6.4. Lesson: Statistiques Spatiales
Note
Leçon développée par Linfiniti et S Motala (Cape Peninsula University of Technology)
Les statistiques spatiales vous permettent d’analyser et de comprendre ce qui se passe dans un ensemble de données vecteur donné. QGIS comprend de nombreux outils utiles pour l’analyse statistique.
Le but de cette leçon: Savoir comment utiliser les outils de statistiques spatiales de QGIS dans la boite à outils traitement.
6.4.1.  Follow Along: Créer un jeu de données test
Follow Along: Créer un jeu de données test
Nous allons créer un ensemble de points aléatoires, pour obtenir un ensemble de données avec lesquelles travailler.
Pour ce faire, vous aurez besoin d’un ensemble de données polygonales pour définir la zone dans laquelle vous souhaitez créer les points.
Nous utiliserons la zone couverte par les rues.
Démarrer un nouveau projet
Ajoutez votre jeu de données
roads, ainsi quesrtm_41_19(données d’élévation) qui se trouve dans le fichierexercise_data/raster/SRTM/.Note
Vous constaterez peut-être que la couche SRTM DEM a un CRS différent de celui de la couche des routes. QGIS reprojette les deux couches dans un seul CRS. Pour les exercices suivants, cette différence n’a pas d’importance, mais n’hésitez pas à faire des reprojections (comme indiqué plus haut dans ce module).
Ouvrir la boite d’outils Traitement
Utilisez l’outil pour générer une zone englobant toutes les routes en sélectionnant
Convex Hullcomme Type de géométrie :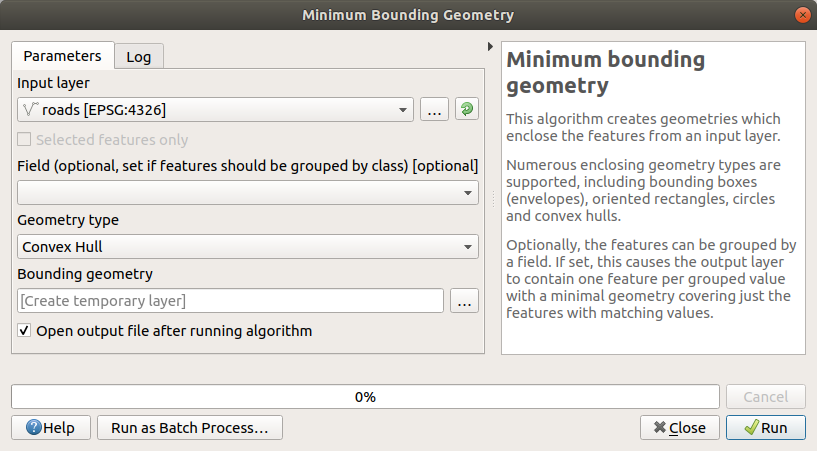
Comme vous le savez, si vous ne spécifiez pas la sortie, Traitement crée des couches temporaires. C’est à vous de sauvegarder les couches immédiatement ou à un stade ultérieur.
Création de points aléatoires
Créez 100 points aléatoires dans cette zone en utilisant l’outil , avec une distance minimale de
0.0: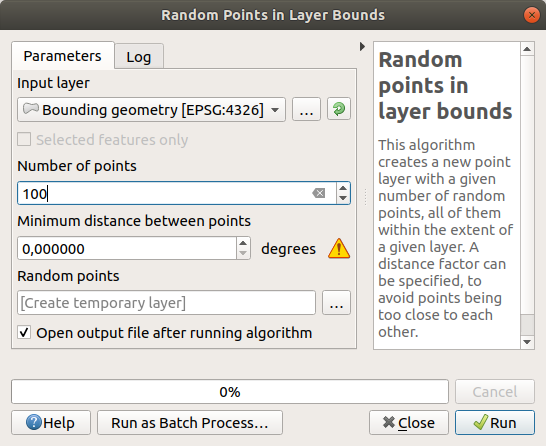
Note
Le panneau d’avertissement jaune vous indique que ce paramètre concerne les distances. La couche Emprise de la géométrie se trouve dans un système de coordonnées géographiques et l’algorithme ne fait que vous le rappeler. Pour cet exemple, nous n’utiliserons pas ce paramètre, vous pouvez donc l’ignorer.
Si nécessaire, déplacez le point aléatoire généré vers le haut de la légende pour mieux les voir :
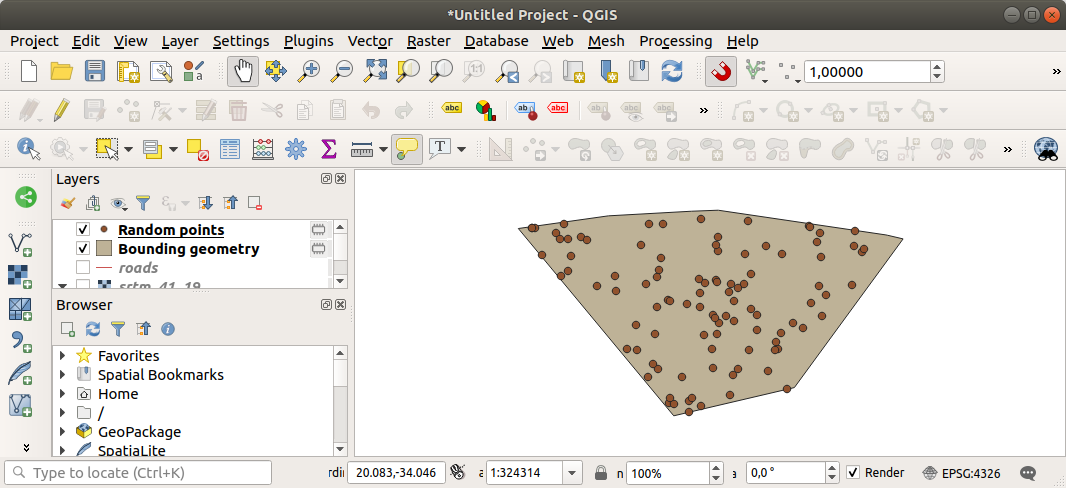
Échantillonage des données
Pour créer un échantillon de données à partir du raster, vous devez utiliser l’algorithme . Cet outil échantillonne le raster à l’emplacement des points et ajoute les valeurs du raster dans de nouveaux champs en fonction du nombre de bandes du raster.
Ouvrez la boîte de dialogue de l’algorithme Exemple de valeurs raster
Sélectionnez
Points_aléatoirescomme couche contenant les points d’échantillonnage, et la trame SRTM comme bande à partir de laquelle obtenir les valeurs. Le nom par défaut du nouveau champ estrvalue_N, oùNest le numéro de la bande du raster. Vous pouvez changer le nom du préfixe si vous le souhaitez.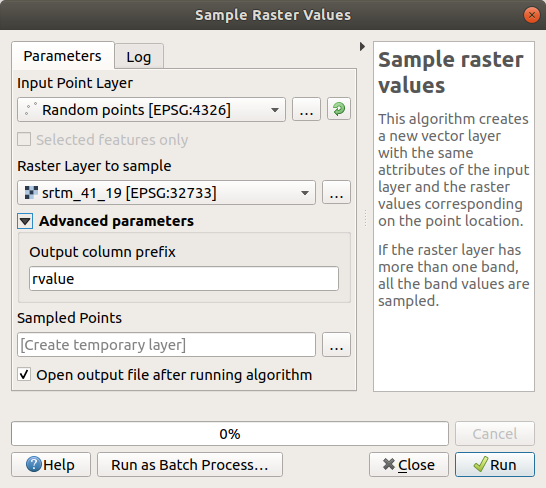
Appuyez sur Run
Vous pouvez maintenant vérifier les données échantillonnées du fichier raster dans la table des attributs de la couche Points échantillonnés. Elles se trouveront dans un nouveau champ avec le nom que vous avez choisi.
Voici un exemple de représentation de la couche:
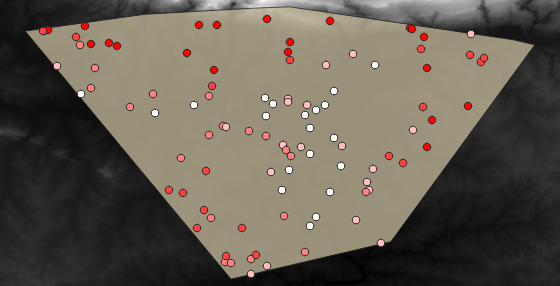
Les points d’échantillonnage sont classés à l’aide du champ « rvalue_1 », de sorte que les points rouges se trouvent à une altitude plus élevée.
Vous utiliserez cette couche d’échantillonnage pour le reste des exercices statistiques.
6.4.2. Follow Along: Statistiques Basiques
Maintenant, récupérez les statistiques basiques de cette couche.
Cliquez sur l’icône
 voir le résumé statistique dans la barre d’outils attribut. Un nouveau panneau apparaîtra.
voir le résumé statistique dans la barre d’outils attribut. Un nouveau panneau apparaîtra.Dans la boîte de dialogue qui apparaît, spécifiez la couche « Points échantillonnés » comme source.
Sélectionnez le champ rvalue_1 dans la liste déroulante des champs. C’est le champ pour lequel vous allez calculer les statistiques.
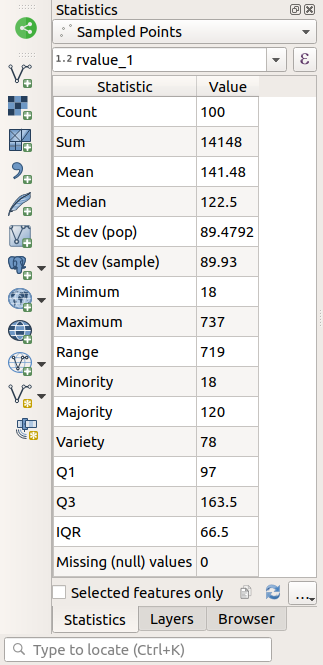
Le panneau Statistiques sera automatiquement mis à jour avec les statistiques calculées:
Note
Vous pouvez copier les valeurs en cliquant sur le bouton
 copier les statistiques dans le presse papier et coller les résultats dans une feuille de calcul.
copier les statistiques dans le presse papier et coller les résultats dans une feuille de calcul.Fermez le panneau statistiques quand vous aurez terminé
De nombreuses statistiques différentes sont disponibles :
- Compte
Le nombre d’échantillons/valeurs.
- Somme
Les valeurs ajoutées ensemble.
- Moyenne
La valeur moyenne est simplement la somme des valeurs divisée par le nombre de valeurs.
- Médiane
Si vous rangez toutes les valeurs de la plus petite à la plus grande, la valeur moyenne (ou la moyenne des deux valeurs moyennes, si N est un nombre pair) est la médiane des valeurs.
- St Dev (pop)
La déviation standard. Donne une indication sur la manière dont les valeurs sont regroupées autour de la moyenne. Plus la déviation est faible, plus les valeurs tendent à se situer à la moyenne.
- Minimum
La valeur minimale.
- Maximum
La valeur maximale.
- Portée
La différence entre les valeurs minimale et maximale.
- Q1
Premier quartile des données.
- Q3
Troisième quartile des données.
- Valeurs (nulles) manquantes
Le nombre de valeurs manquantes.
6.4.3. Follow Along: Calculer des statistiques sur les distances entre points
Créer une nouvelle couche de points temporaire.
Entrez en mode édition, et numérisez trois points parmi les autres points.
Alternativement, utilisez la même méthode de génération de points aléatoires que précédemment, mais spécifiez seulement trois points.
Enregistrez votre nouvelle couche sous distance_points dans le format que vous préférez.
Pour générer des statistiques sur les distances entre les points dans les deux couches:
Ouvrez l’outil .
Sélectionnez la couche
distance_pointscomme couche d’entrée, et la coucheSampled Pointscomme couche cible.Définissez-le comme ceci:
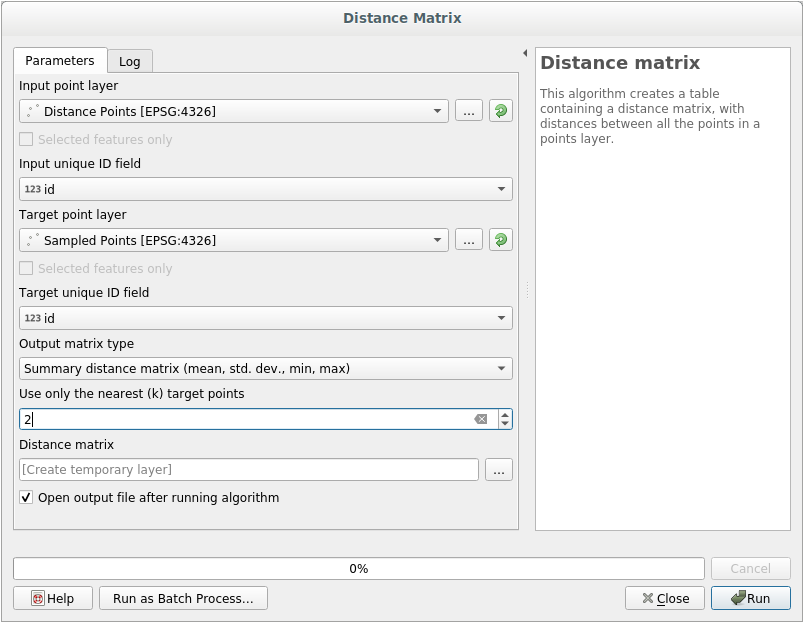
Si vous le souhaitez, vous pouvez enregistrer la couche de sortie sous forme de fichier ou simplement exécuter l’algorithme et enregistrer la couche de sortie temporaire plus tard.
Cliquez sur Exécuter pour générer la couche de matrice de distance.
Ouvrez la table attributaire de la couche générée: les valeurs font référence aux distances entre les entités distance_points et leurs deux points les plus proches dans la couche Sampled Points:
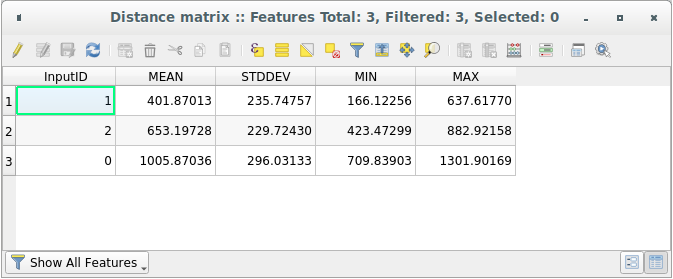
Avec ces paramètres, l’outil Matrice de distance calcule les statistiques de distance pour chaque point de la couche d’entrée par rapport aux points les plus proches de la couche cible. Les champs de la couche de sortie contiennent la moyenne, l’écart-type, le minimum et le maximum des distances par rapport aux voisins les plus proches des points de la couche d’entrée.
6.4.4. Follow Along: Analyse du plus proche voisin (dans la couche)
Pour effectuer une analyse du voisin le plus proche d’une couche de points:
Choisissez .
Dans la boîte de dialogue qui apparaît, sélectionnez la couche Points aléatoires et cliquez sur Exécuter.
Les résultats apparaîtront dans le panneau Processing Visualiseur de résultats.
Cliquez sur le lien bleu pour ouvrir la page
htmlavec les résultats: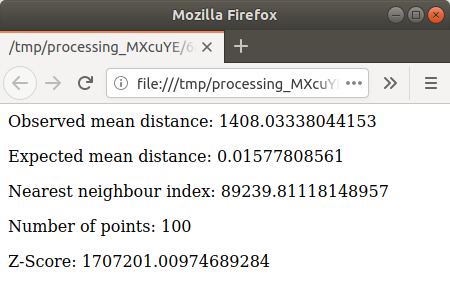
6.4.5. Follow Along: Coordonnées Moyennes
Pour obtenir les coordonnées moyennes d’un jeu de données:
Démarrez
Dans le dialogue qui apparaît, spécifiez Random points comme couche entree, et laissez les choix optionnels inchangés.
Cliquez sur Exécuter.
Comparons cela à la coordonnée centrale du polygone qui a été utilisée pour créer l’échantillon aléatoire.
Démarrer
Dans la boîte de dialogue qui apparaît, sélectionnez
la géométrie limitecomme couche d’entrée.
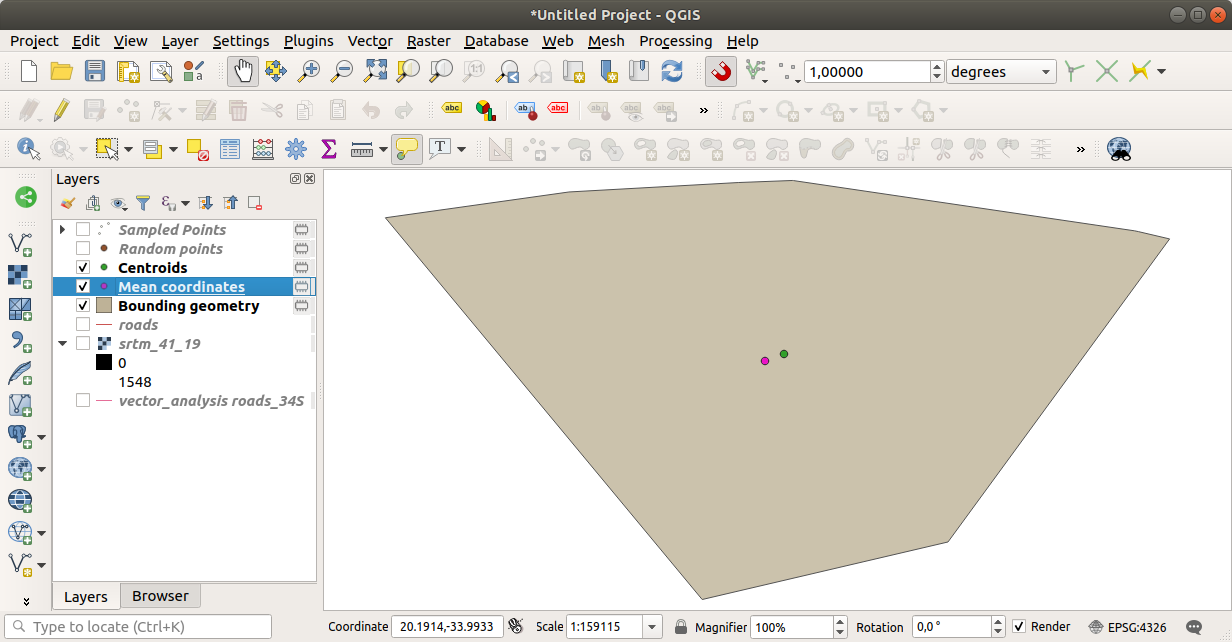
Comme vous pouvez le voir, les coordonnées moyennes (point rose) et le centre de la zone d’étude (en vert) ne coïncident pas nécessairement.
Le centroïde est le barycentre de la couche (le barycentre d’un carré est le centre du carré) tandis que les coordonnées moyennes représentent la moyenne de toutes les coordonnées des nœuds.
6.4.6. Follow Along: Histogrammes d’image
L’histogramme d’un jeu de données montre la distribution de ses valeurs. Le moyen le plus simple de le démontrer dans QGIS est via l’histogramme d’image, disponible dans la boîte de dialogue Propriétés de la couche de n’importe quelle couche d’image (jeu de données raster).
Dans votre panneau couches, faites un clic droit sur la couche
srtm_41_19Sélectionnez
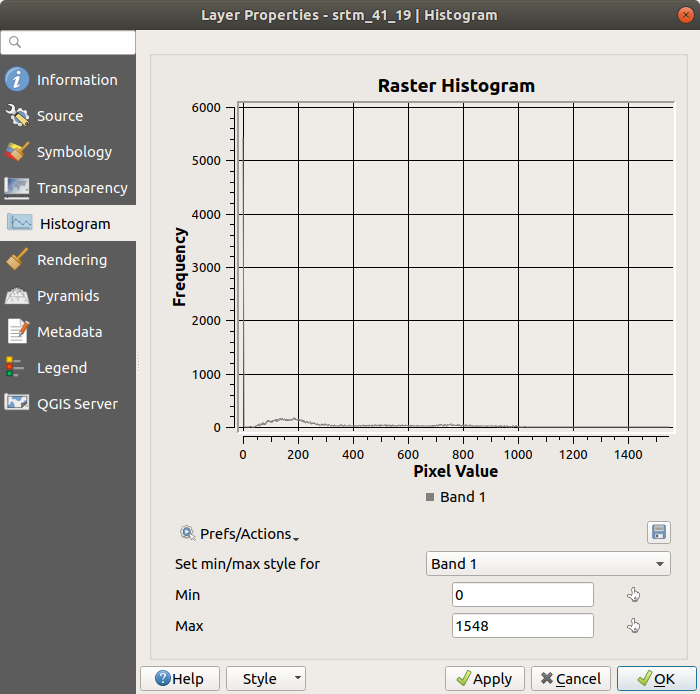
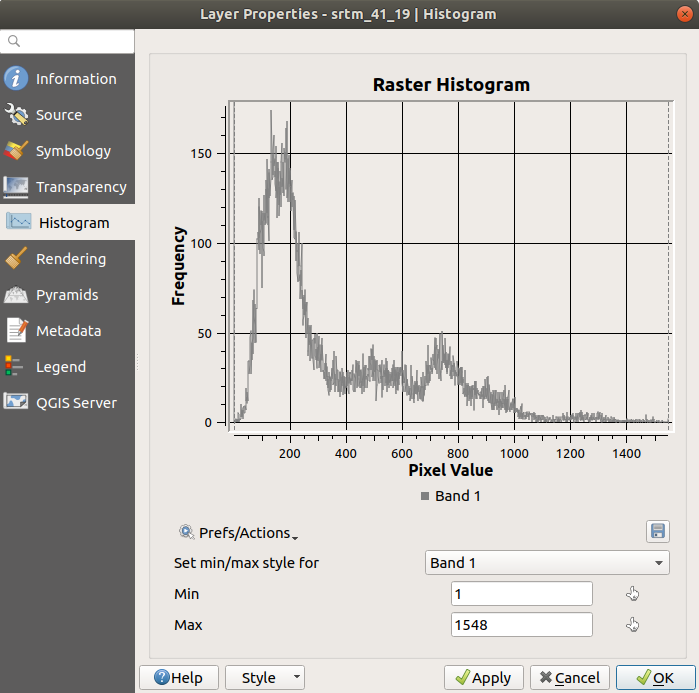
Choisissez l’onglet Histogramme. Vous devrez peut-être cliquer sur le bouton Calculer l’histogramme pour générer le graphique. Vous verrez un graphique qui montre la distribution des fréquences pour les valeurs de raster.
Le graphique peut être exporté comme image à l’aide du bouton
 Enregistrer le graphique
Enregistrer le graphiqueVous pouvez voir des informations plus détaillées sur la couche dans l’onglet Information (les valeurs moyennes et maximales sont estimées, et peuvent ne pas être exactes).
La valeur moyenne est de 332,8 (estimée à 324,3), et la valeur maximale est de 1699 (estimée à 1548) ! Vous pouvez zoomer dans l’histogramme. Comme il y a beaucoup de pixels de valeur 0, l’histogramme semble compressé verticalement. En zoomant pour couvrir tout sauf le pic à 0, vous verrez plus de détails :
Note
Si les valeurs moyennes et maximales ne sont pas les mêmes que celles indiquées ci-dessus, cela peut être dû au calcul de la valeur min/max. Ouvrez l’onglet Symbologie et développez le menu Paramètres des valeurs Min / Max. Choisissez  Min / max et cliquez sur Appliquer.
Min / max et cliquez sur Appliquer.
N’oubliez pas qu’un histogramme vous montre la distribution des valeurs, et que toutes les valeurs ne sont pas nécessairement visibles sur le graphique.
6.4.7. Follow Along: Interpolation Spatiale
Supposons que vous ayez une collection d’exemples de points à partir desquels vous souhaitez extrapoler des données. Par exemple, vous pourriez avoir accès au jeu de données Sampled points que nous avons créé plus tôt, et vous souhaitez avoir une idée de l’apparence du terrain.
Pour commencer, lancez l’outil dans la Boîte à outils Traitement.
Pour Couche de points, sélectionnez
Points échantillonnés.Réglez Pouvoir de pondération sur
5.0.Dans Paramètres avancés, mettez Valeur Z depuis le champ à
rvalue_1Enfin, cliquez sur Exécuter et attendez la fin du traitement
Fermez la boîte de dialogue
Voici une comparaison entre l’ensemble de données original (à gauche) et celui construit à partir de nos points d’échantillonnage (à droite). Les vôtres peuvent sembler différentes en raison de la nature aléatoire de l’emplacement des points d’échantillonnage.
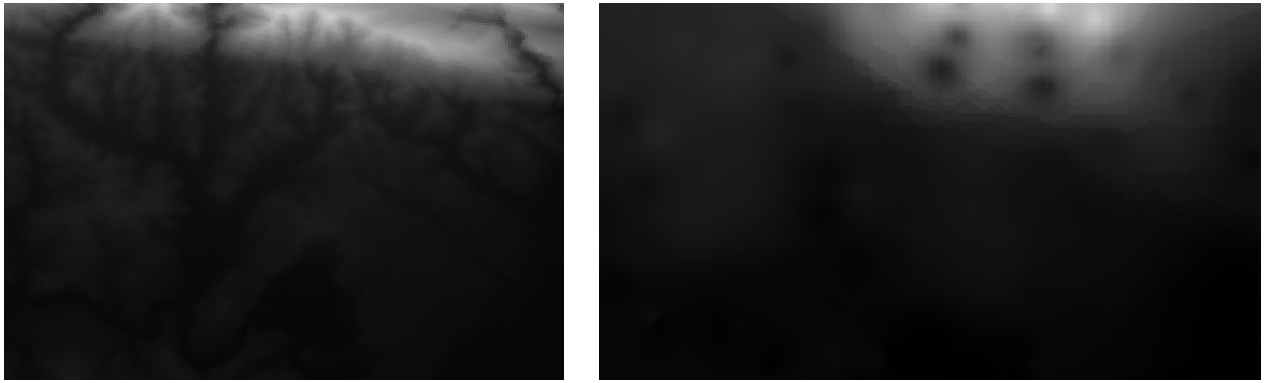
Comme vous pouvez le voir, 100 points d’échantillonnage ne sont pas vraiment suffisants pour obtenir une impression détaillée du terrain. Cela donne une idée très générale, mais elle peut aussi être trompeuse.
6.4.8.  Try Yourself Différentes méthodes d’interpolation
Try Yourself Différentes méthodes d’interpolation
Utilisez les processus indiqués ci-dessus pour créer un ensemble de 10 000 points aléatoires
Note
Si le nombre de points est vraiment important, le temps de traitement peut être long.
Utilisez ces points pour échantillonner le DEM original
Utilisez l’outil Grid (IDW avec recherche du plus proche voisin) sur cet ensemble de données.
Réglez Power et Smoothing sur
5.0et2.0, respectivement.
Les résultats (dépendamment de la position de vos points aléatoires) ressembleront plus ou moins à cela :

C’est une meilleure représentation du terrain, en raison de la plus grande densité des points d’échantillonnage. N’oubliez pas que des échantillons plus grands donnent de meilleurs résultats.
6.4.9. In Conclusion
QGIS dispose d’un certain nombre d’outils pour analyser les propriétés statistiques spatiales des ensembles de données.
6.4.10. What’s Next?
Maintenant que nous avons couvert l’analyse des vecteurs, pourquoi ne pas voir ce que l’on peut faire avec les rasters ? C’est ce que nous ferons dans le prochain module !