25.1.21. Vector table
25.1.21.1. Add autoincremental field
Adds a new integer field to a vector layer, with a sequential value for each feature.
This field can be used as a unique ID for features in the layer. The new attribute is not added to the input layer but a new layer is generated instead.
The initial starting value for the incremental series can be specified. Optionally, the incremental series can be based on grouping fields and a sort order for features can also be specified.
Parameters
Label |
Név |
Type |
Leírás |
|---|---|---|---|
Input layer |
|
[vector: any] |
The input vector layer. |
Field name |
|
[string] Default: «AUTO» |
Name of the field with autoincremental values |
Start values at Optional |
|
[number] Default: 0 |
Choose the initial number of the incremental count |
Modulus value Optional |
|
[number] Default: 0 |
Specifying an optional modulus value will restart the count to START
whenever the field value reaches the modulus value. |
Group values by Optional |
|
[tablefield: any] [list] |
Select grouping field(s): instead of a single count run for the whole layer, a separate count is processed for each value returned by the combination of these fields. |
Sort expression Optional |
|
[expression] |
Use an expression to sort the features in the layer either globally or if set, based on group fields. |
Sort ascending |
|
[boolean] Default: True |
When a |
Sort nulls first |
|
[boolean] Default: False |
When a |
Incremented |
|
[same as input] Default: |
Specify the output vector layer with the auto increment field. One of:
The file encoding can also be changed here. |
Outputs
Label |
Név |
Type |
Leírás |
|---|---|---|---|
Incremented |
|
[same as input] |
Vector layer with auto incremental field |
Python code
Algorithm ID: native:addautoincrementalfield
import processing
processing.run("algorithm_id", {parameter_dictionary})
The algorithm id is displayed when you hover over the algorithm in the Processing Toolbox. The parameter dictionary provides the parameter NAMEs and values. See Using processing algorithms from the console for details on how to run processing algorithms from the Python console.
25.1.21.2. Add field to attributes table
Adds a new field to a vector layer.
The name and characteristics of the attribute are defined as parameters.
The new attribute is not added to the input layer but a new layer is generated instead.
Parameters
Label |
Név |
Type |
Leírás |
|---|---|---|---|
Input layer |
|
[vector: any] |
The input layer |
Field name |
|
[string] |
Name of the new field |
Field type |
|
[enumeration] Default: 0 |
Type of the new field. You can choose between:
|
Field length |
|
[number] Default: 10 |
Length of the field |
Field precision |
|
[number] Default: 0 |
Precision of the field. Useful with Float field type. |
Added |
|
[same as input] Default: |
Specify the output vector layer. One of:
The file encoding can also be changed here. |
Outputs
Label |
Név |
Type |
Leírás |
|---|---|---|---|
Added |
|
[same as input] |
Vector layer with new field added |
Python code
Algorithm ID: native:addfieldtoattributestable
import processing
processing.run("algorithm_id", {parameter_dictionary})
The algorithm id is displayed when you hover over the algorithm in the Processing Toolbox. The parameter dictionary provides the parameter NAMEs and values. See Using processing algorithms from the console for details on how to run processing algorithms from the Python console.
25.1.21.3. Add unique value index field
Takes a vector layer and an attribute and adds a new numeric field.
Values in this field correspond to values in the specified attribute, so features with the same value for the attribute will have the same value in the new numeric field.
This creates a numeric equivalent of the specified attribute, which defines the same classes.
The new attribute is not added to the input layer but a new layer is generated instead.
Parameters
Label |
Név |
Type |
Leírás |
|---|---|---|---|
Input layer |
|
[vector: any] |
The input layer. |
Class field |
|
[tablefield: any] |
Features that have the same value for this field will get the same index. |
Output field name |
|
[string] Default: «NUM_FIELD» |
Name of the new field containing the indexes. |
Layer with index field |
|
[vector: any] Default: |
Vector layer with the numeric field containing indexes. One of:
The file encoding can also be changed here. |
Class summary |
|
[table] Default: |
Specify the table to contain the summary of the class field mapped to the corresponding unique value. One of:
The file encoding can also be changed here. |
Outputs
Label |
Név |
Type |
Leírás |
|---|---|---|---|
Layer with index field |
|
[same as input] |
Vector layer with the numeric field containing indexes. |
Class summary |
|
[table] |
Table with summary of the class field mapped to the corresponding unique value. |
Python code
Algorithm ID: native:adduniquevalueindexfield
import processing
processing.run("algorithm_id", {parameter_dictionary})
The algorithm id is displayed when you hover over the algorithm in the Processing Toolbox. The parameter dictionary provides the parameter NAMEs and values. See Using processing algorithms from the console for details on how to run processing algorithms from the Python console.
25.1.21.4. Add X/Y fields to layer
Adds X and Y (or latitude/longitude) fields to a point layer. The X/Y fields can be calculated in a different CRS to the layer (e.g. creating latitude/longitude fields for a layer in a projected CRS).
Parameters
Label |
Név |
Type |
Leírás |
|---|---|---|---|
Input layer |
|
[vector: point] |
The input layer. |
Coordinate system |
|
[crs] Default: „EPSG:4326” |
Coordinate reference system to use for the generated x and y fields. |
Field prefix Optional |
|
[string] |
Prefix to add to the new field names to avoid name collisions with fields in the input layer. |
Added fields |
|
[vector: point] Default: |
Specify the output layer. One of:
The file encoding can also be changed here. |
Outputs
Label |
Név |
Type |
Leírás |
|---|---|---|---|
Added fields |
|
[vector: point] |
The output layer - identical to the input layer but with two
new double fields, |
Python code
Algorithm ID: native:addxyfieldstolayer
import processing
processing.run("algorithm_id", {parameter_dictionary})
The algorithm id is displayed when you hover over the algorithm in the Processing Toolbox. The parameter dictionary provides the parameter NAMEs and values. See Using processing algorithms from the console for details on how to run processing algorithms from the Python console.
25.1.21.5. Advanced Python field calculator
Adds a new attribute to a vector layer, with values resulting from applying an expression to each feature.
The expression is defined as a Python function.
Parameters
Label |
Név |
Type |
Leírás |
|---|---|---|---|
Input layer |
|
[vector: any] |
Input vector layer |
Result field name |
|
[string] Default: «NewField» |
Name of the new field |
Field type |
|
[enumeration] Default: 0 |
Type of the new field. One of:
|
Field length |
|
[number] Default: 10 |
Length of the field |
Field precision |
|
[number] Default: 3 |
Precision of the field. Useful with Float field type. |
Global expression Optional |
|
[string] |
The code in the global expression section will be executed only once before the calculator starts iterating through all the features of the input layer. Therefore, this is the correct place to import necessary modules or to calculate variables that will be used in subsequent calculations. |
Formula |
|
[string] |
The Python formula to evaluate. Example: To calculate the area of an input polygon layer you can add: value = $geom.area()
|
Calculated |
|
[same as input] Default: |
Specify the vector layer with the new calculated field. One of:
The file encoding can also be changed here. |
Outputs
Label |
Név |
Type |
Leírás |
|---|---|---|---|
Calculated |
|
[same as input] |
Vector layer with the new calculated field |
Python code
Algorithm ID: qgis:advancedpythonfieldcalculator
import processing
processing.run("algorithm_id", {parameter_dictionary})
The algorithm id is displayed when you hover over the algorithm in the Processing Toolbox. The parameter dictionary provides the parameter NAMEs and values. See Using processing algorithms from the console for details on how to run processing algorithms from the Python console.
25.1.21.6. Drop field(s)
Takes a vector layer and generates a new one that has the same features but without the selected columns.
Lásd még
Parameters
Label |
Név |
Type |
Leírás |
|---|---|---|---|
Input layer |
|
[vector: any] |
Input vector layer to drop field(s) from |
Fields to drop |
|
[tablefield: any] [list] |
The field(s) to drop |
Remaining fields |
|
[same as input] Default: |
Specify the output vector layer with the remaining fields. One of:
The file encoding can also be changed here. |
Outputs
Label |
Név |
Type |
Leírás |
|---|---|---|---|
Remaining fields |
|
[same as input] |
Vector layer with the remaining fields |
Python code
Algorithm ID: native:deletecolumn
import processing
processing.run("algorithm_id", {parameter_dictionary})
The algorithm id is displayed when you hover over the algorithm in the Processing Toolbox. The parameter dictionary provides the parameter NAMEs and values. See Using processing algorithms from the console for details on how to run processing algorithms from the Python console.
25.1.21.7. Explode HStore Field
Creates a copy of the input layer and adds a new field for every unique key in the HStore field.
The expected field list is an optional comma separated list. If this list is specified, only these fields are added and the HStore field is updated. By default, all unique keys are added.
The PostgreSQL HStore
is a simple key-value store used in PostgreSQL and OGR (when reading
an
OSM file
with the other_tags field.
Parameters
Label |
Név |
Type |
Leírás |
|---|---|---|---|
Input layer |
|
[vector: any] |
Input vector layer |
HStore field |
|
[tablefield: any] |
The field(s) to drop |
Expected list of fields separated by a comma Optional |
|
[string] Default: «» |
Comma-separated list of fields to extract. The HStore field will be updated by removing these keys. |
Exploded |
|
[same as input] Default: |
Specify the output vector layer. One of:
The file encoding can also be changed here. |
Outputs
Label |
Név |
Type |
Leírás |
|---|---|---|---|
Exploded |
|
[same as input] |
Output vector layer |
Python code
Algorithm ID: native:explodehstorefield
import processing
processing.run("algorithm_id", {parameter_dictionary})
The algorithm id is displayed when you hover over the algorithm in the Processing Toolbox. The parameter dictionary provides the parameter NAMEs and values. See Using processing algorithms from the console for details on how to run processing algorithms from the Python console.
25.1.21.8. Extract binary field
Extracts contents from a binary field, saving them to individual files. Filenames can be generated using values taken from an attribute in the source table or based on a more complex expression.
Parameters
Label |
Név |
Type |
Leírás |
|---|---|---|---|
Input layer |
|
[vector: any] |
Input vector layer containing the binary data |
Binary field |
|
[tablefield: any] |
Field containing the binary data |
File name |
|
[expression] |
Field or expression-based text to name each output file |
Destination folder |
|
[folder] Default: |
Folder in which to store the output files. One of:
|
Outputs
Label |
Név |
Type |
Leírás |
|---|---|---|---|
Folder |
|
[folder] |
The folder that contains the output files. |
Python code
Algorithm ID: native:extractbinary
import processing
processing.run("algorithm_id", {parameter_dictionary})
The algorithm id is displayed when you hover over the algorithm in the Processing Toolbox. The parameter dictionary provides the parameter NAMEs and values. See Using processing algorithms from the console for details on how to run processing algorithms from the Python console.
25.1.21.9. Field calculator
Opens the field calculator (see Kifejezések). You can use all the supported expressions and functions.
A new layer is created with the result of the expression.
The field calculator is very useful when used in The graphical modeler.
Parameters
Label |
Név |
Type |
Leírás |
|---|---|---|---|
Input layer |
|
[vector: any] |
The layer to calculate on |
Output field name |
|
[string] |
The name of the field for the results |
Output field type |
|
[enumeration] Default: 0 |
The type of the field. One of:
|
Output field width |
|
[number] Default: 10 |
The length of the result field (minimum 0) |
Field precision |
|
[number] Default: 3 |
The precision of the result field (minimum 0, maximum 15) |
Create new field |
|
[boolean] Default: True |
Should the result field be a new field |
Formula |
|
[expression] |
The formula to use to calculate the result |
Output file |
|
[vector: any] Default: |
Specification of the output layer.
The file encoding can also be changed here. |
Outputs
Label |
Név |
Type |
Leírás |
|---|---|---|---|
Calculated |
|
[vector: any] |
Output layer with the calculated field values |
Python code
Algorithm ID: native:fieldcalculator
import processing
processing.run("algorithm_id", {parameter_dictionary})
The algorithm id is displayed when you hover over the algorithm in the Processing Toolbox. The parameter dictionary provides the parameter NAMEs and values. See Using processing algorithms from the console for details on how to run processing algorithms from the Python console.
25.1.21.10. Refactor fields
Allows editing the structure of the attribute table of a vector layer.
Fields can be modified in their type and name, using a fields mapping.
The original layer is not modified. A new layer is generated, which contains a modified attribute table, according to the provided fields mapping.
Megjegyzés
When using a template layer with constraints on fields, the information is displayed in the widget with a coloured background and tooltip. Treat this information as a hint during configuration. No constraints will be added on an output layer nor will they be checked or enforced by the algorithm.
The Refactor fields algorithm allows to:
Change field names and types
Add and remove fields
Reorder fields
Calculate new fields based on expressions
Load field list from another layer
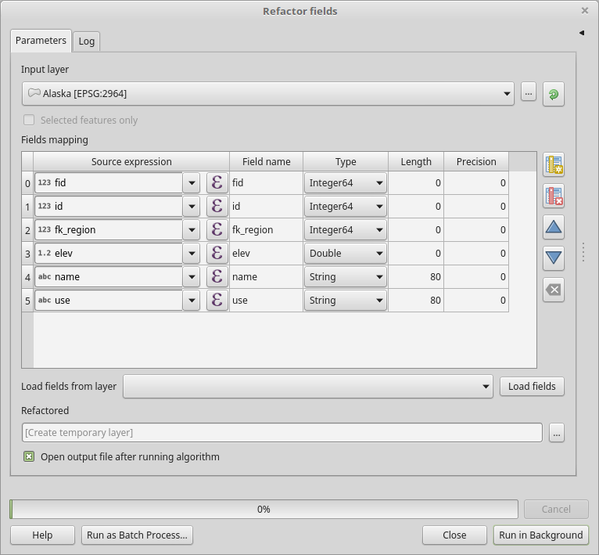
25.113. ábra Refactor fields dialog
Parameters
Label |
Név |
Type |
Leírás |
|---|---|---|---|
Input layer |
|
[vector: any] |
The layer to modify |
Fields mapping |
|
[list] |
List of output fields with their definitions. The embedded table lists all the fields of the source layer and allows you to edit them:
For each of the fields you’d like to reuse, you need to fill the following options:
|
Refactored |
|
[vector: any] Default: |
Specification of the output layer. One of:
The file encoding can also be changed here. |




Outputs
Label |
Név |
Type |
Leírás |
|---|---|---|---|
Refactored |
|
[vector: any] |
Output layer with refactored fields |
Python code
Algorithm ID: native:refactorfields
import processing
processing.run("algorithm_id", {parameter_dictionary})
The algorithm id is displayed when you hover over the algorithm in the Processing Toolbox. The parameter dictionary provides the parameter NAMEs and values. See Using processing algorithms from the console for details on how to run processing algorithms from the Python console.
25.1.21.11. Rename field
Renames an existing field from a vector layer.
The original layer is not modified. A new layer is generated where the attribute table contains the renamed field.
Lásd még
Parameters
Label |
Név |
Type |
Leírás |
|---|---|---|---|
Input layer |
|
[vector: any] |
The input vector layer |
Field to rename |
|
[tablefield: any] |
The field to be altered |
New field name |
|
[string] |
The new field name |
Renamed |
|
[vector: same as input] Default: |
Specification of the output layer. One of:
The file encoding can also be changed here. |
Outputs
Label |
Név |
Type |
Leírás |
|---|---|---|---|
Renamed |
|
[vector: same as input] |
Output layer with the renamed field |
Python code
Algorithm ID: qgis:renametablefield
import processing
processing.run("algorithm_id", {parameter_dictionary})
The algorithm id is displayed when you hover over the algorithm in the Processing Toolbox. The parameter dictionary provides the parameter NAMEs and values. See Using processing algorithms from the console for details on how to run processing algorithms from the Python console.
25.1.21.12. Retain fields
NEW in 3.18
Takes a vector layer and generates a new one that retains only the selected fields. All other fields will be dropped.
Lásd még
Parameters
Label |
Név |
Type |
Leírás |
|---|---|---|---|
Input layer |
|
[vector: any] |
The input vector layer |
Fields to retain |
|
[tablefield: any][list] |
List of fields to keep in the layer |
Retained fields |
|
[vector: same as input] Default: |
Specification of the output layer. One of:
The file encoding can also be changed here. |
Outputs
Label |
Név |
Type |
Leírás |
|---|---|---|---|
Retained fields |
|
[vector: same as input] |
Output layer with the retained fields |
Python code
Algorithm ID: native:retainfields
import processing
processing.run("algorithm_id", {parameter_dictionary})
The algorithm id is displayed when you hover over the algorithm in the Processing Toolbox. The parameter dictionary provides the parameter NAMEs and values. See Using processing algorithms from the console for details on how to run processing algorithms from the Python console.
25.1.21.13. Text to float
Modifies the type of a given attribute in a vector layer, converting a
text attribute containing numeric strings into a numeric attribute
(e.g. «1» to 1.0).
The algorithm creates a new vector layer so the source one is not modified.
If the conversion is not possible the selected column will have
NULL values.
Parameters
Label |
Név |
Type |
Leírás |
|---|---|---|---|
Input layer |
|
[vector: any] |
The input vector layer. |
Text attribute to convert to float |
|
[tablefield: string] |
The string field for the input layer that is to be converted to a float field. |
Float from text |
|
[same as input] Default: |
Specify the output layer. One of:
The file encoding can also be changed here. |
Outputs
Label |
Név |
Type |
Leírás |
|---|---|---|---|
Float from text |
|
[same as input] |
Output vector layer with the string field converted into a float field |
Python code
Algorithm ID: qgis:texttofloat
import processing
processing.run("algorithm_id", {parameter_dictionary})
The algorithm id is displayed when you hover over the algorithm in the Processing Toolbox. The parameter dictionary provides the parameter NAMEs and values. See Using processing algorithms from the console for details on how to run processing algorithms from the Python console.