Important
La traduction est le fruit d’un effort communautaire auquel vous pouvez vous joindre. Cette page est actuellement traduite à 75.00%.
17.23. Plus d’interpolation
Note
Ce chapitre montre un autre cas pratique où les algorithmes d’interpolation sont utilisés.
L’interpolation est une technique commune, et elle peut être utilisée pour démontrer plusieurs techniques qui peuvent être appliquées en utilisant le module de traitements QGIS. Cette leçon utilise certains algorithmes d’interpolation qui ont déjà été introduits, mais utilise une approche différente.
Les données pour cette leçon contiennent également une couche de points, dans ce cas avec des données d’élévation. Nous allons les interpoler principalement de la même façon que nous l’avons fait dans la leçon précédente, mais cette fois nous sauvegarderons une partie des données originales pour les utiliser pour évaluer la qualité du processus d’interpolation.
First, we have to rasterize the points layer and fill the resulting no–data cells, but using just a fraction of the points in the layer. We will save 10% of the points for a later check, so we need to have 90% of the points ready for the interpolation. To do so, we could use the Split shapes layer randomly algorithm, which we have already used in a previous lesson, but there is a better way to do that, without having to create any new intermediate layer. Instead of that, we can just select the points we want to use for the interpolation (the 90% fraction), and then run the algorithm. As we have already seen, the rasterizing algorithm will use only those selected points and ignore the rest. The selection can be done using the Random selection algorithm. Run it with the following parameters.
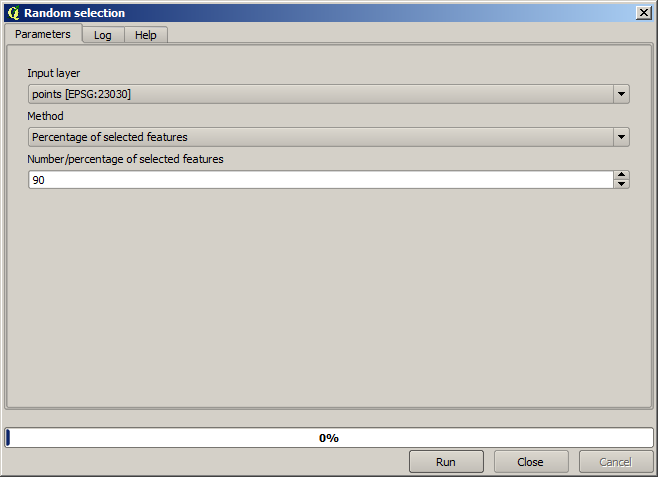
Cela va sélectionner 90% des points dans la couche à pixeliser

La sélection est aléatoire, donc votre sélection devrait différer de la sélection montrée dans l’image ci-dessus.
Now run the Rasterize algorithm to get the first raster layer, and then run the Close gaps algorithm to fill the no-data cells [Cell resolution: 100 m].

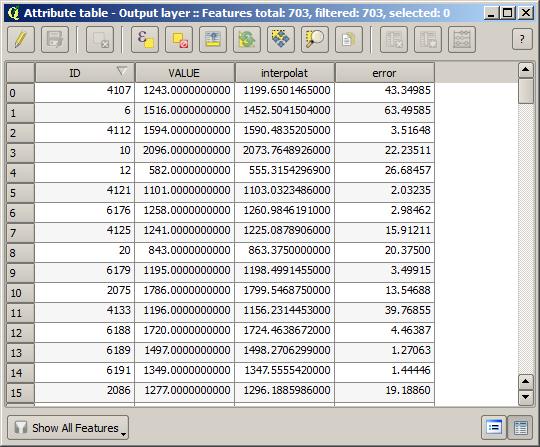
Pour vérifier la qualité de l’interpolation, nous pouvons maintenant utiliser les points qui n’ont pas été sélectionnés. Nous connaissons, en ce point, l’élévation réelle (la valeur dans la couche de points) ainsi que l’élévation interpolée (la valeur présente dans la couche raster interpolée). Nous pouvons comparer les deux en calculant leur différence.
Comme nous allons d’abord utiliser les points qui ne sont pas sélectionné, inversons la sélection.

The points contain the original values, but not the interpolated ones. To add them in a new field, we can use the Add raster values to points algorithm
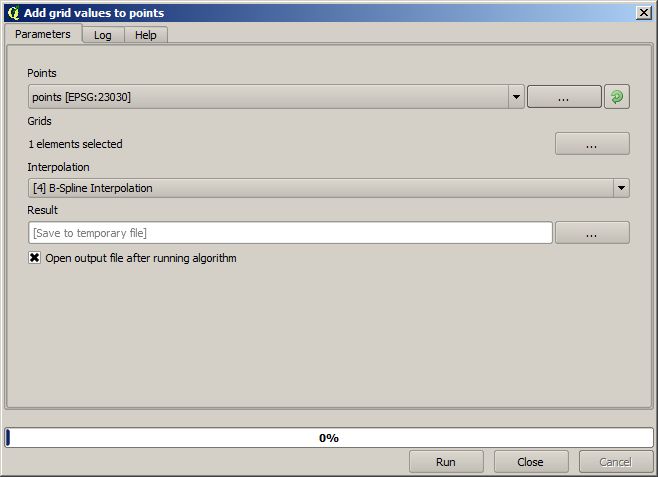
The raster layer to select (the algorithm supports multiple raster, but we just need one) is the resulting one from the interpolation. We have renamed it to interpolate and that layer name is the one that will be used for the name of the field to add.
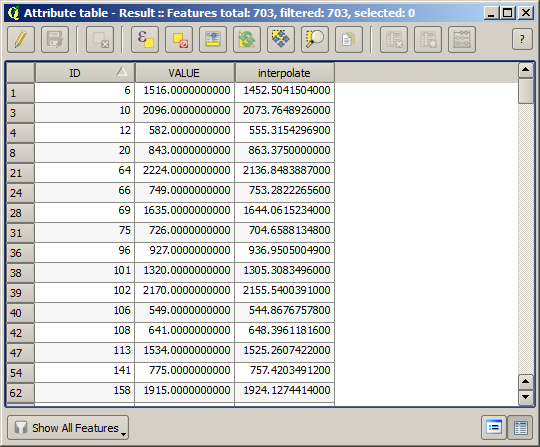
Nous avons maintenant une couche vecteur qui contient ces deux valeurs, avec des points qui n’étaient pas utilisé pour l’interpolation.
Now, we will use the fields calculator for this task. Open the Field calculator algorithm and run it with the following parameters.
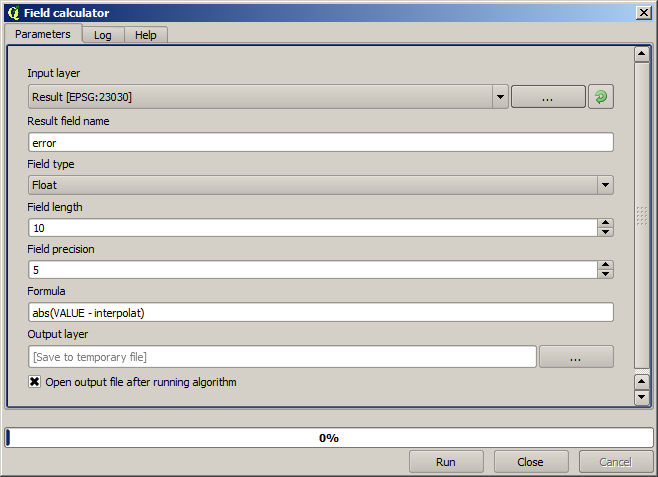
Si votre champ avec les valeurs de la couche raster a un nom différent, vous devrez modifier la formule ci-dessus en conséquence. En exécutant cet algorithme, vous obtiendrez une nouvelle couche avec uniquement les points que nous n’avons pas utilisé pour l’interpolation, chacun d’eux contenant la différence entre les deux valeurs d’élévation.
Représenter cette couche selon cette valeur nous donnera une première idée d’où se trouvent les grands écarts.
Interpoler cette couche vous donnera une couche raster avec l’erreur estimée dans tous les points de la zone interpolée.
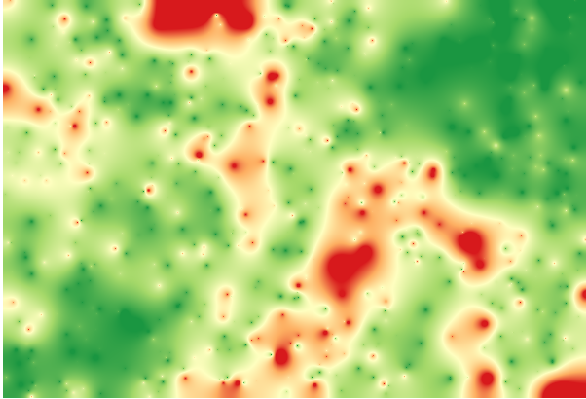
Vous pouvez aussi obtenir la même information (différence entre les valeurs des points d’origine et ceux interpolés) directement avec .
Vos résultats devrait différer de ceux-ci, car il y a une composante aléatoire introduite lors de l’exécution de la sélection aléatoire, au début de cette leçon.