17.16. Hydrologische analyse
Notitie
In deze les zullen we een hydrologische analyse uitvoeren. Deze analyse zal worden gebruikt in enkele van de volgende lessen, omdat het bestaat uit een goed voorbeeld van een werkstroom voor een analyse, en we het zullen gebruiken voor het demonstreren van enkele geavanceerde mogelijkheden.
Doelen: Beginnend met een DEM, zullen we een netwerk van kanalen gaan uitnemen, waterbergingen uittekenen en enkele statistieken berekenen.
Het eerste is om het project te laden met de gegevens voor de les, wat slechts een DEM bevat.
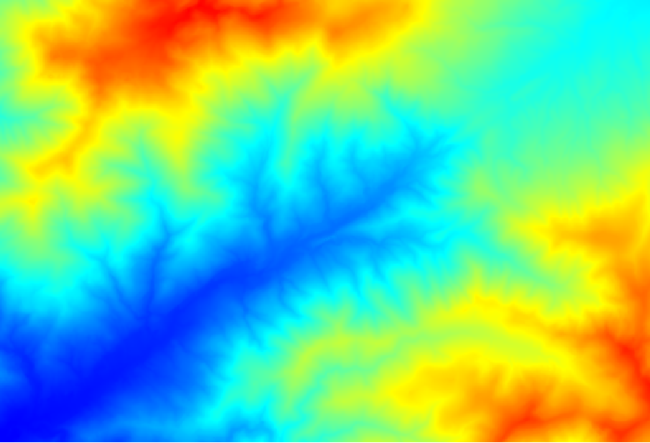
De eerste module die moet worden uitgevoerd is Catchment area (in sommige versies van SAGA wordt hij Flow accumulation (Top Down) genoemd). U kunt elk van de andere, genaamd Catchment area, gebruiken. Zij hebben verschillende onderliggende algoritmes, maar de resultaten zijn in de basis hetzelfde.
Selecteer de DEM in het veld Elevation, en laat de rest van de parameters staan op de standaardwaarden.
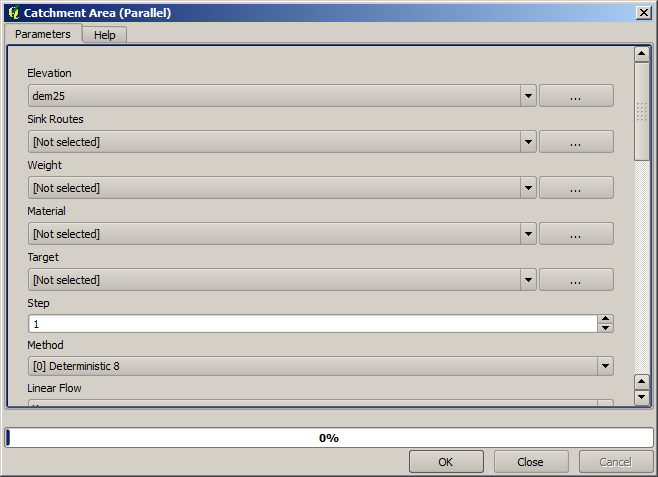
Sommige algoritmes berekenen vele lagen, maar de laag Catchment Area is de enige die we zullen gebruiken. U kunt de andere verwijderen als u dat wilt.
Het renderen van de laag is niet erg informatief.
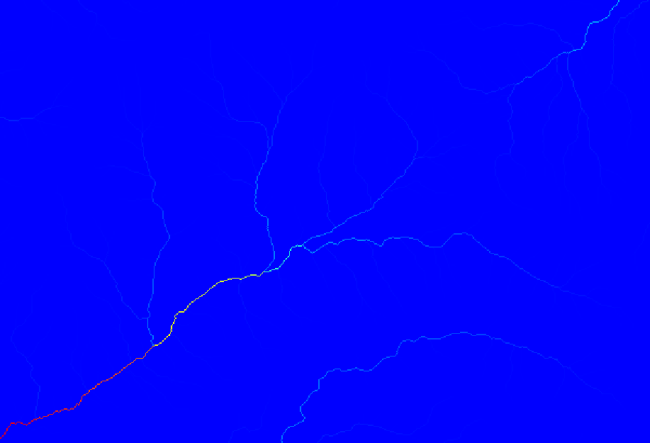
U kunt, om te weten waarom, naar het histogram kijken en u zult zien dat de waarden niet evenredig zijn verdeeld (er zijn enkele cellen met een zeer hoge waarde, die welke overeenkomen met het netwerk van kanalen). Gebruik het algoritme Raster calculator om de logaritme te berekenen van de waarde van het opvanggebied en u zult een laag met veel mer informatie krijgen.

Het opvanggebied (ook bekend als flow accumulation), kan worden gebruikt om een drempel in te stellen voor het initiëren van kanalen. Dit kan worden gedaan met behulp van het algoritme Channel network.
Initiation grid: gebruik de laag Catchment Area en niet die van de logaritme.
Initiation threshold:
10.000.000Initiation type: Greater than
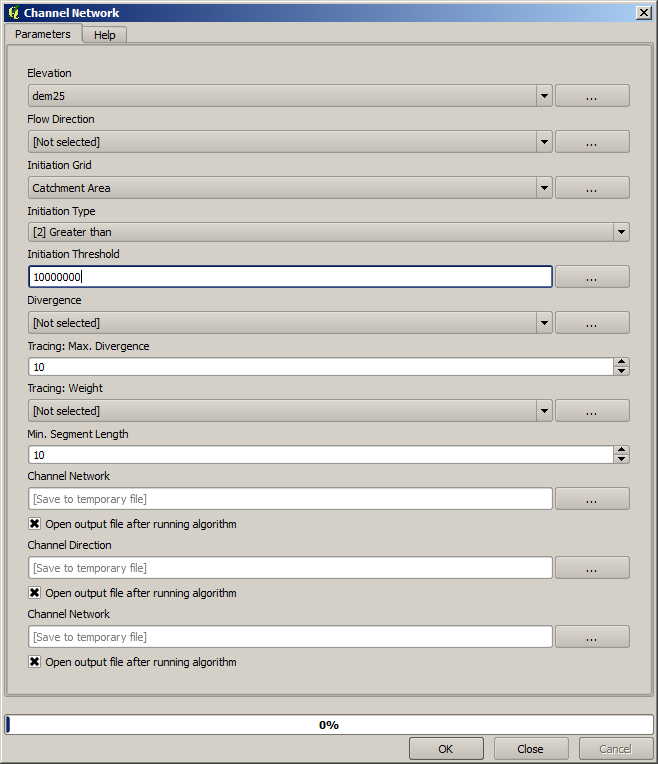
Als u de waarde Initiation threshold verhoogt, zult u een schaarser netwerk van kanalen verkrijgen. Als u het verlaagt, zult u een dichter verkrijgen. Dit is wat u krijgt met de voorgestelde waarde.
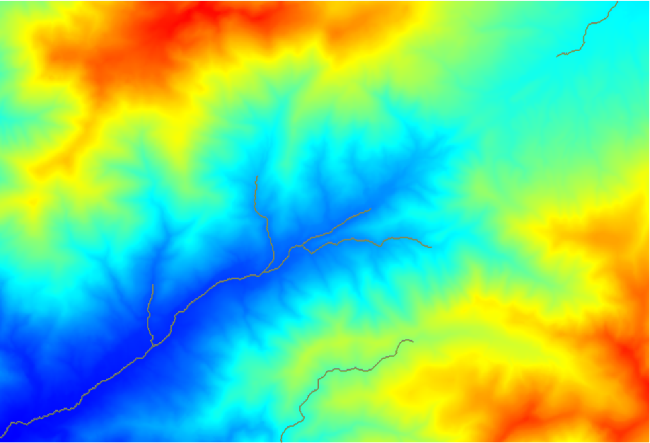
De afbeelding hierboven geeft slechts de resulterende vectorlaag en de DEM weer, maar er zou ook een rasterlaag moeten zijn met hetzelfde netwerk van kanalen. Die rasterlaag zal, in feite, de laag zijn die we zullen gaan gebruiken.
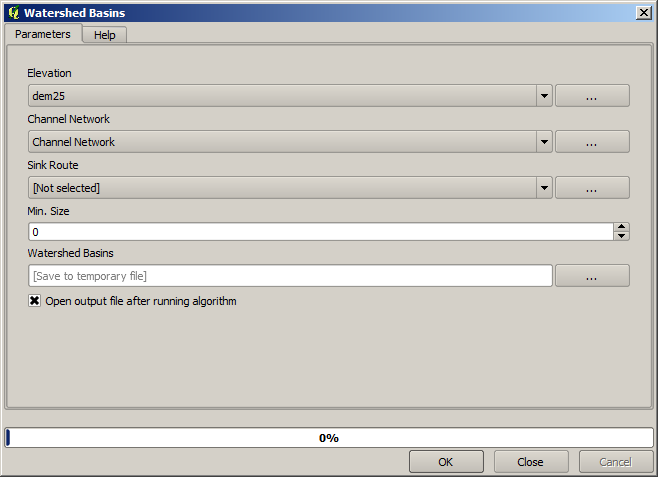
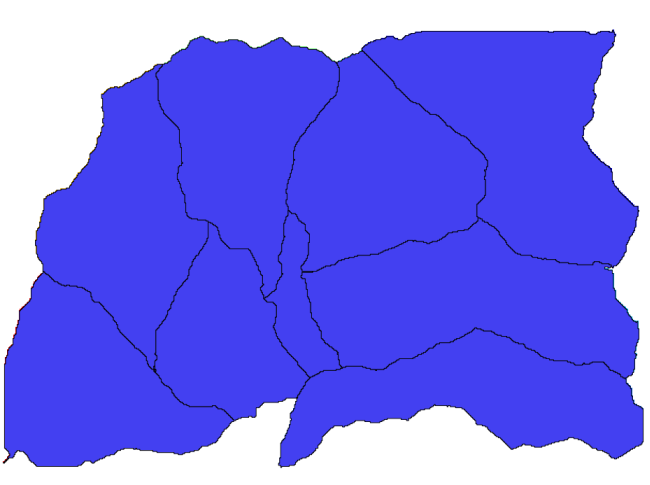
Nu zullen we het algoritme Watersheds basins gaan gebruiken om de subbassins uit te tekenen die overeenkomen met dat netwerk van kanalen, waarbij we alle kruisingen daarin gebruiken als uitlaatpunt. Hier staat hoe u het overeenkomende dialoogvensters met parameters moet instellen.
En dit is wat u zult krijgen.
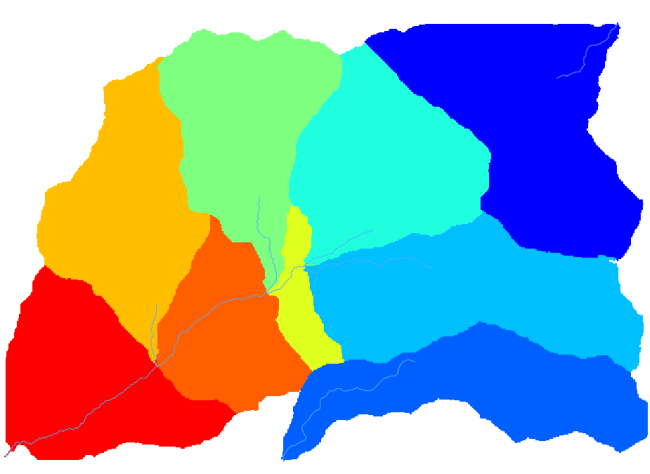
Dit is een resultaat als raster. U kunt het vectoriseren met het algoritme Vectorising grid classes.
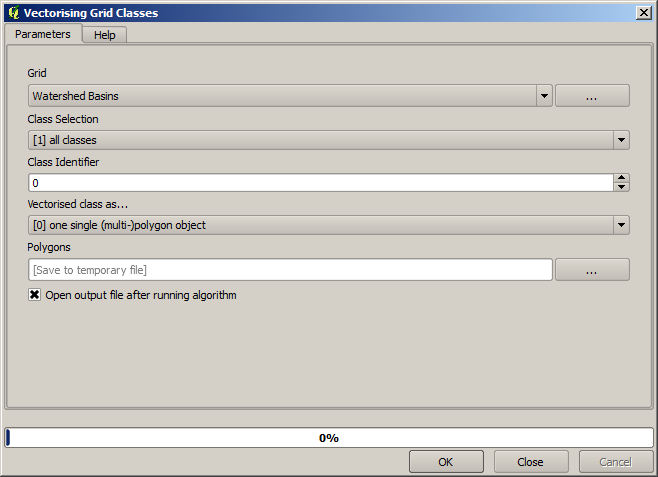
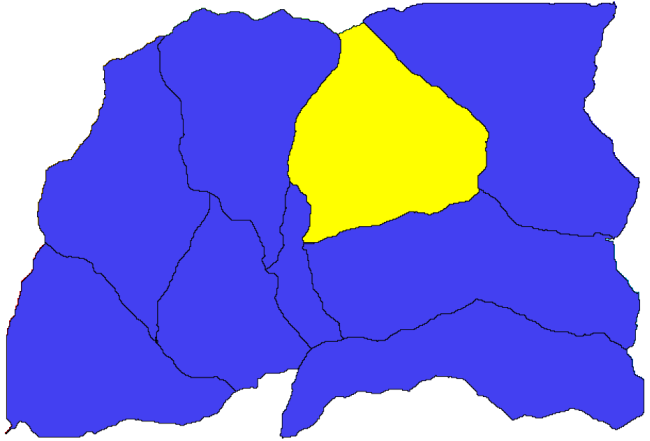
Laten we nu eens proberen statistieken te berekenen over de hoogtewaarden in één van de subbassins. Het idee is om een laag te krijgen die slechts de hoogte binnen dat subbassin weergeeft en die dan doorgeeft naar de module die die statistieken berekent.
Laten we eerst de originele DEM clippen met de polygoon die een subbassin weergeeft. We zullen het algoritme Clip raster with polygon gebruiken. Als we één enkele polygoon voor een subbassin selecteren en dan het algoritme voor het clippen aanroepen, kunnen we de DEM clippen tot het gebied dat wordt bedekt door die polygoon, omdat het algoritme zich bewust is van de selectie.
Selecteer een polygoon
Roep het algoritme om te clippen aan met de volgende parameters:
Het geselecteerde element in het invoerveld is, natuurlijk, de DEM die we willen clippen.
U zult iets krijgen zoals dit.
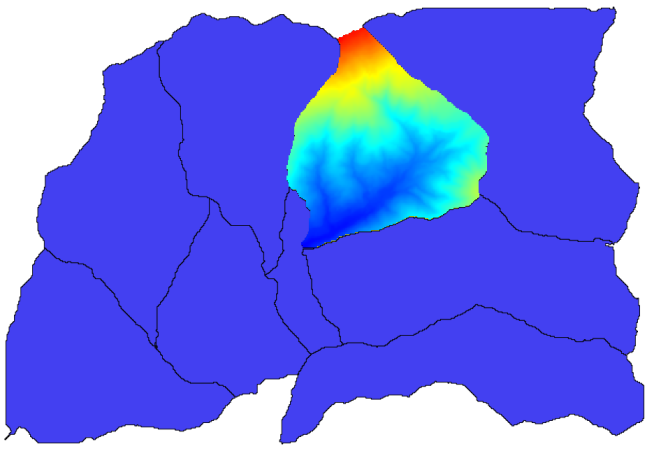
Deze laag is gereed om te worden gebruikt in het algoritme Raster layer statistics.
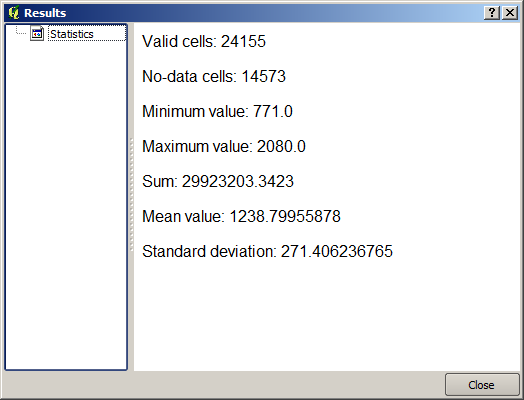
De resulterende statistieken zijn de volgende.
We zullen zowel de procedure voor het berekenen van het bassin gebruiken als de berekeningen voor statistieken uit andere lessen, om uit te zoeken hoe andere elementen ons kunnen helpen om beide te automatiseren en meer effectief te werken.