Viktigt
Översättning är en gemenskapsinsats du kan gå med i. Den här sidan är för närvarande översatt till 100.00%.
23.11. Konfigurera externa applikationer
Ramverket för bearbetning kan utökas med ytterligare applikationer. Algoritmer som förlitar sig på externa applikationer hanteras av sina egna algoritmleverantörer. Ytterligare leverantörer finns som separata tillägg och installeras med QGIS Tilläggshanterare.
I det här avsnittet visas hur du konfigurerar Processing-ramverket så att det omfattar dessa ytterligare applikationer, och några speciella egenskaper hos de algoritmer som baseras på dem förklaras. När du har konfigurerat systemet på rätt sätt kan du köra externa algoritmer från valfri komponent, t.ex. verktygslådan eller modelldesignern, precis som du gör med alla andra algoritmer.
Som standard är algoritmer som förlitar sig på en extern applikation som inte levereras med QGIS inte aktiverade. Du kan aktivera dem i dialogrutan Bearbetningsinställningar om de är installerade på ditt system.
23.11.1. En anmärkning för Windows-användare
Om du inte är en avancerad användare och du kör QGIS på Windows, kanske du inte är intresserad av att läsa resten av detta kapitel. Se till att du installerar QGIS i ditt system med hjälp av den fristående installationsprogrammet. Detta kommer automatiskt att installera SAGA och GRASS i ditt system och konfigurera dem så att de kan köras från QGIS. Alla algoritmer från dessa leverantörer kommer att vara redo att köras utan att behöva någon ytterligare konfiguration. Om du installerar med OSGeo4W-programmet, se till att du också väljer SAGA och GRASS för installation.
23.11.2. En anmärkning om filformat
När du använder extern programvara betyder inte öppnandet av en fil i QGIS att den kan öppnas och bearbetas i den andra programvaran. I de flesta fall kan andra program läsa vad du har öppnat i QGIS, men i vissa fall kanske det inte är sant. När du använder databaser eller ovanliga filformat, oavsett om det gäller raster- eller vektorlager, kan problem uppstå. Om det händer, försök att använda välkända filformat som du är säker på att båda programmen förstår, och kontrollera konsolutmatningen (i loggpanelen) för att ta reda på vad som går fel.
Du kan t.ex. få problem och inte kunna slutföra ditt arbete om du anropar en extern algoritm med ett GRASS-rasterlager som indata. Av denna anledning kommer sådana lager inte att visas som tillgängliga för algoritmer.
Du bör dock inte ha några problem med vektorlager, eftersom QGIS automatiskt konverterar från det ursprungliga filformatet till ett format som accepteras av det externa programmet innan lagret skickas till det. Detta ger extra bearbetningstid, som kan vara betydande för stora lager, så bli inte förvånad om det tar längre tid att bearbeta ett lager från en DB-anslutning än ett lager från en dataset i Shapefile-format av liknande storlek.
Leverantörer som inte använder externa program kan bearbeta alla lager som du kan öppna i QGIS, eftersom de öppnar det för analys genom QGIS.
Alla raster- och vektorformat som produceras av QGIS kan användas som inmatningslager. Vissa leverantörer stöder inte vissa format, men alla kan exportera till vanliga format som senare kan omvandlas automatiskt av QGIS. När det gäller inmatningslager kan det öka bearbetningstiden om det krävs en konvertering.
23.11.3. En anteckning om val av vektorlager
Externa applikationer kan också göras medvetna om de urval som finns i vektorlager inom QGIS. Detta kräver dock att alla ingående vektorlager skrivs om, precis som om de ursprungligen hade ett format som inte stöds av det externa programmet. Endast när inget urval finns, eller om alternativet Use only selected features inte är aktiverat i den allmänna konfigurationen för bearbetning, kan ett lager skickas direkt till ett externt program.
I andra fall behöver endast utvalda funktioner exporteras, vilket medför längre exekveringstider.
23.11.4. Använda tredjepartsleverantörer
23.11.4.1. SAGA
SAGA-algoritmer kan köras från QGIS om SAGA ingår i QGIS-installationen.
Om du kör Windows ingår SAGA i både det fristående installationsprogrammet och installationsprogrammet för OSGeo4W.
Om begränsningar i SAGA:s gridsystem
De flesta SAGA-algoritmer som kräver flera rasterlager som indata kräver att de har samma gridsystem. Det vill säga att de måste täcka samma geografiska område och ha samma cellstorlek, så att deras motsvarande rutnät matchar. När du anropar SAGA-algoritmer från QGIS kan du använda vilket lager som helst, oavsett cellstorlek och utsträckning. När flera rasterlager används som indata för en SAGA-algoritm, samplar QGIS om dem till ett gemensamt rutnätssystem och skickar dem sedan till SAGA (såvida inte SAGA-algoritmen kan arbeta med lager från olika rutnätssystem).
Definitionen av det gemensamma rutnätssystemet styrs av användaren, och du hittar flera parametrar i SAGA-gruppen i inställningsfönstret för att göra detta. Det finns två sätt att ställa in målrastersystemet:
Ställer in den manuellt. Du definierar omfattningen genom att ställa in värdena för följande parametrar:
Återprovtagning min X
Återprovtagning max X
Återhämtning min Y
Återhämtning max Y
Återhämtning av cellstorlek
Observera att QGIS kommer att omsampla inmatningslagren i den utsträckningen, även om de inte överlappar med den.
Ställer in det automatiskt från inmatningslager. För att välja detta alternativ markerar du bara alternativet Use min covering grid system for resampling. Alla andra inställningar ignoreras och den minsta utsträckning som täcker alla inmatningslagren används. Cellstorleken i mållagret är den maximala av alla cellstorlekar i inmatningslagren.
För algoritmer som inte använder flera rasterlager, eller för algoritmer som inte behöver ett unikt grid-system för indata, utförs ingen omsampling innan SAGA anropas, och dessa parametrar används inte.
Begränsningar för flerbandslager
Till skillnad från QGIS har SAGA inget stöd för flerbandslager. Om du vill använda ett flerbandslager (t.ex. en RGB- eller multispektralbild) måste du först dela upp det i enbandsbilder. För att göra detta kan du använda algoritmen ”SAGA/Grid - Tools/Split RGB image” (som skapar tre bilder från en RGB-bild) eller algoritmen ”SAGA/Grid - Tools/Extract band” (för att extrahera ett enda band).
Begränsningar i cellstorlek
SAGA förutsätter att rasterlager har samma cellstorlek i X- och Y-axeln. Om du arbetar med ett lager med olika värden för horisontell och vertikal cellstorlek kan du få oväntade resultat. I så fall kommer en varning att läggas till i bearbetningsloggen, vilket indikerar att ett inmatningslager kanske inte är lämpligt att bearbetas av SAGA.
Loggning
När QGIS anropar SAGA görs det med hjälp av kommandoradsgränssnittet, vilket innebär att en uppsättning kommandon skickas för att utföra alla nödvändiga operationer. SAGA visar sina framsteg genom att skriva information till konsolen, vilket inkluderar procentandelen av bearbetningen som redan har gjorts, tillsammans med ytterligare innehåll. Den här informationen filtreras och används för att uppdatera förloppsindikatorn medan algoritmen körs.
Både de kommandon som skickas av QGIS och den ytterligare information som skrivs ut av SAGA kan loggas tillsammans med andra loggar för bearbetning, och du kan ha nytta av dem för att spåra vad som händer när QGIS kör en SAGA-algoritm. Du hittar två inställningar, nämligen Logga konsolutdata och Logga exekveringskommandon, för att aktivera denna loggning.
De flesta andra leverantörer som använder externa program och anropar dem via kommandoraden har liknande alternativ, så du hittar dem också på andra ställen i listan med bearbetningsinställningar.
23.11.4.2. R-skript och bibliotek
För att aktivera R i Processing måste du installera tillägget Processing R Provider och konfigurera R för QGIS.
Konfigurationen görs i på fliken Processing i .
Beroende på ditt operativsystem kan du behöva använda R folder för att ange var dina R-binärfiler finns.
Observera
På Windows finns den körbara R-filen normalt i en mapp (R-<version>) under C:\Program Files\R\. Ange mappen och INTE den binära filen!
På Linux behöver du bara se till att mappen R finns i miljövariabeln PATH. Om R i ett terminalfönster startar R, är du redo att köra.
När du har installerat Processing R Provider plugin, hittar du några exempelskript i Processing Toolbox:
Scatterplot kör en R-funktion som producerar ett spridningsdiagram från två numeriska fält i det angivna vektorlagret.
test_sf gör vissa operationer som är beroende av
sf-paketet och kan användas för att kontrollera om R-paketetsfär installerat. Om paketet inte är installerat kommer R att försöka installera det (och alla paket som det är beroende av) åt dig, med hjälp av Paketarkiv som anges i i Processing options. Standard är https://cran.r-project.org/. Installationen kan ta lite tid…test_sp kan användas för att kontrollera om R-paketet
spär installerat. Om paketet inte är installerat kommer R att försöka installera det åt dig.
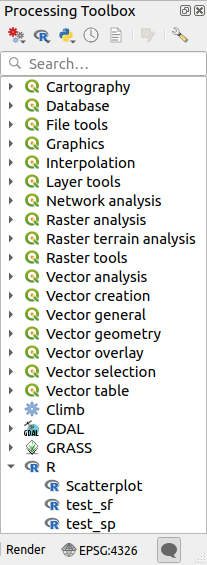
Om du har konfigurerat R korrekt för QGIS bör du kunna köra dessa skript.
Lägga till R-skript från QGIS-samlingen
R-integrationen i QGIS skiljer sig från den i SAGA genom att det inte finns någon fördefinierad uppsättning algoritmer som du kan köra (förutom några exempelskript som medföljer tillägget Processing R Provider).
En uppsättning exempel på R-skript finns tillgängliga i QGIS Repository. Utför följande steg för att ladda och aktivera dem med hjälp av tillägget QGIS Resource Sharing.
Lägg till tillägget QGIS Resource Sharing (du kan behöva aktivera Visa även experimentella tillägg i Tilläggshanterare Inställningar)
Öppna den ()
Välj fliken Inställningar
Klicka på Reload repositories
Välj fliken Alla
Välj QGIS R script collection i listan och klicka på Install-knappen
Samlingen bör nu visas i fliken Installed
Stäng tillägget
Öppna Processing Toolbox, och om allt är OK kommer exempelskripten att finnas under R, i olika grupper (endast några av grupperna är expanderade i skärmdumpen nedan).
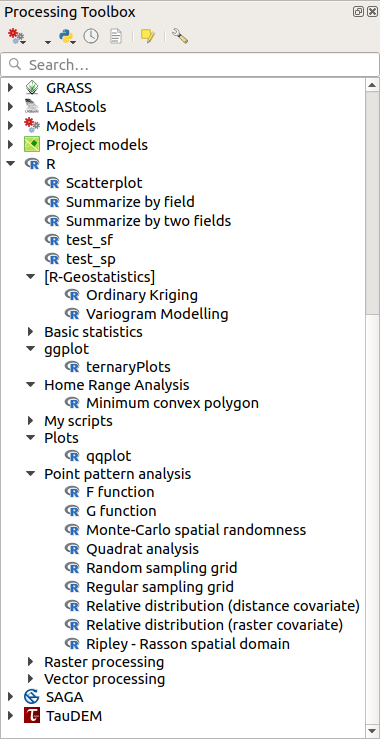
Fig. 23.35 Verktygslådan Processing Toolbox med några R-skript som visas
Skripten längst upp är exempelskript från tillägget Processing R Provider.
Om skripten av någon anledning inte finns tillgängliga i Processing Toolbox kan du försöka:
Öppna bearbetningsinställningarna ( flik)
Gå till
På Ubuntu ställer du in sökvägen till (eller, ännu bättre, inkluderar i sökvägen):
/home/<user>/.local/share/QGIS/QGIS3/profiles/default/resource_sharing/repositories/github.com/qgis/QGIS-Resources/collections/rscripts
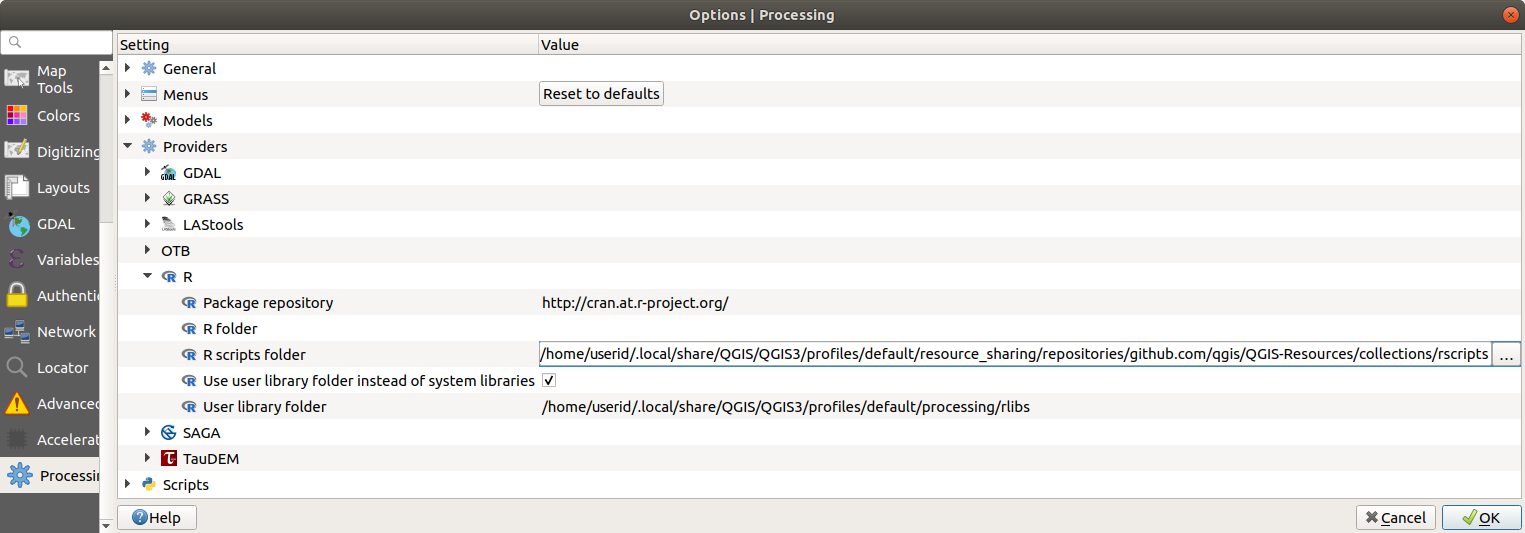
I Windows anger du sökvägen till (eller, ännu bättre, inkluderar i sökvägen):
C:\Users\<user>\AppData\Roaming\QGIS\QGIS3\profiles\default\resource_sharing\repositories\github.com\qgis\QGIS-Resources\collections\rscripts
Dubbelklicka för att redigera. Du kan sedan välja att bara klistra in/skriva sökvägen, eller så kan du navigera till katalogen med hjälp av …-knappen och trycka på Add-knappen i dialogen som öppnas. Det är möjligt att ange flera kataloger här. De kommer att separeras med ett semikolon (”;”).

Om du vill hämta alla R-skript från QGIS 2 online-samlingen kan du välja QGIS R script collection (from QGIS 2) istället för QGIS R script collection. Du kommer förmodligen att upptäcka att skript som är beroende av indata eller utdata för vektordata inte kommer att fungera.
Skapa R-skript
Du kan skriva skript och anropa R-kommandon, precis som du skulle göra från R. I det här avsnittet visas syntaxen för att använda R-kommandon i QGIS, och hur du använder QGIS-objekt (lager, tabeller) i dem.
För att lägga till en algoritm som anropar en R-funktion (eller ett mer komplext R-skript som du har utvecklat och som du vill ska vara tillgängligt från QGIS) måste du skapa en skriptfil som utför R-kommandona.
R-skriptfiler har tillägget .rsx, och det är ganska enkelt att skapa dem om du bara har grundläggande kunskaper om R-syntax och R-skript. De bör lagras i mappen R scripts. Du kan ange mappen (R scripts folder) i inställningsgruppen R i dialogrutan Processing settings).
Låt oss titta på en mycket enkel skriptfil, som anropar R-metoden spsample för att skapa ett slumpmässigt rutnät inom polygonernas gränser i ett givet polygonlager. Denna metod hör till paketet maptools. Eftersom nästan alla algoritmer som du kanske vill införliva i QGIS kommer att använda eller generera spatiala data, är kunskap om spatiala paket som maptools och sp/sf mycket användbar.
##Random points within layer extent=name
##Point pattern analysis=group
##Vector_layer=vector
##Number_of_points=number 10
##Output=output vector
library(sp)
spatpoly = as(Vector_layer, "Spatial")
pts=spsample(spatpoly,Number_of_points,type="random")
spdf=SpatialPointsDataFrame(pts, as.data.frame(pts))
Output=st_as_sf(spdf)
De första raderna, som börjar med ett dubbelt Python-kommentartecken (##), definierar skriptets visningsnamn och grupp och berättar för QGIS om dess in- och utdata.
Observera
Om du vill veta mer om hur du skriver dina egna R-skript kan du läsa avsnittet R Intro i utbildningsmanualen och avsnittet QGIS R Syntax.
När du deklarerar en inmatningsparameter använder QGIS den informationen för två saker: att skapa användargränssnittet för att be användaren om värdet på parametern och att skapa en motsvarande R-variabel som kan användas som inmatning för R-funktionen.
I exemplet ovan har vi deklarerat en indata av typen vektor med namnet Vector_layer. När algoritmen körs kommer QGIS att öppna det lager som användaren valt och lagra det i en variabel med namnet Vector_layer. Namnet på en parameter är alltså namnet på den variabel som du använder i R för att komma åt värdet på den parametern (du bör därför undvika att använda reserverade R-ord som parameternamn).
Spatiala parametrar som vektor- och rasterlager läses med hjälp av kommandona st_read() (eller readOGR) och brick() (eller readGDAL) (du behöver inte tänka på att lägga till dessa kommandon i din beskrivningsfil - QGIS gör det), och de lagras som sf (eller Spatial*DataFrame) objekt.
Tabellfälten lagras som strängar som innehåller namnet på det valda fältet.
Vektorfiler kan läsas med kommandot readOGR() istället för st_read() genom att ange ##load_vector_using_rgdal. Detta kommer att producera ett Spatial*DataFrame-objekt istället för ett sf-objekt.
Rasterfiler kan läsas med kommandot readGDAL() i stället för brick() genom att ange ##load_raster_using_rgdal.
Om du är en avancerad användare och inte vill att QGIS ska skapa objektet för lagret, kan du använda ##pass_filenames för att ange att du föredrar en sträng med filnamnet. I detta fall är det upp till dig att öppna filen innan du utför någon åtgärd på de data som den innehåller.
Med ovanstående information är det möjligt att förstå de första raderna i R-skriptet (den första raden som inte börjar med ett Python-kommentartecken).
library(sp)
spatpoly = as(Vector_layer, "Spatial")
pts=spsample(polyg,numpoints,type="random")
Funktionen spsample tillhandahålls av biblioteket sp, så det första vi gör är att ladda det biblioteket. Variabeln Vector_layer innehåller ett sf-objekt. Eftersom vi ska använda en funktion (spsample) från sp-biblioteket måste vi konvertera sf-objektet till ett SpatialPolygonsDataFrame-objekt med hjälp av funktionen as.
Sedan anropar vi funktionen spsample med detta objekt och inparametern numpoints (som anger antalet punkter som ska genereras).
Eftersom vi har deklarerat en vektorutgång med namnet Output måste vi skapa en variabel med namnet Output som innehåller ett sf-objekt.
Vi gör detta i två steg. Först skapar vi ett SpatialPolygonsDataFrame-objekt från resultatet av funktionen med hjälp av funktionen SpatialPointsDataFrame, och sedan konverterar vi det objektet till ett sf-objekt med hjälp av funktionen st_as_sf (i biblioteket sf).
Du kan använda vilka namn du vill för dina mellanliggande variabler. Se bara till att variabeln som lagrar ditt slutresultat har det definierade namnet (i det här fallet Output) och att den innehåller ett lämpligt värde (ett sf-objekt för vektorlagerutdata).
I det här fallet måste resultatet från metoden spsample uttryckligen konverteras till ett sf-objekt via ett SpatialPointsDataFrame-objekt, eftersom det i sig är ett objekt av klassen ppp, som inte kan returneras till QGIS.
Om din algoritm genererar rasterlager beror sättet de sparas på om du har använt alternativet ##dontuserasterpackage eller inte. Om du har använt det sparas lagren med hjälp av metoden writeGDAL(). Om inte, kommer metoden writeRaster() från paketet raster att användas.
Om du har använt alternativet ##pass_filenames genereras utdata med hjälp av paketet raster (med writeRaster()).
Om din algoritm inte genererar ett lager, utan ett textresultat i konsolen, måste du ange att du vill att konsolen ska visas när exekveringen är klar. Det gör du genom att inleda de kommandorader som ger de resultat som du vill skriva ut med tecknet > (”större än”). Endast utdata från rader med prefixet > visas. Här är t.ex. beskrivningsfilen för en algoritm som utför ett normalitetstest på ett givet fält (kolumn) av attributen i ett vektorlager:
##layer=vector
##field=field layer
##nortest=group
library(nortest)
>lillie.test(layer[[field]])
Utdata från den sista raden skrivs ut, men inte utdata från den första (och inte heller utdata från andra kommandorader som QGIS lägger till automatiskt).
Om din algoritm skapar någon form av grafik (med hjälp av metoden plot()), lägg till följande rad (output_plots_to_html brukade vara showplots):
##output_plots_to_html
Detta gör att QGIS omdirigerar alla grafiska utdata från R till en temporär fil, som öppnas när R-körningen har avslutats.
Både grafik- och konsolresultat kommer att finnas tillgängliga via resultathanteraren för bearbetning.
För mer information, se R-skript i den officiella QGIS-samlingen (du hämtar och installerar dem med hjälp av tillägget QGIS Resource Sharing, som förklaras i Lägga till R-skript från QGIS-samlingen). De flesta av dem är ganska enkla och kommer att hjälpa dig att förstå hur du skapar dina egna skript.
Observera
Biblioteken sf, rgdal och raster laddas som standard, så du behöver inte lägga till motsvarande kommandon library(). Andra bibliotek som du kan behöva måste dock laddas explicit genom att skriva: library(ggplot2) (för att ladda biblioteket ggplot2). Om paketet inte redan finns installerat på din dator kommer Processing att försöka hämta och installera det. På detta sätt kommer paketet också att bli tillgängligt i R Standalone. Tänk på att om paketet måste laddas ner kan det ta lång tid att köra skriptet första gången.
R-bibliotek installerade när sf_test körs
R-skriptet sp_test försöker ladda R-paketen sp och raster.
R-skriptet sf_test försöker ladda sf och raster. Om dessa två paket inte är installerade kan R försöka läsa in och installera dem (och alla bibliotek som de är beroende av).
Följande R-bibliotek hamnar i ~/.local/share/QGIS/QGIS3/profiles/default/processing/rscripts efter att sf_test har körts från Processing Toolbox på Ubuntu med version 2.0 av tillägget Processing R Provider och en ny installation av R 3.4.4 (endast apt-paketet r-base-core):
abind, askpass, assertthat, backports, base64enc, BH, bit, bit64, blob, brew, callr, classInt, cli, colorspace, covr, crayon, crosstalk, curl, DBI, deldir,
desc, dichromat, digest, dplyr, e1071, ellipsis, evaluate, fansi, farver, fastmap, gdtools, ggplot2, glue, goftest, gridExtra, gtable, highr, hms,
htmltools, htmlwidgets, httpuv, httr, jsonlite, knitr, labeling, later, lazyeval, leafem, leaflet, leaflet.providers, leafpop, leafsync, lifecycle, lwgeom,
magrittr, maps, mapview, markdown, memoise, microbenchmark, mime, munsell, odbc, openssl, pillar, pkgbuild, pkgconfig, pkgload, plogr, plyr, png, polyclip,
praise, prettyunits, processx, promises, ps, purrr, R6, raster, RColorBrewer, Rcpp, reshape2, rex, rgeos, rlang, rmarkdown, RPostgres, RPostgreSQL,
rprojroot, RSQLite, rstudioapi, satellite, scales, sf, shiny, sourcetools, sp, spatstat, spatstat.data, spatstat.utils, stars, stringi, stringr, svglite,
sys, systemfonts, tensor, testthat, tibble, tidyselect, tinytex, units, utf8, uuid, vctrs, viridis, viridisLite, webshot, withr, xfun, XML, xtable
23.11.4.3. GRASS
Konfigurationen av GRASS skiljer sig inte mycket från konfigurationen av SAGA. Först måste sökvägen till GRASS-mappen definieras, men bara om du kör Windows.
Som standard försöker Processing-ramverket konfigurera sin GRASS-koppling så att den använder GRASS-distributionen som levereras tillsammans med QGIS. Detta bör fungera utan problem för de flesta system, men om du upplever problem kan du behöva konfigurera GRASS-kopplingen manuellt. Om du vill använda en annan GRASS-installation kan du också ändra inställningen så att den pekar på den mapp där den andra versionen är installerad. GRASS 7 behövs för att algoritmerna ska fungera korrekt.
Om du kör Linux behöver du bara se till att GRASS är korrekt installerat och att det kan köras utan problem från ett terminalfönster.
GRASS-algoritmer använder en region för beräkningar. Denna region kan definieras manuellt med hjälp av värden liknande de som finns i SAGA-konfigurationen, eller automatiskt, genom att ta den minsta utsträckning som täcker alla inmatningslager som används för att exekvera algoritmen varje gång. Om det är det senare tillvägagångssättet du föredrar, markera bara alternativet Use min covering region i GRASS konfigurationsparametrar.
23.11.4.4. LAStools
För att använda LAStools i QGIS måste du ladda ner och installera LAStools på din dator och installera LAStools plugin (tillgängligt från det officiella arkivet) i QGIS.
På Linux-plattformar behöver du Wine för att kunna köra några av verktygen.
LAStools aktiveras och konfigureras i Processing options (, Processing tab, ), där du kan ange platsen för LAStools (LAStools folder) och Wine (Wine folder). På Ubuntu är standardmappen för Wine /usr/bin.
23.11.4.5. OTB-applikationer
OTB-applikationer stöds fullt ut inom ramen för QGIS Processing.
OTB (Orfeo ToolBox) är ett bildbehandlingsbibliotek för fjärranalysdata. Det innehåller också applikationer som tillhandahåller funktioner för bildbehandling. Listan över applikationer och deras dokumentation finns i OTB CookBook
Observera
Observera att OTB inte distribueras med QGIS och måste installeras separat. Binära paket för OTB finns på nedladdningssidan <https://www.orfeo-toolbox.org/download>`_.
För att konfigurera QGIS-bearbetning för att hitta OTB-biblioteket:
Öppna bearbetningsinställningarna:
Du kan se
OTBunder -menyn:Utöka OTB-posten
Ställ in OTB-mapp. Detta är platsen för din OTB-installation.
Ställ in OTB applikationsmapp. Detta är platsen för dina OTB-applikationer (
<PATH_TO_OTB_INSTALLATION>/lib/otb/applications)Klicka på OK för att spara inställningarna och stänga dialogrutan.
Om inställningarna är korrekta kommer OTB-algoritmer att finnas tillgängliga i Processing Toolbox.
Dokumentation av OTB-inställningar tillgängliga i QGIS Processing
OTB-mapp: Detta är den katalog där OTB finns tillgängligt.
OTB applikationsmapp: Detta är platsen/platserna för OTB-applikationer.
Flera sökvägar är tillåtna.
Loggningsnivå (valfritt): Loggarens nivå som ska användas av OTB-applikationer.
Loggningsnivån styr hur mycket detaljer som skrivs ut under algoritmens exekvering. Möjliga värden för loggningsnivå är
INFO,WARNING,CRITICAL,DEBUG. Detta värde ärINFOsom standard. Detta är en avancerad användarkonfiguration.Maximalt RAM-minne att använda (valfritt): som standard använder OTB-program allt tillgängligt RAM-minne i systemet.
Du kan dock instruera OTB att använda en viss mängd RAM (i MB) med hjälp av detta alternativ. Ett värde på 256 ignoreras av OTB:s bearbetningsleverantör. Detta är en avancerad användarkonfiguration.
Geoid-fil (valfritt): Sökväg till geoidfilen.
Detta alternativ anger värdet för parametrarna elev.dem.geoid och elev.geoid i OTB-applikationer. Genom att ställa in detta värde globalt kan användare dela det mellan flera bearbetningsalgoritmer. Tomt som standard.
SRTM tiles folder (valfritt): Katalog där SRTM-plattor finns tillgängliga.
SRTM-data kan lagras lokalt för att undvika nedladdning av filer under bearbetningen. Detta alternativ anger värdet för parametrarna elev.dem.path och elev.dem i OTB-applikationer. Genom att ställa in detta värde globalt kan användare dela det mellan flera bearbetningsalgoritmer. Tomt som standard.
Kompatibilitet och felsökning
Från och med OTB 6.6.1 görs nya versioner av OTB kompatibla med åtminstone den senaste QGIS-versionen som är tillgänglig vid den tidpunkten.
Om du har problem med OTB-applikationer i QGIS Processing, vänligen öppna ett ärende på OTB bug tracker, med etiketten qgis.
Ytterligare information om OTB och QGIS finns i OTB Cookbook.