Importante
La traduzione è uno sforzo comunitario you can join. Questa pagina è attualmente tradotta al 75.00%.
17.23. Ancora sull’interpolazione
Nota
Questo capitolo mostra un altro caso pratico sull’algoritmo dell’interpolazione.
L’interpolazione è una tecnica comune, e puoi usarla per mostrare diverse tecniche utili attraverso gli strumenti di processing QGIS. Questa lezione usa alcuni algoritmi di interpolazione che sono stati già introdotti, ma ha un approccio diverso.
I dati per questa lezione contengono anche uno layer di punti, in questo caso con dati di elevazione. Ti accingi a interpolare in modo assai simile a come hai fatto nella lezione precedente, ma stavolta salverai parte dei dati originali per valutare la qualità del processo di interpolazione.
First, we have to rasterize the points layer and fill the resulting no–data cells, but using just a fraction of the points in the layer. We will save 10% of the points for a later check, so we need to have 90% of the points ready for the interpolation. To do so, we could use the Split shapes layer randomly algorithm, which we have already used in a previous lesson, but there is a better way to do that, without having to create any new intermediate layer. Instead of that, we can just select the points we want to use for the interpolation (the 90% fraction), and then run the algorithm. As we have already seen, the rasterizing algorithm will use only those selected points and ignore the rest. The selection can be done using the Random selection algorithm. Run it with the following parameters.
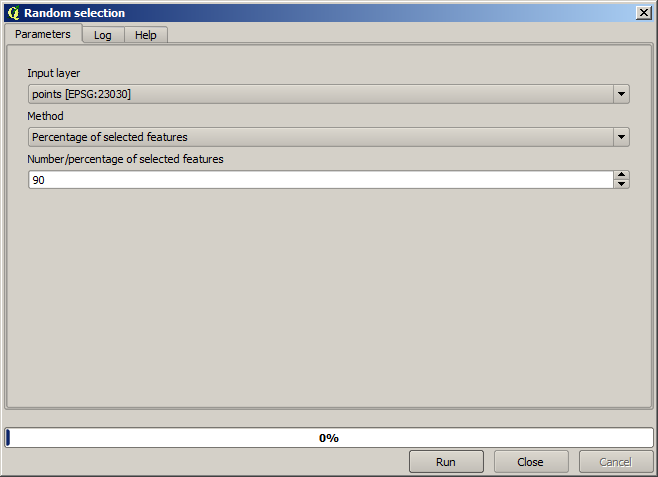
Sarà selezionato il 90% dei punti del layer da rasterizzare.

La selezione è casuale, così la tua selezione potrebbe differire dalla selezione mostrato nell’immagine qui sopra.
Now run the Rasterize algorithm to get the first raster layer, and then run the Close gaps algorithm to fill the no-data cells [Cell resolution: 100 m].

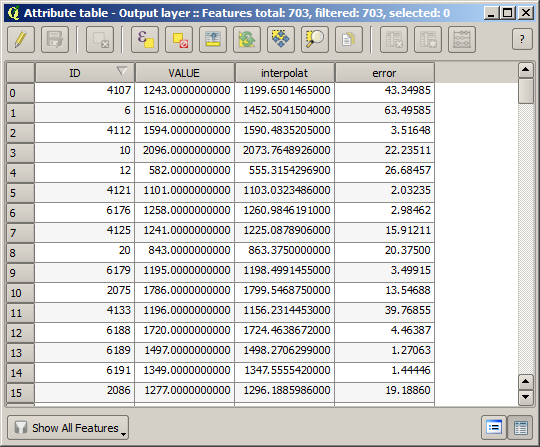
Per controllare la qualità dell’interpolazione, ora puoi utilizzare i punti che non sono stati selezionati. A questo punto, conosci l” elevazione reale (valore nello strato punti) e l’elevazione interpolato (il valore nello strato raster interpolati). Puoi confrontare le due calcolando le differenze tra questi valori.
Dal momento che utilizzarai i punti che non sono stati selezionati prima, inverti la selezione.

The points contain the original values, but not the interpolated ones. To add them in a new field, we can use the Add raster values to points algorithm
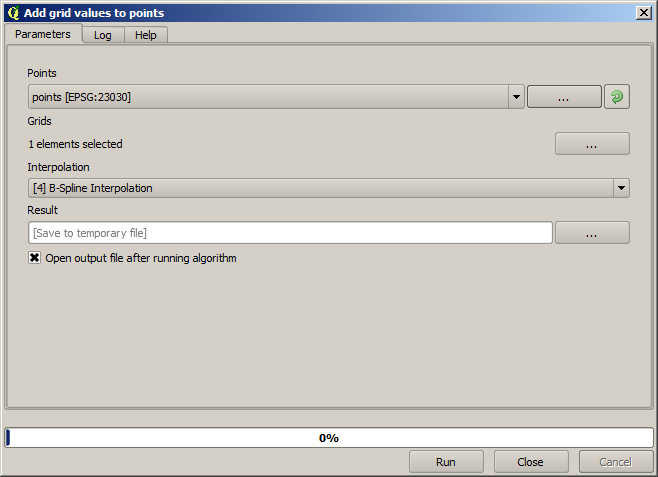
The raster layer to select (the algorithm supports multiple raster, but we just need one) is the resulting one from the interpolation. We have renamed it to interpolate and that layer name is the one that will be used for the name of the field to add.
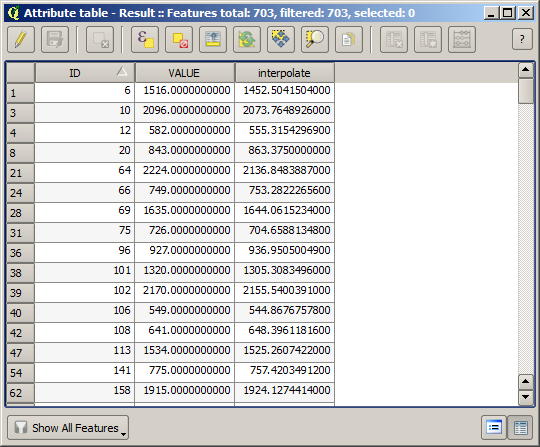
Ora hai un vettore che contiene entrambi i valori, con punti non utilizzati per l’interpolazione
Now, we will use the fields calculator for this task. Open the Field calculator algorithm and run it with the following parameters.
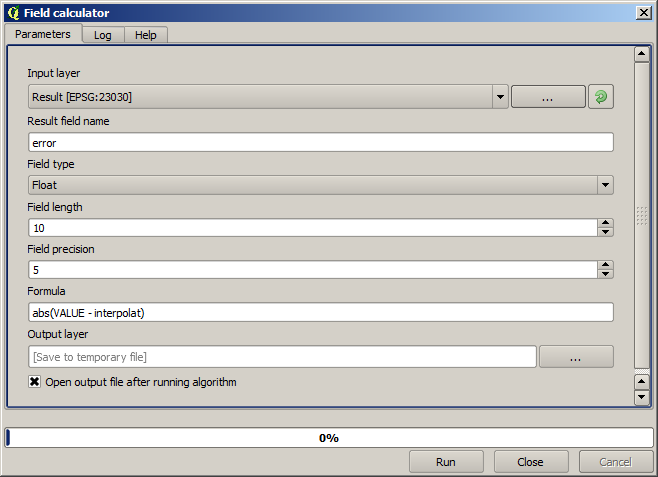
Se il tuo campo con i valori del raster ha un nome diverso, è necessario modificare la formula sopra di conseguenza. XCon l’esecuzione di questo algoritmo, otterrai un nuovo livello con solo i punti che non hai usato per l’interpolazione, ognuno dei quali contiene la differenza tra i due valori di elevazione.
Rappresentare quello strato in base al valore che ci darà una prima idea di dove si trovano le maggiori differenze.
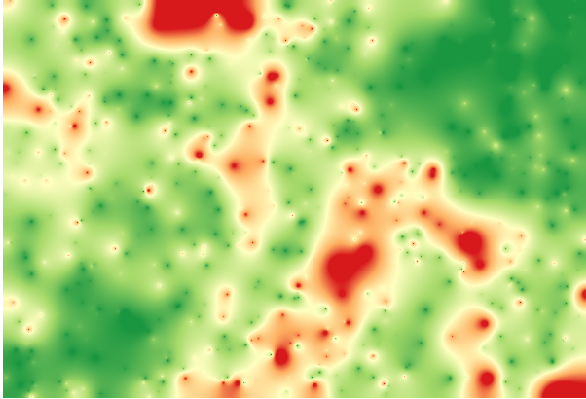
Interpolando quello strato otterrà un raster con l’errore stimato in tutti i punti dell’area interpolata.
Puoi inoltre ottenere le stesse informazioni (differenza tra i valori dei punti di origine e quelli interpolati) direttamente con .
I tuoio risultati potrebbero differire da questi, dato che c’è una componente casuale introdotta durante l’esecuzione all’inizio di questa lezione.