13.2. 함수 목록
QGIS에서 사용할 수 있는 함수, 연산자 및 변수의 목록을 다음에 범주별로 정리했습니다.
13.2.1. 집계 함수
이 그룹은 레이어 및 필드에 있는 값들을 집계하는 함수를 담고 있습니다.
13.2.1.1. aggregate
다른 레이어의 피처를 이용해서 계산한 집계값을 반환합니다.
문법 |
aggregate(layer, aggregate, expression, [filter], [concatenator=’’], [order_by]) [] 괄호는 선택적인 인자를 표시합니다 |
인자 |
|
예제 |
|
13.2.1.2. array_agg
필드 또는 표현식에서 집계한 값들의 배열을 반환합니다.
문법 |
array_agg(expression, [group_by], [filter], [order_by]) [] 괄호는 선택적인 인자를 표시합니다 |
인자 |
|
예제 |
|
13.2.1.3. collect
표현식에서 나온 집계 도형들로 이루어진 다중 부분 도형을 반환합니다.
문법 |
collect(expression, [group_by], [filter]) [] 괄호는 선택적인 인자를 표시합니다 |
인자 |
|
예제 |
|
13.2.1.4. concatenate
필드 또는 표현식에서 나오는 집계된 문자열을 모두 구분자로 결합해서 반환합니다.
문법 |
concatenate(expression, [group_by], [filter], [concatenator], [order_by]) [] 괄호는 선택적인 인자를 표시합니다 |
인자 |
|
예제 |
|
13.2.1.5. concatenate_unique
필드 또는 표현식에서 나오는 유일한 문자열을 모두 구분자로 결합해서 반환합니다.
문법 |
concatenate_unique(expression, [group_by], [filter], [concatenator], [order_by]) [] 괄호는 선택적인 인자를 표시합니다 |
인자 |
|
예제 |
|
13.2.1.6. count
일치하는 객체 수를 반환합니다.
문법 |
count(expression, [group_by], [filter]) [] 괄호는 선택적인 인자를 표시합니다 |
인자 |
|
예제 |
|
13.2.1.7. count_distinct
고유값의 수를 반환합니다.
문법 |
count_distinct(expression, [group_by], [filter]) [] 괄호는 선택적인 인자를 표시합니다 |
인자 |
|
예제 |
|
13.2.1.8. count_missing
누락된 (NULL) 값의 개수를 반환합니다.
문법 |
count_missing(expression, [group_by], [filter]) [] 괄호는 선택적인 인자를 표시합니다 |
인자 |
|
예제 |
|
13.2.1.9. iqr
필드 또는 표현식으로부터 계산한 중간 사분위수 범위(inter quartile range)를 반환합니다.
문법 |
iqr(expression, [group_by], [filter]) [] 괄호는 선택적인 인자를 표시합니다 |
인자 |
|
예제 |
|
13.2.1.10. majority
필드 또는 표현식에서 집계 다수 값(가장 흔하게 나타나는 값)을 반환합니다.
문법 |
majority(expression, [group_by], [filter]) [] 괄호는 선택적인 인자를 표시합니다 |
인자 |
|
예제 |
|
13.2.1.11. max_length
필드 또는 표현식에서 가장 긴 문자열의 길이를 반환합니다.
문법 |
max_length(expression, [group_by], [filter]) [] 괄호는 선택적인 인자를 표시합니다 |
인자 |
|
예제 |
|
13.2.1.12. maximum
필드 또는 표현식에서 나오는 집계 최대값을 반환합니다.
문법 |
maximum(expression, [group_by], [filter]) [] 괄호는 선택적인 인자를 표시합니다 |
인자 |
|
예제 |
|
13.2.1.13. mean
필드 또는 표현식에서 나오는 집계 평균값을 반환합니다.
문법 |
mean(expression, [group_by], [filter]) [] 괄호는 선택적인 인자를 표시합니다 |
인자 |
|
예제 |
|
13.2.1.14. median
필드 또는 표현식에서 나오는 집계 중앙값을 반환합니다.
문법 |
median(expression, [group_by], [filter]) [] 괄호는 선택적인 인자를 표시합니다 |
인자 |
|
예제 |
|
13.2.1.15. min_length
필드 또는 표현식에서 가장 짧은 문자열의 길이를 반환합니다.
문법 |
min_length(expression, [group_by], [filter]) [] 괄호는 선택적인 인자를 표시합니다 |
인자 |
|
예제 |
|
13.2.1.16. minimum
필드 또는 표현식에서 나오는 집계 최소값을 반환합니다.
문법 |
minimum(expression, [group_by], [filter]) [] 괄호는 선택적인 인자를 표시합니다 |
인자 |
|
예제 |
|
13.2.1.17. minority
필드 또는 표현식에서 집계 소수 값(가장 뜸하게 나타나는 값)을 반환합니다.
문법 |
minority(expression, [group_by], [filter]) [] 괄호는 선택적인 인자를 표시합니다 |
인자 |
|
예제 |
|
13.2.1.18. q1
필드 또는 표현식으로부터 계산한 첫 번째 사분위수(quartile)를 반환합니다.
문법 |
q1(expression, [group_by], [filter]) [] 괄호는 선택적인 인자를 표시합니다 |
인자 |
|
예제 |
|
13.2.1.19. q3
필드 또는 표현식으로부터 계산한 세 번째 사분위수를 반환합니다.
문법 |
q3(expression, [group_by], [filter]) [] 괄호는 선택적인 인자를 표시합니다 |
인자 |
|
예제 |
|
13.2.1.20. range
필드 또는 표현식에서 나오는 값들의 (최대 ~ 최소) 집계 범위를 반환합니다.
문법 |
range(expression, [group_by], [filter]) [] 괄호는 선택적인 인자를 표시합니다 |
인자 |
|
예제 |
|
13.2.1.21. relation_aggregate
레이어 관계에서 나오는 파생 객체들 가운데 일치하는 모든 객체를 사용해서 계산한 집계값을 반환합니다.
문법 |
relation_aggregate(relation, aggregate, expression, [concatenator=’’], [order_by]) [] 괄호는 선택적인 인자를 표시합니다 |
인자 |
|
예제 |
|
더 읽어볼 거리: 일대다 또는 다대다 관계 생성
13.2.1.22. stdev
필드 또는 표현식에서 집계 표준 편차값을 반환합니다.
문법 |
stdev(expression, [group_by], [filter]) [] 괄호는 선택적인 인자를 표시합니다 |
인자 |
|
예제 |
|
13.2.1.23. sum
필드 또는 표현식에서 집계 적산값을 반환합니다.
문법 |
sum(expression, [group_by], [filter]) [] 괄호는 선택적인 인자를 표시합니다 |
인자 |
|
예제 |
|
13.2.2. 배열 함수
이 함수 그룹은 (목록 데이터 구조라고도 하는) 배열을 생성하고 처리하는 함수들을 담고 있습니다. 배열 내부의 값의 순서가 중요합니다. 키-값 쌍이 중요하지 않고 값을 값의 키로 식별하는 ‘맵’ 데이터 구조 와는 다릅니다.
13.2.2.1. array
파라미터로써 전달된 모든 값들을 담고 있는 배열을 반환합니다.
문법 |
array(value1, value2, …) |
인자 |
|
예제 |
|
13.2.2.2. array_all
배열이 지정한 배열의 모든 값을 담고 있는 경우 참을 반환합니다.
문법 |
array_all(array_a, array_b) |
인자 |
|
예제 |
|
13.2.2.3. array_append
지정한 값을 맨 끝에 추가한 배열을 반환합니다.
문법 |
array_append(array, value) |
인자 |
|
예제 |
|
13.2.2.4. array_cat
지정한 배열들을 모두 연결해서 담고 있는 배열을 반환합니다.
문법 |
array_cat(array1, array2, …) |
인자 |
|
예제 |
|
13.2.2.5. array_contains
배열이 지정한 값을 담고 있는 경우 참을 반환합니다.
문법 |
array_contains(array, value) |
인자 |
|
예제 |
|
13.2.2.6. array_count
배열에서 지정한 값이 나타나는 횟수를 셉니다.
문법 |
array_count(array, value) |
인자 |
|
예제 |
|
13.2.2.7. array_distinct
지정한 배열의 개별(distinct) 값들을 담고 있는 배열을 반환합니다.
문법 |
array_distinct(array) |
인자 |
|
예제 |
|
13.2.2.8. array_filter
표현식이 참이라고 평가한 항목만 보유한 배열을 반환합니다.
문법 |
array_filter(array, expression, [limit=0]) [] 괄호는 선택적인 인자를 표시합니다 |
인자 |
|
예제 |
|
13.2.2.9. array_find
배열 안에 있는 값의 가장 낮은 인덱스를 반환합니다. (첫 번째 인덱스는 0입니다.) 값을 찾을 수 없는 경우 -1을 반환합니다.
문법 |
array_find(array, value) |
인자 |
|
예제 |
|
13.2.2.10. array_first
배열의 첫 번째 값을 반환합니다.
문법 |
array_first(array) |
인자 |
|
예제 |
|
13.2.2.11. array_foreach
지정한 표현식으로 각 항목을 평가한 배열을 반환합니다.
문법 |
array_foreach(array, expression) |
인자 |
|
예제 |
|
13.2.2.12. array_get
배열의 (0부터 시작하는) N번째 값 또는 (마지막이 -1인) -N번째 값을 반환합니다.
문법 |
array_get(array, pos) |
인자 |
|
예제 |
|
힌트
배열에서 값을 가져오기 위해 인덱스 연산자 ([]) 를 사용할 수도 있습니다.
13.2.2.13. array_insert
지정한 위치에 지정한 값을 삽입한 배열을 반환합니다.
문법 |
array_insert(array, pos, value) |
인자 |
|
예제 |
|
13.2.2.14. array_intersect
array1의 요소 중 적어도 하나 이상이 array2에 있으면 참을 반환합니다.
문법 |
array_intersect(array1, array2) |
인자 |
|
예제 |
|
13.2.2.15. array_last
배열의 마지막 값을 반환합니다.
문법 |
array_last(array) |
인자 |
|
예제 |
|
13.2.2.16. array_length
배열의 요소 개수를 반환합니다.
문법 |
array_length(array) |
인자 |
|
예제 |
|
13.2.2.17. array_majority
배열에서 가장 많이 나타나는 값을 반환합니다.
문법 |
array_majority(array, [option=’all’]) [] 괄호는 선택적인 인자를 표시합니다 |
인자 |
|
예제 |
|
13.2.2.18. array_max
배열의 최대값을 반환합니다.
문법 |
array_max(array) |
인자 |
|
예제 |
|
13.2.2.19. array_mean
배열에 있는 숫자값들의 평균을 반환합니다. 배열에서 숫자가 아닌 값은 무시합니다.
문법 |
array_mean(array) |
인자 |
|
예제 |
|
13.2.2.20. array_median
배열에 있는 숫자값들의 중앙값을 반환합니다. 배열에서 숫자가 아닌 값은 무시합니다.
문법 |
array_median(array) |
인자 |
|
예제 |
|
13.2.2.21. array_min
배열의 최소값을 반환합니다.
문법 |
array_min(array) |
인자 |
|
예제 |
|
13.2.2.22. array_minority
배열에서 가장 적게 나타나는 값을 반환합니다.
문법 |
array_minority(array, [option=’all’]) [] 괄호는 선택적인 인자를 표시합니다 |
인자 |
|
예제 |
|
13.2.2.23. array_prepend
지정한 값을 맨 앞에 추가한 배열을 반환합니다.
문법 |
array_prepend(array, value) |
인자 |
|
예제 |
|
13.2.2.24. array_prioritize
어떤 배열을 다른 배열에 지정된 순서로 재정렬해서 반환합니다. 첫 번째 배열에는 있지만 두 번째 배열에는 없는 값은 산출물의 마지막에 추가될 것입니다.
문법 |
array_prioritize(array, array_prioritize) |
인자 |
|
예제 |
|
13.2.2.25. array_remove_all
모든 항목에서 지정한 값을 제거한 배열을 반환합니다.
문법 |
array_remove_all(array, value) |
인자 |
|
예제 |
|
13.2.2.26. array_remove_at
지정한 인덱스 위치의 항목을 제거한 배열을 반환합니다. (첫 번째 요소가 0인) 양의 인덱스와 (마지막 요소가 -1인) 음의 인덱스를 지원합니다.
문법 |
array_remove_at(array, pos) |
인자 |
|
예제 |
|
13.2.2.27. array_replace
배열을 지정한 값, 배열, 또는 값들의 맵으로 치환해서 반환합니다.
값 및 배열 변이형
지정한 값 또는 값들의 배열을 또 다른 값 또는 값들의 배열로 치환해서 반환합니다.
문법 |
array_replace(array, before, after) |
인자 |
|
예제 |
|
맵 변이형
지정한 맵 키를 짝지어진 값으로 치환한 배열을 반환합니다.
문법 |
array_replace(array, map) |
인자 |
|
예제 |
|
13.2.2.28. array_reverse
입력 배열의 값들의 순서를 역전시킨 배열을 반환합니다.
문법 |
array_reverse(array) |
인자 |
|
예제 |
|
13.2.2.29. array_slice
배열의 일부를 반환합니다. start_pos와 end_pos 인수로 반환할 일부를 정의합니다.
문법 |
array_slice(array, start_pos, end_pos) |
인자 |
|
예제 |
|
13.2.2.30. array_sort
지정한 배열의 요소들을 정렬시킨 배열을 반환합니다.
문법 |
array_sort(array, [ascending=true]) [] 괄호는 선택적인 인자를 표시합니다 |
인자 |
|
예제 |
|
13.2.2.31. array_sum
배열에 있는 숫자값들의 합을 반환합니다. 배열에서 숫자가 아닌 값은 무시합니다.
문법 |
array_sum(array) |
인자 |
|
예제 |
|
13.2.2.32. array_to_string
배열 요소들을 구분자로 구분하고 빈 값은 선택적인 문자열로 대체한 문자열로 연결합니다.
문법 |
array_to_string(array, [delimiter=’,’], [empty_value=’’]) [] 괄호는 선택적인 인자를 표시합니다 |
인자 |
|
예제 |
|
13.2.2.33. generate_series
이어지는 일련의 숫자를 담고 있는 배열을 생성합니다.
문법 |
generate_series(start, stop, [step=1]) [] 괄호는 선택적인 인자를 표시합니다 |
인자 |
|
예제 |
|
13.2.2.34. geometries_to_array
도형 하나를 배열에 더 단순한 도형들로 분할합니다.
문법 |
geometries_to_array(geometry) |
인자 |
|
예제 |
|
13.2.2.35. regexp_matches
그룹을 캡처해서 캡처된 모든 문자열의 배열을, 문자열을 대상으로 지정한 정규 표현식에 그룹 자체가 나타나는 순서대로 반환합니다.
문법 |
regexp_matches(string, regex, [empty_value=’’]) [] 괄호는 선택적인 인자를 표시합니다 |
인자 |
|
예제 |
|
13.2.2.36. string_to_array
문자열을 지정한 구분자와 빈 값을 위한 선택적인 문자열을 사용해서 배열로 분해합니다.
문법 |
string_to_array(string, [delimiter=’,’], [empty_value=’’]) [] 괄호는 선택적인 인자를 표시합니다 |
인자 |
|
예제 |
|
13.2.3. 색상 함수
이 그룹은 색상을 처리하기 위한 함수를 담고 있습니다.
13.2.3.1. color_cmyk
색상의 청록색, 자홍색, 황색, 흑색 요소를 기반으로 색상의 문자열 표현을 반환합니다.
문법 |
color_cmyk(cyan, magenta, yellow, black) |
인자 |
|
예제 |
|
13.2.3.2. color_cmyka
색상의 청록색, 자홍색, 황색, 흑색 및 알파(투명도) 요소를 기반으로 색상의 문자열 표현을 반환합니다.
문법 |
color_cmyka(cyan, magenta, yellow, black, alpha) |
인자 |
|
예제 |
|
13.2.3.3. color_grayscale_average
회색조 필터를 적용하고 지정한 색상에서 나온 문자열 표현을 반환합니다.
문법 |
color_grayscale_average(color) |
인자 |
|
예제 |
|
13.2.3.4. color_hsl
색상의 색조, 채도, 명도 속성을 기반으로 색상의 문자열 표현을 반환합니다.
문법 |
color_hsl(hue, saturation, lightness) |
인자 |
|
예제 |
|
13.2.3.5. color_hsla
색상의 색조, 채도, 명도 그리고 알파(투명도) 속성을 기반으로 색상의 문자열 표현을 반환합니다.
문법 |
color_hsla(hue, saturation, lightness, alpha) |
인자 |
|
예제 |
|
13.2.3.6. color_hsv
색상의 색상, 채도, 명도 속성을 기반으로 색상의 문자열 표현을 반환합니다.
문법 |
color_hsv(hue, saturation, value) |
인자 |
|
예제 |
|
13.2.3.7. color_hsva
색상의 색조, 채도, 명도 그리고 알파(투명도) 속성을 기반으로 색상의 문자열 표현을 반환합니다.
문법 |
color_hsva(hue, saturation, value, alpha) |
인자 |
|
예제 |
|
13.2.3.8. color_mix_rgb
지정한 두 색상의 적색, 녹색, 청색 그리고 알파(투명도) 값을 지정한 비율로 혼합한 색상을 표현하는 문자열을 반환합니다.
문법 |
color_mix_rgb(color1, color2, ratio) |
인자 |
|
예제 |
|
13.2.3.9. color_part
색상 문자열에서 예를 들어 적색 요소 또는 알파 요소 같은 특정 요소를 반환합니다.
문법 |
color_part(color, component) |
인자 |
|
예제 |
|
13.2.3.10. color_rgb
색상의 적색, 녹색, 청색 요소를 기반으로 색상의 문자열 표현을 반환합니다.
문법 |
color_rgb(red, green, blue) |
인자 |
|
예제 |
|
13.2.3.11. color_rgba
색상의 적색, 녹색, 청색 그리고 알파(투명도) 요소를 기반으로 색상의 문자열 표현을 반환합니다.
문법 |
color_rgba(red, green, blue, alpha) |
인자 |
|
예제 |
|
13.2.3.12. create_ramp
색상 문자열 및 단계의 맵에서 나온 그레이디언트 색상표를 반환합니다.
문법 |
create_ramp(map, [discrete=false]) [] 괄호는 선택적인 인자를 표시합니다 |
인자 |
|
예제 |
|
13.2.3.13. darker
더 어두운 (또는 더 밝은) 색상 문자열을 반환합니다.
문법 |
darker(color, factor) |
인자 |
|
예제 |
|
더 읽어볼 거리: lighter
13.2.3.14. lighter
더 밝은 (또는 더 어두운) 색상 문자열을 반환합니다.
문법 |
lighter(color, factor) |
인자 |
|
예제 |
|
더 읽어볼 거리: darker
13.2.3.15. project_color
프로젝트의 색상 스키마에서 색상을 반환합니다.
문법 |
project_color(name) |
인자 |
|
예제 |
|
더 읽어볼 거리: 프로젝트 색상 설정하기
13.2.3.16. ramp_color
색상표에서 색상을 표현하는 문자열을 반환합니다.
저장된 색상표 변수
저장한 색상표에서 색상을 표현하는 문자열을 반환합니다
문법 |
ramp_color(ramp_name, value) |
인자 |
|
예제 |
|
참고
사용 가능한 색상표는 QGIS 설치본마다 다릅니다. QGIS 프로젝트를 서로 다른 설치본 간에 이동하는 경우, 이 함수가 예상 결과를 제공하지 않을 수도 있습니다.
표현식으로 생성된 색상표 변종
표현식으로 생성된 색상표에서 색상을 표현하는 문자열을 반환합니다.
문법 |
ramp_color(ramp, value) |
인자 |
|
예제 |
|
더 읽어볼 거리: 색상표 설정, 색상표 드롭다운 단축키
13.2.3.17. set_color_part
색상 문자열에 대해 예를 들어 적색 요소 또는 알파 요소 같은 특정 색상 요소를 설정합니다.
문법 |
set_color_part(color, component, value) |
인자 |
|
예제 |
|
13.2.4. 조건 함수
이 그룹은 표현식에서 조건 검사를 처리하는 함수를 담고 있습니다.
13.2.4.1. CASE
일련의 조건들을 평가해서 처음으로 만족하는 조건에 대한 결과를 반환하는 데 CASE를 사용합니다. 조건들을 연속적으로 평가하면서, 조건이 참인 경우 평가를 종료하고 대응하는 결과를 반환합니다. 어떤 조건도 참이 아닌 경우, ELSE 구문에 있는 값을 반환합니다. 또한, ELSE 구문을 설정하지 않았는데 어떤 조건도 참이 아닌 경우, NULL을 반환합니다.
CASE
WHEN condition THEN result
[ …n ]
[ ELSE result ]
END
[ ] 괄호는 선택적인 요소를 표시합니다.
인자 |
|
예제 |
|
13.2.4.2. coalesce
표현식 목록에서 NULL이 아닌 첫 번째 값을 반환합니다.
이 함수에는 인수 개수에 대한 제약이 없습니다.
문법 |
coalesce(expression1, expression2, …) |
인자 |
|
예제 |
|
13.2.4.3. if
조건을 검증해서 결과에 따라 서로 다른 결과를 반환합니다.
문법 |
if(condition, result_when_true, result_when_false) |
인자 |
|
예제 |
|
13.2.4.4. nullif
value1이 value2와 동일한 경우 NULL 값을 반환합니다; 그렇지 않은 경우 value1을 반환합니다. 조건에 따라 값을 NULL로 대체하는 데 사용할 수 있습니다.
문법 |
nullif(value1, value2) |
인자 |
|
예제 |
|
13.2.4.5. regexp_match
유니코드 문자열 내부에서 정규 표현식과 첫번째로 일치하는 위치를 반환하거나, 하위 문자열을 찾지 못했을 경우 0을 반환합니다.
문법 |
regexp_match(input_string, regex) |
인자 |
|
예제 |
|
13.2.4.6. try
표현식을 시도하고 오류가 없는 경우 그 값을 반환합니다. 표현식이 오류를 반환하는 경우, 대체값을 지정했다면 대체값을 반환하고, 그렇지 않다면 함수가 NULL을 반환할 것입니다.
문법 |
try(expression, [alternative]) [] 괄호는 선택적인 인자를 표시합니다 |
인자 |
|
예제 |
|
13.2.5. 변환 함수
이 함수 그룹은 어떤 데이터 유형을 다른 데이터 유형으로 변환하는 함수를 담고 있습니다. (예: 문자열을 정수형으로/정수형을 문자열로, 바이너리를 문자열로/문자열을 바이너리로, 문자열을 날짜로 등등)
13.2.5.1. from_base64
Decodes a string in the Base64 encoding into a binary value.
문법 |
from_base64(string) |
인자 |
|
예제 |
|
13.2.5.2. hash
지정한 메소드로 문자열로부터 해시를 생성합니다. 1바이트(8비트)를 16진수 “숫자(digit)” 2개로 표현하기 때문에, ‘md4’ (16바이트)는 16 * 2 = 32문자 길이 16진수 문자열을 생성하고 ‘keccak_512’ (64바이트)는 64 * 2 = 128문자 길이 16진수 문자열을 생성합니다.
문법 |
hash(string, method) |
인자 |
|
예제 |
|
13.2.5.3. md5
문자열로부터 md5 해시를 생성합니다.
문법 |
md5(string) |
인자 |
|
예제 |
|
13.2.5.4. sha256
문자열로부터 sha256 해시를 생성합니다.
문법 |
sha256(string) |
인자 |
|
예제 |
|
13.2.5.5. to_base64
Encodes a binary value into a string, using the Base64 encoding.
문법 |
to_base64(value) |
인자 |
|
예제 |
|
13.2.5.6. to_date
문자열을 날짜 객체로 변환합니다. 문자열을 파싱하기 위해 선택적인 서식 문자열을 지정할 수 있습니다; 해당 서식에 대한 추가 문서를 보고 싶다면 QDate::fromString 또는 format_date 함수 문서를 참조하세요. 기본적으로 현재 QGIS 사용자 로케일을 사용합니다.
문법 |
to_date(string, [format], [language]) [] 괄호는 선택적인 인자를 표시합니다 |
인자 |
|
예제 |
|
13.2.5.7. to_datetime
문자열을 날짜&시간 객체로 변환합니다. 문자열을 파싱하기 위해 선택적인 서식 문자열을 지정할 수 있습니다; 해당 서식에 대한 추가 문서를 보고 싶다면 QDate::fromString, QTime::fromString 또는 format_date 함수 문서를 참조하세요. 기본적으로 현재 QGIS 사용자 로케일을 사용합니다.
문법 |
to_datetime(string, [format], [language]) [] 괄호는 선택적인 인자를 표시합니다 |
인자 |
|
예제 |
|
13.2.5.8. to_decimal
도, 분, 초 좌표를 십진수 좌표로 변환합니다.
문법 |
to_decimal(value) |
인자 |
|
예제 |
|
13.2.5.9. to_dm
좌표를 도, 분으로 변환합니다.
문법 |
to_dm(coordinate, axis, precision, [formatting=]) [] 괄호는 선택적인 인자를 표시합니다 |
인자 |
|
예제 |
|
13.2.5.10. to_dms
좌표를 도, 분, 초로 변환합니다.
문법 |
to_dms(coordinate, axis, precision, [formatting=]) [] 괄호는 선택적인 인자를 표시합니다 |
인자 |
|
예제 |
|
13.2.5.11. to_int
문자열을 정수형 숫자로 변환합니다. 값을 정수형으로 변환할 수 없는 경우 (예를 들어 ‘123asd’는 무결하지 않습니다) 아무것도 반환하지 않습니다.
문법 |
to_int(string) |
인자 |
|
예제 |
|
13.2.5.12. to_interval
문자열을 간격 유형으로 변환합니다. 날짜 유형의 월, 일, 시 등을 추출하는 데 사용할 수 있습니다.
문법 |
to_interval(string) |
인자 |
|
예제 |
|
13.2.5.13. to_real
문자열을 실수형 숫자로 변환합니다. 값을 실수형으로 변환할 수 없는 경우 (예를 들어 ‘123.56asd’ 는 무결하지 않습니다) 아무것도 반환하지 않습니다. 정밀도가 변환 결과보다 작은 경우 변경 사항을 저장한 다음 숫자를 반올림합니다.
문법 |
to_real(string) |
인자 |
|
예제 |
|
13.2.5.14. to_string
숫자를 문자열로 변환합니다.
문법 |
to_string(number) |
인자 |
|
예제 |
|
13.2.5.15. to_time
문자열을 시간 객체로 변환합니다. 문자열을 파싱하기 위해 부가적인 서식 문자열을 지정할 수 있습니다; 해당 서식에 대한 추가 문서를 보고 싶다면 QTime::fromString 을 참조하세요.
문법 |
to_time(string, [format], [language]) [] 괄호는 선택적인 인자를 표시합니다 |
인자 |
|
예제 |
|
13.2.6. 사용자 지정 함수
이 그룹은 사용자가 생성한 함수를 담고 있습니다. 자세한 내용은 함수 편집기 를 참조하세요.
13.2.7. 날짜 및 시간 함수
이 함수 그룹은 날짜 및 시간 데이터를 처리하기 위한 함수들을 담고 있습니다. 이 그룹은 변환 함수 그룹과 몇몇 함수를(to_date, to_time, to_datetime, to_interval) 그리고 ref:string_functions 그룹과도 함수를(format_date) 공유합니다.
참고
필드에 날짜, 날짜&시간, 간격 유형을 저장하기
데이터소스 제공자에 따라 날짜, 시간, 날짜&시간 값을 필드에 직접 저장할 수 있습니다. (예를 들어 Shapefile은 날짜 유형은 받아들이지만 날짜&시간 또는 시간 유형은 받아들이지 못 합니다.) 다음은 이 제약 사항을 넘어서기 위한 몇 가지 제안입니다.
format_date() 함수를 사용하면 텍스트 유형 필드에 날짜, 날짜&시간, 시간 을 저장할 수 있습니다.
간격 을 날짜 추출 함수 중 하나로 처리한 다음 (예: day() 함수는 날짜로 표현된 간격을 반환합니다) 정수 또는 실수 유형 필드에 저장할 수 있습니다.
13.2.7.1. age
두 날짜 또는 두 날짜&시간 사이의 차이를 간격 유형으로 반환합니다.
그 차를 Interval 로 반환하는데, 쓸만한 정보를 추출하려면 다음 함수들 가운데 하나와 함께 사용되어야 합니다:
yearmonthweekdayhourminutesecond
문법 |
age(datetime1, datetime2) |
인자 |
|
예제 |
|
13.2.7.2. datetime_from_epoch
협정 세계시(Qt.UTC) 1970-01-01T00:00:00.000부터 셈한 밀리초(msec)의 개수를 Qt.LocalTime으로 변환한 날짜 및 시간인 날짜&시간을 반환합니다.
문법 |
datetime_from_epoch(int) |
인자 |
|
예제 |
|
13.2.7.3. day
날짜 유형에서 일(日) 부분을, 또는 간격 유형에서 일수를 추출합니다.
날짜 변이형
날짜 또는 날짜&시간에서 일 부분을 추출합니다.
문법 |
day(date) |
인자 |
|
예제 |
|
간격 변이형
길이를 간격의 일 단위로 계산합니다.
문법 |
day(interval) |
인자 |
|
예제 |
|
13.2.7.4. day_of_week
지정한 날짜 또는 날짜&시간에서 해당 주의 요일을 반환합니다. 반환될 값 범위는 0에서 6이며, 0은 일요일, 6은 토요일입니다.
문법 |
day_of_week(date) |
인자 |
|
예제 |
|
13.2.7.5. epoch
유닉스 원기(unix epoch)와 지정한 날짜값 사이의 간격을 밀리초 단위로 반환합니다.
문법 |
epoch(date) |
인자 |
|
예제 |
|
13.2.7.6. format_date
날짜 유형 또는 문자열을 사용자 정의 문자열 서식으로 변환합니다. Qt 날짜&시간 서식 문자열을 사용하십시오. QDateTime::toString 을 참조하세요.
문법 |
format_date(datetime, format, [language]) [] 괄호는 선택적인 인자를 표시합니다 |
||||||||||||||||||||||||||||||||||||||||||||||||
인자 |
|
||||||||||||||||||||||||||||||||||||||||||||||||
예제 |
|
13.2.7.7. hour
날짜&시간 또는 시간에서 시 부분을, 또는 간격에서 시의 개수를 추출합니다.
시간 변이형
시간 또는 날짜&시간에서 시 부분을 추출합니다.
문법 |
hour(datetime) |
인자 |
|
예제 |
|
간격 변이형
길이를 간격의 시간 단위로 계산합니다.
문법 |
hour(interval) |
인자 |
|
예제 |
|
13.2.7.8. make_date
년, 월, 일 숫자로부터 날짜값을 생성합니다.
문법 |
make_date(year, month, day) |
인자 |
|
예제 |
|
13.2.7.9. make_datetime
년, 월, 일, 시, 분, 초 숫자로부터 날짜&시간 값을 생성합니다.
문법 |
make_datetime(year, month, day, hour, minute, second) |
인자 |
|
예제 |
|
13.2.7.10. make_interval
년, 월, 주, 일, 시, 분, 초 값으로부터 간격값을 생성합니다.
문법 |
make_interval([years=0], [months=0], [weeks=0], [days=0], [hours=0], [minutes=0], [seconds=0]) [] 괄호는 선택적인 인자를 표시합니다 |
인자 |
|
예제 |
|
13.2.7.11. make_time
시, 분, 초 숫자로부터 시간값을 생성합니다.
문법 |
make_time(hour, minute, second) |
인자 |
|
예제 |
|
13.2.7.12. minute
날짜&시간 또는 시간에서 분 부분을, 또는 간격에서 분의 개수를 추출합니다.
시간 변이형
시간 또는 날짜&시간에서 분 부분을 추출합니다.
문법 |
minute(datetime) |
인자 |
|
예제 |
|
간격 변이형
길이를 간격의 분 단위로 계산합니다.
문법 |
minute(interval) |
인자 |
|
예제 |
|
13.2.7.13. month
날짜 유형에서 월 부분을, 또는 간격 유형에서 개월수를 추출합니다.
날짜 변이형
날짜 또는 날짜&시간에서 월 부분을 추출합니다.
문법 |
month(date) |
인자 |
|
예제 |
|
간격 변이형
길이를 간격의 월 단위로 계산합니다.
문법 |
month(interval) |
인자 |
|
예제 |
|
13.2.7.14. now
현재 날짜와 시간을 반환합니다. 이 함수는 정적이며 평가하는 동안 일관된 결과를 반환할 것입니다. 반환된 시간은 표현식이 준비된 시간입니다.
문법 |
now() |
예제 |
|
13.2.7.15. second
날짜&시간 또는 시간에서 초 부분을, 또는 간격에서 초의 개수를 추출합니다.
시간 변이형
시간 또는 날짜&시간에서 초 부분을 추출합니다.
문법 |
second(datetime) |
인자 |
|
예제 |
|
간격 변이형
길이를 간격의 초 단위로 계산합니다.
문법 |
second(interval) |
인자 |
|
예제 |
|
13.2.7.16. to_date
문자열을 날짜 객체로 변환합니다. 문자열을 파싱하기 위해 선택적인 서식 문자열을 지정할 수 있습니다; 해당 서식에 대한 추가 문서를 보고 싶다면 QDate::fromString 또는 format_date 함수 문서를 참조하세요. 기본적으로 현재 QGIS 사용자 로케일을 사용합니다.
문법 |
to_date(string, [format], [language]) [] 괄호는 선택적인 인자를 표시합니다 |
인자 |
|
예제 |
|
13.2.7.17. to_datetime
문자열을 날짜&시간 객체로 변환합니다. 문자열을 파싱하기 위해 선택적인 서식 문자열을 지정할 수 있습니다; 해당 서식에 대한 추가 문서를 보고 싶다면 QDate::fromString, QTime::fromString 또는 format_date 함수 문서를 참조하세요. 기본적으로 현재 QGIS 사용자 로케일을 사용합니다.
문법 |
to_datetime(string, [format], [language]) [] 괄호는 선택적인 인자를 표시합니다 |
인자 |
|
예제 |
|
13.2.7.18. to_interval
문자열을 간격 유형으로 변환합니다. 날짜 유형의 월, 일, 시 등을 추출하는 데 사용할 수 있습니다.
문법 |
to_interval(string) |
인자 |
|
예제 |
|
13.2.7.19. to_time
문자열을 시간 객체로 변환합니다. 문자열을 파싱하기 위해 부가적인 서식 문자열을 지정할 수 있습니다; 해당 서식에 대한 추가 문서를 보고 싶다면 QTime::fromString 을 참조하세요.
문법 |
to_time(string, [format], [language]) [] 괄호는 선택적인 인자를 표시합니다 |
인자 |
|
예제 |
|
13.2.7.20. week
날짜 유형에서 주(週) 번호를, 또는 간격 유형에서 주의 개수를 추출합니다.
날짜 변이형
날짜 또는 날짜&시간에서 주의 번호를 추출합니다.
문법 |
week(date) |
인자 |
|
예제 |
|
간격 변이형
길이를 간격의 주 단위로 계산합니다.
문법 |
week(interval) |
인자 |
|
예제 |
|
13.2.7.21. year
날짜 유형에서 연도 부분을, 또는 간격 유형에서 연수를 추출합니다.
날짜 변이형
날짜 또는 날짜&시간에서 연도 부분을 추출합니다.
문법 |
year(date) |
인자 |
|
예제 |
|
간격 변이형
길이를 간격의 연 단위로 계산합니다.
문법 |
year(interval) |
인자 |
|
예제 |
|
다음은 몇몇 예시입니다:
이런 함수들 외에도, - (빼기) 연산자를 통해 날짜, 날짜&시간 또는 시간 유형을 뺄셈하면 간격 유형을 반환할 것입니다.
+ (더하기) 또는 - (빼기) 연산자를 이용해서 날짜, 날짜&시간 또는 시간 유형에 간격 유형을 더하거나 빼면 날짜&시간 유형을 반환합니다.
QGIS 3.0 배포일까지 며칠 남았는지 알아보려면:
to_date('2017-09-29') - to_date(now()) -- Returns <interval: 203 days>
같은 내용을 시간 유형으로:
to_datetime('2017-09-29 12:00:00') - now() -- Returns <interval: 202.49 days>
현재부터 100일 후의 날짜&시간을 얻으려면:
now() + to_interval('100 days') -- Returns <datetime: 2017-06-18 01:00:00>
13.2.8. 필드 및 값
활성 레이어로부터 나온 필드 목록, 그리고 특수값을 담고 있습니다. 필드 목록에는 데이터셋에 저장된 필드, 가상 필드 및 보조 필드 는 물론 결합 으로 생성된 필드도 포함됩니다.
사용자 표현식에 필드명을 추가하려면 필드명을 더블클릭하십시오. 필드명을 (가급적 큰따옴표 안에) 입력하거나, 또는 필드의 별명 을 입력해도 됩니다.
표현식에 사용할 필드값을 가져오려면, 적절한 필드를 선택한 다음 나타나는 위젯에서 10 Samples 와 All Unique 가운데 하나를 선택하십시오. 요청한 값들이 표시되는 목록 맨 위에 있는 Search 란을 통해 결과를 필터링할 수 있습니다. 필드를 오른쪽 클릭해서도 표본 값에 접근할 수 있습니다.
작성 중인 표현식에 값을 추가하려면, 목록에 있는 값을 더블클릭하십시오. 해당 값이 문자열 유형인 경우 작은따옴표를 추가해야 합니다. 그 외 유형은 따옴표가 필요하지 않습니다.
13.2.8.1. NULL
NULL 값과 동등합니다.
문법 |
NULL |
예제 |
|
참고
NULL에 대해 테스트하려면 IS NULL 또는 IS NOT NULL 표현식을 이용하십시오.
13.2.9. 파일 및 경로 함수
이 그룹은 파일 및 경로 이름을 처리하는 함수를 담고 있습니다.
13.2.9.1. base_file_name
디렉터리 또는 파일 확장자 없이 파일의 기본명(base name)을 반환합니다.
문법 |
base_file_name(path) |
인자 |
|
예제 |
|
13.2.9.2. exif
이미지 파일로부터 Exif(Exchangeable image file format) 태그 값을 가져옵니다.
문법 |
exif(path, [tag]) [] 괄호는 선택적인 인자를 표시합니다 |
인자 |
|
예제 |
|
13.2.9.3. file_exists
파일 경로가 실재하는 경우 참을 반환합니다.
문법 |
file_exists(path) |
인자 |
|
예제 |
|
13.2.9.4. file_name
디렉터리를 제외한 (파일 확장자 포함) 파일명을 반환합니다.
문법 |
file_name(path) |
인자 |
|
예제 |
|
13.2.9.5. file_path
파일 경로의 디렉터리 요소를 반환합니다. 파일명을 포함하지 않습니다.
문법 |
file_path(path) |
인자 |
|
예제 |
|
13.2.9.6. file_size
파일의 (바이트 단위) 용량을 반환합니다.
문법 |
file_size(path) |
인자 |
|
예제 |
|
13.2.9.7. file_suffix
파일 경로에서 파일 접미어(확장자)를 반환합니다.
문법 |
file_suffix(path) |
인자 |
|
예제 |
|
13.2.9.8. is_directory
경로가 디렉터리에 대응하는 경우 참을 반환합니다.
문법 |
is_directory(path) |
인자 |
|
예제 |
|
13.2.9.9. is_file
경로가 파일에 대응하는 경우 참을 반환합니다.
문법 |
is_file(path) |
인자 |
|
예제 |
|
13.2.10. 양식 함수
이 함수 그룹은 속성 양식 맥락에서만, 예를 들면 필드 위젯 설정에서 실행되는 함수들을 담고 있습니다.
13.2.10.1. current_parent_value
내장 양식 맥락에서만 사용할 수 있는 이 함수는 현재 편집되고 있는 부모 양식에 있는 필드의 현재 저장되지 않은 값을 반환합니다. 현재 편집되고 있는 또는 부모 레이어에 아직 추가되지 않은 피처에 대한 부모 피처의 실제 속성값과는 다를 것입니다. 값-관계 위젯 필터 표현식에서 사용되는 경우, 이 함수를 양식을 내장 맥락에서 사용하지 않는 경우 레이어에서 실제 부모 피처를 가져올 수 있는 ‘coalesce()’ 형태로 감싸야 합니다.
문법 |
current_parent_value(field_name) |
인자 |
|
예제 |
|
13.2.10.2. current_value
현재 편집중인 양식 또는 테이블 행에 있는 필드의 현재 저장되지 않은 값을 반환합니다. 이 객체의 속성은 현재 편집 중이거나 아직 레이어에 추가되지 않은 객체의 실제 속성 값과 다릅니다.
문법 |
current_value(field_name) |
인자 |
|
예제 |
|
13.2.11. 퍼지 매칭 함수
이 그룹은 값들을 퍼지 비교하기 위한 함수를 담고 있습니다.
13.2.11.1. hamming_distance
두 문자열 사이의 해밍 거리(Hamming distance)를 반환합니다. 이는 입력 문자열들 내에서 대응하는 위치에 있는 문자들이 서로 다른 경우의 개수와 같습니다. 입력 문자열은 동일한 길이여야 하며 대소문자를 구분해서 비교합니다.
문법 |
hamming_distance(string1, string2) |
인자 |
|
예제 |
|
13.2.11.2. levenshtein
두 문자열 사이의 레벤시테인 편집 거리(Levenshtein edit distance)를 반환합니다. 이는 어떤 문자열을 다른 문자열로 변경하는 데 필요한 문자 편집(삽입, 삭제 또는 치환)의 최소 횟수와 같습니다.
레벤시테인 거리란 두 문자열 사이의 유사성을 측정하는 방법입니다. 거리가 짧을수록 두 문자열이 더 유사하고, 거리가 멀수록 두 문자열이 더 다르다는 의미입니다. 이 거리는 대소문자를 구분합니다.
문법 |
levenshtein(string1, string2) |
인자 |
|
예제 |
|
13.2.11.3. longest_common_substring
두 문자열 사이의 가장 긴 공통 하위 문자열을 반환합니다. 이 하위 문자열은 두 입력 문자열의 하위 문자열 가운데 동일하면서 가장 긴 문자열입니다. 예를 들어, “ABABC” 와 “BABCA” 의 가장 긴 공통 하위 문자열은 “ABC” 입니다. 하위 문자열은 대소문자를 구분합니다.
문법 |
longest_common_substring(string1, string2) |
인자 |
|
예제 |
|
13.2.11.4. soundex
문자열의 사운덱스 표현(Soundex representation)을 반환합니다. 사운덱스란 유사 발음 검색 알고리즘으로, 문자열이 서로 비슷하게 발음되는 경우 동일한 사운덱스 코드로 표현될 것입니다.
문법 |
soundex(string) |
인자 |
|
예제 |
|
13.2.12. 일반 함수
이 그룹은 일반으로 분류된 함수를 담고 있습니다.
13.2.12.1. env
환경 변수를 받아 그 내용을 문자열로 반환합니다. 변수를 찾을 수 없는 경우, NULL을 반환할 것입니다. 드라이브 문자 또는 경로 접두어 같은 시스템 전용 환경 설정을 주입하는 데 편리합니다. 환경 변수의 정의는 운영 체제에 따라 달라지기 때문에, 이를 어떻게 설정할 수 있는지에 대해 시스템 관리자 또는 운영 체제 문서를 확인해보십시오.
문법 |
env(name) |
인자 |
|
예제 |
|
13.2.12.2. eval
문자열로 전달된 표현식을 평가합니다. 컨텍스트 변수 또는 필드로 전달되는 동적 파라미터를 확장하는 데 유용합니다.
문법 |
eval(expression) |
인자 |
|
예제 |
|
13.2.12.3. eval_template
문자열로 넘겨진 템플릿을 평가합니다. 컨텍스트 변수 또는 필드로 전달되는 동적 파라미터를 확장하는 데 유용합니다.
문법 |
eval_template(template) |
인자 |
|
예제 |
|
13.2.12.4. is_layer_visible
지정한 레이어가 현재 보이면 참을 반환합니다.
문법 |
is_layer_visible(layer) |
인자 |
|
예제 |
|
13.2.12.5. mime_type
바이너리 데이터의 MIME 유형을 반환합니다.
문법 |
mime_type(bytes) |
인자 |
|
예제 |
|
13.2.12.6. var
지정한 변수 내부에 저장된 값을 반환합니다.
문법 |
var(name) |
인자 |
|
예제 |
|
더 읽어볼 거리: 기본 변수 목록
13.2.12.7. with_variable
이 함수는 제3의 인수로 제공될 모든 표현식 코드를 위한 변수를 설정합니다. 동일한 계산 값을 서로 다른 위치에서 사용해야 하는 복잡한 표현식에서만 유용합니다.
문법 |
with_variable(name, value, expression) |
인자 |
|
예제 |
|
13.2.13. 도형 함수
이 그룹은 도형 객체를 대상으로 하는 (예: buffer, transform, $area 등) 함수를 담고 있습니다.
13.2.13.1. affine_transform
도형을 아핀 변환해서 반환합니다. 이 도형의 공간 좌표계에서 아핀 변환을 계산합니다. 축척, 기울기(회전), 번역(translation) 순서로 연산합니다. Z 또는 M 오프셋이 존재하지만 도형에는 존재하지 않는 경우 도형에 추가할 것입니다.
문법 |
affine_transform(geometry, delta_x, delta_y, rotation_z, scale_x, scale_y, [delta_z=0], [delta_m=0], [scale_z=1], [scale_m=1]) [] 괄호는 선택적인 인자를 표시합니다 |
인자 |
|
예제 |
|
13.2.13.2. angle_at_vertex
라인스트링 도형 상에 지정한 꼭짓점에서 도형에 대한 이등분선 각도(평균 각도)를 반환합니다. 여기서 각도는 진북에서 시계 방향으로 측정한 도 단위입니다.
문법 |
angle_at_vertex(geometry, vertex) |
인자 |
|
예제 |
|
13.2.13.3. apply_dash_pattern
입력 도형에 점선(dash) 패턴을 적용해서 각 라인/고리를 따라 지정한 패턴을 그린 멀티라인스트링 도형을 반환합니다.
문법 |
apply_dash_pattern(geometry, pattern, [start_rule=no_rule], [end_rule=no_rule], [adjustment=both], [pattern_offset=0]) [] 괄호는 선택적인 인자를 표시합니다 |
인자 |
|
예제 |
|
13.2.13.4. $area
현재 객체의 면적을 반환합니다. 이 함수는 현재 프로젝트의 타원체 설정과 면적 단위 설정을 따라 면적을 계산합니다. 예를 들어 프로젝트에 타원체를 설정했다면 타원체 기반으로 면적을 계산하고, 타원체를 설정하지 않았다면 평면 상에서 면적을 계산합니다.
문법 |
$area |
예제 |
|
13.2.13.5. area
도형 폴리곤 객체의 면적을 계산합니다. 언제나 해당 도형의 공간 좌표계(SRS) 안에서 평면 측량해서 계산하므로, 반환한 면적의 단위가 SRS 용 단위와 일치할 것입니다. 이것이 $area 함수가 수행하는 계산과 다른 점인데, $area 함수는 프로젝트의 타원체 및 면적 단위 설정을 기반으로 타원체 상에서 계산을 수행할 것입니다.
문법 |
area(geometry) |
인자 |
|
예제 |
|
13.2.13.6. azimuth
포인트 a의 수직선에서 포인트 b로 시계 방향으로 측정한 진북 기준 방위각을 라디안 단위 각도로 반환합니다.
문법 |
azimuth(point_a, point_b) |
인자 |
|
예제 |
|
13.2.13.7. boundary
입력 도형의 경계(예: 도형의 위상 경계)를 조합한 닫힌 경계를 반환합니다. 예를 들면, 폴리곤 도형은 내부에 있는 각 고리 별로 라인스트링으로 이루어진 경계를 가지게 될 것입니다. 포인트 또는 도형 집합 같은 일부 도형 유형들은 정의된 경계를 보유하고 있지 않기 때문에 NULL을 반환할 것입니다.
문법 |
boundary(geometry) |
인자 |
|
예제 |
|
더 읽어볼 거리: 경계 알고리즘
13.2.13.8. bounds
입력 도형의 경계 상자(bounding box)를 표현하는 도형을 반환합니다. 해당 도형의 공간 좌표계 상에서 경계 상자를 계산합니다.
문법 |
bounds(geometry) |
인자 |
|
예제 |
|
그림 13.4 각 폴리곤 피처의 경계 상자를 표현하는 검은 선
더 읽어볼 거리: 경계 상자 알고리즘
13.2.13.9. bounds_height
도형의 경계 상자(bounding box)의 높이를 표현하는 도형을 반환합니다. 해당 도형의 공간 좌표계 상에서 경계 상자를 계산합니다.
문법 |
bounds_height(geometry) |
인자 |
|
예제 |
|
13.2.13.10. bounds_width
도형의 경계 상자(bounding box)의 너비를 표현하는 도형을 반환합니다. 해당 도형의 공간 좌표계 상에서 경계 상자를 계산합니다.
문법 |
bounds_width(geometry) |
인자 |
|
예제 |
|
13.2.13.11. buffer
도형으로부터의 거리가 지정한 거리 이하인 모든 포인트들을 표현하는 도형을 반환합니다. 해당 도형의 공간 좌표계 상에서 거리를 계산합니다.
문법 |
buffer(geometry, distance, [segments=8], [cap=’round’], [join=’round’], [miter_limit=2]) [] 괄호는 선택적인 인자를 표시합니다 |
인자 |
|
예제 |
|
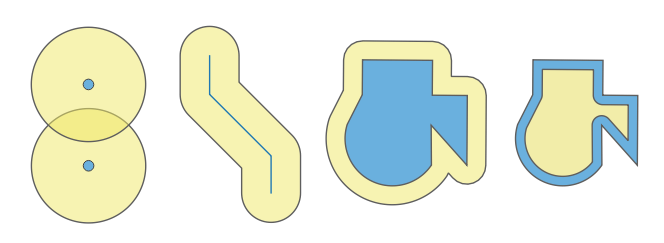
그림 13.5 버퍼(노란색) – 양의 버퍼를 가진 포인트, 라인, 폴리곤 | 음의 버퍼를 가진 폴리곤
더 읽어볼 거리: 버퍼 알고리즘
13.2.13.12. buffer_by_m
버퍼 반경이 라인 꼭짓점의 M 값에 따라 고르게 변하도록 라인 도형을 따라 버퍼를 생성합니다.
문법 |
buffer_by_m(geometry, [segments=8]) [] 괄호는 선택적인 인자를 표시합니다 |
인자 |
|
예제 |
|
그림 13.6 라인 피처의 꼭짓점에 M 값을 사용해서 버퍼 생성하기
더 읽어볼 거리: 변동 너비 버퍼 (M 값으로) 알고리즘
13.2.13.13. centroid
도형의 기하학적 중심을 반환합니다.
문법 |
centroid(geometry) |
인자 |
|
예제 |
|
더 읽어볼 거리: 중심 알고리즘
13.2.13.14. close_line
입력 라인스트링이 이미 닫힌 상태가 아닌 경우, 라인의 마지막 포인트에 첫 번째 포인트를 붙인 닫힌 라인스트링을 반환합니다. 도형이 라인스트링 또는 멀티라인스트링이 아닌 경우 NULL을 반환할 것입니다.
문법 |
close_line(geometry) |
인자 |
|
예제 |
|
13.2.13.15. closest_point
geometry2와 가장 가까이 있는 geometry1의 포인트를 반환합니다.
문법 |
closest_point(geometry1, geometry2) |
인자 |
|
예제 |
|
13.2.13.16. collect_geometries
도형 집합을 다중 부분 도형 객체로 수집합니다.
인자 변이형(variant) 목록
도형 부분을 함수에 대한 개별 인자로 지정합니다.
문법 |
collect_geometries(geometry1, geometry2, …) |
인자 |
|
예제 |
|
배열 변이형
도형 부분을 도형 부분의 배열로 지정합니다.
문법 |
collect_geometries(array) |
인자 |
|
예제 |
|
더 읽어볼 거리: 도형 모으기 알고리즘
13.2.13.17. combine
두 도형의 조합을 반환합니다.
문법 |
combine(geometry1, geometry2) |
인자 |
|
예제 |
|
13.2.13.18. concave_hull
도형에 있는 모든 포인트를 담고 있는 오목한 폴리곤을 반환합니다.
문법 |
concave_hull(geometry, target_percent, [allow_holes=False]) [] 괄호는 선택적인 인자를 표시합니다 |
인자 |
|
예제 |
|
더 읽어볼 거리: convex_hull
13.2.13.19. contains
도형이 또다른 도형을 담고 있는지 검증합니다. geometry2의 포인트 가운데 geometry1 외부에 있는 포인트가 하나도 없고, geometry2 내부의 포인트 가운데 최소한 포인트 1개가 geometry1 내부에 있는 경우에만 참을 반환합니다.
문법 |
contains(geometry1, geometry2) |
인자 |
|
예제 |
|
더 읽어볼 거리: overlay_contains
13.2.13.20. convex_hull
도형의 볼록 껍질(convex hull)을 반환합니다. 볼록 껍질이란 선택 집합에 있는 모든 도형을 감싸는 최소 볼록 도형을 말합니다.
문법 |
convex_hull(geometry) |
인자 |
|
예제 |
|
더 읽어볼 거리: concave_hull, 볼록 껍질 알고리즘
13.2.13.21. crosses
도형이 다른 도형과 공간교차(cross)하는지 검증합니다. 입력 도형들의 내부 포인트 전부가 아니라 일부가 일치할 경우 참을 반환합니다.
문법 |
crosses(geometry1, geometry2) |
인자 |
|
예제 |
|
더 읽어볼 거리: overlay_crosses
13.2.13.22. densify_by_count
폴리곤 또는 라인 레이어 도형을 받아 원본보다 더 많은 꼭짓점을 가지는 새 레이어 도형을 생성합니다.
문법 |
densify_by_count(geometry, vertices) |
인자 |
|
예제 |
|
더 읽어볼 거리: 개수로 치밀화하기 알고리즘
13.2.13.23. densify_by_distance
폴리곤 또는 라인 레이어 도형을 받아, 두 꼭짓점 사이의 최장 거리가 지정한 간격 거리인 꼭짓점들을 경계에 추가해서 치밀화한 새 레이어 도형을 생성합니다.
문법 |
densify_by_distance(geometry, distance) |
인자 |
|
예제 |
|
더 읽어볼 거리: 간격으로 치밀화하기 알고리즘
13.2.13.24. difference
geometry2와 교차하지 않는 geometry1의 부분을 표현하는 도형을 반환합니다.
문법 |
difference(geometry1, geometry2) |
인자 |
|
예제 |
|
더 읽어볼 거리: 차감하기(Difference) 알고리즘
13.2.13.25. disjoint
도형이 공간적으로 교차하지 않는지 여부를 테스트합니다. 도형들이 서로 어떠한 공간도 공유하지 않으면 참을 반환합니다.
문법 |
disjoint(geometry1, geometry2) |
인자 |
|
예제 |
|
더 읽어볼 거리: overlay_disjoint
13.2.13.26. distance
두 도형 사이의 (공간 좌표계 기반) 최단 거리를 투영체 단위로 반환합니다.
문법 |
distance(geometry1, geometry2) |
인자 |
|
예제 |
|
13.2.13.27. distance_to_vertex
도형을 따라 지정한 꼭짓점까지의 거리를 반환합니다.
문법 |
distance_to_vertex(geometry, vertex) |
인자 |
|
예제 |
|
13.2.13.28. end_point
도형에서 마지막 노드를 반환합니다.
문법 |
end_point(geometry) |
인자 |
|
예제 |
|
더 읽어볼 거리: 특정 꼭짓점 추출하기 알고리즘
13.2.13.29. exif_geotag
이미지 파일의 Exif 지오태그로부터 포인트 도형을 생성합니다.
문법 |
exif_geotag(path) |
인자 |
|
예제 |
|
13.2.13.30. extend
라인스트링 도형의 시작과 끝을 지정한 양만큼 연장합니다. 라인에 있는 첫 번째와 마지막 선분의 방향을 사용해서 라인을 연장합니다. 멀티라인스트링의 경우, 모든 부분을 연장합니다. 거리 단위는 해당 도형의 공간 좌표계의 단위입니다.
문법 |
extend(geometry, start_distance, end_distance) |
인자 |
|
예제 |
|
더 읽어볼 거리: 라인 연장하기 알고리즘
13.2.13.31. exterior_ring
폴리곤 도형의 외곽 고리를 표현하는 라인스트링을 반환합니다. 도형이 폴리곤이 아닌 경우 NULL을 반환할 것입니다.
문법 |
exterior_ring(geometry) |
인자 |
|
예제 |
|
13.2.13.32. extrude
입력 [멀티]곡선 또는 [멀티]라인스트링을 지정한 X 및 Y 좌표로 연장한 압출(extruded) 버전을 반환합니다.
문법 |
extrude(geometry, x, y) |
인자 |
|
예제 |
|
13.2.13.33. flip_coordinates
도형의 x와 y 좌표값을 뒤바꾼 복사본을 반환합니다. 실수로 위도와 경도 값이 바뀐 도형을 복구하는데 유용합니다.
문법 |
flip_coordinates(geometry) |
인자 |
|
예제 |
|
더 읽어볼 거리: X좌표와 Y좌표 바꾸기 알고리즘
13.2.13.34. force_polygon_ccw
도형이 외곽 고리의 방향이 반시계 방향이고 내곽 고리의 방향은 시계 방향인 관습을 준수하도록 강제합니다.
문법 |
force_polygon_ccw(geometry) |
인자 |
|
예제 |
|
더 읽어볼 거리: force_polygon_cw, force_rhr
13.2.13.35. force_polygon_cw
도형이 외곽 고리의 방향이 시계 방향이고 내곽 고리의 방향은 반시계 방향인 관습을 준수하도록 강제합니다.
문법 |
force_polygon_cw(geometry) |
인자 |
|
예제 |
|
더 읽어볼 거리: force_polygon_ccw, force_rhr
13.2.13.36. force_rhr
도형이 오른손 규칙을 따르도록 강제합니다. 오른손 규칙이란 폴리곤 경계 안의 영역이 경계의 오른쪽에 있다는 의미입니다. 자세히 말하자면, 외곽 고리는 시계 방향이며 내곽 고리는 반시계 방향입니다. 오른손 규칙의 정의가 몇몇 맥락에서 일관성이 없는 경우가 있기 때문에, 되도록이면 force_polygon_cw 함수만 사용하는 편이 좋습니다.
문법 |
force_rhr(geometry) |
인자 |
|
예제 |
|
더 읽어볼 거리: 오른손 법칙 강제하기 알고리즘, force_polygon_ccw, force_polygon_cw
13.2.13.37. geom_from_gml
도형의 GML 표현으로부터 생성된 도형을 반환합니다.
문법 |
geom_from_gml(gml) |
인자 |
|
예제 |
|
13.2.13.38. geom_from_wkb
WKB(Well-Known Binary) 표현으로부터 생성된 도형을 반환합니다.
문법 |
geom_from_wkb(binary) |
인자 |
|
예제 |
|
13.2.13.39. geom_from_wkt
WKT(well-known text) 표현으로부터 생성된 도형을 반환합니다.
문법 |
geom_from_wkt(text) |
인자 |
|
예제 |
|
13.2.13.40. geom_to_wkb
도형의 WKB(Well-Known Binary) 표현을 반환합니다
문법 |
geom_to_wkb(geometry) |
인자 |
|
예제 |
|
13.2.13.41. geom_to_wkt
SRID 메타데이터를 제외한 도형의 WKT(well-known text) 표현을 반환합니다.
문법 |
geom_to_wkt(geometry, [precision=8]) [] 괄호는 선택적인 인자를 표시합니다 |
인자 |
|
예제 |
|
13.2.13.42. $geometry
현재 피처의 도형을 반환합니다. 다른 함수들의 처리 과정에 사용할 수 있습니다. 경고: 이 함수는 중요도가 떨어져 더 이상 사용되지 않고 앞으로는 사라지게 될 것입니다. 이 함수를 대체하는 @geometry 변수를 사용할 것을 권장합니다.
문법 |
$geometry |
예제 |
|
13.2.13.43. geometry
객체의 도형을 반환합니다.
문법 |
geometry(feature) |
인자 |
|
예제 |
|
13.2.13.44. geometry_n
도형 집합에서 특정 도형을 반환하거나, 입력 도형이 집합이 아닌 경우 NULL을 반환합니다. 다중 부분 도형에서도 한 부분을 반환합니다.
문법 |
geometry_n(geometry, index) |
인자 |
|
예제 |
|
13.2.13.45. geometry_type
도형의 유형을 설명하는 문자열 (Point, Line, 또는 Polygon) 값을 반환합니다.
문법 |
geometry_type(geometry) |
인자 |
|
예제 |
|
13.2.13.46. hausdorff_distance
두 도형 사이의 하우스도르프 거리(Hausdorff distance)를 반환합니다. 하우스도르프 거리란 기본적으로 두 도형이 얼마나 닮았는지 또는 닮지 않았는지를 나타내는 척도입니다. 거리가 짧을수록 도형들이 더 닮았다는 의미입니다.
이 함수는 선택적인 치밀화 분수(densify fraction) 인자와 함께 실행할 수 있습니다. 이 인자를 지정하지 않으면, 표준 하우스도르프 거리의 근사치를 사용합니다. 이 근사치는 활용도가 높은 사례들의 대다수에 대해 정확하거나 충분히 가까운 값입니다. 이에 대한 예는 다음과 같습니다:
서로에 대해 대충 평행하며 대충 길이도 같은 라인스트링들 사이의 거리를 계산합니다. 이 사례는 매칭 선형 네트워크에서 찾아볼 수 있습니다.
도형의 유사성을 검증합니다.
이 방법으로 제공되는 기본 근사값이 충분하지 않은 경우, 선택적인 치밀화 분수(densify fraction) 인자를 지정하십시오. 이 인자를 지정하면 개별 하우스도르프 거리를 계산하기 전에 선분 밀도를 늘리는 작업을 수행합니다. 이 파라미터는 각 선분을 치밀화하는 분수를 설정합니다. 각 선분은 동일한 길이의 하위 선분으로 분할되는데, 이때 전체 길이의 분수가 지정한 분수에 가장 가까워집니다. 치밀화 분수 파라미터의 값을 줄이면 반환된 거리가 도형에 대한 실제 하우스도르프 거리에 근접하게 됩니다.
문법 |
hausdorff_distance(geometry1, geometry2, [densify_fraction]) [] 괄호는 선택적인 인자를 표시합니다 |
인자 |
|
예제 |
|
13.2.13.47. inclination
포인트 a에서 포인트 b로 가는 경사를 천정(zenith, 0)부터 천저(nadir, 180) 범위에서 측정해서 반환합니다.
문법 |
inclination(point_a, point_b) |
인자 |
|
예제 |
|
13.2.13.48. interior_ring_n
폴리곤 도형에서 특정 내곽 고리를 반환하거나, 도형이 폴리곤이 아닌 경우 NULL을 반환합니다.
문법 |
interior_ring_n(geometry, index) |
인자 |
|
예제 |
|
13.2.13.49. intersection
두 도형이 공유하는 부분을 표현하는 도형을 반환합니다.
문법 |
intersection(geometry1, geometry2) |
인자 |
|
예제 |
|
더 읽어볼 거리: 교차(Intersection) 알고리즘
13.2.13.50. intersects
도형들이 서로 교차하는지 검증합니다. 도형들이 공간적으로 교차하는 경우 (공간의 어떤 부분이라도 공유하는 경우) 참을 반환하고 교차하지 않는 경우 거짓을 반환합니다.
문법 |
intersects(geometry1, geometry2) |
인자 |
|
예제 |
|
더 읽어볼 거리: overlay_intersects
13.2.13.51. intersects_bbox
도형의 경계 상자가 다른 도형의 경계 상자와 교차하는지 검증합니다. 도형들의 경계 상자가 공간적으로 교차하는 경우 (공간의 어떤 부분이라도 공유하는 경우) 참을 반환하고 교차하지 않는 경우 거짓을 반환합니다.
문법 |
intersects_bbox(geometry1, geometry2) |
인자 |
|
예제 |
|
13.2.13.52. is_closed
라인스트링이 닫힌 (시작점과 종단점이 일치하는) 경우 참을, 라인스트링이 닫히지 않은 경우 거짓을, 도형이 라인스트링이 아닌 경우 NULL을 반환합니다.
문법 |
is_closed(geometry) |
인자 |
|
예제 |
|
13.2.13.53. is_empty
도형이 비어 있는(좌표가 없는) 경우 참을, 도형이 비어 있지 않은 경우 거짓을, 도형이 없는 경우 NULL을 반환합니다. is_empty_or_null 함수도 참조하세요.
문법 |
is_empty(geometry) |
인자 |
|
예제 |
|
더 읽어볼 거리: is_empty_or_null
13.2.13.54. is_empty_or_null
도형이 NULL이거나 비어 있는(좌표가 없는) 경우 참을 반환하고, 그렇지 않은 경우 거짓을 반환합니다. 이 함수는 ‘$geometry IS NULL or is_empty($geometry)’ 표현식과 비슷합니다.
문법 |
is_empty_or_null(geometry) |
인자 |
|
예제 |
|
13.2.13.55. is_multipart
도형이 멀티 유형인 경우 참을 반환합니다.
문법 |
is_multipart(geometry) |
인자 |
|
예제 |
|
13.2.13.56. is_valid
도형이 무결한 경우, 즉 도형이 2차원에서 OGC 규칙에 따라 잘 형성된 경우 참을 반환합니다.
문법 |
is_valid(geometry) |
인자 |
|
예제 |
|
더 읽어볼 거리: make_valid, 유효성 점검하기 algorithm
13.2.13.57. $length
라인스트링의 길이를 반환합니다. 만약 폴리곤의 둘레 길이가 필요하다면, $perimeter를 대신 사용하십시오. 이 함수는 현재 프로젝트의 타원체 설정과 거리 단위 설정을 따라 거리를 계산합니다. 예를 들어 프로젝트에 타원체를 설정했다면 타원체 기반으로 거리를 계산하고, 타원체를 설정하지 않았다면 평면 상에서 거리를 계산합니다.
문법 |
$length |
예제 |
|
13.2.13.58. length
문자열의 문자 개수 또는 라인스트링 도형의 길이를 반환합니다.
문자열 변이형
문자열에 있는 문자의 개수를 반환합니다.
문법 |
length(string) |
인자 |
|
예제 |
|
도형 변이형
라인 도형 객체의 길이를 계산합니다. 언제나 해당 도형의 공간 좌표계(SRS)에서 평면 측량해서 계산하므로, 반환한 길이의 단위가 SRS 용 단위와 일치할 것입니다. 이것이 $length 함수가 수행하는 계산과 다른 점인데, $length 함수는 프로젝트의 타원체 및 거리 단위 설정을 기반으로 타원체 상에서 계산을 수행할 것입니다.
문법 |
length(geometry) |
인자 |
|
예제 |
|
더 읽어볼 거리: straight_distance_2d
13.2.13.59. length3D
라인 도형 객체의 3차원 길이를 계산합니다. 도형이 3차원 라인 객체가 아닌 경우 2차원 길이를 반환합니다. 언제나 해당 도형의 공간 좌표계(SRS)에서 평면 측량해서 계산하므로, 반환한 길이의 단위가 SRS 용 단위와 일치할 것입니다. 이것이 $length 함수가 수행하는 계산과 다른 점인데, $length 함수는 프로젝트의 타원체 및 거리 단위 설정을 기반으로 타원체 상에서 계산을 수행할 것입니다.
문법 |
length3D(geometry) |
인자 |
|
예제 |
|
13.2.13.60. line_interpolate_angle
라인스트링 도형을 따라 지정한 거리에서 도형과 평행한 각도를 반환합니다. 여기서 각도는 진북에서 시계 방향으로 측정한 도 단위입니다.
문법 |
line_interpolate_angle(geometry, distance) |
인자 |
|
예제 |
|
13.2.13.61. line_interpolate_point
라인스트링 도형을 따라 지정한 거리로 보간한 포인트를 반환합니다.
문법 |
line_interpolate_point(geometry, distance) |
인자 |
|
예제 |
|
더 읽어볼 거리: 라인에 포인트를 보간하기 알고리즘
13.2.13.62. line_locate_point
라인스트링을 따라 라인스트링이 지정한 포인트 도형에 가장 가까워지는 위치에 상응하는 거리를 반환합니다.
문법 |
line_locate_point(geometry, point) |
인자 |
|
예제 |
|
13.2.13.63. line_merge
입력 도형에서 연결된 모든 라인스트링을 단일 라인스트링으로 병합한 라인스트링 또는 멀티라인스트링 도형을 반환합니다. 이 함수는 입력 도형이 라인스트링/멀티라인스트링이 아닌 경우 NULL을 반환할 것입니다.
문법 |
line_merge(geometry) |
인자 |
|
예제 |
|
13.2.13.64. line_substring
지정한 시작점과 종단점 거리 사이에 떨어지는 라인 (또는 곡선) 도형의 부분을 반환합니다(라인의 시작에서부터 측정). Z 및 M 값은 기존 값에서 선형 보간됩니다.
문법 |
line_substring(geometry, start_distance, end_distance) |
인자 |
|
예제 |
|
더 읽어볼 거리: 라인 부스트링 생성하기 알고리즘
13.2.13.65. m
포인트 도형의 (측정) M 값을 반환합니다.
문법 |
m(geometry) |
인자 |
|
예제 |
|
13.2.13.66. m_max
도형의 최대 (측정) M 값을 반환합니다.
문법 |
m_max(geometry) |
인자 |
|
예제 |
|
13.2.13.67. m_min
도형의 최소 (측정) M 값을 반환합니다.
문법 |
m_min(geometry) |
인자 |
|
예제 |
|
13.2.13.68. main_angle
도형을 완전히 덮는 지향(oriented) 최소 경계 직사각형의 (북쪽에서 시계 방향으로 도 단위인) 장축 각도를 반환합니다.
문법 |
main_angle(geometry) |
인자 |
|
예제 |
|
13.2.13.69. make_circle
원형 폴리곤을 생성합니다.
문법 |
make_circle(center, radius, [segments=36]) [] 괄호는 선택적인 인자를 표시합니다 |
인자 |
|
예제 |
|
13.2.13.70. make_ellipse
타원형 폴리곤을 생성합니다.
문법 |
make_ellipse(center, semi_major_axis, semi_minor_axis, azimuth, [segments=36]) [] 괄호는 선택적인 인자를 표시합니다 |
인자 |
|
예제 |
|
13.2.13.71. make_line
일련의 포인트 도형들로부터 라인 도형을 생성합니다.
인자 변이형(variant) 목록
라인 꼭짓점을 함수에 대한 개별 인자로 지정합니다.
문법 |
make_line(point1, point2, …) |
인자 |
|
예제 |
|
배열 변이형
라인 꼭짓점을 포인트 배열로 지정합니다.
문법 |
make_line(array) |
인자 |
|
예제 |
|
13.2.13.72. make_point
Creates a point geometry from an x and y (and optional z and m) value.
문법 |
make_point(x, y, [z], [m]) [] 괄호는 선택적인 인자를 표시합니다 |
인자 |
|
예제 |
|
13.2.13.73. make_point_m
X, Y 좌표와 M 값으로 포인트 도형을 생성합니다.
문법 |
make_point_m(x, y, m) |
인자 |
|
예제 |
|
13.2.13.74. make_polygon
외곽 고리와 부가적인 일련의 내곽 고리 도형으로부터 폴리곤 도형을 생성합니다.
문법 |
make_polygon(outerRing, [innerRing1], [innerRing2], …) [] 괄호는 선택적인 인자를 표시합니다 |
인자 |
|
예제 |
|
13.2.13.75. make_rectangle_3points
포인트 3개로부터 직사각형 폴리곤을 생성합니다.
문법 |
make_rectangle_3points(point1, point2, point3, [option=0]) [] 괄호는 선택적인 인자를 표시합니다 |
인자 |
|
예제 |
|
13.2.13.76. make_regular_polygon
정다각형 폴리곤을 생성합니다.
문법 |
make_regular_polygon(center, radius, number_sides, [circle=0]) [] 괄호는 선택적인 인자를 표시합니다 |
인자 |
|
예제 |
|
13.2.13.77. make_square
대각선으로부터 정사각형을 생성합니다.
문법 |
make_square(point1, point2) |
인자 |
|
예제 |
|
13.2.13.78. make_triangle
삼각형 폴리곤을 생성합니다.
문법 |
make_triangle(point1, point2, point3) |
인자 |
|
예제 |
|
13.2.13.79. make_valid
무결한 도형을, 또는 도형을 무결하게 수정할 수 없는 경우 비어 있는 도형을 반환합니다.
문법 |
make_valid(geometry, [method=structure], [keep_collapsed=false]) [] 괄호는 선택적인 인자를 표시합니다 |
인자 |
|
예제 |
|
13.2.13.80. minimal_circle
도형의 최소 외함 원을 반환합니다. 최소 외함 원이란 도형 집합에 있는 모든 도형을 감싸는 최소 원을 말합니다.
문법 |
minimal_circle(geometry, [segments=36]) [] 괄호는 선택적인 인자를 표시합니다 |
인자 |
|
예제 |
|
더 읽어볼 거리: 최소 외함 원 알고리즘
13.2.13.81. nodes_to_points
입력 도형에 있는 모든 노드로 이루어진 멀티포인트 도형을 반환합니다.
문법 |
nodes_to_points(geometry, [ignore_closing_nodes=false]) [] 괄호는 선택적인 인자를 표시합니다 |
인자 |
|
예제 |
|
더 읽어볼 거리: 꼭짓점 추출하기 알고리즘
13.2.13.82. num_geometries
도형 집합에 있는 도형의 개수를, 또는 다중 부분 도형에 있는 부분들의 개수를 반환합니다. 이 함수는 입력 도형이 집합이 아닌 경우 NULL을 반환합니다.
문법 |
num_geometries(geometry) |
인자 |
|
예제 |
|
13.2.13.83. num_interior_rings
폴리곤 또는 도형 집합에 있는 내곽 고리의 개수를 반환하거나, 또는 입력 도형이 폴리곤 또는 집합이 아닌 경우 NULL을 반환합니다.
문법 |
num_interior_rings(geometry) |
인자 |
|
예제 |
|
13.2.13.84. num_points
도형의 꼭짓점 개수를 반환합니다.
문법 |
num_points(geometry) |
인자 |
|
예제 |
|
13.2.13.85. num_rings
폴리곤 또는 도형 집합에 있는 (외곽 고리를 포함하는) 고리의 개수를 반환하거나, 또는 입력 도형이 폴리곤 또는 집합이 아닌 경우 NULL을 반환합니다.
문법 |
num_rings(geometry) |
인자 |
|
예제 |
|
13.2.13.86. offset_curve
라인스트링 도형을 한쪽으로 오프셋시켜 형성된 도형을 반환합니다. 거리 단위는 해당 도형의 공간 좌표계의 단위입니다.
문법 |
offset_curve(geometry, distance, [segments=8], [join=1], [miter_limit=2.0]) [] 괄호는 선택적인 인자를 표시합니다 |
인자 |
|
예제 |
|
더 읽어볼 거리: 라인 오프셋시키기 알고리즘
13.2.13.87. order_parts
지정한 기준으로 멀티 도형의 부분들을 정렬합니다.
문법 |
order_parts(geometry, orderby, [ascending=true]) [] 괄호는 선택적인 인자를 표시합니다 |
인자 |
|
예제 |
|
13.2.13.88. oriented_bbox
입력 도형의 지향된(oriented) 최소 경계 상자를 표현하는 도형을 반환합니다.
문법 |
oriented_bbox(geometry) |
인자 |
|
예제 |
|
더 읽어볼 거리: 기울어진 최소 경계 상자 알고리즘
13.2.13.89. overlaps
도형이 다른 도형과 중첩하는지 검증합니다. 도형들이 동일한 차원이며 공간을 공유하지만 서로를 완전히 담고 있지 않은 경우 참을 반환합니다.
문법 |
overlaps(geometry1, geometry2) |
인자 |
|
예제 |
|
13.2.13.90. overlay_contains
현재 피처가 공간적으로 대상 레이어의 피처를 적어도 하나 이상 담고 있는지 여부, 또는 현재 피처가 담고 있는 대상 레이어의 피처에 대한 표현식 기반 결과물의 배열을 반환합니다.
기저 GEOS “Contains” 서술부에 대해 자세히 알고 싶다면, PostGIS ST_Contains 함수의 설명을 읽어보세요.
문법 |
overlay_contains(layer, [expression], [filter], [limit], [cache=false]) [] 괄호는 선택적인 인자를 표시합니다 |
인자 |
|
예제 |
|
13.2.13.91. overlay_crosses
현재 피처가 대상 레이어의 피처를 적어도 하나 이상 공간 교차하고 있는지 여부, 또는 현재 피처가 공간 교차하는 대상 레이어의 피처에 대한 표현식 기반 결과물의 배열을 반환합니다.
기저 GEOS “Crosses” 서술부에 대해 자세히 알고 싶다면, PostGIS ST_Crosses 함수의 설명을 읽어보세요.
문법 |
overlay_crosses(layer, [expression], [filter], [limit], [cache=false]) [] 괄호는 선택적인 인자를 표시합니다 |
인자 |
|
예제 |
|
13.2.13.92. overlay_disjoint
현재 피처가 공간적으로 대상 레이어의 모든 피처와 공간적으로 분리되어 있는지 여부, 또는 현재 피처와 분리되어 있는 대상 레이어의 피처에 대한 표현식 기반 결과물의 배열을 반환합니다.
기저 GEOS “Disjoint” 서술부에 대해 자세히 알고 싶다면, PostGIS ST_Disjoint 함수의 설명을 읽어보세요.
문법 |
overlay_disjoint(layer, [expression], [filter], [limit], [cache=false]) [] 괄호는 선택적인 인자를 표시합니다 |
인자 |
|
예제 |
|
13.2.13.93. overlay_equals
현재 피처가 대상 레이어의 피처와 적어도 하나 이상 공간적으로 동등한지 여부, 또는 현재 피처와 공간적으로 동등한 대상 레이어의 피처에 대한 표현식 기반 결과물의 배열을 반환합니다.
기저 GEOS “Equals” 서술부에 대해 자세히 알고 싶다면, PostGIS ST_Equals 함수의 설명을 읽어보세요.
문법 |
overlay_equals(layer, [expression], [filter], [limit], [cache=false]) [] 괄호는 선택적인 인자를 표시합니다 |
인자 |
|
예제 |
|
13.2.13.94. overlay_intersects
현재 피처가 대상 레이어의 피처를 적어도 하나 이상 공간적으로 교차하고 있는지 여부, 또는 현재 피처가 교차하는 대상 레이어의 피처에 대한 표현식 기반 결과물의 배열을 반환합니다.
기저 GEOS “Intersects” 서술부에 대해 자세히 알고 싶다면, PostGIS ST_Intersects 함수의 설명을 읽어보세요.
문법 |
overlay_intersects(layer, [expression], [filter], [limit], [cache=false], [min_overlap], [min_inscribed_circle_radius], [return_details], [sort_by_intersection_size]) [] 괄호는 선택적인 인자를 표시합니다 |
인자 |
|
예제 |
|
더 읽어볼 거리: intersects, 배열 조작, 위치로 선택하기 알고리즘
13.2.13.95. overlay_nearest
현재 피처에서 지정한 거리 안에 대상 레이어의 피처(들)이 있는지 여부, 또는 현재 피처에서 지정한 거리 안에 있는 대상 레이어의 피처에 대한 표현식 기반 결과물의 배열을 반환합니다.
주의: 대용량 레이어의 경우 이 함수는 메모리를 많이 잡아먹고 느릴 수도 있습니다.
문법 |
overlay_nearest(layer, [expression], [filter], [limit=1], [max_distance], [cache=false]) [] 괄호는 선택적인 인자를 표시합니다 |
인자 |
|
예제 |
|
더 읽어볼 거리: 배열 조작, 최근접으로 속성 결합하기 알고리즘
13.2.13.96. overlay_touches
현재 피처가 대상 레이어의 피처를 적어도 하나 이상 공간적으로 접하고 있는지 여부, 또는 현재 피처가 접하고 있는 대상 레이어의 피처에 대한 표현식 기반 결과물의 배열을 반환합니다.
기저 GEOS “Touches” 서술부에 대해 자세히 알고 싶다면, PostGIS ST_Touches 함수의 설명을 읽어보세요.
문법 |
overlay_touches(layer, [expression], [filter], [limit], [cache=false]) [] 괄호는 선택적인 인자를 표시합니다 |
인자 |
|
예제 |
|
13.2.13.97. overlay_within
현재 피처가 공간적으로 적어도 하나 이상의 대상 레이어의 피처 내부에 있는지 여부, 또는 현재 피처를 담고 있는 대상 레이어의 피처에 대한 표현식 기반 결과물의 배열을 반환합니다.
기저 GEOS “Within” 서술부에 대해 자세히 알고 싶다면, PostGIS ST_Within 함수의 설명을 읽어보세요.
문법 |
overlay_within(layer, [expression], [filter], [limit], [cache=false]) [] 괄호는 선택적인 인자를 표시합니다 |
인자 |
|
예제 |
|
13.2.13.98. $perimeter
현재 객체의 둘레 길이를 반환합니다. 이 함수로 계산된 둘레는 현재 프로젝트의 타원체 설정과 거리 단위 설정을 따릅니다. 예를 들어 타원체가 프로젝트에 설정되면 계산된 둘레는 타원체 기반이 되고 타원체가 설정되지 않으면 계산된 둘레는 평면상의 측정이됩니다.
문법 |
$perimeter |
예제 |
|
13.2.13.99. perimeter
도형 폴리곤 객체의 둘레를 계산합니다. 언제나 해당 도형의 공간 좌표계(SRS) 안에서 평면 측량해서 계산하므로, 반환한 둘레의 단위가 SRS 용 단위와 일치할 것입니다. 이것이 $perimeter 함수가 수행하는 계산과 다른 점인데, $perimeter 함수는 프로젝트의 타원체 및 거리 단위 설정을 기반으로 타원체 상에서 계산을 수행할 것입니다.
문법 |
perimeter(geometry) |
인자 |
|
예제 |
|
13.2.13.100. point_n
도형에서 지정한 노드를 반환합니다.
문법 |
point_n(geometry, index) |
인자 |
|
예제 |
|
더 읽어볼 거리: 특정 꼭짓점 추출하기 알고리즘
13.2.13.101. point_on_surface
도형의 표면 상에 있다고 보장된 포인트를 반환합니다.
문법 |
point_on_surface(geometry) |
인자 |
|
예제 |
|
더 읽어볼 거리: 표면에 포인트 생성하기 알고리즘
13.2.13.102. pole_of_inaccessibility
표면에 대한 도달불능극 근사치를 계산합니다. 도달불능극이란 표면의 경계로부터 가장 멀리 떨어져 있는 내부 포인트를 말합니다. 이 함수는 ‘polylabel’ 알고리즘(Vladimir Agafonkin, 2016)을 사용하는데, 이 알고리즘은 지정한 허용 오차 안에서 진짜 도달불능극을 확실히 찾을 수 있는 반복 접근법입니다. 허용 오차가 정밀할수록 더 많이 반복하기 때문에 계산 시간이 더 걸릴 것입니다.
문법 |
pole_of_inaccessibility(geometry, tolerance) |
인자 |
|
예제 |
|
더 읽어볼 거리: 도달불능극 알고리즘
13.2.13.103. project
라디안 단위 거리, 방향(방위각), 그리고 표고를 이용해서 시작점에서부터 투영된 포인트를 반환합니다.
문법 |
project(point, distance, azimuth, [elevation]) [] 괄호는 선택적인 인자를 표시합니다 |
인자 |
|
예제 |
|
더 읽어볼 거리: 포인트 투영하기 (데카르트) 알고리즘
13.2.13.104. relate
두 도형 간의 관계의 DE-9IM(Dimensional Extended 9 Intersection Model) 표현을 검증합니다.
관계 변이형
두 도형 간의 관계의 DE-9IM(Dimensional Extended 9 Intersection Model) 표현을 반환합니다.
문법 |
relate(geometry, geometry) |
인자 |
|
예제 |
|
패턴 매칭 변이형
두 도형 간의 DE-9IM 관계가 지정된 패턴과 일치하는지 여부를 테스트합니다.
문법 |
relate(geometry, geometry, pattern) |
인자 |
|
예제 |
|
13.2.13.105. reverse
라인스트링의 꼭짓점 순서를 역전시켜 라인스트링의 방향을 반전시킵니다.
문법 |
reverse(geometry) |
인자 |
|
예제 |
|
더 읽어볼 거리: 라인 방향 반전시키기 알고리즘
13.2.13.106. rotate
도형의 기울인(rotated) 버전을 반환합니다. 해당 도형의 공간 좌표계에서 계산합니다.
문법 |
rotate(geometry, rotation, [center=NULL], [per_part=false]) [] 괄호는 선택적인 인자를 표시합니다 |
인자 |
|
예제 |
|
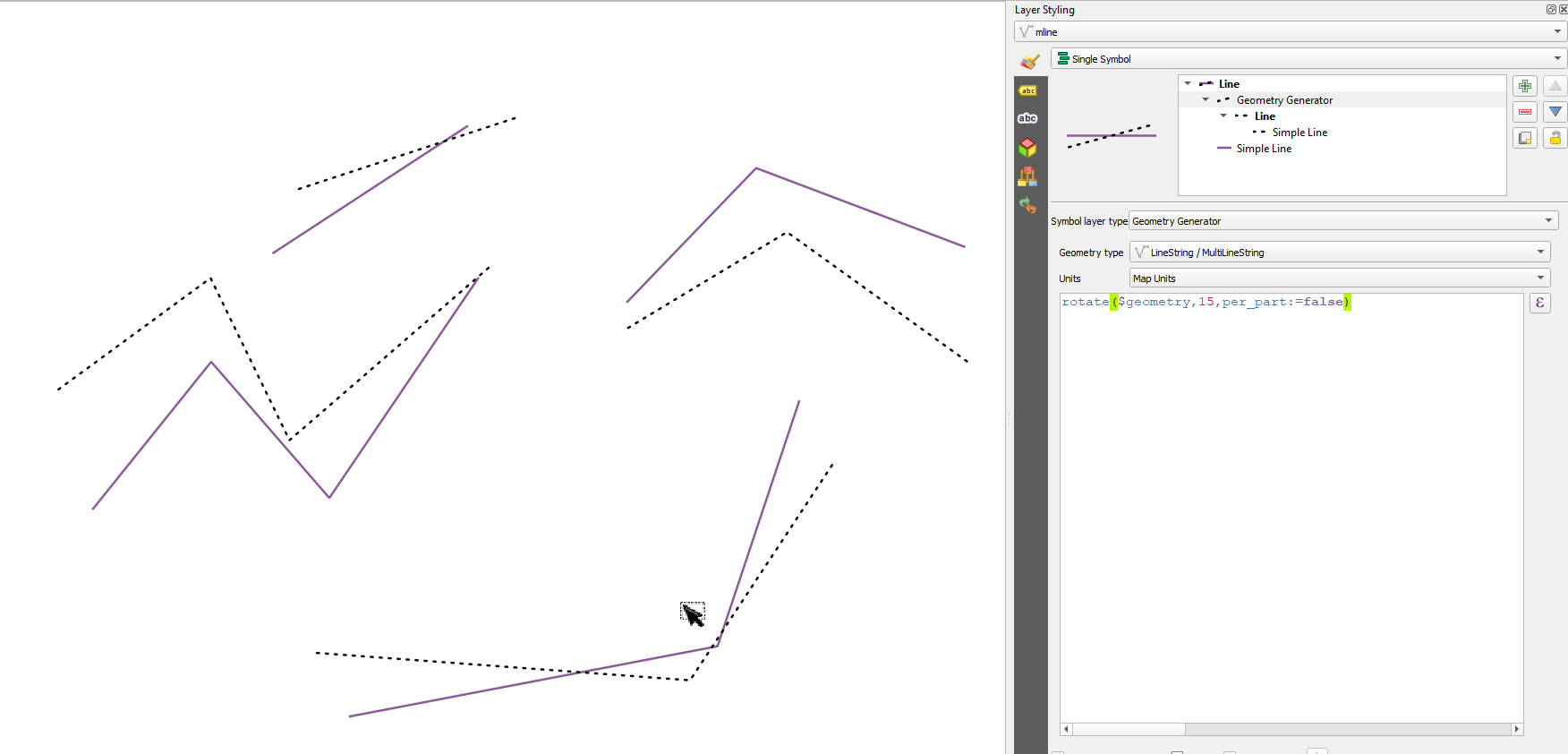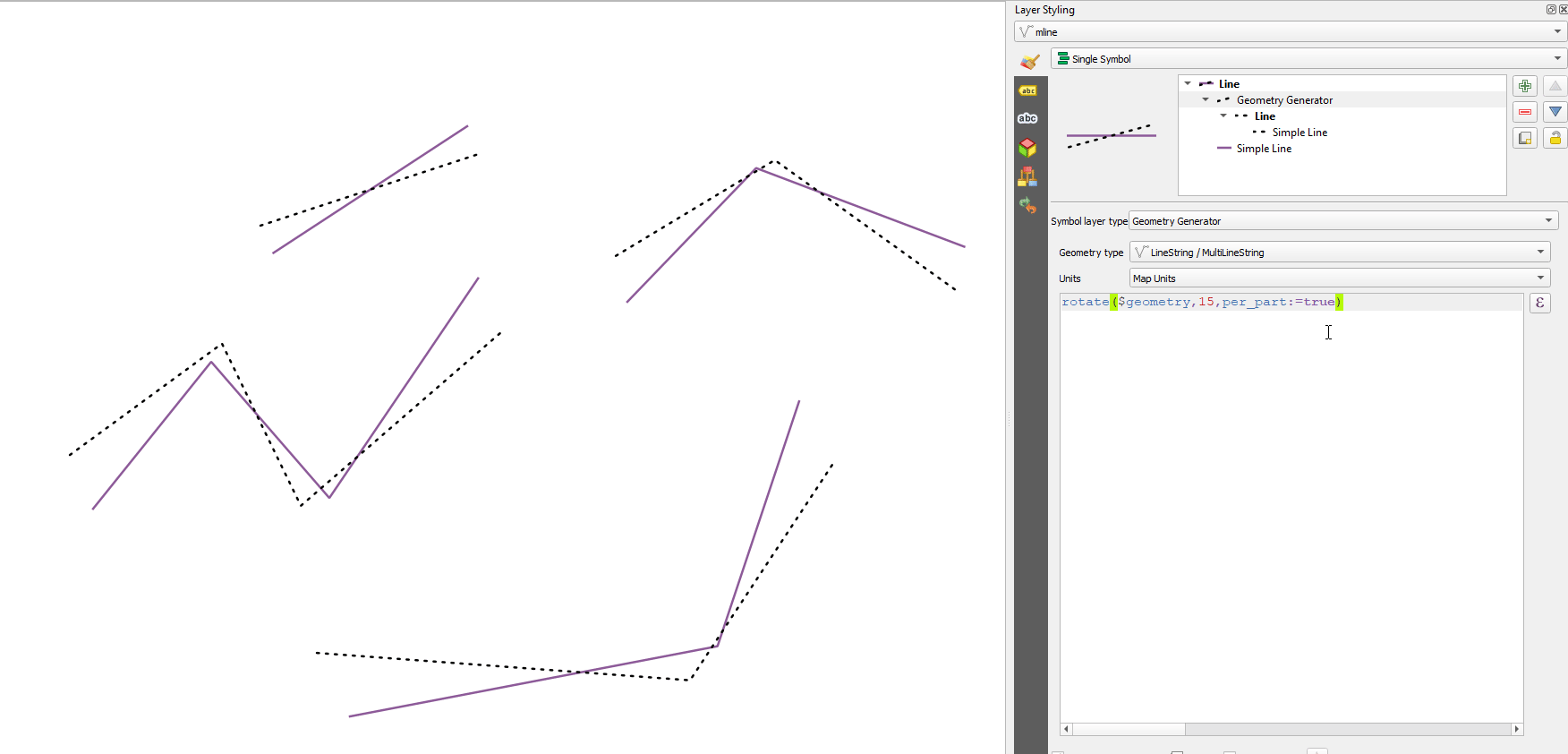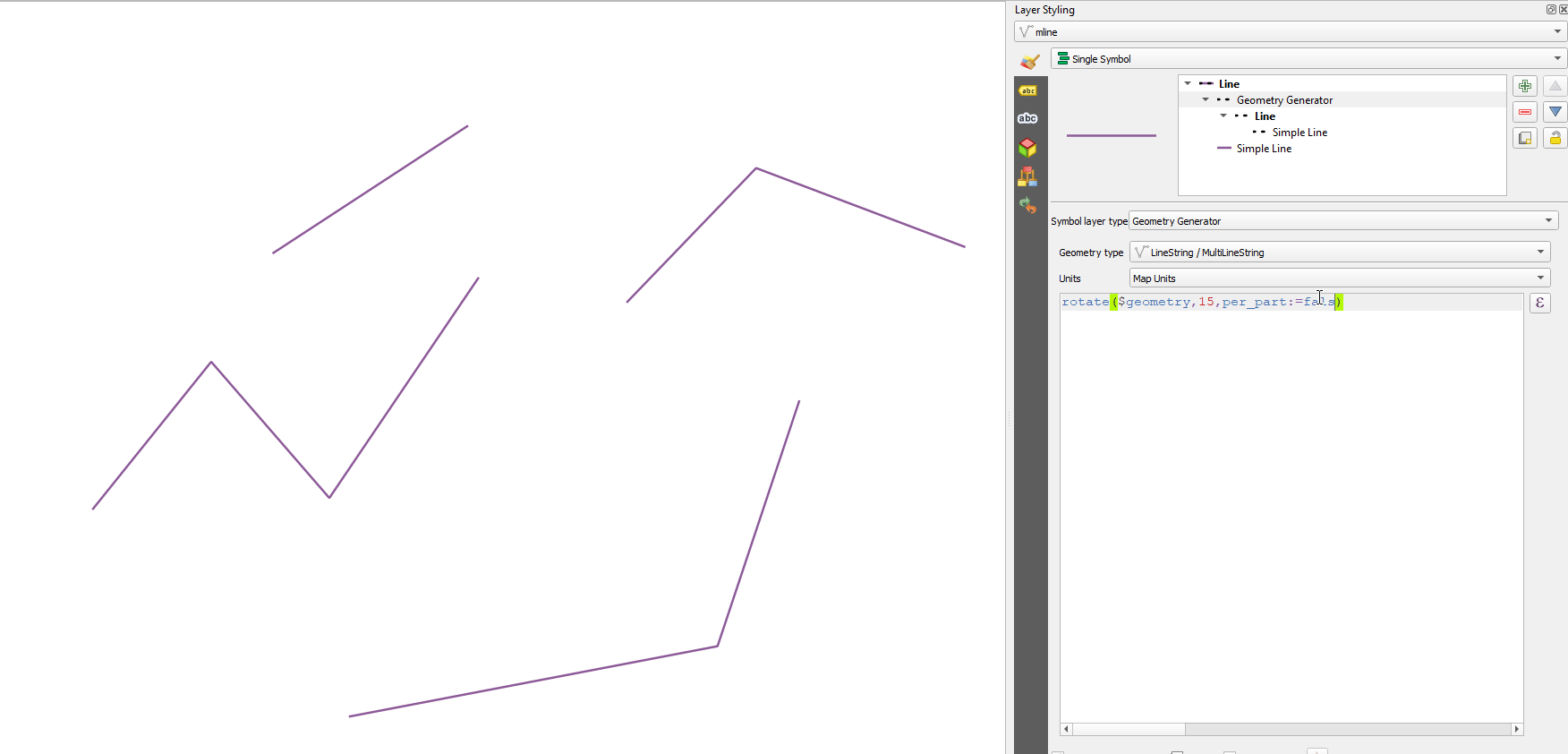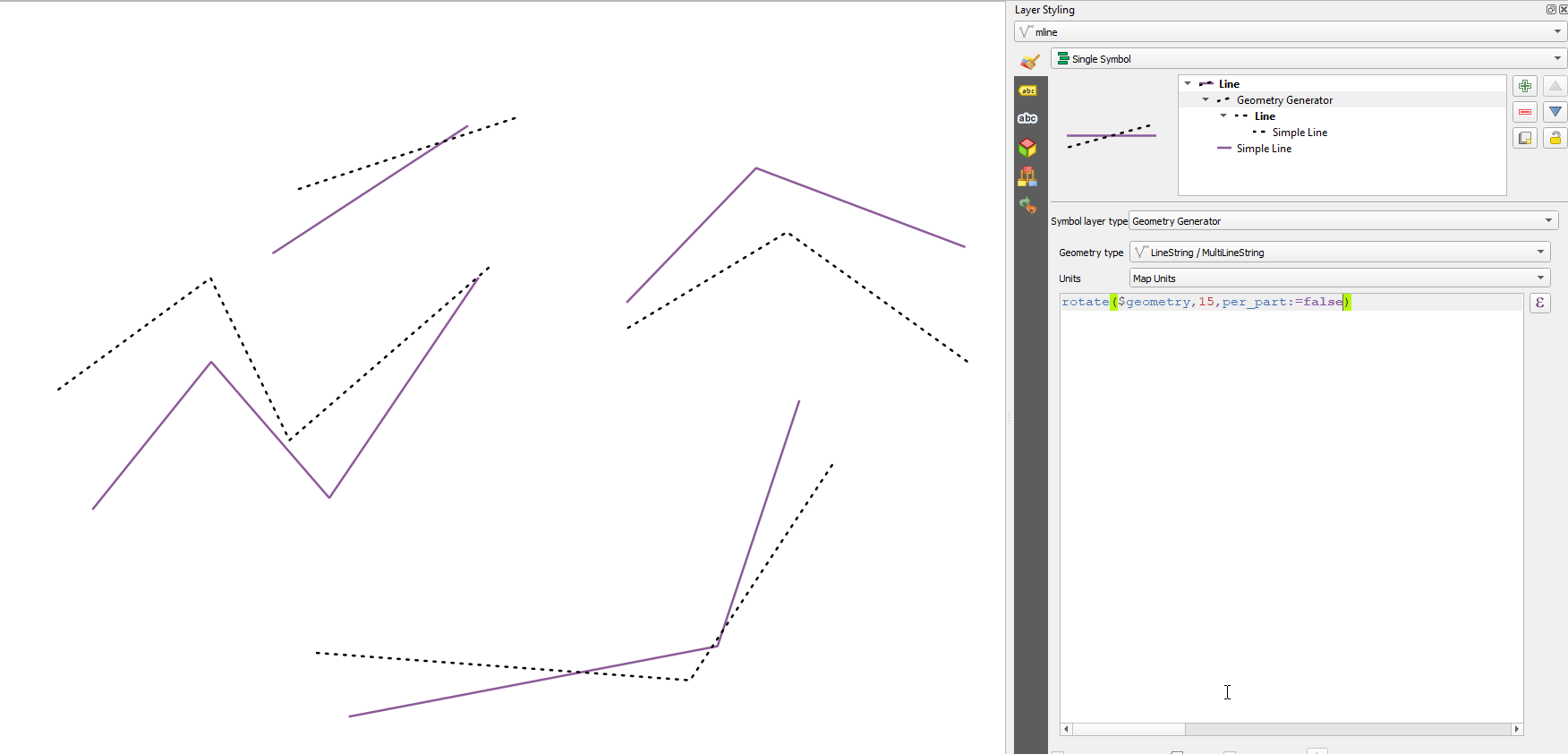
그림 13.7 피처 기울이기
13.2.13.107. roundness
폴리곤 형태가 얼마나 원에 가까운지 계산합니다. 이 함수는 폴리곤 형태가 완벽한 원인 경우 참을, 완전히 평평하면 0을 반환합니다.
문법 |
roundness(geometry) |
인자 |
|
예제 |
|
더 읽어볼 거리: 둥글기 알고리즘
13.2.13.108. scale
도형의 크기를 조정한(scaled) 버전을 반환합니다. 해당 도형의 공간 좌표계에서 계산합니다.
문법 |
scale(geometry, x_scale, y_scale, [center]) [] 괄호는 선택적인 인자를 표시합니다 |
인자 |
|
예제 |
|
13.2.13.109. segments_to_lines
입력 도형에 있는 모든 선분을 표현하는 라인으로 이루어진 멀티라인 도형을 반환합니다.
문법 |
segments_to_lines(geometry) |
인자 |
|
예제 |
|
더 읽어볼 거리: 라인 조각내기 알고리즘
13.2.13.111. shortest_line
도형 2에 도형 1을 결합하는 최단 라인을 반환합니다. 산출된 라인은 도형 1에서 시작돼 도형 2에서 끝납니다.
문법 |
shortest_line(geometry1, geometry2) |
인자 |
|
예제 |
|
13.2.13.112. simplify
거리 기반 한계값을 (예를 들면 더글러스-패커 알고리즘을) 사용해서 노드를 제거해 도형을 단순화합니다. 이 알고리즘은 도형 내부의 큰 편차를 보전하고 거의 직선에 가까운 선분의 꼭짓점 개수를 줄입니다.
문법 |
simplify(geometry, tolerance) |
인자 |
|
예제 |
|
더 읽어볼 거리: 단순화 알고리즘
13.2.13.113. simplify_vw
면적 기반 한계값을 (예를 들면 비쉬왈링감-와이어트 알고리즘을) 사용해서 노드를 제거해 도형을 단순화합니다. 이 알고리즘은 도형에서 작은 면을 - 예를 들어 좁은 돌기(narrow spike) 또는 거의 직선에 가까운 선분을 - 생성하는 꼭짓점을 제거합니다.
문법 |
simplify_vw(geometry, tolerance) |
인자 |
|
예제 |
|
더 읽어볼 거리: 단순화 알고리즘
13.2.13.114. single_sided_buffer
라인스트링 도형의 한쪽에만 버퍼를 적용해서 형성된 도형을 반환합니다. 거리 단위는 해당 도형의 공간 좌표계의 단위입니다.
문법 |
single_sided_buffer(geometry, distance, [segments=8], [join=1], [miter_limit=2.0]) [] 괄호는 선택적인 인자를 표시합니다 |
인자 |
|
예제 |
|
더 읽어볼 거리: 한쪽 버퍼 생성하기 알고리즘
13.2.13.115. sinuosity
만곡 도형의 굽이(sinuosity)를 반환합니다. 굽이란 만곡 도형의 길이와 그 두 종단점의 (2차원) 직선 거리의 비율입니다.
문법 |
sinuosity(geometry) |
인자 |
|
예제 |
|
13.2.13.116. smooth
도형의 모서리를 둥글게 다듬는 노드를 추가하여 도형을 매끄럽게 만듭니다. 입력 도형에 Z 또는 M값이 포함된 경우 이 값들도 평활화하고, 산출 도형은 입력 도형과 동일한 차원을 유지할 것입니다.
문법 |
smooth(geometry, [iterations=1], [offset=0.25], [min_length=-1], [max_angle=180]) [] 괄호는 선택적인 인자를 표시합니다 |
인자 |
|
예제 |
|
더 읽어볼 거리: 평탄화 알고리즘
13.2.13.117. square_wave
도형의 경계선을 따라 정사각/직사각 파형을 구성합니다.
문법 |
square_wave(geometry, wavelength, amplitude, [strict=False]) [] 괄호는 선택적인 인자를 표시합니다 |
인자 |
|
예제 |
|
13.2.13.118. square_wave_randomized
도형의 경계선을 따라 임의의 정사각/직사각 파형을 구성합니다.
문법 |
square_wave_randomized(geometry, min_wavelength, max_wavelength, min_amplitude, max_amplitude, [seed=0]) [] 괄호는 선택적인 인자를 표시합니다 |
인자 |
|
예제 |
|
13.2.13.119. start_point
도형에서 첫 번째 노드를 반환합니다.
문법 |
start_point(geometry) |
인자 |
|
예제 |
|
더 읽어볼 거리: 특정 꼭짓점 추출하기 알고리즘
13.2.13.120. straight_distance_2d
도형의 첫 번째와 마지막 꼭짓점 사이의 직교/유클리드 거리를 반환합니다. 만곡 도형(원호스트링, 라인스트링)이어야 합니다.
문법 |
straight_distance_2d(geometry) |
인자 |
|
예제 |
|
더 읽어볼 거리: length
13.2.13.121. sym_difference
두 도형이 교차하지 않는 부분들을 표현하는 도형을 반환합니다.
문법 |
sym_difference(geometry1, geometry2) |
인자 |
|
예제 |
|
더 읽어볼 거리: 대칭 차감 알고리즘
13.2.13.122. tapered_buffer
라인 도형을 따라 버퍼의 지름이 라인의 길이에 걸쳐 균등하게 달라지는 버퍼를 생성합니다.
문법 |
tapered_buffer(geometry, start_width, end_width, [segments=8]) [] 괄호는 선택적인 인자를 표시합니다 |
인자 |
|
예제 |
|
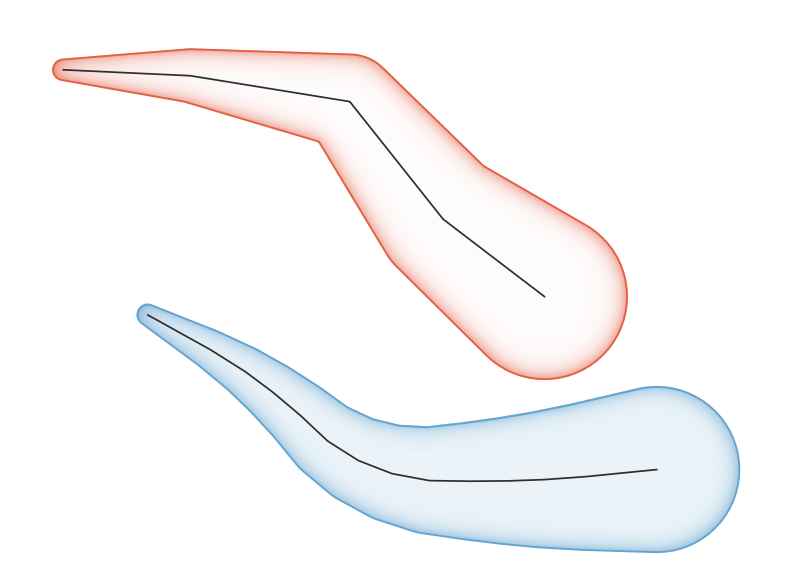
그림 13.8 라인 피처의 테이퍼형 버퍼
더 읽어볼 거리: 줄어드는 버퍼 생성하기 알고리즘
13.2.13.123. touches
도형이 다른 도형과 접하는지 검증합니다. 도형들이 최소한 포인트 1개를 공유하지만 각 도형의 내부가 교차하지 않는 경우 참을 반환합니다.
문법 |
touches(geometry1, geometry2) |
인자 |
|
예제 |
|
더 읽어볼 거리: overlay_touches
13.2.13.124. transform
원본 좌표계에서 대상 좌표계로 변환한 도형을 반환합니다.
문법 |
transform(geometry, source_auth_id, dest_auth_id) |
인자 |
|
예제 |
|
더 읽어볼 거리: 레이어 재투영하기 알고리즘
13.2.13.125. translate
도형의 번역(translated) 버전을 반환합니다. 해당 도형의 공간 좌표계 상에서 계산합니다.
문법 |
translate(geometry, dx, dy) |
인자 |
|
예제 |
|
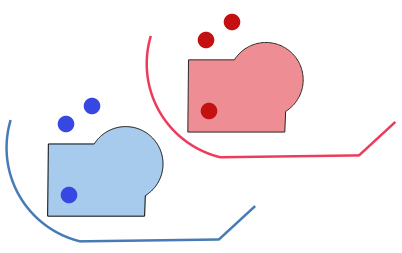
그림 13.9 도형 번역하기
더 읽어볼 거리: 이동시키기(Translate) 알고리즘
13.2.13.126. triangular_wave
도형의 경계선을 따라 삼각 파형을 구성합니다.
문법 |
triangular_wave(geometry, wavelength, amplitude, [strict=False]) [] 괄호는 선택적인 인자를 표시합니다 |
인자 |
|
예제 |
|
13.2.13.127. triangular_wave_randomized
도형의 경계선을 따라 임의의 삼각 파형을 구성합니다.
문법 |
triangular_wave_randomized(geometry, min_wavelength, max_wavelength, min_amplitude, max_amplitude, [seed=0]) [] 괄호는 선택적인 인자를 표시합니다 |
인자 |
|
예제 |
|
13.2.13.128. union
도형들의 모든 포인트를 통합한 집합을 표현하는 도형을 반환합니다.
문법 |
union(geometry1, geometry2) |
인자 |
|
예제 |
|
13.2.13.129. wave
도형의 경계선을 따라 둥근 (사인 곡선 같은) 파형을 구성합니다.
문법 |
wave(geometry, wavelength, amplitude, [strict=False]) [] 괄호는 선택적인 인자를 표시합니다 |
인자 |
|
예제 |
|
13.2.13.130. wave_randomized
도형의 경계선을 따라 임의의 만곡 (사인 곡선 같은) 파형을 구성합니다.
문법 |
wave_randomized(geometry, min_wavelength, max_wavelength, min_amplitude, max_amplitude, [seed=0]) [] 괄호는 선택적인 인자를 표시합니다 |
인자 |
|
예제 |
|
13.2.13.131. wedge_buffer
포인트 도형에서 나온 쐐기 모양의 버퍼를 반환합니다.
문법 |
wedge_buffer(center, azimuth, width, outer_radius, [inner_radius=0.0]) [] 괄호는 선택적인 인자를 표시합니다 |
인자 |
|
예제 |
|
더 읽어볼 거리: 쐐기 버퍼 생성하기 알고리즘
13.2.13.132. within
도형이 다른 도형 내부에 있는지 검증합니다. 도형 1이 도형 2 내부에 완전히 들어가 있는 경우 참을 반환합니다.
문법 |
within(geometry1, geometry2) |
인자 |
|
예제 |
|
더 읽어볼 거리: overlay_within
13.2.13.133. $x
현재 포인트 피처의 X 좌표를 반환합니다. 피처가 다중 부분 피처인 경우, 첫 번째 포인트의 X 좌표를 반환할 것입니다.
문법 |
$x |
예제 |
|
13.2.13.134. x
포인트 도형의 X 좌표를, 또는 포인트가 아닌 도형의 경우 중심점(centroid)의 X 좌표를 반환합니다.
문법 |
x(geometry) |
인자 |
|
예제 |
|
13.2.13.135. $x_at
현재 객체 도형의 X 좌표를 추출합니다.
문법 |
$x_at(i) |
인자 |
|
예제 |
|
13.2.13.136. x_max
도형의 최대 X 좌표를 반환합니다. 해당 도형의 공간 좌표계 상에서 좌표를 계산합니다.
문법 |
x_max(geometry) |
인자 |
|
예제 |
|
13.2.13.137. x_min
도형의 최소 X 좌표를 반환합니다. 해당 도형의 공간 좌표계 상에서 좌표를 계산합니다.
문법 |
x_min(geometry) |
인자 |
|
예제 |
|
13.2.13.138. $y
현재 포인트 피처의 Y 좌표를 반환합니다. 피처가 다중 부분 피처인 경우, 첫 번째 포인트의 Y 좌표를 반환할 것입니다.
문법 |
$y |
예제 |
|
13.2.13.139. y
포인트 도형의 Y 좌표를, 또는 포인트가 아닌 도형의 경우 중심점(centroid)의 Y 좌표를 반환합니다.
문법 |
y(geometry) |
인자 |
|
예제 |
|
13.2.13.140. $y_at
현재 객체 도형의 Y 좌표를 추출합니다.
문법 |
$y_at(i) |
인자 |
|
예제 |
|
13.2.13.141. y_max
도형의 최대 Y 좌표를 반환합니다. 해당 도형의 공간 좌표계 상에서 좌표를 계산합니다.
문법 |
y_max(geometry) |
인자 |
|
예제 |
|
13.2.13.142. y_min
도형의 최소 Y 좌표를 반환합니다. 해당 도형의 공간 좌표계 상에서 좌표를 계산합니다.
문법 |
y_min(geometry) |
인자 |
|
예제 |
|
13.2.13.143. $z
현재 포인트 피처가 3차원인 경우 포인트의 Z 값을 반환합니다. 피처가 다중 부분 피처인 경우, 첫 번째 포인트의 Z 값을 반환할 것입니다.
문법 |
$z |
예제 |
|
13.2.13.144. z
포인트 도형의 Z 좌표를 반환하거나, 도형에 Z 값이 없는 경우 NULL을 반환합니다.
문법 |
z(geometry) |
인자 |
|
예제 |
|
13.2.13.145. z_max
도형의 최대 Z 좌표를 반환하거나, 도형에 Z 값이 없는 경우 NULL을 반환합니다.
문법 |
z_max(geometry) |
인자 |
|
예제 |
|
13.2.13.146. z_min
도형의 최소 Z 좌표를 반환하거나, 도형에 Z 값이 없는 경우 NULL을 반환합니다.
문법 |
z_min(geometry) |
인자 |
|
예제 |
|
13.2.14. 조판 함수
이 그룹은 인쇄 조판기 항목 속성을 처리하는 함수를 담고 있습니다.
13.2.14.1. item_variables
해당 인쇄 조판기 내부에 있는 조판기 항목에서 나온 변수들의 맵을 반환합니다.
문법 |
item_variables(id) |
인자 |
|
예제 |
|
더 읽어볼 거리: 기본 변수 목록
13.2.14.2. map_credits
조판 맵 항목에 표시되는 레이어들에 대한 크레디트(사용 권한) 문자열 목록을 반환합니다.
문법 |
map_credits(id, [include_layer_names=false], [layer_name_separator=’: ‘]) [] 괄호는 선택적인 인자를 표시합니다 |
인자 |
|
예제 |
|
이 함수를 사용하려면 레이어의 메타데이터 속성 접근 권한이 필요합니다.
13.2.15. 맵 레이어
이 그룹은 현재 프로젝트에서 사용할 수 있는 레이어 목록과, 각 레이어 별로 사용할 수 있는 (데이터셋에 저장된 필드, 가상 또는 보조 필드는 물론 결합으로 생성된) 필드를 담고 있습니다. 필드 및 값 에서 설명한 것과 동일한 방법으로 이런 필드를 쌍방향으로 작업할 수 있지만, 필드가 활성 레이어에 속하지 않은 경우 더블클릭하면 표현식에 이름을 필드 참조로서가 아니라 (작은 따옴표로 싸인) 문자열로 추가할 것입니다. 이 습성으로 인해, 예를 들어 집계, 속성 또는 공간 쿼리 수행 시, 서로 다른 레이어를 참조하는 표현식을 더 편리하게 작성할 수 있습니다.
또 레이어를 처리하기 위한 몇몇 편리한 함수들도 제공합니다.
13.2.15.1. decode_uri
레이어를 가져와서 기저 데이터 제공자의 URI를 디코딩합니다. 데이터 제공자 유형에 따라 어떤 데이터를 사용할 수 있는지가 달라집니다.
문법 |
decode_uri(layer, [part]) [] 괄호는 선택적인 인자를 표시합니다 |
인자 |
|
예제 |
|
13.2.15.2. layer_property
일치하는 레이어 속성 또는 메타데이터 값을 반환합니다.
문법 |
layer_property(layer, property) |
인자 |
|
예제 |
|
13.2.16. 맵 함수
이 그룹은 (딕셔너리 객체, 키-값 쌍, 또는 연관 배열(associative array)이라고도 하는) 맵 데이터 구조의 키와 값을 생성하고 처리하는 함수들을 담고 있습니다. 값들의 순서가 중요한 목록 데이터 구조 와는 달리, 맵 객체에 있는 키-값 쌍은 중요하지 않고 값을 값의 키로 식별합니다.
13.2.16.1. from_json
JSON 서식 문자열을 불러옵니다.
문법 |
from_json(string) |
인자 |
|
예제 |
|
13.2.16.2. hstore_to_map
HStore 서식 문자열로부터 맵을 생성합니다.
문법 |
hstore_to_map(string) |
인자 |
|
예제 |
|
13.2.16.3. map
파라미터 쌍으로 전달된 모든 키와 값을 담고 있는 맵을 반환합니다.
문법 |
map(key1, value1, key2, value2, …) |
인자 |
|
예제 |
|
13.2.16.4. map_akeys
맵의 모든 키를 배열로 반환합니다.
문법 |
map_akeys(map) |
인자 |
|
예제 |
|
13.2.16.5. map_avals
맵의 모든 값을 배열로 반환합니다.
문법 |
map_avals(map) |
인자 |
|
예제 |
|
13.2.16.6. map_concat
지정한 맵의 모든 항목들을 담고 있는 맵을 반환합니다. 두 맵이 동일한 키를 담고 있는 경우, 두 번째 맵의 값을 취합니다.
문법 |
map_concat(map1, map2, …) |
인자 |
|
예제 |
|
13.2.16.7. map_delete
지정한 키와 그에 대응하는 값을 삭제한 맵을 반환합니다.
문법 |
map_delete(map, key) |
인자 |
|
예제 |
|
13.2.16.8. map_exist
지정한 키가 맵에 실재하는 경우 참을 반환합니다.
문법 |
map_exist(map, key) |
인자 |
|
예제 |
|
13.2.16.9. map_get
지정한 키에 대응하는 맵의 값을 반환합니다. 키가 실재하지 않는 경우 NULL을 반환합니다.
문법 |
map_get(map, key) |
인자 |
|
예제 |
|
힌트
맵에서 값을 가져오기 위해 인덱스 연산자 ([]) 를 사용할 수도 있습니다.
13.2.16.10. map_insert
추가한 키/값을 가진 맵을 반환합니다. 키가 이미 존재하는 경우, 그 값을 무시합니다.
문법 |
map_insert(map, key, value) |
인자 |
|
예제 |
|
13.2.16.11. map_prefix_keys
모든 키 앞에 지정한 문자열의 접두어를 붙인 맵을 반환합니다.
문법 |
map_prefix_keys(map, prefix) |
인자 |
|
예제 |
|
13.2.16.12. map_to_hstore
맵 요소들을 HStore 서식 문자열로 병합합니다.
문법 |
map_to_hstore(map) |
인자 |
|
예제 |
|
13.2.16.13. to_json
맵, 배열, 또는 다른 값으로부터 JSON 서식 문자열을 생성합니다.
문법 |
to_json(value) |
인자 |
|
예제 |
|
13.2.16.14. url_encode
맵으로부터 URL이 인코딩된 문자열을 반환합니다. 모든 문자를 적절히 인코딩된 양식으로 변형시켜 SQL 서식을 완전하게 준수하는 쿼리 문자열을 생성합니다.
‘+’ 더하기 기호는 변환되지 않는다는 사실을 기억하십시오.
문법 |
url_encode(map) |
인자 |
|
예제 |
|
13.2.17. 수학 함수
이 그룹은 (제곱근, 삼각함수 등의) 수학 함수를 담고 있습니다.
13.2.17.1. abs
숫자의 절댓값을 반환합니다.
문법 |
abs(value) |
인자 |
|
예제 |
|
13.2.17.2. acos
값의 시컨트(역 코사인)를 라디안 단위로 반환합니다.
문법 |
acos(value) |
인자 |
|
예제 |
|
13.2.17.3. asin
값의 코시컨트(역 사인)를 라디안 단위로 반환합니다.
문법 |
asin(value) |
인자 |
|
예제 |
|
13.2.17.4. atan
값의 코탄젠트(역 탄젠트)를 라디안 단위로 반환합니다.
문법 |
atan(value) |
인자 |
|
예제 |
|
13.2.17.5. atan2
결과물의 사분면을 결정하기 위해 두 인자의 사인 값을 이용해서 dy/dx 값의 코탄젠트(역 탄젠트)를 반환합니다.
문법 |
atan2(dy, dx) |
인자 |
|
예제 |
|
13.2.17.6. ceil
숫자를 올림합니다.
문법 |
ceil(value) |
인자 |
|
예제 |
|
13.2.17.7. clamp
입력값을 지정한 범위로 제한합니다.
문법 |
clamp(minimum, input, maximum) |
인자 |
|
예제 |
|
13.2.17.8. cos
각도의 코사인을 반환합니다.
문법 |
cos(angle) |
인자 |
|
예제 |
|
13.2.17.9. degrees
라디안 단위를 도 단위로 변환합니다.
문법 |
degrees(radians) |
인자 |
|
예제 |
|
13.2.17.10. exp
값의 지수(exponential)를 반환합니다.
문법 |
exp(value) |
인자 |
|
예제 |
|
13.2.17.11. floor
숫자를 내림합니다.
문법 |
floor(value) |
인자 |
|
예제 |
|
13.2.17.12. ln
값의 자연로그를 반환합니다.
문법 |
ln(value) |
인자 |
|
예제 |
|
13.2.17.13. log
전달된 값 및 밑(base)의 로그 값을 반환합니다.
문법 |
log(base, value) |
인자 |
|
예제 |
|
13.2.17.14. log10
전달된 표현식의 상용로그(밑이 10인 로그) 값을 반환합니다.
문법 |
log10(value) |
인자 |
|
예제 |
|
13.2.17.15. max
값의 집합에서 가장 큰 값을 반환합니다.
문법 |
max(value1, value2, …) |
인자 |
|
예제 |
|
13.2.17.16. min
값의 집합에서 가장 작은 값을 반환합니다.
문법 |
min(value1, value2, …) |
인자 |
|
예제 |
|
13.2.17.17. pi
계산을 위한 파이(π) 값을 반환합니다.
문법 |
pi() |
예제 |
|
13.2.17.18. radians
도 단위를 라디안 단위로 변환합니다.
문법 |
radians(degrees) |
인자 |
|
예제 |
|
13.2.17.19. rand
최소 및 최대 인자가 지정하는 범위 안에서 임의의 정수를 반환합니다. (최소값, 최대값 포함) 시드를 지정한 경우, 시드에 따라 항상 동일한 값을 반환할 것입니다.
문법 |
rand(min, max, [seed=NULL]) [] 괄호는 선택적인 인자를 표시합니다 |
인자 |
|
예제 |
|
13.2.17.20. randf
최소 및 최대 인자가 지정하는 범위 안에서 임의의 부동소수점형 실수를 반환합니다. (최소값, 최대값 포함) 시드를 지정한 경우, 시드에 따라 항상 동일한 값을 반환할 것입니다.
문법 |
randf([min=0.0], [max=1.0], [seed=NULL]) [] 괄호는 선택적인 인자를 표시합니다 |
인자 |
|
예제 |
|
13.2.17.21. round
숫자를 소수점 이하 자릿수로 반올림합니다.
문법 |
round(value, [places=0]) [] 괄호는 선택적인 인자를 표시합니다 |
인자 |
|
예제 |
|
13.2.17.22. scale_exp
지정한 값을 지수 곡선(exponential curve)을 이용해서 입력 범위에서 출력 범위로 변형합니다. 이 함수를 사용하면 지정한 산출 범위로 값을 부드럽게 조정(ease in or ease out)할 수 있습니다.
문법 |
scale_exp(value, domain_min, domain_max, range_min, range_max, exponent) |
인자 |
|
예제 |
|
13.2.17.23. scale_linear
지정한 값을 선형 보간(linear interpolation)을 이용해서 입력 범위에서 출력 범위로 변형합니다.
문법 |
scale_linear(value, domain_min, domain_max, range_min, range_max) |
인자 |
|
예제 |
|
13.2.17.24. sin
각도의 사인을 반환합니다.
문법 |
sin(angle) |
인자 |
|
예제 |
|
13.2.17.25. sqrt
값의 제곱근을 반환합니다.
문법 |
sqrt(value) |
인자 |
|
예제 |
|
13.2.17.26. tan
각도의 탄젠트를 반환합니다.
문법 |
tan(angle) |
인자 |
|
예제 |
|
13.2.18. 메시 함수
이 그룹은 메시 관련 값들을 계산하거나 반환하는 함수를 담고 있습니다.
13.2.18.1. $face_area
현재 메시 면(mesh face)의 면적을 반환합니다. 이 함수는 현재 프로젝트의 타원체 설정과 면적 단위 설정을 따라 면적을 계산합니다. 예를 들어 프로젝트에 타원체를 설정했다면 타원체 기반으로 면적을 계산하고, 타원체를 설정하지 않았다면 평면 상에서 면적을 계산합니다.
문법 |
$face_area |
예제 |
|
13.2.18.2. $face_index
현재 메시 면의 인덱스를 반환합니다.
문법 |
$face_index |
예제 |
|
13.2.18.3. $vertex_as_point
현재 꼭짓점을 포인트 도형으로 반환합니다.
문법 |
$vertex_as_point |
예제 |
|
13.2.18.4. $vertex_index
현재 메시 꼭짓점의 인덱스를 반환합니다.
문법 |
$vertex_index |
예제 |
|
13.2.18.5. $vertex_x
현재 메시 꼭짓점의 X 좌표를 반환합니다.
문법 |
$vertex_x |
예제 |
|
13.2.18.6. $vertex_y
현재 메시 꼭짓점의 Y 좌표를 반환합니다.
문법 |
$vertex_y |
예제 |
|
13.2.18.7. $vertex_z
현재 메시 꼭짓점의 Z 값을 반환합니다.
문법 |
$vertex_z |
예제 |
|
13.2.19. 연산자
이 그룹은 +, -, * 같은 연산자를 담고 있습니다. 다음에 설명하는 수학 함수들 대부분이, 입력 값 가운데 하나가 NULL인 경우 NULL을 반환한다는 점을 유념하십시오.
13.2.19.1. %
나눗셈의 나머지입니다. 나뉨수(dividend)의 부호를 가집니다.
문법 |
a % b |
인자 |
|
예제 |
|
13.2.19.2. *
두 값을 곱한 값을 반환합니다.
문법 |
a * b |
인자 |
|
예제 |
|
13.2.19.3. +
두 값을 더한 값을 반환합니다. 두 값 가운데 하나가 NULL인 경우 NULL을 산출할 것입니다.
문법 |
a + b |
인자 |
|
예제 |
|
13.2.19.4. -
한 값에서 다른 값을 뺀 값을 반환합니다. 두 값 가운데 하나가 NULL인 경우 NULL을 산출할 것입니다.
문법 |
a - b |
인자 |
|
예제 |
|
13.2.19.5. /
한 값을 다른 값으로 나눈 값을 반환합니다.
문법 |
a / b |
인자 |
|
예제 |
|
13.2.19.6. <
두 값을 비교해서 왼쪽 값이 오른쪽 값 미만인 경우 1로 평가합니다.
문법 |
a < b |
인자 |
|
예제 |
|
13.2.19.7. <=
두 값을 비교해서 왼쪽 값이 오른쪽 값 이하인 경우 1로 평가합니다.
문법 |
a <= b |
인자 |
|
예제 |
|
13.2.19.8. <>
두 값을 비교해서 두 값이 동등하지 않은 경우 1로 평가합니다.
문법 |
a <> b |
인자 |
|
예제 |
|
13.2.19.9. =
두 값을 비교해서 두 값이 동등한 경우 1로 평가합니다.
문법 |
a = b |
인자 |
|
예제 |
|
13.2.19.10. >
두 값을 비교해서 왼쪽 값이 오른쪽 값을 초과하는 경우 1로 평가합니다.
문법 |
a > b |
인자 |
|
예제 |
|
13.2.19.11. >=
두 값을 비교해서 왼쪽 값이 오른쪽 값 이상인 경우 1로 평가합니다.
문법 |
a >= b |
인자 |
|
예제 |
|
13.2.19.12. AND
조건 a와 조건 b가 참이면 참을 반환합니다.
문법 |
a AND b |
인자 |
|
예제 |
|
13.2.19.13. BETWEEN
값이 지정한 범위 내에 있는 경우 참을 반환합니다. 이 범위는 경계 값을 포함한다고 간주합니다. 범위 외에 있는지를 테스트하려면 NOT BETWEEN 함수를 사용하면 됩니다.
문법 |
value BETWEEN lower_bound AND higher_bound |
인자 |
|
예제 |
|
참고
value BETWEEN lower_bound AND higher_bound 는 value >= lower_bound AND value <= higher_bound 와 동일합니다.
더 읽어볼 거리: NOT BETWEEN
13.2.19.14. ILIKE
첫 번째 파라미터가 대소문자를 구분하지 않는 지정 패턴과 일치하는 경우 참을 반환합니다. 대소문자를 구분해도 일치하는지를 보려면 ILIKE 대신 LIKE를 사용하면 됩니다. 숫자값도 입력할 수 있습니다.
문법 |
string/number ILIKE pattern |
인자 |
|
예제 |
|
13.2.19.15. IN
값들의 목록에서 값을 찾은 경우 참을 반환합니다.
문법 |
a IN b |
인자 |
|
예제 |
|
13.2.19.16. IS
a가 b와 동일한 경우 참을 반환합니다.
문법 |
a IS b |
인자 |
|
예제 |
|
13.2.19.17. IS NOT
a와 b가 동일하지 않은 경우 참을 반환합니다.
문법 |
a IS NOT b |
인자 |
|
예제 |
|
13.2.19.18. LIKE
첫 번째 파라미터가 지정 패턴과 일치하는 경우 참을 반환합니다. 숫자 값도 입력할 수 있습니다.
문법 |
string/number LIKE pattern |
인자 |
|
예제 |
|
13.2.19.19. NOT
조건을 부정합니다.
문법 |
NOT a |
인자 |
|
예제 |
|
13.2.19.20. NOT BETWEEN
값이 지정한 범위 내에 없을 경우 참을 반환합니다. 이 범위는 경계 값을 포함한다고 간주합니다.
문법 |
value NOT BETWEEN lower_bound AND higher_bound |
인자 |
|
예제 |
|
참고
value NOT BETWEEN lower_bound AND higher_bound 는 value < lower_bound OR value > higher_bound 와 동일합니다.
더 읽어볼 거리: BETWEEN
13.2.19.21. OR
조건 a 또는 조건 b가 참이면 참을 반환합니다.
문법 |
a OR b |
인자 |
|
예제 |
|
13.2.19.22. []
인덱스 연산자로, 배열 또는 맵 값으로부터 요소를 반환합니다.
문법 |
[index] |
인자 |
|
예제 |
|
13.2.19.23. ^
a의 b 거듭제곱을 반환합니다.
문법 |
a ^ b |
인자 |
|
예제 |
|
13.2.19.24. ||
두 값을 문자열 하나로 결합시킵니다.
두 값 가운데 하나가 NULL인 경우 NULL을 반환할 것입니다. 다른 습성을 원한다면 CONCAT 함수를 찾아보십시오.
문법 |
a || b |
인자 |
|
예제 |
|
13.2.19.25. ~
문자열 값이 정규 표현식과 일치하는 경우 참을 반환합니다. 백슬래시 문자는 이중으로 이스케이프시켜야만 합니다. (예: 공백 문자와 일치시키려면 “\\s”)
문법 |
string ~ regex |
인자 |
|
예제 |
|
더 읽어볼 거리: regexp_match
13.2.20. 공간 처리 함수
이 그룹은 공간 처리 알고리즘을 대상으로 실행되는 함수를 담고 있습니다.
13.2.20.1. parameter
공간 처리 알고리즘의 입력 파라미터의 값을 반환합니다.
문법 |
parameter(name) |
인자 |
|
예제 |
|
13.2.21. 래스터 함수
이 그룹은 래스터 레이어를 대상으로 실행되는 함수를 담고 있습니다.
13.2.21.1. raster_statistic
래스터 레이어의 통계를 반환합니다.
문법 |
raster_statistic(layer, band, property) |
인자 |
|
예제 |
|
13.2.21.2. raster_value
입력 포인트 위치의 래스터 값을 반환합니다.
문법 |
raster_value(layer, band, point) |
인자 |
|
예제 |
|
13.2.22. 레코드 및 속성 함수
이 그룹은 레코드 식별자를 대상으로 하는 함수를 담고 있습니다.
13.2.22.1. attribute
피처로부터 속성을 반환합니다.
변이형 1
현재 피처에서 나온 속성의 값을 반환합니다.
문법 |
attribute(attribute_name) |
인자 |
|
예제 |
|
변이형 2
대상 피처 및 속성 이름을 지정할 수 있게 해줍니다.
문법 |
attribute(feature, attribute_name) |
인자 |
|
예제 |
|
13.2.22.2. attributes
피처의 모든 속성을 담고 있는, 필드명을 맵 키로 가진 맵을 반환합니다.
변이형 1
현재 피처의 모든 속성의 맵을 반환합니다.
문법 |
attributes() |
예제 |
|
변이형 2
대상 피처를 지정할 수 있게 해줍니다.
문법 |
attributes(feature) |
인자 |
|
예제 |
|
더 읽어볼 거리: 맵 함수
13.2.22.3. $currentfeature
현재 피처를 평가해서 반환합니다. ‘attribute’ 함수와 함께 사용하면 현재 피처에서 나온 속성값을 평가할 수 있습니다. 경고: 이 함수는 중요도가 떨어져 더 이상 사용되지 않고 앞으로는 사라지게 될 것입니다. 이 함수를 대체하는 @feature 변수를 사용할 것을 권장합니다.
문법 |
$currentfeature |
예제 |
|
13.2.22.4. display_expression
레이어에서 지정한 피처에 대한 표시(display) 표현식을 반환합니다. 기본적으로 표현식을 평가합니다. 인자를 0개, 1개 또는 그 이상 사용할 수 있습니다. 자세한 내용은 다음을 참조하세요.
파라미터 없음
파라미터 없이 호출하는 경우, 이 함수는 현재 레이어에 있는 현재 피처의 표시 표현식을 평가할 것입니다.
문법 |
display_expression() |
예제 |
|
‘피처’ 1개 파라미터
‘feature’ 파라미터 1개로만 호출하는 경우, 이 함수는 현재 레이어에서 지정한 피처를 평가할 것입니다.
문법 |
display_expression(feature) |
인자 |
|
예제 |
|
레이어와 피처 파라미터
함수를 레이어와 피처와 함께 호출하는 경우, 지정한 레이어에서 지정한 피처를 평가할 것입니다.
문법 |
display_expression(layer, feature, [evaluate=true]) [] 괄호는 선택적인 인자를 표시합니다 |
인자 |
|
예제 |
|
13.2.22.5. get_feature
지정한 속성값과 일치하는 레이어의 첫 번째 피처를 반환합니다.
단일 값 변이형
레이어 ID와 함께, 단일 열과 값을 지정합니다.
문법 |
get_feature(layer, attribute, value) |
인자 |
|
예제 |
|
맵 변이형
레이어 ID와 함께, 열(키)와 그에 대응하는 값을 담고 있는 맵을 지정합니다.
문법 |
get_feature(layer, attribute) |
인자 |
|
예제 |
|
13.2.22.6. get_feature_by_id
레이어에서 ID를 가진 피처를 반환합니다.
문법 |
get_feature_by_id(layer, feature_id) |
인자 |
|
예제 |
|
더 읽어볼 거리: $id
13.2.22.7. $id
현재 행의 피처 ID를 반환합니다. 경고: 이 함수는 중요도가 떨어져 더 이상 사용되지 않고 앞으로는 사라지게 될 것입니다. 이 함수를 대체하는 @id 변수를 사용할 것을 권장합니다.
문법 |
$id |
예제 |
|
13.2.22.8. is_selected
피처를 선택한 경우 참을 반환합니다. 인자를 0개, 1개 또는 그 이상 사용할 수 있습니다. 자세한 내용은 다음을 참조하세요.
파라미터 없음
파라미터 없이 호출하는 경우, 현재 레이어에서 현재 피처를 선택했다면 이 함수는 참을 반환할 것입니다.
문법 |
is_selected() |
예제 |
|
‘피처’ 1개 파라미터
‘feature’ 파라미터 1개로만 호출하는 경우, 현재 레이어에서 지정한 피처를 선택했다면 이 함수는 참을 반환합니다.
문법 |
is_selected(feature) |
인자 |
|
예제 |
|
파라미터 2개
함수를 레이어 및 피처와 함께 호출하는 경우, 지정한 레이어에서 지정한 피처를 선택했다면 이 함수는 참을 반환할 것입니다.
문법 |
is_selected(layer, feature) |
인자 |
|
예제 |
|
13.2.22.9. maptip
레이어에서 지정한 피처에 대한 맵 도움말(maptip)을 반환합니다. 기본적으로 표현식을 평가합니다. 인자를 0개, 1개 또는 그 이상 사용할 수 있습니다. 자세한 내용은 다음을 참조하세요.
파라미터 없음
파라미터 없이 호출하는 경우, 이 함수는 현재 레이어에 있는 현재 피처의 맵 도움말을 평가할 것입니다.
문법 |
maptip() |
예제 |
|
‘피처’ 1개 파라미터
‘feature’ 파라미터 1개로만 호출하는 경우, 이 함수는 현재 레이어에서 지정한 피처를 평가할 것입니다.
문법 |
maptip(feature) |
인자 |
|
예제 |
|
레이어와 피처 파라미터
함수를 레이어와 피처와 함께 호출하는 경우, 지정한 레이어에서 지정한 피처를 평가할 것입니다.
문법 |
maptip(layer, feature, [evaluate=true]) [] 괄호는 선택적인 인자를 표시합니다 |
인자 |
|
예제 |
|
13.2.22.10. num_selected
지정한 레이어에서 선택한 객체들의 개수를 반환합니다. 기본적으로 표현식을 평가한 레이어 상에서 작동합니다.
문법 |
num_selected([layer=current layer]) [] 괄호는 선택적인 인자를 표시합니다 |
인자 |
|
예제 |
|
13.2.22.11. represent_attributes
속성 이름이 키이고 환경 설정된 표현 값이 값인 키-값 쌍을 가진 맵을 반환합니다. 속성의 표현 값은 각 속성에 대해 환경 설정된 위젯 유형에 따라 달라집니다. 인자가 0개, 1개, 또는 그 이상일 수 있습니다. 자세한 내용은 다음을 참조하세요.
파라미터 없음
파라미터 없이 호출하는 경우, 이 함수는 현재 레이어에 있는 현재 피처의 속성 표현 값을 반환할 것입니다.
문법 |
represent_attributes() |
예제 |
|
‘피처’ 1개 파라미터
‘feature’ 파라미터 1개로만 호출하는 경우, 이 함수는 현재 레이어에서 지정한 피처의 속성 표현 값을 반환할 것입니다.
문법 |
represent_attributes(feature) |
인자 |
|
예제 |
|
레이어와 피처 파라미터
‘layer’ 와 ‘feature’ 파라미터 2개로 호출하는 경우, 이 함수는 지정한 레이어에서 지정한 피처의 속성 표현 값을 반환할 것입니다.
문법 |
represent_attributes(layer, feature) |
인자 |
|
예제 |
|
더 읽어볼 거리: represent_value
13.2.22.12. represent_value
필드값에 대해 구성된 표현값을 반환합니다. 구성된 위젯 유형에 따라 다릅니다. 흔히 ‘Value Map’ 위젯에 유용합니다.
문법 |
represent_value(value, [fieldName]) [] 괄호는 선택적인 인자를 표시합니다 |
인자 |
|
예제 |
|
더 읽어볼 거리: widget types, represent_attributes
13.2.22.13. sqlite_fetch_and_increment
SQLite 데이터베이스에서 자동으로 증가하는 값을 관리합니다.
SQLite 기본값들은 삽입할 수 있을 뿐 사전에 불러올 수는 없습니다.
이런 습성 때문에, 데이터베이스에 행을 생성하기 전에 AUTO_INCREMENT를 통해 증가하는 기본 키를 획득할 수 없게 됩니다. 주의: PostgreSQL의 경우, evaluate default values 옵션을 통해 사전에 기본 키를 가져올 수 있습니다.
관계를 가진 새 피처를 추가할 때, 부모 양식이 아직 열려 있어서 부모 피처가 커밋되기 전에 이미 부모에 대한 자식을 추가할 수 있다면 참 편리하겠지요.
이런 제약을 해결하기 위해, GeoPackage 같은 포맷에 기반한 SQLite에 있는 개별 테이블에 일련의 값들을 관리하는 데 이 함수를 사용할 수 있습니다.
시퀀스 ID(filter_attribute 및 filter_value)에 대해 시퀀스 테이블을 필터링하고, id_field의 현재 값을 1씩 증가시킨 다음 증가된 값을 반환할 것입니다.
추가적인 열들이 지정할 값들을 요구하는 경우, 이 목적을 위해 default_values 맵을 사용할 수 있습니다.
주의
이 함수는 대상 SQLite 테이블을 수정합니다. 이 함수는 속성에 대한 기본값 환경 설정을 위해 활용되도록 만들어졌습니다.
데이터베이스 파라미터가 레이어이고 레이어가 트랜잭션 모드인 경우, 트랜잭션 생애 주기 동안 한번만 값을 가져와 캐시에 저장하고 증가시킬 것입니다. 따라서 동일한 데이터베이스에서 여러 프로세스를 병렬 작업하는 것은 안전하지 않습니다.
문법 |
sqlite_fetch_and_increment(database, table, id_field, filter_attribute, filter_value, [default_values]) [] 괄호는 선택적인 인자를 표시합니다 |
인자 |
|
예제 |
|
더 읽어볼 거리: 데이터소스 속성, 일대다 또는 다대다 관계 생성
13.2.22.14. uuid
QUuid::createUuid 메소드를 사용해서 각 행에 대한 범용 고유 식별자(UUID)를 생성합니다.
문법 |
uuid([format=’WithBraces’]) [] 괄호는 선택적인 인자를 표시합니다 |
인자 |
|
예제 |
|
13.2.23. 관계
이 그룹은 현재 프로젝트에서 사용할 수 있는 관계 목록을 그 설명과 함께 담고 있습니다. 이 목록을 통해 표현식을 작성하거나 (예: relation_aggregate 함수) 양식을 사용자 정의하는 데 필요한 관계 ID에 빠르게 접근할 수 있습니다.
13.2.24. 문자열 함수
이 그룹은 문자열을 대상으로 하는 (예: 치환, 대문자 변환 등) 함수를 담고 있습니다.
13.2.24.1. ascii
문자열의 첫 번째 문자와 관련된 유니코드 코드를 반환합니다.
문법 |
ascii(string) |
인자 |
|
예제 |
|
13.2.24.2. char
유니코드 코드와 관련된 문자를 반환합니다.
문법 |
char(code) |
인자 |
|
예제 |
|
13.2.24.3. concat
여러 문자열을 하나로 연결합니다. NULL 값은 빈 문자열로 변환되고, (숫자 같은) 다른 값은 문자열로 변환됩니다.
문법 |
concat(string1, string2, …) |
인자 |
|
예제 |
|
필드 연결에 대해
특수한 몇몇 특성을 가진 || 또는 + 가운데 하나를 사용해서도 문자열 또는 필드값을 연결할 수 있습니다:
+연산자는 덧셈 표현식이기도 합니다. 따라서 정수형(필드 또는 숫자값) 피연산자가 있을 경우 오류를 낼 가능성이 있으므로||연산자 또는concat함수를 사용하는 편이 좋습니다:'My feature id is: ' + "gid" => triggers an error as gid returns an integer
NULL값인 인수가 하나라도 있을 경우,
||또는+둘 다 NULL값을 반환할 것입니다. NULL값에 상관없이 다른 인수를 반환하게 하려면,concat함수를 사용해야 할 수도 있습니다:'My feature id is: ' + NULL ==> NULL 'My feature id is: ' || NULL => NULL concat('My feature id is: ', NULL) => 'My feature id is: '
13.2.24.4. format
지정한 인자를 이용해서 문자열 서식을 변경합니다.
문법 |
format(string, arg1, arg2, …) |
인자 |
|
예제 |
|
13.2.24.5. format_date
날짜 유형 또는 문자열을 사용자 정의 문자열 서식으로 변환합니다. Qt 날짜&시간 서식 문자열을 사용하십시오. QDateTime::toString 을 참조하세요.
문법 |
format_date(datetime, format, [language]) [] 괄호는 선택적인 인자를 표시합니다 |
||||||||||||||||||||||||||||||||||||||||||||||||
인자 |
|
||||||||||||||||||||||||||||||||||||||||||||||||
예제 |
|
13.2.24.6. format_number
천 단위 로케일 구분자로 구분된 서식을 가진 숫자를 반환합니다. 기본적으로 현재 QGIS 사용자 로케일을 사용합니다. 또한 소수점 이하 자릿수도 지정한 자릿수대로 잘라 맞춥니다.
문법 |
format_number(number, [places=0], [language], [omit_group_separators=false], [trim_trailing_zeroes=false]) [] 괄호는 선택적인 인자를 표시합니다 |
인자 |
|
예제 |
|
13.2.24.7. left
문자열 가장 왼쪽에 있는 n 개의 문자를 담은 하위 문자열을 반환합니다.
문법 |
left(string, length) |
인자 |
|
예제 |
|
13.2.24.8. length
문자열의 문자 개수 또는 라인스트링 도형의 길이를 반환합니다.
문자열 변이형
문자열에 있는 문자의 개수를 반환합니다.
문법 |
length(string) |
인자 |
|
예제 |
|
도형 변이형
라인 도형 객체의 길이를 계산합니다. 언제나 해당 도형의 공간 좌표계(SRS)에서 평면 측량해서 계산하므로, 반환한 길이의 단위가 SRS 용 단위와 일치할 것입니다. 이것이 $length 함수가 수행하는 계산과 다른 점인데, $length 함수는 프로젝트의 타원체 및 거리 단위 설정을 기반으로 타원체 상에서 계산을 수행할 것입니다.
문법 |
length(geometry) |
인자 |
|
예제 |
|
13.2.24.9. lower
문자열을 소문자로 변환합니다.
문법 |
lower(string) |
인자 |
|
예제 |
|
13.2.24.10. lpad
채우기 문자를 사용하여 왼쪽에서 지정된 너비까지 채운 문자열을 반환합니다. 대상 너비가 문자열의 길이보다 작은 경우 문자열이 잘립니다.
문법 |
lpad(string, width, fill) |
인자 |
|
예제 |
|
13.2.24.11. regexp_match
유니코드 문자열 내부에서 정규 표현식과 첫번째로 일치하는 위치를 반환하거나, 하위 문자열을 찾지 못했을 경우 0을 반환합니다.
문법 |
regexp_match(input_string, regex) |
인자 |
|
예제 |
|
13.2.24.12. regexp_replace
지정한 정규 표현식을 치환한 문자열을 반환합니다.
문법 |
regexp_replace(input_string, regex, replacement) |
인자 |
|
예제 |
|
13.2.24.13. regexp_substr
문자열에서 지정한 정규 표현식과 일치하는 부분을 반환합니다.
문법 |
regexp_substr(input_string, regex) |
인자 |
|
예제 |
|
13.2.24.14. replace
문자열을 지정한 문자열, 배열, 또는 문자열의 맵으로 치환해서 반환합니다.
문자열 및 배열 변이형
지정한 문자열 또는 문자열 배열을 문자열 또는 문자열 배열로 치환해서 반환합니다.
문법 |
replace(string, before, after) |
인자 |
|
예제 |
|
맵 변이형
지정한 맵 키를 짝지은 값으로 치환한 문자열을 반환합니다. 더 긴 맵 키를 더 먼저 평가합니다.
문법 |
replace(string, map) |
인자 |
|
예제 |
|
13.2.24.15. right
문자열 가장 오른쪽에 있는 n 개의 문자를 담은 하위 문자열을 반환합니다.
문법 |
right(string, length) |
인자 |
|
예제 |
|
13.2.24.16. rpad
채우기 문자를 사용하여 오른쪽에서 지정된 너비까지 채운 문자열을 반환합니다. 대상 너비가 문자열의 길이보다 작은 경우 문자열이 잘립니다.
문법 |
rpad(string, width, fill) |
인자 |
|
예제 |
|
13.2.24.17. strpos
또다른 문자열 안에 있는 하위 문자열 가운데 첫 번째 일치하는 위치를, 또는 하위 문자열을 찾을 수 없는 경우 0을 반환합니다.
문법 |
strpos(haystack, needle) |
인자 |
|
예제 |
|
13.2.24.18. substr
문자열의 부분을 반환합니다.
문법 |
substr(string, start, [length]) [] 괄호는 선택적인 인자를 표시합니다 |
인자 |
|
예제 |
|
13.2.24.19. title
문자열의 모든 단어를 제목 서식 (모든 단어의 첫 문자가 대문자, 나머지 문자는 소문자) 으로 변환합니다.
문법 |
title(string) |
인자 |
|
예제 |
|
13.2.24.20. to_string
숫자를 문자열로 변환합니다.
문법 |
to_string(number) |
인자 |
|
예제 |
|
13.2.24.21. trim
문자열에서 맨 앞과 맨 뒤의 모든 빈 자리(공백, 탭 등)를 제거합니다.
문법 |
trim(string) |
인자 |
|
예제 |
|
13.2.24.22. upper
문자열을 대문자로 변환합니다.
문법 |
upper(string) |
인자 |
|
예제 |
|
13.2.24.23. wordwrap
최대/최소 문자 개수로 행갈이한 문자열을 반환합니다.
문법 |
wordwrap(string, wrap_length, [delimiter_string]) [] 괄호는 선택적인 인자를 표시합니다 |
인자 |
|
예제 |
|
13.2.25. 사용자 표현식
이 그룹은 사용자 표현식 으로 저장된 표현식들을 담고 있습니다.
13.2.26. 변수
이 그룹은 응용 프로그램, 프로젝트 파일 및 기타 설정과 관련된 동적 변수를 담고 있습니다. 즉 다음 맥락에 따라 일부 변수를 사용하지 못 할 수도 있다는 뜻입니다:
 Select by expression 대화창에서
Select by expression 대화창에서 Field calculator 대화창에서
Field calculator 대화창에서레이어 속성 대화창에서
인쇄 조판기에서
표현식에 다음 변수들을 사용하려면, 앞에 @ 문자를 (예: @row_number) 붙여야 합니다:
변수 |
설명 |
|---|---|
algorithm_id |
알고리즘의 유일 ID |
animation_end_time |
애니메이션의 전체 시계열 시간 범위의 종단 (날짜&시간 값으로) |
animation_interval |
애니메이션의 전체 시계열 시간 범위의 기간 (간격 값으로) |
animation_start_time |
애니메이션의 전체 시계열 시간 범위의 시작 (날짜&시간 값으로) |
atlas_feature |
현재 지도 피처 (피처 객체로써) |
atlas_featureid |
현재 지도 피처 ID |
atlas_featurenumber |
현재 조판기에 있는 지도 피처의 번호 |
atlas_filename |
현재 지도 파일명 |
atlas_geometry |
현재 지도 피처 도형 |
atlas_layerid |
현재 지도 커버리지 레이어 ID |
atlas_layername |
현재 지도 커버리지 레이어명 |
atlas_pagename |
현재 지도 페이지 이름 |
atlas_totalfeatures |
지도에 있는 피처의 총 개수 |
canvas_cursor_point |
캔버스 상에서의 프로젝트의 지리 좌표로 된 마지막 커서 위치 |
cluster_color |
군집 내부 심볼의 색상, 또는 심볼이 혼합 색상인 경우 NULL값 |
cluster_size |
군집 내부에 담겨 있는 심볼의 개수 |
current_feature |
현재 속성 양식 또는 테이블 행에서 편집 중인 피처 |
current_geometry |
현재 양식 또는 테이블 행에서 편집 중인 피처의 도형 |
current_parent_feature |
부모 양식에서 현재 편집하고 있는 피처를 나타냅니다. 내장된 양식 맥락에서만 사용할 수 있습니다. |
current_parent_geometry |
부모 양식에서 현재 편집하고 있는 피처의 도형을 나타냅니다. 내장된 양식 맥락에서만 사용할 수 있습니다. |
form_mode |
양식이 사용되는 목적입니다. AddFeatureMode, SingleEditMode, MultiEditMode, SearchMode, AggregateSearchMode 또는 IdentifyMode 같은 문자열로 입력합니다. |
feature |
평가되는 현재 피처입니다. 현재 피처의 속성값을 평가하기 위해 ‘attribute’ 함수와 함께 사용할 수 있습니다. |
frame_duration |
각 애니메이션 프레임의 시계열 기간 (간격 값으로) |
frame_number |
애니메이션 재생 시 현재 프레임 번호 |
frame_rate |
애니메이션 재생 시 초당 프레임 개수 |
fullextent_maxx |
(모든 레이어를 포함하는) 전체 캔버스 범위의 최대 X값 |
fullextent_maxy |
(모든 레이어를 포함하는) 전체 캔버스 범위의 최대 Y값 |
fullextent_minx |
(모든 레이어를 포함하는) 전체 캔버스 범위의 최소 X값 |
fullextent_miny |
(모든 레이어를 포함하는) 전체 캔버스 범위의 최소 Y값 |
geometry |
현재 피처에서 평가된 도형 |
geometry_part_count |
렌더링된 피처의 도형에 있는 부분의 개수 |
geometry_part_num |
렌더링 중인 피처의 현재 도형 부분의 번호 |
geometry_point_count |
렌더링된 도형의 부분에 있는 포인트의 개수 |
geometry_point_num |
현재 렌더링된 도형의 부분에 있는 포인트의 번호 |
geometry_ring_num |
렌더링되는 피처에서 현재 도형 고리 번호입니다. (폴리곤 피처 전용입니다.) 외곽 고리의 번호가 0입니다. |
grid_axis |
현재 그리드 주석 축 (예: 경도는 ‘x’, 위도는 ‘y’) |
grid_number |
현재 그리드 주석 값 |
id |
평가된 현재 피처의 ID |
item_id |
조판기 항목 사용자 ID (유일해야 하는 것은 아닙니다) |
item_uuid |
조판기 항목 유일 ID |
layer |
현재 레이어 |
layer_crs |
현재 레이어의 좌표계 기관 ID |
layer_id |
현재 레이어의 ID |
layer_ids |
현재 프로젝트에 있는 모든 맵 레이어의 ID 목록 |
layer_name |
현재 레이어의 이름 |
layers |
현재 프로젝트에 있는 모든 맵 레이어의 목록 |
layout_dpi |
조판 해상도(DPI) |
layout_name |
조판 이름 |
layout_numpages |
조판한 페이지 수 |
layout_page |
조판기에 있는 현재 항목의 페이지 번호 |
layout_pageheight |
조판에서 활성화된 페이지 높이 (표준 용지 크기의 경우 밀리미터 단위, 또는 사용자 지정 용지 크기의 경우 사용되는 모든 단위) |
layout_pageoffsets |
각 페이지의 상단 Y 좌표 배열. 페이지 크기가 변경될 수도 있다는 맥락에서 페이지에 항목을 동적으로 배치할 수 있게 해줍니다. |
layout_pagewidth |
조판에서 활성화된 페이지 너비 (표준 용지 크기의 경우 밀리미터 단위, 또는 사용자 지정 용지 크기의 경우 사용되는 모든 단위) |
legend_column_count |
범례에 있는 열의 개수 |
legend_filter_by_map |
맵이 범례 내용을 필터링했는지 여부를 표시 |
legend_filter_out_atlas |
범례에서 지도를 필터링했는지 여부를 표시 |
legend_split_layers |
범례에서 레이어를 나눌 수 있는지 여부를 표시 |
legend_title |
범례의 제목 |
legend_wrap_string |
범례 텍스트 행갈이에 쓰이는 문자(들) |
map_crs |
현재 맵의 좌표계 |
map_crs_acronym |
현재 맵 좌표계의 약어 |
map_crs_definition |
현재 맵 좌표계의 완전한 정의 |
map_crs_description |
현재 맵 좌표계의 이름 |
map_crs_ellipsoid |
현재 맵 좌표계 타원체의 약어 |
map_crs_proj4 |
현재 맵 좌표계의 PROJ4 정의 |
map_crs_projection |
맵의 좌표계가 사용하는 투영 메소드를 설명하는 이름 (예: ‘Albers Equal Area’) |
map_crs_wkt |
현재 맵 좌표계의 WKT 정의 |
map_end_time |
맵의 시계열 시간 범위의 종단 (날짜&시간 값으로) |
map_extent |
맵의 현재 범위를 표현하는 도형 |
map_extent_center |
맵의 중앙에 있는 포인트 피처 |
map_extent_height |
맵의 현재 높이 |
map_extent_width |
맵의 현재 너비 |
map_id |
현재 맵의 대상(destination) ID. 캔버스 렌더링인 경우 ‘canvas’, 조판기 맵 렌더링인 경우 해당 항목의 ID가 됩니다. |
map_interval |
맵의 시계열 시간 범위의 기간 (간격 값으로) |
map_layer_ids |
맵에 가시화된 맵 레이어의 ID 목록 |
map_layers |
맵에 가시화된 맵 레이어의 목록 |
map_rotation |
맵의 현재 기울기 |
map_scale |
맵의 현재 축척 |
map_start_time |
맵의 시계열 시간 범위의 시작 (날짜&시간 값으로) |
map_units |
맵 측정 단위 |
model_path |
현재 모델의 (파일 이름 포함) 전체 경로 (또는 모델이 프로젝트에 내장된 경우 프로젝트 경로) |
model_folder |
현재 모델을 담고 있는 폴더 (또는 모델이 프로젝트에 내장된 경우 프로젝트 폴더) |
model_name |
현재 모델의 이름 |
model_group |
현재 모델의 그룹 |
notification_message |
제공자가 전송하는 알림 메시지의 내용 (제공자 알림이 촉발하는 액션에 대해서만 사용할 수 있습니다.) |
parent |
부모 레이어에 있는 현재 피처를 참조. 집계 함수를 필터링하는 경우 해당 피처의 속성 및 도형에 접근할 수 있습니다. |
project_abstract |
프로젝트 요약. 프로젝트 메타데이터에서 가져옵니다. |
project_area_units |
현재 프로젝트에서 쓰이는 면적 단위. 도형 면적 계산 시 사용됩니다. |
project_author |
프로젝트 저자. 프로젝트 메타데이터에서 가져옵니다. |
project_basename |
현재 프로젝트 파일명의 (경로 및 확장자를 제외한) 기본 이름 |
project_creation_date |
프로젝트 생성 날짜. 프로젝트 메타데이터에서 가져옵니다. |
project_crs |
프로젝트 좌표계 |
project_crs_arconym |
프로젝트 좌표계의 약어 |
project_crs_definition |
프로젝트 좌표계의 완전한 정의 |
project_crs_description |
프로젝트 좌표계의 설명 |
project_crs_ellipsoid |
프로젝트 좌표계의 타원체 |
project_crs_proj4 |
프로젝트 좌표계의 PROJ4 표현 |
project_crs_wkt |
프로젝트 좌표계의 WKT 표현 |
project_distance_units |
현재 프로젝트에서 쓰이는 거리 단위. 도형 및 거리의 길이 계산 시 사용됩니다. |
project_ellipsoid |
현재 프로젝트의 타원체 이름. 측지(geodetic) 면적 또는 도형 길이 계산 시 사용됩니다. |
project_filename |
현재 프로젝트의 파일명 |
project_folder |
현재 프로젝트가 있는 폴더 |
project_home |
현재 프로젝트의 홈 경로 |
project_identifier |
프로젝트 식별자. 프로젝트 메타데이터에서 가져옵니다. |
project_keywords |
프로젝트 키워드. 프로젝트 메타데이터에서 가져옵니다. |
project_last_saved |
프로젝트를 마지막으로 저장한 날짜&시간 |
project_path |
현재 프로젝트의 (파일명을 포함한) 전체 경로 |
project_title |
현재 프로젝트의 제목 |
project_units |
프로젝트 좌표계의 단위 |
qgis_locale |
QGIS의 현재 언어 |
qgis_os_name |
현재 운영체제의 이름을 반환 (예: ‘windows’, ‘linux’ 또는 ‘osx’) |
qgis_platform |
QGIS의 플랫폼 (예: ‘desktop’ 또는 ‘server’) |
qgis_release_name |
현재 QGIS 의 배포명 |
qgis_short_version |
현재 QGIS의 버전 문자열 (ShortString 유형) |
qgis_version |
현재 QGIS의 버전 문자열 |
qgis_version_no |
현재 QGIS의 버전 숫자 |
row_number |
현재 행의 번호를 저장 |
snapping_results |
피처 디지타이즈 작업 도중 스냅 작업 결과물에 접근 가능 (피처 추가 시에만 사용할 수 있습니다.) |
scale_value |
현재 축척 막대 거리 값 |
selected_file_path |
외부 저장 시스템에 파일을 업로드하는 경우 파일 선택기 위젯에서 선택한 파일 경로 |
symbol_angle |
피처를 렌더링하는 데 쓰이는 심볼의 각도 (마커 심볼의 경우에만 무결합니다.) |
symbol_color |
피처를 렌더링하는 데 쓰이는 심볼의 색상 |
symbol_count |
(조판기 범례에 표시되는) 심볼이 표현하는 피처의 개수 |
symbol_id |
(조판기 범례에 표시되는) 심볼의 내부 ID |
symbol_label |
(사용자가 정의한 라벨 또는 기본 자동 생성된 라벨 가운데 하나로, 조판기 범례에 표시되는) 심볼 용 라벨 |
symbol_layer_count |
심볼에 있는 심볼 레이어의 총 개수 |
symbol_layer_index |
현재 심볼 레이어 인덱스 |
symbol_marker_column |
마커에 대한 열 번호(포인트 패턴 채우기에 대해서만 무결합니다) |
symbol_marker_row |
마커에 대한 행 번호(포인트 패턴 채우기에 대해서만 무결합니다) |
user_account_name |
현재 사용자의 운영체제 계정명 |
user_full_name |
현재 사용자의 운영체제 사용자명 |
value |
현재 값 |
vector_tile_zoom |
렌더링 중인 맵의 (현재 맵 축척으로부터 파생시킨) 정확한 벡터 타일 확대/축소 수준. 일반적으로 [0, 20] 범위 안의 값입니다. @zoom_level 과는 달리, 이 변수는 정수형 확대/축소 수준 사이의 보간값으로 쓰일 수 있는 부동소수점형 값입니다. |
with_variable |
표현식 내부에서 활용하기 위한 변수를 설정할 수 있고, 동일한 값을 반복해서 재계산하는 일을 피할 수 있습니다. |
zoom_level |
렌더링 중인 맵의 (현재 맵 축척으로부터 파생시킨) 벡터 타일 확대/축소 수준. 일반적으로 [0, 20] 범위 안의 값입니다. |
다음은 몇몇 예시입니다:
조판기 중심에 있는 맵 항목의 X 좌표를 반환합니다:
x( map_get( item_variables( 'map1'), 'map_extent_center' ) )
현재 레이어에 있는 각 피처 별로, 피처와 중첩하는 공항 피처의 개수를 반환합니다:
aggregate( layer:='airport', aggregate:='count', expression:="code", filter:=intersects( $geometry, geometry( @parent ) ) )라인에서 첫번째로 스냅하는 포인트의 object_id를 가져옵니다:
with_variable( 'first_snapped_point', array_first( @snapping_results ), attribute( get_feature_by_id( map_get( @first_snapped_point, 'layer' ), map_get( @first_snapped_point, 'feature_id' ) ), 'object_id' ) )
13.2.27. 최근 함수
이 그룹은 최근 사용한 함수를 담고 있습니다. 그 맥락에 따라 (피처 선택, 필드 계산기, 일반) 최근 적용된 표현식이 대응하는 목록에 (10개까지) 추가되며, 가장 최근에 사용한 함수가 맨 앞으로 오도록 정렬합니다. 이 목록을 통해 이전에 사용했던 표현식을 빠르게 찾아서 다시 적용할 수 있습니다.