24.4.3. 하천망 분석
24.4.3.1. 하류 연결하기
이 알고리즘은 입력 래스터의 (예: 그리드로 변환된 HUC의) 각 구역마다 가장 큰 AreaD8을 가진 포인트를 식별합니다. 식별된 포인트를 배수구(outlet)로 간주하고, OGR 파일을 생성합니다. 유수 방향을 사용해서 각 배수구를 사용자가 제어할 수 있는 (기본값은 1) 그리드 셀 개수만큼 하류 방향으로 이동시킵니다. 해당 포인트가 이동해 간 위치의 ID를 iddown으로 간주합니다. 초기 포인트를 가진 파일과 이동한 포인트를 가진 파일, 2개의 OGR 파일을 생성합니다. 두 파일 모두 ID, iddown 및 AreaD8을 담고 있습니다.
파라미터
라벨 |
명칭 |
유형 |
설명 |
D8 flow directions |
[raster] |
모든 셀에서의 유수가 전부 가장 심한 내리막 경사 방향에 있는 단일 이웃 셀로 흐르는 D8 방법을 사용해서 인코딩된 유수 방향 그리드입니다. |
|
D8 contribution area |
[raster] |
D8 알고리즘을 사용해서 해당 셀 고유의 기여와 해당 셀로 흘러드는 모든 오르막 이웃에서 나오는 기여를 더한 값을 각 셀 별 그리드 셀 개수(또는 가중치의 총체)라는 측면에서 계산한 기여 영역 값을 제공하는 그리드입니다. 일반적으로 이 그리드는 “D8 기여 영역” 알고리즘의 산출물입니다. |
|
Watershed |
[raster] |
GageWatershed 함수 또는 StreamReachWatershed 함수로 그린 집수구역 그리드입니다. 다른 (예: HUC) 집수구역 래스터도 집수구역 그리드로 사용할 수 있습니다. |
|
Grid cells move to downstream |
[number] |
유수 방향을 기반으로 하류 방향으로 이동한 그리드 셀의 개수 |
산출물
라벨 |
명칭 |
유형 |
설명 |
Outlets |
[vector: point] |
각 포인트가 각 구역마다 가장 큰 기여 영역을 가진 집수구역 그리드에서 생성된 포인트 OGR 파일 |
|
Moved Outlets |
[vector: point] |
이동한 관심 배수구를 정의하는 포인트 OGR 파일. 각 배수구는 유수 방향을 사용해서 지정한 그리드 셀 개수만큼 하류 방향으로 이동합니다. |
파이썬 코드
알고리즘 ID: taudem:connectdown
import processing
processing.run("algorithm_id", {parameter_dictionary})
공간 처리 툴박스에 있는 알고리즘 위에 마우스를 가져가면 알고리즘 ID 를 표시합니다. 파라미터 목록(dictionary) 은 파라미터 명칭 및 값을 제공합니다. 파이썬 콘솔에서 공간 처리 알고리즘을 어떻게 실행하는지 자세히 알고 싶다면 콘솔에서 공간 처리 알고리즘 사용 을 참조하세요.
24.4.3.2. D8 오르막 극값
입력 그리드에서 D8 유수 모델을 바탕으로 오르막 극값(최대 또는 최소 가운데 하나)을 판정합니다. 이 알고리즘은 원래 (낙차 분석에 따른) 최적의 하천망을 산출하는 경사와 면적의 곱의 한계값을 식별하기 위한 하천 래스터를 생성하기 위해 개발됐습니다.
부가적인 배출 포인트 shapefile을 사용하는 경우, 배출 셀과 해당 셀의 (D8 유수 모델에 따른) 오르막 셀들이 있는 영역만 평가합니다.
기본적으로, 이 도구는 경계 오염을 확인합니다. 경계 오염이란 영역 바깥에 있는 그리드 셀을 계산에 넣지 않기 때문에 결과가 저평가될 수도 있다는 가능성으로 정의됩니다. 경계 오염은 배수가 경계로부터 안 쪽으로 흐르거나 또는 표고값이 NODATA인 영역에서 발생합니다. 이 알고리즘은 이를 인식하고 이 그리드 셀들의 결과에 대해 NODATA를 보고합니다. 경계선에서 영역으로 들어오는 유수 경로를 따라 NODATA 값들이 쭉 나열되는 것을 흔히 볼 수 있습니다. 이는 기대대로의 효과로서, 해당 그리드 셀들의 결과가 사용할 수 있는 데이터 영역 외부에 있는 지형에 의존하기 때문에 그 기여 영역을 알 수 없다는 사실을 나타냅니다. 사용자가 경계 오염이 문제가 되지 않는다는 사실을 알고 있거나 또는 이런 문제를 무시하고자 하는 경우, 예를 들면 유역 외곽선을 따라 DEM을 잘라낸 경우라면 경계 오염 확인 옵션을 끌 수도 있습니다.
파라미터
라벨 |
명칭 |
유형 |
설명 |
D8 Flow Directions Grid |
[raster] |
각 셀 별로 그 인접 또는 대각선 방향의 이웃 8개 셀 가운데 가장 심한 내리막 경사를 가지고 있는 셀의 방향으로 정의한 D8 유수 방향 그리드입니다. 이 그리드는 “D8 유수 방향” 알고리즘의 산출물로 얻을 수 있습니다. |
|
Upslope Values Grid |
[raster] |
오르막 최대값 또는 최소값을 선택한 값의 그리드입니다. 가장 흔히 쓰이는 값은 낙차 분석에 따라 하천 래스터를 생성하는 경우 필요한 경사와 면적의 곱입니다. |
|
Outlets Shapefile 부가적 |
[vector: point] |
관심 배출 포인트를 정의하는 포인트 shapefile입니다. 이 파일을 입력하는 경우, 알고리즘이 해당 배출 셀의 주변 오르막 영역만 평가할 것입니다. |
|
Check for edge contamination |
[boolean] 기본값: True |
알고리즘이 경계 오염을 확인할지 여부를 나타내는 옵션입니다. |
|
Use max upslope value |
[boolean] 기본값: True |
오르막 경사의 최대값 또는 최소값 가운데 어느 쪽을 계산할지 나타내는 옵션입니다. |
산출물
라벨 |
명칭 |
유형 |
설명 |
Extreme Upslope Values Grid |
[raster] |
오르막 경사의 최대값/최소값 그리드입니다. |
파이썬 코드
알고리즘 ID: taudem:d8flowpathextremeup
import processing
processing.run("algorithm_id", {parameter_dictionary})
공간 처리 툴박스에 있는 알고리즘 위에 마우스를 가져가면 알고리즘 ID 를 표시합니다. 파라미터 목록(dictionary) 은 파라미터 명칭 및 값을 제공합니다. 파이썬 콘솔에서 공간 처리 알고리즘을 어떻게 실행하는지 자세히 알고 싶다면 콘솔에서 공간 처리 알고리즘 사용 을 참조하세요.
24.4.3.3. 측정기 유역
측정기 유역(Gage Watershed) 그리드를 계산합니다. 각 그리드 셀에 해당 셀이 다른 어떤 측정기도 통과하지 않고 직접 흘러드는 측정기의 (id 열에서 나온) 식별자 라벨을 부여합니다.
파라미터
라벨 |
명칭 |
유형 |
설명 |
D-infinity flow directions |
|
[raster] |
D-infinity 유수법을 기반으로 한 유수 방향 그리드 |
D8 Flow Directions Grid |
[raster] |
각 셀 별로 그 인접 또는 대각선 방향의 이웃 8개 셀 가운데 가장 심한 내리막 경사를 가지고 있는 셀의 방향으로 정의한 D8 유수 방향 그리드입니다. 이 그리드는 “D8 유수 방향” 알고리즘의 산출물로 얻을 수 있습니다. |
|
Gages Shapefile |
[vector: point] |
유역을 묘사할 측정기들을 정의하는 포인트 shapefile입니다. 이 shapefile은 |
산출물
라벨 |
명칭 |
유형 |
설명 |
Gage Watershed Grid |
[raster] |
각 측정기 유역을 식별하는 그리드입니다. 각 그리드 셀에 해당 셀이 다른 어떤 측정기도 통과하지 않고 직접 흘러드는 측정기의 ( |
|
Downstream Identifiers File |
[file] |
유역의 내리막 연결성을 지정하는 텍스트 파일입니다. |
파이썬 코드
알고리즘 ID: taudem:gagewatershed
import processing
processing.run("algorithm_id", {parameter_dictionary})
공간 처리 툴박스에 있는 알고리즘 위에 마우스를 가져가면 알고리즘 ID 를 표시합니다. 파라미터 목록(dictionary) 은 파라미터 명칭 및 값을 제공합니다. 파이썬 콘솔에서 공간 처리 알고리즘을 어떻게 실행하는지 자세히 알고 싶다면 콘솔에서 공간 처리 알고리즘 사용 을 참조하세요.
24.4.3.4. 길이 면적 하천원
오르막 경로 길이, D8 기여 영역 그리드 입력, 그리고 파라미터 M 과 y 를 바탕으로 A >= (M)(Ly) 를 평가하는 지표(indicator) 그리드 (1, 0)을 생성합니다. 이 그리드는 하천원(stream source)일 가능성이 높은 그리드 셀들을 표시합니다. 이 알고리즘은 실험적인 메소드로, 하천 L ~ A 0.6 에 대해 앞의 내용을 서술하고 있는 핵의 법칙 을 그 이론적 기반으로 삼고 있습니다. 하지만 산사면(hillslope)의 경우 평행 유수 L ~ A 를 대상으로 합니다. 따라서 산사면에서 하천으로의 전이를 L ~ A 0.8 로 표현할 수도 있는데, 그렇다면 그리드 셀이 A > M (L (1/0.8)) 인 경우 하천 셀이라고 식별할 수 있을 것입니다.
파라미터
라벨 |
명칭 |
유형 |
설명 |
Length Grid |
[raster] |
각 셀 별 최장 오르막 길이를 담고 있는 그리드입니다. 최장 오르막 길이는 각 셀로 흘러드는 셀 가운데 가장 멀리 있는 셀에서 시작되는 유수 경로의 길이로 계산합니다. 이 길이는 셀 크기 및 방향의 인접/대각선 여부를 고려해서 셀 중심점 간의 거리로 측정합니다. 어떤 셀을 하천 셀로 간주할 것인지 결정하기 위한 |
|
Contributing Area Grid |
[raster] |
D8 알고리즘을 사용해서 계산한 각 셀 별 기여 영역 값 그리드입니다. 어느 셀의 기여 영역 값은 해당 셀 고유의 기여와 해당 셀로 흘러드는 모든 오르막 이웃에서 나오는 기여를 더한 값으로, 셀 개수로 측정됩니다. 일반적으로 이 그리드는 “D8 기여 영역” 알고리즘의 산출물입니다. 길이 면적 하천원 알고리즘에서 하천으로의 전이 여부를 결정하는 |
|
Threshold |
[number] 기본값: 0.03 |
하천의 시작을 식별하는 공식 |
|
Exponent |
[number] 기본값: 1.3 |
하천의 시작을 식별하는 공식 |
산출물
라벨 |
명칭 |
유형 |
설명 |
Stream Source Grid |
[raster] |
최장 오르막 경로 길이, D8 기여 영역 그리드 입력, 그리고 파라미터 |
파이썬 코드
알고리즘 ID: taudem:lengtharea
import processing
processing.run("algorithm_id", {parameter_dictionary})
공간 처리 툴박스에 있는 알고리즘 위에 마우스를 가져가면 알고리즘 ID 를 표시합니다. 파라미터 목록(dictionary) 은 파라미터 명칭 및 값을 제공합니다. 파이썬 콘솔에서 공간 처리 알고리즘을 어떻게 실행하는지 자세히 알고 싶다면 콘솔에서 공간 처리 알고리즘 사용 을 참조하세요.
24.4.3.5. 배출 포인트를 하천으로 이동
하천 래스터 그리드에서 하천 셀과 정렬되지 않은 배출 포인트를 내리막 D8 유수 방향을 따라 하천 래스터 셀과 만날 때까지, 또는 그리드 셀들의 max_dist 개수가 판정될 때까지, 또는 유수 경로가 영역을 벗어날 때까지 (예를 들어 D8 유수 방향의 NODATA 값이 나올 때까지) 이동시킵니다. 이 알고리즘의 산출 파일은 새로운 배출 shapefile로, 가능한 경우 각 배출 포인트를 하천 래스터 그리드와 일치하도록 이동시킨 shapefile입니다. 이 새로운 shapefile에는 각 배출 포인트가 변경된 내용을 나타내는 dist_moved 필드가 추가돼 있습니다. 이미 하천 셀 위에 있는 포인트들은 이동되지 않으며, 해당 포인트의 dist_moved 필드엔 0 값이 할당됩니다. 초기에 하천 셀 위에 없던 포인트들은 내리막 D8 유수 방향을 따라 다음 사항 가운데 하나가 일어날 때까지 이동됩니다: 1) 그리드 셀의 max_dist 개수를 넘기 전에 하천 그리드 셀과 만나는 경우, 포인트를 이동시키고 dist_moved 필드에 포인트가 몇 개의 그리드 셀들을 이동했는지 나타내는 값을 할당합니다. 2) 그리드 셀의 max_dist 개수를 넘거나, 또는 3) 영역 밖으로 나가는 경우 (예를 들어 D8 유수 방향의 NODATA 값을 만나는 경우) 배출 포인트를 이동시키지 않고 dist_moved 필드에 -1 값을 할당합니다.
파라미터
라벨 |
명칭 |
유형 |
설명 |
D8 Flow Direction Grid |
[raster] |
각 셀 별로 그 인접 또는 대각선 방향의 이웃 8개 셀 가운데 가장 심한 내리막 경사를 가지고 있는 셀의 방향으로 정의한 D8 유수 방향 그리드입니다. 이 그리드는 “D8 유수 방향” 알고리즘의 산출물로 얻을 수 있습니다. |
|
Stream Raster Grid |
[raster] |
이 입력물은 하천인 경우 그리드 셀 값을 1, 나머지 셀 값을 0으로 해서 하천의 위치를 나타내는 지표(indicator) 그리드 (1, 0)입니다. 그리드입니다. “하천망 분석” 도구 모음 가운데 하나로 이런 그리드를 생성할 수 있습니다. |
|
Outlets Shapefile |
[vector: point] |
관심 포인트 또는 배출 포인트를 정의하는 포인트 shapefile입니다. 이상적으로는 이런 포인트들이 하천 위에 위치해 있어야 하지만, shapefile 포인트 위치가 하천 래스터 그리드에 대해 정확히 등록돼 있지 않을 수도 있기 때문에 하천 위에 정확히 위치하지 않을 수도 있습니다. |
|
Maximum Number of Grid Cells to traverse |
[number] 기본값: 50 |
이 입력 파라미터는 입력 배출 shapefile 안에 있는 포인트들이 산출 배출 shapefile로 저장되기 전에 이동할 최대 그리드 셀 개수입니다. |
산출물
라벨 |
명칭 |
유형 |
설명 |
Output Outlet Shapefile |
[vector: point] |
관심 포인트 또는 배출 포인트를 정의하는 포인트 shapefile입니다. 이 파일이 보유한 포인트 개수는 입력 배출 shapefile 이 보유한 포인트 개수와 동일합니다. 입력 포인트가 하천 위에 존재하는 경우, 포인트는 이동하지 않습니다. 입력 포인트가 하천 위에 존재하지 않는 경우, 포인트를 내리막 D8 유수 방향을 따라 하천을 만날 때까지 또는 최장 거리까지 이동시킵니다. |
파이썬 코드
알고리즘 ID: taudem:moveoutletstostreams
import processing
processing.run("algorithm_id", {parameter_dictionary})
공간 처리 툴박스에 있는 알고리즘 위에 마우스를 가져가면 알고리즘 ID 를 표시합니다. 파라미터 목록(dictionary) 은 파라미터 명칭 및 값을 제공합니다. 파이썬 콘솔에서 공간 처리 알고리즘을 어떻게 실행하는지 자세히 알고 싶다면 콘솔에서 공간 처리 알고리즘 사용 을 참조하세요.
24.4.3.6. 더글러스-포이커
더글러스-포이커 알고리즘 이 생성한 오르막 만곡 그리드 셀들의 지표(indicator) 그리드 (1, 0)을 생성합니다.
이 알고리즘은 먼저 DEM을 중심, 테두리, 그리고 대각선 방향에 가중치를 부여하는 커널을 통해 평활화합니다. 그 다음 Peuker & Douglas (1975) 방법을 사용해서 오르막 만곡 그리드 셀을 식별합니다. (이 방법은 Band (1986)에서도 설명하고 있습니다.) 이 기술은 전체 그리드를 표시한 다음, 그리드 셀 4개로 이루어진 각 사분면을 한번에(single pass) 평가해서 가장 높은 셀의 표시를 지웁니다. 나머지 표시된 셀들을 “오르막 만곡”으로 간주하는데, 이를 살펴보면 수로망과 닮아 있습니다. 이 원시 수로망은 일반적으로 연결성이 부족해서 솎아내기(thinning)를 해야 합니다. Band (1986)에서 이런 문제들을 자세하게 논의하고 있습니다.
파라미터
라벨 |
명칭 |
유형 |
설명 |
Elevation Grid |
[raster] |
표고 값을 보유한 그리드를 지정합니다. 일반적으로 이 그리드는 함몰부 제거 도구의 산출물로, 구덩이를 제거한 표고입니다. |
|
Center Smoothing Weight |
[number] 기본값: 0.4 |
이 알고리즘이 오르막 만곡 그리드 셀을 식별하기 전에 커널이 DEM을 평활화하기 위해 사용하는 중심 가중치 파라미터입니다. |
|
Side Smoothing Weight |
[number] 기본값: 0.1 |
이 알고리즘이 오르막 만곡 그리드 셀을 식별하기 전에 커널이 DEM을 평활화하기 위해 사용하는 테두리 가중치 파라미터입니다. |
|
Diagonal Smoothing Weight |
[number] 기본값: 0.05 |
이 알고리즘이 오르막 만곡 그리드 셀을 식별하기 전에 커널이 DEM을 평활화하기 위해 사용하는 대각선 방향 가중치 파라미터입니다. |
산출물
라벨 |
명칭 |
유형 |
설명 |
Stream Source Grid |
[raster] |
더글러스-포이커 알고리즘이 생성한 오르막 만곡 그리드 셀들의 지표(indicator) 그리드 (1, 0)로, 이를 살펴보면 수로망과 닮아 있습니다. 이 원시 수로망은 일반적으로 연결성이 부족해서 솎아내기(thinning)를 해야 합니다. Band (1986)에서 이런 문제들을 자세하게 논의하고 있습니다. |
파이썬 코드
알고리즘 ID: taudem:peukerdouglas
import processing
processing.run("algorithm_id", {parameter_dictionary})
공간 처리 툴박스에 있는 알고리즘 위에 마우스를 가져가면 알고리즘 ID 를 표시합니다. 파라미터 목록(dictionary) 은 파라미터 명칭 및 값을 제공합니다. 파이썬 콘솔에서 공간 처리 알고리즘을 어떻게 실행하는지 자세히 알고 싶다면 콘솔에서 공간 처리 알고리즘 사용 을 참조하세요.
참고
Band, L. E., (1986), “Topographic partition of watersheds with digital elevation models”, Water Resources Research, 22(1): 15-24.
Peuker, T. K. and D. H. Douglas, (1975), “Detection of surface-specific points by local parallel processing of discrete terrain elevation data”, Comput. Graphics Image Process., 4: 375-387.
24.4.3.7. 포이커 더글러스 하천
DEM 곡률 기반 방법을 사용해서 하천의 위치를 식별하는 하천 지표 그리드 (1,0) 를 생성하기 위해 “더글러스-포이커(Douglas-Peuker)”, “D8 기여 영역(D8 Contributing Area)”, “하천 낙차 분석(Stream Drop Analysis)” 그리고 “한계값으로 하천 정의(Stream Definition by Threshold)” 도구의 기능을 결합합니다. 이 방법은 먼저 DEM을 중심, 테두리, 그리고 대각선 방향에 가중치를 부여하는 커널을 통해 평활화합니다. 그 다음 Peuker & Douglas (1975) 방법을 사용해서 오르막 만곡 그리드 셀을 식별합니다. (이 방법은 Band (1986)에서도 설명하고 있습니다.) 이 기술은 전체 그리드를 표시한 다음, 그리드 셀 4개로 이루어진 각 사분면을 한번에(single pass) 평가해서 가장 높은 셀의 표시를 지웁니다. 나머지 표시된 셀들을 ‘오르막 만곡’ 으로 간주하는데, 이를 살펴보면 수로망과 닮아 있습니다. 이 원시 수로망은 일반적으로 연결성이 부족해서 솎아내기(thinning)를 해야 합니다. Band (1986)에서 이런 문제들을 자세하게 논의하고 있습니다. 여기에서는 이런 오르막 만곡 셀들만을 이용, D8 기여 영역을 계산해서 이 그리드 셀들을 솎아내고 연결합니다. 그 다음 이 셀들의 개수에 대한 누적 한계값을 사용해서 이 한계값을 사용자가 선택적으로 설정하거나, 낙차 분석(drop analysis)을 통해 결정하는 하천망을 매핑합니다.
낙차 분석을 이용하는 경우, 누적 한계값을 위한 값을 지정하는 대신 “Number” 파라미터의 단계 개수를 사용해서 강하 분석 파라미터 “Lowest” 와 “Highest” 사이의 범위를 검색, 누적 한계값을 결정합니다. 낙차 분석의 과학적인 방법론을 알고 싶다면 Tarboton, et al. (1991, 1992) 그리고 Tarboton and Ames (2001) 를 참조하십시오. 선택된 누적 한계값의 값은 t-통계량의 절대값이 2 미만일 때 가장 작은 값입니다. 이 값은 낙차 분석 테이블 텍스트 파일에 작성됩니다. 배출구가 지정된 경우에만 낙차 분석을 할 수 있습니다. 전체 그리드 영역을 분석할 경우, 한계값이 변하면서 경계로 배수되는 더 짧은 하천이 한계값 기준을 충족시키지 못 해 분석에서 제외될 수도 있기 때문입니다. 이렇게 되면 배수 밀도를 정의하는 데 문제가 생겨, 서로 상이한 영역들에서 평가된 통계를 비교하는 데 일관성이 떨어지게 됩니다.
파라미터
산출물
라벨 |
명칭 |
유형 |
설명 |
Stream source |
[raster] |
더글러스-포이커 알고리즘이 생성한 오르막 만곡 그리드 셀들의 지표(indicator) 그리드 (1, 0)로, 이를 살펴보면 수로망과 닮아 있습니다. 이 원시 수로망은 일반적으로 연결성이 부족해서 솎아내기(thinning)를 해야 합니다. Band (1986)에서 이런 문제들을 자세하게 논의하고 있습니다. |
파이썬 코드
알고리즘 ID: taudem:peukerdouglasstreamdef
import processing
processing.run("algorithm_id", {parameter_dictionary})
공간 처리 툴박스에 있는 알고리즘 위에 마우스를 가져가면 알고리즘 ID 를 표시합니다. 파라미터 목록(dictionary) 은 파라미터 명칭 및 값을 제공합니다. 파이썬 콘솔에서 공간 처리 알고리즘을 어떻게 실행하는지 자세히 알고 싶다면 콘솔에서 공간 처리 알고리즘 사용 을 참조하세요.
24.4.3.8. 경사-면적 조합
경사, 특정 집수 영역 그리드 입력물, 그리고 m 과 n 파라미터를 바탕으로 하는 경사-면적 값 (Sm) (An) 을 담고 있는 그리드를 생성합니다. 이 알고리즘은 경사-면적 하천 래스터 묘사 방법의 일부로 사용하기 위해 개발됐습니다.
파라미터
라벨 |
명칭 |
유형 |
설명 |
Slope Grid |
[raster] |
경사 값을 가진 입력 그리드입니다. 이 그리드는 고저차를 거리로 나눈 값으로 경사를 측정하며, “D-Infinity 유수 방향” 알고리즘의 산출물입니다. |
|
Contributing Area Grid |
[raster] |
각 셀의 고유 기여에 해당 셀로 흘러드는 오르막 이웃들의 기여를 더한 각 셀 별 집수 영역 값을 제공하는 그리드입니다. 이 그리드는 “D-Infinity 기여 영역” 알고리즘을 사용해서 얻을 수 있습니다. |
|
Slope Exponent |
[number] 기본값: 2 |
경사-면적 그리드를 생성하는 |
|
Area Exponent |
[number] 기본값: 1 |
경사-면적 그리드를 생성하는 |
산출물
라벨 |
명칭 |
유형 |
설명 |
Slope Area Grid |
[raster] |
경사 그리드, 특정 집수 영역 그리드, 경사 지수 파라미터 |
파이썬 코드
알고리즘 ID: taudem:slopearea
import processing
processing.run("algorithm_id", {parameter_dictionary})
공간 처리 툴박스에 있는 알고리즘 위에 마우스를 가져가면 알고리즘 ID 를 표시합니다. 파라미터 목록(dictionary) 은 파라미터 명칭 및 값을 제공합니다. 파이썬 콘솔에서 공간 처리 알고리즘을 어떻게 실행하는지 자세히 알고 싶다면 콘솔에서 공간 처리 알고리즘 사용 을 참조하세요.
24.4.3.9. 경사 면적 하천 정의
경사, 특정 집수 영역 그리드 입력물, 그리고 m 과 n 파라미터를 바탕으로 하는 경사-면적 값 (Sm) (An) 을 담고 있는 그리드를 생성합니다. 이 알고리즘은 경사-면적 하천 래스터 묘사 방법의 일부로 사용하기 위해 개발됐습니다.
파라미터
라벨 |
명칭 |
유형 |
설명 |
D8 flow directions |
[raster] |
||
D-infinity Contributing Area |
[raster] |
각 셀의 고유 기여에 해당 셀로 흘러드는 오르막 이웃들의 기여를 더한 각 셀 별 집수 영역 값을 제공하는 그리드입니다. 이 그리드는 “D-Infinity 기여 영역” 알고리즘을 사용해서 얻을 수 있습니다. |
|
Slope |
[raster] |
경사 값을 가진 입력 그리드입니다. 이 그리드는 고저차를 거리로 나눈 값으로 경사를 측정하며, “D-Infinity 유수 방향” 알고리즘의 산출물입니다. |
|
Mask grid |
[raster] |
||
Outlets |
[vector: point] |
||
Pit-filled grid for drop analysis |
[raster] |
||
D8 contributing area for drop analysis |
[raster] |
||
Slope Exponent |
[number] 기본값: 2 |
경사-면적 그리드를 생성하는 |
|
Area Exponent |
[number] 기본값: 1 |
경사-면적 그리드를 생성하는 |
|
Accumulation threshold |
[number] |
||
Minimum threshold |
[number] |
||
Maximum threshold |
[number] |
||
Number of drop thresholds |
[number] |
||
Type of threshold step |
[enumeration] 기본값: 0 |
옵션:
|
|
Check for edge contamination |
[boolean] |
||
Select threshold by drop analysis |
[boolean] |
산출물
라벨 |
명칭 |
유형 |
설명 |
Stream raster |
[raster] |
||
Slope area |
[raster] |
경사 그리드, 특정 집수 영역 그리드, 경사 지수 파라미터 |
|
Maximum upslope |
[raster] |
||
Drop analysis |
[file] |
파이썬 코드
알고리즘 ID: taudem:slopeareastreamdef
import processing
processing.run("algorithm_id", {parameter_dictionary})
공간 처리 툴박스에 있는 알고리즘 위에 마우스를 가져가면 알고리즘 ID 를 표시합니다. 파라미터 목록(dictionary) 은 파라미터 명칭 및 값을 제공합니다. 파이썬 콘솔에서 공간 처리 알고리즘을 어떻게 실행하는지 자세히 알고 싶다면 콘솔에서 공간 처리 알고리즘 사용 을 참조하세요.
24.4.3.10. 한계값으로 하천 정의
어떤 그리드를 입력받아 입력값이 한계값 이상인 셀들을 식별하는 지표(indicator) 그리드 (1, 0)을 산출합니다. 일반적으로 집적원(accumulated source) 영역 그리드를 입력받아 하천 래스터 그리드를 생성합니다. 부가적인 입력 마스크 그리드를 사용하는 경우, 마스크 값이 0 이상인 셀 영역만 평가하도록 제한합니다. D-infinity 기여 영역 그리드(*.sca)를 마스크 그리드로 사용하는 경우, 경계 오염 마스크로 기능합니다. 한계값 논리는 다음과 같습니다:
src = ((ssa >= thresh) & (mask >= s0)) ? 1:0
파라미터
라벨 |
명칭 |
유형 |
설명 |
Accumulated Stream Source Grid |
[raster] |
이 그리드는 일반적으로 유역(watershed)의 일부 특성 또는 특성들의 조합을 집적합니다. 정확한 특성(들)은 사용되는 하천망 래스터 알고리즘에 따라 달라집니다. 이 그리드는 산출되는 하천망이 연속하도록 그리드 셀 값이 내리막 D8 유수 방향을 따라 점증하는 속성을 보유해야 합니다. 집적 알고리즘이 이 그리드를 주로 산출하긴 해도, 최장 오르막 함수 같은 다른 알고리즘도 이런 그리드를 생성할 수 있습니다. |
|
Threshold |
[number] 기본값: 100 |
어느 셀을 하천 셀로 간주해야 하는지 여부를 결정하기 위해 이 파라미터와 집적 하천원(Accumulated Stream Source) 그리드( |
|
Mask Grid 부가적 |
[raster] |
이 부가적인 입력물은 관심 영역을 마스크하기 위한 그리드로, 산출물은 이 그리드에서 0 이상의 값을 가진 영역만 커버합니다. 일반적으로 D-Infinity 기여 영역 그리드를 마스크로 사용해서 하천망을 D-Infinity 기여 영역 안으로 제한해서 묘사합니다. 이는 경계 오염 마스크의 기능과 동일합니다. |
산출물
라벨 |
명칭 |
유형 |
설명 |
Stream Raster Grid |
[raster] |
이 입력물은 하천인 경우 그리드 셀 값을 1, 나머지 셀 값을 0으로 해서 하천의 위치를 나타내는 지표(indicator) 그리드 (1, 0)입니다. |
파이썬 코드
알고리즘 ID: taudem:threshold
import processing
processing.run("algorithm_id", {parameter_dictionary})
공간 처리 툴박스에 있는 알고리즘 위에 마우스를 가져가면 알고리즘 ID 를 표시합니다. 파라미터 목록(dictionary) 은 파라미터 명칭 및 값을 제공합니다. 파이썬 콘솔에서 공간 처리 알고리즘을 어떻게 실행하는지 자세히 알고 싶다면 콘솔에서 공간 처리 알고리즘 사용 을 참조하세요.
24.4.3.11. 낙차 분석으로 하천 정의
“하천 낙차 분석(Stream Drop Analysis)” 그리고 “한계값으로 하천 정의(Stream Definition by Threshold)” 도구의 기능을 결합합니다. 이 방법은 (입력 파라미터로 결정된) 일련의 한계값을 입력 누적 하천 소스 그리드(ssa)에 적용해서 하천 낙차 통계 테이블(drp.txt)을 산출합니다. 그 다음 하천 셀들의 지표 (1,0) 그리드인 하천 래스터 그리드를 산출합니다. 누적 하천 소스 값이 하천 낙차 통계로 결정된 최적 한계값 이상인 셀을 하천 셀로 정의합니다. *sca 파일을 경계 오염 마스크로 이용하는 기능을 복제하기 위해 마스크 입력물을 포함하는 옵션이 있습니다. 한계값 논리는 다음과 같아야 합니다: src = ((ssa >= thresh) & (mask >=0)) ? 1:0
파라미터
산출물
파이썬 코드
알고리즘 ID: taudem:streamdefdropanalysis
import processing
processing.run("algorithm_id", {parameter_dictionary})
공간 처리 툴박스에 있는 알고리즘 위에 마우스를 가져가면 알고리즘 ID 를 표시합니다. 파라미터 목록(dictionary) 은 파라미터 명칭 및 값을 제공합니다. 파이썬 콘솔에서 공간 처리 알고리즘을 어떻게 실행하는지 자세히 알고 싶다면 콘솔에서 공간 처리 알고리즘 사용 을 참조하세요.
24.4.3.12. 하천 낙차 분석
입력 집적 하천원 그리드(*ssa)에 (입력 파라미터로 결정된) 일련의 한계값을 적용해서 그 결과를 하천 낙차 통계 테이블 *drp.txt 파일로 산출합니다. 이 알고리즘은 하천을 묘사하는 데 사용되는 지형학적으로 객관적인 한계값을 결정하기 위해 개발됐습니다. 낙차 분석은 한계값들의 범위에서 하천망을 평가하고, 산출되는 스트랄러 하천의 일관적인 낙차 속성을 조사해서 올바른 한계값을 자동적으로 선택하려 합니다. 근본적으로 낙차 분석은 1차 하천의 평균 하천 낙차가 고차 하천의 평균 하천 낙차와 통계적으로 다른지를 T-검증을 사용해서 판정합니다. T-검증으로 두드러진 차이가 드러나는 경우 하천망이 이 “법칙”을 따르지 않는 것이기 때문에 더 큰 한계값을 선택해야 합니다. T-검증으로 두드러진 차이가 드러나지 않는 최소 한계값을 선택하면 지형학적으로 일관적인 하천 낙차 “법칙”을 따르는 최고 해상도의 하천망을 산출하며, 또한 이 최소 한계값은 DEM에서 하천의 “객관적인” 또는 자동적인 매핑을 위해 선택되는 한계값이기도 합니다. 하천망 래스터를 구축하는 데 이 알고리즘을 사용할 수 있습니다. 이때 집적 하천망 그리드에서 집적된 정확한 유역 특성(들)은 하천망 래스터 구축에 사용되는 메소드에 따라 달라집니다.
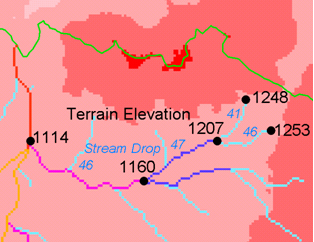
Broscoe (1959)에서 일관적인 하천 낙차 “법칙”을 식별했습니다. 하천 묘사 한계값을 결정하기 위해 이 법칙을 사용하는 데 쓰이는 과학에 대해 알고 싶다면, Tarboton et al. (1991, 1992), Tarboton & Ames (2001)을 참조하십시오.
파라미터
라벨 |
명칭 |
유형 |
설명 |
D8 Contributing Area Grid |
[raster] |
D8 알고리즘을 사용해서 계산한 각 셀 별 기여 영역 값 그리드입니다. 어느 셀의 기여 영역 값은 해당 셀 고유의 기여와 해당 셀로 흘러드는 모든 오르막 이웃에서 나오는 기여를 더한 값으로, 셀 개수로 측정됩니다. 일반적으로 이 그리드는 “D8 기여 영역” 알고리즘의 산출물입니다. 하천 낙차 테이블에 보고된 배수 농도를 평가하는 데 이 그리드를 사용합니다. |
|
D8 Flow Direction Grid |
[raster] |
각 셀 별로 그 인접 또는 대각선 방향의 이웃 8개 셀 가운데 가장 심한 내리막 경사를 가지고 있는 셀의 방향으로 정의한 D8 유수 방향 그리드입니다. 이 그리드는 “D8 유수 방향” 알고리즘의 산출물로 얻을 수 있습니다. |
|
Pit Filled Elevation Grid |
[raster] |
표고 값을 보유한 그리드를 지정합니다. 일반적으로 이 그리드는 함몰부 제거 도구의 산출물로, 구덩이를 제거한 표고입니다. |
|
Accumulated Stream Source Grid |
[raster] |
이 그리드는 내리막 D8 유수 방향을 따라 점증해야만 합니다. 하천의 시작을 결정하기 위해 이 그리드와 일련의 한계값을 비교합니다. 이 그리드는 “D8 기여 영역” 알고리즘으로, 또는 “D8 유수 경로 극값” 알고리즘의 최대값 옵션을 사용해서 유역의 일부 특성들 또는 특성들의 조합을 집적해서 생성하는 경우가 많습니다. 정확한 방법은 사용하는 알고리즘에 따라 달라집니다. |
|
Outlets Shapefile |
[vector: point] |
낙차 분석 수행 대상인 배출 상류를 정의하는 포인트 shapefile입니다. |
|
Minimum Threshold |
[number] 기본값: 5 |
이 파라미터는 낙차 분석으로 가능한 한계값을 탐색하는 범위의 가장 낮은 값입니다. 이 기술은 t-통계의 절대값이 2 미만인 범위에 있는 최소 한계값을 찾습니다. 낙차 분석에 쓰이는 과학에 대해 알고 싶다면 Tarboton et al. (1991, 1992), Tarboton & Ames (2001)을 참조하십시오. |
|
Maximum Threshold |
[number] 기본값: 500 |
이 파라미터는 낙차 분석으로 가능한 한계값을 탐색하는 범위의 가장 높은 값입니다. 이 기술은 t-통계의 절대값이 2 미만인 범위에 있는 최대 한계값을 찾습니다. 낙차 분석에 쓰이는 과학에 대해 알고 싶다면 Tarboton et al. (1991, 1992), Tarboton & Ames (2001)을 참조하십시오. |
|
Number of Threshold Values |
[number] 기본값: 10 |
이 파라미터는 낙차 분석으로 가능한 한계값을 탐색하는 범위를 나누기 위한 단계의 개수입니다. 이 기술은 t-통계의 절대값이 2 미만인 범위에 있는 최소 한계값을 찾습니다. 낙차 분석에 쓰이는 과학에 대해 알고 싶다면 Tarboton et al. (1991, 1992), Tarboton & Ames (2001)을 참조하십시오. |
|
Spacing for Threshold Values |
[enumeration] 기본값: 0 |
이 파라미터는 낙차 분석으로 가능한 한계값을 탐색할 때 로그 간격(logarithmic spacing)을 사용해야 할지 또는 선형 간격을 사용해야 할지를 나타내는 파라미터입니다. 옵션:
|
산출물
라벨 |
명칭 |
유형 |
설명 |
D-Infinity Drop to Stream Grid |
[file] |
다음 헤더 줄을 보유한 쉼표 구분 텍스트 파일입니다: Threshold,DrainDen,NoFirstOrd,NoHighOrd,MeanDFirstOrd,MeanDHighOrd,StdDevFirstOrd,StdDevHighOrd,T
이 파일은 조사한 각 한계값 별 데이터 한 줄, 그 다음으로 최적 한계값을 나타내는 요약 줄을 담고 있습니다. 이 기술은 t-통계의 절대값이 2 미만인 범위에 있는 최소 한계값을 찾습니다. 낙차 분석에 쓰이는 과학에 대해 알고 싶다면 Tarboton et al. (1991, 1992), Tarboton & Ames (2001)을 참조하십시오. |
파이썬 코드
알고리즘 ID: taudem:dropanalysis
import processing
processing.run("algorithm_id", {parameter_dictionary})
공간 처리 툴박스에 있는 알고리즘 위에 마우스를 가져가면 알고리즘 ID 를 표시합니다. 파라미터 목록(dictionary) 은 파라미터 명칭 및 값을 제공합니다. 파이썬 콘솔에서 공간 처리 알고리즘을 어떻게 실행하는지 자세히 알고 싶다면 콘솔에서 공간 처리 알고리즘 사용 을 참조하세요.
참고
Broscoe, A. J., (1959), “Quantitative analysis of longitudinal stream profiles of small watersheds”, Office of Naval Research, Project NR 389-042, Technical Report No. 18, Department of Geology, Columbia University, New York.
Tarboton, D. G., R. L. Bras and I. Rodriguez-Iturbe, (1991), “On the Extraction of Channel Networks from Digital Elevation Data”, Hydrologic Processes, 5(1): 81-100.
Tarboton, D. G., R. L. Bras and I. Rodriguez-Iturbe, (1992), “A Physical Basis for Drainage Density”, Geomorphology, 5(1/2): 59-76.
Tarboton, D. G. and D. P. Ames, (2001), “Advances in the mapping of flow networks from digital elevation data”, World Water and Environmental Resources Congress, Orlando, Florida, May 20-24, ASCE, https://www.researchgate.net/publication/2329568_Advances_in_the_Mapping_of_Flow_Networks_From_Digital_Elevation_Data.
24.4.3.13. 하천 범위 및 유역
이 알고리즘은 하천 래스터 그리드로부터 벡터망 및 shapefile을 생성합니다. 하천 래스터를 따라 유수 경로를 연결하기 위해 유수 방향 그리드를 사용합니다. 각 하천 구간의 스트랄러 순서를 계산합니다. 각 하천 구간(직선 유역)으로 흘러드는 소유역(subwatershed)도 묘사하며, 하천 직선 유역(Stream Reach) shapefile 안에 있는 WSNO(유역 번호)에 대응하는 값 식별자를 라벨로 표시합니다.
이 알고리즘은 하천망을 스트랄러 순서 체계에 따라 순서를 부여합니다. 다른 어떤 하천도 흘러들지 않는 하천이 1차(order 1)입니다. 서로 다른 순서의 하천 구간 2개가 합쳐질 경우 그 하류 구간의 순서는 해당 하천 구간들 가운데 더 높은 순서를 따릅니다. 동일한 순서의 하천 구간 2개가 합쳐질 경우 그 하류 구간의 순서는 1만큼 증가합니다. 하천 구간 2개 이상이 합쳐질 경우 유수 경로 순서는 가장 높은 구간 순서의 최대값, 또는 두 번째로 높은 구간 순서에 1을 더한 값으로 계산됩니다. 어느 한 지점에서 2개 이상의 구간이 합쳐지는 경우 스트랄러 순서는 일반적으로 이렇게 정의됩니다. 하천망의 지형적 연결성은 하천망 트리 파일에 저장되며, 하천망을 따라 각 그리드 셀의 좌표 및 속성은 하천망 좌표 파일에 저장됩니다.
이 알고리즘은 하천 래스터 그리드를 하천망의 소스로 사용하며, 유수 방향 그리드를 하천망 내부의 연결점을 추적하는 데 사용합니다. 하천망 좌표 파일 안에 표고 및 기여 영역 속성을 결정하는 데 표고 그리드 및 기여 영역 그리드를 사용합니다. 관측 지점의 상류 및 하류 유역을 쉽게 표현하기 위해 하천 구간을 논리적으로 나누는 데 배출 shapefile에 있는 포인트들을 사용합니다. 이 알고리즘은 배출 shapefile에 있는 id 속성 필드를 하천망 트리 파일의 식별자로 사용합니다. 그 다음 하천망 트리 및 좌표 파일에 있는 벡터망 표현 텍스트를 shapefile로 변환합니다. 더 많은 속성들도 평가합니다. 이 알고리즘은 산출 유역 그리드에 하천망으로 흘러드는 전체 영역을 단일 값으로 표현해서 단일 유역을 묘사하는 옵션도 가지고 있습니다.
파라미터
라벨 |
명칭 |
유형 |
설명 |
Pit Filled Elevation Grid |
[raster] |
표고 값을 보유한 그리드를 지정합니다. 일반적으로 이 그리드는 함몰부 제거 도구의 산출물로, 구덩이를 제거한 표고입니다. |
|
D8 Flow Direction Grid |
[raster] |
각 셀 별로 그 인접 또는 대각선 방향의 이웃 8개 셀 가운데 가장 심한 내리막 경사를 가지고 있는 셀의 방향으로 정의한 D8 유수 방향 그리드입니다. 이 그리드는 “D8 유수 방향” 알고리즘의 산출물로 얻을 수 있습니다. |
|
D8 Drainage Area |
[raster] |
D8 알고리즘을 사용해서 해당 셀 고유의 기여와 해당 셀로 흘러드는 모든 오르막 이웃에서 나오는 기여를 더한 값을 각 셀 별 그리드 셀 개수(또는 가중치의 총체)라는 측면에서 계산한 기여 영역 값을 제공하는 그리드입니다. 일반적으로 이 그리드는 “D8 기여 영역” 알고리즘의 산출물입니다. 하천망 좌표 파일의 기여 영역 속성을 결정하기 위해 이 그리드를 사용합니다. |
|
Stream Raster Grid |
[raster] |
하천인 경우 그리드 셀 값을 1, 나머지 셀 값을 0으로 해서 하천을 나타내는 지표(indicator) 그리드입니다. “하천망 분석” 도구 모음 가운데 하나로 이런 그리드를 생성할 수 있습니다. 하천 래스터 그리드를 하천망의 소스로 사용합니다. |
|
Outlets Shapefile as Network Nodes 부가적 |
[vector: point] |
관심 지점을 정의하는 포인트 shapefile입니다. 이 파일을 사용하는 경우, 알고리즘이 이 배출 지점 상류의 하천망만을 묘사할 것입니다. 또한, 관측 지점의 상류 및 하류 유역을 쉽게 표현하기 위해 하천 구간을 논리적으로 나누는 데 배출 shapefile에 있는 포인트들을 사용합니다. 이 알고리즘은 배출 shapefile이 정수형 속성 필드 |
|
Delineate Single Watershed |
[boolean] 기본값: True |
산출 유역 그리드에 하천망으로 흘러드는 전체 영역을 단일 값으로 표현해서 단일 유역을 묘사하도록 하는 옵션입니다. 이 옵션을 거짓으로 설정하면 각 하천 구간 별로 개별 유역을 묘사합니다. 기본값은 |
산출물
라벨 |
명칭 |
유형 |
설명 |
Stream Order Grid |
[raster] |
하천 순서 그리드는 스트랄러 순서 체계에 따라 순서를 부여한 하천 셀 값을 담고 있습니다. 스트랄러 순서 체계는 다른 어떤 하천도 흘러들지 않는 하천 구간을 1차(order 1)로 정의합니다. 서로 다른 순서의 하천 구간 2개가 합쳐질 경우 그 하류 구간의 순서는 해당 하천 구간들 가운데 더 높은 순서를 따릅니다. 동일한 순서의 하천 구간 2개가 합쳐질 경우 그 하류 구간의 순서는 1만큼 증가합니다. 하천 구간 2개 이상이 합쳐질 경우 유수 경로 순서는 가장 높은 구간 순서의 최대값, 또는 두 번째로 높은 구간 순서에 1을 더한 값으로 계산됩니다. 어느 한 지점에서 2개 이상의 구간이 합쳐지는 경우 스트랄러 순서는 일반적으로 이렇게 정의됩니다. |
|
Watershed Grid |
[raster] |
이 산출 그리드는 각 구간 유역을 유일 ID 번호로 식별하거나, 또는 단일 유역 옵션을 참으로 설정한 경우 하천망으로 흘러드는 전체 영역을 단일 ID로 식별합니다. |
|
Stream Reach Shapefile |
[vector: line] |
이 산출물은 하천망 내부의 링크를 지정하는 폴리라인 shapefile입니다. 속성 테이블에 있는 열들은 다음과 같습니다:
|
|
Network Connectivity Tree |
[file] |
이 산출물은 하천망 트리 파일에 저장된 하천망의 지형적 연결성을 상세히 설명하는 텍스트 파일입니다. 다음과 같은 열들을 담고 있습니다:
|
|
Network Coordinates |
[file] |
이 산출물은 하천망을 따라 각 포인트의 좌표 및 속성을 담고 있는 텍스트 파일입니다. 다음과 같은 열들을 담고 있습니다:
|
파이썬 코드
알고리즘 ID: taudem:streamnet
import processing
processing.run("algorithm_id", {parameter_dictionary})
공간 처리 툴박스에 있는 알고리즘 위에 마우스를 가져가면 알고리즘 ID 를 표시합니다. 파라미터 목록(dictionary) 은 파라미터 명칭 및 값을 제공합니다. 파이썬 콘솔에서 공간 처리 알고리즘을 어떻게 실행하는지 자세히 알고 싶다면 콘솔에서 공간 처리 알고리즘 사용 을 참조하세요.