17.22. Interpolation
Bemerkung
In diesem Kapitel lernen wir, wie man Punktdaten interpoliert. Wir werden auch ein weiteres reales Beispiel zur räumlichen Analyse kennenlernen
In dieser Lektion werden wir Punktdaten interpolieren, um einen Rasterlayer zu erhalten. Bevor wir beginnen, müssen wir die Daten vorbereiten. Nach dem Interpolation werden wir den resultierenden Layer noch weiter verarbeiten, so dass sich eine vollständige Analyseroutine ergeben wird.
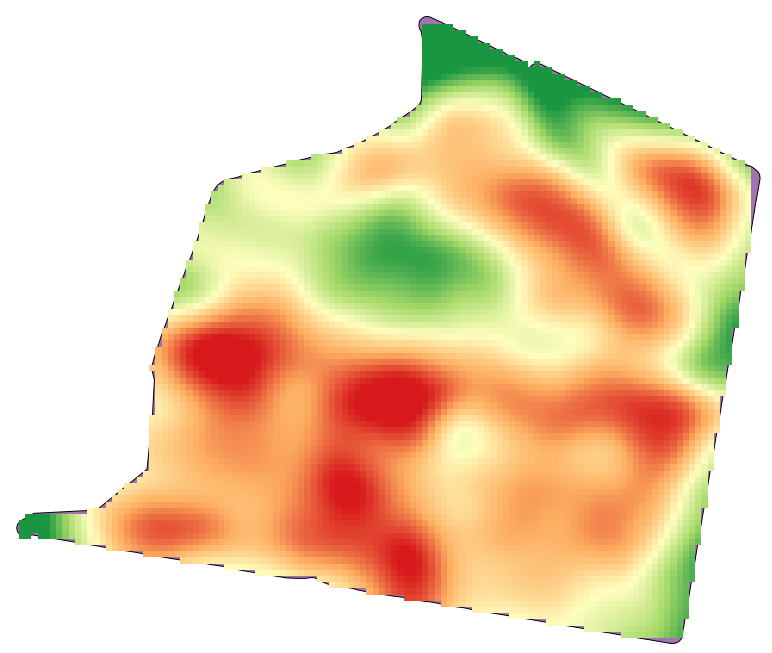
Öffnen Sie die Beispieldaten für diese Lektion, die wie folgt aussehen sollten.

Der Datensatz enthält Daten zum Ernteertrag, so wie er von modernen Erntemaschinen erstellt wird. Wir werden aus diesen Daten einen Rasterlayer des Ernteertrages erstellen. Wir wollen keine weiteren Analysen mit diesem Layer ausführen. Er soll als Hintergrundlayer dienen, der die produktivsten Bereiche und die weniger produktiven Bereiche einfach kennzeichnet.
Als erstes müssen wir den Layer bereinigen, da er redundante Punkte enthält. Sie entstehen durch die Bewegung der Erntemaschine, wenn sie z.B. wendet oder aus bestimmten Gründen ihre Geschwindigkeit verändert. Wir können dafür den Algorithmus Points filter benutzen. Wir verwenden ihn zweimal, um Ausreißer sowohl nach oben als auch nach unten zu entfernen.
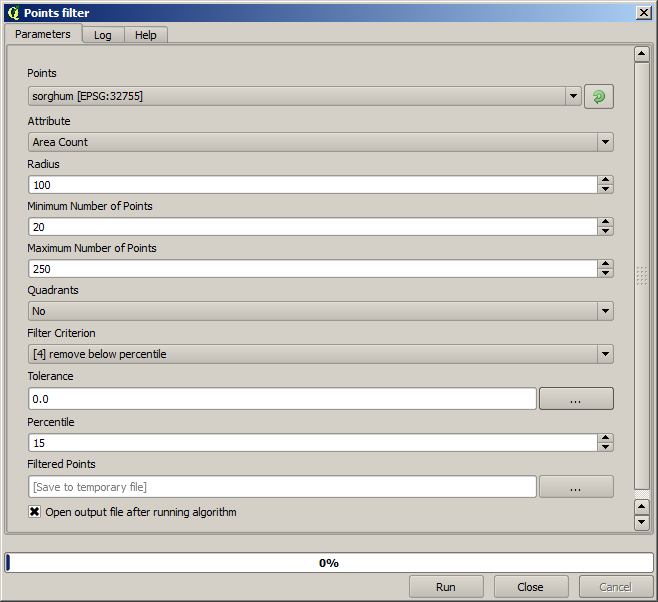
Verwenden Sie bei der ersten Ausführung die folgenden Parameter.
Übernehmen Sie bei der zweiten Ausführung die unten dargestellen Einstellungen.
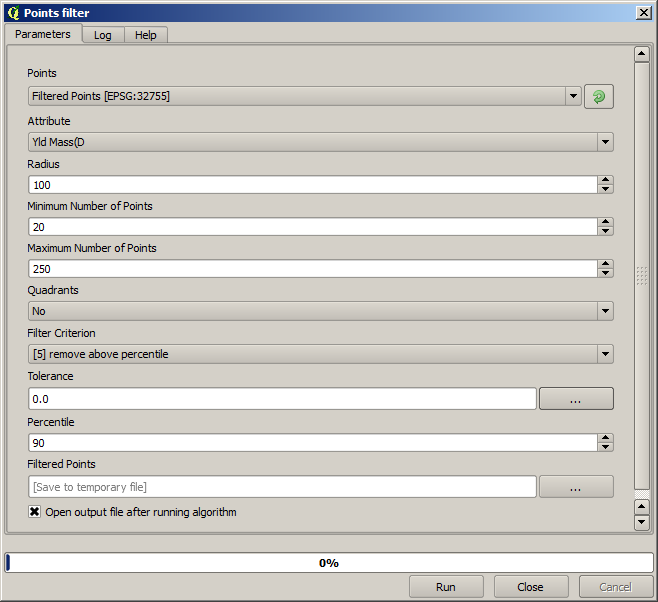
Beachten Sie, dass wir als Eingabe nicht den Ausgangslayer sondern die Ausgabe des ersten Durchlaufes verwenden.
Der Ergebnislayer sollte dem Ausgangslayer ähneln. Er enthält nur weniger Punkte. Wir können das anhand der Attributtabellen überprüfen.
Wir werden den Layer jetzt mit Hilfe des Algorithmus Rasterize rastern.
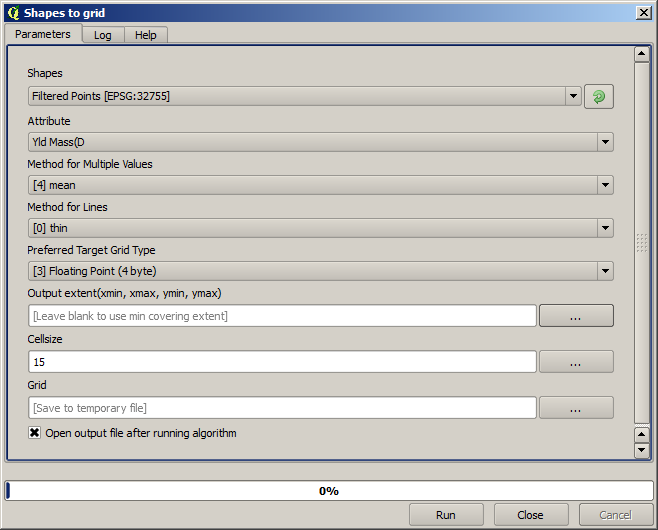
Der Layer Filtered points bezieht sich auf das Ergebnis des zweiten Filters. Er hat denselben Namen wie das Ergebnis des ersten Filters, da der Name vom Algorithmus vergeben wird. Sie sollten das erste Ergebnis nicht verwenden. Da wir den Layer nicht mehr benötigen, können wir das Ergebnis des ersten Filters aus dem Projekt löschen und nur das Ergebnis des zweiten Filters behalten. Wir vermeiden damit weitere Verwechselungen.
Der sich ergebene Rasterlayer sieht wie folgt aus.

Es handelt sich schon um einen Rasterlayer. Allerdings fehlen die Daten in einigen Zellen. Er enthält nur in den Zellen gültige Werte, in denen ein Punkt aus dem Vektorlayer liegt. Die anderen Zellen enthalten einen Leerwert. Um die fehlenden Werte zu füllen, können wir den Algorithmus Close gaps verwenden.
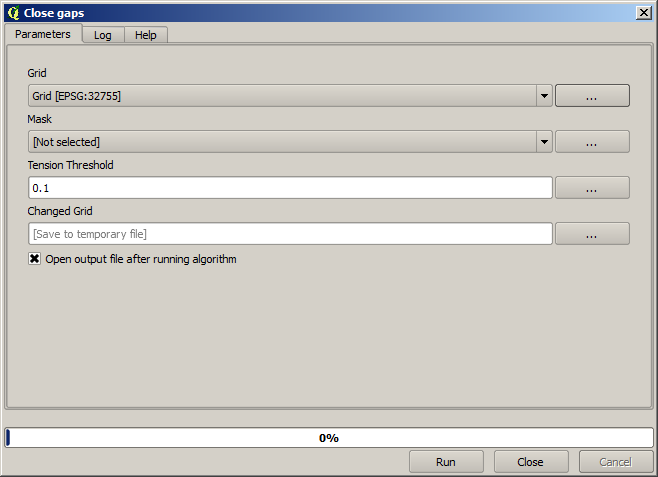
Der Layer ohne Leerwerte sieht wie folgt aus.

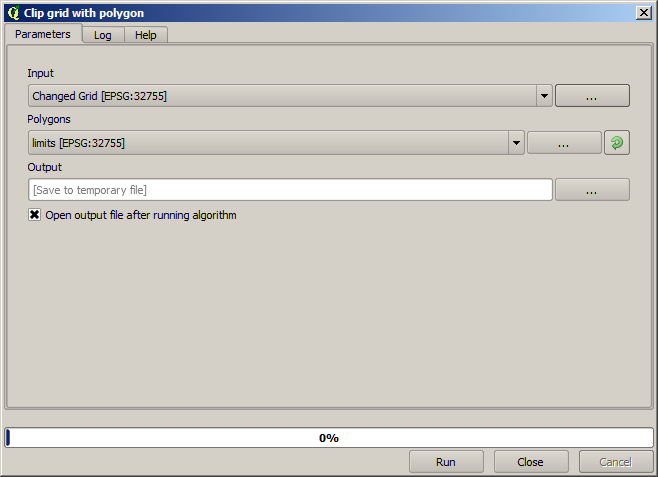
Um die Fläche des Layers genau auf die Region der Messung der Erntemenge zu beschränken, können wir den Layer mit Hilfe des Layer limits zuschneiden.
Um eine geglättetes Ergebnis (weniger akkurat aber besser für die Darstellung als Hintergundlayer geeignet) zu erhalten, können wir den Gaussian filter auf den Layer anwenden.
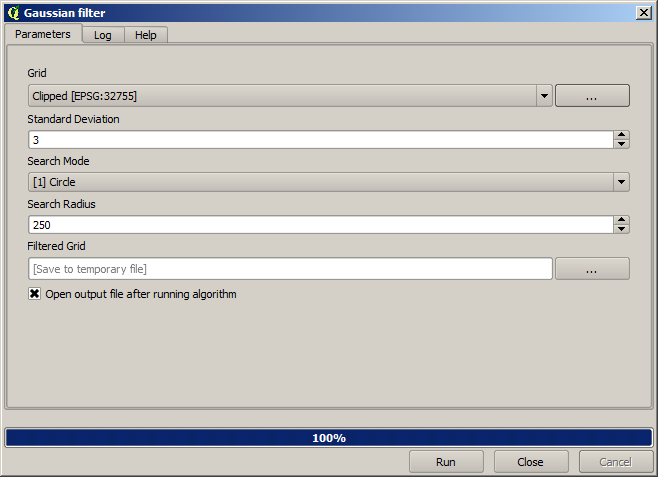
Bei Verwendung der oben aufgeführten Parameter erhalten wir das folgende Ergebnis