Belangrijk
Vertalen is een inspanning van de gemeenschap waaraan u deel kunt nemen. Deze pagina is momenteel voor 100.00% vertaald.
23.11. Configureren externe toepassingen
Het framewerk Processing kan worden uitgebreid met aanvullende toepassingen. Algoritmes die vertrouwen op externe toepassingen worden beheerd door hun eigen providers van de algoritmes. Aanvullende providers kunnen worden gevonden als afzonderlijke plug-ins, en geïnstalleerd met Plug-ins beheren en installeren in QGIS.
Dit gedeelte zal u laten zien hoe het framework Processing te configureren zodat het deze aanvullende toepassingen opneemt, en zal het enkele bijzondere mogelijkheden uitleggen van de algoritmes die op hen gebaseerd zijn. Als u het systeem eenmaal juist hebt geconfigureerd, zult u in staat zijn externe algoritmes uit te voeren vanuit elke component, zoals de Toolbox of Modelontwerper, net zoals u doet met elk ander algoritme.
Standaard zijn algoritmes, die afhankelijk zijn van een externe toepassing en niet worden meegeleverd met QGIS, niet ingeschakeld. U kunt ze inschakelen in het dialoogvenster Opties als zij al zijn geïnstalleerd op uw systeem.
23.11.1. Een opmerking voor gebruikers van Windows
Als u nog geen gevorderde gebruiker bent en u voert QGIS uit op Windows, bent u misschien niet geïnteresseerd in het lezen van de rest van dit hoofdstuk. Zorg er voor dat u QGIS op uw systeem installeert met behulp van het zelfstandige installatieprogramma. Dat zal automatisch GRASS op uw systeem installeren en het configureren, zodat het vanuit QGIS kunnen worden uitgevoerd. Alle algoritmes van deze provider zullen gereed zijn om te worden uitgevoerd, zonder verdere configuratie. Als wordt geïnstalleerd met de toepassing OSGeo4W, zorg er dan voor dat u ook GRASS selecteert om te installeren.
23.11.2. Een opmerking met betrekking tot bestandsindelingen
Bij het gebruiken van externe software, betekent het openen van een bestand in QGIS niet dat het kan worden geopend en verwerkt kan worden in die andere software. In de meeste gevallen kan andere software lezen wat u hebt geopend in QGIS, maar in sommige gevallen hoeft dat niet zo te zijn. Bij het gebruiken van databases of ongebruikelijke bestandsindelingen, voor raster- of vectorlagen, zouden problemen kunnen optreden. Als dat gebeurt, probeer dan goed bekende bestandsindelingen te gebruiken waarvan u weet dat zij door beide programma’s worden begrepen, en controleer de uitvoer in de console (in het paneel Log) om uit te zoeken wat er fout gaat.
U zou problemen kunnen ondervinden en niet in staat zijn uw werk te voltooien als u een extern algoritme aanroept met rasterlagen van GRASS als invoer. Deze lagen zullen, om deze reden, niet verschijnen als beschikbaar voor algoritmes.
U zou echter geen problemen moeten ondervinden met vectorlagen, omdat QGIS automatisch converteert vanuit de originele bestandsindeling naar een die geaccepteerd wordt door de externe toepassing vóórdat de laag daaraan wordt doorgegeven. Dit zorgt voor extra verwerkingstijd, die significant zou kunnen zijn voor zeer grote lagen, wees dus niet verbaasd als het meer tijd vergt om een laag uit een DB-verbinding te verwerken, dan voor een soortgelijke grootte vanuit een gegevensset in de indeling Shapefile.
Providers die geen externe toepassingen gebruiken kunnen elke laag verwerken die u kunt openen in QGIS, omdat zij het voor analyse openen via QGIS.
Alle raster- en vectorindelingen, die worden geproduceerd door QGIS, kunnen als invoerlagen worden gebruikt. Sommige providers ondersteunen bepaalde indelingen niet, maar zij kunnen allemaal worden geëxporteerd naar veelvoorkomende indelingen voor rasterlagen die later automatisch kunnen worden getransformeerd door QGIS. Net als voor invoerlagen, als een conversie nodig is, zou dat de verwerkingstijd kunnen verhogen.
23.11.3. Een opmerking over selecties van vectorlagen
Externe toepassingen kunnen ook bewust worden gemaakt van de selecties die bestaan in vectorlagen binnen QGIS. Dat vereist echter het opnieuw schrijven van alle vectorlagen voor de invoer, net als wanneer zij origineel in een indeling waren die niet wordt ondersteund door de externe toepassing. Alleen wanneer er geen selectie bestaat, of de optie Alleen geselecteerde objecten gebruiken niet is ingeschakeld in de algemene configuratie van Processing, kan een laag direct worden doorgegeven aan een externe toepassing.
In andere gevallen is slechts het exporteren van de geselecteerde objecten nodig, wat er voor zorgt dat de tijd voor uitvoering langer duurt.
23.11.4. Providers van derde partijen gebruiken
23.11.4.1. R scripts en bibliotheken
U dient de plug-in Processing R Provider te installeren en R te configureren voor QGIS om R in Processing in te schakelen.
Configuratie wordt gedaan in op de tab Processing van .
Afhankelijk van uw besturingssysteem zou u misschien R folder moeten gebruiken om te specificeren waar uw binaire bestanden voor R zijn opgeslagen.
Notitie
Op Windows staat het uitvoerbare bestand van R normaal gesproken in een map (R-<version>) onder C:\Program Files\R\. Specificeer de map en NIET het binaire bestand!
Op Linux dient u er slechts voor te zorgen dat de map R in de omgevingsvariabele PATH staat. Als R in een venster van terminal R opstart, dan bent u klaar om te beginnen.
Na het installeren van de plug-in Processing R Provider zult u enkele voorbeeldscripts vinden in de Toolbox van Processing:
Scatterplot voert een functie voor R uit die een spreidingsplot produceert van twee numerieke velden van de opgegeven vectorlaag.
test_sf doet enkele bewerkingen die afhankelijk zijn van het pakket
sfen kan worden gebruikt om te controleren of het pakketsfvoor R is geïnstalleerd. Als het pakket niet is geïnstalleerd, zal R proberen het voor u te installeren (en alle pakketten waarvan het afhankelijk is) met behulp van de gespecificeerde Package repository in in de opties van Processing. De standaard is https://cran.r-project.org/. Installeren kan enige tijd vergen…test_sp kan worden gebruikt om te controleren of het pakket
spvoor R is geïnstalleerd. Als het pakket niet is geïnstalleerd, zal R het voor proberen te installeren.
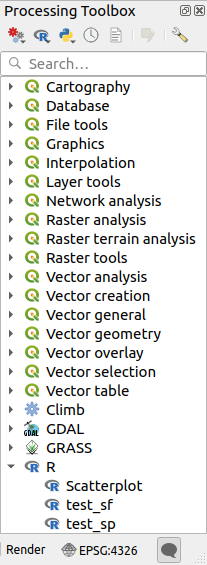
Als u R correct hebt geconfigureerd voor QGIS, zou u deze scripts uit moeten kunnen voeren.
R-scripts toevoegen uit de collectie van QGIS
Integreren van R in QGIS is anders dan die van enkele andere derde partij providers, zoals SAGA, met dien verstande dat er geen vooraf gedefinieerde set met algoritmes is die u kunt uitvoeren (uitgezonderd enkele voorbeeldscripts die aanwezig zijn in de plug-in Processing R Provider).
Een set van voorbeeldscripts voor R is beschikbaar in de QGIS Repository. Voer de volgende stappen uit om ze te laden en in te schakelen met de plug-in QGIS Resource Sharing.
Voeg de plug-in QGIS Resource Sharing toe (u zou misschien Ook de experimentele plug-ins tonen moeten inschakelen in Extra van Plug-ins beheren en installeren)
Open het (Plug-ins –> Resource Sharing –> Resource Sharing)
Kies de tab Settings
Klik op Reload repositories
Kies de tab All
Selecteer QGIS R script collection in de lijst en klik op de knop Install
De collectie zou nu moeten worden weergegeven op de tab Installed
Sluit de plug-in
Open de Toolbox van Processing en als alles goed is gegaan zouden de voorbeeldscripts beschikbaar moeten zijn onder R, in diverse groepen (slechts enkele groepen zijn uitgeklapt in de schermafdruk hieronder).
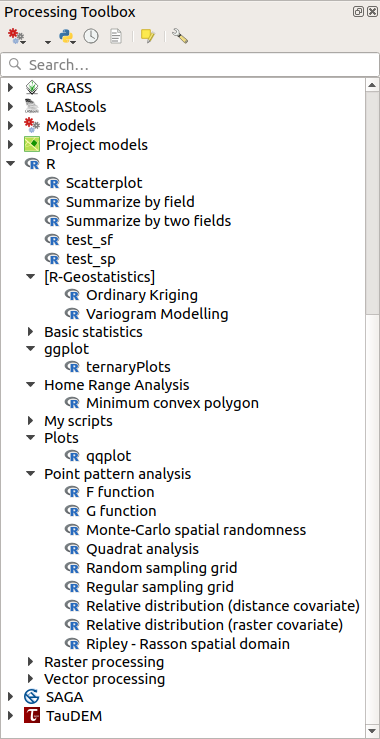
Fig. 23.35 De Toolbox van Processing waarin enkele scripts voor R worden weergegeven
De scripts aan de bovenzijde zijn de voorbeeldscripts uit de plug-in Processing R Provider.
Als, om enige reden, de scripts niet beschikbaar zijn in de Toolbox van Processing, kunt u proberen om:
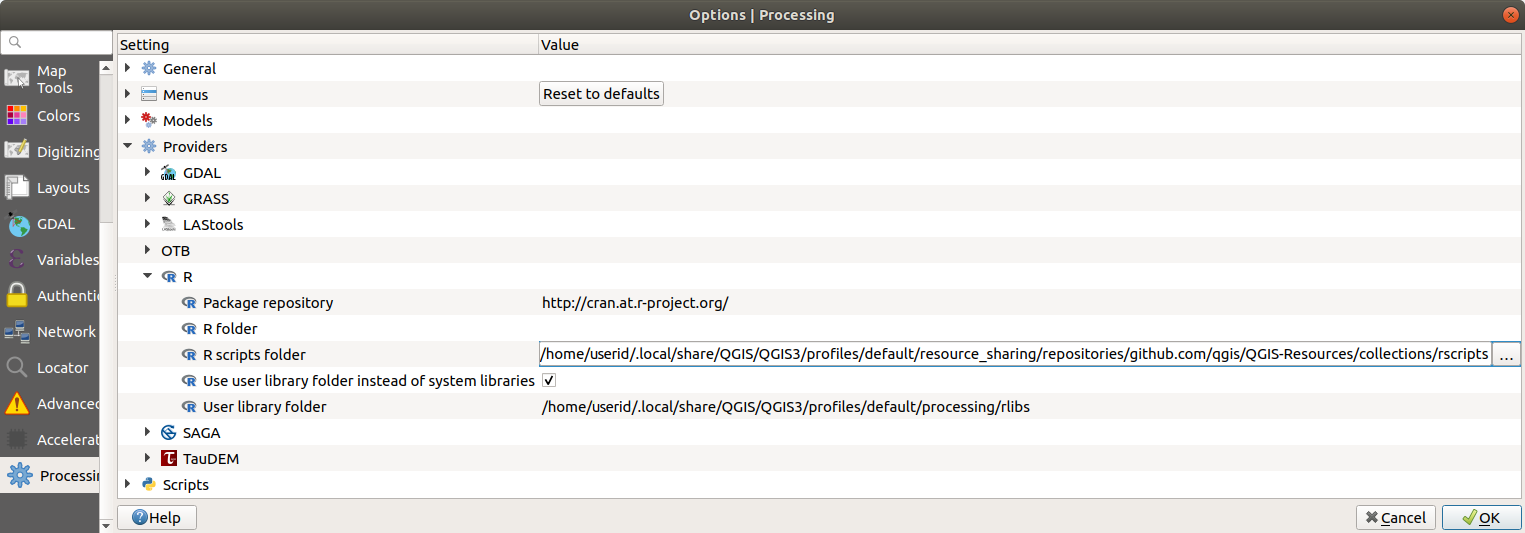
De instellingen voor Processing te openen ()
Ga naar
Op Ubuntu, stel het pad in naar (of, beter nog, neem in het pad op):
/home/<user>/.local/share/QGIS/QGIS3/profiles/default/resource_sharing/repositories/github.com/qgis/QGIS-Resources/collections/rscripts
Op Windows, stel het pad in naar (of, beter nog, neem in het pad op):
C:\Users\<user>\AppData\Roaming\QGIS\QGIS3\profiles\default\resource_sharing\repositories\github.com\qgis\QGIS-Resources\collections\rscripts
Dubbelklik om te bewerken. U kunt dan kiezen om het pad eenvoudigweg te kopiëren/plakken, of u kunt naar de map navigeren met de knop … en druk op de knop Add in het dialoogvenster dat opent. Het is mogelijk om hier meerdere mappen op te geven. Zij zullen worden gescheiden door een puntkomma (“;”).

Wanneer u alle R-scrips uit de QGIS 2 online collectie zou willen ophalen, kunt u QGIS R script collection (from QGIS 2) selecteren, in plaats van QGIS R script collection. U zult waarschijnlijk merken dat scripts, die afhankelijk zijn van in- of uitvoer van vectorgegevens niet zullen werken.
R-scripts maken
U kunt scripts schrijven en alle opdrachten voor R aanroepen, net zoals u zou doen vanuit R. Dit gedeelte laat u de syntaxis zien voor het gebruiken van opdrachten van R in QGIS, en hoe daarin objecten van QGIS (lagen, tabellen) te gebruiken.
U dient een scriptbestand te maken dat opdrachten van R uitvoert om een algoritme toe te voegen dat een functie in R aanroept (of een meer complex script in R dat u heeft ontwikkeld en dat u beschikbaar zou willen hebben vanuit QGIS).
Bestanden voor R-scripts hebben de extensie .rsx, en het maken ervan is heel gemakkelijk als u slechts basiskennis hebt van de syntaxis van R en scripten in R. Zij zouden moeten worden opgeslagen in de R scripts folder. U kunt de map specificeren (R scripts folder) in de groep voor instellingen van R in het dialoogvenster voor de instellingen van Processing).
Laten we eens kijken naar een heel eenvoudig scriptbestand, dat de methode voor R spsample aanroept om een willekeurig raster te maken binnen de grens van de polygonen in een opgegeven polygoonlaag. Deze methode behoort tot het pakket maptools. Omdat bijna alle algoritmes die u zou willen opnemen in QGIS ruimtelijke gegevens zullen gebruiken of maken, is kennis van ruimtelijke pakketten, zoals maptools en sp/sf, heel nuttig.
##Random points within layer extent=name
##Point pattern analysis=group
##Vector_layer=vector
##Number_of_points=number 10
##Output=output vector
library(sp)
spatpoly = as(Vector_layer, "Spatial")
pts=spsample(spatpoly,Number_of_points,type="random")
spdf=SpatialPointsDataFrame(pts, as.data.frame(pts))
Output=st_as_sf(spdf)
De eerste regels, die worden aangeduid met een Python commentaar symbool (##), definiëren de weergavenaam en de groep van het script, en vertellen QGIS over zijn in- en uitvoer.
Notitie
Bekijk het gedeelte R Intro in de Trainingshandleiding en raadpleeg het gedeelte R syntaxis, om meer te weten te komen over hoe uw eigen scripts voor R te schrijven.
Wanneer u een parameter voor de invoer declareert, gebruikt QGIS die informatie voor twee dingen: het maakt de gebruikersinterface om de gebruiker te vragen naar de waarde van die parameter, en maakt een overeenkomende variabele voor R die kan worden gebruikt als invoer voor een functie van R.
In het bovenstaande voorbeeld hebben we een invoer van het type vector, genaamd Vector_layer, gedeclareerd. Bij het uitvoeren van het algoritme, zal QGIS de laag openen die is geselecteerd door de gebruiker en slaat die op in een variabele genaamd Vector_layer. Dus, de naam van een parameter is de naam van de variabele die u in R kunt gebruiken om toegang te krijgen tot de waarde van die parameter (u zou daarom moeten vermijden om gereserveerde woorden voor R te gebruiken als parameters).
Ruimtelijke parameters, zoals vector- en rasterlagen, worden gelezen met behulp van de opdrachten st_read() (of readOGR) en brick() (of readGDAL) (u hoeft zich geen zorgen te maken over het toevoegen van deze opdrachten aan uw bestand voor de beschrijving – QGIS zal dit voor u doen), en zij worden opgeslagen als objecten Spatial*DataFrame.
Tabelvelden worden opgeslagen als tekenreeksen die de naam van het geselecteerde veld bevatten.
Vectorbestanden kunnen worden gelezen met behulp van de opdracht readOGR() in plaats van met st_read() door ##load_vector_using_rgdal te specificeren. Dit zal een object Spatial*DataFrame produceren in plaats van een object sf.
Rasterbestanden kunnen worden gelezen met behulp van de opdracht readGDAL() in plaats van met brick() door ##load_raster_using_rgdal te specificeren.
Als u een gevorderde gebruiker bent en niet wilt dat QGIS het object maakt voor de laag, kunt u ##pass_filenames gebruiken om aan te geven dat u een tekenreeks met de bestandsnaam prefereert. In dat geval is het aan u om het bestand te openen vóórdat een bewerking wordt uitgevoerd op de gegevens die het bevat.
Met bovenstaande informatie zijn de eerste regels van het script voor R nu te begrijpen (de eerste regel die niet begint met een teken voor een opmerking in Python).
library(sp)
spatpoly = as(Vector_layer, "Spatial")
pts=spsample(polyg,numpoints,type="random")
De functie spsample wordt verschaft door de bibliotheek sp, dus het eerste wat we doen is die bibliotheek laden. De variabele Vector_layer bevat een object sf. Omdat we een functie (spsample) gaan gebruiken uit de bibliotheek sp, moeten we het object sf converteren naar een object SpatialPolygonsDataFrame met de functie as.
Dan roepen we de functie spsample aan, met dit object en de parameter voor de invoer numpoints (die het aantal te maken punten specificeert).
Omdat we een vectoruitvoer, genaamd Output, hebben gedeclareerd, moeten we een variabele Output maken die een object sf bevat.
We doen dit in twee stappen. Eerst maken we een object SpatialPolygonsDataFrame uit het resultaat van de functie, met de functie SpatialPointsDataFrame, en dan converteren we dat object naar een object sf met de functie st_as_sf (uit de bibliotheek sf).
U mag voor de tussenliggende variabelen elke naam gebruiken die u wilt. Zorg er alleen voor dat de variabele die uw uiteindelijke resultaat opslaat de gedefinieerde naam heeft (in dit geval Output), en dat het een geschikte waarde bevat (een object sf voor uitvoer naar een vectorlaag).
In dit geval moest het resultaat, dat wordt verkregen uit de methode spsample, expliciet worden geconverteerd naar een object SpatialPointsDataFrame, omdat het zelf een object van de klasse ppp is, dat niet kan worden teruggegeven aan QGIS.
Als uw algoritme rasterlagen genereert, is de manier waarop zij worden opgeslagen afhankelijk van het feit of u al dan niet de optie ##dontuserasterpackage heeft gebruikt. Wanneer u die heeft gebruikt worden lagen opgeslagen met behulp van de methode writeGDAL(). Indien niet, zal de methode writeRaster() uit het pakket raster worden gebruikt.
Als u de optie ##pass_filenames hebt gebruikt, wordt de uitvoer gemaakt met behulp van het pakket raster (met writeRaster()).
Als uw algoritme geen laag maakt, maar een tekstresultaat in de console, dient u aan te geven dat u wilt dat de console wordt weergegeven als de uitvoering eenmaal is voltooid. Start eenvoudigweg de opdrachtregels die de resultaten produceren die u wilt afdrukken met het teken > (‘groter dan’) om dat te doen. Alleen uitvoer van regels die worden voorafgegaan door > zal worden weergegeven. Hier is bijvoorbeeld het bestand voor de beschrijving van een algoritme dat een test voor normalen uitvoert op een bepaald veld (kolom) van de attributen van een vectorlaag:
##layer=vector
##field=field layer
##nortest=group
library(nortest)
>lillie.test(layer[[field]])
De uitvoer van de laatste regel wordt afgedrukt, maar de uitvoer van de eerste wordt dat niet (en ook de uitvoer van de andere opdrachtregels, die automatisch door QGIS werden toegevoegd, worden dat niet).
Als uw algoritme iets grafisch maakt (met behulp van de methode plot()), voeg dan de volgende regel toe (output_plots_to_html was eerder showplots):
##output_plots_to_html
Dit zal er voor zorgen dat QGIS alle grafische uitvoer voor R zal omleiden naar een tijdelijk bestand, wat zal worden geopend als de uitvoering van R is voltooid.
Beide grafische en console-resultaten zullen beschikbaar zijn in het beheer van de resultaten van Processing.
Bekijk, voor meer informatie, de scripts voor R die zijn opgenomen in de officiële collectie van QGIS (u kunt ze downloaden en installeren met de plug-in QGIS Resource Sharing, zoals uitgelegd in R-scripts toevoegen uit de collectie van QGIS). De meeste daarvan zijn redelijk eenvoudig en zullen u enorm helpen te begrijpen hoe u uw eigen scripts kunt maken.
Notitie
De bibliotheken sf, rgdal en raster worden standaard geladen, dus hoeft u de twee overeenkomende opdrachten library() niet toe te voegen. Echter, andere bibliotheken die u denkt nodig te hebben moeten expliciet worden geladen door te typen library(ggplot2) (om de bibliotheek ggplot2 te laden). Als het pakket nog niet is geïnstalleerd op uw machine zal Processing proberen het downloaden en te installeren. Op deze manier zal het pakket ook beschikbaar komen voor R Standalone. Onthoud dat als het pakket moet worden gedownload, het erg lang zou kunnen duren als u uw script voor de eerste keer uitvoert.
R-bibliotheken die worden geïnstalleerd bij het uitvoeren van sf_test
Het R-script sp_test probeert de pakketten voor R sp en raster te laden.
Het script voor R sf_test probeert sf en raster te laden. Als deze twee pakketten niet zijn geïnstalleerd, zou R kunnen proberen ze te laden en te installeren (en alle bibliotheken die daarvan afhankelijk zijn).
De volgende R-bibliotheken eindigen in ~/.local/share/QGIS/QGIS3/profiles/default/processing/rscripts nadat sf_test is uitgevoerd vanuit de Toolbox van Processing op Ubuntu met versie 2.0 van de plug-in Processing R Provider en een verse installatie van R 3.4.4 (apt package r-base-core alleen):
abind, askpass, assertthat, backports, base64enc, BH, bit, bit64, blob, brew, callr, classInt, cli, colorspace, covr, crayon, crosstalk, curl, DBI, deldir,
desc, dichromat, digest, dplyr, e1071, ellipsis, evaluate, fansi, farver, fastmap, gdtools, ggplot2, glue, goftest, gridExtra, gtable, highr, hms,
htmltools, htmlwidgets, httpuv, httr, jsonlite, knitr, labeling, later, lazyeval, leafem, leaflet, leaflet.providers, leafpop, leafsync, lifecycle, lwgeom,
magrittr, maps, mapview, markdown, memoise, microbenchmark, mime, munsell, odbc, openssl, pillar, pkgbuild, pkgconfig, pkgload, plogr, plyr, png, polyclip,
praise, prettyunits, processx, promises, ps, purrr, R6, raster, RColorBrewer, Rcpp, reshape2, rex, rgeos, rlang, rmarkdown, RPostgres, RPostgreSQL,
rprojroot, RSQLite, rstudioapi, satellite, scales, sf, shiny, sourcetools, sp, spatstat, spatstat.data, spatstat.utils, stars, stringi, stringr, svglite,
sys, systemfonts, tensor, testthat, tibble, tidyselect, tinytex, units, utf8, uuid, vctrs, viridis, viridisLite, webshot, withr, xfun, XML, xtable
23.11.4.2. GRASS
Configureren van GRASS is heel gemakkelijk. Eerst moet het pad naar de map GRASS worden gedefinieerd, maar alleen als u werkt op Windows.
Standaard probeert het framework Processing zijn verbinding naar GRASS te configureren om de distributie van GRASS te gebruiken die wordt meegeleverd met QGIS. Dit zou voor de meeste systemen zonder problemen moeten werken, maar als u problemen ondervindt, zou u de verbinding naar GRASS handmatig moeten configureren. Ook als u een andere installatie van GRASS wilt gebruiken kunt u de instelling wijzigen zodat die verwijst naar de map waar die andere versie is geïnstalleerd. GRASS 7 is nodig om de algoritmes juist te laten werken.
Als u werkt op Linux hoeft u er slechts voor te zorgen dat GRASS correct is geïnstalleerd, en dat het zonder problemen kan worden uitgevoerd vanaf een terminalvenster.
Algoritmes van GRASS gebruiken een regio voor berekeningen. Die regio kan handmatig of automatisch worden gedefinieerd, en bestaat uit het minimale bereik dat alle invoerlagen bedekt die worden gebruikt om het algoritme elke keer uit te voeren.
23.11.4.3. LAStools
Voor het gebruiken van LAStools in QGIS, moet u LAStools downloaden en installeren op uw computer en de plug-in LAStools installeren (beschikbaar in de officiële opslagplaats) in QGIS.
Op platformen voor Linux zult u Wine nodig hebben om enkele van de gereedschappen uit te kunnen voeren.
LAStools wordt geactiveerd en geconfigureerd in de opties voor Processing (, tab Processing, ), waar u de locatie van LAStools (map LAStools) en Wine (map Wine) kunt specificeren. Op Ubuntu is de standaardmap voor Wine /usr/bin.
23.11.4.4. OTB-toepassingen
Toepassingen voor OTB worden volledig ondersteund in het QGIS framewerk Processing.
OTB (Orfeo ToolBox) is een bibliotheek voor het verwerken van afbeeldingen voor gegevens van remote sensing. Het verschaft ook toepassingen die functionaliteiten voor het verwerken van afbeeldingen. De lijst met toepassingen en hun documentatie zijn beschikbaar in het OTB CookBook
Notitie
Onthoud dat OTB niet wordt meegeleverd met QGIS en afzonderlijk geïnstalleerd moet worden. Binaire pakketten voor OTB zijn te vinden op de downloadpagina.
QGIS Processing configureren om te zoeken naar de bibliotheek OTB:
De instellingen voor Processing te openen ()
U zult
OTBzien in het menu :Vergroot het item OTB
Stel de OTB-map in. Dat is de locatie van uw installatie van OTB.
Stel de OTB-toepassingsmap in. Dit is de locatie van uw toepassingen voor OTB (
<PATH_TO_OTB_INSTALLATION>/lib/otb/applications)Klik op OK om de instellingen op te slaan en het dialoogvenster te sluiten.
As de instellingen juist zijn, zullen algoritmes van OTB beschikbaar zijn in de Toolbox van Processing.
Documentatie voor beschikbare instellingen van OTB in QGIS Processing
OTB-map: Dit is de map waar OTB beschikbaar is.
OTB-toepassingsmap: Dit is/zijn de locatie(s) van toepassingen van OTB.
Meerdere paden zijn toegestaan.
Niveau logger (optioneel): Niveau van logger te gebruiken door toepassingen van OTB.
Het niveau van loggen beheert de hoeveelheid details die worden afgedrukt bij het uitvoeren van het algoritme. Mogelijke waarden voor niveau van logger zijn
INFO,WARNING,CRITICAL,DEBUG. Deze waarde is standaardINFO. Dit is een configuratie voor gevorderde gebruikers.Maximaal te gebruiken RAM (optioneel): standaard gebruiken toepassingen van OTB alle beschikbare RAM van het systeem.
U kunt met deze optie echter OTB instrueren om een bepaalde hoeveelheid RAM (in MB) te gebruiken. Een waarde van 256 wordt genegeerd door de OTB processing provider. Dit is een configuratie voor gevorderde gebruikers.
Geoïde-bestand (optioneel): Pad naar het geoïde-bestand.
Deze optie stelt de waarden van de parameters elev.dem.geoid en elev.geoid in voor toepassingen van OTB. Instellen van deze waarden als globaal stelt gebruikers in staat dit te delen over meerdere algoritmes van Processing. Standaard leeg.
map SRTM-tegels (optioneel): Map waar SRTM-tegels beschikbaar zijn.
SRTM-gegevens mogen lokaal opgeslagen worden om downloaden van bestanden tijdens het verwerken te vermijden. Deze optie stelt de waarden van de parameters elev.dem.path en elev.dem in voor toepassingen van OTB. Instellen van deze waarden als globaal stelt gebruikers in staat dit te delen over meerdere algoritmes van Processing. Standaard leeg.
Compatibiliteit en oplossen problemen
Vanaf OTB 6.6.1 zijn nieuwe uitgaven van OTB compatibel gemaakt met ten minste de op dat moment laatst beschikbare versie van QGIS.
Als u problemen hebt met toepassingen van OTB in QGIS Processing, open dan een issue op de OTB bug tracker, met het label qgis.
Aanvullende informatie over OTB en QGIS is te vinden in OTB Cookbook.