Important
La traduction est le fruit d’un effort communautaire auquel vous pouvez vous joindre. Cette page est actuellement traduite à 91.29%.
24.1.25. Vecteur général
24.1.25.1. Assigner une projection
Attribue une nouvelle projection à une couche vectorielle.
Il crée une nouvelle couche avec exactement les mêmes entités et géométries que celle en entrée, mais affectée à un nouveau SCR. Les géométries ne sont pas reprojetées, elles sont juste affectées à un SCR différent.
Cet algorithme peut être utilisé pour réparer des couches auxquelles une projection incorrecte a été affectée.
Les attributs ne sont pas modifiés par cet algorithme.
Voir aussi
Define projection, Trouver une projection, Reprojeter la couche
Paramètres
Etiquette |
Nom |
Type |
Description |
|---|---|---|---|
Couche en entrée |
|
[vecteur : géométrie] |
Couche vectorielle avec SCR erroné ou manquant |
SCR attribué |
|
[scr] Par défaut : |
Sélectionnez le nouveau SCR à affecter à la couche vectorielle |
SCR attribué Optionnel |
|
[identique à l’entrée] Par défaut : |
Specify the output vector layer. One of:
L’encodage du fichier peut également être modifié ici. |
Les sorties
Etiquette |
Nom |
Type |
Description |
|---|---|---|---|
SCR attribué |
|
[identique à l’entrée] |
Couche vectorielle avec projection affectée |
Code Python
ID de l’algorithme : native:assignprojection
import processing
processing.run("algorithm_id", {parameter_dictionary})
L”id de l’algorithme est affiché lors du survol du nom de l’algorithme dans la boîte à outils Traitements. Les nom et valeur de chaque paramètre sont fournis via un dictionnaire de paramètres. Voir Utiliser les algorithmes du module de traitements depuis la console Python pour plus de détails sur l’exécution d’algorithmes via la console Python.
24.1.25.2. Batch Nominatim geocoder
Performs batch geocoding using the Nominatim service against an input layer string field. The output layer will have a point geometry reflecting the geocoded location as well as a number of attributes associated to the geocoded location.
 Permet la modification de la couche source pour des entités de type point
Permet la modification de la couche source pour des entités de type point
Note
Cet algorithme respecte la politique d’utilisation du service de géocodage Nominatim fourni par la fondation OpenStreetMap.
Paramètres
Etiquette |
Nom |
Type |
Description |
|---|---|---|---|
Couche en entrée |
|
[vecteur : tout type] |
Vector layer to geocode the features |
Champ d’adresse |
|
[champ : chaîne de caractères] |
Champ contenant les adresses à géocoder |
Géocodé |
|
[vecteur : point] Par défaut : |
Specify the output layer containing only the geocoded addresses. One of:
L’encodage du fichier peut également être modifié ici. |
Les sorties
Etiquette |
Nom |
Type |
Description |
|---|---|---|---|
Géocodé |
|
[vecteur : point] |
Vector layer with point features corresponding to the geocoded addresses |
Code Python
ID de l’algorithme : native:batchnominatimgeocoder
import processing
processing.run("algorithm_id", {parameter_dictionary})
L”id de l’algorithme est affiché lors du survol du nom de l’algorithme dans la boîte à outils Traitements. Les nom et valeur de chaque paramètre sont fournis via un dictionnaire de paramètres. Voir Utiliser les algorithmes du module de traitements depuis la console Python pour plus de détails sur l’exécution d’algorithmes via la console Python.
24.1.25.3. Convertir une couche en signets spatiaux
Crée des signets spatiaux correspondant à l’étendue des entités contenues dans une couche.
Paramètres
Etiquette |
Nom |
Type |
Description |
|---|---|---|---|
Couche d’entrée |
|
[vecteur : ligne, polygone] |
La couche de vecteur d’entrée |
Marque-page de destination |
|
[énumération] Par défaut : 0 |
Sélectionnez la destination des signets. Un des:
|
Nom de champ |
|
[expression] |
Champ ou expression qui donnera des noms aux signets générés |
Champ de groupe |
|
[expression] |
Champ ou expression qui fournira des groupes pour les signets générés |
Les sorties
Etiquette |
Nom |
Type |
Description |
|---|---|---|---|
Nombre de signets ajoutés |
|
[numérique : entier] |
Code Python
ID de l’algorithme : native:layertobookmarks
import processing
processing.run("algorithm_id", {parameter_dictionary})
L”id de l’algorithme est affiché lors du survol du nom de l’algorithme dans la boîte à outils Traitements. Les nom et valeur de chaque paramètre sont fournis via un dictionnaire de paramètres. Voir Utiliser les algorithmes du module de traitements depuis la console Python pour plus de détails sur l’exécution d’algorithmes via la console Python.
24.1.25.4. Convertir des signets spatiaux en couche
Crée une nouvelle couche contenant des entités surfaciques pour les signets spatiaux stockés. L’exportation peut être filtrée uniquement sur les signets appartenant au projet en cours, sur tous les signets utilisateur ou sur une combinaison des deux.
Paramètres
Etiquette |
Nom |
Type |
Description |
|---|---|---|---|
Marque-page source |
|
[énumération] [liste] Par défaut : [0,1] |
Sélectionnez la ou les sources des signets parmi :
|
SCR en sortie |
|
[scr] Par défaut : |
Le SCR de la couche de sortie |
Rendu |
|
[vecteur : polygone] Par défaut : |
Specify the output layer. One of:
L’encodage du fichier peut également être modifié ici. |
Les sorties
Etiquette |
Nom |
Type |
Description |
|---|---|---|---|
Rendu |
|
[vecteur : polygone] |
La couche vectorielle de sortie (signets) |
Code Python
ID de l’algorithme : native:bookmarkstolayer
import processing
processing.run("algorithm_id", {parameter_dictionary})
L”id de l’algorithme est affiché lors du survol du nom de l’algorithme dans la boîte à outils Traitements. Les nom et valeur de chaque paramètre sont fournis via un dictionnaire de paramètres. Voir Utiliser les algorithmes du module de traitements depuis la console Python pour plus de détails sur l’exécution d’algorithmes via la console Python.
24.1.25.5. Créer un index d’attribut
Crée un index sur un champ de la table attributaire pour accélérer les requêtes. La prise en charge de la création d’index dépend à la fois du fournisseur de données de la couche et du type de champ.
Aucune sortie n’est créée : l’index est stocké sur la couche elle-même.
Paramètres
Etiquette |
Nom |
Type |
Description |
|---|---|---|---|
Couche d’entrée |
|
[vecteur : tout type] |
Sélectionnez la couche vectorielle pour laquelle vous souhaitez créer un index d’attribut |
Attribut à indexer |
|
[champ : tout type] |
Champ de la couche vecteur |
Les sorties
Etiquette |
Nom |
Type |
Description |
|---|---|---|---|
Couche indexée |
|
[identique à l’entrée] |
Une copie de la couche vecteur d’entrée avec un index pour le champ spécifié |
Code Python
ID de l’algorithme : native:createattributeindex
import processing
processing.run("algorithm_id", {parameter_dictionary})
L”id de l’algorithme est affiché lors du survol du nom de l’algorithme dans la boîte à outils Traitements. Les nom et valeur de chaque paramètre sont fournis via un dictionnaire de paramètres. Voir Utiliser les algorithmes du module de traitements depuis la console Python pour plus de détails sur l’exécution d’algorithmes via la console Python.
24.1.25.6. Créer un index spatial
Crée un index pour accélérer l’accès aux entités d’une couche en fonction de leur emplacement spatial. La prise en charge de la création d’index spatial dépend du fournisseur de données de la couche.
Aucune nouvelle couche de sortie n’est créée.
Menu par défaut:
Paramètres
Etiquette |
Nom |
Type |
Description |
|---|---|---|---|
Couche d’entrée |
|
[vecteur : géométrie] |
Couche vectorielle en entrée |
Les sorties
Etiquette |
Nom |
Type |
Description |
|---|---|---|---|
Couche indexée |
|
[identique à l’entrée] |
Une copie de la couche vectorielle d’entrée avec un index spatial |
Code Python
ID de l’algorithme : native:createspatialindex
import processing
processing.run("algorithm_id", {parameter_dictionary})
L”id de l’algorithme est affiché lors du survol du nom de l’algorithme dans la boîte à outils Traitements. Les nom et valeur de chaque paramètre sont fournis via un dictionnaire de paramètres. Voir Utiliser les algorithmes du module de traitements depuis la console Python pour plus de détails sur l’exécution d’algorithmes via la console Python.
24.1.25.7. Define projection
Sets an existing layer’s projection to the provided CRS without reprojecting features.
Contrairement à l’algorithme Assigner une projection, il modifie la couche courante et ne sortira pas de nouvelle couche.
Note
Pour les jeux de données Shapefile, les fichiers .prj et .qpj seront écrasés - ou créés s’ils sont manquants - pour correspondre au SCR fourni.
Menu par défaut:
Paramètres
Etiquette |
Nom |
Type |
Description |
|---|---|---|---|
Couche en entrée |
|
[vecteur : géométrie] |
Couche vectorielle avec des informations de projection manquantes |
SCR |
|
[scr] |
Sélectionnez le SCR à affecter à la couche vectorielle |
Les sorties
Etiquette |
Nom |
Type |
Description |
|---|---|---|---|
|
[identique à l’entrée] |
La couche vectorielle d’entrée avec la projection définie |
Code Python
Algorithm ID: native:definecurrentprojection
import processing
processing.run("algorithm_id", {parameter_dictionary})
L”id de l’algorithme est affiché lors du survol du nom de l’algorithme dans la boîte à outils Traitements. Les nom et valeur de chaque paramètre sont fournis via un dictionnaire de paramètres. Voir Utiliser les algorithmes du module de traitements depuis la console Python pour plus de détails sur l’exécution d’algorithmes via la console Python.
24.1.25.8. Supprimer les géométries dupliquées
Recherche et supprime les géométries dupliquées.
Les attributs ne sont pas vérifiés, donc si deux entités ont des géométries identiques mais des attributs différents, un seul d’entre eux sera ajouté à la couche de résultat.
Note
This algorithm does not require valid geometries as input.
Voir aussi
Supprimer les géométries, Supprimer les géométries nulles, Supprimer les doublons par attribut
Paramètres
Etiquette |
Nom |
Type |
Description |
|---|---|---|---|
Couche en entrée |
|
[vecteur : géométrie] |
La couche avec des géométries en double que vous souhaitez nettoyer |
Nettoyé |
|
[identique à l’entrée] Par défaut : |
Specify the output layer containing the unique features. One of:
L’encodage du fichier peut également être modifié ici. |
Les sorties
Etiquette |
Nom |
Type |
Description |
|---|---|---|---|
Nombre d’enregistrements en double supprimés |
|
[numérique : entier] |
Nombre d’enregistrements en double supprimés |
Nettoyé |
|
[identique à l’entrée] |
La couche de sortie sans géométrie dupliquée |
Nombre d’enregistrements conservés |
|
[numérique : entier] |
Nombre d’enregistrements uniques |
Code Python
ID de l’algorithme : native:deleteduplicategeometries
import processing
processing.run("algorithm_id", {parameter_dictionary})
L”id de l’algorithme est affiché lors du survol du nom de l’algorithme dans la boîte à outils Traitements. Les nom et valeur de chaque paramètre sont fournis via un dictionnaire de paramètres. Voir Utiliser les algorithmes du module de traitements depuis la console Python pour plus de détails sur l’exécution d’algorithmes via la console Python.
24.1.25.9. Supprimer les doublons par attribut
Deletes duplicate rows by only considering the specified field(s). The first matching row will be retained, and duplicates will be discarded.
Facultativement, ces enregistrements en double peuvent être enregistrés sur une sortie distincte pour analyse.
Voir aussi
Paramètres
Etiquette |
Nom |
Type |
Description |
|---|---|---|---|
Couche en entrée |
|
[vecteur : tout type] |
La couche d’entrée |
Champs pour faire correspondre les doublons par |
|
[champ : tout type] [liste] |
Champs définissant les doublons. Les entités ayant des valeurs identiques pour tous ces champs sont considérées comme des doublons. |
Filtré (pas de doublons) |
|
[identique à l’entrée] Par défaut : |
Specify the output layer containing the unique features. One of:
L’encodage du fichier peut également être modifié ici. |
Filtré (doublons) Optionnel |
|
[identique à l’entrée] Par défaut : |
Spécifiez la couche de sortie contenant uniquement les doublons. Une des options suivantes:
L’encodage du fichier peut également être modifié ici. |
Les sorties
Etiquette |
Nom |
Type |
Description |
|---|---|---|---|
Filtré (doublons) |
|
[identique à l’entrée] |
Vector layer containing the duplicate features. |
Nombre d’enregistrements en double supprimés |
|
[numérique : entier] |
Nombre d’enregistrements en double supprimés |
Filtré (pas de doublons) |
|
[identique à l’entrée] |
Couche vectorielle contenant les entités uniques. |
Nombre d’enregistrements conservés |
|
[numérique : entier] |
Nombre d’enregistrements uniques |
Code Python
ID de l’algorithme : native:removeduplicatesbyattribute
import processing
processing.run("algorithm_id", {parameter_dictionary})
L”id de l’algorithme est affiché lors du survol du nom de l’algorithme dans la boîte à outils Traitements. Les nom et valeur de chaque paramètre sont fournis via un dictionnaire de paramètres. Voir Utiliser les algorithmes du module de traitements depuis la console Python pour plus de détails sur l’exécution d’algorithmes via la console Python.
24.1.25.10. Détecter les modifications d’un jeu de données
Compare deux couches vectorielles, et détermine quelles entités sont inchangées, ajoutées ou supprimées entre les deux. Il est conçu pour comparer deux versions différentes d’un même jeu de données.
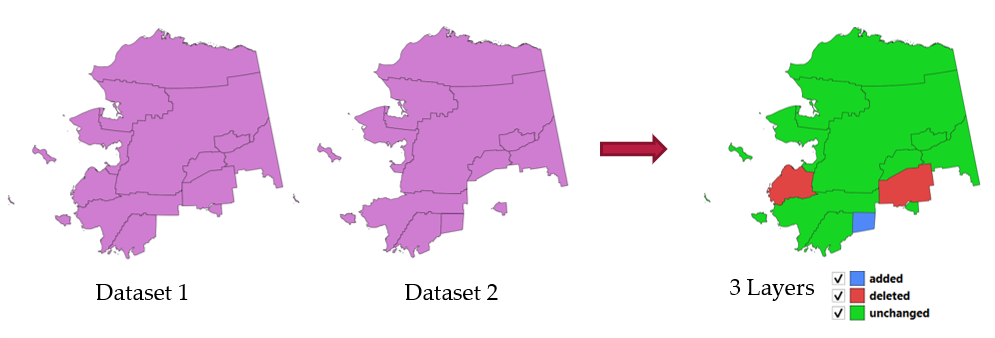
Fig. 24.96 Exemple de détection de changement d’un jeu données
Paramètres
Etiquette |
Nom |
Type |
Description |
|---|---|---|---|
Couche originale |
|
[vecteur : géométrie] |
La couche vecteur considérée comme la version originale |
Couche révisée |
|
[vecteur : géométrie] |
La couche vecteur révisée ou modifiée |
Attributs à prendre en compte pour le match Optionnel |
|
[champ : tout type] [liste] |
Attributs à considérer pour le match. Par défaut, tous les attributs sont comparés. |
Comportement de la comparaison géométrique Optionnel |
|
[énumération] Par défaut : 1 |
Définit le critère pour la comparaison. Options:
|
Entités inchangées Optionnel |
|
[vecteur: identique à la couche originale] |
Specify the output vector layer containing the unchanged features. One of:
L’encodage du fichier peut également être modifié ici. |
Entités ajoutées Optionnel |
|
[vecteur: identique à la couche originale] |
Specify the output vector layer containing the added features. One of:
L’encodage du fichier peut également être modifié ici. |
Entités supprimées Optionnel |
|
[vecteur: identique à la couche originale] |
Specify the output vector layer containing the deleted features. One of:
L’encodage du fichier peut également être modifié ici. |
Les sorties
Etiquette |
Nom |
Type |
Description |
|---|---|---|---|
Entités inchangées |
|
[vecteur: identique à la couche originale] |
Couche vectorielle contenant les entités inchangées. |
Entités ajoutées |
|
[vecteur: identique à la couche originale] |
Couche vecteur contenant les entités sélectionnées. |
Entités supprimées |
|
[vecteur: identique à la couche originale] |
Couche vecteur contenant les entités supprimées. |
Nombre d’entités inchangées |
|
[numérique : entier] |
Nombre d’entités inchangées. |
Nombre d’entités ajoutées dans la couche révisée* |
|
[numérique : entier] |
Nombre d’entités ajoutées dans la couche révisée. |
Nombre d’entités supprimées de la couche originale |
|
[numérique : entier] |
Nombre d’entités supprimées de la couche originale. |
Code Python
ID de l’algorithme : native:detectvectorchanges
import processing
processing.run("algorithm_id", {parameter_dictionary})
L”id de l’algorithme est affiché lors du survol du nom de l’algorithme dans la boîte à outils Traitements. Les nom et valeur de chaque paramètre sont fournis via un dictionnaire de paramètres. Voir Utiliser les algorithmes du module de traitements depuis la console Python pour plus de détails sur l’exécution d’algorithmes via la console Python.
24.1.25.11. Supprimer les géométries
Crée une simple copie sans géométrie de la table d’attributs de couche en entrée. Il conserve la table attributaire de la couche source.
Si le fichier est enregistré dans un dossier local, vous pouvez choisir entre de nombreux formats de fichier.
Permet la modification de la couche source pour des entités de type point, ligne ou polygone
Paramètres
Etiquette |
Nom |
Type |
Description |
|---|---|---|---|
Couche en entrée |
|
[vecteur : géométrie] |
La couche de vecteur d’entrée |
Géométries supprimées |
|
[vecteur : table] |
Specify the output geometryless layer. One of:
L’encodage du fichier peut également être modifié ici. |
Les sorties
Etiquette |
Nom |
Type |
Description |
|---|---|---|---|
Géométries supprimées |
|
[vecteur : table] |
La couche de sortie sans géométrie. Une copie de la table d’attributs d’origine. |
Code Python
ID de l’algorithme : native:dropgeometries
import processing
processing.run("algorithm_id", {parameter_dictionary})
L”id de l’algorithme est affiché lors du survol du nom de l’algorithme dans la boîte à outils Traitements. Les nom et valeur de chaque paramètre sont fournis via un dictionnaire de paramètres. Voir Utiliser les algorithmes du module de traitements depuis la console Python pour plus de détails sur l’exécution d’algorithmes via la console Python.
24.1.25.12. Exécuter SQL
Runs a simple or complex query based only on SELECT with SQL syntax
on the source layer.
Les données d’entrée sont identifiées par input1, input2… inputN et une simple requête ressemblera à ça : SELECT * FROM input1.
Beside a simple query, you can add expressions or variables within the
SQL query parameter itself. This is particularly useful if this algorithm is
executed within a Processing model and you want to use a model input as a
parameter of the query. An example of a query will then be SELECT * FROM
[% @table %] where @table is the variable that identifies the model input.
Le résultat de la requête sera ajouté en tant que nouvelle couche.
Voir aussi
Paramètres
Etiquette |
Nom |
Type |
Description |
|---|---|---|---|
Sources de données d’entrée supplémentaires (appelées input1, .., inputN dans la requête) |
|
[vecteur : tout type] [liste] |
Liste des couches à interroger. Dans l’éditeur SQL, vous pouvez référencer ces couches avec leur vrai nom ou aussi avec input1, input2, inputN selon le nombre de couches choisies. |
Requête SQL |
|
[Chaîne de caractères] |
Saisissez la chaîne de votre requête SQL, par exemple |
Champ d’identifiant unique Optionnel |
|
[Chaîne de caractères] |
Spécifiez la colonne avec un ID unique |
Champ de géométrie Optionnel |
|
[Chaîne de caractères] |
Spécifiez le champ de géométrie |
Type de géométrie Optionnel |
|
[énumération] Par défaut : 0 |
Choisissez la géométrie du résultat. Par défaut, l’algorithme le détectera automatiquement. Un des:
|
SCR Optionnel |
|
[scr] |
Le SCR à affecter à la couche de sortie |
Sortie SQL |
|
[vecteur : géométrie] Par défaut : |
Specify the output layer created by the query. One of:
L’encodage du fichier peut également être modifié ici. |
Les sorties
Etiquette |
Nom |
Type |
Description |
|---|---|---|---|
Sortie SQL |
|
[vecteur : géométrie] |
Couche vectorielle créée par la requête |
Code Python
ID de l’algorithme : qgis:executesql
import processing
processing.run("algorithm_id", {parameter_dictionary})
L”id de l’algorithme est affiché lors du survol du nom de l’algorithme dans la boîte à outils Traitements. Les nom et valeur de chaque paramètre sont fournis via un dictionnaire de paramètres. Voir Utiliser les algorithmes du module de traitements depuis la console Python pour plus de détails sur l’exécution d’algorithmes via la console Python.
24.1.25.13. Export layers to DXF
Exports layers to DXF file. For each layer, you can choose a field whose values are used to split features in generated destination layers in DXF output.
Voir aussi
Paramètres
Etiquette |
Nom |
Type |
Description |
|---|---|---|---|
Couches en entrée |
|
[vecteur : géométrie] [liste] |
List of input vector layers with options associated (filled as a
Allow data defined symbol blocks [boolean] (
|
Symbology mode |
|
[énumération] Par défaut : 0 |
Type of symbology to apply to output layers. You can choose between:
|
Symbology scale |
|
[scale] Par défaut : 1:1 000 000 |
Default scale of data export. |
Map theme Optionnel |
|
[map theme] |
Match layer styling to the provided map theme. |
Codage |
|
[énumération] |
Encodage à appliquer aux couches. |
SCR |
|
[scr] |
Choose the CRS for the output layer. |
Emprise Optionnel |
|
[emprise] |
Limit exported features to those with geometries intersecting the provided extent. |
Use layer title as name |
|
[booléen] Par défaut : Faux |
Name the output layer with the layer title (as set in layer metadata or QGIS Server properties) instead of the layer name. |
Force 2D |
|
[booléen] Par défaut : Faux |
|
Export labels as MTEXT elements |
|
[booléen] Par défaut : Vrai |
Exports labels as MTEXT or TEXT elements |
Use only selected features |
|
[booléen] Par défaut : Faux |
Exports only the selected features. |
DXF |
|
[fichier] Par défaut : |
Specification of the output DXF file. One of:
|
Les sorties
Etiquette |
Nom |
Type |
Description |
|---|---|---|---|
DXF |
|
[fichier] |
|
Code Python
ID de l’algorithme : native:dxfexport
import processing
processing.run("algorithm_id", {parameter_dictionary})
L”id de l’algorithme est affiché lors du survol du nom de l’algorithme dans la boîte à outils Traitements. Les nom et valeur de chaque paramètre sont fournis via un dictionnaire de paramètres. Voir Utiliser les algorithmes du module de traitements depuis la console Python pour plus de détails sur l’exécution d’algorithmes via la console Python.
24.1.25.14. Extraire les entités sélectionnées
Enregistre les entités sélectionnées en tant que nouvelle couche.
Note
Si la couche sélectionnée n’a pas d’entités sélectionnées, la couche nouvellement créée sera vide.
Paramètres
Etiquette |
Nom |
Type |
Description |
|---|---|---|---|
Couche d’entrée |
|
[vecteur : tout type] |
couche pour enregistrer la sélection |
Entités sélectionnées |
|
[identique à l’entrée] Par défaut : |
Specify the vector layer for the selected features. One of:
L’encodage du fichier peut également être modifié ici. |
Les sorties
Etiquette |
Nom |
Type |
Description |
|---|---|---|---|
Entités sélectionnées |
|
[identique à l’entrée] |
Couche vectorielle avec uniquement les entités sélectionnées, ou aucune entité si aucune n’a été sélectionnée. |
Code Python
ID de l’algorithme : native:saveselectedfeatures
import processing
processing.run("algorithm_id", {parameter_dictionary})
L”id de l’algorithme est affiché lors du survol du nom de l’algorithme dans la boîte à outils Traitements. Les nom et valeur de chaque paramètre sont fournis via un dictionnaire de paramètres. Voir Utiliser les algorithmes du module de traitements depuis la console Python pour plus de détails sur l’exécution d’algorithmes via la console Python.
24.1.25.15. Extraire l’encodage du Shapefile
Extracts the attribute encoding information embedded in a Shapefile.
Both the encoding specified by an optional .cpg file and
any encoding details present in the .dbf LDID header block are considered.
Paramètres
Etiquette |
Nom |
Type |
Description |
|---|---|---|---|
Couche d’entrée |
|
[vecteur : géométrie] |
Couche ESRI Shapefile ( |
Les sorties
Etiquette |
Nom |
Type |
Description |
|---|---|---|---|
Encodage du Shapefile |
|
[Chaîne de caractères] |
Information d’encodage spécifiée dans le fichier d’entrée |
Encodage CPG |
|
[Chaîne de caractères] |
Information d’encodage spécifiée dans un potentiel fichier |
Encodage LDID |
|
[Chaîne de caractères] |
Information d’encodage spécifiée dans le bloc d’entête LDID du fichier .dbf |
Code Python
ID de l’algorithme : native:shpencodinginfo
import processing
processing.run("algorithm_id", {parameter_dictionary})
L”id de l’algorithme est affiché lors du survol du nom de l’algorithme dans la boîte à outils Traitements. Les nom et valeur de chaque paramètre sont fournis via un dictionnaire de paramètres. Voir Utiliser les algorithmes du module de traitements depuis la console Python pour plus de détails sur l’exécution d’algorithmes via la console Python.
24.1.25.16. Trouver une projection
Crée une liste restreinte de systèmes de référence de coordonnées candidats, par exemple pour une couche avec une projection inconnue.
La surface que la couche est censée couvrir doit être spécifiée via le paramètre de surface cible. Le système de référence de coordonnées pour cette surface cible doit être connu de QGIS.
L’algorithme fonctionne en testant l’étendue de la couche dans tous les systèmes de référence connus, puis en répertoriant ceux dont les limites seraient proches de la surface cible si la couche était dans cette projection.
Voir aussi
Assigner une projection, Define projection, Reprojeter la couche
Paramètres
Etiquette |
Nom |
Type |
Description |
|---|---|---|---|
Couche d’entrée |
|
[vecteur : géométrie] |
Couche avec projection inconnue |
Surface cible pour la couche (xmin, xmax, ymin, ymax) |
|
[emprise] |
The area that the layer covers. Les méthodes disponibles sont:
|
SCR candidats |
|
[vecteur : table] Par défaut : |
Specify the table (geometryless layer) for the CRS suggestions (EPSG codes). One of:
L’encodage du fichier peut également être modifié ici. |
Les sorties
Etiquette |
Nom |
Type |
Description |
|---|---|---|---|
SCR candidats |
|
[vecteur : table] |
Une table avec tous les SCR (codes EPSG) des critères correspondants. |
Code Python
Algorithm ID: native:findprojection
import processing
processing.run("algorithm_id", {parameter_dictionary})
L”id de l’algorithme est affiché lors du survol du nom de l’algorithme dans la boîte à outils Traitements. Les nom et valeur de chaque paramètre sont fournis via un dictionnaire de paramètres. Voir Utiliser les algorithmes du module de traitements depuis la console Python pour plus de détails sur l’exécution d’algorithmes via la console Python.
24.1.25.17. Relation aplanie
Aplatit une relation pour une couche vectorielle, en exportant une couche unique contenant une entité parente pour chaque entité liée. Cette entité principale contient tous les attributs des entités liées. Cela permet d’avoir la relation sous la forme d’une table simple qui peut être exportée par exemple au format CSV.
Avertissement
Cet algorithme supprime les clés primaires ou les valeurs FID existantes et les régénère dans les couches de sortie.
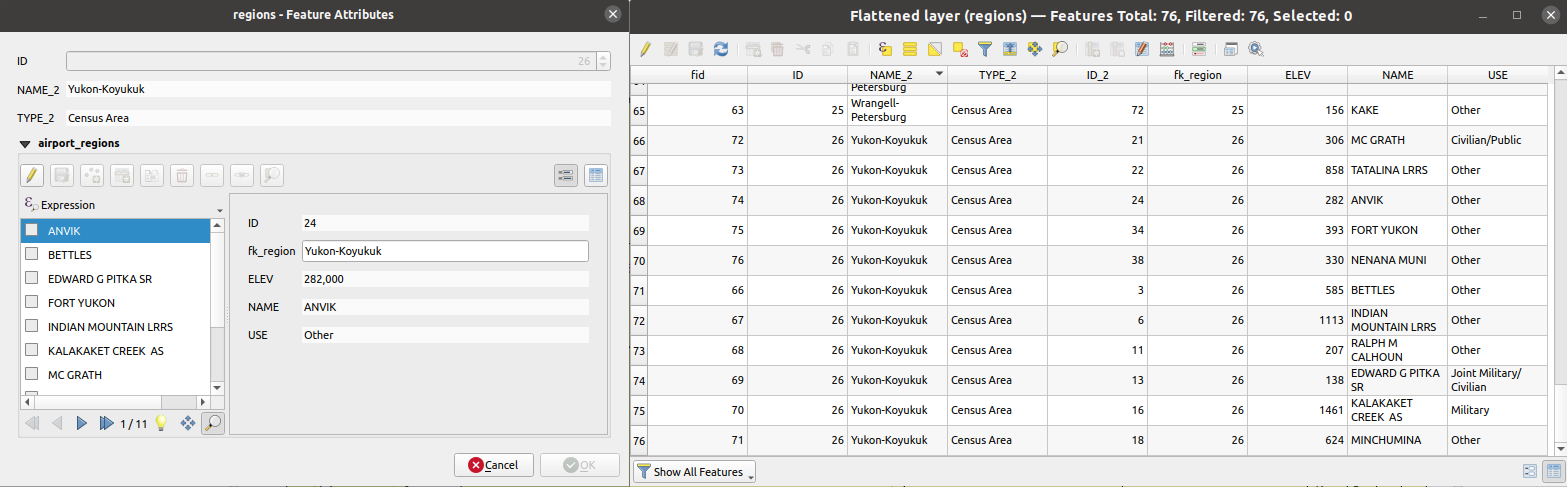
Fig. 24.97 Formulaire d’ue région avec les entités enfants en lien (gauche) - Pour chaque entité enfant, l’entité région est dupliquée, avec tous les attributs joints (droite)
Paramètres
Etiquette |
Nom |
Type |
Description |
|---|---|---|---|
Couche d’entrée |
|
[vecteur : tout type] |
Couche avec la relation qui doit être dénormalisée |
Couche aplanie Optionnel |
|
[identique à l’entrée] Par défaut : |
Specify the output (flattened) layer. One of:
L’encodage du fichier peut également être modifié ici. |
Les sorties
Etiquette |
Nom |
Type |
Description |
|---|---|---|---|
Couche aplanie |
|
[identique à l’entrée] |
Une couche contenant des entités principales avec tous les attributs des entités connexes. |
Code Python
ID de l’algorithme : native:flattenrelationships
import processing
processing.run("algorithm_id", {parameter_dictionary})
L”id de l’algorithme est affiché lors du survol du nom de l’algorithme dans la boîte à outils Traitements. Les nom et valeur de chaque paramètre sont fournis via un dictionnaire de paramètres. Voir Utiliser les algorithmes du module de traitements depuis la console Python pour plus de détails sur l’exécution d’algorithmes via la console Python.
24.1.25.18. Joindre des attributs par valeur de champ
Prend une couche vectorielle d’entrée et crée une nouvelle couche vectorielle qui est une version étendue de celle d’entrée, avec des attributs supplémentaires dans sa table d’attributs.
Les attributs supplémentaires et leurs valeurs proviennent d’une deuxième couche vectorielle. Un attribut est sélectionné dans chacun d’eux pour définir les critères de jointure.
Avertissement
Cet algorithme supprime les clés primaires ou les valeurs FID existantes et les régénère dans les couches de sortie.
Paramètres
Etiquette |
Nom |
Type |
Description |
|---|---|---|---|
Couche d’entrée |
|
[vecteur : tout type] |
Couche vectorielle d’entrée. La couche de sortie sera constituée des entités de cette couche avec des attributs des entités correspondantes dans la deuxième couche. |
Champ de table |
|
[champ : tout type] |
Champ de la couche source à utiliser pour la jointure |
Couche d’entrée 2 |
|
[vecteur : tout type] |
Couche avec la table attributaire à joindre |
Champ de table 2 |
|
[champ : tout type] |
Champ de la deuxième couche (jointure) à utiliser pour la jointure Le type du champ doit être égal (ou compatible avec) le type de champ de la table d’entrée. |
Champs de la couche 2 à copier Optionnel |
|
[champ : tout type] [liste] |
Sélectionnez les champs spécifiques que vous souhaitez ajouter. Par défaut, tous les champs sont ajoutés. |
Type de jointure |
|
[énumération] Par défaut : 1 |
Type de la couche finale jointe. Un des:
|
Supprimer les enregistrements qui n’ont pas pu être joints |
|
[booléen] Par défaut : Vrai |
Vérifiez si vous ne souhaitez pas conserver les entités qui n’ont pas pu être jointes |
Préfixe de champ joint Optionnel |
|
[Chaîne de caractères] |
Ajoutez un préfixe aux champs joints afin de les identifier facilement et d’éviter la collision des noms de champs |
Couche jointe Optionnel |
|
[identique à l’entrée] Par défaut : |
Specify the output vector layer for the join. One of:
L’encodage du fichier peut également être modifié ici. |
Entités non joignables de la première couche Optionnel |
|
[identique à l’entrée] Par défaut : |
Specify the output vector layer for unjoinable features from first layer. One of:
L’encodage du fichier peut également être modifié ici. |
Les sorties
Etiquette |
Nom |
Type |
Description |
|---|---|---|---|
Nombre d’entités jointes de la table d’entrée |
|
[numérique : entier] |
|
Entités non joignables de la première couche Optionnel |
|
[identique à l’entrée] |
Couche vectorielle avec les entités non appariées |
Couche jointe Optionnel |
|
[identique à l’entrée] |
Couche vectorielle de sortie avec des attributs ajoutés à partir de la jointure |
Nombre d’entités non joignables de la table d’entrée Optionnel |
|
[numérique : entier] |
Code Python
ID de l’algorithme : native:joinattributestable
import processing
processing.run("algorithm_id", {parameter_dictionary})
L”id de l’algorithme est affiché lors du survol du nom de l’algorithme dans la boîte à outils Traitements. Les nom et valeur de chaque paramètre sont fournis via un dictionnaire de paramètres. Voir Utiliser les algorithmes du module de traitements depuis la console Python pour plus de détails sur l’exécution d’algorithmes via la console Python.
24.1.25.19. Joindre les attributs par localisation
Prend une couche vectorielle d’entrée et crée une nouvelle couche vectorielle qui est une version étendue de celle d’entrée, avec des attributs supplémentaires dans sa table d’attributs.
Les attributs supplémentaires et leurs valeurs proviennent d’une deuxième couche vectorielle. Un critère spatial est appliqué pour sélectionner les valeurs de la deuxième couche qui sont ajoutées à chaque entité de la première couche.
Menu par défaut:
Avertissement
Cet algorithme supprime les clés primaires ou les valeurs FID existantes et les régénère dans les couches de sortie.
Voir aussi
Joindre les attributs par le plus proche, Joindre des attributs par valeur de champ, Joindre des attributs par localisation (résumé)
Explorer les relations spatiales
Les prédicats géométriques sont des fonctions booléennes utilisées pour déterminer la relation spatiale d’une entité avec une autre en comparant si et comment leurs géométries partagent une portion d’espace.
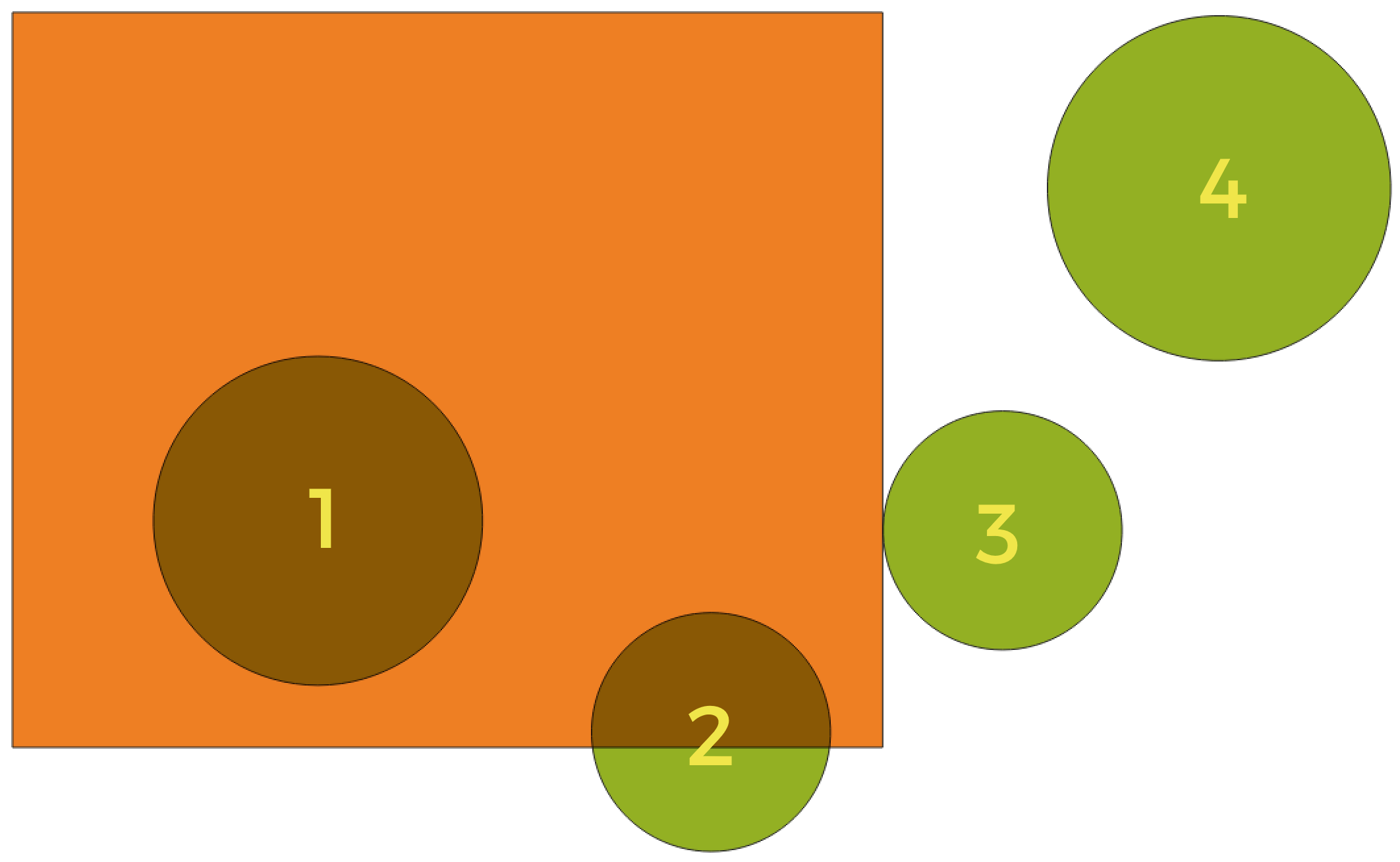
Fig. 24.98 Recherche de relations spatiales entre les couches
En utilisant la figure ci-dessus, nous recherchons les cercles verts en les comparant spatialement à l’entité rectangle orange. Les prédicats géométriques disponibles sont :
- Intersection
Teste si une géométrie en intersecte une autre. Renvoie 1 (vrai) si les géométries se coupent spatialement (partagent une partie de l’espace - se chevauchent ou se touchent) et 0 si ce n’est pas le cas. Dans l’image ci-dessus, cela renvoie les cercles 1, 2 et 3.
- Contient
Retourne 1 (vrai) si et seulement si aucun point de b ne se trouve à l’extérieur de a, et qu’au moins un point de l’intérieur de b se trouve à l’intérieur de a. Dans l’image, aucun cercle n’est retourné, mais le rectangle le serait si vous le cherchiez dans l’autre sens, car il contient complètement le cercle 1. C’est le contraire de *sont à l’intérieur *.
- Disjoint
Renvoie 1 (vrai) si les géométries ne partagent aucune portion d’espace (pas de chevauchement, pas de contact). Seul le cercle 4 est renvoyé.
- Egal
Renvoie 1 (vrai) si et seulement si les géométries sont exactement les mêmes. Aucun cercle ne sera renvoyé.
- Touche
Teste si une géométrie en touche une autre. Renvoie 1 (vrai) si les géométries ont au moins un point en commun, mais que leurs intérieurs ne se croisent pas. Seul le cercle 3 est renvoyé.
- Chevauchement
Teste si une géométrie en recouvre une autre. Renvoie 1 (vrai) si les géométries partagent l’espace et ont la même dimension, mais ne sont pas complètement contenues l’une par l’autre. Seul le cercle 2 est renvoyé.
- Sont à l’intérieur de
Teste si une géométrie est à l’intérieur d’une autre. Renvoie 1 (vrai) si la géométrie a est complètement à l’intérieur de la géométrie b. Seul le cercle 1 est renvoyé.
- Croise
Retourne 1 (vrai) si les géométries en entrée comportent certains points intérieurs en commun , mais pas tous, et si le croisement concerné est d’une dimension inférieure à la géométrie en entrée de plus grande dimension. Par exemple, une ligne traversant un polygone le traversera en tant que ligne (vrai). Le croisement entre deux lignes sera considéré comme un point (vrai). Deux polygones s’entrecroiseront en tant que polygone (faux). Dans l’image, aucun cercle ne sera renvoyé.
Paramètres
Etiquette |
Nom |
Type |
Description |
|---|---|---|---|
Join to features in |
|
[vecteur : géométrie] |
Couche vectorielle d’entrée. La couche de sortie sera constituée des entités de cette couche avec des attributs des entités correspondantes dans la deuxième couche. |
Where the features |
|
[énumération] [liste] Par défaut : [0] |
Type of spatial relation the source feature should have with the target feature so that they could be joined. One or more of:
Si plusieurs conditions sont choisies, au moins une d’entre elles (opération OR) doit être remplie pour qu’une entité soit extraite. |
By comparing to |
|
[vecteur : géométrie] |
The join layer. Features of this vector layer will add their attributes to the source layer attribute table if they satisfy the spatial relationship. |
Champs à ajouter (laissez vide pour utiliser tous les champs) Optionnel |
|
[champ : tout type] [liste] |
Select the specific fields you want to add from the join layer. By default all the fields are added. |
Type de jointure |
|
[énumération] |
Type de la couche finale jointe. Un des:
|
Supprimer les enregistrements qui n’ont pas pu être joints |
|
[booléen] Par défaut : Faux |
Remove from the output the input layer’s features which could not be joined |
Préfixe de champ joint Optionnel |
|
[Chaîne de caractères] |
Ajoutez un préfixe aux champs joints afin de les identifier facilement et d’éviter la collision des noms de champs |
Couche jointe Optionnel |
|
[identique à l’entrée] Par défaut : |
Specify the output vector layer for the join. One of:
L’encodage du fichier peut également être modifié ici. |
Entités non joignables de la première couche Optionnel |
|
[identique à l’entrée] Par défaut : |
Specify the output vector layer for unjoinable features from first layer. One of:
L’encodage du fichier peut également être modifié ici. |
Les sorties
Etiquette |
Nom |
Type |
Description |
|---|---|---|---|
Nombre d’entités jointes de la table d’entrée |
|
[numérique : entier] |
|
Entités non joignables de la première couche Optionnel |
|
[identique à l’entrée] |
Couche vectorielle des entités non appariées |
Couche jointe |
|
[identique à l’entrée] |
Couche vectorielle de sortie avec des attributs ajoutés à partir de la jointure |
Code Python
ID de l’algorithme : native:joinattributesbylocation
import processing
processing.run("algorithm_id", {parameter_dictionary})
L”id de l’algorithme est affiché lors du survol du nom de l’algorithme dans la boîte à outils Traitements. Les nom et valeur de chaque paramètre sont fournis via un dictionnaire de paramètres. Voir Utiliser les algorithmes du module de traitements depuis la console Python pour plus de détails sur l’exécution d’algorithmes via la console Python.
24.1.25.20. Joindre des attributs par localisation (résumé)
Prend une couche vectorielle d’entrée et crée une nouvelle couche vectorielle qui est une version étendue de celle d’entrée, avec des attributs supplémentaires dans sa table d’attributs.
Les attributs supplémentaires et leurs valeurs proviennent d’une deuxième couche vectorielle. Un critère spatial est appliqué pour sélectionner les valeurs de la deuxième couche qui sont ajoutées à chaque entité de la première couche.
L’algorithme calcule un résumé statistique pour les valeurs des entités correspondantes dans la deuxième couche (par exemple, valeur maximale, valeur moyenne, etc.).
Voir aussi
Explorer les relations spatiales
Les prédicats géométriques sont des fonctions booléennes utilisées pour déterminer la relation spatiale d’une entité avec une autre en comparant si et comment leurs géométries partagent une portion d’espace.
Fig. 24.99 Recherche de relations spatiales entre les couches
En utilisant la figure ci-dessus, nous recherchons les cercles verts en les comparant spatialement à l’entité rectangle orange. Les prédicats géométriques disponibles sont :
- Intersection
Teste si une géométrie en intersecte une autre. Renvoie 1 (vrai) si les géométries se coupent spatialement (partagent une partie de l’espace - se chevauchent ou se touchent) et 0 si ce n’est pas le cas. Dans l’image ci-dessus, cela renvoie les cercles 1, 2 et 3.
- Contient
Retourne 1 (vrai) si et seulement si aucun point de b ne se trouve à l’extérieur de a, et qu’au moins un point de l’intérieur de b se trouve à l’intérieur de a. Dans l’image, aucun cercle n’est retourné, mais le rectangle le serait si vous le cherchiez dans l’autre sens, car il contient complètement le cercle 1. C’est le contraire de *sont à l’intérieur *.
- Disjoint
Renvoie 1 (vrai) si les géométries ne partagent aucune portion d’espace (pas de chevauchement, pas de contact). Seul le cercle 4 est renvoyé.
- Egal
Renvoie 1 (vrai) si et seulement si les géométries sont exactement les mêmes. Aucun cercle ne sera renvoyé.
- Touche
Teste si une géométrie en touche une autre. Renvoie 1 (vrai) si les géométries ont au moins un point en commun, mais que leurs intérieurs ne se croisent pas. Seul le cercle 3 est renvoyé.
- Chevauchement
Teste si une géométrie en recouvre une autre. Renvoie 1 (vrai) si les géométries partagent l’espace et ont la même dimension, mais ne sont pas complètement contenues l’une par l’autre. Seul le cercle 2 est renvoyé.
- Sont à l’intérieur de
Teste si une géométrie est à l’intérieur d’une autre. Renvoie 1 (vrai) si la géométrie a est complètement à l’intérieur de la géométrie b. Seul le cercle 1 est renvoyé.
- Croise
Retourne 1 (vrai) si les géométries en entrée comportent certains points intérieurs en commun , mais pas tous, et si le croisement concerné est d’une dimension inférieure à la géométrie en entrée de plus grande dimension. Par exemple, une ligne traversant un polygone le traversera en tant que ligne (vrai). Le croisement entre deux lignes sera considéré comme un point (vrai). Deux polygones s’entrecroiseront en tant que polygone (faux). Dans l’image, aucun cercle ne sera renvoyé.
Paramètres
Etiquette |
Nom |
Type |
Description |
|---|---|---|---|
Join to features in |
|
[vecteur : géométrie] |
Couche vectorielle d’entrée. La couche de sortie sera constituée des entités de cette couche avec des attributs des entités correspondantes dans la deuxième couche. |
Where the features |
|
[énumération] [liste] Par défaut : [0] |
Type of spatial relation the source feature should have with the target feature so that they could be joined. One or more of:
Si plusieurs conditions sont choisies, au moins une d’entre elles (opération OR) doit être remplie pour qu’une entité soit extraite. |
By comparing to |
|
[vecteur : géométrie] |
The join layer. Features of this vector layer will add summaries of their attributes to the source layer attribute table if they satisfy the spatial relationship. |
Champs à résumer (laissez vide pour utiliser tous les champs) Optionnel |
|
[champ : tout type] [liste] |
Select the specific fields you want to add from the join layer. By default all the fields are added. |
Résumés à calculer (laisser vide pour utiliser tous les champs) Optionnel |
|
[énumération] [liste] Par défaut : [] |
For each input feature, statistics are calculated on joined fields of their matching features. One or more of:
|
Supprimer les enregistrements qui n’ont pas pu être joints |
|
[booléen] Par défaut : Faux |
Remove from the output the input layer’s features which could not be joined |
Couche jointe |
|
[identique à l’entrée] Par défaut : |
Specify the output vector layer for the join. One of:
L’encodage du fichier peut également être modifié ici. |
Les sorties
Etiquette |
Nom |
Type |
Description |
|---|---|---|---|
Couche jointe |
|
[identique à l’entrée] |
Couche vectorielle de sortie avec des attributs résumés de la jointure |
Code Python
Algorithm ID: native:joinbylocationsummary
import processing
processing.run("algorithm_id", {parameter_dictionary})
L”id de l’algorithme est affiché lors du survol du nom de l’algorithme dans la boîte à outils Traitements. Les nom et valeur de chaque paramètre sont fournis via un dictionnaire de paramètres. Voir Utiliser les algorithmes du module de traitements depuis la console Python pour plus de détails sur l’exécution d’algorithmes via la console Python.
24.1.25.21. Joindre les attributs par le plus proche
Prend une couche vectorielle d’entrée et crée une nouvelle couche vectorielle avec des champs supplémentaires dans sa table attributaire. Les attributs supplémentaires et leurs valeurs proviennent d’une deuxième couche vectorielle. Les entités sont jointes en trouvant les entités les plus proches de chaque couche.
Par défaut, seule l’entité la plus proche est jointe, mais la jointure peut également se joindre aux k entités voisines les plus proches.
Si une distance maximale est spécifiée, seules les entités plus proches que cette distance seront mises en correspondance.
Avertissement
Cet algorithme supprime les clés primaires ou les valeurs FID existantes et les régénère dans les couches de sortie.
Voir aussi
Analyse du plus proche voisin, Joindre des attributs par valeur de champ, Joindre les attributs par localisation, Matrice de distance
Paramètres
Etiquette |
Nom |
Type |
Description |
|---|---|---|---|
Couche en entrée |
|
[vecteur : géométrie] |
La couche d’entrée. |
Couche d’entrée 2 |
|
[vecteur : géométrie] |
La couche de jointure. |
Champs de couche 2 à copier (laissez vide pour copier tous les champs) |
|
[champ : tout type] [liste] |
Joindre les champs de couche à copier (s’ils sont vides, tous les champs seront copiés). |
Supprimer les enregistrements qui n’ont pas pu être joints |
|
[booléen] Par défaut : Faux |
Supprimer de la sortie les enregistrements de couche d’entrée qui n’ont pas pu être joints |
Préfixe de champ joint |
|
[Chaîne de caractères] |
Préfixe de champ joint |
Maximum de voisins les plus proches |
|
[numérique : entier] Par défaut : 1 |
Nombre maximum de voisins les plus proches |
Distance maximale |
|
[numérique: décimal] |
Distance de recherche maximale |
Couche jointe Optionnel |
|
[identique à l’entrée] Par défaut : |
Specify the vector layer containing the joined features. One of:
L’encodage du fichier peut également être modifié ici. |
Entités non joignables de la première couche |
|
[identique à l’entrée] Par défaut : |
Specify the vector layer containing the features that could not be joined. One of:
L’encodage du fichier peut également être modifié ici. |
Les sorties
Etiquette |
Nom |
Type |
Description |
|---|---|---|---|
Couche jointe |
|
[identique à l’entrée] |
La couche jointe en sortie. |
Entités non joignables de la première couche |
|
[identique à l’entrée] |
Couche contenant les entités de la première couche qui n’ont pu être jointes à aucune entité de la couche de jointure. |
Nombre d’entités jointes de la table d’entrée |
|
[numérique : entier] |
Nombre d’entités de la table d’entrée qui ont été jointes. |
Nombre d’entités non joignables de la table d’entrée |
|
[numérique : entier] |
Nombre d’entités de la table d’entrée qui n’ont pas pu être jointes. |
Code Python
ID de l’algorithme : native:joinbynearest
import processing
processing.run("algorithm_id", {parameter_dictionary})
L”id de l’algorithme est affiché lors du survol du nom de l’algorithme dans la boîte à outils Traitements. Les nom et valeur de chaque paramètre sont fournis via un dictionnaire de paramètres. Voir Utiliser les algorithmes du module de traitements depuis la console Python pour plus de détails sur l’exécution d’algorithmes via la console Python.
24.1.25.22. Fusionner les couches vecteur
Combine plusieurs couches vectorielles de même type de géométrie en une seule.
The attribute table of the resulting layer will contain the fields from all input layers. If fields with the same name but different types are found then the exported field will be automatically converted into a string type field. Optionally, new fields storing the original layer name and source can be added.
Si des couches d’entrée contiennent des valeurs Z ou M, la couche de sortie contiendra également ces valeurs. De même, si l’une des couches d’entrée est en plusieurs parties,la couche de sortie sera également une couche en plusieurs parties.
Facultativement, le système de référence de coordonnées de destination (SCR) pour la couche fusionnée peut être défini. S’il n’est pas défini, le SCR sera extrait de la première couche d’entrée. Toutes les couches seront reprojetées pour correspondre à ce SCR.
Menu par défaut:
Avertissement
Cet algorithme supprime les clés primaires ou les valeurs FID existantes et les régénère dans les couches de sortie.
Voir aussi
Paramètres
Etiquette |
Nom |
Type |
Description |
|---|---|---|---|
Couches d’entrée |
|
[vecteur : tout type] [liste] |
Les couches à fusionner en une seule couche. Les couches doivent être du même type de géométrie. |
SCR cible Optionnel |
|
[scr] |
Choisissez le SCR pour la couche de sortie. S’il n’est pas spécifié, le SCR de la première couche d’entrée est utilisé. |
Add source layer information (layer name and path)
|
|
[booléen] Par défaut : Vrai |
Add fields storing the original layer name and path |
Fusionné |
|
[identique à l’entrée] Par défaut : |
Specify the output vector layer. One of:
L’encodage du fichier peut également être modifié ici. |
Les sorties
Etiquette |
Nom |
Type |
Description |
|---|---|---|---|
Fusionné |
|
[identique à l’entrée] |
Couche vectorielle de sortie contenant toutes les entités et tous les attributs des couches en entrée. |
Code Python
ID de l’algorithme : native:mergevectorlayers
import processing
processing.run("algorithm_id", {parameter_dictionary})
L”id de l’algorithme est affiché lors du survol du nom de l’algorithme dans la boîte à outils Traitements. Les nom et valeur de chaque paramètre sont fournis via un dictionnaire de paramètres. Voir Utiliser les algorithmes du module de traitements depuis la console Python pour plus de détails sur l’exécution d’algorithmes via la console Python.
24.1.25.23. Ordonner par expression
Trie une couche vectorielle en fonction d’une expression: modifie l’indice d’entité en fonction d’une expression.
Attention, cela pourrait ne pas fonctionner comme prévu avec certains fournisseurs, la commande pourrait ne pas être conservée à chaque fois.
Avertissement
Cet algorithme supprime les clés primaires ou les valeurs FID existantes et les régénère dans les couches de sortie.
Paramètres
Etiquette |
Nom |
Type |
Description |
|---|---|---|---|
Couche d’entrée |
|
[vecteur : tout type] |
Couche vectorielle d’entrée à trier |
Expression |
|
[expression] |
Couche vectorielle d’entrée à trier |
Trier par ordre croissant |
|
[booléen] Par défaut : Vrai |
Si cette case est cochée, la couche vectorielle sera triée de petites à grandes valeurs. |
Trier les valeurs nulles en premier |
|
[booléen] Par défaut : Faux |
Si coché, les valeurs nulles sont placées en premier |
Ordonné |
|
[identique à l’entrée] Par défaut : |
Specify the output vector layer. One of:
L’encodage du fichier peut également être modifié ici. |
Les sorties
Etiquette |
Nom |
Type |
Description |
|---|---|---|---|
Ordonné |
|
[identique à l’entrée] |
Couche vectorielle de sortie (triée) |
Code Python
ID de l’algorithme : native:orderbyexpression
import processing
processing.run("algorithm_id", {parameter_dictionary})
L”id de l’algorithme est affiché lors du survol du nom de l’algorithme dans la boîte à outils Traitements. Les nom et valeur de chaque paramètre sont fournis via un dictionnaire de paramètres. Voir Utiliser les algorithmes du module de traitements depuis la console Python pour plus de détails sur l’exécution d’algorithmes via la console Python.
24.1.25.24. Réparer le shapefile
Répare un jeu de données ESRI Shapefile rompu en recréant le fichier SHX.
Paramètres
Etiquette |
Nom |
Type |
Description |
|---|---|---|---|
Shapefile en entrée |
|
[fichier] |
Chemin d’accès complet au jeu de données ESRI Shapefile dont le fichier SHX est manquant ou cassé. |
Les sorties
Etiquette |
Nom |
Type |
Description |
|---|---|---|---|
Couche réparée |
|
[vecteur : géométrie] |
La couche de vecteurs d’entrée avec le fichier SHX réparé |
Code Python
ID de l’algorithme : native:repairshapefile
import processing
processing.run("algorithm_id", {parameter_dictionary})
L”id de l’algorithme est affiché lors du survol du nom de l’algorithme dans la boîte à outils Traitements. Les nom et valeur de chaque paramètre sont fournis via un dictionnaire de paramètres. Voir Utiliser les algorithmes du module de traitements depuis la console Python pour plus de détails sur l’exécution d’algorithmes via la console Python.
24.1.25.25. Reprojeter la couche
Reprojete une couche vectorielle dans un SCR différent. La couche reprojetée aura les mêmes caractéristiques et attributs que la couche d’entrée.
Permet la modification de la couche source pour des entités de type point, ligne ou polygone
Paramètres
Paramètres basiques
Etiquette |
Nom |
Type |
Description |
|---|---|---|---|
Couche d’entrée |
|
[vecteur : géométrie] |
Couche vectorielle d’entrée à reprojeter |
SCR cible |
|
[scr] Par défaut : |
Système de référence des coordonnées de destination |
Convert curved geometries to straight segments
|
|
[booléen] Par défaut : Faux |
If checked, curved geometries will be converted to straight segments in the process, avoiding potential distortion issues. |
Reprojeté |
|
[identique à l’entrée] Par défaut : |
Specify the output vector layer. One of:
L’encodage du fichier peut également être modifié ici. |
Paramètres avancés
Etiquette |
Nom |
Type |
Description |
|---|---|---|---|
Opération de coordination Optionnel |
|
[Chaîne de caractères] |
Opération spécifique à utiliser pour une tâche de reprojection particulière, au lieu de toujours forcer l’utilisation des paramètres de transformation du projet actuel. Utile lorsque l’on reprojette une couche particulière et que l’on souhaite contrôler le transformation exact. Nécessite une version de proj >= 6. Pour en savoir plus, consultez Transformations de systèmes géodésiques (datum). |
Les sorties
Etiquette |
Nom |
Type |
Description |
|---|---|---|---|
Reprojeté |
|
[identique à l’entrée] |
Couche vectorielle de sortie (reprojetée) |
Code Python
ID de l’algorithme : native:reprojectlayer
import processing
processing.run("algorithm_id", {parameter_dictionary})
L”id de l’algorithme est affiché lors du survol du nom de l’algorithme dans la boîte à outils Traitements. Les nom et valeur de chaque paramètre sont fournis via un dictionnaire de paramètres. Voir Utiliser les algorithmes du module de traitements depuis la console Python pour plus de détails sur l’exécution d’algorithmes via la console Python.
24.1.25.26. Save vector features to file
Saves vector features to a specified file dataset.
For dataset formats supporting layers, an optional layer name parameter can be used to specify a custom string. Optional GDAL-defined dataset and layer options can be specified. For more information on this, read the online GDAL documentation on the format.
Paramètres
Paramètres basiques
Etiquette |
Nom |
Type |
Description |
|---|---|---|---|
Vector features |
|
[vecteur : tout type] |
Input vector layer. |
Saved features |
|
[identique à l’entrée] Par défaut : |
Specify the file to save the features to. One of:
|
Paramètres avancés
Etiquette |
Nom |
Type |
Description |
|---|---|---|---|
Layer name Optionnel |
|
[Chaîne de caractères] |
Name to use for the output layer |
GDAL dataset options Optionnel |
|
[Chaîne de caractères] |
GDAL dataset creation options of the output format. Separate individual options with semicolons. |
GDAL layer options Optionnel |
|
[Chaîne de caractères] |
GDAL layer creation options of the output format. Separate individual options with semicolons. |
Action to take on pre-existing file |
|
[énumération] Par défaut : 0 |
How to manage existing features. Valid methods are:
|
Les sorties
Etiquette |
Nom |
Type |
Description |
|---|---|---|---|
Saved features |
|
[identique à l’entrée] |
Vector layer with the saved features. |
File name and path |
|
[Chaîne de caractères] |
Output file name and path. |
Layer name |
|
[Chaîne de caractères] |
Nom de la couche, si fourni. |
Code Python
ID de l’algorithme : native:savefeatures
import processing
processing.run("algorithm_id", {parameter_dictionary})
L”id de l’algorithme est affiché lors du survol du nom de l’algorithme dans la boîte à outils Traitements. Les nom et valeur de chaque paramètre sont fournis via un dictionnaire de paramètres. Voir Utiliser les algorithmes du module de traitements depuis la console Python pour plus de détails sur l’exécution d’algorithmes via la console Python.
24.1.25.27. Définir l’encodage d’une couche
Sets the encoding used for reading a layer’s attributes. No permanent changes are made to the layer, rather it affects only how the layer is read during the current session.
Note
Changing the encoding is only supported for some vector layer data sources.
Paramètres
Etiquette |
Nom |
Type |
Description |
|---|---|---|---|
Saved features |
|
[vecteur : géométrie] |
Vector layer to set the encoding. |
Codage |
|
[Chaîne de caractères] |
Text encoding to assign to the layer in the current QGIS session. |
Les sorties
Etiquette |
Nom |
Type |
Description |
|---|---|---|---|
Couche en sortie |
|
[identique à l’entrée] |
Input vector layer with the set encoding. |
Code Python
ID de l’algorithme : native:setlayerencoding
import processing
processing.run("algorithm_id", {parameter_dictionary})
L”id de l’algorithme est affiché lors du survol du nom de l’algorithme dans la boîte à outils Traitements. Les nom et valeur de chaque paramètre sont fournis via un dictionnaire de paramètres. Voir Utiliser les algorithmes du module de traitements depuis la console Python pour plus de détails sur l’exécution d’algorithmes via la console Python.
24.1.25.28. Couper les entités par caractère
Les entités sont divisées en plusieurs entités de sortie en divisant la valeur d’un champ à un caractère spécifié. Par exemple, si une couche contient des entités avec plusieurs valeurs séparées par des virgules contenues dans un seul champ, cet algorithme peut être utilisé pour répartir ces valeurs entre plusieurs entités en sortie. Les géométries et autres attributs restent inchangés dans la sortie. Facultativement, la chaîne de séparation peut être une expression régulière pour plus de flexibilité.
Permet la modification de la couche source pour des entités de type point, ligne ou polygone
Avertissement
Cet algorithme supprime les clés primaires ou les valeurs FID existantes et les régénère dans les couches de sortie.
Paramètres
Etiquette |
Nom |
Type |
Description |
|---|---|---|---|
Couche d’entrée |
|
[vecteur : tout type] |
Couche vectorielle en entrée |
Couper en utilisant des valeurs dans le champ |
|
[champ : tout type] |
Champ à utiliser pour le fractionnement |
Fractionner la valeur en utilisant le caractère |
|
[Chaîne de caractères] |
Caractère à utiliser pour le fractionnement |
Utilisez un séparateur d’expressions régulières |
|
[booléen] Par défaut : Faux |
|
Fractionner |
|
[identique à l’entrée] Par défaut : |
Specify the output vector layer. One of:
L’encodage du fichier peut également être modifié ici. |
Les sorties
Etiquette |
Nom |
Type |
Description |
|---|---|---|---|
Fractionner |
|
[identique à l’entrée] |
La couche de vecteur de sortie. |
Code Python
ID de l’algorithme : native:splitfeaturesbycharacter
import processing
processing.run("algorithm_id", {parameter_dictionary})
L”id de l’algorithme est affiché lors du survol du nom de l’algorithme dans la boîte à outils Traitements. Les nom et valeur de chaque paramètre sont fournis via un dictionnaire de paramètres. Voir Utiliser les algorithmes du module de traitements depuis la console Python pour plus de détails sur l’exécution d’algorithmes via la console Python.
24.1.25.29. Séparer une couche vecteur
Crée un ensemble de vecteurs dans un dossier de sortie basé sur une couche d’entrée et un attribut. Le dossier de sortie contiendra autant de couches que les valeurs uniques trouvées dans le champ souhaité.
Le nombre de fichiers générés est égal au nombre de valeurs différentes trouvées pour l’attribut spécifié.
C’est l’opposé de fusionner.
Menu par défaut:
Voir aussi
Paramètres
Paramètres basiques
Etiquette |
Nom |
Type |
Description |
|---|---|---|---|
Couche d’entrée |
|
[vecteur : tout type] |
Couche vectorielle en entrée |
Champ ID unique |
|
[champ : tout type] |
Champ à utiliser pour le fractionnement |
Répertoire de destination |
|
[répertoire] Par défaut : |
Specify the directory for the output layers. One of:
|
Paramètres avancés
Etiquette |
Nom |
Type |
Description |
|---|---|---|---|
Type de fichier en sortie Optionnel |
|
[énumération] Par défaut : |
Select the extension of the output files. If not specified or invalid, the output files format will be the one set in the « Default output vector layer extension » Processing setting. |
Les sorties
Etiquette |
Nom |
Type |
Description |
|---|---|---|---|
Répertoire de destination |
|
[répertoire] |
Le répertoire des couches de sortie |
Couches de sortie |
|
[identique à l’entrée] [liste] |
Les couches vectorielles de sortie résultant de la scission. |
Code Python
ID de l’algorithme : native:splitvectorlayer
import processing
processing.run("algorithm_id", {parameter_dictionary})
L”id de l’algorithme est affiché lors du survol du nom de l’algorithme dans la boîte à outils Traitements. Les nom et valeur de chaque paramètre sont fournis via un dictionnaire de paramètres. Voir Utiliser les algorithmes du module de traitements depuis la console Python pour plus de détails sur l’exécution d’algorithmes via la console Python.
24.1.25.30. Tronquer la table
Tronque une couche en supprimant toutes les entités de la couche.
Avertissement
Cet algorithme modifie la couche en place et les entités supprimées ne peuvent pas être restaurées!
Paramètres
Etiquette |
Nom |
Type |
Description |
|---|---|---|---|
Couche d’entrée |
|
[vecteur : tout type] |
Couche vectorielle en entrée |
Les sorties
Etiquette |
Nom |
Type |
Description |
|---|---|---|---|
Couche tronquée |
|
[répertoire] |
The input layer, all features deleted |
Code Python
ID de l’algorithme : native:truncatetable
import processing
processing.run("algorithm_id", {parameter_dictionary})
L”id de l’algorithme est affiché lors du survol du nom de l’algorithme dans la boîte à outils Traitements. Les nom et valeur de chaque paramètre sont fournis via un dictionnaire de paramètres. Voir Utiliser les algorithmes du module de traitements depuis la console Python pour plus de détails sur l’exécution d’algorithmes via la console Python.