중요
번역은 여러분이 참여할 수 있는 커뮤니티 활동입니다. 이 페이지는 현재 97.14% 번역되었습니다.
17.10. 래스터 계산기와 NODATA 값
참고
이 수업에서 래스터 계산기를 사용해서 래스터 레이어에 대한 몇몇 작업을 수행하는 방법을 배워보겠습니다. 또 NODATA 값이 무엇인지, 래스터 계산기와 다른 알고리즘이 NODATA 값을 어떻게 다루는지도 배울 것입니다.
래스터 계산기는 가장 강력한 알고리즘 가운데 하나입니다. 매우 탄력적이고 다용도인 알고리즘으로 여러 가지 계산에 쓸 수 있어, 사용자가 툴박스에서 정말 자주 사용하게 될 것입니다.
이 수업에서 래스터 계산기를 써서 대부분 간단한 편인 몇 가지 계산을 수행할 것입니다. 이를 통해 래스터 계산기를 어떻게 사용하는지, 특별한 상황이 발생할 경우 어떻게 그런 상황을 다루는지 알게 될 것입니다. 이후 래스터 계산기 사용 시 기대한 결과를 얻기 위해 이런 것들뿐만 아니라 일반적으로 적용되는 특정 기법들을 이해하는 것이 중요합니다.
이 수업에 해당하는 QGIS 프로젝트를 여십시오. 래스터 레이어 몇 개를 담고 있습니다.
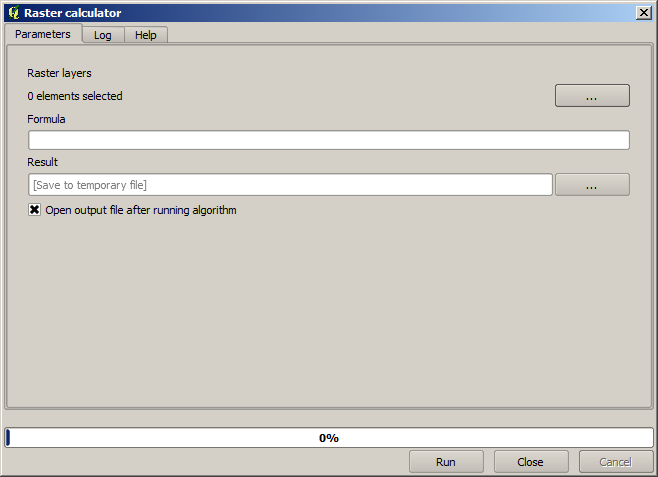
이제 툴박스를 열고 래스터 계산기 대화창을 실행하십시오.
참고
최신 버전의 인터페이스는 달라졌습니다.
이 대화창은 파라미터 2개를 가지고 있습니다.
Raster layers 는 분석에 쓰일 레이어입니다. 사용자가 원하는 만큼 많은 레이어를 선택할 수 있는 다중 입력이 가능합니다. 오른쪽에 있는 버튼을 클릭하면 나타나는 대화창에서 사용자가 사용하길 원하는 레이어들을 선택하십시오.
‘Formula’는 적용할 공식입니다. 이 공식은 앞에서 선택한 레이어를 파라미터로 사용하는데, 알파벳 문자(
a, b, c...) 또는g1, g2, g3...를 변수명으로 사용합니다. 즉a + 2 * b와g1 + 2 * g2는 동일하며, 첫 번째 레이어의 값에 두 번째 레이어의 값의 두 배를 더한 합계를 계산할 것입니다. 이 레이어들의 순서는 선택 대화창에 보이는 순서와 동일합니다.
경고
래스터 계산기는 대소문자를 구분합니다.
DEM의 단위를 미터에서 피트로 변경하는 작업부터 시작할 것입니다. 다음 공식을 사용하면 됩니다:
h' = h * 3.28084
Raster layers 필드에서 DEM을 선택한 다음 Formula 필드에 a * 3.28084 를 입력하십시오.
경고
소수점으로 , 가 아니라, 언제나 . 를 써야 합니다.
Run 을 클릭해서 알고리즘을 실행하십시오. 입력 레이어와 동일한 모양이지만 값이 다른 레이어를 얻게 됩니다. 우리가 사용한 입력 레이어가 모든 셀에 유효한 값을 담고 있으므로, 마지막 파라미터는 어떤 영향도 끼치지 못 합니다.
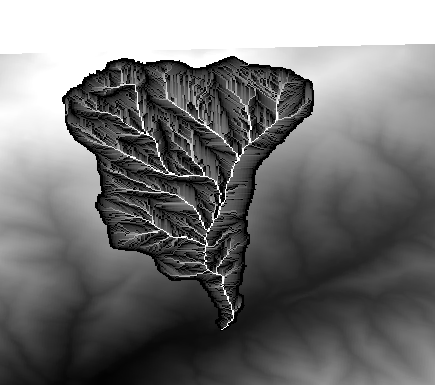
이번에는 accflow 레이어에 대해 다른 계산을 수행해봅시다. 이 레이어는 수자원 파라미터인 누적 수량(accumulated flow) 값을 담고 있습니다. 지정한 유역의 영역 안에 있는 값만을 담고 있으며, 영역 밖은 NODATA 값입니다. 값들이 분포되어 있는 방식 때문에 렌더링된 레이어에서 정보를 얻기가 힘든 것을 볼 수 있습니다. 누적 수량의 로그를 쓰면 훨씬 유익하게 표현할 수 있습니다. 래스터 계산기를 써서 로그를 계산해보겠습니다.
알고리즘 대화창을 다시 열고, 입력 레이어에 accflow 레이어만 선택한 다음, log(a) 라는 공식을 입력하십시오.
다음과 같은 레이어를 얻게 될 것입니다.
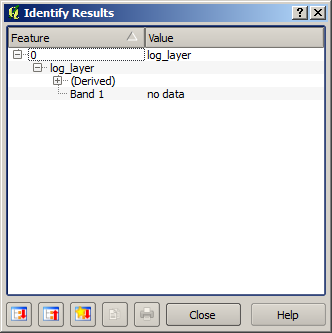
레이어의 어떤 포인트의 값을 알기 위해 Identify 도구를 선택할 경우, 방금 생성한 레이어를 선택한 다음 유역 바깥의 아무 포인트나 클릭해보십시오. NODATA 값을 담고 있다는 것을 알 수 있습니다.
다음 예제에서 레이어 하나가 아니라 두 개를 사용해서 두 번째 레이어가 정의하고 있는 유역 범위 안에 있는 무결한 표고값만을 가진 DEM을 얻어보겠습니다. 래스터 계산기 대화창을 열고 Raster layers 필드에 프로젝트의 두 레이어를 모두 선택하십시오. Formula 필드에 다음 공식을 입력하십시오:
a/a * b
a 가 (목록에 첫 번째로 나타나기 때문에) 누적 수량 레이어를 가리키고, b 가 DEM을 가리킵니다. 공식의 처음 부분에서 누적 수량 레이어를 자기 자신으로 나누어 유역 안의 값을 모두 1로, 바깥의 값을 NODATA 값으로 만듭니다. 이것을 DEM으로 곱하면 유역 안의 셀에 표고값이 (DEM * 1 = DEM) 생성되고, 바깥의 셀에 NODATA 값이 (DEM * no_data = no_data) 생성됩니다.
다음과 같은 레이어가 산출됩니다.

이 기술은 래스터 레이어 안의 값을 마스킹 하는 데 자주 쓰입니다. 래스터 레이어가 사용하는 임의적인 사각형 지역이 아닌 다른 모양의 지역에 대해 계산을 수행하고자 할 때 유용합니다. 예를 들면 래스터 레이어의 표고 히스토그램에는 그렇게 큰 의미가 없습니다. 하지만 유역에 해당하는 값만을 사용해서 (앞의 경우와 같이) 계산할 경우 얻게 되는 것은 실제로 유역의 지형에 대한 정보를 제공하는 의미 있는 결과입니다.
There are other interesting things about this algorithm that we have just run, apart from the no–data values and how they are handled. If you have a look at the extents of the layers that we have multiplied (you can do it double-clicking on the names of the layers in the table of contents and looking at the properties), you will see that they are not the same, since the extent covered by the flow accumulation layer is smaller that the extent of the full DEM.
즉 두 레이어가 일치하지 않으며, 레이어 하나 혹은 모두를 리샘플링해서 레이어의 크기와 범위를 통일하지 않으면 일대일로 곱할 수 없다는 의미입니다. 그런데 우리는 아무 일도 하지 않았습니다. QGIS가 이 상황을 처리해서, 필요할 경우 자동적으로 입력 레이어들을 리샘플링하는 것입니다. 산출물의 범위는 입력 레이어들로부터 계산된 최소 범위이며, 셀 크기는 두 레이어의 최소 셀 크기가 됩니다.
이 경우 (그리고 거의 대부분의 경우) 래스터 계산기가 훌륭한 결과물을 생산하지만, 그 아래에서 이루어지는 추가적인 작업에 대해서도 알고 있어야 합니다. 결과에 영향을 끼칠 수도 있기 때문입니다. 래스터 계산기가 바람직하지 않은 결과를 내놓을 경우, 미리 수작업으로 리샘플링 작업을 해놓아야 합니다. 이후 다른 수업들에서 복수의 래스터 레이어를 사용할 때 알고리즘이 어떻게 동작하는지에 대해 자세히 배울 것입니다.
다른 마스킹 예제로 이 수업을 끝내겠습니다. 표고가 1000에서 1500미터 사이인 모든 영역의 경사도를 계산해보겠습니다.
이 경우 마스킹 레이어로 사용할 레이어가 없지만, 래스터 레이어를 이용해서 계산할 수 있습니다.
입력 레이어에 DEM만 선택하고, 다음 공식을 써서 래스터 계산기를 실행하십시오.
ifelse(abs(a-1250) < 250, 1, 0/0)
이와 같이 래스터 계산기는 간단한 산술적인 작업만이 아니라 조건문을 이용하는 좀 더 복잡한 계산도 실행할 수 있습니다.
우리가 작업하고자 하는 영역 내부의 셀은 1, 외부 셀은 NODATA 값을 가지는 결과물이 생성됩니다.

NODATA 값은 0/0 표현식에서 나옵니다. NODATA 값이 부정확한 값이기 때문에, SAGA는 NaN(Not a Number) 값을 추가해서 실제 NODATA 값인 것처럼 처리합니다. 이런 방법으로 셀의 NODATA 값이 실제로 어떤 값인지 알 필요 없이 NODATA 값을 설정할 수 있습니다.
이제 이 결과물 레이어를 프로젝트에 포함된 경사도 레이어와 곱하기만 하면 원하던 결과를 얻을 수 있습니다.
래스터 계산기에서 이 모든 작업을 단 한 번에 처리할 수도 있습니다. 어떻게 할 수 있는지 여러분이 직접 시험해보십시오.