Important
La traduction est le fruit d’un effort communautaire auquel vous pouvez vous joindre. Cette page est actuellement traduite à 97.14%.
17.10. La calculatrice raster. Valeurs No-data
Note
Dans cette leçon, nous verrons comment utiliser la calculatrice raster pour effectuer des opérations sur des couches raster. Nous expliquerons également qu’est-ce que sont les valeurs no–data et comment la calculatrice et les autres algorithmes réagissent avec elles.
La calculatrice rester est un des plus puissants algorithmes que vous trouverez. C’est un algorithme très flexible et souple qui peut être utilisé pour beaucoup de calculs différents, et il deviendra bientôt une partie importante de votre boîte à outils.
Dans cette leçon, nous allons réaliser quelques calculs, plutôt simples, à l’aide de la calculatrice raster. Cela nous permettra de voir comment l’utiliser et comment gérer certaines situations particulières que nous pourrons rencontrer. Comprendre est une étape importante pour obtenir à l’avenir des résultats adaptés en utilisant la calculatrice et également pour maîtriser certaines techniques qui sont courramment employées avec.
Ouvrez le projet QGIS correspondant à cette leçon et vous verrez qu’il contient plusieurs couches raster.
Ouvrez maintenant la boîte à outils et ouvrez la boîte de dialogue correspondant à la calculatrice raster.
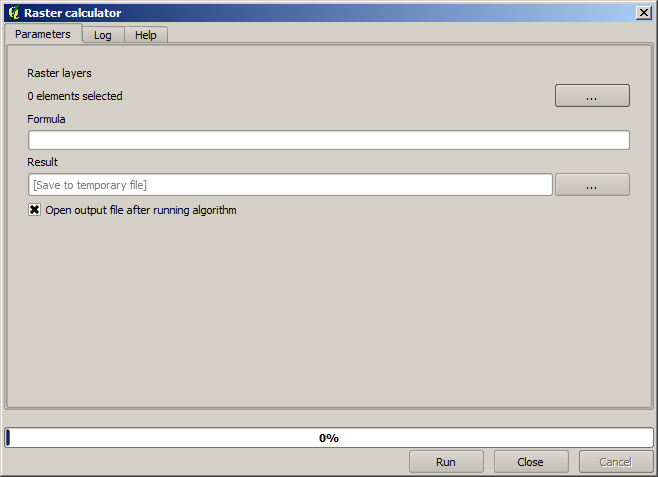
Note
L’interface est différente dans les versions récentes.
La boîte de dialogue contient 2 paramètres.
Les couches à utiliser pour l’analyse. C’est une entrée multiple, ce qui signifie que vous pouvez sélectionner autant de couches que vous voulez. Cliquez sur le bouton sur le côté droit et sélectionnez ensuite les couches que vous voulez utiliser dans la boîte de dialogue qui apparaît.
La formule à appliquer. La formule utilise les couches sélectionnées dans le paramètre du haut, qui sont nommées en utilisant les lettres de l’alphabet (
a, b, c...) oug1, g2, g3...comme nom de variable. Autrement dit, la formulea + 2 * best la même queg1 + 2 * g2et calculera la somme des valeurs dans la première couche plus deux fois la valeur dans la seconde couche. L’ordre des couches est le même ordre que vous voyez dans la boîte de dialogue de sélection.
Avertissement
La calculatrice est sensible à la casse.
Pour commencer, nous changerons les unités du MNE des mètres aux pieds. La formule dont nous avons besoin est la suivante :
h' = h * 3.28084
Sélectionnez le MNE dans le champ des couches et tapez a * 3.28084 dans le champ de formule.
Avertissement
Pour les utilisateurs non anglophones : utilisez toujours « . », et non « , ».
Cliquez sur Exécuter pour lancer l’algorithme. Vous obtiendrez une couche qui a la même apparence que la couche d’entrée, mais avec des valeurs différentes. La couche d’entrée que nous avons utilisée possède des valeurs valides dans toutes ses cellules, donc le dernier paramètre n’a pas du tout d’effet.
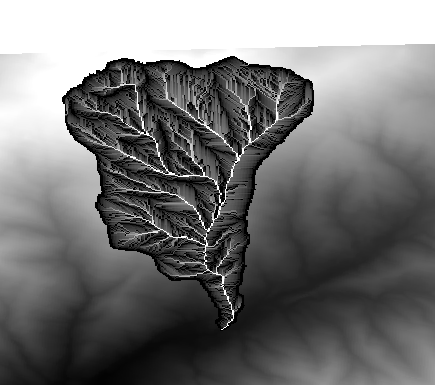
Effectuons maintenant un autre calcul, cette fois sur la couche accflow. Cette couche contient des valeurs de flux cumulés, un paramètre hydrologique. Elle contient des valeurs seulement dans la zone d’un bassin hydrographique donné, avec des valeurs no–data en dehors de celui-ci. Comme vous pouvez le voir, le rendu n’est pas très instructif, en raison de la façon dont les valeurs sont distribuées. L’utilisation du logarithme de cette accumulation de flux donnera une représentation beaucoup plus instructive. Nous pouvons calculer cela en utilisant la calculatrice raster.
Ouvrez à nouveau la boîte de dialogue de l’algorithme, sélectionnez la couche accflow comme la seule couche d’entrée, et entrez la formule suivante : log(a)`.
Voici la couche que vous obtiendrez.
Si vous sélectionnez l’outil Identifier pour connaître la valeur d’une couche à un point donné, sélectionnez la couche que nous venons juste de créer, et cliquez sur un point en dehors du bassin, vous verrez qu’il contient une valeur no–data.
Pour l’exercice suivant, nous allons utiliser deux couches à la place d’une, et nous allons obtenir un MNE avec des valeurs d’élévation valides seulement dans le bassin défini dans la seconde couche. Ouvrez la boîte de dialogue de la calculatrice et sélectionnez les deux couches du projet dans le champ des couches d’entrée. Entrez la formule suivant dans le champ correspondant :
a/a * b
a fait référence à la couche de flux cumulé (car il est la premier à apparaître dans la liste) et b fait référence au MNE. Ce que nous allons faire dans la première partie de cette formule ici est de diviser la couche de flux cumulé par elle-même, ce qui donnera une valeur de 1 dans le bassin, et une valeur no–data à l’extérieur. Puis nous multiplions par le MNE, pour obtenir la valeur d’élévation dans les cellules dans le bassin (MNE * 1 = MNE) et des valeurs no–data à l’extérieur (MNE * no_data = no_data)
Voici la couche de résultat.

Cette technique est fréquemment utilisée pour masquer des valeurs dans une couche raster, et est utile toute les fois que vous voulez effectuer des calculs pour une région autre que la région rectangulaire arbitraire qui est utilisée par une couche raster. Par exemple, un histogramme des élévations d’une couche raster n’a pas beaucoup de sens. S’il est à la place calculé en utilisant seulement des valeurs qui correspondent à un bassin (comme dans le cas ci-dessus), le résultat que nous obtenons a un sens et donne effectivement des informations sur la configuration du bassin.
There are other interesting things about this algorithm that we have just run, apart from the no–data values and how they are handled. If you have a look at the extents of the layers that we have multiplied (you can do it double-clicking on the names of the layers in the table of contents and looking at the properties), you will see that they are not the same, since the extent covered by the flow accumulation layer is smaller that the extent of the full DEM.
Cela signifie que ces couches ne correspondent pas et qu’elles ne peuvent pas être multipliées directement sans homogénéiser leur tailles et leur emprises en ré-échantillonnant une ou les deux couches. Cependant, nous n’avons rien fait. QGIS prend soin de cette situation et ré-échantillonne automatiquement les couches d’entrée lorsque nécessaire. L’emprise de sortie est la couverture de l’emprise minimum calculée à partir des couches d’entrée et la taille de cellule minimum de leurs tailles de cellule.
Dans ce cas (et dans la plupart des cas), cela produit les résultats souhaités, mais vous devriez toujours être conscient des opérations supplémentaires qui ont lieu, car elles pourraient influencer sur le résultat. Dans les cas où ce comportement ne devrait pas être désiré, un ré-échantillonnage manuel doit être appliqué à l’avance. Dans les chapitres suivants, nous en verrons plus sur le comportement des algorithmes lors de l’utilisation de plusieurs couches raster.
Finissons cette leçon avec un autre exercice de masquage. Nous allons calculer la pente dans toutes les aires ayant une élévation entre 1000 et 1500 mètres.
Dans ce cas, nous n’avons pas de couche à utiliser comme masque, mais nous pouvons en créer une en utilisant la calculatrice.
Lancez la calculatrice en utilisant le MNE comme seule couche d’entrée et la formule suivante
ifelse(abs(a-1250) < 250, 1, 0/0)
Comme vous pouvez le voir, nous pouvons utiliser la calculatrice non seulement pour faire de simples opérations algébriques, mais aussi pour exécuter des calculs plus complexes impliquant des propositions conditionnelles, comme celui ci-dessus.
Le résultat a une valeur de 1 dans la plage avec laquelle nous voulons travailler, et no–data dans les cellules à l’extérieur de celle-ci.

La valeur no–data vient de l’expression 0/0. Comme c’est une valeur indéterminée, SAGA ajoutera une valeur NaN (Not a Numbre, pas un nombre en anglais), qui est en fait traitée comme une valeur no–data. Avec ce petit truc, vous pouvez mettre une valeur no–data sans avoir besoin de savoir qu’est-ce que la valeur no–data de la cellule.
Vous n’avez plus qu’à maintenant la multiplier avec la couche de pente intégrée au projet, et vous obtiendrez le résultat désiré.
Tout cela peut être fait en une simple opération avec la calculatrice. Nous laissons cela comme exercice au lecteur.