6.4. Занятие: Пространственная статистика
Примечание
Урок подготовлен Linfiniti и S Motala (Технологический университет Кейп-Пенинсула).
Пространственная статистика позволяет вам сделать анализ и понять, что происходит в данном наборе векторных данных. QGIS имеет множество полезных инструментов для статистического анализа.
Цель этого урока: Узнать, как использовать инструменты пространственной статистики QGIS внутри Processing Toolbox.
6.4.1.  Идем дальше: Создаем тестовый набор данных
Идем дальше: Создаем тестовый набор данных
Мы создадим случайный набор точек и получим набор данных для работы.
Чтобы это сделать вам понадобится набор данных полигона, чтобы определить местность, в которой вы хотите создать точки.
Мы будем использовать площадь, покрытую улицами.
Начните новый проект.
Добавьте свой набор данных
roads, а такжеsrtm_41_19(данные о высоте) вexercise_data/raster/SRTM/.Примечание
Вы возможно обнаружите, что слой SRTM DEM имеет другую ССК, которая отличается от слоя дорог. QGIS пере-проецирует оба слоя в одной ССК. Для следующих упражнений эта разница не имеет значения, но вы можете пере-проецировать (как было показано ранее в этом модуле).
Откройте ящик для инструментов Processing.
Используйте инструмент для создания местности, привязав все дороги, выбрав
Convex Hullв качестве Geometry Type: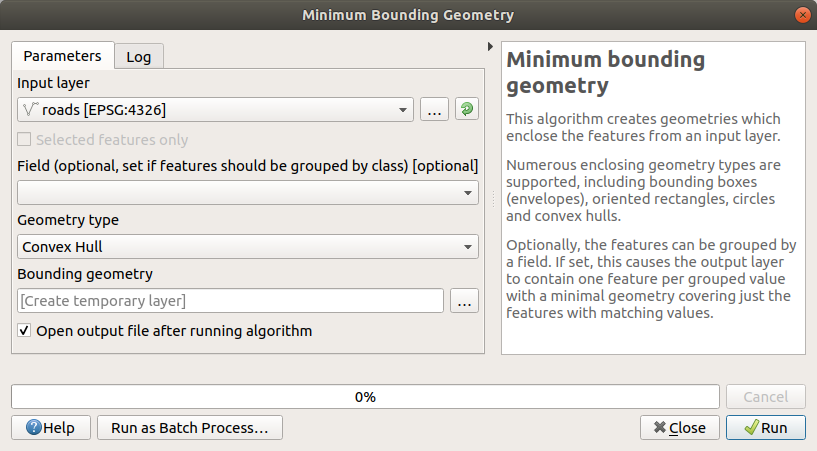
Как известно, если вы не укажете выход, Обработка создаст временные слои. Вы можете сразу сохранить слои или сделать это позже.
Создание случайных точек
Создайте 100 случайных точек в этой местности, используя инструмент в с минимальным расстоянием
0.0: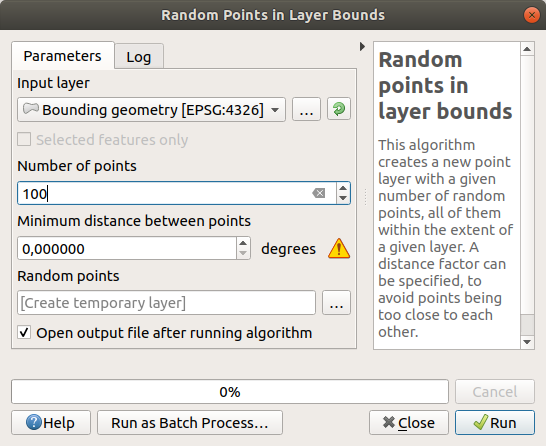
Примечание
Желтый предупреждающий знак говорит вам, что этот параметр относится к расстояниям. Слой Bounding geometry находится в географической системе координат и алгоритм просто напоминает вам об этом. В этом примере мы не будем использовать этот параметр, поэтому вы можете его проигнорировать.
Если надо, переместите сгенерированные случайные точки в верхнюю часть условного обозначения, чтобы лучше их увидеть:
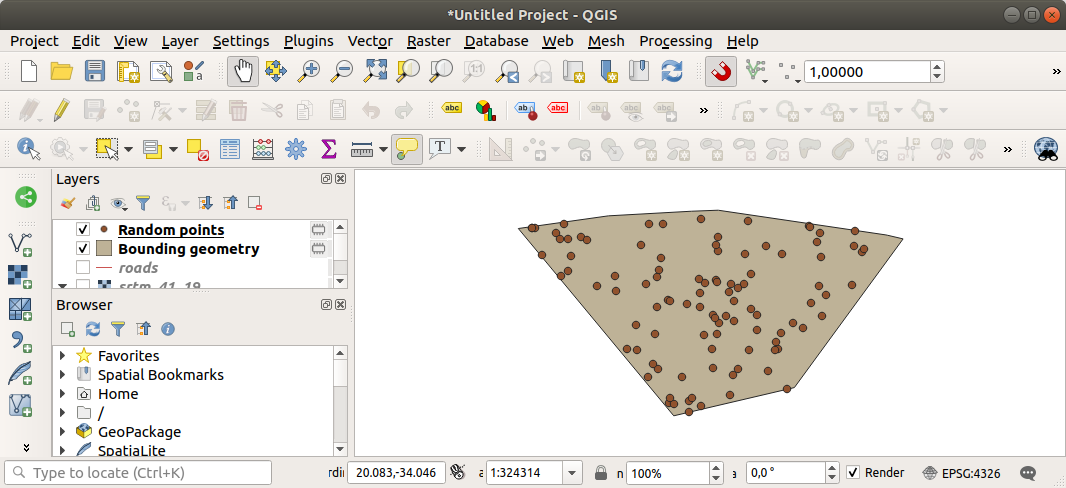
Выборка данных
Для создания выборочного набора данных из растра, вам надо использовать алгоритм . Этот инструмент производит выборку растра в местах расположения точек и добавляет значения растра в новое поле (поля) в зависимости от количества каналов в растре.
Откройте диалоговое окно алгоритма Sample raster values.
Выберите
Random_pointsкак слой, содержащий точки выборки, и растр SRTM как диапазон, из которого нужно получить значения. Название нового поля по умолчанию:rvalue_N, гдеN- номер полосы растра. Вы можете изменить название приставки, если хотите.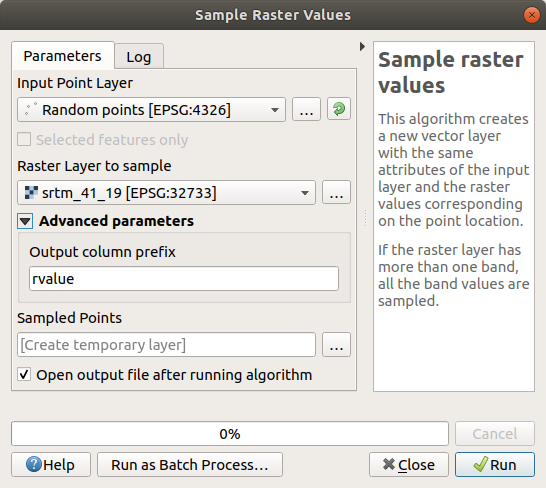
Кликните на кнопку Run.
Вы теперь сможете проверить выборочные данные из растрового файла в таблице атрибутов слоя Sampled Points. Они появятся в новом поле с названием, которое вы выбрали.
Возможный образец слоя показан здесь:
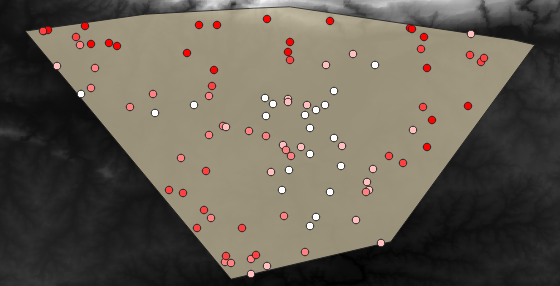
Выборочные точки классифицируются с использованием поля rvalue_1 так, чтобы красные точки находились на большей высоте.
Вы будете использовать этот слой для остальных статистических упражнений.
6.4.2. Идем дальше: Базовая статистика
Вам теперь надо получить базовую статистику для этого слоя.
Кликни на значок Показать статистку
 Show statistical summary в Attributes Toolbar. Появится новая панель.
Show statistical summary в Attributes Toolbar. Появится новая панель.В появившемся диалоговом окне укажите слой
Sampled Pointsв качестве источника.Выберите поле rvalue_1 в поле со списком полей. Это поле, для которого вы будете рассчитывать статистику.
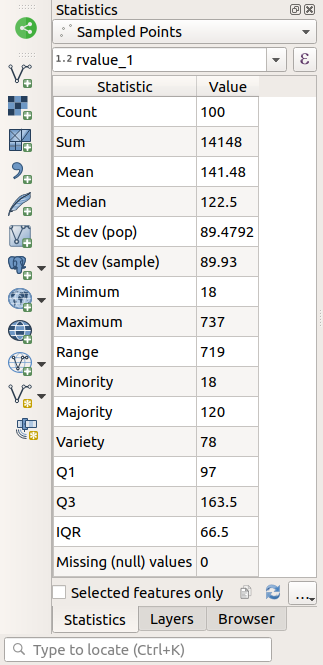
Панель Statistics автоматически обновится с расчетными статданными:
Примечание
Вы можете скопировать значения, нажав на кнопку
 Copy Statistics To Clipboard и вставив результаты в таблицу.
Copy Statistics To Clipboard и вставив результаты в таблицу.Закройте панель Statistics когда закончите.
Появятся много команд, связанных со статистикой:
- Count/Считать
Количество выборок /значений.
- Sum/Сумма
Сложение значений.
- Mean/Среднее значение
Среднее (среднее) значение - это просто сумма значений, разделенная на количество значений.
- Median/Медиана
Если вы расположите все значения от наименьшего к наибольшему, значение в середине (или среднее из двух средних значений, если N - четное число) будет медианным значением.
- St Dev (pop)/Стандартное отклонение
Стандартное отклонение. Указывает, насколько близко значения сгруппированы вокруг среднего. Чем меньше стандартное отклонение, тем ближе значения к среднему.
- Minimum/Минимум
Минимальное значение.
- Maximum/Максимум
Максимальное значение.
- Range/Диапазон
Разница между минимальным и максимальным значениями.
- Q1
Первый квартиль данных.
- Q3
Третий квартиль данных.
- Missing (null) values/Пропущенные (нулевые) значения
Количество пропущенных значений.
6.4.3. Идем дальше: Вычисляем статистические данные относительно расстояний между точками
Создайте новый временный точечный слой.
Зайдите в режим редактирования и оцифруйте три точки где-нибудь среди других точек.
В качестве альтернативы вы можете использовать тот же метод генерации случайных точек, как ранее мы делали, но надо указать только три точки.
Сохраните ваш новый слой как distance_points в том формате, к котором вам хочется.
Чтобы получить статистику расстояний между точками в двух слоях необходимо сделать следующее:
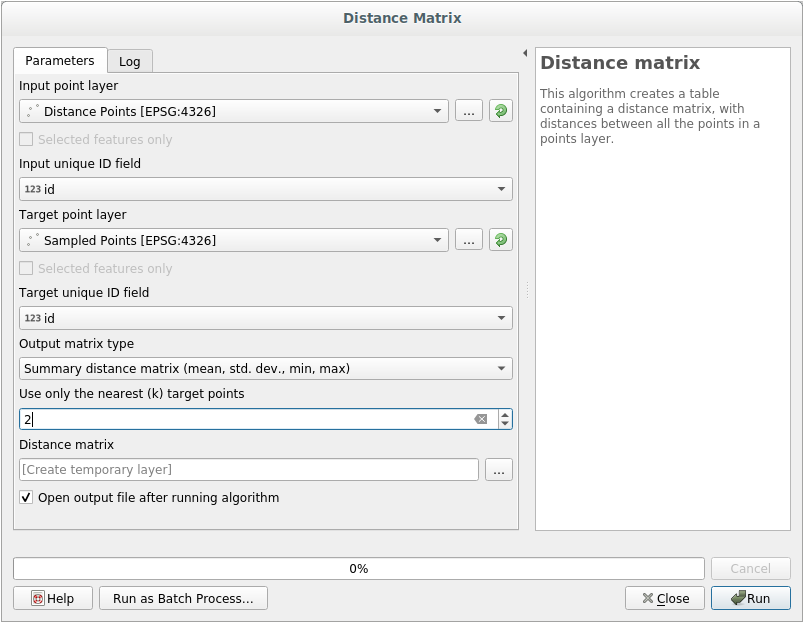
Откройте инструмент .
Выберите слой
distance_pointsв качестве входного слоя, а слойSampled Points- в качестве целевого слоя.Сделайте это так:
Если хотите, вы можете сохранить выходной слой как файл или просто можете запустить алгоритм и сохранить временный выходной слой позже.
Кликните на кнопку Run чтобы получить слой матрицы расстояний.
Откройте таблицу с атрибутами сгенерированного слоя: значения относятся к расстояниям между объектами distance_points и их двумя ближайшими точками в слое Sampled Points:
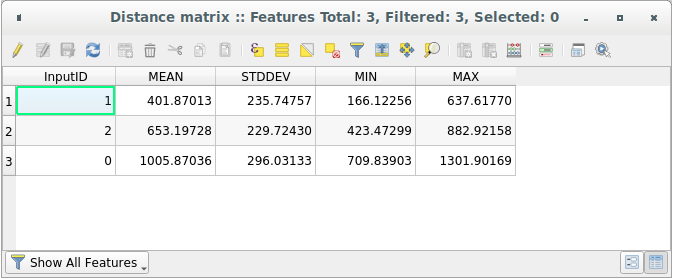
С помощью этих параметров инструмент Матрица расстояний рассчитает статистику расстояний для каждой точки входного слоя по отношению к ближайшим точкам целевого слоя. Поля выходного слоя содержат среднее значение, стандартное отклонение, минимальные и максимальные значения в отношении расстояний до ближайших соседних точек входного слоя.
6.4.4. Идем дальше: Анализ методом «ближайший сосед» (внутри слоя)
Чтобы выполнить анализ методом «ближайший сосед» точечного слоя, необходимо сделать следующее:
Выберите .
В появившемся диалоговом окне выберите слой Random points и кликните Run.
Результаты появятся в панели «Обработка» Result Viewer.
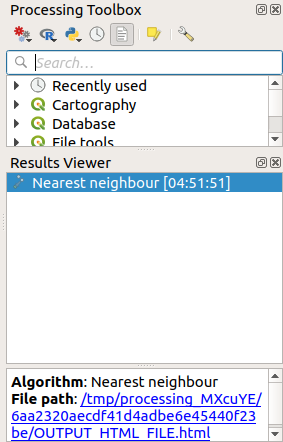
Кликните синюю ссылку, чтобы открыть страницу
htmlс результатами: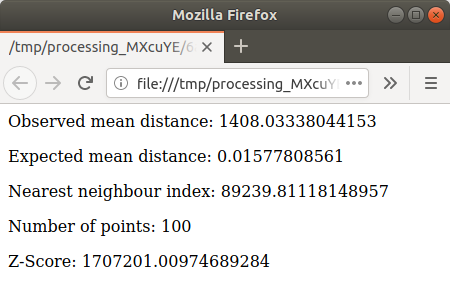
6.4.5. Идем дальше: Средние координаты
Для того, чтобы получить средние координаты набора данных необходимо сделать следующее:
Запустите .
В появившемся диалоговом окне укажите Random points как Input layer, и оставьте необязательные варианты без изменений.
Кликните на кнопку Run.
Давайте сравним это с центральной координатой полигона, который был использован для создания случайной выборки.
Запустите .
В появившемся диалоговом окне выберите
Bounding geometryв качестве входного слоя.
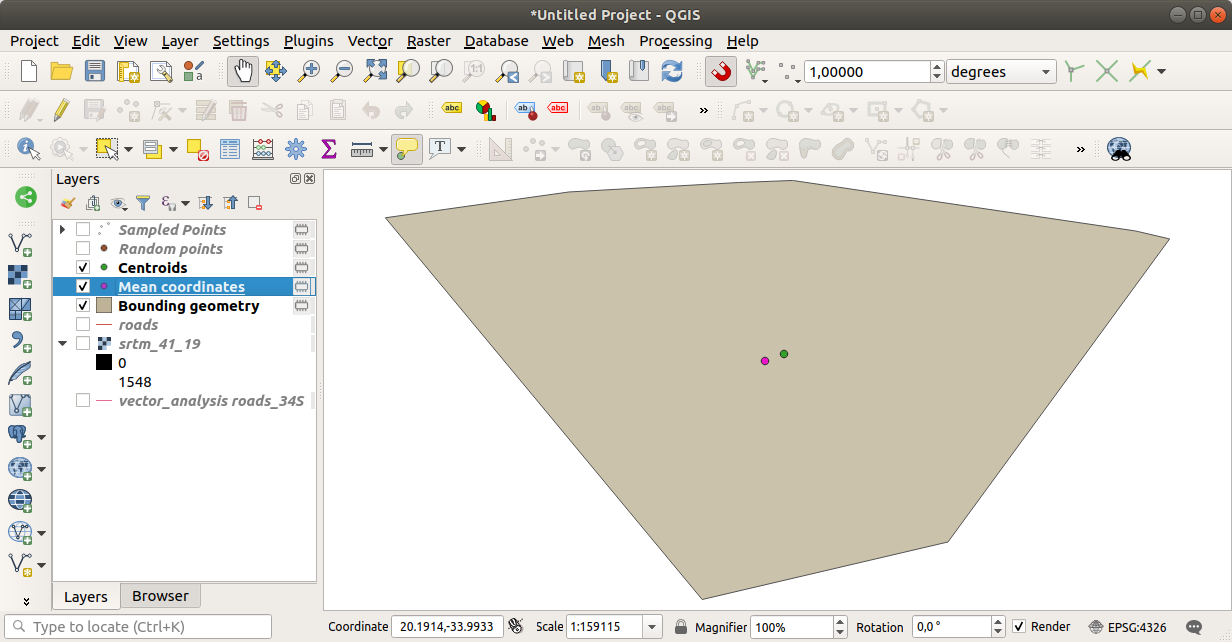
Как видите, средние координаты (розовая точка) и центр исследуемой местности (зеленый) не обязательно совпадают.
Центроид - это барицентр слоя (барицентр квадрата - это центр квадрата), а средние координаты представляют собой среднее значение всех координат узлов.
6.4.6. Идем дальше: Гистограммы изображений
Гистограмма набора данных показывает распределение его значений. Самый простой способ показать это в QGIS – через использование гистограммы изображения, которая имеется в диалоговом окне Layer Properties любого слоя изображения (набор растровых данных).
В вашей панели Layers кликните правой кнопкой мыши на слой
srtm_41_19.Выберите .
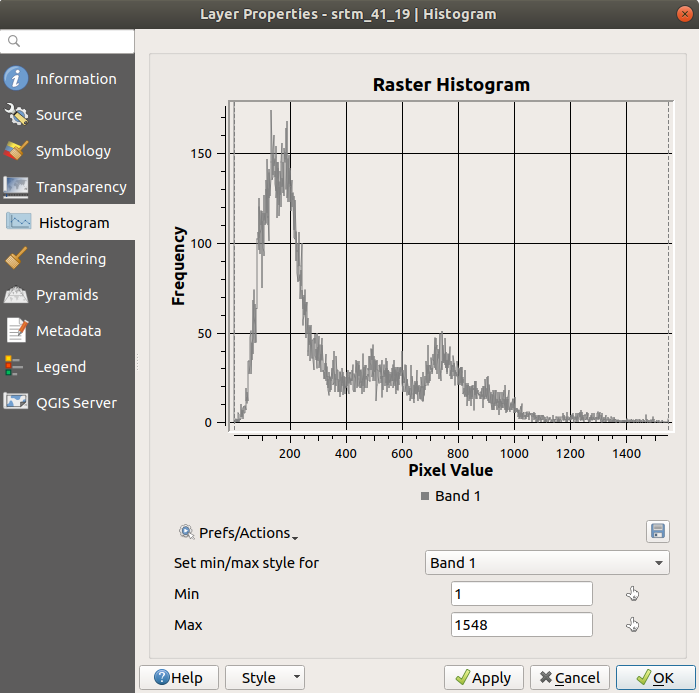
Выберите Histogram. Вам надо кликнуть на кнопку Compute Histogram для того, чтобы создать график. Вы увидите график, показывающий частотное распределение значений растра.

График можно экспортировать как изображение с помощью кнопки с
 Save plot.
Save plot.Более подробную информацию можно получить о слое нажав на вкладку Information (среднее и максимальное значения являются расчетными и могут быть неточными).
Среднее значение 332.8 (расчетная 324,3), а максимальное значение равно 1699 (расчетная 1548)! Вы можете увеличить гистограмму. Поскольку там много пикселей со значением 0, гистограмма выглядит сжатой по вертикали. Увеличьте масштаб чтобы охватить все, кроме пика на 0, и вы увидите более подробную информацию:
Примечание
Если средние и максимальные значения не такие, как выше, это может быть из-за вычисления минимального/максимального значения. Откройте вкладку Symbology и расширьте меню Min / Max Value Settings. Выберите  Min / max и кликните на кнопку Apply.
Min / max и кликните на кнопку Apply.
Помните, что гистограмма показывает вам распределение значений и не все значения обязательно должны отображаться на графике.
6.4.7. Идем дальше: Пространственная интерполяция
Предположим, что у вас набор точек выборки, на базе которого вы хотите экстраполировать данные. Например, у вас может быть доступ к набору данных Sampled points, который мы создали ранее, и вы хотели бы иметь некоторое представление о том, как выглядит местность.
Для начала вам надо запустить инструмент , который находится в Processing Toolbox.
В качестве Point layer выберите
Sampled points.Установите Weighting power на
5.0.Внутри Advanced parameters, установите Z value from field на
rvalue_1.И наконец, кликните на кнопку Run и подождите до окончания обработки.
Закройте диалоговое окно.
Вы сможете сравнить исходный набор данных (слева) с тем, который был построен на базе наших точек выборки (справа). Ваш набор данных может выглядеть иначе из-за случайного расположения точек.
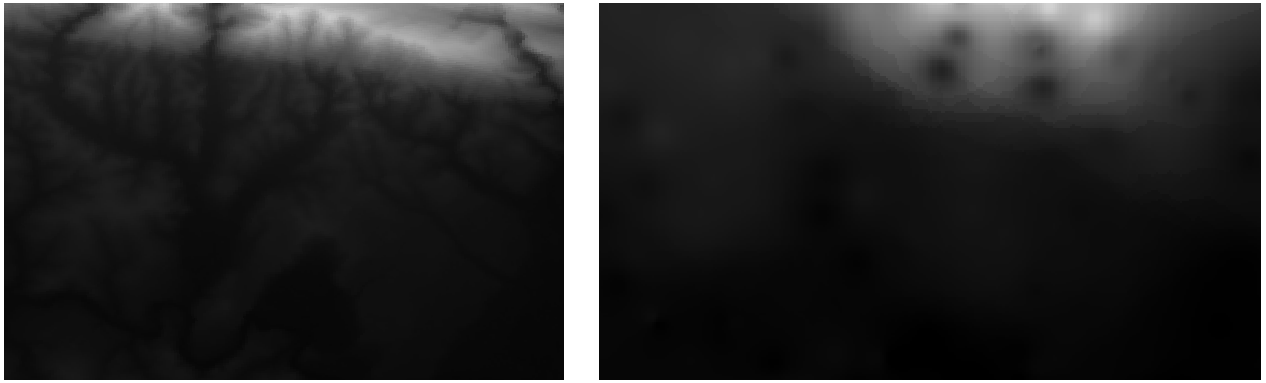
Как вы можете видеть, 100 выборочных точек недостаточно, чтобы получить подробное представление о местности. Вы получите только очень общее представление, но оно может вводить в заблуждение.
6.4.8.  Попробуйте сами: Различные методы интерполяции
Попробуйте сами: Различные методы интерполяции
Следуйте описанному выше процессу для того, чтобы создать набор из 10 000 случайных точек.
Примечание
Если точек действительно много, обработка может занять много времени.
Используйте эти точки для того сделать выборку исходной DEM / Цифровой модели рельефа.
Используйте инструмент Grid (IDW with nearest neighbor searching) в этом наборе данных.
Установите Power и Smoothing на
5.0и2.0, соответственно.
Результаты (в зависимости от расположения ваших случайных точек) будут примерно такими:

Это более улучшенное представление ландшафта, так как плотность выборочных точек выше. Помните, что чем больше выборка, тем лучше результат.
6.4.9. В заключении
У QGIS есть ряд инструментов для анализа пространственных статистических свойств набора данных.
6.4.10. Что дальше?
Теперь, после того как мы рассмотрели векторный анализ, почему бы не посмотреть, что можно сделать с растрами? Этим мы и займемся в следующем модуле!