15.1. Lesson: データベースの概要
PostgreSQLのを使用する前に、一般的なデータベース理論をさらうことによって私たちの根拠を確認してみましょう。サンプルコードはどれも入力する必要はありません。それは説明目的のためだけにあります。
このレッスンの目標: 基本的なデータベースの概念を理解します。
15.1.1. データベースとは何ですか?
データベースは、典型的にはデジタル形式の、1つ以上の用途のための組織化されたデータの集合からなる。 -ウィキペディア
データベース管理システム(DBMS)は、データベースを操作し、ストレージ、アクセス、セキュリティ、バックアップなどの機能を提供するソフトウェアで構成されています。 -ウィキペディア
15.1.2. テーブル
リレーショナルデータベースとフラットファイルデータベースにおいてテーブルは、(名前で識別される)縦の列と横の行のモデルを使って構成されたデータ要素(値)の集合です。テーブルの列の数は指定されますが、行の数は任意です。各行は、特定の列の部分集合に現れる候補キーとして識別された値によって識別されます。 -ウィキペディア
id | name | age
----+-------+-----
1 | Tim | 20
2 | Horst | 88
(2 rows)
SQLデータベースではテーブルは 関係 としても知られています。
15.1.3. 列/フィールド
列とは、特定の単純型のデータ値の集合であり、テーブルの各行に対して1つずつ存在します。列は、行を構成するための構造を提供します。フィールドという用語はしばしば列と互換的に使われますが、1つの行と1つの列の交点に存在するひとつの項目を指すときは、フィールド(またはフィールド値)を使う方が正しいと考える人も多い。 -ウィキペディア
列:
| name |
+-------+
| Tim |
| Horst |
フィールド:
| Horst |
15.1.4. レコード
レコードは、テーブル行に格納されている情報です。各レコードには、テーブル内の各列のフィールドがあります。
2 | Horst | 88 <-- one record
15.1.5. データ型
データ型は、列に格納できる情報の種類を制限します。* - ティムとホルスト*
データ型には多くの種類があります。最も一般的なものに焦点を当ててみましょう:
String- 自由形式のテキストデータを格納しますInteger- 整数を格納しますReal- 小数を保存しますDate- 誰も忘れないよう、ホルストの誕生日を格納しますBoolean- 単純な真/偽の値を格納します
フィールドに何も保存しないようにデータベースに指示することができます。フィールドに何もない場合、フィールドの中身は 'null'値 と呼ばれます:
insert into person (age) values (40);
select * from person;
結果:
id | name | age
---+-------+-----
1 | Tim | 20
2 | Horst | 88
4 | | 40 <-- null for name
(3 rows)
使えるデータ型には更に多くがあります- PostgreSQLマニュアルを確認してください
15.1.6. 住所データベースをモデル化
データベースが構築されるかを確認するために、単純なケーススタディを使ってみましょう。住所のデータベースを作成したいとします。
Try Yourself 
簡単な住所を構成し、そしてデータベースに格納される、プロパティを書き出します。
答え
私たちの理論上の住所テーブルの場合、次のようなプロパティを保存しておくとよいでしょう:
House Number
Street Name
Suburb Name
City Name
Postcode
Country
住所オブジェクトを表すテーブルを作成するとき、これらのプロパティのそれぞれを表す列を作成し、SQLに準拠したできるだけ短い名前を付けます:
house_number
street_name
suburb
city
postcode
country
住所の構造
住所を記述するプロパティは列です。各列に格納される情報のタイプは、そのデータ型です。次のセクションでは、概念的な住所テーブルを分析して、それをより良くする方法を見てみましょう。
15.1.7. データベース理論
データベースを作成するプロセスには、現実世界のモデルを作成することが含まれます。現実世界の概念を取り入れ、エンティティとしてデータベースに表現します。
15.1.8. 正規化
データベースの主なアイデアの1つは、データの重複/冗長性を避けることです。データベースから冗長性を除去するプロセスを正規化といいます。
正規化は、データベース構造が汎用的な照会に適しており、挿入、更新、および削除の異常(データの整合性が失われる可能性がある)などの望ましくない特性がないことを確実にする体系的な方法です。 -ウィキペディア
正規「形」には様々な種類があります。
簡単な例を見てみましょう:
Table "public.people"
Column | Type | Modifiers
----------+------------------------+------------------------------------
id | integer | not null default
| | nextval('people_id_seq'::regclass)
| |
name | character varying(50) |
address | character varying(200) | not null
phone_no | character varying |
Indexes:
"people_pkey" PRIMARY KEY, btree (id)
select * from people;
id | name | address | phone_no
---+---------------+-----------------------------+-------------
1 | Tim Sutton | 3 Buirski Plein, Swellendam | 071 123 123
2 | Horst Duester | 4 Avenue du Roix, Geneva | 072 121 122
(2 rows)
友達が同じ名前の通りや都市に多いとしましょう。このデータが複製されるたびに、領域が消費されます。さらに悪いことに、都市の名称が変わった場合は、データベースを更新するために多くの作業が必要になります。
15.1.9. Try Yourself
重複を低減し、データ構造を正規化するために、上記の理論 people テーブルを再設計します。
データベースの正規化については ここ に読み物があります
答え
people テーブルの大きな問題は、ある人の住所全体を含んだ単一のアドレスフィールドです。このレッスンで前に学んだ理論的な address テーブルについて考えてみると、住所は多くの異なるプロパティで構成されていることがわかります。これらのプロパティをすべて1つのフィールドに格納すると、データの更新や問い合わせが非常に困難になります。したがって、住所フィールドをさまざまなプロパティに分割する必要があります。そうすると、次のような構造を持つテーブルができます:
id | name | house_no | street_name | city | phone_no
--+---------------+----------+----------------+------------+-----------------
1 | Tim Sutton | 3 | Buirski Plein | Swellendam | 071 123 123
2 | Horst Duester | 4 | Avenue du Roix | Geneva | 072 121 122
次のセクションでは、データベースの構造をさらに改善するために、この例で使用することができる外部キー関係について学びます。
15.1.10. 索引
データベース索引は、データベース表のデータ検索操作の速度を向上させるデータ構造です。 -ウィキペディア
たとえば教科書を読んで、ある概念の説明を探しているが、その教科書には索引がなかったとします。表紙から読み始め、必要な情報が見つかるまで、本全体を通して作業を進めなければなりません。教科書の裏にある索引は、関連情報を持つページに素早くジャンプするのに役立ちます:
create index person_name_idx on people (name);
名前の検索が高速になります:
Table "public.people"
Column | Type | Modifiers
----------+------------------------+-------------------------------------
id | integer | not null default
| | nextval('people_id_seq'::regclass)
| |
name | character varying(50) |
address | character varying(200) | not null
phone_no | character varying |
Indexes:
"people_pkey" PRIMARY KEY, btree (id)
"person_name_idx" btree (name)
15.1.11. シーケンス
シーケンスは、一意の番号ジェネレータです。通常、テーブル内の列の一意の識別子を作成するために使用されます。
この例では、IDはシーケンスで、その数はレコードがテーブルに追加されるたびに1つ増えます:
id | name | address | phone_no
---+--------------+-----------------------------+-------------
1 | Tim Sutton | 3 Buirski Plein, Swellendam | 071 123 123
2 | Horst Duster | 4 Avenue du Roix, Geneva | 072 121 122
15.1.12. エンティティ・リレーションシップ図の作成
正規化されたデータベースでは、通常、多くのリレーション(テーブル)があります。エンティティ・リレーションシップ図(ER図)は、そのリレーションの間の論理依存関係を設計するために使用されます。レッスン前半の正規化されていない people テーブルを考えてみましょう:
select * from people;
id | name | address | phone_no
----+--------------+-----------------------------+-------------
1 | Tim Sutton | 3 Buirski Plein, Swellendam | 071 123 123
2 | Horst Duster | 4 Avenue du Roix, Geneva | 072 121 122
(2 rows)
ちょっとした作業で2つのテーブルに分割でき、同じ通りに住む人のために通りの名前を繰り返す必要がなくなります:
select * from streets;
id | name
----+--------------
1 | Plein Street
(1 row)
および:
select * from people;
id | name | house_no | street_id | phone_no
----+--------------+----------+-----------+-------------
1 | Horst Duster | 4 | 1 | 072 121 122
(1 row)
その後、「キー」 streets.id と people.streets_id を使用して2つのテーブルをリンクできます。
この2つのテーブルのためのER図を描く場合は、次のようになります。

ER図は、関係「一対多」を表現する助けになります。この場合、矢印記号は、1つの通りに対して住んでいる人々は何人もいることがあると示しています。
Try Yourself 
この people モデルにはまだいくつかの正規化の問題があります - さらに正規化して、ER図を用いて自分の考えを示すことができるかどうか確認してみてください。
答え
people テーブルは今このように見えます:
id | name | house_no | street_id | phone_no
---+--------------+----------+-----------+-------------
1 | Horst Duster | 4 | 1 | 072 121 122
street_id 列は、人オブジェクトと、streets テーブルにある関係した通りオブジェクトの間の「一対多」の関係を表しています。
テーブルをさらに正規化する方法のひとつは、名前フィールドを first_name と last_name に分割することです:
id | first_name | last_name | house_no | street_id | phone_no
---+------------+------------+----------+-----------+------------
1 | Horst | Duster | 4 | 1 | 072 121 122
また町か市の名称と国で別々のテーブルを作り、「一対多」関係で people テーブルとリンクすることもできます:
id | first_name | last_name | house_no | street_id | town_id | country_id
---+------------+-----------+----------+-----------+---------+------------
1 | Horst | Duster | 4 | 1 | 2 | 1
これを表すER図は次のようになるでしょう:
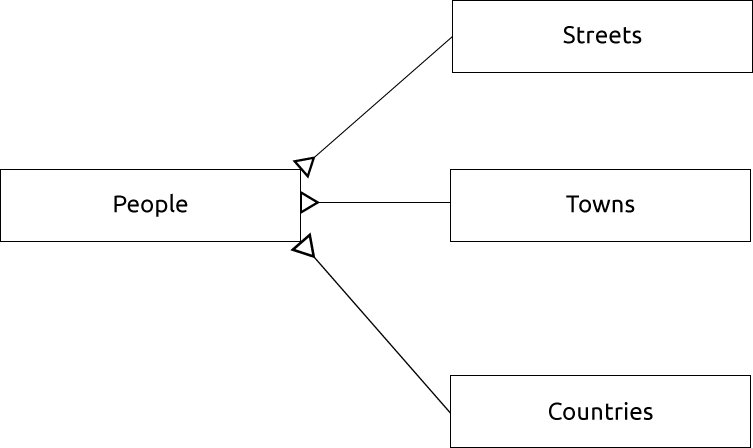
15.1.13. 制約、主キーと外部キー
リレーション内のデータがモデラーのデータの格納方法と一致するように、データベースの制約が使用されます。たとえば、郵便番号の制約により、数字が 1000 と 9999 の間に入ることが保証されます。
主キーは、レコードを一意にする1つ以上のフィールドの値です。通常、主キーはidというシーケンスです。
外部キーは、(他のテーブルの主キーを使用して)別のテーブルに一意のレコードを参照するために使用されます。
ER図では、テーブル間の結合は、通常、主キーにリンクする外部キーに基づいています。
ここでのpeopleの例を見てみると、テーブルの定義によれば、street列はstreetsテーブルの主キーを参照する外部キーです:
Table "public.people"
Column | Type | Modifiers
-----------+-----------------------+--------------------------------------
id | integer | not null default
| | nextval('people_id_seq'::regclass)
name | character varying(50) |
house_no | integer | not null
street_id | integer | not null
phone_no | character varying |
Indexes:
"people_pkey" PRIMARY KEY, btree (id)
Foreign-key constraints:
"people_street_id_fkey" FOREIGN KEY (street_id) REFERENCES streets(id)
15.1.14. トランザクション
データベース内のデータを追加、変更、または削除するときは、何か問題が生じた場合にデータベースを良好な状態に保つことが常に重要です。ほとんどのデータベースは、トランザクションサポートと呼ばれる機能を提供します。トランザクションを使用すると、データベースへの変更が計画通りに実行されなかった場合に戻ることができるロールバック位置を作成できます。
会計システムを持っているというシナリオを取ります。1つの口座から資金を転送し、他にそれらを追加する必要があります。一連のステップは次のように進むでしょう。
JoeからR20を削除
AnneをR20に追加
処理の間に何か問題(例えば停電)が発生した場合、トランザクションはロールバックされます。
15.1.15. In Conclusion
データベースを使用すると、簡単なコードの構造を使用して構造化された方法でデータを管理できます。
15.1.16. What's Next?
これでデータベースが理論的にどのように動作するか見てしまいましたので、カバーしてきた理論を実装する新しいデータベースを作成してみましょう。