Viktigt
Översättning är en gemenskapsinsats du kan gå med i. Den här sidan är för närvarande översatt till 100.00%.
6.4. Lektion: Spatial statistik
Observera
Lektion utvecklad av Linfiniti och S Motala (Cape Peninsula University of Technology)
Spatial statistik gör att du kan analysera och förstå vad som händer i en given vektordatauppsättning. QGIS innehåller många användbara verktyg för statistisk analys.
Målet för den här lektionen: Att veta hur man använder QGIS spatiala statistikverktyg i verktygslådan Processing Toolbox.
6.4.1. ★☆☆ Följ med: Skapa en testdatauppsättning
Vi kommer att skapa en slumpmässig uppsättning punkter för att få ett dataset att arbeta med.
För att göra det behöver du en polygondatauppsättning för att definiera det område där du vill skapa punkterna.
Vi kommer att använda det område som täcks av gator.
Starta ett nytt projekt
Lägg till din
roads-datauppsättning samtrtm_41_19(höjddata) som finns iexercise_data/raster/SRTM/.Observera
Du kanske upptäcker att SRTM DEM-lagret har ett annat CRS än väglagret. QGIS omprojicerar båda lagren i ett enda CRS. För de följande övningarna spelar denna skillnad ingen roll, men du får gärna omprojicera (som visats tidigare i denna modul).
Öppna Processing verktygslåda
Använd verktyget för att generera ett område som omsluter alla vägar genom att välja
Convex Hullsom Geometrityp: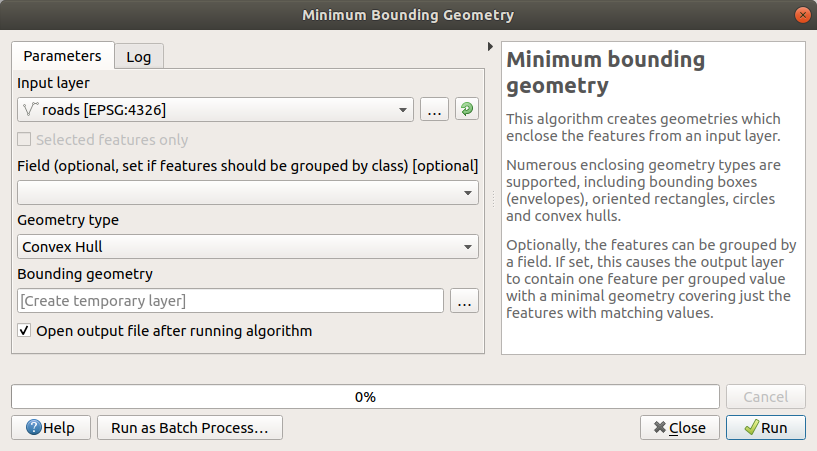
Som du vet skapar Processing tillfälliga lager om du inte specificerar utdata. Det är upp till dig att spara lagren omedelbart eller i ett senare skede.
Skapa slumpmässiga punkter
Skapa 100 slumpmässiga punkter i detta område med hjälp av verktyget i , med ett minsta avstånd på
0.0: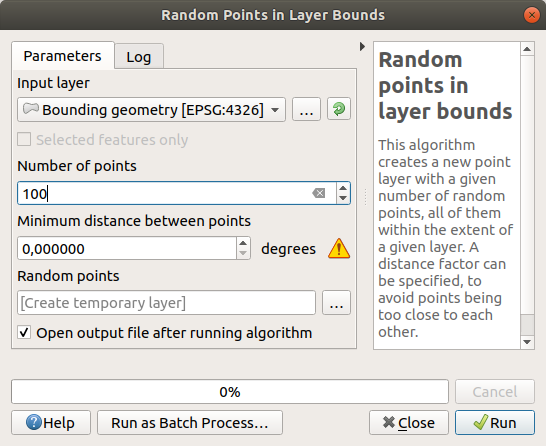
Observera
Den gula varningssymbolen visar att parametern gäller avstånd. Lagret Bounding geometry är i ett geografiskt koordinatsystem och algoritmen påminner dig bara om detta. I det här exemplet kommer vi inte att använda den här parametern, så du kan ignorera den.
Om det behövs kan du flytta den genererade slumpmässiga punkten till toppen av förklaringen för att se dem bättre:
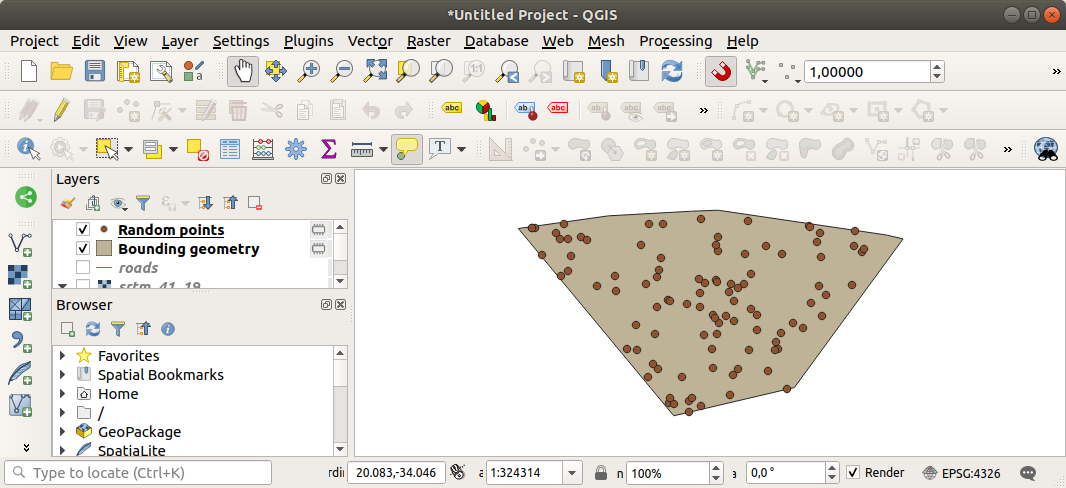
Sampling av data
För att skapa en provdatauppsättning från rastret måste du använda algoritmen . Detta verktyg samplar rastret på punkternas platser och lägger till rastervärdena i nya fält beroende på antalet band i rastret.
Öppna dialogrutan Sampla rastervärden för algoritmen
Välj
Random_pointssom det lager som innehåller provtagningspunkter och SRTM-rastret som det band som värdena ska hämtas från. Standardnamnet på det nya fältet ärrvalue_N, därNär numret på rasterbandet. Du kan ändra namnet på prefixet om du vill.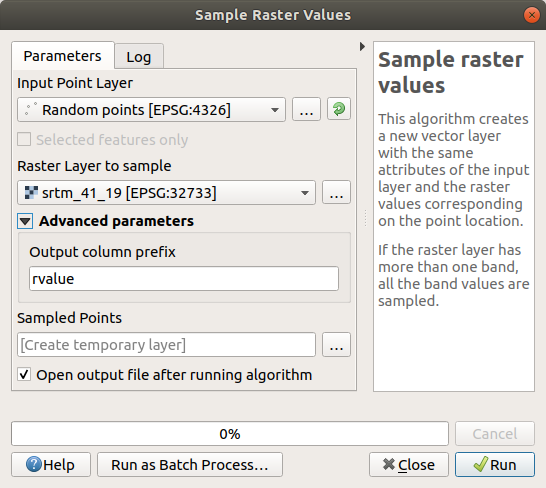
Tryck på Run
Nu kan du kontrollera samplingsdata från rasterfilen i attributtabellen för lagret Sampled Points. De kommer att finnas i ett nytt fält med det namn du har valt.
Här visas ett möjligt exempel på ett lager:
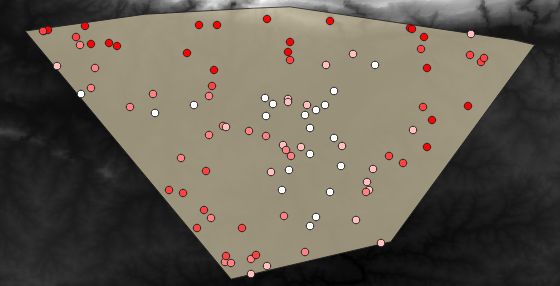
Provpunkterna klassificeras med hjälp av fältet rvalue_1 så att röda punkter ligger på högre höjd.
Du kommer att använda detta provlager under resten av statistikövningarna.
6.4.2. ★☆☆ Följ med: Grundläggande statistik
Nu får du den grundläggande statistiken för detta lager.
Klicka på ikonen
 Visa statistisk sammanfattning i verktygsfältet Attributes. En ny panel kommer att dyka upp.
Visa statistisk sammanfattning i verktygsfältet Attributes. En ny panel kommer att dyka upp.I dialogrutan som visas anger du lagret
Sampled Pointssom källa.Välj fältet rvalue_1 i kombinationsrutan för fält. Detta är det fält som du ska beräkna statistik för.
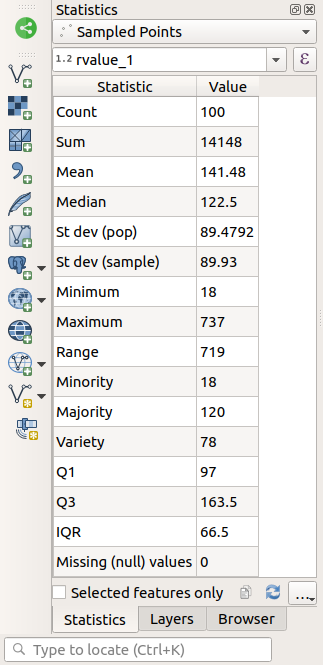
Panelen Statistics kommer automatiskt att uppdateras med den beräknade statistiken:
Observera
Du kan kopiera värdena genom att klicka på knappen
 Copy Statistics To Clipboard och klistra in resultaten i ett kalkylblad.
Copy Statistics To Clipboard och klistra in resultaten i ett kalkylblad.Stäng Statistics-panelen när du är klar
Många olika statistiska uppgifter finns tillgängliga:
- Antal
Antalet prover/värden.
- Sum
Värdena läggs samman.
- Genomsnitt
Medelvärdet (genomsnittet) är helt enkelt summan av värdena dividerat med antalet värden.
- Median
Om du ordnar alla värden från det minsta till det största, är det mittersta värdet (eller genomsnittet av de två mittersta värdena, om N är ett jämnt tal) medianen av värdena.
- St Dev (pop)
Standardavvikelsen. Ger en indikation på hur tätt värdena är grupperade runt medelvärdet. Ju mindre standardavvikelsen är, desto närmare tenderar värdena att ligga medelvärdet.
- Minimum
Det lägsta värdet.
- Maximal
Det maximala värdet.
- Intervall
Skillnaden mellan minimi- och maximivärdena.
- Q1
Första kvartilen av uppgifterna.
- Q3
Tredje kvartilen av uppgifterna.
- Saknade värden (null)
Antalet saknade värden.
6.4.3. ★☆☆ Följ med: Beräkna statistik på avstånd mellan punkter
Skapa ett nytt tillfälligt punktlager.
Gå in i redigeringsläge och digitalisera tre punkter någonstans bland de andra punkterna.
Alternativt kan du använda samma metod för att generera slumpmässiga punkter som tidigare, men ange endast tre punkter.
Spara ditt nya lager som distance_points i det format du föredrar.
För att generera statistik över avstånden mellan punkter i de två lagren:
Öppna verktyget .
Välj lagret
distance_pointssom inmatningslager och lagretSampled Pointssom mållager.Ange deras fält
idsom unika fältreferenserÄndra alternativet Output matrix type till Summary distance matrix.
ställ in värdet för Use only the nearest (k) target points till
2.Om du vill kan du spara utdatalagret som en fil eller bara köra algoritmen och spara det tillfälliga utdatalagret senare.
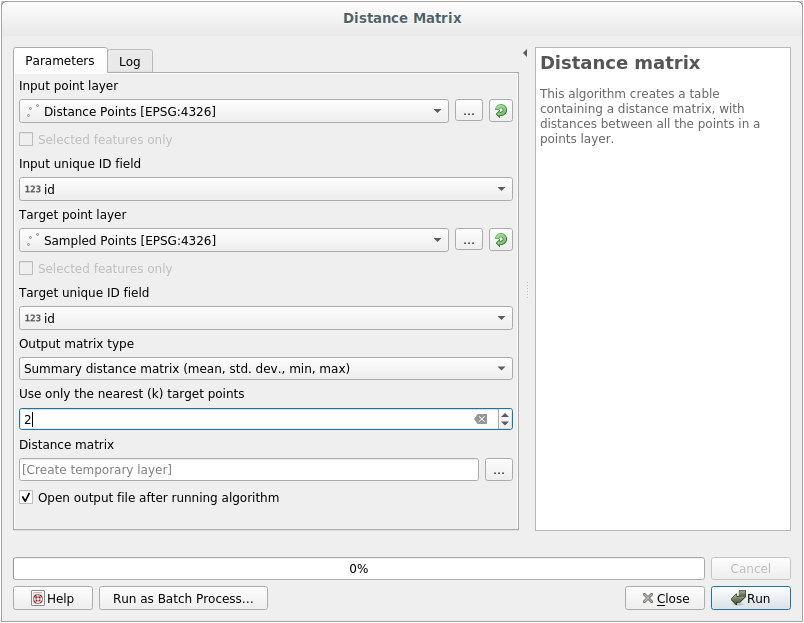
Klicka på Run för att generera avståndsmatrislagret.
Öppna attributtabellen för det genererade lagret: värdena avser avstånden mellan funktionerna distance_points och deras två närmaste punkter i lagret Sampled Points:
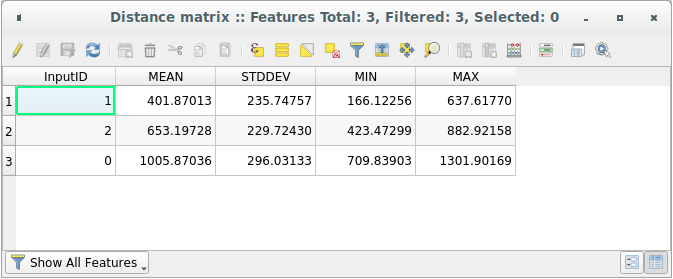
Med dessa parametrar beräknar verktyget Distance Matrix avståndsstatistik för varje punkt i inmatningslagret i förhållande till de två närmaste punkterna i mållagret. Fälten i utdatalagret innehåller medelvärde, standardavvikelse, minimum och maximum för de beräknade avstånden.
För ytterligare tester kanske du vill ändra alternativet Output matrix type eller antalet målpunkter.
6.4.4. ★☆☆ Följ med: Närmaste granne-analys (inom lager)
För att göra en närmaste granne-analys av ett punktlager:
Välj .
I dialogrutan som visas väljer du lagret Random points och klickar på Run.
Resultaten kommer att visas i panelen Processing Result Viewer.
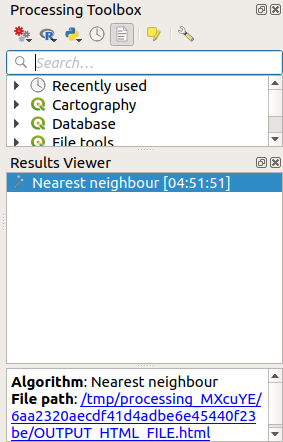
Klicka på den blå länken för att öppna
html-sidan med resultaten: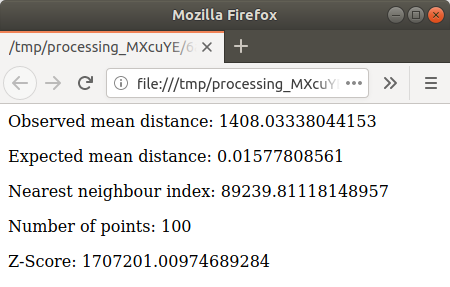
6.4.5. ★☆☆ Följ med: Genomsnittliga koordinater
För att få fram medelkoordinaterna för en dataset:
Start
I dialogrutan som visas anger du Random points som Input layer och låter de valfria alternativen vara oförändrade.
Klicka på Run.
Låt oss jämföra detta med den centrala koordinaten för den polygon som användes för att skapa det slumpmässiga urvalet.
Starta
I dialogrutan som visas väljer du
Bounding geometrysom inmatningslager.
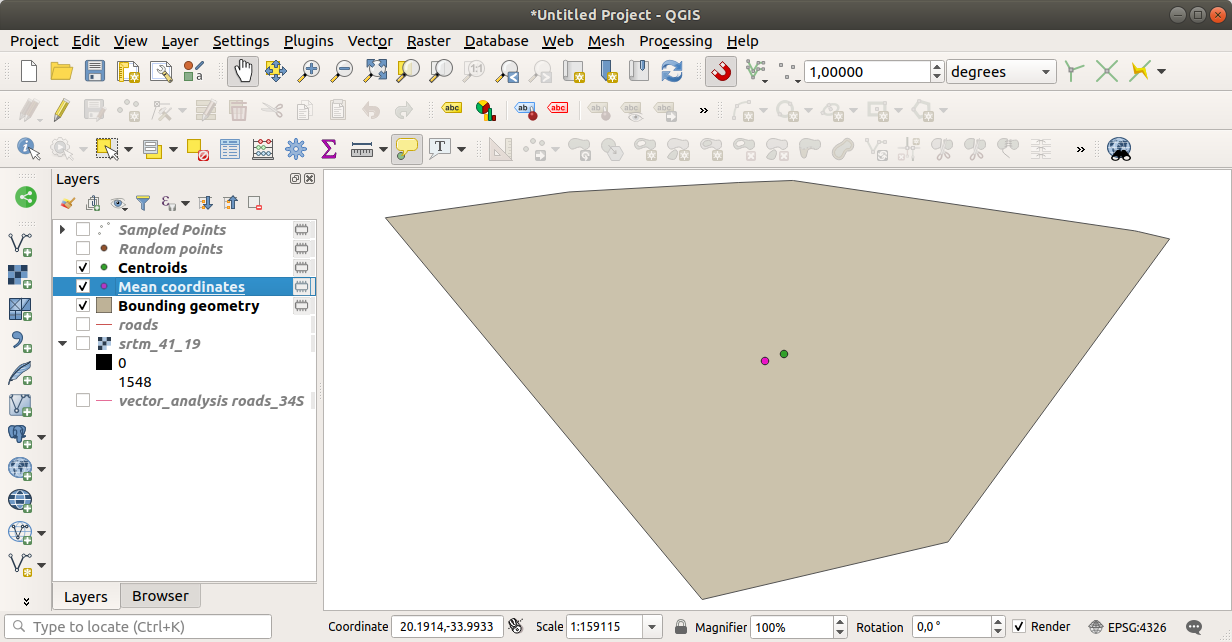
Som du kan se sammanfaller inte nödvändigtvis medelkoordinaterna (rosa punkt) och studieområdets centrum (i grönt).
Centroiden är lagrets barycentrum (barycentrum i en kvadrat är kvadratens centrum) medan medelkoordinaterna representerar genomsnittet av alla nodkoordinater.
6.4.6. ★☆☆ Följ med: Histogram för bilder
Histogrammet för en datauppsättning visar fördelningen av dess värden. Det enklaste sättet att visa detta i QGIS är via bildhistogrammet, som finns i dialogrutan Lageregenskaper för alla bildlager (rasterdataset).
I panelen Layers högerklickar du på lagret
srtm_41_19Välj
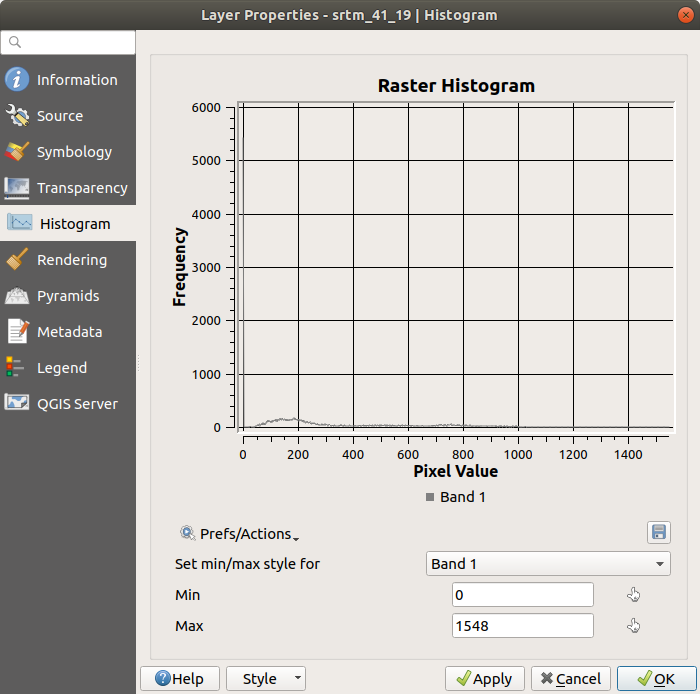
Välj fliken Histogram. Du kan behöva klicka på knappen Compute Histogram för att generera grafiken. Du kommer att se en graf som visar frekvensfördelningen för rastervärdena.
Grafen kan exporteras som en bild med knappen
 Save plot
Save plotDu kan se mer detaljerad information om lagret på fliken Information (medel- och maxvärdena är uppskattade och kanske inte exakta).
Medelvärdet är 332,8 (uppskattat till 324,3), och det maximala värdet är 1699 (uppskattat till 1548)! Du kan zooma in i histogrammet. Eftersom det finns många pixlar med värdet 0 ser histogrammet ut att vara komprimerat vertikalt. Genom att zooma in så att allt utom toppen vid 0 täcks, ser du fler detaljer:
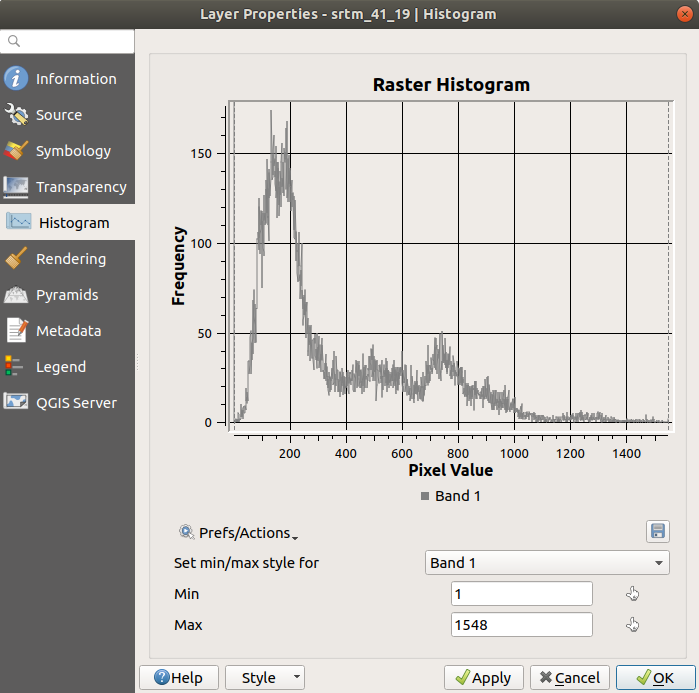
Observera
Om medel- och maxvärdena inte är desamma som ovan kan det bero på beräkningen av min/max-värdet. Öppna fliken Symbology och expandera menyn Min / Max Value Settings. Välj  Min / max och klicka på Apply.
Min / max och klicka på Apply.
Tänk på att ett histogram visar fördelningen av värden, och att alla värden inte nödvändigtvis syns i diagrammet.
6.4.7. ★☆☆ Följ med: Spatial interpolation
Låt oss säga att du har en samling provpunkter från vilka du skulle vilja extrapolera data. Du kanske till exempel har tillgång till Sampled points-datasetet som vi skapade tidigare och vill få en uppfattning om hur terrängen ser ut.
Börja med att starta verktyget i Processing Toolbox.
För Point layer välj
Sampled pointsStäll in Viktningskraft till
5.0I Avancerade parametrar, ställ in Z värde från fält till
rvalue_1Klicka slutligen på Run och vänta tills bearbetningen är klar
Stäng dialogrutan
Här är en jämförelse mellan den ursprungliga datauppsättningen (vänster) och den som konstruerats utifrån våra provpunkter (höger). Du kan se annorlunda ut på grund av den slumpmässiga placeringen av provpunkterna.
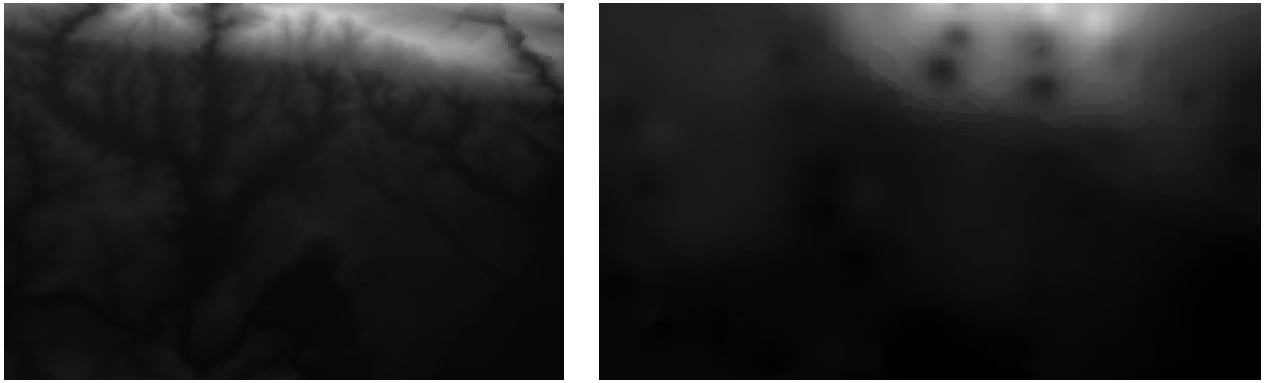
Som du kan se är 100 provpunkter inte tillräckligt för att få ett detaljerat intryck av terrängen. Det ger en mycket allmän uppfattning, men det kan också vara missvisande.
6.4.8. ★★☆ Prova själv: Olika interpolationsmetoder
Använd de processer som visas ovan för att skapa en uppsättning med 10 000 slumpmässiga punkter
Observera
Om antalet punkter är mycket stort kan bearbetningstiden ta lång tid.
Använd dessa punkter för att prova den ursprungliga DEM
Använd verktyget Grid (IDW with nearest neighbor searching) på den här datauppsättningen.
Sätt Power och Smoothing till
5.0respektive2.0.
Resultatet (beroende på placeringen av dina slumpmässiga punkter) kommer att se ut ungefär så här:

Detta är en bättre representation av terrängen, eftersom provpunkterna har större täthet. Kom ihåg att större stickprov ger bättre resultat.
6.4.9. Sammanfattningsvis
QGIS har ett antal verktyg för att analysera de spatiala statistiska egenskaperna hos datauppsättningar.
6.4.10. Vad händer härnäst?
Nu när vi har gått igenom vektoranalys, varför inte se vad man kan göra med raster? Det är vad vi ska göra i nästa modul!