Importante
La traducción es un esfuerzo comunitario puede unirse. Esta página está actualmente traducida en |progreso de traducción|.
17.23. Más de interpolación
Nota
Este capítulo mostrará otro caso practico donde se utilice los algoritmos de interpolación.
La interpolación es una técnica común y se puede utilizar para demostrar varias técnicas que se pueden aplicar utilizando el marco de procesamiento de QGIS. Esta lección utiliza algunos algoritmos de interpolación que ya se introdujeron, pero tiene un enfoque diferente.
Los datos de esta lección también contienen una capa de puntos, en este caso con datos de elevación. Lo vamos a interpolar de la misma forma que hicimos en la lección anterior, pero esta vez guardaremos parte de los datos originales para usarlos para evaluar la calidad del proceso de interpolación.
First, we have to rasterize the points layer and fill the resulting no–data cells, but using just a fraction of the points in the layer. We will save 10% of the points for a later check, so we need to have 90% of the points ready for the interpolation. To do so, we could use the Split shapes layer randomly algorithm, which we have already used in a previous lesson, but there is a better way to do that, without having to create any new intermediate layer. Instead of that, we can just select the points we want to use for the interpolation (the 90% fraction), and then run the algorithm. As we have already seen, the rasterizing algorithm will use only those selected points and ignore the rest. The selection can be done using the Random selection algorithm. Run it with the following parameters.
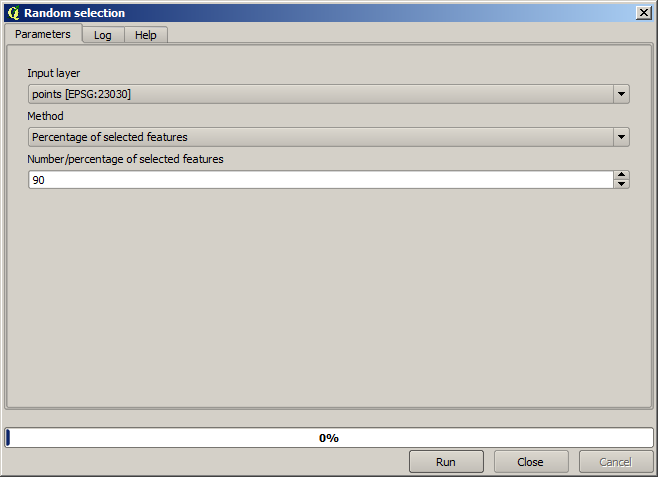
Eso seleccionará el 90% de los puntos en la capa a rasterizar

La selección es aleatoria, por lo que su selección puede diferir de la selección que se muestra en la imagen de arriba.
Now run the Rasterize algorithm to get the first raster layer, and then run the Close gaps algorithm to fill the no-data cells [Cell resolution: 100 m].

Para comprobar la calidad de la interpolación, ahora podemos utilizar los puntos que no están seleccionados. En este punto, conocemos la elevación real (el valor en la capa de puntos) y la elevación interpolada (el valor en la capa ráster interpolada). Podemos comparar los dos calculando las diferencias entre esos valores.
Como vamos a usar los puntos que no están seleccionados, primero invirtamos la selección.

The points contain the original values, but not the interpolated ones. To add them in a new field, we can use the Add raster values to points algorithm
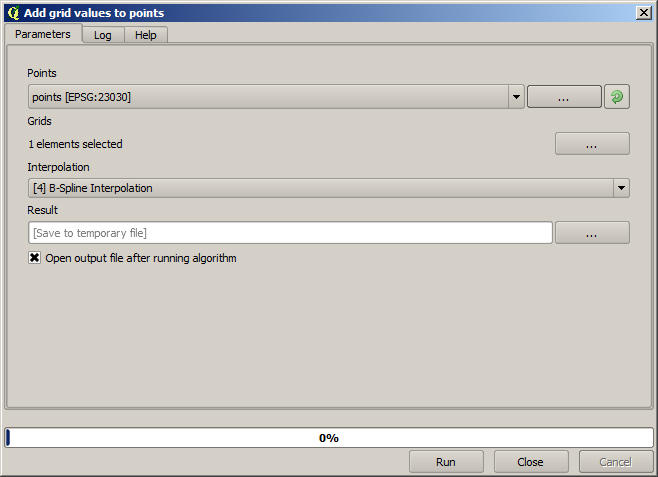
The raster layer to select (the algorithm supports multiple raster, but we just need one) is the resulting one from the interpolation. We have renamed it to interpolate and that layer name is the one that will be used for the name of the field to add.
Ahora tenemos una capa vectorial que contiene ambos valores, con puntos que no se usaron para la interpolación.
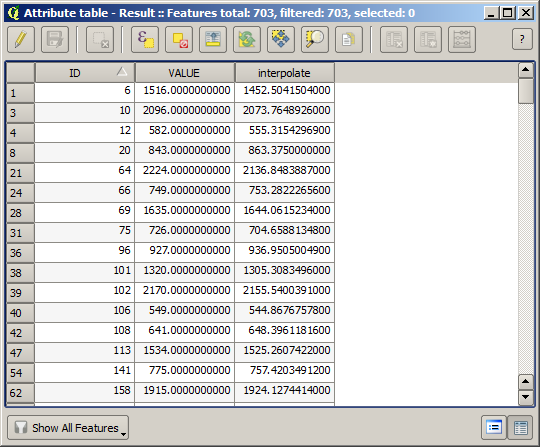
Now, we will use the fields calculator for this task. Open the Field calculator algorithm and run it with the following parameters.

Si su campo con los valores de la capa ráster tiene un nombre diferente, debe modificar la fórmula anterior en consecuencia. Al ejecutar este algoritmo, obtendrá una nueva capa con solo los puntos que no hemos usado para la interpolación, cada uno de los cuales contiene la diferencia entre los dos valores de elevación.
Representar esa capa de acuerdo con ese valor nos dará una primera idea de dónde se encuentran las mayores discrepancias.
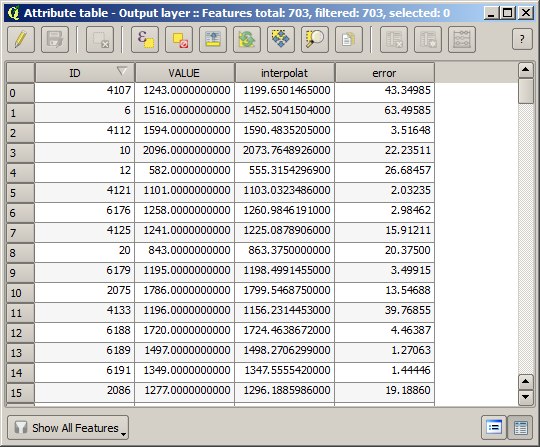
Al interpolar esa capa, obtendrá una capa ráster con el error estimado en todos los puntos del área interpolada.
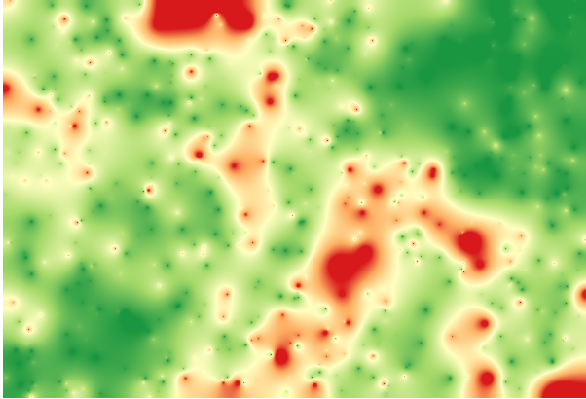
También puede obtener la misma información (diferencia entre los valores de puntos originales y los interpolados) directamente with .
Sus resultados pueden diferir de estos, ya que se introduce un componente aleatorio al ejecutar la selección aleatoria, al comienzo de esta lección.