Important
La traduction est le fruit d’un effort communautaire auquel vous pouvez vous joindre. Cette page est actuellement traduite à 89.34%.
23.11. Configuration d’applications externes
The Processing framework can be extended using additional applications. Algorithms that rely on external applications are managed by their own algorithm providers. Additional providers can be found as separate plugins, and installed using the QGIS Plugin Manager.
Cette section vous montrera comment configurer l’infrastructure de traitement pour inclure ces applications supplémentaires, et elle expliquera certaines caractéristiques particulières des algorithmes basés sur celles-ci. Une fois que vous avez correctement configuré le système, vous pourrez exécuter des algorithmes externes à partir de n’importe quel composant comme la boîte à outils ou le modeleur graphique, comme vous le faites avec n’importe quel autre algorithme.
Par défaut, les algorithmes qui reposent sur une application externe non fournie avec QGIS ne sont pas activés. Vous pouvez les activer dans la boîte de dialogue Paramètres de traitement s’ils sont installés sur votre système.
23.11.1. Note pour les utilisateurs de Windows
If you are not an advanced user and you are running QGIS on Windows, you might not be interested in reading the rest of this chapter. Make sure you install QGIS in your system using the standalone installer. That will automatically install GRASS in your system and configure it so it can be run from QGIS. All the algorithms from this provider will be ready to be run without needing any further configuration. If installing with the OSGeo4W application, make sure that you also select GRASS for installation.
23.11.2. A propos des formats de fichiers
Lorsque vous utilisez un logiciel externe, l’ouverture d’un fichier dans QGIS ne signifie pas qu’il peut être ouvert et traité dans cet autre logiciel. Dans la plupart des cas, d’autres logiciels peuvent lire ce que vous avez ouvert dans QGIS, mais dans certains cas, cela peut ne pas être vrai. Lors de l’utilisation de bases de données ou de formats de fichiers inhabituels, que ce soit pour des couches raster ou vectorielles, des problèmes peuvent survenir. Si cela se produit, essayez d’utiliser des formats de fichiers bien connus qui sont sûrs d’être compris par les deux programmes et vérifiez la sortie de la console (dans le panneau de journal) pour découvrir ce qui ne va pas.
Vous pourriez par exemple avoir des problèmes et ne pas être en mesure de terminer votre travail si vous appelez un algorithme externe avec des couches raster GRASS en entrée. Pour cette raison, ces couches n’apparaîtront pas comme disponibles pour les algorithmes.
Cependant, vous ne devriez pas avoir de problèmes avec les couches vectorielles, car QGIS convertit automatiquement du format de fichier d’origine en un format accepté par l’application externe avant de lui passer la couche. Cela ajoute du temps de traitement supplémentaire, qui peut être important pour les couches de gros volume, donc ne soyez pas surpris s’il faut plus de temps pour traiter une couche à partir d’une connexion DB qu’une couche d’un jeu de données au format Shapefile de taille similaire.
Les algorithmes n’utilisant pas d’application tierce peuvent traiter toutes les couches qui peuvent s’ouvrir dans QGIS puisque qu’ils sont lancés depuis QGIS.
Tous les formats de sortie raster et vecteur produits par QGIS peuvent être utilisés comme couches d’entrée. Certains fournisseurs ne prennent pas en charge certains formats, mais tous peuvent exporter vers des formats communs qui peuvent ensuite être transformés automatiquement par QGIS. Quant aux couches d’entrée, si une conversion est nécessaire, cela pourrait augmenter le temps de traitement.
23.11.3. A propos des sélections sur les couches vectorielles
Les applications tierces peuvent prendre en compte les sélections qui existent sur les couches vecteur dans QGIS. Cependant, cela nécessite de réécrire toutes les couches vecteur d’entrée, comme si elles étaient dans un format non géré par l’application tierce. Une couche peut être passée directement à une application tierce uniquement lorsqu’il n’y a pas de sélection ou que l’option N’utiliser que les entités sélectionnées n’est pas activée dans les paramètres de configuration généraux du module de traitement.
Dans d’autres cas, l’exportation uniquement des entités sélectionnées est nécessaire, ce qui entraîne des temps d’exécution plus longs.
23.11.4. Using third-party Providers
23.11.4.1. R scripts and libraries
Pour activer R dans le Processing, vous devez installer le plug-in Processing R Provider et configurer R pour QGIS.
La configuration se fait dans dans l’onglet Traitements du menu .
Selon votre système d’exploitation, vous devrez peut-être utiliser dossier R pour spécifier l’emplacement de vos fichiers binaires R.
Note
Sous Windows, le fichier exécutable R se trouve normalement dans un dossier (R-<version>) sous C:\Program Files\R\. Spécifiez le dossier et PAS le binaire!
Sous Linux, il vous suffit de vous assurer que le dossier R se trouve dans la variable d’environnement PATH. Si R dans une fenêtre de terminal démarre R, alors vous êtes prêt.
Après avoir installé le plugin Processing R Provider, vous trouverez des exemples de scripts dans Processing Toolbox:
Scatterplot exécute une fonction R qui produit un nuage de points à partir de deux champs numériques de la couche vectorielle fournie.
test_sf effectue certaines opérations qui dépendent du package
sfet peut être utilisé pour vérifier si le paquet Rsfest installé. Si le paquet n’est pas installé, R essaiera de l’installer (et tous les paquets dont il dépend) pour vous, en utilisant le dépôt de paquets spécifié dans dans les options de traitement. La valeur par défaut est https://cran.r-project.org/. L’installation peut prendre un certain temps…test_sp peut être utilisé pour vérifier si le package R
spest installé. Si le package n’est pas installé, R essaiera de l’installer pour vous.
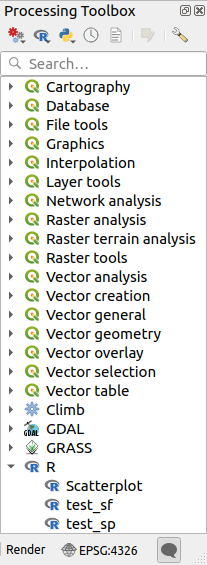
Si vous avez correctement configuré R pour QGIS, vous devriez pouvoir exécuter ces scripts.
Ajout de scripts R à partir de la collection QGIS
R integration in QGIS is different from that of some other third party providers like SAGA in that there is not a predefined set of algorithms you can run (except for some example script that come with the Processing R Provider plugin).
Un ensemble d’exemples de scripts R est disponible dans le référentiel QGIS. Effectuez les étapes suivantes pour les charger et les activer à l’aide du plug-in QGIS Resource Sharing.
Ajoutez le plugin QGIS Resource Sharing (vous devrez peut-être activer Afficher également les plugins expérimentaux dans le gestionnaire de plugins Paramètres)
Ouvrez-le ()
Choisir l’onglet Paramètre
Cliquer sur Recharger les référentiels
Choisir l’onglet Tous
Sélectionnez Collection de scripts QGIS R dans la liste et cliquez sur le bouton Installer
La collection devrait maintenant être répertoriée dans l’onglet Installé
Fermer la fenêtre plugin.
Ouvrez Boîte à outils de traitement, et si tout va bien, les scripts d’exemple seront présents sous R, dans différents groupes (seuls certains des groupes sont développés dans la capture d’écran ci-dessous).
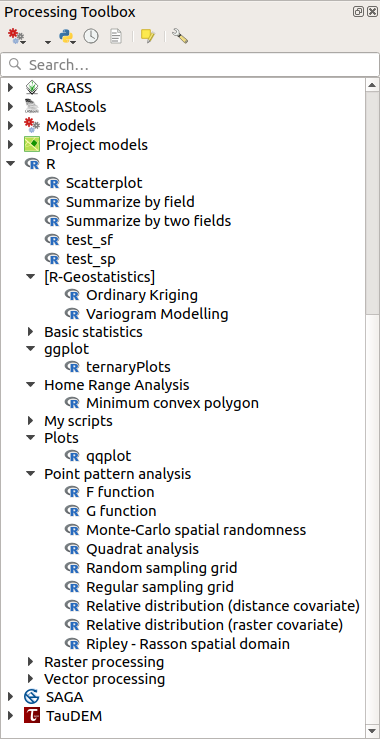
Fig. 23.35 La Boîte à outils de traitement avec quelques scripts R affichés
Les scripts en haut sont des exemples de scripts du plugin Processing R Provider.
Si, pour une raison quelconque, les scripts ne sont pas disponibles dans la boite à outils traitement, vous pouvez essayer de :
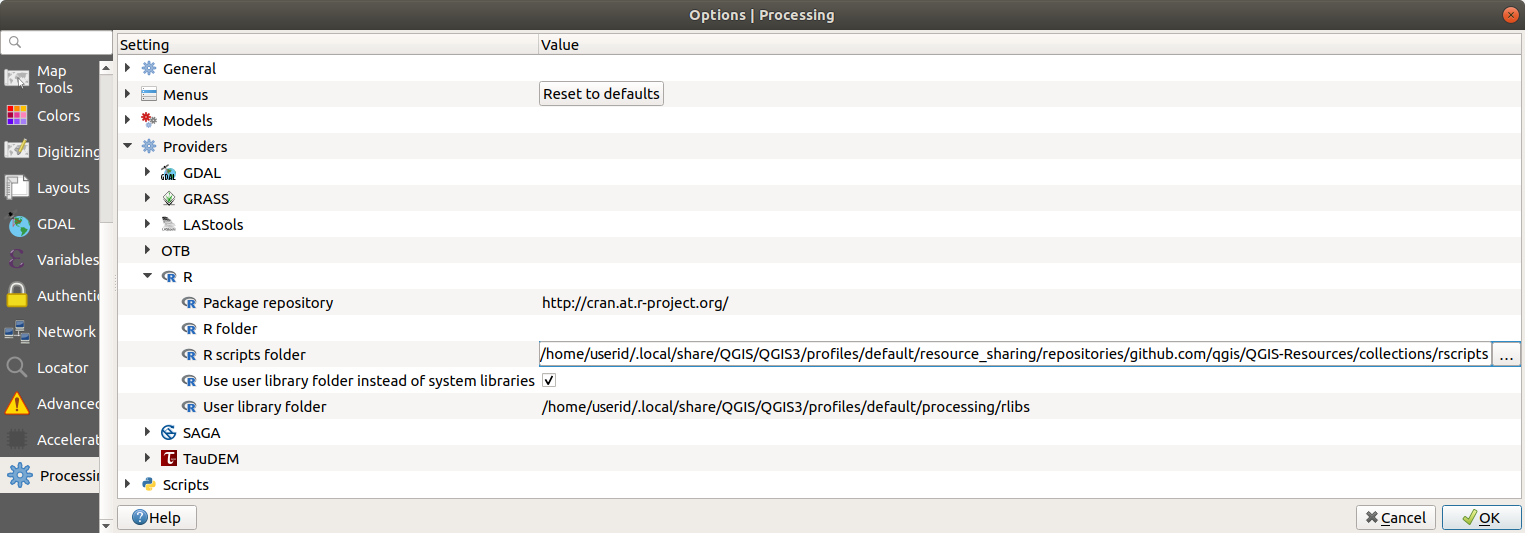
Ouvrir les paramètres de traitement ( )
Aller dans
Sur Ubuntu, définissez le chemin d’accès (ou, mieux, incluez-le dans le chemin d’accès) :
/home/<user>/.local/share/QGIS/QGIS3/profiles/default/resource_sharing/repositories/github.com/qgis/QGIS-Resources/collections/rscripts
Sous Windows, définissez le chemin d’accès (ou, mieux, incluez-le dans le chemin d’accès):
C:\Users\<user>\AppData\Roaming\QGIS\QGIS3\profiles\default\resource_sharing\repositories\github.com\qgis\QGIS-Resources\collections\rscripts
Pour modifier, double-cliquez. Vous pouvez alors choisir de simplement coller/taper le chemin, ou vous pouvez accéder au répertoire en utilisant le bouton … et appuyez sur le bouton Ajouter dans la fenêtre qui s’ouvre. Il est possible de fournir ici plusieurs répertoires. Ils seront séparés par un point-virgule (« ; »).

If you would like to get all the R scripts from the QGIS 2 on-line collection, you can select QGIS R script collection (from QGIS 2) instead of QGIS R script collection. You will probably find that scripts that depend on vector data input or output will not work.
Création scripts R
Vous pouvez écrire des scripts et appeler des commandes R, comme vous le feriez à partir de R. Cette section vous montre la syntaxe d’utilisation des commandes R dans QGIS, et comment utiliser des objets QGIS (couches, tables).
Pour ajouter un algorithme qui appelle une fonction R (ou un script R plus complexe que vous avez développé et que vous aimeriez avoir disponible à partir de QGIS), vous devez créer un fichier de script qui exécute les commandes R.
Les fichiers de script R ont l’extension .rsx, et leur création est assez facile si vous avez juste une connaissance de base de la syntaxe R et du script R. Ils doivent être stockés dans le dossier des scripts R. Vous pouvez spécifier le dossier ( dossier de scripts R) dans le groupe de paramètres R dans la boîte de dialogue Paramètres de traitement).
Examinons un fichier de script très simple, qui appelle la méthode R spsample pour créer une grille aléatoire à l’intérieur des limites des polygones dans une couche de polygones donnée. Cette méthode appartient au package maptools. Étant donné que presque tous les algorithmes que vous aimeriez intégrer à QGIS utiliseront ou généreront des données spatiales, la connaissance des packages spatiaux tels que maptools et sp/sf est très utile.
##Random points within layer extent=name
##Point pattern analysis=group
##Vector_layer=vector
##Number_of_points=number 10
##Output=output vector
library(sp)
spatpoly = as(Vector_layer, "Spatial")
pts=spsample(spatpoly,Number_of_points,type="random")
spdf=SpatialPointsDataFrame(pts, as.data.frame(pts))
Output=st_as_sf(spdf)
Les premières lignes, qui commencent par un double signe de commentaire Python (##), définissent le nom d’affichage et le groupe du script et indiquent à QGIS ses entrées et sorties.
Note
Pour en savoir plus sur la façon d’écrire vos propres scripts R, consultez la section Introduction à R dans le manuel de formation et la section Syntax R dans QGIS.
Lorsque vous déclarez un paramètre d’entrée, QGIS utilise ces informations pour deux choses : la création de l’interface utilisateur pour demander à l’utilisateur la valeur de ce paramètre et la création d’une variable R correspondante qui peut être utilisée comme entrée de fonction R.
Dans l’exemple ci-dessus, nous avons déclaré une entrée de type vecteur, nommée Vector_layer. Lors de l’exécution de l’algorithme, QGIS ouvrira la couche sélectionnée par l’utilisateur et la stockera dans une variable nommée Vector_layer. Ainsi, le nom d’un paramètre est le nom de la variable que vous pouvez utiliser dans R pour accéder à la valeur de ce paramètre (vous devez donc éviter d’utiliser des mots R réservés comme noms de paramètres).
Les paramètres spatiaux tels que les couches vectorielles et raster sont lus à l’aide des commandes st_read() (ou readOGR) et brick() (ou readGDAL) (vous n’avez pas à vous soucier d’ajouter ces commandes à votre fichier de description – QGIS le fera), et ils sont stockés en tant qu’objets sf (ou Spatial*DataFrame).
Les champs de table sont stockés sous forme de chaînes contenant le nom du champ sélectionné.
Les fichiers vectoriels peuvent être lus en utilisant la commande readOGR() au lieu de st_read() en spécifiant ##load_vector_using_rgdal. Cela produira un objet Spatial*DataFrame au lieu d’un objet sf.
Les fichiers raster peuvent être lus à l’aide de la commande readGDAL() au lieu de brick() en spécifiant ##load_raster_using_rgdal.
Si vous êtes un utilisateur avancé et que vous ne voulez pas que QGIS crée l’objet pour la couche, vous pouvez utiliser ##pass_filenames pour indiquer que vous préférez une chaîne avec le nom de fichier. Dans ce cas, c’est à vous d’ouvrir le fichier avant d’effectuer toute opération sur les données qu’il contient.
Avec les informations ci-dessus, il est possible de comprendre les premières lignes du script R (la première ligne ne commençant pas par un caractère de commentaire Python).
library(sp)
spatpoly = as(Vector_layer, "Spatial")
pts=spsample(polyg,numpoints,type="random")
La fonction spsample est fournie par la bibliothèque sp, donc la première chose que nous faisons est de charger cette bibliothèque. La variable Vector_layer contient un objet sf. Puisque nous allons utiliser une fonction (spsample) de la bibliothèque sp, nous devons convertir l’objet sf en objet SpatialPolygonsDataFrame en utilisant la fonction as.
Ensuite, nous appelons la fonction « spsample » avec cet objet et le paramètre d’entrée « numpoints » (qui spécifie le nombre de points à générer).
Puisque nous avons déclaré une sortie vectorielle nommée Sortie, nous devons créer une variable nommée Sortie contenant un objet sf.
Nous procédons en deux étapes. Nous créons d’abord un objet SpatialPolygonsDataFrame à partir du résultat de la fonction, en utilisant la fonction SpatialPointsDataFrame, puis nous convertissons cet objet en objet sf en utilisant la fonction st_as_sf (de la librairie*sf*).
Vous pouvez utiliser les noms que vous souhaitez pour vos variables intermédiaires. Assurez-vous simplement que la variable stockant votre résultat final a le nom défini (dans ce cas, Sortie) et qu’elle contient une valeur appropriée (un objet sf pour la sortie de la couche vectorielle).
Dans ce cas, le résultat obtenu à partir de la méthode spsample doit être converti explicitement en objet sf via un objet SpatialPointsDataFrame, car il est lui-même un objet de classe ppp, qui ne peut pas être retourné à QGIS .
Si votre algorithme génère des couches raster, la façon dont elles sont enregistrées varie selon que vous ayez utilisé l’option ##dontuserasterpackage ou pas. Si oui, les couches seront sauvegardées en utilisant la méthode writeGDAL(). Si non, la méthode writeRaster() du paquet raster sera utilisée.
Si vous avez utilisé l’option ##pass_filenames, les sorties sont générées à l’aide du package raster (avec writeRaster()).
Si votre algorithme ne génère pas de couche, mais un résultat sous forme de texte dans la console à la place, vous devez indiquer que vous souhaitez que la console soit affichée une fois l’exécution terminée. Pour ce faire, il suffit de démarrer les lignes de commande qui produisent les résultats que vous souhaitez imprimer avec le signe > (“supérieur”). Seules les sorties des lignes préfixées par > seront affichées. Par exemple, voici le fichier de description d’un algorithme qui effectue un test de normalité sur un champ (colonne) donné des attributs d’une couche vectorielle :
##layer=vector
##field=field layer
##nortest=group
library(nortest)
>lillie.test(layer[[field]])
La sortie de la dernière ligne est affichée, mais la sortie de la première ne l’est pas (ni celles des commandes ajoutées automatiquement par QGIS).
Si votre algorithme crée des graphiques (par la méthode plot()), ajoutez la ligne suivante (showplots a été remplacé par output_plots_to_html) :
##output_plots_to_html
Ceci va indiquer à QGIS de rediriger toutes les sorties graphiques de R vers un fichier temporaire qui sera chargé une fois l’exécution de R terminée.
Les graphiques et les résultats dans la console seront disponibles via le gestionnaire de résultats.
Pour plus d’informations, veuillez vérifier les scripts R dans la collection officielle de QGIS (vous les téléchargez et installez à l’aide du plugin QGIS Resource Sharing, comme expliqué dans Ajout de scripts R à partir de la collection QGIS). La plupart d’entre eux sont assez simples et vous aideront grandement à comprendre comment créer vos propres scripts.
Note
Les bibliothèques « sf », « rgdal » et « raster » sont chargées par défaut, vous n’avez donc pas à ajouter les commandes « library()` » correspondantes. Cependant, les autres bibliothèques dont vous pourriez avoir besoin doivent être explicitement chargées en tapant : library(ggplot2) (pour charger la bibliothèque ggplot2). Si le paquet n’est pas déjà installé sur votre machine, Processing essaiera de le télécharger et de l’installer. De cette façon, le paquet sera également disponible dans R Standalone. Soyez conscient que si le paquet doit être téléchargé, le script peut prendre beaucoup de temps pour s’exécuter la première fois.
Bibliothèques R installées lors de l’exécution de sf_test
Le script R sp_test essaie de charger les packages R sp et raster.
Le script R sf_test essaie de charger sf et raster. Si ces deux packages ne sont pas installés, R peut essayer de les charger et de les installer (et toutes les librairies dont ils dépendent).
Les bibliothèques R suivantes se retrouvent dans ~/.local/share/QGIS/QGIS3/profiles/default/processing/rscripts après l’exécution de sf_test à partir de la boîte à outils de traitement sur Ubuntu avec la version 2.0 de l’extension Processing R Provider et une installation à neuf de R 3.4.4 (uniquement le paquet apt r-base-core) :
abind, askpass, assertthat, backports, base64enc, BH, bit, bit64, blob, brew, callr, classInt, cli, colorspace, covr, crayon, crosstalk, curl, DBI, deldir,
desc, dichromat, digest, dplyr, e1071, ellipsis, evaluate, fansi, farver, fastmap, gdtools, ggplot2, glue, goftest, gridExtra, gtable, highr, hms,
htmltools, htmlwidgets, httpuv, httr, jsonlite, knitr, labeling, later, lazyeval, leafem, leaflet, leaflet.providers, leafpop, leafsync, lifecycle, lwgeom,
magrittr, maps, mapview, markdown, memoise, microbenchmark, mime, munsell, odbc, openssl, pillar, pkgbuild, pkgconfig, pkgload, plogr, plyr, png, polyclip,
praise, prettyunits, processx, promises, ps, purrr, R6, raster, RColorBrewer, Rcpp, reshape2, rex, rgeos, rlang, rmarkdown, RPostgres, RPostgreSQL,
rprojroot, RSQLite, rstudioapi, satellite, scales, sf, shiny, sourcetools, sp, spatstat, spatstat.data, spatstat.utils, stars, stringi, stringr, svglite,
sys, systemfonts, tensor, testthat, tibble, tidyselect, tinytex, units, utf8, uuid, vctrs, viridis, viridisLite, webshot, withr, xfun, XML, xtable
23.11.4.2. GRASS
Configuring GRASS is very easy. First, the path to the GRASS folder has to be defined, but only if you are running Windows.
Par défaut, l’infrastructure de traitement essaie de configurer son connecteur GRASS pour utiliser la distribution GRASS livrée avec QGIS. Cela devrait fonctionner sans problème pour la plupart des systèmes, mais si vous rencontrez des problèmes, vous devrez peut-être configurer le connecteur GRASS manuellement. De plus, si vous souhaitez utiliser une installation GRASS différente, vous pouvez modifier le paramètre pour pointer vers le dossier dans lequel l’autre version est installée. GRASS 7 est nécessaire pour que les algorithmes fonctionnent correctement.
Si vous utilisez Linux, il vous suffit de vous assurer que GRASS est correctement installé et qu’il peut être exécuté sans problème à partir d’une fenêtre de terminal.
GRASS algorithms use a region for calculations. This region can be defined manually or automatically, taking the minimum extent that covers all the input layers used to execute the algorithm each time.
23.11.4.3. LAStools
To use LAStools in QGIS, you need to download and install LAStools on your computer and install the LAStools plugin (available from the official repository) in QGIS.
On Linux platforms, you will need Wine to be able to run some of the tools.
LAStools est activé et configuré dans les options de traitement (, onglet Traitements, ), où vous pouvez spécifier l’emplacement des LAStools (Dossier LAStools) et Wine ( Dossier Wine). Sur Ubuntu, le dossier Wine par défaut est /usr/bin.
23.11.4.4. Applications OTB
Les applications OTB sont intégralement supportées par le module de Traitements de QGIS.
OTB (Orfeo ToolBox) is an image processing library for remote sensing data. It also provides applications that provide image processing functionalities. The list of applications and their documentation are available in OTB CookBook
Note
Notez qu’OTB n’est pas distribué avec QGIS et doit être installé séparément. Les paquets binaires pour OTB peuvent être trouvés sur la page de téléchargement.
Pour configurer le traitement QGIS afin de trouver la bibliothèque OTB :
Ouvrir les paramètres de traitement :
Vous pouvez voir
OTBsous le menu :Développez l’entrée OTB
Définissez le dossier OTB. C’est l’emplacement de votre installation OTB.
Définissez le dossier d’application OTB. C’est l’emplacement de vos applications OTB (
<PATH_TO_OTB_INSTALLATION>/lib/otb/applications)Cliquez sur OK pour enregistrer les paramètres et fermer la boîte de dialogue.
Si les paramètres sont corrects, les algorithmes OTB seront disponibles dans la Processing Toolbox.
Documentation des paramètres OTB disponibles dans le traitement QGIS
Répertoire OTB : Il s’agit du répertoire où OTB est disponible.
Répertoire des applications OTB : C’est le(s) lieu(x) où se trouvent les applications OTB.
Plusieurs chemins sont autorisés.
Niveau du logger (facultatif) : Niveau de l’enregistreur à utiliser par les applications OTB.
Le niveau d’enregistrement contrôle la quantité de détails imprimés pendant l’exécution de l’algorithme. Les valeurs possibles pour le niveau de journalisation sont « INFO », « AVERTISSEMENT », « CRITICAL », « DÉBUG ». Cette valeur est « INFO » par défaut. Il s’agit d’une configuration utilisateur avancée.
Maximum de RAM à utiliser (facultatif) : par défaut, les applications OTB utilisent toute la RAM système disponible.
Vous pouvez toutefois demander a OTB d’utiliser une quantité spécifique de mémoire vive (en Mo) en utilisant cette option. Une valeur de 256 est ignorée par le fournisseur de traitement OTB. Il s’agit d’une configuration utilisateur avancée.
Fichier Geoid (facultatif) : Chemin d’accès au fichier géoïd.
Cette option définit la valeur des paramètres elev.dem.geoid et elev.geoid dans les applications OTB. Le fait de définir cette valeur globalement permet aux utilisateurs de la partager entre plusieurs algorithmes de traitement. Vide par défaut.
Dossier de tuiles SRTM (facultatif) : Répertoire où les tuiles SRTM sont disponibles.
Les données SRTM peuvent être stockées localement pour éviter le téléchargement de fichiers pendant le traitement. Cette option permet de définir la valeur des paramètres elev.dem.path et elev.dem dans les applications OTB. Le fait de définir cette valeur globalement permet aux utilisateurs de la partager entre plusieurs algorithmes de traitement. Vide par défaut.
Compatibility and Troubleshoot
Starting from OTB 6.6.1, new releases of OTB are made compatible with at least the latest QGIS version available at that time.
Si vous avez des problèmes avec les applications OTB dans le traitement du QGIS, veuillez ouvrir un problème sur le dépôt de signalement de bugs d’OTB, en utilisant le label qgis.
Des informations complémentaires sur OTB et QGIS sont disponibles dans OTB Cookbook.