6.4. Lesson: Estadísticas Espaciales
Nota
Lección desarrollada por Linfiniti y S Motala (Universidad Tecnológica de Península del Cabo)
A estatística espacial permite analisar e entender o que está acontecendo em um determinado conjunto de dados vetoriais. O QGIS inclui muitas ferramentas úteis para análise estatística.
The goal for this lesson: To know how to use QGIS’ spatial statistics tools within the Processing Toolbox.
6.4.1.  Follow Along: Crear un Conjunto de Datos de Prueba
Follow Along: Crear un Conjunto de Datos de Prueba
Criaremos um conjunto aleatório de pontos, para obter um conjunto de dados com os quais trabalhar.
Para isso, você precisará de um conjunto de dados poligonais para definir a área em que deseja criar os pontos.
Utilizaremos a área coberta pelas ruas.
Iniciar um novo projeto
Add your
roadsdataset, as well assrtm_41_19(elevation data) found inexercise_data/raster/SRTM/.Nota
You might find that the SRTM DEM layer has a different CRS to that of the roads layer. QGIS is reprojecting both layers in a single CRS. For the following exercises this difference does not matter, but feel free to reproject (as shown earlier in this module).
Open Processing toolbox
Use the tool to generate an area enclosing all the roads by selecting
Convex Hullas the Geometry Type: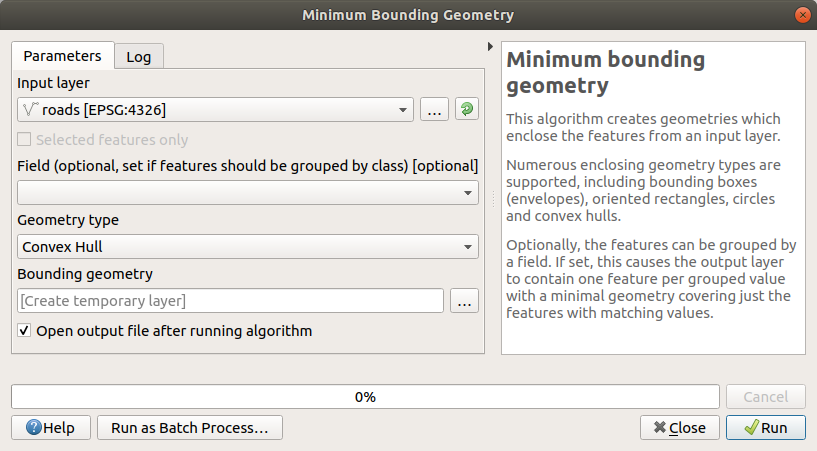
As you know, if you don’t specify the output, Processing creates temporary layers. It is up to you to save the layers immediately or at a later stage.
Creación de puntos al azar
Create 100 random points in this area using the tool at , with a minimum distance of
0.0: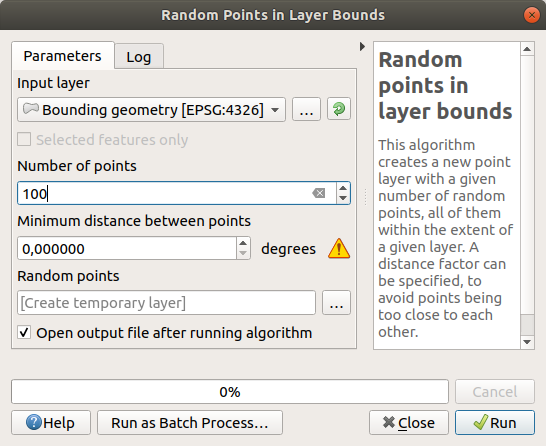
Nota
The yellow warning sign tells you that that parameter concerns distances. The Bounding geometry layer is in a Geographical Coordinate System and the algorithm is just reminding you this. For this example we won’t use this parameter so you can ignore it.
If needed, move the generated random point to the top of the legend to see them better:
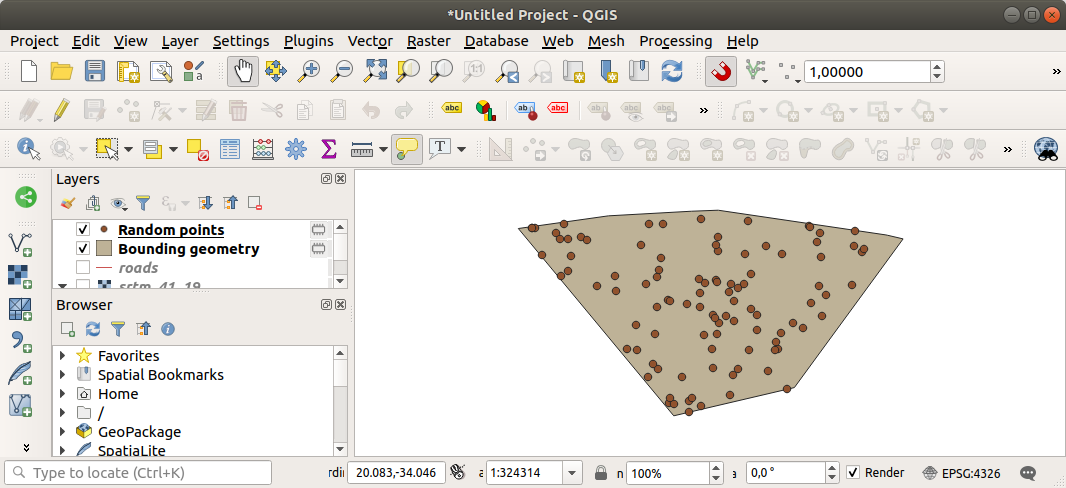
Muestreo de los datos
To create a sample dataset from the raster, you’ll need to use the algorithm. This tool samples the raster at the locations of the points and adds the raster values in new field(s) depending on the number of bands in the raster.
Abra a caixa de diálogo do algoritmo Amostrar valores do raster
Select
Random_pointsas the layer containing sampling points, and the SRTM raster as the band to get values from. The default name of the new field isrvalue_N, whereNis the number of the raster band. You can change the name of the prefix if you want.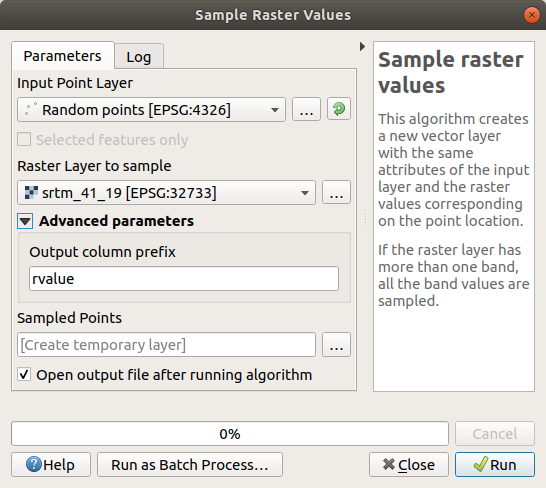
Pressione Executar
Agora você pode verificar os dados amostrados do arquivo raster na tabela de atributos da camada Pontos Amostrados. Eles estarão em um novo campo com o nome que você escolheu.
Aquí tienes una posible capa de muestreo:
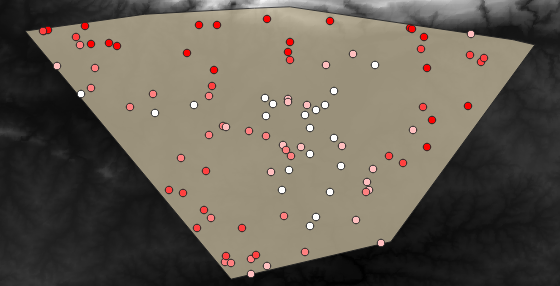
The sample points are classified using the rvalue_1 field such
that red points are at a higher altitude.
Você usará essa camada de exemplo para o restante dos exercícios estatísticos.
6.4.2. Follow Along: Estadísticas Básicas
Ahora obtén lsa estadísticas básica de esta capa.
Click on the
 Show statistical summary icon in the
Attributes Toolbar.
A new panel will pop up.
Show statistical summary icon in the
Attributes Toolbar.
A new panel will pop up.Na caixa de diálogo que aparece, especifique a camada
Pontos amostradoscomo fonte.Select the rvalue_1 field in the field combo box. This is the field you will calculate statistics for.
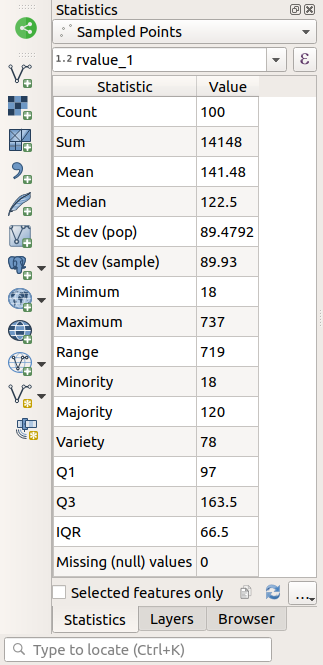
O painel Estatísticas será atualizado automaticamente com as estatísticas calculadas:
Nota
You can copy the values by clicking on the
 Copy Statistics To Clipboard button and paste the results
into a spreadsheet.
Copy Statistics To Clipboard button and paste the results
into a spreadsheet.Fechar o painel Estatística quando terminado
Muitas estatísticas diferentes estão disponíveis:
- Contagem
O número de amostras/valores.
- Suma
Os valores somados.
- Media
O valor médio (média) é simplesmente a soma dos valores dividido pelo número de valores.
- Mediana
Se você organizar todos os valores do menor para o maior, o valor do meio (ou a média dos dois valores do meio, se N for um número par) será a mediana dos valores.
- St Dev (pop)
La desviación estándar. Da una indicación de cómo de cerca se agrupan los valores alrededor de la media. Cuanto menor sea la desviación estándar, más cerca estarán los valores a la media.
- Mĩnimo
El valor mínimo
- Máximo
El valor máximo.
- Intervalo
La diferencia entre los valores mínimo y máximo.
- Q1
Primeiro quartil dos dados
- Q3
Terceiro quartil dos dados
- Missing (null) values
O número de valores ausentes.
6.4.3. Follow Along: Compute statistics on distances between points
Criar uma nova camada de ponto temporária.
Entrar no modo de edição e digitalizar três pontos em algum lugar entre os outros pontos.
Como alternativa, use o mesmo método de geração de pontos aleatórios de antes, mas especifique apenas três pontos.
Salve sua nova camada como distance_points no formato que você preferir.
Para gerar estatísticas sobre as distâncias entre pontos nas duas camadas:
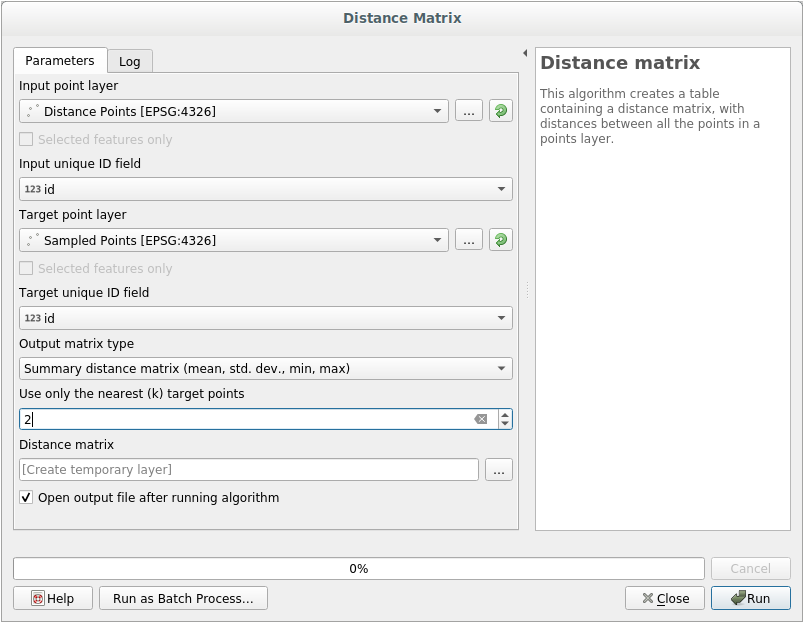
Open the tool.
Select the
distance_pointslayer as the input layer, and theSampled Pointslayer as the target layer.Ajústalo así:
Se você quiser, pode salvar a camada de saída como um arquivo ou apenas executar o algoritmo e salvar a camada de saída temporária mais tarde.
Clique em Executar para gerar a camada da matriz de distância.
Abra a tabela de atributos da camada gerada: valores referem-se às distâncias entre as feições distance_points e seus dois pontos mais próximos na camada Pontos de amostra
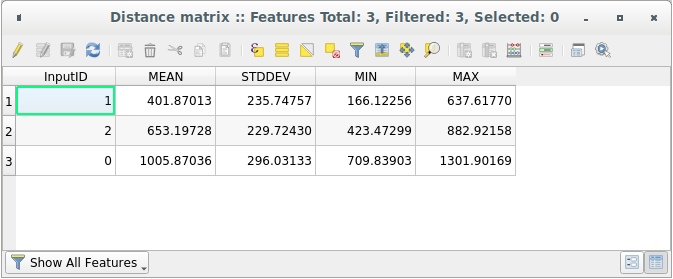
With these parameters, the Distance Matrix tool calculates distance statistics for each point of the input layer with respect to the nearest points of the target layer. The fields of the output layer contain the mean, standard deviation, minimum and maximum for the distances to the nearest neighbors of the points in the input layer.
6.4.4. Follow Along: Análise de Vizinhos mais Próximos (dentro da camada)
Para fazer uma análise de vizinho mais próximo de uma camada de pontos:
Choose .
Na caixa de diálogo exibida, selecione a camada Pontos aleatórios e clique em Executar.
The results will appear in the Processing Result Viewer Panel.
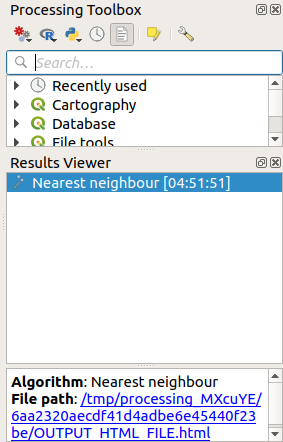
Clique no link azul para abrir a página
htmlcom os resultados: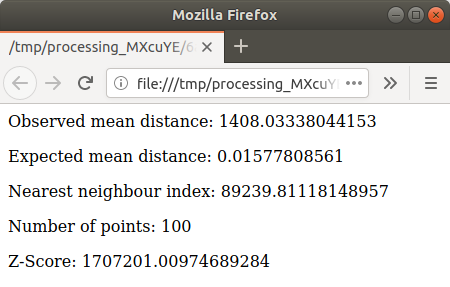
6.4.5. Follow Along: Coordenadas Medias
Para obtener las coordenadas medias de un conjunto de datos:
Start
In the dialog that appears, specify Random points as Input layer, and leave the optional choices unchanged.
Haz clic en Run.
Vamos comparar isto com a coordenada central do polígono que foi usada para criar a amostra aleatória.
Início
Na caixa de diálogo que aparece, selecione
Geometria envolventecomo a camada de entrada.
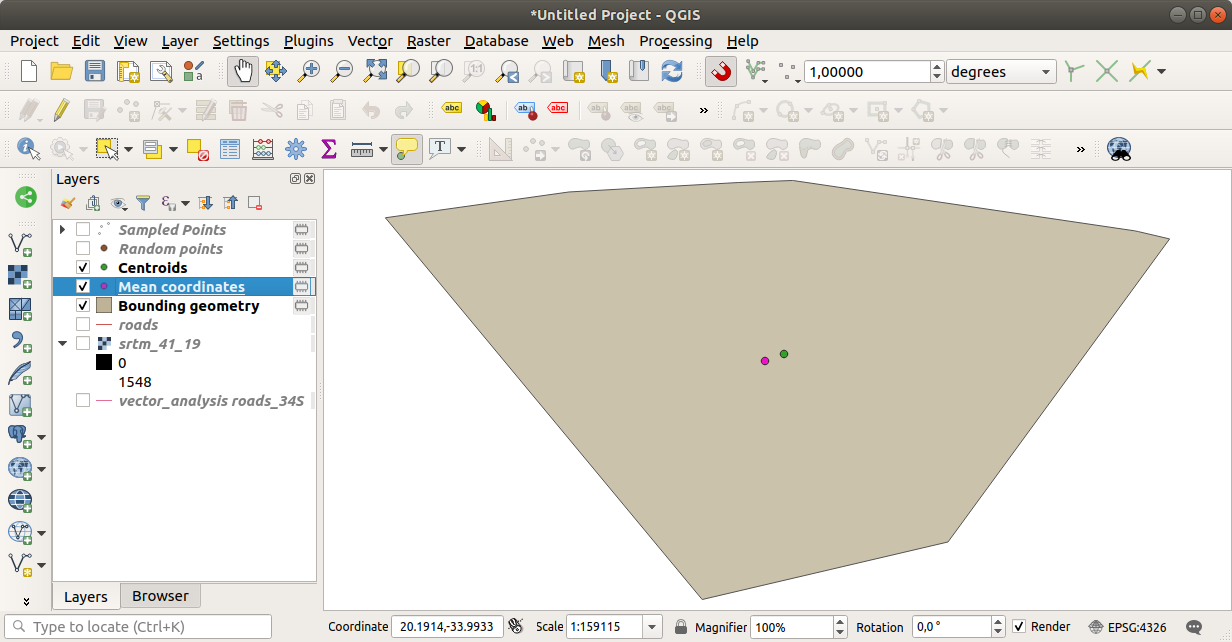
Como você pode ver, as coordenadas médias (ponto rosa) e o centro da área de estudo (em verde) não necessariamente coincidem.
O centróide é o baricentro da camada (o baricentro de um quadrado é o centro do quadrado) enquanto as coordenadas médias representam a média de todas as coordenadas dos nós.
6.4.6. Follow Along: Histogramas de Imagenes
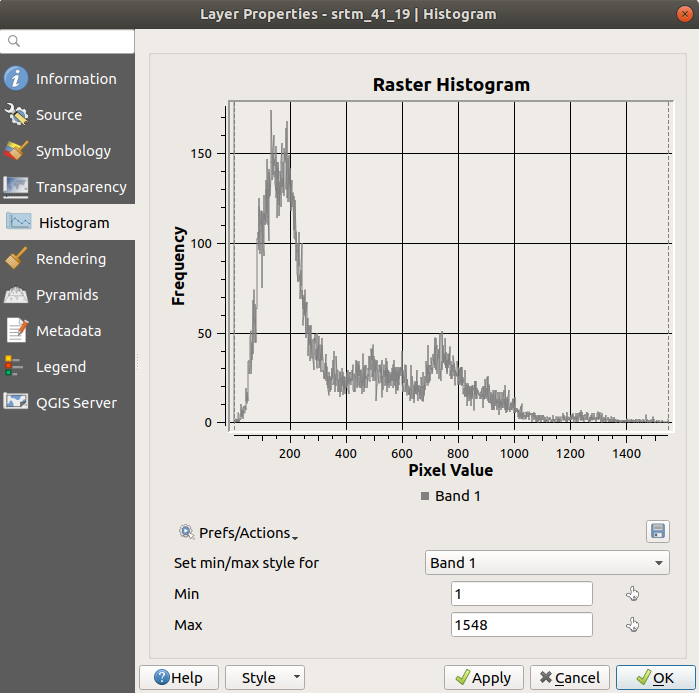
O histograma de um conjunto de dados mostra a distribuição de seus valores. A maneira mais simples de demonstrar isso no QGIS é através do histograma da imagem, disponível na caixa de diálogo Propriedades da Camada de qualquer camada da imagem (conjunto de dados raster).
In your Layers panel, right-click on the
srtm_41_19layerSelecione
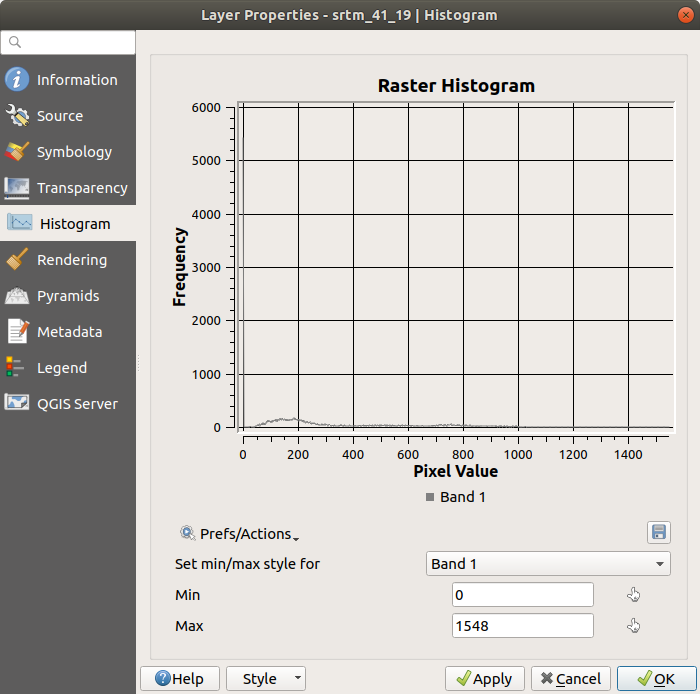
Choose the Histogram tab. You may need to click on the Compute Histogram button to generate the graphic. You will see a graph that shows the frequency distribution for the raster values.
The graph can be exported as an image with the
 Save plot button
Save plot buttonYou can see more detailed information about the layer in the Information tab (the mean and max values are estimated, and may not be exact).
The mean value is 332.8 (estimated to 324.3), and the maximum
value is 1699 (estimated to 1548)!
You can zoom in the histogram.
Since there are a lot of pixels with value 0, the histogram looks
compressed vertically.
By zooming in to cover everything but the peak at 0, you will see
more details:
Nota
If the mean and maximum values are not the same as above, it
can be due to the min/max value calculation.
Open the Symbology tab and expand the
Min / Max Value Settings menu.
Choose  Min / max and click on
Apply.
Min / max and click on
Apply.
Tenha em mente que um histograma mostra a distribuição de valores, e nem todos os valores são necessariamente visíveis no gráfico.
6.4.7. Follow Along: Interpolación Espacial
Let’s say you have a collection of sample points from which you would like to extrapolate data. For example, you might have access to the Sampled points dataset we created earlier, and would like to have some idea of what the terrain looks like.
To start, launch the tool in the Processing Toolbox.
For Point layer select
Sampled pointsSet Weighting power to
5.0In Advanced parameters, set Z value from field to
rvalue_1Finalmente clique em :guilabel:`Executar’ e aguarde até que o processamento termine
Feche a caixa de diãlogo
Here is a comparison of the original dataset (left) to the one constructed from our sample points (right). Yours may look different due to the random nature of the location of the sample points.
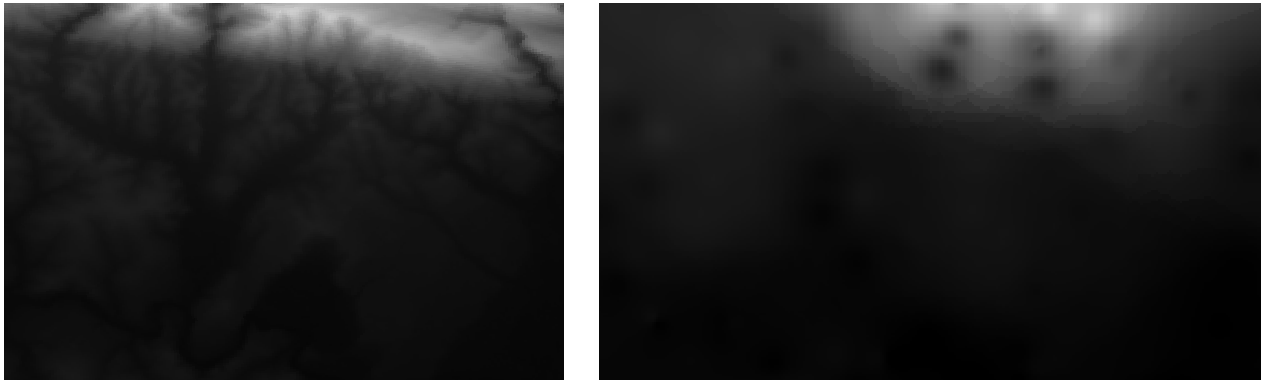
Como você pode ver, 100 pontos de amostra não são suficientes para obter uma impressão detalhada do terreno. Dá uma ideia muito geral, mas também pode ser enganosa.
6.4.8.  Try Yourself Mẽtodos de interpolação diferentes
Try Yourself Mẽtodos de interpolação diferentes
Use os processos mostrados acima para criar um conjunto de 10.000 pontos aleatórios
Nota
Se o número de pontos for muito grande, o tempo de processamento pode demorar muito.
Use estes pontos para amostrar o MDE original
Use the Grid (IDW with nearest neighbor searching) tool on this dataset.
Set Power and Smoothing to
5.0and2.0, respectively.
Los resultados (dependiendo de la posición de tus puntos aleatorios) se verán más o menos como esto:

This is a better representation of the terrain, due to the greater density of sample points. Remember, larger samples give better results.
6.4.9. In Conclusion
QGIS has a number of tools for analyzing the spatial statistical properties of datasets.
6.4.10. What’s Next?
Agora que abordamos a análise vetorial, por que não ver o que pode ser feito com rasters? É isso que faremos no próximo módulo!