Важно
Перевод - это работа сообщества : ссылка:Вы можете присоединиться. Эта страница в настоящее время переводится |прогресс перевода|.
15.1. Урок: Введение в базы данных
Прежде чем приступить к работе с PostgreSQL, давайте разберемся с общей теорией баз данных. Вам не понадобится вводить код примеров, он приведен только для наглядности.
Цель этого урока: Понять фундаментальные концепции баз данных.
15.1.1. Что такое база данных?
База данных представляет собой организованную коллекцию данных для одного или нескольких видов использования, обычно в цифровой форме. - Википедия
Система управления базами данных (СУБД) состоит из программного обеспечения, которое управляет базами данных, обеспечивая хранение, доступ, безопасность, резервное копирование и другие возможности. - Википедия
15.1.2. Таблицы
В реляционных базах данных и базах данных с плоскими файлами таблица - это набор элементов данных (значений), организованный по модели вертикальных столбцов (которые идентифицируются по их имени) и горизонтальных строк. Таблица имеет определенное количество столбцов, но может иметь любое количество строк. Каждая строка идентифицируется значениями, появляющимися в определенном подмножестве столбцов, которое было определено как ключ-кандидат. - Википедия
id | name | age
----+-------+-----
1 | Tim | 20
2 | Horst | 88
(2 rows)
В базах данных SQL таблица также известна как **отношение*.
15.1.3. Колонки / Поля
Столбец - это набор значений данных определенного простого типа, по одному на каждую строку таблицы. Столбцы обеспечивают структуру, в соответствии с которой формируются строки. Термин поле часто используется как взаимозаменяемый со столбцом, хотя многие считают более правильным использовать поле (или значение поля) для обозначения единственного элемента, который существует на пересечении одной строки и одного столбца. - Википедия
Колонка:
| name |
+-------+
| Tim |
| Horst |
Поле:
| Horst |
15.1.4. Записи
Запись - это информация, хранящаяся в строке таблицы. В каждой записи есть поле для каждого столбца таблицы.
2 | Horst | 88 <-- one record
15.1.5. Типы данных
Типы данных ограничивают тип информации, которая может храниться в столбце. - Тим и Хорст
Существует множество типов данных. Давайте остановимся на самых распространенных:
Строка- для хранения текстовых данных произвольной формыInteger- для хранения целых чиселReal- для хранения десятичных чиселDate- хранить дату рождения Хорста, чтобы никто не забылBoolean- для хранения простых значений true/false
Вы можете указать базе данных, чтобы она также позволяла хранить в поле ничего. Если в поле ничего нет, то содержимое поля называется «нулевым» значением:
insert into person (age) values (40);
select * from person;
Результат:
id | name | age
---+-------+-----
1 | Tim | 20
2 | Horst | 88
4 | | 40 <-- null for name
(3 rows)
Существует множество других типов данных, которые вы можете использовать - посмотрите руководство по PostgreSQL!
15.1.6. Моделирование базы данных адресов
Давайте на простом примере посмотрим, как создается база данных. Мы хотим создать базу данных адресов.
★☆☆ Попробуй себя:
Запишите свойства, из которых состоит простой адрес и которые мы хотели бы хранить в нашей базе данных.
Ответить
Для нашей теоретической таблицы адресов мы, возможно, захотим хранить следующие свойства:
House Number
Street Name
Suburb Name
City Name
Postcode
Country
При создании таблицы для представления объекта адреса мы создадим столбцы для представления каждого из этих свойств и назовем их именами, соответствующими стандарту SQL и, возможно, сокращенными:
house_number
street_name
suburb
city
postcode
country
Структура адреса
Свойства, описывающие адрес, - это столбцы. Тип информации, хранящейся в каждом столбце, является его типом данных. В следующем разделе мы проанализируем нашу концептуальную таблицу адресов и посмотрим, как сделать ее лучше!
15.1.7. Теория баз данных
Процесс создания базы данных включает в себя создание модели реального мира; взятие понятий реального мира и представление их в базе данных в виде сущностей.
15.1.8. Нормализация
Одна из основных идей базы данных - избегать дублирования/избыточности данных. Процесс удаления избыточности из базы данных называется нормализацией.
Нормализация - это систематический способ обеспечения того, чтобы структура базы данных была пригодна для выполнения запросов общего назначения и не содержала некоторых нежелательных характеристик - аномалий вставки, обновления и удаления, - которые могут привести к потере целостности данных. - Википедия
Существуют различные виды «форм» нормализации.
Давайте рассмотрим простой пример:
Table "public.people"
Column | Type | Modifiers
----------+------------------------+------------------------------------
id | integer | not null default
| | nextval('people_id_seq'::regclass)
| |
name | character varying(50) |
address | character varying(200) | not null
phone_no | character varying |
Indexes:
"people_pkey" PRIMARY KEY, btree (id)
select * from people;
id | name | address | phone_no
---+---------------+-----------------------------+-------------
1 | Tim Sutton | 3 Buirski Plein, Swellendam | 071 123 123
2 | Horst Duester | 4 Avenue du Roix, Geneva | 072 121 122
(2 rows)
Представьте, что у вас много друзей с одинаковым названием улицы или города. Каждый раз, когда эти данные дублируются, они занимают много места. Хуже того, если название города меняется, вам придется проделать большую работу, чтобы обновить базу данных.
15.1.9. ★☆☆ Попробуй себя:
Переработайте теоретическую таблицу Люди, приведенную выше, чтобы уменьшить дублирование и нормализовать структуру данных.
Подробнее о нормализации баз данных вы можете прочитать здесь <https://en.wikipedia.org/wiki/Database_normalization>`_
Ответить
Основная проблема таблицы люди заключается в том, что в ней есть единственное поле адреса, которое содержит весь адрес человека. Вспоминая нашу теоретическую таблицу адрес, о которой мы говорили ранее в этом уроке, мы знаем, что адрес состоит из множества различных свойств. Храня все эти свойства в одном поле, мы значительно усложняем обновление и запрос данных. Поэтому нам нужно разделить поле адреса на различные свойства. В результате у нас получится таблица со следующей структурой:
id | name | house_no | street_name | city | phone_no
--+---------------+----------+----------------+------------+-----------------
1 | Tim Sutton | 3 | Buirski Plein | Swellendam | 071 123 123
2 | Horst Duester | 4 | Avenue du Roix | Geneva | 072 121 122
В следующем разделе вы узнаете о связях внешнего ключа, которые можно использовать в данном примере для дальнейшего улучшения структуры нашей базы данных.
15.1.10. Индексы
Индекс базы данных - это структура данных, которая повышает скорость операций по поиску данных в таблице базы данных. - Википедия
Представьте, что вы читаете учебник и ищете объяснение какой-то концепции, а в учебнике нет указателя! Вам придется начать читать с одной обложки и пролистать всю книгу, пока вы не найдете нужную информацию. Указатель в конце книги поможет вам быстро перейти на страницу с нужной информацией:
create index person_name_idx on people (name);
Теперь поиск по имени будет осуществляться быстрее:
Table "public.people"
Column | Type | Modifiers
----------+------------------------+-------------------------------------
id | integer | not null default
| | nextval('people_id_seq'::regclass)
| |
name | character varying(50) |
address | character varying(200) | not null
phone_no | character varying |
Indexes:
"people_pkey" PRIMARY KEY, btree (id)
"person_name_idx" btree (name)
15.1.11. Последовательности
Последовательность - это генератор уникальных чисел. Обычно он используется для создания уникального идентификатора для столбца в таблице.
В данном примере id представляет собой последовательность - число увеличивается каждый раз, когда в таблицу добавляется запись:
id | name | address | phone_no
---+--------------+-----------------------------+-------------
1 | Tim Sutton | 3 Buirski Plein, Swellendam | 071 123 123
2 | Horst Duster | 4 Avenue du Roix, Geneva | 072 121 122
15.1.12. Диаграммы отношений между сущностями
В нормализованной базе данных, как правило, имеется множество отношений (таблиц). Диаграмма «сущность-связь» (ER-диаграмма) используется для определения логических зависимостей между отношениями. Рассмотрим нашу ненормализованную таблицу people из предыдущего урока:
select * from people;
id | name | address | phone_no
----+--------------+-----------------------------+-------------
1 | Tim Sutton | 3 Buirski Plein, Swellendam | 071 123 123
2 | Horst Duster | 4 Avenue du Roix, Geneva | 072 121 122
(2 rows)
Немного поработав, мы можем разделить его на две таблицы, избавившись от необходимости повторять название улицы для людей, живущих на одной и той же улице:
select * from streets;
id | name
----+--------------
1 | Plein Street
(1 row)
и:
select * from people;
id | name | house_no | street_id | phone_no
----+--------------+----------+-----------+-------------
1 | Horst Duster | 4 | 1 | 072 121 122
(1 row)
Затем мы можем связать эти две таблицы с помощью «ключей» streets.id и people.streets_id.
Если мы нарисуем ER-диаграмму для этих двух таблиц, она будет выглядеть примерно так:

ER-диаграмма помогает нам выразить отношения «один ко многим». В данном случае символ стрелки показывает, что на одной улице может жить много людей.
★★★☆ Попробуйте себя:
Наша модель людей все еще имеет некоторые проблемы с нормализацией - попробуйте посмотреть, сможете ли вы нормализовать ее еще больше и показать свои мысли с помощью ER-диаграммы.
Ответить
В настоящее время наша таблица люди выглядит следующим образом:
id | name | house_no | street_id | phone_no
---+--------------+----------+-----------+-------------
1 | Horst Duster | 4 | 1 | 072 121 122
Столбец street_id представляет собой отношение «один ко многим» между объектом люди и связанным с ним объектом улица, который находится в таблице улицы.
Один из способов дальнейшей нормализации таблицы - разделить поле имени на first_name и last_name:
id | first_name | last_name | house_no | street_id | phone_no
---+------------+------------+----------+-----------+------------
1 | Horst | Duster | 4 | 1 | 072 121 122
Мы также можем создать отдельные таблицы для названия города и страны, связав их с нашей таблицей люди с помощью отношений «один ко многим»:
id | first_name | last_name | house_no | street_id | town_id | country_id
---+------------+-----------+----------+-----------+---------+------------
1 | Horst | Duster | 4 | 1 | 2 | 1
ER-диаграмма для представления этого выглядит следующим образом:
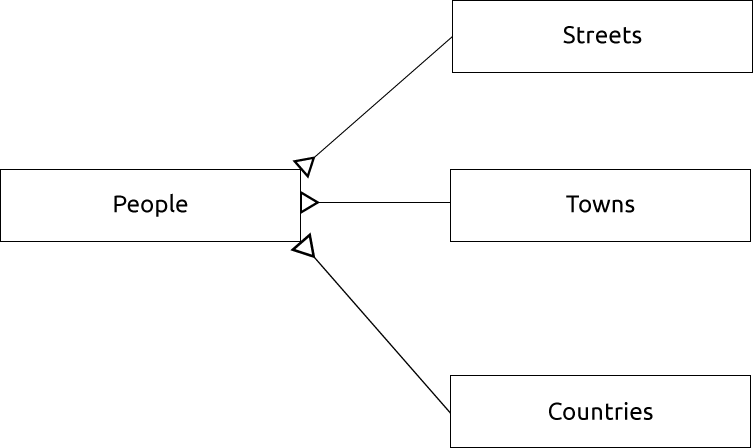
15.1.13. Ограничения, первичные ключи и внешние ключи
Ограничение базы данных используется для того, чтобы данные в отношении соответствовали представлениям разработчика модели о том, как эти данные должны храниться. Например, ограничение на ваш почтовый индекс может гарантировать, что номер находится между 1000 и 9999.
Первичный ключ - это одно или несколько значений поля, которые делают запись уникальной. Обычно первичный ключ называется id и представляет собой последовательность.
Внешний ключ используется для ссылки на уникальную запись в другой таблице (с использованием первичного ключа этой таблицы).
В ER-диаграммах связь между таблицами обычно основана на внешних ключах, связанных с первичными ключами.
Если мы посмотрим на наш пример с людьми, то в определении таблицы видно, что столбец улицы является внешним ключом, который ссылается на первичный ключ в таблице улиц:
Table "public.people"
Column | Type | Modifiers
-----------+-----------------------+--------------------------------------
id | integer | not null default
| | nextval('people_id_seq'::regclass)
name | character varying(50) |
house_no | integer | not null
street_id | integer | not null
phone_no | character varying |
Indexes:
"people_pkey" PRIMARY KEY, btree (id)
Foreign-key constraints:
"people_street_id_fkey" FOREIGN KEY (street_id) REFERENCES streets(id)
15.1.14. Транзакции
При добавлении, изменении или удалении данных в базе данных всегда важно, чтобы база данных оставалась в хорошем состоянии, если что-то пойдет не так. Большинство баз данных предоставляют функцию, называемую поддержкой транзакций. Транзакции позволяют создать позицию отката, на которую можно вернуться, если изменения в базе данных прошли не так, как планировалось.
Возьмем сценарий, в котором у вас есть бухгалтерская система. Вам нужно перевести средства с одного счета и добавить их на другой. Последовательность действий будет выглядеть следующим образом:
удалить R20 из Джо
добавить R20 Анне
Если во время процесса что-то пойдет не так (например, отключение питания), транзакция будет откачена.
15.1.15. В заключение
Базы данных позволяют управлять данными в структурированном виде, используя простые структуры кода.
15.1.16. Что дальше?
Теперь, когда мы рассмотрели, как базы данных работают в теории, давайте создадим новую базу данных, чтобы реализовать изученную теорию.