6.4. Lesson: Statistiche spaziali
Nota
Lezione sviluppata da Linfiniti e S Motala (Cape Peninsula University of Technology)
Le statistiche spaziali permettono di comprendere cosa sta succedendo in un determinato insieme di dati vettoriali. QGIS include molti strumenti utili per l’analisi statistica.
Scopo della lezione: Comprendere come utilizzare gli strumenti QGIS in Strumenti di Processing per le statistiche spaziali.
6.4.1.  Follow Along: Creare un insieme di dati per il test
Follow Along: Creare un insieme di dati per il test
Creeremo un insieme di punti casuali, per avere un dataset con cui lavorare
Per questo, è necessario un insieme poligonale per definire l’area in cui creare i punti.
Useremo l’area coperta da strade.
Inizia un nuovo progetto
Aggiungi il dataset
roads, così comesrtm_41_19(dati di altitudine) che si trova inexercise_data/raster/SRTM/.Nota
Potresti trovare che il layer SRTM DEM ha un diverso SR da quello del layer roads. QGIS riproietta entrambi i layer in un singolo SR. Per il seguente esercizio questa differenza non ha importanza, sei libero di riproiettarli (come mostrato in questo modulo).
Apri gli strumenti di Processing
Usa lo strumento per generare un’area che racchiuda tutte le strade selezionando
Poligono Convessoin the Tipo di geometria: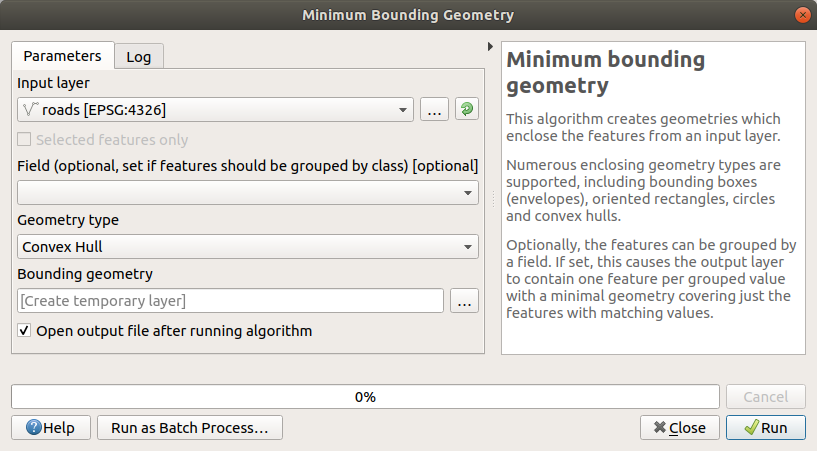
Come sai, se non specifici l’uscita, Processing crea un layer temporaneo. Sta a te salvare subito il layer o più tardi.
Creare punti casuali
Creeremo 100 punti casuali in questa area utilizzando lo strumento , con una distanza minima di
0.0: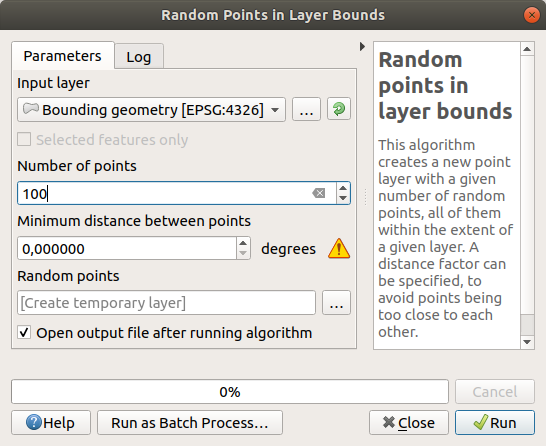
Nota
Il segno di avviso giallo segnala che il parametro riguarda le distanze. Il layer Bounding geometry è in un sistema di coordinate geografiche e l’algoritmo te lo sta ricordando. Per questo esempio non useremo questo parametro perciò può essere ignorato.
Se necessario, muovi i punti generati casualmente in coma alla legenda per vederli meglio:
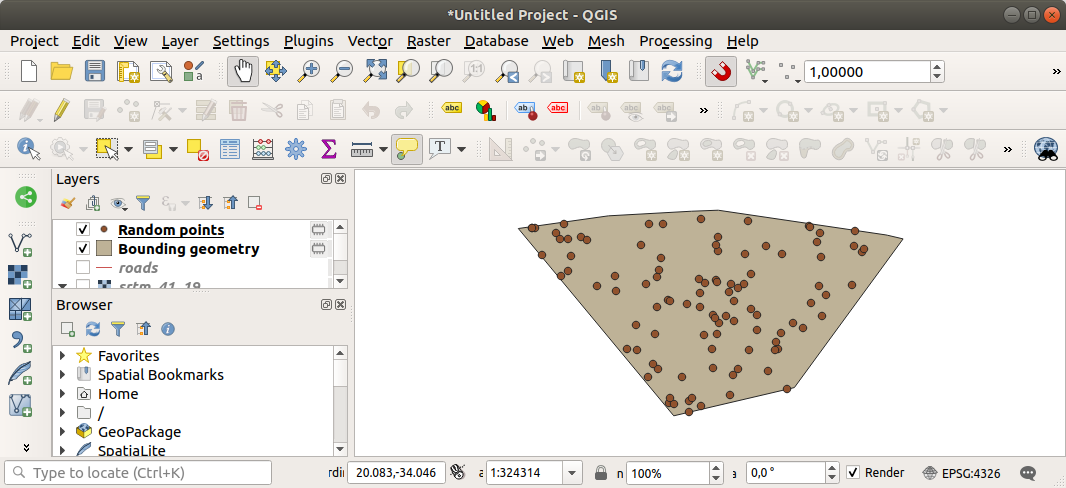
Campionamento dei dati
Per creare un insieme di dati di esempio dal raster, avrai bisogno dell’algoritmo . Questo strumento campiona il raster nelle locazioni dei punti e aggiunge i valori raster in nuovi campi in base al numero di bande nel raster.
Apri la finestra di dialogo dell’algoritmo Campiona valori raster
Seleziona
Punti casualicome layer contenente i punti da campionare, e il raster SRTM come banda da cui prendere i valori. Il nome predefinito per il nuovo campo èrvalue_N, doveNè il numero della banda raster. Se vuoi puoi cambiare il nome del prefisso.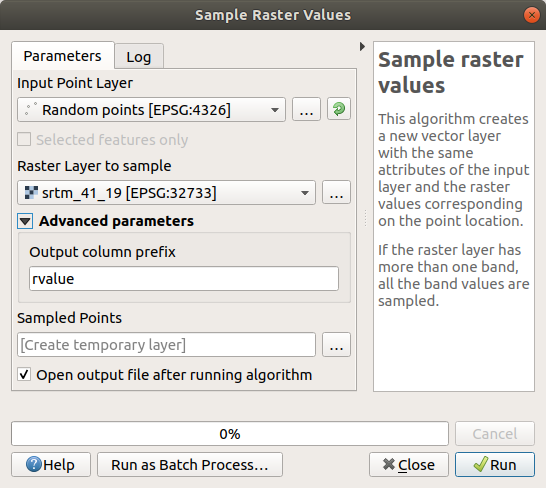
Premi Esegui
Ora puoi controllare i dati campionati dal file raster nella tabella degli attributi del layer Punti Campionati. Saranno in un nuovo campo con il nome che hai scelto.
Un possibile layer campionato è mostrato qui:
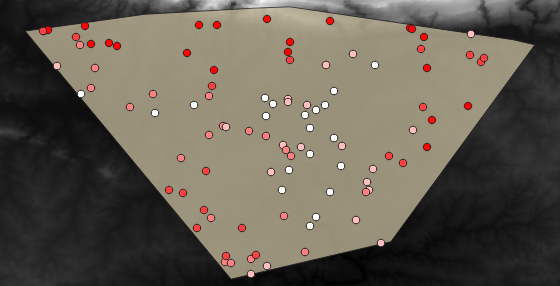
I punti campionati sono classificati usando il campo rvalue_1 così che i punti rossi sono ad un’altitudine maggiore.
Useremo questo layer di esempio per il resto degli esercizi statistici.
6.4.2. Follow Along: Statistiche elementari
Ora vediamo le statistiche elementari per questo layer
Clicca sull’icona
 Mostra sintesi delle statistiche nella Barra degli strumenti attributi. Apparirà un nuovo pannello.
Mostra sintesi delle statistiche nella Barra degli strumenti attributi. Apparirà un nuovo pannello.Nel dialogo che apparirà, indica il layer
Punti Campionaticome sorgente.Seleziona il campo
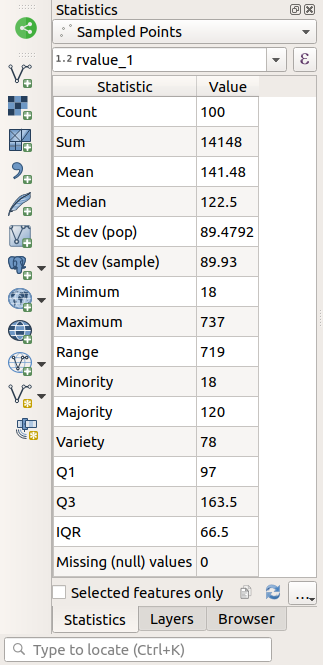
rvalue_1nella lista a comparsa dei campi. Questo è il campo per cui calcoleremo le statistiche.Il pannello Statistiche si aggiornerà automaticamente con le statistiche calcolate:
Nota
Puoi copiare i valori cliccando sul pulsante
 Copia Statistiche negli Appunti ed incollare i risultati in un foglio di calcolo.
Copia Statistiche negli Appunti ed incollare i risultati in un foglio di calcolo.Quando hai fatto chiudi il pannello Statistiche
Sono disponibili molte statistiche:
- Conteggio
Il numero di campioni/valori.
- Somma
I valori sommati assieme.
- Media
Il valore medio (media) è la somma dei valori diviso per il numero di valori.
- Mediana
Se si ordinano tutti i valori dal più piccolo al più grande, il valore in mezzo (o la media dei due valori in mezzo, se N è un numero pari) è la mediana dei valori.
- Deviazione standard (popolazione)
La deviazione standard. Dà una indicazione di quanto vicino alla media sono raggruppati i valori. Più piccola è la deviazione standard, più i valori tendono ad essere vicini alla media.
- Minimo
Il valore minimo.
- Massimo
Il valore massimo.
- Intervallo
La differenza fra i valori minimo e massimo.
- Q1
Primo quartile dei dati.
- Q3
Terzo quartile dei dati.
- Valori mancanti (nulli)
Il numero di valori mancanti.
6.4.3. Follow Along: Calcolo di statistiche sulle distanze fra i punti
Crea un nuovo layer puntuale temporaneo.
Entra in modalità modifica, e digitalizza tre punti in mezzo agli altri punti.
Alternativamente, usa il metodo di generazione casuale dei punti visto precedentemente, ma specifica solo tre punti.
Salva il nuovo layer come distance_points nel formato che preferisci.
Per creare statistiche sulla distanza fra i punti nei due layer:
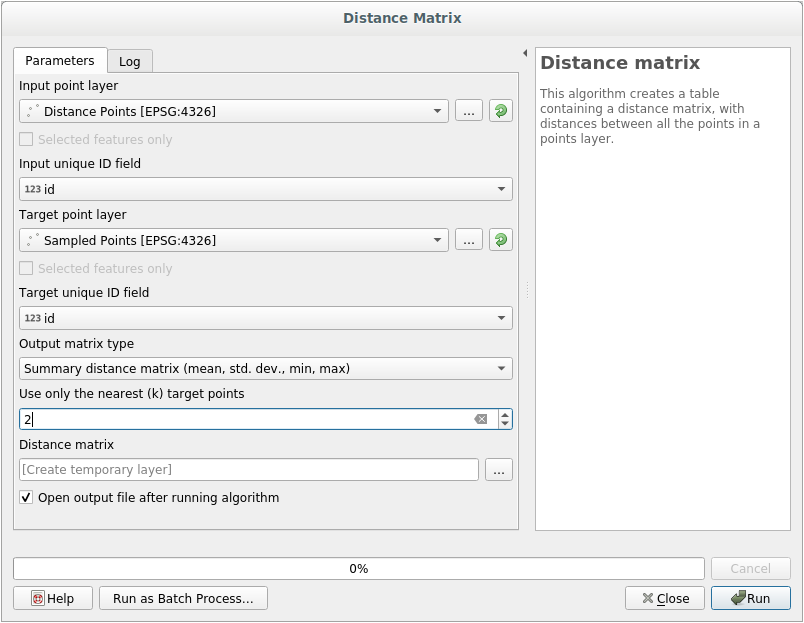
Apri lo strumento .
Seleziona il layer
distance_pointscome layer di ingresso, e il layerPunti Campionaticome layer di uscita.Impostalo come questo:
Sei vuoi puoi salvare il layer di uscita come un file oppure esegui l’algoritmo e salva il layer di uscita temporaneo più tardi.
Clicca su Esegui per generare il layer matrice delle distanze
Apri la tabella degli attributi del layer generato: i valori si riferiscono alle distanze fra gli elementi distance_points ed i loro due punti più vicini nel layer Punti Campionati:
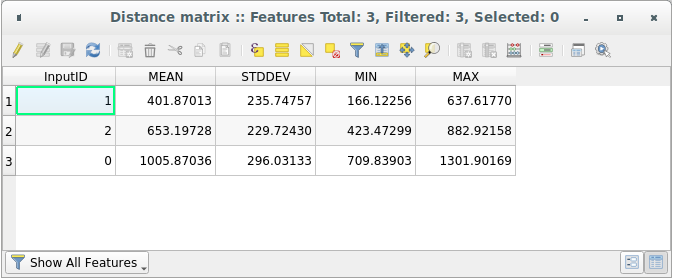
Con questi parametri, lo strumento Matrice di distanza calcola statistiche di distanza per ogni punto del layer di ingresso rispetto ai punti più vicini del layer destinazione. I campi del layer di uscita contengono la media, la deviazione standard, il minimo e massimo per le distanze dai punti più prossimi ai punti del layer di ingresso.
6.4.4. Follow Along: Analisi dei vicini più prossimi (all’interno del layer)
Per analizzare il vicino più prossimi in un layer puntuale:
Scegli .
Nel dialogo che appare, seleziona il layer Punti casuali e clicca Esegui.
I risultati appariranno nel pannello Visualizzatore risultati di Processing.
Clicca sul collegamento in blu per aprire la pagina
htmlcon i risultati: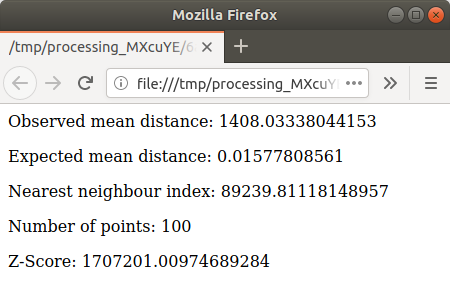
6.4.5. Follow Along: Media coordiante
Per avere la media delle coordinate di un insieme di dati:
Scegli
Nel dialogo che appare, come Layer in ingresso seleziona Punti casuali, e lascia le altre opzioni invariate.
Clicca su Esegui.
Confrontiamo il risultato con le coordinate centrali del poligono usato per creare punti casuali.
Scegli
Nel dialogo che appare, seleziona
Bounding geometrycome layer di ingresso.
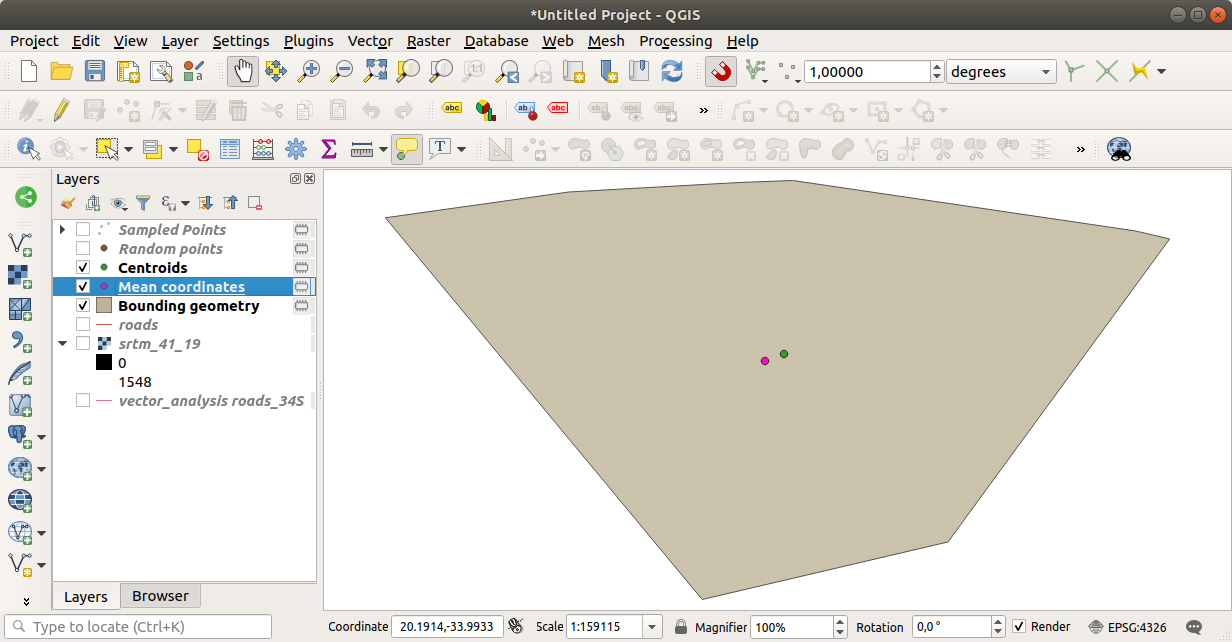
Come puoi vedere, la media coordinate (punto rosa) ed il centro dell’area di studio (in verde) non necessariamente coincidono.
Il centroide è il baricentro del layer (il baricentro di un quadrato è il centro del quadrato) mentre la media delle coordinate rappresenta la media delle coordinate di tutti i nodi.
6.4.6. Follow Along: Istogrammi
L’istogramma di un insieme di dati mostra la distribuzione dei suoi valori. Il modo migliore per dimostrarlo in QGIS è tramite l’istogramma immagine, disponibile nel dialogo Proprietà Layer di qualunque layer immagine (dati raster).
Nel pannello Layer, clicca col tasto destro sul layer
srtm_41_19Seleziona
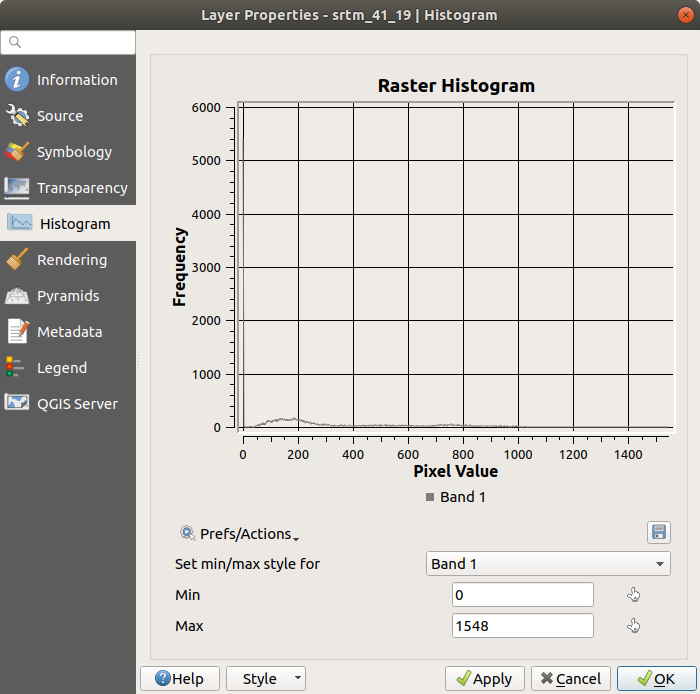
Scegli la scheda Istogramma. Clicca sul pulsante Calcola l’istogramma per generare il grafico. Dovresti vedere un grafico che mostra la distribuzione di frequenza per i valori raster.
Il grafico può essere esportato come immagine con il pulsante
 Salava la stampa
Salava la stampaPuoi vedere informazioni più dettagliate sul layer nella scheda Informazioni (i valori medio e massimo sono stimati, potrebbero non essere esatti).
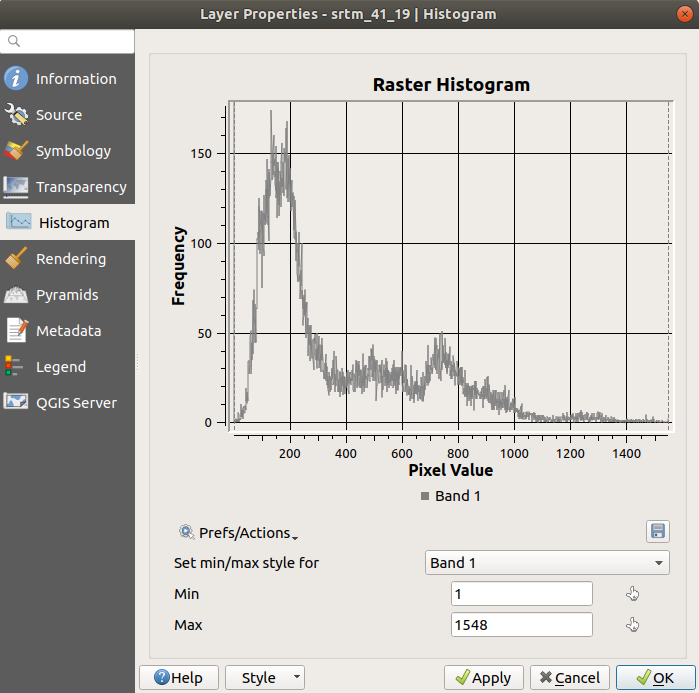
Il valore medio è 332.8 (stimato in 324.3), ed il valore massimo è 1699 (stimato in 1548)! Puoi ingrandire l’istogramma. Dato che ci sono molti punti con valore 0, l’istogramma appare compresso verticalmente. Ingrandendo coprendo tutto tranne il picco a 0, si vedranno maggiori dettagli:
Nota
Se i valori medio e massimo non sono gli stessi come sopra, può dipendere dal calcolo del valore min/max. Apri la scheda Simbologia ed espandi il menu Impostazioni dei valori di Min e Max. Scegli  Min / max e clicca su Applica.
Min / max e clicca su Applica.
Tieni a mente che un istogramma mostra la distribuzione dei valori, e non tutti i valori sono necessariamente visibili sul grafico.
6.4.7. Follow Along: Interpolazione spaziale
Mettiamo di avere un insieme di punti campione da cui vogliamo estrapolare dei dati. Per esempio, potresti aver accesso all’insieme Punti campionati creato in precedenza, e vorremmo avere qualche idea di come appare il terreno.
Per iniziare, esegui lo strumento in Strumenti di Processing.
Seleziona
Punti campionatiper Point layerImposta Weighting power a
5.0In Advanced parameters, imposta Z value from field a
rvalue_1Infine clicca su Esegui ed attendi la fine dell’elaborazione
Chiudi il dialogo
Qui trovi un confronto fra l’insieme originale (a sinistra) e quello costruito dai nostri punti campionati (a destra). Il tuo potrà apparire diverso data la natura casuale dei punti campionati.
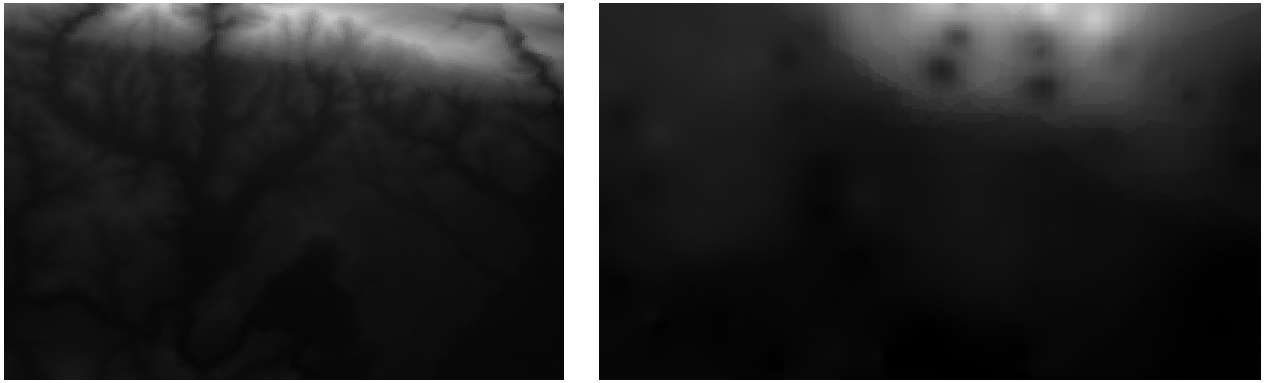
Come puoi vedere, 100 punti non sono abbastanza per avere un’idea dettagliata del terreno. Dà un’idea molto generica, può essere anche fuorviante.
6.4.8.  Try Yourself Metodi diversi di interpolazione
Try Yourself Metodi diversi di interpolazione
Usa i procedimenti visti in precedenza per creare un insieme di 10 000 punti casuali
Nota
Se il numero di punti è grande, il tempo di calcolo può essere lungo.
Usa questi punti per campionare il DEM originale
Usa lo strumento Grid (IDW with nearest neighbor searching) su questo insieme di dati.
Imposta Power e Smoothing a
5.0e2.0, rispettivamente.
I risultati (dipendentemente dalla posizione dei tuoi punti casuali) apparirà più o meno come questo:

Questa è una rappresentazione migliore del terreno, grazie alla maggiore densità dei punti campione. Ricorda, più sono i campioni migliori sono i risultati.
6.4.9. In Conclusion
QGIS ha numerosi strumenti per l’analisi delle proprietà statistiche spaziali degli insiemi di dati.
6.4.10. What’s Next?
Ora che abbiamo visto l’analisi vettoriale, perché non vedere cosa può essere fatto con i raster? È quello che faremo nel prossimo modulo!