중요
번역은 여러분이 참여할 수 있는 커뮤니티 활동입니다. 이 페이지는 현재 92.31% 번역되었습니다.
17.25. 알고리즘 심화 반복 실행
참고
이 수업에서 자동화를 더 심화시킬 수 있도록 모델 설계자와 알고리즘의 반복 실행을 결합하는 방법을 살펴보겠습니다.
내장된 알고리즘에서만이 아니라, 사용자가 직접 생성할 수 있는 알고리즘, 즉 모델에서도 알고리즘을 반복 실행할 수 있습니다. 더 복잡한 결과물을 더 쉽게 얻을 수 있도록, 모델과 알고리즘의 반복 실행을 결합하는 방법을 살펴보겠습니다.
이 수업에서 사용할 데이터는 직전 수업에서 사용했던 것과 동일합니다. 이 경우 DEM을 각 유역 폴리곤으로 잘라내는 것만이 아니라, 유역 안에서 표고가 어떻게 분포되어 있는지 연구하기 위해 몇몇 단계를 추가해서 잘라낸 각 레이어에 대해 표고분포 곡선을 계산할 것입니다.
몇 단계로 (잘라내기 + 표고분포 곡선 계산) 이루어진 워크플로이기 때문에, 모델 설계자를 실행해서 해당 워크플로에 상응하는 모델을 생성해야 합니다.
이 수업을 위한 데이터 폴더에 이미 모델이 생성되어 있지만, 먼저 사용자가 직접 생성해보는 편이 좋습니다. 이 경우 표고분포 곡선이 중요하기 때문에, 잘라낸 레이어가 최종 결과물이 아닙니다. 즉 이 모델은 어떤 레이어도 생성하지 않습니다. 곡선 데이터를 담은 테이블을 생성할 뿐입니다.
모델이 다음과 같이 보여야 합니다:
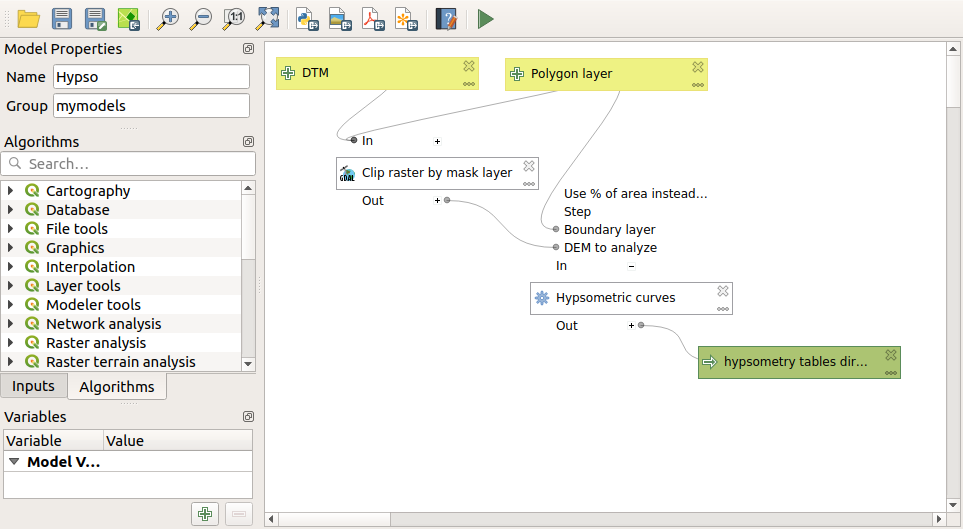
이 모델을 툴박스에서 실행할 수 있도록, 사용자 모델 폴더에 이 모델을 추가하십시오.
DEM과 유역 분지를 선택하십시오.
알고리즘이 모든 분지에 대해 테이블을 생성해서 산출 디렉터리에 저장할 것입니다.
We can make this example more complex by extending the model and computing some slope statistics. Add the Slope algorithm to the model, and then the Raster statistics algorithm, which should use the slope output as its only input.
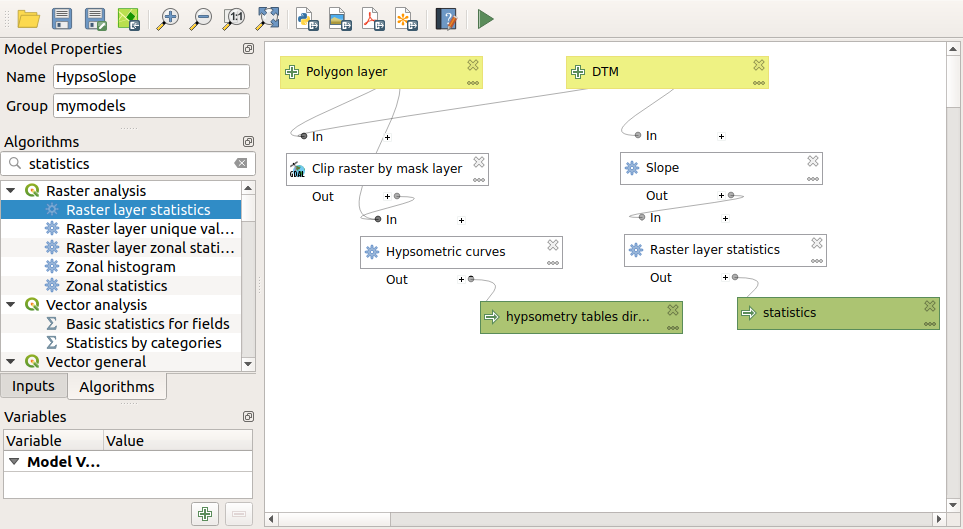
이제 모델을 실행하면, 테이블 외에 통계를 담은 페이지들도 얻게 될 것입니다. Results 대화 창에서 이 페이지들을 사용할 수 있습니다.