna enligt värdena i detta fält. Istället för en enda punkt med masscentrum för hela lagret, kommer utdatalagret att innehålla ett masscentrum för funktionerna i varje kategori.
Standardmeny:
Parametrar
Etikett |
Namn |
Typ |
Beskrivning |
|---|---|---|---|
Inmatningslager |
|
[vektor: geometri] |
Ingångsvektorlager |
Viktfält Valfritt |
|
[tabellfält: numerisk] |
Fält som ska användas om du vill göra ett viktat medelvärde |
Unikt ID-fält |
|
[tabellfält: alla] |
Unikt fält på vilket beräkningen av medelvärdet kommer att göras |
Medelkoordinater |
|
[vektor: punkt] Standard: |
Ange (punktvektor)-lagret för resultatet. Ett av:
Här kan du också ändra filkodningen. |
Utgångar
Etikett |
Namn |
Typ |
Beskrivning |
|---|---|---|---|
Medelkoordinater |
|
[vektor: punkt] |
Resulterande punkt(er) lager |
Python-kod
Algoritm-ID: native:medelvärde koordinater
import processing
processing.run("algorithm_id", {parameter_dictionary})
algoritm id visas när du håller muspekaren över algoritmen i verktygslådan Processing Toolbox. I parameter dictionary finns parameternamn och värden. Se Använda bearbetningsalgoritmer från konsolen för information om hur du kör bearbetningsalgoritmer från Python-konsolen.
24.1.19.12. Analys av närmaste granne
Utför närmaste granne-analys för ett punktlager. Utdata visar hur dina data är fördelade (klustrade, slumpmässigt eller fördelade).
Utdata genereras som en HTML-fil med de beräknade statistiska värdena:
Observerat medelavstånd
Förväntat medelavstånd
Index för närmaste granne
Antal poäng
Z-poäng: Genom att jämföra Z-Score med normalfördelningen får du reda på hur dina data är fördelade. En låg Z-score innebär att det är osannolikt att data är resultatet av en spatialt slumpmässig process, medan en hög Z-score innebär att det är sannolikt att dina data är resultatet av en spatialt slumpmässig process.
Observera
Den här algoritmen använder ellipsoidbaserade mätningar och respekterar de aktuella ellipsoidinställningarna.
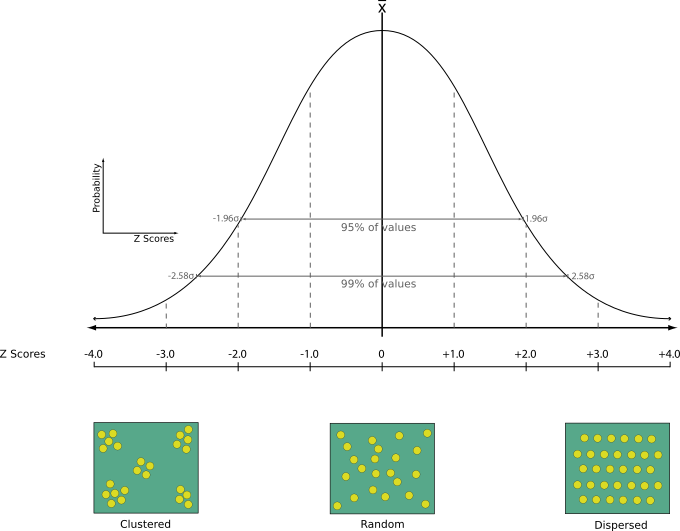
Standardmeny:
Parametrar
Etikett |
Namn |
Typ |
Beskrivning |
|---|---|---|---|
Inmatningslager |
|
[vektor: punkt] |
Punktvektorlager för att beräkna statistiken över |
Närmaste granne Valfritt |
|
[html] Standard: |
Specifikation av HTML-filen för den beräknade statistiken. En av:
|
Utgångar
Etikett |
Namn |
Typ |
Beskrivning |
|---|---|---|---|
Närmaste granne |
|
[html] |
HTML-fil med den beräknade statistiken |
Observerat medelavstånd |
|
[numerisk: dubbel] |
Observerat medelavstånd |
** Förväntat medelavstånd** |
|
[numerisk: dubbel] |
Förväntat medelavstånd |
Index för närmaste granne |
|
[numerisk: heltal] |
Index för närmaste granne |
Antal poäng |
|
[numerisk: heltal] |
Antal poäng |
Z-poäng |
|
[numerisk: dubbel] |
Z-poäng |
Python-kod
Algoritm-ID: original:analys av närmaste granne
import processing
processing.run("algorithm_id", {parameter_dictionary})
algoritm id visas när du håller muspekaren över algoritmen i verktygslådan Processing Toolbox. I parameter dictionary finns parameternamn och värden. Se Använda bearbetningsalgoritmer från konsolen för information om hur du kör bearbetningsalgoritmer från Python-konsolen.
24.1.19.13. Analys av överlappning
Beräknar den yta och procentuella täckning med vilken objekt från ett inmatningslager överlappas av objekt från ett urval av överlagringslager.
Nya attribut läggs till i utdatalagret som rapporterar den totala överlappningsytan och procentandelen av indatafunktionen som överlappas av vart och ett av de valda överlagringslagren.
Observera
Den här algoritmen använder ellipsoidbaserade mätningar och respekterar de aktuella ellipsoidinställningarna.
Parametrar
Grundläggande parametrar
Etikett |
Namn |
Typ |
Beskrivning |
|---|---|---|---|
Inmatningslager |
|
[vektor: polygon] |
Det ingående lagret. |
Overlay-lager |
|
[vektor: polygon] [lista] |
De överliggande lagren. |
Överlappning |
|
[samma som inmatning] Standard: |
Ange det utgående vektorlagret. En av:
Här kan du också ändra filkodningen. |
Avancerade parametrar
Etikett |
Namn |
Typ |
Beskrivning |
|---|---|---|---|
Nätstorlek Valfritt |
|
[numerisk: dubbel] Standard: Ej inställd |
Om det anges, snappas indatageometrierna till ett rutnät med den angivna storleken och resultatets hörn beräknas på samma rutnät. Kräver GEOS 3.9.0 eller senare. |
Utgångar
Etikett |
Namn |
Typ |
Beskrivning |
|---|---|---|---|
Överlappning |
|
[samma som inmatning] |
Utmatningslagret med ytterligare fält som rapporterar överlappningen (i kartenheter och procent) av den ingående funktionen som överlappas av vart och ett av de valda lagren. |
Python-kod
Algoritm-ID: `native:beräkna vektoröverlappningar
import processing
processing.run("algorithm_id", {parameter_dictionary})
algoritm id visas när du håller muspekaren över algoritmen i verktygslådan Processing Toolbox. I parameter dictionary finns parameternamn och värden. Se Använda bearbetningsalgoritmer från konsolen för information om hur du kör bearbetningsalgoritmer från Python-konsolen.
24.1.19.14. Kortaste linjen mellan funktionerna
Skapar ett linjelager som den kortaste linjen mellan käll- och destinationsskiktet. Som standard tas endast hänsyn till den första närmaste funktionen i destinationslagret. Antalet n-närmaste grannfunktioner kan specificeras. Om ett maximalt avstånd anges kommer endast objekt som ligger närmare än detta avstånd att beaktas.
De utgående funktionerna innehåller alla källagrets attribut, alla attribut från den n-närmaste funktionen och det extra fältet för avståndet.
Viktigt
Denna algoritm använder rent kartesiska beräkningar för avstånd och tar inte hänsyn till geodetiska eller ellipsoidiska egenskaper när den bestämmer objektets närhet. Koordinatsystemet för mätning och utdata baseras på koordinatsystemet för källagret.
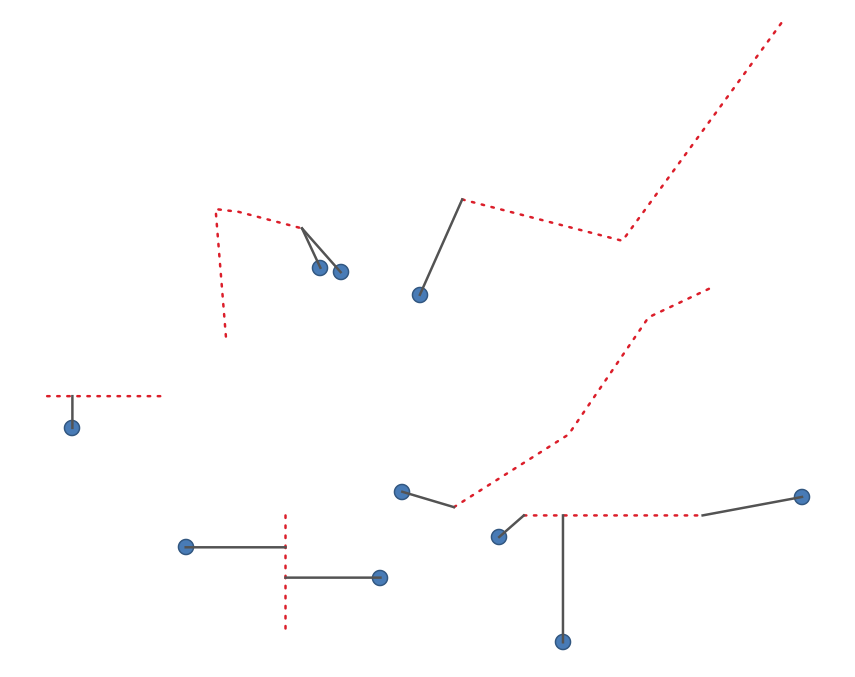
Fig. 24.44 Kortaste linjen från punkter till linjer
Parametrar
Etikett |
Namn |
Typ |
Beskrivning |
|---|---|---|---|
Källager |
|
[vektor: geometri] |
Ursprungslager för vilket man söker efter närmaste grannar |
Destinationslager |
|
[vektor: geometri] |
Mållager i vilket man söker efter närmaste grannar |
Metod |
|
[uppräkning] Standard: 0 |
Beräkningsmetod för kortaste avstånd Möjliga värden är:
|
Maximalt antal grannar |
|
[numerisk: heltal] Standard: 1 |
Maximalt antal grannar att leta efter |
Maximalt avstånd Valfritt |
|
[numerisk: dubbel] |
Endast destinationsfunktioner som ligger närmare än detta avstånd kommer att beaktas. |
Kortaste linjerna |
|
[vektor: linje] Standard: |
Ange det utgående vektorlagret. En av:
Här kan du också ändra filkodningen. |
Utgångar
Etikett |
Namn |
Typ |
Beskrivning |
|---|---|---|---|
Utdatalager |
|
[vektor: linje] |
Linjevektorlager som sammanfogar källfunktioner med deras närmaste granne(r) i destinationslagret. Innehåller alla attribut för både käll- och destinationsobjekten samt det beräknade avståndet. |
Python-kod
Algoritm-id: native:shortestline
import processing
processing.run("algorithm_id", {parameter_dictionary})
algoritm id visas när du håller muspekaren över algoritmen i verktygslådan Processing Toolbox. I parameter dictionary finns parameternamn och värden. Se Använda bearbetningsalgoritmer från konsolen för information om hur du kör bearbetningsalgoritmer från Python-konsolen.
24.1.19.15. ST-DBSCAN klustring
Klustrar punktfunktioner baserat på en 2D-implementering av spatiotemporal Density-based clustering of applications with noise (ST-DBSCAN)-algoritm.
Se även
Parametrar
Grundläggande parametrar
Etikett |
Namn |
Typ |
Beskrivning |
|---|---|---|---|
Inmatningslager |
|
[vektor: punkt] |
Lager att analysera |
Datum/tid-fält |
|
[tabellfält: datum] |
Fält som innehåller den temporala informationen |
Minsta klusterstorlek |
|
[numerisk: heltal] Standard: 5 |
Minsta antal funktioner för att generera ett kluster |
Maximalt avstånd mellan klustrade punkter |
|
[numerisk: dubbel] Standard: 1,0 |
Avstånd bortom vilket två funktioner inte kan tillhöra samma kluster (eps) |
Maximal tidslängd mellan klustrade punkter |
|
[numerisk: dubbel] Standard: 0,0 (dagar) |
Tidsperiod efter vilken två funktioner inte kan tillhöra samma kluster (eps2). Tillgängliga tidsenheter är millisekunder, sekunder, minuter, timmar, dagar och veckor. |
Clusters |
|
[vektor: punkt] Standard: |
Ange vektorlagret för resultatet av klustringen. Ett av:
Här kan du också ändra filkodningen. |
Avancerade parametrar
Etikett |
Namn |
Typ |
Beskrivning |
|---|---|---|---|
Behandla gränspunkter som brus (DBSCAN*) |
|
[boolean] Standard: Falsk |
Om den är markerad behandlas punkter på gränsen till ett kluster som punkter utan kluster, och endast punkter i det inre av ett kluster taggas som klustrade. |
Klustrets fältnamn |
|
[sträng] Standard: ”CLUSTER_ID |
Namn på det fält där det associerade klusternumret ska lagras |
Namn på fält för klusterstorlek |
|
[sträng] Standard: ”CLUSTER_SIZE |
Namnet på fältet med antalet funktioner i samma kluster |
Utgångar
Etikett |
Namn |
Typ |
Beskrivning |
|---|---|---|---|
Clusters |
|
[vektor: punkt] |
Vektorlager som innehåller de ursprungliga objekten med ett fält som anger vilket kluster de tillhör |
Antal kluster |
|
[numerisk: heltal] |
Antalet kluster som upptäckts |
Python-kod
Algoritm-id: native:stdbscanclustering
import processing
processing.run("algorithm_id", {parameter_dictionary})
algoritm id visas när du håller muspekaren över algoritmen i verktygslådan Processing Toolbox. I parameter dictionary finns parameternamn och värden. Se Använda bearbetningsalgoritmer från konsolen för information om hur du kör bearbetningsalgoritmer från Python-konsolen.
24.1.19.16. Statistik per kategori
Beräknar statistik för ett fält beroende på en överordnad klass. Den överordnade klassen är en kombination av värden från andra fält.
Parametrar
Etikett |
Namn |
Typ |
Beskrivning |
|---|---|---|---|
Input vektorlager |
|
[vektor: vilken som helst] |
Vektorlager för indata med unika klasser och värden |
Fält att beräkna statistik på (om tomt beräknas endast antal) Valfritt |
|
[tabellfält: alla] |
Om den är tom kommer endast antalet att beräknas |
Fält med kategorier |
|
[tabellfält: valfritt] [lista] |
De fält som (tillsammans) definierar kategorierna |
Statistik per kategori |
|
[vektor: tabell] Standard: |
Ange utmatningstabellen för den genererade statistiken. En av:
Här kan du också ändra filkodningen. |
Utgångar
Etikett |
Namn |
Typ |
Beskrivning |
|---|---|---|---|
Statistik per kategori |
|
[vektor: tabell] |
Tabell som innehåller statistiken |
Beroende på vilken typ av fält som analyseras returneras följande statistik för varje grupperat värde:
Statistik |
Text |
Numeric |
Datum |
|---|---|---|---|
Räkna ( |
|
|
|
Unika värden ( |
|
|
|
Tomma (null) värden ( |
|
|
|
Icke-tomma värden ( |
|
|
|
Minimivärde ( |
|
|
|
Maximalt värde ( |
|
|
|
Område ( |
|
||
Summa ( |
|
||
Medelvärde ( |
|
||
Medianvärde ( |
|
||
Standardavvikelse ( |
|
||
Variationskoefficient ( |
|
||
Minoritet (sällsynt förekommande värde - |
|
||
Majoritet (mest frekvent förekommande värde - |
|
||
Första kvartilen ( |
|
||
Tredje kvartilen ( |
|
||
Interkvartilt intervall ( |
|
||
Minsta längd ( |
|
||
Medellängd ( |
|
||
Maximal längd ( |
|
Python-kod
Algoritm-ID: qgis:statisticsbycategories
import processing
processing.run("algorithm_id", {parameter_dictionary})
algoritm id visas när du håller muspekaren över algoritmen i verktygslådan Processing Toolbox. I parameter dictionary finns parameternamn och värden. Se Använda bearbetningsalgoritmer från konsolen för information om hur du kör bearbetningsalgoritmer från Python-konsolen.
24.1.19.17. Summera linjelängder
Tar ett polygonlager och ett linjelager och mäter den totala längden på linjerna och det totala antalet linjer som korsar varje polygon.
Det resulterande lagret har samma egenskaper som det ingående polygonlagret, men med två ytterligare attribut som innehåller längden och antalet linjer över varje polygon.
Observera
Den här algoritmen använder ellipsoidbaserade mätningar och respekterar de aktuella ellipsoidinställningarna.
Tillåter features in-place modification av polygonfeatures
Standardmeny:
Parametrar
Etikett |
Namn |
Typ |
Beskrivning |
|---|---|---|---|
Linjer |
|
[vektor: linje] |
Ingångsvektor linjelager |
Polygoner |
|
[vektor: polygon] |
Polygon vektorlager |
Linjelängd fältnamn |
|
[sträng] Standard: ”LENGTH” (längd) |
Namn på fältet för linjelängd |
Fältnamn för antal rader |
|
[sträng] Standard: ”COUNT |
Namn på fältet för antal rader |
Linjens längd |
|
[vektor: polygon] Standard: |
Ange det utgående polygonlagret med genererad statistik. Ett av:
Här kan du också ändra filkodningen. |
Utgångar
Etikett |
Namn |
Typ |
Beskrivning |
|---|---|---|---|
Linjens längd |
|
[vektor: polygon] |
Polygonutgångsskikt med fält för linjelängd och linjeantal |
Python-kod
Algoritm-ID: native:sumlinelengths
import processing
processing.run("algorithm_id", {parameter_dictionary})
algoritm id visas när du håller muspekaren över algoritmen i verktygslådan Processing Toolbox. I parameter dictionary finns parameternamn och värden. Se Använda bearbetningsalgoritmer från konsolen för information om hur du kör bearbetningsalgoritmer från Python-konsolen.