25.1.11. Raster analysis
25.1.11.1. Cell stack percent rank from value
Calculates the cell-wise percentrank value of a stack of rasters based on a single input value and writes them to an output raster.
At each cell location, the specified value is ranked among the respective values in the stack of all overlaid and sorted cell values from the input rasters. For values outside of the stack value distribution, the algorithm returns NoData because the value cannot be ranked among the cell values.
There are two methods for percentile calculation:
Inclusive linear interpolation (PERCENTRANK.INC)
Exclusive linear interpolation (PERCENTRANK.EXC)
The linear interpolation method return the unique percent rank for different values. Both interpolation methods follow their counterpart methods implemented by LibreOffice or Microsoft Excel.
The output raster’s extent and resolution is defined by a reference raster.
Input raster layers that do not match the cell size of the reference
raster layer will be resampled using nearest neighbor resampling.
NoData values in any of the input layers will result in a NoData cell output
if the “Ignore NoData values” parameter is not set.
The output raster data type will always be Float32.
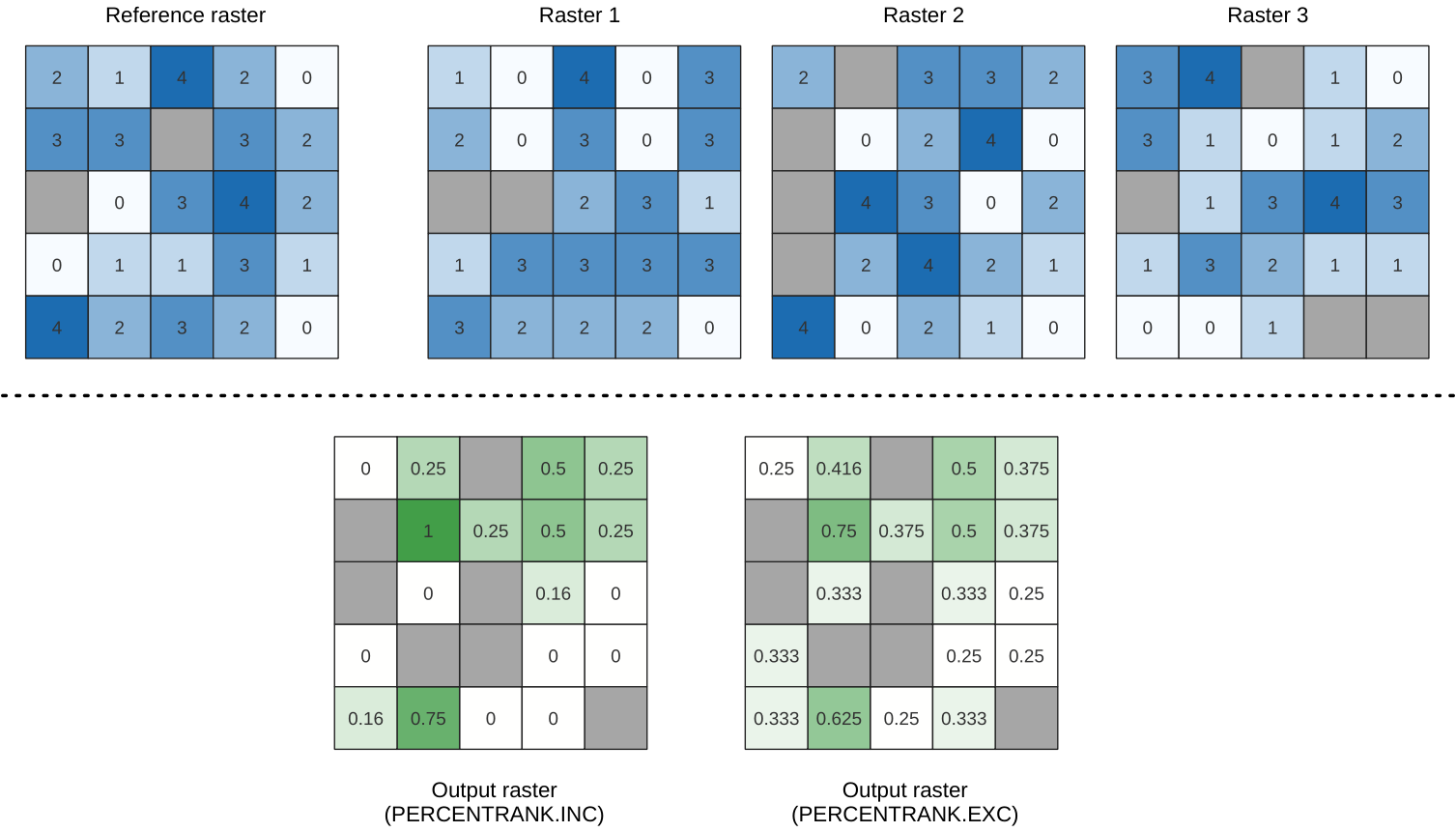
Fig. 25.10 Percent ranking Value = 1. NoData cells (grey) are ignored.
Parameters
Basic parameters
Label |
Name |
Type |
Description |
|---|---|---|---|
Input layers |
|
[raster] [list] |
Raster layers to evaluate. If multiband rasters are used in the data raster stack, the algorithm will always perform the analysis on the first band of the rasters |
Method |
|
[enumeration] Default: 0 |
Method for percentile calculation:
|
Value |
|
[number] Default: 10.0 |
Value to rank among the respective values in the stack of all overlaid and sorted cell values from the input rasters |
Ignore NoData values |
|
[boolean] Default: True |
If unchecked, any NoData cells in the input layers will result in a NoData cell in the output raster |
Reference layer |
|
[raster] |
The reference layer for the output layer creation (extent, CRS, pixel dimensions) |
Output layer |
|
[same as input] Default: |
Specification of the output raster. One of:
|
Advanced parameters
Label |
Name |
Type |
Description |
|---|---|---|---|
Output no data value |
|
[number] Default: -9999.0 |
Value to use for nodata in the output layer |
Outputs
Label |
Name |
Type |
Description |
|---|---|---|---|
Output layer |
|
[raster] |
Output raster layer containing the result |
CRS authority identifier |
|
[string] |
The coordinate reference system of the output raster layer |
Extent |
|
[string] |
The spatial extent of the output raster layer |
Width in pixels |
|
[integer] |
The number of columns in the output raster layer |
Height in pixels |
|
[integer] |
The number of rows in the output raster layer |
Total pixel count |
|
[integer] |
The count of pixels in the output raster layer |
Python code
Algorithm ID: native:cellstackpercentrankfromvalue
import processing
processing.run("algorithm_id", {parameter_dictionary})
The algorithm id is displayed when you hover over the algorithm in the Processing Toolbox. The parameter dictionary provides the parameter NAMEs and values. See Using processing algorithms from the console for details on how to run processing algorithms from the Python console.
25.1.11.2. Cell stack percentile
Calculates the cell-wise percentile value of a stack of rasters and writes the results to an output raster. The percentile to return is determined by the percentile input value (ranges between 0 and 1). At each cell location, the specified percentile is obtained using the respective value from the stack of all overlaid and sorted cell values of the input rasters.
There are three methods for percentile calculation:
Nearest rank: returns the value that is nearest to the specified percentile
Inclusive linear interpolation (PERCENTRANK.INC)
Exclusive linear interpolation (PERCENTRANK.EXC)
The linear interpolation methods return the unique values for different percentiles. Both interpolation methods follow their counterpart methods implemented by LibreOffice or Microsoft Excel.
The output raster’s extent and resolution is defined by a reference raster.
Input raster layers that do not match the cell size of the reference
raster layer will be resampled using nearest neighbor resampling.
NoData values in any of the input layers will result in a NoData cell output
if the “Ignore NoData values” parameter is not set.
The output raster data type will always be Float32.
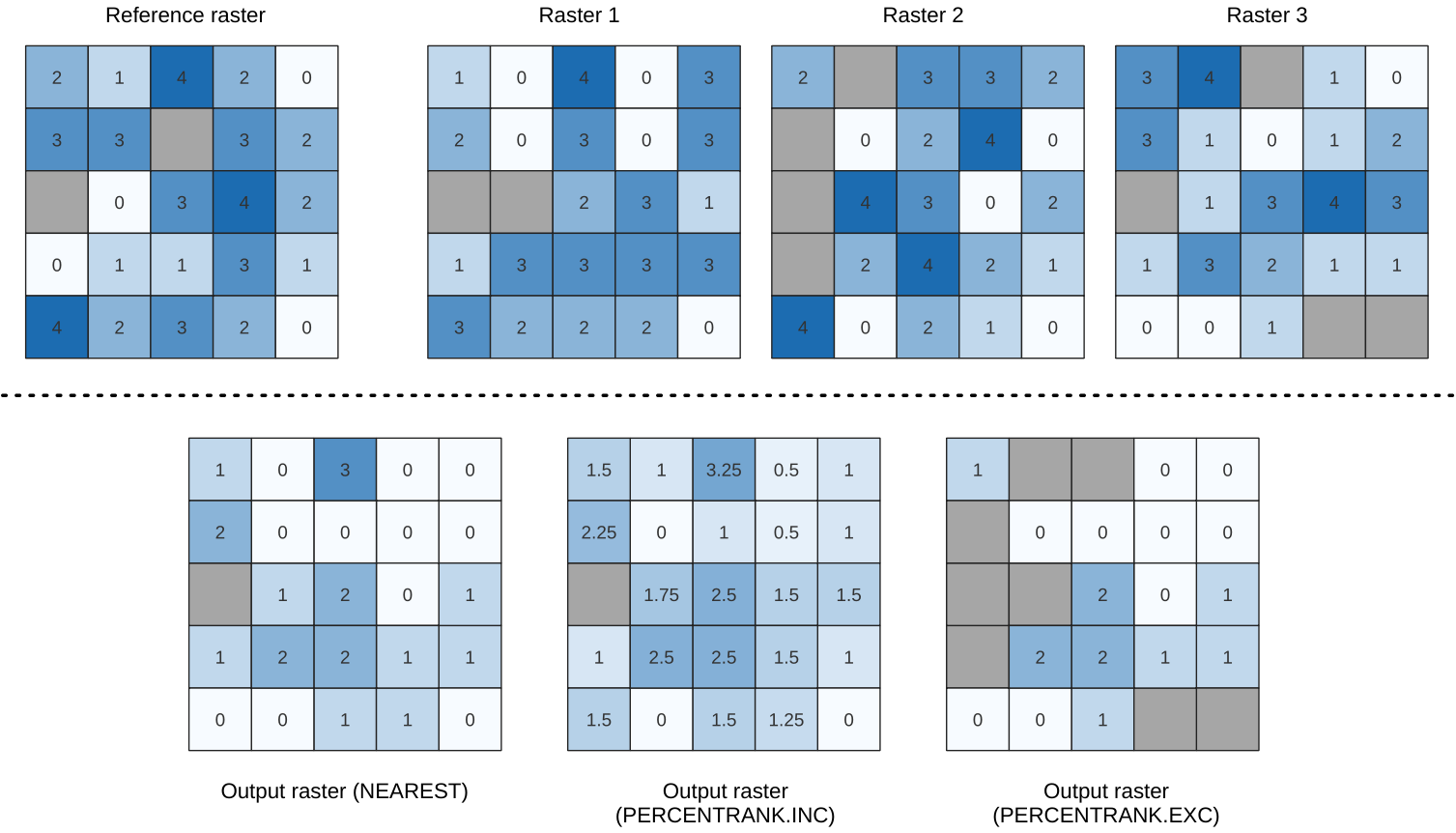
Fig. 25.11 Percentile = 0.25. NoData cells (grey) are ignored.
Parameters
Basic parameters
Label |
Name |
Type |
Description |
|---|---|---|---|
Input layers |
|
[raster] [list] |
Raster layers to evaluate. If multiband rasters are used in the data raster stack, the algorithm will always perform the analysis on the first band of the rasters |
Method |
|
[enumeration] Default: 0 |
Method for percentile calculation:
|
Percentile |
|
[number] Default: 0.25 |
Value to rank among the respective values in the stack of all overlaid and sorted cell values from the input rasters. Between 0 and 1. |
Ignore NoData values |
|
[boolean] Default: True |
If unchecked, any NoData cells in the input layers will result in a NoData cell in the output raster |
Reference layer |
|
[raster] |
The reference layer for the output layer creation (extent, CRS, pixel dimensions) |
Output layer |
|
[same as input] Default: |
Specification of the output raster. One of:
|
Advanced parameters
Label |
Name |
Type |
Description |
|---|---|---|---|
Output no data value |
|
[number] Default: -9999.0 |
Value to use for nodata in the output layer |
Outputs
Label |
Name |
Type |
Description |
|---|---|---|---|
Output layer |
|
[raster] |
Output raster layer containing the result |
CRS authority identifier |
|
[string] |
The coordinate reference system of the output raster layer |
Extent |
|
[string] |
The spatial extent of the output raster layer |
Width in pixels |
|
[integer] |
The number of columns in the output raster layer |
Height in pixels |
|
[integer] |
The number of rows in the output raster layer |
Total pixel count |
|
[integer] |
The count of pixels in the output raster layer |
Python code
Algorithm ID: native:cellstackpercentile
import processing
processing.run("algorithm_id", {parameter_dictionary})
The algorithm id is displayed when you hover over the algorithm in the Processing Toolbox. The parameter dictionary provides the parameter NAMEs and values. See Using processing algorithms from the console for details on how to run processing algorithms from the Python console.
25.1.11.3. Cell stack percentrank from raster layer
Calculates the cell-wise percentrank value of a stack of rasters based on an input value raster and writes them to an output raster.
At each cell location, the current value of the value raster is ranked among the respective values in the stack of all overlaid and sorted cell values of the input rasters. For values outside of the the stack value distribution, the algorithm returns NoData because the value cannot be ranked among the cell values.
There are two methods for percentile calculation:
Inclusive linear interpolation (PERCENTRANK.INC)
Exclusive linear interpolation (PERCENTRANK.EXC)
The linear interpolation methods return the unique values for different percentiles. Both interpolation methods follow their counterpart methods implemented by LibreOffice or Microsoft Excel.
The output raster’s extent and resolution is defined by a reference raster.
Input raster layers that do not match the cell size of the reference
raster layer will be resampled using nearest neighbor resampling.
NoData values in any of the input layers will result in a NoData cell output
if the “Ignore NoData values” parameter is not set.
The output raster data type will always be Float32.
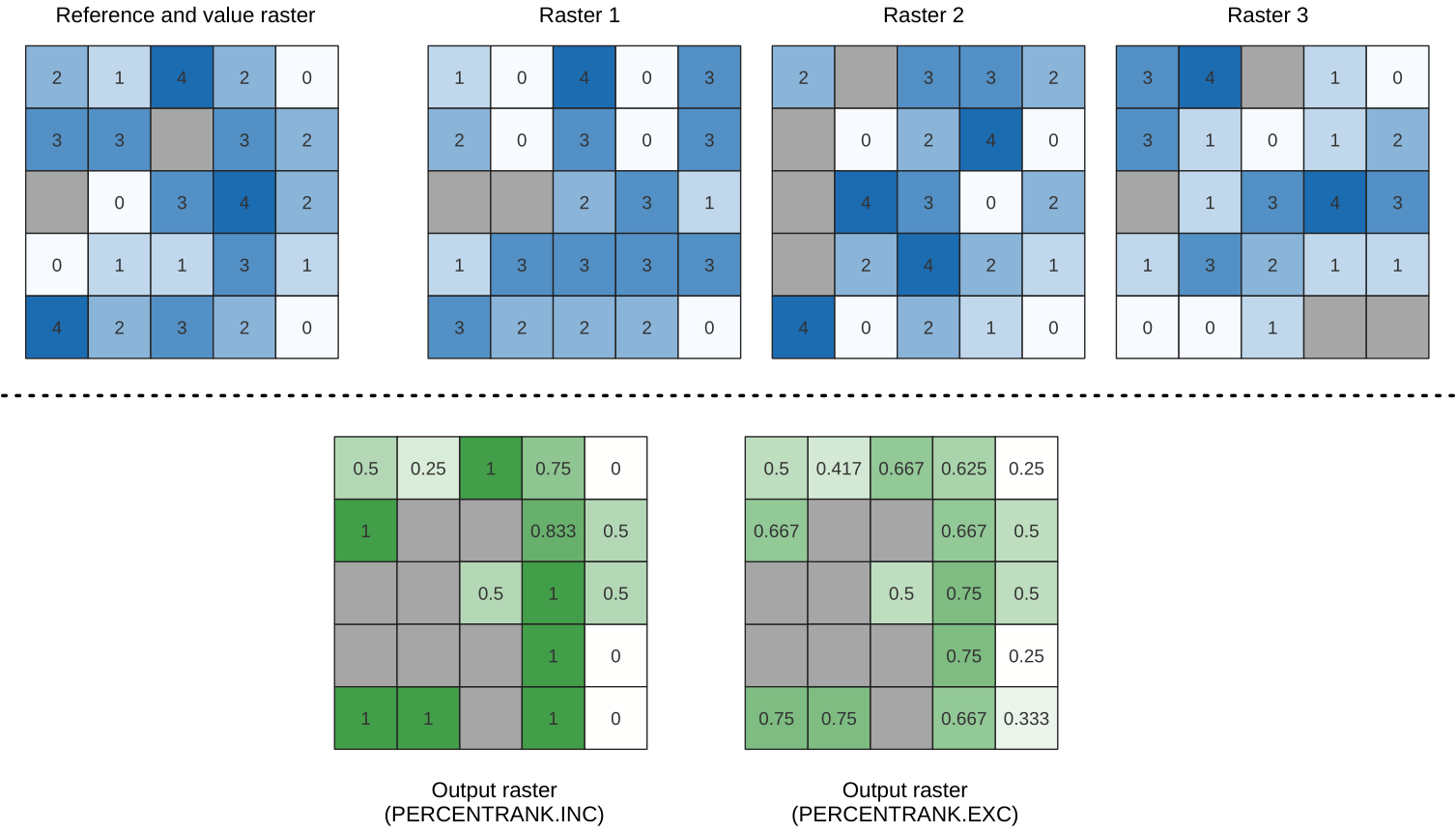
Fig. 25.12 Ranking the value raster layer cells. NoData cells (grey) are ignored.
Parameters
Basic parameters
Label |
Name |
Type |
Description |
|---|---|---|---|
Input layers |
|
[raster] [list] |
Raster layers to evaluate. If multiband rasters are used in the data raster stack, the algorithm will always perform the analysis on the first band of the rasters |
Value raster layer |
|
[raster] |
The layer to rank the values among the stack of all overlaid layers |
Value raster band |
|
[integer] Default: 1 |
Band of the “value raster layer” to compare to |
Method |
|
[enumeration] Default: 0 |
Method for percentile calculation:
|
Ignore NoData values |
|
[boolean] Default: True |
If unchecked, any NoData cells in the input layers will result in a NoData cell in the output raster |
Reference layer |
|
[raster] |
The reference layer for the output layer creation (extent, CRS, pixel dimensions) |
Output layer |
|
[same as input] Default: |
Specification of the output raster. One of:
|
Advanced parameters
Label |
Name |
Type |
Description |
|---|---|---|---|
Output no data value |
|
[number] Default: -9999.0 |
Value to use for nodata in the output layer |
Outputs
Label |
Name |
Type |
Description |
|---|---|---|---|
Output layer |
|
[raster] |
Output raster layer containing the result |
CRS authority identifier |
|
[string] |
The coordinate reference system of the output raster layer |
Extent |
|
[string] |
The spatial extent of the output raster layer |
Width in pixels |
|
[integer] |
The number of columns in the output raster layer |
Height in pixels |
|
[integer] |
The number of rows in the output raster layer |
Total pixel count |
|
[integer] |
The count of pixels in the output raster layer |
Python code
Algorithm ID: native:cellstackpercentrankfromrasterlayer
import processing
processing.run("algorithm_id", {parameter_dictionary})
The algorithm id is displayed when you hover over the algorithm in the Processing Toolbox. The parameter dictionary provides the parameter NAMEs and values. See Using processing algorithms from the console for details on how to run processing algorithms from the Python console.
25.1.11.4. Cell statistics
Computes per-cell statistics based on input raster layers and for each cell writes the resulting statistics to an output raster. At each cell location, the output value is defined as a function of all overlaid cell values of the input rasters.
By default, a NoData cell in ANY of the input layers will result in a NoData cell in the output raster. If the Ignore NoData values option is checked, then NoData inputs will be ignored in the statistic calculation. This may result in NoData output for locations where all cells are NoData.
The Reference layer parameter specifies an existing raster layer to use as a reference when creating the output raster. The output raster will have the same extent, CRS, and pixel dimensions as this layer.
Calculation details:
Input raster layers that do not match the cell size of the reference
raster layer will be resampled using nearest neighbor resampling.
The output raster data type will be set to the most complex
data type present in the input datasets except when using the
functions Mean, Standard deviation and Variance (data type is always
Float32 or Float64 depending on input float type) or Count
and Variety (data type is always Int32).
Count: The count statistic will always result in the number of cells without NoData values at the current cell location.Median: If the number of input layers is even, the median will be calculated as the arithmetic mean of the two middle values of the ordered cell input values.Minority/Majority: If no unique minority or majority could be found, the result is NoData, except all input cell values are equal.
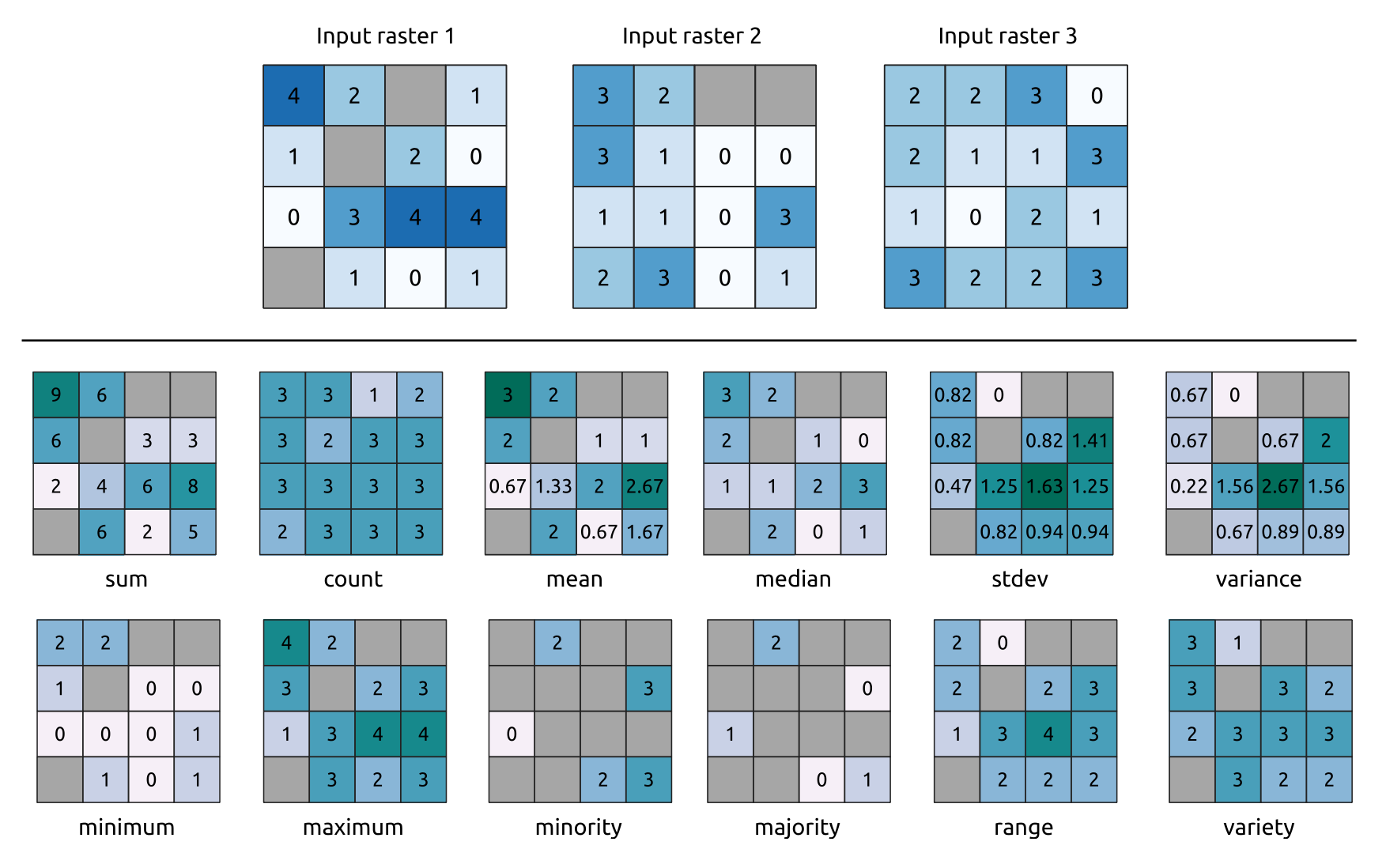
Fig. 25.13 Example with all the statistic functions. NoData cells (grey) are taken into account.
Parameters
Basic parameters
Label |
Name |
Type |
Description |
|---|---|---|---|
Input layers |
|
[raster] [list] |
Input raster layers |
Statistic |
|
[enumeration] Default: 0 |
Available statistics. Options:
|
Ignore NoData values |
|
[boolean] Default: True |
Calculate statistics also for all cells stacks, ignoring NoData occurrence. |
Reference layer |
|
[raster] |
The reference layer to create the output layer from (extent, CRS, pixel dimensions) |
Output layer |
|
[same as input] Default: |
Specification of the output raster. One of:
|
Advanced parameters
Label |
Name |
Type |
Description |
|---|---|---|---|
Output no data value Optional |
|
[number] Default: -9999.0 |
Value to use for nodata in the output layer |
Outputs
Label |
Name |
Type |
Description |
|---|---|---|---|
CRS authority identifier |
|
[crs] |
The coordinate reference system of the output raster layer |
Extent |
|
[string] |
The spatial extent of the output raster layer |
Height in pixels |
|
[integer] |
The number of rows in the output raster layer |
Output raster |
|
[raster] |
Output raster layer containing the result |
Total pixel count |
|
[integer] |
The count of pixels in the output raster layer |
Width in pixels |
|
[integer] |
The number of columns in the output raster layer |
Python code
Algorithm ID: native:cellstatistics
import processing
processing.run("algorithm_id", {parameter_dictionary})
The algorithm id is displayed when you hover over the algorithm in the Processing Toolbox. The parameter dictionary provides the parameter NAMEs and values. See Using processing algorithms from the console for details on how to run processing algorithms from the Python console.
25.1.11.5. Equal to frequency
Evaluates on a cell-by-cell basis the frequency (number of times) the values
of an input stack of rasters are equal to the value of a value layer.
The output raster extent and resolution are defined by the input raster layer
and is always of Int32 type.
If multiband rasters are used in the data raster stack, the algorithm will always perform the analysis on the first band of the rasters - use GDAL to use other bands in the analysis. The output NoData value can be set manually.
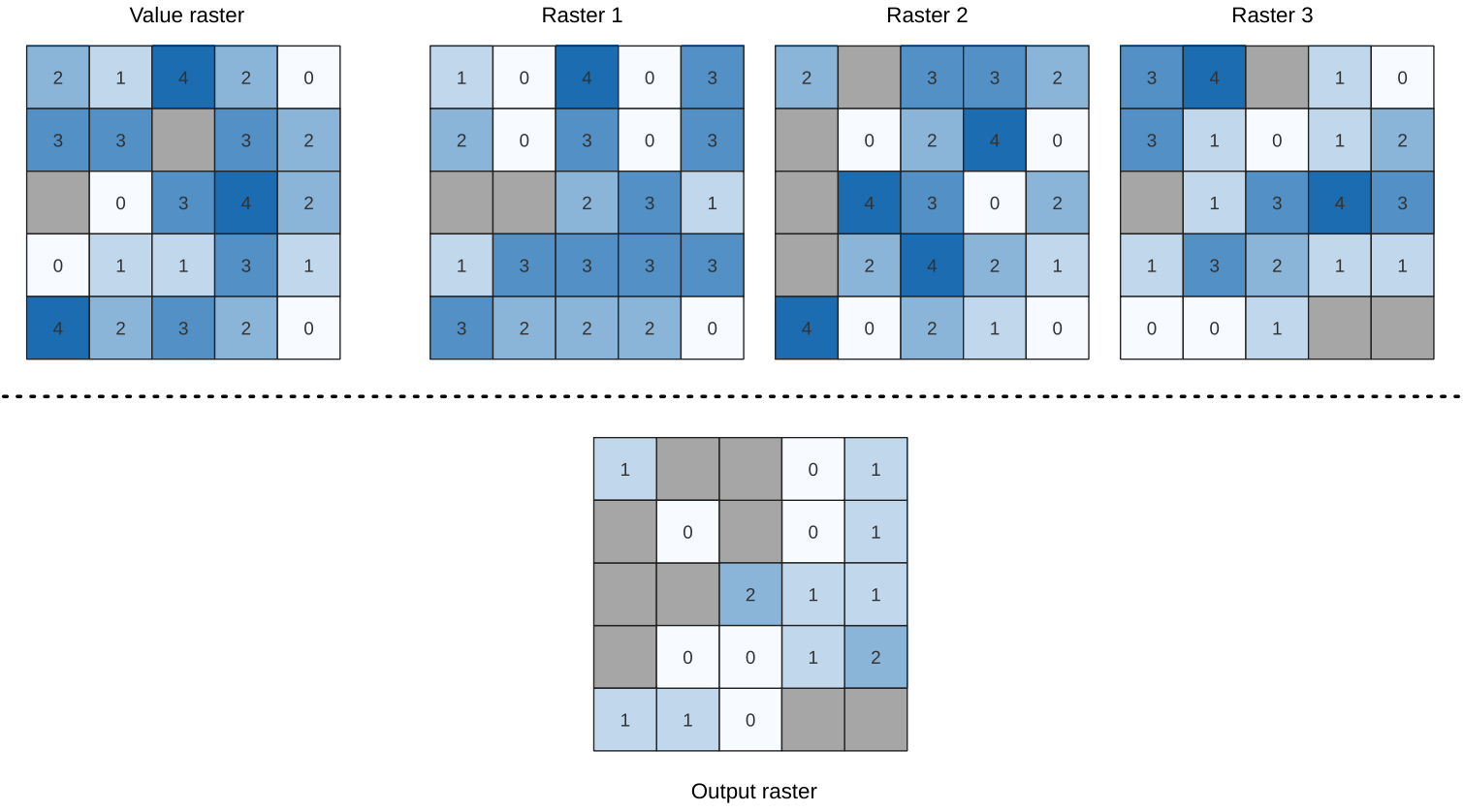
Fig. 25.14 For each cell in the output raster, the value represents the number of times
that the corresponding cells in the list of rasters are the same as the value raster.
NoData cells (grey) are taken into account.
See also
Parameters
Basic parameters
Label |
Name |
Type |
Description |
|---|---|---|---|
Input value raster |
|
[raster] |
The input value layer serves as reference layer for the sample layers |
Value raster band |
|
[raster band] Default: The first band of the raster layer |
Select the band you want to use as sample |
Input raster layers |
|
[raster] [list] |
Raster layers to evaluate. If multiband rasters are used in the data raster stack, the algorithm will always perform the analysis on the first band of the rasters |
Ignore NoData values |
|
[boolean] Default: False |
If unchecked, any NoData cells in the value raster or the data layer stack will result in a NoData cell in the output raster |
Output layer |
|
[same as input] Default: |
Specification of the output raster. One of:
|
Advanced parameters
Label |
Name |
Type |
Description |
|---|---|---|---|
Output no data value Optional |
|
[number] Default: -9999.0 |
Value to use for nodata in the output layer |
Outputs
Label |
Name |
Type |
Description |
|---|---|---|---|
Output layer |
|
[raster] |
Output raster layer containing the result |
CRS authority identifier |
|
[string] |
The coordinate reference system of the output raster layer |
Extent |
|
[string] |
The spatial extent of the output raster layer |
Count of cells with equal value occurrences |
|
[number] |
|
Height in pixels |
|
[number] |
The number of rows in the output raster layer |
Total pixel count |
|
[integer] |
The count of pixels in the output raster layer |
Mean frequency at valid cell locations |
|
[number] |
|
Count of value occurrences |
|
[number] |
|
Width in pixels |
|
[integer] |
The number of columns in the output raster layer |
Python code
Algorithm ID: native:equaltofrequency
import processing
processing.run("algorithm_id", {parameter_dictionary})
The algorithm id is displayed when you hover over the algorithm in the Processing Toolbox. The parameter dictionary provides the parameter NAMEs and values. See Using processing algorithms from the console for details on how to run processing algorithms from the Python console.
25.1.11.6. Fuzzify raster (gaussian membership)
Transforms an input raster to a fuzzified raster by assigning a
membership value to each pixel, using a Gaussian membership function.
Membership values range from 0 to 1.
In the fuzzified raster, a value of 0 implies no membership of the
defined fuzzy set, whereas a value of 1 means full membership.
The gaussian membership function is defined as 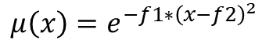 ,
where f1 is the spread and f2 the midpoint.
,
where f1 is the spread and f2 the midpoint.
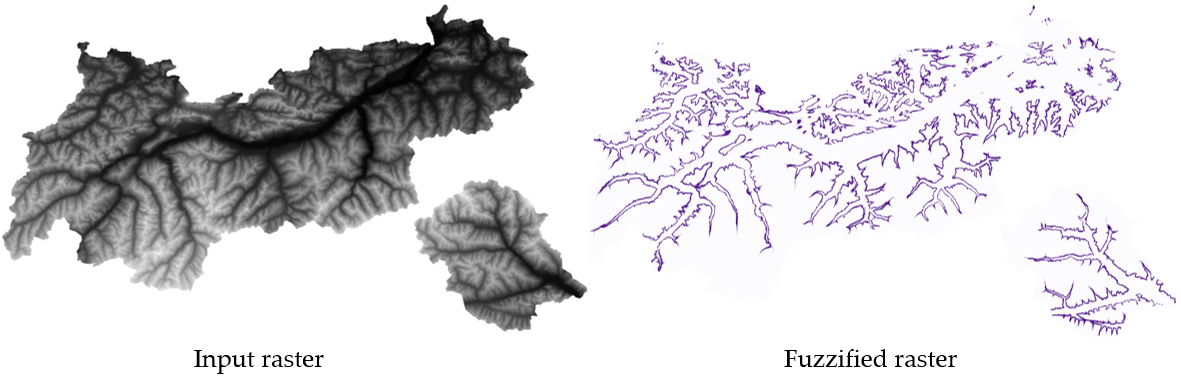
Fig. 25.15 Fuzzify raster example. Input raster source: Land Tirol - data.tirol.gv.at.
See also
Fuzzify raster (large membership) Fuzzify raster (linear membership), Fuzzify raster (near membership), Fuzzify raster (power membership), Fuzzify raster (small membership)
Parameters
Label |
Name |
Type |
Description |
|---|---|---|---|
Input Raster |
|
[raster] |
Input raster layer |
Band Number |
|
[raster band] Default: The first band of the raster layer |
If the raster is multiband, choose the band that you want to fuzzify. |
Function midpoint |
|
[number] Default: 10 |
Midpoint of the gaussian function |
Function spread |
|
[number] Default: 0.01 |
Spread of the gaussian function |
Fuzzified raster |
|
[same as input] Default: |
Specification of the output raster. One of:
|
Outputs
Label |
Name |
Type |
Description |
|---|---|---|---|
Fuzzified raster |
|
[same as input] |
Output raster layer containing the result |
CRS authority identifier |
|
[crs] |
The coordinate reference system of the output raster layer |
Extent |
|
[string] |
The spatial extent of the output raster layer |
Width in pixels |
|
[integer] |
The number of columns in the output raster layer |
Height in pixels |
|
[integer] |
The number of rows in the output raster layer |
Total pixel count |
|
[integer] |
The count of pixels in the output raster layer |
Python code
Algorithm ID: native:fuzzifyrastergaussianmembership
import processing
processing.run("algorithm_id", {parameter_dictionary})
The algorithm id is displayed when you hover over the algorithm in the Processing Toolbox. The parameter dictionary provides the parameter NAMEs and values. See Using processing algorithms from the console for details on how to run processing algorithms from the Python console.
25.1.11.7. Fuzzify raster (large membership)
Transforms an input raster to a fuzzified raster by assigning a
membership value to each pixel, using a Large membership function.
Membership values range from 0 to 1.
In the fuzzified raster, a value of 0 implies no membership of the
defined fuzzy set, whereas a value of 1 means full membership.
The large membership function is defined as 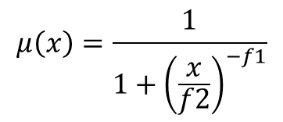 ,
where f1 is the spread and f2 the midpoint.
,
where f1 is the spread and f2 the midpoint.
See also
Fuzzify raster (gaussian membership), Fuzzify raster (linear membership), Fuzzify raster (near membership), Fuzzify raster (power membership), Fuzzify raster (small membership)
Parameters
Label |
Name |
Type |
Description |
|---|---|---|---|
Input Raster |
|
[raster] |
Input raster layer |
Band Number |
|
[raster band] Default: The first band of the raster layer |
If the raster is multiband, choose the band that you want to fuzzify. |
Function midpoint |
|
[number] Default: 50 |
Midpoint of the large function |
Function spread |
|
[number] Default: 5 |
Spread of the large function |
Fuzzified raster |
|
[same as input] Default: |
Specification of the output raster. One of:
|
Outputs
Label |
Name |
Type |
Description |
|---|---|---|---|
Fuzzified raster |
|
[same as input] |
Output raster layer containing the result |
CRS authority identifier |
|
[crs] |
The coordinate reference system of the output raster layer |
Extent |
|
[string] |
The spatial extent of the output raster layer |
Width in pixels |
|
[integer] |
The number of columns in the output raster layer |
Height in pixels |
|
[integer] |
The number of rows in the output raster layer |
Total pixel count |
|
[integer] |
The count of pixels in the output raster layer |
Python code
Algorithm ID: native:fuzzifyrasterlargemembership
import processing
processing.run("algorithm_id", {parameter_dictionary})
The algorithm id is displayed when you hover over the algorithm in the Processing Toolbox. The parameter dictionary provides the parameter NAMEs and values. See Using processing algorithms from the console for details on how to run processing algorithms from the Python console.
25.1.11.8. Fuzzify raster (linear membership)
Transforms an input raster to a fuzzified raster by assigning a
membership value to each pixel, using a Linear membership function.
Membership values range from 0 to 1. In the fuzzified raster, a value
of 0 implies no membership of the defined fuzzy set, whereas a value
of 1 means full membership.
The linear function is defined as 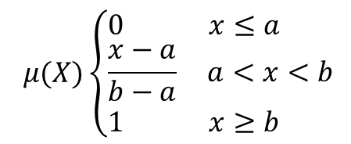 , where a
is the low bound and b the high bound. This equation assigns
membership values using a linear transformation for pixel values
between the low and high bounds.
Pixels values smaller than the low bound are given 0 membership
whereas pixel values greater than the high bound are given 1
membership.
, where a
is the low bound and b the high bound. This equation assigns
membership values using a linear transformation for pixel values
between the low and high bounds.
Pixels values smaller than the low bound are given 0 membership
whereas pixel values greater than the high bound are given 1
membership.
See also
Fuzzify raster (gaussian membership), Fuzzify raster (large membership), Fuzzify raster (near membership), Fuzzify raster (power membership), Fuzzify raster (small membership)
Parameters
Label |
Name |
Type |
Description |
|---|---|---|---|
Input Raster |
|
[raster] |
Input raster layer |
Band Number |
|
[raster band] Default: The first band of the raster layer |
If the raster is multiband, choose the band that you want to fuzzify. |
Low fuzzy membership bound |
|
[number] Default: 0 |
Low bound of the linear function |
High fuzzy membership bound |
|
[number] Default: 1 |
High bound of the linear function |
Fuzzified raster |
|
[same as input] Default: |
Specification of the output raster. One of:
|
Outputs
Label |
Name |
Type |
Description |
|---|---|---|---|
Fuzzified raster |
|
[same as input] |
Output raster layer containing the result |
CRS authority identifier |
|
[crs] |
The coordinate reference system of the output raster layer |
Extent |
|
[string] |
The spatial extent of the output raster layer |
Width in pixels |
|
[integer] |
The number of columns in the output raster layer |
Height in pixels |
|
[integer] |
The number of rows in the output raster layer |
Total pixel count |
|
[integer] |
The count of pixels in the output raster layer |
Python code
Algorithm ID: native:fuzzifyrasterlinearmembership
import processing
processing.run("algorithm_id", {parameter_dictionary})
The algorithm id is displayed when you hover over the algorithm in the Processing Toolbox. The parameter dictionary provides the parameter NAMEs and values. See Using processing algorithms from the console for details on how to run processing algorithms from the Python console.
25.1.11.9. Fuzzify raster (near membership)
Transforms an input raster to a fuzzified raster by assigning a
membership value to each pixel, using a Near membership function.
Membership values range from 0 to 1.
In the fuzzified raster, a value of 0 implies no membership of the
defined fuzzy set, whereas a value of 1 means full membership.
The near membership function is defined as 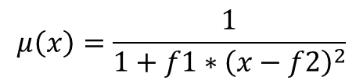 , where
f1 is the spread and f2 the midpoint.
, where
f1 is the spread and f2 the midpoint.
See also
Fuzzify raster (gaussian membership), Fuzzify raster (large membership), Fuzzify raster (linear membership), Fuzzify raster (power membership), Fuzzify raster (small membership)
Parameters
Label |
Name |
Type |
Description |
|---|---|---|---|
Input Raster |
|
[raster] |
Input raster layer |
Band Number |
|
[raster band] Default: The first band of the raster layer |
If the raster is multiband, choose the band that you want to fuzzify. |
Function midpoint |
|
[number] Default: 50 |
Midpoint of the near function |
Function spread |
|
[number] Default: 0.01 |
Spread of the near function |
Fuzzified raster |
|
[same as input] Default: |
Specification of the output raster. One of:
|
Outputs
Label |
Name |
Type |
Description |
|---|---|---|---|
Fuzzified raster |
|
[same as input] |
Output raster layer containing the result |
CRS authority identifier |
|
[crs] |
The coordinate reference system of the output raster layer |
Extent |
|
[string] |
The spatial extent of the output raster layer |
Width in pixels |
|
[integer] |
The number of columns in the output raster layer |
Height in pixels |
|
[integer] |
The number of rows in the output raster layer |
Total pixel count |
|
[integer] |
The count of pixels in the output raster layer |
Python code
Algorithm ID: native:fuzzifyrasternearmembership
import processing
processing.run("algorithm_id", {parameter_dictionary})
The algorithm id is displayed when you hover over the algorithm in the Processing Toolbox. The parameter dictionary provides the parameter NAMEs and values. See Using processing algorithms from the console for details on how to run processing algorithms from the Python console.
25.1.11.10. Fuzzify raster (power membership)
Transforms an input raster to a fuzzified raster by assigning a
membership value to each pixel, using a Power membership function.
Membership values range from 0 to 1.
In the fuzzified raster, a value of 0 implies no membership of the
defined fuzzy set, whereas a value of 1 means full membership.
The power function is defined as 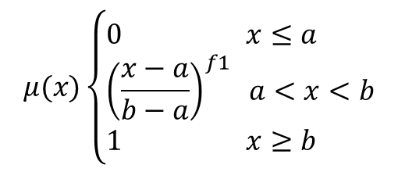 , where a is the
low bound, b is the high bound, and f1 the exponent.
This equation assigns membership values using the power transformation
for pixel values between the low and high bounds.
Pixels values smaller than the low bound are given 0 membership
whereas pixel values greater than the high bound are given 1
membership.
, where a is the
low bound, b is the high bound, and f1 the exponent.
This equation assigns membership values using the power transformation
for pixel values between the low and high bounds.
Pixels values smaller than the low bound are given 0 membership
whereas pixel values greater than the high bound are given 1
membership.
See also
Fuzzify raster (gaussian membership), Fuzzify raster (large membership), Fuzzify raster (linear membership), Fuzzify raster (near membership), Fuzzify raster (small membership)
Parameters
Label |
Name |
Type |
Description |
|---|---|---|---|
Input Raster |
|
[raster] |
Input raster layer |
Band Number |
|
[raster band] Default: The first band of the raster layer |
If the raster is multiband, choose the band that you want to fuzzify. |
Low fuzzy membership bound |
|
[number] Default: 0 |
Low bound of the power function |
High fuzzy membership bound |
|
[number] Default: 1 |
High bound of the power function |
High fuzzy membership bound |
|
[number] Default: 2 |
Exponent of the power function |
Fuzzified raster |
|
[same as input] Default: |
Specification of the output raster. One of:
|
Outputs
Label |
Name |
Type |
Description |
|---|---|---|---|
Fuzzified raster |
|
[same as input] |
Output raster layer containing the result |
CRS authority identifier |
|
[crs] |
The coordinate reference system of the output raster layer |
Extent |
|
[string] |
The spatial extent of the output raster layer |
Width in pixels |
|
[integer] |
The number of columns in the output raster layer |
Height in pixels |
|
[integer] |
The number of rows in the output raster layer |
Total pixel count |
|
[integer] |
The count of pixels in the output raster layer |
Python code
Algorithm ID: native:fuzzifyrasterpowermembership
import processing
processing.run("algorithm_id", {parameter_dictionary})
The algorithm id is displayed when you hover over the algorithm in the Processing Toolbox. The parameter dictionary provides the parameter NAMEs and values. See Using processing algorithms from the console for details on how to run processing algorithms from the Python console.
25.1.11.11. Fuzzify raster (small membership)
Transforms an input raster to a fuzzified raster by assigning a
membership value to each pixel, using a Small membership function.
Membership values range from 0 to 1.
In the fuzzified raster, a value of 0 implies no membership of the
defined fuzzy set, whereas a value of 1 means full membership.
The small membership function is defined as 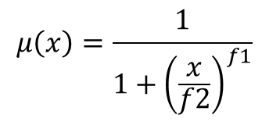 , where
f1 is the spread and f2 the midpoint.
, where
f1 is the spread and f2 the midpoint.
See also
Fuzzify raster (gaussian membership), Fuzzify raster (large membership) Fuzzify raster (linear membership), Fuzzify raster (near membership), Fuzzify raster (power membership)
Parameters
Label |
Name |
Type |
Description |
|---|---|---|---|
Input Raster |
|
[raster] |
Input raster layer |
Band Number |
|
[raster band] Default: The first band of the raster layer |
If the raster is multiband, choose the band that you want to fuzzify. |
Function midpoint |
|
[number] Default: 50 |
Midpoint of the small function |
Function spread |
|
[number] Default: 5 |
Spread of the small function |
Fuzzified raster |
|
[same as input] Default: |
Specification of the output raster. One of:
|
Outputs
Label |
Name |
Type |
Description |
|---|---|---|---|
Fuzzified raster |
|
[same as input] |
Output raster layer containing the result |
CRS authority identifier |
|
[crs] |
The coordinate reference system of the output raster layer |
Extent |
|
[string] |
The spatial extent of the output raster layer |
Width in pixels |
|
[integer] |
The number of columns in the output raster layer |
Height in pixels |
|
[integer] |
The number of rows in the output raster layer |
Total pixel count |
|
[integer] |
The count of pixels in the output raster layer |
Python code
Algorithm ID: native:fuzzifyrastersmallmembership
import processing
processing.run("algorithm_id", {parameter_dictionary})
The algorithm id is displayed when you hover over the algorithm in the Processing Toolbox. The parameter dictionary provides the parameter NAMEs and values. See Using processing algorithms from the console for details on how to run processing algorithms from the Python console.
25.1.11.12. Greater than frequency
Evaluates on a cell-by-cell basis the frequency (number of times) the values
of an input stack of rasters are equal to the value of a value raster.
The output raster extent and resolution is defined by the input raster layer
and is always of Int32 type.
If multiband rasters are used in the data raster stack, the algorithm will always perform the analysis on the first band of the rasters - use GDAL to use other bands in the analysis. The output NoData value can be set manually.
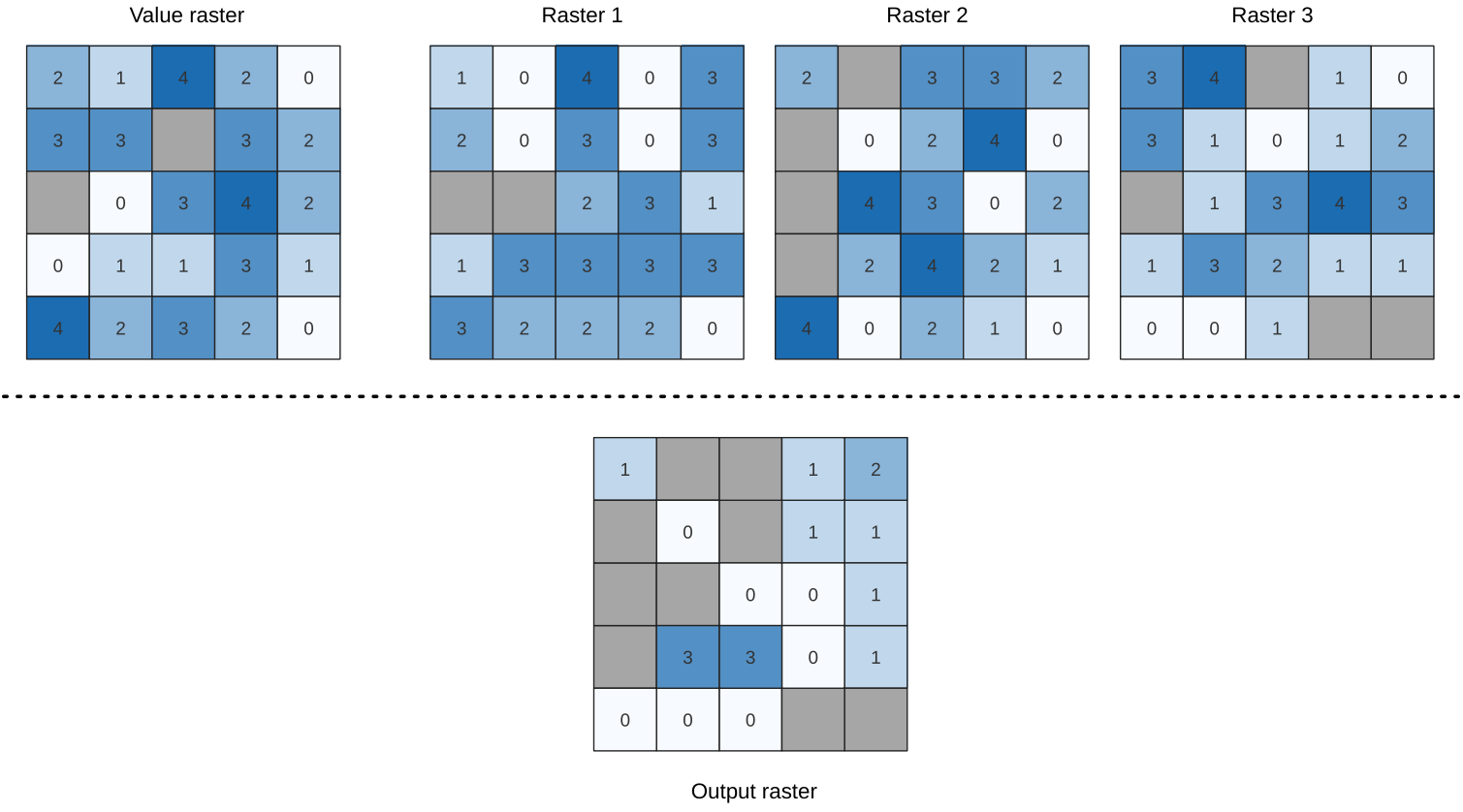
Fig. 25.16 For each cell in the output raster, the value represents the number of times
that the corresponding cells in the list of rasters are greater than the value raster.
NoData cells (grey) are taken into account.
See also
Parameters
Basic parameters
Label |
Name |
Type |
Description |
|---|---|---|---|
Input value raster |
|
[raster] |
The input value layer serves as reference layer for the sample layers |
Value raster band |
|
[raster band] Default: The first band of the raster layer |
Select the band you want to use as sample |
Input raster layers |
|
[raster] [list] |
Raster layers to evaluate. If multiband rasters are used in the data raster stack, the algorithm will always perform the analysis on the first band of the rasters |
Ignore NoData values |
|
[boolean] Default: False |
If unchecked, any NoData cells in the value raster or the data layer stack will result in a NoData cell in the output raster |
Output layer |
|
[same as input] Default: |
Specification of the output raster. One of:
|
Advanced parameters
Label |
Name |
Type |
Description |
|---|---|---|---|
Output no data value Optional |
|
[number] Default: -9999.0 |
Value to use for nodata in the output layer |
Outputs
Label |
Name |
Type |
Description |
|---|---|---|---|
Output layer |
|
[raster] |
Output raster layer containing the result |
CRS authority identifier |
|
[string] |
The coordinate reference system of the output raster layer |
Extent |
|
[string] |
The spatial extent of the output raster layer |
Count of cells with equal value occurrences |
|
[number] |
|
Height in pixels |
|
[number] |
The number of rows in the output raster layer |
Total pixel count |
|
[integer] |
The count of pixels in the output raster layer |
Mean frequency at valid cell locations |
|
[number] |
|
Count of value occurrences |
|
[number] |
|
Width in pixels |
|
[integer] |
The number of columns in the output raster layer |
Python code
Algorithm ID: native:greaterthanfrequency
import processing
processing.run("algorithm_id", {parameter_dictionary})
The algorithm id is displayed when you hover over the algorithm in the Processing Toolbox. The parameter dictionary provides the parameter NAMEs and values. See Using processing algorithms from the console for details on how to run processing algorithms from the Python console.
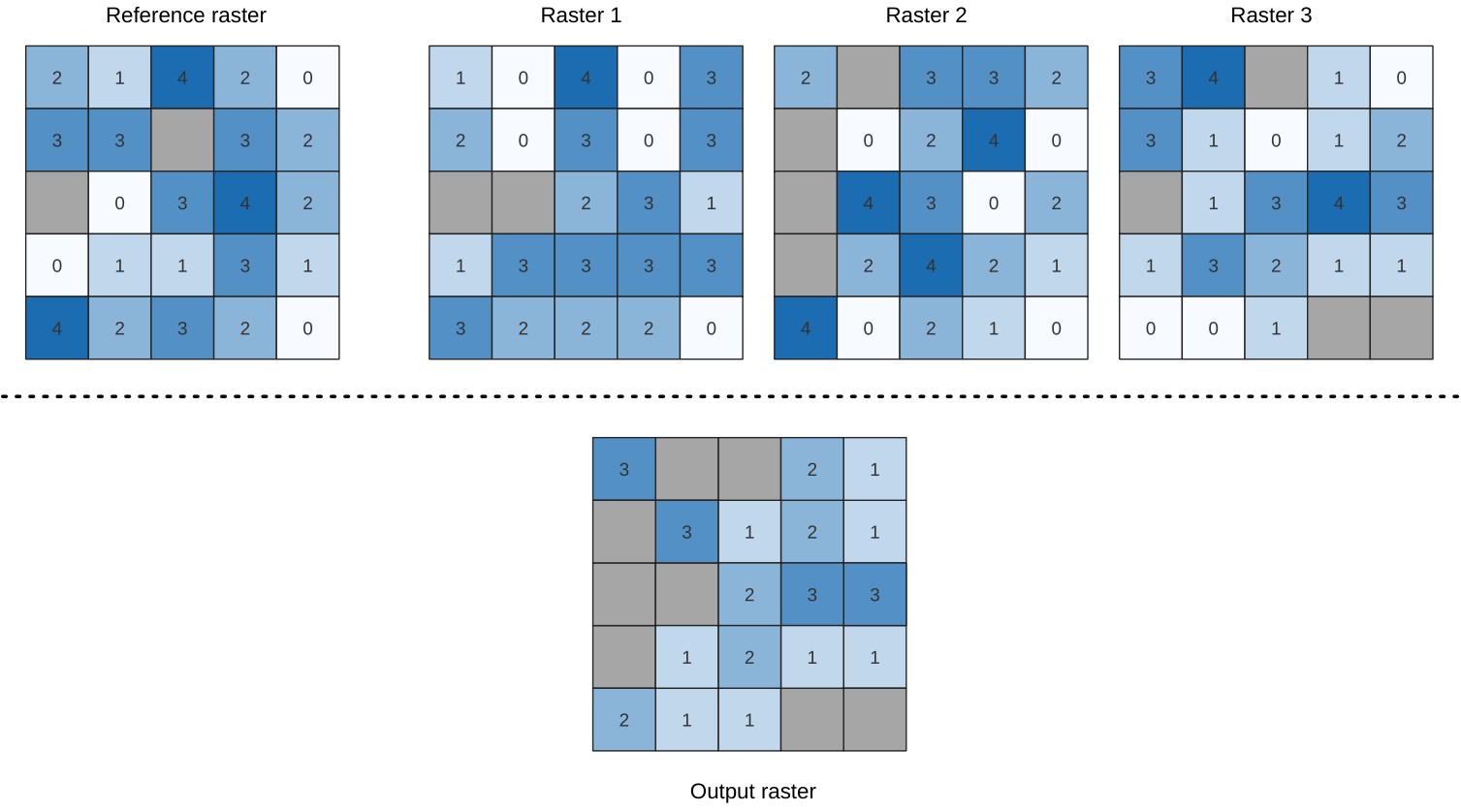
25.1.11.13. Highest position in raster stack
Evaluates on a cell-by-cell basis the position of the raster with the highest value in a stack of rasters. Position counts start with 1 and range to the total number of input rasters. The order of the input rasters is relevant for the algorithm. If multiple rasters feature the highest value, the first raster will be used for the position value.
If multiband rasters are used in the data raster stack, the algorithm will
always perform the analysis on the first band of the rasters - use GDAL to use
other bands in the analysis.
Any NoData cells in the raster layer stack will result in a NoData cell
in the output raster unless the “ignore NoData” parameter is checked.
The output NoData value can be set manually. The output rasters extent and
resolution is defined by a reference raster layer and is always of Int32 type.
See also
Parameters
Basic parameters
Label |
Name |
Type |
Description |
|---|---|---|---|
Input raster layers |
|
[raster] [list] |
List of raster layers to compare with |
Reference layer |
|
[raster] |
The reference layer for the output layer creation (extent, CRS, pixel dimensions) |
Ignore NoData values |
|
[boolean] Default: False |
If unchecked, any NoData cells in the data layer stack will result in a NoData cell in the output raster |
Output layer |
|
[raster] Default: |
Specification of the output raster containing the result. One of:
|
Advanced parameters
Label |
Name |
Type |
Description |
|---|---|---|---|
Output no data value |
|
[number] Default: -9999.0 |
Value to use for nodata in the output layer |
Outputs
Label |
Name |
Type |
Description |
|---|---|---|---|
Output layer |
|
[raster] |
Output raster layer containing the result |
CRS authority identifier |
|
[string] |
The coordinate reference system of the output raster layer |
Extent |
|
[string] |
The spatial extent of the output raster layer |
Width in pixels |
|
[integer] |
The number of columns in the output raster layer |
Height in pixels |
|
[integer] |
The number of rows in the output raster layer |
Total pixel count |
|
[integer] |
The count of pixels in the output raster layer |
Python code
Algorithm ID: native:highestpositioninrasterstack
import processing
processing.run("algorithm_id", {parameter_dictionary})
The algorithm id is displayed when you hover over the algorithm in the Processing Toolbox. The parameter dictionary provides the parameter NAMEs and values. See Using processing algorithms from the console for details on how to run processing algorithms from the Python console.
25.1.11.14. Less than frequency
Evaluates on a cell-by-cell basis the frequency (number of times) the values
of an input stack of rasters are less than the value of a value raster.
The output raster extent and resolution is defined by the input raster layer
and is always of Int32 type.
If multiband rasters are used in the data raster stack, the algorithm will always perform the analysis on the first band of the rasters - use GDAL to use other bands in the analysis. The output NoData value can be set manually.
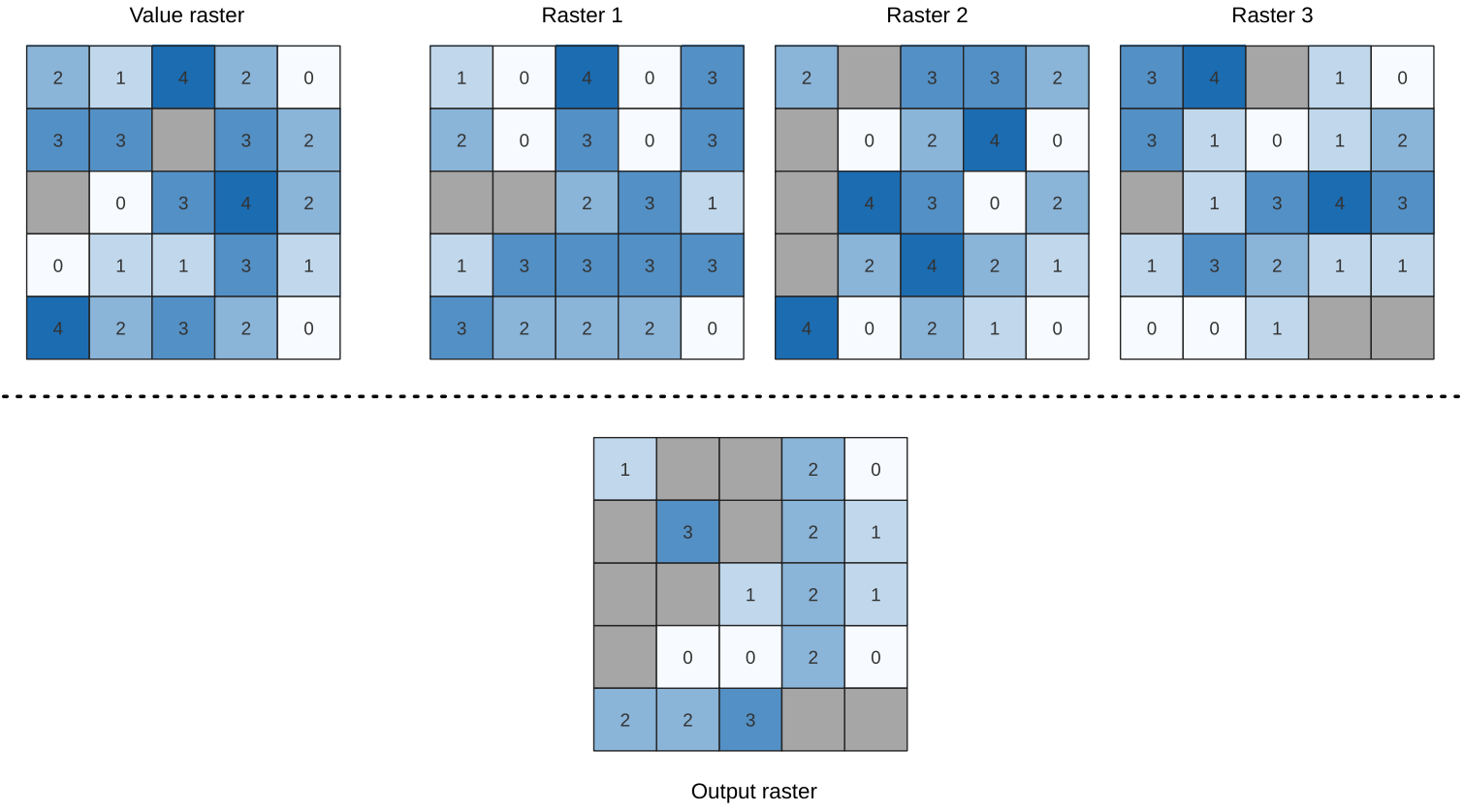
Fig. 25.17 For each cell in the output raster, the value represents the number of times
that the corresponding cells in the list of rasters are less than the value raster.
NoData cells (grey) are taken into account.
See also
Parameters
Basic parameters
Label |
Name |
Type |
Description |
|---|---|---|---|
Input value raster |
|
[raster] |
The input value layer serves as reference layer for the sample layers |
Value raster band |
|
[raster band] Default: The first band of the raster layer |
Select the band you want to use as sample |
Input raster layers |
|
[raster] [list] |
Raster layers to evaluate. If multiband rasters are used in the data raster stack, the algorithm will always perform the analysis on the first band of the rasters |
Ignore NoData values |
|
[boolean] Default: False |
If unchecked, any NoData cells in the value raster or the data layer stack will result in a NoData cell in the output raster |
Output layer |
|
[same as input] Default: |
Specification of the output raster. One of:
|
Advanced parameters
Label |
Name |
Type |
Description |
|---|---|---|---|
Output no data value Optional |
|
[number] Default: -9999.0 |
Value to use for nodata in the output layer |
Outputs
Label |
Name |
Type |
Description |
|---|---|---|---|
Output layer |
|
[raster] |
Output raster layer containing the result |
CRS authority identifier |
|
[string] |
The coordinate reference system of the output raster layer |
Extent |
|
[string] |
The spatial extent of the output raster layer |
Count of cells with equal value occurrences |
|
[number] |
|
Height in pixels |
|
[number] |
The number of rows in the output raster layer |
Total pixel count |
|
[integer] |
The count of pixels in the output raster layer |
Mean frequency at valid cell locations |
|
[number] |
|
Count of value occurrences |
|
[number] |
|
Width in pixels |
|
[integer] |
The number of columns in the output raster layer |
Python code
Algorithm ID: native:lessthanfrequency
import processing
processing.run("algorithm_id", {parameter_dictionary})
The algorithm id is displayed when you hover over the algorithm in the Processing Toolbox. The parameter dictionary provides the parameter NAMEs and values. See Using processing algorithms from the console for details on how to run processing algorithms from the Python console.
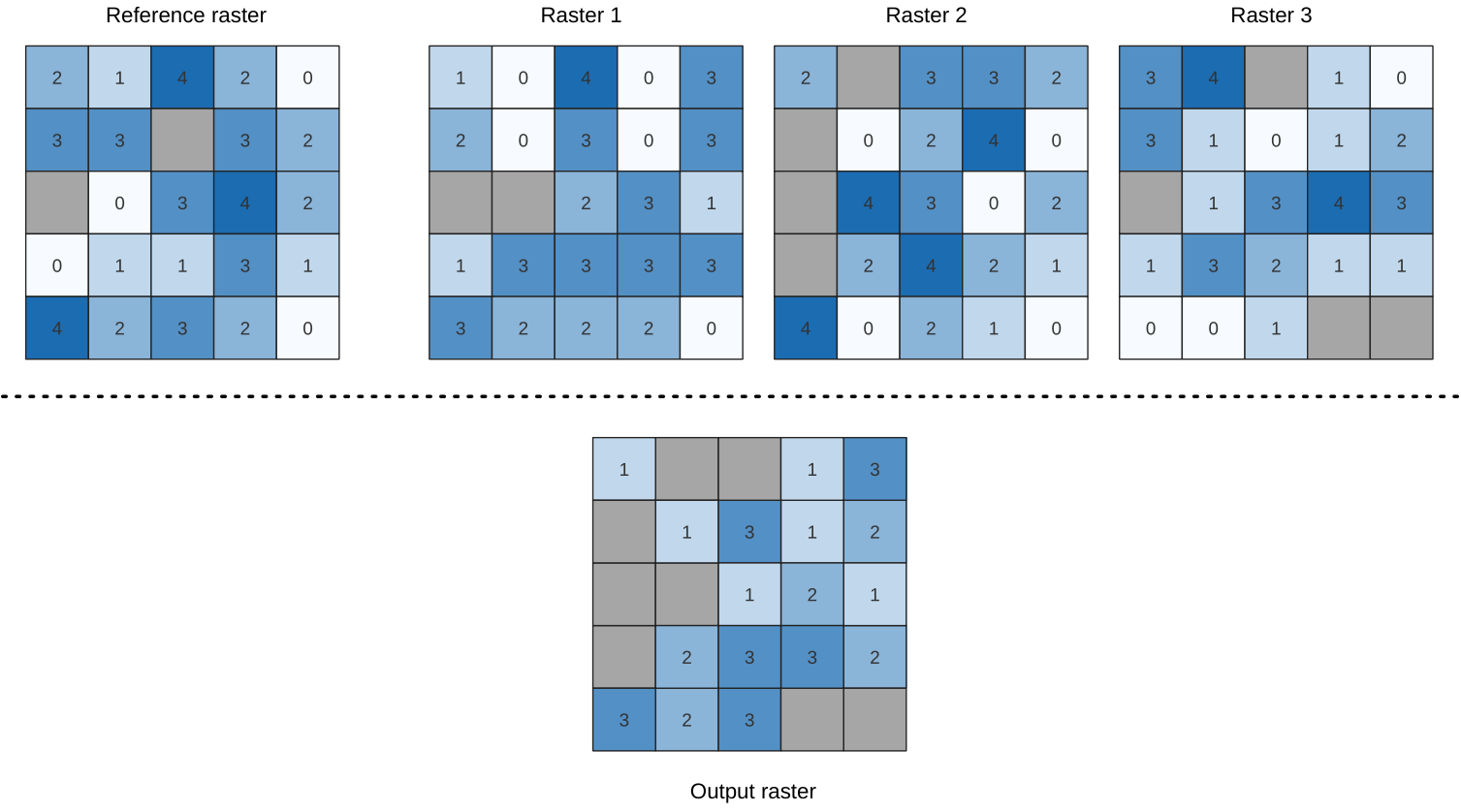
25.1.11.15. Lowest position in raster stack
Evaluates on a cell-by-cell basis the position of the raster with the lowest value in a stack of rasters. Position counts start with 1 and range to the total number of input rasters. The order of the input rasters is relevant for the algorithm. If multiple rasters feature the lowest value, the first raster will be used for the position value.
If multiband rasters are used in the data raster stack, the algorithm will
always perform the analysis on the first band of the rasters - use GDAL to use
other bands in the analysis.
Any NoData cells in the raster layer stack will result in a NoData cell
in the output raster unless the “ignore NoData” parameter is checked.
The output NoData value can be set manually. The output rasters extent and
resolution is defined by a reference raster layer and is always of Int32 type.
See also
Parameters
Basic parameters
Label |
Name |
Type |
Description |
|---|---|---|---|
Input raster layers |
|
[raster] [list] |
List of raster layers to compare with |
Reference layer |
|
[raster] |
The reference layer for the output layer creation (extent, CRS, pixel dimensions) |
Ignore NoData values |
|
[boolean] Default: False |
If unchecked, any NoData cells in the data layer stack will result in a NoData cell in the output raster |
Output layer |
|
[raster] Default: |
Specification of the output raster containing the result. One of:
|
Advanced parameters
Label |
Name |
Type |
Description |
|---|---|---|---|
Output no data value |
|
[number] Default: -9999.0 |
Value to use for nodata in the output layer |
Outputs
Label |
Name |
Type |
Description |
|---|---|---|---|
Output layer |
|
[raster] |
Output raster layer containing the result |
CRS authority identifier |
|
[string] |
The coordinate reference system of the output raster layer |
Extent |
|
[string] |
The spatial extent of the output raster layer |
Width in pixels |
|
[integer] |
The number of columns in the output raster layer |
Height in pixels |
|
[integer] |
The number of rows in the output raster layer |
Total pixel count |
|
[integer] |
The count of pixels in the output raster layer |
Python code
Algorithm ID: native:lowestpositioninrasterstack
import processing
processing.run("algorithm_id", {parameter_dictionary})
The algorithm id is displayed when you hover over the algorithm in the Processing Toolbox. The parameter dictionary provides the parameter NAMEs and values. See Using processing algorithms from the console for details on how to run processing algorithms from the Python console.
25.1.11.16. Raster boolean AND
Calculates the boolean AND for a set of input rasters.
If all of the input rasters have a non-zero value for a pixel, that
pixel will be set to 1 in the output raster.
If any of the input rasters have 0 values for the pixel it will
be set to 0 in the output raster.
The reference layer parameter specifies an existing raster layer to use as a reference when creating the output raster. The output raster will have the same extent, CRS, and pixel dimensions as this layer.
By default, a nodata pixel in ANY of the input layers will result in a
nodata pixel in the output raster.
If the Treat nodata values as false option is checked,
then nodata inputs will be treated the same as a 0 input value.
See also
Parameters
Basic parameters
Label |
Name |
Type |
Description |
|---|---|---|---|
Input layers |
|
[raster] [list] |
List of input raster layers |
Reference layer |
|
[raster] |
The reference layer to create the output layer from (extent, CRS, pixel dimensions) |
Treat nodata values as false |
|
[boolean] Default: False |
Treat nodata values in the input files as 0 when performing the operation |
Output layer |
|
[raster] Default: |
Specification of the output raster containing the result. One of:
|
Advanced parameters
Label |
Name |
Type |
Description |
|---|---|---|---|
Output no data value |
|
[number] Default: -9999.0 |
Value to use for nodata in the output layer |
Output data type |
|
[enumeration] Default: 5 |
Output raster data type. Options:
|
Outputs
Label |
Name |
Type |
Description |
|---|---|---|---|
Extent |
|
[string] |
The spatial extent of the output raster layer |
CRS authority identifier |
|
[crs] |
The coordinate reference system of the output raster layer |
Width in pixels |
|
[integer] |
The number of columns in the output raster layer |
Height in pixels |
|
[integer] |
The number of rows in the output raster layer |
Total pixel count |
|
[integer] |
The count of pixels in the output raster layer |
NODATA pixel count |
|
[integer] |
The count of nodata pixels in the output raster layer |
True pixel count |
|
[integer] |
The count of True pixels (value = 1) in the output raster layer |
False pixel count |
|
[integer] |
The count of False pixels (value = 0) in the output raster layer |
Output layer |
|
[raster] |
Output raster layer containing the result |
Python code
Algorithm ID: native:rasterbooleanand
import processing
processing.run("algorithm_id", {parameter_dictionary})
The algorithm id is displayed when you hover over the algorithm in the Processing Toolbox. The parameter dictionary provides the parameter NAMEs and values. See Using processing algorithms from the console for details on how to run processing algorithms from the Python console.
25.1.11.17. Raster boolean OR
Calculates the boolean OR for a set of input rasters.
If all of the input rasters have a zero value for a pixel, that
pixel will be set to 0 in the output raster.
If any of the input rasters have 1 values for the pixel it will
be set to 1 in the output raster.
The reference layer parameter specifies an existing raster layer to use as a reference when creating the output raster. The output raster will have the same extent, CRS, and pixel dimensions as this layer.
By default, a nodata pixel in ANY of the input layers will result in a
nodata pixel in the output raster.
If the Treat nodata values as false option is checked,
then nodata inputs will be treated the same as a 0 input value.
See also
Parameters
Basic parameters
Label |
Name |
Type |
Description |
|---|---|---|---|
Input layers |
|
[raster] [list] |
List of input raster layers |
Reference layer |
|
[raster] |
The reference layer to create the output layer from (extent, CRS, pixel dimensions) |
Treat nodata values as false |
|
[boolean] Default: False |
Treat nodata values in the input files as 0 when performing the operation |
Output layer |
|
[raster] Default: |
Specification of the output raster containing the result. One of:
|
Advanced parameters
Label |
Name |
Type |
Description |
|---|---|---|---|
Output no data value |
|
[number] Default: -9999.0 |
Value to use for nodata in the output layer |
Output data type |
|
[enumeration] Default: 5 |
Output raster data type. Options:
|
Outputs
Label |
Name |
Type |
Description |
|---|---|---|---|
Extent |
|
[string] |
The spatial extent of the output raster layer |
CRS authority identifier |
|
[crs] |
The coordinate reference system of the output raster layer |
Width in pixels |
|
[integer] |
The number of columns in the output raster layer |
Height in pixels |
|
[integer] |
The number of rows in the output raster layer |
Total pixel count |
|
[integer] |
The count of pixels in the output raster layer |
NODATA pixel count |
|
[integer] |
The count of nodata pixels in the output raster layer |
True pixel count |
|
[integer] |
The count of True pixels (value = 1) in the output raster layer |
False pixel count |
|
[integer] |
The count of False pixels (value = 0) in the output raster layer |
Output layer |
|
[raster] |
Output raster layer containing the result |
Python code
Algorithm ID: native:rasterbooleanor
import processing
processing.run("algorithm_id", {parameter_dictionary})
The algorithm id is displayed when you hover over the algorithm in the Processing Toolbox. The parameter dictionary provides the parameter NAMEs and values. See Using processing algorithms from the console for details on how to run processing algorithms from the Python console.
25.1.11.18. Raster calculator
Performs algebraic operations using raster layers.
The resulting layer will have its values computed according to an expression. The expression can contain numerical values, operators and references to any of the layers in the current project.
Note
When using the calculator in The batch processing interface or from
the QGIS Python console the files to use have to be specified.
The corresponding layers are referred using the base name of the
file (without the full path).
For instance, if using a layer at path/to/my/rasterfile.tif,
the first band of that layer will be referred as
rasterfile.tif@1.
See also
Parameters
Label |
Name |
Type |
Description |
|---|---|---|---|
Layers |
GUI only |
Shows the list of all raster layers loaded in the legend.
These can be used to fill the expression box (double click to
add).
Raster layers are referred by their name and the number of the
band: |
|
Operators |
GUI only |
Contains some calculator like buttons that can be used to fill the expression box. |
|
Expression |
|
[string] |
Expression that will be used to calculate the output raster layer. You can use the operator buttons provided to type directly the expression in this box. |
Predefined expressions |
GUI only |
You can use the predefined |
|
Reference layer(s) (used for automated extent, cellsize, and CRS) Optional |
|
[raster] [list] |
Layer(s) that will be used to fetch extent, cell size and CRS.
By choosing the layer in this box you avoid filling in all the
other parameters by hand.
Raster layers are referred by their name and the number of
the band: |
Cell size (use 0 or empty to set it automatically) Optional |
|
[number] |
Cell size of the output raster layer. If the cell size is not specified, the minimum cell size of the selected reference layer(s) will be used. The cell size will be the same for the X and Y axes. |
Output extent Optional |
|
[extent] |
Specify the spatial extent of the output raster layer. If the extent is not specified, the minimum extent that covers all the selected reference layers will be used. Available methods are:
|
Output CRS Optional |
|
[crs] |
CRS of the output raster layer. If the output CRS is not specified, the CRS of the first reference layer will be used. |
Output |
|
[raster] Default: |
Specification of the output raster. One of:
|
Outputs
Label |
Name |
Type |
Description |
|---|---|---|---|
Output |
|
[raster] |
Output raster file with the calculated values. |
Python code
Algorithm ID: qgis:rastercalculator
import processing
processing.run("algorithm_id", {parameter_dictionary})
The algorithm id is displayed when you hover over the algorithm in the Processing Toolbox. The parameter dictionary provides the parameter NAMEs and values. See Using processing algorithms from the console for details on how to run processing algorithms from the Python console.
25.1.11.19. Raster layer properties
NEW in 3.20
Returns basic properties of the given raster layer, including the extent, size in pixels and dimensions of pixels (in map units), number of bands, and no data value.
This algorithm is intended for use as a means of extracting these useful properties to use as the input values to other algorithms in a model - e.g. to allow to pass an existing raster’s pixel sizes over to a GDAL raster algorithm.
Parameters
Label |
Name |
Type |
Description |
|---|---|---|---|
Input layer |
|
[raster] |
Input raster layer |
Band number Optional |
|
[raster band] Default: Not set |
Whether to also return properties of a specific band. If a band is specified, the noData value for the selected band is also returned. |
Outputs
Label |
Name |
Type |
Description |
|---|---|---|---|
Number of bands in raster |
|
[number] |
The number of bands in the raster |
CRS authority identifier |
|
[string] |
The coordinate reference system of the output raster layer |
Extent |
|
[string] |
The raster layer extent in the CRS |
Band has a NoData value set |
|
[Boolean] |
Indicates whether the raster layer has a value set for NODATA pixels in the selected band |
Height in pixels |
|
[integer] |
The number of columns in the raster layer |
Band NoData value |
|
[number] |
The value (if set) of the NoData pixels in the selected band |
Pixel size (height) in map units |
|
[integer] |
Vertical size in map units of the pixel |
Pixel size (width) in map units |
|
[integer] |
Horizontal size in map units of the pixel |
Width in pixels |
|
[integer] |
The number of rows in the raster layer |
Maximum x-coordinate |
|
[number] |
|
Minimum x-coordinate |
|
[number] |
|
Maximum y-coordinate |
|
[number] |
|
Minimum y-coordinate |
|
[number] |
Python code
Algorithm ID: native:rasterlayerproperties
import processing
processing.run("algorithm_id", {parameter_dictionary})
The algorithm id is displayed when you hover over the algorithm in the Processing Toolbox. The parameter dictionary provides the parameter NAMEs and values. See Using processing algorithms from the console for details on how to run processing algorithms from the Python console.
25.1.11.20. Raster layer statistics
Calculates basic statistics from the values in a given band of the raster layer. The output is loaded in the menu.
Parameters
Label |
Name |
Type |
Description |
|---|---|---|---|
Input layer |
|
[raster] |
Input raster layer |
Band number |
|
[raster band] Default: The first band of the input layer |
If the raster is multiband, choose the band you want to get statistics for. |
Statistics |
|
[html] Default: |
Specification of the output file:
|
Outputs
Label |
Name |
Type |
Description |
|---|---|---|---|
Maximum value |
|
[number] |
|
Mean value |
|
[number] |
|
Minimum value |
|
[number] |
|
Statistics |
|
[html] |
The output file contains the following information:
|
Range |
|
[number] |
|
Standard deviation |
|
[number] |
|
Sum |
|
[number] |
|
Sum of the squares |
|
[number] |
Python code
Algorithm ID: native:rasterlayerstatistics
import processing
processing.run("algorithm_id", {parameter_dictionary})
The algorithm id is displayed when you hover over the algorithm in the Processing Toolbox. The parameter dictionary provides the parameter NAMEs and values. See Using processing algorithms from the console for details on how to run processing algorithms from the Python console.
25.1.11.21. Raster layer unique values report
Returns the count and area of each unique value in a given raster layer.
Parameters
Label |
Name |
Type |
Description |
|---|---|---|---|
Input layer |
|
[raster] |
Input raster layer |
Band number |
|
[raster band] Default: The first band of the input layer |
If the raster is multiband, choose the band you want to get statistics for. |
Unique values report |
|
[file] Default: |
Specification of the output file:
|
Unique values table |
|
[table] Default: |
Specification of the table for unique values:
The file encoding can also be changed here. |
Outputs
Label |
Name |
Type |
Description |
|---|---|---|---|
CRS authority identifier |
|
[string] |
The coordinate reference system of the output raster layer |
Extent |
|
[string] |
The spatial extent of the output raster layer |
Height in pixels |
|
[integer] |
The number of rows in the output raster layer |
NODATA pixel count |
|
[number] |
The number of NODATA pixels in the output raster layer |
Total pixel count |
|
[integer] |
The count of pixels in the output raster layer |
Unique values report |
|
[html] |
The output HTML file contains the following information:
|
Unique values table |
|
[table] |
A table with three columns:
|
Width in pixels |
|
[integer] |
The number of columns in the output raster layer |
Python code
Algorithm ID: native:rasterlayeruniquevaluesreport
import processing
processing.run("algorithm_id", {parameter_dictionary})
The algorithm id is displayed when you hover over the algorithm in the Processing Toolbox. The parameter dictionary provides the parameter NAMEs and values. See Using processing algorithms from the console for details on how to run processing algorithms from the Python console.
25.1.11.22. Raster layer zonal statistics
Calculates statistics for a raster layer’s values, categorized by zones defined in another raster layer.
See also
Parameters
Basic parameters
Label |
Name |
Type |
Description |
|---|---|---|---|
Input Layer |
|
[raster] |
Input raster layer |
Band number |
|
[raster band] Default: The first band of the raster layer |
If the raster is multiband choose the band for which you want to calculate the statistics. |
Zones layer |
|
[raster] |
Raster layer defining zones. Zones are given by contiguous pixels having the same pixel value. |
Zones band number |
|
[raster band] Default: The first band of the raster layer |
If the raster is multiband, choose the band that defines the zones |
Statistics |
|
[table] Default: |
Specification of the output report. One of:
The file encoding can also be changed here. |
Advanced parameters
Label |
Name |
Type |
Description |
|---|---|---|---|
Reference layer Optional |
|
[enumeration] Default: 0 |
Raster layer used to calculate the centroids that will be used as reference when determining the zones in the output layer. One of:
|
Outputs
Label |
Name |
Type |
Description |
|---|---|---|---|
CRS authority identifier |
|
[string] |
The coordinate reference system of the output raster layer |
Extent |
|
[string] |
The spatial extent of the output raster layer |
Height in pixels |
|
[integer] |
The number of rows in the output raster layer |
NODATA pixel count |
|
[number] |
The number of NODATA pixels in the output raster layer |
Statistics |
|
[table] |
The output layer contains the following information for each zone:
|
Total pixel count |
|
[number] |
The count of pixels in the output raster layer |
Width in pixels |
|
[number] |
The number of columns in the output raster layer |
Python code
Algorithm ID: native:rasterlayerzonalstats
import processing
processing.run("algorithm_id", {parameter_dictionary})
The algorithm id is displayed when you hover over the algorithm in the Processing Toolbox. The parameter dictionary provides the parameter NAMEs and values. See Using processing algorithms from the console for details on how to run processing algorithms from the Python console.
25.1.11.23. Raster surface volume
Calculates the volume under a raster surface relative to a given base level. This is mainly useful for Digital Elevation Models (DEM).
Parameters
Label |
Name |
Type |
Description |
|---|---|---|---|
INPUT layer |
|
[raster] |
Input raster, representing a surface |
Band number |
|
[raster band] Default: The first band of the raster layer |
If the raster is multiband, choose the band that shall define the surface. |
Base level |
|
[number] Default: 0.0 |
Define a base or reference value.
This base is used in the volume calculation according to the
|
Method |
|
[enumeration] Default: 0 |
Define the method for the volume calculation given by the
difference between the raster pixel value and the
|
Surface volume report |
|
[html] Default: |
Specification of the output HTML report. One of:
The file encoding can also be changed here. |
Surface volume table |
|
[table] Default: |
Specification of the output table. One of:
The file encoding can also be changed here. |
Outputs
Label |
Name |
Type |
Description |
|---|---|---|---|
Volume |
|
[number] |
The calculated volume |
Area |
|
[number] |
The area in square map units |
Pixel_count |
|
[number] |
The total number of pixels that have been analyzed |
Surface volume report |
|
[html] |
The output report (containing volume, area and pixel count) in HTML format |
Surface volume table |
|
[table] |
The output table (containing volume, area and pixel count) |
Python code
Algorithm ID: native:rastersurfacevolume
import processing
processing.run("algorithm_id", {parameter_dictionary})
The algorithm id is displayed when you hover over the algorithm in the Processing Toolbox. The parameter dictionary provides the parameter NAMEs and values. See Using processing algorithms from the console for details on how to run processing algorithms from the Python console.
25.1.11.24. Reclassify by layer
Reclassifies a raster band by assigning new class values based on the ranges specified in a vector table.
Parameters
Basic parameters
Label |
Name |
Type |
Description |
|---|---|---|---|
Raster layer |
|
[raster] |
Raster layer to reclassify |
Band number |
|
[raster band] Default: The first band of the raster layer |
If the raster is multiband, choose the band you want to reclassify. |
Layer containing class breaks |
|
[vector: any] |
Vector layer containing the values to use for classification. |
Minimum class value field |
|
[tablefield: numeric] |
Field with the minimum value of the range for the class. |
Maximum class value field |
|
[tablefield: numeric] |
Field with the maximum value of the range for the class. |
Output value field |
|
[tablefield: numeric] |
Field with the value that will be assigned to the pixels that fall in the class (between the corresponding min and max values). |
Reclassified raster |
|
[raster] Default: |
Specification of the output raster. One of:
|
Advanced parameters
Label |
Name |
Type |
Description |
|---|---|---|---|
Output no data value |
|
[number] Default: -9999.0 |
Value to apply to no data values. |
Range boundaries |
|
[enumeration] Default: 0 |
Defines comparison rules for the classification. Options:
|
Use no data when no range matches value |
|
[boolean] Default: False |
Applies the no data value to band values that do not fall in any class. If False, the original value is kept. |
Output data type |
|
[enumeration] Default: 5 |
Defines the format of the output raster file. Options:
|
Outputs
Label |
Name |
Type |
Description |
|---|---|---|---|
Reclassified raster |
|
[raster] |
Output raster layer with reclassified band values |
Python code
Algorithm ID: native:reclassifybylayer
import processing
processing.run("algorithm_id", {parameter_dictionary})
The algorithm id is displayed when you hover over the algorithm in the Processing Toolbox. The parameter dictionary provides the parameter NAMEs and values. See Using processing algorithms from the console for details on how to run processing algorithms from the Python console.
25.1.11.25. Reclassify by table
Reclassifies a raster band by assigning new class values based on the ranges specified in a fixed table.
Parameters
Basic parameters
Label |
Name |
Type |
Description |
|---|---|---|---|
Raster layer |
|
[raster] |
Raster layer to reclassify |
Band number |
|
[raster band] Default: 1 |
Raster band for which you want to recalculate values. |
Reclassification table |
|
[table] |
A 3-columns table to fill with the values to set the boundaries
of each class ( |
Reclassified raster |
|
[raster] Default: |
Specification of the output raster layer. One of:
|
Advanced parameters
Label |
Name |
Type |
Description |
|---|---|---|---|
Output no data value |
|
[number] Default: -9999.0 |
Value to apply to no data values. |
Range boundaries |
|
[enumeration] Default: 0 |
Defines comparison rules for the classification. Options:
|
Use no data when no range matches value |
|
[boolean] Default: False |
Applies the no data value to band values that do not fall in any class. If False, the original value is kept. |
Output data type |
|
[enumeration] Default: 5 |
Defines the format of the output raster file. Options:
|
Outputs
Label |
Name |
Type |
Description |
|---|---|---|---|
Reclassified raster |
|
[raster] |
Output raster layer with reclassified band values |
Python code
Algorithm ID: native:reclassifybytable
import processing
processing.run("algorithm_id", {parameter_dictionary})
The algorithm id is displayed when you hover over the algorithm in the Processing Toolbox. The parameter dictionary provides the parameter NAMEs and values. See Using processing algorithms from the console for details on how to run processing algorithms from the Python console.
25.1.11.26. Rescale raster
Rescales raster layer to a new value range, while preserving the shape (distribution) of the raster’s histogram (pixel values). Input values are mapped using a linear interpolation from the source raster’s minimum and maximum pixel values to the destination minimum and miximum pixel range.
By default the algorithm preserves the original NODATA value, but there is an option to override it.
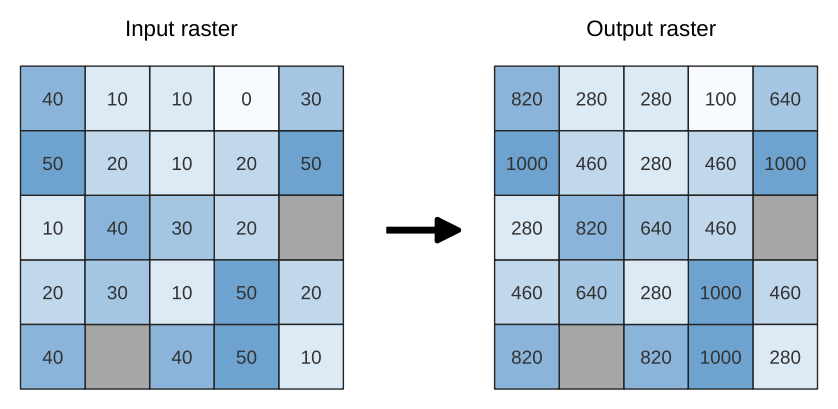
Fig. 25.18 Rescaling values of a raster layer from [0 - 50] to [100 - 1000]
Parameters
Label |
Name |
Type |
Description |
|---|---|---|---|
Input Raster |
|
[raster] |
Raster layer to use for rescaling |
Band number |
|
[raster band] Default: The first band of the input layer |
If the raster is multiband, choose a band. |
New minimum value |
|
[number] Default value: 0.0 |
Minimum pixel value to use in the rescaled layer |
New maximum value |
|
[number] Default value: 255.0 |
Maximum pixel value to use in the rescaled layer |
New NODATA value Optional |
|
[number] Default value: Not set |
Value to assign to the NODATA pixels. If unset, original NODATA values are preserved. |
Rescaled |
|
[raster] Default: |
Specification of the output raster layer. One of:
|
Outputs
Label |
Name |
Type |
Description |
|---|---|---|---|
Rescaled |
|
[raster] |
Output raster layer with rescaled band values |
Python code
Algorithm ID: native:rescaleraster
import processing
processing.run("algorithm_id", {parameter_dictionary})
The algorithm id is displayed when you hover over the algorithm in the Processing Toolbox. The parameter dictionary provides the parameter NAMEs and values. See Using processing algorithms from the console for details on how to run processing algorithms from the Python console.
25.1.11.27. Round raster
Rounds the cell values of a raster dataset according to the specified number of decimals.
Alternatively, a negative number of decimal places may be used to round values to powers of a base n. For example, with a Base value n of 10 and Decimal places of -1, the algorithm rounds cell values to multiples of 10, -2 rounds to multiples of 100, and so on. Arbitrary base values may be chosen, the algorithm applies the same multiplicative principle. Rounding cell values to multiples of a base n may be used to generalize raster layers.
The algorithm preserves the data type of the input raster. Therefore byte/integer rasters can only be rounded to multiples of a base n, otherwise a warning is raised and the raster gets copied as byte/integer raster.
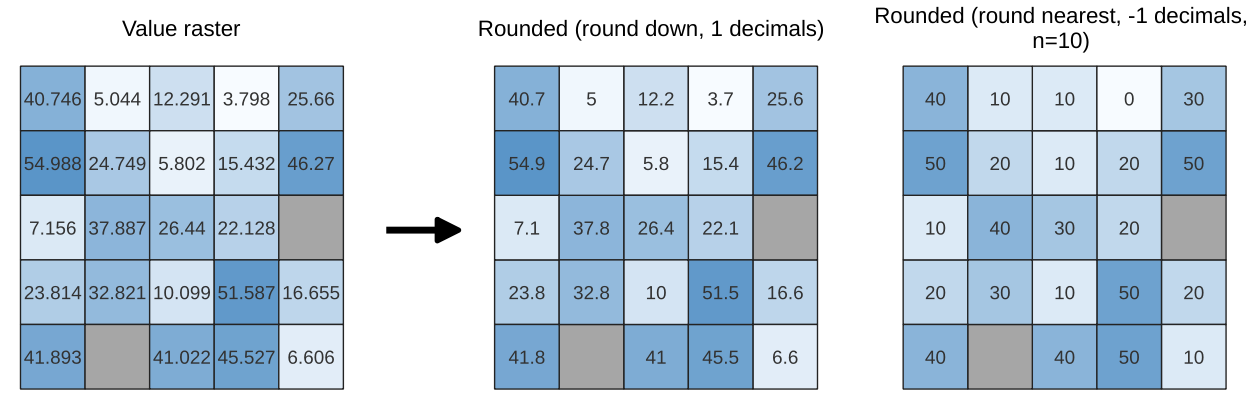
Fig. 25.19 Rounding values of a raster
Parameters
Basic parameters
Label |
Name |
Type |
Description |
|---|---|---|---|
Input raster |
|
[raster] |
The raster to process. |
Band number |
|
[number] Default: 1 |
The band of the raster |
Rounding direction |
|
[list] Default: 1 |
How to choose the target rounded value. Options are:
|
Number of decimals places |
|
[number] Default: 2 |
Number of decimals places to round to. Use negative values to round cell values to a multiple of a base n |
Output raster |
|
[raster] Default: |
Specification of the output file. One of:
|
Advanced parameters
Label |
Name |
Type |
Description |
|---|---|---|---|
Base n for rounding to multiples of n |
|
[number] Default: 10 |
When the |
Outputs
Label |
Name |
Type |
Description |
|---|---|---|---|
Output raster |
|
[raster] |
The output raster layer with values rounded for the selected band. |
Python code
Algorithm ID: native:roundrastervalues
import processing
processing.run("algorithm_id", {parameter_dictionary})
The algorithm id is displayed when you hover over the algorithm in the Processing Toolbox. The parameter dictionary provides the parameter NAMEs and values. See Using processing algorithms from the console for details on how to run processing algorithms from the Python console.
25.1.11.28. Sample raster values
Extracts raster values at the point locations. If the raster layer is multiband, each band is sampled.
The attribute table of the resulting layer will have as many new columns as the raster layer band count.
Parameters
Label |
Name |
Type |
Description |
|---|---|---|---|
Input Layer |
|
[vector: point] |
Point vector layer to use for sampling |
Raster Layer |
|
[raster] |
Raster layer to sample at the given point locations. |
Output column prefix |
|
[string] Default: ‘SAMPLE_’ |
Prefix for the names of the added columns. |
Sampled Optional |
|
[vector: point] Default: |
Specify the output layer containing the sampled values. One of:
The file encoding can also be changed here. |
Outputs
Label |
Name |
Type |
Description |
|---|---|---|---|
Sampled |
|
[vector: point] |
The output layer containing the sampled values. |
Python code
Algorithm ID: native:rastersampling
import processing
processing.run("algorithm_id", {parameter_dictionary})
The algorithm id is displayed when you hover over the algorithm in the Processing Toolbox. The parameter dictionary provides the parameter NAMEs and values. See Using processing algorithms from the console for details on how to run processing algorithms from the Python console.
25.1.11.29. Zonal histogram
Appends fields representing counts of each unique value from a raster layer contained within polygon features.
The output layer attribute table will have as many fields as the unique values of the raster layer that intersects the polygon(s).
Fig. 25.20 Raster layer histogram example
Parameters
Label |
Name |
Type |
Description |
|---|---|---|---|
Raster layer |
|
[raster] |
Input raster layer. |
Band number |
|
[raster band] Default: The first band of the input layer |
If the raster is multiband, choose a band. |
Vector layer containing zones |
|
[vector: polygon] |
Vector polygon layer that defines the zones. |
Output column prefix |
Optional |
[string] Default: ‘HISTO_’ |
Prefix for the output columns names. |
Output zones |
|
[vector: polygon] Default: |
Specify the output vector polygon layer. One of:
The file encoding can also be changed here. |
Outputs
Label |
Name |
Type |
Description |
|---|---|---|---|
Output zones |
|
[vector: polygon] |
The output vector polygon layer. |
Python code
Algorithm ID: native:zonalhistogram
import processing
processing.run("algorithm_id", {parameter_dictionary})
The algorithm id is displayed when you hover over the algorithm in the Processing Toolbox. The parameter dictionary provides the parameter NAMEs and values. See Using processing algorithms from the console for details on how to run processing algorithms from the Python console.
25.1.11.30. Zonal statistics
Calculates statistics of a raster layer for each feature of an overlapping polygon vector layer.
Parameters
Label |
Name |
Type |
Description |
|---|---|---|---|
Input layer |
|
[vector: polygon] |
Vector polygon layer that contains the zones. |
Raster layer |
|
[raster] |
Input raster layer. |
Raster band |
|
[raster band] Default: The first band of the input layer |
If the raster is multiband, choose a band for the statistics. |
Output column prefix |
|
[string] Default: ‘_’ |
Prefix for the output columns names. |
Statistics to calculate |
|
[enumeration] [list] Default: [0,1,2] |
List of statistical operator for the output. Options:
|
Zonal Statistics |
|
[vector: polygon] Default: |
Specify the output vector polygon layer. One of:
The file encoding can also be changed here. |
Outputs
Label |
Name |
Type |
Description |
|---|---|---|---|
Zonal Statistics |
|
[vector: polygon] |
The zone vector layer with added statistics. |
Python code
Algorithm ID: native:zonalstatisticsfb
import processing
processing.run("algorithm_id", {parameter_dictionary})
The algorithm id is displayed when you hover over the algorithm in the Processing Toolbox. The parameter dictionary provides the parameter NAMEs and values. See Using processing algorithms from the console for details on how to run processing algorithms from the Python console.